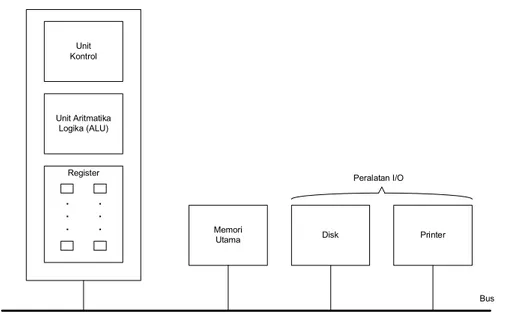
Register Peralatan I/O. Gambar 7.1. Organisasi komputer sederhana dengan CPU dan dua peralatan I/O
Teks penuh
Gambar
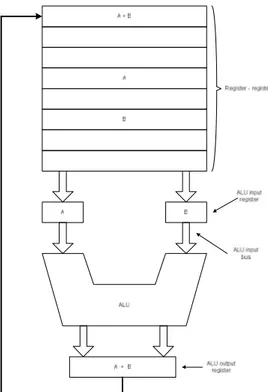
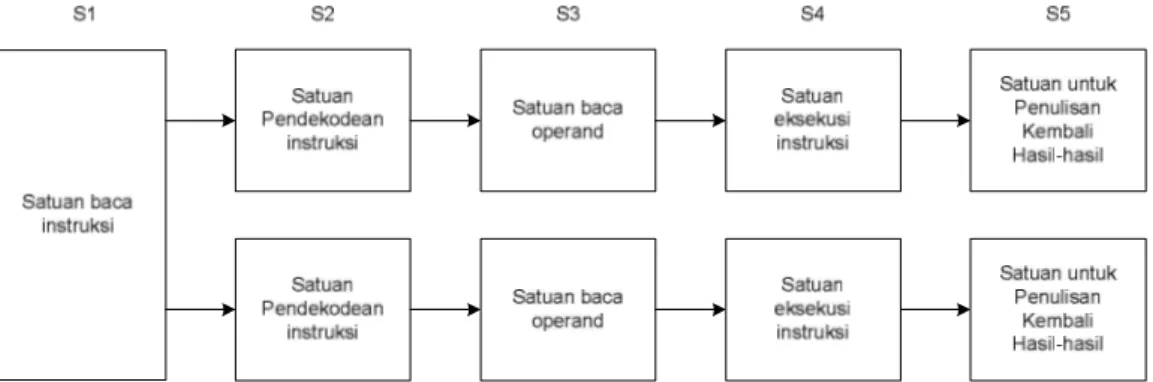
Dokumen terkait
Sehingga pada makalah ini akan dijelaskan secara rinci tentang apa yang dapat terjadi pada molekul pada saat klimaks reaksi (keadaan yang mana akan mulai membentuk produk dalam
Oleh karena itu, pantai- pantai yang rawan gempa bumi dan tsunami adalah pantai-pantai yang berhadapan dengan daerah penunjangan (subduksi) antara dua lempengan taktonik
+ INDONESIAN FCPF CARBON FUND: Program Pengurangan Emisi Berbasis Lahan di Kalimantan Timur JAKARTA, 29 APRIL 2016... + Konteks Strategis dan Latar
Dari data yang telah diolah menghasilakan perbedaan tarif pajak terhutang dengan menerapkan metode gross up PPh Badan atau PPh pasal 29 sebesar Rp Rp 51.460.154,- sedangkan
Keseluruhan hasil penelitian yang diperoleh, pada reaktor konsentrasi rendah hingga konsentrasi tinggi selama tahap aklimatisasi- running, efisiensi penyisihan paling
Apakah (orang-orang kafir itu sama dengan) orang-orang yang ada mempunyai bukti yang nyata (Al Qur 'an) dari Tuhannya, dan diikuti pula oleh seorang saksi (Muhammad) [715] dari
Teori penciptaan dalam Islam adalah kepercayaan bahwa alam semesta (termasuk umat manusia dan semua makhluk yang lain) tidak hanya yang diciptakan oleh Allah, tetapi juga
Sistem adalah kumpulan elemen yang saling berhubungan satu sama lain yang membentuk satu kesatuan dalam usaha mencapai suatu tujuan [5].Sedangkan dalam buku yang berbeda
