1
Leukemia merupakan kanker yang terjadi pada sel darah manusia. Ketika terjadi leukemia, tubuh akan memproduksi sel–sel darah yang abnormal dan dalam jumlah yang besar.Penyakit leukemia biasa terjadi pada seseorang yang berusia di bawah 15 tahun [1]. Saat ini penyakit leukemia menjadi salah satu penyakit yang sangat menakutkan, hal ini terlihat dari angka harapan hidup penderita kanker yaitu sebesar 60% dan banyaknya angka kematian.Melihat permasalahan tersebut, maka perlu adanya pendeteksian penyakit leukemia pada diri remaja.
akurasi yang cukup tinggi yaitu 83,33% dengan pengujian sebanyak 20 kali. Hasil dari penelitian ini dapat lebih akurat apabila menggunakan teknik pengklasifikasian yang lebih baik [4]. Berdasarkan penelitian sebelumnya oleh I Rohmana [5], telah dilakukan penelitian perbandingan jaringan syaraf tiruan dan naïve bayes dalam deteksi seseorang terkena penyakit stroke. Pada penelitian ini metode naïve bayes menghasilkan tingkat akurasi 80,555% dan metode jaringan syaraf tiruan menghasilkan tingkat akurasi 71,11%. Dari penelitian tersebut, diperoleh kesimpulan bahwa metode naïve bayes lebih akurat daripada jaringan syaraf tiruan. Dengan demikian, metode naïve bayes lebih handal daripada jaringan syaraf tiruan dalam hal pengambilan keputusan. Naïve bayes adalah salah satu metode klasifikasi yang menggunakan konsep probabilitas.
Dari permasalahan dan solusi yang telah dijelaskan, maka penelitian skripsi ini akan mengimplementasikan metode run length sebagai metode untuk ekstraksi citra dan metode naïve bayes untuk mengklasifikasikan penyakit leukemia berdasarkan citra darah, diharapkan metode run length dan naïve bayes dapat melakukan pengklasifikasian terhadap penyakit leukemia berdasarkan citra darah dengan akurat.
1.2 Rumusan Masalah
Berdasarkan latar belakang yang telah diuraikan, maka yang menjadi pokok permasalahan adalah sebagai berikut :
1. Bagaimana mengimplementasikan metode run length dan naïve bayes dalam pengolahan citra dengan teknik analisis citra darah untuk pengklasifikasian penyakit leukemia.
1.3 Maksud dan Tujuan
Maksud dari penelitian skripsi ini adalah untuk mengimplementasikan metode naïve bayes dalam mengklasifikasikan penyakit leukemia berdasarkan hasil ekstraksi citra darah.
Adapun tujuan dari penelitian skripsi ini adalah:
1. Dapat mengklasifikasikan penyakit leukemia berdasarkan citra darah menggunakan metode naïve bayes.
2. Dapat mengetahui tingkat akurasinya.
1.4 Batasan Masalah
Batasan Masalah yang ditentukan dalam penelitian ini adalah sebagai berikut:
1. Citra yang digunakan adalah citra darah manusia, dan pengambilan citra yang sudah disediakan.
2. Berdasarkan tekstur darah, citra yang dapat diklasifikasi adalah citra penyakit Chronic Lymphocytic Leukemia, Chronic Myeloid Leukemia, Acute Lymphoblastic Leukemia dan Acute Myelogenous Leukemia.
3. Penyakit leukemia yang akan dideteksi dibatasi hanya penyakit leukemia yang dapat dilihat secara visual berdasarkan hasil ct-scan dan menghasilkan gambar dengan format gambar JPG.
4. Metode analisis perancangan yang digunakan adalah analisis dan perancangan perangkat lunak berorientasi objek dengan menggunakan pemodelan Unified Modeling Language (UML).
5. Piksel arah bertetangga yang digunakan untuk run length adalah sudut simetris 00, 450, 900, 1350 dan fitur ciri yang digunakan adalah Short Run
1.5 Metodologi Penelitian
Metodologi penelitian yang digunakan adalah metodologi analisis deskriptif. Analisis deskriptif adalah metode analisis dengan mendeskripsikan atau menggambarkan data yang telah terkumpul sebagaimana adanya tanpa membuat kesimpulan yang berlaku untuk umum. Metodologi ini terbagi menjadi dua metode yaitu metode pengumpulan data dan metode pembangunan perangkat lunak.
1.5.1 Metode Pengumpulan Data
Metode pengumpulan data yang digunakan dalam penelitian ini adalah studi pustaka. Metode ini digunakan untuk mencari informasi dengan cara mengumpulkan literature, jurnal, paper dan bacaan-bacaan yang berkaitan dengan tujuan penelitian, yaitu tentang objek penelitian seperti darah dan penyakit leukemia, serta tentang metode yang digunakan seperti metode run length dan naïve bayes.
1.5.2 Metode Pembangunan Perangkat Lunak
Perangkat lunak dikembangkan dan dibangun dengan menggunakan metode agile, yang meliputi beberapa tahap yaitu:
a. Planning, pada tahap ini dilakukan analisis tentang pengenalan penyakit leukemia berdasarkan citra darah, analisis tentang solusi yang akan dicapai dari penelitian ini, analisis tentang metode yang akan digunakan yaitu run length dan naïve bayes serta analisis kebutuhan fungsional dan non-fungsional.
c. Coding, adalah tahap menterjemahkan data yang telah dirancang kedalam bahasa pemrograman tertentu dimana dalam kasus ini menggunakan bahasa pemrograman JAVA.
d. Testing, adalah proses pengujian terhadap metode run length dan metode naïve bayes yang telah diterapkan dalam suatu sistem untuk mengetahui apakah ke-2 metode ini telah terimplementasikan dengan baik dan menghasilkan output yang akurat.
Model proses metode pembangunan perangkat lunak agile dapat dilihat pada Gambar 1.1
Gambar 1. 1 Metode Agile, XP Process[6]
1.6 Sistematika Penulisan
BAB I PENDAHULUAN
Bab ini menguraikan tentang latar belakang permasalahan dari penyakit leukemia, bagaimana menyelesaikan permasalahan penyakit leukemia, penelitian yang telah ada beserta masalahnya dan solusi yang ditawarkan, bagaimana merumuskan inti permasalahan yang dihadapi, menentukan maksud dan tujuan penelitian, batasan masalah, metodologi penelitian serta sistematika penulisan.
BAB II. LANDASAN TEORI
Bab ini membahas berbagai konsep dasar dan teori-teori yang berkaitan dengan topik penelitian yang dilakukan dan hal-hal yang berguna dalam proses analisis permasalahan serta tinjauan terhadap penelitian, seperti penjelasan mengenai konsep metode run length, metode naïve bayes, JAVA dan pemodelan pembangunan perangkat lunak
BAB III. ANALISIS DAN PERANCANGAN
Bab ini memaparkan penjelasan mengenai analisis sistem seperti analisis masalah, analisis non fungsional (hardware, software, dan brainware), analisis basis data, kebutuhan fungsional serta perancangan sistem seperti perancangan antarmuka, perancangan pesan dan jaringan semantik.
BAB IV. IMPLEMENTASI DAN PENGUJIAN
Bab ini membahas mengenai implementasi seperti implementasi kebutuhan hardware dan software, implementasi basis data, dan implementasi antarmuka, serta penjelasan megenai hasil pengujian sistem yang telah dilakukan.
BAB V. KESIMPULAN DAN SARAN
7
Darah adalah suatu cairan tubuh yang terdapat di dalam pembuluh darah yang warnanya merah. Darah berfungsi sebagai alat pengangkut yaitu mengambil oksigen dari paru-paru untuk diedarkan ke seluruh jaringan tubuh, mengangkut karbondioksida dari jaringan untuk dikeluarkan melalui paru-paru, mengambil zat makanan dari usus halus untuk diedarkan dan dibagikan ke seluruh jaringan tubuh, mengeluarkan zat-zat yang tidak berguna bagi tubuh untuk dikeluarkan melalui kulit dan ginjal, sebagai pertahanan tubuh terhadap serangan penyakit, menyebarkan panas ke seluruh tubuh [7].
Berdasarkan komposisinya, darah terdiri dari sekitar 99% sel darah merah (eritrosit), 0.6 - 1.0% keping-keping darah (trombosit) dan 0.2% sel darah putih (leukosit). Sel darah merah berfungsi untuk mengedarkan oksigen dan berperan dalam menentukan golongan darah, keping darah bertanggung jawab dalam proses pembekuan darah, sel darah putih berfungsi sebagai sistem imun tubuh dan bertugas untuk memusnahkan virus atau bakteri. Berikut ini gambar citra darah dari Department of Histology, Jagiellonian University Medical College:
Gambar 2. 1 Citra Darah
adanya perubahan komposisi pada sel-sel darah yaitu anemia, leukopenia dan leukemia.
2.2 Leukemia
Leukemia atau kanker darah adalah penyakit dalam klasifikasi kanker pada darah atau sumsum tulang yang ditandai oleh perubahan komposisi secara tak normal atau transformasi maligna dari sel-sel pembentuk darah di sumsum tulang dan jaringan limfoid, umumnya terjadi pada sel darah putih [8]. Pada tahun 2000, terdapat sekitar 256.000 orang di seluruh dunia menderita penyakit leukemia, dan 209.000 orang diantaranya meninggal karena penyakit tersebut. Sekitar 90% dari semua penderita yang terdiagnosa adalah orang dewasa.
