Fakultas Ilmu Komputer
3843
Implementasi Algoritma Support Vector Machine (SVM) Untuk Penentuan
Seleksi Atlet Pencak Silat
Eni Hartika Harahap1, Lailil Muflikhah2, Bayu Rahayudi3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 2[email protected]
Abstrak
Pencak silat merupakan seni beladiri tradisional yang berasal dari Indonesia. Seiring perkembangan zaman pencak silat tidak hanya digunakan untuk melindungi dan mempertahankan diri dari lawan, namun juga diikut ajangkan dalam suatu perlombaan. Penentuan hasil akhir dalam seleksi perlombaan yang masih menghitung manual menjadi kendala utama juri saat ada salah satu pihak yang tidak bisa menerima kekalahan. Terlebih kurangnya pemahaman dari penyelenggara seleksi dalam hal perwasitan dan penjurian yang dapat mempengaruhi mental pesilat, dan menimbulkan perselisihan pihak lain karena perbedaan persepsi saat seleksi. Untuk mengatasi permasalahan tersebut dibutuhkan suatu sistem klasifikasi yang mampu mengklasifikasi penerimaan seleksi atlet pencak silat yang layak lolos menggunakan metode support vector machine (SVM) yang mana dengan metode SVM mengklasifikasi data menjadi dua kelas. Data yang digunakan sebanyak 110 data yang dibagi menjadi data latih dan data uji dengan dua kelas hasil penerimaan seleksi yaitu lolos dan tidak lolos. Hasil akurasi dari penelitian ini mendapatkan akurasi terbaik berdasarkan percobaan perbandingan rasio data 70%:30%, dengan menggunakan kernel Polynomial Degree d = 2 dan nilai parameter λ (lamda) = 0,1,
γ (gamma) = 0,0001, ε (Epsilon) = 0,000001, C (Complexity) = 0,00001 dan Itermax = 250. Hasil rata-rata akurasi menggunakan metode SVM pada klasifikasi penerimaan seleksi atlet pencak silat sebesar 69,09%.
Kata Kunci : Pencak Silat, Klasifikasi, Support Vector Machine (SVM), Kernel Polynomial Degree.
Abstract
Pencak Silat is a traditional martial art originating from Indonesia. Along with an evolution of the time pencak silat is not only used to protect and defend themselves from opponents, but also show in a contest. Determination of the final result in selection that still counts the manual becomes main obstacle of the jury when one of the parties can’t accept defeat while competing. To overcome these problems required a classification system that is able to classify enrolment acceptance of the pencak silat athletes had eligible pass the support vector machine (SVM) method by the SVM classifying the data into two classes. The data used in this research is 110 whitch is divided into training data and test data with 2 classes of acceptance of selection is pass and not pass. The best accuracy result in this research based on experiment ratio of data 70% : 30%, using kernel Polynomial Degree d = 2 and parameter value λ (lamda) = 0,1, γ (gamma) = 0,0001, ε (Epsilon) = 0.000001, C (Complexity) = 0.00001 and Itermax = 250. Kernel use in this research value of Polynomial Degree 2. The average result of accuracy using SVM method in the classification enrolment of the Pencak Silat athletes is 69,09 %.
Keywords: Pencak silat, Classification, Support Vector Machine (SVM), Kernel Polynomial Degree.
1. PENDAHULUAN
Pencak Silat merupakan salah satu seni beladiri tradisional yang berasal dari Indonesia. Di Indonesia pencak silat sendiri sudah dapat
terdapat kesalahan saat perhitungan nilai hasil akhir. Karena itu diperlukan sebuah sistem yang mampu mengklasifikasikan data seleksi atlet pencak silat berdasarkan kelasnya. Klasifikasi merupakan proses menemukan sekumpulan model maupun fungsi yang menjelaskan dan membedakan data kedalam kelas – kelas tertentu, dengan tujuan menggunakan model tersebut dalam menentukan kelas dari suatu objek yang belum diketahui kelasnya (Han & Kamber, 2006).
Penentuan penerimaan seleksi atlet sebelumnya pernah dilakukan dengan menggunakan metode Analytic Network Process and Technique for Order Preference by Similiarity of Ideal Solution (ANP-TOPSIS). Cara kerja dari metode ini yaitu dengan memecah sebuah masalah yang tidak terstruktur dan terdapat ketergantungan hubungan antar elemennya (Dewayana & Budi, 2009). Akurasi yang didapat yaitu sebesar 83 % dengan data uji sebanyak 44 data (Wicaksono, 2016).
