Abstrak— Demam Berdarah Dengue (DBD) adalah penyakit yang disebabkan oleh virus Dengue melalui gigitan nyamuk Aedes aegypti. Di Indonesia, timbulnya penyakit DBD ini ketika musim pancaroba dimana merupakan pergantian dari musim kemarau ke musim hujan ataupun sebaliknya. Pada musim pancaroba (pergantian), curah hujan meningkat seiring dengan meningkatnya perkembangbiakan nyamuk seperti nyamuk Aedes aegypti. Namun DBD bukan hanya disebabkan oleh nyamuk Ae, faktor lingkungan serta pendidikan juga mempengaruhi banyaknya kejadian DBD. Selain itu, tenaga kesehatan masyarakat juga sangat berperan aktif sebagai pemberantas kasus DBD di Indonesia, sehingga pada penelitian ini akan diuraikan pengaruh faktor-faktor yang dapat menyebabkan meningkatnya jumlah kasus DBD berdasarkan kabupaten/kota di Indonesia pada tahun 2011 dengan menggunakan metode analisis faktor dengan principal component analysis (PCA). Faktor-faktor yang digunakan dalam penelitian ini ada 10 faktor antara lain: jumlah penduduk, persentase penduduk melek huruf, jumlah kasus DBD, insiden DBD, rumah tangga PHBS, rumah sehat, akses air bersih, jumlah tenaga sanitasi, jumlah tenaga kesmas, dan jumlah puskesmas. Sebelum melakukan analisis faktor, dilakukan pengujian asumsi distribusi normal multivariat pada data namun hasil menunjukkan data tidak mengikuti distribusi normal multivariat, namun diasumsikan berdistribusi normal multivariat. Hasil dari data jumlah kasus DBD tiap kabupaten/kota di Indonesia tahun 2011, hanya tujuh variabel yang memiliki korelasi antar variabel yang cukup tinggi yaitu X3,X1, X4, X5,X6,X9 dan X10. Hasis analisis faktor mereduksi sepuluh variabel awal menjadi dua komponen baru dimana komponen satu merupakan faktor sumber daya manusia yang terdiri dari variabel jumlah penduduk, jumlah puskesmas, jumlah tenaga kesmas dan jumlah kasus DBD, sedangkan pada faktor dua atau faktor pengetahuan masyarakat yang terdiri dari variabel jumlah tenaga sanitasi dan penduduk melek huruf.
Kata Kunci : Analisis faktor, demam berdarah dengue (DBD), principal component analysis (PCA).
I. PENDAHULUAN
Indonesia merupakan salah satu negara yang memiliki dua musim yaitu musim hujan dan musim kemarau. Diantara dua musim tersebut ada jarak sebagai musim pergantian (pancaroba) pada musim inilah banyak timbul kasus penyakit seperti DBD karena meningkatnya curah hujan dapat meningkatkan tempat-tempat perkembangbiakan nyamuk penular DBD dan berbagai penyakit lainnya. Demam berdarah
dengue atau DBD merupakan penyakit yang disebabkan oleh virus Dengue yang ditularkan dari orang ke orang melalui gigitan nyamuk Aedes (Ae). Ae aegypti merupakan vektor yang paling utama, namun spesies lain seperti Ae.albopictus juga dapat menjadi vektor penular. Nyamuk penular dengue ini terdapat hampir di seluruh pelosok Indonesia, kecuali di tempat yang memiliki ketinggian lebih dari 1000 meter di atas permukaan laut. Penyakit DBD banyak dijumpai terutama di daerah tropis dan sering menimbulkan kejadian luar biasa (KLB). [1]
Pada tahun 2008 angka kejadiannya DBD sebesar 59,02% per 100.000 penduduk. Sedangkan di tahun 2009 IR penyakit DBD sebesar 68,22 per 100.000 penduduk. Berdasarkan data Profil Kesehatan Indonesia tahun 2010 jumlah kasus DBD pada tahun 2010 sebanyak 156.086 kasus dengan jumlah kematian akibat DBD sebesar 1.358 orang. Inciden Rate (IR) penyakit DBD pada tahun 2010 adalah 65,7 per 100.000 penduduk.[1]
Bila diamati secara berturut-turut kasus demam berdarah dengue mengalami peningkatan setiap tahunnya. Demam berdarah dengue bukan seluruhnya kesalahan dari nyamuk Ae, faktor lingkungan serta pendidikan juga mempengaruhi banyaknya kejadian demam berdarah dengue ini. Tenaga kesehatan masyarakat juga sangat berperan aktif sebagai pemberantas kasus DBD di Indonesia melalui penyuluhan-penyuluhan mengenai pemberantasan sarang nyamuk (PSN) yang dapat mengurangi resiko terjadinya penyakit demam berdarah.
