Hasil output untuk mencari korelasi:
Format Kuisioner
Nama
:... NIM :112407... Asal Sekolah :... Rata – Rata Raport di Kelas XII : Semester 1
:... Semester 2
:... Indeks Prestasi (IP) pada Semester I :
Indeks Prestasi (IP) pada Semester II : Indeks Prestasi (IP) pada Semester III :
Untuk waktu dan data yang telah Anda isi dengan benar, Saya mengucapkan terima kasih.
DAFTAR PUSTAKA
Dicky Samuel, B. 2008. Pengaruh Lama Belajar, Keberadaan Orang Tua dan Jalur Masuk Terhadap Indeks Prestasi Mahasiswa Program Studi D3 Statistika FMIPA USU Angkatan 2010. Tugas Akhir. Medan.
Drs. Djarwanto, Ps. Statistik Nonparametrik. Yogyakarta.
Hartono. 2004. Statistik Untuk Penelitian. Yogyakarta: Pustaka Pelajar. Silalahi, U. 2009. Metode Penelitian Sosial. Bandung: Refika Aditama.
Soepono, Bambang. 1997. Statistik Terapan Dalam Penelitian Ilmu – Ilmu Sosial dan Pendidikan. Jakarta: Rineka Cipta.
Sudjana. 1992. Metode Statistika. Edisi Keenam. Bandung: Tarsito. Sudjana. 2001. Metode Statistika. Bandung: Tarsito.
Supranto. 1998. Teknik Sampling untuk Survei dan Eksperimen. Jakarta: Rineka Cipta.
Syani, Abdul. 1995. Pengantar Metode Statistika Nonparametrik. Jakarta: Pustaka Jaya.
BAB 3
PENGOLAHAN DATA
3.1Analisis Data
Dalam proses analisis data, penulis menggolongkan, mengurutkan, dan menyederhanakan data. Tujuan analisis data ini adalah untuk menyederhanakan data ke dalam bentuk yang lebih mudah dibaca dan diinterpretasi. Dalam proses analisis ini seringkali digunakan metode – metode statistik. Dengan menggunakan metode statistik ini dapat diperbandingkan hasil yang diperoleh dengan hasil yang terjadi secara kebetulan, sehingga penulis mampu menguji apakah hubungan yang diamatinya memang betul – betul terjadi karena hubungan sistematis antara variabel yang diteliti atau hanya terjadi secara kebetulan.
Proses analisis data tidak berhenti sampai sekian. Hasil analisis harus dapat diinterpretasikan, artinya harus diadakan “interferensi” tentang hubungan yang diteliti. Peneliti melakukan interferensi ini dalam usaha untuk mencari makna dan impikasi yang lebih luas dari hasil – hasil penelitiannya. Interpretasi dapat dilakukan menurut pengertian yang sempit, hanya melibatkan data dan hubungan – hubungan yang diperolehnya. Interpretasi juga dapat dilakukan dalam makna yang lebih luas, penulis berupaya membandingkan hasil penelitianya dengan hasil – hasil peneliti lain serta menghubungkan kembali hasil inferensinya dengan teori.
menginterpretasikan data untuk mendapatkan informasi yang dapat menjawab pertanyaan – pertanyaan yang dihadapi. Sedangkan penafsiran hasil analisis data merupakan tahap selanjutnya dari proses analisis untuk sampai kepada kesimpulan.
Dengan demikian analisis data dan interpretasi hasilnya merupakan dua macam proses yang tidak dapat dipisah – pisahkan. Oleh karena itu bobot informasi atau kesimpulan yang diperoleh sangat tergantung pada kejelian penafsiran dan ketajaman dalam menganalisis data. Atau data yang dianalisis belum memenuhi syarat yang diperlukan (tidak lengkap).
Analisa korelasi merupakan salah satu teknik statistik yang sering digunakan untuk mencari hubungan antara dua variabel. Korelasi diartikan sebagai hubungan analisis korelasi bertujuan untuk mengetahui pola dan keeratan hubungan antara dua variabel atau lebih. Dua variabel yang hendak diselidiki korelasinya biasanya dilambangkan dengan X dan Y. Perlu diingat bahwa uji korelasi tidak membedakan adanya variabel dependen dan variabel independen. Arah korelasi menunjukkan pola gerakan variabel Y terhadap gerakan variabel X. Terdapat dua arah korelasi, yaitu positive correlation, negative correlation, dan nihil correlation.
• Possitive Correlation
• Negatif Correlation
Jika kenaikan nilai X justru diiringi dengan penurunan nilai Y dan sebaliknya penurunan nilai X dibarengi dengan kenaikan nilai Y, atau dengan kata lain perubahan pada satu variabel diikuti oleh perubahan variabel yang lain secara teratur dengan arah gerakan yang berlawanan, hubungan seperti ini yang disebut sebagai negative correlation.
3.2Koefisien Korelasi
Penyelidikan untuk mengetahui hubungan antara dua variabel diawali dengan usaha untuk menemukan bentuk terdekat dari hubungan tersebut dengan cara menyajikan dalam bentuk diagram pencar (scater plot). Diagram ini menggambarkan titik – titik pada bidang X dan Y, di mana setiap titik – titik ditentukan oleh pasangan nilai X dan Y. Apabila dari diagram pencar tersebut dapat ditarik garis yang sesuai dengan pola diagram pencar tersebut, berarti variabel – variabel itu memiliki hubungan yang linier. Sebaliknya jika pada diagram pencar tersebut tidak dapat ditarik garis yang mengandung pola tertentu, hubungan yang terjadi adalah hubungan non linier.
korelasi dinyatakan dengan bilangan bergerak antara 0 sampai +1 atau 0 sampai -1. Nilai korelasi mendekati +1 atau -1 berarti terdapat hubungan yang kuat, sebaliknya korelasi yang mendekati nilai 0 berarti terdapat hubungan yang lemah. Apabila korelasi sama dengan 0, berarti antara kedua variabel tidak terdapat hubungan sama sekali. Apabila korelasi sama dengan +1 atau -1 berarti terdapat hubungan yang sempurna antara kedua variabel.
Notasi positif (+) atau negatif (-) menunjukkan arah hubungan antara kedua variabel. Notasi positif (+) berarti hubungan antara kedua variabel searah (possitive correlation), jika variabel satu naik, maka variabel yang lain juga naik. Notasi negatif (-) berarti kedua variabel berhungan terbalik (negative correlation), artinya kenaikan satu variabel akan diikuti dengan penurunan variabel lainnya. Arah dan notasi koefisien dapat dirangkum sebagai berikut:
Tabel 3.1. Arah dan notasi koefisien korelasi
Nilai Keterangan
& ,
Telah terjadi hubungan yang linier positif, yaitu makin besar nilai variabel Y atau makin kecil nilai variabel X makin kecil pula nilai variabel Y yang diperoleh.
