ANALISIS PENGARUH PANJANG BIT KODE PADA KINERJA PROGRAM KOMPRESI YANG MENGGUNAKAN
ALGORITMA LEMPEL ZIV WELCH (LZW)
SKRIPSI
Diajukan untuk melengkapi tugas akhir dan memenuhi syarat mencapai gelar
Sarjana Komputer
FAHRUR RAZI 041401023
PROGRAM STUDI S1 ILMU KOMPUTER DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
MEDAN
PERSETUJUAN
Judul : ANALISIS PENGARUH PANJANG BIT KODE
PADA KINERJA PROGRAM KOMPRESI YANG MENGGUNAKAN ALGORITMA LEMPEL ZIV WELCH (LZW)
Kategori : SKRIPSI
Nama : FAHRUR RAZI
Nomor Induk Mahasiswa : 041401023
Program Studi : SARJANA (S1) ILMU KOMPUTER
Departemen : ILMU KOMPUTER
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN
ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, 10 Maret 2009
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Drs. Haluddin Panjaitan Prof. Dr. Herman Mawengkang
NIP 130 701 888 NIP 130 442 447
Diketahui/Disetujui oleh Prog. Studi Ilmu Komputer S-1 Ketua,
PERNYATAAN
ANALISIS PENGARUH PANJANG BIT KODE PADA KINERJA
PROGRAM KOMPRESI YANG MENGGUNAKAN
ALGORITMA LEMPEL ZIV WELCH (LZW)
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya
Medan, 10 Maret 2009
PENGHARGAAN
Syukur Alhamdulillah penulis nyatakan kehadirat ALLAH SWT Yang Maha Pengasih dan Maha Penyayang, dengan limpahan rahmat dan karunia-Nya skripsi ini berhasil diselesaikan dalam waktu yang telah ditetapkan.
ABSTRAK
THE EFFECT OF CODEWORD LENGTH TO PERFORMANCE OF COMPRESSION PROGRAM USED LZW ALGORITHM
ABSTRACT
LZW algorithm is compression algorithm based on dictionary coding where codeword length is a factor that very important to performance of LZW algorithm. But compression with bad codeword length result not optimal compression ratio. Problem solving method are some codeword length are test with program based on LZW, with the result conclusion how effect codeword length to performance of compression program used LZW algorithm. Test file are Calgary Corpus and Canterbury Corpus. From research the result are in Calgary Corpus optimal codeword length is 14 bit, in Canterbury Corpus optimal codeword length is 13 bit, and in Canterbury Corpus Large File optimal codeword length is 19 bit.
DAFTAR ISI
Halaman
Persetujuan ii
Pernyataan iii
Penghargaan iv
Abstrak v
Abstract vi
Daftar Isi vii
Daftar Tabel ix
Daftar Gambar x
Bab 1 Pendahuluan 1
1.1Latar Belakang 1
1.2Perumusan Masalah 2
1.3Batasan Masalah 2
1.4Tujuan 2
1.5Manfaat 2
1.6Tinjauan Pustaka 3
1.7Metodologi Penelitian 4
1.8Sistematika Penulisan 4
Bab 2 Landasan Teori 6
2.1 Pengertian Kompresi 6
2.2 Metode Kompresi 7
2.3 Rasio Kompresi 7
2.4 Dictionary Coding 7
2.5 Algoritma Lempel Ziv 77 (LZ77) 9
2.6 Algoritma Lempel Ziv 78 (LZ78) 12
2.7 Algoritma Lempel Ziv Welch (LZW) 15
2.8 Struktur Data pada Dictionary 19
2.8.1 Struktur Data Binary Tree 19
Bab 3 Perancangan dan Implementasi Perangkat Lunak 21
3.1 Karateristik Algoritma LZW 21
3.1.1 Proses Kompresi LZW 21
3.1.2 Proses Dekompresi LZW 24
3.2 Pemodelan Fungsional 24
3.2.1 DFD Level 0 ( Context Diagram ) 25
3.2.2 DFD Level 1 26
3.2.3 DFD Level 2 27
3.2.5 Perancangan Struktur Data 31
3.2.6 Perancangan Prosedural 31
3.3 Perangkat Keras Dan Perangkat Lunak Pengujian 37
3.4 Implementasi Antarmuka 37
Bab 4 Analisis Pengaruh Panjang Bit Kode pada Kinerja Program Kompresi yang
Menggunakan Algoritma LZW 42
4.1 File Yang Dicoba 42
4.1.1 Calgary Corpus 42
4.1.2 Canterbury Corpus 43
4.2 Analisis Pengaruh Panjang Bit Kode pada Program Kompresi yang
Menggunakan Algoritma LZW 43
4.2.1 Analisis Pada Calgary Corpus 44
4.2.2 Analisis Pada Canterbury Corpus 51
4.2.3 Analisis Menggunakan Canterbury Corpus Large File 53
Bab 5 Penutup 56
5.1 Kesimpulan 56
5.2 Saran 56
DAFTAR TABEL
Halaman
Tabel 2.1 Proses kompresi 17
Tabel 2.2 Proses dekompresi 19
Tabel 3.1 Contoh proses kompresi 22
Tabel 3.2 Contoh proses dekompresi 24
Tabel 3.3 Spesifikasi proses context diagram perangkat lunak kompresi LZW 26
Tabel 3.4 Spesifikasi proses diagram level 1 P.0 27
Tabel 3.5 Spesifikasi proses diagram level 2 P.1 28
Tabel 3.6 Spesifikasi proses diagram level 2 P.2 29
Tabel 3.7 Kamus data 30
Tabel 4.1 Daftar ukuran file pada Calgary Corpus 45
Tabel 4.2 Hasil pengujian rata-rata rasio algoritma LZW pada Calgary Corpus 46 Tabel 4.3 Hasil pengujian waktu proses rata-rata kompresi algoritma LZW pada
Calgary Corpus 48
Tabel 4.4 Jumlah item rata-rata proses kompresi algoritma LZW pada Calgary
Corpus 50
Tabel 4.5 Daftar ukuran file pada Canterbury Corpus 51
DAFTAR GAMBAR
Halaman
Gambar 2.1 Ilustrasi contoh cara kerja algoritma LZ77 9
Gambar 2.2 Ilustrasi penggeseran window pada algoritma LZ77 10
Gambar 2.3 Ilustrasi penggunaan token (offset,length) 10
Gambar 2.4 Ilustrasi contoh fragmen lookahead yang terdapat pada history 11
Gambar 2.5 Ilustrasi implementasi dari algoritma LZ77 12
Gambar 2.6 Ilustrasi proses encoding algoritma LZ78 14
Gambar 2.7 Ilustrasi proses decoding algoritma LZ78 15
Gambar 2.8 Ilustrasi binary tree 20
Gambar 3.1 Ilustrasi binary tree pada proses kompresi 23
Gambar 3.2 DFD level 0 25
Gambar 3.3 DFD level 1 26
Gambar 3.4 DFD level 2 Proses P.1 27
Gambar 3.5 DFD level 2 Proses P.2 28
Gambar 3.6 Flowchart proses encoding algoritma LZW 33
Gambar 3.7 Flowchart proses decoding algoritma LZW 36
Gambar 3.8 Tampilan halaman utama 38
Gambar 3.9 Tampilan proses kompresi 39
Gambar 3.10 Tampilan proses dekompresi 39
Gambar 3.11 Tampilan pencarian file 40
Gambar 3.12 Tampilan bantuan 41
Gambar 4.1 Grafik rasio rata-rata hasil kompresi algoritma LZW pada
Calgary Corpus 47
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Perkembangan teknologi komputer yang sangat pesat menyebabkan data digital
menjadi media yang umum dalam masyarakat. Pemakaian data digital ini meliput i
seluruh lapisan masyarakat mulai dari perseorangan, lembaga, dan bisnis. Pemakaian
data digital sangat efektif karena pada media dengan ukuran relatif kecil kita dapat
menyimpan sangat banyak berkas dibandingkan pada media kertas yang berukuran
relatif lebih besar.
Akan tetapi media penyimpanan data digital memiliki keterbatasan dalam
ukuran data yang dapat disimpan. Sedangkan data digital terus bertambah besar dan
banyak sehingga pada suatu saat media penyimpanan data digital akan penuh oleh
data digital tersebut.
Pengiriman data digital membutuhkan bandwidth dalam pengirimannya dan
bandwidth tersebut memerlukan biaya. Sehingga semakin besar data digital yang
dikirim maka makin besar pula biaya yang dikeluarkan. Oleh karena sebab-sebab
inilah maka kompresi data menjadi solusi tepat dalam menghemat pemakaian
perangkat keras serta menurunkan biaya pengiriman data melalui internet. Selain lebih
murah juga mengirim data yang telah terkompresi akan lebih cepat karena ukuran file
telah diperkecil.
Menurut Yair Wiseman algoritma Lempel Ziv terbagi atas dua kelompok.
Kelompok pertama didasarkan pada penggunaan referensi pada data yang berulang,
kelompok ini kemudian dikenal dengan LZ77 dan kelompok yang kedua
data, grup ini dikenal dengan LZ78. Menurut David Salomon algoritma LZW adalah
varian dari algoritma LZ78.
