Abstrak— Pada Tugas Akhir ini telah dibuat sistem konversi dokumen identitas individu menjadi suatu tabel, yaitu sebuah sistem yang mampu mengkonversi citra dokumen menjadi karakter-karakter digital yang tersusun ke dalam sebuah tabel. Dokumen yang digunakan adalah dokumen yang memiliki format baku, seperti eKTP/SIM. Sistem ini digunakan untuk memudahkan entri data pada dokumen secara otomatis menjadi suatu tabel. Pembacaan karakter demi karakter menjadi suatu tabel adalah berdasar koordinat yang telah ditentukan sesuai bentuk dokumen. Pembuatan sistem ini menggunakan algoritma Learning Vector Quantization (LVQ) dalam mengenali karakter pada dokumen tersebut. Citra dokumen didapatkan dengan menggunakan scanner sehingga dokumen berbentuk format .jpg. Kemudian dilakukan tahap konversi citra untuk membedakan karakter dan latar belakangnya. Citra karakter kemudian disegmentasi dan dinormalisasi menjadi 10x18 piksel untuk didapatkan cirinya sebagai masukan algoritma LVQ. Berdasarkan hasil pengujian dari 25 dokumen eKTP/SIM, sistem dengan algoritma LVQ ini mampu mengenali karakter pada citra dokumen eKTP dengan rata-rata akurasi sebesar 62.51%. Sedangkan pada dokumen SIM, sistem mampu mengenali karakter dengan rata-rata akurasi sebesar 91.87%.
Kata Kunci—Konversi Dokumen, eKTP, SIM, Learning Vector Quantization, Koordinat, Tabel.
I. PENDAHULUAN
ERKEMBANGAN teknologi telah memberikan dampak yang signifikan bagi ilmu pengetahuan dan kehidupan manusia. Teknologi dibuat dalam rangka mempermudah bahkan mempercepat pekerjaan, yang dahulunya menggunakan cara manual berganti menjadi otomatis. Salah satunya adalah perkembangan dibidang pengenalan pola (pattern recognition). Pengenalan pola merupakan suatu ilmu untuk mengklasifikasikan atau menggambarkan sesuatu berdasarkan pengukuran kuantitatif fitur (ciri) atau sifat utama dari suatu objek.
Penelitian mengenai pengenalan pola telah banyak dilakukan, diantaranya dalam bidang biometrika. Biometrika yaitu sistem pengenalan berdasarkan bentuk fisik dan perilaku manusia yang memiliki karakteristik tertentu. Selain biometrika terdapat juga pengenalan objek atau selain dari manusia. Sebagai contoh pengenalan objek dalam
bentuk karakter (huruf), tulisan tangan, dan benda-benda disekitar.
OCR (Optical Character Recognition) adalah salah satu area studi dalam pengenalan pola, yaitu sistem pengenalan karakter berupa huruf, angka, maupun simbol-simbol. OCR dapat dimanfaatkan untuk mengkonversi image yang mengandung teks hasil cetak mesin atau printer menjadi file dokumen berupa teks biasa. Sehingga informasi yang terkandung di dalam suatu image dapat diambil tanpa melalui proses pengetikan ulang. Hal ini karena pola-pola huruf dalam image dikenali dan dicocokkan sesuai basis pengetahuannya.
Pemanfaatan OCR sebagai solusi pengenalan karakter dalam suatu image, dapat juga dikembangkan ketahap penyimpanan hasil pengenalan, ke dalam data berbentuk tabel. Dokumen yang telah dikonversi menjadi image, akan melalui proses OCR, dan hasilnya dikelompokkan dalam tabel sesuai field-field yang ada. Oleh karena itu, diperlukan suatu dokumen yang standar untuk menyimpan data dalam bentuk tabel misalnya, kartu identitas berupa eKTP, SIM, STNK, dan lain-lain. Kartu identitas yang standar akan memiliki field-field yang sama dan memudahkan dalam mengelompokkan data.
Oleh karena itu, dalam tugas akhir ini dibuat perangkat lunak yang dapat mengkonversi dokumen identitas individu berupa e-KTP/SIM sehingga hasil outputnya berupa karakter yang disusun dalam sebuah tabel. Metode yang digunakan dalam pengenalan karakter pada citra dokumen adalah metode Learning Vector Quantization. Pemilihan metode ini berdasar penelitian yang menggunakan algoritma LVQ oleh Ronny, dkk, dengan input suatu gambar karakter dari 5 jenis font, menyimpulkan dengan banyaknya data pelatihan akan menghasilkan akurasi yang baik. Pada 4 data pelatiha menghasilkan akurasi 59.7%, 8 data pelatihan menghasilkan akurasi 69.5%, dan 12 data pelatihan tingkat akurasi pengenalannya sebesar 76%. Selain itu metode ini dipilih untuk menunjukkan tingkat keefektifan penggunaan LVQ dalam mengenali karakter dari sebuah dokumen identitas eKTP/SIM.
