BAB II
LANDASAN TEORI 2.1 Tinjauan studi
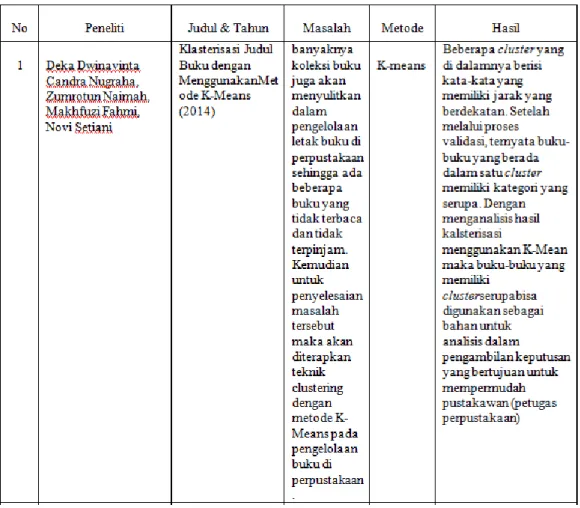
Penelitian terkait dengan topik yang diangkat peneliti pernah dilakukan oleh Deka Dwinavinta Candra Nugraha, dkk pada tahun 2014 dengan judul “Klasterisasi Judul Buku dengan Menggunakan Metode K-Means “. Membahas mengenai Teknik clustering merupakan sebuah teknik pengelompokan sejumlah data/obyek ke dalam cluster (group) sehingga dalam setiap cluster akan berisi data yang semirip mungkin . Teknik clustering akan mengelompokan judul buku sesuai dengan kategorinya. Buku-buku yang memiliki cluster yang sama akan digunakan sebagai bahan untuk analisis dalam pengambilan keputusan yang bertujuan untuk mempermudah pustakawan(petugas perpustakaan) dalam pengelolaan peletakan buku yang diminati dan merancang strategi dalam meningkatkan minat baca seseorang. Penelitian serupa di lakukan oleh surya bagus prasetyan yang berjudul “Penerapan Data Mining Clastering Menggunakan Algoritma K-Means Dalam Menentukan Alokasi Penempatan Buku Perpustakaan Udinus “. dimana nantinya dapat mengolah suatu data mining untuk menghasilkan sebuah pengetahuan yang baru. Salah satu teknik di dalam data mining algoritma yang akan digunakan adalah algoritma K-Means untuk mengetahui keterkaitan dari transaksi buku yang terjadi sehari-hari. Yaitu dengan melihat ketertarikan buku yang dapat dijadikan sebagai alokasi penempatan buku pada perpustaka
2.1.1 Pengertian Information Retrival
Information retrival adalah istilah untuk mempelajari sistem pencarian sehingga mendapat informasi yang dicari, mulai dari indexing(index), searching(penggalian), dan realiing data( pemanggilan data kembali). Berlaku juga terhadap pencarian data yang tidak terstruktur.
Sistem temu kembali informasi digunakan untuk menemukan kembali ( retrive) informasi-informasi yang relevan terhadap kebutuhan pengguna dari suatu kumpulan informasi secara otomatis.
Salah satu aplikasi umum dari sistem temun kembali informasi adalah search engine atau mesin pencarian yang terdapat pada jaringan internet. Pengguna dapat mencari halaman pada web yang dibutuhkannya. Contoh lain dari sistem temu kembali informasi adalah sistem informasi perpustakaan.
2.1.2 Pengertian Clustering
Clustering merupakan proses pembagian (partisi) atau pengelompokan data. Menurut Jyoti Bora dan Kumar Gupta (2014: 108), clustering adalah suatu proses pembagian elemen-elemen data ke dalam kelompok yang berbeda (disebut sebagai cluster) sedemikian rupa sehingga elemen-elemen data dalam suatu kelompok memiliki kesamaan yang tinggi dan elemen-elemen data pada kelompok tersebut berbeda dengan elemen-elemen yang berada dalam kelompok lain.
Istilah “kesamaan” yang dimiliki elemen-elemen data harus dipahami sebagai kesamaan secara matematis, dimana ukurannya dapat didefinisikan dengan baik. Kesamaan dapat juga didefinisikan sebagai ukuran jarak. Jarak dapat diukur dari vektor data itu sendiri atau sebagai sebuah jarak dari sebuah vektor data terhadap pusat cluster (Babuska, 2009: 60). Pusat cluster biasanya tidak diketahui sebelumnya.
