i TESIS-SS142501
ANALISIS RISIKO INVESTASI SAHAM SYARIAH
MENGGUNAKAN METODE
VALUE AT RISK
DENGAN
PENDEKATAN BAYESIAN
MIXTURE LAPLACE
AUTOREGRESSIVE
(MLAR)
BRINA MIFTAHURROHMAH NRP. 1315 201 025
DOSEN
Prof. Drs. Nur Iriawan, M.Ikom., Ph.D. Dr. Kartika Fithriasari, M.Si.
HALAMAN JUDUL
PROGRAM MAGISTER JURUSAN STATISTIKAFAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT TEKNOLOGI SEPULUH NOPEMBER
iii THESIS-SS142501
ISLAMIC STOCK INVESTMENT RISK ANALYSIS
USING VALUE AT RISK BY APPROACH OF
MIXTURE LAPLACE AUTOREGRESSIVE (MLAR)
BRINA MIFTAHURROHMAH NRP. 1315 201 025
SUPERVISOR
Prof. Drs. Nur Iriawan, M.Ikom., Ph.D. Dr. Kartika Fithriasari, M.Si.
MAGISTER PROGRAM
DEPARTMENT OF STATISTICS
FACULTY OF MATHEMATICS AND NATURAL SCIENCE SEPULUH NOPEMBER INSTITUTE OF TECHNOLOGY SURABAYA
vii
ANALISIS RISIKO INVESTASI SAHAM SYARIAH
MENGGUNAKAN METODE
VALUE AT RISK
DENGAN PENDEKATAN BAYESIAN
MIXTURE LAPLACE
AUTOREGRESSIVE
(MLAR)
Nama Mahasiswa : Brina Miftahurrohmah NRP : 13 15 201 025
Pembimbing : Prof. Drs. Nur Iriawan, M.Ikom., Ph.D. Ko-Pembimbing : Dr. Kartika Fithriasari, M.Si.
ABSTRAK
Investasi saham merupakan salah satu hal yang sangat menarik di bidang bisnis. Hal itu dikarenakan dengan melakukan investasi, banyak keuntungan yang akan didapatkan. Namun, investasi saham juga rawan terhadap risiko terjadinya kerugian. Oleh sebab itu, sebelum melakukan investasi, investor perlu mengetahui kemungkinan risiko yang akan terjadi. Value at Risk (VaR) sebagai metode pengukuran risiko yang paling populer, sering mengabaikan pola data yang tidak Normal uni-modal. Perhitungan risiko menggunakan metode VaR dengan Mixture Normal Autoregressive (MNAR) telah dilakukan. Laporan ini mengusulkan VaR dengan Mixture Laplace Autoregressive (MLAR) yang akan dilakukan untuk menganalisis data return saham syariah tiga perusahaan yang tergabung dalam JII dengan kapitalisasi terbesar, yaitu PT. Astra International Tbk (ASII), PT. Telekomunikasi Indonesia Tbk (TLMK) dan PT. Unilever Indonesia Tbk (UNVR). Estimasi parameter dilakukan dengan menggunakan pendekatan Bayesian Markov Chain Monte Carlo (MCMC). Hasil analisis menunjukkan bahwa Risiko tertinggi hingga terendah secara berturut-turut dalam investasi akan dialami saham ASII, UNVR, dan TLKM.
viii
ix
ISLAMIC STOCK INVESTMENT RISK ANALYSIS
USING VALUE AT RISK BY APPROACH OF MIXTURE
LAPLACE AUTOREGRESSIVE (MLAR)
Name : Brina Miftahurrohmah
NRP : 1315 201 025
Supervisor : Prof. Drs. Nur Iriawan, M.Ikom., Ph.D. Co-Supervisor : Dr. Kartika Fithriasari, M.Si.
ABSTRACT
Investment in stocks is something very interesting in the field of business. It is because by investing, a lot of profit to be obtained. However, investments in stocks are also vulnerable to the risk of loss. Therefore, before investing, investors need to be aware of the possibility that the risk will occur. Value at Risk (VaR) as the most popular risk measurement method, is frequently ignore when the pattern of return is not uni-modal Normal. The calculation of the risks using VaR method with the Normal Mixture Autoregressive (MNAR) approach has been considered. This paper proposes VaR method couple with the Mixture Laplace Autoregressive (MLAR) that would be implemented for analyzing the first three biggest capitalization Islamic stock return in JII, namely PT. Astra International Tbk (ASII), PT. Telekomunikasi Indonesia Tbk (TLMK), and PT. Unilever Indonesia Tbk (UNVR). Parameter estimation is performed by employing Bayesian Markov Chain Monte Carlo (MCMC) approaches. Results of analysis showed that the highest risk to the lowest level of investment will be experienced by ASII, TLKM, and UNVR stocks.
Keywords:Mixture Normal Autoregressive (MNAR), Mixture Laplace
x
xi
KATA PENGANTAR
Assalamu’alaikum Warahmatullah Wabarokatuh.
Puji syukur penulis panjatkan atas kehadirat Allah SWT atas segala rahmat, nikmat, ridho serta hidayah yang telah diberikan. Sholawat serta salam tetap tercurahkan kepada Nabi Muhammad SAW atas suri tauladan yang telah diberikan, sehingga Tesis yang berjudul “Analisis Risiko Investasi Saham Syariah Menggunakan Metode Value At Risk Dengan Pendekatan Bayesian Mixture
Laplace Autoregressive (MLAR) ” dapat terselesaikan. Ucapan terima kasih yang
tak terhingga penulis sampaikan kepada pihak-pihak yang telah membantu dalam menyelesaikan Tesis ini, diantaranya:
1. Bapak Dr. Suhartono, M.Sc. selaku Ketua Jurusan Statistika ITS yang selalu memberikan dukungan dan motivasi selama menjalani perkuliahan di Program Studi Magister Jurusan Statistika ITS.
2. Bapak Prof. Drs. Nur Iriawan, M.Ikom., Ph.D dan Ibu Dr. Dra. Kartika Fithriasari, M.Si. selaku dosen pembimbing Tesis yang telah bersedia memberikan bimbingan, motivasi, arahan serta dukungan kepada penulis dari awal hingga akhir penyusunan Tesis ini.
3. Bapak Dr.rer.pol. Heri Kuswanto, M.Si. selaku Ketua Program Studi Magister Jurusan Statistika ITS Surabaya dan dosen penguji yang telah memberikan motivasi, arahan, dukungan, kritik dan saran yang sangat bermanfaat dalam penyusunan Tesis.
4. Bapak Dr. Brodjol Sutijo Suprih Ulama, M.Si. selaku dosen penguji yang telah memberikan kritik dan saran yang membangun sehingga laporan Tesis ini menjadi lebih baik.
5. Ibu Irhamah, M.Si., Ph.D selaku dosen wali penulis selama kuliah di Program Studi Magister Jurusan Statistika ITS.
xii
7. Kedua orang tua yang telah memberikan banyak do’a serta dukungan, sehingga penulis dapat menjalani kuliah sampai sekarang dan dapat menyelesaikan Tesis ini.
8. Almarhumah Bu Dhe Sumani dan Almarhum Pak Dhe Tokol yang telah merawat penulis dari bayi dan secara tidak langsung telah memotivasi dan memberi semangat untuk menuntut ilmu setinggi-tingginya.
9. Teman-teman seperjuangan selama kuliah di Program Studi Magister Jurusan Statistika ITS atas dukungan, pengalaman dan seluruh kebaikan yang tidak dapat diungkapkan satu per satu.
10. Semua pihak yang tidak dapat disebutkan satu per satu atas seluruh bantuan yang telah diberikan kepada penulis.
Dalam Penulisan laporan ini penulis merasa masih banyak kekurangan baik dalam teknis penulisan maupun materi, mengingat akan kemampuan yang dimiliki penulis. Untuk itu kritik dan saran dari semua pihak sangat penulis harapkan demi penyempurnaan pembuatan Tesis ini. Semoga laporan Tesis ini bermanfaat bagi pembaca dan memberikan sumbangsih kepada semua pihak yang membutuhkan.
Wassalamu’alaikum Warahmatullah Wabarokatuh.
