PENERAPAN PARTICLE SWARM OPTIMIZATION UNTUK SELEKSI ATRIBUT
PADA METODE SUPPORT VECTOR MACHINE UNTUK PENENTUAN PENILAIAN
KREDIT
Rinawati
STMIK Nusa Mandiri Jakarta Jl. Damai No.8, Warung Jati Barat
(Margasatwa), Jakarta Selatan [email protected]
ABSTRAK — Kredit macet merupakan salah satu resiko
kredit yang dihadapi oleh pelaku industri keuangan dan perbankan. Kredit macet dapat dihindari dengan cara melakukan analisa kredit yang akurat terhadap calon debitur. Keakuratan penilaian kredit sangat penting untuk profitabilitas lembaga keuangan. Peningkatan akurasi penilaian kredit dapat dilakukan dengan cara melakukan seleksi terhadap atribut, karena seleksi atribut mengurangi dimensi dari data sehingga operasi algoritma data mining dapat berjalan lebih efektif dan lebih cepat. Banyak penelitian yang telah dilakukan untuk penentuan penilaian kredit. Salah satu metode yang paling banyak digunakan adalah metode support vector machine. Dalam penelitian ini akan digunakan metode support vector machine dan akan dilakukan seleksi atribut dengan menggunakan particle swarm optimization untuk penentuan penilaian kredit. Setelah dilakukan pengujian maka hasil yang didapat adalah support vector machine menghasilkan nilai akurasi sebesar 75,3 %, nilai precision 63,29% dan nilai AUC sebesar 0,78. Kemudian dilakukan seleksi atribut dengan menggunakan particle swarm optimization dimana atribut yang semula berjumlah 20 variabel prediktor terpilih 15 atribut yang digunakan. Hasil menunjukkan nilai akurasi yang lebih tinggi yaitu sebesar 77,4%, nilai precision 66,62% dan nilai AUC sebesar 0,786. Sehingga dicapai peningkatan akurasi sebesar 2,1 %, dan peningkatan AUC sebesar 0,006. Dengan melihat nilai akurasi dan AUC, maka algoritma support vector machines berbasis particle swarm optimization masuk kedalam kategori klasifikasi cukup.
Kata kunci: penilaian kredit, seleksi atribut, support
vector machine, particle swarm optimization
ABSTRACT - Bad debt is one of credit risk faced by financial industry and banking industry. Bad credit can be avoided by conducting accurate credit analysis of prospective borrowers. The accuracy of credit scoring is essential for profitability of financial institutions. Improving the accuracy of credit scoring can be done by selecting attributes, because attribute selection reduces the dimensions of the data so that data mining algorithm operation can run more effectively and faster. Much research has been done for the
determination of credit ratings. One of the most widely used methods is the support vector machine. In this research will be used support vector machine method and will do the selection of attributes by using particle swarm optimization for determination of credit rating. After testing, the result obtained is the support vector machine to produce accuracy of 75.3%, precision value 63.29% and AUC value of 0.78. Then the attribute selection is done using particle swarm optimization where the original attribute is 20 predictor variables selected 15 attributes used. The results showed a higher accuracy value of 77.4%, precision value 66.62% and AUC value of 0.786. So achieved an increase in accuracy of 2.1%, and an increase of AUC by 0.006. By looking at the accuracy and AUC values, the particle swarm optimization-based vector machines support algorithm falls into the category of sufficient classification.
Keywords: credit rating, attribute selection, support vector machine, particle swarm optimization
PENDAHULUAN
Penilaian kredit merupakan topik yang penting dalam pengelolaan resiko keuangan. Laporan bank Indonesia menunjukkan bahwa pada akhir tahun 2011 tercatat kredit macet senilai Rp. 33.401.000.000.000 naik hingga 17,64% dibandingkan dengan th 2010 sebesar Rp. 28.396.000.000.000 (Indonesia, Bank;, 2012). Hal tersebut menunjukkan bahwa tingkat kredit macet mengalami kenaikan yang tajam.
Kredit macet merupakan salah satu resiko kredit yang dihadapi oleh pelaku industri keuangan dan perbankan. Kredit macet terjadi apabila dalam jangka panjang, lembaga keuangan atau perbankan tidak dapat menarik pinjaman kredit dalam waktu yang telah ditentukan (Jianguo & Tao, 2008). Kredit macet memiliki dampak yang buruk bagi penyedia kredit yaitu berupa resiko kerugian (Hian, Wei & Chwee, 2006).
kredit tetap lancar sampai berakhirnya perjanjian kredit. Keakuratan penilaian kredit sangat penting untuk profitabilitas lembaga keuangan (Gang, Jinxing, Jian & Hongbing, 2011).