Pusat cluster akan terlihat ketika algoritma clustering telah disimulasikan untuk pembagian data. Algoritma clustering tidak hanya ditunjukkan bagaimana bentuk dan isi dari tiap cluster, tetapi juga dengan relasi dan jarak antar cluster.
2.1.3 Konsep Clustering
Menurut Babuska (2009: 61), secara umum metode clustering dibedakan menjadi dua yaitu clustering klasik dan fuzzy clustering. Metode clustering klasik (atau disebut juga sebagai hard clustering) didasarkan pada teori himpunan klasik yang menunjukan apakah suatu objek merupakan anggota atau bukan anggota dari suatu cluster. Clustering klasik bertujuan untuk membagi atau mempartisi (partitioning) data ke dalam suatu kelompok (cluster) secara eksklusif. Artinya apabila suatu elemen data telah menjadi anggota dari satu cluster, maka elemen tersebut tidak mungkin menjadi anggota dari cluster yang lain.
Berbeda dengan clustering klasik yang mempartisi data ke dalam suatu cluster secara eksklusif, metode fuzzy clustering memungkinkan suatu objek menjadi anggota dari beberapa cluster secara bersamaan dengan derajat keanggotaan yang berbeda. Setiap objek dalam suatu cluster tidak dibatasi secara tegas menjadi anggota cluster tersebut melainkan ditentukan oleh derajat keanggotaan yaitu antara 0 sampai dengan 1. Derajat keanggotaan tersebut yang akan mengindikasikan keberadaan suatu objek pada suatu cluster, dimana semakin besar derajat keanggotaan suatu objek dalam suatu cluster, maka semakin dekat objek tersebut dengan pusat clusternya. Hal ini berarti suatu objek akan cenderung menjadi anggota suatu cluster yang memiliki derajat keanggotaan yang paling besar.
Algoritma Clustering merupakan proses pengelompokan suatu objek informasi diperoleh dari data yang menjelaskan hubungan antar objek dengan prinsip untuk memaksimalkan kesamaan antar anggota satu kelas dan meminimumkan kesamaan antar kelas atau cluster. Clustering juga berguna untuk menemukan pola distribusi didalam sebuah dataset untuk proses analisa data. Tujuannya menemukan cluster yang berkualitas dalam waktu yang layak. Objek yang sama biasanya diperoleh dari kedekatan nilai-nilai atribut yang menjelaskan objek-objek data, sedangkan objek-objek data biasanya diperoleh dari presentasi sebagai titik dalam ruang multidimensi. Menurut Zeniarja et al 2013 menyatakan bahwa clustering merupakan metode untuk mengatur secara otomatis kumpulan data yang jumlahnya besar dengan partisi dataset, sehingga objek dalam cluster yang sama lebih mirip satu sama lain daripada objek dalam cluster yang lain. Pada pengelompokan dokumen tersebut mengatur pengumpulan data teks besar. Dalam bidang Information Retrieval (IR), clustering dokumen digunakan secara otomatis sebagai mengelompokkan dokumen yang memiliki kemiripan yang sama.
2.1.5 Algoritma Clustering
Clustering adalah sekumpulan data yang memiliki kesamaan terhadap data lain yang ada dalam satu cluster dan tidak memiliki kesamaan dengan objek di cluster yang berbeda (Han, 2007:383). Clustering atau yang biasa disebut data segmentation di dalam sebuah aplikasi karena clustering membagi data yang sangat besar ke dalam kelompok-kelompok berdasarkan kepada kesamaan yang ada. Clustering juga dapat digunakan untuk outlier detection, dimana jarak terluar lebih menarik dari kasus-kasus yang biasanya. Sebagai cabang dari statistika, analisis cluster telah lebih luas dipelajari dalam beberapa tahun, mengutakaman pada distance-based cluster analysis (Han, 2007: 384). Metode clustering pada dasarnya melakukan segmentasi atau pengelompokkan suatu populasi data yang heterogen menjadi beberapa sub group atau cluster. Metode ini dikategorikan ke dalam teknik undirect knowledge atau unsuppervised learning karena tidak membutuhkan proses pelatihan untuk klasifikasi awal data dalam masing-masing group atau
cluster. Ada beberapa kategori pendekatan clustering (Gunadarma, 2008), diantaranya : a. Algoritma Partisi : mempartisi objek-objek ke dalam k cluster dan realokasi objek-objek secara iteratif untuk memperbaiki clustering. b. Algoritma Hirarkis : Agglomerative dimana setiap objek merupakan cluster, gabungan dari cluster-cluster membentuk cluster yang besar dan Divisive dimana semua objek berada dalam suatu cluster, pembagian cluster tersebut membentuk cluster-cluster yang kecil. c. Metode berbasis densitas : berbasis koneksitas dan fungsi densitas dan noise disaring, kemudian temukan cluster-cluster dalam bentuk sembarang. d. Metode berbasis grid : kuantitas ruang objek ke dalam struktur grid. e. Berbasis Model : menggunakan model untuk menemukan keadaan data yang baik.