Untuk membatasi ruang lingkup pembahasan permasalahan maka ditentukan beberapa batasan sebagai berikut:
1. Dokumen identitas yang digunakan adalah e-KTP/SIM yang dikeluarkan oleh Pemerintah Republik Indonesia yang masih berlaku.
2. Dokumen e-KTP/SIM yang digunakan harus bebas dari kerusakan, baik cetak maupun cacat penggunaan.
SISTEM KONVERSI
DOKUMEN IDENTITAS INDIVIDU
MENJADI SUATU TABEL
Muhammad Mushonnif Junaidi dan Nurul Hidayat
Jurusan Matematika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Teknologi Sepuluh Nopember (ITS)
Jl. Arief Rahman Hakim, Surabaya 60111
Email:
[email protected]
3. Citra dokumen eKTP/SIM diambil secara manual menggunakan mesin scanner dan dipotong (crop) bagian yang tidak dibutuhkan jika ada.
4. Sistem konversi dokumen identitas individu menjadi suatu tabel diimplementasikan menjadi sebuah program dengan bahasa pemrograman Visual C#.
II. DASAR TEORI A. Dokumen Identitas
Dokumen identitas merupakan suatu dokumen yang memuat informasi identitas (jati diri) seseorang sebagai tanda keanggotaan suatu perkumpulan, perusahaan, instansi, dsb. Beberapa contoh dokumen identitas yang umum bagi masyarakat adalah KTP dan SIM.
KTP atau Kartu Tanda Penduduk adalah kartu bukti diri bagi setiap penduduk dalam wilayah Republik Indonesia. KTP diwajibkan bagi setiap penduduk yang berumur diatas 17 tahun dan masa berlakunya adalah 5 tahun. Sedangkan SIM adalah kartu yang dikeluarkan oleh Polri kepada seseorang yang telah memenuhi persyaratan administrasi, jasmani dan rohani, serta pemahaman berlalu lintas sesuai jenis kendaraan. Golongan SIM berdasarkan Pasal 82 UU No. 22 Tahun 2009 diantaranya : SIM A, SIM B1, SIM B2, SIM C, dan SIM D.
B. Optical Character Recognition
Optical Character Recognition (OCR) merupakan sistem yang dapat mengenali karakter baik cetak maupun tulisan tangan. Untuk mengenali karakter dalam sebuah dokumen, maka dokumen harus diubah menjadi citra digital terlebih dahulu menggunakan mesin scanner. Pengenalan karakter seperti ini merupakan metode penganalan offline atau tidak secara langsung. Pengenalan secara langsung dengan metode online dilakukan dengan tulisan tangan secara real time.
Secara umum tahap pengenalana karakter secara offline adalah sebagai berikut :
Gambar 1 Tahap Sistem OCR Offline C. Pengolahan Citra Digital
Merupakan proses pengubahan citra dari fungsi kontinu menjadi fungsi diskrit. Citra yang dihasilkan dari proses ini disebut sebagai citra digital. Secara umum, citra digital berbentuk persegi empat dengan dimensi ukurannya dinyatakan oleh panjang dan lebar. Misal suatu citra dengan
panjang M dan lebar N dinyatakan dengan bentuk matriks yang berukuran M x N sebagai berikut :
( )
( )
( )
(
)
( )
( )
(
)
(
) (
)
(
)
− − − − − − = 1 , 1 .... 1 , 1 1 .... .... .... .... 1 , 1 .... 1 , 1 0 , 1 1 , 0 .... 1 , 0 0 , 0 , N M f M f M f N f f f N f f f y x fPengolahan citra digital adalah pemrosesan citra, khususnya dengan menggunakan komputer, menjadi citra yang kualitasnya lebih baik. Pengolahan citra dilakukan untuk memperbaiki kualitas citra agar mudah diinterpretasi oleh manusia atau mesin (dalam hal ini komputer). Operasi-operasi yang dilakukan di dalam pengolahan citra banyak jenisnya, antara lain konversi citra segmentasi dan scalling.
1. Inverting
Inverting atau bisa disebut citra negatif adalah pengolahan citra dengan menampilkan warna citra yang berlawanan dengan warna aslinya.
