8
LANDASAN TEORI
2.1 Pendekatan Basis data 2.1.1 Definisi Basis data
Menurut Connolly and Begg (2005, p15), “Database is a shared collection of logically related data, and a description of this data, designed to meet the information needs of an organization”, artinya Basis data merupakan kumpulan data yang berhubungan secara logik, dan gambaran data tersebut dirancang untuk memenuhi kebutuhan informasi suatu perusahaan.
Menurut W. H. Inmon (2002, p388), “Database is a collection of interrelated data stored (often with controlled, limited redudancy) according to a schema, a database can serve single or multiple applications”, yang artinya Basis data adalah koleksi data yang saling berkaitan (Seringkali dengan dikontrol, dengan dibatasi redudansi) sesuai dengan skemanya, Basis data dapat melayani satu atau banyak aplikasi.
Menurut C.J Date (1999,p5), Suatu sistem Basis data adalah suatu sistem yang pada dasarnya menyimpan record – record di dalam suatu sistem yang dilakukan secara komputerisasi yang tujuannya secara keseluruhan adalah untuk memelihara informasi dan untuk membuat informasi tersebut tersedia berdasarkan permintaan.
Jadi, Basis data merupakan kumpulan data yang saling berhubungan secara logik yang terdiri dari record – record di dalam suatu sistem yang dilakukan secara komputerisasi yang tujuannya secara keseluruhan adalah untuk memelihara informasi dan melayani satu atau lebih aplikasi untuk memenuhi kebutuhan informasi suatu perusahaan.
2.1.2 Database Management System (DBMS)
Menurut Connoly dan Begg (2005, p16), Database Management System (DBMS) merupakan suatu sistem piranti lunak yang membuat pemakain dapat mendefinisikan, menciptakan, mengatur, dan mengontrol akses kedalam basis data.
DBMS menyediakan beberapa fasilitas fsfsebagai berikut :
Memperoleh user untuk mendefinisikan data, membuat spesifikasi tipe data, dan constraint pada data yang akan disimpan dalam basis data. Biasanya menggunakan Data Definition Language (DDL). Constraint adalah peraturan konsistensi nilai pada basis data yang tidak dapat dilanggar.
Memperbolehkan user untuk menambah data, mengubah data, menghapus data, dan mengambil data dari basis data. Biasanya menggunakan Data Manipulation language (DML). Bahasa yang umum digunakan adalah Structured Query Language (SQL).
Menyediakan fungsi-fungsi yang mengontrol akses basis data:
a. Sistem keamanan (security system), mencegah user yang tidak berwenang agar tidak mengakses ke basis data.
b. Sistem integritas (Integrity system),menjaga konsitensi data yang disimpan.
c. Sistem control (Concurency control), mengijinkan agar data dapat dipakai bersama-sama oleh user lainnya.
d. Sistem kontol perbaikan (Recovery control system), memperbaiki atau mengembalikan basis data ke kondisi sebelumnya jika terjadi kerusakan pada perangkat kerasa dan perangkar lunak.
e. Catalog yang dapat diakses user (User- accessible catalog), catatan yang berisi deskripsi data pada basis data.
Menurut Raghu Ramakrishnan dan Johannes Gehrke (2003, p4), DBMS adalah piranti lunak yang dirancang untuk membantu dalam memelihara dan memanfaatkan kumpulan data dalam jumlah besar, dan kebutuhan untuk system maupun pemakaiannya yang berkembang dengan cepat.
Menurut Gerald V.Post (2005, p2), DBMS adalah piranti lunak yang mendefinisikan sebuah basis data, menyimpan data, mendukung bahasa query, membuat laporan dan menciptakan layer masuk data.
Menurut Connoly dan Begg (2005, p17), Database Application program adalah suatu program komputer yang berinteraksi dengan database sesuai dengan permintaan DBMS.
2.1.2.1 Komponen Database management System (DBMS)
Menurut Connoly dan Begg (2005, p18), Komponen Lingkungan DBMS antara lain :
1. Perangkat Keras (hardware)
Perangkat keras berupa komputer tunggal personal, mainframe tunggal, hingga jaringan komputer. Perangkat keras dapat tergantung pada kebutuhan perusahaan dan DBMS yang digunakan.
2. Perangkat Lunak (software)
Program aplikasi yang digunakan biasanya adalah 3rd GL (third generation language), seperti C, C++, Java, Visual Basic, COBOL, Fortan, Ada, Pascal, atau
bahkan 4th GL (fourth generation language) seperti SQL yang digabungkan pada 3rd GL.