' ,
Nilai Keterangan
,
Tidak ada hubungan sama sekali antara variabel X dan variabel Y.
M Telah terjadi hubungan linier sempurna, berupa garis lurus.
Hal yang harus dijelaskan di sini adalah bahwa analisis korelasi hanya mengukur ko-variansi. Pengukuran ini bersifat numeric dan menunjukkan suatu korelasi yang terdapat antara dua atau lebih variabel. Pengukuran ini tidak menunjukkan adanya hubungan sebab – akibat, ini adalah suatu hal yang harus digaris bawahi. Dua variabel yang sudah terbukti mempunyai hubungan sebab – akibat, tetapi hubungan sebab – akibat pasti menunjukkan bahwa kedua variabel mempunyai hubungan. Terdapat tiga jenis pembagian korelasi, yaitu: pertama: korelasi positif dan korelasi negatif yang telah diuraikan di atas. Kedua: korelasi sederhana, parsial, dan ganda. Ketiga: korelasi linier dan non linier.
Korelasi sederhana terjadi apabila variabel yang dipelajari hanya dua buah, sedangkan untuk korelasi parsial dan ganda lebih dari dua variabel terlibat dan mempelajarinya secara bersamaan. Korelasi ganda berisi pengukuran hubungan antara salah satu variabel dependent (bebas) dan dua atau lebih variabel independent (terikat). Sedangkan dalam korelasi parsial, mengukur hubungan antara satu variabel dependent (bebas) dan satu variabel independent (terikat) dengan mengansumsikan bahwa variabel yang lainnya dalam keadaan konstan.
yang lain. Sedangkan korelasi non – linier terjadi apabila perbandingan besar perubahan yang terjadi pada satu variabel tidak sama dengan besar perubahan yang terjadi pada variabel lain. Hubungan linier – non linier dapat dilihat ketika memetakan hubungan yang ada dalam grafik, terlihat korelasi linier membentuk garis lurus sedangkan korelasi non – linier membentuk kurva. Uji hubungan melalui teknik statistik korelasi dapat dilakukan terhadap bermacam data, baik data yang berskala interval, ordinal maupun nominal.
Adapun tujuan analisis korelasional adalah untuk mengetahui apakah benar terdapat korelasi antara variabel yang satu dengan variabel yang lainnya berdasarkan data yang ada atau diperoleh, dan apakah korelasi antar variabel tersebut termasuk korelasi yang kuat, cukup, atau lemah, dan apakah antar variabel tersebut merupakan korelasi yang signifikan atau tidak.
Untuk mengadakan interpretasi mengenai besarnya koefisien korelasi dengan ketentuan dalam tabel berikut:
Tabel 3.2. Interpretasi mengenai besarnya koefisien korelasi
Nilai Keterangan
0,8 s/d 1,0 Sangat tinggi
0,6 s/d 0,8 Tinggi
0,4 s/d 0,6 Cukup
0,2 s/d 0,4 Rendah
3.3 Pengertian Korelasi Tata Jenjang
Telah dijelaskan di depan bahwa teknik korelasi adalah teknik statistika yang digunakan untuk mengetahui hubungan antara dua buah gejala. Jika gejala yang dihadapi kedua gejala itu berskala interval, maka teknik korelasi yang sesuai adalah korelasi product moment. Jika menghadapi gejala dua gejala yang masing – masing berskala ordinal, maka teknik korelasi product moment tidak tepat lagi, karena itu harus digunakan teknik korelasi yang lain yang lebih tepat, yaitu teknik korelasi tata jenjang.
Teknik korelasi tata jenjang disebut juga rank order correlation dikembangkan oleh Charles Spearman, dimaksudkan untuk menghitung dan menentukan tingkat hubungan (korelasi) antara dua gejala yang kedua – duanya berskala ordinal atau tata jenjang. Data ordinal selalu menunjukkan perbedaan besar antara variabel yang satu dengan yang lain.
Apabila peneliti memiliki data yang jenisnya interval atau rasio, maka data tersebut harus diubah dahulu ke dalam urutan ranking – ranking yang merupakan ciri dari data ordinal. Perhatikan tabel 3.3 berikut:
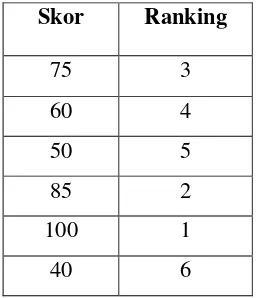
Tabel 3.3. Contoh skor dan urutan rankingnya
Skor Ranking
75 3
60 4
50 5
85 2
100 1
Cara mengubah menjadi ranking (ordinal) dilakukan dengan mengurutkan skor dari yang tinggi sampai yang terendah di mana secara berurutan mulai dari skor yang tertinggi itu diberi ranking 1, 2, 3, 4, dan seterusnya sampai skor terendah.
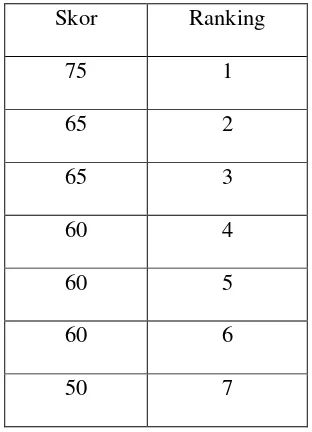
Permasalah pengubahan data interval ke data ordinal timbul jika ada beberapa data (skor) yang sama. Misalnya, 75, 65, 65, 60, 60, 60, 50. Jika diurutkan begitu saja, dengan ranking/urutan seperti: 1, 2, 3, 4, 5, 6, 7, maka tentu saja ini tidak proporsional, karena skor yang sama diberi bobot tidak sama. Perhatikan tabel 3.4.
Tabel 3.4. Contoh skor dan urutan rankingnya yang tidak proporsional
Skor Ranking
75 1
65 2
65 3
60 4
60 5
60 6
50 7
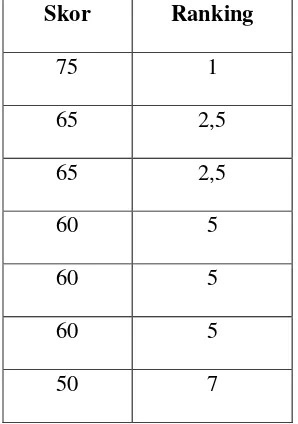
Perhatikan bahwa skor yang tertinggi hanya ada satu yaitu 75, maka tidak ada masalah dan skor 75 ini ditransformasikan menjadi 1. Kemudian skor tertinggi kedua adalah dua skor yang sama yaitu 65 dan skor tertinggi ketiga ada tiga buah skor yang sama yaitu 60. Di sinilah letak permasalahan bagaimana membuat ranking secara proporsional bahwa skor yang sama harus diberi bobot/ranking yang sama. Untuk itu memberi ranking pada skor 65 yang mestinya menduduki ranking 2 dan 3 supaya proporsional, maka ranking 2 dan 3 untuk skor 65 dicari rata – ratanya , yaitu (2 + 3) : 2 = 2,5. Demikian juga untuk memberi ranking skor pada skor 60 yang mestinya menduduki ranking 4, 5, dan 6, maka diubah masing – masing menjadi (4 + 5 + 6) : 3 = 5. Sehingga urutan ranking yang proporsional untuk data tersebut adalah seperti pada tabel 3.5.