Penyakit kanker leukemia diklasifikasikan menjadi:
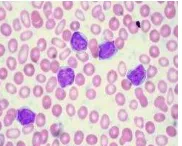
1. Chronic Lymphocytic Leukemia (CLL) adalah gangguan monoklonal ditandai dengan akumulasi progresif limfosit fungsional tidak kompeten. Pasien dengan CLL memiliki jumlah sel darah putih lebih tinggi dari biasanya. Penyakit ini sering terjadi pada orang dewasa yang berumur lebih dari 55 tahun, kadang-kadang juga diderita oleh dewasa muda, dan hampir tidak pernah terjadi pada anak-anak. Beberapa pasien meninggal dengan cepat, dalam waktu 2-3 tahun setelah didiagnosis, karena komplikasi dari CLL, tetapi kebanyakan pasien dapat bertahan hidup 5-10 tahun.
Gambar 2. 2 Chronic Lymphocytic Leukemia
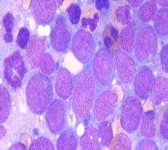
dari sel myeloid di dalam sumsum tulang dan terakumulasi juga di dalam darah. Penyakit ini sering terjadi pada orang dewasa, dapat juga terjadi pada anak-anak.
Gambar 2. 3 Chronic Myeloid Leukemia
3. Acute Lymphoblastic Leukemia (ALL) adalah suatu penyakit dimana sel-sel yang dalam keadaan normal berkembang menjadi limfosit berubah menjadi ganas dan dengan segera akan menggantikan sel-sel normal didalam sumsum tulang. ALL merupakan leukemia yang biasa terjadi pada anak-anak dibawah umur 15 tahun. Paling sering terjadi pada anak usia antara 3-5 tahun, tetapi kadang terjadi pada usia remaja dan orang dewasa yang telah berumur 65 tahun atau lebih.
Gambar 2. 4 Acute Lymphoblastic Leukemia
produksi sel darah normal. Penyakit ini mempengaruhi sel-sel darah yang belum matang dan berkembang dengan cepat. Penyakit ini biasa terjadi pada anak-anak dan orang dewasa.
Gambar 2. 5 Acute Myelogenous Leukemia
2.3 Kecerdasan Buatan
Kecerdasan buatan (Artificial inteligence) adalah salah satu cabang ilmu pengetahuan yang berhubungan dengan pemanfaatan mesin untuk memecahkan persoalan yang rumit dengan cara yang lebih manusiawi. Hal ini biasanya dilakukan dengan mengikuti karakteristik dan analogi berpikir dari kecerdasan manusia, dan menerapkannya sebagai algoritma yang dikenal oleh komputer.
Semakin pesatnya perkembangan teknologi menyebabkan adanya perkembangan dan perluasan lingkup yang membutuhkan kehadiran kecerdasan buatan. Karakteristik cerdas sudah mulai dibutuhkan di berbagai disiplin ilmu dan teknologi. Kecerdasan Buatan tidak hanya merambah di berbagai disiplin ilmu yang lain. Irisan antara psikologi dan kecerdasan buatan melahirkan sebuah area yang dikenal dengan nama cognition & psycolinguistics. Irisan antara teknik elektro dengan kecerdasan buatan melahirkan berbagai ilmu seperti pengolahan citra, teori kendali, pengenalan pola dan robotika.
lebih sederhana, pengertian memanipulasi simbol-simbol tersebut untuk memudahkan penggalian suatu informasi tertentu, dan aksi menerjemahkan simbol-simbol yang telah dimanipulasi menjadi sinyal lain yang dapat merupakan hasil akhir [9].
2.4 Pengolahan Citra (Image Processing)
Untuk melakukan pengenalan suatu objek berdasarkan tekstur yang dimiliki objek tersebut maka dibutuhkanlah suatu teknik untuk pengolahan citra. Pengolahan citra adalah pemrosesan citra dengan menggunakan komputer untuk menghasilkan citra yang kualitasnya lebih baik. Umumnya, operasi-operasi pada pengolahan citra diterapkan pada citra bila :
1. Perbaikan atau memodifikasi citra perlu dilakukan untuk meningkatkan kualitas penampakan atau untuk menonjolkan beberapa aspek informasi yang terkandung di dalam citra,
2. Elemen di dalam citra perlu dikelompokkan, dicocokkan, atau diukur, 3. Sebagian citra perlu digabung dengan bagian citra yang lain.
Pengolahan Citra bertujuan memperbaiki kualitas citra agar mudah diinterpretasi oleh manusia atau mesin (dalam hal ini komputer). Teknik-teknik pengolahan citra mentransformasikan citra menjadi citra lain. Jadi, masukannya adalah citra dan keluarannya juga citra, namun citra keluaran mempunyai kualitas lebih baik daripada citra masukan[10].
2.4.1 Preprocessing
Berikut ini gambar dari proses preprocessing :
Gambar 2. 6 Proses Preprocessing
2.4.1.1Resize
Berikut ini gambar dari proses resize :
Gambar 2. 7 Proses Resize
2.4.1.2Grayscale
Berikut ini gambar dari proses grayscale :
Gambar 2. 8 Proses Grayscale
2.5 Elemen Citra
Dalam pengolahan citra objek yang digunakan adalah sebuah citra dari sebuah objek tertentu yang mana citra tersebut mengandung sejumlah elemen dasar. Elemen dasar tersebut di manipulasi dalam pengolahan citra, elemen tersebut adalah:
1. Warna
2. Kecerahan (brightness)
Kecerahan disebut juga intensitas cahaya. Kecerahan pada sebuah piksel (titik) didalam citra bukanlah intensitas yang rell, tetapi sebenarnya adalah intensitas rata-rata dari suatu area yang melingkupinya.
3. Kontras (contrast)
Kontras menyatakan sebaran terang dan gelap di dalam sebuah gambar. Citra dengan kontras rendah dicirikan oleh sebagian besar komposisi citranya adalah terang atau sebagian besar gelap. Pada citra dengan kontras yang baik, komposisi gelap dan terang tersebar secara merata.
4. Kontur (contour)
Kontur adalah keadaan yang ditimbulkan oleh perubahan intensitas pada piksel yang bertetangga. Karena adanya perubahan intensitas, mata manusia dapat mendeteksi tepi objek didalam citra.
5. Bentuk (shape)
Bentuk adalah properti intrinsik dari objek tiga dimensi, dengan pengertian bahwa shape merupakan properti intrinsik utama untuk sistem visual manusia. Pada umumnya citra yang dibentuk oleh mata merupakan citra dwimatra (dua dimensi), sedangkan objek yang dilihat umumnya berbentuk trimatra (tiga dimensi). Informasi bentuk objek dapat diekstraksi dari citra pada permulaan pra-pengolahan dan segmentasi citra. 6. Tekstur (texture)
Tekstur diartikan sebagai distribusi spasial dari derajat keabuan di dalam sekumpulan piksel-piksel yang bertetangga. Jadi tekstur tidak dapat didefinisikan untuk sebuah piksel. Sistem visual manusia menerima informasi citra sebagai suatu kesatuan. Resolusi citra yang diamati ditentukan oleh skala dimana tekstur tersebut dipersepsi.
7. Waktu dan Pergerakan
8. Deteksi dan Pengenalan
Dalam mendeteksi dan mengenali suatu citra, ternyata tidak hanya sistem visual manusia saja yang bekerja, tetapi juga ikut melibatkan ingatan dan daya pikir manusia.
2.6 Citra analog dan Citra Digital
Secara umum terdapat 2 jenis citra yaitu citra analog dan citra digital. Citra analog adalah citra yang bersifat kontinu, seperti gambar pada monitor televisi, foto sinar-X, foto yang tercetak dikertas foto, lukisan, pemandangan, hasil CT scan, gambar-gambar yang terekam pada pita kaset, dan lain-lain sebagainya.
Citra analog tidak dapat direpresentasikan dalam komputer sehingga tidak dapat diproses dikomputer secara langsung. Oleh sebab itu, agar citra ini dapat diproses dikomputer, proses konversi analog ke digital harus dilakukan terlebih dahulu. Citra analog dihasilkan dari alat-alat analog, video kamera analog, kamera foto analog, Web Cam, CT scan, sensor ultrasound pada system USG, dan lain-lain .
Citra digital adalah citra yang dapat diolah oleh komputer dan citra digital yaitu gambar pada bidang dua dimensi. Dalam tinjauan matematis, citra merupakan fungsi kontinu dari intensitas cahaya pada bidang dua dimensi. Ketika sumber cahaya menerangi objek, objek memantulkan kembali sebagian cahaya tersebut. Pantulan ini ditangkap oleh alat-alat pengindera optik, misalnya mata manusia, kamera, scanner dan sebagainya. Bayangan objek tersebut akan terekam sesuai intensitas pantulan cahaya. Ketika alat optik yang merekam pantulan cahaya itu merupakan mesin digital, misalnya kamera digital, maka citra yang dihasilkan merupakan citra digital. Pada citra digital, kontinuitas intensitas cahaya dikuantisasi sesuai resolusi alat perekam.
2.7 Tekstur
Pengertian dari tekstur dalam hal ini adalah keteraturan pola-pola tertentu yang terbentuk dari susunan piksel-piksel dalam citra digital [9].
