5. Proses penghilangan data dilakukan secara acak untuk memenuhi asumsi mekanisme kehilangan data yang acak (MAR).
6. Ulangan yang digunakan sebanyak 10 kali pada setiap simulasi untuk memberikan peluang hilang yang sama kepada setiap data.
7. Setiap gugus data diimputasi ganda dengan m=5 (pada proc MI nimpute=5).
8. Setelah didapatkan nilai dugaan semua data hilang, dihitung selisih antara nilai dugaan dengan nilai aslinya. Dari selisih tersebut kemudian dihitung rata-rata dan ragam dari rata-rata tersebut.
9. Dari gugus data yang telah terlengkapi dengan nilai dugaan data hilang kemudian dihitung dugaan nilai tengah peubah X3. Karena dilakukan ulangan 10 kali maka akan didapatkan 10 gugus data contoh yang kemudian akan didapatkan pendekatan bagi nilai KTS, dengan rumus:
) ( )
( )
(x Ragam x Bias2 x
KTS = +
dimana
( ) ∑ [ ( ) ]
=
−
= n
i
i E x n
x x Ragam
1
2 1 . dan Bias
( ) ( )
x = xE −μ10. Metode imputasi yang baik akan menghasilkan selisih antara nilai dugaan data hilang dengan nilai aslinya yang lebih kecil dan ragam dari rata-rata yang kecil pula. Gugus data contoh yang dibentuk dari metode imputasi tersebut juga mempunyai nilai KTS yang lebih kecil dalam pendugaan parameter populasi.
11. Menerapkan metode imputasi ganda ke dalam contoh kasus.
HASIL DAN PEMBAHASAN Suatu penduga nilai akan dikatakan lebih baik dari penduga lainnya jika nilainya lebih mendekati nilai yang diduga. Pembandingan kedua metode imputasi ganda yang dilakukan adalah dengan membandingkan nilai penduga, dalam hal ini selisih nilai imputan dengan nilai sebenarnya.
Proses Imputasi pada Proc MI
Dengan mempertahankan urutan letak peubah X1, X2, dan X3 , maka cara kerja proc MI pada SAS 9.1 konsep proses imputasinya adalah dengan terlebih dahulu memprediksi data hilang pada peubah X2. Caranya adalah dengan membentuk model regresi dari unit- unit dengan data teramati pada peubah X1 dan
X2, dengan X2 sebagai peubah respon sedangkan X1 sebagai peubah penjelas. Dari model regresi yang terbentuk maka akan terdapat parameter regresi dan kuadrat tengah galat (σ2) yang kemudian akan disimulasikan sehingga terbentuk model regresi baru yang berbeda dengan model regresi awal. Pada model regresi baru terdapat tambahan unsur yang dapat dianggap sebagai galat. Data hilang pada peubah X2 pada unit ke-i akan diprediksi melalui model regresi baru dengan memasukkan nilai peubah X1 pada unit yang sama. Karena banyaknya imputasi yang digunakan adalah 5 (m = 5) maka proses tersebut diulang sebanyak 5 kali. Perbedaan nilai hasil imputasi berasal dari pengambilan bilangan acak dari sebaran tertentu yang berbeda-beda dalam simulasi terhadap parameter regresi dan kuadrat tengah galat.
Setelah data hilang pada peubah X2 diduga, proses imputasi dilanjutkan ke data hilang pada peubah X3. Pada proses ini model regresi awal dibentuk dari unit-unit dengan data teramati untuk peubah X1, X2, dan X3, dengan peubah X3
sebagai peubah respon. Selanjutnya serupa dengan proses imputasi pada peubah X2, pada akhirnya akan diperoleh model regresi baru setelah melalui simulasi terhadap parameter- parameter regresi dan kuadrat tengah galat regresi. Data hilang pada peubah X3 pada unit ke-i akan diprediksi melalui model regresi baru dengan memasukkan nilai peubah X1 dan X2
pada unit yang sama. Nilai hasil imputasi pada peubah X2 juga digunakan untuk menduga data hilang pada peubah X3.
