8
Teknik pengkodean video konvensional cocok digunakan untuk televisi digital, penyimpanan digital dan video streaming dimana informasi sumber dikodekan sekali dan didekodekan beberapa kali. Seiring dengan munculnya berbagai macam aplikasi video digital, dibutuhkan standar pengkodean video yang dapat meningkatkan kompresi. Teknik pengkodean video konvensional ini menerapkan pengkodean prediksi yakni memperkirakan arah pergerakan objek (motion estimation) dan kompensasi pergerakan (motion compensation) untuk
frame berikutnya (interframe) di enkoder. Informasi prediksi dari arah pergerakan objek untuk interframe diperoleh dengan mengkombinasikan teknik prediksi temporal kompensasi gerak dan pengkodean transformasi berbasis blok, dimana enkoder menjadi lebih kompleks dibandingkan dengan dekodernya.
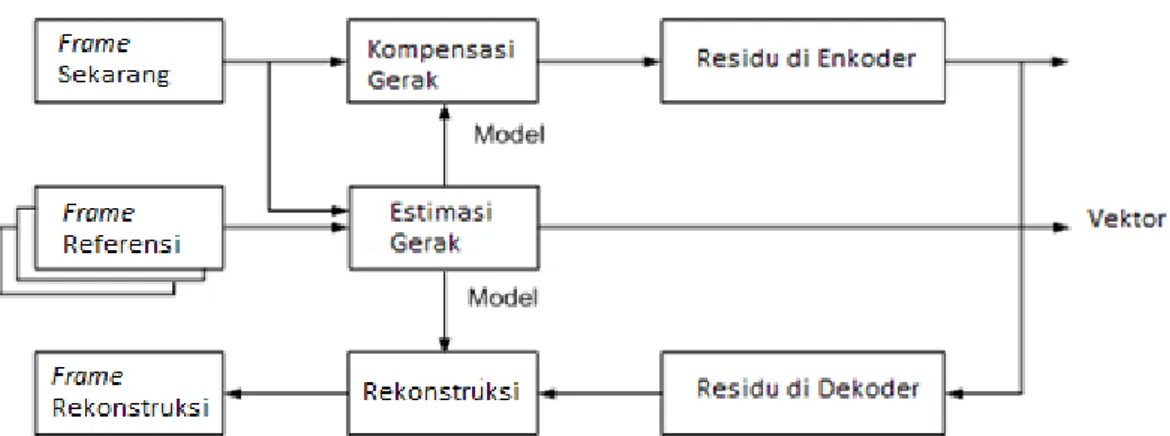
Gambar 2.1 merupakan model dan arsitektur dari teknik estimasi pergeseran dan kompensasi pergeseran yang dilakukan di enkoder pada pengkodean video konvensional (Richardson, I., 2002). Dapat dijelaskan pada gambar 2.1 bahwa proses prediksi interframe (motion estimation) pengkodean video konvensional terjadi di enkoder. Untuk proses prediksi ini digunakan informasi yang diperoleh dari eksploitasi spasial dan temporal pada objek yang sama antara dua frame yang berurutan di enkoder. Sehingga fungsi dekoder hanya merekontruksi interframe
yang dikirim oleh enkoder.
Gambar 2.1 Model teknik pengkodean video konvensional
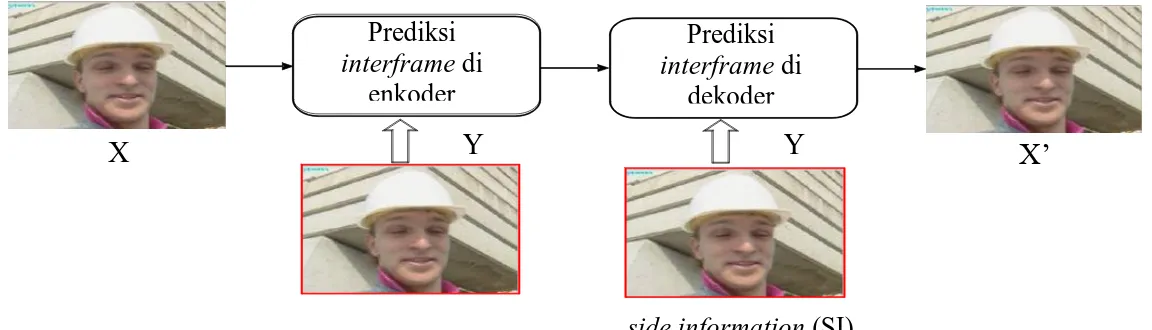
side information (SI) Prediksi interframe di enkoder X Y Y X’ Prediksi interframe di dekoder
Gambar 2.2 Arsitektur teknik pengkodean video konvensional (Sumber : Richardson, I., 2002)
Dari gambar 2.2 dapat dijelaskan sebagai berikut :
1. Proses Perkiraan Arah Pergerakan (motion estimation)
Proses ini bertujuan untuk membentuk prediksi arah pergerakan frame
sekarang dari frame yang menjadi frame referensi. Frame yang menjadi frame
referensi adalah frame sebelumnya atau frame yang telah direkonstruksi. Teknik yang paling akurat digunakan dalam proses perkiraan arah pergerakan yaitu teknik
Block Matching. Proses ini membandingkan piksel antara frame sekarang dengan
frame referensi dalam jendela pencarian yang telah diatur, dapat dilihat pada gambar 2.3.
Gambar 2.3 Perkiraan pergerakan dengan teknik Block Matching (Sumber : Kondoz, A., 2009)
2. Kompensasi Pergerakan (Motion Compensation)
Kompensasi pergerakan frame sekarang yaitu mengurangkan frame
terkompensasi pergerakannya. Frame ini kemudian dikirimkan dan ditambah dengan informasi-informasi (frame encode residual) yang diperlukan oleh dekoder untuk merekontruksi sebuah ’model’. Di dekoder, frame residu yang telah di kodekan (frame decode residual) ditambahkan dengan ’model’ sehingga diperoleh hasil rekonstruksi frame sekarang. Frame hasil rekonstruksi ini kemudian disimpan untuk digunakan sebagai frame referensi.
