(Studi kasus: Pemodelan Indeks Prestasi Kumulatif Mahasiswa IPB
dan STAIN Purwokerto)
MARIA ULPAH
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2008
MARIA ULPAH. Comparison of Generalized Additive Models and Multivariate Adaptive Regression Splines (Case Study: Modeling of Grade Point Average of IPB and STAIN Purwokerto Students). Under direction of I Made Sumertajaya and Aji Hamim Wigena.
Regression analysis is used to capture influences of independent variables to dependent ones. It can be done in two ways, parametric and nonparametric approach. The parametric approach needs assumptions, while nonparametric approach is more flexible than the parametric one. The nonparametric approach used in this research is Generalized Additive Models (GAM) and Multivariate Adaptive Regression Splines (MARS). Essentially, GAM and MARS can accommodate nonlinearity data.
The aims of this research are to study influences of outlier and influential observations for least square method, GAM and MARS, and to find the best fit model that captures relationship between admission test score to grade point average (GPA). This particular data was taken from Faculty of Mathematics and Natural Sciences, Bogor Agriculture University (IPB) and Islamic State University (STAIN), Purwokerto. Admission test score as predictor and GPA as response.
Outlier simulation with least square, GAM and MARS is the first step that done, then exploration to data and modeling with GAM and MARS. The best model was chosen based on the R2, R2-adjusted, R2GPAvs GPAprediction and root mean
square error prediction (RMSEP).
Result of simulation to outlier shows that GAM and MARS robust to outlier, while least square method is not. It can be seen from GAM and MARS R2 was not change when outlier in there or not. The other results show that all predictors (biology, physics, chemical and mathematics) are affect significantly to GPA for IPB data. For STAIN data, all predictors (religious science, general science, arabic language and english) are affect significantly to GPA. Then, MARS results R2, R2-adjusted, R2GPAvs GPAprediction and RMSEP better than GAM.
It is mean that MARS has better model and predictive ability than GAM.
Maaf……….
Halaman ini Pada Lembar Aslinya
Memang Tidak Ada.
MAAF ………
DAFTAR ISI PADA HALAMAN INI MEMANG
TIDAK ADA PADA LEMBAR ASLINYA
1.1 Latar Belakang
Dalam rangka mencari bibit-bibit unggul dari calon-calon mahasiswa, beberapa perguruan tinggi menciptakan suatu mekanisme untuk menyaring dengan tepat setiap lulusan SMA sesuai dengan kemampuan mereka melalui suatu seleksi penerimaan mahasiswa baru. Ada beberapa pola seleksi yang biasa digunakan dalam seleksi penerimaan mahasiswa baru, diantaranya adalah:
a) Pola seleksi yang didasarkan pada ujian masuk.
Pola ini menilai calon mahasiswa atas dasar total atau rata-rata hasil ujiannya dari berbagai bidang studi.
b) Pola seleksi yang didasarkan atas penilaian terhadap prestasi akademik calon mahasiswa selama di SMA.
Pola ini menilai calon mahasiswa berdasarkan nilai raport dari beberapa bidang studi.
Institut Pertanian Bogor (IPB) adalah salah satu perguruan tinggi yang menggunakan pola seleksi yang didasarkan atas penilaian terhadap prestasi akademik calon mahasiswa selama di SMA (nilai raport). Seleksi ini dilakukan melalui jalur Undangan Seleksi Masuk IPB (USMI). USMI bukan satu-satunya seleksi yang dilakukan IPB dalam menjaring calon mahasiswa, terdapat seleksi lain seperti SPMB (Seleksi Penerimaan Mahasiswa Baru) dan jalur khusus. Mahasiswa yang diterima melalui jalur USMI menarik untuk dipelajari, karena selain prosentasenya yang besar (USMI 75%, non-USMI 25%), ternyata jalur ini dapat menjaring calon mahasiswa yang lebih berkualitas (Setiadi, 1991). Sedangkan Sekolah Tinggi Agama Islam Negeri (STAIN) Purwokerto adalah salah satu perguruan tinggi yang menggunakan pola seleksi yang didasarkan pada hasil ujian masuk.
Dalam penelitian ini, nilai-nilai yang diperoleh dari ujian masuk ataupun nilai raport akan dimodelkan untuk memprediksi Indeks Prestasi Kumulatif (IPK). IPK merupakan salah satu indikator yang biasa digunakan dalam melihat potensi akademik seorang mahasiswa, karena potensi akademik mahasiswa merupakan suatu hal yang tidak dapat diukur secara langsung. IPK yang digunakan adalah
IPK selama setahun yaitu tahun pertama (semester 1 dan 2) atau pada masa Tingkat Persiapan Bersama (TPB).
Hasil penelitian yang dilakukan oleh Budiantara, et al. (2006) menunjukkan bahwa nilai-nilai yang diperoleh dari ujian masuk mempunyai pola hubungan atau berpengaruh terhadap IPK. Sedangkan hasil penelitian Rezeki (2002) menyebutkan bahwa IPK mahasiswa di tahun pertama mempunyai pengaruh yang nyata terhadap daya tahan mahasiswa untuk menyelesaikan studi, sedangkan faktor jenis kelamin, asal sekolah, status sekolah dan NEM tidak menunjukkan pengaruh yang nyata terhadap resiko kegagalan mahasiswa.
Dalam statistika, analisis yang biasa digunakan untuk pemodelan adalah analisis regresi. Analisis regresi digunakan untuk memodelkan hubungan antara peubah respon dengan satu atau beberapa peubah bebas/penjelas/prediktor. Pola hubungan tersebut dapat diduga dengan pemodelan regresi parametrik maupun nonparametrik. Pada pemodelan regresi parametrik diperlukan asumsi-asumsi yang ketat antara lain: (1) bentuk fungsional kurva diketahui, (2) ragam yang homogen, dan (3) sisaan berdistribusi normal. Asumsi-asumsi tersebut harus dipenuhi karena jika terjadi pelanggaran terhadap asumsi-asumsi tersebut akan mengakibatkan ketidaksahihan model regresi. Metode yang biasa digunakan dalam pendekatan parametrik adalah metode kuadrat terkecil (MKT).
Adanya asumsi-asumsi yang ketat seringkali menyulitkan karena tidak jarang data di lapangan tidak memenuhi asumsi. Seringkali ditemukan dalam berbagai kasus di mana sisaan tidak berdistribusi normal atau pola data (bentuk kurva)nya tidak jelas sehingga agak sulit untuk ditetapkan ke dalam salah satu bentuk fungsi keluarga parametrik. Alternatif yang dapat digunakan untuk mengatasi masalah tersebut adalah melalui pendekatan regresi nonparametrik. Pemodelan regresi nonparametrik memilki kelenturan terutama dalam penentuan bentuk kurva tidak perlu ditetapkan secara a priori, tetapi kurva dibentuk sesuai dengan datanya (data driven). Ada beberapa metode yang digunakan dalam regresi nonparametrik, diantaranya adalah model aditif terampat (Generalized
Additive Model, GAM) dan regresi spline adaptif berganda (Multivariate Adaptive Regression Splines, MARS).
GAM pertama kali dikembangkan oleh Hastie dan Tibshirani pada tahun 1986 (Hastie & Tibshirani 1990). Metode ini dapat mengakomodasi dengan baik adanya pengaruh nonlinear tanpa harus mengetahui bentuk pengaruh tersebut secara eksplisit (Beck & Jackman 1997) dan metode ini juga tegar (robust) terhadap pencilan (Hastie & Tibshirani 1990). Sukarsa (2001) menerapkan metode GAM dalam pendugaan model produksi susu. Hasil yang diperoleh memperlihatkan bahwa GAM lebih baik daripada MKT. Sedangkan Jacobson dan Dimock pada tahun 1994 menerapkan GAM dalam memprediksi jumlah suara pada pemilu di Perot. Hasil yang diperoleh memperlihatkan bahwa GAM lebih baik daripada MKT (Beck & Jackman 1997).
MARS pertama kali dikembangkan oleh Friedman pada tahun 1990. Metode ini dapat mengatasi masalah kenonlinearan dan dapat membentuk model-model dugaan yang akurat baik untuk data respon kontinu maupun biner dan juga metode ini mampu menganalisis data yang besar, 50≤N≤1000, dengan jumlah peubah prediktor 3≤n≤20 (Friedman 1990).
Sutikno (2002) menerapkan MARS untuk mengatasi masalah nonlinear pada data timeseries dalam memodelkan hubungan indikator ENSO dengan curah hujan bulanan. Hasil yang diperoleh memperlihatkan bahwa metode MARS lebih baik dari metode kuadrat terkecil (MKT). Sedangkan Aziz (2005) menerapkan MARS untuk data respon biner dalam pemodelan resesi di Indonesia dan memperlihatkan hasil yang menjanjikan untuk peramalan resesi di dalam contoh, sedangkan untuk peramalan resesi di luar contoh model MARS dapat membantu tetapi secara umum tidak memberikan hasil yang tepat.
1.2 Permasalahan
Pada pemodelan IPK mahasiswa STAIN Purwokerto dan mahasiswa Fakultas Matematika dan Ilmu Pengetahuan Alam (FMIPA) IPB dalam beberapa kaitannya dengan nilai tes masuk, sebagian peubah bebas (nilai tes masuk) mengikuti siklus nonlinear serta bentuk kurvanya tidak diketahui. Di samping itu, pada data IPK seringkali tidak memenuhi asumsi kenormalan serta terdapat beberapa pencilan dan pengamatan berpengaruh, sehingga dalam hal ini jika digunakan pemodelan regresi parametrik tidak dapat menghasilkan dugaan yang
baik. Permasalahan tersebut mendasari penggunaan GAM dan MARS sebagai alternatif untuk pendugaan model IPK pada penelitian ini.
1.3 Tujuan Penelitian
Tujuan penelitian ini adalah:
1. Mengkaji pengaruh pencilan dan pengamatan berpengaruh dari metode MKT, GAM dan MARS.
2. Membandingkan metode GAM dan MARS berdasarkan kriteria R2, R2terkoreksi,
R2IPK vs IPKpred dan RMSEP.