3. Data
Data merupakan komponen yang paling penting dari lingkungan DBMS. Data berperan sebagai penghubung antara komponen mesin dengan komponen manusia. 4. Prosedur (procedure)
Prosedur mengandung intruksi dan peraturan yang mengatur rancangan dan kegunaan basis data, seperti bagamana masuk kedalam DBMS, menjalankan dan menghentikan DBMS, dan bagaimana membuat cadangan dari basis data.
5. Manusia (people)
Manusia merupakan komponen terakhir yang terlibat langsung dengan sitem, termasuk didalamnya adalah Database Administrator (DBA), perancangan basis data, pengembangan aplikasi dan pemakainan akhir.
2.1.2.2 Keuntungan Database management System (DBMS) Menurut Connoly dan Begg (2005, p26), Keuntungan DBMS antara lain : 1. Kontrol redundansi data
2. Pendekatan basis data berusaha menghapus redundansi dengan menggabungkan file sehingga data yang sama tidak akan disimpan kembali. Bagaimanapun, pendekatan basis tidak menghapus rendudansi secara keseluruhan, tetapi mengontol jumlah redundasi yang terdapat pada database. Pada waktu yang berbeda, beberapa data yang diperlukan untuk meningkatkan performance.
Dengan menghapus atau mengontol redudansi, maka akan mengurangi resiko ketidak konsistensian yang akan muncul. Jika sebuah data disimpan hanya satu kali pada basis data, update apapun terhadap nilai data tersebut hanya dilakukan satu kali dan nilai baru tersedia untuk user.
4. Semakin banyak informasi yang didapat dari data yang sama
Dengan integrasi dari data operasional, maka mungkinkan perusahaan untuk menurunkan informasi tambahan dari data yang sama.
5. Data yang berbagi
File biasanya dimiliki oleh orang atau departemen yang menggunakannya. Disisi lain, basis data adalah miliki keseluruhan organisasi dan dapat dibagi-bagi kepada user yang berhak mengakses.
6. Meningkatkan integritas data
Integritas data merujuk pada fasilitas dan konsistensi data yang disimpan. Integritas biasanya digambarkan dalam bentuk constraint, yang merupakan peraturan yang konsitensi pada database yang tidak diijinkan untuk dilanggar.
7. Meningkatkan keamanan.
Keamanan basis data adalah perlindungan basis data dari user yang tidak memiliki akses. Hal ini dapat dilakukan dengan cara membuat username dan password untuk mengedifikasi user yang mempunyai hak akses ke basis data. Akses yang diberikan kepada user dapat dibatasi oleh jenis operasi yaitu insert, update, delete, dan retrieval data.
Integrasi memungkinkan DBA mendefinisikan dan menjalankan standar yang diperlukan. Standar ini dapat meliputi standar department, organisasi, nasional, atau internasional untuk pemformatan data dalam memfasilitasi pertukaran data antara sistem, aturan penamaan, standar dokumentasi, prosedur update dan aturan akses. 9. Meningkatkan maintance melalui independensi data
Pada sistem berbasis file, deskripsi data dan logika untuk mengakses data dibagun kedalam setiap program aplikasi, membuat program bergantung pada data. Pada DBMS, deskripsi data dan aplikasi dipisahkan sehingga membuat aplikasi terpisah dari perubahan deskripsi data.ini diseput dengan independensi data.
10.Meningktkan concurrency
DBMS mengatur akses ke basis data dimana jika terjadi akses terhadap data secara bersamaan, maka akses satu tidak akan menggangu akses lainnya sehingga tidak terjadi kehilangan informasi.
2.1.2.3 Kerugian Database management System (DBMS) Menurut Connuly dan Begg (2005, p29), Kerugian DBMS antara lain : 1. Kompleksitas
Perancangan dan pengembangan basis data, data dan database administrator, serta user harus memahami keseluruhan fungsionalitas DBMS yang kompleks. Kegagalan dalam memahami system dapat membawa keputusan rancangan yang buruk dimana akan terdapat konsekuensi yang serius untuk perusahaan.
Fungsionalitas yang kompleks menjadikan DBMS sebagai sebuah perangkat lunak yang membutuhkan tempat penyimpanan yang sangat besar dan jumlah memori yang besar yang menjalankan DBMS secara efisien.
3. Biaya DBMS
Biaya untuk suatu DBMS sangat bervariasi tergantung pada lingkungan dan fungsionalitas yang diberikan.
4. Biaya perangkat keras tambahan
Kebutuhan tempat penyimpangan untuk DBMS dan basis data membutuhkan pembelian tempat penyimpanan tambahan. Selain itu untuk mendapatkan performance yang diinginkan, maka diperlukan untuk membeli mesin yang lebih besar untuk menjalankan DBMS. Penambahan perangkat keras baru akan menghasilkan pengeluaran biaya tamnbahan.