Pada sinyal video, selain terdapat redundansi temporal juga terdapat redundansi spasial dan sumber yang perlu untuk dihilangkan, sehingga diperoleh
bit rate sekecil mungkin. Berikut ini (Kondoz, A., 2009) adalah penjelasan dari pengelompokkan redundansi pada sinyal video.
1. Redundansi Spasial
Redundansi spasial adalah redundansi yang terdapat dalam suatu frame yang disebabkan adanya korelasi antara sebuah piksel dengan piksel disekitarnya. Redundansi ini terjadi ketika terdapat perubahan nilai piksel dalam jumlah yang kecil (nilai piksel yang sangat mirip) pada area video atau gambar. Pada gambar 2.4 ditunjukkan redundansi spasial pada area kulit seperti siku.
Gambar 2.4 Redundansi spasial (Sumber : Kondoz, A., 2009)
2. Redundansi Temporal
Redundansi temporal adalah redundansi yang terdapat diantara sebuah frame
dengan frame sebelum atau sesudahnya. Hal ini disebabkan piksel-piksel yang berkorelasi diantara frame-frame tersebut. Redundansi ini terjadi ketika terdapat
banyak kemiripan pada frame video yang berurutan. Pada gambar 2.5 ditunjukkan dua frame secara berturut-turut pada rangkaian video dan sangat jelas dapat dilihat terdapat perbedaan yang sangat kecil pada kedua frame video yang berurutan tersebut.
Gambar 2.5 Redundansi temporal (Sumber : Kondoz, A., 2009)
3. Redundansi Pengkodean Sumber
Redundansi ini terjadi jika simbol yang dihasilkan oleh video codec tidak efisien jika disimbolkan menjadi aliran bit biner. Teknik entropi dapat digunakan untuk mengeksploitasi probabilitas keluaran dari data video ketika beberapa simbol memiliki probabilitas kemunculan lebih banyak dari yang lainnya.
2.2 Teknik Pengkodean Video H.264
H.264 (MPEG-4 Part 10) atau lebih dikenal dengan Advance Video Coding
(AVC) merupakan standar pengkodean video yang tujuan utamanya adalah untuk menghasilkan kualitas video yang baik dengan tingkat kompresi tinggi pada bit rate yang lebih kecil dibandingkan dengan standar video digital sebelumnya tanpa melakukan perubahan yang kompleks dan dapat diimplementasikan dengan biaya yang murah sekaligus mampu diaplikasikan pada berbagai macam jaringan dan layanan seperti video telephony, storage, broadcast dan streaming. H.264 dikembangkan oleh oleh ITU-T Video Coding Expert Group (VCEG) bersama-sama dengan ISO/IEC Moving Picture Expert Group (MPEG) yang dinamakan
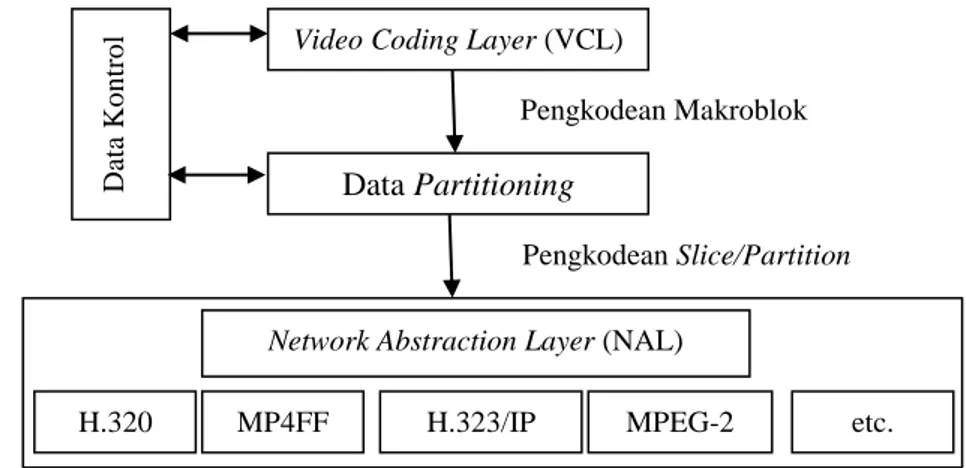
Standar H.264 dirancang berdasarkan dua konsep layer utama, yaitu Video Coding Layer (VCL) untuk merepresentasikan data video secara efisien dan
Network Abstraction Layer (NAL) untuk memformat representasi VCL agar sesuai dengan berbagai macam transport layer. Untuk lebih jelasnya konsep layer
pada standar H.264 (Suryadi, A., 2008) dapat dilihat pada gambar 2.6.
