IMPLEMENTASI ALGORITMA ID3 UNTUK MENGETAHUI
FAKTOR YANG MEMPENGARUHI TINGKAT KELULUSAN
(STUDI KASUS DI FAKULTAS TEKNIK UMY)
Skripsi
untuk memenuhi sebagian persyaratan mencapai derajat sarjana S-1
Disusun oleh :
Andri Gustiawan
20120140054
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK UNIVERSITAS MUHAMMADIYAH
YOGYAKARTA
iv
PERNYATAAN
Saya sebagai penulis menyatakan dengan sesungguhhnya bahwa penelitian ini adalah hasil penelitian asli dari diri saya sendiri. Jika terdapat karya orang lain atau pun referensi dari karya orang lain saya akan mencantumkan sumber dengan jelas
Demikian pernyataan ini saya buat dengan keadaan sadar tanpa paksaan dari pihak manapun.
Yogyakarta, 06 Februari 2017
Penulis,
Andri Gustiawan
v
PRAKATA
Puji syukur dengan kehadirat Allah SWT yang telah melimpahkan rahmat dan hidayahnya, sehingga penulis dapat menyelesaikan tugas akhir yang berjudul ”IMPLEMENTASI ALGORITMA ID3 UNTUK MENGETAHUI FAKTOR YANG MEMPENGARUHI TINGKAT KELULUSAN (STUDI KASUS DI FAKULTAS TEKNIK UMY)”. Laporan skripsi ini disusun untuk memenuhi salah satu syarat dalam memperoleh gelar Sarjana Teknik (ST) pada Program Studi S1 Teknik Informatika Universitas Muhammadiyah Yogyakarta.
Penulis menyadari bahwasanya laporan skripsi tidak dapat terselesaikan tanpa bantuan dan dukungan dari berbagai pihak. Penulis mengucapkan terima kasih yang tak terhingga kepada:
1. Bapak Ir. Eko Prasetyo, M.Eng., selaku pembimbing utama yang dengan penuh kesabaran memberikan ilmu, masukan, bimbingan, bantuan dan pengetahuan kepada penulis baik dalam hal teknis atau non teknis, selama penulisan skripsi maupun selama masa perkuliahan penulis dan atas setiap kepercayaan yang diberikan.
2. Bapak Asroni, S.T., M.Eng. , selaku dosen pembimbing pendamping yang telah meluangkan waktunya dan sangat sabar membimbing penulis dalam pembuatan skripsi.
vi
4. Bapak Muhammad Helmi Zain, S.T., M.T., selaku Ketua Program Studi S1 Teknik Informatika Universitas Muhammadiyah Yogyakarta, yang telah dengan tulus berbagi ilmu dan pengalaman selama perkuliahan penulis.
5. Para Dosen dan Staff Teknik Informatika yang senantiasan dengan iklas memberikan ilmu dan berbagi cerita atau pengalaman yang bermanfaat bagi penulis.
6. Ibu, bapak, Ade, Meisi dan keluarga besar Riduan adalah sebuah anugerah dan kebahagian yang tak terhingga di berikan oleh Allah SWT dapat berada diantara kalian, sungguh hati ini sangat menyayangi kalian dengan sepenuh jiwa.
7. Dede, yudi yang telah membantu memberikan masukan dan saran selama pembuatan skripsi ini sehingga penulis dapat menyelasaikanya.
8. Teman teman Teknik Informatika khususnya teman seperjuangan angkatan 2012 B sungguh mengenal kalian sebagai sahabat yang bersama-sama meraih impian dan asa adalah suatu hal terindah yang dikirimkan oleh Allah SWT dalam hidup penulis.
9. Terimakasih Elvan diano, maga ringga, Wasis pancoro, Arya mardhani, Suryatman, Dwiki, Hidayatul, Aditya Herwanto, yang telah memberi semangat penulis dalam mengerjakan skripsi.
vii
DAFTAR ISI
HALAMAN PENGESAHAN I ... ii
HALAMAN PENGESAHAN II ...iii
1.5. Manfaaat Penelitian ... 3
1.6. Sistematika Penulisan ... 4
BAB II ... 6
TINJAUAN PUSTAKA DAN LANDASAN TEORI ... 6
2.1. Tinjauan Pustaka... 6
2.2. Landasan Teori ... 9
2.2.1. Data Mining ... 9
2.2.1.1. Pengelompokan data mining ... 12
2.2.2. Pohon keputusan (Decision Tree) ... 16
2.2.3. Algoritma Induction Decision Tree (ID3) ... 17
2.2.3.1. Konsep Entropy ... 18
2.2.3.2. Konsep Gain ... 19
2.2.4. Software Development Life Cycle (SDLC) ... 19
viii
2.2.5.1. Pengenalan Interface ... 23
2.2.6. Microsoft SQL Server ... 32
2.2.7. Microsoft Excel ... 32
BAB III... 33
METODE PENELITIAN ... 33
3.1. Tempat dan Waktu Penelitian... 33
3.2. Peralatan Penelitian ... 33
3.2.1. Software ... 33
3.2.2. Hardware ... 34
3.3. Alur penelitian ... 34
3.3.1. Studi Literatur ... 35
3.3.2.Pengumpulan Data ... 36
3.3.3. Seleksi data (Data Selection) ... 36
3.3.4. Pembersihan data (Cleaning Data) ... 37
3.3.5. Transformasi data (Data Transformation) ... 37
3.3.6. Implementasi ... 37
BAB IV ... 38
HASIL DAN PEMBAHASAN ... 38
4.1.Pengumpulan data ... 38
4.2. Seleksi Data (data selection) ... 41
4.3. Pembersihan Data (cleaning data) ... 42
4.4. Transformasi Data (data transformation) ... 43
4.5. Implementasi ... 44
4.5.1. Pengujian software RapidMiner ... 45
4.5.2.Algoritma ID3 ... 59
BAB V ... 76
KESIMPULAN DAN SARAN ... 76
5.1. Kesimpulan ... 76
5.2. Saran ... 76
DAFTAR PUSTAKA ... 78
ix
DAFTAR GAMBAR
Gambar 2.1 Bidang Ilmu Data Mining ... 10
Gambar 2.2 Bentuk Decision Tree Secara Umum ... 17
Gambar 2.3 Tampilan Welcome Perpective ... 23
Gambar 2.4 Welcome Perspective... 25
Gambar 2.5 Header Tab... 25
Gambar 2.6 Tampilan Design Perspective ... 27
Gambar 2.7 Kelompok Operator dalam Bentuk Hierarki... 28
Gambar 2.8 Tampilan Parameter View ... 30
Gambar 2.9 Problem & Log View ... 31
Gambar 3.2 Alur Penelitian ... 35
Gambar 4.1 Menghubungkan ke server. ... 38
Gambar 4.2create database. ... 39
Gambar 4.3Add table. ... 40
Gambar 4.11Import configuration wizard. ... 46
Gambar 4.12 Alur proses import data. ... 47
Gambar 4.13 Alur proses import data. ... 47
Gambar 4.14 Alur proses import data. ... 48
Gambar 4.15 Alur proses import data. ... 49
Gambar 4.16 Operator read csv dan split validation. ... 50
Gambar 4.17 Menghubungkan tabel read csv dengan operator split validation. 50 Gambar 4.18 Tampilan split validation. ... 52
x
Gambar 4.20 Susunan Operator ID3, Apply Model, Peformance. ... 53
Gambar 4.21 parameter ID3. ... 54
Gambar 4.22Criterion. ... 55
Gambar 4.23Icon run ... 56
Gambar 4.24 Hasil berupa graph pohon keputusan ... 56
Gambar 4.25 Hasil dari text view (operator ID3) ... 57
Gambar 4.26 Hasil accuracy dari table (peformanceVector) ... 58
xi
DAFTAR TABEL
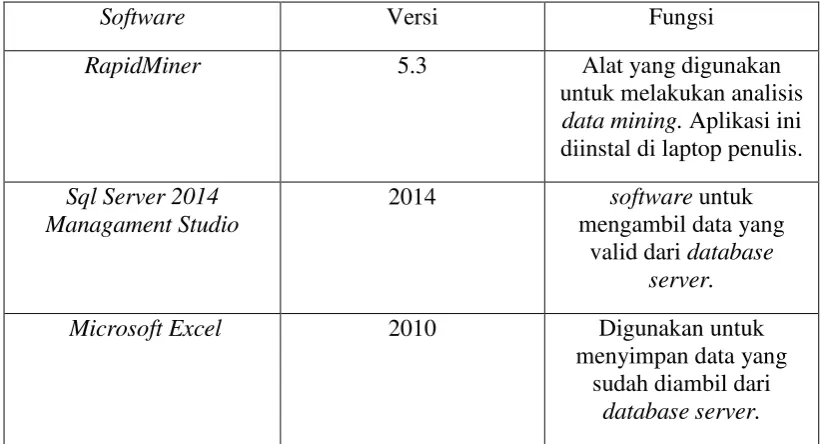
Tabel 3.1Software yang digunakan ... 33
Tabel 3.2Hardware yang digunakan ... 34
Tabel 4.1 Keterangan warna predikat kelulusan ... 56
Tabel 4.2 Data kelulusan mahasiswa Fakultas Teknik tahun 2013-2015 (UMY) 59
Tabel 4.3 Keterangan tentang atribut provinsi ... 69
ABSTRACT
The one of quality indicator of state university or private university is graduation rates of the student. Some of the data from the student who have graduated were analyzed to determine the factors that influence students' graduation rates. The process of the student data analysis using data mining techniques that aims to extract and discover patterns from the collection of valuable information. In this research, data mining using decision tree ID3. The information of collection is derived from the Universitas Muhammadiyah
Yogyakarta’s database. Research use data of the graduated students who
graduated in 2013, 2014, and 2015 which amounts to 272 students with the attributes of provincial origin, sex and high school majors. The data mining process using few software such as RapidMiner, Sql Server 2014 management studio and Microsoft Excel.