Tabel 3.5. Contoh skor dan urutan rankingnya yang proporsional
Skor Ranking
75 1
65 2,5
65 2,5
60 5
60 5
60 5
3.4 Penggunaan Korelasi Tata Jenjang
Hasil pengukuran dalam bidang psikologi tidak pernah memperoleh data rasio, maksimal hanya memperoleh data level interval. Bahkan sebagian orang berpendapat bahwa hasil pengukuran psikologi maksimal hanya mencapai tataran ordinal, dan tidak pernah mencapai tataran interval. Sebagai contoh hasil pengukuran sikap, misalnya, maksimal hanya dapat menunjukkan bahwa si A sikapnya lebih positif daripada si B, tetapi tidak pernah mampu menunjukkan seberapa besar lebih positifnya itu, dan korelasi tata jenjang menjadi sangat penting dalam bidang psikologi.
Penggunaan rumus:
BAB 4
IMPLEMENTASI SISTEM
4.1 Pengertian
Implementasi sistem adalah prosedur yang dilakukan untuk menyelesaikan desain sistem yang ada dalam desain sistem yang disetujui, menginstal dan memulai sistem baru atau sistem yang diperbaiki.
Tahapan implementasi merupakan tahapan penerapan hasil desain tertulis ke dalam programming. Dalam pengolahan data pada tulisan ini penulis menggunakan perangkat lunak (software) sebagai implementasi sistem yaitu SPSS 16.0 for Windows dalam masalah memperoleh hasil perhitungan.
4.2 Statistik dan Komputer
Dalam ilmu statistik baik itu statistik deskriptif maupun statistik inferensi, pada dasarnya adalah ilmu yang ‘penuh’ puls dengan operasi perhitungan matematika. Statistik berasal dari kata ‘statistik’ yang dapat didefenisikan sebagai data yang telah terolah yang kemudian mengalami proses pengolahan data. Tentunya proses tersebut dapat berlangsung hanya dengan didasarkan pada pengolahan data yang berbasis perhitungan matematika, sesuatu yang dapat dikerjakan dengan cepat oleh komputer. Jadi, jika statistik menyediakan cara/metode pengolahan data yang ada, maka komputer menyediakan sarana pengolahan datanya. Dengan bantuan komputer, pengolahan data statistik hingga dihasilkan informasi yang relavan menjadi lebih cepat dan lebih akurat.
Untuk mengolah data, komputer mempunyai tiga keunggulan utama dibandingkan manusia yaitu kecepatan, ketepatan dan keandalan yang membuat komputer sangat dibutuhkan dalam mengolah data-data statistik. Selain mempunyai kecepatan yang sangat tinggi dalam mengolah data-data statistik, serta menghasilkan output yang mempunyai presisi (ketepatan) tinggi, komputer juga mempunyai daya tahan yang tinggi.
4.3 SPSS dan Komputer Statistik
SPSS pertama kali dibuat tahun 1968 oleh tiga mahasiswa Stanford University, yang dioperasikan pada computer mainframe. Pada tahun 1984, SPSS pertama kali muncul dengan versi PC (dapat dipakai untuk komputer desktop) dengan nama SPSS/PC+ dan sejalan dengan mulai populernya system operasi Windows, SPSS pada tahun 1992 juga mengeluarkan versi Windows.
SPSS yang tadinya ditujukan bagi pengolahan data statistik untuk ilmu social (SPSS saat itu adalah singkatan dari Statistical Package for the Social Sciences), sekarang diperluas untuk melayani berbagai jenis user, seperti untuk proses produksi di pabrik, riset ilmu-ilmu sains dan lainnya. Sehingga sekarang kepanjangan SPSS adalah Statistical Product and Service Solutions.
4.4 Mengoperasikan SPSS
Secara umum ada tiga tahapan yang harus dilakukan dalam mengoperasikan SPSS supaya hasil yang diperoleh berdayaguna yaitu : tahap Penyiapan Data yang mencakup Pemasukan (input) data, Penyuntingan (editing) data, Penyimpanan Data, tahap Proses Analisis Data, dan Tahap Analisis Hasil.
Langkah-langkah pengolahan data dengan menggunakan program SPSS adalah :
1. Aktifkan program SPSS pada Windows dengan perintah Start lalu all program pilih SPSS 16.0 for Windows.
2. Pemasukan data ke SPSS
Langkah-langkahnya sebagai berikut :
Pengisian
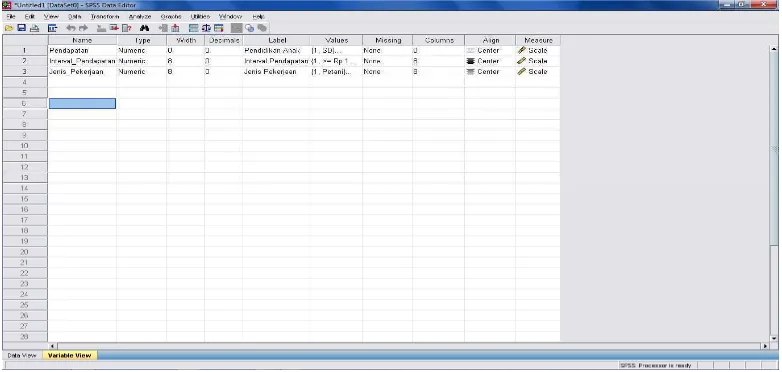
1. Name. klik ganda pada sel tersebut, dan ketik pendidikan.
2. Type. Pilih string dalam bentuk data dan pilih numeric jika dalam bentuk angka.
3. Width. Untuk keseragaman, ketik 8
4. Decimals. Oleh karena type data numeric dengan kode, maka ketik 0 yang berarti tidak ada decimal.
5. Label. Sesuai kasus, letakkan kursor dibawah label, klik kemudian ketik keterangan dari responden menjadi pendidikaan anak
6. Values. Pilihan ini untuk proses pemberian kode. Klik mouse pada sel values, dan memberikan coding pada data yang diproses, misalkan : Value. Ketik 1 lalu value label ketik SD
Value. Ketik 2 lalu value label ketik SLTP Value. Ketik 3 lalu value label ketik SLTA Value. Ketik 4 lalu value label ketik PT
Gambar 4.1: Tampilan Variable View pada SPSS
3. Menyimpan data
Data yang diisi dalam SPSS disimpan dengan langkah-langkah sebagai berikut:
Klik menu file, klik save data lalu tulis nama file yang hendak disimpan, klik OK atau enter.