Menurut Yair Wiseman algoritma LZW merupakan algoritma yang
menggunakan pointer. Dan jumlah bit yang digunakan pointer akan mempengaruhi
efesiensi kompresi dari kedua algoritma tersebut. Analisis akan dilakukan dengan
mencoba jumlah bit pointer yang berbeda-beda sehingga dapat disimpulkan jumlah bit
mana yang paling tepat pada jenis file tertentu.
1.2. Rumusan Masalah
Dari latar belakang diatas dapatlah dirumuskan masalah yang menjadi latar belakang
tugas akhir ini, yaitu bagaimana pengaruh panjang bit kode pada kinerja program
kompresi yang menggunakan algoritma LZW dimana kinerja tersebut diukur dengan
parameter rasio file hasil kompresi dan waktu yang dibutuhkan untuk proses kompresi
dan dekompresi.
1.3. Batasan masalah
Batasan masalah adalah file-file yang dicoba terbatas pada Calgary Corpus dan
Canterbury Corpus sebagai set file yang digunakan.
1.4. Tujuan
Tujuan dari penulisan tugas akhir ini adalah untuk mengetahui pengaruh panjang bit
kode pada program kompresi yang menggunakan algoritma LZW.
Manfaat dari penulisan Tugas Akhir ini menambah pengetahuan bagaimana pengaruh
panjang bit kode pada program kompresi yang menggunakan algoritma LZW.
1.6. Tinjauan Pustaka
Menurut David Salomon kompresi data adalah proses pengkodean informasi dengan
menggunakan bit yang lebih sedikit dibandingkan dengan kode yang sebelumnya
dipakai dengan menggunakan skema pengkodean tertentu. Kompresi data, terutama
untuk komunikasi, dapat bekerja jika kedua pihak antara pengirim dan penerima data
komunikasi memiliki skema pengkodean yang sama (Salomon, 2005).
Menurut Mengyi (2006, hal:117) Dictionary Coding adalah metode yang
menggunakan sekumpulan daftar frase (kamus), yang diharapkan berisikan banyak
frase yang terdapat pada file sumber, dimana kamus digunakan untuk menggantikan
fragmen dari sumber dengan pointer kamus tersebut. Kompresi hanya dapat dilakukan
jika pointer yang dibutuhkan kurang dari ukuran fragmen tersebut. Dalam banyak hal,
metode dictionary lebih mudah dimengerti daripada metode probabilistik.
Algoritma Lempel Ziv ini terbagi atas dua varian utama yaitu LZ77 dan LZ78.
Perbedaan utama kedua algoritma ini adalah pada teknik pembuatan dictionary. Pada
LZ77 dictionary adalah fragmen dari sebuah window (sliding window). LZ78
menggunakan frase-frase yang pada file sebagai dictionary. Algoritma LZW adalah
varian dari algoritma LZ78. Keunggulan masing-masing adalah algoritma LZ78
menggunakan struktur data yang lebih kompleks dalam mengelola penyimpanan
dictionary, LZ77 mengubah dengan cepat dictionary dan lebih cepat pada saat
decoding. Pada aplikasi pemilihan skema dapat sangat kompleks karena telah
dipatenkan (Hankerson et al, 2003).
Algoritma Lempel-Ziv-Welch (LZW) menggunakan teknik adaptif dan
berbasiskan “kamus” Pendahulu LZW adalah LZ77 dan LZ78 yang dikembangkan
mengembangkan teknik tersebut pada tahun 1984. LZW banyak dipergunakan pada
UNIX, GIF, V.42 untuk modem.
Algoritma ini bersifat adaptif dan efektif karena banyak karakter dapat
dikodekan dengan mengacu pada string yang telah muncul sebelumnya dalam teks.
Prinsip kompresi tercapai jika referensi dalam bentuk pointer dapat disimpan dalam
jumlah bit yang lebih sedikit dibandingkan string aslinya. Panjang bit yang digunakan
akan berpengaruh pada rasio hasil kompresi maupun kecepatan kompresi.
1.7. Metodologi Penelitian
Metodologi penelitian yang digunakan adalah metodologi penelitian komparatif.
Dimana untuk menunjukkan pengaruh panjang bit kode pada kinerja program
kompresi yang menggunakan algoritma LZW, beberapa panjang bit kode dicoba
untuk dibandingkan. Kinerja program kompresi tersebut diukur dari rasio file hasil
kompresi dan waktu proses yang dibutuhkan. Setelah dibandingkan maka dari hasil
tersebut dibuat grafik untuk mempermudah analisis pengaruh panjang bit kode pada
program kompresi yang menggunakan algoritma LZW. Dan kemudian disimpulkan
bagaimana pengaruh panjang bit kode pada program kompresi yang menggunakan
algoritma LZW. File-file yang digunakan dalam perbandingan ini adalah Calgary
Corpus dan Canterbury Corpus.
1.8. Sistematika Penulisan
Dalam penulisan tugas akhir ini, Penulis membagi sistematika penulisan menjadi 5
Bab, yang lebih jelasnya dapat dilihat di bawah ini :
BAB 1 PENDAHULUAN
Berisi tentang latar belakang diambilnya judul Tugas Akhir “Pengaruh
Algoritma Lempel Ziv Welch”, rumusan masalah, batasan masalah,
tujuan, manfaat, tinjauan pustaka, metodologi penelitian, dan
sistematika penulisan Tugas Akhir yang menjelaskan secara garis besar
susbstansi yang diberikan pada masing-masing bab.
BAB 2 LANDASAN TEORI
Membahas tentang pengertian pemampatan data (file compression)
secara umum, metode dan cara kerja dari algoritma LZW.
BAB 3 PERANCANGAN DAN IMPLEMENTASI PERANGKAT
LUNAK
Membahas bagaimana perancangan program kompresi. Dimana
perancangan sangat penting dalam pembuatan sebuah program. Pada
bab ini juga dibahas mengenai hasil implementasinya pada perangkat
lunak.
BAB 4 ANALISIS PENGARUH PANJANG BIT KODE PADA KINERJA PROGRAM KOMPRESI YANG MENGGUNAKAN ALGORITMA LZW
Membahas bagaimana pengaruh panjang bit kode pada program
kompresi yang menggunakan algoritma LZW. Program yang telah
implementasi sebelumnya kemudian digunakan sebagai alat penguji.
Panjang bit kode yang berbeda-beda akan dicoba untuk mendapatkan
kesimpulan.
BAB 5 KESIMPULAN DAN SARAN
BAB 2
LANDASAN TEORI
2.1 Pengertian Kompresi
Menurut David Salomon kompresi data adalah proses pengkodean informasi dengan
menggunakan bit yang lebih sedikit dibandingkan dengan kode yang sebelumnya
dipakai dengan menggunakan skema pengkodean tertentu. Kompresi data, terutama
untuk komunikasi, dapat bekerja jika kedua pihak antara pengirim dan penerima data
komunikasi memiliki skema pengkodean yang sama (Salomon, 2005).
Pemampatan merupakan salah satu dari bidang teori informasi yang bertujuan
untuk menghilangkan redundansi dari sumber. Pemampatan bermanfaat dalam
membantu mengurangi konsumsi sumber daya yang mahal, seperti ruang hard disk
atau perpindahan data melalui internet (Nelson, 1996).
Kompresi data ditujukan untuk mereduksi penyimpanan data yang redundan
atau merepresentasikan kembali data tersebut kedalam bentuk yang lebih efisien dari
segi kapasitas. Kompresi data terdiri dari dua kategori yaitu kompresi lossy dan
lossless, dan pada citra digital kompresi jenis lossy yang sering digunakan. Kompresi
jenis lossy merupakan suatu teknik kompresi yang pada prosesnya menghilangkan
sebagian dari data sehingga file tidak dapat dikembalikan secara utuh, sebaliknya
kompresi lossless merupakan teknik kompresi yang tetap mempertahankan informasi
asli dari suatu data secara utuh. Pada citra digital kompresi lossy merupakan kategori
yang sering digunakan. Akan tetapi tidak menutup kemungkinan untuk melakukan
2.2 Metode Kompresi
Terdapat banyak metode kompresi dan metode-metode tersebut dapat dibagi menjadi:
1. Metode Lossless
Menurut Mengyi (2006, hal:5) kompresi lossless adalah kompresi data yang
menghasilkan file data hasil kompresi yang dapat dikembalikan menjadi file
data asli sebelum dikompresi secara utuh tanpa perubahan apapun. Kompresi
jenis ini ideal untuk kompresi teks. Algoritma yang termasuk dalam metode
kompresi lossless diantaranya adalah dictionary coding dan huffman coding.
2. Metode Lossy
Menurut Mengyi (2006, hal:6) kompresi data yang menghasilkan file data hasil
kompresi yang tidak dapat dikembalikan menjadi file data sebelum dikompresi
secara utuh. Ketika data hasil kompresi di-decode kembali, data hasil decoding
tersebut tidak dapat dikembalikan menjadi sama dengan data asli tetapi ada
bagian data yang hilang.