5. Biaya konversi
Biaya tambahan untuk melakukan konversi aplikasi yang telah ada agar berjalan pada DBMS dan perangkat keras yang baru. Selain itu juga meliputi biaya tambahan untuk pelatihan staff untuk menggunakan system baru dan mungkin memperkerjakan staff ahli untuk membatu dalam melakukan konversi dan menjalankan system baru.
6. Performance
DBMS digunakan untuk memenuhi banyak permintaan aplikasi sehingga beberapa aplikasi tidak berjalan sesuai yang seharusnya.
2.1.3 Data Definition Language (DDL)
Menurut Connoly dan Begg (2005, p40), Data Definition Language (DDL) adalah suatu bahasa yang memungkinkan DBA (Database Admistrator) atau user untuk mendeskripsikan dan memberi nama entity, atribut, dan relasi yang diperlukan aplikasi, bersama dengan segala integritas dan batasan keamanan.
2.1.4 Data Manipulation Language (DML)
Menurut Connoly dan Begg (2005, p40), Data Manipulation Language adalah sebuah bahasa yang menyediakan sekumpulan operasi untuk mendukung operasi manipulasi data utama pada data didalam basis data.
Menurut Connoly dan Begg (2005, p41), Operasi manipulasi data antara lain: a. Mengentri data baru kedalam basis data.
b. Modifikasi data yang disimpan dalam basis data. c. Menampilkan kembali data didalam basis data. d. Menghapus data dari basis data.
Menurut Connuly dan Begg (2005, p41), Terdapat dua tipe DML yaitu :
a. Procedural DML, yaitu sebuah bahasa yang memberikan fasilitas kepada user untuk memberitahukan kepada system, data apa yang diperlukan dan bagaimana seharusnya data tersebut diambil.
b. Non-procedural DML, yaitu sebuah bahasa yang memberikan fasilitas kepada user untuk menyatakan data apa yang diperlukan daripada tentang bagaimana data tersebut diambil.
2.1.5 Fourth-Generation Languages (4GL)
Menurut Connoly dan Begg (2005, p42), 4GL adalah bahasa pemprograman yang tidak memiliki prosedur standar dimana user mendefinisikan apa yang harus diselesaikan, bukan cara yang digunakan. User tidak mendefinisikan langkah-langkah yang dibutuhkan program untuk mengerjakan sebuah tugas, tetapi mendefinisikan parameter bagi tools yang akan digunakan untuk menghasilkan sebuah program aplikasi.
Menurut Connoly dan Begg (2005, p42), 4GL meliputi:
a. Presentation Language, seperti query languages dan report generators. b. Speciality language, seperti spreadsheets dan sistem basis data languages.
c. Application generators yang mendefinisikan, meng-insert, meng-update, dan me-retrieve data dari sistem basis data untuk membangun aplikasi.
d. Bahas-bahasa tingkat tinggi yang digunakan untuk menghasilkan kode aplikasi. Menurut Connoly dan Begg (2005, p42), Salah satu contoh 4th GL adalah SQL (Structured Query Language). Menurut Connoly dan Begg (2005, p113), SQL adalah sebuah bahasa yang dirancang mengunakan relasi untuk mengubah input ke output yang diinginkan. SQL memiliki dua komponen utama yaitu : Data Definition Language (DDL) dan Data Manipulation Languange (DML).
2.1.6 Database System Development Life Cycle
Menurut Connoly dan Begg (2005, p282), Pengertian sistem informasi adalah sumber-sumber mengenai koleksi, managemen, kontrol dan penyebaran informasi perusahaan.
Menurut Connoly dan Begg (2005, p283), Sistem Basis data adalah komponen dasar dari organisasi yang besar dengan sistem informasi yang luas. Hal penting yang perlu di perhatikan dalam Database Application Lifecycle adalah bahwa tingkatanya tidak sepenuhnya berurutan (sequential). Dimana ada beberapa tingkatan yang berulang dengan alur-balik (feedback loop), misalnya, masalah ditemukan pada tingkatan perancangan basis data yang membutuhkan tambahan kumpulan kebutuhan dan analisis. Untuk aplikasi basis data yang kecil dengan pemakai yang sedikit maka lifecycle -nya tidak terlalu kompleks. Sebalik-nya, ketika merancang basis data yang sedang sampai ke basis data yang besar dengan puluhan ribu pemakai, menggunakan ratusan query dan program aplikasi maka lifecycle akan menjadi sangat kompleks.