1.5 Pengolahan Data Dengan Metode Korelasi Jenjang Sperman Dalam SPSS
1.5.1 Correlation
Gambar 4.2: Tampilan menu Analyze dalam SPSS
2. Setelah diklik akan muncul tampilan seperti dibawah ini:
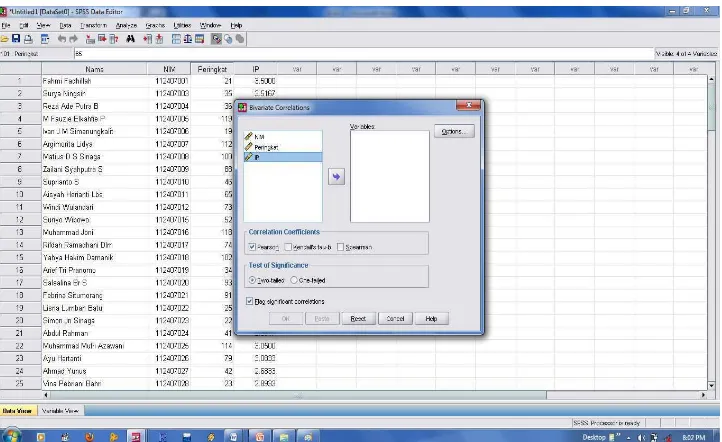
Gambar 4.3: Tampilan Bivariate Correlation dalam SPSS
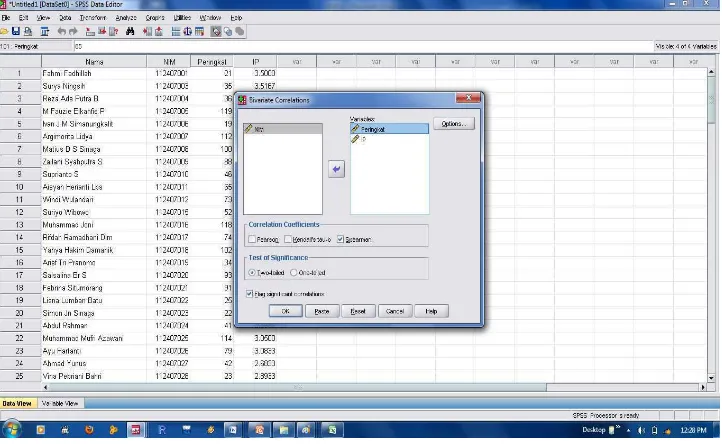
Gambar 4.4: Tampilan sub menu Bivariate Correlation dalam SPSS
1.5.2 Uji T
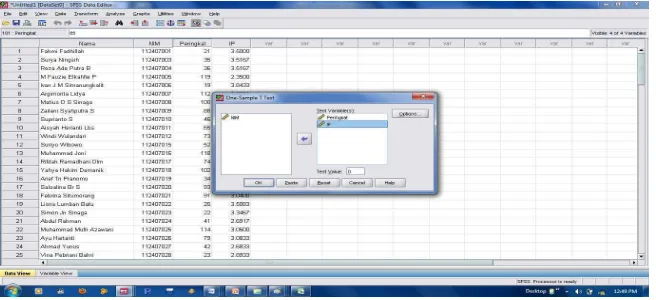
1. Dalam menu SPSS, pilih menu Analyze kemudian sub menu Compare Means, lalu pilih One – Sample T Test. Seperti gambar di bawah ini:
2. Setelah diklik akan muncul tampilan seperti berikut:
Gambar 4.6: Tampilan sub menu One Sample T Test dalam SPSS
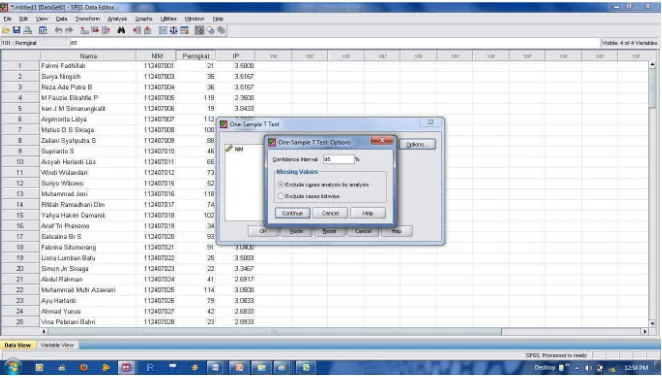
[image:30.612.171.499.394.544.2]Variable peringkat dan IP dipindah dikolom Test Variable(s), seperti gambar berikut:
Gambar 4.7: Tampilan sub menu One Sample T Test dalam SPSS
Gambar 4.8: Tampilan sub menu One Sample T Test Options dalam SPSS
BAB 5
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Berdasarkan analisa dan evaluasi, maka penulis mengambil kesimpulan sebagai berikut :
1. Koefisien korelasi teoritik yang terdapat pada table nilai – nilai ] ,
dengan n = 121 pada taraf signifikan 5% menunjukkan pada angka 1,960 dan pada taraf signifikansi 1% menunjukkan angka 2,576. (Lihat pada tabel nilai t). Nilai korelasi sebesar 0,2816 menunjukkan bahwa korelasi antara peringkat kelas di Sekolah Menengah Atas (SMA) dengan Indeks Prestasi (IP) berkorelasi rendah.
2. Nilai uji t sebesar 3,2012 adalah lebih besar dari pada t teoritik pada taraf signikansi 5% (=1,960) dan lebih kecil dari pada t teoritik pada taraf signifikansi 1% (=2,576).
5.2 Saran
BAB 2
LANDASAN TEORI
2.1 Statistik Non Parametrik
Penelitian di bidang ilmu sosial seringkali menjumpai kesulitan untuk
memperoleh data kontinu yang menyebar mengikuti distribusi normal. Data
penelitian ilmu – ilmu sosial yang diperoleh kebanyakan hanya berupa kategori
yang hanya dapat dihitung frekuensinya atau berupa data yang hanya dapat
dibedakan berdasarkan tingkatan atau rankingnya.
Menghadapi kasus data kategorikal atau data ordinal seperti itu, jelas
peneliti tidak mungkin mempergunakan metode statistik parametrik sebagai
gantinya diciptakan oleh para pakar metode statistik lain yang sesuai yaitu yang
disebut metode statisik nonparametrik.
Metode statistik nonparametrik ini sering juga disebut metode bebas
sebaran (distribution free) karena model uji statistiknya tidak menetapkan syarat –
syarat tertentu tentang bentuk distribusi parameter populasinya. Artinya bahwa
metode statistika nonparametrik ini tidak menetapkan syarat bahwa observasi –
observasinya harus ditarik dari populasi yang berdistribusi normal dan tidak
menetapkan syarat homoscedasticity. Dalam jumlah uji statistik nonparametrik
hanya menetapkan asumsi/persyaratan bahwa observasi – observasinya harus
independen dan bahwa variabel yang diteliti pada dasarnya harus memiliki
sebagai “uji ranking”, karena teknik – teknik nonparametrik ini dapat digunakan
untuk skor yang bukan skor eksak dalam pengertian keangkaan, melainkan berupa
skor yang semata – mata berupa jenjang – jenjang (rank).