3. Menerapkan metode GAM dan MARS dalam pemodelan IPK berdasarkan nilai tes masuk.
2.1 Metode Regresi
Analisis regresi merupakan bagian dalam analisis statistika yang digunakan untuk memodelkan hubungan antara peubah tidak bebas (respon) dengan satu atau beberapa peubah bebas (prediktor). Secara umum model regresi mempunyai 3 (tiga) tujuan yaitu: (1) menjelaskan pola hubungan sebab akibat yang terjadi antara peubah respon dengan peubah bebas; (2) mengetahui kontribusi relatif setiap peubah bebas untuk menjelaskan peubah respon; (3) memprediksi nilai peubah respon untuk beberapa nilai peubah bebas tertentu (Aunuddin 2005).
Hubungan di antara peubah respon dan peubah bebas ini dapat dinyatakan dalam suatu persamaan matematik yang disebut persamaan regresi yang linear atau non linear. Jika hubungan peubah respon dengan peubah bebas bersifat linear dan asumsi-asumsinya dipenuhi, maka model regresi linear adalah model terbaik yang dapat memberikan deskripsi sederhana tentang data dan memperlihatkan kontribusi setiap peubah bebas dengan satu parameter. Salah satu model regresi linear yang sering digunakan adalah:
E(y|x1, x2, …, xp) = β0 + β1x1 + … + βpxp
Metode yang paling sering digunakan dalam pendugaan parameter model adalah metode kuadrat terkecil (MKT), karena relatif mudah dan sederhana dalam perhitungannya.
2.2 Model Aditif Terampat (Generalized additive models, GAM)
GAM pertama kali dikembangkan oleh Hastie dan Tibshirani pada tahun 1986 (Hastie & Tibshirani 1990). GAM merupakan perluasan dari model aditif dengan memodelkan y sebagai kombinasi aditif fungsi univariat dari peubah bebas. Metode ini dapat secara langsung mengakomodasi dengan baik adanya pengaruh nonlinear peubah bebas tanpa harus mengetahui bentuk pengaruh tersebut secara eksplisit (Beck & Jackman 1997).
Peubah respon y dalam GAM diasumsikan mempunyai fungsi kepekatan peluang dari keluarga eksponensial, yaitu:
di mana θ disebut parameter alami dan adalah parameter dispersi. E(y|x1, x2, …, xp) = µ dihubungkan ke peubah prediktor dengan fungsi penghubung η, di mana:
) ( 1 ij p j j x f
∑
= + =α η + ε; i = 1, 2, …, n (1) di mana fj adalah bentuk hubungan fungsional antara peubah respon denganpeubah bebas x, sedangkan ε bebas stokastik terhadap peubah bebas x, dan memenuhi E(ε) = 0, cov (ε) = σ2I. Sedangkan metode pendugaan yang terkenal dalam proses pendugaan f1, f2, …, fp dari model regresi pada persamaan (1) adalah
algoritma backfitting.
Hastie & Tibshirani (1986) memulai algoritma backfitting dengan
memisalkan model ( ) 1 ij p j j x f
∑
= + =αη + ε adalah benar dan mengasumsikan bahwa f1, …, fj-1, fj+1, …, fp diketahui. Selanjutnya suatu galat parsial
didefinisikan sebagai berikut: ) ( k j k k j y f x R
∑
≠ − − = αdengan menetapkan E(Rj|xj) = fj(xj) dan meminimumkan 2 1 )) ( ( k p k k x f y E
∑
= − −α
maka penduga fj akan diperoleh secara iteratif jika diberikan penduga fi untuk i≠j.
2.2.1 Pemulusan (Smoothing)
Teknik pemulusan pertama kali dikemukakan oleh Ezekiel pada tahun 1941. Pemulusan pada dasarnya merupakan suatu proses yang secara sistematik dapat menghilangkan pola data yang kasar (berfluktuasi) dan selanjutnya dapat mengambil pola data yang dijelaskan secara umum (Montgomery, Johnson & Gardiner 1990). Teknik pemulusan nonparametrik digunakan untuk memodelkan hubungan antar peubah tanpa penetapan bentuk khusus tentang fungsi regresinya.
Jika diberikan beberapa fungsi f(x) yang kontinu pada turunan ke-m dan terdapat satu fungsi dari beberapa fungsi tersebut yang meminimumkan PRSS (penalized residual sum of squares) yang diformulasikan sebagai berikut:
dt t f x f y b a m i n i i 2 2 1 )} ( { )} ( {
∫
∑
− + = λ (2) di mana λ adalah konstanta dan a ≤ x1 ≤ … ≤ xn ≤ b. Maka fungsi tersebutdinamakan fungsi pemulus spline (Hastie & Tibshirani 1990).
Perimbangan antara fleksibilitas dan kemulusan dugaan kurva dikontrol oleh nilai parameter pemulus atau jumlah knot. Parameter pemulus yang relatif besar atau jumlah knot yang relatif kecil akan menghasilkan dugaan kurva yang sangat mulus sehingga perilaku data yang rinci tidak terlihat, sedangkan parameter pemulus yang relatif kecil atau jumlah knot yang relatif besar menghasilkan dugaan kurva yang kasar karena besarnya pengaruh variasi lokal. Pemulus spline mempunyai sifat fleksibel dan efektif dalam menangani sifat lokal suatu fungsi atau data (Aunuddin 2003, diacu dalam Aziz 2005).
2.3 Regresi Spline Adaptif Berganda (Multivariate Adaptive Regression
Splines, MARS)
Metode regresi spline merupakan salah satu metode yang digunakan untuk menangani pola data yang mengikuti siklus nonlinear serta bentuk kurvanya tidak diketahui. Regresi spline terdiri atas beberapa penggal polinom berorde tertentu yang saling bersambung pada titik-titik ikat. Nilai absis dari titik ikat ini disebut knot. Regresi spline bersifat fleksibel sehingga model yang didapat akan cenderung sedekat mungkin menggambarkan kondisi sebenarnya (Kurnia & Handayani 1998).
Spline kubik merupakan fungsi spline yang sering digunakan karena polinom yang digunakan berordo relatif rendah (polinom berderajat tiga) dan menghasilkan pemulusan yang cukup baik. Kekontinuan sampai turunan kedua polinom-polinom yang digunakan menjamin kemulusan fungsi (Hasti & Tibshirani 1990). Spline kubik diformulasikan sebagai berikut:
3 1 3 3 2 2 1 0 ( ) ) ( + = − + + + + =
∑
k j j j x x x x x sβ
β
β
β
θ
ξ
(3) di mana: a+ = bagian positif dari aModel pada persamaan (3) merupakan suatu kombinasi linier dari k+4 fungsi basis yang dikenal sebagai deret berpangkat terbatas (the truncated power
series basis), dalam hal ini berpangkat tiga. Fungsi-fungsi basis tersebut adalah 1,
x1, x2, x3, {(x j)3}1k +
−
ξ
.2.3.1 Recursive Partitioning
MARS adalah salah satu metode regresi nonparametrik yang dikembangkan oleh Jerome H. Friedman (1990). Bentuk model MARS merupakan perluasan hasil kali fungsi-fungsi basis spline, di mana jumlah fungsi basis beserta parameter-parameternya ditentukan secara otomatis oleh data dengan menggunakan algoritma recursive partitioning yang dimodifikasi. Dalam MARS, fungsi basis adalah satu set fungsi yang menggambarkan informasi yang terdiri dari satu atau lebih peubah. Seperti komponen utama, fungsi basis menggambarkan hal-hal yang memberikan kontribusi paling besar dalam hubungan peubah bebas dan peubah respon. Nilai fungsi basis dalam MARS dapat digambarkan sebagai berikut:
max (0, x-t) atau max (0, t-x)
dengan t adalah nilai yang menggambarkan letak titik knot dan x adalah peubah bebas.
Recursive partitioning (RP) adalah salah satu metode pemodelan regresi
yang biasa digunakan untuk data berdimensi tinggi karena penentuan knot tergantung (otomatis) dari data. Namun demikian, metode RP masih memiliki beberapa kelemahan, diantaranya yaitu model RP menghasilkan himpunan bagian yang saling lepas dan diskontinu pada batas himpunan bagian, serta model RP tidak cukup mampu dalam menduga fungsi linear atau aditif. Metode MARS mampu mengatasi semua kelemahan yang dimiliki metode RP dengan menggunakan algoritma RP yang dimodifikasi, sehingga selain penentuan knot yang dilakukan secara otomatis dari data, juga menghasilkan model yang kontinu pada knot dengan turunan yang kontinu.
Jika H[η] merupakan suatu fungsi tangga (step function) yang berbentuk: 1, untuk η ≥ 0
H[η] =
Maka fungsi basis yang dihasilkan pada langkah maju prosedur RP dapat dinyatakan sebagai berikut:
Bm(x) =
∏
= m K k km s H 1 . [ (xv(k,m) – tkm)] (4) di mana: H[.] = fungsi tanggaKm = jumlah pilahan himpunan bagian ke-m untuk menghasilkan Bm
(derajat interaksi)
xv(k,m) = peubah prediktor ke-v, pilahan ke-k dan himpunan bagian ke-m
tkm = knot dari peubah xv(k,m)
skm = nilainya 1 atau -1 jika knotnya terletak di sebelah kanan atau
kiri himpunan bagian
2.3.2 Modifikasi Friedman
MARS merupakan hasil modifikasi Friedman terhadap algoritma RP untuk mengatasi kekurangan-kekurangan yang dimiliki metode RP. Beberapa inovasi dilakukan oleh Friedman (1990) untuk mengatasi kelemahan metode RP diantaranya yaitu:
a) Mengganti fungsi tangga H[±(x-t)] dengan suatu fungsi splines pangkat terbatas [±(x−t)]q+. di mana q = 1 untuk mengatasi diskontinu pada titik knot. b) Membatasi perkalian pada masing-masing fungsi basis hanya melibatkan
peubah-pubah prediktor yang berbeda. Hal ini dilakukan untuk mengatasi ketergantungan pada peubah secara individu dengan pangkat yang lebih tinggi dari q.
