Integrasi Data Terstruktur dan Tidak Terstruktur dalam Sistem
Inteligensi Bisnis
Choerul Afifanto
Komputasi Statistik, Sekolah Tinggi Ilmu Statistik, Jakarta, Indonesia [email protected]
Abstract— Kuantitas data berkembang sangat pesat tiap harinya baik dari dalam maupun luar perusahaan. Sangatlah penting untuk memanfaatkan data-data tersebut untuk dianalisa sehingga bisa digunakan dalam inteligensi bisnis maupun pengambilan keputusan yang strategis dan taktis.
Data diklasifikasikan dalam 2 jenis, yatu terstruktur dan tidak terstruktur. Data terstruktur direpresentasikan dalam skema yang jelas sehingga mudah untuk dianalisa maupun diintegrasikan dengan data terstruktur lainnya. Sedangkan data tidak terstruktur direpresentasikan dalam berbagai bentuk sehingga sangat sulit untuk dianalisa maupun diintegrasikan dengan sumber data lain.
Data terstruktur dan tidak terstruktur apabila diintegrasikan dalam menganilisa suatu permasalahan akan memberikan pemahaman dan solusi yang lebih lengkap dan tepat sasaran. Namun, bukanlah hal yang mudah untuk mengintegrasikan kedua jenis data tersebut. Dibutuhkan teknik maupun arsitektur yang tepat untuk mengatasi permasalahan tersebut.
Beberapa teknik yang bisa digunakan adalah text tagging dan annotation. Teknik tersebut merupakan teknik yang popular dalam natural processing techniques untuk preprocessing data tidak terstruktur agar bisa dengan mudah diintegrasikan dengan data terstruktur
Keywords— inteligensi bisnis, text tagging, annotation, natural processing techniques.
I.
P
ENDAHULUANBesarnya data yang tersimpan di dalam sebuah perusahaan berkembang sangat cepat tiap harinya. Kemampuan untuk mengakses dan menganalisa data tersebut dalam pembuatan keputusan yang cepat dan cerdas menjadi kunci kesuksesan sebuah perusahaan. Banyak perusahaan yang terus berkembang seiring dengan berputarnya waktu, sehingga menghasilkan informasi yang heterogen dari data yang terdistribusi di berbagai sumber. Data tersebut disimpan dalam lokasi, sistem, format dan skema yang berbeda dan memberikan tantangan dalam penggunaan maupun integrasinya.
Dalam pengambilan keputusan yang efektif dan taktis, diperlukan kumpulan metodologi, proses, arsitektur dan teknologi yang mengubah data mentah menjadi informasi yang bermakna yang disebut Inteligensi Bisnis (IB)[2]. IB menggunakan
Gudang Data (GD) untuk mengelola data-datanya dalam jumlah besar. Namun tidak semua IB menggunakan GD dalam mengelola data-datanya.
digabungkan, data eksternal dan internal bisa menyediakan gambaran yang lebih lengkap [1].
Secara umum, ada dua kategori data yaitu data terstruktur dan tidak terstruktur. Data terstruktur tersedia sebesar 20% dari seluruh data, serta direpresentasikan dalam bentuk relasi yang mudah dipetakan dan disimpan dalam database relasional. Sedangkan data tidak terstruktur tersedia sebanyak 80% dari seluruh data yang direpresentasikan dalam berbagai bentuk dokumen seperti laporan, artikel berita, e-mail, dan konten web[3].
Data terstruktur biasanya disimpan dengan skema yang terdefinisi sehingga mudah untuk dilakukan query, dianalisa, dan diintegrasikan dengan data terstruktur lainnya. Berbeda dengan data tidak terstruktur, yang secara alami susah untuk dilakukan query, dianalisa, maupun diintegrasikan dengan sumber data lain. Namun di balik itu semua, informasi tersembunyi yang tersimpan dalam data tidak terstruktur bisa sangat berperan dalam pengambilan keputusan. Sehingga apabila dalam pengambilan keputusan menggunakan integrasi data terstruktur dan data tidak terstruktur bisa menambah nilai yang signifikan serta kebenaran yang sejati bagi perusahaan/organisasi. Inilah yang menjadi tantangan sekaligus manfaat dalam integrasi data terstruktur dan tidak terstruktur.
