7 BAB 2
LANDASAN TEORI
2.1 Latar Belakang
2.1.1 Definisi Penyakit Sosial
Penyakit sosial adalah perilaku menyimpang dari anggota masyarakat yang dapat menimbulkan keresahan dan ketidaktentraman dalam kehidupan masyarakat. Penyakit sosial di masyarakat saat ini sudah semakin marak di kalangan masyarakat dan sangat meresahkan masyarakat yang tinggal di daerah tersebut. Penyakit sosial timbul karena adanya pelanggaran yang dilakukan oleh orang atau sekelompok orang terhadap norma dan aturan yang berlaku dalam masyarakat. Pelanggaran terhadap norma dan aturan masyarakat inilah yang kemudian dikenal dengan penyimpangan sosial.
2.1.2 Jenis-Jenis Penyakit Sosial
Berikut ini adalah contoh dari perilaku masyarakat yang tergolong penyakit sosial karena melanggar norma masyarakat, norma-norma hukum dan agama antara lain:
1. Perjudian
Perjudian adalah pertaruhan dengan sengaja, yaitu mempertaruhkan suatu nilai atau yang dianggap bernilai dengan menyadari adanya sebuah resiko dan harapan tertentu pada peristiwa permainan, pertandingan, perlombaan dan kejadian yang belum pasti hasilnya. Jenis judi bermacam-macam dari yang sembunyi-sembunyi sampai terbuka. Contoh : togel, main kartu, sabung ayam dikalangan masyarakat.
2. Penyalahgunaan Narkoba/Napza
Napza (Narkotika, Psikotropika dan Zat Adiktif) merupakan zat atau obat-obatan yang berpengaruh terhadap susunan syaraf atau otak.Terkadang dipakai dokter untuk membius pasien operasi,tentunya dengan takaran tertentu. Apabila
pemakaiannya disalahgunakan akan menimbulkan ketagihan dan merusak menimbulkan ketidakmampuan dan fungsi sosial, pekerjaan, dam sekolah. Penggunaan narkoba akan berdampak negatif terhadap fisik dan mentals seseorang, bahkan Napza menimbulkan segudang masalah seperti pelacuran (PSK), kriminal bahkan paling berpotensi menularkan penyakit HIV/AIDS.
3. Alkoholisme/Mabuk-Mabukan
Alkoholisme adalah orang yang kecanduan minum minuman keras yanag mengandung alkohol dalam dosis yang tinggi. Konsumsi alkohol yang berlebihan akan berdamapak negatif bagi kesehatan karena mengganggu sistem syaraf. Akibatnya dia tidak dapat mengendalikan diri baik secara psikologis, fisik maupun sosial. Alkoholisme dapat mengakibatkan kejahatan beruntun seperti perkelahian, penodongan, pemerkosaan, dan lain-lain. Di Indonesia pesta miras sering dilakukan dan sering mengorbankan korban jiwa yang tidak sedikit. Berbeda dengan orang luar negeri yang meminum minuman yang mengandung alkohol pada saat musim dingin untuk menghangatkan tubuhnya, dan tentunya dengan takaran tertentu.
4. Pelacuran
Pelacuran merupakan peristiwa penjualan diri dengan jalan memperjual belikan badan, kehormatan dan kepribadian kepada banyak orang untuk memuaskan nafsu seks dengan imbalan bayaran uang. Pelacuran atau sekarang dikenal dengan istilah Pekerja Seks Komersial (PSK) berpotensi menularkan penyakit HIV/AIDS, selain itu dapat juga menimbulkan :
a) Penyakit kelamin,
b) Merusak kehidupan keluarga,
c) Merusak moral, hukum, susila,dan agama,
d) Adanya eksploitasi manusia oleh manusia lainnya, bahkan sekarang
dikenal dengan istilah “Trafficking” yaitu penjualan manusia oleh manusia.
5. Korupsi
Korupsi berasal dari bahas latin “Corruptio” atau “Corrumpere” yang berarti buruk, busuk, rusak, menggoyangkan atau memutar balikan. Korupsi merupakan perilaku penyelewengan dari tugas tertentu yang sengaja dilakukan untuk memperoleh keuntungan pribadi atau kelompoknya baik uang maupun harta kekayaan.Bentuk-bentuk korupsi antara lain: penyogokan, penggelapan, pemutar balikkan fakta, penipuan ataupun penggunaan uang negara secara tidak semestinya. Korupsi merugikan kehidupan pribadi, keluarga, masyarakat, maupun negara. Di Indonesia saat ini korupsi marak terjadi, dan dilakukan oleh pejabat baik pejabat pusat maupun daerah. Dan ini sangat merugikan masyarakat dan negara.
Selain itu beberapa perilaku penyakit sosial lainnya adalah mencuri, menipu, pembunuhan, pemerasan, pornografi dan pornoaksi, dan lain-lain.
2.1.3 Faktor Penyebab Penyakit Sosial
Beberapa penyebab penyakit sosial antara lain :
1. Faktor ekonomi
Tidak terpenuhinya kebutuhan ekonomi dapat mendorong orang melakukan kegiatan apa saja, asal bisa memperoleh sesuatu yang dapat digunakan untuk memenuhi kebutuhan ekonominya. Tidak jarang orang mengkhalalkan segala cara untuk mendapatkan uang atau sesuatu, yang dapat memenuhi kebutuhan ekonominya. Hal inilah yang menyebabkan orang melakukan kegiatan tanpa menghiraukan norma-norma dan aturan masyarakat. Akibatnya terjadilah penyakit sosial dari orang yang bersangkutan.