Uji statistik nonparametrik atau uji bebas sebaran (distribution free)
digunakan dalam kondisi sebagai berikut:
1. Bentuk distirbusi populasinya, dari mana sampel atau sampel – sampel
penelitiannya diambil, tidak diketahui menyebar secara normal.
2. Variabel penelitiannya hanya dapat diukur dalam skala nominal
(diklasifikasikan dalam kategori dan hitung frekuensinya).
3. Variabel penelitiannya hanya dapat diukur dalam skala ordinal (disusun
dalam tingkatan dan dinyatakan dalam ranking pertama, kedua, ketiga, dan
seterusnya).
4. Ukuran sampel atau sampel – sampel penelitiannya kecil dan sifat
distribusi frekuensinya tidak diketahui secara pasti.
2.2 Kelebihan dan Kekurangan Metode Statistik Nonparametrik
Manfaat atau kelebihan metode statistik nonparametrik dibanding metode statistik
parametrik, antara lain sebagai berikut:
1. Nilai probabilitas dari sebagian besar uji statistik nonparametrik diperoleh
dalam bentuk yang lebih pasti (kecuali untuk kasus sampel yang besar),
tak peduli bagaimana bentuk distribusi populasi yang merupakan induk
dari sampel – sampelnya. Ketetapan nilai probabilitas itu tidaklah
dua distribusi populasi atau lebih, dan beberapa uji yang lain menganggap
bahwa distribusi populasinya simetris. Dalam kasus – kasus uji
nonparametrik tertentu memang menganggap bahwa distribusi yang
mendasarinya adalah kontinu, suatu anggapan yang juga dibuat dalam uji
– uji parametrik.
2. Apabila sampel – sampelnya kecil atau terpaksa kecil karena sifat hakikat
sampel itu sendiri (misalnya n = 6), hanya uji statistik nonparametrik yang
dapat digunakan, kecuali jika sifat distribusi populasinya diketahui secara
pasti.
3. Uji – uji statistik nonparametrik dapat digunakan untuk mengalisis data
yang pada dasarnya merupakan jenjang atau ranking dan juga untuk data
yang skor – skor keangkaannya secara sepintas kelihatan memiliki
kekuatan ranking, dan bahkan bagi data yang hanya dapat dikategorikan
sebagai plus atau minus, lebih atau kurang, lebih baik atau lebih buruk,
dan sebagainya.
4. Uji – uji statistik nonparametrik dapat digunakan untuk menganalisis data
yang hanya merupakan klasifikasi semata, yakni data yang diukur dalam
skala nominal.
5. Tersedia uji – uji statistik nonparametrik untuk menganalisis sampel –
sampel yang terdiri dari observasi – observasi dari beberapa populasi yang
berlainan.
6. Uji – uji statistik nonparametrik sederhana perhitungannya sehingga lebih
Di samping kelebihan – kelebihan tersebut, uji – uji statistik
nonparametrik juga mempunyai kekurangan – kekurangan. Adapun kekurangan –
kekurangan yang dapat dikemukakan dari uji statistik nonparametrik adalah:
1. Apabila persyaratan – persyaratan bagi model statistik parametrik dapat
dipenuhi dan apabila pengukuran data mempunyai kekuatan seperti yang
disyaratkan, pemakaian uji statistik nonparametrik, kekuatan efisiensinya
menjadi lebih rendah.
2. Uji statistik nonparametrik tidak dapat dipergunakan untuk menguji
interaksi seperti dalam model analisis varians.
3. Metode statistik nonparametrik tidak dapat dipergunakan untuk membuat
prediksi (ramalan) seperti dalam model analisis regresi, karena asumsi
normal tidak dapat dipenuhi.
4. Macam uji statistik nonparametrik terlalu banyak sehingga menyulitkan
peneliti dalam memilih uji mana yang paling sesuai.
2.3 Pengukuran Kofisien Korelasi Nonparametrik
2.3.1 Metode Korelasi Jenjang Spearman (Rank Correlation Method)
Metode korelasi jenjang ini dikemukakan oleh Carl Spearman pada tahun 1904.
Metode ini diperlukan untuk mengukur keeratan hubungan antara dua variabel di
mana dua variabel itu tidak mempunyai joint normal distribution dan conditional
variance tidak diketahui sama. Korelasi rank dipergunakan apabila pengukuran
Untuk menghitung rank correlation coefficientnya, yang dinotasikan
dengan rs, dilakukan langkah – langkah sebgai berikut:
1. Nilai pengamatan dari dua variabel yang akan diukur hubungannya diberi
jenjang. Bila ada nilai pengamatan yang sama dihitung jenjang rata –
ratanya.
2. Setiap pasang jenjang dihitung perbedaannya.
3. Perbedaan setiap pasang jenjang tersebut dikuadratkan dan dihitung
jumlahnya.
4. Nilai rs (koefisien korelasi Spearman) dihitung dengan rumus:
Keterangan:
menunjukkan perbedaan setiap pasang rank.
menunjukkan jumlah pasangan rank.
Hipotesis nihil yang akan diuji mengatakan bahwa dua variabel yang
diteliti dengan nilai jenjangnya itu independen, tidak ada hubungan antara jenjang
variabel yang satu dengan jenjang dari variabel lainnya.
1 23 ,
Kriteria pengambilan keputusannya adalah:
diterima apabila $ 2 6
% ditolak apabila & 2 6
Nilai 2 6 dapat dilihat pada tabel nilai r (lampiran 2)
Untuk n 10 dapat dipergunakan Tabel nilai t, di mana nilai t sampel dapat
dihitung dengan rumus:
diterima apabila
!" # $ $ !" #
ditolak apabila &
!" # atau ' !" #
2.3.2 Metode Korelasi Jenjang Kendall
Selain koefisien korelasi Spearman, terdapat metode pengukuran lain tentang
keeratan hubungan antara variabel random X dan Y, di mana X dan/atau Y tidak
berdistribusi normal atau tidak diketahui distribusinya. Metode ini disebut Kendall
rank Correlation Coefficient (metode ini dikemukakan untuk pertama kalinya oleh
Maurice G. Kendall pada tahun 1938). Koefisien korelasi Kendall dinotasikan
dengan 7 (huruf Junani, dibaca: tau).