Pada penelitian ini akan diuraikan pengaruh faktor-faktor yang dapat menyebabkan meningkatnya jumlah kasus demam berdarah dengue berdasarkan kabupaten/kota di Indonesia pada tahun 2011 dengan menggunakan metode analisis faktor dengan principal component analysis.
II. TINJAUANPUSTAKA A. Distribusi Normal Multivariat
Variabel X1, X2, Xp dikatakan berditribusi normal multivariat jika mempunyai probability density function:
) ( )' ( 2 1
2 / 2 / 2
1
) 2 (
1 )
,..., ,
(
X X
X X
X e
f p
p p
i
Analisis Faktor Pada Data Jumlah Kasus Penyakit
Demam Berdarah Dengue (DBD) di Indonesia
tahun 2011
Desy Ariyanti
[1]1313100009, Amalia Aisyah
[2]1313100045, Dinni Ari Rizky Taufanie
[3]1312100017
dan Dr.Bambang Widjanarko Otok, M.Si
[4][1][2][3][4]
Jurusan Statistika, FMIPA, Institut Teknologi Sepuluh Nopember (ITS)
Jl. Arief Rahman Hakim, Surabaya 60111 Indonesia
: [email protected], [email protected], [email protected],
Jika X1, X2, Xp berdistribusi normal multivariate maka
maka pemeriksaan distribusi multinormal dapat dilakukan dengan cara membuat Q-Q plot dari nilai memenuhi asumsi normalitas. Plot tersebut dapat digunakan untuk distribusi marjinal dari pengamatan pada setiap variabel. Q-Q plot akan memperkirakan untuk mengobservasi jika pengamatan berdistrisibusi normal. Ketika titik-titik berada disekitar garis lurus, maka asumsi normalitas terpenuhi [1].
Tahapan dari pembuatan Q-Q plot ini adalah sebagai berikut:
1. Tentukan nilai vektor rata-rata: X
2. Tentukan nilai matriks varians-kovarians: S
3. Tentukan nilai jarak Mahalanobis setiap titik pengamatan dengan vektor rata-ratanya
S
i n4. Mengurutkan nilai 2 i
d dari kecil ke besar. 5. Menentukan nilai
n
6. Tentukan nilai pi sedemikian hingga
i
7. Membuat scatterplot 2 ) (i
d dengan qi.
8. Data berdistribuisi normal multivariate jika scatterplot ini cenderung membentuk garis lurus dan lebih dari 50% nilai
2
Pengujian asumsi distribusi normal multivariate dilakukan dengan hipotesis sebagai berikut:
H0 : Data berdistribusi normal multivariat H1 : Data tidak berdistribusi normal multivariat
Statistik uji yang digunakan adalah t dimana didapatkan dari menjumlahkan nilai 2
50 berada disekitar 0.5.
B. Analisis Faktor
Analisis faktor adalah analisis statistika yang bertujuan untuk mereduksi dimensi data dengan cara menyatakan variabel asal sebagai kombinasi linear sejumlah faktor, sedemikian hingga sejumlah faktor tersebut mampu menjelaskan sebesar mungkin keragaman data yang dijelaskan oleh variabel asal.
Tujuan dari analisis faktor adalah untuk menggambarkan hubungan-hubungan kovarian antara beberapa variabel yang mendasari tetapi tidak teramati, kuantitas random yang disebut faktor [1]. Vektor random teramati X dengan p komponen, memiliki rata-rata dan matrik kovarian S. Model analisis faktor adalah sebagai berikut :
1 disebut komunalitas ke–i yang merupakan jumlah kuadrat dari
loading variabel ke –i pada m common faktor [1], dengan Tujuan analisis faktor adalah menggunakan matriks korelasi hitungan untuk 1) Mengidentifikasi jumlah terkecil dari faktor umum (yaitu model faktor yang paling parsimoni) yang mempunyai penjelasan terbaik atau menghubungkan korelasi diantara variabel indikator. 2) Mengidentifikasi, melalui faktor rotasi, solusi faktor yang paling masuk akal. 3) Estimasi bentuk dan struktur loading, komunality dan varian unik dari indikator. 4) Intrepretasi dari faktor umum. 5) Jika perlu, dilakukan estimasi faktor skor [2].
C. KMO dan Bartlett’s Test
Pengujian kecukupan data dapat menggunakan banyak metode, salah satunya adalah metode Kaiser-Meyer-Olkin (KMO). Metode KMO menguji apakah semua data yang telah terambil telah cukup untuk dilakukan analisis faktor.[2] Hipotesis dalam uji KMO sebagai berikut.