Hampir sama dengan metode regresi, metode PMM melakukan proses imputasi dimana model regresi awal yang terbentuk dari unit-unit dengan data teramati pada peubah X1
dan X2 untuk imputasi data hilang pada peubah X2 dan unit-unit dengan data teramati pada peubah X1, X2, dan X3 untuk imputasi data hilang pada peubah X3. Dari model regresi awal, parameter-parameter regresi dan ragam dari galat disimulasikan. Selanjutnya diperoleh model regresi baru, hanya saja tidak ada penambahan unsur seperti model regresi baru pada metode regresi. Data hilang pada peubah dan unit tertentu akan diprediksi dengan nilai pada unit lain dari peubah yang sama dimana nilainya paling dekat dengan nilai respon yang dihasilkan dari model regresi baru.
Hasil Pendugaan untuk Data Hilang 2%
pada Peubah X2 dan 2% pada Peubah X3
Dari contoh berukuran 100 unit, simulasi yang pertama dilakukan adalah dengan menghilangkan data sebanyak 2% pada peubah
X2 dan 2% pada peubah X3 (selisih 0%).
Simulasi ini dilakukan dengan ulangan 10 kali, sehingga terdapat 10 posisi kehilangan data yang berbeda. Adapun data yang dihilangkan pada simulasi ini dapat dilihat di tabel 2.
Tabel 2. Data Asli yang Dihilangkan Data Asli Unit
X2 X3 89 159.6610 73.2011 90 157.4080 71.5882
Hasil pendugaan data hilang dengan menggunakan metode regresi dan PMM dapat dilihat pada tabel 3 dan 4.
Tabel 3. Data Hasil Imputasi dengan Metode Regresi pada Ulangan 1
Data Dugaan Regresi Unit Imputasi
X2 X3 89 1 159.9240 73.1073 90 1 157.2100 71.8198 89 2 159.7820 73.1000 90 2 157.2380 71.7408 89 3 159.7270 73.0918 90 3 157.2260 71.6288 89 4 159.4330 73.2599 90 4 157.3670 71.6781 89 5 160.0730 73.1870 90 5 157.4490 71.8304 Tabel 4. Data Hasil Imputasi dengan Metode PMM pada Ulangan 1
Data Dugaan PMM Unit Imputasi
X2 X3 89 1 159.4970 73.2354 90 1 157.5050 71.6040 89 2 159.8590 73.0111 90 2 157.0830 71.6272 89 3 159.5880 73.3183 90 3 157.4790 71.3163 89 4 159.5880 73.0111 90 4 157.5050 71.3163 89 5 159.5880 73.0707 90 5 157.1110 71.3045
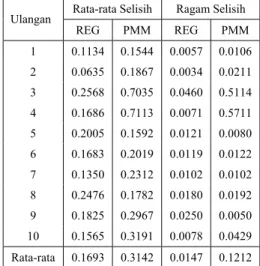
Dari hasil yang diperoleh menunjukkan bahwa metode imputasi ganda regresi lebih baik dari metode PMM. Hal ini dapat ditunjukkan oleh nilai rata-rata beda antara nilai imputan dan nilai sebenarnya, 0.16928 untuk metode regresi dan 0.314217 untuk metode PMM. Dan dari rata-rata ragam selisih pun metode regresi lebih kecil dari metode PMM (Tabel 5).
Tabel 5. Nilai Rata-rata Selisih dan Ragam Selisih Antara Data Asli dan Data Dugaan untuk Peubah X3
Rata-rata Selisih Ragam Selisih Ulangan
REG PMM REG PMM 1 0.1134 0.1544 0.0057 0.0106 2 0.0635 0.1867 0.0034 0.0211 3 0.2568 0.7035 0.0460 0.5114 4 0.1686 0.7113 0.0071 0.5711 5 0.2005 0.1592 0.0121 0.0080 6 0.1683 0.2019 0.0119 0.0122 7 0.1350 0.2312 0.0102 0.0102 8 0.2476 0.1782 0.0180 0.0192 9 0.1825 0.2967 0.0250 0.0050 10 0.1565 0.3191 0.0078 0.0429 Rata-rata 0.1693 0.3142 0.0147 0.1212
Hasil Pendugaan untuk Data Hilang 2%
pada Peubah X2 dan 5% pada Peubah X3
Simulasi yang dilakukan berikutnya adalah dengan menghilangkan data 2% pada peubah X2
dan 5% pada peubah X3 (selisih 3%).