2.3 Rasio Kompresi
Menurut Mengyi (2006, hal:11) rasio kompresi adalah ukuran dari output stream
dibagi dengan ukuran dari input stream. Misalnya nilai rasio kompresi adalah 0.6 itu
berarti data yang terkompres menggunakan hanya 60% dari ukuran sebenarnya. Dan
nilai rasio kompresi yang lebih dari 1 berarti data yang dikompres malah membesar.
Rasio = 100%
_ _ _ _ × asli file Ukuran i terkompres file Ukuran
( 2.1 )
Menurut Mengyi (2006, hal:117) Dictionary Coding adalah metode yang
menggunakan sekumpulan daftar frase (kamus), yang diharapkan berisikan banyak
frase yang terdapat pada file sumber, dimana kamus digunakan untuk menggantikan
fragmen dari sumber dengan pointer kamus tersebut. Kompresi hanya dapat dilakukan
jika pointer yang dibutuhkan kurang dari ukuran fragmen tersebut. Dalam banyak hal,
metode dictionary lebih mudah dimengerti daripada metode probabilistik.
Metode dictionary yang termudah dibuat adalah metode dengan menggunakan
kamus yang tetap (statis) dimana kamus ini telah ada pada coder dan decoder. Untuk
file teks misalnya teks bahasa inggris, beberapa ribu kata yang paling sering
digunakan sebagai dictionary. Jika file sumber adalah file yang berisi kode sumber
sebuah bahasa pemrograman tertentu misalnya bahasa C, maka daftar keyword dan
standard library function dapat digunakan sebagai dictionary. Dictionary yang tetap
(statis) lebih baik untuk situasi tertentu, tetapi setidaknya terdapat dua permasalahan
serius. Penambahan, perubahan, penghapusan pada dictionary harus mengubah juga
seluruh program kompresi yang telah tersebar luas. Permasalah kedua adalah
dictionary yang statis tidak dapat melakukan kompresi pada teks yang tidak terdapat
pada dictionary. Misalnya bahasa pemrograman C, dimana kompresi tidak dapat
dilakukan pada nama variabel yang dibuat oleh programer (Hankerson et al, 2003).
Hal yang terpenting pada metode Dictionary adalah bagaimana menciptakan
algoritma yang dapat mengadaptasi seluruh jenis file sumber, dan biasanya untuk
melakukan harus dilakukan scan pada file tersebut. Akan tetapi, komunikasi melalui
modem yang misalnya V.42bis dimana penggunaan dictionary yang statis tidak
digunakan melainkan penambahan dictionary akan dilakukan secara on-the-fly
(Hankerson et al, 2003).
Metode Adaptive dictionary ditemukan oleh Ziv dan Lempel pada tahun 1977
dan 1978. Sehingga kedua algoritma tersebut kemudian dikenal luas sebagai LZ77 dan
LZ78. Algoritma LZ77 telah diaplikasikan pada Lharc, PKZIP, GNU zip, Info-ZIP,
didesain sebagai penerus dari GIF. Algoritma LZ78 telah digunakan pada standar
komunikasi modem (V.42bis), dan program kompres Unix bernama compress, dan
pada GIF format file citra (Hankerson et al, 2003).
Algoritma Lempel Ziv ini terbagi atas dua varian utama yaitu LZ77 dan LZ78.
Perbedaan utama kedua algoritma ini adalah pada teknik pembuatan dictionary. Pada
LZ77 dictionary adalah fragmen dari sebuah window (sliding window). LZ78
menggunakan frase-frase yang pada file sebagai dictionary. Algoritma LZW adalah
varian dari algoritma LZ78. Keunggulan masing-masing adalah algoritma LZ78
menggunakan struktur data yang lebih kompleks dalam mengelola penyimpanan
dictionary, LZ77 mengubah dengan cepat dictionary dan lebih cepat pada saat
decoding. Pada aplikasi pemilihan skema dapat sangat kompleks karena telah
dipatenkan (Hankerson et al, 2003).
2.5 Algoritma Lempel Ziv 77 (LZ77)
Pada dasarnya algoritma LZ77 membagi window dengan dua bagian yaitu history dan
lookahead. Dalam pertimbangan pembuatan dictionary maka history akan digunakan
sebagai dictionary sehingga history harus memiliki panjang lebih dari lookahead.
Idenya adalah menggantikan segmen dari lookahead dengan pointer pada dictionary,
dan menggeser prosesnya sepanjang window (Hankerson et al, 2003).
Gambar 2.1 Ilustrasi contoh cara kerja algoritma LZ77
Pada Gambar 2.1 misalkan segmen inisial ‘he’ sama dengan karakter kedua
dan dihitung dari kanan ke kiri. Dimana komponen ketiga adalah karakter selanjutnya
dari file sumber dan kemudian window digeser lihat Gambar 2.2.
Gambar 2.2 Ilustrasi penggeseran window pada algoritma LZ77
Kemudian ‘he’ diganti menjadi sebuah token yaitu (10,2,spasi). Dimana 10
berarti jarak karakter dengan karakter lookahead, 2 berarti panjang string yang sama,
dan spasi adalah karakter setelah karakter ‘he’ tersebut. Kompresi akan sukses jika
token ini menghasilkan jumlah bit yang lebih sedikit dari pada file sumber.
Selanjutnya karakter yang tidak sama pada token dapat mengakibatkan suatu kasus
dimana tidak ada karakter yang sama pada history. Maka penggunaan (offset,length)
dapat digunakan ketimbang token triple sebelumnya. Gambar 2.3 menunjukkan
beberapa langkah proses pada contoh masalah:
Gambar 2.3 Ilustrasi penggunaan token (offset,length)
Sebuah decoder menerima output token, dimana token tersebut akan dibangun
ulang. Menurut Hankerson (2003, hal:231) ada beberapa hal yang harus diperhatikan
1. Decoder harus dapat membedakan antara sebuah token dengan sebuah karakter
asli.
2. Kualitas kompresi akan bergantung pada token, tepatnya pada panjang string
token. Dimana panjang yang terlalu pendek dapat menyebabkan rasio kompresi
membesar.
3. String yang sama didasarkan pada lookahead. Seperti pada Gambar 2.4 dimana
window berisi fragmen tersebut.
Gambar 2.4 Ilustrasi contoh fragmen lookahead yang terdapat pada history
4. Setiap langkah, maka digunakan greedy parsing dimana dictionary dicari untuk
sebuah string sama yang terpanjang pada inisial segmen. Tidak ada jaminan
penggunaan greedy parsing adalah maksimal. Pencarian untuk longest match
pada dictionary adalah hal yang cukup sulit. Dimana banyak varian LZ77 yang
menggunakan struktur data yang baik untuk mempercepat pencarian.
5. Banyak varian LZ77 yang mempunyai kecepatan tinggi saat proses decoding,
akan tetapi diperlukan kerja keras untuk mencari algoritma dan struktur data
yang cepat pada proses encoding.
6. Sebuah token dapat dikompres lagi dengan metode kompresi tertentu. Sebuah
contoh, seharusnya digunakan jumlah bit yang tetap untuk menyimpan match
length kemudian match length tersebut dikompres lagi dengan menggunakan
metode kompresi probabilistik seperti Huffman akan menambah efektivitas dari
Implementasi dari LZ77 file sumber tentu berisi ASCII akan terdiri dari 256
karakter dan panjang bit adalah 8 bit. Kemudian history dan lookahead keduanya
mempunyai panjang yang tetap, dengan offsets menggunakan 12 bits dan length
menggunakan 4 bits. Dan 1 bit digunakan sebagai penanda atau flag yang
membedakan antara token dengan sebuah karakter asli.
Sehingga total bit yang dibutuhkan adalah 17 bits sedangkan sebuah karakter
asli membutuhkan 9 bits. Oleh sebab itu, maka token hanya digunakan untuk match
length minimal 2 karakter. Penggunaan 4 bits pada length merepresentasikan panjang
2 sampai 17. Pada Gambar 2.5 dapat dilihat ilustrasi cara kerja dari implementasi
algoritma LZ77.
Gambar 2.5 Ilustrasi implementasi dari algoritma LZ77
File sumber membutuhkan 36 x 8 = 288 bits. Sedangkan hasil kompresi
algoritma LZ77 adalah 6 token dan 18 karakter asli sehingga jumlah bit hasil kompresi
adalah 6 x 17 + 18 x 9 = 264 bits. Sehingga proses kompresi dapat menghemat 24 bit.
LZ78 adalah algoritma yang tipikal menggunakan sebuah trie untuk
menyimpan seluruh pola string. Sebuah dictionary pada algoritma LZ78 adalah
sebuah set entry pola, dimana diindex dari 0 dan bernilai integer. Mirip dengan LZ77
dimana index menunjuk (pointing) pada sebuah kata pada dictionary yang disebut
token. Berbeda dengan algoritma LZ77 output dari proses encoding algoritma LZ78
hanya berupa deretan token saja sehingga tidak dibutuhkan bit tambahan yang
digunakan sebagai flag seperti algoritma LZ77.