Surabaya, Januari 2017
xiii
DAFTAR ISI
Halaman
HALAMAN JUDUL ... i
LEMBAR PENGESAHAN ... v
ABSTRAK ... vii
ABSTRAK ... ix
KATA PENGANTAR ... xi
DAFTAR ISI ... xiii
DAFTAR TABEL ... xv
DAFTAR GAMBAR ... xvii
DAFTAR LAMPIRAN ... xix
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 4
1.3 Tujuan ... 4
1.4 Manfaat ... 5
1.5 Batasan Masalah ... 5
BAB 2 TINJAUAN PUSTAKA ... 7
2.1 Kemiringan dan Kurtosis ... 7
2.2 Model Autoregressive (AR) ... 8
2.3 Stasioneritas Time Series ... 9
2.3.1 Uji Levene ... 9
2.3.2 Autocorrelation Function (ACF)... 10
2.3.3 Partial Autocorrelation Function (PACF) ... 11
2.4 Proses Non Stationeritas ... 11
2.4.1 Differencing... 11
2.4.2 Transformasi Box-Cox ... 12
2.5 Diagnostic Check ... 13
2.6 Distribusi Laplace ... 14
xiv
2.8 Model Mixture Laplace Autoregressive ... 17
2.9 Stationeritas Model MLAR ... 19
2.10 Penaksiran Parameter ... 20
2.10.1 Metode Bayesian ... 21
2.10.2 Distribusi Prior ... 21
2.10.3 Markov Chain Monte Carlo (MCMC) dengan Gibbs Sampler ... 23
2.11 Uji Signifikansi Parameter ... 25
2.12 Kriteria Pemilihan Model Terbaik ... 25
2.13 Value at Risk (VaR) ... 27
2.14 Return Saham ... 29
2.15 Backtesting ... 31
BAB 3 METODOLOGI PENELITIAN ... 33
3.1 Sumber Data dan Variabel Penelitian ... 33
3.2 Langkah Penelitian ... 33
3.3 Penelitian sebelumnya ... 38
BAB 4 ANALISIS DAN PEMBAHASAN ... 41
4.1 Penentuan Distribusi prior ... 41
4.2 Pemodelan Mixture Laplace Autoregressive (MLAR) ... 44
4.3 Pemilihan Model Terbaik ... 59
4.4 Perhitungan Value at Risk (VaR) ... 60
4.5 Backtesting saham ASII, TLKM dan UNVR ... 63
BAB 5 KESIMPULAN DAN SARAN ... 65
5.1 Kesimpulan ... 65
5.2 Saran ... 65
DAFTAR PUSTAKA ... 67
xv
DAFTAR TABEL
Halaman
Tabel 2. 1 Transformasi Box-Cox ... 12
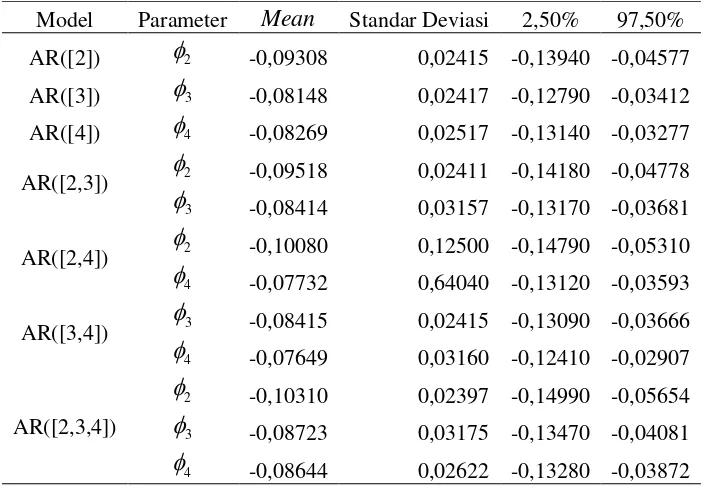
Tabel 4.1 Estimasi Parameter Saham ASII ... 42
Tabel 4.2 Estimasi Parameter Saham TLKM ... 43
Tabel 4.3 Estimasi Parameter Saham UNVR ... 44
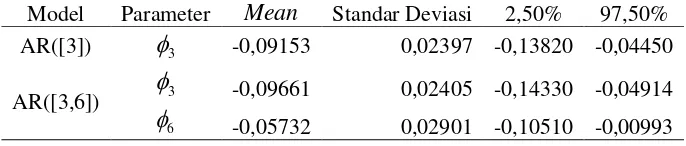
Tabel 4.4 Estimasi Parameter Model MLAR(2;[3],[3,6])... 48
Tabel 4.5 Estimasi Parameter Model MLAR(3;[3],[3,6], 0)... 49
Tabel 4.6 Estimasi Parameter Model MLAR(2;[2],[3])... 51
Tabel 4.7 Estimasi Parameter Model MLAR(2;[2],[4])... 51
Tabel 4.8 Estimasi Parameter Model MLAR(2;[3],[4])... 52
Tabel 4.9 Estimasi Parameter Model MLAR(2;[2,3],[3,4])... 53
Tabel 4.10 Estimasi Parameter Model MLAR(3;[2,3],[3,4],[2,3,4]) ... 54
Tabel 4.11 Estimasi Parameter Model MLAR(3;[2],[3],[4]) ... 56
Tabel 4.12 Estimasi Parameter Model MLAR(2;2,[11]) ... 57
Tabel 4.13 Estimasi Parameter Model MLAR(3;2,[11],(2,[11])) ... 58
Tabel 4.14 Perbandingan Model MNAR dan MLAR berdasarkan DIC ... 59
Tabel 4.15 Hasil Perhitungan VaR ... 63
Tabel 4.16 Uji Kupiec ... 63
xvi
xvii
DAFTAR GAMBAR
Halaman
Gambar 2. 1 Kurtosis ... 8
Gambar 2. 2 Perbedaan distribusi Laplace klasik dan standar ... 16
Gambar 3.1 Kapitalisasi pasar saham JII ... 34
Gambar 3. 2 Diagram alir penelitian ... 36
Gambar 3. 3 Diagram alir penelitian ARIMA ... 37
Gambar 3. 4 Diagram alir penelitian MLAR ... 38
xviii
xix
DAFTAR LAMPIRAN
Halaman
Lampiran A Data Return Saham ASII ... 71
Lampiran B Data Return Saham TLKM ... 72
Lampiran CData Return Saham UNVR ... 73
Lampiran DASII MLAR(2;[3],[3,6]) ... 74
Lampiran E ASII MLAR(3;[3],[3,6],0) ... 78
Lampiran F TLKM MLAR(2;[2,3],[3,4]) ... 85
Lampiran G TLKM MLAR(2;[2],[3]) ... 90
Lampiran H TLKM MLAR(2;[2],[4]) ... 94
Lampiran I TLKM MLAR(2;[3],[4]) ... 98
Lampiran J TLKM MLAR(3;[2,3],[3,4],[2,3,4]) ... 102
Lampiran K TLKM MLAR(3;[2],[3],[4]) ... 110
Lampiran L UNVR MLAR(2;2,[11]) ... 115
xx
1
BAB 1
PENDAHULUAN
Dalam bab ini akan dijelaskan lima subbab, yaitu mengenai latar belakang, rumusan masalah, tujuan, manfaat yang ingin dicapai dan batasan masalah dari penelitian ini. Masing-masing subbab akan dijelaskan sebagai berikut.
1.1 Latar Belakang
Salah satu instrumen-instrumen keuangan yang diperjualbelikan di pasar modal adalah saham.Saham merupakan salah satu sekuiritas yang memiliki tingkat risiko yang tinggi. Risiko tinggi ditunjukkan oleh ketidakpastian return yang akan diterima investor di masa datang. Semakin tinggi return yang diinginkan, maka semakin besar pula risiko yang ditimbulkan. Oleh sebab itu pengukuran risiko sangat penting pada bidang investasi. Dengan diketahuinya risiko, maka kebijakan investasi dapat dilakukan dengan lebih terukur. Hal utama yang harus dilakukan dalam pengelolaan risiko adalah mengidentifikasi penyebab risiko itu.
Metode yang digunakan dalam mengukur risiko sangat banyak sekali. Metode-metode tersebut diantaranya Value at Risk (VaR) dan Expected-Shortfall
(ES) atau return-level (Gilli & Kellezi, 2006). Namun, metode yang banyak digunakan dan sangat popular saat ini adalah VaR. Hasil perhitungan VaR yang akurat sangat diperlukan dalam menentukan modal yang akan dikeluarkan oleh perusahaan. Dengan demikian, risiko yang dihadapi perusahaan semakin kecil dan kerugian yang mungkin terjadi dapat ditanggulangi. Risiko merupakan kemung-kinan dampak yang akan terjadi di masa depan, oleh sebab itu perlu dilakukan peramalan.
Peramalan merupakan suatu kegiatan yang bertujuan untuk memper-kirakan kejadian yang akan terjadi pada masa yang akan datang, berdasarkan kejadian-kejadian di masa lampau. Metode peramalan telah banyak dikembangkan dalam analisis time series linier. Metode-metode tersebut sebagian besar dikem-bangkan berdasarkan asumsi residual berdistribusi Normal. Dengan demikian,
2
metode peramalan yang menerapkan asumsi tersebut adalah ARIMA Box’s Jenkins. ARIMA Box’s Jenkins adalah suatu metode yang sangat tepat untuk menangani atau mengatasi kerumitan deret waktu dan situasi peramalan lainnya. Metode Box Jenkins (ARIMA) akan tepat guna jika observasi dari data runtun waktu bersifat dependen atau berhubungan satu sama lain secara statistik. Salah satu model ARIMA yang sering menggambarkan kondisi return saham adalah model Autoregressive. Model Autoregressive merupakan model yang menggambarkan bahwa variabel dependen dipengaruhi oleh variabel dependen itu sendiri pada periode-periode dan waktu-waktu sebelumnya. Model ini meng-haruskan residual berdistribusi Normal dengan mean nol dan varians tertentu.