Penilaian kredit mengelompokkan para calon debitur menjadi dua jenis yaitu debitur baik dan debitur buruk. Debitur baik memiliki kemungkinan besar akan membayar kewajiban keuangannya dengan lancar, sedangkan debitur buruk memiliki kemungkinan besar mengalami kredit macet (Gang, Jinxing, Jian & Hongbing, 2011). Penilaian kredit sangat penting karena banyak keuntungan yang diperoleh yaitu mengurangi biaya analisa kredit, pengambilan keputusan lebih cepat, pemantauan lebih dekat dengan data yang ada dan memungkinkan untuk menetapkan calon debitur prioritas (Ping, 2009). Penilaian kredit juga bermanfaat bagi penyedia kredit untuk mengukur dan mengelola risiko keuangan dalam memberikan kredit sehingga mereka dapat membuat keputusan yang lebih baik, lebih cepat dan lebih obyektif (Hian, Wei & Chwee, 2006).
Penelitian terdahulu mengenai topik penilaian kredit telah banyak dilakukan seperti penelitian yang dilakukan oleh Tony Bellotti dan Jonathan Crook yang berjudul Support vector machines for credit scoring and discovery of significant features. Menggunakan model
Support Vector Machine (SVM), Logistic Regression (LR), Linear Discriminant Analysis (LDA) dan k-Nearest Neighbours (kNN) untuk penentuan kelayakan pemberian kredit dan menentukan fitur yang berpengaruh. Hasil menunjukkan bahwa metode Support Vector Machine (SVM) mengungguli ketiga metode lainnya dan dapat digunakan sebagai metode yang baik dalam seleksi fitur yang berpengaruh secara signifikan terhadap dasar keputusan kelayakan pemberian kartu kredit dan juga sangat tepat dalam pengolahan data dengan jumlah besar (Bellotti & Crook, 2007). Penelitian selanjutnya dilakukan oleh Jianguo Zhou dan Tao Bai yang berjudul Credit risk assessment using rough set theory and GA-based SVM.
Meneliti tentang penilaian resiko kredit pada bank komersial. Dilakukan pengurangan terhadap fitur tanpa kehilangan informasi penting, setelah itu dilakukan optimasi terhadap parameter. Hasil menunjukkan bahwa optimasi dengan Genetic Algorithm - Support Vector Machine (GA-SVM)menghasilkan akurasi yang lebih tinggi dibandingkan dengan modelDiscriminant analysis (DA), BP Neural networks (BPN) dan SVM standar (Jianguo & Tao, 2008). Selanjutnya Wei Xu, Shenghu Zhou, Dongmei Duan dan Yanhui Chen melakukan penelitian dengan judul A support vector machine based method for credit risk assessment. Mengangkat permasalahan tentang penilaian resiko kredit dalam industri kartu kredit. Pertama-tama dilakukan pemilihan fitur yang tepat dengan menggunakan
principles component analysis (PCA),tahap kedua pelatihan dilakukan dengan menggunakan beberapa kernel yang berbeda dalam genetic algorithm untuk mengoptimalkan parameter. Tahap ketiga dilakukan pelatihan dengan menggunakan beberapa strategi ansambel. Hasil menunjukkan bahwa kinerja penilaian resiko kredit
dengan menggunakan strategi ansambel berbasis SVM lebih baik dari strategi SVM tunggal (Wei, Shenghu, Dongmei & Yanhui, 2010).
Hasil penelitian menunjukkan metode Support Vector Machine (SVM) banyak digunakan karena SVM memiliki kemampuan generalisasi yang sangat baik untuk memecahkan masalah walaupun dengan sampel yang terbatas (Ming-hui & Xu-chuang, 2007). Keberhasilan SVM tergantung pada pemilihan yang memadai terhadap fitur dan parameter. Dengan kata lain dapat dikatakan bahwa pemilihan fitur dan pemilihan parameter dalam SVM secara signifikan mempengaruhi akurasi klasifikasi (Mingyuan, Chong, ke & Mingtian, 2011).
Seleksi fitur adalah langkah untuk memilih dan mendapatkan informasi yang lebih berharga dari data dengan fitur yang besar. Atribut dan informasi yang berlebihan yang dimasukkan kedalam model penilaian kredit mengakibatkan banyaknya waktu dan biaya yang dikorbankan bahkan akan mengurangi tingkat akurasi dan kompleksitas yang lebih tinggi. Untuk itu diperlukan metode seleksi atribut pada data set dengan jumlah atribut yang besar untuk meningkatkan hasil akurasi (Ping, 2009).