Selain menggunakan metode (ANP-TOPSIS), salah satu metode klasifikasi yaitu Support Vector Machine (SVM). Metode SVM memiliki kelebihan menggunakan Empirical Risk Minimization (ERM) yaitu metode machine learning yang difokuskan pada usaha untuk meminimalkan error pada training set, dan dalam SVM diwujudkan dengan memilih hyperplane dengan margin terbesar. Berbagai studi empiris menunjukkan bahwa pendekatan SRM pada SVM memberikan error generalisasi yang lebih kecil dibandingkan yang diperoleh dari strategi ERM pada neural netwok maupun metode yang lain (Nugroho, et al., 2003). Berdasarkan penjelasan diatas penulis ingin merancang sebuah aplikasi sistem klasifikasi penerimaan seleksi atlet pencak silat dengan menggunakan metode support vector machine (SVM).
1.1. Pencak Silat
Pencak silat merupakan warisan asli budaya bangsa Indonesia, yang terdiri dari berbagai perguruan/aliran pencak silat. Sejarah lahirnya pencak silat tidak diketahui secara pasti, namun beladiri pencak silat dimungkinkan sudah ada di tanah air sejak peradaban manusia ada di Indonesia.
Menurut Notosoejitno (1999: 4-6) perkembangan sejarah pencak silat dapat dibagi menjadi dua zaman, yang terdiri dari:
1. Zaman Pra Sejarah
2. Zaman Sejarah, yang dibagi menjadi lima yaitu: (a) Zaman Kerajaan-Kerajaan, (b) Zaman Kerajaan Islam, (c) Zaman Penjajahan Belanda, (d) Zaman Penjajahan Jepang, dan (e) Zaman Kemerdekaan
1.2. Seleksi Atlet Pencak Silat
Untuk mendapatkan atlet yang handal, dalam seleksi atlet pencak silat diperlukan beberapa komponen fisik yang harus dilakukan oleh seorang atlet(Groot, 2013).
MFT Tendangan Sabit 5 detik Tendangan Sabit 10 detik Tendangan 1 menit Pukulan 1 menit Back Up
1.3. Support Vector Machine (SVM)
Support Vector Machine (SVM) dikembangkan oleh Boser, Guyon, Vapnik, dan pertama kali dipresentasikan pada tahun 1992 di Annual Workshop on Computational Learning Theory. Konsep dasar SVM sebenarnya merupakan kombinasi harmonis dari teori-teori komputasi yang telah ada puluhan tahun sebelumnya, seperti margin hyperplane yang diperkenalkan oleh Aronszajn tahun 1950. Demikian juga dengan konsep-konsep pendukung yang lain. Akan tetapi hingga tahun 1992 belum pernah ada upaya merangkaikan komponen – komponen tersebut. Prinsip dasar SVM adalah linear classifier, dan selanjutnya dikembangkan agar dapat bekerja pada problem non-linear dengan memasukkan konsep kernel trick pada ruang kerja berdimensi tinggi (Chapple, 2004).
Sequential Training memiliki algoritme yang lebih sederhana dan waktu yang diperlukan lebih cepat. Adapun algoritma Sequential Training adalah sebagai berikut : 1. Menginisialisasi
i
0
dan parameterKemudian menghitung matriks Hessian dapat dihitung dengan rumus:
.
3. Langkah kedua dilakukan terus-menerus hingga kondisi iterasi maksimum tercapai atau max .
Selanjutnya didapatkan nilai support vector (SV), SV = (Threshold SV). Nilai Threshold SV didapatkan dari beberapa percobaan, biasanya digunakan threshold > 0. Kemudian dilakukan proses testing untuk mendapatkan keputusan di mana fungsi keputusan yang digunakan adalah
aaaaaaaaaaaaaaaaaa dengan nilai b = .
2. PERANCANGAN DAN
IMPLEMENTASI
Langkah awal yang digunakan dalam proses SVM adalah mengambil dataset, kemudian tahap selanjutnya perhitungan dengan kernel yang digunakan yaitu kernel polynomial yang akan menghasilkan matriks Hessian. Tahapan proses SVM dapat dilihat pada Gambar 1.