Koefisien korelasi Kendall dihitung dengan rumus:
Nilai 7 ini akan bergerak berkisar antara -1 sampai +1. Untuk n yang lebih
besar dari 10, maka 7 mendekati distribusi normal, dengan mean:
9: ,
Dan standar deviasi:
;: > < =
Pengujian hipotesis nihil yang mengatakan bahwa tidak ada
korelasi/asosiasi yang nyata antara dua set pengamatan lawan hipotesis alternatif
terdapat korelasi, dengan menghitung nilai ?:
? 7 9;: : 7
-> < =
Kriteria pengambilan keputusan:
diterima apabila ? $ ? !
ditolak apabila ? & ? !
2.3.3 Koefisien Kontingensi C
Untuk mengukur derajat hubungan, asosiasi, atau dependensi dari klasifikasi –
klasifikasi dalam tabel kontingensi, digunakan koefisien kontingensi (coefficient
@ A <A
Keterangan:
A = nilai chi-square
= besar sampel
Nilai A dihitung dengan rumus:
A B B C CCD D E
F G
CD C HIHLM I N OH IC J K
2.3.4 Koefisien Cramer C
Koefisien Cramer C merupakan suatu ukuran derajat asosiasi atau hubungan
antara dua pasangan atribut atau variabel, terutama apabila salah satu kedua
variabel tersebut hanya berupa serangkaian kategori (skala nominal) yang tidak
menunjukkan tingkatan.
Koefisien Cramer dihitung dari tabel kontingensi . Tabel kontingensi
tersebut disusun berdasarkan data dari dua pasangan variabel kategorikal
yang tidak menunjukkan tingkatan. Misalnya dua variabel itu adalah A dan B.
Variabel A dengan kategori A1, A2, ... , Ak dan variabel B dengan kategori B1, B2,
Tabel 2.1. Tabel kontingensi
Keterangan:
Tabel dapat berupa Tabel , Tabel =, Tabel P P, Tabel Q R, dan
seterusnya.
Koefisien Cramer C dihitung dengan rumus:
@ SA
Keterangan:
A = nilai chi square
= besar sampel
2.3.5 Koefisien Phi Untuk Tabel T T
Untuk dua pasangan atribut dengan skala nominal yang terdiri dari dua kategori
(tabel kontingensi ), ukuran asosiasi, hubungan, atau dependensinya dapat
dipergunakan koefisien phi U.
Untuk menghitung koefisien phi U, variabel berskala nominal dengan dua
kategori (dikotomi atau binary), misalnya dengan kode 0 dan 1, disusun dalam
[image:43.612.143.505.325.456.2]bentuk Tabel seperti tabel 2.2 di bawah ini:
Tabel 2.2. Tabel
Variable Y Variabel X Jumlah
0 1
1
0
A
C
B
D
A+B
C+D
Jumlah A+C B+D N
Koefisien phi untuk Tabel dihitung denrgan rumus:
V WXY Z@W
8 X < Z @ < Y X < @ Z < Y
Nilai V berkisar antara nol dan satu. Signifikansi nilai koefisien phi diuji dengan
menggunakan statistik A yang dihitung dengan rumus:
BAB 1
PENDAHULUAN
1.1Latar Belakang
Semenjak dibuka pada tahun ajaran 1993/1994, Program Studi D3 Statistika
FMIPA USU, telah banyak menghasilkan ahli madya yang profesional di bidang
pengolahan data dan informasi yang sesuai dengan tujuan dari program studi,
yakni menghasilkan lulusan ahli madya yang mampu menguasai prinsip – prinsip
dasar ilmu statistika, pengolahan data, dan penerapannya dalam teknologi
informasi.
Meski kebanyakan orang menganggap hanya sebagai alternatif dari
program penerimaan untuk strata satu, dengan semakin meningkatnya kesadaran
akan kebutuhan sumber daya manusia yang mampu mengolah data dengan
menggunakan aplikasi ilmu statistika dan terbatasnya program studi yang relevan,
Program Studi D3 Statistika FMIPA USU tetap menjadi salah satu tujuan calon
mahasiswa untuk melanjutkan pendidikan. Setiap tahunnya, melalui jalur
Penelusuran Minat dan Prestasi (PMP) serta Seleksi Penerimaan Mahasiswa
Program Diploma (SPMPD), Program Studi D3 Statistika FMIPA USU menerima
ratusan mahasiswa dari berbagai daerah. Mahasiswa yang disaring melalui jalur
PMP kemudian mendapatkan pendidikan penyerataan yang biasanya disebut
dengan program martikulasi, agar dapat menyeragamkan dasar – dasar
Mahasiswa dalam Program Studi D3 Statistika FMIPA USU, sebagaimana
di ketahui telah menjalani pendidikan terlebih dahulu di Sekolah Menengah Atas
(SMA). Di SMA, tingkat belajar mahasiswa dapat diukur melalui peringkat kelas
yang diperoleh setiap semesternya di kelas X, XI, dan XII.
Dalam kondisi ini, penulis ingin melihat bagaimana hubungan antara
peringkat kelas di Sekolah Menengah Atas (SMA) dengan Indeks Prestasi (IP)
yang diperoleh mahasiswa di perguruan tinggi, khususnya mahasiswa D3
Statistika angkatan 2011 FMIPA USU. Apakah ada hubungan antara peringkat
kelas di Sekolah Menengah Atas (SMA) dengan Indeks Prestasi (IP), atau
sebaliknya.
Seperti telah diketahui bersama, dalam penilaian terhadap tingkat
pengetahuan mahasiswa dalam mengikuti pendidikan di perguruan tinggi, telah
diterapkan sistem penilaian yang dinamakan Indeks Prestasi (IP). Sistem ini
menggunakan huruf dimulai dari huruf A untuk yang sangat baik, B untuk baik, C
untuk cukup, D untuk kurang, dan E untuk yang sangat buruk dalam menunjukkan
kemampuan mahasiswa dalam menguasai suatu materi perkuliahan.
Dari uraian di atas, penulis memilih judul “Aplikasi Metode Korelasi
Jenjang Spearman (Rank Correlation Method) Dalam Mencari Hubungan
Antara Peringkat Kelas di Sekolah Menengah Atas (SMA) Dengan Indeks
1.2Identifikasi Masalah
Berdasarkan latar belakang masalah di atas, penulis merumuskan masalah
penelitian ini yaitu bagaimana korelasi antara peringkat kelas di Sekolah
Menengah Atas (SMA) dengan Indeks Prestasi (IP) mahasiswa D3 Statistika
FMIPA USU angkatan 2011 semester I s/d semester III.
1.3Batasan Masalah
Untuk memberikan kejelasan dan memberikan kemudahan penelitian ini agar
tidak jauh menyimpang dari sasaran yang ingin dicapai, penulis hanya meneliti
seputar peringkat kelas di SMA sebagai faktor yang mempengaruhi Indeks
Prestasi (IP) Mahasiswa D3 Statistika FMIPA USU, dalam hal ini adalah
mahasiswa D3 Statistika FMIPA USU Angkartan 2011.