BAB I
PENDAHULUAN
1.1. Latar Belakang
Di zaman yang modern saat ini teknologi informasi semakin berkembang sangat pesat hampir di setiap bidang, salah satunya di bidang pendataan. Saat ini kita dapat melihat suatu contoh di universitas begitu banyak data yang terdapat di sana seperti data mahasiswa, karyawan, alumni dan calon mahasiswa baru. Tingkat akurasi suatu data sangat dibutuhkan dalam kehidupan sehari-hari. Dari setiap data bisa ditemukan sebuah informasi yang sangat bermanfaat jika dilakukan sebuah analisa terhadap data tersebut. Informasi yang didapat dari analisa tersebut dapat digunakan oleh pihak terkait untuk melakukan keputusan tertentu.
Universitas Muhammadiyah Yogyakarta (UMY) merupakan salah satu perguruan tinggi swasta yang ada di Yogyakarta yang memiliki kualitas yang sangat baik dan terakreditasi oleh Badan Akreditasi Nasional Perguruan Tinggi (BAN-PT). Setiap tahun begitu banyak mahasiswa Universitas Muhammadiyah Yogyakarta (UMY) yang diwisudakan, tercatat ribuan mahasiswa yang wisuda setiap tahunya dari seluruh fakultas yang ada di Universitas Muhammadiyah Yogyakarta (UMY) dengan berbagai tingkat kelulusan. Banyaknya mahasiswa yang wisuda dari tahun ketahun maka semakin banyak juga data yang tersimpan di server databaseuniversitas.
2,76 (dua koma tujuh enam) sampai dengan 3,00 (tiga koma nol nol) dan yang kedua dengan predikat sangat memuaskan dengan Indeks Prestasi Komulatif
(IPK) 3,01 (tiga koma nol satu) sampai 3,50 (tiga koma 5 puluh) dan yang terakhir dengan predikat cumlaude dengan Indeks Prestasi Komulatif (IPK) lebih dari 3,50 (tiga koma lima nol) data ini diambil dari PERMENRISTEKDIKTI-NOMOR-44-TAHUN 2015. Pada penelitian ini penulis akan melakukan analisa untuk mengetahui Faktor apa saja yang mempengaruhi tingkat kelulusan mahasiswa di fakultas teknik Universitas Muhammadiyah Yogyakarta. Pada penelitian ini penulis menggunakan teknik data mining. Teknik data mining adalah proses yang menggunakan teknik statisik, matematika, kecerdasan buatan dan machine learning untuk mengekstrasi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar[4] dan disini penulis menggunakan metode decision tree.
1.2. Rumusan Masalah
Permasalahan yang dibahas dalam penelitian ini adalah bagaimana cara mengimplementasikan algoritma ID3 untuk menghasilkan informasi yang berguna tentang faktor apa saja yang mempengaruhi tingkat kelulusan mahasiswa.
1.3. Batasan Masalah
Sebelum penulis melakukan penelitian lebih jauh ada baiknya jika penulis menjelaskan batasan-batasan masalah pada penelitian ini, diantaranya:
2. Data yang digunakan dalam penelitian ini data kelulusan tahun 2013-2015.
3. Penulis menggunakan metode pohon keputusan (decission tree) dan menggunakan algoritma ID3.
4. Software yang digunakan dalam penelitian ini yaitu RapidMiner, Sql server 2014 dan Microsoft excel.
5. Atribut yang digunakan yaitu Province_Of_birth, Gender_Name dan High_School_Major_Name.
1.4. Tujuan Penelitian
Adapun tujuan dari penelitian ini adalah untuk:
1. Mengetahui informasi tentang faktor apa saja yang dapat mempengaruhi mahasiswa untuk mendapatkan predikat kelulusan di Fakultas Teknik. 2. Mengimplementasikan metode decision tree dengan algoritma ID3 dalam
proses penelitian ini.
1.5. Manfaaat Penelitian
Manfaat yang didapatkan dari penelitian ini adalah sebagai berikut:
1. Bagi penulis :
Penulis dapat lebih mengetahui cara menerapkan ilmu-ilmu yang telah dipelajari selama ini dalam teknik data mining serta sebagai syarat dalam memperoleh gelar sarjana.
Diharapkan dengan adanya penelitian ini dapat membantu pihak fakultas mengetahui tingkat kelulusan mahasiswanya dan mengetahui faktoryang mempengaruhi tingkat kelulusan
1.6. Sistematika Penulisan
Dalam penulisan skripsi ini, untuk memudahkan dalam hal penyusunan, penulis membaginya kedalam beberapa bab. Adapun sistematika penulisan skripsi ini adalah sebagai berikut:
BAB I PENDAHULUAN
Bab I berisi tentang pelaksanaan penelitian secara umum. Pada bab ini akan dijelaskan mengenai latar belakang masalah, rumusan massalah, batasan masalah, tujuan penelitian, manfaat penelitian dan sistematika penulisan.
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI
Bab II berisi tinjauan pustaka dan teori-teori yang berkaitan dengan topik yang sedang diteliti sebagai bahan acuan dalam melakukan penelitian. Dalam bab ini dijelaskan mengenai penelitian-penelitian yang pernah dilakukan sebelumnya serta teori-teori yang berkaitan dengan algoritma ID3.
BAB III METODOLOGI PENELITIAN
Bab III berisi penjelasan mengenai metode dan alat-alat yang digunakan dalam melakukan penelitian dengan mengacu pada teori-teori penunjang yang telah dijelaskan pada Bab II
Bab IV berisi penjelasan mengenai implementasi algoritma ID3 dan hasil yang telah diperoleh dari seluruh penelitian sesuai dengan permasalahan.
BAB V KESIMPULAN DAN SARAN
BAB II
TINJAUAN PUSTAKA DAN LANDASAN TEORI
1.1. Tinjauan Pustaka
Berikutnya penulis mengutip dari artikel dengan judul “Data mining
menggunakan algoritma Naïve bayes untuk klasifikasi kelulusan mahasiswa Universitas dian nuswantoro” [2]. Data mahasiswa dan data kelulusan mahasiswa Dian Nuswantoro menghasilkan data yang sangat berlimpah berupa data profil mahasiswa dan data akademik. Hal tersebut terjadi secara berulang dan menimbulkan penumpukan terhadap data mahasiswa sehingga mempengaruhi pencarian informasi terhadap data tersebut. Penelitian ini bertujuan untuk melakukan klasifikasi terhadap data mahasiswa Universitas Dian Nuswantoro Fakultas Ilmu Komputer angkatan 2009 berjenjang DIII dan S1 dengan memanfaatkan proses data mining dengan menggunakan teknik klasifikasi. Metode yang digunakan adalah CRISP-DM dengan melalui proses business understanding, data understanding¸ data preparation, modeling, evaluation dan
Selanjutnya penulis mengambil referensi jurnal dari internet dengan judul “ Implementasi data mining dengan algoritma C4.5 untuk memprediksi tingkat kelulusan mahasiswa” [3]. Pada penelitian ini penulis menggunakan algoritma
C4.5 dalam menentukan prediksi kelulusan berdasarkan attribute jenis kelamin, asal sekolah SMA dan IP semester satu sampai dengan semester enam. Algoritma
C4.5 merupakan algoritma klasifikasi pohon keputusan yang banyak digunakan karena memiliki kelebihan utama dari algoritma yang lainya. Kelebihan algoritma
C4.5 dapat menghasilkan pohon keputusan yang mudah diinterprestasikan, memiliki tingkat akurasi yang dapat diterima,efisien dalam menangani atribut bertipe diskrit dan numeric. Dalam mengkontruksi pohon, Algoritma C4.5
membaca seluruh sampel data training dari stoage dan memuatnya ke memori. Hal ini lah yang menjadi salah satu kelemahan algoritma C4.5 dalam kategori “skalabilitas” adalah algoritma ini hanya dapat digunakan jika data training dapat disimpan secara keseluruhan dan pada waktu yang bersamaan dimemori. Data training yang akan digunakan oleh peneliti adalah data alumni mahasiswa program studi teknik informatika universitas multimedia nusantara angkatan 2007dan 2008 sedangkan untuk data testing akan digunakan data alumni angkatan 2009. Dari kumpulan data training dan data testing, dapat diketahui informasi kelulusan yang dapat mempengaruhi beberapa keputusan program studi menggunakan data mining algoritma C4.5.
