DECISION SUPPOR SYSTEM
DECISION SUPPOR SYSTEM
ROFIUDDIN
ROFIUDDIN
UNIVERSITAS AMIKOM
UNIVERSITAS AMIKOM
YOGYAKARTA
YOGYAKARTA
DAFTAR ISI
DAFTAR ISI
DAFTAR
DAFTAR ISI ISI ... ... 22
BAB I ARSITEKTUR DSS DAN MANAJEMENT DATA
BAB I ARSITEKTUR DSS DAN MANAJEMENT DATA... ... 44
1.1.
1.1. PENDAHULUANPENDAHULUAN... ... 44
1.2.
1.2. ARSITEKTUR DSSARSITEKTUR DSS... ... 44
1.2.1.
1.2.1. Sistem InformasiSistem Informasi... .... 44
1.2.2.
1.2.2. Jenis Sistem InformasiJenis Sistem Informasi... ... 44
1.2.3.
1.2.3. Decision Support SystemDecision Support System... ... 55
1.2.4.
1.2.4. Penerapan DssPenerapan Dss... ... 55
1.2.5.
1.2.5. Perbedaan DssPerbedaan Dss... ... 66
1.2.6.
1.2.6. Pengertian MasalahPengertian Masalah... ... 66
1.2.7.
1.2.7. KeputusanKeputusan... ... 66
1.2.8.
1.2.8. Macam-Macam KeputusanMacam-Macam Keputusan... ... 66
1.3.
1.3. MANAJEMEN DATAMANAJEMEN DATA... ... 77
1.3.1.
1.3.1. DatabaseDatabase ... ... 77
1.3.2.
1.3.2. Database Management SystemDatabase Management System... ... 77
1.3.3.
1.3.3. Query FacilityQuery Facility... ... 77
1.3.4.
1.3.4. Data DirectoryData Directory... ... 88
1.3.5.
1.3.5. Data SourceData Source ... ... 88
1.4.
1.4. MANAJEMEN MODELMANAJEMEN MODEL... .... 88
1.4.1.
1.4.1. Model BaseModel Base... ... 99
1.4.2.
1.4.2. Model Base Management SystemModel Base Management System... .... 99
1.4.3.
1.4.3. Model DirectoryModel Directory... .... 99
1.4.4.
1.4.4. Model Execution, Integration, And CommandModel Execution, Integration, And Command... 9... 9
1.5.
1.5. USER INTERFACE (UI)USER INTERFACE (UI)... .... 99
1.6.
1.6. KNOWLEDGE BASEKNOWLEDGE BASE... ... 1010
BAB 2 DATA MINING DAN DATA WAREHOUSE
BAB 2 DATA MINING DAN DATA WAREHOUSE... ... 2525
2.1.
2.1. DATA MININGDATA MINING... ... 2525
2.1.1.
2.1.1. Pengertian Data MiningPengertian Data Mining... ... 2525
2.1.2.
2.1.2. EstimationEstimation... ... 2525
2.1.3.
2.1.3. PredictionPrediction... ... 2626
2.1.4.
2.1.4. Pengertian KlasifikasiPengertian Klasifikasi... ... 2626
2.1.5.
2.1.5. Metode KlasifikasiMetode Klasifikasi... . 2626
2.1.7.
2.1.7. Metode KlasteringMetode Klastering... . 2727
2.1.8.
2.1.8. AsosiasiAsosiasi... ... 2828
2.2.
2.2. DATA WAREHOUSEDATA WAREHOUSE... . 2828
2.3.
2.3. DATA CLEANINGDATA CLEANING... ... 2929
2.4.
BAB I ARSITEKTUR DSS DAN MANAJEMENT DATA
1.1. PENDAHULUAN
System computer terdiri atas berbagai tipe, tergantung dari bidang tertentu yang akan dibuat. Secara umum system computer dibuat berdasarkan kebutuhan dari suatu bidan atau ilmu pengetahuan, dalam banyak kasus system computer dibuat berdasarkan suatu masalah kehidupan, dengan kata lain system dibuat untuk membantu menangani kegiatan manusia agar lebih mudah.
Computer mambantu manusia dalam berbagai aspek kehidupan, dari suatu masalah dalam kehidupan sehari-hari, mulai dari yang paling simple hingga yang sangat rumit. Sebagai contoh system computer pengambilan keputusan pada perusahaan, system dibuat berdasarkan masalah perusahaan yang apa bila hal tersebut di lakukan oleh manusia membutuhkan waktu yang cukup lama, sehingga berdasarkan penelitian dibuat suatu system pengambil keputusan dengan menggukan pendekatan tertentu dan data pengalaman selama beberapa waktu tertentu. System ini disebut sebagai system pendukung keputusan atau pengambil keputusan.
1.2. ARSITEKTUR DSS 1.2.1. Sistem Informasi
System informasi adalah kombinasi dari teknologi informasi dan aktivitas manusia yang menggunakan teknologi itu untuk kepentingan kegiatan dan manajemen. Sistem informasi juga bisa di artikan sebagai alat yang menyediakan informasi untuk pengelolaan dalam pengambilan keputusan dan menjalakan kegiatan perusahaan. Pada dasarnya system informasi tebentuk dari kegiatan mengumpulkan data, mengelompokkan data, menghitung, menganalisa dan menyajikannya dalam bentuk laporan, sehingga system informasi dapat menghimpun dan menyajikan berbagai jenis data yang
akurat untuk berbagai jenis kebutuhan.
System informasi berperan penting dalam sebagian besar organisasi. Bank tidak dapat memproses aktivitas pembayaran, supermarket tidak dapat mengatur rak, pemerintah kesulitan dalam penarikan pajak, rumah sakit kesulitan mengatur system pengelolaan pasien tanpa dukungan system
informasi. Hamper semua sector system informasi berperan penting. 1.2.2. Jenis Sistem Informasi
1) System informasi personal 2) System informasi perusahaan 1.2.3. Decision Support System
Decision support system (DSS) atau di Indonesia yang lebih dikenal sebagai system pendukung keputusan (SPK) merupakan system yang sangat bagus untuk membantu dalam penyelesaian pengambilan keputusan yang cukup rumit atau kompleks. System pendukung keputusan adalah system berbasis computer yang ditujukan untuk membantu dalam pengambilan keputusan dengan
memanfaatkan data dan model tertentu untuk memecahkan berbagai persoalan yang tidak terstruktur. Secara garis besar DSS dibangun oleh 3 bagian:
1) Database
Database merupakan kumpulan data yang di miliki oleh suatu organisasi, baik yang berupa transaksi sehari-hari, atau data dasar. Sedangkan untuk keperluan DSS data harus relevan dengan permasalahan yang akan dipecahkan melalui simulasi yang di atur oleh perangkat lunak yang disebut DBMS (Database manajement system).