Particle swarm optimization (PSO) merupakan teknik komputasi evolusioner yang mampu menghasilkan solusi optimal secara global dalam ruang pencarian melalui interaksi individu dalam segerombolan partikel. Setiap partikel menyampaikan informasi berupa posisi terbaiknya kepada partikel yang lain dan menyesuaikan posisi dan kecepatan masing-masing berdasarkan informasi yang diterima mengenai posisi yang terbaik tersebut (Shuzhou & Bo, 2011). Particle swarm optimization dapat digunakan sebagai teknik optimasi untuk mengoptimalkansubset fitur dan parameter secara bersamaan (Yun, Qiu-yan & Hua, 2011). Algoritma PSO sederhana dan memiliki kompleksitas yang lebih rendah. sehingga dapat memastikan solusi optimal dengan menyesuaikan pencarian global dan lokal, sehingga kinerja klasifikasi SVM dapat ditingkatkan (Yun, Qiu-yan & Hua, 2011). Melihat kemampuan dari metodeParticle swarm optimization (PSO) tersebut, maka pada penelitian ini metodeParticle swarm optimization (PSO)akan diterapkan untuk seleksi atribut dalam penentuan penilaian kredit sehingga akan diperoleh peningkatan akurasi.
BAHAN DAN METODE
Penilaian kredit ini merupakan kumpulan data nasabah yang diambil dari data aplikasi pinjaman nasabah. Prinsip dasar dalam menganilisis kredit yang lazim dikenal dengan prinsip 6 C’s, yaitu (Rivai, 2006):
1) Character
Adalah keadaan watak atau sifat dari nasabah, baik dalam kehidupan pribadi maupun dalam lingkungan usaha. Kegunaan dari penilaian terhadap karakter ini adalah untuk mengetahui sampai sejauh mana itikad atau kemauan nasabah untuk memenuhi kewajibannya
(willingness to pay)sesuai dengan perjanjian yang telah ditetapkan.
2) Capital
Adalah jumlah dana atau modal sendiri yang dimiliki oleh calon nasabah. Semakin besar modal sendiri dalam perusahaan, tentu semakin tinggi kesungguhan calon nasabah dalam menjalankan usahanya dan lembaga pemberi kredit akan merasa lebih yakin dalam memberikan kredit.
3) Capacity
Adalah kemampuan yang dimiliki calon nasabah dalam menjalankan usahanya guna memperoleh laba yang diharapkan. Kegunaan dari penilaian ini adalah untuk mengetahui atau mengukur sampai sejauh mana calon nasabah mampu untuk mengembalikan atau melunasi utang-utang (ability to pay)secara tepat dari usahanya yang diperolehnya.
4) Collateral
adalah barang-barang yang diserahkan nasabah sebagai agunan terhadap kredit yang diterimanya. Collateral
tersebut harus dinilai oleh bank untuk mengetahui sejauh mana dari usaha yang diperolehnya.
5) Condition of Economic
Yaitu situasi dan kondisi politik, sosial, ekonomi, budaya yang memengaruhi keadaan perekonomian pada suatu saat yang kemungkinannya memengaruhi kelancaran perusahaan calon kreditur.
6) Constrain
Adalah batasan dan hambatan yang tidak memungkinkan suatu bisnis untuk dilaksanakan pada tempat tertentu, misalkan pendirian suatu usaha pompa bensin yang disekitarnya banyak bengkel las atau pembakaran batu baru.
Data miningadalah aplikasi algoritma spesifik untuk mengekstrak pola dari data (Abraham, Grosan & Ramos, 2006). Data Mining didefinisikan sebagai proses penemuan pola dalam data (Witten, 2011). Data mining
sering juga disebut analisis data eksploratif. Data dalam jumlah besar yang diperoleh dari mesin kasir, pemindaian
barcode dan dari berbagai basis data dalam perusahaan, kemudiaan ditelaah, dianalisis, dihapus dan dipakai ulang. Pencarian dilakukan pada model yang berbeda untuk memprediksi penjualan, respon pasar, keuntungan dan lain-lain (Olson & Shi, 2008). Cross-Industry Standard Process for Data Mining (CRISP-DM) diperlukan dalam perusahaan untuk penggalian data yang dimiliki, terbagi dalam enam fase yaitu pemahaman bisnis, pemahaman data, pengolahan data, pemodelan, evaluasi dan
penyebaran (Larose, 2005). Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu (Larose, 2005):
1) Deskripsi
Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecenderungan.
2) Estimasi
Model dibangun menggunakan record lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi. Pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nilai variabel prediksi.
3) Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi menghasilkan nilai dari hasil di masa mendatang.
4) Klasifikasi
Dalam klasifikasi terdapat target variabel kategori. 5) Pengklusteran
Pengklusteran merupakan pengelompokan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan.
6) Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja.
Klasifikasi adalah proses menempatkan obyek atau konsep tertentu kedalam satu set kategori, berdasarkan sifat obyek atau konsep yang bersangkutan (Gorunescu, 2011). Metode klasifikasi ditujukan untuk pembelajaran fungsi-fungsi berbeda yang memetakan masing-masing data terpilih kedalam salah satu dari kelompok kelas yang telah ditetapkan sebelumnya. Proses klasifikasi didasarkan pada komponen (Gorunescu, 2011):
1) Kelas(class)
Merupakan variabel dependen dari model yang merupakan kategori variabel yang mewakili label-label yang diletakkan pada obyek setelah pengklasifikasian.