H0 : Terdapat korelasi parsial yang cukup pada data H1 : Tidak terdapat korelasi parsial yang cukup pada data Statistik uji dalam uji KMO sebagai berikut.
rij = Koefisien korelasi antara variabel i dan j, aij = Koefisien korelasi parsial antara variabel i dan j.
Jika nilai KMO lebih besar 0.5 maka berarti terdapat korelasi parsial yang cukup pada data untuk dilakukan analisis faktor.[2]
D. Principal Component Analysis (PCA)
Analisis komponen utama adalah analisis statistika yang bertujuan untuk mereduksi dimensi data dengan cara membangkitkan variabel baru (komponen utama) yang merupakan kombinasi linear dari variabel asal sedemikan hingga varians komponen utama menjadi maksimum dan antar komponen utama bersifat saling bebas. Model analisis komponen utama dapat ditulis sebagai berikut.
varians terbesar ke-m
X2 = variabel asal kedua Xp = variabel asal ke-p
m = banyaknya komponen utama p = banyaknya variabel asal
cara memaksimumkan varians Yi dengan syarat ' 1
i
pengganda Lagrange pemaksimuman ini dapat ditulis dalam fungsi Lagrange sebagai berikut.
) L menjadi maksimum jika turunan pertama L terhadap '
i
a dan
sama dengan nol sebagai berikut. 0 (characteristic equation), yang pe-nyelesaiannya dapat dilakukan dengan menyelesaikan persamaan
I
0
. Dari peneyelesaian persamaan ini diperoleh p buah , i=1,..,p (akar ciri atau eigenvalue) dan p buah ai (vektor ciri ataueigen-vector) yang bersesuaian.
Nilai dapat juga diintepretasikan sebagai varians dari komponen utama ke-i, sehingga besarnya sumbangan relatif komponen utama ke-i terhadap total keragaman (variation) yang dijelaskan oleh seluruh variabel asal ialah sebagai berikut. menjelaskan keragaman data yang dijelaskan oleh seluruh variabel asal sebesar :
%
Untuk satuan variabel asal tidak sama, seringkali dilakukan pembakuan (standardization)dulu sebelum dilakukan analisis komponen utama. Pembakuan tersebut dilakukan dengan cara:
x Akibat adanya pembakuan data ini maka matriks varians-kovarians dari data yang dibakukan akan sama dengan matriks korelasi data sebelum dibakukan dan besarnya total varians kompomem utama sama dengan banyaknya variabel asal (p). Banyaknya komponen utama (m) dapat ditentukan dengan berbagai kriteria, salah satu kriteria yang biasa dipakai adalah dengan menggunakan kriteria besarnya varians komponen utama ( ). Untuk data yang sudah dibakukan disyaratkan besarnya , syarat ini diberlakukan mengingat jika nilai maka komponen utama ini hanya menjelaskan keragaman yang dijelaskan oleh satu variabel asal. [2]
E. Demam Berdarah Dengue (DBD)
DBD adalah penyakit yang disebabkan oleh virus Dengue dari genus Flavivirus, family Flaviviridae melalui gigitan nyamuk Aedes aegypti dan Aedes albopictus. Adapun nyamuk Aedes aegypti memiliki kemampuan terbang mencapai radius 100-200 meter. Oleh karena itu, jika di suatu lingkungan terkena kasus DBD, maka masyarakat yang berada pada radius tersebut harus waspada [4]. Nyamuk Aedes aegypti lebih menyukai tempat yang gelap, berbau, dan lembab. Tempat perindukan yang sering dipilih Aedes aegypti adalah kawasan yang padat dengan sanitasi yang kurang memadai, terutama digenangan air dalam rumah, seperti pot, vas bunga, bak mandi atau tempat penyimpanan air lainnya seperti tempayan, drum, atau ember plastik [7].
Faktor lingkungan memegang peranan penting dalam penularan penyakit, terutama lingkungan rumah yang tidak memenuhi syarat. Lingkungan rumah merupakan salah satu faktor yang memberikan pengaruh besar terhadap status kesehatan penghuninya [7]. Penyakit DBD sering terjadi di daerah tropis dan muncul pada musim penghujan. Kurangnya kesadaran manusia dalam menjaga kebersihan lingkungan juga merupakan hal yang berpengaruh terhadap penyakit DBD [1].