2) Model base
Model merupakan representasi dari suatu masalah yang di tuangkan dalam format kuantitatif sebagai dasar pengambilan keputusan. Terdiri atas tujuan dari permasalahan, komponen terkait, Batasan, dan hal terkait lainnya.
3) Communication
Merupakan fasilitas yang mampu menyatukan system yang terpasang dengan pengguna secara interaktif yang dikenal dengan subsitem dialog. Dapat berinteraksi dan memberikan perintah pada DSS melalui dialog dengan menyediakan antarmuka.
1.2.4. Penerapan Dss
Aplikasi DSS banyak digunakan dalam berbagai bidang karena kemampuannya dalam memberikan solusi terhadap suatu masalah atau untuk mengevaluasi suatu peluang. DSS membantu memberikan alternative dalam pengambilan keputusan, sedangkan keputusan akhir tetap di tentukan oleh pengambil keputusan.
DSS merupakan pendekatan (metodologi) untuk mendukung pengambilan keputusan. Aplikasi dikembangkan secara khusus menggunakan Computer Base Information System (CBIS) yang interaktif, fleksibel, dan mudah digunakan. Menggunakan data dengan antarmuka yang mudah dan dapat menggabungkan wawasan dari pembuat aplikasi. Biasanya DSS dibangun menggunakan suatu model
yang mendukung semua tahap pengambilan keputusan dan komponen pengetahuan. Dan hasil akhirnya berupa aplikasi PC atau web yang dapat di gunakan oleh ban yak orang di berbagai tempat.
1.2.5. Perbedaan Dss
DSS berbeda dengan system pengambil keputusan lainya. DSS memilki kemampuan yang sangat berbeda, berikut merupakan perbedaan DSS dengan Sistem Informasi Manajemen dan Sistem Pakar:
- Sistem Informasi Manajemen
Sistem Informasi manajemen didekasikan untuk otomatisasi tugas-tugas operasional. Dalam h al pengambilan keputusan, SIM berfokus pada keputusan terstruktur. (Lukacs & Bhadra, 2003) - System Pakar
1.2.6. Pengertian Masalah
Masalah merupakan kondisi dimana suatu kasus harus dipecahkan. Umumnya kasus yang harus di pecahkan berkaitan dengan data yang hilang, data yang tidak valid, dan atau p encarian data. Pada kasus
tertentu harus dipecahkan dengan suatu metode, misalnya metode klasifikasi, yang menangani kasus berdasarkan catatan tertentu, namun sering terdapat pengecualian karena terkadang informasi yang di
hasilkan tidak akurat.
Metode klasifikasi paling sering digunakan dalam memecahkan suatu masalah dalam bidang machine learning / data mining dan jaringan saraf tiruan merupakan metode yang sesuai dalam pemecahan masalah dengan cara klasifikasi.
1.2.7. Keputusan
Keputusan adalah proses pengambilan keputusan yang kompleks. Keputusan di anggap baik apa bila memenuhi kriteria masing-masing pengambil keputusan dan tingkat aspirasi mereka untuk keputusan tertentu.
Faktor-faktor pengambilan keputusan
- Cara dimana suatu masalah dapat direpresentasikan oleh ban yak hal yang terkait dengan kualitas solusi yang ditemukan
- Memberikan banyak alternatif yang dapat dipilih oleh pembuat keputusan terkait dengan asumsi tetang kondisi suatu masalah.
- Rumusan masalah yang buruk adalah masalah. Proses peruumusan masalah dan pencarian solusi adalah identik, oleh karena itu spesifikasi masalah adalah spesifikasi arah yang mana suatu perawatan di pertimbangkan.
1.2.8. Macam-Macam Keputusan Macam-macam keputusan
- Terstruktur
Contoh: Management Information System, Management Science Model - Semistruktur
Contoh: SS, KMS, GSS, CRM, SCM - Tidak terstruktur
Contoh: GSS, KMS, ES, neural network. 1.3. MANAJEMEN DATA
Menajemen data dalam DSS terdiri atas beberapa baigian, yaitu: - DSS database
- Database management system - Data directory
- Query facility 1.3.1. Database
Database adalah kumpulan data yang saling terkait yang dalam suatu organisasi dan dapat digunakan oleh lebih dari satu orang untuk lebih dari satu aplikasi. Dalam banyak contoh DSS, data di kirim dari warehouse, atau system database utama (mainframe) melalui web server.
Data terdiri atas dua bagian, yaitu internal data dan external data. Internal data (data internal) merupakan data yang datang dari pemprosesan transaksi perusahaan. Sebagai contoh, daftar gaji bulanan, anggaran perusahaan, perkiraan penjualan yang akan datang, dan rencana perekrutan dimasa depan. Data external
merupakan data yang berasal dari luar organisasi seperti data pajak, p eraturan pemerintah, lapangan kerja daerah, data sensus, dan data ekonomi daerah.
1.3.2. Database Management System
Database management system (DBMS) merupakan system pengelola data agar dapat di buat dan di akses. DSS biasanya dibangun menggunakan standart DBMS rasional yang baik. Pengelolaan database yang baik dapat mendukung banyak kegiatan manajerial; mendukung pemeliharaan serangkaian data yang beragam dan pembuatan laporan.
1.3.3. Query Facility
Dalam membangun dan menerapkan DSS, seringkali diperlukan untuk mengakses, memanipulasi, dan query data. Dan ini merupakan tugas dari Query Facility. Menerima permintaan dari komponen DSS liainnya, merumuskan rincian permintaan, dan memberikan hasil dari permintaan. Query Facility
mencakup dari sebuah Bahasa khusus (contoh: SQL). Fungsi penting dari system query DSS adalah untuk operasi pemilihan dan manipulasi data, meski dapat dilihat oleh pengguna, tetapi ini sangat penting. Pengguna dapat menggunakan aplikasi dengan tampilan data yang sederhana dengan hanya sekali tekan tombol dan mendapatkan hasil yang disajikan dengan rapi dan dinamis.
1.3.4. Data Directory
Data directory adalah katalog dari semua data dalam database. Berisi definisi data dan fungsinya menjawab semua pertanyaan tentang ketersediaan data, sumber dan informasi lainnya. Direktori data sangat penting dalam proses pemindaian data identifikasi masalah. Seperti model katalog, direktori dapat di tambah, di hapus dan pengambilan informasi pada data tertentu.
1.3.5. Data Source
Sumber data database DSS berasal dari data internal dan eksternal, serta data pribadi (privat) yang dimiliki oleh sutu pengguna atau lebih. Hasil proses masuk ke database khusus atau ke database perusahaan, jika ada. Juga bisa digunakan untuk aplikasi lain. (Turban, E. Aronson, & Liang, 2007: 111)
- Sumber data internal
Sumber data internal merupakan data yang berasal dari system transaksi organisasi. Sebagai contoh data gaji bulanan karyawan, data operasional, data pemasaran. Contoh lain adalah data penjadwalan perawatan mesin dan alokasi anggaran, dan lain-lain.