2. Pengaruh lingkungan
Penyakit sosial bisa juga terjadi karena pengaruh lingkungan. Orang yang hidup di lingkungan penjudi, akan cenderung ikut berjudi; orang yag berada di lngkungan peminum (pemabuk), akan cenderung ikut mabuk-mabukan; orang yang hidup di lingkungan preman, akan cenderung berperilaku seperti preman. Contoh-contoh tersebut menggambarkan betapa lingkungan mudah mempengaruhi perilaku
seseorang yang berada di lingkungan tersebut. Oleh karena itu, apabila kehidupan lingkungan tidak sesuai dengan norma-norma sosial, maka orang yang berada di lingkungan tersebut cenderung juga berperilaku menyimpang. Akibatnya terjadilah penyakit-penyakit sosial yang dilakukan oleh orang-orang yang berada di lingkungan tersebut.
3. Kurangnya pemahaman dasar tentang agama
Masalah kesehatan / ketenangan jiwa adalah masalah erat kaitannya dengan masalah supra logis, yaitu keimanan dan kepercayaan yang merupakan awal beragamanya seseorang. Keimanan dan kepercayaan ini menjadi integral dari kepribadian, asal bukan pengakuan di lisan semata, sebab penyelewengan-penyelewengan yang datangnya dari orang-orang yang mengaku ber Tuhan itu karena kurang tertanamnya jiwa agama (mental religius) dalam kepribadiannya. Terkadang dalam diri seseorang yang tak takut akan dosa mereka sering melakukan dosa. Karena jika seseorang tidak mendapat pendidikan agama yang baik mereka akan jauh dari Tuhan dan pasti tingkah laku mereka akan sembarangan.
4. Pengaruh perkembangan teknologi modern
Kemajuan iptek di bidang telekomunikasi dan informasi menjadikan media massa seperti TV, Film, CD/DVD, majalah , koran, buku, internet dan lain-lain akrab dalam kehidupan masyarakat. Namun tidak jarang apa yang di sajikan dalam tayangan film, sinetron, majalah, internet dan lain-lain tidak sesuai dengan nilai dan norma yang berlaku dalam masyarakat bahkan kini penyimpangan sosial juga terjadi akibat jejaring sosial facebook seperti terjadinya penculikan, pemerkosaan dan penipuan.
5. Hubungan keluarga yang tidak harmonis
Ketidakharmonisan keluarga yang di akibatkan oleh keadaan keluarga yang
berantakan dapat mendorong individu melakukan perilaku menyimpang.Keluarga
merupakan tempat di mana anak atau orang pertama kali melakukan interaksi dengan orang lain. Keluarga memiliki pengaruh yang sangat kuat dalam
pembentukan watak (perangai) seseorang. Oleh karena itulah keadaan keluarga akan sangat mempengaruhi perilaku orang yang menjadi anggota keluarga tersebut. Dalam keluarga yang brocken home biasanya hubugan antaranggota keluarga menjadi tidak harmonis. Keadaan keluarga tidak bisa memberikan ketenteraman dan kebahagiaan pada anggota keluarga. Masing-masing anggota keluarga tidak bisa saling melakukan kendali atas perilakunya. Akibatnya setiap anggota keluarga cenderung berperilaku semaunya, dan mencari kebahagiaan di luar keluarga. Ia tidak menyadari lagi, apakah perilakunya itu melanggar norma-norma kemasyarakatan atau tidak, yan penting mereka merasa bahagia. Hal inilah yang mendorong terjadinya penyakit sosial dari masing-masing anggota keluarga.
6. Pengaruh teman
Salah satu fungsi terpenting dari kelompok teman adalah untuk memberikan sumber informasi dan komparasi tentang dunia di luar keluarga. Karena teman adalah seseorang yang sangat butuhkan, namun teman juga bisa menjerumuskan seseorang pada hal-hal yang kurang bermanfaat bahkan merusak diri serta masa depan seseorang. Untuk itu kita harus hati-hati dalam berteman. Karena teman bisa memberikan efek negatif pada kepribadian seseorang.
2.2 Data
Data merupakan kumpulan fakta atau angka atau segala sesuatu yang dapat dipercaya kebenarannya sehingga dapat digunakan sebagai dasar penarikkan kesimpulan. Data dapat dikelompokkan dalam beberapa golongan antara lain berdasarkan aspek sifat, dimensi waktu, cara memperoleh dan pengukurannya
(Muhidin, 2009).
2.2.1 Data Menurut Cara Memperolehnya
1. Data Primer
Data primer adalah data yang diperoleh secara langsung dari objek yang diteliti, baik dari objek individual (responden) maupun dari suatu instansi yang mengolah data untuk keperluan dirinya sendiri. Contoh: hasil wawancara dengan responden,
hasil perhitungan suara dari masyarakat yang melaksanakan pemilihan kepala desa atau lainnya, data jumlah mahasiswa yang diperoleh dari lembaga pendidikan yang bersangkutan, dan lainnya.
2. Data Sekunder
Data sekunder adalah data yang diperoleh secara tidak langsung untuk mendapatkan informasi (keterangan) dari objek yang diteliti, biasanya data tersebut diperoleh dari tangan kedua baik dari objek secara individual (responden) maupun dari suatu badan (instansi) yang dengan sengaja melakukan pengumpulan data dari instansi-instansi atau badan lainnya untuk keperluan penelitian dari para pengguna. Badan yang biasa mengumpulkan data tersebut antara lain BPS (Badan Pusat Statistik), misal data mengenai laju inflasi, statistik penduduk, statistik pertanian, statistik ekonomi, data tingkat kemajuan pembangunan suatu daerah yang diperoleh dari BAPPEDA setempat, dan sebagainya.