Text tagging dan annotation merupakan teknik
yang cukup popular dalam Natural Language
Processing (NLP) dan Machine Learning. Serta
merupakan komponen penting dalam pemrosesan dokumen dan information extraction system. Text
tagging dan annotation terdiri atas analisa teks
bebas dan identifikasi kata seperti kata benda, kerja, maupun ekspresi numerik. Text annotation juga disebut sebagai Named Entity (NE)
Extraction. Dulu, teknik Named Entity Extraction
digunakan untuk mengidentifikasi entiti umum seperti nama orang, lokasi, perusahaan, tanggal, besarnya pengeluaran dari kumpulan teks bebas. Teknik tersebut banyak dijadikan subjek penelitian selama beberapa dekade terakhir dan telah
dikembangkan menjadi sistem komersil maupun
open-source. Saat ini sistem named entity
detection telah memberikan akurasi yang akurat
dan banyak digunakan di berbagai bidang dalam aplikasinya pada data mining, information
extraction (IE), serta natural language processing
(NLP).
Paper ini akan menjelaskan peran text tagging
dan annotation pada tahap preprocessing dalam
integrasi data terstruktur dan tidak terstruktur sehingga informasi berguna yang didapat dari kumpulan teks berjumlah sangat besar bisa diintegrasikan dengan data terstruktur untuk analisa selanjutnya.
II.
T
EKNIK DANA
RSITEKTURA. Text Tagging dan Annotation
Text tagging dan annotation atau biasa disebut
named entitiy extraction merupakan teknik yang
popular digunakan dalam pemrosesan data tidak terstruktur seperti teks yang berdasarkan pada
Natural Language Processing (NLP) dan machine
learning. Texttagging dan annotation membentuk
komponen yang penting dalam tugas pemrosesan bahasa, termasuk di dalamnya seperti text mining,
information retrieval, dan information extraction.
Named entity extraction terdiri dari identifikasi
nama entitas dalam teks bebas atau data tidak terstruktur. Tipe entitas yang umum seperti kata benda, nama, produk, perusahaan, lokasi, alamat
e-mail, waktu dan tanggal, serta nilai numerik seperti
ukuran, persentase, nilai keuangan, dll.
Named entity extraction sudah banyak
Beberapa pendekatan maupun teknik telah dikembangkan untuk meningkatkan performa
named entity extraction, mulai dari
mengembangkan secara manual kumpulan dari aturan menggunakan sebuah kamus serta sebuah daftar yang nilainya didapat dari querydatabase.
B. Generic and High-Level Architecture Diagram
Proses pengumpulan inteligensi atau kecerdasan dari sumber data terstruktur dan tidak terstruktur dibagi menjadi 2 fase. Pada fase pertama, data tidak terstruktur (seperti CMS, scan dokumen, email, web konten) diubah menjadi data intermediate yang karakteristiknya sama seperti data terstruktur dengan teknik text tagging dan
annotation. Hasilnya akan diintegrasikan dengan
data terstruktur dengan bantuan alat untuk mengekstrak, mentransform dan memuat data yang disebut Extract, Transform, and Load (ETL) dari database terpisah menjadi satu penyimpanan utuh yaitu Complete Data Warehouse (CDW) untuk pelaporan dan analisis.
Untuk membangun landasan pengambilan keputusan yang efektif, diperlukan informasi yang sifatnya bisa dipercaya. Informasi tersebut direpresentasikan oleh CDW yang merupakan tempat dimana data terstruktur dan tidak terstruktur diintegrasikan. Proses pengintegraian tersebut melalui proses ETL, yaitu sebuah proses yang fungsinya untuk memodifikasi dan membersihkan data sesuai dengan format tertentu yang standar sebelum data tersebut disimpan ke dalam CDW untuk menjadi informasi yang digunakan sebagai landasan dalam pengambilan keputusan secara strategis dan taktis.