pada data yang telah menumpuk di dalam database sebuah Universitas. Informasi yang dicari di dalam database ini yaitu tentang faktor yang mempengaruhi tingkat kelulusan mahasiswa agar informasi yang di dapat bisa dijadikan sebagai salah satu bahan evaluasi bagi Universitas untuk selanjutnya bisa menjadi strategi dalam proses perkuliahan, supaya tingkat kelulusan semakin meningkat. Perbedaan penelitian yang dilakukan oleh peneliti diatas terletak pada atribut dan algoritma yang digunakan, peneliti yang pertama dan ketiga menggunakan algoritma C4.5 sedangkan peneliti kedua menggunakan algoritama Naïve bayes.
Penelitian yang pertama dan ketiga hampir sama kasusnya dengan yang dibuat oleh penulis, perbedaan terletak pada atribut dan algoritma yang digunakan.
2.2. Landasan Teori
2.2.1. Data Mining
Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan didalam database. Data mining adalah prosses yang menggunakan teknik statistic, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terakit dari berbagai database besar [4].
Kemampuan luar biasa yang terus berlanjut dalam bidang data mining
didorong oleh beberapa factor, antara lain [4]:
1. Pertumbuhan yang cepat dalam kumpulan data.
2. Penyimpanan data dalam data warehouse, sehingga seluruh perusahaan memiliki akses kedalam database yang andal.
4. Tekanan kompetisi bisnis untuk meningkatkan penguasaan pasar dalam globalisasi ekonomi.
5. Perkembangan teknologi perangkat lunak untuk data mining (ketersedian Teknologi).
6. Perkembangan yang hebat dalam kemampuan komputasi dan pengembangan kapasitas media penyimpanan.
Gambar 2.1 Bidang ilmu data mining.
Data mining bukanlah suatu bidang yang sama sekali baru. Salah satu kesulitan untuk mendefinisikan data mining adalah kenyataan bahwa data mining
mewarisi banyak aspek dan teknik dari bidang-bidang ilmu Yang sudah mapan terlebih dahulu. Gambar 2.1 menunjukan bahwa data mining memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligent),
Istilah data mining dan knowledge discovery in databases (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yag besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda, tetapi berkaitan satu sama lain. Dan salah satu tahapan dalam keseluruhan proses KDD adalah data mining. Proses KDD secara garis besar dapat dijelaskan sebagai berikut [4]:
1. Data selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Pre-processing
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses
cleaning pada data yang menjadi focus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa yang inkonsiste, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Juga dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah
ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformation
merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data mining
Data mining adalah proses mencari pola atau informasi menarik dalam data teripilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretationall
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
2.2.1.1. Pengelompokan data mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan yaitu [4]:
1. Deskripsi
dari pola dan kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecenderungan.
2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variable target estimasi lebih kearah numeric dari pada ke arah kategori. Model dibangun menggunakan record lengkap yang menyediakan nilai dari variable target sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variable target dibuat berdasarkan nilai variable prediksi. Sebagai contoh, akan dilakukan estimasi tekanan darah sistolik pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, indeks berat badan, dan level sodium darah. Hubungan antara tekanan darah sistolik dan nilai variable prediksi dalam proses pembelajaran akan menghasilkan model estimasi. Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainya. Contoh lainya yaitu estimasi nilai indeks prestasi komulatif mahasiswa program pascasarjana dengan melihat nilai indeks prestasi mahasiswa tersebut pada saaat mengikuti program sarjana.
3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada dimasa mendatang.
Contoh prediksi dalam bisnis dan penelitian:
Prediksi harga beras dalam tiga bulan yang akan datang.
Prediksi persentase kenaikan kecelakaan lalu lintas tahun depan
Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi.
4. Klasifikasi
Dalam klasifikasi, terdapat target variable kategori. Sebagai contoh, penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu pendapatan tinggi pendapatan sedang, pendapatan rendah.
Contoh lain dalam klasifikasi dalam bisnis dan penelitian adalah:
Menentukan apakah suatu transaksi kartu kredit merupakan
transaksi yang curang apa bukan.
Memperkirakan apakah suatu pengajuan hipotek oleh nasabah
merupakan suatu kredit yang baik atau buruk.
Mendiagnosis penyakit seseorang pasien untuk mendapatkan
termasuk kategori penyakit apa.
5. Clustering
Clustering merupakan pengelompokan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan. Kluster adalah kumpulan record yang memiliki kemiripan satu dengan yang lainya dan memiliki ketidakmiripan dengan record-record
dalam kluster lain.
keseluruhan data menjadi kelompok-kelompokan yang memiliki kemiripan (homogen), yang mana kemiripan record dalam satu kelompok akan bernilai maksimal, sedangkan kemiripan dengan record dalam kelompok lain akan bernilai minimal.
Contoh clustering dalam bisnis dan penelitian adalah:
Mendapatkan kelompok-kelompok konsumen untuk target
pemasaran dari suatu produk bagi perusahaan yang tidak memiliki dana pemasaran yang besar.
Untuk tujuan audit akuntansi, yaitu melakukan pemisahan
terhadap prilaku finansial dalam baik dan mencurigakan.
Melakukan pengklusteran terhadap ekspresi dari gen, untuk
mendapatkan kemiripan perilaku dari gen dalam jumlah besar. 6. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja.
Contoh asosiasi dalam bisnis dan penelitian adalah :
Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler
yang diharapkan untuk memberikan respons positif terhadap penawaran upgrade layanan yang diberikan.
Menemukan barang dalam supermarket yang dibeli bersamaan dan
2.2.2. Pohon keputusan (Decision Tree).
Seiring dengan perkembangan kemajuan pola pikir manusia, manusia mulai mengembangkan sebuah sistem yang dapat membantu manusia dalam menghadapi masalah-masalah yang timbul sehingga dapat menyelesaikannya dengan mudah. Pohon keputusan atau yang lebih dikenal dengan istilah Decision Tree ini merupakan implementasi dari sebuah sistem yang manusia kembangkan dalam mencari dan membuat keputusan untuk masalah-masalah tersebutdengan memperhitungkan berbagai macam faktor yang berkaitan di dalam lingkup masalah tersebut. Dengan pohon keputusan, manusia dapat dengan mudah mengidentifikasi dan melihat hubungan antara faktor-faktor yang mempengaruhi suatu masalah sehingga dengan memperhitungkan faktor-faktor tersebut dapat dihasilkan penyelesaian terbaik untuk masalah tersebut. Pohon keputusan ini juga dapat menganalisa nilai resiko dan nilai suatu informasi yang terdapat dalam suatu
alternatif pemecahan masalah[5].
oleh manusia sejak perkembangan teori pohon yang dilandaskan pada teori graf. Seiring dengan perkembangannya, pohon keputusan kini telah banyak dimanfaatkan oleh manusia dalam berbagai macam sistem pengambilan keputusan[5].
Decision tree adalah struktur flowchart yang menyerupai tree (pohon), dimana setiap simpul internal menandakan suatu tes pada atribut, setiap cabang merepresentasikan hasil tes, dan simpul daun merepresentasikan kelas atau distribusi kelas. Alur pada decision tree di telusuri dari simpul akar ke simpul daun yang memegang prediksi.
Gambar 2.2 Bentuk Decision Tree Secara Umum[5].
2.2.3. Algoritma Induction Decision Tree (ID3)
ID3 merupakan sebuah metode yang digunakan untuk membangkitkan pohon keputusan. Input dari algoritma ini adalah sebuah database dengan beberapa variable yang juga dikenal dengan atribut. Setiap masukan dalam
database menyajikan sebuah objek dari domain yang disebut dengan variable
Proses klasifikasi dilakukan dari node yang paling atas yaitu akar pohon (root). Dilanjutkan kebawah melalui cabang-cabang sampai dihasilkan node daun (leaves) dimana node daun ini menunjukan hasil akhir klasifikasi. Sebuah objek yang diklasifikasikan dalam pohon harus dites nilai entropynya. Entropy adalah ukuran dari teori informasi yang dapat mengetahui karateristik impurity dan
homogeneity dari kumpulan data. Dari nilai entropy tersebut kemudian dihitung nilai information gain (IG) masing-masing atribut independent terhadap atribut
dependent-nya. IG merupakan nilai rata-rata entropy pada semua atribut[11].