Berbeda dengan LZ77 yang menggunakan token yang terdiri dari 3 bagian, LZ78
hanya membutuhkan 2 bagian untuk satu token. Token ini direpresentasikan sebagai
<f,c> dimana f merepresentasikan offset yang berisi posisi awal dari sebuah match
string dan c adalah karakter yang merupakan simbol selanjutnya pada file sumber.
Sedangkan panjang match telah tersimpan pada dictionary, sehingga tidak dibutuhkan
lagi komponen panjang match pada kode output. Jika simbol tidak ditemukan pada
dictionary, token <0,x> digunakan sebagai penanda bahwa string adalah null string +
x. Awalnya sebuah dictionary diisi dengan seluruh 256 karakter ASCII. Berikut
algoritma encoding LZ78, yaitu:
INPUT: file sumber
OUTPUT : Sekumpulan token <index(word), c>, dictionary yang telah diupdate
1. while not EOF do
2. word ← empty
3. c ← next_char()
4. while word + c is in the Dictionary do
5. word ← word + c
6. c ← next_char()
7. end while
8. output token <index(word), c>
{ Dimana index(word) adalah index dari word pada dictionary }
9. add word + c into the dictionary at the nex available location
10.end while
Misalkan input string ”a date at a date” akan dikompres menggunakan
algoritma LZ78 maka proses encoding dimulai dengan dictionary yang kosong. Proses
Gambar 2.6 Ilustrasi proses encoding algoritma LZ78
Proses decoding adalah membaca elemen dari token dari file yang terkompresi
kemudian membangun dictionary dengan cara yang sama pada proses encoding.
Misalnya <x,c> adalah sebuah token, dimana x adalah index dari dictionary dan c
adalah karakter selanjutnya. Algoritma proses decoding algoritm LZ78 adalah sebagai
berikut:
INPUT: Sekumpulan token <x,c>
OUTPUT : string dari simbol yang telah didecode
1. while not EOF do
2. x ← next_codeword()
3. c ← next_char()
4. output dictionary_word(x) + c
5. add dictionary_word(x) + c into dictionary at the nex available location
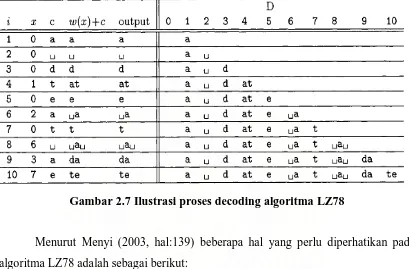
Misalnya input dari proses encoding adalah token-token : 0a 0<spasi> 0d 1t 0e
2a 0t 6<spasi> 3a 7e. Proses decoding dapat dilihat pada Gambar 2.7. Dari proses ini
didapat hasil berupa string asli yaitu “a date at a date” kembali.
Gambar 2.7 Ilustrasi proses decoding algoritma LZ78
Menurut Menyi (2003, hal:139) beberapa hal yang perlu diperhatikan pada
algoritma LZ78 adalah sebagai berikut:
1. LZ78 telah membuat perbaikan-perbaikan daripada LZ77. Dimana komponen
token yang digunakan lebih sedikit dibanding LZ77.
2. Tidak diperlukannya tambahan bit sebagai flag seperti LZ77 sehingga lebih
efisien.
3. LZ78 mempunyai banyak varian dan LZW adalah salah satu varian LZ78 yang
sangat populer.
2.7 Algoritma Lempel Ziv Welch (LZW)
Algoritma Lempel-Ziv-Welch (LZW) menggunakan teknik adaptif dan berbasiskan
dan Abraham Lempel pada tahun 1977 dan 1978. Terry Welch mengembangkan
teknik tersebut pada tahun 1984. LZW banyak dipergunakan pada UNIX, GIF, V.42
untuk modem.
Algoritma ini bersifat adaptif dan efektif karena banyak karakter dapat
dikodekan dengan mengacu pada string yang telah muncul sebelumnya dalam teks.
Prinsip kompresi tercapai jika referensi dalam bentuk pointer dapat disimpan dalam
jumlah bit yang lebih sedikit dibandingkan string aslinya.
Menurut David Salomon (2005, hal:123) algoritma ini adalah versi aplikasi dari
algoritma dictionary LZ78. Algoritma ini mempunyai ciri-ciri sebagai berikut :
Dictionary diinisialisasi dengan semua symbol dari sumber input, sehingga jika
symbol pertama kali muncul sudah punya entry dalam dictionary.
Algoritma ini mengeluarkan output berupa indeks untuk string yang ada dalam
dictionary. Jika kombinasi string tersebut tidak ada, maka kombinasi tersebut
akan ditambahkan dalam dictionary dan algoritma akan mengeluarkan output
dari kombinasi yang ada.
Menurut Mengyi (2006, hal:120) algoritma untuk proses kompresi dengan
1. CHAR = get input character
2. WHILE there are still input characters DO
3. NEXT = get input character
4. IF CHAR+NEXT is in the string table then
5. CHAR = CHAR+NEXT
6. ELSE
7. output code for CHAR
8. add CHAR+NEXT to the string table
9. CHAR = NEXT
10. END of IF
11.END of WHILE
12.output the code for STRING
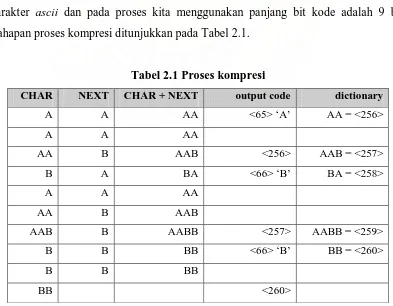
Contoh proses kompresi yaitu misal string “AAABAABBBB” akan
dikompresi dengan LZW. Dictionary akan diisi dengan nilai awal dan kode untuk
karakter ascii dan pada proses kita menggunakan panjang bit kode adalah 9 bit.
Tahapan proses kompresi ditunjukkan pada Tabel 2.1.
Tabel 2.1 Proses kompresi
CHAR NEXT CHAR + NEXT output code dictionary
A A AA <65> ‘A’ AA = <256>
A A AA
AA B AAB <256> AAB = <257>
B A BA <66> ‘B’ BA = <258>
A A AA
AA B AAB
AAB B AABB <257> AABB = <259>
B B BB <66> ‘B’ BB = <260>
B B BB
Sehingga output yang dihasilkan dari proses kompresi adalah sebagai berikut :
<65><256><66><257><66><260>. Hasil kompresi menghasilkan 6 codeword
dengan panjang 9 bit, maka jumlah bit yang digunakan adalah 54 bit. Sedangkan file
sumber mempunyai 10 karakter ASCII dengan masing-masing karakter 8 bit sehingga
berjumlah 80 bit. Sehingga dapat dihitung rasio kompresi adalah :
Rasio = 100%
_ _ _ _ × asli file Ukuran i terkompres file Ukuran
= 100% 80 54 × = 67,5%
Menurut Mengyi (2006, hal:125) algoritma untuk proses dekompresi dengan
algoritma Lempel Ziv Welch adalah sebagai berikut :
1. read x from the compressed file
2. look up dictionary for element at x
3. output element
4. word = element
5. while not E0F do
6. read x
7. look up dictionary for element at x
8. if there is no entry yet for index x then
9. element = word + firstCharOfWord
10. end if
11. output element
12. add word + firstCharOfElement to the dictionary
13. word = element
Contoh Proses dekompresi misalnya output yang didapat dari hasil kompresi
yang telah dilakukan yaitu <65><256><66><257><66><260> kemudian akan
didekompresi menggunakan algoritma dekompresi Lempel Ziv Welch (LZW), proses
dekompresi sebagai berikut :
Tabel 2.2 Proses dekompresi
x element output word in loop dictionary
65 A A
256 AA AA AA AA = 256
66 B B B AAB = 257
257 AAB AAB AAB BA = 258
66 B B B AABB = 259
260 BB BB BB BB = 260
Setelah proses dekompresi dilakukan maka file tersebut kembali pada data
semula yaitu : “AAABAABBBB”. Algoritma LZW telah banyak diaplikasikan
diantaranya program utilitas Unix yang bernama compress.
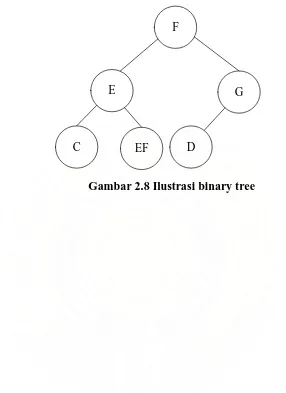
2.8 Struktur Data pada Dictionary
Pemilihan struktur data sangat penting pada algoritma LZW, terutama pemilihan
struktur data pada dictionary. Struktur data binary tree sangat tepat digunakan pada
dictionary, karena binary tree akan menghemat waktu pencarian. Karena waktu
pencarian dapat dikurangi maka akan berdampak pada kecepatan waktu kompresi dan
dekompresi yang semakin baik. Hal ini akan menambah tingkat efisiensi dari
algoritma tersebut.