2) Prediktor(predictors)
Merupakan variabel independen dari model yang diwakili oleh karakteristik atau atribut dari data yang diklasifikasikan berdasarkan klasifikasi yang dibuat. 3) Dataset Pelatihan(training dataset)
Merupakan dataset yang berisi dua komponen nilai yang digunakan untuk pelatihan untuk mengenali model yang sesuai dengan kelasnya, berdasarkan prediktor yang ada.
4) Dataset Pengujian(testing dataset)
Merupakan dataset baru yang akan diklasifikasikan oleh model yang dibangun sehingga dapat dievaluasi hasil akurasi klasifikasi tersebut.
Support Vector Machine (SVM) diperkenalkan oleh Vapnik, Boser dan Guyon pada tahun 1992.Support Vector Machine (SVM) adalah metode learning machine yang bekerja atas prinsip Structural Risk Minimization (SRM)
min
Crook, 2007). Hyperplaneterbaik adalah hyperplaneyang terletak ditengah-tengah antara dua set obyek dari dua class.Hyperplanepemisah terbaik antara kedua class dapat ditemukan dengan mengukur margin hyperplanetersebut dan mencari titik maksimalnya. Margin adalah jarak antara
hyperplanetersebut dengan patternterdekat dari masing-masingclass. Patternyang paling dekat ini disebut sebagai
support vector (Aydin, Karakose & Akin, 2011). Yang menjadi karakteristik dari Support Vector Machine (SVM)
adalah sebagai berikut:
1) Secara prinsip SVM adalahlinear classifier.
2)Pattern recognition dilakukan dengan mentransformasikan data pada input space ke ruang yang berdimensi lebih tinggi, dan optimisasi dilakukan pada ruangvectoryang baru tersebut.
3) Menerapkan strategi Structural Risk Minimization (SRM).
4) Prinsip kerja SVM pada dasarnya hanya mampu menangani klasifikasi duaclass.
Data yang tersedia dinotasikan sebagai x ∈ R d sedangkan
label masing-masing dinotasikan yi ∈{-1+1} untuk i =
1,2,....,1 yang mana l adalah banyaknya data. Diasumsikan keduaclass–1 dan +1 dapat terpisah secara sempurna oleh hyperplaneberdimensi d , yang didefinisikan:
w.x + b = 0
Sebuah pattern xi yang termasuk class –1 (sampel negatif) dapat dirumuskan sebagai pattern yang memenuhi pertidaksamaan:
w.x + b = -1
Sedangkan pattern yang termasuk class +1 (sampel positif):
w.x + b = +1
Margin terbesar dapat ditemukan dengan memaksimalkan nilai jarak antara hyperplane dan titik terdekatnya, yaitu 1/||w||. Hal ini dapat dirumuskan sebagai Quadratic Programming (QP) problem, yaitu mencari titik minimal persamaan
w τ(w) = ||w||2
dengan memperhatikan constraint persamaan yi(xi.w+b) -1 0, i
Seleksi atribut adalah masalah terkait erat dengan pengurangan dimensi. Proses data mining membutuhkan biaya komputasi yang tinggi ketika berhadapan dengan kumpulan data dalam jumlah besar. Mengurangi dimensi yaitu jumlah atribut set data atau kelompok atribut, secara efektif dapat memotong biaya tersebut. Pengurangan dimensi tersebut dilakukan dengan menekan seminimal mungkin kerugian yang dapat terjadi akibat kehilangan sebagian informasi. Tujuan pengurangan dimensi dalam domaindata mining adalah untuk mengidentifikasi biaya terkecil di mana algoritma data mining dapat menjaga tingkat kesalahan di bawah perbatasan garis efisiensi. Yang dimaksud dengan biaya adalah fungsi dari kompleksitas teoritis dari algoritma data mining yang berasal dari model, dan berkorelasi dengan waktu yang dibutuhkan algoritma tersebut dalam menjalankan model, serta
ukuran dari kumpulan data (Maimon & Rokach, 2010). Tujuan seleksi atribut adalah untuk mengidentifikasi tingkat kepentingan atribut dalam kumpulan data, dan membuang semua atribut lain seperti informasi yang tidak relevan dan berlebihan. Karena seleksi atribut mengurangi dimensi dari data, maka hal ini akan memungkinkan operasi algoritma data mining dapat berjalan lebih efektif dan lebih cepat. Dalam beberapa kasus dengan dilakukannya seleksi atribut dihasilkan peningkatan tingkat akurasi klasifikasi (Maimon & Rokach, 2010). Alasan untuk melakukan pengurangan dimensi yaitu (Maimon & Rokach, 2010):
1) Penurunan biaya model pembelajaran 2) Meningkatkan kinerja model pembelajaran 3) Mengurangi dimensi yang tidak relevan 4) Mengurangi dimensi yang berlebihan
Metode seleksi fitur dapat diklasifikasikan ke dalam tiga kategori utama (Vercellis, 2009):
1) Metodefilter
Metode Filter adalah memilih atribut yang relevan sebelum pindah ke tahap pembelajaran berikutnya, atribut yang dianggap paling penting yang dipilih untuk pembelajar, sedangkan sisanya dikecualikan.