Metode MARS menentukan lokasi dan jumlah knot berdasarkan pemilihan peubah pada langkah maju (forward) dan langkah mundur (backward) algoritma RP yang dimodifikasi, di mana lokasi dan jumlah knot yang optimum disesuaikan dengan perilaku data.
1) Langkah maju
Dalam pembentukan model, terlebih dahulu ditentukan fungsi basis maksimum. Pada tahap ini, digunakan kriteria pemilihan fungsi basis yaitu
dengan meminimumkan average sum of square residual (ASR), untuk mendapatkan jumlah fungsi basis maksimum.
2) Langkah mundur
Setelah mendapatkan jumlah fungsi basis maksimum, proses dilanjutkan ke tahap kedua atau langkah mundur yaitu tahap untuk menentukan ukuran fungsi basis yang layak. Pada tahap ini, dilakukan penghapusan fungsi basis yang kontribusinya terhadap nilai dugaan respon kecil sampai diperoleh perimbangan antara bias dan ragam serta model yang layak, yaitu dengan meminimumkan nilai generalized cross validation (GCV) yang diformulasikan pada persamaan (5). Semakin kecil GCV (semakin besar nilai GCV-1) dari suatu peubah, semakin penting peubah tersebut terhadap model yang dibangun. 2 1 2 ] / )) ( ( 1 [ )] ( ˆ [ ) / 1 ( ) ( N M C x f y N M GCV N i i M i − − =
∑
= (5)di mana pembilang pada persamaan (5) adalah rataan jumlah kuadrat galat, N adalah jumlah pengamatan dan M menunjukkan jumlah himpunan bagian atau jumlah fungsi basis (nonkonstan) pada model MARS. Penyebutnya merupakan penalti fungsi model kompleks. Kriteria GCV adalah rataan jumlah kuadrat galat hasil pengepasan data (sebagai pembilang) dikali suatu penalti (merupakan kebalikan penyebut) yang menyebabkan kenaikan ragam sehubungan dengan meningkatnya kompleksitas model (jumlah fungsi basis M).
Dengan modifikasi Friedman fungsi basis pada persamaan (4) dapat dinyatakan sebagai berikut:
+ = − =
∏
[ ( )] ) ( ( , ) 1 . vkm km Km k km m x s x t B (6)Hasil modifikasi algoritma recursive partitioning adalah model MARS yang dinyatakan sebagai berikut:
fˆ(x) = a0 +
∑
= M m m a 1∏
= m K k km s 1 . [ (xv(k,m) – tkm)] (7)di mana a0 adalah basis fungsi induk, am adalah koefisien dari basis fungsi ke-m
M m m
a } 1
{ = ditentukan dengan menggunakan metode kuadrat terkecil (Friedman 1990). Persamaan (7) dapat ditulis dalam bentuk lain sebagai berikut:
k k BF B BF B BF B B yˆ= 0 + 1* 1+ 2* 2+...+ * di mana: y = peubah respon
B0 = konstanta
B1, B2, …, Bk = koefisien fungsi basis spline ke 1, 2, …, k
BF1, BF2, …, BFk = fungsi basis ke 1, 2, …, k
2.4 Pendeteksian Pencilan dan Pengamatan Berpengaruh
Pencilan merupakan elemen data yang tidak sesuai, sangat menyalahi atau tidak wajar, dibandingkan dengan mayoritas data (Martens dan Naes 1989). Pencilan dapat disebabkan oleh kesalahan dalam data, suatu komposisi atau status fisik yang ganjil dari objek yang dianalisis. Kesalahan dalam data dapat berupa gangguan, penyimpangan instrumen, kesalahan operator ataupun kesalahan pencetakan.
Pendeteksian pengamatan berpengaruh terhadap nilai-nilai X dapat digunakan matriks H (hat matrix) yang didefinisikan sebagai:
H = X(X’X)-1 X’
Unsur ke-i pada diagonal utama matriks H yaitu hii, biasanya dinamakan pengaruh
(leverage) kasus ke-i merupakan ukuran jarak antara nilai X untuk pengamatan
ke-i dan rataan X untuk semua pengamatan, yang diperoleh dari:
di mana adalah vektor baris ke-i dari matriks X. Nilai hii berkisar antara 0 dan 1
dan , dengan p adalah banyaknya koefisien regresi di dalam fungsi
termasuk konstanta (Neter et al. 1990). Leverage ke-i yang besar menunjukkan bahwa pengamatan ke-i berada jauh dari pusat semua pengamatan X. Leverage
ke-i dianggap besar atau dinyatakan sebagai pengamatan pencilan dan berpengaruh jika nilainya lebih dari dua kali rataan semua leverage (2p/n). Nilai
hii yang semakin besar menunjukkan semakin besar potensinya untuk berpengaruh
Pendeteksian pencilan juga dapat dilakukan dengan menggunakan nilai
R-student (externally R-studentized residual) yang didefinisikan sebagai:
di mana: yi = nilai peubah tak bebas pada pengamatan ke-i
= nilai pendugaan yi pada pengamatan ke-i
s(-i) = dugaan simpangan baku tanpa pengamatan ke-i
hii = unsur ke-i dari diagonal matriks H
R-student menyebar mengikuti sebaran t-student dengan derajat bebas (n-p-1).
Suatu pengamatan dikatakan pencilan jika |t| > t(n-p-1;α/2) (Myers 1990).
Pendeteksian pengamatan berpengaruh ditentukan berdasarkan nilai
DFFITS dan Cook’s D. DFFITSi merupakan suatu ukuran pengaruh yang
ditimbulkan oleh pengamatan ke-i terhadap nilai dugaan apabila pengamatan
ke-i dihapus. Nilai DFFITSi diperoleh dari rumus berikut:
dengan adalah nilai dugaan yi tanpa pengamatan ke-i. Suatu pengamatan
dikatakan berpengaruh apabila nilai |DFFITS|i > .
Cook’s D merupakan suatu ukuran pengaruh pengamatan ke-i terhadap
semua koefisien regresi dugaan. Pada Cook’s D, pengaruh pengamatan ke-i diukur oleh jarak Di. Jarak tersebut diperoleh dari rumus berikut:
di mana: b-i = vektor koefisien regresi dugaan tanpa pengamatan ke-i
b = vektor koefisien regresi dugaan termasuk pengamatan ke-i e = nilai sisaan pada pengamatan ke-i
Suatu pengamatan merupakan pengamatan berpengaruh apabila mempunyai nilai Di > F(p;n-p; α) dengan taraf nyata α (Myers 1990).
Pemilihan model terbaik dapat dilakukan dengan memperhatikan beberapa kriteria kebaikan model pada data penyusun model dan data validasi.
a) Kriteria kebaikan model pada data penyusun model menggunakan R2 dan R2 terkoreksi.
b) Kriteria kebaikan model pada data validasi digunakan RMSEP (root mean
square error of prediction) yang diformulasikan sebagai berikut:
n y y RMSEP n i i i
∑
= − = 1 2 ) ˆ (di mana: n = banyaknya data validasi
i
yˆ = dugaan untuk data validasi yi
Semakin besar R2 atau R2 terkoreksi maka model semakin baik. Sedangkan jika GCV dan RMSEP semakin kecil maka model yang diperoleh semakin baik.
3.1 Sumber Data
Data yang digunakan pada penelitian ini adalah:
1. Data nilai raport dan IPK mahasiswa IPB Fakultas Matematika dan Ilmu Pengetahuan Alam (FMIPA) angkatan 2003 sampai 2005 yaitu sebanyak 1041 mahasiswa. Nilai tes ini berupa nilai raport dari mahasiswa yang masuk IPB melalui jalur USMI (Undangan Seleksi Masuk IPB), yaitu nilai-nilai untuk mata pelajaran IPA. Nilai tes sebagai peubah prediktor sedangkan IPK sebagai peubah respon. Adapun pada data nilai tes masuk, peubah yang diukur adalah:
Mat = matematika Bio = biologi Kim = kimia Fis = fisika
2. Data nilai tes masuk tahun ajaran 2006/2007 dan IPK dari 384 mahasiswa STAIN Purwokerto. IPK sebagai peubah respon (y), sedangkan nilai tes masuk sebagai peubah prediktor. Adapun pada data nilai tes masuk, peubah yang diukur adalah:
IPA = ilmu pengetahuan agama IPU = ilmu pengetahuan umum Ar = bahasa arab
Ing = bahasa inggris
3.2 Metode Analisis 3.2.1 Simulasi Pencilan
Sebelum dilakukan analisis data dengan menggunakan metode GAM dan MARS, akan dilakukan simulasi untuk mengetahui ke-robust-an dari kedua metode tersebut (GAM dan MARS) terhadap pencilan dan pengamatan berpengaruh. Langkah-langkah yang dilakukan adalah sebagai berikut:
1) Pengambilan sampel data secara acak sebanyak n buah (10%) dari data STAIN dan data IPB
2) Memodelkan data sampel tersebut dengan menggunakan MKT, GAM dan MARS.
3) Memeriksa pencilan berdasarkan nilai hii dan R-student, serta pengamatan
berpengaruh berdasarkan nilai DFFITS dan Cook’s D.
4) Jika terdapat pencilan dan pengamatan berpengaruh maka pencilan dan pengamatan berpengaruh tersebut dibuang, kemudian data sampel kembali dimodelkan dengan menggunakan metode MKT, GAM dan MARS.
5) Langkah 1 sampai 5 diulangi sebanyak 30 kali (data sampel yang sudah diambil dikembalikan).
6) Membandingkan R2 yang dihasilkan berdasarkan MKT, GAM dan MARS.
3.2.2 Pemeriksaan Asumsi dan Eksplorasi Data
Data dibagi dua secara acak yaitu data untuk menyusun model (data penyusun model) dan data untuk validasi model (data validasi). Pada data penyusun model dilakukan beberapa langkah sebagai berikut:
1) Pembentukan model dengan menggunakan MKT, serta pemeriksaan asumsi kehomogenan ragam dan multikolinearitas. Pemeriksaan kehomogenan ragam dengan membuat plot sisaan dengan nilai dugaan. Jika hasil plot ini menunjukkan pola acak disekitar garis nol, maka asumsi kehomogenan ragam terpenuhi. Sedangkan multikolinearitas dilihat berdasarkan nilai VIF (Variance Inflation Factor). Jika nilai VIF > 10 maka indikasi adanya multikolinear.