Karena Mahasiswa D3 Statisika FMIPA USU Angkatan 2012 baru
menjalani dua semester dan baru sekali mendapatkan hasil penilaian atau Indeks
Prestasi (IP), yaitu pada semester 1 (Satu), maka Indeks Prestasi (IP) yang
dimaksud adalah Indeks Prestasi (IP) semester 1 (Satu) tersebut.
1.4Tujuan dan Manfaat
Adapun tujuan dari penelitian ini adalah untuk mengetahui secara empiris
seberapa besar hubungan antara peringkat kelas di Sekolah Menengah Atas
(SMA) dengan Indeks Prestasi (IP) Mahasiswa D3 Statistika FMIPA USU
1.5Waktu dan Lokasi Penelitian
Penelitian dan riset data dilakukan pada tanggal 18 Maret 2013 sampai dengan 30
Maret 2013 di Kampus Fakultas Matematika dan Ilmu Pengetahuan Alam
Universitas Sumatera Utara (FMIPA USU), Medan.
1.6Metodologi Penelitian
1.6.1 Metode Pengumpulan Data
Adapun metode pengumpulan data yang digunakan untuk penelitian ini ialah
dengan menggunakan metode pengumpulan data primer, yaitu metode
pengumpulan data di mana orang berkepentingan atau orang yang akan memakai
data tersebut melakukan observasi langsung ke lapangan.
Data yang diperoleh penulis melalui pengisian kuisioner yang diberikan
kepada mahasiswa D3 Statistika FMIPA USU angkatan 2011.
1.6.2 Metode Pengolahan Data
1.6.2.1Penentuan variabel
Menentukan variabel pada kelompok data, seperti:
a. Variabel bebas atau independent variable sebagai
1.6.2.2Uji Jenjang Korelasi Spearman
Pengujian ini dilakukan untuk mengukur keeratan hubungan antara dua variabel di
mana dua variabel itu tidak mempunyai joint normal distribution dan conditional
variance tidak diketahui sama.
Perumusan hipotesis:
= Tidak ada hubungan antara peringkat kelas di Sekolah Menengah Atas
(SMA) dengan Indeks Prestasi (IP) Mahasiswa D3 Statistika Angkatan 2011
FMIPA USU.
= Ada hubungan antara peringkat kelas di Sekolah Menengah Atas (SMA)
dengan Indeks Prestasi (IP) Mahasiswa D3 Statistika Angkatan 2011 FMIPA
USU.
Dengan uji t, yaitu
Nilai r selalu terletak antara -1 dan 1, sehingga nilai r tersebut dapat ditulis:
Untuk r = +1, berarti ada korelasi positip sempurna antara X dan Y, sebaliknya
jika r = -1, berarti korelasi negatif sempurna antara X dan Y, sedangkan r = 0,
Tabel 1.1
Interpretasi Koefisien Korelasi Nilai r
R Interpretasi
0
0,01 – 0,20
0,21 – 0,40
0,41 – 0,60
0,61 – 0,80
0,81 – 0,99
1 Tidak berkorelasi Sangat rendah Rendah Agak rendah Cukup Tinggi Sangat tinggi
Kriteria pengujian:
diterima apabila
!" # $ $ !" #
% ditolak apabila & !" # atau ' !" #
1.7 Tinjauan Pustaka
Metode korelasi jenjang ini dikemukakan oleh Carl Spearman pada tahun 1904.
Metode ini diperlukan untuk mengukur keeratan hubungan antara dua variabel di
mana dua variabel itu tidak mempunyai joint normal distribution dan conditional
variance tidak diketahui sama. Korelasi rank dipergunakan apabila pengukuran
Buku Ulber Silalahi, 2009. Metode Penelitian Sosial, Bandung, Refika Aditama.
Pada halaman 280 – 291 dijelaskan tentang definisi data, jenis data, dan sumber
data. Data adalah suatu fakta – fakta tertentu sehingga menghasilkan suatu
kesimpulan dalam menarik suatu keputusan.
Buku J. Supranto, 1998. Teknik Sampling Untuk Survei dan Eksperimen,
Jakarta, Rineka cipta. Dalam buku ini dijelaskan tentang sampling secara umum.
Sampel yang baik adalah yang dapat mewakili sebanyak mungkin karakteristik
populasi. Dalam bahasa pengkuran, artinya sampel harus valid, yaitu bisa diukur
sesuatu yang seharusnya diukur.
Sebelum melakukan analisis data, langkah awal yang harus dilakukan
adalah melakukan pengujian terhadap anggota sampel. Pengujian ini dimaksudkan
untuk mengetahui apakah data yang diperoleh dapat diterima sebagai sampel atau
tidak.
Rumus yang digunakan untuk menentukan jumlah data pada tingkat
kepercayaan 95% dengan tingkat kesalahan yang dapat diterima adalah sebesar
5%:
(#
) * * + ,-(
1.8 Sistematika Penulisan
BAB 1 : PENDAHULUAN
Pada Bab ini berisi tentang latar belakang masalah, identifikasi
masalah, batasan masalah, maksud dan tujuan, metodologi
penelitian, tinjauan pustaka dan sistematika penulisan.
BAB 2 : LANDASAN TEORI
Pada Bab ini berisi tentang pengertian data, statistik non
parametrik, pengukuran koefisien korelasi non parametrik.
BAB 3 : ANALISA DATA
Pada Bab ini berisi tentang cara penggunaan rumus yang telah
ditentukan penulis.
BAB 4 : IMPLEMENTASI SISTEM
Pada Bab ini berisi tentang cara memasukkan data dan
menganalisis data pada program SPSS.