- Sumber data eksternal
Data ekternal merupakan data yang berasal dari luar organisasi seperti data industry, data risert pemasaran, data sensus, data lapangan kerja regional, peraturan pemerintah, jadwal tarif pajak dan data ekonomi nasional.
- Sumber data privat
Data pribadi mencakup pedoman yang digunakan oleh pembuat kebijakan khusus dan penilaian data dan atau situasi tertentu.
1.4. MANAJEMEN MODEL
Manajemen model terdiri atas beberapa bagian, yaitu: - Model base
- Model base management system - Model directory
1.4.1. Model Base
Model base berisi rutin dan statistic special, keuangan, peramalan, ilmu manajemen dan model kuantitatif lainnya yang mampu menganalisa dalam DSS. Kemampuan utnuk memanggil, menjalankan, mengubah, menggabungkan, dan memeriksa model adalah kunci utama kemampuan DSS yang membedakan dari system informasi lainnya. Model dalam model base di bagi menjadi 4, yaitu strategis, taktis, operasional, dan analisis.
1.4.2. Model Base Management System
Model Base Management system (MBMS) adalah pembuatan model dengan menggunakan Bahasa pemrograman, alat DSS dan atau subrutin, dan pembuatan blok lainnya, rutinitas baru dan laporan, model pembaruan dan perubahan, dan model manipulasi data. MBMS mampu menggabungkan semua model
dengan hal yang terkait secara tepat melalui database. 1.4.3. Model Directory
Model Directory fungsinya mirip dengan model database. Ini merupakan katalog dari semua model dan perangkat lunak lainnya di lingkungan model. Berisi definisi model, dan fungsi utamanya adalah
menjawab pertanyaan tentang ketersediaan dan kemampuan model. 1.4.4. Model Execution, Integration, And Command
Model Excecution adalah proses pengontrolan model sebenarnya. Model Integration menggabungkan beberapa model saat dibutuhkan atau mengintegrasikan DSS dengan aplikasi lain. Model Commad
digunakan untuk menerima dan menafsirkan perintah pemodelan dari komponen antarmuka pengguna dan mengarahkannya ke MBMS, Model Execution atau Model Integrasi.(Turban et al., 2007)
1.5. USER INTERFACE (UI)
System computer berisi pengolah Bahasa yang ramah dan berorientasi masalah antara pengguna dan computer. Komunikasi ini terjalin dalam Bahasa alami. Karena keterbatasan teknologi, sebagian besar system computer menggunakan pendekatan tanya jawab untuk berinteraksi. Terkadang system di lengkapi dengan menu-menu yang di sajikan dalam bentuk grafis.
Dalam aplikasi berbasis web, antarmuka grafis menjadi sangat penting, dengan tampilan yang baik dan dinamis. Aplikasi berbasis web memberi peluang bersar data dapat di akses di seluruh dunia sehingga menjadi penting sajian antarmuka yang umum dan mudah digunakan.
User interface dalam system pendukung keputusan menjadi sangat penting. ini tidak diragukan lagi karena aplikasi berbasis web memberikan kemudah dengan teknologi web / internet. Dan ini sangat
berpotensi pada deversifikasi DSS. Dukungan dapat diberikan dalam berbagai konfigurasi. Teknologi ini dibangun atas empat komponen dasar: data, model, atarmuka pengguna, dan pengetahuan. (Turban et al., 2007: 102)
1.6. KNOWLEDGE BASE
Knowledge base (basis pengetahuan) berisi pengetahuan yang relevan yang digunakan untuk memahami, merumuskan, dan memecahkan masalah. Mencakup dua masalah utama: fakta, seperti situasi masalah dan teori area masalah, dan heuristic khusus atau peraturan yang mengarahkan pemanfaatan pengetahu an untuk memecahkan masalah tertentu dalam area tertentu.
Penelusuran pengetahuan di dalam data memberikan contoh penerapan berbagai algoritma pada kumpulan data actual yang sebenarnya. Faktanya. Proses penemuan pengetahuan akan membantu manusia menemukan pola perilaku. Sekali lagi, tergantung manusia untuk mengidentifikasi penyebabnya. (Larose & Larose, 2014)
1.7. CONTOH KASUS 1.7.1. GAP Kompetensi
Sebuah perusahaan properti ingin mencarikan lokasi rumah yang sesuai dengan keinginan Pak Ali. Dalam menentukan pilihan, perusahaan tersebut menggunakan metodeGap Kompetensi.Jika diketahui kriteria dan nilainya adalah sebagai berikut:
Kode Kriteria
Nilai
1 2 3 4 5
K1 Kedekatan dengan sarana pendidikan Sangat jaun Jauh Cukup dekat Dekat Sangat dekat K2 Frekuensi banjir Sangat
sering
Sering Jarang Agak jarang
Tidak pernah K3 Kedekatan dengan pasar Sangat
jauh
Jauh Cukup dekat
Dekat Sangat dekat
K4 Kedekatan dengan sarana hiburan Sangat jauh Jauh Cukup dekat Dekat Sangat dekat K5 Kedekatan dengan sarana
ibadah Sangat jauh Jauh Cukup dekat Dekat Sangat dekat Sementara lokasi yang tersedia adalah sebagai berikut:
Lokasi K1 K2 K3 K4 K5
L1 3 2 1 2 1
L2 2 1 5 2 3
Lakukan perhitungan untuk menentukan lokasi nama yang lebih tepat untuk pak Ali jika dia mengingikan:
1. Lokasi dekat dengan sarana Pendidikan 2. Tidak pernah banjir
3. Jauh dari pasar
4. Jauh dari sarana hiburan 5. Dekat dengan sarana ibadah
Pak ali menganggap frekuensi banjir dan kedekatan dengan sarana ibadah merupakan faktor penting dengan prosentase kepentingan 70:30.
Pembahasan I
a. Menggunakan metode Gap Kompetensi. Berikut penyelesaian kasus di atas.
1) Menentukan Core Factor dan Second Factor Core Factor = K2, K5
Second Factor = K1, K3, K4. 2) Matrik Gap Kompetensi
Alternatif K1 K2 K3 K4 K5
L2 2 1 5 2 3
Preferensi 3 4 4 2 2
L1 0 -2 -3 -3 -1
L2 -1 -3 1 0 1
Pembobotan nilai Gap
NO SELISIH BOBOT KETERANGAN
1 0 5 Kompetensi sesuai yang di butuhkan 2 1 4.5 Kompetensi kelebihan 1 tingkat 3 -1 4 Kompetensi kurang 1 tingkat 4 2 3.5 Kompetensi kelebihan 2 tingkat 5 -2 3 Kompetensi kurang 2 tingkat 6 3 2.5 Kompetensi kelebihan 3 tingkat 7 -3 2 Kompetensi kurang 3 tingkat 8 4 1.5 Kompetensi kelebihan 4 tingkat 9 -4 1 Kompetensi kurang 4 tingkat Dapat disimpulkan bobot tiap alternative lokasi adalah:
Alternatif K1 K2 K3 K4 K5
L1 5 3 2 5 4
L2 4 2 4.5 5 4.5
3) Perhitungan Terhadap Lokasi 1
+
7
3.5
++
4
4) Perhitungan Terhadap Lokasi 2
+.