Gambar 2.6 Konsep layer pada standar H.264/AVC (Sumber :Suryadi, A., 2008)
Pada teknik pengkodean H.264, data video dipisahkan menjadi komponen Y, Cb dan Cr. Dimana komponen Y memberikan informasi luminance yang
merepresentasikan tingkat kecerahan (brightness). Sedangkan komponen Cb dan
Cr memberikan informasi chrominance yang merepresentasikan intensitas warna
dari keabuan hingga merah dan biru. Karena sistem penglihatan manusia lebih sensitif pada informasi kecerahan dibandingkan resolusi warna, H.264 menggunakan teknik sampling 4:2:0, dimana frekuensi sampling komponen
chrominance adalah setengah frekuensi komponen luminance. Karena format
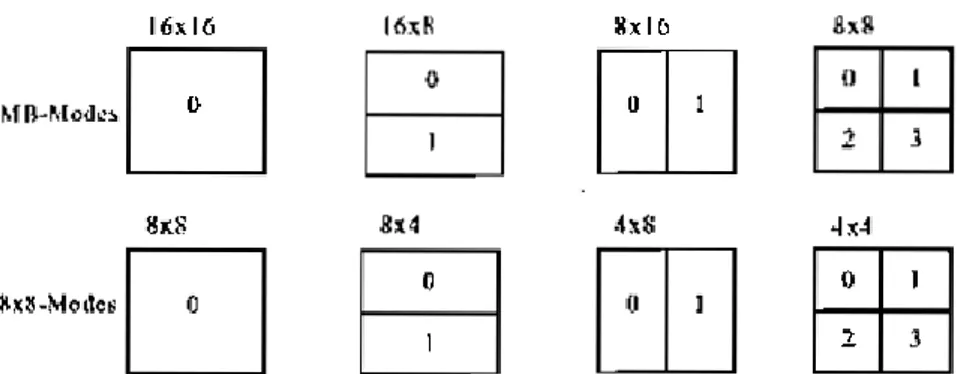
sampling yang dipakai adalah 4:2:0, maka setiap makroblok akan memiliki satu blok 16x16 piksel komponen luminance dan dua blok 8x8 piksel komponen
chrominance. Makroblok tersebut akan dibagi lagi menjadi sub makroblok yang berukuran 16x8, 8x16, 8x8, 8x4, 4x8 dan 4x4 piksel. Untuk lebih jelasnya dapat dilihat pada gambar 2.7 (Suryadi, A., 2008).
Data
Ko
n
tr
o
l Video Coding Layer (VCL)
Data Partitioning
Network Abstraction Layer (NAL)
H.320 MP4FF H.323/IP MPEG-2 etc.
Pengkodean Makroblok
Gambar 2.7 Segmentasi makroblok untuk proses perkiraan arah pergerakan (Sumber :Suryadi, A., 2008)
Terdapat dua kompresi pada teknik pengkodean video H.264, yaitu kompresi intraframe dan kompresi interframe. Kompresi intraframe
memanfaatkan redundansi spasial yang terdapat dalam satu frame. Kompresi
interframe menggunakan redundansi temporal yang terdapat dalam sekelompok
frame.
2.3 Pengkodean Citra Joint Photographic Expert Group (JPEG)
JPEG adalah standar kompresi file yang dikembangkan oleh Group Joint Photographic Experts. JPEG menggunakan kombinasi DCT (Discrete Cosinus Transform) dan pengkodean Huffman untuk mengkompresikan suatu file citra. JPEG adalah suatu algoritma kompresi yang bersifat lossy (yang berarti kualitas citranya kurang baik). JPEG menggunakan teknik kompresi grafis high color bit mapped. Teknik kompresi grafis high color bit mapped merupakan teknik dan standar universal untuk kompresi dan dekompresi citra tidak bergerak untuk digunakan pada kamera digital dan sistem pencitraan menggunakan komputer. Umumnya digunakan untuk kompresi citra berwarna maupun grayscale.
Kompresi citra adalah aplikasi kompresi data yang dilakukan terhadap citra digital dengan tujuan untuk mengurangi redundansi dari data-data yang terdapat dalam citra sehingga dapat disimpan atau ditransmisikan secara efisien. Ada dua tipe utama kompresi data, yaitu kompresi tipe tanpa rugi (lossless) dan kompresi tipe rugi (lossy). Kompresi tipe rugi adalah kompresi dimana terdapat data yang hilang selama proses kompresi. Akibatnya kualitas data yang dihasilkan jauh lebih
rendah daripada kualitas data asli. Sementara itu, kompresi tipe tanpa rugi tidak menghilangkan informasi setelah proses kompresi terjadi, akibatnya kualitas citra hasil kompresi tidak menurun. Namun demikian, rasio kompresi yang digunakan untuk kompresi tipe tanpa rugi lebih kecil daripada rasio kompresi pada kompresi tipe rugi.
Format file JPEG mampu mengkompresi objek dengan tingkat kualitas sesuai dengan pilihan yang disediakan. Format file ini sering dimanfaatkan untuk menyimpan gambar yang akan digunakan untuk keperluan halaman web, multimedia dan publikasi elektronik lainnya. Format file ini mampu menyimpan gambar dengan mode warna RGB (Red, Green, Blue), CMYK (Cyan, Magenta, Yellow, Key), dan Grayscale. Format file ini juga mampu menyimpan alpha channel, namun karena orientasinya ke publikasi elektronik maka format ini berukuran relatif lebih kecil dibandingkan dengan format file lainnya.
2.4 Teorema Dasar Pengkodean Video Terdistribusi
Pengkodean video terdistribusi diidentifikasi sebagai adaptasi dari struktur teori dari Distributed Source Coding (DSC) yakni teorema Slepian-Wolf dan
Wyner-Ziv (WZ) untuk pengkodean video. Konsep pengkodean video terdistribusi menyimpang dari paradigma pengkodean sumber secara konvensional dalam konteks proses pengkodean sumber yang berkorelasi. Pada pendekatan konvensional sumber yang berkorelasi secara statistik dapat dikodekan dan didekodekan kembali secara bersama-sama. Sebaliknya pada DSC mengusulkan proses independen pengkodean sumber dari sumber yang secara statistik dependen namun dikodekan kembali secara bersama-sama.
2.4.1 Teorema Slepian-Wolf
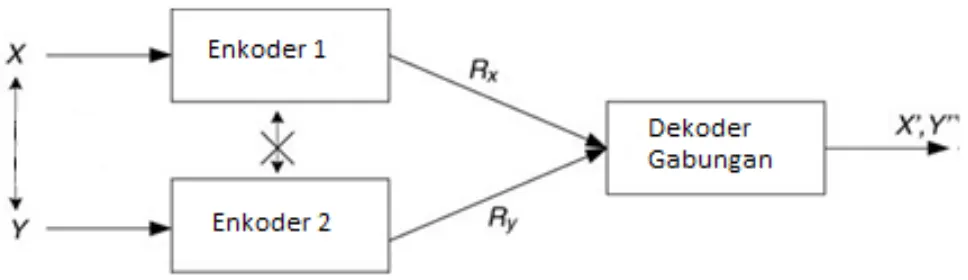
Teorema Slepian-Wolf melakukan pengkodean tanpa rugi. Teorema ini menunjukkan jika dua sumber informasi yang berkorelasi, contohnya sumber X dan Y yang dikodekan secara terpisah, dapat didekodekan secara gabungan (Aaron, A., 2002), seperti ditunjukan pada gambar 2.8.