Gambar 1 Alur Proses Algoritme SVM Berdasarkan Gambar 1, tahap pertama yaitu masukkan dataset dengan format .xls yang mana data dari penelitian ini berupa data atlet
seleksi pencak silat yang berjumlah 110 data. Data tersebut berasal dari IPSI (Ikatan Pencak Silat Indonesia) kabupaten Jember dan untuk pemilihan data latih dan data uji dilakukan secara acak. Tahap kedua yaitu proses training SVM yang terdiri dari matriks Hessian yang hasilnya akan digunakan untuk perhitungan berikutnya yaitu menghitung nilai δαi dan nilai
αi. Selanjutnya menghitung sequential training yaitu melakukan perhitungan terhadap testing SVM, langkah pertama dalam proses testing adalah menghitung nilai bias, kemudian menghitung nilai K(xi , xtest) yaitu dengan
melihat nilai terbesar pada kelas positif dan negatif dengan menggunakan fungsi kernel yang digunakan. Setelah nilai K(xi , xtest)
didapatkan langkah selanjutnya adalah menghitung nilai f (x)test , kemudian jika sudah didapat nilai f (x)test maka sudah dapat diklasifikasikan berdasarkan hasil dari nilai f (x)test tersebut. Jika nilai > 0 maka data tersebut masuk pada kategori positif yaitu lolos sedangkan jika bernilai < 0 maka data tersebut masuk dalam kategori negatif yaitu tidak lolos.
3. PENGUJIAN DAN ANALISIS
3.1 Pengujian Rasio Data
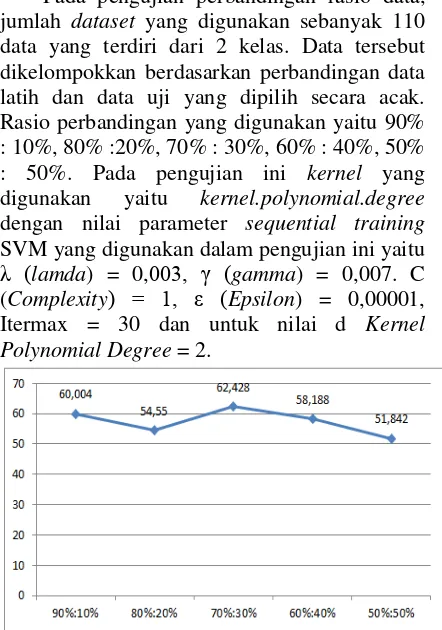
Pada pengujian perbandingan rasio data, jumlah dataset yang digunakan sebanyak 110 data yang terdiri dari 2 kelas. Data tersebut dikelompokkan berdasarkan perbandingan data latih dan data uji yang dipilih secara acak. Rasio perbandingan yang digunakan yaitu 90% : 10%, 80% :20%, 70% : 30%, 60% : 40%, 50% : 50%. Pada pengujian ini kernel yang digunakan yaitu kernel.polynomial.degree dengan nilai parameter sequential training SVM yang digunakan dalam pengujian ini yaitu
λ (lamda) = 0,003, γ (gamma) = 0,007. C (Complexity) = 1, ε (Epsilon) = 0,00001, Itermax = 30 dan untuk nilai d Kernel Polynomial Degree = 2.
Gambar 2 Hasil Pengujian Rasio Data
Pada pengujian rasio data analisis yang dapat dilakukan yaitu semakin banyak jumlah data latih tidak berpengaruh terhadap tingkat akurasi semakin tinggi begitu sebaliknya sedikit data latih juga tidak membuat akurasi semakin rendah karena pengambilan data secara acak memungkinkan akurasi tidak stabil pada setiap percobaan. Gambar 2 menunjukkan bahwa akurasi paling baik atau paling tinggi saat pembagian data pada rasio perbandingan 70% : 30%.
3.2 Pengujian λ (lamda)
Nilai parameter λ (lamda) yang digunakan yaitu 0,001, 0,01, 0,1, 0,5, 1, 5, 10, 20, dan 50. Nilai parameter sequential training SVM yang
digunakan dalam pengujian ini γ (gamma) = 0,007, ε (Epsilon) = 0,00001, C (Complexity) = 1, Itermax = 30 dan untuk nilai d Kernel Polynomial Degree = 2. Penggunaan pembandingan rasio data yaitu pada 70%:30% untuk pengujian selanjutnya, seperti pada Gambar 3 yang menunjukkan hasil dari
pengujian nilai parameter λ (lamda).
Gambar 3 Hasil Pengujian Nilai Lamda
Dari Gambar 3 dapat disimpulkan
bahwa nilai λ (lamda) pada saat 0,01 memiliki akurasi paling tinggi sebesar 60,004% dan pada
saat nilai λ (lamda) bernilai 1 sampai 20 mengalami kenaikan akurasi yang hampir
konvergen. Semakin banyak nilai λ (lamda) tidak menentukan jumlah akurasi semakin besar. Jika nilai lamda terlalu besar dapat mengakibatkan waktu komputasi pada perhitungan matriks hessian lebih lama, yang dikarenakan augmented factor (lamda) dapat menjadikan sistem lambat dalam mencapai konvergensi dan tidak stabilnya pada saat proses pembelajaran (Vijayakumar & Wu, 1999).