Untuk membentuk suatu tekstur setidaknya ada dua persyaratan yang harus dipenuhi antara lain :
1. Terdiri dari satu atau lebih piksel yang membentuk pola-pola primitif (bagian-bagian terkecil). Bentuk-bentuk pola primitif ini dapat berupa titik, garis lurus, garis lengkung, luasan dan lain-lain yang merupakan elemen dasar dari sebuah bentuk.
2. Munculnya pola-pola primitif yang berulang-ulang dengan interval jarak dan arah tertentu sehingga dapat diprediksi atau ditemukan karakteristik perulangannya.
Suatu citra memberikan interpretasi tekstur yang berbeda apabila dilihat dengan jarak dan sudut yang berbeda, manusia memandang tekstur berdasarkan deskripsi yang bersifat acak, seperti halus, kasar, teratur, tidak teratur, dan lain sebgainya. Hal ini merupakan deskripsi yang tidak tepat dan non-kuantitatif, sehingga diperlukan adanya suatu deskripsi yang kuantitatif (matematis) untuk memudahkan analisis [9].
2.7.1 Analisis Tekstur
metode yang berdasarkan analisis frekuensi seperti transformasi gabor dan transformasi wavelet [9].
2.8 Metode Run Length
Grey level run length matrix yang biasa disingkat dengan GLRLM merupakan salah satu metode yang populer untuk mengekstrak tekstur sehingga diperoleh ciri statistik atau atribut yang terdapat dalam tekstur dengan mengestimasi piksel-piksel yang memiliki derajat keabuan yang sama. Ekstraksi tekstur dengan metode run-length dilakukan dengan membuat rangkaian pasangan nilai (i,j) pada setiap baris piksel. Perlu diketahui maksud dari run length adalah jumlah piksel berurutan dalam arah tertentu yang memiliki derajat keabuan/nilai intensitas yang sama. Jika diketahui sebuah matriksrun-lengthdengan elemen matriksq ( i, j | θ) dimana i adalah derajat keabuan pada masing-masing piksel, j adalah nilai run-length, dan θ adalah orientasi arah pergeseran tertentu yang dinyatakan dalam derajat. Orientasi dibentuk dengan empat arah pergeseran dengan interval 450, yaitu 00, 450, 900 , dan 1350.
Berdasarkan penelitian yang dilakukan oleh Galloway[11], terdapat beberapa jenis ciri tekstural yang dapat diekstraksi dari matriks run-length. Berikut variabel-variabel yang terdapat di dari ekstraksi citra dengan menggunakan metode statistikal Grey Level Run Length Matrix :
i = nilai derajat keabuan j = piksel yang berurutan (run)
M = Jumlah derajat keabuan pada sebuah gambar N = Jumlah piksel berurutan pada sebuah gambar
r(j) = Jumlah piksel berurutan berdasarkan banyak urutannya (run length) g(i) = Jumlah piksel berurutan berdasarkan nilai derajat keabuannya s = Jumlah total nilai run yang dihasilkan pada arah tertentu
p(i,j) = himpunan matrik i dan j n = jumlah baris * jumlah kolom.
1. Short Run Emphasis (SRE)
SRE mengukur distribusi short run. SRE sangat tergantung pada banyaknya short run dan diharapkan bernilai besar pada tekstur halus.
2. Long Run Emphasis (LRE)
LRE mengukur distribusi long run. LRE sangat bergantung pada banyaknya long run dan diharapkan bernilai besar pada tekstur kasar.
3. Grey Level Uniformity (GLU)
GLU mengukur persamaan nilai derajat keabuan seluruh citra dan diharapkan bernilai kecil jika nilai derajat keabuan serupa diseluruh citra.
4. Run Length Uniformity (RLU)
5. Run Percentage (RPC)
RPC mengukur kebersamaan dan distribusi run dari sebuah citra pada arah tertentu. RPC bernilai paling besar jika panjangnya run adalah 1 untuk semua derajat keabuan pada arah tertentu.
2.9 Klasifikasi Naïve Bayes
Naïve bayes adalah teknik prediksi berbasis probabilistik sederhana yang berdasar pada penerapan teorema Bayes[12].
1. Asumsi independensi (ketidaktergantungan) yang kuat (naif). 2. Model yang digunakan adalah “model fitur independen”.
Independensi yang kuat pada fitur adalah bahwa sebuah fitur pada sebuah data tidak ada kaitannyadengan adanya atau tidak adanya fitur yang lain dalam data yang sama. Contoh: kasus klasifikasi hewan dengan fitur: penutup kulit, melahirkan, berat, dan menyusui.
1. Dalam dunia nyata, hewan yang berkembang biak dengan cara melahirkan dipastikan hewan tersebut menyusui juga, disini ada ketergantungan pada fitur menyusui karena hewan yang menyusui biasanya melahirkan, atau hewan yang bertelur biasanya tidak menyusui.
2. Dalam Bayes, hal tersebut tidak dipandang, sehingga masing-masing fitur seolah tidak ada hubungan apa-apa.
Kasus lain: prediksi hujan
1. Hujan tergantung angin, cuaca kemarin, kelembaban udara (tidak ada kaitan satu sama lain).
2. Tapi juga tidak boleh memasukkan fitur lain yang tidak ada hubungannya dengan hujan, seperti: gempa bumi, kebakaran, dsb.
bersifat bebas (independence). Karena asumsi variabel tidak saling terikat, maka didapatkan :
Data yang digunakan dapat bersifat kategorial (diskrit) maupun continue. Namun, pada tugas akhir ini akan digunakan data continue, karena hasil ekstraksi ciri citra merupakan data continue berupa angka angka hasil pengukuran tingkat Short Run Emphasis (SRE), Long Run Emphasis (LRE), Grey Level Uniformity (GLU), Run Length Uniformity (RLU), dan Run Percentage (RPC) pada ekstraksi ciri. Maka dari itu untuk data continue dapat diselesaikan dengan menggunakan langkah-langkah berikut.
Training :
1. Hitung rata-rata (mean) tiap fitur dalam dataset training dengan.
Dimana: = mean
= banyaknya data = jumlah nilai data
2. Kemudian hitung nilai varian dari diat dataset training tersebut seperti pada.
Dimana: = varians µ= mean
banyaknya data Testing :
1. Hitung probabilitas (Prior) tiap kelas yang ada dengan cara menghitung jumlah data tiap kelas dibagi jumlah total data secara keseluruhan.
2. Selanjutnya menghitung densitas probabilitasnya. Fungsi densitas mengekspresikan probabilitas relatif. Data dengan mean μ dan standar deviasi σ, fungsi densitas probabilitasnya adalah :
Dimana :
= data masukan π = 3,14
standar deviasi µ = mean
3. Setelah didapatkan nilai densitas probabilitasnya, selanjutnya menghitung posterior masing-masing kelas dengan menggunakan persamaan 2.10.
Atau bisa ditulis
2.10 Pengujian Black Box
Pengujian black box merupakan pendekatan komplementer dari teknik white box, karena pengujian black box diharapkan dapat mengetahui kesalahan kelas yang lebih luas dibandingkan teknik white box. Pengujian black box terfokus pada pengujian persyaratan fungsional perangkat lunak untuk menghasilkan serangkaian kondisi input yang sesuai dengan persayaratan fungsional suatu program.
Pengujian black box berusaha untuk menemukan kesalahan dalam kategori: 1. Fungsi yang hilang atau tidak tepat
2. Kesalahan interface
3. Kesalahan dalam struktur data 4. Kesalahan kinerja
5. Inisialisasi dan kesalahan terminasi
2.11 Pengujian Confusion Matrix
Confusion matrix adalah sebuah tabel yang menyatakan jumlah data uji yang benar diklasifikasikan. Berikut ini contoh confusion matrix untuk klasifikasi biner:
Tabel 2. 1 Confusion Matrix Untuk Klasifikasi Biner
Kelas Prediksi
1 0
Kelas Sebenarnya 1 TP FN 0 FP TN
Keterangan:
True Positive (TP), yaitu jumlah dokumen dari kelas 1 yang benar dan diklasifikasikan sebagai kelas 1.
True Negative (TN), yaitu jumlah dokumen dari kelas 0 yang benar diklasifikasikan sebagai kelas 0.
False Negative (FN), yaitu jumlah dokumen dari kelas 1 yang salah diklasifikasikan sebagai kelas 0.
Untuk menghitung akurasi digunakan persamaan [18]::
2.12 Object Oriented Programming (OOP)
Metodologi berorientasi objek adalah suatu strategi pembangunan perangkat lunak yang mengorganisasikan perangkat lunak sebagai kumpulan objek yang berisi data dan operasi yang diberlakukan terhadapnya. Metodologi berorientasi objek merupakan suatu cara bagaimana sistem perangkat lunak dibangun melalui pendekatan objek secara sistematis. Metode berorientasi objek didasarkan pada penerapann prinsip-prinsip pengelolaan kompleksitas. Metode berorientasi objek meliputi rangkaian aktifitas analisis beorientasi objek, perancangan berorientasi objek, pemrograman berorientasi objek, dan pengujian berorientasi objek [13].
Pada saat ini, metode berorientais objek banyak dipilih karena metodologi lama banyak menimbulkan masalah seperti adanya kesulitan pada saat mentranformasi hasil dari satu tahap pengembangan ke tahap berikutnya, misalnya pada metode pendekatan terstruktur, jenis aplikasi yang dikembangkan saat ini berbeda dengan masa lalu. Aplikasi yang dikembangkan saat ini sangat beragam (aplikasi bisnis, real-time, utility dan sebagainya) dengan platform yang berbeda-beda, sehingga menimbulkan tuntutan kebutuhan metodologi pengembangan yang dapat mengakomodasi ke semua jenis aplikasi.