𝑓(𝑥, 𝑦)
′= 255 − 𝑓(𝑥, 𝑦)
2. GrayscallingGrayscalling adalah teknik yang digunakan untuk mengubah citra berwarna (RGB) menjadi citra yang memiliki nilai keabuan (dari hitam menuju putih). Pengubahan dari citra berwarna ke bentuk grayscale mengikuti aturan berikut :
𝑠 =𝑟 + 𝑔 + 𝑏3 dengan :
S = Nilai intensitas citra grayscale
r = Nilai intensitas warna merah dari citra asal g = Nilai intensitas warna hijau dari citra asal b = Nilai intensitas warna biru dari citra asal
3. Binerisasi Citra
Binerisasi citra merupakan proses merubah citra ke dalam bentuk biner (0 dan 1). Dengan merubah ke bentuk biner, citra hanya akan mempunyai 2 warna yakni, hitam dan putih. Thresholding digunakan untuk mengatur jumlah derajat keabuan yang ada pada citra. Dengan adanya thresholding maka derajat keabuan bisa diubah sesuai keingin dengan persamaan berikut :
𝑓(𝑥, 𝑦)′= �𝑎1, 𝑓(𝑥, 𝑦) < 𝑇
𝑎2, 𝑓(𝑥, 𝑦) ≥ 𝑇
dengan :
𝑓(𝑥, 𝑦)′ = Nilai intensitas yang baru
𝑓(𝑥, 𝑦) = Nilai intensitas yang lama T = Nilai Threshold
4. Segmentasi
Segmentasi adalah teknik untuk memisahkan objek yang diinginkan dari objek lain. Dalam pengenalan objek pada suatu citra maka segementasi dilakukan dengan momotong area objek yang akan diproses dan dipisahkan dari latar belakangnya.
5. Normalisasi
Normalisasi (scalling) adalah merubah ukuran suatu citra. Ukuran citra dari proses sebelumnya dinormalkan supaya memiliki ukuran yang sama. Ukuran yang sama ini akan diproses dan dijadikan masukan untuk algoritma LVQ. D. Ekstraksi Ciri
Ekstraksi ciri bertujuan untuk mendapatkan karakteristik suatu karakter yang membedakannya dari karakter lain. Citra hasil segementasi yang ukurannya telah dinormalkan kemudian diektraksi cirinya dengan menandai piksel-piksel dengan nilai tertentu. Dalam penelitian ini ditandai piksel putih (0) dan piksel hitam (1).
E. Learning Vector Quantization
Learning Vector Quantization (LVQ) adalah suatu metode untuk melakukan pembelajaran pada lapisan kompetitif yang terawasi. Suatu lapisan kompetitif akan secara otomatis belajar untuk mengklasifikasikan vektor-vektor input. Kelas-kelas yang didapatkan sebagai hasil dari lapisan kompetitif ini hanya tergantung pada jarak antara vektor-vektor input. Jika 2 vektor input mendekati sama, maka lapisan kompetitif akan meletakkan kedua vektor tersebut ke dalam kelas yang sama. Beberapa notasi yang digunakan dalam algoritma ini adalah :
x : vektor pelatihan (x1, ..., xj, ..., xn)
T : kategori atau kelas yang benar untuk vektor pelatihan wj : vektor bobot untuk unit luaran ke-j (w1j, .., wij, .., wnj) cj : kategori atau kelas hasil komputasi oleh unit luaran j ||x – wj|| : jarak Eucledian antara vektor masukan dengan
unit luaran
Adapun langkah-langkah dari algoritma LVQ adalah sebagai berikut :
Langkah 1 : Inisialisasi vektor referensi dan learning rate Langkah 2 : Selama kondisi berhenti bernilai salah,
kerjakan a, b, dan c berikut:
a. Untuk setiap vektor x, kerjakan point 1 dan 2 berikut:
1. Temukan J sehingga ||x – wj|| minimum 2. Update wj dengan mengikuti rumus:
Jika T = cj maka wj = wj + α[x - wj] Jika T ≠ cj maka wj = wj - α[x – wj] b. Kurangi learning rate
c. Periksa kondisi berhenti III. PERANCANGAN SISTEM a. Perancangan Data
1. Data Masukan
Data msukan dalam sistem ini adalah citra dokumen eKTP/SIM dalam format .jpg, yang bisa didapatkan dari hasil scanning menggunakan mesin scanner atau bisa juga dengan mengambil gambar menggunakan kamera sehingga data berbentuk digital.