2.8.1 Struktur Data Binary Tree
Binary Tree adalah tree yang terurut yang pada setiap node dapat mempunyai satu,
berurut berdasarkan abjad dari string dictionary. Sehingga pencarian dapat dilakukan
dengan lebih cepat, hal ini adalah salah satu keuntungan pemakaian binary tree jika
dibandingkan struktur data list biasa (Weiss, 2003).
F
E G
[image:30.595.158.444.163.556.2]C EF D
BAB 3
PERANCANGAN DAN IMPLEMENTASI PERANGKAT LUNAK
3.1 Karateristik Algoritma LZW
Cara kerja algoritma LZW adalah menyimpan karakter yang berulang pada sebuah
dictionary. Kemudian output berupa kode dari string yang terdapat pada input
tersebut. Sehingga efisiensi algoritma ini sangat bergantung pada dictionary, dimana
implementasi dictionary akan mempengaruhi kecepatan serta hasil dari kompresi.
Sebuah dictionary dapat menyimpan jumlah item bergantung pada pemilihan panjang
kode bit, semakin panjang kode bit yang digunakan maka semakin banyak item yang
dapat disimpan pada program.
3.1.1 Proses Kompresi LZW
Proses kompresi LZW adalah membaca karakter dari file sumber kemudian karakter
tersebut digabung dengan karakter yang telah dibaca sebelumnya menjadi sebuah
string. String tersebut kemudian dicari pada dictionary jika tidak terdapat maka
tambahkan string tersebut pada dictionary kemudian output string tersebut. Berikut
contoh proses kerja algoritma LZW.
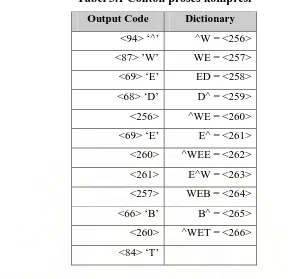
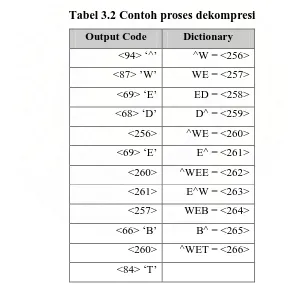
Contoh proses kompresi yaitu misalnya string
“^WED^WE^WEE^WEB^WET” akan dikompresi dengan LZW. Dictionary akan
diisi dengan nilai awal dan kode untuk karakter ascii. Kompresi akan menghasilkan
Tabel 3.1 Contoh proses kompresi
Output Code Dictionary
<94> ‘^’ ^W = <256>
<87> ’W’ WE = <257>
<69> ‘E’ ED = <258>
<68> ‘D’ D^ = <259>
<256> ^WE = <260>
<69> ‘E’ E^ = <261>
<260> ^WEE = <262>
<261> E^W = <263>
<257> WEB = <264>
<66> ‘B’ B^ = <265>
<260> ^WET = <266>
<84> ‘T’
Proses pembuatan dictionary menggunakan struktur data binary tree. Hal ini
dimaksudkan agar kecepatan pencarian pada dictionary dapat ditingkatkan. Dari
dictionary yang dilihat pada tabel maka contoh binary tree yang dihasilkan pada
“^W” 256 “^WE” 259 “E^” 260 “^WEE” 261 “E^W” 262 “WEB” 263 “B^” 264 “^WET” 265 “ED” 257 “D^” 258 “WE” 257
Gambar 3.1 Ilustrasi binary tree pada proses kompresi
Proses pencarian pada binary tree rata-rata membutuhkan O (log n) waktu dan
worst case dari proses pencarian adalah O(n) untuk n adalah banyak data pada
dictionary. Dengan waktu rata-rata yang cukup baik maka kecepatan kompresi dan
dekompresi akan semakin cepat. Hal ini adalah keuntungan pemakaian stuktur data
binary tree.
Misalkan kita memilih kompresi menggunakan jumlah bit kode 9 bit maka
jumlah data dictionary adalah 2 9 = 512 data yang dapat disimpan pada dictionary.
Semakin besar jumlah bit kode yang digunakan maka jumlah item dictionary akan
semakin banyak. Dampak dari jumlah item dictionary adalah rasio kompresi yang
dihasilkan. Dan hasil kompresi adalah sebagai berikut : <94><87><69><68>
<256><69> <260><261><257><66><260><84>. Dan masing-masing kode yang
dihasilkan adalah sebuah data dengan panjang kode 9 bit. Sehingga jumlah kode bit
akan menentukan jumlah item data pada dictionary, hal ini sangat mempengaruhi
3.1.2 Proses Dekompresi LZW
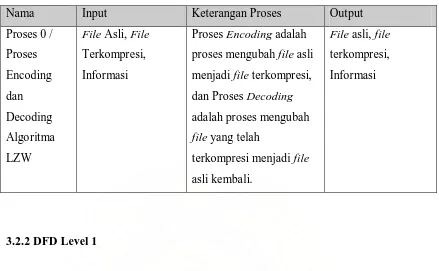
Proses dekompresi yaitu membaca satu-persatu kode bit dan menerjemahkan pada
dictionary kemudian output hasilnya. Karateristik algoritma LZW adalah membangun
kembali dictionary berdasarkan kode bit yang diterima. Proses pembuatan dictionary
ini tetap menggunakan struktur data binary tree. Sesuai proses kompresi yang telah
dilakukan maka kode-kode bit tersebut adalah : <94><87><69><68> <256><69>
<260><261><257><66><260><84>. Kemudian hasil dekompresi algoritma LZW
[image:34.595.154.446.325.609.2]dapat dilihat pada Tabel 3.2:
Tabel 3.2 Contoh proses dekompresi
Output Code Dictionary
<94> ‘^’ ^W = <256>
<87> ’W’ WE = <257>
<69> ‘E’ ED = <258>
<68> ‘D’ D^ = <259>
<256> ^WE = <260>
<69> ‘E’ E^ = <261>
<260> ^WEE = <262>
<261> E^W = <263>
<257> WEB = <264>
<66> ‘B’ B^ = <265>
<260> ^WET = <266>
<84> ‘T’
3.2 Pemodelan Fungsional
Pemodelan fungsional diharapkan agar sebuah sistem yang dibangun memiliki fungsi
perlu dianalisis. Pada perangkat lunak kompresi yang menggunakan algoritma LZW,
secara garis besar terdapat dua fungsi utama yaitu kompresi dan dekompresi
menggunakan algoritma LZW.
Pemodelan fungsional menggambarkan aspek dari sistem yang berhubungan
dengan transformasi dari nilai, seperti fungsi, pemetaan, batasan, dan ketergantungan
fungsional. Pemodelan fungsional menangkap sesuatu yang dikerjakan oleh sistem
tanpa memperhatikan bagaimana dan kapan hal itu dikerjakan. Data Flow Diagram
(DFD) adalah representasi grafis yang menggambarkan aliran informasi dan
transformasi yang terjadi pada data dari input sampai output.
3.2.1 DFD Level 0 ( Context Diagram )
DFD level 0 atau disebut juga context diagram yang menggambarkan interaksi sistem
dengan entitas-entitas eksternal. Semua proses sistem digambarkan pada sebuah
lingkaran proses yang bertujuan agar diagram dapat menggambarkan bagaimana
entitas-entitas luar mengirim dan menerima data dari sistem tersebut. DFD level 0
untuk sistem ini ditunjukan pada gambar 3.2.
P.0
Proses Encoding dan Decoding Algoritma
LZW User
File Asli File Terkompresi
File Asli File Terkompresi
[image:35.595.138.498.453.619.2]Informasi
Tabel 3.3 Spesifikasi proses context diagram perangkat lunak kompresi LZW
Nama Input Keterangan Proses Output
Proses 0 /
Proses Encoding dan Decoding Algoritma LZW
File Asli, File
Terkompresi,
Informasi
Proses Encoding adalah
proses mengubah file asli
menjadi file terkompresi,
dan Proses Decoding
adalah proses mengubah
file yang telah
terkompresi menjadi file
asli kembali.
File asli, file
terkompresi,
Informasi
3.2.2 DFD Level 1
DFD Level 1 memberikan gambaran umum dari sistem. Pada level ini juga terdapat
proses utama pada sistem. Serta pada level ini juga terdapat hubungan sistem dengan
entitas, baik entitas eksternal maupun entitas internal. Masing-masing entitas data
yang tercantum pada DFD level 0 sama dengan entitas data pada tabel 3.3.
P.1 Proses Encoding User P.2 Proses Decoding File Asli File Terkompresi File Terkompresi File Asli Informasi Informasi
[image:36.595.136.489.442.708.2]Tabel 3.4 Spesifikasi Proses DFD Level 1 P.0
Nama Input Keterangan Proses Output
Proses 1 /
Proses
Encoding
File Asli Proses Encoding adalah
proses mengubah file asli
menjadi file terkompresi.