Keuntungan menggunakan metodologi berorientasi objek adalah sebagai berikut :
a. Meningkatkan Produktivitas
Karena kelas dan objek yang ditemukan dalam suatu masalah masih dapat dipakai ulang untuk masalah lainnya yang melibatkan objek tersebut (reuseable).
Karena sistem yang dibangun dengan baik dan benar pada saat analisis dan perancangan akan menyebabkan berkurangnya kesalahan pada saat pengkodean
c. Kemudahan Pemeliharaan
Karena dengan model objek, pola-pola yang cenderung tetap dan stabil dapat dipisahkan dan pola-pola yang mungkin sering diubah-ubah.
d. Adanya Konsistensi
Karena sifat pewarisan dan penggunaan notasi yang sama pada saat analisis, perancangan maupun pengkodean.
e. Meningkatkan Kualitas Perangkat Lunak
Karena adanya pendekatan pengembangan lebih dekat dengan dunia nyata dan adanya konsistensi pada saat pengambangannya, perangkat lunak yang dihasilkan akan mampu memenuhi kebutuhan pemakai serta mempunyai sedikit kesalahan.
Berikut beberapa contoh bahasa pemograman yang mendukung pemrograman berorientasi objek adalah :
a. Smalltalk
Smalltalk adalah salah satu bahasa pemograman yang diekmbangkan untuk mendukung pemrograman beroirentasi objek.
b. Bahasa Pemrograman Eiffel
Eiffel merupakan bahsa pemrograman yang kembangkan untuk mendukung pemrograman berorientasi objek oleh Bertrand Meyer dan compiler.
c. Bahasa Pemrograman Web (PHP)
Php dibuat pertama kali oleh seorang perekayasa perangkat (software engineering) yang bernama Rasmus Lerdoff.
d. Bahasa Pemrograman C++
C++ merupakan pengembangan lebih lanjut dari bahasa pemrograman C untuk mendukung pemrograman berorientasi objek.
Java dikembangkan oleh perusahaan Sun Microsystem. Java menurut definisi dari Sun Microsystem adalah nama untuk sekumpulan teknologi untuk membuat dan menjalankan perangkat lunak pada komputer standalone ataupun pada lingkungan jaringan.
2.13 Pemrograman JAVA
2.13.1 Sejarah JAVA
Pada tahun 1991 sekelompok insinyur Sun yang dipimpin Patrick Naughton dan James Gosling ingin merancang bahasa komputer untuk perangkat konsumer seperti cable TV box yg bernama “Green”. Karena perangkat itu tidak mempunyai banyak memory, maka harus menggunakan bahasa yang berukuran kecil dan menghasilkan kode.
Karena orang-orang di proyek Green berbasis C++ bukan Pascal, maka kebanyakan sintaks yang diambil dari C++, serta mengadopsi orientasi objek bukan prosedural. Mulanya bahasa yang diciptakan diberi nama “Oak“, kemudian diganti Java karena telah ada bahasa pemrograman yang bernama sama.
Pada tahun 1995, Netscape memutuskan membuat browser yang dilengkapi dengan Java. Setelah itu diikuti oleh IBM, Symantec, Insprise, bahkan Microsoft. Setelah itu gaung Java mulai terdengar, berbagai industri mulai meliriknya. Dengan strategi terbukanya, banyak universitas di Amerika, Jepang dan Eropa yang mengubah pengenalan bahasa pemrograman komputer menjadi Java, dan meninggalkan C++. Beberapa teknologi bahasa Java diantaranya:
a. J2EE (Java 2 Enterprise Edition)
mendukung pengembangan dan rutin standard untuk aplikasi client maupun server, termasuk aplikasi yang berjalan di web browser.
b. J2SE (Java 2 Standard Edition)
J2SE adalah inti/dasar dari bahasa pemrograman Java. JDK (Java Development Kit) adalah salah satu tool dari J2SE untuk mengkompilasi dan menjalankan program Java. Tool J2SE yang salah satunya adalah JDK 1.5 merupakan tool open source dari Sun Microsystem.
c. J2ME (Java 2 Micro Edition)
J2ME adalah lingkungan pengembangan yang dirancang untuk meletakkan perangkat lunak Java pada barang elektronik beserta perangkat pendukungnya. Pada J2ME, jika perangkat lunak berfungsi baik pada sebuah perangkat, maka belum tentu juga berfungsi baik pada perangkat yang lainnya. J2ME membawa Java ke dunia informasi, komunikasi, dan perangkat komputasi selain perangkat komputer desktop yang biasanya lebih kecil dibandingkan perangkat komputer desktop. J2ME biasa digunakan pada telepon selular, pager, Personal Digital Assistants (PDA) dan sejenisnya.
2.13.2 Konsep Pemrograman Berorientasi Objek pada JAVA
Pemrograman berorientasi objek atau Object Oriented Programing (OOP) adalah inti dari pemrograman Java. Semua program Java merupakan objek. Maka dari itu, sebelum memulai penulisan kode-kode program Java sebaiknya mengetahui terlebih dahulu dasar-dasar dari konsep yang terkandung dalam pemrograman berorientasi objek. Beberapa ciri dari pemrograman berorientasi objek adalah:
a. Abstraksi (abstraction)
transportasi, sehingga mereka tinggal mengendarainya tanpa harus mengetahui kerumitan proses yang terdapat di dalam mobil tersebut. Ini artinya, si pembuat mobil telah menyembunyikan semua kerumitan-kerumitan proses yang terdapat di dalam mobil dan pengguna tidak perlu mengetahui bagaimana sistem mesin, transmisi, dan rem bekerja. Konsep seperti inilah yang dinamakan dengan abstraksi.
b. Pembungkusan (encapsulation)
Secara kode program, proses abstraksi dapat dilakukan dengan cara pembungkusan semua kode dan data yang berkaitan ke dalam satu entitas tunggal yang disebut dengan objek. Dengan kata lain, sebenarnya proses pembungkusan itu sendiri merupakan cara untuk melakukan abstraksi. Dalam pemrograman tradisional, proses semacam ini dinamakan penyembunyian informasi (information hidding). Dalam melakukan pembungkusan kode dan data dalam Java, terdapat tiga tingkat akses, yaitu: private, protected, dan public.
c. Pewarisan (inheritance)
d. Polimorfisme (polimorphism).
Polimorfisme adalah kemampuan suatu objek untuk mengungkap banyak hal yang melalui satu cara yang sama. Sebagai contoh, terdapat kelas A yang diturunkan menjadi kelas B, C, dan D. Dengan konsep polimorfisme, maka dapat menjalankan method-method yang terdapat pada kelas B, C, dan D hanya dari objek yang diinstansiasi dengan kelas A. Polimorfisme dinamakan dengan dynamic binding, late binding, maupun runtime binding.
2.14 Unified Modelling Language (UML)
Unified Modelling Language (UML) adalah sekumpulan spesifikasi yang dikeluarkan oleh OMG. UML terbaru adalah UML 2.3 yang terdiri dari 4 macam spesifikasi, yaitu : Diagram Interchange Spesification, UML Infrastrukture, UML Superstrukture, dan Object Constraint Language (OCL). Pada UML 2.3 terdiri 13 macam diagram yang dikelompokan pada 3 kategori, yaitu:
1. Structure Diagram, yaitu kumpulan diagram yang digunakan untuk menggambarkan suatu struktur statis dari sistem yang dimodelkan.
a. Diagram Kelas
Diagram kelas menggambarkan struktur sistem dari segi pendefinisian kelas-kelas yang akan dibuat untuk membangun sistem. Kelas memiliki apa yang disebut attribut dan metode atau operasi.
Gambar 2. 9 Diagram Kelas
b. Diagram Objek
Gambar 2. 10 Diagram Objek
c. Diagram Komponen
Diagram komponen dibuat untuk menunjukan organisasi dan ketergantungan diantara kumpulan komponen dalam sebuah sistem.
Gambar 2. 11 Diagram Komponen
d. Composite Structure Diagram
Composite Structure Diagram baru mulai ada pada UML versi 2.0. diagram ini dapat digunakan untuk menggambarkan struktur dari bagian-bagian yang saling terhubung maupun mendeskripsikan struktur pada saat berjalan (runtime).
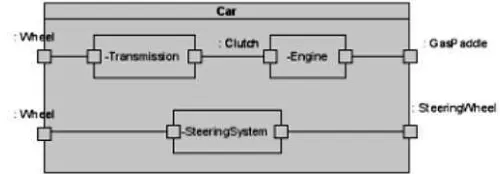
Gambar 2. 12 Composite Structure Diagram
e. Package Diagram
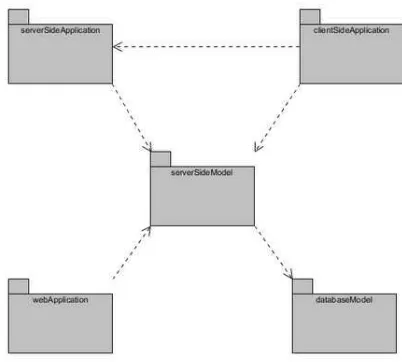
Package diagram menyediakan cara mengumpulkan elemen-elemen yang saling terkait dalam diagram UML. Hampir semua diagram dalam UML dapat dikelompokan menggunakan Package Diagram.