Wong dan Li (2000) menyatakan bahwa dalam kenyataannya, banyak data
time series yang tidak stasioner terhadap mean dan cenderung bersifat multimodal. Selain itu, banyak juga data time series yang bersifat heteroskedastisitas yang memberikan pola marjinal dan membawa sifat leptokurtik, sehingga asumsi Normal dilanggar (Wong & Li, 2000).
Model Gaussian Mixture Transition Distribution (GMTD) diperkenalkan oleh Le, Martin dan Raftery (1996) untuk menangkap adanya ketidaknormalan dan ketidaklinieran suatu data time series. Model telah terbukti berguna dalam pemo-delan beberapa kasus non-linier. Namun, model ini tidak mampu memodelkan data Canadian lynx (Wong & Li, 2000) karena ada pola siklus. Dengan demikian, Wong dan Li (2000) menggeneralisir model GMTD menjadi model Mixture Autore-gressive (MAR).
Model MAR terdiri dari gabungan komponen K Gaussian AR. Sifat stasioner dan Autocorrelation Function (ACF) sangat mudah diturunkan. Wong dan Li (2000) menggunakan algoritma Expectation-Maximization (EM) untuk meng-estimasi parameter. Perubahan fitur conditional distributions membuat model ini mampu memodelkan time series dengan distribusi bersyarat multimodal dan dengan heteroskedastisitas. Model yang diterapkan untuk dua set data riil dan dibandingkan dengan model alternetif lainnya. Model MAR mampu menangkap fitur data yang lebih baik model alternetif lainnya.
3
menggunakan distribusi Laplace hasil yang didapatkan akan lebih robust daripada menggunakan distribusi Normal. Berdasarkan pernyataan tersebut, Nguyen, dkk (2016) memperkenalkan model Mixture Laplace Autoregressive (MLAR) yang menggunakan model gabungan conditional Laplace, sebagai alternatif model MAR. Hasil analisis yang dilakukan oleh Nguyen, dkk (2016) pada data calcium imaging of zebrafish brain menunjukkan bahwa hasil bahwa model yang dibentuk dengan MLAR telah mampu menangkap pola data yang menggambarkan kondisi yang sebenarnya.
Penelitian mengenai risiko saham syariah menggunakan metode VaR dengan pendekatan Mixture Normal Autoregressive (MNAR) pernah dilakukan oleh Putri (2016). Analisis tersebut diimplementasikan pada 3 perusahaan yang tergabung dalam JII dengan kapitalisasi terbesar, diantaranya PT. Astra International Tbk (ASII), PT. Telekomunikasi Indonesia Tbk (TLKM) dan PT. Unilever Indonesia Tbk (UNVR). Analisis tersebut dilakukan oleh Putri (2006) karena return saham ketiga perusahaan memiliki variabilitas yang berbeda karena adanya nilai ektrim pada ujung kanan dan kiri. Selain itu ketiga return saham juga tidak Normal, yang ditunjukkan dengan distribusi return
yang lebih runcing daripada distribusi normal atau biasa disebut leptokurtik. Hasil dari analisis tersebut menunjukkan bahwa model MNAR belum lebih baik dalam menangkap pola data return saham yang tidak homogen yang meyebabkan ketidaknormalan data sehingga untuk menangani hal tersebut dilakukan analisis menggunakan metode yang lebih sesuai.
Berdasarkan uraian di atas, pada penelitian tugas akhir ini akan dilakukan analisis risiko dengan MLAR akan diimplementasikan pada data return saham yang sama seperti yang digunakan oleh Putri (2016). Metode MLAR digunakan karena distribusi return dari saham syariah lebih runcing daripada distribusi Normal (leptokurtik) yang menyerupai sifat distribusi Laplace dan terindikasi adanya multimodal.
4
Estimation), karena masing-masing fungsi distribusi harus dilikelihoodkan dan akan menghasilkan persamaan yang rumit.
1.2 Rumusan Masalah
Saham merupakan salah satu sekuiritas yang memiliki tingkat risiko yang tinggi. Oleh sebab itu pengukuran risiko sangat penting pada bidang investasi. Dengan diketahuinya risiko, maka kebijakan investasi dapat dilakukan dengan lebih terukur. Salah satu metode yang digunakan untuk mengukur risiko adalah Value at Risk (VaR). Risiko merupakan kemungkinan dampak yang akan terjadi di masa depan, oleh sebab itu perlu dilakukan peramalan. Banyak metode yang telah dikembangkan untuk peramalan. Nguyen, dkk (2016) memperkenalkan model
Mixture Laplace Autoregressive (MLAR) yang menyatakan bahwa dengan MLAR,
masalah-masalah yang terjadi pada saat diterapkan asumsi Normal untuk residual akan teratasi. Dengan demikian maka dalam penelitian ini ingin didapatkan model MLAR dengan pendekatan Bayesian MCMC yang terbentuk dan hasil pengukuran risiko saham syariah pada data return PT. Astra International Tbk (ASII), PT. Telekomunikasi Indonesia Tbk (TLKM) dan PT. Unilever Indonesia Tbk (UNVR).
1.3 Tujuan
Berdasarkan permasalahan yang telah diuraikan di atas, tujuan yang ingin dicapai dalam penelitian ini adalah.
1. Menentukan model MLAR dengan pendekatan Bayesian MCMC yang terbentuk pada data return PT. Astra International Tbk (ASII), PT. Telekomunikasi Indonesia Tbk (TLKM) dan PT. Unilever Indonesia Tbk (UNVR).
5
1.4 Manfaat
Hasil penelitian ini diharapkan dapat menambah khasanah keilmuan, khususnya dalam pengembangan metode untuk menyelesaikan masalah yang berkaitan dengan model MLAR. Selain itu, penelitian ini juga bermanfaat bagi investor yang ingin melakukan investasi dengan mempertimbangkan VaR pada saham-saham emiten yang tercatat di Jakarta Islamic Index (JII) khususnya perusahaan yang digunakan sebagai sampel.
1.5 Batasan Masalah
Analisis yang dilakukan dalam penelitian ini memiliki batasan masalah yaitu estimasi parameter model MLAR menggunakan analisis Bayesian MCMC dengan Gibbs Sampler. Jumlah mixture yang digunakan maksimal 3 komponen yang didapatkan dengan mengkombinasikan komponen autoregressive yang mungkin terbentuk. Selain itu, distribusi prior yang digunakan adalah pseudo prior
6
7
BAB 2
TINJAUAN PUSTAKA
Bab ini akan membahas mengenai landasan teori yang digunakan dalam penelitian ini. Teori-teori tersebut meliputi konsep kemiringan dan kurtosis, ARIMA, Mixture Autoregressive, Mixture Laplace Autoregressive (MLAR), analisis Bayesian, Uji Signifikansi, Deviance In Criterion (DIC) untuk pemilihan model terbaik, Value at Risk (VaR) dan Return saham. Dalam paparan teori tersebut terdapat subbab yang membahas hal-hal yang berkaitan dengan teori-teori yang telah disebutkan. Penjelasan teori-teori tersebut lebih detail adalah sebagai berikut.
2.1 Kemiringan dan Kurtosis
Sebelum dilakukan pemodelan, sebaiknya terlebih dulu dilakukan identifikasi distribusi data, sehingga pemodelan yang dilakukan lebih valid. Identifikasi distribusi data dapat dilakukan secara deskriptif maupun inferensi. Salah satu cara identifikasi data yang bersifat deskriptif adalah dengan melihat bentuk kurva pendekatan distribusi empirisnya, yaitu dengan menghitung nilai kemiringan (skewness) dan keruncingan (kurtosis).
Kemiringan (skewness) merupakan derajat ketidaksimetrian, atau dapat juga didefinisikan sebagai penyimpangan dari kesimetrian, dari suatu distribusi. Jika suatu kurva frekuensi dari suatu distribusi memiliki ekor kurva yang lebih panjang ke arah sisi kanan dibandingkan ke arah sisi kiri dari nilai maksimum tengah, maka distribusi seperti ini dikenal dengan distribusi miring kanan, atau memiliki kemiringan positif. Sebaliknya, jika ekor kurva yang lebih panjang ke arah sisi kiri dibandingkan ke arah sisi kanan dari nilai maksimum tengah, maka distribusi seperti ini dikenal dengan distribusi miring kiri, atau memiliki kemiringan negatif (Spiegel & Stephens, 1999). Jika nilai dari kemiringan adalah nol maka distribusi datanya adalah simetris.