Hasil dari simulasi ini menunjukkan bahwa metode regresi lebih baik daripada metode PMM, ditinjau dari nilai rata-rata selisih antara data asli dan data dugaannya juga dari nilai rata-rata ragam selisihnya. Nilai rata-rata selisih metode regresi lebih kecil daripada metode PMM, demikian juga nilai ragam selisihnya.
Hasil tersebut dapat dilihat pada tabel 6.
Tabel 6. Nilai Rata-rata Selisih dan Ragam Selisih Antara Data Asli dan Data Dugaan untuk Peubah X3
Rata-rata Selisih Ragam Selisih Ulangan
REG PMM REG PMM 1 0.1682 0.2161 0.0137 0.0378 2 0.1956 0.1557 0.0170 0.0316 3 0.1963 0.4949 0.0197 0.2151 4 0.2294 0.3940 0.0232 0.1972 5 0.1804 0.4163 0.0162 0.3303 6 0.1827 0.2514 0.0171 0.0392 7 0.1500 0.1290 0.0159 0.0093 8 0.2204 0.2199 0.0155 0.0350 9 0.1631 0.4485 0.0198 0.3460 10 0.1682 0.2161 0.0137 0.0378 rata-rata 0.1854 0.2942 0.0172 0.1279
Ringkasan Hasil Seluruh Simulasi Dari semua simulasi yang dilakukan, jumlah data hilang 2%, 5%, 10%, dan 15%
serta selisih jumlah data hilang 0, 3, 5, 10, 15, dan 20 didapatkan hasil bahwa metode regresi selalu lebih baik daripada metode PMM ditinjau dari nilai rata-rata selisih antara data
asli dengan data dugaan dan ragam selisih antara data asli dengan data dugaan.
Dari gambar 3 tampak bahwa nilai rata- rata selisih antara data asli dengan data dugaan dari metode regresi cenderung lebih kecil dan lebih stabil dari kondisi jumlah data hilang satu ke kondisi lainnya jika dibandingkan dengan nilai rata-rata selisih dari metode PMM.
0 0.1 0.2 0.3 0.4 0.5
1 3 5 7 9 11 13 15 17 19 21 23 Kelas Jumlah Data Hilang Rata-rata Selisih Data Asli vs Data Dugaan
reg pmm
Gambar 3. Rata-rata Selisih antara Data Asli dengan Data Dugaan Peubah X3 untuk Seluruh Kelompok Beda Jumlah Data Hilang
Nilai rata-rata selisih antara data asli dengan data dugaan metode PMM dari kondisi jumlah data hilang terkecil sampai terbesar cenderung mengalami kenaikan. Hal ini dapat disebabkan oleh data bangkitan yang nilainya berbeda untuk setiap unit. Sehingga semakin banyak jumlah data hilang akan membuat selisih dugaan dengan data asli semakin besar.
Penjelasannya adalah berdasarkan teori imputasi ganda metode PMM, nilai imputan unit tertentu didapat dari nilai unit lain yang jaraknya paling dekat dengan nilai hasil regresi antara peubah respon dengan penjelas yang ditunjuk. Kandidat donor atau unit yang nilainya akan dipakai sebagai dugaan bagi data hilang semakin berkurang jumlahnya jika jumlah data hilang semakin banyak.
Sedangkan nilai rata-rata selisih antara data asli dengan data dugaan pada metode regresi, seiring dengan peningkatan jumlah kehilangan data, relatif stabil. Berbeda dengan metode PMM, metode regresi mendapatkan nilai dugaan untuk data hilang langsung dari model regresi baru yang terbentuk melalui simulasi koefisien regresi awal. Nilai dugaan data hilangnya bukan diambil dari unit lain (donor).