2.3 Variabel
Variabel adalah suatu sebutan yang dapat diberi angka (kuantitatif) atau nilai mutu (kualitatif). Variabel merupakan pengelompokkan secara logis dari dua atau lebih atributdari objek yang diteliti. Misalnya: tidak sekolah, tidak tamat SD, tidak tamat SMP, dan sebagainya. Maka variabelnya adalah tingkat pendidikan dari objek penelitian itu.Variabel tingkat pendidikan merangkum semua atribut tadi.
Variabel merupakan suatu istilah yang berasal dari kata vary dan able yang
berarti “berubah” dan “dapat”. Jadi, kata variabel berarti dapat berubah-ubah.Nilai itu berupa nilai kuantitatif maupun kualitatif. Dilihat dari segi nilainya, variabel dibedakan atas 2, yaitu variabel diskrit dan variabel kontiniu.Variabel diskritnya nilai kuantitatifnya selalu berupa bilangan bulat, sedangkan variabel kontiniu nilai
kuantitatifnya bisa berupa pecahan.
Variabel penelitian pada dasarnya adalah segala sesuatu yang berbentuk apa saja yang ditetapkan oleh peneliti untuk dipelajari sehingga diperoleh
informasi tentang hal tersebut, kemudian ditarik kesimpulannya, (Sugiyono, 2007).
Menurut hubungan antara suatu variabel dengan variabel lainnya, variabel terbagi atas beberapa yaitu :
1. Variabel bebas (independent variable) yaitu variabel yang menjadi sebab
terjadinya atau terpengaruhnya variabel tak bebas.
2. Variabel tak bebas (dependent variable) yaitu variabel yang nilainya
dipengaruhi oleh variabel bebas.
3. Variabel moderator yaitu variabel yang memperkuat atau memperlemah
hubungan antara suatu variabel bebas dengan tak bebas.
4. Variabel intervening, seperti halnya variabel moderator, tetapi nilainya tidak
dapat diukur, seperti kecewa, marah, gembira, senang, sedih, dan lain sebagainya.
5. Variabel control, yaitu variabel yang dapat dikendalikan oleh peneliti.
2.4 Matriks
Matriks adalah suatu kumpulan angka-angka yang juga sering disebut elemen-elemen yang disusun secara teratur menurut baris dan kolom sehingga berbentuk persegi panjang, dimana panjang dan lebarnya ditunjukkan oleh banyaknya kolom
dan baris serta dibatasi tanda “[ ]” atau “( )” (Anton, 1987).
Matriks A yang berukuran dari n baris dan p kolom (𝑛𝑛×𝑝𝑝) adalah:
𝐴𝐴 =� 𝑎𝑎11 𝑎𝑎12 … 𝑎𝑎1𝑝𝑝 𝑎𝑎21 𝑎𝑎22 … 𝑎𝑎2𝑝𝑝 ⋮ 𝑎𝑎𝑛𝑛1 ⋮ 𝑎𝑎𝑛𝑛2 ⋮ … 𝑎𝑎𝑛𝑛𝑝𝑝⋮ � (2.1)
2.4.1 Nilai Eigen (Eigen Value)
Misalkan A adalah matriks persegi berukuran 𝑝𝑝×𝑝𝑝 dan I adalah matriks identitas
berukuran 𝑝𝑝×𝑝𝑝. Skalar 𝜆𝜆1, 𝜆𝜆2, … , 𝜆𝜆𝑝𝑝 yang memenuhi persamaan: |A - 𝜆𝜆I| = 0
disebut nilai eigen atau akar karakteristik. Dan suatu matriks A berukuran 𝑝𝑝×𝑝𝑝
dan 𝜆𝜆 adalah nilai eigen dari matriks A jika terdapat suatu vektor x tak nol
sedemikian sehingga Ax = 𝜆𝜆x, maka x disebut vektor eigen atau vektor
karakteristik dari matriks A yang bersesuaian dengan nilai eigen 𝜆𝜆. Untuk mencari
nilai eigen matriks A yang berukuran 𝑝𝑝× 𝑝𝑝, dapat ditulis kembali sebagai suatu
persamaan homogen |A - 𝜆𝜆I| = 0. Dengan I adalah matriks identitas yang berordo
sama dengan matriks A.
2.5 Pengujian Data
2.5.1 Sampel dan Uji Kecukupan Sampel
Sampel adalah sebagian anggota dari populasi yang dipilih dengan menggunakan prosedur tertentu sehingga diharapkan dapat mewakili populasinya. Untuk menentukan jumlah sampel dari suatu populasi dapat menggunakan rumus Slovin, sebagai berikut: n = 𝑁𝑁 1+𝑁𝑁𝑒𝑒2 (2.2) keterangan: n = Jumlah sampel N = Jumlah populasi
e = Batas toleransi kesalahan
2.5.2 Teknik Penarikan Sampel
Teknik penarikan sampel atau teknik sampling adalah suatu cara mengambil sampel yang representatif dari populasi. Pengambilan sampel harus dilakukan sedemikian rupa, sehingga diperoleh sampel yang benar-benar dapat mewakili dan menggambarkan keadaan populasi yang sebenarnya. Ada dua macam teknik penarikan sampel, yaitu:
1. Probability Sampling
Probability sampling adalah teknik sampling untuk memberikan peluang yang sama pada setiap anggota populasi untuk dipilih menjadi anggota sampel. Ada
beberapa jenis probability samplingyang banyak digunakan, antara lain:
1) Sampel Acak Sederhana (Simple Random Sampling)
Sampel acak sederhana adalah cara pengambilan sampel dari anggota populasi dengan menggunakan acak tanpa memperhatikan strata (tingkatan) dalam anggota populasi tersebut. Untuk itu dapat menggunakan dua cara:
a. Cara undian, yaitu dilakukan dengan memberi nomor-nomor pada
seluruh anggota populasi, kemudian secara acak dipilih nomor-nomor sesuai dengan banyaknya jumlah sampel yang dibutuhkan.
b. Cara tabel bilangan random adalah suatu tabel yang terdiri dari
bilangan-bilangan yang disajikan dengan sangat tidak berurutan.