Perencanaan Basisdata
Definisi Sistem
Analisis dan Pengumpulan Kebutuhan
Perancangan Basisdata Konseptual Perancangan Basisdata Logikal Perancangan Basisdata Fisikal Implementasi
Konversi Data dan Loading
Testing Pemeliharaan Operasional Prototyping (optional) Pemilihan DBMS (optional) Perancangan Aplikasi Perancangan Basisdata Gambar 2.1
Skema Tahapan Siklus Hidup Pengembangan Sistem Basisdata (Sumber : Connolly and Begg, 2005, p284)
Menurut Connoly dan Begg (2005, p285), Berikut ini adalah keterangan dari tahap Pengembagan aplikasi basis data diatas :
2.1.6.1 Perencanaan Basis Data
Menurut Connoly dan Begg (2005, p285), Database Planning adalah aktivitas manajemen yang memungkinkan tahapan dari siklus hidup pengembangan aplikasi basis data untuk dapat realisasikan seefisien dan seefektif mungkin. Ada tiga isu pokok yang berkaitan dengan perumusan strategi sistem informasi, antara lain :
a. Mengenali rencana dan tujuan perusahaan, kemudian menentukan kebutuhan sistem informasi.
b. Mengevaluasi sistem informasi yang sedang berjalan untuk menentukan kekuatan dan kelemahan.
c. Penilaian dari kesempatan teknologi informasi yang menghasilkan kekuatan kompetitif.
2.1.6.2 Definisi Sistem
Menurut Connoly dan Begg (2005, p286), System Definition adalah proses menspesifikasikan ruang lingkup dan batasan dari aplikasi basis data dan user view utama. Sebelum mencoba merancang suatu aplikasi basis data, diperlukan untuk mengenali batasan sistem dan bagaimana antarmuka dengan bagian sistem informasi lainnya dalam organisasi.
2.1.6.3 Analisis dan Pengumpulan Kebutuhan
Menurut Connoly dan Begg (2005, p288), Requirement Collection and Analisis adalah proses mengumpulkan danmenganalisa informasi yang mendukung aplikasi basis data dan menggunakan informasi ini untuk mengidentifikasi kebutuhan pengguna pada system yang baru. Fact-findding adalah cara untuk mendapatkan informasi. Menurut Connoly dan Begg (2005, p317), Ada beberapa teknik Fact-finding :
1. Mengevaluasi dokumen 2. Wawancara
3. Mengamati jalannya kegiatan kerja pada perusahaan. 4. Penelitian
5. Kuesioner
2.1.6.4 Perancangan Basis Data
Menurut Connoly dan Begg (2005, p291), Database Design adalah proses dari pembuatan sebuah rancangan yang mendukung visi dan misi perusahaan yang dibutuhkan untuk sebuah sistem basis data. Perancangan basis data dibagi menjadi tiga tahapan utama yaitu conceptual database design, logical database design, dan physical database design.
Dua pendekatan perancangan basis data : a. Pendekatan bottom-up
Dimulai dari level atribut dasar dimana melalui analisis atribut yang berhubungan yang dikelompokan kedalam relasi yang mempresentasikan tipe entity dan relasi antar entity.
b. Pendekatan top-down
Dimulai dengan perkembangan model data yang mengandung beberapa entity level tinggi dan relasi lalu turun untuk mengedifikasi entity level rendah, relasi dan atribut yang berhubungan.
2.1.6.5 Pemilihan DBMS (Optional)
Menurut Connoly dan Begg (2005, p288), DBMS Selection (optional) adalah meyeleksi DBMS yang sesuai untuk mendukung aplikasi basis data. Pemilihan DBMS dilakukan antara tahapan logical database design dan conceptual database design. Tujuan dari pemilihan DBMS adalah untuk kecukupan sekarang dan kebutuhan masa mendatang pada perusahaan, membuat keseimbangan biaya termasuk pembelian produk DBMS, piranti lunak/ perangkat keras lainnya untuk mendukung aplikasi basis data, biaya yang berhubungan dengan perubahan dan pelatihan pegawai. Pendekatan sederhana dalam pemilihan DBMS adalah memeriksa keistimewaan DBMS dalam memenuhi kebutuhan. Alam memilih produk DBMS baru, ini adalah kesempatan untuk memastikan bahwa proses pemilihan sudah direncanakan dan hasil yang diberikan sistem benar-benar bermanfaat bagi perusahan.