2) Eksplorasi data
Eksplorasi dilakukan untuk melihat indikasi awal apakah ada pengaruh nonlinear pada data. Eksplorasi dilakukan dengan membuat plot matriks data.
3.2.3. Pemodelan GAM
Analisis terhadap data dilanjutkan dengan menggunakan GAM dengan langkah-langkah sebagai berikut:
1) Menduga fungsi fj untuk mendapatkan model GAM:
) ( 1 ij p j j x f
∑
= + =α2) Dari model aditif yang didapat, digambar grafik penduga parsial untuk melihat bentuk ketergantungan peubah respon terhadap masing-masing peubah bebas. 3) Data validasi digunakan untuk validasi model, sehingga diperoleh RMSEP. 4) Membuat plot IPK dengan IPKpred dan menghitung R2IPK vs IPKpred.
Tahap analisis di atas dilakukan dengan bantuan paket program S-PLUS 8.0 dan Minitab 14.
3.2.4 Pemodelan MARS
Setelah data dianalisis dengan menggunakan metode GAM, selanjutnya data dianalisis dengan menggunakan metode MARS dengan langkah-langkah sebagai berikut:
1) Menentukan lokasi dan jumlah knot berdasarkan pemilihan peubah pada langkah maju dan langkah mundur dengan menggunakan algoritma recursive
partitioning yang dimodifikasi, hingga diperoleh model yang layak dan
kontribusi peubah yang paling penting.
2) Data validasi digunakan untuk validasi model, sehingga diperoleh RMSEP. 3) Membuat plot IPK dengan IPKpred dan menghitung R2IPK vs IPKpred.
Untuk mendapatkan model MARS, analisis data dilakukan dengan bantuan paket program MARS for windows versi 2.0 dan SPSS 13.0.
3.2.5 Perbandingan Model
Setelah model GAM dan model MARS diperoleh, selanjutnya kedua model tersebut dibandingkan berdasarkan kriteria R2, R2terkoreksi, RMSEP dan R2 IPK vs IPKpred.
4.1 Deskripsi Data 4.1.1 Data IPB
Nilai raport mahasiswa FMIPA IPB, secara keseluruhan mempunyai rata-rata > 80 (Tabel 1) dan sekitar 70% nilai berada di atas 80 untuk masing-masing mata pelajaran (Tabel 2). Sedangkan karakteristik nilai-nilai untuk IPK ≤ 2 mempunyai rata-rata ≤ 80 untuk masing-masing mata pelajaran (Tabel 3).
Tabel 1 Nilai rata-rata, minimum dan maksimum mahasiswa FMIPA IPB Mata pelajaran Rata-rata Minimum Maksimum
Biologi Fisika Kimia Matematika 81,664 80,989 81,366 81,231 70,133 70,000 70,000 70,000 90,000 90,000 91,000 91,000
Tabel 2 Prosentase berbagai nilai mahasiswa FMIPA IPB
Nilai Prosentase (%)
Biologi Fisika Kimia Matematika 70,000-74,999 75,000-79,999 80,000-84,999 85,000-89,999 90,000-94,999 1,25 28,72 50,14 19,31 0,58 5,86 26,22 56,20 11,43 0,29 8,26 23,53 46,49 20,08 1,63 1,73 29,01 54,18 13,74 1,34
Tabel 3 Karakteristik nilai-nilai mahasiswa FMIPA IPB untuk IPK ≤ 2 IPK Biologi Fisika Kimia Matematika 1,29 1,64 1,69 1,78 1,85 1,97 2,00 73,543 74,129 76,111 75,774 76,329 87,444 77,733 76,857 74,555 78,989 70,333 78,999 77,444 72,857 70,000 73,343 76,071 70,200 75,589 75,660 75,129 70,000 71,571 76,200 75,154 74,996 74,776 72,714
IPB memberikan batasan nilai minimal yang harus dipenuhi agar calon mahasiswa diterima melalui jalur USMI yaitu Biologi = 70, Fisika = 70, Kimia = 70 dan Matematika = 70. Namun, mahasiswa yang diterima mempunyai rata-rata
sudah di atas 80. Hal ini dikarenakan calon-calon mahasiswa yang mendaftar ke IPB sangat banyak, sehingga IPB lebih leluasa dalam menyeleksi.
4.1.2 Data STAIN
Nilai tes mahasiswa STAIN secara keseluruhan mempunyai rata-rata > 35 (Tabel 3), 88,81% nilai berada di atas 40 untuk IPA, 31,77% nilai berada di atas 40 untuk IPU, 50,27% nilai berada di atas 40 untuk Ar dan 42,19% nilai berada di atas 40 untuk Ing (Tabel 4). Sedangkan karakteristik nilai-nilai untuk IPK ≤ 2 mempunyai rata-rata ≤ 30 untuk masing-masing bidang studi (Tabel 6).
Tabel 4 Nilai rata-rata, minimum dan maksimum mahasiswa STAIN Bidang studi Rata-rata Minimum Maksimum IPA IPU Ar Ing 48,292 34,661 39,352 39,250 20,000 14,000 16,000 15,000 73,000 60,000 70,000 75,000
Tabel 5 Prosentase berbagai nilai mahasiswa STAIN
Nilai Prosentase (%)
IPA IPU Ar Ing
< 30 30-39 40-49 50-59 ≥ 60 2,34 8,85 44,53 34,64 9,64 26,56 41,67 24,74 6,77 0,26 17,71 32,03 29,69 15,63 4,95 19,01 38,80 23,18 8,07 10,94
Tabel 6 Karakteristik nilai-nilai mahasiswa STAIN untuk IPK ≤ 2
IPK IPA IPU Ar Ing
1,69 1,76 1,81 1,95 2,00 23 30 25 20 25 25 31 29 25 15 25 30 30 25 29 25 33 20 15 28
STAIN memberikan batasan nilai minimal yang harus dipenuhi agar calon mahasiswa diterima melalui seleksi yaitu 40 untuk masing-masing bidang studi. Hal ini sesuai dengan kondisi nilai rata-rata mahasiswa yaitu 40 untuk masing-masing bidang studi (Tabel 4).
4.2 Simulasi Pencilan
Hasil simulasi terhadap pencilan dari data IPB dan STAIN memperlihatkan bahwa metode GAM dan MARS robust terhadap pencilan, sedangkan MKT tidak. Hal ini terlihat dari R2 GAM dan MARS yang relatif tidak berubah ketika ada pencilan atau tidak (Lampiran 1 dan Gambar 1), sehingga kedua metode ini lebih tepat digunakan untuk kedua data.
R-sq u a re MARSTP MARSP GAMTP GAMP MKTTP MKTP 100 90 80 70 60
Boxplot of MKTP, MKTTP, GAMP, GAMTP, MARSP, MARSTP
MKTP = MKT denga n pencilan, MKTTP = MKT tanpa pencilan GAMP = GAM denga n pencilan, GAMTP = GAM tanpa pencila n MARSP = MARS denga n pencila n, MARSTP = MARS ta npa pencila n
Gambar 1 Boxplot R2 untuk MKT, GAM dan MARS dengan dan tanpa pencilan.
4.3 Data IPB 4.3.1 GAM
Analisis dengan menggunakan MKT untuk data mahasiswa IPB menghasilkan R2 = 69,10%, R2terkoreksi = 68,80% dan nilai-nilai VIF yang lebih
kecil dari 10 sehingga asumsi tidak adanya multikolinearitas dipenuhi. Analisis ini secara lengkap dapat dilihat pada Lampiran 2.
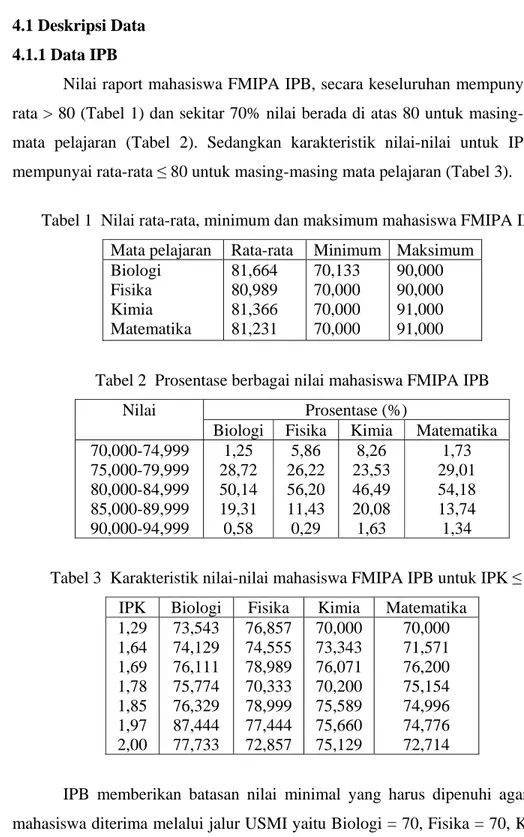
Pemeriksaan asumsi kehomogenan ragam dilakukan dengan membuat plot antara sisaan dengan nilai dugaan. Plot antara sisaan dengan nilai dugaan dari data IPB berpola acak (tidak berpola), yang mengindikasikan bahwa asumsi kehomogenan ragam dipenuhi (Gambar 2).
Fit t e d V a lue Re si d u a l 4 .0 3 .5 3.0 2.5 2 .0 1.0 0.5 0.0 -0.5 -1.0 -1.5
R e s idua ls V e r s us the F itte d V a lue s (re s po nse is IPK)
Gambar 2 Plot antara sisaan dan nilai dugaan data IPB.