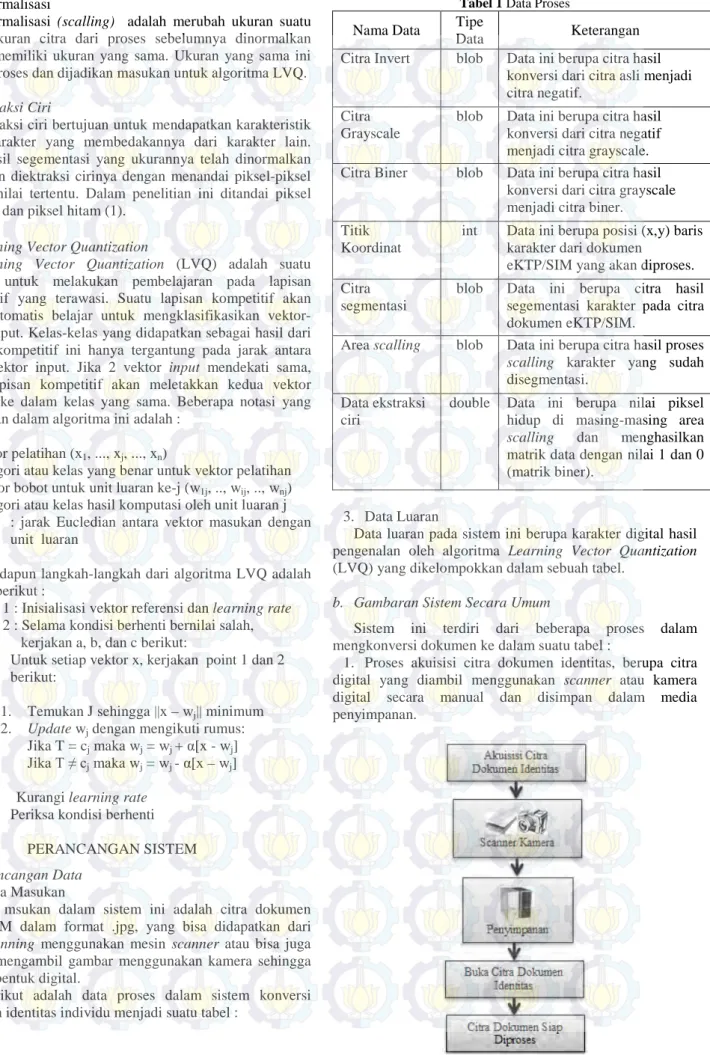
2. Berikut adalah data proses dalam sistem konversi dokumen identitas individu menjadi suatu tabel :
Tabel 1 Data Proses Nama Data Tipe
Data Keterangan Citra Invert blob Data ini berupa citra hasil
konversi dari citra asli menjadi citra negatif.
Citra Grayscale
blob Data ini berupa citra hasil konversi dari citra negatif menjadi citra grayscale. Citra Biner blob Data ini berupa citra hasil
konversi dari citra grayscale menjadi citra biner.
Titik Koordinat
int Data ini berupa posisi (x,y) baris karakter dari dokumen
eKTP/SIM yang akan diproses. Citra
segmentasi
blob Data ini berupa citra hasil segementasi karakter pada citra dokumen eKTP/SIM.
Area scalling blob Data ini berupa citra hasil proses scalling karakter yang sudah disegmentasi.
Data ekstraksi ciri
double Data ini berupa nilai piksel hidup di masing-masing area scalling dan menghasilkan matrik data dengan nilai 1 dan 0 (matrik biner).
3. Data Luaran
Data luaran pada sistem ini berupa karakter digital hasil pengenalan oleh algoritma Learning Vector Quantization (LVQ) yang dikelompokkan dalam sebuah tabel.
b. Gambaran Sistem Secara Umum
Sistem ini terdiri dari beberapa proses dalam mengkonversi dokumen ke dalam suatu tabel :
1. Proses akuisisi citra dokumen identitas, berupa citra digital yang diambil menggunakan scanner atau kamera digital secara manual dan disimpan dalam media penyimpanan.
2. Proses Konversi Citra
Konversi citra merupakan proses untuk mengolah citra masukan sehingga dapat dibedakan antara objek dan latar belakangnya. Beberapa langkah konverci citra diantaranya, inverting, grayscalling, dan binerisasi citra.
Pada
Gambar 2 menampilkan urutan dari proses konversi citra pada NIK eKTP. Terlihat perbedaan masing-masing citra, dari citra asli sampai menjadi citra biner sehingga dapat dibedakan antara objek karakter (warna putih) dan latar belakangnya (warna hitam).(a) (b) (c) (d)
Gambar 3 Proses Konversi Citra. (a) Citra Asli, (b) Citra Negatif, (c) Citra Grayscale, (d) Citra Biner.