Dimana pada proses ini
dilakukan encoding
dengan menggunakan
algoritma LZW
File terkompresi,
informasi
Proses 2 /
Proses
Decoding
File terkompresi Proses Decoding adalah
proses mengubah file
terkompresi menjadi file
asli. Dimana pada proses
ini dilakukan decoding
dengan menggunakan
algoritma LZW
File Asli, informasi
3.2.3 DFD Level 2
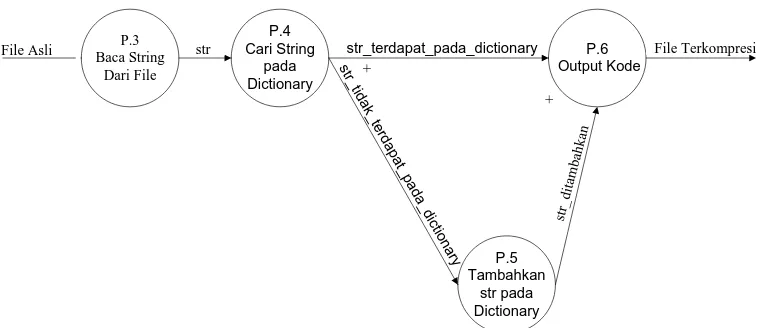
DFD level 2 merepresentasikan proses yang terjadi pada algoritma LZW. Berikut
P.3 Baca String Dari File P.4 Cari String pada Dictionary
File Asli str str_terdapat_pada_dictionary
[image:38.595.131.511.81.245.2]P.5 Tambahkan str pada Dictionary str_tidak_terdapat_pada_dictionary + P.6 Output Kode str_ditambahkan File Terkompresi +
Gambar 3.4 DFD level 2 Proses P.1
Tabel 3.5 Spesifikasi Proses DFD Level 2 P.1
Nama Input Keterangan Proses Output
Proses 3 /
Baca String
Dari File
File Asli Membaca string dari file
sampai End of File
str
Proses 4 /
Cari String
pada
Dictonary
str Mencari str yang terdapat
pada Dictonary
str_terdapat_pada_d
ictionary,
str_tidak_terdapat_p
ada_dictionary
Proses 5 /
Tambahkan
str pada
dictionary
str_terdapat_pada_
dictionary
Tambahkan str_terdapat
_pada_dictionary pada
dictionary
str_ditambahkan
Proses 6 /
Output Kode
str_ditambahkan Output kode dari
str_ditambahkan sehingga
menghasilkan File
Terkompresi
[image:38.595.105.540.310.653.2]P.7 Baca codeword Dari File Terkompresi File Terkompresi P.8 Cari word untuk codeword pada Dictionary codeword P.9 Output word
[image:39.595.114.513.83.151.2]word File Asli
Gambar 3.5 DFD level 2 Proses P.2
Tabel 3.6 Spesifikasi Proses DFD Level 2 P.2
Nama Input Keterangan Proses Output
Proses 7 /
Baca token
dari File
Terkompresi
File Terkompresi Membaca token dari file
terkompresi
codeword
Proses 8 /
Cari word
untuk token
pada
Dictionary
codeword Mencari string asli dari
token yang telah dibaca.
Kemudian menghasilkan
word sebagai string asli.
word
Proses 9 /
Output word
word Output word sehingga
didapat file asli
File Asli
3.2.4 Kamus Data
Kamus data merupakan sekumpulan data yang terdapat pada sistem, dimana data
disusun untuk memudahkan selama proses analisis dan desain. Kamus data
[image:39.595.102.543.265.618.2]data membantu analis sistem untuk mendesain sistem dimana tidak ada data yang
menggunakan nama berbeda padahal isi data tersebut identik, ataupun kesalahan
dimana nama data berulang pada desain. Kamus data juga sangat berguna untuk
menjelaskan sistem yang telah didesain dan mempermudan pemeliharaan maupun
penambahan fungsi pada sistem.
Masukan-masukan kamus data bisa dibuat setelah diagram aliran data
dilengkapi atau bisa juga disusun saat diagram aliran data sedang dikembangkan.
Penganalisis sistem bisa saja membuat suatu diagram aliran data level 0 dan sekaligus
membuat masukan-masukan data awal. Selanjutnya, sewaktu penganalisis sistem
mengembangkan diagram level data menjadi diagram anak, penganalisis juga bisa
memodifikasi masukan-masukan kamus data yang baru sesuai dengan aliran data pada
diagram alir anak.
Berikut ini merupakan kamus data yang berisikan data yang digunakan pada
[image:40.595.102.532.379.731.2]diagram alir data mulai dari diagram konteks, DFD level 1, DFD level 2.
Tabel 3.7 Kamus data
Nama Tipe Data Keterangan
File Asli File File yang akan dikompresi
File Terkompresi File File yang telah terkompresi
dengan algoritma LZW
informasi String Informasi ukuran file, rasio
kompresi, dan waktu yang
dibutuhkan pada proses
kompresi maupun dekompresi
str String String yang dibaca dari file asli
str_terdapat_pada_dictionary String String yang dibaca dari file asli
str_tidak_terdapat_pada_dictionary String String yang dibaca dari file asli
dan tidak terdapat pada
dictionary
str_ditambahkan String String yang dibaca dari file asli
dan ditambahkan pada
dictionary
codeword String Data yang dibaca dari file
terkompresi, yang disimpan
dalam memori dengan tipe data
string.
word String String yang didapat dari
penerjemahan token dengan
menggunakan dictionary
3.2.5 Perancangan Struktur Data
Perancangan struktur data berguna untuk dapat menghasilkan desain struktur data
terbaik pada implementasi. Dalam algoritma LZW struktur data terpenting adalah
struktur data yang digunakan dictionary. Struktur data yang baik sangat berpengaruh
pada kecepatan proses decoding maupun encoding.
Struktur Data Dictionary :
TYPE
TreeNode = Pointer BinaryTreeNode;
BinaryTreeNode = record
Key : integer;
Data : String;
RighChild : TreeNode;
LeftChild : TreeNode;
TYPE
DictionaryStructure = record
Key : integer;
Data : String;
DictionarySize : integer;
RighChild : TreeNode;
LeftChild : TreeNode;
END TYPE
3.2.6 Perancangan Prosedural
Tahapan selanjutnya dalam perancangan perangkat lunak adalah tahapan perancangan
prosedural atau detail algoritma. Tahapan ini disajikan dalam bentuk prosedur dan
flowchart. Hal ini dilakukan untuk mempermudah dalam pengkodean yang akan
dilakukan. Berikut ini prosedur dan flowchart proses encoding algoritma LZW:
Prosedur 1. Proses Encoding LZW
{ Input : File asli }
{ Proses : Melakukan proses encoding algoritma LZW }
{ Output : File terkompresi dan informasi kompresi }
Kamus Data :
String1 : string;
Karakter1 : char;
Dictionary : DictionaryStucture;
Algoritma Encoding LZW :
11. String 1 ← karakter pertama dari file sumber
12. while not EOF do
13. Karakter1 ← baca karakter dari file sumber
15. if Gabungan String1, Karakter1 terdapat pada Dictionary then
16. String1 ← String1 + Karakter1
17. else
18. Output kode untuk String1
19. Tambahkan Gabungan String1, Karakter1 pada
Dictionary
20. String1 ← Karakter1
21. end if
22. else
23. Output kode untuk String1
24. String1 = Karakter1
25. end if
26. end while
String1 = Baca Karakter
While NOT EOF
Karakter1 = Baca Karakter
IF String1 + Karakter1 Terdapat Pada
Dcitionary
Output Kode Untuk String1
String1 = String1+ Karakter1
Tambahkan String1 + Karakter1 Pada
Dictionary
String1 = Karakter1 Start
End IF Dictionary Not
Full
Output Kode Untuk String1
String1 = Karakter1
Output Kode Untuk String1
Yes
Yes
No
[image:44.595.145.489.71.627.2]No
Gambar 3.6 Flowchart proses encoding algoritma LZW
Berikut ini prosedur proses pencarian string pada dictionary pada algoritma
Prosedur 2. Proses pencarian string pada dictionary
{ Input : String yang dicari }
{ Proses : Melakukan proses pencarian string pada dictionary }
{ Output : Nilai indeks untuk string pada dictionary, -1 artinya tidak ditemukan }
Kamus Data :
StringFind : string;
Dictionary : DictionaryStructure;
RightTemp : BinaryTreeNode;
LeftTemp : BinaryTreeNode;
Algoritma proses pencarian string pada dictionary:
1. if Dictionary= NULL then
2. return -1
3. end if
4. while TRUE
5. if Dictionary.Data = StringFind then
6. return Dictionary.Key
7. else
8. RightTemp = Dictionary.Right
9. LeftTemp = Dictionary.Left
10. if (RightTemp = NULL) and (LeftTemp = NULL) then
11. return -1
12. end if
13. if RightTemp.Data >= StringFind then
14. Dictionary= Dictionary.Right
15. else
16. Dictionary= Dictionary.Left
18. end if
19.end while
Prosedur penambahan string pada dictionary dapat dilihat pada Lampiran D.