Gambar 2.8 Teorema Slepian-Wolf untuk sumber-sumber dependen secara statistik (Sumber : Brites, C., 2005)
Asumsi X dan Y adalah dua rangkaian acak diskrit bergantung secara statistik yang mana didistribusikan secara bebas dan sama. Teorema Slepian-Wolf
ditunjukkan pada persamaan dibawah ini.
X Y
H RX / ... (2.1)
Y X
H RY / ... (2.2)
X Y
H R RX Y , ... (2.3) Dimana H
X/Y
dan H
Y/X
adalah kondisi entropi masing-masing dan
X Y
H , adalah entropi bersama pada X dan Y. Untuk menghitung entropi
digunakan persamaan 2.4. simbol bit p p H ij n i ij i / 1 log2 1
... (2.4) Menurut teorema Slepian-Wolf, jika total semua bit rate melebihi penyajian terakhir pada bit rate RX dan RY dan kondisi entropi antara X dan Y lebih kecil dari penyajian terakhir, itu berarti aliran dari enkoder yang secara terpisah dapat dikodekan kembali secara bersama-sama dengan probabilitas error bit yang terkecil. Gambar 2.9 merupakan ilustrasi daerah pencapaian rate pada distribusi pengkodean video untuk dua statistik yang saling bergantung dengan sumber X dan Y pada informasi yang didapat dari probabilitas error terkecil menurut teorema Slepian-Wolf.Gambar 2.9 Daerah pencapaian rate Slepian-Wolf
(Sumber : Brites, C., 2005) 2.4.2 Teorema Wyner-Ziv
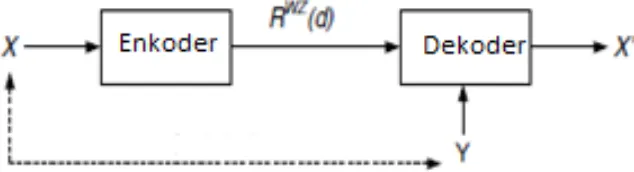
Teorema WZ melakukan pengkodean dengan rugi dari video WZ dengan meningkatkan kinerja kompresi yakni eksploitasi spasial di enkoder dan eksploitasi temporal di dekoder. Eksploitasi spasial dilakukan karena korelasi dalam frame selalu berbeda dan dapat tangani dengan proses transformasi dan kuantisasi. Sedangkan eksploitasi temporal adalah teknik prediksi frame WZ yang akan di dekodekan menggunakan teknik estimasi gerak yang berbeda. Konsep WZ menunjukkan distorsi level d yang cocok secara terbatas antara sumber informasi X dan dekode output X’ yang sesuai. Maka dari itu disebut “lossy compression”,
ditunjukkan pada gambar 2.10.
Gambar 2.10 Kompresi beban bengan side information (SI) dekoder
(Sumber : Brites, C., 2005)
Asumsi sebuah informasi komponen Y bergantung secara statistik pada X maka pada WZ secara umum terdapat rate loss yang ditunjukkan pada persamaan 2.5. ) ( ) (d R / d RWZ X Y ... (2.5)
Dimana RWZ(d) disebut dengan minimum pencapaian rate menggunakan pengkodean WZ. Sedangkan RX/Y(d) adalah rate yang dihasilkan oleh nilai
entropi di enkoder.
2.5 Teknik Pengkodean Video Wyner-Ziv Existing
Teknik pengkodean video WZ adalah paradigma baru dalam pengkodean video, didasarkan pada Slepian-Wolf dan informasi teoritis di tahun 1970-an untuk memperoleh hasil kinerja pembangkitan SI yang maksimal. Kualitas SI memiliki pengaruh yang sangat besar pada efisiensi kompresi pada sistem pengkodean video WZ, semakin baik kualitas SI maka unjuk kerja RD juga semakin baik. Akan tetapi, selama SI dihasilkan di dekoder dengan informasi sangat minimal, memperkirakan SI secara akurat menjadi pekerjaan yang sangat sulit.
Teknik pengkodean video WZ, melakukan pengkodean secara rugi dari 2 (dua) sumber yang berkorelasi, dimana sumber X dikodekan tanpa akses ke sumber Y (yang menjadi korelasinya) atau sering disebut dengan blind motion estimation. Asumsi yang digunakan adalah bahwa sumber Y tersedia hanya di dekoder, untuk membentuk joint decoding. Ini mengimplikasikan paradigma baru dimana korelasi data video dieksploitasi di dekoder, yang memungkinkan kompleksitas pengkoden di enkoder dapat diturunkan, karena pemrosesan prediksi pergerakan yang banyak memakan biaya komputasi dipindahkan ke dekoder.
Proses prediksi arah pergerakan interframe pada pengkodean video WZ terjadi di dekoder. Namun untuk proses prediksi ini dekoder tidak memperoleh informasi intraframe dari enkoder. Untuk mendapatkan informasi itu maka dekoder harus menggunakan teknik prediksi arah pergerakan tertentu sehingga
interframe yang di prediksi di dekoder mendekati dengan intraframe, seperti yang terlihat pada gambar 2.11.