8
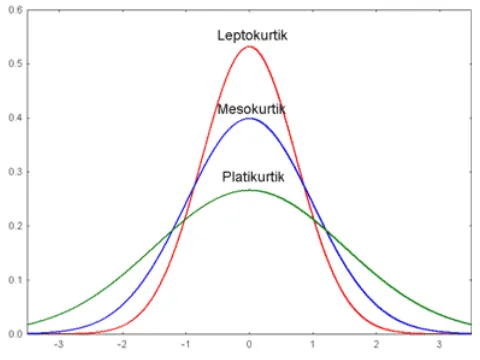
Gambar 2. 1 Kurtosis
Gambar 2.1 menunjukkan visualisasi kurtosis yaitu leptokurtik, mesokurtik dan platikurtik. Distribusi leptokurtik memiliki ekor tebal (fat tail) yang menunjukkan peluang adanya nilai ekstrim yang lebih tinggi dan memiliki bentuk yang lancip, dimana nilai-nilai observasi terkonsentrasi dalam rentang nilai yang sempit. Distribusi yang memiliki sifat leptokurtik adalah distribusi Laplace dan Logistik. Distribusi mesokurtik memiliki bentuk yang tidak datar dan tidak lancip dan biasa disebut distribusi Normal. Distribusi platikurtik memiliki ekor tipis (thin tail) dan berbentuk datar, dimana nilai-nilai observasi didistribusikan secara merata di semua kelas. Kurtosis distribusi mesokurtik (Normal) adalah tiga, untuk distribusi leptokurtik adalah lebih dari tiga. Sedangkan untuk distribusi yang platikurtik nilai kurtosisnya adalah kurang dari tiga.
2.2 Model Autoregressive (AR)
Model Autoregressive atau AR(p) menyatakan bahwa situasi yang diamati pada masa sekarang bergantung pada pengamatan pada masa lalu. Persamaan model AR (p) dapat dituliskan dengan persamaan.
,p B yt at
9 dengan
1 1
,p
p B B PB
(2.2)
maka persamaan matematis dari AR(p) adalah
1 1
pP t t
B B y a
1 1
t t p t p t
y y y a
1 1 ; ,
t t p t p t t t
y y y a y y (2.3)
keterangan:
p
= parameter Autoregressive lag ke-p
t
a = residual observasi ke-t
2.3 Stasioneritas Time Series
Suatu series dinyatakan stasioner dalam mean jika proses pembangkitan yang mendasari suatu time series didasarkan pada mean atau penyebaran series
yang konstan. Begitu pula untuk stasioner dalam varians, series dinyatakan stasioner dalam varians jika proses pembangkitan yang mendasari suatu time series
didasarkan pada varians atau penyebaran series yang konstan. Untuk mengetahui data sudah stasioner atau tidak, dilakukan uji Levene untuk menguji apakah data sudah stasioner terhadap varians atau tidak serta melihat time series plot, ACF dan PACF untuk mengetahui apakah data sudah stasioner terhadap mean atau tidak.
2.3.1 Uji Levene
10
diketahui distribusi dari data, uji Levene cocok untuk menguji homogenitas varians. Hipotesis uji Levene adalah.
Hipotesis:
2.3.2 Autocorrelation Function (ACF)
Autocorrelation Function (ACF) merupakan analisis time series yang menunjukkan kovarians dan korelasi antara 𝑦𝑡 dan 𝑦𝑡+𝑘 dari proses yang sama,
autocorrelation function (ACF) populasi dan ˆk disebut ACF sampel. Mean sampel
11
2.3.3 Partial Autocorrelation Function (PACF)
PACF (
ˆ
kk) merupakan analisis time series yang menunjukkan varians2.4 Proses Non Stationeritas
Dalam menarik kesimpulan mengenai struktur dari proses stokastik berdasarkan jumlah pengamatan yang terbatas, harus dilakukan penyederhanaan asumsi dari struktur tersebut. Asumsi penting yang digunakan adalah stasioneritas data. Untuk memenuhi asumsi stasioneritas, pada suatu time series yang non stasioner perlu dilakukan transformasi untuk nonstasioner pada varians dan
difference untuk kasus non stasioner terhadap mean (Wei, 2006).
2.4.1 Differencing
Suatu series dikatakan stasioner dalam mean jika proses pembangkitan yang mendasari suatu time series didasarkan pada mean yang konstan. Pada proses nonstasioner dalam mean ini dapat dilakukan difference dimana tujuannya untuk mencapai stasioneritas. Notasi yang sangat bermanfaat adalah backward shift (B). Operator tersebut mempunyai pengaruh menggeser data satu periode kebelakang. Operasi pembeda orde ke-d menghasilkan series baru yaitu Wt (Makridakris,
Wheelwright, & McGee, 1999).
1
dt t
12
Untuk memeriksa ke stasionetitas, dapat digunakan time series plot dari data. Jika plot berfuktuasi di sekitar garis yang sejajar sumbu waktu, dapat dikatakan series
telah stasioner terhadap mean.
2.4.2 Transformasi Box-Cox
Differencing belum tentu akan mengubah data yang tidak stasioner menjadi stasioner. Banyak data yang stasioner terhadap mean tetapi tidak stasioner terhadap varians. Oleh karena itu, perlu dilakukan transformasi yang bertujuan untuk menstabilkan varians yaitu dengan transformasi Box-Cox (Wei, 2006).
t 1t
y T y
(2.9)
Tabel 2. 1 Transformasi Box-Cox
Transformasi
-1 1
𝑦𝑡
-0,5 1
√𝑦𝑡
0 ln 𝑦𝑡
0,5 √𝑦𝑡
1 𝑦𝑡
Sumber: Wei, 2006
Tabel 2.1 merupakan tabel transformasi Box-Cox yang digunakan dalam menstabilkan varians.
Adapun syarat untuk melakukan transformasi adalah sebagai berikut. a. Transformasi dilakukan hanya untuk deret 𝑦𝑡yang positif.
b. Transformasi dilakukan sebelum melakukan differencing.
13
2.5 Diagnostic Check
Time series dimulai dengan identifikasi model dan estimasi parameter. Setelah estimasi parameter, langkah selanjutnya adalah menaksir kecukupan model.
Diagnostic check dilakukan dengan menguji apakah residual sudah identik, independen dan berdistribusi Normal atau tidak. Hal itu dilakukan untuk mendapatkan hasil peramalan yang baik. Uji yang digunakan untuk asumsi independenadalah uji Ljung-Box (Wei, 2006).
Hipotesis:
H0 : 1 2 0
H1 : minimal ada satu k 0
k 1, 2,...,
statistik uji:
2*
1
2 k ,
k
Q n n
n k
(2.10)daerah penolakan:
tolak H0 jika Q* x2,df, dengan derajat bebas
df p q.Uji homogenitas residual dapat dilakukan dengan uji Lagrange Multiplier
(LM). Hipotesis:
0 2
H : ξ = ξ = ...= ξ1 p = 0
1
H : minimal ada satu ξi 0
i = 1,2,..., p
statistik uji:
2
LM T R . (2.11)
daerah penolakan:
tolak H0 jika LMx2,df, dengan derajat bebas
df p (banyaknya periode waktu14
T adalah ukuran sampel
ns
dan R2adalah koefisien determinasi yang dihitung dari regresi menggunakan estimasi dari residual
2 2 2
t 0 1 t -1 p t - p t
a =ξ +ξ a +....+ξ a +u
(Andersen, Davis, K., & Mikhosch, 2009).
Diagnostic Check lainnya adalah menguji asumsi distribusi residual. Pengujian asumsi distribusi residual yang digunakan adalah uji Kolmogorov smirnov (Daniel, 1989).
Hipotesis:
H0 : 𝐹(𝑥) = 𝐹0(𝑥)
H1 : 𝐹(𝑥) ≠ 𝐹0(𝑥)
statistik uji:
𝐷 = 𝑆𝑢𝑝|𝑆(𝑥) − 𝐹0(𝑥)|, (2.12)
keterangan:
𝑆(𝑥) : fungsi peluang kumulatif yang dihitung dari sampel 𝐹0(𝑥): fungsi peluang kumulatif distribusi tertentu
𝐹(𝑥) : fungsi distribusi yang belum diketahui 𝑆𝑢𝑝 : nilai supremum semua x dari |𝑆(𝑥) − 𝐹0(𝑥)| daerah penolakan:
tolak H0 jika 𝐷 > 𝐷1−𝛼,𝑛 dengan derajat n adalah jumlah sampel dan 𝐷1−𝛼,𝑛 adalah
nilai D dari tabel Kolmogorov smirnov.
2.6 Distribusi Laplace
Distribusi Laplace klasik adalah sebuah distribusi peluang dengan
probability distribution function (pdf)
1 | |/; , , ,
2
y
f y s e y
s
(2.13)
15
sehingga disebut distribusi double exponential, distribusi two-tailed exponential
dan the bilateral exponential law.