III.METODOLOGIPENELITIAN A. Sumber Data
Data yang digunakan dalam praktikum analisis faktor multivariat kali ini merupakan data sekunder yang diambil dari website database Kementrian Kesehatan Republik Indonesia tahun 2011 pada hari Kamis, 21 April 2016 dengan terdapat sepuluh variabel mengenai faktor-faktor jumlah kasus DBD berdasarkan kabupaten/kota di Indonesia.
B. Struktur Data
Struktur data dari data faktor penyebab jumlah kasus DBD di Indonesia tahun 2011 adalah sebagai berikut,
Tabel 3. 1 Struktur Data
No X1 X2 X3 X4 ... X10 C. Variabel Penelitian
Variabel penelitian yang digunakan dalam data praktikum kali ini terdiri dari sepuluh variabel independen yang dijelaskan di bawah ini,
Tabel 3. 2 Variabel Penelitian
Variabel Keterangan Skala Data
X1 Jumlah Penduduk (jiwa) Rasio
X2 % Penduduk Melek Huruf Rasio
X3 Jumlah Kasus DBD Rasio
X4 Insidens DBD (per 1000) Rasio
X5 % Rumah Tangga PHBS Rasio
X6 % Rumah Sehat Rasio
X7 % Akses Air Bersih Rasio
X8 Jumlah Tenaga Sanitasi Rasio
X10 Jumlah Puskesmas Rasio
D. Langkah Analisis
Untuk melakukan analisis faktor dalam praktikum ini terdapat langkah-langkah analisis antara lain,
1. Mencari data yang memenuhi asumsi analisis faktor 2. Menguji normal multivariat data
3. Menguji kecukupan data untuk analisis faktor dengan uji KMO dan uji independensi dengan Uji Bartlett.
4. Melakukan analisis komponen utama (PCA) 5. Melakukan analisis faktor
6. Menarik Kesimpulan
IV. ANALISISDANPEMBAHASAN A. Analisis Karakteristik Data
Sebelum melakukan analisis faktor perlu diketahui karakteristik data dari variabel-variabel yang akan diolah. Berikut ini adalah analisis deskiptif data.
Tabel 4. 1 Analisis Deskriptif Variabel Mean Varians
X1 915694 7,10E+11
X2 73,82 1368,32
X3 381,8 326685,1
X4 30,87 3023,85
X5 45,61 503,91
X6 63,05 444,9
X7 66,41 1200,63
X8 14,62 207,09
X9 24,38 844,34
X10 21,86 271,37
Berdasarkan Tabel 4.1 rata-rata jumlah penduduk Indonesia tahun 2011 tiap kabupaten kota adalah 915694 dengan rata-rata persentase penduduk melek huruf adalah 73,82%. Rata-rata jumlah kasus DBD dan insiden DBD adalah 381 kasus dengan 30,87 insiden per 1000. Persentase rata-rata rumah tangga PHBS dan rumah sehat 45,61 dan 63,05. Sedangkan rata-rata akses air bersih 66,41. Rata-rata jumlah tenaga sanitasi lebih sedikit daripada tenaga kesehaan masyarakat. Untuk rata-rata jumlah puskesmas adalah sebesar 21,86. Setiap variabel independen memiliki hubungan antar variabel yang dapat ditunjukkan oleh nilai korelasinya. Beberapa variabel memiliki korelasi yang cukup tinggi yaitu korelasi antara X3 dengan X1 sebesar 0,551 korelasi X3 dengan X4 sebesar 0,614, korelasi X5 dengan X6 sebesar 0,576, korelasi yang cukup tinggi adalah korelasi X9 dengan X1 yaitu 0,625 dan X10 dengan X1 yaitu 0,752. Korelasi X3 dengan X9 dan X10 adalah 0,584 dan 0,532. Sedangkan korelasi X10 dengan X9 sebesar 0,674.
B. Pengujian Normal Multivariat
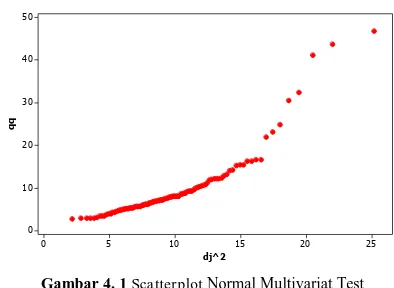
Pengujian normal multivariat digunakan untuk mengetahui distribusi data variabel-variabel yang akan dianalisis apakah mengikuti distribusi normal multivariat. Untuk mengetahui apakah mengikuti distribusi normal multivariat dapat dilakukan dengan menggunakan tiga metode yaitu scatterplot, nilai t berdasarkan hasil macro dan metode ketiga yaitu korelasi antara dj2 dengan nilai qq.