Berikut ini prosedur dan flowchart proses decoding algoritma LZW:
Prosedur 4. Proses Decoding LZW
{ Input : File terkompresi }
{ Proses : Melakukan proses decoding algoritma LZW }
{ Output : File asli }
Kamus Data :
element : string;
word : string;
x : integer;
Dictionary : DictionaryStucture;
Algoritma Decoding LZW :
15.baca token x dari file terkompresi
16.cari nilai element dengan indeks x
17.output element
18.word = element
19.while not E0F do
20. baca x
21. cari nilai element dengan indeks x
22. if tidak entri untuk indeks x then
23. element = word + karakter pertama pada word
24. end if
25. output element
26. tambahkan entri word + karakter pertama pada word pada dictionary
baca token x dari file terkompresi
While NOT EOF Start
End
Cari Nilai element Dengan indeks x
Output element
word = element
If tidak ada entri untuk indeks x
baca x
Cari Nilai element Dengan indeks x
element = word + karakter pertama pada word
Output element
Tambahkan entri word + karakter pertama pada word pada
dictionary
Gambar 3.7 Flowchart proses decoding algoritma LZW 3.3 Perangkat Keras Dan Perangkat Lunak Pengujian
Sebelum menganalisis perlu diketahui spesifikasi komputer yang digunakan. Karena
hasil yang diperoleh dipengaruhi oleh kinerja dari komputer. Terutama waktu dan
kecepatan proses karena perangkat keras yang lebih baik mempengaruhi waktu dan
kecepatan proses. Sistem operasi yang digunakan adalah Windows XP. Bahasa
pemrograman yang digunakan adalah bahasa pemrograman C++ yaitu menggunakan
compiler Visual C++ 2003. Perangkat keras yang digunakan adalah komputer
personal dengan spesifikasi sebagai berikut :
1. Prosessor AMD Sempron 2500+ (1,75 GHz)
2. RAM 896 MB
3. Hardisk 80 GB
3.4 Implementasi Antarmuka
Antarmuka perangkat lunak sangat penting untuk memudahkan pengguna dalam
memakainya. Dalam hal ini walaupun perangkat lunak dibuat untuk analisis penulis,
namun tetap saja aspek antarmuka sangat penting terutama dalam penyajian informasi
hasil program tersebut. Implementasi antarmuka adalah sebagai berikut:
1. Tampilan Utama
Tampilan utama menampilkan menu File untuk memilih menu LZW dimana
menu tersebut akan menampilkan halaman untuk melakukan proses kompresi
maupun dekompresi File. Menu Help adalah menu yang menampilkan
Gambar 3.8 Tampilan halaman utama
2. Tampilan Proses Kompresi dan Dekompresi
Pada Tampilan inilah proses utama dari program dapat diakses. Untuk
melakukan proses kompresi maka pengguna harus menentukan file sumber dan
file tujuan proses kompresi tersebut. Cara menentukan file sumber adalah
dengan melakukan klik pada tombol “Get File” pada “Source” kemudian pilih
file. Cara menentukan file tujuan adalah dengan melakukan klik pada tombol
“Get File” pada “Destination” kemudian pilih file. Kemudian pilih panjang bit
yang akan digunakan dengan memilih dari combo box “Bit Length”.
.Kemudian untuk mengkompres file maka klik pada tombol “Compress”.
Untuk melakukan proses dekompresi maka pengguna harus menentukan file
sumber dan file tujuan proses dekompresi. Cara menentukan file sumber
adalah dengan melakukan klik pada tombol “Get File” pada “Source”
kemudian pilih file. Cara menentukan file tujuan adalah dengan melakukan
klik pada tombol “Get File” pada “Destination” kemudian pilih file. Kemudian
Gambar 3.10 Tampilan proses dekompresi
3. Tampilan Dialog Pencarian File
Tampilan dialog pencarian file dilakukan pada halaman proses kompresi dan
dekompresi dengan melakukan klik pada button “Get File”. Maka pengguna
akan mendapatkan tampilan untuk mencari serta memilih file yang akan
[image:52.595.111.526.271.553.2]diproses seperti pada Gambar 3.9.
Gambar 3.11 Tampilan pencarian file
4. Tampilan Bantuan
Tampilan bantuan (Help) berguna sebagai halaman yang menjelaskan
bagaimana cara menggunakan program. Hal ini berguna agar pengguna tidak
BAB 4
ANALISIS PENGARUH PANJANG BIT KODE PADA KINERJA PROGRAM KOMPRESI YANG MENGGUNAKAN ALGORITMA LZW
4.1 File Yang Dicoba
Oleh sebab pada analisis penulis harus mencoba file-file tertentu dengan perangkat
lunak yang telah dibuat, maka terlebih dahulu file-file yang dicoba haruslah file-file
yang dapat memaksimalkan analisis. Untuk itu penulis memilih Calgary Corpus serta
Canterbury Corpus dalam analisis. Calgary Corpus dan Canterbury Corpus penulis
pilih karena keduanya telah umum digunakan dalam membandingkan algoritma
kompresi. Selain itu penelitian penulis dapat lebih mudah dibandingkan dengan
penelitian lain tentang kompresi karena menggunakan file-file yang telah umum
digunakan untuk penelitian mengenai kinerja kompresi. Canterbury Corpus
merupakan penyempurnaan dari Calgary Corpus dan Canterbury Corpus belum
digantikan oleh standar yang lebih baru.
4.1.1 Calgary Corpus
Calgary Corpus adalah sebuah set file yang dibuat sebagai standar dalam pengujian
dan perbandingan algoritma kompresi. Calgary Corpus dibuat oleh Ian Witten dan
Tim Bell pada tahun 1987 kemudian dipakai secara luas pada tahun 1990-an. Pada
pembuatan Calgary Corpus terdapat beberapa kriteria sehingga Calgary Corpus
sangat tepat digunakan untuk membandingkan kinerja algoritma kompresi.
Kriteria-kriteria tersebut adalah :
2. Corpus harus tersebar luas, seperti melalui internet sehingga peneliti dapat
dengan mudah mendapatkannya.
3. Corpus harus berisi materi yang umum pada masyarakat, bukan materi atau
content yang jarang pada masyarakat umum.
4. Besar ukuran Corpus haruslah sesuai, tidak boleh terlalu besar juga tidak boleh
terlalu kecil.
5. Corpus harus valid, bukan data rekaan.
4.1.2 Canterbury Corpus
Canterbury Corpus adalah sebuah set file yang dibuat sebagai standar dalam
pengujian dan perbandingan algoritma kompresi sebagai penyempurnaan dari Calgary
Corpus. Canterbury Corpus dibuat untuk mengikuti perkembangan tipe file baru yang
umum dipakai masyarakat. Canterbury Corpus berisi file teks bacaan, fax image, kode
sumber bahasa c, spreadsheet file, file biner, dokumentasi teknik, puisi berbahasa
inggris, HTML, kode sumber lisp, dan buku manual GNU. Walaupun Calgary Corpus
sudah disempurnakan dengan Canterbury Corpus, mencoba keduanya pada analisis
ini akan memberikan hasil analisis yang lebih baik. Semakin banyak file yang dicoba
diharapkan dapat memberikan analisis yang lebih baik.
4.2 Analisis Pengaruh Panjang Bit Kode pada Program Kompresi yang Menggunakan Algoritma LZW
Analisis pengaruh panjang bit kode pada program kompresi yang menggunakan
algoritma LZW adalah mencoba set file pada program kompresi yang telah
diimplementasikan dengan menggunakan panjang bit yang berbeda-beda. Dari analisis
ini diharapkan didapatkan kesimpulan mengenai pengaruh panjang bit kode pada
4.2.1 Analisis Pada Calgary Corpus
File-file Calgary Corpus bib, book1, book2, paper1, paper2, paper3, paper4, paper5,
paper6 adalah file teks berisi teks bahasa inggris baik berupa fiksi maupun non fiksi.
File news adalah file yang berisi berita. File progc, progl, progp adalah file teks berisi
kode sumber program. File trans adalah file yang berisi transkip dari sebuah sesi pada
terminal komputer. File obj1 dan obj2 adalah excutable file dan file pic berisi gambar
bitmap hitam putih dan file geo adalah file yang berisi data geophysical. File-file ini
akan dikompresi menggunakan program yang telah dibuat sebelumnya. Setelah itu
rasio file hasil kompresi akan dicatat dan dibandingkan untuk mendapatkan
kesimpulan keunggulan masing-masing panjang bit kode. Ukuran file merupakan
faktor yang menentukan hasil kompresi oleh sebab itu ukuran file dapat dilihat pada
Tabel 4.1 Daftar ukuran file pada Calgary Corpus
File-file Calgary Corpus dikompresi menggunakan program yang telah dibuat
sebelumnya. Program memberikan informasi ukuran file asli, file terkompresi, rasio
kompresi dalam persen dan waktu yang dibutuhkan untuk melakukan proses
kompresi. Hasil pengujian dapat dilihat pada Tabel 4.2 yang merupakan hasil rata-rata
dari keseluruhan file yang dicoba, sedangkan hasil pengujiannya secara lengkap
terdapat pada tabel Lampiran A.