2.2.3.1 Konsep Entropy
Entropy (S) merupakan jumlah bit yang diperkirakan dibutuhkan untuk dapat mengekstrak suatu kelas (+ atau -) dari sejumlah data acak pada ruang sampel S. Entropy dapat dikatakan sebagai kebutuhan bit untuk menyatakan suatu kelas. Semakin kecil nilai entropy maka akan semakin entropydigunakan dalam mengekstrak suatu kelas. Entropy digunakan untuk mengukur ketidakaslian S[4].
Untuk menghitung nilai entropy harus menggunakan rumus entropy yang dapat dilihat pada persamaan 1 berikut.
Entropy(S) =
∑
Keterangan :
S : himpunan kasus
A : fitur
pi : proporsi dari Si terhadap S
2.2.3.2 Konsep Gain
Gain (S,A) merupakan perolehan informasi dari atribut A relative terhadap output data S. Perolehan informasi didapat dari output data atau variable
dependent S yang dikelompokan berdasarkan atribut A, dinotasikan dengan gain
(S,A) [7]. Untuk menghitung nilai gain harus menggunakan rumus gain yang dapat dilihat pada persamaan 2 berikut.
Gain(S, A) = Entropy(S) –
∑
| |Keterangan:
A : Atribut
S : Sampel
n : Jumlah partisi himpunan atribut A
|Si| : jumlah sampel pada partisi ke –i |S| : jumlah sampel dalam S
2.2.4. Software Development Life Cycle (SDLC)
model yaitu waterfall, prototype, RAD, Agile Software Development. Disini penulis menggunakan waterfall.
Menurut Pressman(2010) Classic life cycle atau model waterfall
merupakan model yang paling banyak digunakan di dalam software engginering.
Model ini melakukan pendekatan secara sistematis. Model ini disebut juga model berulang karena jika terjadi kesalahan dalam salah satu daftar tahapan maka dapat kembali ketahapan sebelumnya sampai selesai sehingga bisa melanjutkan ketahapan selanjutnya.
2.2.5 RapidMiner
RapidMiner merupakan perangakat lunak yang bersifat terbuka (open source). RapidMiner adalah sebuah solusi untuk melakukan analisis terhadap data mining, text mining dan analisis prediksi. RapidMiner menggunakan berbagai teknik deskriptif dan prediksi dalam memberikan wawasan kepada pengguna sehingga dapat membuat keputusan yang paling baik. RapidMiner memiliki kurang lebih 500 operator data mining, termasuk operator untuk input, output,
data preprocessing dan visualisasi. RapidMiner merupakan software yang berdiri sendiri untuk analisis data dan sebagai mesin data mining yang dapat diintegrasikan pada produknya sendiri. RapidMiner ditulis dengan munggunakan bahasa java sehingga dapat bekerja di semua sistem operasi [5].
dari University of Dortmund. RapidMiner didistribusikan di bawah lisensi AGPL (GNU Affero General Public License) versi 3. Hingga saat ini telah ribuan aplikasi yang dikembangkan mengunakan RapidMiner di lebih dari 40 negara.
RapidMiner sebagai software open source untuk data mining tidak perlu diragukan lagi karena software ini sudah terkemuka di dunia. RapidMiner
menempati peringkat pertama sebagai Software data mining pada polling oleh KDnuggets, sebuah portal data-mining pada 2010-2011[5].
RapidMiner menyediakan GUI (Graphic User Interface) untuk merancang sebuah pipeline analitis. GUI ini akan menghasilkan file XML(Extensible Markup Language) yang mendefenisikan proses analitis keinginan pengguna untuk diterapkan ke data. File ini kemudian dibaca oleh RapidMiner untuk menjalankan analis secara otomatis[5].
RapidMiner memiliki beberapa sifat sebagai berikut[5]:
Ditulis dengan bahasa pemegroman java sehingga dapat dijalankan di
berbagai sistem operasi.
Proses penemuan pengetahuan dimodelkan sebagai operator trees.
Representasi XML internal untuk memastikan format standar pertukaran
data.
Bahasa scripting memungkinkan untuk eksperiman skala besar dan
otomatisasi eksperimen.
Konsep multi-layer untuk menjamin tampilan data yang efisien dan
Memiliki GUI, command line mode dan Java API yang dapat dipanggil
dari program lain.
Beberapa fitur dari RapidMiner, antara lain [5]:
Banyaknya algoritma data mining, seperti decision tree danself-organization map.
Bentuk grafis yang canggih, seperti tumbang tindih diagram histogram,tree chart dan 3D scatter plots.
Banyaknya variasi plugin, seperti text plugin untuk melakukan analisisteks.
Menyediakan prosedur data mining dan machine learning termasuk: ETL(extraction, transformation, loading) data preprocessing, visualisasi, modeling dan evalualisasi.
Proses data mining tersusun atas operator-operator yang nestable,dideskripsikan dengan XML, dan dibuat dengan GUI.
Mengintegrasikan proyek data mining Weka dan statistic R.2.2.5.1. Pengenalan Interface
RapidMiner menyediakan tampilan yang user friendly untuk memudahkan penggunanya ketika menjalankan aplikasi. Tampilan pada RapidMiner dikenal dengan istilah Perspective, yaitu; welcome perspective, design perspective dan
a. Welcome Perspective
Ketika membuka aplikasi anda akan disambut dengan tampilan yang disebut dengan welcome perspective, seperti yang ditunjukan gambar 2.3. Pada bagian toolbar, terdapat toolbar perspective yang terdiri dari ikon-ikon untuk menampilkan persepective dari RapidMiner. Toolbar ini dapat dikonfigurasikan sesuai dengan kebutuhan Anda. Sedangkan Views menunjukkan pandangan (view) yang sedang Anda tampilkan
Gambar 2.3 Tampilan welcome perpective.
Jika komputer Anda terhubung dengan internet, maka pada bagian bawah
yang dapat Anda lakukan setelah membuka RapidMiner. Berikut ini rincian lengkap daftar aksi tersebut:
New : Aksi ini berguna untuk memulai proses analis baru. Untuk memulai
proses analisis, pertama-tama Anda harus menentukan nama dan lokasi proses dan Data repository. Setelah itu, Anda bisa mulai merancang sebuah analisis baru.
Open Recent Process: Aksi ini berguna untuk membuka proses yang baru
saja ditutup. Selain aksi ini, Anda juga bisa membuka proses yang baru ditutup dengan mengklik dua kali salah satu daftar yang ada pada Recent Process. Kemudian tampilan welcome perspective akan otomotasi beralih ke design perspective.
Open Process : Aksi ini untuk membuka repository browser yang berisi
daftar proses. Anda juga bisa memilih proses untuk dibuka pada design perspective.
Open Template : Aksi ini menunjukkan pilihan lain yang sudah ditentukan
oleh proses analisis.
Online Tutorial : Aksi digunakan untuk memulai tutorial secara online
RapidMiner dapat menampilkan beberapa view pada saat bersamaan. Seperti yang ditunjukkan pada Gambar 2.4, pada tampilan welcome perspective
terdapat welcome view dan log view. Ukuran dari setiap view tersebut dapat diubah sesuai dengan kebutuhan Anda dengan mengklik dan menarik garis batas diantara keduanya ke atas atau ke bawah.
Gambar 2.4Welcome perspective.
Gambar 2.5Header Tabm.
Close : Aksi ini untuk menutup view yang ditampilkan pada perspective.
Anda bisa menampilkan view kembali dengan mengklik menu view dan memilih view yang ingin ditampilkan.
Maximize : Aksi ini untuk memperbesar ukuran view pada perspective.