Berikut ini hasil pengujian normal multivariat dari data faktor-faktor jumlah kasus DBD di Indonesia tahun 2011.
25 20 15 10 5
0 50
40
30
20
10
0
dj^2
q
q
Gambar 4. 1 Scatterplot Normal Multivariat Test
Berdasarkan hasil Gambar 4.1 scatterplot tidak menunjukkan bahwa titik-titik pengamatan tidak membentuk garis linier sehingga tidak normal multivariat. Dapat pula dilihat dari nilai t yaitu 0,67 yang cukup jauh dari 50% serta nilai korelasi Pearson sebesar 0,912 kurang dari critical value Pearson maka dapat dikatakan data tidak berdistribusi normal multivariat. Untuk analisis selanjutnya dapat diasumsikan data telah mengikuti distribusi normal multivariat.
C. Uji Kecukupan Data dan Bartlett’s Test
Uji kecukupan data dilakukan untuk mengetahui apakah data yang akan digunakan memenuhi untuk dilakukan analisis faktor atau tidak sedangkan uji Bartlett menunjukkan ada tidaknya korelasi antar variabel.
Tabel 4. 2 Uji KMO dan Uji Bartlett
Kaiser-Meyer-Olkin Measure
Bartlett’s Test
Approx.Chi Square P-Value
0,747 228,064 0,000
Data dikatakan cukup untuk dilakukan analisis faktor jika nilai KMO > 0,5, berdasarkan pada Tabel 4.2 didapatkan nilai KMO sebesar 0,747 yang lebih besar 0,5 maka data dapat digunakan untuk analisis faktor. Dapat dilihat juga bahwa pada Tabel 4.2 memiliki nilai Bartlett yang signifikan yaitu nilai p-value < taraf signifikan (α) yaitu 0,05 yang artinya antar variabel terdapat korelasi.
D. Analisis Faktor
Analisis faktor digunakan untuk mengetahui jumlah variabel yang terbentuk yang dapat mewakili kondisi keragaman variabel yang diuji, sehingga dapat diduga jumlah faktor yang terbentuk. Variabel yang digunakan untuk analisis faktor dapat dilihat dari nilai Measure of Sampling Adequacy (MSA) yang > 0,5. Nilai MSA ditampilkan pada tabel di bawah ini.
Tabel 4. 3 MSA Anti-Image Correlation
X1 X2 X3 X8 X9 X10
X1 ,735a ,191 -,200 -,115 -,172 -,579 X2 ,191 ,523a -,033 ,366 ,035 -,297 X3 -,200 -,033 ,867a -,012 -,314 -,065 X8 -,115 ,366 -,012 ,559a ,118 ,031 X9 -,172 ,035 -,314 ,118 ,833a -,321 X10 -,579 -,297 -,065 ,031 -,321 ,724a
namun untuk variabel X4,X5,X6 dan X7 memiliki nilai MSA yang kurang dari 0,5 sehingga tidak dapat diikutsertakan dalam analisis faktor. Nilai MSA merupakan nilai diagonal pada Tabel 4.3.
Nilai komunalitas menunjukkan seberapa besar keragaman dari variabel dapat dijelaskan oleh faktor yang terbentuk. Dengan menggunakan metode analisis komponen utama didapatkan nilai komunalitas sebagai berikut.
Tabel 4. 4 Communalities Initial Extraction X1 1,000 0,785
X2 1,000 0,702
X3 1,000 0,603
X8 1,000 0,709
X9 1,000 0,727
X10 1,000 0,790
Berdasarkan nilai extraction pada Tabel 4.4 menunjukkan bahwa untuk variabel jumlah penduduk sebesar 78,5% keragaman dari variabel jumlah penduduk dapat dijelaskan oleh faktor yang terbentuk, sedangkan untuk keragaman dari variabel jumlah penduduk melek huruf dapat dijelaskan oleh faktor yang terbentuk sebesar 70,2%. Keragaman jumlah kasus DBD dijelaskan oleh faktor yang terbentuk sebesar 60,3%, sedangkan sebesar 70,9% keragaman jumlah tenaga sanitasi dijelaskan oleh faktor yang terbentuk. Untuk keragaman jumlah tenaga kesmas dan puskesmas dijelaskan oleh faktor yang terbentuk sebesar 72,7% dan 79%.
Selanjutnya dapat diketahui banyak faktor yang terbentuk berdasarkan nilai eigen. Variabel yang dinyatakan dapat mewakili variabel lainnya adalah variabel yang memiliki nilai eigen lebih dari 1. Hasil nilai eigen dari masing-masing variabel sebagai berikut.