2.1.6.6 Perancangan Aplikasi
Menurut Connoly dan Begg (2005, p299), Applicattion Design adalah Perancangan antarmuka pengguna dan program aplikasi yang menggunakan dan memproses sistem basis data. Perancangan basis data dan perancangan aplikasi adalah aktivitas yang dilakukan secara bersamaan pada database application lifecycle. Dalam
kasus sebenarnya, tidak mungkin dapat menyelesaikan perancangan aplikasi sebelum perancangan basis data selesai. Dalam perancangan aplikasi harus memastikan semua pernyataan fungsional dari spesifikasi kebutuhan pemakai (user requirement specification) yang menyangkut perancangan aplikasi program yang mengakseskan basis data dan merancang transaksi yaitu cara akses ke basis data dan perubahan terhadap isi basis data. Artinya bagaimana fungsi yang dibutuhkan bias terpenuhi dan merancang antarmuka pemakai yang tepat. Antarmuka dirancang harus memberikan informasi yang dibutuhkan dengan cara menciptakan “user-friendly”.
2.1.6.7 Prototyping (Optional)
Menurut Connoly dan Begg (2005, p304), Ptototyping adalah Pembuatan model kerja dari system basis data, yang mengizinkan perancangan maupun pengguna untuk mengevaluasi hasil akhir sistem. Tujuan dari pengembangan prototype aplikasi basis data adalah memungkinkan pengguna menggunakan prototype untuk mengidentifikasi kelebihan atau kekurangan system dan memungkinkan perancang untuk memperbaiki atau melengkapi kelebihan dari aplikasi basis data baru.
Ada dua strategi prototyping yang umum digunakan yaitu requirement prototyping dan evolutionary prototyping. Requirement prototyping yaitu menggunakan prototype untuk menetapkan kebutuhan daru tujuan aplikasi basis data dan ketika kebutuhan sudah terpenuhi, prototype tidak digunakan lagi atau dibuang. Sedangkan evolutionary prototype menggunakan tujuan yang sama, tetapi perbedaannya adalah prototype tetap digunakan.
2.1.6.8 Implementasi
Menurut Connoly dan Begg (2005, p304), Implementation adalah realisasi secara fisik dari basis data dan rancangan aplikasi. Implementasi basis data dicapai menggunakan Data Definition Language (DDL) dari DBMS yang terpilih atau Graphical User Interface (GUI).
2.1.6.9 Konversi Data dan Loading
Menurut Connoly dan Begg (2005, p305), Data Conversion and Loading adalah Proses mengirim data dari sistem yang lama ke sistem yang baru dan jika mungkin, mengkonversikan aplikasi yang ada untuk dijalankan pada sistem basis data yang baru. Tahap ini dibutuhkan ketika sistem basis data menggantikan sistem yang lama. Pada masa sekarang, umumnya DBMS memiliki kegunaan untuk memasukkan file ke dalam basis data baru. Biasanya membutuhkan spesifikasi dari sumber file dan sasaran basis datanya. Kegunaan ini memungkinkan pengembangan untuk mengkonversikan dan menggunakan aplikasi program lama untuk digunakan oleh sistem baru. Ketika conversion and loading dibutuhkan prosesnya harus direncanakan untuk memastikan kelancaran transaksi dari keseluruhan operasi.
2.1.6.10 Testing
Menurut Connoly dan Begg (2005, p305), Testing adalah proses mengeksekusi program dengan tujuan mencari kesalahan (error). Sebelum digunakan, aplikasi basis data yang baru dikembangkan harus diuji secara menyeluruh. Untuk menvapainya harus hati-hati dalam menggunakan perancangan strategi uji dan menggunakan data asli untuk
proses pengujian. Didalam definisi ini tidak menggunakan pandangan yang biasa, testing adalah proses demonstrasi tanpa kesalahan. Dalam kenyataan testing tidak luput dari kesalahan, maka pengujian akan menemukan kesalahan pada program aplikasi dan mungkin struktur basis datanya.
Di dalam merancang basis data, pemakai menggunakan sistem baru seharusnya terlibat didalam proses testing. Situasi yang ideal untuk melakukan uji sistem adalah menguji basis data pada perangkat keras yang berbeda, tetapi hal ini sering tidak dilakukan. Jika data yang asli digunakan, perlu backup untuk mengantisipasi kesalahan. Setelah testing selesai, system aplikasi siap digunakan dan diserahkan kepada pemakai.
2.1.6.11 Pemeliharaan Operasional
Menurut Connoly dan Begg (2005, p306), Operational Maintance adalah Proses memonitor dan menjaga system setelah dilakukan instalasi.
Yang termasuk aktivitas dari tahapan pemeliharaan adalah sebagai berikut :
a. Memantau kinerja dari sistem. Jika kinerjanya menurun dibawah level yang dapat diterima, mungkin basis data perlu diperbaiki.
b. Memelihara dan mengupgrade sistem basis datanya (jika diperlukan).