Minimize : Aksi ini untuk memperkecil ukuran view pada perspective. Detach : Aksi ini untuk melepaskan view dari perspective menjadi jendela
terpisah, kemudian Anda juga dapat memindahkannya sesuai dengan keinginan Anda.
b. Design Perspective
Design Perspective merupakan lingkungan kerja RapidMiner. Dimana
design perspective ini merupakan perspective utama dari RapidMiner yang digunakan sebagai area kerja untuk membuat dan mengelola proses analisis. Seperti yang ditunjukkan pada Gambar 2.6, perspective ini memiliki beberapa
view dengan fungsinya masing-masing yang dapat mendukung Anda dalam melakukan proses analisis data mining. Anda bisa mengganti perspective dengan mengklik salah satu ikon dari tollbar perspective yang sebelumnya telah dijelaskan. Selain dengan cara tersebut, Anda juga bisa mengganti perspective
dengan mengklik menu view, kemudian pilih perspective, lalu pilih perspective
Gambar 2.6 Tampilan Design Perspective
Sebagai Lingkungan kerja, design perspective memiliki beberapa view. Berikut ini beberapa view yang ditampilkan pada design perspective:
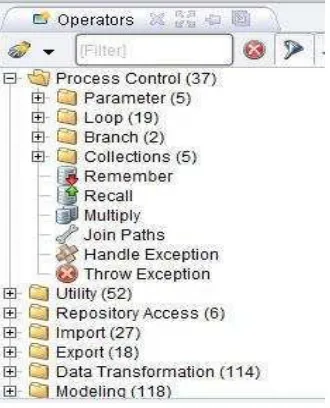
Operator View
Operator view merupakan view yang paling penting pada perspective ini. Semua operator atau langkah kerja dari RapidMiner disajikan dalam bentuk kelompok hierarki di operator view ini sehingga operator-operator tersebut dapat digunakan pada proses analisis, seperti yang ditunjukkan pada Gambar 2.7. Hal ini akan memudahkan Anda dalam mencari dan menggunakan operator yang sesuai dengan kebutuhan Anda. Pada operator view ini terdapat beberapa kelompok operator sebagai berikut:
1. Process Control: Operator ini terdiri dari operator perulangan dan percabangan yang dapat mengatur aliran proses.
2. Utility: Operator bantuan, seperti operator macros, loggin, subproses, dan lain-lain.
3. Repository Access: Kelompok ini terdiri dari operator-operator yang
4. Import: Kelompok ini terdiri dari banyak operator yang dapat digunakan untuk membaca data dan objek dari format tertentu seperti file, database, dan lain-lain.
5. Export: Kelompok ini terdiri dari banyak operator yang dapat digunakan untuk menulis data dan objek menjadi format tertentu. 6. Data Transformation: kelompok ini terdiri dari semua operator yang
berguna untuk transformasi data dan meta data.
7. Modeling: kolompok ini berisi proses data mining untuk menerapkan model yang dihasilkan menjadi set data yang baru.
8. Evaluation: kelompok ini berisi operator yang dapat digunakan untuk menghitung kualitas pemodelan dan untuk data baru.
Repository View
Repository view merupakan komponen utama dalam design perspective
selain operator view. View ini dapat Anda gunakan untuk mengelola dan menata proses Analisis Anda menjadi proyek dan pada saat yang sama juga dapat digunakan sebagai sumber data dan yang berkaitan dengan meta data.
Process View
Process view menunjukkan langkah-langkah tertentu dalam proses analisis dan sebagai penghubung langkah-langkah tersebut. Anda dapat menambahkan langkah baru dengan beberapa cara hubungan diantara langkah-langkah ini dapat dibuat dan dilepas kembali. Pada dasarnya bekerja dengan RapidMiner ialah mendefinisikan proses analisis, yaitu dengan menunjukkan serangkaian langkah kerja tertentu. Dalam RapidMiner, komponen proses ini dinamakan sebagai operator. Operator pada RapidMiner didefinisikan sebagai berikut:
1. Deskripsi dari input yang diharapkan. 2. Deskripsi dari output yang disediakan.
3. Tindakan yang dilakukan oleh operator pada input, yang akhirnya mengarah dengan penyediaan output.
4. Sejumlah parameter yang dapat mengontrol action performed.
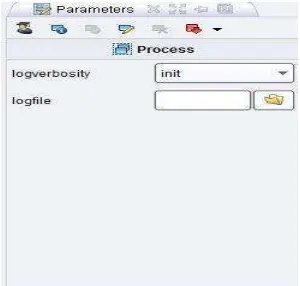
Parameter View
memiliki toolbar sendiri sama seperti view-view yang lain. Pada Gambar 2.8, Anda dapat melihat bahwa pada parameter view ini terdapat beberapa ikon dan nama-nama operator terkini yang dikuti dengan aktual parameter.
Gambar 2.8 Tampilan Parameter View.
Huruf tebal berarti bahwa parameter mutlak harus didefinisikan oleh analis dan tidak memiliki nilai default. Sedangkan huruf miring berarti bahwa parameter diklasifikasikan sebagai parameter ahli dan seharusnya tidak harus diubah oleh pemula untuk analisis data. Poin pentingnya ialah beberapa parameter hanya ditunjukkan ketika parameter lain memiliki nilai tertentu.
Help & Comment View
Setiap kali Anda memilih operator pada operator view atau process view,
maka jendela bantuan dalam help view akan menunjukkan penjelasan mengenai operator ini. Penjelasn yang ditampilkan dalam help view meliputi:
1. Sebuah penjelasan singkat mengenai fungsi operator dalam satu atau beberapa kalimat.
3. Daftar semua parameter termasuk deskripsi singkat dari parameter, nilai default (jika tersedia), petunjuk apakah parameter ini adalah parameter ahli serta indikasi parameter dependensi.
Sedangkan comment view merupakan area bagi Anda untuk menuliskan komentar pada langkahlangkah proses tertentu. Untuk membuat komentar, Anda hanya perlu memilih operator dan menulis teks di atasnya dalam bidang komentar. Kemudian komentar tersebut disimpan bersama-sama dengan definisi proses Anda. Komentar ini dapat berguna untuk melacak langkah-langkah tertentu dalam rancangan nantinya.
Problem & Log View
Problem view merupakan komponen yang sangat berharga dan merupkan sumber bantuan bagi Anda selama merancang proses analisis. Setiap peringatan dan pesan kesalahan jelas ditunjukkan dalam problem view, seperti yang ditunjukkan pada Gambar 2.9
Gambar 2.9 Problem & Log view.
(jika hanya ada satu kemungkinan solusi) atau sebagai indikasi dari berapa banyak kemungkinan yang berbeda untuk memecahkan masalah.
2.2.6. Microsoft SQL Server
SQL Server merupakan Relational Database Management System (RDMS) yang menghubungkan pengguna dengan data untuk pengelolaan basis data. SQL Server dapat digunakan untuk menghubungkan satu ataupun beberapa server. Bahasa basis data yang digunakan SQL Server adalah Transact-SQL. Transact-SQL merupakan bahasa SQL yang dimiliki oleh SQL Server yang berguna bagi pengguna untuk mendapatkan satu atau kumpulan data pada basis data dengan cara menjalankan perintah dari suatu pernyataan SQL [8].
2.2.7. Microsoft Excel
Microsoft excel adalah software spreadsheet paling terkenal di dunia bisnis dan perkantoran. Excel digunakan hampir semua bidang bisnis. Excel dapat dijumpai di mana-mana dan bisa dikatakan sebagai aplikasi yang universal dan dipakai semua orang. Aplikasi excel memiliki fitur kalkulasi dan pembuatan grafik, serta mudah dipakai sehingga excel menjadi salah satu program komputer yang populer digunakan di PC hingga saat ini. Bahkan, saat ini excel merupakan program spreadsheet paling banyak digunakan, baik platform PC berbasis
BAB III
METODE PENELITIAN
3.1. Tempat dan Waktu Penelitian
Penelitian ini dilaksanakan di Universitas Muhammadiyah Yogyakarta di ruang Biro Sistem Informasi, gedung AR. Fachruddin B. Adapun waktu penelitian ini dilaksanakan dari bulan Agustus 2016 - Oktober 2016.
3.2. Peralatan Penelitian
3.2.1. Software
Untuk melakukan penelitian data mining ini, dibutuhkan beberapa
software yang di instalpada sebuah laptop untuk digunakan oleh penulis.
Tabel 3.1Software yang digunakan.
Software Versi Fungsi
RapidMiner 5.3 Alat yang digunakan
untuk melakukan analisis
data mining. Aplikasi ini diinstal di laptop penulis.
Microsoft Excel 2010 Digunakan untuk
menyimpan data yang sudah diambil dari
3.2.2. Hardware
Selain perangkat lunak dibutuhkan juga perangkat keras yang digunakan untuk mendukung proses penelitian ini yaitu:
Tabel 3. 2Hardware yang digunakan.