2) Sampel Acak Stratifikasi (Stratified Random Sampling)
3) Area Sampel (Cluster Sampling)
4) Sampel Sistematis (Systematic/ Quasi Random Sampling)
5) Sampel Bertahap (Multistage Sampling)
2. Non Probability Sampling
Dalam non probability sampling, setiap unsur dalam populasi tidak memiliki kesempatan atau peluang yang sama untuk dipilih sebagai sampel, bahkan probabilitas anggota populasi tertentu untuk terpilih tidak diketahui. Beberapa jenis non probability sampling yang sering dijumpai:
1) Quota Sampling
2) Accidental Sampling
3) Purposive Sampling (Judgmental Sampling)
4) Snowball Sampling
Validitas merupakan alat ukur untuk melihat atau mengetahui apakah kuesioner
dapat digunakan untuk mengukur keadaan responden sebenarnya (Azuar Juliandi
2013). Untuk menguji validitas keadaan responden digunakan rumus korelasi
product moment pearsons, yaitu :
r = 𝑛𝑛(∑ 𝑋𝑋𝑋𝑋)− (∑ 𝑋𝑋 ∑ 𝑋𝑋) �[𝑛𝑛 ∑ 𝑋𝑋2−(∑ 𝑋𝑋)2][𝑛𝑛 ∑ 𝑋𝑋2−(∑ 𝑋𝑋)2] (2.3) keterangan: r = Koefisien Korelasi n = Jumlah sampel
X = Variabel bebas (Skor Pertanyaan)
Y = Variabel Terikat (Skor Total)
Jika nilai 𝑟𝑟ℎ𝑖𝑖𝑖𝑖𝑖𝑖𝑛𝑛𝑖𝑖 ≥ 𝑟𝑟𝑖𝑖𝑎𝑎𝑏𝑏𝑒𝑒𝑡𝑡 maka kuesioner dinyatakan valid dan jika nilai
𝑟𝑟ℎ𝑖𝑖𝑖𝑖𝑖𝑖𝑛𝑛𝑖𝑖 < 𝑟𝑟𝑖𝑖𝑎𝑎𝑏𝑏𝑒𝑒𝑡𝑡 maka kuesioner dinyatakan tidak valid . 2.5.4 Uji Reliabilitas
Reliabilitas adalah indeks yang menunjukkan sejauh mana alat ukur dapat dipercaya atau diandalkan dan sejauh mana hasil pengukuran konsisten bila dilakukan dua kali atau lebih terhadap gejala yang sama, dengan alat ukur yang
sama. Untuk mengukur reliabilitas alat ukur digunakan teknik Cronbach Alpha.
Rumus yang digunakan adalah :
𝛼𝛼= �𝑘𝑘−𝑘𝑘1� �1−∑ 𝑆𝑆𝑗𝑗2
𝑆𝑆𝑥𝑥2 � (2.4)
keterangan:
= reliabilitas instrumen
k = banyaknya butir pertanyaan
∑ 𝑆𝑆𝑗𝑗2 = jumlah varian variabel
Suatu konstruk atau variabel dikatakan reliabel jika memberikan nilai Cronbach Alpha > 0,60.
2.6 Transformasi Data Ordinal menjadi Interval
Mentransformasi data ordinal menjadi data interval gunanya untuk memenuhi sebagian dari syarat analisis parametrik yang mana data setidaknya berskala interval. Pada penelitian ini variabel yang digunakan berskala ordinal. Oleh
karena itu, untuk pemenuhan asumsi pada analisis diskriminan bahwa variabel
independen harus berskala interval, maka terlebih dahulu data ordinal ditransformasikan menjadi data interval menggunakan Method of Successive Interval (MSI). Langkah-langkah transformasi data ordinal ke data interval adalah:
1. Pertama perhatikan setiap butir jawaban responden dari angket yang disebar,
2. Pada setiap butir ditentukan berapa orang yang mendapat skor 1, 2, 3, dan 4
yang disebut sebagai frekuensi,
3. Setiap frekuensi dibagi dengan banyaknya responden dan hasilnya disebut
proporsi,
𝑃𝑃𝑖𝑖 = ∑ 𝑓𝑓𝑓𝑓𝑖𝑖
𝑖𝑖 (2.5)
keterangan:
𝑃𝑃𝑖𝑖 = proporsi pada skor i
𝑓𝑓𝑖𝑖 = frekuensi pada skor i
∑ 𝑓𝑓𝑖𝑖 = jumlah total frekuensi
4. Tentukan nilai proporsi kumulatif dengan jalan menjumlahkan nilai proporsi
secara berurutan perkolom skor.