BAB 5 : KESIMPULAN DAN SARAN
Pada Bab ini berisi tentang kesimpulan yang diambil penulis dari
APLIK
(RANK
HUBUN
MENENG
FAKULT
LIKASI MET
RANK CORRE
NGAN ANTA
ENGAH ATA
MAHASI
PROG
DEP
LTAS MATE
UNIV
ETODE KO
ELATION
NTARA PE
AS (SMA)
ASISWA D3
ANGK
TUG
DAYAN
1
OGRAM STU
DEPARTEM
TEMATIKA
IVERSITAS
M
ORELASI
N METHO
PERINGKA
) DENGAN
D3 STATIST
ANGKATAN 2
TUGAS AKH
ANA FRANS
102407065
STUDI D3 S
TEMEN MAT
Diaj
APLIK
(RANK
HUBUN
MENENG
ajukan UntukFAKULT
LIKASI MET
RANK CORRE
NGAN ANTA
ENGAH ATA
MAHASI
k MelengkapiPROG
DEP
LTAS MATE
UNIV
ETODE KO
ELATION
NTARA PE
AS (SMA)
ASISWA D3
ANGK
TUG
pi Tugas Dan M
DAYAN
1
OGRAM STU
DEPARTEM
TEMATIKA
IVERSITAS
M
ORELASI
N METHO
PERINGKA
) DENGAN
D3 STATIST
ANGKATAN 2
TUGAS AKH
n Memenuhi S
ANA FRANS
102407065
STUDI D3 S
TEMEN MAT
A DAN ILM
ITAS SUMATE
MEDAN
2013
I JENJANG
OD) DALA
AT KELAS
AN INDEKS
TIKA FMI
N 2011
HIR
i Syarat Memp
PERSETUJUAN
Judul : Aplikasi Metode Korelasi Jenjang Spearman
(Rank Correlation Method) Dalam Mencari Hubungan Antara Peringkat Kelas di Sekolah Menengah Atas (SMA) Dengan Indeks Prestasi (IP) Mahasiswa D3 Statistika FMIPA USU Angkatan 2011
Kategori : Tugas Akhir
Nama : Dayana Fransisca
Nomor Induk Mahasiswa : 102407065
Program Studi : D3 Statistika
Departemen : Matematika
Fakultas : Matematika Dan Ilmu Pengetahuan Alam
Universitas Sumatera Utara
Diluluskan di Medan, Juli 2013
Disetujui Oleh
Departemen Matematika FMIPA USU
Ketua, Pembimbing,
Prof. Dr. Tulus, M.Si. Ph.D Drs. Faigiziduhu Bu’ulölö, M.Si
PERNYATAAN
APLIKASI METODE KORELASI JENJANG SPEARMAN (RANK
CORRELATION METHOD) DALAM MENCARI HUBUNGAN
ANTARA PERINGKAT KELAS DI SEKOLAH MENENGAH
ATAS (SMA) DENGAN INDEKS PRESTASI (IP)
MAHASISWA D3 STATISTIKA FMIPA
USU ANGKATAN 2011
TUGAS AKHIR
Saya mengakui bahwa tugas akhir ini adalah hasil kerja saya sendiri, kecuali
beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Juli 2013
Dayana Fransisca
PENGHARGAAN
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Pemurah dan Maha
Penyayang dengan limpahan Karunia-Nya penulis dapat menyelesaikan
penyusunan Tugas Akhir ini dengan judul Aplikasi Metode Korelasi Jenjang
Spearman (Rank Correlation Method) Dalam Mencari Hubungan Antara
Peringkat Kelas Di Sekolah Menengah Atas (SMA) Dengan Indeks Prestasi (IP)
Mahasiswa D3 Statistika FMIPA USU Angkatan 2011.
Terimakasih penulis sampaikan kepada Bapak Drs. Faigiziduhu Bu’ulölö,
M.Si selaku pembimbing dan Ketua Program Studi D3 Statistika FMIPA USU
yang telah meluangkan waktunya selama penyusunan tugas akhir ini. Terimakasih
kepada Bapak Drs. Suwarno Ariswoyo, M.Si selaku Sekretaris Program Studi D3
Statistika FMIPA USU, Bapak Prof. Dr. Tulus, M.Si. PhD dan Ibu Dra.
Mardiningsih, M.Si selaku Ketua Dan Sekretaris Departemen Matematika FMIPA
USU Medan, Bapak Dr.SutaArman M.Sc selaku Dekan FMIPA USU Medan,
seluruh Staff dan Dosen Program Studi D3 Statistika FMIPA USU, Pegawai
FMIPA USU dan rekan-rekan kuliah. Akhirnya tidak terlupakan kepada Bapak
Niman, Ibu Saftiyah dan keluarga yang selama ini memberikan bantuan dan
DAFTAR ISI
Halaman
Persetujuan ii
Pernyataan iii
Penghargaan iv
Daftar Isi v
Daftar Tabel vii
Daftar Gambar viii
Bab 1 Pendahuluan 1
1.1Latar Belakang 1
1.2Identifikasi Masalah 3
1.3Batasan Masalah 3
1.4Tujuan dan Manfaat 3
1.5Waktu dan Lokasi Penelitian 4
1.6Metodelogi Penelitian 4
1.6.1 Metode Pengumpulan Data 4
1.6.2 Metode Pengolahan Data 4
1.6.2.1 Penentuan Variabel 4
1.6.2.2 Uji Jenjang Korelasi Spearman 5
1.7Tinjauan Pustaka 6
1.8Sistematika Penulisan 8
Bab 2 Landasan Teori 9
2.1 Statistik Non Parametrik 9
2.2 Kelebihan dan Kekurangan Metode Statistika Nonparametrik 10
2.3 Pengukuran Koefisien Korelasi Nonparametrik 12
2.3.1 Metode Korelasi Jenjang Spearman 12
(Rank Correlation Method)
2.3.2 Metode Korelasi Jenjang Kendall 14
2.3.3 Koefisien Kontingensi C 15
2.3.4 Koefisien Cramer C 16
2.3.5 Koefisien Phi untuk Tabel 18
Bab 3 Pengolahan Data 19
3.1 Analisis Data 19
3.2 Koefisien Korelasi 21
3.3 Pengertian Korelasi Tata Jenjang 25
Bab 4 Implementasi Sistem 39
4.1 Pengertian 39
4.2 Statistik Dan Komputer 39
4.3 SPSS Dan Komputer Statistik 40
4.4 Mengoperasikan SPSS 41
4.5 Pengolahan Data Dengan Metode Korelasi Jenjang 43
Spearman Dalam SPSS
4.5.1 Correlation 43
4.5.2 Uji T 45
Bab 5 Kesimpulan Dan Saran 48
5.1 Kesimpulan 48
5.2 Saran 49
Daftar Pustaka
DAFTAR TABEL
Halaman
Tabel 1.1 Interpretasi Koefisien Korelasi Nilai r 6
Tabel 2.1 Tabel Kontingensi 17
Tabel 2.2 Tabel 18
Tabel 3.1 Arah dan Notasi Koefisien Korelasi 22
Tabel 3.2 Interpretasi Mengenai Besarnya Koefisien Korelasi 24
Tabel 3.3 Contoh Skor Dan Urutan Rankingnya 25
Tabel 3.4 Contoh Skor Dan Urutan Rankingnya Yang Tidak Proporsional 26
Tabel 3.5 Contoh Skor Dan Urutan Rankingnya Yang Proporsional 27
DAFTAR GAMBAR
Halaman
Gambar 4.1 Tampilan Variabel View Pada SPSS 43
Gambar 4.2 Tampilan Menu Analyze Dalam SPSS 44
Gambar 4.3 Tampilan Bivariate Correlation Dalam SPSS 44
Gambar 4.4 Tampilan Sub Menu Bivariate Correlation Dalam SPSS 45
Gambar 4.5 Tampilan Menu Analyze Dalam SPSS 46
Gambar 4.6 Tampilan Sub Menu One Sample T Test Dalam SPSS 46
Gambar 4.7 Tampilan Sub Menu One Sample T Test Dalam SPSS 47