Personal Compute (PC) atau Laptop Spesifikasi
Processor AMD A8-6410 APU with AMD
Radeon R5 Graphics
RAM 4.00 GB
System type 64-bit OS
3.3. Alur penelitian
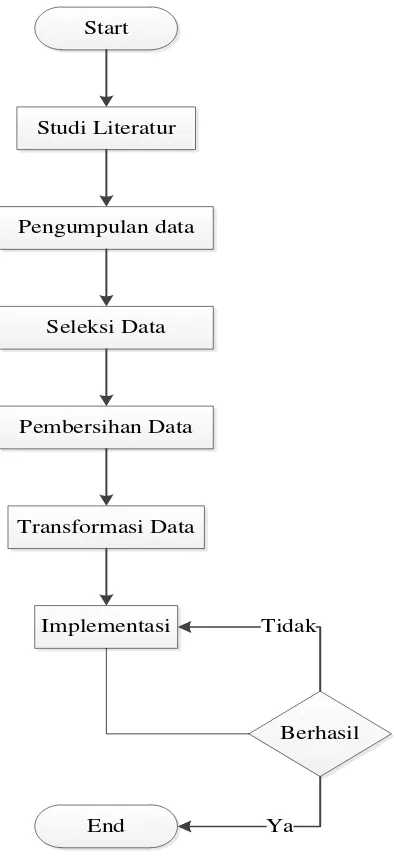
Dalam melakukan penelitian ini, penulis menggunakan model SDLC
Start
Studi Literatur
Pengumpulan data
Seleksi Data
Pembersihan Data
Transformasi Data
Implementasi
Berhasil Tidak
End Ya
Gambar 3.1 Alur Penelitian.
3.3.1. Studi Literatur
persamaan ataupun perbedaan terhadap penelitian yang dilakukan oleh penulis maupun dengan peneliti lainya.
3.3.2. Pengumpulan Data
Tahapan berikutnya yaitu pengumpulan data. Dalam penelitian ini tahapan pengumpulan data sangat la penting untuk penulis karena dari pengumpulan data penulis memperoleh sebuah informasi yang dibutuhkan dalam proses penelitian. Karena data sangatlah penting dalam sebuah penelitian maka dalam tahap proses pengumpulan data harus la dilakukan dengan benar, jika terjadi kesalahan dalam proses pengumpulan data maka akan membuat proses analisis data akan menjadi sulit. Selain itu hasil dan kesimpulan akan menjadi rancu jika terjadi kesalahan dalam pengumpulan data.
Analisis data hanya dilakukan di database Universitas Muhammadiyah Yogyakarta, dikarenakan informasi data tentang bagian mahasiswa berada pada
database tersebut. Di database Universitas Muhammadiyah Yogyakarta ini lah terdapat informasi yang dibutuhkan dalam pembangunan data mining
3.3.3. Seleksi data (Data Selection)
Data yang ada di database tidak semuanya dipakai untuk penelitian ini, oleh karena hanya data yang sesuai untuk dianalisis yang akan diambil di
database. Sebagai contoh faktor kecenderungan orang membeli dalam kasus
3.3.4 Pembersihan data (Cleaning Data).
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten. Pada umumnya data yang diperoleh, baik dari database
Universitas maupun hasil eksperimen, mempunyai isi yang tidak sempurna seperti data yang hilang, data yang tidak valid. Selain itu ada juga atribut-atribut data yang tidak relevan itu juga lebik baik dibuang. Pembersihan data juga juga akan mempengaruhi performas dari teknik data mining karena data yang ditangani akan berkurang jumlah dan kompleksitasnya.
3.3.5 Transformasi data (Data Transformation).
Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam data mining karena beberapa metode data mining membutuhkan format data yang khusus sebelum bisa diaplikasikan. Contoh bebrapa metode standar seperti analisis asosiasi dan clustering yang hanya bisa menerima input data kategorikal. Karenanya data berupa angka numerik yang berlanjut perlu dibagi – bagi menjadi beberapa interval.
3.3.6 Implementasi
Merupakan suatu proses utama saat metode ini dilakukan untuk menemukan pengetahuan berharga atau sebuah informasi dari data. Teknik yang digunakan pada proses mining ini adalah decision tree dengan menggunakan algoritma ID3 dan software yang digunakan dalam proses mining ini yaitu
BAB IV
HASIL DAN PEMBAHASAN
1.1.Pengumpulan data
Data yang digunakan dalam penelitian ini adalah data warehouse Graduation Universitas Muhammadiyah Yogyakarta pada Fakultas Teknik UMY tahun kelulusan 2013, 2014 dan 2015. Software yang digunakan untuk mengakses
data warehouse ini yaitu SQL Server Management 2014 dan untuk dapat mengakses data warehouse peneliti harus mempunyai hak akses ke database Server Universitas Muhammadiyah Yogyakarta. Server name dari databaseserver
BSI (Biro Sarana Informasi) adalah 10.0.1.68\DATAWAREHOUSE seperti pada gambar 4.1 dibawah ini
Setelah masuk ke database server penulis membuat database baru di dalam folder analisa data agar lebih muda digunakan jika suatu waktu ingin menggunakan lagi data tersebut. Untuk membuat database baru penulis harus melakukan expand pada folder Analisis Data dan selanjutnya klik new view pada folder view seperti gambar 4.2 dibawah ini.
Gambar 4.2 create database.
Gambar 4.3 Add table.
Data yang diambil dari data warehouse ini menggunakan dua tabel factual
yaitu fact_graduation dan fact_perkuliahan sedangkan untuk tabel dimensional
memiliki 7 tabel yaitu: dim_student, dim_gender, dim_graduation_periode,
Gambar 4.4 Tampilan view dari data warehouse.
Setelah memilih atribut yang ingin digunakan langkah selanjutnya yaitu memfilter data seperti gambar 4.5 dibawah ini.
Gambar 4.5 Proses filterdata dari data warehouse. 1.2. Seleksi Data (data selection)
Data selection adalah proses menganalisis data-data yang relevan dari
database karena sering ditemukan bahwa tidak semua data dibutuhkan dalam proses data mining. Data tersebut dipilih dan diseleksi dari database untuk di analisis. Sumber data yang digunakan dalam penelitian ini berasal dari data mahasiswa yang telah lulus tahun 2013 sampai dengan 2015 pada Fakultas Teknik Universitas Muhammadiyah Yogyakarta. Dari semua data yang digunakan hanya
Predicate Name. Karena informasi yang terkandung didalamnya sudah mewakili informasi yang dibutuhkan untuk dijadikan indicator penelitian.
1.3. Pembersihan Data (cleaning data)
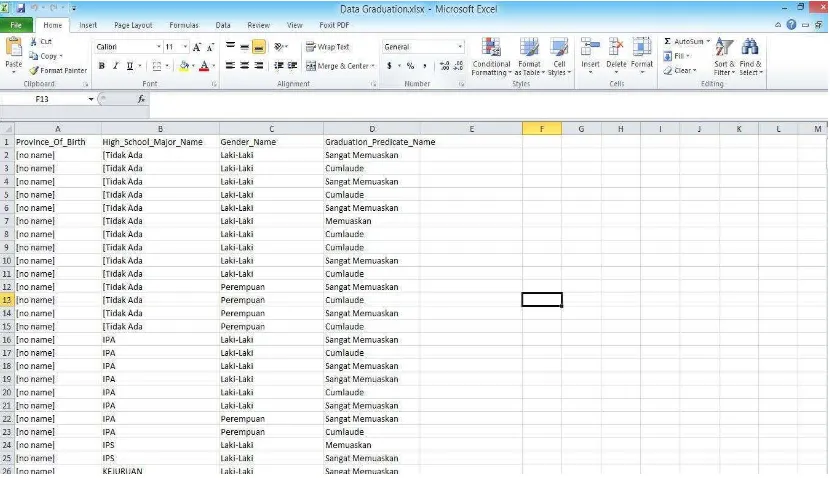
Setelah tahap pengumpulan data dan filter data maka tahap selanjutnya yaitu cleaning data agar tidak ada duplikasi data, memeriksa data yang inkonsisten dan memperbaiki kesalahan pada data seperti kesalahan cetak, sehingga data tersebut dapat diolah dan dilakukan proses data mining. Setelah semua data yang di butuhkan telah melalui tahap cleaning data maka data akan disimpan dalam dataset baru yang menggunakan Microsoft Office Excel dengan format csv. Data yang diambil dari fakultas Teknik ini ada data yang unknown yaitu data pada atribut Province_Of_Birth sebanyak 28 data dan atribut
High_School_Major_Name sebanyak 28 data. Prosess pembersihan data dapat di lihat di gambar 4.6.
1.4. Transformasi Data (data transformation).
Data Transformation adalah tahap mengubah data menjadi bentuk yang sesuai untuk diproses dalam data mining. Beberapa metode data mining
membutuhkan format data yang khusus sebelum bisa di aplikasikan. Dalam penelitian ini data yang akan diproses dari database SQL Server 2014 Management Studio akan diubah menjadi file CSV (comma delimited) yang dapat digunakan untuk pengolahan data pada Software RapidMiner dan nama atribut data juga di ubah dari Province_Of Birth, Senior_High_School, Gender_Name
dan Graduation_Predicate_Name. di ubah menjadi Provinsi, Jenis Kelamin, Jurusan SMA, Predikat Kelulusan dan nilai yang ada pada atribut Provinsi juga di ubah sesuai dengan kebutuhan. Gambar 4.7 adalah data yang belum di ubah oleh penulis atau yang belum di lakukan transformasi data.