3.3 Pengujian γ (gamma)
Nilai γ (gamma) yang digunakan yaitu 0,00001, 0,0001, 0,001, 0,01, 0,1, 0,1, 1, 1,5, dan 2. Nilai parameter yang digunakan dalam
pengujian λ (lamda) = 0,5, ε (Epsilon) = 0,00001, C (Complexity) =1, dan Itermax = 30 dan untuk nilai d Kernel Polynomial Degree = 2. Pada Gambar 4 dapat dilihat hasil dari proses
pengujian nilai parameter γ (gamma).
Gambar 4 Hasil Pengujian Nilai Gamma
Pada pengujian parameter konstanta γ (gamma) didapatkan akurasi yang berbeda di mana akurasi yang menunjukkan penurunan didapatkan nilai 0,1. Pada metode sequential training SVM ini, konstanta γ (gamma) digunakan untuk mengontrol kecepatan proses learning dengan kecepatan tersebut ditunjukkan oleh jumlah iterasi yang dibutuhkan untuk mencapai konvergen. Hasil pengujian menunjukkan bahwa semakin kecil
nilai konstanta γ (gamma) maka iterasi yang diperlukan semakin banyak dan dapat memberikan akurasi yang lebih baik. Hal ini
disebabkan karena nilai konstanta γ (gamma) memengaruhi perhitungan δα. Nilai δα tersebut akan berkurang yang selisihnya tidak jauh dari nilai konstanta γ (gamma). Sehingga memerlukan proses iterasi lebih banyak untuk mencapai nilai δα yang kurang dari ε (epsilon). Tetapi dengan iterasi yang lebih banyak tersebut memberikan algoritme untuk dapat melakukan proses learning menjadi lebih baik. Sehingga dapat memberikan akurasi yang lebih baik.
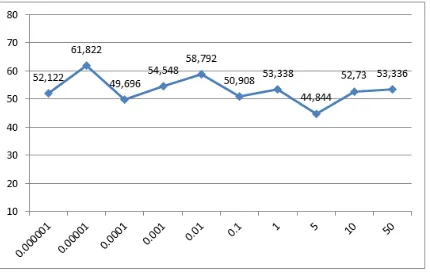
3.4 Pengujian C (complexity)
Selanjutnya dilakukan pengujian terhadap nilai C pada Gambar 5 yang menunjukkan akurasi terbesar yaitu 61,822% dengan
menggunakan variabel tetap yaitu λ (lamda) =
Gambar 5 Hasil Pengujian Nilai Complexity
Pada metode sequentialtraining SVM ini, nilai C digunakan untuk mengontrol tradeoff antara margin dan error klasifikasi. Tetapi pada pengujian yang telah dilakukan, nilai C tidak berpengaruh terhadap akurasi. Hal ini disebabkan karena data yang diuji dengan nilai C pada pengujian tersebut memiliki error klasifikasi yang tidak berpengaruh pada margin. Sehingga akurasi yang didapatkan selalu sama. Selain itu nilai C (Complexity) > 0 relatif penting untuk memaksimumkan margin dan meminimumkan jumlah slack (C.Corttes dan V.Vapnik, 1995).
3.5 Pengujian ε (epsilon)
Nilai ε (Epsilon) yang digunakan yaitu 0,000001, 0,00001, 0,0001, 0,001 dan 0,01. Nilai parameter sequential training SVM yang digunakan dalam pengujian λ (lamda) = 0,1, γ (gamma) = 0,00001, C (Complexity) = 0,000001 dan Itermax = 30 dan untuk nilai d kernel Polynomial Degree 2. Data yang digunakan dalam pengujian ini yaitu perbandingan rasio data 70% : 30%.
Gambar 6 Hasil Pengujian Nilai Epsilon
Berdasarkan uji coba yang telah dilakukan
ditunjukkan bahwa nilai variabel ε (epsilon)
yang semakin kecil menghasilkan akurasi yang semakin meningkat. Hal ini disebabkan karena
nilai variabel ε (epsilon) yang semakin kecil
dapat menghasilkan nilai α yang optimal
sehingga dapat menentukan support vector
yang tepat. Support vector yang tepat tersebut dapat menghasilkan hyperplane (garis pemisah) untuk memisahkan kedua kelas tersebut semakin optimal.