.
3.25
+.+
.
4.5
5) Pengelompokan Nilai Gap CF dan SF Terbobot
Alternatif K1 K2 K3 K4 K5 NCI NSI
L1 5 3 2 5 4 3.5 4
L2 4 2 4.5 5 4.5 13.5 4.5
6) Mencari Hasil
L1 => NSK = (0.7 x 3.5) + (0.3 x 4) = 3.65 L2 => NSK = (0.7 X 3.25) + (0.3 X 4.5) = 3.625 Nilai terbesar diperoleh L1 dengan nilai sebesar 3.65
Pembahasan II
Jika preferensi yang diberikan pak Ali terhadap kriteria adalah {3, 4, 4, 2, 2}, bagaimana penyelesaina kasus ini dengan menggunakan metode TOPSIS, SAW, dan WP.
a. Metode TOPSIS
Metode TOPSIS merupakan salah satu metode yang digunakan dalam system pendukung keputusan. Berdasarkan contoh soal di atas langkahnya sebagai berikut:
1) Konvesi data keladam bentuk matrik.
Matrik ini bersal dari data lokasi dan nilai masing-masing kriteria yang di i nginkan.
K1 K2 K3 K4 K5
L1 3 2 1 2 1
L2 2 1 5 2 3
2) Menghitung matrik ternormalisasi
Untuk menghitung matrik ternormalisasi disini kita gunakan rumus seperti berikut:
√ ∑
dimana i = 1, 2, …, m dan j = 1, 2, …, n.Hasilnya sebagai berikut:
L1 0.83205 0.894427 0.196116 0.707107 0.316228 L2 0.5547 0.447214 0.980581 0.707107 0.948683 3) Menghitung matrik ternormalisasi terbobot
Untuk menghitung matrik ternormalisasi terbobot, caranya bobot kriteria (W) dikalikan dengan kriteria ternormalisasi terbobot (Y), maka rumusnya
; dengan i = 1, 2, …, m dan j = 1, 2, …, n. dan hasilnya seperti berikut:L1 2.496151 3.577709 0.784465 1.414214 0.632456 L2 1.664101 1.788854 3.922323 1.414214 1.897367 4) Menentukan solusi ideal postif dan solusi ideal negative.
Untuk menghitung solusi ideal digunakan rumus A+ =
max
,
,…,
dan A- =max,,…,
hasilnya:A+ 2.496151 3.577709 3.922323 1.414214 1.897367 A- 1.664101 1.788854 0.784465 1.414214 0.632456
5) Menghitung jarak solusi ideal positif dan solusi ideal negative
Menghitung jarak solusi ideal digunakan rumus
+ √ ∑ +
=
dan−
√ ∑ −
=
dimana i=1, 2, …, m dan j=1, 2, …, n.D+ TOTAL D1 1.664101 2.683282 3.726207 0.707107 1.581139 10.36183 D2 1.941451 3.130495 2.941742 0.707107 0.948683 9.669478 D- TOTAL D1 0.83205 1.788854 0 0 0 2.620905 D2 0 0 3.137858 0 1.264911 4.402769 6) Menentukan jarak pereferensi alternative.
Untuk menghitung nilai pereferensi alternative digunakan rumus sebagai berikut:
−
− +
V
V1 11.36183 V2 10.66948
b. Metode SAW
Seperti halnya metode TOPSIS, metode SAW merupakan salah satu metode system pendukung keputusan multi kriteria (MCDA) yang sangat terkenal. Sebagai contoh penerapannya pada kasus di atas, langkahnya sebagai berikut:
1) Normalisasi
Data alternative pada table alternative dinormalisasi dengan rumus seba gai berikut:
/max
Dan hasilnya adalah sebagai berikut:
K1 K2 K3 K4 K5
L1 1 1 0.2 1 0.33
L2 1 1 1 1 1
2) Normalisasi Terbobot
Untuk menghitung normalisasi terbobot digunakan rumus seperti berikut:
=
Dan hasilnya sebagai berikut:
TOTAL L1 3 4 0.8 2 0.67 10.47 L2 3 4 4 2 2 15
3) Alternative akhir.
Dari table di atas dapat disimpulkan pilihan alternative terbaik adalah L2
Metode WP merupakan salah satu metode yang sering digunakan dalam system pendukung keputusan. Penyelesaian kasus di atas dengan metode WP langkahnya sebagai berikut:
1) Perbaikan referensi bobot
Referensi bobot yang diberikan adalah sebagai berikut:
REFERENSI BOBOT 3 4 4 2 2
Dengan menggunakan rumus
∑
hasilnya sebagai berikut:PERBAIKAN BOBOT 0.2 0.3 0.5 0.5 1
2) Menentukan nilai Vector S
Rumus untuk menentukan nilai vector adalah
∏
=
dan hasilnya sebagai berikut: HASIL1.245731 1.259921 1 1.414214 1 2.21964 1.148698 1 2.236068 1.414214 3 10.89751
3) Perengkingan
Rumus yang digunakan untuk perengkingan adalah sebagai berikut:
∏
∏
>
+
Dan hasilnya sebagai berikut: V1 0.169217
V2 0.830783
Dari hasil perengkingan di atas dapat disimpulkan hasilnya adalah V2 = L2
Linear programming merupakan metode matematik dalam operation research untuk menentukan atau menyelesaikan masalah pengalokasian sumber daya terbaik untuk mencari ke untungan maksimum dan minimum. Linear programing dapat diseslesaikan dengan metode grafik atau simpleks. Metode simpleks merupakan metode yang digunakan untuk mengatasi kekurangan pada metode grafik dimana metode simpleks dapat menggunakan variable lebih dari 2. Berikut merupakan contoh kasus linear programming.
Contoh Kasus
Jaringa toko serba ada The Biggs menyewa perusahaan periklanan untuk jenis dan jumlah iklan yang harus diperoleh untuk toko.
Tiga jenis iklan yang tersedia adalah iklan komersial radio, televisi dan iklan surat kabar.
Jaringan toko ingin mengetahui jumlah setiap jenis iklan yang harus dibeli dalam rangka memaksimumkan tujuannya.
Berikut ini perkiraan setiap iklan komersial yang akan mencapai pemirsa potensial dari biaya tertentu.