Langkah selanjutnya dilakukan eksplorasi terhadap data. Eksplorasi dilakukan untuk melihat indikasi awal apakah ada pengaruh nonlinear atau tidak, sehingga model GAM layak dicoba. Eksplorasi dilakukan dengan membuat plot matriks data. B i o IPK 9 0 8 0 7 0 4 . 0 3 . 5 3 . 0 2 . 5 2 . 0 1 . 5 1 . 0 F i s 9 0 8 0 7 0 K i m 9 0 8 0 7 0 M a t 9 0 8 0 7 0 M a t r i x P l o t o f I P K v s B i o , F i s , K i m , M a t
Gambar 3 Plot matriks data IPB.
Gambar 3 memperlihatkan bahwa hubungan parsial antara peubah respon dengan masing-masing peubah bebas ada yang tidak linear, terutama terlihat dengan jelas pada peubah Biologi (Bio) dan Kimia (Kim). Oleh karena itu, dengan memperhatikan hasil plot matriks tersebut maka sudah selayaknya di dalam penentuan model pengaruh nonlinear ini diakomodasi. Sebab jika tidak dilakukan hal ini, maka model yang dihasilkan tidak cukup baik.
Dengan adanya petunjuk secara visual bahwa terdapat pengaruh nonlinear dari peubah bebas, maka dilakukan analisis lanjut terhadap data dengan menggunakan GAM. Model GAM mempunyai R2 dan R2terkoreksi yang lebih besar
daripada yang dihasilkan MKT yaitu R2 = 82,32% dan R2terkoreksi = 81,75%. Hal
ini berarti bahwa model GAM lebih mampu dalam menerangkan keragaman nilai peubah IPK. Hasil analisis dengan GAM dapat dilihat secara lengkap pada Lampiran 3. Bio s( B io ) 70 75 80 85 90 -1 .5 -1 .0 -0 .5 0 .0 0 .5 1 .0 1 .5
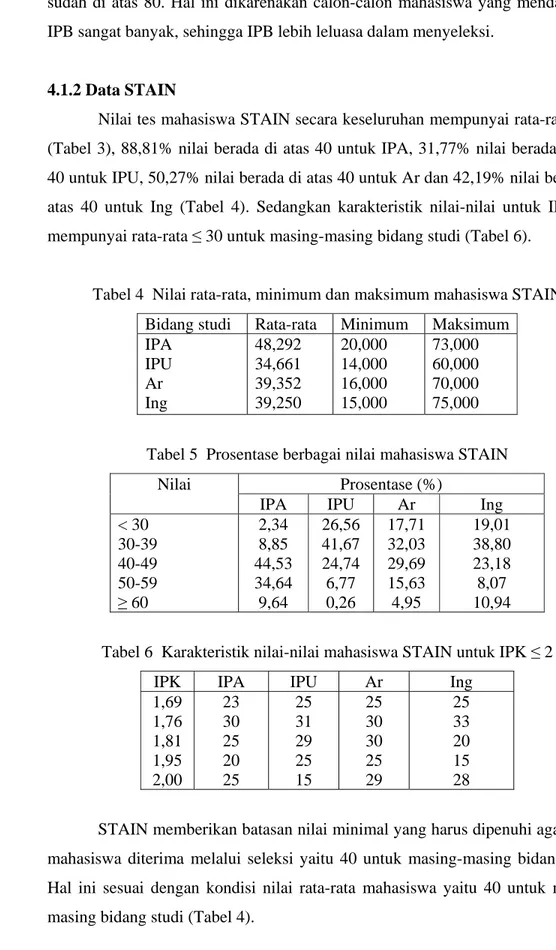
Gambar 4a Plot parsial peubah Biologi
Fis s( F is) 70 75 80 85 90 -1 .5 -1 .0 -0 .5 0 .0 0 .5 1 .0
Gambar 4b Plot parsial peubah Fisika
Kim s( K im ) 70 75 80 85 90 -1 .5 -1 .0 -0 .5 0 .0 0 .5 1 .0
Gambar 4c Plot parsial peubah Kimia
Mat s( M a t) 70 75 80 85 90 -2 .0 -1 .5 -1 .0 -0 .5 0 .0 0 .5 1 .0
Gambar 4d Plot parsial peubah Matematika
Metode GAM juga menghasilkan grafik pengaruh parsial peubah bebas (Gambar 4). Grafik tersebut mempertegas hasil sebelumnya, di mana hubungan
antara respon dengan peubah bebas ada yang nonlinear. Dari Gambar 4 terlihat bahwa peubah Biologi, Kimia dan Matematika memberikan pengaruh nonlinear. Sedangkan peubah Fisika tidak menunjukkan pengaruh nonlinear karena grafiknya cenderung lurus.
Setelah model GAM dibentuk dengan menggunakan data penyusun model, kemudian model divalidasi menggunakan data validasi, dalam kasus ini data yang digunakan untuk validasi sebanyak 520 data. Dari proses validasi diperoleh nilai dugaan dari model yang mencerminkan bentuk peubah asalnya. Nilai RMSEP yang dihasilkan dari data validasi sebesar 0,19875, nilai ini lebih kecil bila dibandingkan dengan RMSEP yang dihasilkan dari validasi MKT yaitu sebesar 0,224318. Jadi, GAM mampu mereduksi RMSEP sebesar 11,40%, sehingga dapat dikatakan bahwa model yang dihasilkan GAM mempunyai kemampuan prediksi yang lebih baik dibandingkan dengan hasil dari MKT.
4.3.2 MARS
Analisis dengan menggunakan metode MARS menghasilkan model regresi sebagai berikut:
Y = 4,044 – 0,044 * BF1 – 0,054 * BF2 + 0,095 * BF3 – 0,223 * BF4 + 0,049 * BF5 – 0,032 * BF8 – 0,029 * BF9 + 0,012 * BF10 – 0,011 * BF11 + 0,018 * BF13 – 0,074 * BF17 – 0,017 * BF20
Model regresi tersebut terdiri dari satu intersep dan 12 fungsi basis yang meliputi 7 interaksi level pertama dan 5 interaksi level dua. Nilai R2 = 85,50% dan R2terkoreksi = 85,10%, di mana nilai-nilai ini merupakan yang paling tinggi jika
dibandingkan dengan R2 dan R2terkoreksi yang dihasilkan oleh MKT ataupun GAM.
Analisis ini secara lengkap dapat dilihat pada Lampiran 4.
Model regresi tersebut memberikan gambaran bahwa kontribusi peubah Mat (BF3) terhadap model sebesar 0,095 bila nilai Mat > 84,986. Sedangkan untuk interaksi level 2 seperti Kim dan Mat (BF9) memberikan arti bahwa fungsi basis ini memberikan kontribusi sebesar -0.029 bila nilai peubah Kim > 82,999 dan Mat < 84,986.
Peubah prediktor yang relatif penting dalam pembentukan model MARS untuk data IPB disajikan pada Tabel 7.
Tabel 7 Peringkat peubah yang relatif penting untuk data IPB Peringkat Peubah GCV-1 1 2 3 4 Mat Bio Kim Fis 0,064 0,053 0,051 0,048
Tabel 7 memperlihatkan bahwa peubah Mat (Matematika) merupakan peubah yang mempunyai tingkat kepentingan paling tinggi dalam pembentukan model di antara peubah lainnya. Hal ini ditunjukkan oleh nilai GCV-1 yang paling besar yaitu 0,064 (terkecil untuk nilai GCV). Sedangkan peubah yang peringkat kepentingannya paling rendah adalah Fis (Fisika), hal ini ditunjukkan juga oleh nilai GCV-1 yang paling kecil yaitu 0,048. Peubah yang relatif penting memberikan arti bahwa peubah tersebut mempunyai pengaruh yang besar terhadap kebaikan model, demikian sebaliknya.
Nilai RMSEP yang dihasilkan dari data validasi dengan menggunakan MARS adalah sebesar 0,198294. Nilai ini merupakan nilai RMSEP yang paling kecil bila dibandingkan dengan nilai RMSEP yang dihasilkan oleh GAM.
Regresi IPKprediksi terhadap IPK data validasi menghasilkan R2 = 79,8%
untuk GAM dan R2 = 80,0% untuk MARS. Plot IPK dan IPKprediksi yang paling
mendekati pola garis lurus 45˚ melalui titik nol adalah plot IPKprediksi dan IPK
untuk hasil MARS (Gambar 5). Hal ini menunjukkan bahwa nilai prediksi yang diperoleh MARS lebih dekat dengan nilai yang sebenarnya bila dibandingkan dengan nilai prediksi yang diperoleh GAM.
Tabel 8 menyajikan hasil analisis beberapa model dengan menggunakan data penyusun model dan data validasi. Berdasarkan Tabel 8, model yang dihasilkan oleh MARS merupakan model yang paling baik dan mempunyai kemampuan prediksi yang lebih baik dibandingkan dengan hasil dari GAM. Hal ini ditunjukkan dengan nilai R2, R2terkoreksi, R2 IPK vs IPKpred yang lebih besar dan
IPK. Y-D a ta 4.0 3.5 3.0 2.5 2.0 1.5 1.0 4.0 3.5 3.0 2.5 2.0 1.5 1.0 Variable IPK^MKT IPK^GA M IPK^MA RS Garis 45
Plot IPK dan IPK Prediksi
Gambar 5 Plot IPK dan IPK prediksi untuk data IPB dengan metode MKT, GAM dan MARS.
Tabel 8 Nilai R2, R2terkoreksi, RMSEP, R2IPK vs IPKpred dari model MKT, GAM dan
MARS untuk data IPB
4.3.3 Penerapan Model untuk Prediksi IPK di IPB
Model terbaik yang diperoleh yaitu model MARS akan digunakan dalam prediksi IPK dengan menggunakan beberapa nilai raport untuk mengetahui batas-batas nilai raport yang dapat menghasilkan IPK tertentu. Hal ini dilakukan dengan melakukan simulasi terhadap nilai-nilai raport, karena MARS belum bisa mengakomodasi prediksi terhadap peubah bebas jika peubah respon sudah ditentukan.