Gambar 2.11 Model teknik pengkodean video terdistribusi
2.5.1 Pengkodean Video Wyner-Ziv Stanford
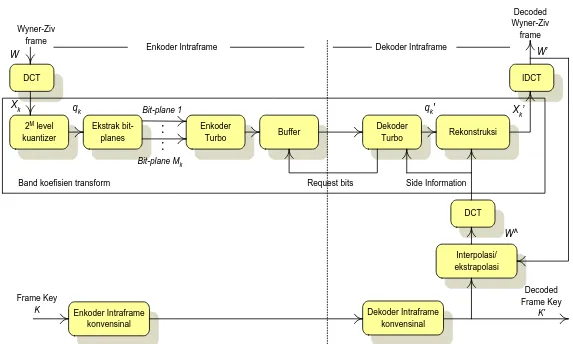
Solusi pengkodean video WZ Stanford, pertama kali diperkenalkan sekitar tahun 2002 oleh Stanford University, untuk kawasan piksel dan kemudian dilanjutkan ke kawasan transform pada tahun 2004. Pendekatan pada kawasan
transform, koefisien-koefisien transform dikodekan WZ, untuk eksploitasi redundansi spasial dan menurunkan kompleksitas, seperti ditunjukan pada gambar 2.12. DCT 2M level kuantizer Ekstrak bit-planes Enkoder Turbo : : Buffer Wyner-Ziv frame Xk q k Bit-plane 1 Bit-plane Mk Dekoder Turbo Rekonstruksi DCT IDCT Interpolasi/ ekstrapolasi Decoded Wyner-Ziv frame
Band koefisien transform Request bits Side Information
qk' X k’ W W’ W^ Dekoder Intraframe konvensinal Enkoder Intraframe konvensinal Frame Key K Decoded Frame Key K’
Enkoder Intraframe Dekoder Intraframe
Gambar 2.12 Arsitektur pengkodean video WZ Stanford (Sumber : Aaron, A., 2004)
Interframe Wyner-Ziv
di dekoder
X Y X’
side information (SI)
Intraframe Wyner-Ziv
Dari gambar 2.12 dapat dijelaskan sebagai berikut : A. Pada Sisi Enkoder
1. Klasifikasi Frame
Deretan video dibagi kedalam frame-frame WZ dan frame key, masing-masing diidentifikasi sebagai frame X dan Y. Frame key secara periodik disisipkan untuk menentukan ukuran Group Of Picture (GOP). Frame key
dikodekan Intra, dalam arti pengkodean dengan tanpa eksploitasi redundansi temporal yaitu tanpa membentuk prosedur estimasi gerak. Pengkodean dapat menggunakan standar H.263+ intra, H.264/AVC atau JPEG.
2. Transformasi Spasial
Transformasi berbasis blok menggunakan Discrete Cosinus Transform
(DCT), diterapkan pada semua frame WZ. Koefisien DCT dari masing-masing
frame WZ kemudian dikelompokkan bersama-sama, sesuai dengan posisi koefisien DCT dalam sebuah blok, membentuk band-band koefisien DCT.
3. Kuantisasi
Setiap band DCT dikuantisasi seragam (uniform) dengan jumlah level bergantung pada kualitas target. Untuk sebuah band, bit-bit dari simbol-simbol yang terkuantisasi dikelompokan bersama-sama membentuk bit plane selanjutnya
bit plane ini dikodekan dengan pengkodean turbo (Turbo Code) secara independen.
4. Pengkodean Turbo
Setiap band DCT dikodekan Turbo dimulai dengan Most Significant Bit-plane (MSB). Informasi parity dibangkitkan untuk setiap Bit-plane kemudian disimpan dalam buffer. Informasi parity akan dikirimkan ke dekoder dalam bentuk paket disesuaikan dengan permintaan dekoder. Prosedur meminta bit parity menggunakan sebuah kanal feedback.
B. Pada Sisi Dekoder
1. Pembuatan Side Information (SI)
Dekoder membuat SI untuk setiap frame WZ dengan membentuk motion-compensation frame interpolation (atau extrapolation) menggunakan frame-frame
terdekodekan sebelumnya yang paling dekat. SI untuk setiap frame WZ diambil dari sebuah estimasi dari frame WZ asli. Kualitas estimasi yang baik, maka jumlah error yang harus diperbaiki oleh turbo dekoder menjadi lebih sedikit dan makin sedikit jumlah bit parity yang harus dikirimkan oleh enkoder.
2. Pemodelan Derau Korelasi
Statistik residu di antara koefisien-koefisien DCT yang saling berhubungan dalam frame WZ dan frame SI diasumsikan dapat dimodelkan sebagai distribusi Laplacian, yang mana, parameter-parameternya telah diestimasi sebelumnya menggunakan fase pelatihan. Pendekatan ini sebenarnya tidak realistis karena mengasumsikan data asli tersedia di dekoder atau SI tersedia di enkoder.
3. Pendekodean Turbo
Saat sebuah band diketahui koefisien-koefisien DCT, SI dan statistik residunya, masing-masing Bit-plane kemudian di turbo dekoder (dimulai dari MSB). Turbo dekoder menerima sederetan potongan-potongan bit parity dari enkoder, sesuai dengan permintaannya yakni melalui sebuah kanal feedback. Untuk memutuskan apakah diperlukan bit-bit parity tambahan atau tidak untuk keberhasilan sebuah proses pendekodean dari sebuah Bit-plane, dekoder menggunakan kriteria pemberhentian mekanisme request. Di awal, kriteria ini diasumsikan tersedianya frame asli di dekoder. Pendekatan ini tentunya masih tidak realistis. Setelah proses pendekodean turbo MSB sebuah Bit-plane dari sebuah band DCT berhasil, dekoder turbo diproses dengan cara analog dengan menjaga Bit-plane yang tergabung dalam band yang sama. Jika seluruh Bit-plane
dari sebuah band DCT telah berhasil di turbo dekoder, maka Turbo dekoder mulai mendekodekan band DCT berikutnya.