Gambar 2. 13 Package Diagram
f. Deployment Diagram
Deployment diagram menunjukan konfigurasi komponen dalam proses eksekusi aplikasi.
Gambar 2. 14 Deployment Diagram
a. Use Case Diagram
Use case diagram merupakan pemodelan untuk kelakuan (behavior)
sistem informasi yang akan dibuat,. Use case mendeskripsikan sebuah interaksi antara satu atau lebih aktor dengan sistem informasi yang akan dibuat.
Gambar 2. 15 Use Case Diagram
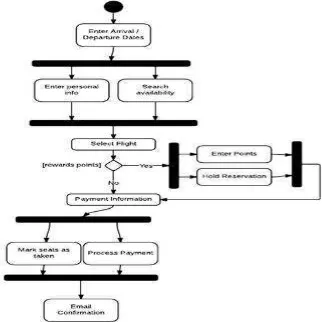
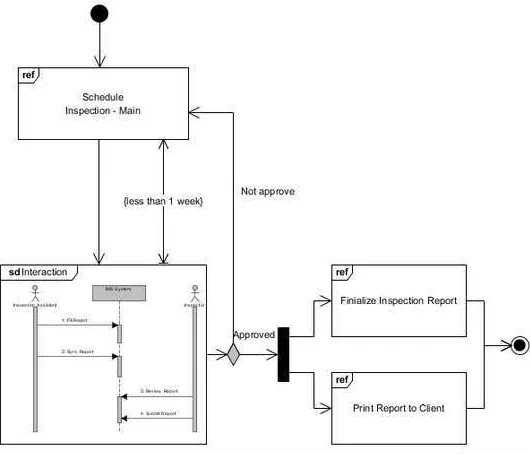
b. Activity Diagram
Activity diagram menggambarkan workflow atau aktivitas dari sebuah sistem atau proses bisnis atau menu yang ada pada perangkat lunak.
c. State Machine Diagram
State machine diagram digunakan untuk menggambarkan perubahan
status atau transisi status dari sebuah mesin atau sistem atau objek.
Gambar 2. 17 State Machine Diagram
3. Interactions Diagram, yaitu kumpulan diagram yang digunakan untuk menggambarkan interaksi antar subsistem pada suatu sistem. Pada Interactions Diagram dibagi menjadi 4 bagian :
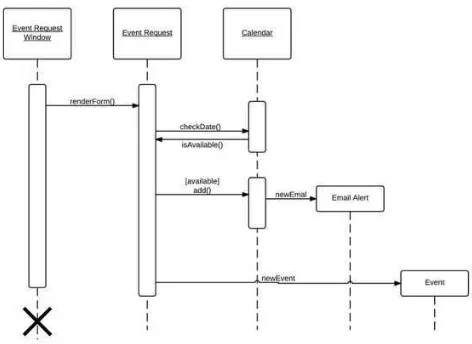
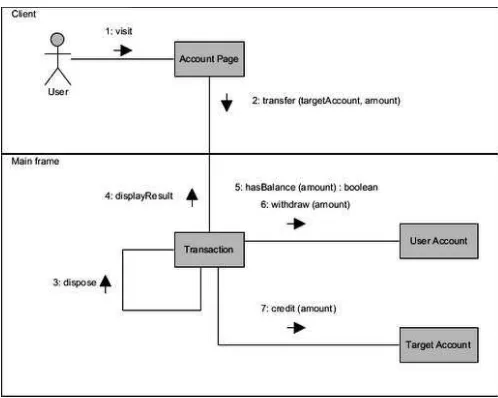
a. Sequence Diagram
Sequence diagram menggambarkan kelakuan objek pada use case dengan mendeskripsikan waktu hidup objek dan message yang dikirimkan dan diterima antar objek.
Gambar 2. 18 Sequence Diagram
b. Communication Diagram
Communication diagram menggambarkan interaksi antar bojek/bagian
dalam bentuk urutan pengiriman pesan. Diagram komunikasi merepresentasikan informasi yang diperoleh dari diagram kelas, diagram sequence, dan diagram use case untuk mendeskripsikan gabungan antara struktur statis dan tingkah laku dinamis dari suatu sistem.
Gambar 2. 19 Communication Diagram
c. Timing Diagram
Timing diagram merupakan diagram yang fokus pada penggambaran terkait batas waktu.
Gambar 2. 20 Timing Diagram
d. Interaction Overview Diagram
Interaction overview diagram mirip dengan diagram aktivitas yang
berfungsi untuk menggarbarkan sekumpulan urutan aktivitas, diagram ini adalah bentuk aktivias diagram yang setiap titik merepresentasikan diagram interaksi.
Gambar 2. 21 Interaction Overview Diagram
93
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Dari hasil penelitian, analisis pengolahan citra, pelatihan dan pengujian metode run-length dan naïve bayes untuk klasifikasi citra berdasarkan tekstur ini didapatkan kesimpulan sebagai berikut:
1. Algoritma naïve bayes dapat mengklasifikasikan citra penyakit leukemia melalui hasil ekstraksi citra darah menggunakan metode run-length
2. Algoritma naïve bayes menghasilkan tingkat keakurasian 91.25% dengan total 20 data latih dan 20 data uji.
5.2 Saran
Dari hasil penelitian, analisis, pengolahan citra, pelatihan dan pengujian terdapat saran-saran yang mungkin akan bermanfaat jika ada yang akan melakukan penelitian yang sejenis, yaitu :
1. Dari hasil penelitian ini, maka disarankan untuk mengembangkan penelitian identifikasi penyakit leukemia terhadap tekstur dan warna, sehingga dapat membantu pihak rumah sakit agar dapat mengidentifikasi jenis penyakit leukemia yang terdapat pada citra darah pasien.
TTL
: Jakarta, 1 Agustus 1988
Alamat
: Kp. Kalibata RT. 003 RW. 06 No. 32
Kel. Srengseng Sawah, Kec. Jagakarsa
Jakarta Selatan 12640
No. Telp
: 081284295008
: [email protected]
RIWAYAT PENDIDIKAN
1994-2000 : SD Desa Putera, Jakarta
2000-2003 : SLTP Desa Putera, Jakarta
2003-2007 : SMU PSKD 7, Depok
SKRIPSI
Diajukan untuk menempuh Ujian Akhir Sarjana
LEONART JEFRY
10111675
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
UNIVERSITAS KOMPUTER INDONESIA
iv
ABSTRACT ... ii
KATA PENGANTAR ... iii DAFTAR ISI ... iv DAFTAR GAMBAR ... viii DAFTAR TABEL ... x DAFTAR SIMBOL ... xii DAFTAR LAMPIRAN ... xvi BAB I PENDAHULUAN ... 1 1.1 Latar Belakang Masalah ... 1 1.2 Rumusan Masalah ... 2 1.3 Maksud dan Tujuan ... 3 1.4 Batasan Masalah... 3 1.5 Metodologi Penelitian ... 4
1.5.1 Metode Pengumpulan Data ... 4 1.5.2 Metode Pembangunan Perangkat Lunak ... 4 1.6 Sistematika Penulisan ... 5 BAB II LANDASAN TEORI ... 7 2.1 Darah ... 7 2.2 Leukemia ... 8 2.3 Kecerdasan Buatan ... 10 2.4 Pengolahan Citra (Image Processing) ... 11
v
2.4.1.1 Resize ... 12 2.4.1.2 Grayscale ... 13 2.5 Elemen Citra... 14 2.6 Citra analog dan Citra Digital ... 16 2.7 Tekstur... 16
2.7.1 Analisis Tekstur ... 17 2.8 Metode Run Length... 18 2.9 Klasifikasi Naïve Bayes ... 20 2.10 Pengujian Black Box ... 22 2.11 Pengujian Confusion Matrix ... 23 2.12 Object Oriented Programming (OOP) ... 24 2.13 Pemrograman JAVA ... 26
2.13.1 Sejarah JAVA ... 26 2.13.2 Konsep Pemrograman Berorientasi Objek pada JAVA ... 27 2.14 Unified Modelling Language (UML) ... 29 BAB III ANALISIS DAN PERANCANGAN ALGORITMA ... 37 3.1 Analisis Masalah ... 37 3.2 Analisis Sistem ... 38 3.2.1 Analisis Prosedur Sistem ... 38 3.2.1.1 Analisis Data Masukan ... 40 3.2.1.2 Analisis Pengolahan Citra ... 41 3.2.1.3 Analisis Pelatihan Naïve Bayes ... 43 3.2.1.4 Analisis Pengujian Naïve Bayes ... 45 3.3 Analisis Metode / Algoritma ... 46
vi
3.3.1.1 Resize ... 46 3.3.1.2 Grayscale ... 47 3.3.1.3 Ekstraksi Ciri Run Length ... 48 3.3.2 Analisis Pelatihan ... 55 3.3.3 Analisis Pengujian ... 57 3.3.4 Analisis Data Keluaran ... 61 3.4 Analisis Kebutuhan Basis Data ... 61
3.4.1 Entity Relationship Diagram (ERD) ... 61 3.5 Analisis Kebutuhan Perangkat Lunak ... 62
3.5.1 Analisis Kebutuhan Non Fungsional ... 64 3.5.2 Analisis Kebutuhan Fungsional ... 65 3.5.2.1 Use Case Diagram ... 65 3.5.2.2 Activity Diagram ... 68 3.5.2.3 Sequence Diagram ... 69 3.5.2.4 Class Diagram ... 71 3.5.3 Perancangan Basis Data ... 72
3.5.3.1 Skema Relasi ... 72 3.5.3.2 Diagram Relasi ... 73 3.5.3.3 Struktur File ... 73 3.5.4 Perancangan Simulasi ... 74 3.5.4.1 Perancangan Antarmuka ... 75 3.5.4.2 Perancangan Pesan ... 79 3.5.5 Jaringan Semantik ... 79 BAB IV IMPLEMENTASI DAN PENGUJIAN SISTEM ... 81
vii
4.1.1 Implementasi Perangkat Keras ... 81 4.1.2 Implementasi Perangkat Lunak ... 81 4.1.3 Implementasi Basis Data ... 82 4.1.4 Implementasi Class ... 83 4.1.5 Implementasi Antarmuka ... 84 4.2 Rencana Pengujian ... 87
95
1. Rizkiana, U. 2009.“Penerimaan Diri Pada Remaja Penderita Leukemia”. Jurnal Psikologi Vol. 2 No. 2 : 114-122. Universitas Gunadarma, Depok. 2. Bharathivanan, A. 2015. “Local Binary Texture Based Method for
Segmentation of Leukemia in Blood Microscopic Images”. Journal of Applied Engineering Research Vol. 10 No. 20 : 16291-16296. Valliammai Engineering College, India.