2) Metodewrapper
Metode wrapper menilai sekelompok variabel dengan menggunakan klasifikasi yang sama atau algoritma regresi digunakan untuk memprediksi nilai dari variabel target.
3) Metodeembedded
Untuk metodeembedded,proses seleksi atribut terletak di dalam algoritma pembelajaran, sehingga pemilihan set optimal atribut secara langsung dibuat selama fase generasi model.
AlgoritmaParticle swarm optimization PSOpertama kali diusulkan oleh Kennedy dan Eberhart pada tahun 1995. Particle swarm optimization (PSO) adalah jenis algoritma kecerdasan yang berasal dari perilaku kawanan burung mencari makan (Yun, Qiu-yan & Hua, 2011). Dapat diasumsikan dengan sekelompok burung yang secara acak mencari makanan di suatu daerah. Hanya ada satu potong makanan di daerah yang dicari tersebut. Burung-burung tidak tahu di mana makanan tersebut. Tapi mereka tahu seberapa jauh makanan tersebut dan posisi rekan-rekan mereka. Jadi strategi terbaik untuk menemukan makanan adalah dengan mengikuti burung yang terdekat dari makanan (Abraham, Grosan & Ramos, 2006). Untuk menemukan solusi yang optimal, maka setiap partikel akan bergerak kearah posisi yang terbaik sebelumnya (pbest)
dan posisi terbaik secara global (gbest). Modifikasi kecepatan dan posisi tiap partikel dapat dihitung menggunakan kecepatan saat ini dan jarak pbesti,d ke
pbestdseperti ditunjukkan oleh persamaan berikut: vi,m= w.vi,m+ c1* R * (pbesti,m- xi,m) + c2* R*(gbestm- xi,m) xid= xi,m+ vi,m
Dimana:
vi,m : kecepatan partikel ke-i pada iterasi ke-i
w : faktor bobot inersia
c1, c2 : konstanta akeselerasi (learning rate)
R : bilangan random (0-1)
xi,d : posisi saat ini dari partikel ke-i pada iterasi
ke-i
pbesti : posisi terbaik sebelumnya dari partikel ke-i gbest : partikel terbaik diantara semua partikel
dalam satu kelompok atau populasi
Cross Validation adalah teknik validasi dengan membagi data secara acak kedalam k bagian dan masing-masing bagian akan dilakukan proses klasifikasi (Han & Kamber, 2006). Dengan menggunakan cross validation
akan dilakukan percobaan sebanyak k. Data yang digunakan dalam percobaan ini adalah data training untuk mencari nilaierror ratesecara keseluruhan. Secara umum pengujian nilai k dilakukan sebanyak 10 kali untuk memperkirakan akurasi estimasi. Dalam penelitian ini nilai k yang digunakan berjumlah 10 atau 10-fold Cross Validation. tiap percobaan akan menggunakan satu data testing dan k-1 bagian akan menjadi data training, kemudian data testing itu akan ditukar dengan satu buah data training sehingga untuk tiap percobaan akan didapatkan data testing yang berbeda-beda.
Confusion matrix memberikan keputusan yang diperoleh dalam traning dan testing, confusion matrix
memberikan penilaian performance klasifikasi berdasarkan objek dengan benar atau salah (Gorunescu, 2011). Confusion matrix berisi informasi aktual (actual)
dan prediksi (predicted) pada sistem klasifikasi. Adapun persamaan modelconfusion matrixadalah:
1) Nilai Accuracy adalah proporsi jumlah prediksi yang benar.
2) Sensitivity digunakan untuk membandingkan proporsi TP terhadap tupel yang positif.
3) Specificity digunakan untuk membandingan proporsi TN terhadap tupel yang negatif.
4) PPV (positive predictive value) adalah proporsi kasus dengan hasil diagnosa positif.
5) NPV (negative predictive value) adalah proporsi kasus dengan hasil diagnosa negatif.