3.6 Pengujian jumlah Itermax
Nilai itermax = 30, 40, 50, 100, 150, 200, 250, 300, 500 dan 1000. Nilai parameter sequential training SVM yang digunakan dalam
pengujian λ (lamda) = 0,1, γ (gamma) =
0,00001, ε (Epsilon) = 0,0000001, C (Complexity) = 0,0001 dan Itermax = 30 dan untuk nilai d kernel Polynomial Degree 2. Data yang digunakan dalam pengujian ini yaitu perbandingan rasio data 70%:30%.
Gambar 7 Hasil Pengujian Itermax
Pada skenario ini menunjukkan nilai akurasi paling besar yaitu pada saat iterasi 250 dengan nilai rata – rata akurasi sebesar 69,092 % dan akurasi tertinggi yaitu 69,7%. Nilai iterasi akan berhenti jika memenuhi syarat konvergen yaitu Max(|δαi|)<ε. Meskipun saat
iterasi 250 menghasilkan akurasi yang tinggi, namun pada pengujian data ini semakin besar jumlah iterasi tidak menjamin nilai akurasi yang lebih tinggi karena nilai αi belum
mencapai nilai konvergen. Pada pengujian iterasi maksimum ini nilai iterasi berhenti berpengaruh pada perubahan nilai α (alpha). Menurunnya akurasi disaat iterasi bertambah terjadi karena rasio support vector yang tidak seimbang dan beberapa data terletak jauh dari bidang pemisah (hyperplane) yang ideal.
3.7 Pengujian jumlah Itermax
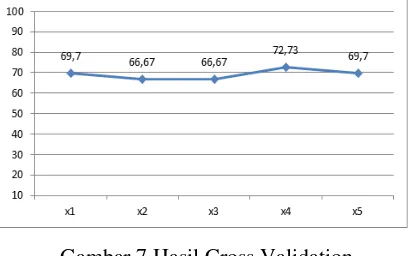
Tabel 1 Hasil Cross Validation
Percobaan Akurasi X1 69,7 X2 66,67 X3 66,67 X4 72,73 X5 69,7 Rata-rata 69,094
Berdasarkan Tabel 1 dapat diketahui bahwa rata-rata tingkat akurasi dari 5 percobaan sebesar 69.094%.
Gambar 7 Hasil Cross Validation
pada pengujian validasi ini dapat disimpulkan bahwa sistem yang dibuat valid karena pada Gambar 7 Grafik Uji Validasi menunjukkan tingkat akurasi grafik yang stabil.
4. KESIMPULAN
Berdasarkan hasil penelitian, pengujian, dan analisis tentang klasifikasi seleksi penerimaan atlet pencak silat menggunakan metode Support Vector Machine dapat disimpulkan sebagai berikut:
1. Algoritme Support Vector Machine (SVM) dapat diimplementasikan pada penentuan penerimaan seleksi atlet pencak silat. 2. Rata-rata akurasi terbaik sebesar 69,094%
menggunakan kernel polynomial degree 2 dengan kombinasi nilai variabel atau parameter λ (lamda) = 0,1, γ (gamma) =
0,00001, ε (Epsilon) = 0,0000001, C (Complexity) = 0,0001 dan Itermax = 250.
DAFTAR PUSTAKA
C.Cortes dan V. Vapnik. 1995. Machine Learning, Support Vector Network. Vol 20, Hal 273 – 297.
Chapple, Olivier. 2004. Support Vector Machine : Induction principles, Adaptive Tuning and Prior Knowledge. UMR 7606. Informatics laboratory. University of Piere et Marie Curie.
Dewayana, Triwulandari S. dan Budi, Ahmad. 2009. Pemilihan Pemasok Cooper ROD Menggunakan Metode ANP. J@TI UNDIP, IV (3). Pp. 212-217. ISSN 1907–1434.
Groot, George. 2013. Pencak Silat Seni Beladiri Indonesia. Yogyakarta:Zafana Publishing
Han, J. & Kamber, M. 2006. Data Mining Concepts and Techniques. Asma Stephan ed. Amerika : Diane Cerra.
Notosoejitno. 1989. Sejarah Perkembangan Pencak silat di Indonesia. Jakarta: Humas PB IPSI.
Nugroho, A. S., Witarto, A. B. & Handoko, D. 2003. Support Vector Machine Teori dan Aplikasinya dalam Bioinformatika. S.I. :s.n.
Sukowinadi. 1989. Sejarah Pertumbuhan Pencak Silat. Yogyakarta: Per.P.I Harimurti.
Vijayakumar, Sethu and Si Wu. 1999. Sequential Support Vector Classifiers and Regression. Proceeding International Conference on Soft Computing (SOCO
‘99), Genoa, Italy, pp. 610-619.