Batasan sumber daya
o Batas anggaran untuk iklan adalah 1.000.000.000 o Stasiun televisi memiliki 4 waktu komersial o Stasiun radio memiliki 10 waktu komersial
o Surat kabar mempunyai jatah yang tersedia untuk 7 iklan
o Perusahaan iklan hanya mempunyai waktu dan karyawan untuk memproduksi tidak
melebihi 15 iklan. Pertanyaan
o Variable-variabel keputusan o Fungsi tujuan
o Batasan-batasan model
o Penyelesaian model dengan metode simplex
Penyelesaian
1) Variable-bariable keputusan
Variabel-variabel keputusan untuk kasus ini terdiri dari: a) Variabel C mewakili Cost (total biaya promosi) b) Variabel X mewakili jenis iklan Televisi
c) Variabel Y mewakili jenis iklan Radio
d) Variabel Z mewakili jenis iklan Surat Kabar 2) Fungsi tujuan
Fungsi tujuan untuk kasus ini dapat dibentuk menjadi suatu formula berikut:
150 60 40 →
. 3) Batasan-batasan modelModel dari pembatas-pembatas untuk kasus ini meliputi: a) Model Linear Programming
(a) Fungsi Tujuan
Minimumkan: C (Cost ) = X (150)+ Y (60)+ Z (40) → dalam jutaan. (b) Fungsi Pembatas
X (150) +Y (60)+ Z (40)≤ 1.000 → dalam jutaan.
4 X + Y + Z ≤ 80.000 X + 10Y + Z ≤ 120.000 X + Y + 7 Z ≤ 63.000 X (4) +Y (10)+ Z (7)≤ 15 X , Y , Z ≥ 0 b) Model Simplex
(a) Fungsi Tujuan
C – 150 X – 60Y – 40 Z – 0S 1 – 0S 2 – 0S 3 = 0 (b) Fungsi Pembatas
150 X + 60Y + 40 Z + 0S 1 + 0S 2 + 0S 3 = 1.000 (dalam jutaan) 4 X + Y + Z + S 1 = 80.000
X + Y + 7 Z + S 3 = 63.000
4 X + 10Y + 7 Z + S 1 + S 2 + S 3 = 15 X , Y , Z , S 1, S 2, S 3 ≥ 0
4) Penyelesaian dengan metode simplex a) Membuat Tabel Simplex
Variabel X Y Z S 1 S 2 S 3 Nilai Kanan (Solusi) C -150 -60 -40 0 0 0 0
S 1 4 1 1 1 0 0 80.000 S 2 1 10 1 0 1 0 120.000 S 3 1 1 7 0 0 1 63.000 b) Menentukan Kolom Kunci (Pivot)
Dengan table pada langkah (1), kolom kunci terletak pada baris C untuk kolom dengan nilai terkecil, yaitu pada kolom X dengan nilai -150. Sehingga kolom kunci terletak pada kolom dengan warna kuning pada tabel di bawah ini.
Variabel X Y Z S 1 S 2 S 3 Nilai Kanan (Solusi) C -150 -60 -40 0 0 0 0
S 1 4 1 1 1 0 0 80.000 S 2 1 10 1 0 1 0 120.000 S 3 1 1 7 0 0 1 63.000 c) Menentukan baris Kunci (Pivot)
Dengan tabel pada langkah (2), baris kunci terletak pada kolom Nilai Kanan untuk baris S 1 sampai baris S 3 dengan nilai terkecil, yaitu pada baris S 3 dengan nilai 63.000. Sehingga baris kunci terletak pada baris dengan warna biru pada tabel di bawah ini.
Variabel X Y Z S 1 S 2 S 3 Nilai Kanan (Solusi) C -150 -60 -40 0 0 0 0
S 1 4 1 1 1 0 0 80.000 S 2 1 10 1 0 1 0 120.000 S 3 1 1 7 0 0 1 63.000 d) Menentukan Angka Kunci
Dengan tabel pada langkah (3), angka kunci terletak pada perpotongan antara Kolom Kunci dengan Baris Kunci, yaitu dengan nilai 1 pada baris S 3. Angka kunci ditandai dengan warna merah pada tabel di bawah ini.
Variabel X Y Z S 1 S 2 S 3 Nilai Kanan (Solusi) C -150 -60 -40 0 0 0 0
S 1 4 1 1 1 0 0 80.000 S 2 1 10 1 0 1 0 120.000 S 3 1 1 7 0 0 1 63.000 e) Membuat Baris Baru Kunci (BBK)
Karena nilai kunci terletak pada kolom X maka baris S1 diubah nama menjadi baris X , dan nilai-nilai pada baris S 3 diubah pula dengan cara membagi nilai-nilai pada baris itu dengan angka kunci, sehingga diperoleh nilai-nilai pada BBK seperti pada tabel di bawah ini:
Variabel X Y Z S 1 S 2 S 3 Nilai Kanan (Solusi) C -150 -60 -40 0 0 0 0
S 1 4 1 1 1 0 0 80.000 S 2 1 10 1 0 1 0 120.000 X 1/1 1/1 7/1 0 0 1/1 63.000
Catatan: Pada kasus ini Angka Kunci bernilai 1, sehingga sebenarnya nilai-nilai untuk setiap cells pada tabel di langkah (4) boleh tidak diubah. Oleh karena itu pada langkah selanjutnya dapat dilakukan pemilihan solusi untuk permasalahan ini.
f) Mengingat fungsi tujuan adalah untuk meminimalkan biaya periklanan, maka solusi diperoleh pada baris S 1 sampai baris X yang memiliki Nilai Kanan paling minimum, yaitu pada baris X dengan Nilai Kanan 63.000. Sehingga dengan mengacu kepada nama
X = 1 Y = 1 Z = 7
NK = 63.000
Artinya: Iklan melalui Televisi dan Radio masing-masing dapat dilakukan sebanyak 1 kali, dan Iklan melalui Surat Kabar dapat dilakukan sebanyak 7 kali.
Total bianya periklanan dapat di hitung dengan formula pada Fungsi Tujuan adalah sebagai berikut:
C (Cost ) = X (150)+Y (60)+ Z (40) → dalam jutaan = 1(150) + 1(60) + 7(40)
= 150 + 60 + 280 → dalam jutaan = 210 + 280 → dalam jutaan = 490 → dalam jutaan.
Jadi, dengan melakukan periklanan melalui Televisi dan Radio masing-masing dapat dilakukan sebanyak 1 kali, dan periklanan melalui Surat Kabar dapat dilakukan sebanyak 7 kali, memerlukan total biaya periklanan sebesar Rp 490.000.000, yang mana total biaya ini masih lebih kecil daripada anggaran yang disediakan yaitu sebesar Rp 1 milyar.
1.7.3. TREND MOMENT
Metode Trend Moment adalah salah satu metode yang digunakan dalam melakukan forecasting, yang nantinya akan di jadikan acuan pada masa berikutnya. Dalam trend moment dapat dilakukan dengan menggunakan beberapa rumus tertentu, adapun rumus yang digunakan dalam penyusunan dari metode ini adalah sebagai berikut:
1.
2.
∑ . .∑
3.∑ ∑ ∑2
Rumus 1 merupakan persamaan garis trend yang akan di gambarkan (nilai trend).