Kurva ROC (Receiver Operating Characteristic)
adalah alat visual yang berguna untuk membandingkan dua model klasifikasi. ROC mengekspresikan confusion matrix. ROC adalah grafik dua dimensi dengan false positivessebagai garis horisontal dantrue positivessebagai garis vertikal (Vecellis, 2009). Dengan kurva ROC, kita dapat melihattrade offantara tingkat dimana suatu model dapat mengenali tuple positif secara akurat dan tingkat dimana model tersebut salah mengenali tuple negatif
sebagai tuple positif. Sebuah grafik ROC adalah plot dua dimensi dengan proporsi positif salah (fp) pada sumbu X dan proporsi positif benar (tp) pada sumbu Y. Titik (0,1) merupakan klasifikasi yang sempurna terhadap semua kasus positif dan kasus negatif. Nilai positif salah adalah tidak ada (fp = 0) dan nilai positif benar adalah tinggi (tp = 1). Titik (0,0) adalah klasifikasi yang memprediksi setiap kasus menjadi negatif {-1}, dan titik (1,1) adalah klasifikasi
yang memprediksi setiap kasus menjadi positif {1}. Tingkat akuransi nilai AUC dalam klasifikasi data mining
dibagi menjadi lima kelompok (Gorunescu, 2011), yaitu: 1) 0.90 - 1.00 = klasifikasi sangat baik (excellent
classification)
2) 0.80 - 0.90 = klasifikasi baik(good classification)
3) 0.70 - 0.80 = klasifikasi cukup(fair classification)
4) 0.60 - 0.70 = klasifikasi buruk(poor classification)
5) 0.50 - 0.60 = klasifikasi salah(failure)
Penelitian adalah sebuah kegiatan yang bertujuan untuk membuat kontribusi orisinal terhadap ilmu pengetahuan (Dawson, 2009). Penelitian ini menggunakan penelitian eksperimen. Penelitian eksperimen melibatkan penyelidikan perlakuan pada parameter atau variabel tergantung dari penelitinya dan menggunakan tes yang dikendalikan oleh si peneliti itu sendiri. Dengan metode penelitian sebagai berikut:
1) Pengumpulan data
Pada bagian ini dijelaskan tentang bagaimana dan darimana data dalam penelitian ini didapatkan.
2) Pengolahan awal data
Pada bagian ini dijelaskan tentang tahap awal data mining. Pengolahan awal data meliputi proses input data ke format yang dibutuhkan, pengelompokan dan penentuan atribut data, serta pemecahan data (split)
untuk digunakan dalam proses pembelajaran(training)
dan pengujian(testing).
3) Model yang diusulkan
Pada tahap ini data dianalisis, dikelompokan variabel mana yang berhubungan dengan satu sama lainnya. Setelah data dianalisis lalu diterapkan model-model yang sesuai dengan jenis data. Pembagian data kedalam data latihan (training data) dan data uji(testing data)
juga diperlukan untuk pembuatan model. 4) Eksperimen dan pengujian model
Pada bagian ini dijelaskan tentang langkah-langkah eksperimen meliputi cara pemilihan arsitektur yang tepat dari model atau metode yang diusulkan sehingga didapatkan hasil yang dapat membuktikan bahwa metode yang digunakan adalah tepat.
5) Evaluasi dan validasi hasil
Pada bagian ini dilakukan evaluasi dan validasi hasil penerapan terhadap model penelitian yang dilakukan untuk mengetahui tingkat keakurasian model.
Adapaun variabel prediktor yaitu: checking account, Duration, history, Purpose, amount, Savings account, Present employment since, Installment rate in percentage of disposable income, Personal status and sex, Other debtors / guarantors, Present residence since, Property, Age in years, Other installment plans, Housing, Number of existing credits at this bank, Job, Number of people being liable to provide maintenance for, Telephone, foreign worker. Sendangkan variabel tujuannya yaituResponse(UCI, 1996).
Jumlah data awal yang diperoleh dari pengumpulan data yaitu sebanyak 1.000 data, namun tidak semua data dapat digunakan dan tidak semua atribut digunakan karena harus melalui beberapa tahap pengolahan awal data (preparation data). Untuk mendapatkan data yang berkualitas, beberapa teknik yang dilakukan sebagai berikut (Vercellis, 2009):
1) Data validation
Untuk mengidentifikasikan dan menghapus data yang ganjil (outlier/noise), data yang tidak konsisten, dan data yang tidak lengkap(missing value).
2) Data integration and transformationi
Untuk meningkatkan akurasi dan efisiensi algoritma.
3) Data size reduction and discritization
Untuk memperoleh data set dengan jumlah atribut dan record yang lebih sedikit tetapi bersifatinformative.
Setelah dilakukan replace missing hasil menunjukkan bahwa tidak terdapat missing attribute yang terjadi, sehingga semua data dapat digunakan.
Model yang diusulkan pada penelitian ini adalah menggunakan algoritma support vector machine berbasis
particle swarm optimization, yang terlihat pada Gambar 1 dibawah ini.
Particle Swarm Optiization Given a population of particles
with random positions and velocities
A particle in the population
Atribute Weighting represented by this particle
Traning SVM Model
Evaluation fitness of particle
Update particle best and global best
Update particle velocity and global position
No
Is stop condition satisfied ?
Yes
Optimal SVM Atribute obtined
Optimal SVM clasification model obtined
Sumber: Hasil penelitian (2013)
Gambar 1 Model yang Diusulkan
HASIL DAN PEMBAHASAN
Dilakukan observasi terhadap variabel C, ε dan
populationdarisupport vector machinedanparticle swarm optimization. Hasilnya ditunjukkan oleh Tabel 1 dibawah ini.