4. Rekonstruksi
Setelah pendekodean turbo, seluruh Bit-plane yang berhubungan dengan masing-masing band DCT digabungkan bersama-sama untuk membentuk deretan simbol terkuantisasi yang berhubungan dengan masing-masing band. Setelah seluruh simbol-simbol terkuantisasi ini diperoleh, maka seluruh koefisien DCT dapat direkontruksi dengan bantuan koefisien SI.
M
E Step M Step
SI 5. Inverse Transform
Setelah seluruh band DCT direkonstruksi, sebuah inverse DCT (IDCT) dibentuk dan frame WZ terdekodekan dapat diperoleh dari penggabungan frame. Untuk memperoleh deretan video yang telah didekodekan, maka frame key yang terdekodekan dan frame WZ yang telah direkontruksi kemudian digabungkan.
2.5.2 Pengkodean Video Wyner-Ziv dengan Unsupervised Motion Vector Learning Berbasis Algoritma Expectation Maximization
Tujuan utama dari algoritma EM adalah untuk memperkirakan parameter tanpa informasi sebelumnya atau data observasi lengkap. Kerangka kerja algoritma EM untuk mendapatkan forward motion vector pada pengkodean video WZ, ditunjukan oleh gambar 2.13.
Gambar 2.13 Arsitektur EM-Based Unsupervised Motion Vector Learning
(Sumber : Widyantara, I. M. O., 2011)
Pada gambar 2.13, dijelaskan bahwa X adalah frame WZ luminance
sekarang dan Ŷ adalah frame luminance yang telah dikodekan sebelumnya, dimana X berkaitan dengan Ŷ melalui sebuah forward motion field (M). Sebuah model a posteriori probability distribution (Papp) dari sumber X didasarkan pada
parameter θ, yang dapat dinyatakan dengan :
j i app X P X i j X i j P , , , , ;
………...…....…….. (2.6) dimana :θ (I,j,w) = Papp{X(i,j) = w} adalah soft estimate dari X(i,j) pada nilai luminance
Dalam hal ini dekoder bermaksud untuk menghitung model a posteriori probability distribution (Papp) dari gerakan M, dengan tahap kedua menggunakan
hukum Bayes,yaitu :
M
P
M|
Y
;S;θ
P
M
P
Y
;S|M;θ
P
app
ˆ
ˆ
………... (2.7)Dimana P
M|Yˆ;S;θ
adalah probabilitas observasi medan gerak vektor Mdiperoleh ketika θ dan S, diketetahui. Bentuk persamaan di atas mengekspresikan sebuah solusi iteratif EM. Algoritma EM melakukan proses iterasi dengan tahapan, E-step memperbaharui distribusi medan vektor dengan referensi ke parameter-parameter model sumber, sedangkan M-step memperbaharui parameter-parameter model sumber dengan referensi ke distribusi medan vektor. Adapun tahapan perbaikan SI pada algoritma EM adalah sebagai berikut :
1. E-step
E-step memperbaharui distribusi estimasi pada M dari θ(t-1) yang diperoleh dari inisialisasi awalditulis sebagai :
Papp(t)
M : Papp(t1)
M P
Yˆ,S|M;(t1)
....………...……... (2.8)Dimana persamaan ini sangat mahal karena nilai M yang harus diproses terlalu besar. Penyerderhanaan dilakukan pada tugas akhir ini, yaitu pertama, mengabaikan sindrom S, karena ini dapat dieksploitasi di M-step dan kedua adalah estimasi medan vektor M, dilakukan dengan vektor gerak berbasis blok,
Mu,v.
Pada proses E-step untuk ukuran blok yang sudah ditetapkan sebesar k, setiap blok k-by-k dari θ(t-1) di bandingkan dengan blok Yˆ pada posisi
co-locatednya. Untuk blok ( 1) ,
t v u
dengan piksel kiri atas dilokasikan di (u,v), distribusi pergeseran Mu,v diperbaharui dan dinormalisasi menurut persamaan di bawah ini :
( 1)
, , , ) , ( ) 1 ( , ) ( : ˆ | ; t v u v u v u M v u t app v u t app M P M PY M P ……..…... (2.9) Dimana : Yuv Muv , ) , (
( 1)
, , , ) , ( | ; ˆ Muv uv utv v u M YP adalah probabilitas observasi
v u M v u Y , ) , ( ˆ ketika
vektor Mu,vdari Xu,vdiparameterkan oleh u(,tv1) diketahui.
2. M-step
M-Step memperbaharui soft estimasi (θ) dengan memaksimalkan kemungkinan nilai Ŷ dan sindrom (S).
m t app t m M S Y P m M P S Y P ˆ, ; argmax ˆ, | ; max arg : () .…... (2.10)Dimana, penjumlahannya adalah semua konfigurasi M dari bidang gerak. JIka nilai M-step sudah maksimal, pendekatan ini dilakukan dengan membuat soft
SI
ᴪ
(t) diikuti dengan iterasi dari gabungan Bit-plane LDPC dekoding untukmenghasilkan (t) . Soft Matching Motion pmf Weights
k k -m -m + m + m Papp(Mu,v) Mu,vŶ
Estimate motion pmf per block
Ŷ1
Gambar 2.14 Algoritma EM bidang gerak pada codec WZVC
Blockwise pada bidang gerak terdistribusi Papp(t){Mu,v}, bobot pergerakan
dari masing-masing blok Ŷ(u,v)+Mu,v, yang kemudian dijumlahkan menjadi soft SI
ˆ (, )
) ( j i Y p m M P Z m m t app
u,v(t) seperti ditunjukkan pada probabilitas model gambar 2.14. Secara umum, probabilitas yang dicampur SI memiliki nilai W pada piksel (i, j) adalah :
m t app t Y m M j i X P m M P j i, , () (, ) | ,ˆ ) ( ……... (2.11)dimana pZ(z) adalah fungsi probabilitas massa dari noise additive independen Z,
dan Ŷm adalah kerangka direkonstruksi sebelumnya dikompensasikan melalui
konfigurasi gerak m.