3. Proses Menentukan Koordinat Objek
Untuk dapat menyusun barisan karakter dari dokumen ke dalam suatu tabel maka ditentukan koordinat sesuai format dokumen yang dipakai. Penentuan koordianat dilakukan dengan trial-error atau mengukur dan mecoba posisi yang tepat dalam area dokumen.
4. Proses Segmentasi
Proses memotong objek pada citra dokumen sesuai area masing-masing. Segementasi dilakukan pada proses pelatihan dan pengujian karakter. Gambar 3 berikut menunjukkan contoh proses segmentasi karakter pada NIK.
Gambar 4 Contoh Proses Segmentasi 5. Proses Normalisasi
Proses ini dilakukan untuk mendapatkan ukuran citra hasil segementasi selalu sama. Ukuran yang dipakai dalam sistem adalah 10x18 piksel yang selanjurnya diproses untuk diektraksi cirinya.
6. Proses Ekstraksi Ciri
Merupakan proses-proses yang dilakukan untuk mendapatkan ciri dari citra karakter yang terdapat pada dokumen identitas yang diperoses. Ciri dari citra karakter tersebut dibutuhkan untuk pemrosesan algoritma LVQ.
7. Proses tahap JST
Terdiri dari 2 proses yang dilakukan, yaitu :
a. Proses pelatihan (training), yaitu proses melatih sistem dengan masukan yang ada sehingga mampu mengenali apabila diberi masukan yang baru.
b. Proses pengujian (testing), yaitu proses pencocokan atau membandingkan ciri masukan baru dengan ciri yang ada pada referensi yang sebelumnya sudah dilatih kepada sistem.
8. Proses Penyimpanan
Proses menyimpan hasil pengenalan karakter dari dokumen identitas yang diproses dan dikelompokkan dalam bentuk tabel.
Gambar 5 Flowchart Pelatihan (a) dan Flowchart Proses Pengujian (b)
IV. HASIL DAN PENGUJIAN
Perangkat yang digunakan dalam pengujian sistem terdiri dari beberapa perangkat keras dan perangkat lunak. Perangkat keras yang digunakan yaitu komputer dengan Prosesor Intel Core i3 2.13 GHz, Memory 4 GB DDR3, dan Hard Disk 298 GB. Sedangkan perangkat lunak yang digunakan adalah Sistem Operasi Windows 8.1 Pro 32-bit dan perangkat lunak Microsoft Visual Studio C# 2010. a. Pengujian Tahap Akuisisi
Menghasilkan dokumen dalam bentuk citra digital dengan menggunakan scanner. Berikut hasil scanning yang sesuai dengan kebutuhan sistem.
(a)
(b)
b. Pengujian Tahap Pra-pengolahan 1. Pengujian Proses Konversi Citra
Pengujian proses konversi citra bertujuan untuk mengetahui bahwa citra dokumen yang sudah diload ke dalam sistem sudah dapat dibedakan antara objek dan latar belakangnya. Proses yang dilakukan dengan merubah citra asalm menjadi citra negatif, citra grayscale, dan terkahir citra biner. Gambar menunjukkan citra yang sudah dibedakan antar objek karakter (warna putih) dan latar belakangnya (warna hitam).
(a)
(b)
Gambar 7 Hasil Konversi Citra. (a) eKTP, (b) SIM A. 2. Pengujian Proses Segmentasi
a. Segmentasi Data Pelatihan
Pengambilan citra karakter secara manual dengan seleksi kursor. Gambar 8 berikut adalah hasil seleksi citra karakter pada data pelatihan.
(a) (b)
(c) (d)
Gambar 8 Hasil Segmentasi pada Data Data Pelatihan. (a) Kararkter NIK, (b) Karakter Non-NIK, (c) – (d) Karakter SIM.
b. Segmentasi Data Pengenalan
Pengambilan citra karakter secara otomatis oleh sistem. Gambar 9 berikut adalah hasil segmentasi citra karakter oleh sistem.
Gambar 9 Hasil Segmentasi 3 Karakter NIK
3. Pengujian Proses Normalisasi
Pengujian proses scalling bertujuan untuk mengetahui bahwa sistem telah menormalisasi ukuran citra hasil segmentasi. Gambar 10 berikut menunjukkan bahwa cutra telah melalui proses noralisasi.