5. Gunakan tabel distribusi normal, hitung nilai Z untuk setiap proporsi
6. Menghitung nilai densitas dari nilai Z yang diperoleh dengan cara memasukkan nilai Z tersebut kedalam fungsi densitas normal baku sebagai berikut:
𝑓𝑓(𝑧𝑧) = √12𝜋𝜋exp�−12𝑧𝑧2� (2.6)
keterangan:
𝜋𝜋 = 3,141593
exp = 2,718282
7. Tentukan nilai skala dengan menggunakan rumus:
𝑠𝑠𝑠𝑠𝑎𝑎𝑡𝑡𝑒𝑒𝑣𝑣𝑎𝑎𝑡𝑡𝑖𝑖𝑒𝑒=((𝑑𝑑𝑒𝑒𝑛𝑛𝑠𝑠𝑖𝑖𝑖𝑖𝑑𝑑 𝑎𝑎𝑖𝑖𝑡𝑡𝑙𝑙𝑙𝑙𝑒𝑒𝑟𝑟 𝑡𝑡𝑖𝑖𝑙𝑙𝑖𝑖𝑖𝑖)−(𝑑𝑑𝑒𝑒𝑛𝑛𝑠𝑠𝑖𝑖𝑖𝑖𝑑𝑑 𝑎𝑎𝑖𝑖𝑖𝑖𝑝𝑝𝑝𝑝𝑒𝑒𝑟𝑟 𝑡𝑡𝑖𝑖𝑙𝑙𝑖𝑖𝑖𝑖)
𝑎𝑎𝑟𝑟𝑒𝑒𝑎𝑎 𝑏𝑏𝑒𝑒𝑡𝑡𝑙𝑙𝑙𝑙 𝑖𝑖𝑝𝑝𝑝𝑝𝑒𝑒𝑟𝑟 𝑡𝑡𝑖𝑖𝑙𝑙𝑖𝑖𝑖𝑖)−(𝑎𝑎𝑟𝑟𝑒𝑒𝑎𝑎 𝑏𝑏𝑒𝑒𝑡𝑡𝑙𝑙𝑙𝑙 𝑡𝑡𝑙𝑙𝑙𝑙𝑒𝑒𝑟𝑟 𝑡𝑡𝑖𝑖𝑙𝑙𝑖𝑖𝑖𝑖) (2.7)
Menghitung skor (nilai transformasi) untuk setiap kategori dengan rumus:
𝑠𝑠𝑠𝑠𝑎𝑎𝑡𝑡𝑒𝑒 =𝑠𝑠𝑠𝑠𝑎𝑎𝑡𝑡𝑒𝑒𝑣𝑣𝑎𝑎𝑡𝑡𝑖𝑖𝑒𝑒+ [1 + |𝑠𝑠𝑠𝑠𝑎𝑎𝑡𝑡𝑒𝑒𝑣𝑣𝑎𝑎𝑡𝑡𝑖𝑖𝑒𝑒𝑙𝑙𝑖𝑖𝑛𝑛|] (2.8)
𝑠𝑠𝑠𝑠𝑎𝑎𝑡𝑡𝑒𝑒𝑣𝑣𝑎𝑎𝑡𝑡𝑖𝑖𝑒𝑒𝑙𝑙𝑖𝑖𝑛𝑛 artinya adalah nilai scale value absolut (tanpa
memperhatikan tanda positif atau negatif) paling kecil.
2.7 Analisis Korelasi
Analisis korelasi adalah alat statistik yang dapat digunakan untuk mengetahui derajat hubungan linear antara satu variabel dengan variabel yang lain. Dalam ilmu statistika, istilah korelasi diartikan sebagai hubungan linier antara dua
variabel atau lebih. Hubungan antara dua variabel dikenal dengan istilah bivariate
correlation, sedangkan hubungan antar lebih dari dua variabel disebut
multivariate correlation.
Formula untuk menghitung koefisien korelasi dengan menggunakan teknik
koefisien korelasi Product Moment Correlation dari Karl Pearson. Penggunaan
skala pengukuran interval. Untuk menghitung koefisien korelasi product moment pearsons antara dua variabel dapat digunakan rumus:
𝑟𝑟𝑥𝑥𝑑𝑑 =�{𝑛𝑛 ∑ 𝑋𝑋𝑛𝑛 ∑ 𝑋𝑋𝑋𝑋−2−(∑ 𝑋𝑋)(2∑ 𝑋𝑋}{𝑛𝑛 ∑ 𝑋𝑋)(∑ 𝑋𝑋2−)(∑ 𝑋𝑋)2} (2.9) keterangan:
rxy = Koefisien korelasi antara X dan Y
X = Variabel bebas
Y = Variabel terikat
Nilai r selalu terletak antara -1 dan 1, sehingga nilai r tersebut dapat ditulis :
-1≤ r ≤+1. Untuk r = +1, berarti ada korelasi positif sempurna antara X dan Y,
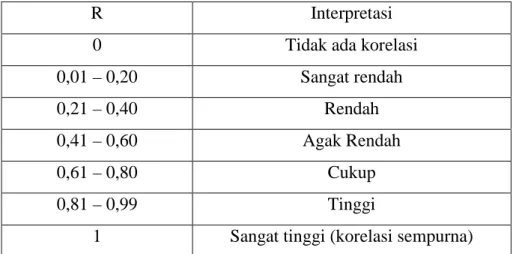
sebaliknya jika r = -1, berarti korelasi negatif sempurna antara X dan Y, sedangkan r = 0, berarti tidak ada korelasi antara X dan Y. Jika kenaikan didalam suatu variabel diikuti dengan kenaikan didalam variabel lain, maka dapat dikatakan bahwa kedua variabel tersebut mempunyai korelasi yang positif. Tetapi jika kenaikan didalam suatu variabel diikuti oleh penurunan didalam variabel lain, maka dapat dikatakan bahwa variabel tersebut mempunyai korelasi yang negatif. Dan jika tidak ada perubahan pada variabel walaupun variabel lainnya berubah maka dikatakan bahwa kedua variabel tersebut tidak mempunyai hubungan. Interpretasi harga r akan disajikan dalam tabel berikut:
Tabel 2.1 Interpretasi Koefisien Korelasi
R Interpretasi
0 Tidak ada korelasi
0,01 – 0,20 Sangat rendah
0,21 – 0,40 Rendah
0,41 – 0,60 Agak Rendah
0,61 – 0,80 Cukup
0,81 – 0,99 Tinggi
1 Sangat tinggi (korelasi sempurna)
Hubungan antara variabel dapat dikelompokkan menjadi tiga jenis:
1. Korelasi Positif
Terjadinya korelasi positif apabila perubahan antara variabel yang satu diikuti oleh variabel lainnya dengan arah yang sama (berbanding lurus). Artinya variabel yang satu meningkat, maka akan diikuti peningkatan variabel lainnya.