Secara umum, jika nilai raport untuk tiga mata pelajaran ditetapkan sama dan nilai raport untuk satu mata pelajaran lainnya ditentukan (dengan diubah-ubah), maka mata pelajaran yang mempunyai pengaruh cukup tinggi terhadap IPK adalah Matematika (Gambar 6).
Model R2 R2terkoreksi RMSEP R2IPK vs IPKpred
MKT 69,10% 68,80% 0,224318 74,20% GAM 82,32% 81,75% 0,198750 79,80% MARS 85,50% 85,10% 0,198294 80,00% MKT: R2=74,2% GAMs: R2=79,8% MARS: R2=80,0%
Nilai Y-D a ta 100 95 90 85 80 75 70 4.0 3.5 3.0 2.5 2.0 1.5 1.0 Variable IPK-Fis IPK-Bio IPK-Kim IPK-Mat Plot IPK vs Nilai
Gambar 6 Plot IPK untuk berbagai kombinasi nilai raport
Ada banyak kombinasi nilai-nilai raport yang mungkin untuk menghasilkan IPK = 2,00 dan 2,80, diantaranya adalah:
1. Untuk mencapai IPK = 2,00, nilai-nilai raport yang harus dipenuhi adalah: a. Biologi = 75, Fisika = 70, Kimia = 75 dan Matematika = 75.
b. Biologi = 75, Fisika = 75, Kimia = 75 dan Matematika = 75.
2. Untuk mencapai IPK = 2,80, nilai-nilai raport yang harus dipenuhi adalah: a. Biologi = 80, Fisika = 70, Kimia = 80 dan Matematika = 80.
b. Biologi = 80, Fisika = 75, Kimia = 80 dan Matematika = 80 (Lampiran 5). IPB memberikan batasan nilai minimal yang harus dipenuhi agar calon mahasiswa diterima melalui jalur USMI yaitu Biologi = 70, Fisika = 70, Kimia = 70 dan Matematika = 70. Secara harapan, jika mahasiswa berada dalam kondisi ini, maka dengan menggunakan model MARS akan menghasilkan nilai prediksi IPK sebesar 1,03. Namun, berdasarkan deskripsi data, rata-rata nilai raport mahasiswa IPB sudah di atas 80 (Tabel 1) dan prosentase mahasiswa yang nilai raportnya 70 untuk masing-masing mata pelajaran sangatlah kecil (Tabel 2).
4.4 Data STAIN 4.4.1 GAM
Analisis dengan menggunakan MKT untuk data mahasiswa STAIN menghasilkan R2 = 77,90%, R2terkoreksi = 77,40% dan nilai-nilai VIF yang lebih
kecil dari 10 sehingga asumsi tidak adanya multikolinearitas dipenuhi. Analisis ini secara lengkap dapat dilihat pada Lampiran 6. Sedangkan pemeriksaan asumsi
kehomogenan ragam dilakukan dengan membuat plot antara sisaan dengan nilai dugaan. Plot antara sisaan dengan nilai dugaan berpola acak (tidak berpola), yang mengindikasikan bahwa asumsi kehomogenan ragam dipenuhi (Gambar 7).
Fit t e d V a lue Re si d u a l 4.0 3.5 3.0 2.5 2.0 0.50 0.25 0.00 -0.25 -0.50 -0.75
R e s idua ls V e r s us the F itte d V a lue s (re sponse is IPK)
Gambar 7 Plot antara sisaan dan nilai dugaan data STAIN.
Langkah selanjutnya dilakukan eksplorasi terhadap data. Eksplorasi dilakukan untuk melihat indikasi awal apakah ada pengaruh nonlinear atau tidak, sehingga model GAM layak dicoba. Eksplorasi dilakukan dengan membuat plot matriks data. Hasil dari plot tersebut dapat dilihat pada Gambar 8.
I P A IPK 6 0 4 0 2 0 4 . 0 3 . 5 3 . 0 2 . 5 2 . 0 I P U 6 0 4 0 2 0 A r 6 0 4 0 2 0 I n g 6 0 4 0 2 0 M a t r i x P l o t o f I P K v s I P A , I P U , A r , I n g Gambar 8 Plot matriks data STAIN.
Dari Gambar 8 terlihat bahwa hubungan parsial antara peubah respon dengan masing-masing peubah bebas ada yang tidak linear, terutama terlihat
dengan jelas pada peubah IPU dan Ing. Oleh karena itu, dengan memperhatikan hasil plot matriks tersebut maka sudah selayaknya di dalam penentuan model pengaruh nonlinear ini diakomodasi. Sebab jika tidak dilakukan hal ini, maka model yang dihasilkan tidak cukup baik.
Dengan adanya petunjuk secara visual bahwa terdapat pengaruh nonlinear dari peubah bebas, maka dilakukan analisis lanjut terhadap data dengan menggunakan GAM. Model GAM mempunyai R2 dan R2terkoreksi yang lebih besar
daripada yang dihasilkan MKT yaitu R2 = 83,75% dan R2terkoreksi = 82,27%. Hal
ini berarti bahwa model GAM lebih mampu dalam menerangkan keragaman nilai peubah IPK. Hasil analisis dengan GAM dapat dilihat secara lengkap pada Lampiran 7.
Metode GAM juga menghasilkan grafik pengaruh parsial peubah bebas (Gambar 9). Grafik tersebut mempertegas hasil sebelumnya, di mana hubungan antara respon dengan peubah bebas ada yang nonlinear. Dari Gambar 9 terlihat bahwa peubah IPU dan Ing memberikan pengaruh nonlinear. Sedangkan peubah IPA dan Ar tidak menunjukkan pengaruh nonlinear karena grafiknya cenderung lurus. IPA s (I PA) 20 30 40 50 60 -1 .0 -0 .5 0 .0 0 .5
Gambar 9a Plot parsial peubah IPA IPU s( IP U ) 20 30 40 50 -1 .0 -0 .5 0 .0 0 .5
Ar s( A r) 20 30 40 50 60 70 -1 .0 -0 .5 0 .0 0 .5 1 .0
Gambar 9c Plot parsial peubah Ar
Ing s( In g ) 20 30 40 50 60 70 -1 .0 -0 .5 0 .0 0 .5 1 .0
Gambar 9d Plot parsial peubah Ing
Setelah model GAM dibentuk dengan menggunakan data penyusun model, kemudian model divalidasi menggunakan data validasi, dalam kasus ini data yang digunakan untuk validasi sebanyak 192 data. Dari proses validasi diperoleh nilai dugaan dari model yang mencerminkan bentuk peubah asalnya. Nilai RMSEP yang dihasilkan dari data validasi sebesar 0,180023, nilai ini lebih kecil bila dibandingkan dengan RMSEP yang dihasilkan dari validasi MKT yaitu sebesar 0,218381. Jadi, GAM mampu mereduksi RMSEP sebesar 17,56%, sehingga dapat dikatakan bahwa model yang dihasilkan GAM mempunyai kemampuan prediksi yang lebih baik dibandingkan dengan hasil dari MKT.
4.4.2 MARS
Analisis dengan menggunakan metode MARS menghasilkan model regresi sebagai berikut:
Y = 0,015 + 0,125 * BF1 – 0,040 * BF2 + 0,082 * BF3 + 0,003 * BF5 + 0,010 * BF6 + 0,009 * BF7 – 0,006 * BF8 + 0,020 * BF9 – 0,143 * BF10 – 0,012 * BF13 + 0,003 * BF15 – 0,040 * BF16 + 0,022 * BF18 – 0,003 * BF20 + 0,004 * BF22 + 0,003 * BF24 + 0,097 * BF25 + 0,007 * BF30;
Model regresi tersebut terdiri dari satu intersep dan 18 fungsi basis yang meliputi 9 interaksi level pertama dan 9 interaksi level dua. Nilai R2 = 89,20% dan R2terkoreksi = 88,10%, di mana nilai-nilai ini merupakan yang paling tinggi jika
dibandingkan dengan R2 dan R2terkoreksi yang dihasilkan oleh MKT ataupun GAM.
Analisis ini secara lengkap dapat dilihat pada Lampiran 8.
Model regresi tersebut memberikan gambaran bahwa kontribusi peubah IPA (BF1) terhadap model sebesar 0,125 bila nilai IPA > 20. Sedangkan untuk interaksi level 2 seperti IPA dan Ing (BF5) memberikan arti bahwa fungsi basis ini memberikan kontribusi sebesar 0,003 bila nilai peubah IPA < 43 dan Ing > 39.
Peubah prediktor yang relatif penting dalam pembentukan model MARS untuk data STAIN disajikan pada Tabel 9.
Tabel 9 Peringkat peubah yang relatif penting untuk data STAIN Peringkat Peubah GCV-1 1 2 3 4 IPA Ing IPU Ar 0,064 0,040 0,033 0,030
Tabel 9 memperlihatkan bahwa peubah IPA (Ilmu Pengetahuan Agama) merupakan peubah yang relatif penting di antara peubah lainnya. Hal ini ditunjukkan oleh nilai GCV-1 yang paling besar yaitu 0,064 (terkecil untuk nilai GCV). Sedangkan peubah yang peringkat kepentingannya paling rendah adalah Ar (Arab) dengan nilai GCV-1 paling kecil yaitu 0,030. Peubah yang relatif penting memberikan arti bahwa peubah tersebut mempunyai pengaruh yang besar terhadap kebaikan model, demikian sebaliknya.
Nilai RMSEP yang dihasilkan dari data validasi dengan menggunakan MARS adalah sebesar 0,179758. Nilai ini merupakan nilai RMSEP yang paling kecil bila dibandingkan dengan nilai RMSEP yang dihasilkan oleh GAM.
Regresi IPKprediksi terhadap IPK data validasi menghasilkan R2 sebesar
67,5% untuk MKT, R2 = 77,9% untuk GAM dan R2 = 78,8% untuk MARS. Plot IPK dan IPKprediksi yang paling mendekati pola garis lurus 45˚ melalui titik nol
adalah plot IPK dan IPKprediksi untuk hasil MARS (Gambar 10). Hal ini
menunjukkan bahwa nilai prediksi yang diperoleh MARS lebih dekat dengan nilai yang sebenarnya bila dibandingkan dengan nilai prediksi yang diperoleh GAM.