Selanjutnya penulis melakukan transformasi data agar penelitian ini bisa berjalan dengan baik dan gambar 4.8 di bawah ini adalah data yang telah terjadi transformasi data.
Gambar 4.8 Data yang telah diubah.
1.5. Implementasi
Pada tahap ini dilakukan pemodelan data, metode yang dipakai pada penelitian ini adalah decision tree (pohon keputusan) dengan menggunakan algoritma ID3. Data yang telah di kumpul, diseleksi dan di transformasi akan di kelola menggunakan metode decision tree. Metode ini adalah sebuah struktur yang dapat digunakan untuk membagi kumpulan data yang besar menjadi himpunan-himpunan record yang lebih kecil dengan menerapkan serangkaian aturan keputusan.
4.9 adalah data graduation dari fakultas teknik dengan format .CSV yang akan diakses melalui software RapidMiner.
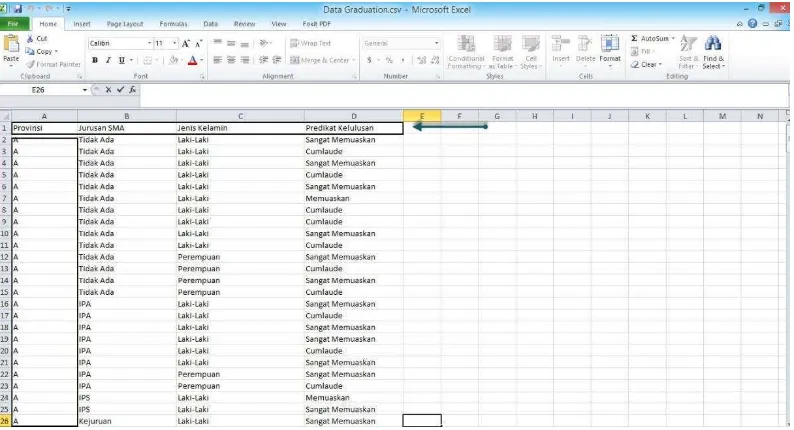
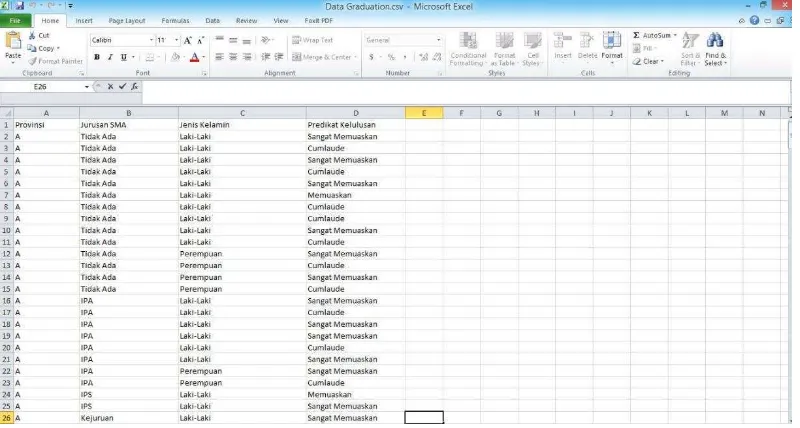
Gambar 4.9 Data graduation fakultas teknik Format .csv.
1.5.1. Pengujian software RapidMiner.
Atribut yang digunakan sebagai label adalah predikat kelulusan, penulis akan menganalisis faktor apa saja yang mempengaruhi tingkat kelulusan
mahasiswa menggunakan data yang telah dipilih yaitu data graduation fakultas teknik. Data terlebih dahulu kita tranformasi ke dalam format .csv agar bisa diakses menggunakan software RapidMiner.
Gambar 4.10 drag and dropread csv.
Gambar 4.11 Import configuration wizard.
Gambar 4.12 Alur proses import data.
Setelah data telah kita pilih langkah selanjutnya yaitu klik Next dan akan muncul form data import wizard step 2 seperti gambar 4.13.
Gambar 4.13 Alur proses import data.
Gambar 4.14 Alur proses import data.
Pada step ke 3 ini tidak ada dilakukan apapun maka dari itu langsung ke
Gambar 4.15 Alur proses import data.
Setelah muncul formdata import wizard step 4 seperti gambar diatas lalu pilih salah satu atribut target karena pada klasifikasi tentu ada atribut target atau
label dan atribut yang dipilih sebagai label yaitu atribut predikat. Setelah ditentukan label yang dipilih maka klik Finish. Setelah data selesai di import
maka selanjutnya drag and drop Split Validation seperti gambar 4.16. Didalam
Gambar 4.16 Operator read csv dan split validation.
Selanjutnya, hubungkan operator read csv dengan split validation dengan menarik garis tabel read csv ke operator split validation dan menarik garis lagi dari operator split validation ke result di sisi kanan seperti gambar 4.17.
Gambar 4.17 Menghubungkan tabel read csv dengan operator split validation.
Operator split validation memiliki port input yaitu, training example set
(tra) sebagai port input memperkirakan ExampleSet untuk melatih sebuah model (training data set). ExampleSet yang sama akan digunakan selama subproses pengujian untuk menguji model. Selain itu, operator ini juga memiliki port output
Model (mod), pelatihan subprocess harus mengembalikan sebuah model
yang dilatih pada input exampleset dan model yang dibangun exampleset
disampaikan melalui port ini.
Training ExampleSet (tra), the exampleset yang diberikan sebagai
masukan pada port input pelatihan dilewatkan tanpa mengubah ke output melalui port ini. Port ini biasa digunakan untuk menggunakan kembali
exampleset sama dioperator lebih lanjut atau untuk melihat exampleset
dalam workspace result.
Averagable (ave), subproses pengujian harus mengembalikan vector
kinerja. Hal ini biasanya dihasilkan dengan menerapkan model dan mengukur kinerjanya. Dua port tersebut diberikan tetapi hanya digunakan jika diperlukan. Kinerja statistic dihitung dengan skema estimasi hanya perkiraan (bukan perhitungan yang tepat) dari kinerja yang akan dicapai dengan model yang akan dibangung pada set data yang disampaikan secara lengkap.
Gambar 4.18 Tampilan split validation.
Setelah muncul form seperti gambar diatas maka selanjutnya kita drag and drop algoritma ID3 dari operator ke dalam box training, karena dalam penelitian kita menggunakan algoritma ID3, selain ID3 kita juga drag and dropapply model
dan performance(classification) Kedalam box testing Seperti gambar 4.19.
Gambar 4.19 Tampilan split validation.
Selanjutnya susun dan hubungkan port-port dari operator ID3, operator
Gambar 4.20 Susunan Operator ID3, Apply Model, Peformance.
Pada operator ID3 terdapat input training set (tra), port ini merupakan output dari operator read csv. Output dari operator lain juga dapat digunakan oleh port ini. Port ini menghasilkan ExampleSet yang dapat diproses menjadi decision tree. Selain itu pada operator ini juga terdapat output model (mod) dan example set (exa). Mod akan mengokonversi atribut yang dimasukan menjadi model keputusan dalam bentuk decision tree. Exa merupakan port yang menghasilkan output tanpa megubah inputan yang masuk melalui port ini. Port ini biasa digunakan untuk menggunakan kembali sama ExampleSet dioperator lebih lanjut atau untuk melihat ExampelSet dalam hasil workspace.
Pada operator Apply Model terdapat port input yaitu, model (mod) port ini memastikan bahwa peran atribut dari ExampleSet pada model yang dilatih konsisten dengan ExampleSet pada port input data unlabeled. Unlabeled data (unl) port ini memastikan bahwa peran atribut ExampleSet ini konsisten dengan
output. Dan model (mod), model yang diberikan sebagai masukan dilewatkan tanpa megubah ke output melalui port ini.
Operator Performance memiliki port input yaitu, labelled data (lab), port ini mengharapkan ExampleSet berlabel. Dan apply model merupakan contoh yang baik dari operator yang menyediakan data yang berlabel. Pastikan bahwa
ExampleSet memiliki atribut label dan atribut prediksi. Performance (per) ini adalah parameter opsional yang membutuhkan performance vector. Selain itu, operator ini juga memiliki port output yaitu, performance (per), port ini memberikan performance vector. Performance vector adalah daftar nilai kinerja kriteria. Example Set (exa), example set yang diberikan sebagai masukan dilewatkan tanpa mengubah ke output melalui port ini.
Langkah selanjutnya adalah mengatur parameter yang dibutuhkan. Setelah selesai menghubungkan port-port dari setiap operator atur parameter ID3 seperti pada gambar 4.21 dan 4.22.
Gambar 4.22 Criterion.