Seperti telah dipaparkan pada persamaan 2.11 metode Unsupervised Motion Vector Learning dengan algoritma EM, melakukan estimasi bidang gerak Papp(M) pada basis block-by-block. Iterasi pada penerapan estimasi bidang gerak berbasis blok pada algoritma EM, menyebabkan profil bidang gerak dibatasi oleh granularitas blok. Proses kerja dekoder berhenti dengan baik jika estimasi
X (i, j) = arg maxwθ(i, j,w) menghasilkan sindrom yang sama dengan S.
Perbaikan profil bidang gerak dapat dilakukan dengan memperkirakan batas dari profil bidang gerak menggunakan teknik interpolasi dari basis blok ke piksel dan perbaikannya dilakukan pada setiap iterasi. Pada aplikasi pengkodean video terdistribusi, perbedaan karakteristik profil bidang gerak di antara deretan frame
video memungkinkan desain pengkodean WZVC menerapkan teknik interpolasi yang berbeda, dengan batasan pada kinerja RD dan kompleksitas dekoding. Maka pada tugas akhir ini mengadopsi metode interpolasi Bilinear untuk memperbaiki profil bidang gerak dan membandingkan kinerjanya pada pengkodean WZVC dengan sekuen video masukan yang berbeda.
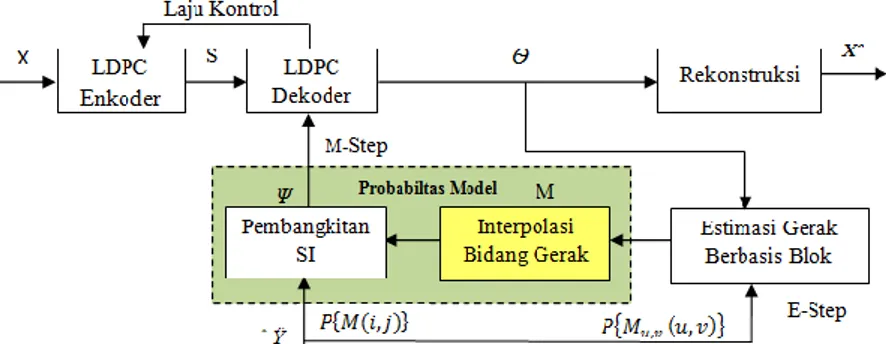
Kerangka kerja algoritma EM dengan perbaikan profil bidang gerak, ditunjukan pada gambar 2.15, dimana prosedur interpolasi ditambahkan untuk memperbaiki kualitas profil bidang gerak yang dihasilkan oleh proses estimasi gerak berbasis blok.
Gambar 2.15 Arsitektur codec WZVC (Sumber : Widyantara, I. M. O., 2011)
2.6 Geometric Image Transform
Dalam transformasi geometri, grid dari piksel citra input tidak harus dipetakan ke grid piksel dalam gambar output. Oleh karena itu, untuk menghitung intensitas piksel dalam citra output, fungsi transformasi geometri perlu interpolasi nilai intensitas piksel beberapa masukan yang disimbolkan ke kode tertentu dari output piksel.
Transformasi geometri dapat menggunakan berbagai algoritma interpolasi. Ketika memanggil fungsi transformasi geometri Intel ® Integrated Perfomance Primitives (IPP), kode aplikasi menentukan modus interpolasi, yaitu jenis algoritma interpolasi dengan menggunakan interpolasi parameter. Intel ® IPP mengimplementasikan fungsi-fungsi pengolahan citra yang melakukan operasi geometri dengan pemutaran dan penskalaan gambar.
2.6.1 Rotate (Pemutaran)
Rotasi merupakan transformasi geometri untuk memindahkan nilai piksel dari posisi awal (x1, y1), ke posisi akhir (x2, y2) dan ditentukan oleh rotasi sebesar θ terhadap koordinat titik pusat (m,n). Adapun persamaan proses rotasi adalah sebagai berikut :
………. (2.13) dimana
(x1, y1) adalah ukuran citra input (x2, y2) adalah ukuran citra output (m, n) adalah koordinat titik pusat
θ adalah sudut rotasi
2.6.2 Scaling (Penskalaaan)
Penskalaan adalah operasi geometri transformasi spasial untuk memberikan efek memperbesar atau memperkecil ukuran citra input sesuai dengan variabel penskalaannya. Transformasi semacam ini dapat dilakukan untuk poligon dengan mengalikan masing-masing koordinat poligon oleh faktor skala. Sp dan Si yang pada gilirannya menghasilkan koordinat baru (x, y) sebagai (x1, y1). Adapun
persamaannya adalah sebagai berikut :
……….. (2.14) dimana
(x, y) adalah ukuran citra input
(x1, y1) adalah ukuran citra output (Sp, Si) adalah variabel penskalaan S adalah scaling matriks
Jika nilai-nilai faktor skala lebih besar dari 1 maka objek diperbesar dan jika kurang dari 1 objek diperkecil. Apabila nilai faktor skala sama dengan 1 maka tidak akan ada perubahan pada objek. Adapun beberapa jenis penskalaan (Wibowo, E., 2010) yaitu :
1. Uniform Scaling
Nilai faktor skala pengali tiap komponen adalah sama. Dimana dapat dilihat pada gambar 2.16 nilai faktor skala untuk x dan y adalah 2.
n n y m x y m n y m x x ) ( ) cos( ) ( ) sin( ) ( ) sin( ) ( ) cos( 1 1 2 1 1 2 y S y x S x l P 1 1
Gambar 2.16 Uniform Scaling
(Sumber : Wibowo, E., 2010)
2. Non-Uniform Scaling
Nilai faktor skala pengali tiap komponen adalah berbeda. Dimana dapat dilihat pada gambar 2.17 nilai faktor skala untuk x adalah 2 dan y adalah 0,5.