2.1.6 Algoritma K-Means
Pengelompokan objek (objek clustering) adalah salah satu proses dari objek mining yang bertujuan untuk mempartisi objek yang ada kedalam satu atau lebih cluster objek berdasarkan karakteristiknya. Objek dengan karakteristik yang sama dikelompokkan dalam satu cluster dan objek dengan karakteristik berbeda dikelompokkan kedalam cluster yang lain. Algoritma K-Means Cluster Analysis termasuk dalam kelompok metode cluster analysis non hirarki, dimana jumlah kelompok yang akan dibentuk sudah terlebih dahulu diketahui atau ditetapkan jumlahnya. Algoritma K-Means Cluster Analysis menggunakan metode perhitungan jarak (distance) untuk mengukur tingkat kedekatan antara objek dengan titik tengah (centroid). Algoritma K-Means tidak terpengaruh terhadap urutan objek yang digunakan, hal ini dibuktikan ketika penulis mencoba menentukan secara acak titik awal pusat cluster dari salah satu objek pada permulaan perhitungan. Jumlah keanggotaan cluster yang dihasilkan berjumlah sama ketika menggunakan objek yang lain sebagai titik awal pusat cluster tersebut. Namun, hal ini hanya berpengaruh pada jumlah iterasi yang dilakukan. Algoritma K-Means Cluster Analysis pada dasarnya dapat diterapkan pada permasalahan dalam memahami perilaku konsumen, mengidentifikasi peluang produk baru dipasaran dan algoritma
K-Means ini juga dapat digunakan untuk meringkas objek dari jumlah besar sehingga lebih memudahkan untuk mendiskripsikan sifat-sifat atau karakteristik dari masing-masing kelompok.
2.1.7 Algoritma K-Means Clustering
K-Means Clustering adalah suatu metode penganalisaan data atau metode Data Mining yang melakukan proses pemodelan tanpa supervisi (unsupervised) dan merupakan salah satu metode yang melakukan pengelompokan data dengan sistem partisi. Dasar algoritma K-Means: 1. Pilih K sebagai centorid awal
2. Ulangi
3. Bentuk K cluster dengan menetapkan semua poin ke centroid terdekat. 4. Menghitung berubah centroid setiap cluster
5. Sampai centroid tidak. 2.2. Beberapa Algoritma Clustering
2.2.1 Algotirma Naive Bayes Classifier (NBC)
Algoritma Naïve Bayes Classifier memberikan sebuah kerangka pencocokan parsial tetapi masih belum maksimal. Untuk tercapainya hasil yang maksimal yaitu menerapkan bobot non-bilangan terhadap istilah indeks query dan dokumen. Biasanya nilai bobot dapat digunakan untuk menghitung tingkat kesamaan setiap dokumen yang tersimpan dalam sistem. Hasilnya merupakan kumpulan dokumen yang sudah diambil jauh lebih akurat atau sesuai yang dibutuhkan dari pengguna.
Ada dua langkah penting dalam klasifikasi dengan Naïve Bayes yaitu pelatihan dan pengklasifikasian :
a. Pelatihan
Pada tahap pelatihan ini pertama menghitung probabilitas setiap genre data pelatihan dengan rumus :
𝑃(𝐶) = 𝑛𝑐+ 𝑠
𝑁+𝑠𝑘 (1)
Yang kedua hitung katalog setiap nilai dari suatu atribut sebagai berikut : 𝑃(𝐴𝑖 = 𝑎𝑗|𝑐) = 𝑛𝑗+ 𝑠 (2)
Keterangan :
Nc = jumlah data
S = konstanta dari (s > 0) K = jumlah katalog
P(Ai=aj|c) = nilai fitur aj-i untuk katalog
Vi = jumlah nilai dari atribut Ai
Nj = jumlah contoh dalam katalog
b. Pengklasifikasian
Pada tahap ini hitung probabilitas dari sebuah jenis untuk setiap katalog. Rumus :
𝑃(y|𝐴) = 𝑃(𝑦) ∏ 𝑃 (𝐴𝑖|𝑦)𝑡 (3)
Keterangan :
P (y | A)= probabilitas jenis katalog y jika memiliki fitur A P (y) = probabilitas dari sebuah jenis katalog y
P (Ai | y) = probabilitas yang memiliki nilai fiturAi dengan katalog y.