IPK. Y-D a ta 4.0 3.5 3.0 2.5 2.0 4.0 3.5 3.0 2.5 2.0 1.5 Variable IP K^MKT IP K^GA M IP K^MA RS Garis 45
Plot IPK dan IPK Prediksi
Gambar 10 Plot IPK dan IPK prediksi untuk data STAIN dengan metode MKT, GAM dan MARS.
Tabel 10 menyajikan hasil analisis beberapa model dengan menggunakan data penyusun model dan data validasi. Berdasarkan Tabel 10, model yang dihasilkan oleh MARS merupakan model yang paling baik dan mempunyai kemampuan prediksi yang lebih baik dibandingkan dengan hasil dari GAM. Hal ini ditunjukkan dengan nilai R2, R2terkoreksi dan R2IPK vs IPKpred yang lebih besar dan
RMSEP yang lebih kecil bila dibandingkan dengan yang dihasilkan oleh GAM.
Tabel 10 Nilai R2, R2terkoreksi, RMSEP dan R2IPK vs IPKpred dari model MKT, GAM
dan MARS untuk data STAIN
4.4.3 Penerapan Model untuk Prediksi IPK di STAIN
Model terbaik yang diperoleh yaitu model MARS akan digunakan dalam prediksi IPK dengan menggunakan beberapa nilai tes untuk mengetahui batas-batas nilai tes yang dapat menghasilkan IPK > 2,75. Hal ini dilakukan dengan melakukan simulasi terhadap nilai-nilai tes, karena MARS belum bisa mengakomodasi prediksi terhadap peubah bebas jika peubah respon sudah
Model R2 R2terkoreksi RMSEP R2IPK vs IPKpred
MKT 77,90% 77,40% 0,218381 67,50% GAM 83,75% 82,27% 0,180023 77,90% MARS 89,20% 88,10% 0,179758 78,80% MKT: R2=67,5% GAMs: R2=77,9% MARS: R2=78,8%
ditentukan. Secara umum, jika nilai tes untuk tiga bidang studi ditetapkan sama dan nilai tes untuk satu bidang studi lainnya ditentukan (dengan diubah-ubah), maka bidang studi yang mempunyai pengaruh cukup tinggi terhadap IPK adalah IPA (Gambar 11). Nilai Y-D a ta 70 65 60 55 50 45 40 3.8 3.7 3.6 3.5 3.4 3.3 3.2 3.1 3.0 2.9 Variable IPK-Ar IPK-Ing IPK-IPU IPK-IPA Plot IPK vs Nilai
Gambar 11 Plot IPK untuk berbagai kombinasi nilai tes.
Ada banyak kombinasi nilai-nilai tes yang mungkin untuk menghasilkan IPK > 2,75, diantaranya adalah:
1. Untuk mencapai IPK = 2,80, nilai-nilai tes yang harus dipenuhi adalah: a. IPA = 40, IPU = 35, Ar = 35 dan Ing = 35.
b. IPA = 37, IPU = 35, Ar = 35 dan Ing = 37.
2. Untuk mencapai IPK = 3,00, nilai-nilai tes yang harus dipenuhi adalah: a. IPA = 40, IPU = 40, Ar = 40 dan Ing = 40.
b. IPA = 50, IPU = 35, Ar = 35 dan Ing = 35 (Lampiran 9).
Jika STAIN akan memberikan batasan nilai minimal yang harus dipenuhi agar calon mahasiswa diterima berdasarkan tes seleksi, maka sebaiknya adalah IPA = 40, IPU = 35, Ar = 35 dan Ing = 35. Secara harapan, jika mahasiswa berada dalam kondisi ini, maka dengan menggunakan model MARS akan menghasilkan nilai prediksi IPK sebesar 2,80. Sehingga untuk menjaring calon mahasiswa dengan prediksi IPK > 2,75, nilai-nilai tes yang harus dipenuhi ini sudah cukup baik, karena berdasarkan deskripsi data, rata-rata nilai tes mahasiswa STAIN adalah 40 (Tabel 4) dan prosentase mahasiswa yang nilai tesnya < 40 untuk masing-masing bidang studi sangatlah kecil (Tabel 5).
5.1 Kesimpulan
Berdasarkan hasil analisis terhadap data IPB dan data STAIN dapat disimpulkan hal-hal sebagai berikut:
1. Hasil simulasi terhadap pencilan memperlihatkan bahwa metode GAM dan MARS robust terhadap pencilan.
2. Pada data IPB, peubah Biologi, Fisika, Kimia dan Matematika mempunyai pengaruh yang nyata terhadap nilai peubah IPK.
3. Pada data STAIN, peubah Ilmu Pengetahuan Agama, Ilmu Pengetahuan Umum, Bahasa Arab dan Bahasa Inggris mempunyai pengaruh yang nyata terhadap nilai peubah IPK.
4. MARS menghasilkan model yang lebih baik dari GAM dan mempunyai kemampuan prediksi yang lebih baik pula. Hal ini ditunjukkan dengan nilai R2, R2terkoreksi dan R2 IPK vs IPKpred yang lebih besar dan RMSEP yang lebih kecil
bila dibandingkan dengan yang dihasilkan oleh GAM.
5. Jika diharapkan calon mahasiswa IPB dengan prediksi IPK > 2,00, maka batas seleksi nilai raport yang sebaiknya digunakan adalah Biologi, Kimia dan Matematika masing-masing 75, sedangkan Fisika 70.
6. Jika diharapkan calon mahasiswa STAIN dengan prediksi IPK > 2,75, maka batas seleksi nilai tes yang sebaiknya digunakan adalah IPA = 40, IPU = 35, Ar = 35 dan Ing = 35.
5.2 Saran
1. Prediksi terhadap salah satu peubah bebas dapat dilakukan jika peubah respon dan beberapa peubah bebas yang lain diketahui. Hal-hal tersebut pada metode GAM dan MARS belum bisa diakomodasi, oleh karena itu perlu dilakukan penelitian lebih lanjut mengenai hal tersebut.
2. Agar model MARS menghasilkan proyeksi 0 ≤ IPK ≤ 4, disarankan input nilai berada dalam selang 67 ≤ nilai ≤ 100 pada masing-masing bidang studi untuk data IPB dan 10 ≤ nilai ≤ 80 untuk data STAIN.
Lampiran 1 Hasil simulasi pencilan untuk metode MKT, GAM dan MARS
Data ke-
MKT (R2) GAM (R2) MARS (R2)
Ada pencilan Tidak ada Ada pencilan Tidak ada Ada pencilan Tidak ada
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 70,20% 62,70% 73,10% 75,50% 79,20% 77,40% 78,90% 75,80% 75,10% 81,20% 64,30% 80,00% 68,70% 68,10% 79,90% 75,20% 74,30% 73,40% 73,90% 78,30% 70,30% 63,70% 77,70% 70,80% 75,00% 75,30% 73,20% 73,10% 69,00% 70,80% 74,50% 66,90% 75,80% 76,90% 83,60% 81,10% 81,30% 77,30% 80,10% 83,40% 69,90% 83,60% 70,90% 72,30% 81,70% 79,20% 80,10% 74,90% 76,20% 80,30% 75,90% 66,60% 81,30% 74,90% 80,40% 80,60% 75,90% 76,20% 76,10% 80,10% 90,83% 79,52% 82,33% 85,21% 86,40% 86,48% 86,42% 84,34% 80,23% 85,22% 77,22% 89,65% 74,39% 75,99% 85,89% 90,55% 92,67% 88,88% 85,52% 93,25% 91,44% 80,00% 92,33% 91,85% 94,68% 94,66% 82,43% 82,78% 87,90% 87,10% 90,87% 79,72% 82,89% 85,55% 86,97% 86,49% 86,93% 84,30% 80,77% 85,35% 77,52% 90,13% 74,89% 76,24% 86,22% 91,10% 93,11% 88,90% 85,99% 94,00% 91,95% 80,67% 92,78% 91,87% 95,23% 95,46% 82,99% 82,99% 88,28% 87,77% 87,90% 80,30% 81,70% 85,40% 88,40% 88,10% 85,70% 86,10% 86,10% 86,60% 82,50% 88,10% 78,20% 79,80% 90,10% 92,90% 95,00% 96,00% 89,00% 95,20% 90,30% 80,50% 96,30% 87,90% 95,40% 95,30% 81,90% 86,70% 90,00% 92,30% 88,10% 80,80% 82,00% 86,10% 88,20% 87,50% 87,00% 87,10% 86,20% 86,80% 83,00% 88,50% 78,50% 79,90% 90,50% 93,20% 94,88% 96,20% 89,40% 95,80% 90,40% 80,90% 96,90% 88,00% 95,80% 95,70% 82,30% 87,00% 90,60% 92,60%
Lampiran 2 Hasil analisis MKT untuk data IPB
Regression Analysis: IPK versus Bio, Fis, Kim, Mat The regression equation is
IPK = - 7.77 + 0.0218 Bio + 0.0442 Fis + 0.0168 Kim + 0.0488 Mat Predictor Coef SE Coef T P VIF
Constant -7.7718 0.3182 -24.43 0.000 Bio 0.021764 0.003145 6.92 0.000* 1.3 Fis 0.044235 0.003368 13.14 0.000* 1.3 Kim 0.016769 0.002754 6.09 0.000* 1.3 Mat 0.048763 0.003648 13.37 0.000* 1.4 S = 0.255972 R-Sq = 69.1% R-Sq(adj) = 68.8% Analysis of Variance Source DF SS MS F P Regression 4 75.445 18.861 287.86 0.000 Residual Error 516 33.809 0.066 Total 520 109.255