2.1.7 Metodologi Perancangan Basis data
Menurut Connoly dan Begg (2005, p438), Metodologi Desain adalah Sebuah Pendekatan terstruktur yang menggunakan prosedur, teknik, tool, dan dokumentasi yang mendukung dan memfasilitasi proses desain.
Menurut Connoly dan Begg (2005, p439), Dalam Metodologi desain, proses desain dibagi kedalam tiga tahapan utama, yaitu:
2.1.7.1 Perancangan Basis data Konseptual
Tujuan dari perancangan konseptual basisdata menurut Connolly and Begg (2005, p442) adalah untuk memproses pembuatan suatu model dari informasi yang akan digunakan dalam suatu organisasi, yang tidak tergantung pada segala pertimbangan fisikal. Langkah-langkah dalam pembuatan model Basis data kondeptual adalah :
Langkah 1 : Membangun Model Data Konseptual
Tujuan dari langkah ini adalah untuk membangun model data konseptual terhadap kebutuhan data suatu perusahaan.
Langkah 1.1 : Mengidentifikasi tipe entity
Tujuan dari langkah ini adalah untuk mengidentifikasi entity utama yang diminta oleh user.
Langkah pertama yang diperlukan dalam membangun suatu lokal konseptual data model adalah untuk mendefinisikan objek utama atau entity dimana user memang membutuhkannya. Salah satu metode untuk mengidentifikasi tipe entity yang utama adalah dengan mengidentifikasi kata benda atau frase kata benda yang telah disebutkan oleh user.
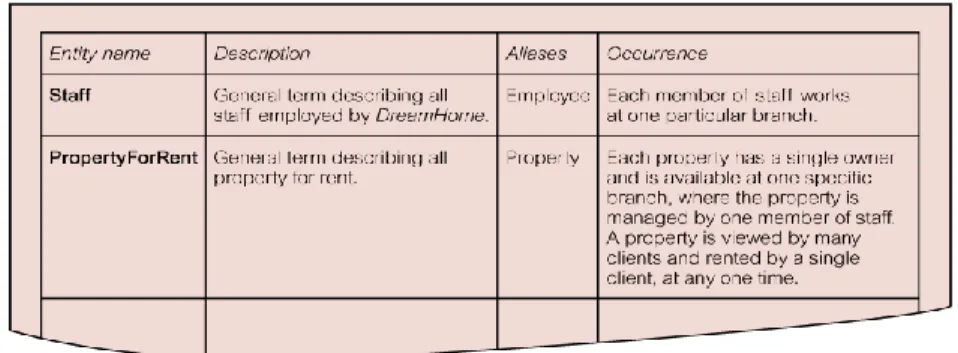
Setelah tipe entity diidentifikasi, dilakukan pemberian nama yang berarti dan jelas kepada user. Mencatat nama dan deskripsi entity dalam kamus data. Apabila
dimungkinkan, mendokumentasikan jumlah occurences yang diharapkan dari tiap entity. Jika entity dikenal dengan nama yang berbeda, nama tersebut menunjuk kepada sinonim atau alias, yang dicatat dalam kamus data.
Gambar 2.2 Contoh Kamus Data Entity Yang Mendeskripsikan Entity Untuk Staff UserView DreamHome
Langkah 1.2 : Mengidentifikasi tipe relasi
Tujuan dari langkah ini adalah untuk mengidentifikasi relasi yang penting antara berbagai tipe entity yang telah diidentifikasikan. Biasanya relasi diidentifikasi dengan menggunakan kata kerja atau frase kata kerja.
Relasi yang paling umum adalah relasi binary. Yang artinya relasi antar entity yang persis antara dua entity saja. Bagaimanapun, relasi kompleks yang melibatkan lebih dari dua entity dan relasi rekursif yang hanya melibatkan satu entity harus diperhatikan.
Adapun langkah-langkah dalam mengidentifikasi tipe relasi sebagai berikut : a. Menggunakan Entity-Relationship(ER)Diagram
Hal yang sering terjadi adalah user akan lebih cepat mengerti suatu perancangan Basis data dengan cara divisualisasikan dibanding dengan perancangan
Basis data yang dituliskan dalam bentuk tekstual. Dalam hal ini, ERD digunakan untuk merepresentasikan entity dan bagaimana relasi antar entity. Oleh karena itu, sangat disarankan menggunakan ERD untuk membantu dalam pembuatan gambaran umum dari perancangan Basis data yang sedang dikembangkan.