Tabel 4. 5 Nilai eigen Setiap Variabel Faktor Initial Eigenvalues
Total % of Variance Cumulative %
X1 2.937 48.946 48.6946
X2 1.379 22.983 71.929
X3 0.604 10.061 81.989
X8 0516 8.600 90.589
X9 0.358 5.965 96.554
X10 0.207 3.446 100.00
Berdasarkan pada Tabel 4.5, dapat diketahui bahwa eigen value yang lebih dari satu terdapat dua faktor yaitu faktor satu dan faktor dua. Pada faktor pertama memiliki nilai eigen value sebesar 2,937 dan faktor dua memiliki nilai eigen value sebesar 1,379. Dari keenam variabel dapat direduksi dan dibentuk menjadi dua faktor yang mana dua faktor tersebut mampu menjelaskan 71,929% dari keragaman total.
Selain menggunakan nilai eigenvalue, untuk mengetahui jumlah faktor yang terbentuk dan dapat mewakili variabel yang lainnya dapat dilihat dari bentuk scree plot nya, yaitu banyak faktor terbentuk berdasarkan garis yang turun curam seperti yang ditampilkan berikut.
Gambar 4. 2 Scree Plot
Gambar 4.2 menunjukkan bahwa secara visual terbentuk 3 fakor karena garis ke-1 dan 2 turun curam, sedangkan garis-garis selanjutnya turun landai dan mendekati konvergen.
Tabel 4. 6 Rotated Component Matrix Variabel Komponen
1 2
X1 0,882 -0,079
X10 0,868 0,192
X9 0,843 0,129
X3 0,776 0,035
X8 -0,005 -0,842
X2 0,123 0,829
Tabel 4,6 menunjukkan bahwa korelasi variabel yang tinggi dengan faktor 1 yaitu jumlah penduduk memiliki korelasi sebesar 0,882, jumlah puskesmas yang memiliki korelasi sebesar 0,868, jumlah tenaga kesmas memiliki korelasi sebesar 0,843, dan jumlah kasus DBD memiliki korelasi sebesar 0,776, Korelasi variabel yang tinggi dengan faktor 2 yaitu jumlah tenaga sanitasi memiliki korelasi sebesar -0,842 dan penduduk melek huruf yang memiliki korelasi sebesar 0,829, Sehingga pada komponen 1 terdiri dari variabel X10 , X9, X1, dan X3 atau dapat juga diberi nama untuk faktor 1 yaitu faktor sumber daya manusia sedangkan pada komponen 2 adalah variabel X8 dan X2 atau dapat diberi nama yaitu faktor pengetahuan masyarakat,
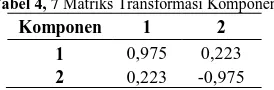
Tabel 4, 7 Matriks Transformasi Komponen
Komponen 1 2
1 0,975 0,223
2 0,223 -0,975
Tabel 4,7 menunjukkan bahwa nilai komponen > 0,5 baik untuk faktor sumber daya manusia ataupun faktor pengetahuan masyarakat dengan nilai masing-masing 0,975 dan -0,975 sehingga faktor tersebut sudah tepat untuk mewakili variable-variabel yang ada di dalamnya,
III. KESIMPULAN
Berdasarkan hasil analisis yang telah dilakukan terdapat beberapa hal yang dapat disimpulkan yaitu,
X5,X6,X9 dan X10,
2, Pengujian normal multivariat pada data jumlah kasus DBD di Indonesia tidak mengikuti distribusi normal multivariat sehingga untuk analisis selanjutnya dilakukan asumsi normal multivariat,
3, Berdasarkan uji KMO didapatkan bahwa data jumlah kasus DBD sudah mencukupi untuk dilakukan analisis faktor dan berdasar Bartlett’s test terdapat korelasi antar variabel, 4, Analisis faktor mereduksi sepuluh variabel awal menjadi
dua komponen baru dimana komponen satu merupakan faktor sumber daya manusia yang terdiri dari variabel jumlah penduduk, jumlah puskesmas, jumlah tenaga kesmas dan jumlah kasus DBD sedangkan pada faktor dua atau faktor pengetahuan masyarakat yang terdiri dari variabel jumlah tenaga sanitasi dan penduduk melek huruf,