2. Korelasi Negatif
Terjadinya korelasi negatif apabila perubahan antara variabel yang satu diikuti oleh variabel lainnya dengan arah yang berlawanan (berbanding terbalik). Artinya apabila variabel yang satu meningkat, maka akan diikuti penurunan variabel lainnya.
3. Korelasi Nihil
Korelasi nihil artinya tidak adanya korelasi antara variabel.
2.8 Analisis Diskriminan
2.8.1 Pengertian Analisis Diskriminan
Analisis diskriminan merupakan teknik menganalisis data dimana variabel tak bebas merupakan kategorik (non-metrik, nominal atau ordinal, bersifat kualitatif) sedangkan variabel bebas sebagai prediktor merupakan metrik (interval atau rasio,
bersifat kuantitatif). (J. Supranto 2004).
Tujuan analisis diskriminan adalah membuat suatu fungsi diskriminan dari variabel independen yang bisa mendiskriminasi atau membedakan kelompok variabel dependen artinya mampu membedakan suatu objek masuk kelompok
yang mana. (Yasril & Heru subaris 2009). Dengan kata lain, analisis dikriminan
digunakan untuk mengklasifikasikan individu kedalam salah satu dari dua kelompok atau lebih.
Teknik analisis diskriminan dibedakan menjadi 2 yaitu analisis diskriminan dua kelompok/kategori, jika variabel tak bebas Y dikelompokkan
menjadi 2. Diperlukan satu fungsi diskriminan. Kalau variabel tak bebas dikelompokkan menjadi lebih dari 2 kelompok disebut analisis diskriminan
berganda (multiple discriminant analysis) diperlukan fungsi diskriminan sebanyak
(k - 1) kalau memang ada k kategori. (J. Supranto 2004).
Model analisis diskriminan berkenaan dengan kombinasi linier yang disebut juga fungsi diskriminan bentuknya sebagai berikut :
𝐷𝐷𝑖𝑖= 𝑏𝑏0+ 𝑏𝑏1𝑋𝑋𝑖𝑖1+𝑏𝑏2𝑋𝑋𝑖𝑖2 +𝑏𝑏3𝑋𝑋𝑖𝑖3+⋯+𝑏𝑏𝑗𝑗𝑋𝑋𝑖𝑖𝑗𝑗 (2.10) keterangan:
𝐷𝐷𝑖𝑖 = Nilai (skor) diskriminan dari responden (objek) ke-i.
i = 1,2, ..., n. D merupakan variabel dependen.
𝑏𝑏0 = Intersep
𝑏𝑏𝑗𝑗 = koefisien atau timbangan diskriminan dari variabel independen ke-j.
𝑋𝑋𝑖𝑖𝑗𝑗 = Variabel independen ke-j dari responden ke-i.
2.8.2 Tujuan Analisis Diskriminan
1. Membuat suatu fungsi diskriminan atau kombinasi linier dari prediktor atau
variabel bebas yang bisa mendiskriminasi atau membedakan kategori
variabel tak bebas atau criterion atau kelompok, artinya mampu
membedakan suatu objek masuk kelompok kategori yang mana.
2. Menguji apakah ada perbedaan signifikan antara kategori/kelompok,
dikaitkan dengan variabel bebas atau prediktor.
3. Menentukan prediktor/variabel bebas yang mana yang memberikan
sumbangan terbesar terhadap terjadinya perbedaan antar kelompok.
4. Mengklarifikasi/mengelompokkan objek/kasus kedalam suatu
kelompok/kategori didasarkan pada nilai variabel bebas.
2.8.3 Asumsi Analisis Diskriminan
Asumsi-asumsi yang harus dipenuhi untuk analisis diskriminan adalah:
1. Variabel independen seharusnya berdistribusi normal multivariat
(Multivariate Normality), jika data tidak berdistribusi normal, akan menyebabkan masalah pada ketepatan fungsi (model) diskriminan.
2. Matriks varians kovarians grup dari semua variabel independen seharusnya
sama.
3. Tidak ada data yang sangat ekstrim (outlier) pada variabel independen, jika
ada data ekstrim yang tetap diproses, hal ini bisa berakibat berkurangnya ketepatan klasifikasi dari fungsi diskriminan
4. Tidak ada korelasi yang kuat antar-variabel independen , jika dua variabel
independen mempunyai korelasi yang kuat,dikatakan terjadi multikolinieritas, untuk mengetahui adanya multikolinieritas dapat dilakukan dengan melihat korelasi antar variabel independen (r) yaitu jika nilai r > 0.6 menunjukkan adanya multikolinieritas.