3. Mita, I. 2007. “Analisis Tekstur Menggunakan Metode Run Length”. Tugas Akhir Teknik Elektro, Universitas Diponegoro, Semarang.
4. Praida, A, R. 2008. “Pengenalan Penyakit Darah Menggunakan Teknik Pengolahan Citra dan Jaringan Syaraf Tiruan”. Tugas Akhir Teknik Elektro. Universitas Indonesia, Depok.
5. Rohmana, I. 2014. “Perbandingan Jaringan Syaraf Tiruan dan Naïve Bayes Dalam Deteksi Seseorang Terkena Penyakit Stroke”. Jurnal MIPA Vol. 37 No. 1 : 92-104. Universitas Negeri Semarang, Semarang.
6. Pressman, S, R. 2010. “Rekayasa Perangkat Lunak”. Yogyakarta: Andi. 7. Saifuddin. 2006. “Pelayanan Kesehatan Maternal & Neonatal”. Jakarta:
Yayasan Bina Pustaka Sarwono Prawirohardjo.
8. Simon, Sumanto, dr. Sp. PK. 2003. “Neoplasma Sistem Hematopoietik: Leukemia”. Fakultas Kedokteran Unika Atma Jaya Jakarta.
9. Ahmad, U. 2005. “Pengolahan Citra Digital & Teknik Pemrogramannya”. Yogyakarta: Graha Ilmu.
10. Munir, R. 2002. “Pengolahan Citra Digital”. Bandung: Informatika.
11. Galloway, M. 1975. “Texture Analysis Using Gray Level Run Length”. Computer Graphics Image Process vol. 4, pp. 172-179.
12. Prasetyo, E. 2012. “Pengenalan Pola Naïve Bayes”. Universitas Pembangunan Nasional. Jawa Timur.
Dan Tekstur Dengan Kombinasi Fungsi Klustering Terpisah Dan Pembobotan Manual”. Jurnal Teknologi Informasi dan Komunikasi Vol. 9 No. 1 : 47-52. Institut Teknologi Sepuluh November, Surabaya.
15. Nona, D. 2015. “Identifikasi Penyakit Tanaman Padi Menggunakan Jense Shannon Divergence Berbasis Android”. Tugas Akhir Teknik Informatika, Universitas Halu Oleo, Kendari.
16. La, O, H, S, S. 2014. “Perbandingan Ekstraksi Ciri Full, Blocks, dan Row Mean Spectogram Image Dalam Mengidentifikasi Pembicara”. Jurnal Ilmu Komputer dan Elektronika Vol. 8 No. 2 : 155-164. Universitas Gajah Mada, Yogyakarta.
17. Imam, S. 2007. “Kinerja Pengenalan Citra Tekstur Menggunakan Analisis Tekstur Metode Run Length”. Tugas Akhir Teknik Elektro, Universitas Diponegoro, Semarang.
18. Visa, S. 2011. “Confusion Matrix-Based Feature Selection”. Proceedings of the 22nd Midwest Artficial Intelligence and Cognitive Science
Leukemia Berdasarkan Citra Darah
Leonart Jefry
Teknik Informatika – Universitas Komputer Indonesia Jl. Dipatiukur 112-114 Bandung
Email : [email protected]
ABSTRAK
Penyakit leukemia adalah penyakit dalam klasifikasi kanker pada darah. Penyakit leukemia memiliki suatu ciri yang berbeda. Mengenali perbedaan tekstur pada citra penyakit leukemia merupakan suatu cara untuk membedakan ciri tersebut. Ada beberapa metode untuk memperoleh ciri-ciri tekstur dalam suatu citra, salah satu metode untuk memperoleh ciri-ciri citra tekstur adalah dengan menggunakan metode run length. Ciri-ciri yang terdapat pada metode run length adalah SRE
(Short Run Emphasis), LRE (Long Run Emphasis),
GLU (Grey Level Uniformity), RLU (Run Length
Uniformity) dan RPC (Run Percentage). Dari hasil
ciri-ciri tersebut kemudian algoritma naïve bayes akan menentukan hasil klasifikasi berdasarkan nilai probabilitas terbesar. Citra yang diuji adalah citra darah yang teridentifikasi penyakit leukemia.
Berdasarkan penelitian yang telah dilakukan, dapat ditarik kesimpulan bahwa: algoritma naïve bayes dapat melakukan klasifikasi citra penyakit leukemia berdasarkan tekstur yang diekstraksi dengan metode run length. Data hasil ekstraksi ciri metode run length adalah berupa data kontinu, sehingga data hasil ekstraksi ciri tersebut dapat langsung digunakan sebagai masukan dalam klasifikasi naïve bayes.
Berdasarkan hasil pengujian, kesimpulan yang didapatkan adalah algoritma naïve bayes dapat mengklasifikasikan citra penyakit leukemia berdasarkan hasil ekstraksi citra darah menggunakan metode run length dan menghasilkan tingkat keakurasian 91.25% dengan total 20 data latih dan 20 data uji. Dikarenakan data hasil ekstraksi ciri tekstur penyakit leukemia dengan metode run-length memiliki keunggulan membedakan antara tekstur halus dan tekstur kasar, sehingga klasifikasi naïve bayes dapat berjalan lebih maksimal saat melakukan klasifikasi citra darah yang teridentifikasi penyakit leukemia.
Kata Kunci : Penyakit Leukemia, Citra Darah, Metode Run Length, Algoritma Naïve Bayes
1. PENDAHULUAN salah satu penyakit yang sangat menakutkan, hal ini terlihat dari angka harapan hidup penderita kanker yaitu sebesar 60% dan banyaknya angka kematian.Melihat permasalahan tersebut, maka perlu adanya pendeteksian penyakit leukemia pada diri remaja.
Pendeteksian penyakit leukemia dapat dilakukan
dengan melihat gejala yang dialami oleh penderita. Namun seiring dangan perkembangan teknologi saat ini pendeteksian penyakit leukemia dapat dilakukan dengan bantuan suatu sistem yang dapat mengelola suatu citra. Pengenalan tekstur merupakan salah satu teknik yang dapat digunakan dalam mendeteksi penyakit leukemia. Selain pengenalan tekstur dalam proses pengenalan citra juga dibutuhkan proses pengklasifikasian agar pengenalan yang dihasilkan memiliki hasil yang baik. Berdasarkan penelitian sebelumnya, proses pengenalan citra dapat dilakukan untuk mendeteksi penyakit leukemia [2].
Pada dasarnya penyakit leukemia dapat dikenali berdasarkan beberapa aspek diantaranya adalah warna, pola dan tekstur dari sel darah. Salah satu metode yang dapat digunakan untuk pengenalan tekstur adalah metode run length. Hasil dari penelitian ini dapat lebih akurat apabila menggunakan teknik pengklasifikasian yang lebih baik [3]. Naïve bayes adalah salah satu metode klasifikasi yang menggunakan konsep probabilitas.
1.1 Leukemia
Leukemia atau kanker darah adalah penyakit dalam
klasifikasi kanker pada darah atau sumsum tulang yang ditandai oleh perubahan komposisi secara tak normal atau transformasi maligna dari sel-sel
kompeten. Pasien dengan CLL memiliki jumlah sel darah putih lebih tinggi dari biasanya. Penyakit ini sering terjadi pada orang dewasa yang berumur lebih dari 55 tahun, kadang-kadang juga diderita oleh dewasa muda, dan hampir tidak pernah terjadi pada anak-anak. Beberapa pasien meninggal dengan cepat, dalam waktu 2-3 tahun setelah didiagnosis, karena komplikasi dari CLL, tetapi kebanyakan pasien dapat bertahan hidup 5-10 tahun.
Gambar 1 Chronic Lymphocytic Leukemia
2. Chronic Myeloid Leukemia (CML) adalah
salah satu bentuk dari leukemia yang ditandai
dengan meningkatnya dan pertumbuhan yang tidak teratur dari sel myeloid di dalam sumsum tulang dan terakumulasi juga di dalam darah. Penyakit ini sering terjadi pada orang dewasa, dapat juga terjadi pada anak-anak.