DAFTARPUSTAKA
[1] Kristina, Isminah, Wulandari L, (2004), Kajian Masalah
Kesehatan, [Online],
http://www,litbang,depkes,go,id/maskes/052004/demambe rdarahl,
[2] Johnson, N, And Wichern, D, (1998), Applied Multivariate Statistical Analysis, New Jersey: Prentice-Hall, Englewood Cliffs,
[3] Sharma, S, (1996), Applied Multivariate Techniques, New York: John Wiley & Sons, Inc,
[4] Dinas Kesehatan Provinsi Jawa Timur, (2014), Profil Kesehatan Provinsi Jawa Timur Tahun 2013, Surabaya : Dinas Kesehatan Provinsi Jawa Timur,
[5] Cameron, A, C,, & Trivedi, P, K, (1998), Regression Analysis of Count Data, Cambridge: Cambridge University Press,
[6] Tobing, TMDNL, (2011), Pemodelan Kasus DBD (DBD) di Jawa Timur dengan Model Poisson dan Binomial Negatif, Bogor : Thesis Institut Pertanian Bogor,
LAMPIRAN Lampiran 1, Data yang digunakan
Jumlah Penduduk (jiwa)
% Penduduk Melek Huruf
Jumlah kasus DBD
Insidens DBD (per 1000)
% Rumah Tangga ber-PHBS
% Rumah sehat
% RT Akses Air Bersih
Jumlah Tenaga Sanitasi
Jumlah Tenaga Kesmas
Jumlah Puskesmas
626637 0 88 14,04 32,87 71,31 97,23 28 5 22
330701 98 20 0,1 79,91 79,91 59 4 13 16
263815 99 1 0 44,52 55,92 0 1 4 16
568532 7 901 158 74,49 85,54 100,01 24 10 17
2127791 90,76 591 27,69 41,63 55,2 65,18 5 92 48
404945 99 0 0 26,7 0 64 7 8 26
1099253 0 117 10,64 19,39 32,8 100 24 25 23
1510284 97,92 857 55,27 32,17 27,33 35,99 2 56 31
3178543 97,99 1180 37,82 48,98 50,15 83,11 0 33 61
726332 78,73 67 9,22 13,59 33,8 85,22 27 0 11
154445 99 61 0,4 82,39 59,5 0 9 0 8
189817 74,28 34 17,91 26,09 67,74 99,19 7 8 14
2630401 88,66 1183 54,86 45,31 58,08 63,21 0 70 39
488072 59,5 292 0,29 61,21 68,26 100 42 71 21
2912197 0 1008 34,61 61,39 81,21 100 63 61 17
882533 89,13 237 26,85 34,14 81,44 100 37 2 22
131377 92 40 0,3 83,75 73,27 95 0 2 8
817720 98 719 0,9 69,41 84,02 0 22 10 34
2404121 98,06 567 22,55 25,3 55,55 63,04 0 73 64
1465157 89,1 475 32,1 32,47 66,56 79,21 1 41 40
1144891 91,42 35 3,06 34,8 65,65 63,03 19 0 22
277673 99 8 0 56,31 72,66 0 6 8 11
175317 0 9 5,13 44,65 69,97 90,71 14 9 3
81807 86 27 0,3 0 0 0 0 0 5
120271 97,15 14 11,64 53,33 67,23 76,25 7 2 7
175157 96,83 99 54,47 48,49 49,15 88,08 0 30 10
1005836 0 67 6,66 33,36 57,05 75,94 28 11 18
,,, ,,, ,,, ,,
, ,,, ,,, ,,, ,,, ,,, ,,,
375885 96 105 0,3 38,28 73,98 99 4 4 11
1778209 97,82 125 7,03 47,87 68,06 73,18 23 5 15
350960 98 207 0,6 37,35 84,68 0 41 18 19
84481 99 61 0,7 56,36 77,4 0 4 5 4
455946 65 759 0,76 100 87,59 78,77 9 11 18
1675675 97,7 519 28,78 24,28 60,11 47,44 2 29 40
399093 7 114 29 69,76 71,35 91,87 30 16 23
942579 0 628 0,63 77,89 65,1 100 62 36 27
140082 7 0 0 28,57 28,57 26,43 0 10 3
Lampiran 2, Output Software SPSS Analisis Faktor
Descriptive Statistics
Mean Std, Deviation Analysis N
X1 9,1569E5 8,42860E5 100
X2 73,5600 36,90099 100
X3 3,8182E2 571,56377 100
X4 30,8683 54,97860 100
X5 45,6144 22,44794 100
X6 63,0458 21,09277 100
X7 66,4081 34,65005 100
X8 14,6200 14,39050 100
X9 24,3800 29,05751 100
X10 21,8600 16,47344 100
Correlation Matrix
X1 X2 X3 X4 X5 X6 X7 X8 X9 X10