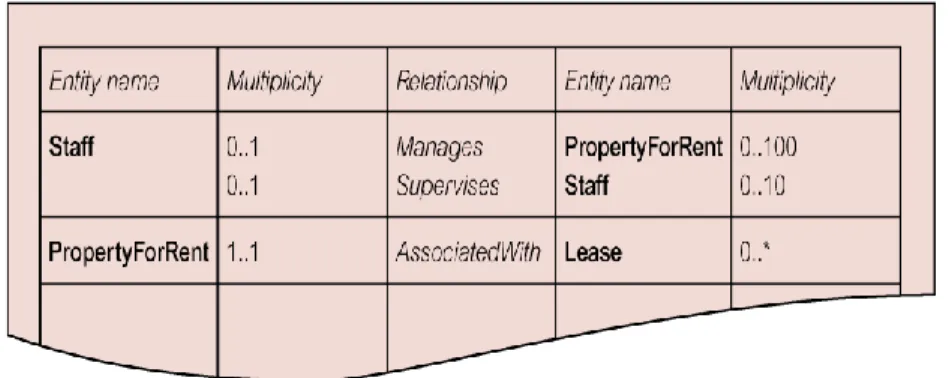
b. Menentukan multiplicity constraints dari tipe relasi
Setelah mendapat relasi antar entity, maka langkah berikutnya adalah menentukan multiplicity setiap relasi. Jika memang ada suatu nilai yang spesifik dari suatu multiplicity maka akan lebih baik apabila didokumentasikan.
Multiplicity constraints digunakan untuk mengecek dan memelihara kualitas data. Constraints ini menyatakan entity ocurrences yang dapat dimasukkan ketika database di-update untuk menentukan apakah peng-update-an tersebut melanggar aturan enterprise atau tidak. Suatu model yang menyertakan multiplicity constraints secara eksplisit lebih merepresentasikan relasi semantik dan menghasilkan representasi yang lebih baik untuk kebutuhan data enterprise.
c. Mengecek Fan Traps dan Chasm Traps
Setelah relasi yang dibutuhkan antar entity didefinisikan, maka langkah berikutnya adalah mencek fantraps dan chasm traps.
Definisi dari fan traps adalah suatu model yang merepresentasikan suatu relasi antar entity. Tetapi alur relasinya memperlihatkan ambiguitas.
Chasm traps adalah suatu model dimana terdapat hubungan antar entity yang satu dengan yang lain, tetapi tidak ada relasi antar kedua entity yang utama.
d. Mengecek bahwa setiap entity mempunyai minimal sebuah relasi
dengan entity yang lain. Jika memang setiap entity sudah memiliki minimal satu relasi dengan entity yang lain, maka langkah berikutnya adalah memperhatikan kamus data. e. Mendokumentasikan tipe relasi
Setelah tipe relasi diidentifikasi, langkah selanjutnya adalah memberi nama yang mempunyai makna dan jelas kepada user. Selain itu, juga me-record deskripsi relasi dan multiplicity constraints pada kamus data.
Gambar 2.3 Contoh Kamus Data Relationship Yang Mendeskripsikan Relatioship Untuk Staff User View DreamHome
Langkah 1.3 : Mengidentifikasi dan mengasosiasikan atribut suatu tipe entity atau tipe relasi.
Tujuan dari langkah ini adalah untuk mengidentifikasi dan mengasosiasikan atribut yang sesuai dengan tipe entity atau tipe relasi.
a. Simple atau Composite Atribut
Salah satu hal yang penting adalah perlunya memperhatikan apakah suatu atribut tertentu adalah simple atau composite. Composite atribut adalah atribut yang dibangun dari simple atribut. Sebagai contoh, atribut alamat bisa saja dibuat simple
dan menyimpan beberapa detail dari alamat sebagai suatu nilai. Contohnya, ‘115 Dumbarton Road, Glasgow, G11 6YG’. Bagaimanapun juga, atribut alamat dapat pula merepresentasikan sebuah composite atribut, yang dibuat dari simple atribut dan terdiri dari beberapa detail alamat yang mempunyai nilai terpisah pada atribut street (‘115 Dumbarton Road’), city (‘Glasgow’), dan postcode (‘G11 6YG’). Atribut alamat dapat dijadikan simple atribut atau composite atribut tergantung dengan kebutuhan user.