Analisis Data untuk Data yang Telah Dilengkapi Data Dugaan
Suatu gugus data yang sebelumnya mempunyai beberapa data hilang tentunya akan dianalisis lebih lanjut. Dalam pendugaan parameter, hasil analisis berdasarkan metode imputasi ganda merupakan kombinasi dari hasil analisis setiap gugus data terlengkapi.
Salah satu contoh penggunaan hasil nilai
dugaan dari imputasi ganda yang dilakukan dalam penelitian ini adalah pendugaan nilai tengah populasi, dalam hal ini nilai tengah peubah lingkar pinggang X3.
Pembandingan kedua metode imputasi selanjutnya adalah dengan cara melihat nilai KTS pada saat melakukan pendugaan nilai tengah ukuran lingkar pinggang (X3) dari sebuah populasi. Simulasi yang dilakukan adalah dengan cara menghitung rata-rata peubah lingkar pinggang dari semua gugus data contoh hasil imputasi.
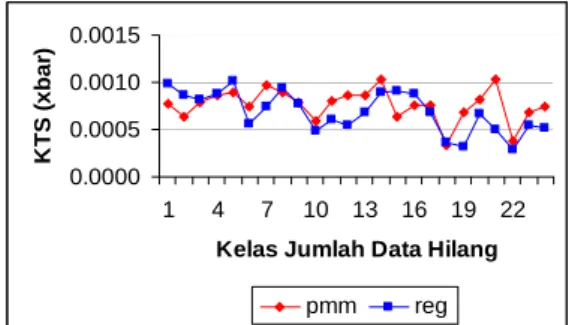
Terdapat 24 gugus data dengan karakteristik yang berbeda-beda sesuai dengan jumlah data hilang pada peubah X3 dan jumlah data hilang pada peubah X2. Gugus- gugus data yang telah diberi perlakuan penghilangan data kemudian dilengkapi kembali nilai-nilainya yang hilang dengan kedua metode imputasi ganda. Dari satu gugus data tak lengkap yang telah diimputasi ganda akan didapatkan 5 gugus data terlengkapi (m=5), sehingga terdapat 5 nilai statistik peubah X2. Dari SAS (dengan Proc MI) akan secara otomatis dihasilkan satu nilai rata-rata dari kelima nilai statistik tersebut.
0.0000 0.0005 0.0010 0.0015
1 4 7 10 13 16 19 22 Kelas Jumlah Data Hilang
KTS (xbar)
pmm reg
Gambar 4. Nilai KTS untuk Pendugaan Nilai Tengah Peubah X3
0.000 0.010 0.020 0.030 0.040
1 3 5 7 9 11 13 15 17 19 21 23 Kelas Jumlah Data Hilang
Bias (xbar)
pmm reg
Gambar 5. Nilai Bias (xbar) untuk Pendugaan Nilai Tengah Peubah X3
Karena simulasi yang dilakukan dengan ulangan 10 kali maka akan didapatkan 10 nilai rata-rata untuk menduga nilai tengah X2. Dari nilai-nilai itulah nilai KTS dihitung (nilai tengah peubah lingkar pinggang yang sebenarnya adalah 71.854).
Hasil dari simulasi dapat dilihat pada gambar 4. tidak terdapat perbedaan yang berarti antara nilai KTS yang dihasilkan dari metode imputasi regresi dan PMM.
Dilihat dari nilai biasnya juga tidak terdapat perbedaan yang berarti di antara kedua metode tersebut (gambar 5). Kedua metode menghasilkan penduga yang nilainya lebih besar dari nilai parameter yang sebenarnya (overestimate).
Pembandingan Metode Imputasi Ganda dengan Metode Baku untuk Data Lengkap
Pada praktiknya, metode baku untuk data lengkap sering digunakan dalam menganalisis data yang mengandung data hilang. Metode tersebut dilakukan dengan cara menghapus unit-unit yang mempunyai data hilang.
Untuk melihat akibat dari penggunaan metode penghapusan unit pada data yang mengandung data hilang dilakukan pendugaan parameter populasi dengan jumlah kehilangan data yang berbeda. Kemudian hasilnya dibandingkan dengan pendugaan parameter melalui metode imputasi ganda, baik PM maupun regresi.