Gambar 2 Chronic Myeloid Leukemia
3. Acute Lymphoblastic Leukemia (ALL) adalah
suatu penyakit dimana sel-sel yang dalam keadaan normal berkembang menjadi limfosit berubah menjadi ganas dan dengan segera akan menggantikan sel-sel normal didalam sumsum tulang. ALL merupakan leukemia yang biasa terjadi pada anak-anak dibawah umur 15 tahun. Paling sering terjadi pada anak usia antara 3-5 tahun, tetapi kadang terjadi pada usia remaja dan orang dewasa yang telah berumur 65 tahun atau lebih.
Gambar 3 Acute Lymphoblastic Leukemia
4. Acute Myelogenous Leukemia (AML) adalah
salah satu jenis kanker darah dan sumsum tulang. AML ditandai dengan pesatnya pertumbuhan sel darah putih abnormal yang menumpuk di sumsum tulang dan mengganggu produksi sel darah normal. Penyakit ini mempengaruhi sel-sel darah yang belum matang dan berkembang dengan cepat. Penyakit ini biasa terjadi pada anak-anak dan orang dewasa.
Gambar 4 Acute Myelogenous Leukemia
1.2 Kecerdasan Buatan
Kecerdasan buatan (Artificial inteligence) adalah salah satu cabang ilmu pengetahuan yang berhubungan dengan pemanfaatan mesin untuk memecahkan persoalan yang rumit dengan cara yang lebih manusiawi.
Kecerdasan buatan digunakan untuk menganalisis pemandangan dalam citra dengan perhitungan simbol-simbol yang mewakili isi pemandangan tersebut setelah citra diolah untuk memperoleh ciri khas. Kecerdasan buatan bisa dilihat sebagai tiga kesatuan yang terpadu yaitu persepsi, pengertian dan aksi. Persepsi menerjemahkan sinyal dari dunia nyata dalam citra menjadi simbol-simbol yang lebih sederhana, pengertian memanipulasi simbol-simbol tersebut untuk memudahkan penggalian suatu informasi tertentu, dan aksi menerjemahkan simbol-simbol yang telah dimanipulasi menjadi sinyal lain yang dapat merupakan hasil akhir [5].
1.3 Metode Run Length
Grey level run length matrix yang biasa disingkat
dan 1350.
Berdasarkan penelitian yang dilakukan oleh Galloway[6], terdapat beberapa jenis ciri tekstural yang dapat diekstraksi dari matriks run-length. Berikut variabel-variabel yang terdapat di dari ekstraksi citra dengan menggunakan metode statistikal Grey Level Run Length Matrix :
i = nilai derajat keabuan j = piksel yang berurutan (run)
M = Jumlah derajat keabuan pada sebuah gambar N = Jumlah piksel berurutan pada sebuah gambar r(j) = Jumlah piksel berurutan berdasarkan banyak urutannya (run length)
g(i) = Jumlah piksel berurutan berdasarkan nilai derajat keabuannya
s = Jumlah total nilai run yang dihasilkan pada arah tertentu
p(i,j) = himpunan matrik i dan j n = jumlah baris * jumlah kolom.
Dimana variabel-variabel tersebut akan digunakan untuk mencari nilai dari atribut-atribut tekstur seperti SRE, LRE, GLU, RLU dan RPC.
1.4 Klasifikasi Naive Bayes
Naïve bayes adalah teknik prediksi berbasis probabilistik sederhana yang berdasar pada penerapan teorema Bayes[7]. Naïve bayes merupakan suatu metode pengklasifikasian paling sederhana dengan menggunakan peluang yang ada, dimana diasumsikan bahwa setiap variable X bersifat bebas (independence).
1. Hitung rata-rata (mean) tiap fitur dalam dataset training dengan dengan cara menghitung jumlah data tiap kelas dibagi jumlah total data secara keseluruhan
2. Selanjutnya menghitung densitas
probabilitasnya
3. Setelah didapatkan nilai densitas
probabilitasnya, selanjutnya menghitung posterior masing-masing kelas
4. Setelah didapat nilai posterior, kemudian menentukan kelas yang sesuai dengan melihat nilai posterior terbesar.
1.5 Pengujian Confusion Matrix
Confusion matrix adalah sebuah tabel yang
menyatakan jumlah data uji yang benar diklasifikasikan. Berikut ini contoh confusionmatrix
Kelas Sebenarnya 1 TP FN
0 FP TN
Keterangan:
1. True Positive (TP), yaitu jumlah dokumen dari
kelas 1 yang benar dan diklasifikasikan sebagai kelas 1.
2. True Negative (TN), yaitu jumlah dokumen
dari kelas 0 yang benar diklasifikasikan sebagai kelas 0.
3. False Positive (FP), yaitu jumlah dokumen dari kelas 0 yang salah diklasifikasikan sebagai kelas 1.
4. False Negative (FN), yaitu jumlah dokumen dari kelas 1 yang salah diklasifikasikan sebagai kelas 0.
Untuk menghitung akurasi digunakan persamaan [8]::
2. ISI PENELITIAN
2.1 Analisis Prosedur Sistem
Prosedur adalah kumpulan dari proses dalam suatu sistem yang saling terkait antara satu dengan yang lainnya untuk mencapai tujuan yang telah diterapkan. Berikut ini adalah tahapan-tahapan proses dalam melakukan klasifikasi mulai dari data masukan sampai data keluaran.
Gambar 5 Alur Analisis Prosedur Sistem
Merupakan langkah pengambilan data citra pada media masukan kedalam sistem. Citra masukan berupa file gambar yang didalamnya terdapat kelainan jenis penyakit leukemia pada darah lalu kemudian di scan.
2. Pengolahan citra
Pada tahap ini citra yang dimasukan akan dilakukan proses merubah ukuran gambar (resize) menjadi 32x32 piksel [16], setelah itu dilakukan proses grayscale dengan merubah warna gambar menjadi keabu-abuan untuk mendapatkan nilai matriks grayscale. Setelah
didapat matriks grayscale kemudian dilakukan proses ekstraksi ciri run-length dan menyimpan data klasifikasi setelah didapat nilai fitur rata-rata run-length.
3. Pelatihan naïve bayes
Tahap pelatihan pada naïve bayes yaitu mengambil data yang telah diberi nama klasifikasi dan memiliki nilai rata-rata fitur run-length untuk dihitung dan mencari nilai mean dan varian.
4. Pengujian naïve bayes
Pada proses pengujian naïve bayes, masukan citra yang akan diujikan. Citra yang dimasukan akan diproses untuk mencari nilai densitas probabilitas dan mencari nilai posterior terbesar. Setelah didapat nilai posterior terbesar maka diketahui hasil klasifikasi dari citra uji.
2.2 Analisis Metode
Analisis algoritma adalah analisis terhadap suatu sistem yang terdapat langkah-langkah dari alur proses algoritma. Analisis ini bertujuan untuk menganalisis cara kerja metode naïve bayes dalam
mengklasifikasi citra berdasarkan tekstur. Berikut ini
tahapan-tahapan yang dilakukan dalam
mengklasifikasikan citra:
2.2.1 Analisis Tahapan Pengolahan Citra
Analisis tahapan pengolahan citra merupakan suatu tahap untuk mendapatkan ekstraksi ciri yang ada pada suatu citra. Langkah awal pada analisis tahapan pengolahan citra adalah dengan memasukkan citra masukan.
grayscale terhadap citra masukan untuk menghasilkan matriks grayscale.
Gambar 7 Citra hasil resize dan grayscale
Gambar 8 Matriks Grayscale
2.2.2 Ekstraksi Ciri Run Length
Langkah utama dalam proses ekstraksi ciri run length adalah dengan mengambil nilai matriks
grayscale. Nilai ekstraksi ciri yang akan dicari
adalah nilai SRE (short run emphasis), LRE (long
run emphasis), GLU (grey level uninformity), RLU
(run length uninformity) dan RPC (run percentage).
Nilai ekstraksi ciri didapat melalui table matriks run length.
Tabel 1 Matriks Run Length 00
Tabel 2 Matriks Run Length 450
Tabel 4 Matriks Run Length 1350
Perhitungan matriks run length 00
Dengan menggunakan langkah yang sama untuk sudut simetris 450, 900 dan 1350 maka akan
didapatkan nilai sebagai berikut:
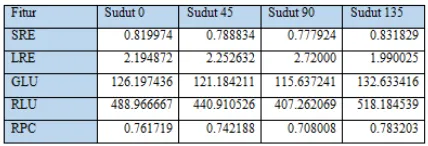
Tabel 5 Nilai Fitur Sudut Citra Masukan
2.3 Analisis Pelatihan
Pada tahapan analisis ini akan dilakukan pelatihan dengan menggunakan algoritma naïve bayes, pelatihan dalam naïve bayes dilakukan untuk mendapatkan data pelatihan yang diestimasi dengan nilai mean dan varians. Langkah – langkah pada tahap pelatihan ini adalah mencari nilai mean dan varians dari setiap fitur pada setiap kelas data latih.
Tabel 6 Dataset untuk pelatihan
Dengan menggunakan perhitungan mean dan varians yang sama maka didapat nilai SRE, LRE, GLU,RLU dan RPC untuk kelas ALL, AML, CLL dan CML
terhadap data baru, langkah awal yang dilakukan adalah memasukkan citra uji, kemudian hitung nilai fitur ekstraksi cirri dari citra uji.