Langkah selanjutnya yaitu, memilih parameter criterion ID3 dan parameter criterion yang digunakan adalah information_gain dengan metode ini, semua entropy dihitung. Kemudian atribut dengan entropi minimum yang dipilih untuk dilakukan perpecahan pohon (split). Metode ini memiliki bias dalam memilih atribut dengan sejumlah besar nilai. Minimal size of split adalah ukuran untuk membuat simpul-simpul pada decision tree. Simpul dibagi berdasarkan ukuran yang lebih besar dari atau sama dengan parameter minimal size of split. Minimal leaf size yaitu, pohon yang dihasilkan sedemikian rupa memiliki himpunan bagian simpul daun setidaknya sebanyak jumlah minimal leaf size.
Minimal gain merupakan nilai gain minimal yang ditentukan untuk menghasilkan simpul pohon keputusan.
Gambar 4.23 Icon run
Setelah beberapa detik maka RapidMiner akan menampilkan hasil keputusan pada view result. Jika kita pilih graph view maka akan ditampilkan hasilnya berbentuk pohon keputusan (tree) seperti gambar 4.24
Gambar 4.24 Hasil berupa graph pohon keputusan
Tabel 4.1 Keterangan warna predikat kelulusan
Warna Keterangan
Biru Sangat Memuaskan
Merah Memuaskan
Hasil proses klasifikasi predicate kelulusan dengan metode Decision tree
atau pohon keputusan ditunjukan seperti gambar 4.24 diatas dapat dilihat bahwa atribut yang memiliki pengaruh paling tinggi untuk menentukan klasifikasi predicate kelulusan mahasiswa adalah Provinsi yang mana atribut ini menjadi node akar pertama. Selain menampilkan hasil decision tree berupa graph atau tampilan pohon keputusan, RapidMiner juga menyediakan tool untuk menampilkan hasil berupa text view, table dan scatter plot view.
Gambar 4.25 Hasil dari text view (operator ID3)
Seperti gambar 4.25 dapat dilihat penjelasan RapidMiner menggunakan
Gambar 4.26 Hasil accuracy dari table (peformanceVector)
Dapat dilihat pada gambar 4.26 tingkat accuracy dari performance vector
yaitu 69.51%.
Gambar 4.27 Grafikscatter plotview.
1.5.2.Algoritma ID3
Dalam penelitian algoritma yang digunakan adalah ID3 dan untuk memudahkan menjelaskan tentang algoritma ID3 dalam penelitian ini maka penulis membuat tabel data yang digunakan dalam penelitian seperti tabel 4.2
Tabel 4.2 Data kelulusan mahasiswa Fakultas Teknik tahun 2013-2015 (UMY)
NO Provinsi Jurusan SMA Jenis kelamin Predikat kelulusan
Tabel 4.3 Data kelulusan mahasiswa Fakultas Teknik tahun 2013-2015 (UMY)
NO Provinsi Jurusan SMA Jenis kelamin Predikat kelulusan
21 A IPA Perempuan Sangat Memuaskan
22 A IPA Perempuan Cumlaude
23 A IPS Laki-Laki Memuaskan
24 A IPS Laki-Laki Sangat Memuaskan
25 A KEJURUAN Laki-Laki Sangat Memuaskan
26 A KEJURUAN Laki-Laki Cumlaude
27 A KEJURUAN Laki-Laki Sangat Memuaskan
28 A KEJURUAN Perempuan Cumlaude
38 C KEJURUAN Laki-Laki Sangat Memuaskan
39 B IPA Laki-Laki Memuaskan
40 B IPA Perempuan Cumlaude
41 B IPA Perempuan Sangat Memuaskan
42 B IPS Laki-Laki Sangat Memuaskan
43 B IPS Laki-Laki Sangat Memuaskan
44 B KEJURUAN Laki-Laki Sangat Memuaskan
45 B KEJURUAN Laki-Laki Sangat Memuaskan
Tabel 4.4 Data kelulusan mahasiswa Fakultas Teknik tahun 2013-2015 (UMY)
NO Provinsi Jurusan SMA Jenis kelamin Predikat kelulusan
47 B KEJURUAN Laki-Laki Sangat Memuaskan
48 B KEJURUAN Laki-Laki Sangat Memuaskan
49 C [Tidak Ada Laki-Laki Sangat Memuaskan
68 C KEJURUAN Laki-Laki Sangat Memuaskan
69 C KEJURUAN Laki-Laki Sangat Memuaskan
70 C KEJURUAN Laki-Laki Cumlaude
71 C KEJURUAN Laki-Laki Sangat Memuaskan
Tabel 4.5 Data kelulusan mahasiswa Fakultas Teknik tahun 2013-2015 (UMY)
NO Provinsi Jurusan SMA Jenis kelamin Predikat kelulusan
73 C KEJURUAN Laki-Laki Sangat Memuaskan
74 C KEJURUAN Laki-Laki Sangat Memuaskan
75 C KEJURUAN Laki-Laki Sangat Memuaskan
76 C KEJURUAN Laki-Laki Sangat Memuaskan
77 C KEJURUAN Laki-Laki Cumlaude
78 C KEJURUAN Laki-Laki Sangat Memuaskan
79 C KEJURUAN Laki-Laki Sangat Memuaskan
80 C KEJURUAN Laki-Laki Cumlaude
81 C KEJURUAN Perempuan Sangat Memuaskan
82 C IPA Laki-Laki Sangat Memuaskan
83 C IPA Perempuan Cumlaude
84 C KEJURUAN Laki-Laki Sangat Memuaskan
85 B [Tidak Ada Laki-Laki Sangat Memuaskan
91 B KEJURUAN Laki-Laki Sangat Memuaskan
92 B KEJURUAN Laki-Laki Sangat Memuaskan
Tabel 4.6 Data kelulusan mahasiswa Fakultas Teknik tahun 2013-2015 (UMY)
NO Provinsi Jurusan SMA Jenis kelamin Predikat kelulusan
99 C IPA Laki-Laki Sangat Memuaskan
109 C KEJURUAN Laki-Laki Sangat Memuaskan
110 C KEJURUAN Laki-Laki Sangat Memuaskan
111 C KEJURUAN Laki-Laki Sangat Memuaskan
Tabel 4.7 Data kelulusan mahasiswa Fakultas Teknik tahun 2013-2015 (UMY)
NO Provinsi Jurusan SMA Jenis kelamin Predikat kelulusan
Tabel 4.8 Data kelulusan mahasiswa Fakultas Teknik tahun 2013-2015 (UMY)
NO Provinsi Jurusan SMA Jenis kelamin Predikat kelulusan
151 C IPS Laki-Laki Sangat Memuaskan
152 C IPS Laki-Laki Sangat Memuaskan
153 C IPS Laki-Laki Sangat Memuaskan
154 C KEJURUAN Laki-Laki Sangat Memuaskan
155 C KEJURUAN Laki-Laki Cumlaude
156 C KEJURUAN Laki-Laki Sangat Memuaskan
157 C KEJURUAN Laki-Laki Sangat Memuaskan
158 C KEJURUAN Laki-Laki Sangat Memuaskan
159 C KEJURUAN Laki-Laki Sangat Memuaskan
160 C KEJURUAN Laki-Laki Sangat Memuaskan
161 C KEJURUAN Laki-Laki Sangat Memuaskan
162 C KEJURUAN Laki-Laki Memuaskan
163 C KEJURUAN Laki-Laki Sangat Memuaskan
164 C KEJURUAN Laki-Laki Sangat Memuaskan
165 C KEJURUAN Laki-Laki Sangat Memuaskan
166 C KEJURUAN Laki-Laki Sangat Memuaskan
167 C KEJURUAN Laki-Laki Sangat Memuaskan
168 C KEJURUAN Laki-Laki Sangat Memuaskan
169 C KEJURUAN Laki-Laki Sangat Memuaskan
Tabel 4.9 Data kelulusan mahasiswa Fakultas Teknik tahun 2013-2015 (UMY)
NO Provinsi Jurusan SMA Jenis kelamin Predikat kelulusa
177 C IPA Perempuan Sangat Memuaskan
185 D KEJURUAN Laki-Laki Sangat Memuaskan
186 D IPA Laki-Laki Cumlaude
187 D IPA Laki-Laki Sangat Memuaskan
188 D KEJURUAN Laki-Laki Sangat Memuaskan
189 D KEJURUAN Laki-Laki Memuaskan
190 D BAHASA Perempuan Sangat Memuaskan
191 D IPA Laki-Laki Cumlaude
197 D KEJURUAN Laki-Laki Sangat Memuaskan
198 D KEJURUAN Laki-Laki Sangat Memuaskan
199 D IPA Laki-Laki Memuaskan
200 D IPS Laki-Laki Sangat Memuaskan
201 D IPS Laki-Laki Sangat Memuaskan