-0.05 0 0.05 0.1 0.15 0.2
2% 5% 10% 15% 20% 25%
jumlah data hilang
bias (xbar)
hapus unit PMM reg Gambar 6. Pembandingan Nilai Bias Metode Penghapusan Unit dengan Metode Imputasi Ganda pada Pendugaan Parameter X3.
0 0.01 0.02 0.03 0.04
2% 5% 10% 15% 20% 25%
junmlah data hilang
KTS (xbar)
hapus unit PMM reg Gambar 7. Pembandingan Nilai KTS Metode Penghapusan
Unit dengan Metode Imputasi Ganda pada Pendugaan Parameter X3.
Pembandingan masih dilihat dari nilai bias dan nilai KTS, dengan jumlah data hilang yang dicobakan adalah 2%, 5%, 10%, 15%, 20%
dan 25% baik pada peubah X2 maupun X3. Gambar 6 dan 7 menunjukkan bahwa metode penghapusan menghasilkan nilai bias dan KTS yang jauh lebih tinggi daripada kedua metode imputasi ganda pada jumlah kehilangan data
lebih besar dan sama dengan 5%. Pada jumlah kehilangan data 2% ketiga metode tersebut memberikan nilai bias yang tidak jauh berbeda.
Terlebih dengan meningkatnya jumlah data hilang, semakin banyak data hilang pada data maka nilai dugaan terhadap parameter populasi akan semakin buruk jika metode penghapusan unit dengan data hilang digunakan. Dari contoh pembandingan tersebut maka dapat ditunjukkan bahwa penggunaan metode baku untuk data lengkap kurang tepat dalam proses analisis data yang mengandung data hilang.
Contoh Kasus untuk Penerapan Imputasi Ganda
Dari data sekunder yang didapatkan peneliti hanya mengambil beberapa peubah untuk digunakan sebagai contoh penerapan metode imputasi ganda.
Peubah-peubah yang digunakan adalah Sistem Kekerabatan (X1), Jenis Kelamin Bayi (X2), Umur Bayi (X3), Bobot Ibu (X4), dan Bobot Bayi (X5), sedangkan peubah yang mempunyai data hilang adalah X4 dan X5
dengan total jumlah kehilangan data sebesar 9.73% dan pola kehilangan data yang terbentuk adalah pola data hilang monoton. Keterangan tersebut dapat dilihat di lampiran 6. Untuk menduga nilai data hilang yang ada pada peubah-peubah tersebut digunakan proc MI dengan menggunakan metode PMM.
Adapun analisis lanjut yang digunakan setelah menduga data hilang adalah analsis regresi untuk menduga hubungan antara peubah respon X5 dengan peubah penjelas X1,
X2, X3, dan X4. Oleh karena itu, setelah dilakukan pendugaan data hilang dengan metode imputasi ganda dilakukan analisis regresi dengan menggunakan proc reg terhadap tiap gugus data yang telah dilengkapi datanya.
Hasil analisis masing-masing gugus data yang telah dilengkapi dapat dilihat pada lampiran 7.
Tabel 7. Penduga-penduga Koefisien Regresi
Gugus b0 b1 BB2 b3 b4
1 3.047 -0.086 -0.299 0.328 0.048 2 3.298 -0.101 -0.408 0.350 0.043 3 2.540 -0.055 -0.377 0.345 0.057 4 2.836 -0.088 -0.298 0.339 0.051 5 2.889 -0.116 -0.176 0.306 0.052 Mean 2.922 -0.089 -0.312 0.333 0.050
Var 0.078 0.001 0.008 0.000 0.000
Pada tabel 7 dapat dilihat hasil akhir pendugaan koefisien regresi yang merupakan kombinasi tiap pendugaan dari gugus data yang telah dilengkapi (rata-rata penduga koefisien
hilang tidak memberikan pengaruh yang besar terhadap perubahan nilai KTS.
regresi dari tiap gugus data). Sedangkan ragam dari tiap penduga koefisien menduga keragaman nilai penduga koefisien karena dilakukan imputasi sebanyak 5 kali.