2.2.2 Algoritma K-Nearest Neighbor (KNN)
Algoritma Nearest Neightbor atau KNN adalah sebuah metode klasifikasi terhadap sekumpulan data berdasarkan pembelajaran data yang sudah diklasifikasikan sebelumnya. Termasuk dalam supervised learning, dimana hasil query instance yang baru diklasifikasikan berdasarkan kelompok dengan jarak kedekatan dari kategori yang ada dalam KNN. Diberikan titik query, akan ditemukan sejumlah obyek atau titik training yang paling dekat
dengan titik query. Algoritma KNN menggunakan klasifikasi ketetanggaan sebagai nilai prediksi dari query instance yang baru [15].
2.2.3 Algoritma Vector Space Model (VSM)
Algoritma VSM merupakan algoritma yang dilakukan denganjarak kedekatan atau kesamaan (smilaritas) pada term dengan cara pembobotan term. Dengan prinsip dasar dokumen dianggap sebagai sebuah ruang (vektor) yang berhubungan dengan melihat kesamaan (similaritas) vektor dokumen dan vektor query berdasarkan jarak dan arah. [16].
Dasar pemikiran pada algoritma VSM, bahwa di sebuah dokumen berasal dari istilah yang merupakan dokumen. VSM mewakili kedua dokumen dan query sebagai vektor dalam ruang yang tinggi, di mana masing-masing dimensi dari ruang sesuai dengan term dalam koleksi dokumen. Vektor dari koleksi dokumen dikumpulkan sebagai matriks disebut matriks jangka dokumen. Cara kerja pengambilan dari sebuah model VSM tergantung pada bobot term, yang menunjukkan derajat hubungan antara term dan dokumen. Referensi menunjukkan bahwa mengindeks dengan berat badan jangka lebih efisien daripada sistem biner. cosines sudut antara dokumen dan vektor query digunakan sebagai kesamaan numerik antara vektor.
Pengkategorian Pada Perpustakaan Kunci Ilmu Kendal
Katalog adalah suatu daftar yang terurut yang berisi informasi tertentu dari benda atau barang yang didaftar. Secara lebih luas pengertian katalog adalah metode penyusunan item (berisi informasi atau keterangan tertentu) dilakukan secara sistematis baik menurut abjad maupun urutan logika yang lain. Pemakai perpustakaan menggunakan koleksi perpustakaan untuk mencari bacaan rekresioanal, atau informasi untuk melakukan kegiatan penelitian, dan sebagai alat bantu belajar maupun kegiatan lainnya. Mungkin saja pemakai tidak dapat menemukan buku yang diinginkan dalam rak. Untuk mengetahui buku apa saja yang dimiliki perpustakaan diperlukan alat bantu
yang disebut katalog perpustakaan. Jadi katalog perpustakaan adalah daftar buku dalam sebuah perpustakaan atau dalam sebuah koleksi.
Beberapa jenis katalog yangdikatagorikandalam perpstakaan Kunci Ilmu Kendal :
a. Agama
Sebuah koleksi terorganisir dari kepercayaan,sistembudaya, danpandangan dunia yangmenghubungkan manusiadengan tatanan/perintah darikehidupan.
b. Bahasa
Kemampuan manusia untuk berkomunikasi dengan manusia lainnya menggunakan tanda, misalnya kata dan gerakan.
c. Kesenian
Kesenian dalam kompleks dari berbagai ide-ide,norma-norma,gagasan, nilai-nilai,serta peraturan dimana kompleks aktivitas dantindakantersebut berpoladari manusiaitusendiri danpada umumnyaberwujud berbagai benda-bendahasilciptaan manusia [19].