Persamaan (2.13) sama dengan2s2. Dengan demikian varians dari distribusi Laplace klasik standar, yang memiliki kepadatan
1 | |sama dengan 2. Untuk berbagai derivasi tampaknya lebih baik memasukkan kembali parameter dari kepadatan distribusi Laplace
; ,
1 2| |/ , . Dengan location sama dengan 1, bentuk kepadatan peluang dapat ditulis
1 2| |;0,1 , ,
2
y
g y e y (2.16)
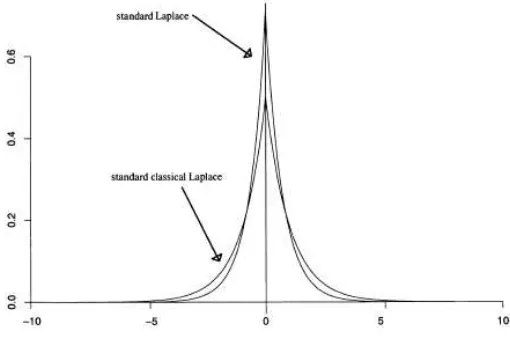
Perbedaan distribusi Laplace klasik dan standar divisualisasikan pada Gambar 2.2
Cumulative distribution function (Cdf)untuk persamaan (2.13) adalah
Distribusi ini simetris terhadap , untuk sembarang y, maka
; ,
; ,
16
Konsekuensi yang didapat adalah mean, median dan modus dari distribusi ini semua sama dengan (Kotz, Kozubowski, & Podgorski, 2001).
Gambar 2. 2 Perbedaan distribusi Laplace klasik dan standar
2.7 Model Mixture Autoregressive
Jika diketahui data yang apabila dilakukan terhadap distribusi (goodness of fit) secara univariate unimodal selalu menolak hipotesis nul, meskipun sudah dilakukan terhadap distribusi Exponential Power, Normal miring dan MSNBurn, maka layak data tersebut untuk diduga mempunyai pola yang akan mengikuti distribusi campuran atau bahkan layak untuk diduga berdistribusi univariate multimodal. Pendekatan rumus pola distribusi campuran dan univariate multi modal sebagai berikut (Iriawan, 2012).
1
| |
θ, K θ
mix j j j
j
f y w w g y (2.19)
dengan fmix
y|θ,w
adalah fungsi densitas distribusi mixture, gj
y|θj
adalah fungsi densitas ke-j sebanyak K komponen penyusun model distribusi campuran, θj adalah vektor parameter setiap distribusi komponen penyusun distribusi17
dengan elemen-elemen
w w ,...,w1, 2 i
. wj adalah parameter proporsi komponendistribusi campuran dengan
1 1
Kj
j w serta 0wj 1,j1, 2,...,K dan K adalah
banyaknya distribusi sebagai komponen penyusun distribusi campuran.
Model distribusi campuran yang dinyatakan pada persamaan (2.19) berlaku untuk pemodelan distribusi campuran dengan banyaknya komponen tertentu (finite mixture model). Jika data berdistribusi Normal dengan mean j dan varians 2
j sebanyak K komponen, maka persamaan (2.19) dapat dituliskan dalam persamaan berikut.
2
2
2
1 1 1
| | , ... | ,
mix K K K
f y w, , w N y w N y (2.20)
2.8 Model Mixture Laplace Autoregressive
Wong dan Li (2000) telah memperkenalkan metode Mixture Autoregressive (MAR) dengan menggunakan model gabungan K komponen conditional Gaussian dengan persamaan
1
,0 j,Mixture Laplace Autoregressive (MLAR) merupakan model yang dikenalkan oleh Nguyen, dkk (2016) dengan menggunakan model gabungan
18
residual akan teratasi. Yt dinyatakan berasal dari sebuah K komponen model MLAR order p (model MLAR
K p,
) Yt |Ft1; jika mempunyai bentuk kepadatan memiliki distribusi Laplace (Nguyen & McLachlan, Laplace mixture of linear experts, 2016).19
dimana
y
t1
1,
y
t1,...,
y
t p
T. Jika vektor parameter diketahui atau diestimasi,Persamaan (2.25) dan (2.26) dapat digunakan untuk melakukan prediksi dari yt
berdasarkan Ft1.
2.9 Stationeritas Model MLAR
Analog dengan Teorema 1 dalam Wong dan Li (2000), stasioneritas order pertama dari model MLAR
K p,
, menggunakan persamaan (2.25) dan ketentuantotal harapan sebagai berikut.
Teorema 1 (Nguyen, Geoffrey, Ullmann, & Janke, 2016). Syarat perlu dan cukup agar Yt stasioner dalam mean (orde pertama) adalah akar-akar persamaan
,
semuanya berada di dalam unit circle.
Asumsikan bahwa Yt mempunyai mean nol. Dengan menggunakan
ketentuan total harapan, memungkinkan untuk menunjukkan bahwa Yt adalah
stasioner orde kedua. Maka untuk setiap k1, 2,...,p
t t k
t t k | t 1
20
Seperti Wong dan Li (2000), stasioneritas order kedua dari model MLAR
K,1
dan MLAR
K, 2
, menggunakan persamaan (2.27) sampai (2.29) danketentuan total harapan sebagai berikut.
Teorema 2 (Nguyen, Geoffrey, Ullmann, & Janke, 2016). Yt diambil dari model MLAR
K,1
yang telah stasioner orde pertama. Syarat perlu dan cukup agar Ytstasioner orde kedua adalah
Kj1 j j,12 1.Teorema 3 (Nguyen, Geoffrey, Ullmann, & Janke, 2016). Yt diambil dari model MLAR
K, 2
yang telah stasioner orde pertama. Syarat perlu dan cukup agar Yt2.10 Penaksiran Parameter
21
2.10.1 Metode Bayesian
Model bayesian dikembangkan dari metode bayes. Metode yang digunakan untuk model bayesian dinamakan metode bayes. Dasar dari metode ini adalah teorema bayes. Dalam teorema bayes klasik, teori probabilitas dapat ditulis dengan persamaan (2.32).
p y
pp y
p y
(2.32)
dimana yang menunjukkan parameter yang akan diestimasi.
Dalam Teorema Bayes terdapat pembaruan informasi prior dengan menggunakan informasi sampel yang terdapat dalam data melalui fungsi likelihood yang dituliskan sebagai berikut.
𝑝(𝛉|𝑦) =𝑓(𝑦|𝛉)𝑝(𝛉)𝑝(𝑦) (2.33)
dengan 𝑝(𝛉|𝑦) adalah distribusi posterior, 𝑝(𝛉) adalah distribusi prior, 𝑓(𝑦|𝛉) adalah nilai likelihood dari sampel dan 𝑝(𝑦) adalah normalized constant yang dapat diabaikan, sehingga distribusi posterior dapat ditulis
|
.p y f y p (2.34)
2.10.2 Distribusi Prior
22
sampel yang berukuran besar, pilihan yang sesuai dari distribusi sebelumnya akan memiliki efek kecil pada kesimpulan posterior (Gelman, 2002). Adapun jenis-jenis distribusi prior sebagai berikut.
1. Prior informatif (informative prior)
Prior informatif (informative prior) mengacuh pada pemberian nilai parameter yang berdasarkan informasi-informasi permasalahan yang ada. Prior informatif (informative prior) dikelompokkan menjadi tiga, yaitu prior tidak informatif (noninformative prior), prior informatif tinggi (highly informative prior) dan prior informatif menengah/cukup (moderately informative hierarchical prior). Prior tidak informatif (noninformative prior)
mempertimbangkan parameter varians 𝜎12 dan 𝜎22, yang sebenarnya cukup baik diidentifikasi dalam distribusi posterior. Prior informatif tinggi (highly informative prior) cukup tepat digunakan pada kondisi ekstrim yaitu saat informasi ilmiah menyediakan beberapa parameter 𝛉 dalam model. Prior informatif menengah/ cukup (moderately informative hierarchical prior)
digunakan jika beberapa parameter fisiologis 𝛉 yang tidak baik diperkirakan oleh data tetapi informasi ilmiah yang dimiliki terbatas (Gelman, 2002). 2. Conjungate dan Non-conjungate prior
Conjungate prior merupakan metode estimasi parameter yang banyak digunakan yang memungkinkan semua hasil yang akan diturunkan dalam bentuk tertutup. Conjungate prior selalu mempertimbangkan pemilihan distribusi prior dalam bentuk sekawan dengan distribusi pembentuk fungsi likelihoodnya (Murphy, 2007). Sebuah konjugat sebelumnya dibangun dengan memfaktorkan fungsi likelihood menjadi dua bagian. Faktor pertama harus independen dari parameter yang menarik tetapi mungkin tergantung pada data. Faktor kedua adalah fungsi tergantung pada parameter yang menarik dan tergantung pada data hanya melalui statistik yang cukup.