Nama File Ukuran File (Byte)
bib 111261
book1 768771
book2 610856
geo 102400
news 377109
obj1 21504
obj2 246814
paper1 53161
paper2 82199
paper3 46526
paper4 13286
paper5 11954
paper6 38105
pic 513216
progc 39611
progl 71646
progp 49379
Tabel 4.2 Hasil pengujian rasio kompresi algoritma LZW pada Calgary Corpus
Penggunaan bit kode yang terlalu pendek maka jumlah item pada dictionary
akan menjadi sedikit dan berdampak pada rasio kompresi yang tidak maksimal. Begitu
juga penggunaan bit kode yang terlalu panjang juga akan menyebabkan rasio yang
tidak maksimal. Semakin kecil rasio artinya hasil kompresi semakin kecil. Oleh sebab
itu setelah menganalisis dan mencoba file satu persatu disimpulkan jika panjang bit
kode lebih panjang dari 24 bit maka rasio kompresi semakin besar, begitu juga jika
panjang bit kode lebih pendek dari 12 bit maka rasio kompresi semakin besar. Panjang Bit Kode Rasio rata-rata (%)
9 Bit 71,39
10 Bit 63,94
11 Bit 59,48
12 Bit 56,29
13 Bit 54,16
14 Bit 52,98
15 Bit 54,20
16 Bit 56,24
17 Bit 58,89
18 Bit 62,18
19 Bit 65,63
20 Bit 68,87
21 Bit 72,54
22 Bit 75,99
23 Bit 79,28
Pemilihan panjang kode bit tidak lebih dari 24 bit disebabkan karena panjang bit lebih
dari 24 bit tidak akan optimal, disebabkan oleh panjang bit 24 bit tersebut mempunyai
jumlah item dictionary yang tidak terpakai yang sangat banyak sehingga terjadi
pemborosan pemakaian bit.
Hasil Rasio Rata-rata Kompresi Algoritma LZW pada Calgary Corpus
0 20 40 60 80 100
9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
Panjang bit(bit)
R
asi
o
(%
[image:59.595.132.498.169.408.2])
Gambar 4.1 Grafik rasio rata-rata hasil kompresi algoritma LZW pada Calgary Corpus
Dari Tabel 4.2 rata-rata hasil kompresi yang terbaik adalah pada panjang bit
kode 14 bit. Sehingga dapat disimpulkan bahwa untuk file-file Calgary Corpus hasil
kompresi terbaik secara rata-rata adalah menggunakan panjang bit kode 14 bit. Dan
semakin panjang bit kode setelah lebih besar dari 14 bit makin membesar pula rasio
kompresi. Hal ini disebabkan karena pada panjang kode 14 bit jumlah item dictionary
untuk menyimpan frase telah mencukupi sehingga untuk panjang bit berikutnya
terdapat bit-bit yang tidak digunakan. Sehingga dapat disimpulkan bahwa panjang bit
kode setelah 14 bit seterusnya tidak akan optimal.
Setelah analisis pengaruh panjang bit kode pada rasio hasil kompresi, waktu
proses kompresi harus bandingkan juga. Hal ini dimaksudkan agar efisiensi algoritma
dapat diketahui tidak dari parameter rasio saja tetapi juga dari waktu proses. Semakin
sedikit waktu yang dibutuhkan dalam sebuah proses maka semakin efisien algoritma
Tabel 4.3 Hasil pengujian waktu proses rata-rata kompresi algoritma LZW pada Calgary Corpus
Dari Tabel 4.3 dan Lampiran B dapat dilihat bahwa waktu rata-rata tercepat
adalah pada 12 bit sampai 15 bit, setelah itu waktu rata-rata dari 16 bit sampai 24 bit
perbedaan tidak begitu signifikan. Sehingga panjang bit kode berpengaruh pada waktu
kompresi akan tetapi tidak dapat dipastikan bahwa semakin panjang bit kode tersebut
maka semakin lama pula proses kompresi. Untuk lebih jelas dapat dilihat pada
Gambar 4.2.
Panjang Bit Kode Waktu Rata-rata (milisekon)
9 Bit 251
10 Bit 257
11 Bit 260
12 Bit 255
13 Bit 267
14 Bit 275
15 Bit 290
16 Bit 301
17 Bit 308
18 Bit 308
19 Bit 308
20 Bit 311
21 Bit 309
22 Bit 308
23 Bit 306
Grafik Waktu Rata-rata Proses Kompresi Algoritma LZW pada Calgary Corpus
0 50 100 150 200 250 300 350
9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
Panjang Bit(bit)
W
akt
u
(m
il
iseko
n
)
Gambar 4.2 Grafik waktu rata-rata proses kompresi pada Calgary Corpus
Selain faktor panjang bit kode, faktor yang menentukan waktu proses
kompresi adalah jumlah item dictionary pada proses kompresi. Item dictionary
berpengaruh pada waktu proses disebabkan oleh semakin banyak item dictionary yang
digunakan maka semakin banyak pencarian pada binary tree yang menyimpan
dictionary dan berdampak semakin lama waktu yang dibutuhkan pada setiap
Tabel 4.4 Jumlah item dictionary rata-rata proses kompresi algoritma LZW pada Calgary Corpus
Pada Tabel 4.4 dapat dilihat bahwa pada 17 bit sampai 24 bit jumlah item
rata-rata sama, dan dilihat pada Gambar 4.2 pada 17 bit sampai 24 bit perbedaan waktu
rata-rata kompresi tidak signifikan. Sedangkan pada 12 bit sampai 16 bit mempunyai
jumlah item rata-rata yang cukup signifikan berdampak pula pada waktu proses
kompresi yang cukup signifikan. Sehingga dapat disimpulkan bahwa semakin banyak
jumlah item yang digunakan pada proses kompresi maka akan semakin lama pula
proses kompresi tersebut.
Panjang Bit
Kode
Jumlah Rata-rata Item
Dictionary (item)
9 Bit 4096
10 Bit 4096
11 Bit 4096
12 Bit 4096
13 Bit 7829
14 Bit 13838
15 Bit 20557
16 Bit 28554
17 Bit 36853
18 Bit 36853
19 Bit 36853
20 Bit 36853
21 Bit 36853
22 Bit 36853
23 Bit 36853
4.2.2 Analisis Pada Canterbury Corpus
Ukuran file sangat berpengaruh pada rasio maupun waktu yang dibutuhkan untuk
kompresi. Canterbury Corpus terdiri dari file-file serta ukurannya dapat dilihat pada
[image:63.595.156.442.282.525.2]Tabel 4.5.
Tabel 4.5 Daftar ukuran file pada Canterbury Corpus
Setelah itu seluruh file Canterbury Corpus dicoba dengan panjang bit yang berbeda.
Seluruh hasil percobaan file Canterbury Corpus terdapat pada Lampiran C. Berikut
hasil pengujian rasio rata-rata kompresi dapat dilihat pada Tabel 4.6.
Nama File Ukuran File (Byte)
Alice29.txt 82028
Asyoulik.txt 71929
Cp.html 24603
Fields.c 5318
Grammar.lsp 3721
Kennedy.xls 1029744
Lcet10.txt 426754
Ptt5 513216
Sum 38240
Tabel 4.6 Hasil pengujian rasio kompresi algoritma LZW pada Canterbury Corpus
Dari Tabel 4.6 dapat dilihat bahwa rasio kompresi terbaik didapat pada
panjang bit yaitu 13 Bit. Hal ini berbeda dengan hasil yang didapat pada pengujian
menggunakan Calgary Corpus yaitu panjang bit paling optimalnya adalah 14 bit. Panjang Bit Kode Rasio Rata-rata (%)
9 Bit 49,46
10 Bit 49,46
11 Bit 49,46
12 Bit 49,46
13 Bit 48,77
14 Bit 49,66
15 Bit 50,71
16 Bit 52,92
17 Bit 55,43
18 Bit 58,17
19 Bit 61,80
20 Bit 65,05
21 Bit 68,30
22 Bit 71,07
23 Bit 74,37
Rasio Rata-rata Hasil Kompresi Algoritma LZW pada Canterbury Corpus
0 20 40 60 80 100
9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
Panjang Bit (bit)
R
asi
o
R
at
a-rat
a (
%
[image:65.595.133.499.85.297.2])
Gambar 4.3 Grafik rasio rata-rata kompresi pada Canterbury Corpus
Dari Gambar 4.3 dapat dilihat bahwa dimulai dari panjang kode bit 16 sampai
24 bit rasio kompresi semakin membesar secara signifikan. Hasil yang sama juga
ditunjukkan pada Calgary Corpus dimana grafik pada Gambar 4.1 juga menunjukkan
bahwa dimulai dari panjang bit 16 sampai 24 bit rasio kompresi semakin membesar
secara signifikan. Sehingga penggunaan panjang bit kode 16 bit sampai 24 bit pada
Calgary Corpus maupun Canterbury Corpus tidak optimal.
4.2.3 Analisis Menggunakan Canterbury Corpus Large File
Penggolongan file yang besar dan kecil it