Rumus 2 dan 3 digunakan untuk menghitung nilai “a” dan nilai “b” yang akan digunakan sebagai dasar penerapan garis linear (garis trend).
Contoh Kasus
Berikut merupakan data kasus DBD dari bulan Desember 2011 sampai Desember 2012, pertanyaanya berapa jumlah pasien DBD pada Desember 213?
BULAN JUMLAH December-11 120 January-12 79 February-12 99 March-12 143 April-12 57 May-12 106 June-12 120 July-12 74 August-12 65 September-12 125 October-12 102 November-12 66 December-12 105 December-13 ? Penyelesaian 1) Menentukan Parameter X
Parameter X selalu dimulai dari 0, dan
∑
= 2) Menentukan Parameter X2 dan XYSetelah parameter X ditentukan, selanjutnya nilai X di kuadratkan berdasarkan data historis dari masing-masing bulan, sehingga menjadi seperti pada table.
BULAN (X) JUMLAH (Y) Xi Xi.Yi X 2 December-11 120 0 0 0 January-12 79 1 79 1 February-12 99 2 198 4 March-12 143 3 429 9 April-12 57 4 228 16 May-12 106 5 530 25
June-12 120 6 720 36 July-12 74 7 518 49 August-12 65 8 520 64 September-12 125 9 1125 81 October-12 102 10 1020 100 November-12 66 11 726 121 December-12 105 12 1260 144
1261 78 1339 6503) Menentukan Nilai “a” dan “b”. Diketahui:
∑
1261∑ . .∑
1261 = 12a 78b∑ ∑ ∑
1339 = 78a 650bUntuk mencari nilai b, rumus 2 dikalikan 2, dan rumus 3 dikalikan 1. 2522 = 24a 156b
1339 = 78a 650b _ 1183 = -54a -494b b = 2.4
setelah di ketahui nilai b, maka nilai a dapat di tentukan. 1261 = 12a 78b
1261 = 12a 78 (2.4) 1261 = 12a 187.2 1073.8 = 12a a = 89.5
4) Menentukan Fungsi Y dan Nilai Trend.
Karena nilai a dan b telah di ketahui, maka fungsi Y sebagai berikut. Y = 89.5 2.4 x
BAB 2 DATA MINING DAN DATA WAREHOUSE
2.1. DATA MINING
Menurut majalah teknologi daring ZDNETNews (8 Feb 2001), Penamban gan data (Data mining) akan menjadi salah satu perkembangan yang paling revolusioner pada era yang akan datang. Faktanya, MIT Technology Review memilih data mining sebagai salah satu dari sepuluh teknologi baru yang akan mengubah dunia. Menurut Gartner Group, data mining adalah proses menemukan korelasi, pola dan tren baru yang bermakna dengan memilah-milah sejumlah besar data yang tersimpan direpositori, menggunakan teknologi pengenalan pola serta Teknik statistic dan matematika.
2.1.1. Pengertian Data Mining
Defisinisi data mining berdasarkan Gartner Group:
Data mining adalah analisis kumpulan data observasi untuk menemukan hubungan yang tidak terduga dan meringkas data dengan cara baru yang dapat dimengerti dan berguna bagi pemiliknya. Data mining adalah bidang interdisipliner yang menyatukan Teknik dari pembelajaran mesin, pengenalan pola, statistic, database, dan visualisasi untuk mengatasi masalah ekstraksi dari basis
data yang besar. 2.1.2. Estimation
Estimasi serupa dengan klasifikasi, kecuali bahwa variable target bersifat numerik, bukan kategorikal. Model dibangun menggunakan record “lengkap”, yang memberikan nilai dari variable target serta predictor. Kemudian, untuk pengamatan baru, perkiraan nilai variable target dibuat, berdasarkan nilai-nilai predictor. Misalnya, kami mungkin tertarik untuk memperkirakan pembacaan tekanan darah sistolik pasien rumah sakit, berdasarkan usia pasien, jenis kelamin, indeks massa tubuh, dan kadar natrium darah. Hubungan antara tekanan darah dan variable predictor dalam set pelatihan akan memberi model estimasi. Kemudian dapat kita terapkan model
it uke kasus yang lain.
Contoh kasus estimasi dalam bisnis dan penelitian diantaranya:
- Memperkirakan jumlah uang yang dipilih empat keluarga secara acak akan dibelanjakan untuk belanja kembali ke sekolah.
- Memperkirakan penurunan persentase cedera lutut dalam gerakan berputar yang di laksanakan liga sepakbola nasional.
- Memperkirakan nilai rata-rata IPK dari seorang mahasiswa pascasarjana, berdasarkan IPK mahasiswa itu.
2.1.3. Prediction
Prediksi serupa dengan klasifikasi dan estimasi, kecuali untuk prediksi, hasilnya ada di masa depan. Contoh kasus dalam bisnis dan penelitian di antaranya:
- Memprediksi harga saham tiga bulan ke depan
- Memprediksi persentase peningkatan trafik kematian tahun depan jika batas kepatan dinaikkan
- Memprediksi pemenang seri bola dunia berdasarkan perbandingan statistic tim. 2.1.4. Pengertian Klasifikasi
Klsifikasi adalah variable kategori target. Pada data mining, proses memeriksa kumpulan catatan besar, masing-masing catatan yang berisi informasi tentang target serta satu set variable input
atau variable predictor.
Contoh tugas klasifikasi dalam bisnis dan penelitian meliputi:
- Menentukan apakah transaksi kartu kredit tertentu adalah penipuan
- Menempatkan siswa baru ke dalam jalur tertentu berkenaan dengan kebutuhan khusus. - Menilai apakah aplikasi hipotek adalah risiko kredit yang baik atau buruk
- Mendiagnosa apakah ada suatu penyakit tertentu
- Menentukan apakan suatu wasiat ditulis oleh orang yang sebenarnya yang telah meninggal atau orang lain.
- Mengidentifikasi apakah perilaku keuangan atau pribadi tertentu menunjukkan kemungkinan ancaman teroris.
2.1.5. Metode Klasifikasi 2.1.5.1.K-Nearest neighbor
Algoritma K-Nearest Neighbor (KNN) algoritma berbasis tetangga terdekat, algoritma ini merupakan algoritma yang paling sering digunakan untuk klasifiasi, meskipun dapat juga
digunakan untuk estimasi, dan prediksi. KNN adalah contoh dari pembelajaran berbasis contoh, dimana set data pelatihan disimpan, sehingga klasifikasi untuk catatan baru yang tidak terklasifikasi dapat ditemukan hanya dengan membandingkannya dengan catatan yang paling mirip dengan data latih.
2.1.5.2.Naïve Bayes
Algoritma Naïve Bayes merupakan metode klasifikasi berdasarkan teorema Bayes dengan asumsi antar variable saling besabas. Dalam hal ini, di asumsikan bahwa ada atau tidaknya dari suatu kejadian tertentu dari suantu kelas tidak berhubungan dengan ada atau tidaknya dari kejadian lainnya.