23 3. Proper dan Non-proper prior
Proper prior atau improper prior, yaitu prior yang terkait pada pemberian pembobotan/densitas disetiap titik untuk setiap titik di sepanjang domain parameter dengan pertimbangan uniformly distributed atau tidak (Box & Tiao, 1973).
4. Pseudo prior
Pseudo prior, yaitu prior yang berhubungan yang penentuan nilainya didasarkan pada estimasi secara frequentist (Charlin dan Chib, 1995).
2.10.3 Markov Chain Monte Carlo (MCMC) dengan Gibbs Sampler
Markov Chain Monte Carlo (MCMC) adalah metode umum yang dilakukan dengan menentukan nilai-nilai dari pendekatan distribusi dan kemudian nilai-nilai tersebut diperbaiki untuk lebih mendekati target distribusi posterior p
|y
. Sampel diambil secara berurutan, dengan distribusi sampel yangdiambil tergantung pada nilai terakhir yang diambil, dengan demikian sampel yang diambil membentuk rantai markov Chain. Sebuah rantai markov merupakan rangkaian variabel random 1, 2,...,b
. Distribusi dari b
yang diberikan hanya bergantung pada semua sebelumnya pada nilai yang baru saja muncul yaitu b1. Kunci kesuksesan metode terletak pada pendekatan distribusi yang diperbaiki pada setiap tahap simulasi, dalam hal ini adalah kondisi konvergen.
Dalam aplikasi MCMC, beberapa rangkaian pengambilan simulasi independen dibentuk. Setiap rangkaian b, 1, 2,3,...
b
dibuat dengan menentukan titik 0 sebagai langkah awal, selanjutnya untuk setiap t dilakuakan pengambilan
b
dari sebuah distribusi transisi yaitu
b| b 1
bT yang tergantung pada pengambilan sebelumnya, b1
. Distribusi peluang transisi harus dibuat sehingga rantai Markov konvergen untuk sebuah distribusi stationer yang unik yaitu distribusi posterior.
MCMC digunakan ketika rantai Markov tidak mungkin untuk menghitung sampel langsung dari p
|y
; sebaliknya dengan menggunakan sampel iteratif24
mengambil sampel dari distribusi yang mendekati p
|y
. Pendekatan initampaknya menjadi cara termudah untuk mendapatkan hasil yang reliabel, setidaknya ketika digunakan dengan hati-hati (Gelman, 2002).
Algoritma rantai Markov tertentu yang telah ditemukan dan berguna dalam banyak masalah multidimensi adalah Gibbs sampler atau disebut juga alternating conditional sampling, yang didefinisikan dalam subvektor dari . Misalkan para-meter telah dibagi menjadi d komponen atau subvektor,
1, 2,...,d
. Setiap iterasi dari siklus Gibbs sampler melalui subvektor , menggambar setiap bagian tergantung pada nilai lain. Pada setiap iterasi b, sebuah urutan dari d subvektor dipilih dan, pada gilirannya, setiap bj
adalah sampel dari distribusi bersyarat diberikan semua komponen lain dari :
| b 1,
,kemudian, setiap subvektor j di-update secara kondisional pada nilai terakhir dari komponen lain dari, dimana iterasi b nilai dari komponen-komponen siap
di-update dan iterasi b1 nilai-nilai dari komponen yang lain.
Dalam kasus Normal, berarti
, ,w
sehingga bentuk posteriorjointnya adalah p
, ,w|y
. Gibss Sampler akan membantu menaksir parameter,
dan w secara iteratif dengan mengikuti skema sampling sebagai berikut. 1. Diberikan state: b
, ,
bw
pada iterasi ke b = 0 2. Membangkitkan parameter komponen setiap mixture.
25
b. Membangkitkan b1 dari
p
| ,
y
b1,
w
b
. c. Membangkitkan w b1 darip w y
| ,
b,
b1
. 3. Mengulangi langkah 2 sebanyak T kali, dimana T Pada langkah 2 harus dilakukan estimasi sebanyak K komponen mixture
dari sebuah parameter baik , maupun
w
. Data yang dibangkitkan dengan menggunakan algoritma di atas akan mempunyai pola data yang konvergen dan stasioner serta akan proporsional mengikuti distribusi masing-masing.2.11 Uji Signifikansi Parameter
Pengujian signifikasi parameter digunakan untuk mengetahui parameter mana yang signifikan sehingga dapat digunakan dalam model. Pengujian parameter hasil estimasi dengan Bayesian MCMC untuk setiap parameter yang diperoleh digunakan pengujian hipotesis sebagai berikut.
0
H : = 0
0
H : 0
Penolakan H0 didasarkan pada selang kepercayaan 95% dari distribusi posterior,
yaitu dengan melihat credible interval, jika credible interval tidak memuat 0 (nol).
2.12 Kriteria Pemilihan Model Terbaik
Pada umumnya, asumsi distribusi suatu data, y
y y1, 2,...,yn
,ter-gantung pada banyaknya parameter (p-dimensi parameter) 𝛉. Dari sudut pandang frekuentif, model taksiran didasarkan pada deviance, selisih dalam log-likelihood antara model fit dan saturated. Model saturated merujuk pada model pada model dengan jumlah parameter sebanyak jumlah observasi, dimana hasil yang diperoleh sesuai dengan data. Berdasarkan analogi, Dempster (1974) menyarankan untuk memeriksa distribusi posterior dari penyimpangan klasik yang didefinisikan
2 ln
|
2 ln
26
untuk pemilihan model Bayesian. p
y|
adalah fungsi likelihood yang merupakan conditional joint probability density function dari observasi yang diberikan parameter yang tidak diketahui, dan lng
y menunjukkan syarat standarisasi penuh. Dempster (1974) mengusulkan untuk membandingkan plot danmean posterior dari D
dan Spiegelhalter, dkk. (2002) menyarankan agarmenggunakan pengembangan dari DIC sebagai kriteria pemilihan model terbaik. Berdasarkan distribusi posterior dari D
, DIC terdiri dari dua komponen yaitu mengukur goodness of fit dan sebuah kondisi penalty untuk meningkatkan kompleksitas model:2 D,
DICD p (2.38)
1. Syarat pertama, sebuah ukuran Bayesian dari model yang sesuai didefiisikan sebagai ekspektasi posterior dari penyimpangan
| | 2 ln |
DEyD Ey f y (2.39) Model paling sesuai dari data dan lebih baik adalah nilai untuk log-likelihood.
D didefinisikan sebagai -2 kali log-likelihood, meskipun memperoleh nilai lebih kecil untuk model yang lebih baik.
2. Komponen kedua mengukur kompleksitas model dengan jumlah parameter yang efektif, pD didefinisikan sebagai perbedaan antara mean posterior dari
penyimpangan tersebut dan penyimpangan yang dievaluasi pada posterior mean
dari parameter:
Dp D D (2.40)
| |
E D D E
y y
| 2 ln | 2 ln |
E L f
27
Dengan mendefinisikan 2 ln p
y|
sebagai informasi residual dalam data y bersyarat dan mengintepretasikan itu sebagai ukuran ketidakpastian, persamaan (2.40) menunjukkan bahwa pD dapat dianggap sebagai ekpektasiberlebih dari kebenaran atas informasi residual estimasi data y bersyarat . Dengan demikian pD dapat ditafsirkan sebagai pengurangan yang diharapkan dalam
ketidakpastian karena estimasi.
Model dikatakan baik, jika model tersebut mempunyai DIC yang lebih kecil dibandingkan model alternetif lainnya (Berg, Meyer, & Yu, 2004).
2.13 Value at Risk (VaR)
Value at Risk (VaR) atau disebut juga Quantile Risk Metrics menggambar-kan estimasi dari kerugian maksimum yang mungkin terjadi pada portofolio bank akibat risiko pasar dalam periode waktu tertentu dan dalam tingkat keyakinan statistik tertentu. Menurut Butler (1999), VaR merupakan metodologi yang dominan untuk memperkirakan secara tepat berapa banyak uang yang berisiko setiap hari di pasar keuangan. Berdasarkan definisi VaR, jika berbicara tentang VaR pasti tidak lepas dengan istilah risiko. Risiko merupakan kombinasi peluang suatu kejadian dengan konsekuensinya atau akibatnya. Risiko juga dapat didefinisikan sebagai risiko murni (pure risk) dan risiko spekulasi (speculative risk). Risiko murni (pure risk) adalah kemungkinan terjadinya sesuatu yang jika terjadi pasti menyebabkan kerugian, sedangkan risiko spekulasi juga merupakan kemungkinan terjadinya sesuatu, tetapi jika terjadi akibatnya mungkin rugi tetapi juga mungkin untung (Siahaan, 2009). Vaughan (1978) dalam Suswinarno (2013) mengemukakan beberapa definisi risiko, diantaranya risiko didefinisikan sebagai kemungkinan terjadinya kerugian, risiko adalah ketidakpastian, risiko merupakan penyebaran hasil aktual dari hasil yang diharapkan dan risiko sebagai peluang suatu outcome
berbeda dengan outcome yang diharapkan. Ahli statistik mendefinisikan risiko sebagai derajat penyimpangan suatu nilai sekitar suatu posisi sentral atau di sekitar titik mean (Suswinarno, 2013).