2.8.4 Langkah-langkah Analisis Diskriminan
1. Pemilihan variabel dependen dan independen
Variabel dependen merupakan variabel kategorik sedangkan variabel independen merupakan variabel numerik. Analisis diskriminan dibedakan menjadi dua yaitu :
a) Analisis diskriminan dua kategori/kelompok, dimana variabel dependen
dikelompokkan menjadi 2 (dikotomi), diperlukan satu fungsi diskriminan.
b) Analisis diskriminan berganda (Multiple Discriminant Analysis/MDA),
dimana variabel dependen dikelompokkan menjadi 1. lebih dari 2 kelompok (multikotomi), diperlukan fungsi diskriminan sebanyak (k-1) kalau ada k kategori.
2. Melakukan uji equality
Untuk memenuhi asumsi bahwa semua variabel independen harus equal dilihat pada significancy dari Wilk’s Lambda jika nilai p > 0,05 menunjukkan bahwa
variabel equal. Untuk melihat bahwa variabel tersebut equal, juga dilihat dari
group covariance adalah relative sama
3. Pembentukan fungsi diskriminan
a) Pembentukan Fungsi Linier ( teoritis)
Fungsi diskriminan merupakan fungsi atau kombinasi linier peubah-peubah asal yang akan menghasilkan cara terbaik dalam pemisahan kelompok-kelompok. Fungsi ini akan memberikan nilai-nilai yang sedekat mungkin dalam kelompok dan sejauh mungkin antar kelompok. Apabila fungsi diskriminan yang terbentuk sebanyak lebih dari satu fungsi, maka dapat dikatakan bahwa fungsi diskriminan pertama akan menjadi kekuatan pembeda yang paling besar, demikian berturut-turut untuk fungsi berikutnya. Misalnya ada kelompok/kategori sebanyak G, dimana masing-masing kelompok terdapat sebanyak n objek (elemen atau responden) sebagai sampel maka:
𝑥𝑥̅𝑖𝑖 = 𝑛𝑛𝑖𝑖1 � 𝑥𝑥𝑖𝑖𝑗𝑗 𝑖𝑖 𝑗𝑗=1
(2.11)
keterangan:
𝑥𝑥̅𝑖𝑖 = vektor rata-rata sampel dalam kelompok ke-i
𝑛𝑛𝑖𝑖 = banyaknya elemen objek ke-i
𝑥𝑥𝑖𝑖𝑗𝑗 = menyatakan variabel x ke-j dalam kelompok ke-i
Kemudian dengan mendefinisikan vektor rata-rata keseluruhan.
𝑥𝑥 = 𝑖𝑖1 � 𝑥𝑥̅𝑖𝑖 𝑖𝑖 𝑖𝑖=1
(2.12)
keterangan:
𝑥𝑥 = vektor rata-rata keseluruhan
𝑖𝑖 = banyaknya kelompok
Maka didapat: 𝑩𝑩= �(𝑥𝑥̅𝑖𝑖 − 𝑥𝑥)(𝑥𝑥̅𝑖𝑖 − 𝑥𝑥 𝑖𝑖 𝑖𝑖=1 )′ (2.14) keterangan:
𝑩𝑩 = metrik jumlah kuadrat dan jumlah cross products antar kelompok
𝑥𝑥̅𝑖𝑖 = vektor rata-rata sampel dalam kelompok ke-i
𝑥𝑥 = vektor rata-rata keseluruhan
(𝑥𝑥̅𝑖𝑖 − 𝑥𝑥)′ = transpos dari (𝑥𝑥̅𝑖𝑖− 𝑥𝑥) Sehingga: 𝑊𝑊 = �(𝑛𝑛𝑖𝑖 −1)𝑆𝑆𝑖𝑖 𝑖𝑖 𝑖𝑖=1 (2.14) keterangan:
𝑊𝑊 = matriks sampel dalam grup
𝑆𝑆𝑖𝑖 = matriks varians kovarians kelompok ke-i
Matriks varians kovarians untuk sebuah sampel ukuran n yang terdiri atas p buah
variabel 𝑋𝑋1, 𝑋𝑋2, 𝑋𝑋3, … , 𝑋𝑋𝑝𝑝 disusun dalam sebuah matriks yang disebut dengan
matriks varians-kovarians (S) dengan bentuk sebagai berikut:
𝑆𝑆= ⎝ ⎜ ⎜ ⎛ 𝑆𝑆11 𝑆𝑆12 𝑆𝑆13 … 𝑆𝑆1𝑝𝑝 𝑆𝑆21 𝑆𝑆22 𝑆𝑆23 … 𝑆𝑆2𝑝𝑝 𝑆𝑆31 ... 𝑆𝑆𝑝𝑝1 𝑆𝑆32 ... 𝑆𝑆𝑝𝑝2 𝑆𝑆33 ... 𝑆𝑆𝑝𝑝3 … ... … 𝑆𝑆3𝑝𝑝 ... 𝑆𝑆𝑝𝑝𝑝𝑝⎠ ⎟ ⎟ ⎞ (2.15) Dimana 𝑆𝑆𝑖𝑖𝑘𝑘 = 𝑛𝑛 −1 1��𝑥𝑥𝑗𝑗𝑖𝑖 − 𝑥𝑥̅𝑖𝑖��𝑥𝑥𝑗𝑗𝑘𝑘 − 𝑥𝑥̅𝑘𝑘� 𝑛𝑛 𝑗𝑗=1 (2.16)
Matriks varians-kovarians gabungannya dapat dihitung dengan menggunakan rumus sebagai berikut:
𝑆𝑆𝑝𝑝𝑙𝑙𝑙𝑙𝑡𝑡𝑒𝑒𝑑𝑑 = (𝑛𝑛1− 1)𝑆𝑆1+(𝑛𝑛2− 1)𝑆𝑆2+(𝑛𝑛3− 1)𝑆𝑆3+⋯+(𝑛𝑛𝑡𝑡− 1)𝑆𝑆𝑡𝑡 𝑛𝑛1+𝑛𝑛2+𝑛𝑛3+⋯+𝑛𝑛𝑖𝑖−𝑖𝑖 (2.17) Atau 𝑆𝑆𝑝𝑝𝑙𝑙𝑙𝑙𝑡𝑡𝑒𝑒𝑑𝑑 = (𝑛𝑛 𝑊𝑊 1+𝑛𝑛2+⋯+𝑛𝑛𝑖𝑖−𝑖𝑖) (2.18)
Fungsi diskriminan yang terbentuk mempunyai bentuk umum berupa Fisher’s
Sample Linear Discriminant Function (persamaan linier) yaitu:
𝑋𝑋=𝑎𝑎′𝑋𝑋 (2.19)
keterangan:
a = Vektor koefisien pembobot fungsi diskriminan
a’= tranpose a
Y = Variabel terikat (skor diskriminan)
X = Variabel bebas (Vektor variabel acak yang dimasukkan ke dalam fungsi
diskriminan).