Naïve Bayes dapat digunakan untuk berbagai macam keperluan seperti klasifikasi document, deteksi spam atau filtering spam, dan masalah klasifikasi lainnya.
2.1.5.3.Decision Tree
Decision Tree merupakan salah satu algoritma klasifikasi yang digunakan dalam data mining. Metode ini melibatkan konstruksi pohon keputusan, kumpulan simpul keputusan, di hubungkan oleh cabang, memanjang ke bawah dari simpul akar sampai berakhir di simpul daun. Di mulai pada simpul akar yang berdasarkan konvensi ditempatkan dibagian atas diagram pohon keputusan, atribut di uji di simpul keputusan , dengan setiap hasil yang mungkin menghasilkan cabang. Setiap cabang kemudian mengarah ke simpul keputusan lain atau ke simpul daun yang terakhir.
2.1.6. Pengertian Klastering
Klastering mengacu pada pengelompokan record, observasi, atau kasus kedalam kelas objek serupa. Klister adalah kumpulan record yang mirip satu sama lain, dan berbeda dengan record dalam kelompok lain. Clustering berbeda dari klasifikasi di mana tidak ada variable teraget untuk pengelompokan. Tugas pengelompokan tidak mencoba mengklasifikasikan, memperkirakan, atau memprediksi nilai variable target. Alih-alih, algoritma clustering berusaha men gelompokan seluruh kumpulan data ke dalam subkelompok atau gugus yang relative homogen, di mana kesamaan record dalam kluster dimaksimalkan dan kemiripan dengan record di luar klaster diminimallkan.
2.1.7. Metode Klastering 2.1.7.1.K-Means Clustering
Algoritma K-Means Clustering adalah algoritma yang membagi data menjadi beberapa kelompok. Algoritma ini terdiri dari beberapa proses, yaitu:
- Menanyakan kepada pengguna berapa banyak kumpulan data yang harus di partisi. - Menentukan k record sebagai pusat klaster secara acak.
- Mencari pusat klaster dari sertiap record. Dengan demikian setiap pusat klaster “memiliki” subset dari record, sehingga mewakili partisi dari kumpulan data.
- Untuk masing-masing klaster k, temukan centroid klaster, dan perbarui lokasi setiap pusat klaster ke nilai baru dari centroid.
- Ulangi langkah 3 hingga 5 hingga konvergensi atau penghentian. 2.1.8. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang berjalan Bersama. Paling umum dalam dunia bisnis, dimana ia dikenal sebagai affinity analysis atau analisis pasar, tugas asosiasi berusaha untuk mengungkap aturan yuntuk mengukur hubungan atara dua atau lebih atribut. Aturan asosiasi adalah “jika anteseden, maka konsekuen” Bersama dengan ukuran dukungan dan kepercayaan yang terkait dengan aturan. Misalnya, supermarket tertentu mungkin menemukan bahwa dari 1000 pelanggan yang berbelanja pada Kamis malam, 200 membeli popok, dan 200 dari pembeli popok, 50 membeli sayur. Jadi aturan asosiasi adalah “jika membeli popok, kemudian membeli sayur” dengan dukungan 200/1000 = 20% dan kepercayaan 20/200 =
25%.
2.2. DATA WAREHOUSE
Data warehouse adalah sistem yang menyediakan infrastruktur data skala besar untuk dukungan keputusan. Di masa depan revolusi pemrosesan analitik oline (OLAP), yang memungkinkan analisis multi dimensi (misalnya pendapatan dilihat pada sumbu feografis, waktu, produk dank lien) yang akan dilakukan dari database atau data warehouse (yang terakhir mulcul dalamperiode yang sama). Pandangan multi dimensi dikonseptualisasikan melalui hyercube (hiper karena dapat memiliki lebih dari tiga dimensi).
Data warehouse memerlukan alat khusu seperti extract-transform-load (ETL), yang memungkinkan warehouse untuk dimuat secara otomatis dari sumber basis data. Alat khusu memungkinkan kueri untuk dibuat (alat kueri) dan laporan, dasbor, analisis, dan lain-lain utnuk di produksi (alat pelaporan).
Datamart mengumpulkan satu set data yang relative lebih kecil (dibandingkan dengan data warehouse) tentang satu depertemen di perusahaan (keuangan, manajemen SDM, pemasaran, komersial, dan lainnya). Dta dapat berasal dari database dari sistem IT konvensional dan suber eksternal, tetapi datamart merupakan bagian dari data warehouse.
Kapasitas data yang sangat besar di proses menggunakan data mining, text mining dan web mining. Algoritma yang memungkinkan pemrosesan berasal dari statistic dan kecerdasan buatan. Selama belasan tahun terakhir, alat BI telah di adaptasi ke web (antarmuka pengguna, sumber data dan lainnya) dan, yang lebih baru, ke aplikasi seluler. Perlu dicatata bahwa spreadsheet (misalnya Excel) sebagian besar digunakan di BI sebagai alat untuk menyajikan hasil (dasbor, kartu skor, dan lainnya). Dan mengembangkan aplikasi lengkap serta dukungan untuk pembuatan prototipe.
2.3. DATA CLEANING
Agar berguna untuk tujuan data mining, dabase perlu menjalani preprocessing, dalam bentuk data cleaning dan data transformation. Data mining sering kali berkaitan dengan data yang belum pernah dilihat selama bertahun-tahun, sehingga banyak data yang mengandung nilai yang telah
kadaluarsa, tidak lagi relevan, atau hanya hilang. Tujuan utama adalah untuk meminimalkan GIGO: untuk meminimalkan “garbage” (sampah) yang masuk ke dalam model sehingga kita dapat meminimalkan jumlah sampah yang diberikan model.