28
kata lain kemungkinan itu sudah menunjukkan adanya ketidakpastian. Oleh sebab itu, untuk menghindari risiko yang tidak diinginkan dilakukan perhitungan VaR.
VaR dapat dihitung secara analitis, pada dasar Normal linier, simulasi historis atau simulasi monte carlo. VaR dapat dirumuskan secara matematis sebagai nilai kerugian pada tingkat kepercayaan tertentu
1
dan hal itu sama dengan menurunkan kuantil dari distribusi probabilitas dari variabel random, sehingga
P X x (2.41)
dimana x adalah -VaR
Jika fungsi distribusi F x
dari X diketahui maka kuantil yang sesuai untuk setiap nilai yang diberikan dari α dapat dihitung sebagai
1
x F (2.42)
sehingga
1
VaR x F . (2.43)
Metode perhitungan VaR Normal linier merupakan metode yang mengasumsikan bahwa distribusi dari return adalah Normal dan portofolio harus linier. Dengan demikian
X x x ,P X x P P Z
(2.44)
dimana Z adalah sebuah variable Normal standard. Jadi
1
,
x
29 dengan fungsi distribusi Normal yang simetri,
Oleh karena itu, dengan mensubtitusikan VaR x ke persamaan (2.46) maka
1
VaR 1 . (2.47)
Dengan demikian, persamaan yang digunakan untuk menghitung VaR pada horizon
h adalah dapat ditulis
1 ,
VaRh 1 hh. (2.48)
Dalam kondisi riil, rezim pasar antara pasar yang satu dengan yang lainnya tidak selalu sama. Metode mixture dirancang untuk menangkap rezim pasar yang berbeda. Persamaan yang digunakan untuk menghitung mixture VaR pada horizon
h adalah
2.14 Return Saham
30
dilakukan perusahaan kepada pemegang sahamnya, termasuk hak klaim atas aset perusahaan, dengan prioritas setelah hak klaim pemegang surat berharga lain dipenuhi jika terjadi likuiditas. Menurut Husnan (2002) sekuritas (saham) merupakan secarik kertas yang menunjukkan hak pemodal (yaitu pihak yang memiliki kertas tersebut) untuk memperoleh bagian dari prospek atau kekayaan organisasi yang menerbitkan sekuritas tersebut dan berbagai kondisi yang memungkinkan pemodal tersebut menjalankan haknya, sedangkan menurut Tandelilin (2001), saham merupakan surat bukti bahwa kepemilikan atas aset-aset perusahaan yang menerbitkan saham. Jadi, saham adalah surat berharga yang diperdagangkan di pasar modal yangdikeluarkan oleh sebuah perusahaan yang berbentuk Perseroan Terbatas (PT), dimana saham tersebut menyatakan bahwa pemilik saham tersebut adalah juga pemilik sebagian dari perusahaan tersebut (Sani, 2013).
Motivasi investor untuk melakukan investasi salah satunya adalah dengan membeli saham perusahaan dengan harapan untuk mendapatkan kembalian (return) investasi yang sesuai dengan apa yang telah diinvestasikannya. Return saham menurut Jogiyanto (2000) merupakan hasil yang diperoleh dari investasi. Return dapat berupa return realisasi yang sudah terjadi maupun return ekspektasi yang belum terjadi namun diharapkan akan terjadi di masa mendatang. Return realisasi merupakan return yang sudah terjadi. Return realisasi dihitung berdasarkan data historis. Return ini penting karena digunakan sebagai salah satu pengukur kinerja perusahaan dan juga berguna sebagai dasar penentuan return ekspektasi dan resiko di masa datang. Rumus yang digunakan untuk menentukan return adalah
1
1
,
t t
t t
d d
X
d
(2.51)
dimana Xt adalah return harga saham pada hari ke-t, dt adalah harga saham pada
31
2.15 Backtesting
Backtesting adalah prosedur statistik di mana keuntungan dan kerugian aktual secara sistematis dibandingkan dengan VaR yang sesuai perkiraan. Pengujian
Backtesting yang paling banyak digunakan adalah uji kupiec. Uji kupiec, juga dikenal sebagai uji POF (Proportion Of Failure), mengukur apakah jumlah
exception konsisten dengan kuantil ke- (Dowd, 2006). Jumlah exception
mengikuti distribusi binomial:
T x
1
T x.Oleh karena itu, satu-satunya informasi yang diperlukan untuk melaksanakan uji kupiec adalah jumlah observasi (T ), jumlah exception (
x
) dan kuantil ke- . (Kansantaloustiede, Tutkielma, & Nieppola, 2009)Hipotesis untuk uji kupiec adalah
0
Tingkat kegagalan pˆ berbeda dengan p yaitu tingkat kegagalan yang mengacu pada kuantil ke- . Statistik uji yang digunakan adalah likelihood ratio
LR32
33
BAB 3
METODOLOGI PENELITIAN
Dalam bab ini akan dijelaskan mengenai sumber data, variabel-variabel yang akan diteliti serta metodologi penelitian berisi penjelasan mengenai langkah-langkah yang dilakukan dalam analisis. Selain itu, dalam bab ini juga disajikan diagram alir proses analisis data yang merupakan versi ringkas dari langkah-langkah yang dilakukan dalam proses analisis data. Berikut ini adalah pemaparan secara detail mengenai bab 3.
3.1 Sumber Data dan Variabel Penelitian
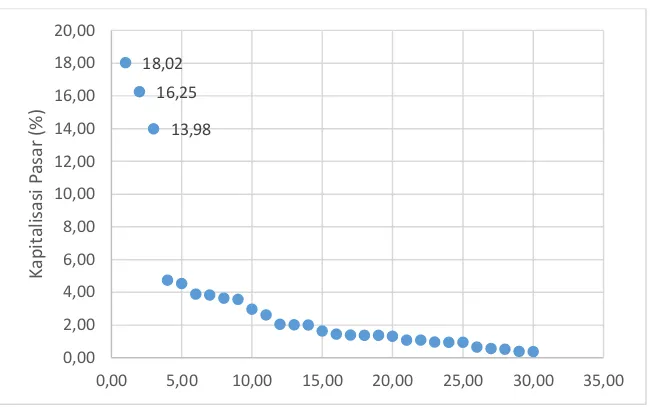
Data yang digunakan dalam penelitian ini merupakan data sekunder yaitu data harian return saham syariah dari tiga perusahaan yang tergabung di Jakarta Islamic Index (JII) yaitu PT Astra Internasional Tbk (ASII), PT Telekomunikasi Indonesia Tbk (TLKM) dan PT Unilever Indonesia Tbk (UNVR). Data diperoleh dari situs resmi yahoo finance berupa data harian penutupan harga saham (close price) mulai Januari 2010 hingga Juli 2016. Saham ketiga perusahaan tersebut dipilih karena perusahaan memiliki kapitalisasi pasar terbesar, sehingga dapat mewakili perdagangan pasar harian, bahkan mampu menjadi indeks mover dalam pembentukan JII maupun IHSG (Indeks Harga Saham Gabungan) di Bursa Efek Indonesia (BEI). Selain itu, Saham-saham tersebut merupakan saham-saham aktif dan likuid memenuhi kriteria JII selama 6 tahun terakhir dan salah satu market leader pada sektor industrinya, sehingga dapat dijadikan benchmark. Alasan lain dipilih tiga perusahaan tersebut diteliti karena berdasarkan Gambar 3.1, dengan menggunakan tiga perusahaan tersebut telah mewakili 48,43% kapitalisasi saham JII.
3.2 Langkah Penelitian
Berdasarkan sumber data dan variable penelitian yang telah dipaparkan, langkah penelitian yang dilakukan sebagai berikut.
34
2. Mendeskripsikan karakteristik masing-masing saham. 3. Menghitung return saham dengan Persamaan (2.51).
Gambar 3.1 Kapitalisasi pasar saham JII
4. Membentuk model ARIMA dari masing-masing return saham dengan langkah-langkah sebagai berikut.
a. Mengidentifikasi kestasioneran data terhadap mean dan varians dengan menggunakan time series plot, ACF dan PACF.
b. Melakukan transformasi terhadap mean dan/atau varians jika data tidak stasioner. Jika data tidak stasioner terhadap mean dan varians, maka data ditransformasi Box-Cox terlebih dahulu kemudian dilakukan differen-cing.
c. Menduga model ARIMA yang terbentuk berdasarkan plot ACF dan PACF.
d. Melakukan estimasi dan pengujian signifikansi parameter model ARIMA dengan pendekatan Bayesian.
e. Diagnostic check dengan melakukan pengujian white Noise mengguna-kan Persamaan (2.10) dan (2.11) serta distribusi Normal pada residual. 5. Pembentukan model MLAR dengan pendekatan Bayesian dapat dilakukan
dengan langkah sebagai berikut. 18,02
0,00 5,00 10,00 15,00 20,00 25,00 30,00 35,00
35
a. Identifikasi mixture pada data return yang telah stasioner dengan menggunakan histogram dan marginal plot serta melakukan uji distribusi.
b. Menentukan orde AR berdasarkan orde ARIMA yang signifikan dan jumlah komponen mixture yang terbentuk untuk model MLAR.
c. Melakukan estimasi dan pengujian signifikansi parameter model MLAR dengan pendekatan Bayesian.
d. Pemilihan model terbaik dengan kriteria DIC.