Gambar 2.17 Non-Uniform Scaling
(Sumber : Wibowo, E., 2010)
Untuk setiap titik pada citra hasil, dengan koordinat x1 dan y1 diketahui,
maka dapat dicari titik asalnya yaitu koordinat x dan y dengan transformasi balik. Titik asal dapat dicari dengan membagi titik hasil dan nilai faktor skala. Karena adanya operasi pembagian, seringkali diperoleh nilai koordinat titik asal yang tidak bulat. Untuk mengatasinya harus menggunakan salah satu interpolasi yang ada.
Interpolasi Nearest Neighbor (Tetangga Terdekat)
Interpolasi Tetangga Terdekat adalah nilai keabuan titik hasil diambil dari nilai keabuan pada titik asal yang paling dekat dengan koordinat hasil perhitungan transformasi spasial. Metode ini memperkirakan nilai tunggal untuk setiap variabel bidang gerak daerah perbatasan dan menyempurnakannya pada setiap iterasi. Seluruh piksel pada blok k-by-k bidang gerak model a posteriori probability distribution Papp(t){Mu,v} bernilai tunggal. Maka, model a posteriori
probability distribution gerak berbasis pixel-by-pixel, dinyatakan dengan persamaan sebagai berikut :
k j k i M P j i M P uv t app t app , , , ) ( ) ( ………... (2.15)dimana, M(i,j) adalah bidang gerak berbasis piksel dan Mu,v adalah bidang gerak berbasis blok serta k adalah ukuran blok yang digunakan.
Ketika terdapat korelasi yang erat antara blok-blok pada frame WZ sekarang dengan blok-blok pada frame sebelumnya, maka interpolasi berbasis piksel Tetangga Terdekat dapat secara efisien memanfaatkan nilai rata-rata piksel pada blok tersebut, untuk posisi piksel pada bidang gerak sekarang.
Interpolasi Bilinear
Interpolasi Bilinear adalah nilai keabuan dari keempat titik yang bertetangga yang memberikan sumbangan terhadap nilai keabuan hasil, dengan bobot masing-masing yang linear dengan jaraknya terhadap koordinat yang dimaksud. Untuk menginterpolasi bidang gerak dari basis blok ke piksel, teknik interpolasi Bilinear hanya menggunakan 4 distribusi probabilitas blok terdekat yang terletak di arah diagonal dari sebuah piksel (i,j) yang diberikan untuk menemukan nilai-nilai intensitas warna piksel yang tepat. Maka, model a posteriori probability distribution gerak berbasis pixel-by-pixel, dinyatakan dengan persamaan sebagai berikut :
1 , 1 1 , , 1 , , , 4 , 3 , 2 , 1 k j k i M P a k j k i M P a k j k i M P a k j k i M P a j i M P v u app v u app v u app v u app app …..……. (2.16) dengan
2 1 1 1 k j k j k i k i k a ,
2 2 1 1 k j k j k k i k i a
2 3 1 1 k k j k j i k i k a ,
2 4 1 1 k k j k j k i k i a ……….. (2.17)Koefisien a1 sampai dengan a4 dipilih sehingga blok-blok yang lebih dekat secara spasial berkontribusi lebih banyak untuk penambahan jumlah bobot.
2.7 Perbandingan Tertinggi Sinyal Video Terhadap Gangguan (PSNR) Penilaian secara obyektif dilakukan dengan suatu simulasi terhadap pengamatan dengan model matematis. Penilaian obyektif yang sering digunakan adalah perbandingan tertinggi sinyal video terhadap gangguan atau peak to peak signal to noise ratio (PSNR) yaitu pengukuran distorsi relatif suatu frame
terhadap frame referensi dan diukur dalam dB (Kondoz., A, 2009). Komponen utama dalam penghitungan PSNR adalah pengukuran MSE untuk setiap frame
video dari sekuen video. Berikut ini adalah persamaan untuk MSE setiap frame
video : 2 1 0 )) ( ) ( ( 1 n X n X N MSE f N n f f
... (2.18) Dimana Xf adalah nilai piksel dari frame referensi dan X f
adalah nilai piksel dari frame terdistorsi, sedangkan n adalah jumlah frame dari sekuen video. Setiap frame terdiri dari N piksel. PSNR dari suatu frame dapat diukur dengan persamaan sebagai berikut :
PSNRf = 10 log10 f k MSE 2 ) 1 2 ( .…………... (2.19) Dimana k adalah bit per piksel dari suatu frame. Nilai k adalah 8 yakni nilai untuk uji coba untuk sebuah frame video. Maka dari persamaan 2.19 dengan nilai
k=8 diperoleh persamaan 2.20. PSNRf = 10 log10 2 1 0 2 )) ( ) ( ( 1 255 n X n X N f N n f
... (2.20)Dalam perumusan ini, sinyal puncak dari resolusi 8-bit per piksel adalah 255, dan noise-nya adalah kuadrat antara perbedaan piksel-piksel (error) antara
frame referensi dan frame yang sedang diproses.
Secara umum, nilai PSNR yang tinggi mengindikasikan kualitas frame yang tinggi pula. Penurunan kualitas akibat proses pengkodean atau error pada proses transmisi mengakibatkan penurunan nilai PSNR (Winkler, S., 2004). Untuk mendapatkan perbandingan rata-rata dari kualitas dua deretan video dilakukan
dengan membandingkan PSNR dari setiap frame dalam setiap deretan, relatif terhadap deretan video aslinya.
Untuk komponen luminance pada pengkodean video, nilai PSNR secara umum dapat dinyatakan dalam tabel 2.1 sebagai berikut (Klaune, J., 2003).
Tabel 2.1 Kategori PSNR untuk komponen luminance
Kategori Nilai PSNR Sangat Baik > 37 dB Baik 31 dB – 37 dB Cukup 25 dB – 31 dB Kurang 20 – 25 dB Sangat Kurang < 20 dB