Agar dapat mendiskriminasi kelompok secara maksimal, fungsi diskriminan Y
harus diestimasi untuk memaksimumkan variabel antar kelompok. Koefisien 𝑎𝑎
dihitung dengan membuat 𝜆𝜆 maksimum, yaitu:
𝐚𝐚�′𝐁𝐁𝐚𝐚�
𝐚𝐚�′𝐖𝐖𝐚𝐚� (2.20)
Biarkan 𝜆𝜆̂1+𝜆𝜆̂2+⋯+𝜆𝜆̂𝑖𝑖 > 0 menunjukkan 𝑠𝑠 ≤min(𝑖𝑖 −1,𝑝𝑝) eigenvalue dari
matriks 𝑊𝑊−1B dan 𝑒𝑒̂1,⋯,𝑒𝑒̂𝑠𝑠 menjadi eigen vektor. Untuk menyelesaikan 𝑠𝑠 ≤
min(𝑖𝑖 −1,𝑝𝑝) eigenvalue dari matriks 𝑊𝑊−1B, dengan menggunakan rumus:
Nilai 𝜆𝜆 maksimum merupakan nilai eigen value terbesar dari matriks 𝑊𝑊−1B dan 𝒂𝒂�
adalah associated eigenvektors. Elemen a, seperti 𝑎𝑎1 sampai dengan 𝑎𝑎𝑘𝑘
merupakan koefisien fungsi diskriminan, berasosiasi dengan fungsi diskriminan pertama. Pada umumnya, dimungkinkan untuk mengestimasi sampai eigen value terkecil yaitu yang ke (G-1) atau k fungsi diskriminan masing-masing dengan eigenvaluenya. Maksudnya, setiap fungsi diskriminan mempunyai nilai eigenvalue dan nilai eigen value ini semakin mengecil dari fungsi ke fungsi.
b) Fungsi Linier (dengan bantuan SPSS)
Pada output SPSS, koefisien untuk tiap variabel yang masuk dalam model dapat
dilihat pada tabel Canonical Discriminant Function Coefficient. Tabel ini akan
dihasilkan pada output apabila pilihan Function Coefficient bagian
Unstandardized diaktifkan.
c) Menghitung Discriminant Score (nilai diskriminan)
Setelah dibentuk fungsi liniernya, maka dapat dihitung skor diskriminan untuk tiap observasi dengan memasukkan
nilai-nilai variabel penjelasnya.
d) Perhitungan Hit Ratio
Setelah semua observasi diprediksi keanggotaannya, dapat dihitung hit ratio yaitu rasio antara observasi yang tepat pengklasifikasiannya dengan total seluruh observasi. Misalkan ada sebanyak n observasi, akan dibentuk fungsi linier dengan observasi sebanyak n-1. Observasi yang tidak disertakan dalam pembentukan fungsi linier ini akan diprediksi keanggotaannya dengan fungsi yang sudah dibentuk tadi. Proses ini akan diulang dengan kombinasi observasi yang berbedabeda, sehingga fungsi linier yang dibentuk ada sebanyak n. Inilah yang
disebut dengan metode Leave One Out.
e) Kriteria Posterior Probability
Aturan pengklasifikasian yang ekivalen dengan model linier Fisher ialah berdasarkan nilai peluang suatu observasi dengan karakteristik tertentu (x) berasal
dari suatu kelompok. Nilai peluang ini disebut posterior probability dan bisa
ditampilkan pada sheet SPSS dengan mengaktifkan option probabilities of group
membership pada bagian Save di kotak dialog utama.
f) Akurasi Statistik
Dapat di uji secara statistik apakah klasifikasi yang dilakukan (dengan menggunakan fungsi diskriminan) akurat atau tidak. Uji statistik tersebut ialah
prees-Q Statistik. Ukuran sederhana ini membandingkan jumlah kasus yang diklasifikasi secara tepat dengan ukuran sampel dan jumlah grup. Nilai yang
diperoleh dari perhitunngan kemudian dibandingkan dengan nilai kritis (critical
velue) yang diambil dari tabel Chi-Square dan tingkat keyakinan sesuai yang diinginkan. Statistik Q ditulis dengan rumus:
𝑃𝑃𝑟𝑟𝑒𝑒𝑒𝑒𝑠𝑠 − 𝑄𝑄= [𝑁𝑁−𝑁𝑁((𝑘𝑘−𝑛𝑛𝑘𝑘1))]2 (2.22) keterangan:
N= jumlah populasi n = jumlah sampel k = jumlah grup