6. Menghitung besar risiko investasi saham dengan model VaR Normal Linier dengan cara:
a. Menentukan lama investasi (h) yang akan dianalisis. b. Menentukan besaran
yang akan digunakan.c. Menentukan , dan dari hasil estimasi parameter model MLAR yang terbaik.
d. Menghitung VaR menggunakan persamaan (2.50) berdasarkan informasi pada bagian 6a hingga 6c.
7. Menarik kesimpulan dan memberikan saran.
Estimasi parameter model ARIMA dan MLAR dengan pendekatan Bayesian dilakukan dengan tahapan sebagai berikut.
1) Menentukan distribusi prior yang sesuai untuk pemodelan ARIMA dan MLAR.
2) Membangun struktur ARIMA dan MLAR dengan Bayesian full conditional distribution secara iteratif dengan metode Gibbs Sampler untuk menaksir parameter.
3) Membuat doodle untuk mengimplementasikan model ARIMA dan MLAR menggunakan WinBUGS.
36
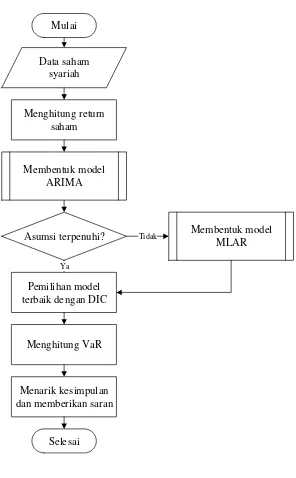
Mulai
Data saham syariah
Menghitung return saham
Membentuk model ARIMA
Asumsi terpenuhi?
Pemilihan model terbaik dengan DIC
Ya
Menghitung VaR
Selesai
Membentuk model MLAR Tidak
Menarik kesimpulan dan memberikan saran
37
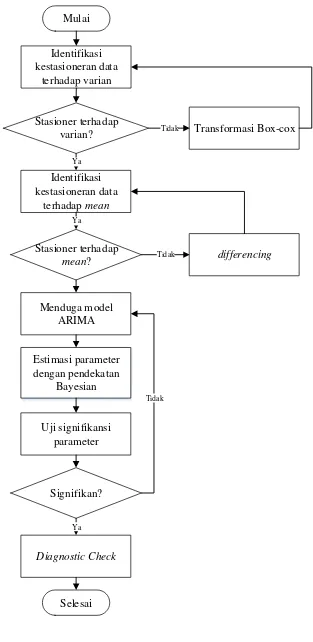
Mulai
Identifikasi kestasioneran data
terhadap varian
Estimasi parameter dengan pendekatan
Bayesian Stasioner terhadap
mean?
Selesai Stasioner terhadap
varian?
Ya
Identifikasi kestasioneran data
terhadap mean
Transformasi Box-cox
Tidak
Ya
differencing
Tidak
Menduga model ARIMA
Diagnostic Check
Signifikan? Uji signifikansi
parameter
Ya
Tidak
38
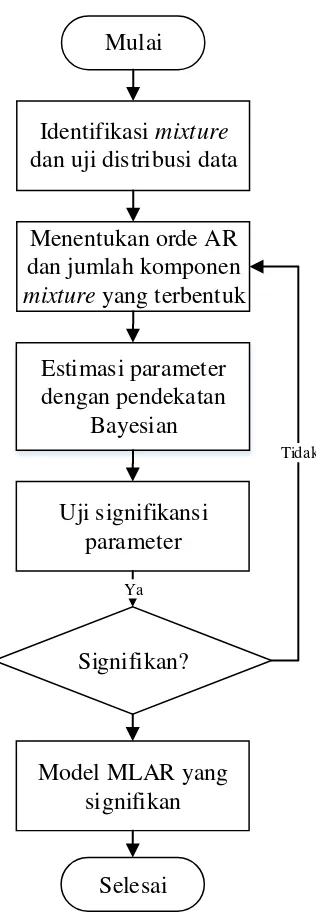
Mulai
Identifikasi mixture
dan uji distribusi data
Selesai
Menentukan orde AR dan jumlah komponen
mixture yang terbentuk
Estimasi parameter dengan pendekatan
Bayesian
Uji signifikansi parameter
Signifikan?
Ya
Tidak
Model MLAR yang signifikan
Gambar 3. 4 Diagram alir penelitian MLAR
3.3 Penelitian sebelumnya
39
Mixture Normal Autoregressive (MNAR). Dalam analisis tersebut dijelaskan bahwa return sudah stasioner terhadap mean dan varians. Selain itu, didapatkan pula model ARIMA yang signifikan akan tetapi tidak memenuhi asumsi distribusi Normal dan white noise. Model tersebut adalah AR([3]) dan AR([3,6]) untuk saham ASII, AR([2]), AR([3]), AR([4]), AR([2,3]), AR([2,4]), AR([3,4]), dan AR([2,3,4]) serta AR(2), AR([11]), dan AR(2,[11]). Hal tersebut mengindikasikan bahwa model yang diperoleh belum sesuai untuk merepresentasikan data return saham ASII, TLKM dan UNVR. Oleh karena itu perlu dilakukan analisis lebih lanjut untuk mendapatkan model yang lebih bisa menerangkan atau mengakomodir data karena adanya kasus heteroskedastisitas yang disebabkan adanya data outlier, sehingga mengakibatkan distribusi pada data menjadi tidak Normal.
(a) (b)
(c)
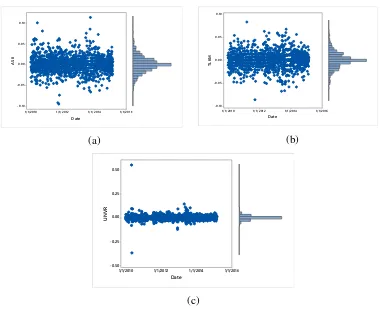
Gambar 3.5 Marginal Plot dari Return Saham (a)ASII, (b)TLKM dan (c)UNVR
Gambar 3.5 memperlihatkan bahwa data return saham PT Astra International Tbk, PT Telekomunikasi Indonesia Tbk dan PT Unilever Indonesia
40
Tbk membawa sifat kemiringan dan kurtosis yang mengindikasi adanya ketidaknormalan pada data return saham. Selain itu ditunjukkan bahwa variabilitas
41
BAB 4
ANALISIS DAN PEMBAHASAN
Bab 4 akan membahas mengenai pemodelan return saham ASII, TLKM dan UNVR beserta perhitungan Value at Risk (VaR). Subbab pertama dimulai dengan penentuan distribusi prior. Dalam penentuan distribusi prior inilah estimasi model ARIMA diterapkan untuk mendapatkan parameter prior yang akan digunakan untuk analisis Bayesian MLAR. Orde ARIMA yang digunakan diperoleh dari penelitian sebelumnya. Subbab kedua akan menjelaskan mengenai pemodelan MLAR pada PT Astra International Tbk (ASII), PT Telekomunikasi Indonesia Tbk (TLKM) dan PT Unilever Indonesia Tbk (UNVR). Subbab ketiga akan membahas mengenai pemilihan model terbaik berdasarkan DIC. Model yang dipilih merupakan model yang didapatkan dari subbab kedua. Subbab terakhir berisi penjelasan mengenai VaR yang telah dihitung.
4.1 Penentuan Distribusi prior
Analisis Bayesian dinyatakan sebagai kombinasi dari fungsi likelihood yang dikombinasikan dengan distribusi prior sehingga membentuk distribusi posterior. Penggunaan prior yang tepat sangat diperlukan dalam analisis Bayesian. Hal itu disebabkan jika salah dalam memilih prior, hasil yang didapatkan akan salah.
Dalam mengestimasi parameter model MLAR menggunakan Bayesian, distribusi prior untuk parameter standar deviasi adalah conjugate prior berupa invers Gamma, sedangkan untuk parameter Autoregressive menggunakan pseudo prior. Pseudo prior yang digunakan dalam analisis ini adalah distribusi Laplace dengan parameter scale dan location. Nilai parameter untuk distribusi tersebut didapatkan dari mengestimasi parameter Autoregressive untuk tiap komponen pada saham tertentu dengan analisis Bayesian. Analisis Bayesian untuk analisis parameter Autoregressive tiap komponen menggunakan conjugate prior distribusi Normal.