Pada kasus sumber data tidak terstruktur, text
tagging dan annotation platform mengekstrak
informasi berdasarkan pada domain ontology atau makna, properti maupun relasi dari data tersebut terhadap suatu domain atau bidang menjadi sebuah database XML.
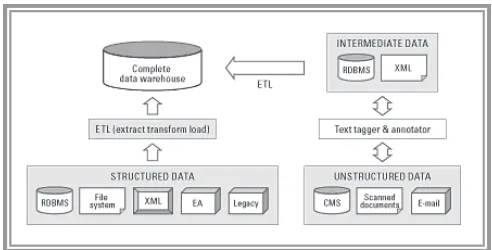
Figure 1 menunjukkan bahwa data terstruktur di dalam perusahaan berasal dari sumber transaksi
tradisional seperti Relational Database Manegement System (RDBMS), legacy systems,
dan aplikasi tempat penyimpanan perusahaan. Sedangkan data tidak terstrukturnya berasal dari dokumen, Content Management System (CMS), serta mail system.
Output dari fase pertama yaitu penyimpanan integrasi data terstruktur dan tidak terstruktur atau disebut CDW berperan sebagai input dalam fase kedua. Pada fase kedua ini, aplikasi Inteligensi Bisnis dibangun di atas sebuah versi kebenaran yang bisa dipercaya. Kebenaran tersebut direpresentasikan dalam bentuk CDW.
CDW meliputi semua pandangan dari aset data perusahaan dalam pembangunan Inteligensi Bisnis dan aplikasi pendukung pengambilan keputusan. Figure 2 menunjukkan pembangunan IB dan aplikasi pendukung pengambilan keputusan itu secara menyeluruh dengan menggunakan semua data perusahaan dari internal maupun eksternal.
Figure 1. Text tagging dan annotation serta ETL dalam pembentukan complete data warehouse (fase pertama)
Dengan menggunakan CDW, aplikasi lain seperti manajemen performa perusahaan bisa menghasilkan output yang handal dan bisa dipercaya.
III.
M
ETODOLOGIA. Studi Kasus
Studi kasus yang digunakan pada paper ini adalah studi kasus tentang mendapatkan informasi yang lebih aktual dan berguna dari data terstruktur dari BPS dengan data tidak terstruktur dari media massa online, SINDONEWS, tentang informasi ekspor dan impor nonmigas.
B. Prosedur Pengambilan Data
Data terstruktur BPS tentang nilai ekspor nonmigas bulan Mei 2015 yang berupa tabel
di-capture dan dicatat nilainya, sehingga didapat
angka mentah nilai ekspor nonmigas.
Sedangkan untuk data tidak terstruktur yang diambil dari salah satu berita pada koran SINDONEWS yaitu berita berjudul Wow! Butuh
Tujuh Tahun Pisang RI tembus Jepang[6] .Artikel
berita tersebut berisin tentang informasi yang lebih detail mengenai ekpor pisang Indonesia ke negara Jepang, seperti total ekspor pisang dari Indonesia ke Jepang, total konsumsi buah impor Jepang, supermarket yang menjual buah-buah impor, dsb.
C. Analisis Data
Data tidak terstruktur yang berupa artikel berita dari SINDONEWS pertama kali diubah formatnya terlebih dahulu menjadi data terstruktur dengan teknik text tagging dan annotation. Sedangkan data terstruktur berupa data mentah ekspor nonmigas Indonesia bulan Mei 2015. Kemudian kedua jenis data, terstruktur dan tidak terstruktur, dilakukan proses ekstrak, transform maupun muat dengan alat ETL agar bisa diintegrasikan dan
kemudian disimpan ke dalam CDW berupa informasi aktual.