Keterangan: *) berpengaruh nyata pada α = 0.05, α = 0.01
Lampiran 3 Hasil analisis GAM untuk data IPB
*** Generalized Additive Model ***
Call: gam(formula = IPK ~ s(Bio) + s(Fis) + s(Kim) + s(Mat), data = M1) Null Deviance: 109.2545 on 520 degrees of freedom
Residual Deviance: 19.32012 on 503.9972 degrees of freedom
R2 : 82.32% R2-adj : 81.75% Df Npar Df Npar F Pr(F) (Intercept) 1 s(Bio) 1 3 50.03298 0.000000e+000* s(Fis) 1 3 12.17533 1.049574e-007* s(Kim) 1 3 31.09479 0.000000e+000* s(Mat) 1 3 20.86746 9.000000e-013*
Lampiran 4 Hasil analisis MARS untuk data IPB
R-SQUARED: 0.855 ADJ R-SQUARED: 0.851
PARAMETER ESTIMATE S.E. T-RATIO P-VALUE --- Constant | 4.044 0.178 22.757 .999201E-15 Basis Function 1 | -0.044 0.005 -9.100 .999201E-15 Basis Function 2 | -0.054 0.005 -10.982 .999201E-15 Basis Function 3 | 0.095 0.024 4.051 .589800E-04 Basis Function 4 | -0.223 0.024 -9.485 .999201E-15 Basis Function 5 | 0.049 0.004 12.554 .999201E-15 Basis Function 8 | -0.032 0.004 -8.732 .999201E-15 Basis Function 9 | -0.029 0.003 -11.065 .999201E-15 Basis Function 10 | 0.012 0.001 7.785 .393019E-13 Basis Function 11 | -0.011 0.002 -7.147 .309253E-11 Basis Function 13 | 0.018 0.002 8.380 .999201E-15 Basis Function 17 | -0.074 0.021 -3.560 .405384E-03 Basis Function 20 | -0.017 0.003 -4.837 .175071E-05 --- F-STATISTIC = 248.720 S.E. OF REGRESSION = 0.177 P-VALUE = .999201E-15 RESIDUAL SUM OF SQUARES = 15.891 [MDF,NDF] = [ 12, 508 ] REGRESSION SUM OF SQUARES = 93.364 --- Basis Functions =============== BF1 = max(0, BIO - 83.286); BF2 = max(0, 83.286 - BIO ); BF3 = max(0, MAT - 84.986); BF4 = max(0, 84.986 - MAT ); BF5 = max(0, FIS - 80.098); BF6 = max(0, 80.098 - FIS ); BF8 = max(0, 86.098 - KIM ); BF9 = max(0, KIM - 82.999) * BF4; BF10 = max(0, 82.999 - KIM ) * BF4; BF11 = max(0, MAT - 80.540) * BF2; BF13 = max(0, KIM - 76.143) * BF4; BF17 = max(0, MAT - 76.200); BF20 = max(0, 74.120 - KIM ) * BF6; Y = 4.044 - 0.044 * BF1 - 0.054 * BF2 + 0.095 * BF3 - 0.223 * BF4 + 0.049 * BF5 - 0.032 * BF8 - 0.029 * BF9 + 0.012 * BF10 - 0.011 * BF11 + 0.018 * BF13 - 0.074 * BF17 - 0.017 * BF20;
Lampiran 5 Hasil simulasi penerapan metode MARS untuk data IPB
Bio Fis Kim Mat IPKpred
70 70 70 70 1.03 70 70 70 75 1.39 70 70 70 80 1.47 70 70 75 70 1.02 70 70 80 70 1.34 70 75 70 70 1.38 70 80 70 70 1.73 75 70 70 70 1.30 80 70 70 70 1.57 75 70 70 75 1.66 80 70 70 80 2.01 80 70 80 80 2.80 80 70 80 85 2.87 75 70 75 75 1.94 75 75 75 70 1.29 75 75 75 75 1.94 75 75 75 80 2.32 80 75 80 80 2.80 80 80 80 80 2.80 80 80 80 85 2.87 82 70 80 83 3.01 85 85 85 85 3.53 90 90 90 70 1.55 90 90 90 75 2.45 90 90 90 80 3.07 90 90 90 85 3.59 90 90 90 90 3.70 100 100 100 100 3.98
Lampiran 6 Hasil analisis MKT untuk data STAIN
Regression Analysis: IPK versus IPA, IPU, Ar, Ing The regression equation is
IPK = 1.01 + 0.0321 IPA + 0.00280 IPU + 0.00455 Ar + 0.00392 Ing Predictor Coef SE Coef T P VIF
Constant 1.00957 0.08209 12.30 0.000 IPA 0.032125 0.002173 14.78 0.000* 1.9 IPU 0.002795 0.001539 1.82 0.071 1.1 Ar 0.004550 0.001758 2.59 0.010* 1.8 Ing 0.003920 0.001480 2.65 0.009* 1.5 S = 0.193434 R-Sq = 77.9% R-Sq(adj) = 77.4% Analysis of Variance Source DF SS MS F P Regression 4 24.5932 6.1483 164.32 0.000 Residual Error 187 6.9970 0.0374 Total 191 31.5901
Keterangan: *) Berpengaruh nyata pada α = 0.05, α = 0.01
Lampiran 7 Hasil analisis GAM untuk data STAIN
*** Generalized Additive Model ***
Call: gam(formula = IPK ~ s(IPA) + s(IPU) + s(Ar) + s(Ing), data = ST1) Null Deviance: 31.59012 on 191 degrees of freedom
Residual Deviance: 5.133106 on 175.0006 degrees of freedom
R2 : 83.75%
R2-adj : 82.27%
DF for Terms and F-values for Nonparametric Effects Df Npar Df Npar F Pr(F) (Intercept) 1 s(IPA) 1 3 2.74091 0.04486213* s(IPU) 1 3 6.49841 0.00034241*,** s(Ar) 1 3 2.80454 0.04124046* s(Ing) 1 3 12.60948 0.00000017*,**
Keterangan: *) Berpengaruh nyata pada α = 0.05 **) Berpengaruh nyata pada α = 0.01
Lampiran 8 Hasil Analisis MARS untuk data STAIN
R-SQUARED: 0.892 ADJ R-SQUARED: 0.881
PARAMETER ESTIMATE S.E. T-RATIO P-VALUE --- Constant | 0.015 0.451 0.033 0.974 Basis Function 1 | 0.125 0.027 4.661 .627087E-05 Basis Function 2 | -0.040 0.010 -4.143 .536148E-04 Basis Function 3 | 0.082 0.027 2.985 0.003 Basis Function 5 | 0.003 0.001 2.861 0.005 Basis Function 6 | 0.010 0.002 4.676 .586008E-05 Basis Function 7 | 0.009 0.004 2.469 0.015 Basis Function 8 | -0.006 0.002 -2.926 0.004 Basis Function 9 | 0.020 0.004 5.508 .129280E-06 Basis Function 10 | -0.143 0.028 -5.097 .896248E-06 Basis Function 13 | -0.012 0.003 -4.226 .384253E-04 Basis Function 15 | 0.003 .950175E-03 3.301 0.001 Basis Function 16 | -0.040 0.009 -4.534 .107942E-04 Basis Function 18 | 0.022 0.005 4.179 .464416E-04 Basis Function 20 | -0.003 .627981E-03 -4.544 .103098E-04 Basis Function 22 | 0.004 .651590E-03 6.067 .799620E-08 Basis Function 24 | 0.003 0.001 2.436 0.016 Basis Function 25 | 0.097 0.031 3.193 0.002 Basis Function 30 | 0.007 0.002 3.036 0.003 --- F-STATISTIC = 79.229 S.E. OF REGRESSION = 0.141 P-VALUE = .999201E-15 RESIDUAL SUM OF SQUARES = 3.418 [MDF,NDF] = [ 18, 173 ] REGRESSION SUM OF SQUARES = 28.173 --- Basis Functions =============== BF1 = max(0, IPA - 20.000); BF2 = max(0, ING - 39.000); BF3 = max(0, 39.000 - ING ); BF5 = max(0, 43.000 - IPA ) * BF2; BF6 = max(0, IPU - 31.000); BF7 = max(0, 31.000 - IPU ); BF8 = max(0, IPA - 23.000) * BF3; BF9 = max(0, 23.000 - IPA ) * BF3; BF10 = max(0, IPA - 37.000); BF11 = max(0, 37.000 - IPA ); BF13 = max(0, 24.000 - ING ) * BF11; BF15 = max(0, 32.000 - ING ) * BF7; BF16 = max(0, IPA - 59.000) * BF3; BF18 = max(0, IPA - 57.000) * BF3; BF20 = max(0, ING - 27.000) * BF1; BF22 = max(0, ING - 21.000) * BF1; BF24 = max(0, AR - 21.000); BF25 = max(0, 21.000 - AR ); BF30 = max(0, IPA - 38.000) * BF3; Y = 0.015 + 0.125 * BF1 - 0.040 * BF2 + 0.082 * BF3 + 0.003 * BF5 + 0.010 * BF6 + 0.009 * BF7 - 0.006 * BF8 + 0.020 * BF9 - 0.143 * BF10 - 0.012 * BF13 + 0.003 * BF15 - 0.040 * BF16 + 0.022 * BF18 - 0.003 * BF20 + 0.004 * BF22 + 0.003 * BF24 + 0.097 * BF25 + 0.007 * BF30;
Lampiran 9 Hasil simulasi penerapan metode MARS untuk data STAIN
IPA IPU Ar Ing IPKpred
35 35 35 35 2.52 37 35 35 37 2.79 40 35 35 35 2.82 50 35 35 35 3.00 35 40 35 35 2.57 35 50 35 35 2.67 35 35 40 35 2.54 35 35 50 35 2.58 35 35 35 40 2.53 35 35 35 50 2.57 40 40 40 40 2.97 45 40 40 40 3.06 50 40 40 40 3.15 40 45 40 40 3.02 40 50 40 40 3.06 40 40 45 40 2.98 40 40 50 40 3.00 40 40 40 45 2.93 40 40 40 50 2.89 42 40 40 40 3.00 45 45 45 45 3.06 47 47 47 47 3.12 50 50 50 50 3.22 60 50 50 50 3.52 52 52 52 52 3.29 55 55 55 55 3.43 57 57 57 57 3.53 57 55 55 55 3.50 60 60 60 60 3.69 70 70 70 70 3.78 80 80 80 80 3.99