Ta bel 1 Observasi C, ε danpopulation
C ε Population Accuracy AUC
1.0 0.0 5 77.20 % 0.776
1.0 0.0 10 77.40 % 0.786
0.0 1.0 20 70.00 % 0.500
0.0 1.0 30 70.00 % 0.500
1.0 1.0 40 70.00 % 0.500
2.0 2.0 100 70.00 % 0.500
1.0 1.0 200 70.00 % 0.500
Sumber: Hasil penelitian (2013)
digunakan. Dari hasil eksperiment dengan menggunakan algoritmasupport vector machine berbasis particle swarm optimizationdiperoleh hasil seperti dalam Tabel 2 dibawah ini.
Tabel 2 Hasil Seleksi Atribut
Atribute Weight
checking account 0.040
Duration 1
history 0.449
Purpose 0.970
amount 0.591
Savings account 1
Present employment since 1
Installment rate in percentage of 1 disposable income
Personal status and sex 0.737
Other debtors / guarantors 1
Present residence since 1
Property 0
Age in years 1
Other installment plans 0
Housing 0
Number of existing credits at this bank 1
Job 0
Sumber: Hasil penelitian (2013)
Gambar 2 Kurva ROC dengan Metode SVM
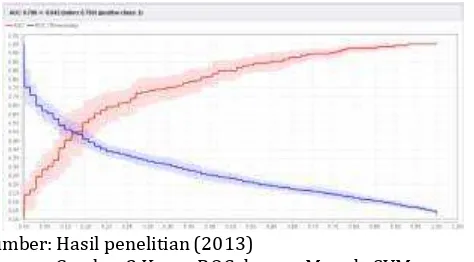
Sedangkan kurva ROC untuk algoritma Support Vector Machine berbasis Particle Swarm Optimization.
Kurva ROC pada Gambar 3 mengekspresikan confusion matrixdari Tabel 3. Garis horizontal adalah false positives
dan garis vertikal true positives. Menghasilkan nilai AUC
(Area Under Curve) sebesar 0.786 dengan nilai akurasi klasifikasi cukup(fair classification).
Number of people being liable to 0 provide maintenance for
Telephone 0.651
foreign worker 0.037
Sumber: Hasil penelitian (2013)
Hasil menunjukkan 20 variabel prediktor dilakukan seleksi atribut sehingga menghasikan terpilihnya 15 atribut yang digunakan.
Hasil pengujian dengan Confusion Matrik dari metode algoritma Support Vector Machine dan Support Vector MachineberbasisParticle Swarm Optimization (PSO)
ditunjukkan dalam Tabel 3, dibawah ini.
Tabel 3 Nilaiaccuracy, sensitivity, specificity, ppvdannpv
Sumber: Hasil penelitian (2013)
Gambar 3 Kurva ROC dengan Metode SVM berbasis PSO Dari tabel 3, Gambar 2 dan Gambar 3 diatas, terlihat bahwa nilai accuracy dan AUC Support Vector Machine
berbasis Particle Swarm Optimization lebih tinggi dibandingkan Support Vector Machine tunggal. Penerapan
Particle Swarm Optimization untuk seleksi atribut menghasilkan peningkatan akurasi sebesar 2.1% dan AUC sebesar 0.006.
Support Vector
Support Vector
Machine Berbasis
KESIMPULAN
Machine PSO
Accuracy 75.30 77.40
Sensitivity 78.78 80.54
Specificity 62.44 66.52
PPV 88.57 89.29
NPV 44.33 49.67
Sumber: Hasil penelitian (2013)
Hasil perhitungan divisualisasikan dengan kurva ROC. Perbandingan kedua class bisa dilihat pada Gambar 2 yang merupakan kurva ROC untuk algoritma Support Vector Machine. Kurva ROC pada Gambar 2 mengekspresikan confusion matrix dari Tabel 3 Garis horizontal adalah false positives dan garis vertikal true positives. Menghasilkan nilai AUC (Area Under Curve)
sebesar 0.780 dengan nilai akurasi klasifikasi cukup (fair classification).
Dalam penelitian ini dilakukan pengujian model dengan menggunakanSupport Vector MachinedanSupport Vector Machine berbasis Particle Swarm Optimization
dengan menggunakan data kredit German. Model yang dihasilkan diuji untuk mendapatkan nilai accuracy dan AUC dari setiap algoritma sehingga didapat pengujian dengan menggunakansupport vector machinedidapat nilai
accuracy adalah 75.30 % dan nilai AUC adalah 0.780. Sedangkan pengujian dengan mengunakan support vector machine berbasis Particle Swarm Optimization dilakukan seleksi atribut dan penyesuaian pada parameter C, ε dan
dalam pemilihan atribut didapat bahwa metode tersebut lebih akurat dalam penentuan penilaian kredit dibandingkan dengan metode support vector machine
tunggal, ditandai dengan peningkatan nilai akurasi sebesar 2.1% dan nilai AUC sebesar 0.006, dengan nilai tersebut masuk kedalam klasifikasi akurasi cukup (fair classification).