Gambar 10 Citra Segmentasi dan Citra Normal 4. Pengujian Proses Ekstraksi Ciri
Dari hasil normalisasi ukuran 10x18 piksel maka tiap piksel ditandai dengan angka 1 dan 0. Untuk piksel berwarna hitam ditandai angka 1 dan piksel berwarna putih ditandai angka 0. Tabel 1 berikut adalah hasil ekstraksi ciri dari gambar 8 (d), tentunya setelah melewati proses scalling.
Tabel 2 Tabel Matrik Biner Ekstraksi Ciri
Pada basisdata hasil ekstraksi ciri membentuk 180 kode biner yang disebut dengan matrik data. Matrik data ini disusun dari Tabel 2 sebagai berikut :
1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 c. Pengujian Tahap JST
1. Pengaruh Learning Rate
Learning rate dalam algoritma LVQ merupakan konstanta yang digunakan untuk mencari bobot. Rumus untuk mencari bobot dalam algoritma LVQ adalah sebagai berikut:
𝑤𝑗 = 𝑤𝑗∓ 𝛼�𝑥 − 𝑤𝑗�
dengan:
Wj adalah bobot ke-𝑗 X adalah vektor pelatihan α adalah learning rate
Untuk mengetahui pengaruh alpha terhadap akurasi maka sistem dilatih dengan memasukkan nilai epoh sama dan apha berbeda-beda. Nilai alpha yang dipilih sebagai uji coba adalah 0.01, 0.05, 0.1, 0.5, 1. Sistem akan diuji pada masing-masing proses dengan nilai alpha bervariasi dan epoh 100.
Tabel 3 Pengujian nilai apha berbeda pada field NIK eKTP Dokumen eKTP Alpha Epoh Maks. Akurasi (%) Field NIK 0.01 100 100 0.05 100 100 0.1 100 100 0.5 100 100 1 100 100
Pada Tabel 3 dilakukan pengujian dokumen eKTP pada field NIK dengan nomor 3525200407630001 dan diadapatkan akurasi mencapai 100% .
Tabel 4 Pengujian nilai apha berbeda pada field Nomor SIM Dokumen SIM Alpha Epoh
Maks. Akurasi (%) Field Nomor 0.01 100 23,08 0.05 100 15,38 0.1 100 7.69 0.5 100 7,69 1 100 7,69
Pada Tabel 4 dilakukan pengujian dokumen SIM pada field Nomor dengan nomor 630715540336 dan menghasikan akurasi sedikit berbeda dan naik dengan nilai alpha semakin kecil.
2. Pengaruh Epoh
Untuk mengetahui pengaruh epoh terhadap akurasi maka sistem dilatih dengan memasukkan nilai alpha sama dan epoh berbeda-beda. Nilai alpha yang dipilih sebagai uji coba adalah 1000, 500, 100, 50, 10. Sistem akan diuji pada masing-masing proses dengan nilai epoh bervariasi dan alpha 0.01.
Tabel 5 Pengujian nilai epoh berbeda pada field NIK Dokumen eKTP Alpha Epoh Maks. Akurasi (%) Field NIK 0.01 1000 100 0.01 500 100 0.01 100 100 0.01 50 100 0.01 10 90.91
Pada Tabel 5 dilakukan pengujian dokumen eKTP pada field NIK dengan nomor 3525200407630001 dan diadapatkan akurasi semakin baik dengan nilai epoh tinggi.
Tabel 6 Pengujian nilai apha berbeda pada field Nomor SIM Dokumen SIM Alpha Epoh Maks. Akurasi
(%) Field Nomor “630715540336” 0.01 1000 23,08 0.01 500 7.69 0.01 100 7.69 0.01 50 7,69 0.01 10 7,69
Pada Tabel 6 dilakukan pengujian dokumen SIM pada field Nomor dengan nomor 630715540336 dan diadapatkan akurasi semakin baik dengan nilai epoh tinggi.
3. Pengaruh Nilai Ambang
Untuk mengetahui pengaruh nilai ambang (threshold) terhadap akurasi, maka sistem dilatih dengan memasukkan nilai ambang sama atau berbeda-beda. Nilai ambang sama ditetapkan dengan nilai 128 untuk semua field dan nilai ambang berbeda dipilih berdasar tingkat akurasi terbesar pada nilai ambang pilihan untuk masing-masing field.