Hasil yang tersimpan dalam ETL tersebut digunakan sebagai pembangunan inteligensi bisnis yang dapat digunakan sebagai landasan pendukung dalam pengambilan keputusan yang strategis dan taktis. Selain itu, inteligensi bisnis dapat diterapkan untuk tujuan bisnis seperti perkiraan, analitis, pelaporan perusahaan, kolaborasi serta manajemen pengetahuan.
IV.
H
ASIL DAND
ISKUSIInformasi yang bersifat real-time tentang suatu produk kita maupun kompetitor sangat krusial jika kita tidak bisa menganalisanya secara bijak untuk kepentingan perusahaan kita. Seorang pengambil keputusan harus bisa menyerap dan menganalisa informasi yang tersedia dalam jumlah yang sangat besar yang muncul setiap saat. Umtuk menjaga persaingan antar perusahaan, sebuah perusahaan harus sadar dan waspada akan perubahan trend pasar, kebijakan kompetitor, produk terbaru kompetitor, perubahan manajemen, penggabungan dan akuisisi perusahaan yang diterbitkan dalam media cetak/online seperti koran, majalah, dan website.
Artikel berita harian berupa kumpulan teks yang tersusun rapi dalam beberapa paragraf. Untuk
mengumpulkan data yang tidak terstruktur tersebut tidaklah mudah dan butuh waktu cukup lama untuk melakukan review dan analisa. Kualitas dari
sebuah keputusan yang strategis dan taktis terletak pada kualitas masukan informasi tersebut. Sehingga sangatlah penting untuk menganalisa kualitas informasi sebaik mungkin dalam rentang waktu yang terbatas.
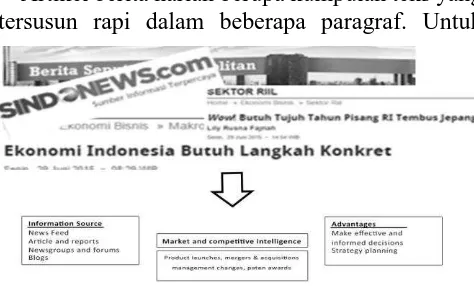
Figure 3 mengilustrasikan sebuah skenario dalam mendapatkan informasi dengan cara mencari informasi dari sumber berita harian, forum, blogs, artikel dan laporan. Kebanyakan orang mendapatkan informasi secara cepat dari artikel berita yaitu dengan cara membaca
headline/judulnya. Namun jika diimplementasikan
oleh sistem, hal itu tidaklah mudah untuk dilakukan dengan melakukan query pada natural
language text dari headline/judul untuk bisa
dianalisis maksudnya. Kemudian bagaimana peran dari text annotation tool dalam data tidak terstruktur sehingga makna dari hasil bisa diterima dengan baik.
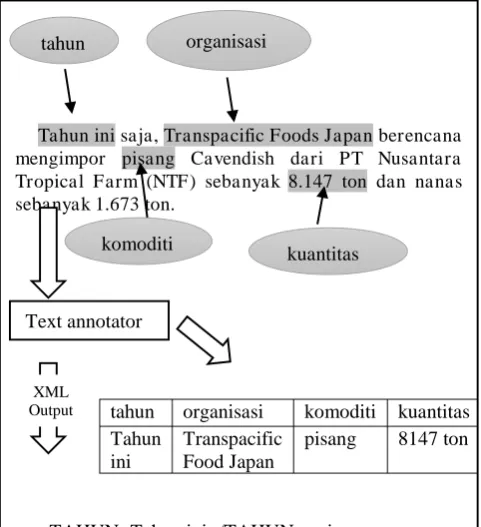
Salah satu contoh kalimat dalam artikel berita SINDONEWS adalah:
“Tahun ini saja, Transpacific Foods Japan
berencana mengimpor pisang Cavendish dari PT Nusantara Tropical Farm (NTF) sebanyak 8.147
ton dan nanas sebanyak 1.673 ton”
Entitas yang bisa didapat dari cuplikan berita tersebut diantaranya tahun, komoditi, organisasi, dan kuantitas. Seperti yang ditampilkan pada Figure 4, text annotator mengidentifikasi entitas serta memberikan tags pada cuplikan berita tersebut. Output yang dihasilkan dapat berupa dokumen XML dan tabel database. Memberikan tag pada informasi yang penting dapat mempermudah dalam mendapatkan link entitas dan analisis relasinya. Tag XML dan skema tabel database harus didefinisikan terlebih dahulu sebelumnya. Selain itu, text annotator tool juga harus diatur dan diprogram supaya bisa mendeteksi entitas tertentu secara spesifik. Sehingga query
pada SQL bisa secara mudah dilakukan pada tabel yang telah dihasilkan melalui proses text tagging
dan annotation.