d. Olahraga
Olah raga sebagaisalah satu aktivitasfisik maupun psikis seseorang yang berguna untukmenjaga danmeningkatkankualitaskesehatan seseorang setelaholahraga.
e. Sejarah
Sejarah umum adalahkejadianyang terjadi di masalampau yangdisusun berdasarkanpeninggalan-peninggalan berbagaiperistiwa.Peninggalan-peninggalantersebutadalahsumbersejarah. Sejarahdapat jugadiartikan sebagai cabang ilmuyang mengkajisecarasistematiskeseluruhan perkembanganproses perubahandan dinamikakehidupan masyarakat dengan segala aspekkehidupannya yang terjadi di masalampau.
f. Anak-anak
Buku anak adalah buku yang sesuaidengan tingkatkemampuan untuk membacadan minatanak-anak atau tingkatan pendidikan mulai prasekolah sampai dengan sekolah dasar.
Microsoft Visual Basic (sering disingkat sebagai VB saja) merupakan sebuah bahasa pemrograman yang menawarkan integrated Development Environtment (IDE) visual untuk membuat program perangkat lunak berbasis sistem operasi Microsoft Windows dengan menggunakan model pemrograman (COM).
Visual Basic merupakan turunan bahasa pemrograman BASIC dan menawarkan pengembangan perangkat lunak komputer berbasis grafik dengan cepat.
Beberapa bahasa skrip seperti Visual Basic for Applications (VBA) dan Visual Basic Scripting Edition (VBScript), mirip seperti halnya Visual Basic, tetapi cara kerjanya yang berbeda.
2.3 XAMP
XAMPP adalah sebuah software web server dari Apache yang didalamnya sudah tersedia database server MySQL dan mendukung untuk PHP programming. XAMPP singkatan dari Cross-Platform (X), Apache (A), MySQL (M), PHP (P) dan Perl (P). XAMPP ini telah menyediakan dalam satu paket instalasi berupa apache, PHP, dan MySQL yang secara instant. Dengan cara pembuatan yang sederhana dan ringan, Apache membuatnya untuk memudahkan para pengembang web atau pemula untuk membuat server web lokal dengan tujuan yaitu pengujian serta membuat sebuah web server yang menggunakan aplikasi (Apache), basis data (MySQL), dan bahasa scripting (PHP) [30].
2.4 MySQL
MySQL merupakan perangkat lunak sistem manajemen basis data SQL (bahasa Inggris: database management system) atau DBMS yang multi thread, multi-user, dengan sekitar 6 juta instalasi di seluruh dunia. MySQL AB membuat MySQL tersedia sebagai perangkat lunak gratis dibawah lisensi GNU General Public License (GPL), tetapi mereka juga menjual dibawah
lisensi komersial untuk kasus - kasus di mana penggunaannya tidak cocok dengan penggunaan GPL[31].
Pengertian lain dari MySQL adalah Relational Database Management System (RDBMS) yang didistribusikan secara gratis dibawah lisensi GPL (General Public License). Dimana setiap orang bebas untuk menggunakan MySQL, namun tidak boleh dijadikan produk turunan yang bersifat komersial. MySQL sebenarnya merupakan turunan salah satu konsep utama dalam database sejak lama, yaitu SQL (Structured Query Language).
2.5 Cara Kerja Algoritma K-Means
2.6 Kerangka Pemikiran Latar Belakang
Kebanyakan pengunjung sulit mendapatkan buku referensi yang tepat sesuai dengan kebutuhan mereka. Hal itu dikarenakan kurangnya fasilitas dalam sebuah perpustakaan yang dapat mengelompokkan buku sesuai dengan kategorinya.
Masalah
Bagaimana mengklasterisasikan katagori buku agama, bahasa, kesenian, olahraga, kesustraan, sejarah umum, anak-anak dengan menggunakan metode Naive Bayes ?
Tujuan
Mengklasteringkan agama, bahasa, kesenian, olahraga, sejarah umum, anak-anak dengan menggunakan metode K-Means.
Eksperimen
Data Metode Tools
1. Text Dokumen 2. Jumlah buku sebanyak 60 buah. Sebaran 10 buku untuk setiap katalognya.
K-Means Coding K-means : PHP, MySQL
Hasil
Dalam penelitian ini menghasilkan katagori agama, bahasa, kesenian, olahraga, sejarah umum, anak-anak yang dapat dikelompokkan secara otomatis dengan menggunakan metode K-Means.