Tabel 7 Pengujian nilai ambang sama pada masing-masing field eKTP
Dokumen eKTP Nilai Ambang Akurasi (%) 3525100407630001 128 100 Ahmad Luthfi 128 33.33 Pongangan Rejo 128 41.67 001 003 128 100 Pongangan 128 25.53 Manyar 128 100
Tabel 8 Pengujian nilai ambang berbeda pada masing-masing field eKTP
Dokumen eKTP Nilai Ambang Akurasi (%) 3525100407630001 77 100 Ahmad Luthfi 113 100 Pongangan Rejo 132 64 001 003 104 100 Pongangan 103 35.29 Manyar 84 100
Tabel 9 Pengujian nilai ambang sama pada masing-masing field SIM
Dokumen SIM Nilai Ambang Akurasi (%) 630715540336 128 60.87 A 128 100 Ahmad Luthfi 128 100 DS Pongangan Rejo RT1 RW 3 128 100 Tabel 10 Pengujian nilai ambang berbeda pada masing-masing
field SIM
Dokumen SIM Nilai Ambang Akurasi (%) 630715540336 156 100 A 138 100 Ahmad Luthfi 113 100 DS Pongangan Rejo RT1 RW 3 119 100 Tabel 7 s/d Tabel 10 menunjukkan pengaruh nilai ambang terhadap tingkat akurasi pengenalan.
4. Pengujian LVQ
Pengujian LVQ bertujuan untuk mengetahui akurasi algoritma LVQ dalam sistem konversi dokumen identitas individu menjadi suatu tabel ini. Dengan mempertimbangkan pengaruh nilai alpha dan epoh terhadap akurasi, sistem akan diuji dengan menggunakan alpha sebesar 0.01 dan epoh sebanyak 1000.
Pada tahap pengujian ini, sistem akan diuji dengan dokumen eKTP dan SIM yang berbeda-beda dan pada field yang lebih banyak.
Tabel 11 Pengujian pengenalan field Nama eKTP Sebenarnya Pengenalan Akurasi
(%) AHMAD LUTHFI AHMALY L
LVTHFI 33.33 AZIFATUL ANIFAH AZIFATUL ATN F AFI 62.07 NURUL HIDAYAT NLJRLVL FXTEVAYA 14.81 FATHOLAH FATROLLAH 58.82 MUHAMAD YASIR BURHAN MJFTAMAU YASIC LUHHAN 10.81 Tabel 12 Pengujian pengenalan field NIK eKTP Sebenarnya Pengenalan Akurasi
(%) 3525100407630001 3525100407630001 100 3525106309710001 3525106309710001 100 3515130404630004 3515130404630004 100 3509170412810001 3509170412810001 100 1221131607830003 1221131607830003 100
Tabel 13 Pengujian pengenalan field eKTP Sebenarnya Pengenalan Akurasi
(%) PONGANGAN
REJO PUNGANVN REX 41.67 PONGANGAN
REJO ALNVNGAN REY 8.33
BINGIN BENDO BRINCTIN FT
NDU 8.33
DUSUN
PATEMON DUSUN PATELN 78.26 KRAMAT
LANGON IV 10
KRAMA
LANUON IV JJ 32.26 Tabel 14 Pengujian pengenalan field RT/RW eKTP Sebenarnya Pengenalan Akurasi
(%) 001 003 001 003 100 001 003 OO1 O03 50 003 001 OO3 OQT 16.67 002 004 QO2 J3 18.18 002 007 O3 JO7 0
Tabel 15 Pengujian pengenalan field Kel/Desa eKTP Sebenarnya Pengenalan Akurasi
(%) PONGANGAN PLLTVNVN 25.53 PONGANGAN PONVNGAN 35.29 BINGINBENDO BRINOTNBLNDO 8.7 MANGARAN MYYRAN 28.57 SIDOKUMPUL SIJUKUMPUV 70
Tabel 16 Pengujian pengenalan field Kecamatan eKTP Sebenarnya Pengenalan Akurasi
(%) MANYAR MANYAR 100 MANYAR VANYAP 66.67 TAMAN TAMAN 100 AJUNG YUNC 0 GRESIK GRESIK 100
Pada Tabel 11 s/d Tabel 16 untuk field Nama, NIK, Alamat, RT/RW, Kel/Desa, Kecamatan masing-masing untuk 25 dokumen eKTP menghasilkan rata-rata pengenalan sebesar 71.31%, 100%, 46.36%, 53.21%, 36.14%, dan 68.04%. Rata-rata keseluruhan pengenalan sebesar 62.51%.