Sedangkan dari tabel 8 dapat diperoleh informasi bahwa rata-rata dari nilai S2b0
sebesar 0.658, nilai ini menduga keragaman dalam b0 karena penarikan contoh (sampling).
Pada simulasi sederhana yang dilakukan dalam penelitian ini, telah ditunjukkan bahwa metode penghapusan unit yang mengandung data hilang memberikan hasil yang kurang baik, terlebih dengan jumlah kehilangan data yang cenderung besar.
Dari analisis regresi yang dihasilkan dari proc MIAnalyze dapat disimpulkan bahwa peubah Sistem Kekerabatan dan Jenis Kelamin Bayi tidak berpengaruh nyata terhadap peubah Bobot Bayi. Hasil tersebut dapat dilihat pada pengujian parsial terhadap tiap penduga koefisien regresi dalam output proc MIAnalyze (lampiran 8).
Saran
Maka para analis data hendaknya lebih berhati-hati dalam penanganan data yang mengandung data hilang, sehubungan dengan metode analisis baku untuk data lengkap atau metode penghapusan unit yang sering diterapkan pada kasus dengan data hilang.
Sebagai saran untuk penelitian selanjutnya yaitu perlu dilakukan simulasi serupa tapi dengan data yang tidak semua unitnya mempunyai nilai yang berbeda (terdapat beberapa unit yang mempunyai nilai sama). Hal ini dimungkinkan akan memberikan hasil yang berbeda khususnya untuk metode PMM.
Tabel 8. Statistik untuk b0
Gugus b0 SEb0 S2b0
1 3.047 0.803 0.644 2 3.298 0.816 0.665 3 2.540 0.834 0.695 4 2.836 0.828 0.685 5 2.889 0.776 0.602 Mean 2.922 0.658
Var 0.078
Masih terdapat faktor-faktor yang dapat dan perlu dilihat untuk membandingkan metode imputasi ganda regresi dan PMM selain dari yang sudah diteliti dalam penelitian ini.
KESIMPULAN & SARAN DAFTAR PUSTAKA
Kesimpulan Cochran, W. G. 1977. Sampling Technique.
New York: Wiley.
Dalam hal pendugaan terhadap data hilang dalam data contoh metode imputasi ganda regresi lebih baik daripada metode PMM, karena nilai dugaan yang dihasilkan lebih dekat dengan nilai sebenarnya. Dengan jumlah kehilangan data yang semakin meningkat, selisih nilai dugaan dengan nilai aslinya juga akan meningkat pada metode PMM.
Sedangkan pada metode regresi, peningkatan jumlah kehilangan data tersebut tidak mempengaruhi selisih nilai dugaan dengan nilai aslinya (cenderung stabil). Dengan kata lain, keragaman selisih nilai dugaan dengan nilai asli pada metode regresi lebih kecil daripada keragaman yang diperoleh pada metode PMM.
Kish, Leslie. 1965. Survey Sampling. New York: Wiley.
Levy, P. S. and Lemeshow, S. 1999. Sampling of Populations: Methods & Applications 3rd ed. New York: Willey.
Little, R. J. A. and Rubin, D. B. 1987.
Statistical Analysis with Missing Data.
New York: Wiley.
Longford, N. T. 2005. Missing Data and Small- Area Estimation. New York: Springer.
Rubin, D. B. 1987. Multiple Imputation for Nonresponse in Sample Surveys. New York: Willey
Lepkowski, J. M. 1989. Treatment of Wave Nonresponse in Panel Surveys dalam Panel Surveys. New York: John Willey & Sons.
Sedangkan dari segi pendugaan parameter populasi melalui data contoh yang telah dilengkapi dengan data imputan, kedua metode imputasi ganda tersebut tidak memiliki perbedaan yang nyata. Hal ini bisa dilihat dari nilai KTS untuk pendugaan parameter populasi yang dihasilkan. Meningkatnya jumlah data
Little, R. J. A. & Su, Hong Lin. 1989. Item Nonresponse in Panel Surveys dalam Panel Surveys. New York: John Willey & Sons.
Musa, Sjarkani. 2007. Metodologi Penelitian dengan Statistika. Departemen Statistika IPB. Bogor: inpress.