Gambar 9 Citra Uji
Tabel 8 Nilai Fitur Ekstraksi Ciri Citra Uji
Setelah didapat nilai fitur ekstraksi ciri dari citra uji, langkah selanjutnya menghitung nilai densitas probabilitas.
Tabel 9 Nilai Densitas Probabilitas Data Testing
Kemudian hitung nilai evidence dan posterior
Evidence =
Implementasi Antarmuka menjelaskan dan menggambarkan implementasi dari setiap proses yang ada didalam sistem ini :
Gambar 10 Tampilan Menu Utama
Gambar 11 Tampilan Menu Pengolahan
Gambar 13 Tampilan Menu Pengujian
3. KESIMPULAN
Berdasarkan hasil dari pengujian yang telah dilakukan maka didapatkanlah kesimpulan bahwa metode naïve bayes dapat mengklasifikasikan citra dengan masukan data statistik yang langsung membandingkan jarak terdekat dengan pelatihannya. Pengujian klasifikasi citra berdasarkan tekstur dengan menggunakan data citra yang telah dilatih memiliki rata-rata tingkat akurasi 100% dan untuk citra yang belum dilatih rata-rata tingkat akurasi 90% dan tingkat akurasi menggunakan 3 data latih adalah 85% dan menggunakan 4 data latih adalah 90%.
Dari hasil seluruh pengujian, algoritma naïve bayes menghasilkan tingkat keakurasian 91.25% dengan total 20 data latih dan 20 data uji
4. DAFTAR PUSTAKA
[1] Rizkiana, U. 2009.“Penerimaan Diri Pada Remaja Penderita Leukemia”. Jurnal Psikologi Vol. 2 No. 2 : 114-122. Universitas Gunadarma, Depok.
[2] Bharathivanan, A. 2015. “Local Binary Texture Based Method for Segmentation of Leukemia in Blood Microscopic Images”. Journal of
Applied Engineering Research Vol. 10 No. 20 :
16291-16296. Valliammai Engineering College, India.
[3] Praida, A, R. 2008. “Pengenalan Penyakit Darah Menggunakan Teknik Pengolahan Citra dan Jaringan Syaraf Tiruan”. Tugas Akhir
Teknik Elektro. Universitas Indonesia, Depok.
[4] Simon, Sumanto, dr. Sp. PK. 2003.
“Neoplasma Sistem Hematopoietik:
Leukemia”. Fakultas Kedokteran Unika Atma Jaya Jakarta.Sreenivasulu M, 2011, Performance Evaluation of EFCI and ERICA Schemes for ATM Networks”.
[5] Ahmad, U. 2005. “Pengolahan Citra Digital & Teknik Pemrogramannya”. Yogyakarta: Graha Ilmu.
[6] Galloway, M. 1975. “Texture Analysis Using Gray Level Run Length”. Computer Graphics Image Process vol. 4, pp. 172-179.
[8] Visa, S. 2011. “Confusion Matrix-Based Feature Selection”. Proceedings of the 22nd
Based On Image Of Blood
Leonart Jefry
Informatics Engineering – Universitas Komputer Indonesia Jl. Dipatiukur 112-114 Bandung
Email : [email protected]
ABSTRACT
Leukemia is a disease in cancer classification. Leukemia has a different characteristic. How to differentiate these characteristics is to recognize the difference of a texture from image of leukemia. There are several methods to obtain the characteristics of texture from image, a method to obtain the characteristics of texture from image is use run length method. The texture characteristics of run length method are SRE (Short Run Emphasis), LRE (Long Run Emphasis), GLU (Gray Level Uniformity), RLU (Run Length Uniformity) and RPC (Run Percentage). From the results of these characteristics then naïve bayes algorithm will determine the largest value of probability. The object being tested is a blood image of leukemia.
From the research has been done, can be concluded as follows: naïve bayes algorithm can do image classification based on the texture extracted by run length method. Data from feature extraction using run length method is continuous data, so the process of data classification from feature extraction can be directly used as an input in the naïve bayes classification.
From the result, a conclusion obtained is naïve bayes algorithm can classify images of leukemia from distinguishing between smooth texture and rough texture, so naïve bayes classification can run more leverage when performing image classification of blood were identified of leukemia.
Keywords : Leukemia, Blood of Image, Run Length Method, Naïve Bayes Algorithm
under 15 years [1]. Currently leukemia disease into a disease that is very frightening, it is seen from the life expectancy of cancer patients which decreased by 60% and the number of digits kematian.Melihat these problems, hence the need for detection of leukemia in adolescents.
Leukemia disease detection can be done by looking at the symptoms experienced by the patient. But with the invitation current technological developments leukemia disease detection can be done with the help of a system that can manage an image. The introduction of texture is one technique that can be used in detecting leukemia. In addition to the introduction of the texture in the image recognition process is also needed so that the introduction of the classification process which has produced good results. Based on previous research, the process of image recognition can be performed to detect the leukemia disease [2].
Basically leukemia can be identified based on several aspects including the color, pattern and texture of the blood cells. One method that can be used for the introduction of the texture is run length method. The results of this study can be more accurately when using a better classification techniques [3]. Naïve Bayes classification method is one that uses the concept of probability.
1.1 Leukemia
Leukemia or blood cancer is a disease in the classification of cancer of the blood or bone marrow characterized by an abnormal change in the composition or the malignant transformation of blood-forming cells in the bone marrow and lymphoid tissue, generally occurs in the white blood cells [4]. Leukemia cancer diseases are classified into:
Picture 1 Chronic Lymphocytic Leukemia
2. Chronic Myeloid Leukemia (CML) is a form of leukemia characterized by the increased and unregulated growth of myeloid cells in the bone marrow and also accumulates in the blood. This disease often occurs in adults, can also occur in children.
Picture 2 Chronic Myeloid Leukemia
3. Acute lymphoblastic leukemia (ALL) is a disease in which cells that normally develop into lymphocytes become malignant and will soon replace the normal cells in the bone marrow. ALL is a common leukemia in children under the age of 15 years. Most often occurs in children aged between 3-5 years, but it sometimes occurs in the teens and adults who are aged 65 years or more.
Picture 3 Acute Lymphoblastic Leukemia
4. Acute Myelogenous Leukemia (AML) is a type of cancer of the blood and bone marrow. AML is characterized by rapid growth of abnormal white blood cells that accumulate in the bone marrow and interfere with normal blood cell production. This disease affects the blood cells are immature and growing rapidly. This disease usually occurs in children and adults.
Picture 4 Acute Myelogenous Leukemia
1.2 Artificial Intelligence
Artificial intelligence (Artificial Intelligence) is a branch of science which deals with the use of machines to solve complex problems in a more humane way.
Artificial intelligence is used to analyze the image of the scenery in the calculation of the symbols that represent the content of the scene after the image is processed to obtain a special characteristic. Artificial intelligence can be seen as three integrated unity of perception, understanding and action. Perception decodes the signals from the real world in images become symbols of a more simple, understanding manipulating these symbols to facilitate extracting certain information, and action to translate the symbols that have been manipulated into other signals that can be the end result [5].
1.3 Run Length Method
Grey level run length matrix commonly abbreviated with GLRLM is one popular method to extract the texture in order to obtain statistical characteristics or attributes contained in texture to estimate the pixels that have the same degree of gray. Extraction texture with run-length method is done by making a series of value pairs (i, j) in each row of pixels. Orientation is formed by a four-way shift at intervals of 450,
which is 00, 450, 900, and 1350.
Based on research conducted by Galloway [6], there are several types of textural characteristics that can be extracted from the matrix run-length. The following variables contained in the extraction of the image by using statistical methods Grey Level Run Length Matrix:
i = the value of the degree of gray j = pixels in sequence (run)
M = Number of degrees of gray in an image N = number of pixels in an image sequence r (j) = Number of pixels sequentially by many the sequence (run length)
g (i) = number of pixels in sequence by value grey degrees
s = Number of total value of the resulting run on the direction certain
1.4 Naive Bayes Classification
Naïve Bayes is a simple probabilistic based prediction techniques are based on the application of Bayes' theorem [7]. Naïve Bayes classification is a method simplest to use the existing opportunities, where it is assumed that every variable X is free (independence).
In naïve classification steps are as follows: training:
2. Then calculate the variance of the training dataset
Where: = varians µ= mean
= value of data
the number of data values
Test:
data
2. Next, calculate the probability density
Where :
= input of data π = 3,14
standar deviation µ = mean
3. Having obtained the probability density values, then calculate the posterior of each class.
4. Having obtained the posterior value, and then determine the appropriate grade to see the value of the largest posterior.
1.5 Confusion Matrix Test
Confusion matrix is a table that states the amount of test data that is properly classified. Here's an example confusion matrix for binary classification:
Tabel 1 Confusion Matrix for Biner Classification Prediction Class
1 0
Real Class 1 TP FN
0 FP TN
Information:
1. True Positive (TP), ie the number of documents from Grade 1 right and are classified as Class 1.
2. True Negative (TN), ie the number of documents of class 0 is correctly classified as grade 0.
3. False Positive (FP), ie the number of documents from grade 0 incorrectly classified as Class 1.
4. False Negative (FN), ie the number of documents from one class incorrectly classified as grade 0.