Tabel 17 Pengujian pengenalan field Nama SIM Sebenarnya Pengenalan
Akurasi (%) AHMAD LUTHFI AHMAD LUTHFI 100 AHMAD LUTHFI AHMAD LUTHFI 100 JOKO WAHYONO CAHYO JOKO WAHYONO CAHYO 100 MUHAMAD YASIR BURHAN MUHAMAD YASIR BURHAN 100 NURUL WIJI SRI
UTAMI
NURUL WIJI SRI
UTAMI 100
Tabel 18 Pengujian pengenalan field Nomor SIM Sebenarnya Pengenalan Akurasi
(%) 630715540336 630715540336 100 630715540731 630715540731 100 780915540395 780915540395 100 830715540825 830715540825 100 710115531414 710115531414 100
Tabel 19 Pengujian pengenalan field Jenis SIM Sebenarnya Pengenalan Akurasi
(%) A A 100 C C 100 A A 100 C C 100 C C 100
Tabel 20 Pengujian pengenalan field Alamat SIM Sebenarnya Pengenalan Akurasi
(%) DS PONGANGAN REJO RT1 RW3 DS PONGANGAN REJO RT1 RW3 100 DS PONGANGAN REJO RT1 RW3 DS FONGANGAN REJO RT1 RW3 95.24 DS RANDUAGUNG RT3 RW3 DS RANDUAGUNG RT3 RW3 100 DS KRAMAT LANGON IV 10 DS KRAMAT LANGON IV 10 100 BRINGIN BENDO TAMAN NHINGTN BL NOC T AMAN 64.71 Pada Tabel 17 s/d Tabel 20 untuk field Nama, Nomor, Jenis, Alamat masing-masing untuk 25 dokumen SIM menghasilkan rata-rata pengenalan sebesar 90.92%, 88.95%, 98.66%, dan 88.97%. Rata-rata keseluruhan pengenalan sebesar 62.51%.
V. KESIMPULAN
Berdasarkan analisis terhadap hasil pengujian yang telah dilakukan terhadap sistem konversi dokumen identitas individu menjadi suatu tabel menggunakan algoritma Learning Vector Quantization, maka dapat diambil beberapa kesimpulan sebagai berikut:
1. Proses-proses yang dilakukan sebelum karakter pada citra dokumen dapat dikenali adalah proses konversi citra, proses segmentasi, proses normalisasi, dan proses ekstraksi ciri.
2. Penentuan nilai ambang (threshold) sangat berpengaruh pada akurasi yang didapatkan masing-masing field dokumen. Nilai ambang yang digunakan untuk dokumen eKTP sebesar 126 dan untuk dokumen SIM sebesar 170. 3. Karakter pada dokumen SIM lebih mudah dikenali
daripada karakter pada dokumen eKTP. Dilihat dari bentuk fisik karakter dokumen SIM memiliki huruf yang tegas dan jelas serta minim noise pada latar belakang. Sedangkan pada dokumen eKTP karakter lebih kecil dan kadang berhimpit satu sama lain sehingga sulit dikenali. 4. Metode Learning Vector Quantization lebih baik dalam
mengenali karakter dokumen SIM dengan rata-rata pengenalan dari 25 dokumen SIM untuk beberapa field sebesar 91.87% sedangkan pada dokumen eKTP akurasinya sebesar 62.51%.
5. Sitem mampu mengkonversi citra dokumen eKTP/SIM menjadi karakter sesuai dengan field-field yang dikehendaki dan dikelompokkan ke dalam suatu tabel.
DAFTAR PUSTAKA
[1] Putra, D. 2009. “Pengolahan Citra Digital”. Yogyakarta : Penerbit Andi.
[2] Hartanto, S., Sugiharto, A., Endah, S.N. 2012. “Optical Character Recognition Menggunakan Algoritma Template Matching Correlation” . Semarang : Undip [3] Rohwana, Ulir. 2013.”Pengenalan Tulisan Huruf Latin
Bersambung Secara Real Time Menggunakan Algoritma Learning Vector Quantization”. Surabaya: Institut Teknologi Sepuluh Nopember.
[4] Ronny, Rahman, S., Munir, A. 2012. “Pengenalan Karakter Dengan Segmentasi Citra dan Algoritma Learning Vector Quantization”. Makassar : STMIK Kharisma
[5] Gonzales, RC. Woods, RE. 2002. “Digital Image Processing”. New Jersey : Prentice Hall, Inc.
[6] Fausett, L. 1994. “Fundamentals of Neural Networks: Architectures, Algorithms, and Applications”. Prentice Hall International.Inc
[7] Asworo.2010. “Comparison Between Kohonen Neural Network Method and Learning Vector Quantization in The Online Handwriting Recognition System”. Institut Teknologi Sepuluh Nopember, Surabaya.
[8] KKPS. 2009. BERSERI “Belajar Menulis Benar, Rapi, dan Indah” untuk siswa kelas satu, dua, dan tiga Sekolah Dasar. Bandung.