Correlation X1 1,000 ,048 ,551 ,072 -,024 ,088 ,062 ,026 ,626 ,752
X2 ,048 1,000 ,119 ,011 -,193 -,032 -,387 -,411 ,157 ,278
X3 ,551 ,119 1,000 ,614 ,201 ,200 -,089 -,055 ,584 ,532
X4 ,072 ,011 ,614 1,000 ,074 ,165 ,080 -,149 ,316 ,072
X5 -,024 -,193 ,201 ,074 1,000 ,576 ,131 ,295 -,002 -,055
X6 ,088 -,032 ,200 ,165 ,576 1,000 ,205 ,184 ,060 -,028
X7 ,062 -,387 -,089 ,080 ,131 ,205 1,000 ,237 -,054 -,039
X8 ,026 -,411 -,055 -,149 ,295 ,184 ,237 1,000 -,135 -,125
X9 ,626 ,157 ,584 ,316 -,002 ,060 -,054 -,135 1,000 ,674
X10 ,752 ,278 ,532 ,072 -,055 -,028 -,039 -,125 ,674 1,000
KMO and Bartlett's Testa
Kaiser-Meyer-Olkin Measure of Sampling Adequacy, ,747
Bartlett's Test of Sphericity Approx, Chi-Square 228,064
df 15
Sig, ,000
Anti-image Matrices
X1 X2 X3 X8 X9 X10
Anti-image Covariance X1 ,362 ,099 -,093 -,062 -,070 -,198
X2 ,099 ,746 -,022 ,285 ,020 -,146
X3 -,093 -,022 ,598 -,008 -,164 -,029
X8 -,062 ,285 -,008 ,812 ,072 ,016
X9 -,070 ,020 -,164 ,072 ,455 -,123
X10 -,198 -,146 -,029 ,016 -,123 ,324
Anti-image Correlation X1 ,735a ,191 -,200 -,115 -,172 -,579
X2 ,191 ,523a -,033 ,366 ,035 -,297
X3 -,200 -,033 ,867a -,012 -,314 -,065
X8 -,115 ,366 -,012 ,559a ,118 ,031
X9 -,172 ,035 -,314 ,118 ,833a -,321
X10 -,579 -,297 -,065 ,031 -,321 ,724a
a, Measures of Sampling Adequacy(MSA)
Communalities
Initial Extraction
X1 1,000 ,785
X2 1,000 ,702
X3 1,000 ,603
X8 1,000 ,709
X9 1,000 ,727
X10 1,000 ,790
Extraction Method: Principal
Component Analysis,
Total Variance Explained
Compo
nent
Initial Eigenvalues
Extraction Sums of Squared
Loadings
Rotation Sums of Squared
Loadings
Total
% of
Variance
Cumulative
% Total
% of
Variance
Cumulative
% Total
% of
Variance
Cumulative
%
1 2,937 48,946 48,946 2,937 48,946 48,946 2,859 47,656 47,656
2 1,379 22,983 71,929 1,379 22,983 71,929 1,456 24,272 71,929
3 ,604 10,061 81,989
5 ,358 5,965 96,554
6 ,207 3,446 100,000
Extraction Method: Principal Component Analysis
Component Matrixa
Component
1 2
X10 ,889 ,006
X9 ,850 ,062
X1 ,842 ,274
X3 ,764 ,139
X8 -,192 ,820
X2 ,305 -,780
Extraction Method: Principal
Component Analysis,
a, 2 components extracted, Component Matrixa
Component
1 2
X10 ,889 ,006
X9 ,850 ,062
X1 ,842 ,274
X3 ,764 ,139
X8 -,192 ,820
X2 ,305 -,780
Extraction Method: Principal Component
Analysis,
a, 2 components extracted,
Rotated Component Matrixa
Component
1 2
X1 ,882 -,079
X10 ,868 ,192
X9 ,843 ,129
X3 ,776 ,035
X8 -,005 -,842
X2 ,123 ,829
Extraction Method: Principal Component
Analysis,
Rotation Method: Varimax with Kaiser
Normalization,
a, Rotation converged in 3 iterations,
Component Transformation Matrix
Component 1 2
1 ,975 ,223
2 ,223 -,975
Extraction Method: Principal Component
Analysis,
Rotation Method: Varimax with Kaiser
Normalization,
Component Score Covariance Matrix
Component 1 2
1 1,000 ,000
2 ,000 1,000
Extraction Method: Principal
Component Analysis,
Rotation Method: Varimax with Kaiser
Normalization,
Component Scores,
Component Score Coefficient Matrix
Component
1 2
X1 ,324 -,130
X2 -,025 ,575
X3 ,276 -,040
X8 ,069 -,594
X9 ,292 ,021
X10 ,296 ,063
Extraction Method: Principal Component
Analysis,
Rotation Method: Varimax with Kaiser
Normalization,