2.4. CONTOH KASUS 2.4.1. Algoritma C4.5
Table 1. Dataset
Diket:
log2 0/1: tak terhingga log2 2/5: -1.321928095 log2 0/4: tak terhingga log2 3/4: -0.415037499
log2 1/1: 0 log2 3/5: -0.736965594
log2 1/3: -1.584962501 log2 3/8: -1.415037499
log2 1/4: -2 log2 4/4: 0
log2 2/3: -0.584962501 log2 5/8: -0.678071905
log2 2/4: -1 log2 5/8: -0.678071905
SOAL: Buat pohon keputusan dengan algoritma C4.5 PEMBAHASAN:
a. Mencari Entropi dengan rumus:
∑
=
Keterangan:
S adalah himpunan (dataset) kasus
k adalah banyaknya partisi S
Jadi
(
8
8
)(
8
8
)
=0.954434003Table 2. Hasil Perhitungan Entropi Dataset
Total Kasus SUM(Banyak) SUM(Sedikit) Entropi Total 8 3 5 0.954434003
b. analisis pada setiap atribut dan nilai-nilainya, hitung entropinya dan hitung gainnya. Rumus gain:
|
||
|
=
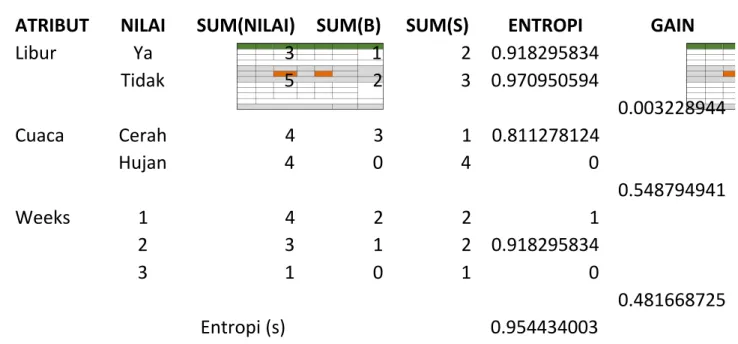
Table 3. Tabel Nilai, Entropi dan Gain
ATRIBUT NILAI SUM(NILAI) SUM(B) SUM(S) ENTROPI GAIN Libur Ya 3 1 2 0.918295834 Tidak 5 2 3 0.970950594 0.003228944 Cuaca Cerah 4 3 1 0.811278124 Hujan 4 0 4 0 0.548794941 Weeks 1 4 2 2 1 2 3 1 2 0.918295834 3 1 0 1 0 0.481668725 Entropi (s) 0.954434003
c. karena nilai gain terbesar adalah gain Cuaca. Maka Cuaca menjadi node akar (root node). d. Pada Cuaca, memiliki 4 kasus dan jawabannya adalah sedikit (sum(total) / sum(s) = 4/4 = 1).
Dengan demikian cuaca = hujan menjadi daun atau leaf.
cuaca
1.1 Y
e. Berdasarkan pembentukan pohon keputusan node 1, node 1.1 akan di analisis lebih lanjut. Untuk mempermudah, table 1 di filter, dengan mengambil data cuaca = cerah.
Table 4. Dataset Cuaca = Cerah No Libur Cuaca Minggu Jumlah
1 Ya Cerah 1 Banyak 2 Tidak Cerah 1 Banyak 3 Tidak Cerah 2 Banyak 4 Tidak Cerah 2 Sedikit
Kemudia data di atas di analisis dan di hitung lagi. Setelah itu tentukan atribut dengan gain tertinggi untuk di buatkan node berikutnya.
Table 5. Hasil analisis node 1.1
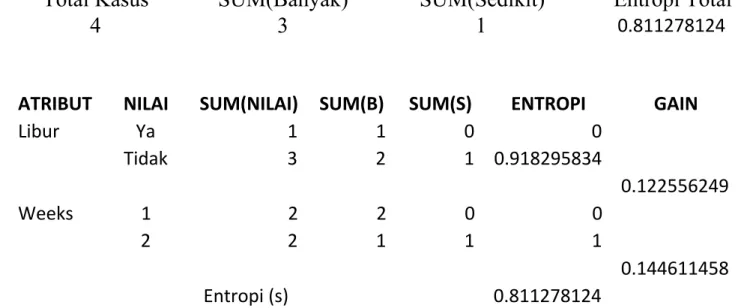
Total Kasus SUM(Banyak) SUM(Sedikit) Entropi Total 4 3 1 0.811278124
ATRIBUT NILAI SUM(NILAI) SUM(B) SUM(S) ENTROPI GAIN Libur Ya 1 1 0 0 Tidak 3 2 1 0.918295834 0.122556249 Weeks 1 2 2 0 0 2 2 1 1 1 0.144611458 Entropi (s) 0.811278124
Dari table 5, gain tertinggi ada pada atribut Weeks (Minggu-ke), dan nilai yang di jadikan leaf adalah weeks-ke 1. Dan hasil analisis pohon keputusan tampak seperti gamber berikut:
f. Analisis node 1.1.1 sama seperti analisis sebelumnya.
Table 6. hasil analisis 1.1.1. No Libur Cuaca Minggu Jumlah
1 Ya Cerah 1 Banyak 2 Tidak Cerah 1 Banyak
cuaca
1.1 Week Y
Cerah hu a
1.1.1 ? Y
Total Kasus SUM(Banyak) SUM(Sedikit) Entropi Total
2 2 0 0
2.4.2. KNN
Bobot antar variable
Kedekatan jenis kelamin
cuaca 1.1 Week Y Cerah hu a 1.1.1 Libur Y 1 2 Y T
Kedekatan Pendidikan
Kedekatan Agama
Pembahasan
Jika di ketahui:
Department = marketing Age = 26 – 30 Salary = 46 – 50K
Tentukan kemungkinan status dari orang tersebut? PEMBAHASAN ID X1 Class X2 X3 1 Sales Senior 31-35 46-50K 2 Sales Junior 26-30 26-30K 3 Sales Junior 31-35 31-35K 4 Systems Junior 21-25 46-50K 5 Systems Senior 31-35 66-70K 6 Systems Junior 26-30 46-50K 7 Systems Senior 41-45 66-70K 8 Marketing Senior 36-40 46-50K 9 Marketing Junior 31-35 41-45K 10 Secretary Senior 46-50 36-40K 11 Secretary Junior 26-30 26-30K P(Y=Senior) = 5/11 P(Y=Junior) = 6/11 P(X1=Marketing|Y=Senior) = 1/5
P(X1=Marketing|Y=Junior) = 1/6 P(X2=26-30|Y=Senior) = 0/5 P(X2=26-30|Y=Junior) = 3/6 P(X3=46-50K|Y=Senior) = 2/5 P(X3=46-50K|Y=Junior) = 2/6 Sehingga: P (X1=Marketing, X2=26-30, X3=46-50K | Y=Senior) => ={P(X1=Mar|Y=Senior).P(X2=26-30|Y=Senior).P(X3=46-50K|Y=Senior).P(Y=Senior)} = {(1/5) (0/5) (2/5) (5/11)} = 0 P (X1=Marketing, X2=26-30, X3=46-50K | Y=Junior) => ={P(X1=Mar|Y=Senior).P(X2=26-30|Y=Senior).P(X3=46-50K|Y=Senior).P(Y=Junior)} = {(1/6) (3/6) (2/6) (6/11)} = 0.015152
Sehingga keputusannya adalahJunior 2.4.4. Metode K-Mean Clustering
NIM Mid (40%) UA (60%) 1 56 71 2 49 81 3 98 78 4 42 32 5 48 29 6 85 71 7 87 97 8 80 90 9 69 47 10 45 31 11 24 25 12 97 63 13 84 75 14 52 87 15 70 43 16 63 53 17 25 46 18 69 80
19 56 26
20 78 46
Ditentukan delta =0,1
Diinginkan untuk membagi menjadi 3 kelas nilai (C,B dan A) Tentukan centroid masing-masing kelas
Tentukan nilai masing-masing mahasiswa PEMBAHASAN