Dari hasil pengujian yang telah dilakukan dan hasil kesimpulan yang diberikan maka ada saran atau usul yang di berikan antara lain:
1) Untuk meningkatkan hasil optimasi dapat dilakukan metode pemilihan parameter dengan metode Genetic Algorithmdan lain-lain.
2) Mencoba menerapkan metode optimasi yang lain sebagai bahan perbandingan.
UCAPAN TERIMA KASIH
Terima kasih kepada orang tua, kerabat, teman dan semua pihak yang tidak dapat disebutkan satu persatu sehingga penelitian ini selesai dilakukan.
REFERENSI
Abraham, A., Grosan, C., Ramos, V., (2006). Swarm Intelligence in Data Mining. Springer-Verlag Berlin Heidelberg.
Aydin, I., Karakose, M., & Akin, E. (2011). A multi-objective artificial immune algorithm for parameter optimization in support vector machine. Journal Applied Soft Computing,11, 120-129.
Bellotti, T., & Crook, J. (2007) Support vector machines for credit scoring and discovery of significant features.
Expert System with Application: An International Journal,36, 3302-3308.
Bank Indonesia (2012). Statistik Perbankan Indonesia Indonesian Banking Statistic. June, 2012. http://www.bi.go.id/NR/rdonlyres/B03D425D-
9BEE-42A7-B500-DE7C023507CE/26392/BISPIApril20121.pdf
Dawson, C. W. (2009). Projects in Computing and Information System A Student's Guide. England: Addison-Wesley.
Gang, W., Jinxing, H., Jian, M., & Hongbing, J. (2011). A comparative assessment of ensemble learning for credit scoring. Expert Systems with Applications: An International Journal.38, 223-230.
Gorunescu, Florin (2011). Data Mining: Concepts, Models, and Techniques. Verlag Berlin Heidelberg: Springer.
Han, J., & Kamber, M. (2006). Data Mining Concepts and technique.San Francisco: Diane Cerra
Heiat, A. (2011). Modeling Consumer Credit Scoring Through Bayes Network. World Journal of Social Sciences.3, 132-141.
Hian, C.K., Wei, C.T., & Chwee, P.G (2006). A Two-step Method to Construct Credit Scoring Models with Data Mining Techniques.International Journal of Business and Information,1, 96-118.
Jianguo, Z., & Tao, B. (2008). Credit Risk Assessment using Rough Set Theory and GA-based SVM. The 3rd International Conference on Grid and Pervasive Computing,320-325.
Larose, D. T. (2005).Discovering Knowledge in Data. New Jersey: John Willey & Sons, Inc.
Maimon, O., & Rokach, L. (2010). Data Mining and Knowledge Discovery Handbook (2nd ed). New York: Springer Dordrecht Heidelberg London
Mingyuan, Z., Chong, F., Luping, J., Mingtian, Z. (2011). Feature selection and parameter optimization for support vector machines: A new approach based on genetic algorithm with feature chromosomes. Expert Systems with Applications: An International Journal,
38, 5197-5204.
Ming-hui.J., & Xu-chuang, Y. (2007). Construction and Application of PSO-SVM Model for Personal Credit Scoring. ICCS '07 Proceedings of the 7th international conference on Computational Science,158-161.
Olson, D, & Shi, Y. (2008). Pengantar Ilmu Penggalian Data Bisnis.Jakarta: Penerbit Salemba Empat.
Ping, Y. (2009). Feature selection based on SVM for credit scoring. International. Conference on Computational Intelligence and Natural Computing,2, 44-47.
Rivai, V., & Veithzal, A.P. (2006). Credit Management Handbook.Jakarta: Raja GrafindoPersada.
Shuzhou, W., & Bo, M. (2011). Parameter Selection Algorithm for Support Vector Machine. Procedia Environmental Sciences,11, 538-544.
UCI (1994, November 12).German Credit data.Desember 3, 1996. http://archive.ics.uci.edu/ml/machine-learning- databases/statlog/german/german.data
UU Perbankan No.10 Tahun 1998.
Southern Gate, Chichester, West Sussex: John Willey & Sons, Ltd.
Wei, X., Shenghu, Z., Dongmei, D. & Yanhui, C.(2010). A Support Vector Machine Based Method For Credit Risk Assessment. IEEE 7thInternational Conference on e-Business Engineering,50-55.
Witten, I. H., Frank, E., & Hall, M. A. (2011).Data Mining: Practical Machine Learning and Tools. Burlington: Morgan Kaufmann Publisher.
Yun, L., Qiu-yan, C. & Hua, Z. (2011). Application of the PSO-SVM model for Credit Scoring. Seventh International Conference on Computational Intelligence and Security,