Keuntungan yang bisa diperoleh dari penggabugan data terstruktur dengan data tidak terstruktur bisa dirasakan jika kita ingin mengetahui jawaban dari pertanyaan misal seperti berikut: “Perusahaan apa saja yang berencana mengimpor pisang dari Indonesia, serta berapa presentase pisang yang diimpor terhadap total ekspor komoditas buah-buahan Indonesia?” Jika untuk menjawab pertanyaan tersebut hanya menggunakan sumber data tunggal yaitu data terstruktur. Pertanyaan tersebut belum bisa terjawab secara sempurna. Namun, jika menggunakan informasi yang tersimpan dalam CDW yang merupakan integrasi dari data terstruktur dan tidak terstruktur, maka pertanyaan tersebut bisa terjawab dengan lengkap.
Tahun ini saja, Transpacific Foods Japan berencana mengimpor pisang Cavendish dari PT Nusantara Tropical Farm (NTF) sebanyak 8.147 ton dan nanas sebanyak 1.673 ton.
tahun organisasi komoditi kuantitas Tahun PT Nusantara Tropical Farm (NTF) sebanyak
<KUANTITAS>8.147 ton</KUANTITAS> dan nanas sebanyak 1.673 ton
V
. K
ESIMPULANText tagging dan annotation berperan sangat
significant dalam integrasi data terstruktur dan
tidak terstruktur. Output dari integrasi data tersebut, complete data warehouse, memberikan landasan yang kuat dalam pendukung pengambilan keputusan dan inteligensi bisnis.
Menghilangkan pembatas antara data terstruktur dan tidak terstruktur berdampak pada cara perusahaan dalam memperlakukan dan mengolah datanya. Memang secara alami, data tidak terstruktur tersebut sangat sulit untuk diekstraks dan diintegrasikan dengan data terstruktur. Namun output dari integrasi data terstruktur dan tidak terstruktur tersebut memberikan manfaat yang besar bagi perusahaan/organisasi.
Seperti yang telah diperlihatkan pada pembahasan, teknologi ini bisa membantu perusahaan dalam mengambil keputusan yang strategis dan taktis dalam inteligensi bisnis dengan
memanfaatkan data dari berbagai sumber baik itu data terstruktur maupun tidak terstruktur.
R
EFERENSI[1] Coker, Frank (2014). Pulse: Understanding the Vital Signs of Your Business. Ambient Light Publishing. hlm. 41-42. ISBN 978-0-9893086-0-1.
[2] Evelson, Boris (21 November 2008). "Topic Overview: Business Intelligence"
[3] Knox, Rita, T. Eid, & A. White. “Management Update: Companies should align their structured
and unstructured data,” Gartner Research, Feb 2005
[4] K.P. Byung & Y.S. Il. “Toward Total Business Intelligence Incorporating Structured and Unstructured Data”. 2011.
[5] Sukumuran. Sreekumar & Sureka, Ashish.
“Integrating Structured and Unstructured Data Using Text Tagging and Annotation”
[6] http://ekbis.sindonews.com/read/1018103/34/wow- butuh-tujuh-tahun-pisang-ri-tembus-jepang-1435564455 [terakhir diakses 30 Juni 2015] [7] https://id.wikipedia.org/wiki/Inteligensi_bisnis