Apabila user tidak membutuhkan pengaksesan komponen terhadap atribut alamat secara terpisah, seperti street, city, dan postcode, maka sebaiknya atribut alamat itu dibuat sebagai simple atribut. Sedangkan, apabila user membutuhkan pengaksesan terhadap komponen atribut alamat secara individual, maka sebaiknya atribut alamat tersebut dibuat sebagai composite atribut.
b. Single atau Multi-valued Atribut
Suatu atribut, selain dapat menjadi single atau composite, dapat pula mempunyai satu atau lebih nilai, sebagai contohnya yaitu atribut nomor telepon. Seseorang bisa saja mempunyai nomor telepon lebih dari satu, keadaan seperti itu dapat disebut multi-valued atribut. Tetapi apabila atribut tertentu hanya mempunyai satu nilai maka disebut single atribut.
c. Derived Atribut
Derived atribut adalah atribut yang nilainya tergantung dengan nilai atribut yang lain. Contoh, umur seorang staff, banyaknya properti yang dikelola oleh seorang staff, dan pinjaman deposit yang dihitung dua kali pada pinjaman bulanannya.
Setelah atribut diidentifikasi, dilakukan pemberian nama yang berarti kepada user. Kemudian mencatat beberapa informasi untuk tiap atribut antara lain :
a. Nama atribut dan deskripsinya; b. Tipe data dan panjangnya;
c. Semua alias yang dikenal atribut;
d. Apakah atribut termasuk composite atau tidak. Jika termasuk simple atribut, maka dibuat menjadi composite;
e. Apakah atribut termasuk multi-valued atau tidak;
f. Apakah atribut diturunkan atau tidak. Jika benar, bagaimana perhitungannya; g. Semua nilai default untuk atribut.
Gambar 2.4 Contoh Kamus Data Atribut Yang Mendeskripsikan Atribut Untuk Staff User View DreamHome
Langkah 1.4 : Menentukan domain atribut
Tujuan dari langkah ini adalah untuk menentukan domain dari atribut yang ada di dalam model data konseptual lokal.
Domain atribut dari nomor staff (staffNo) terdiri dari lima karakter string dimana dua karakter awal berupa huruf, sedangkan tiga karakter berikutnya berupa angka yang berkisar dari 1-999.
Nilai yang mungkin untuk atribut sex adalah „M‟ atau „F‟. Domain dari atribut ini adalah karakter string tunggal yang berisi nilai „M‟ atau „F‟.
Langkah 1.5 : Mengidentifikasi candidate key, primary key dan alternate key Tujuan dari langkah ini adalah untuk mengidentifikasi candidate key dari setiap tipe entity, dan jika memang terdapat lebih dari satu candidate key, pilihlah salah satunya untuk menjadi primary key, dan yang lainnya sebagai alternate key.
Pada saat memilih primary key diantara candidate key, gunakanlah petunjuk berikut untuk membantu pemilihan :
a. Merupakan candidate key dengan jumlah set atribut paling sedikit. b. Merupakan candidate key yang nilainya jarang sekali berubah. c. Merupakan candidate key dengan jumlah karakter paling sedikit.
d. Merupakan candidate key dengan nilai maksimalnya yang terkecil (untuk tipe atribut dengan tipe numeric).
e. Merupakan candidate key yang paling mudah digunakan dari sudut pandang user.
Langkah 1.6 : Menggunakan konsep enhanced modeling (langkah optional) Tujuan dari langkah ini adalah untuk mempertimbangkan penggunaan konsep enhanced modeling, seperti specialization, generalization, aggregation dan composition
Jika kita menggunakan pendekatan specialization, maka perhatikan perbedaan antara entity dengan mendefinisikan satu atau lebih subclass dari superclass entity. Jika kita menggunakan pendekatan generalization, maka kita akan mengidentifikasikan fitur umum antara entity yang ada untuk mendefinisikan generalisasi entitysuperclass. Untuk aggregation digunakan representasi relasi „has-a‟ atau „is-part-of‟ antara tipe entity, dimana salah satunya merepresentasikan „whole‟ dan lainnya „part‟. Sedangkan pengguanan composition (tipe khusus aggregation) untuk merepresentasikan asosiasi antara tipe entity dimana terdapat kepemilikan yang kuat dan coincidental lifetime antara „whole‟ dan „part‟.
Langkah 1.7 : Mengecek model dari redundancy
Tujuan dari langkah ini adalah untuk mengecek apakah ada redundansi dalam model Basis data.
Pada langkah ini, dilakukan pengujian model data konseptual lokal dengan mengidentifikasi apakah terdapat redundansi dan menghilangkannya jika ada. Adapun langkah untuk menghilangkannya yaitu :
a. Menguji kembali relasi one-to-one (1:1); b. Menghilangkan relasi redundansi; c. Mempertimbangkan dimensi waktu.
Langkah 1.8 : Memvalidasi model konseptual dengan transaksi user
Tujuan dari langkah ini adalah untuk memastikan bahwa model konseptual lokal mendukung transaksi yang diperlukan oleh user. Pengujian dilakukan dengan dua
pendekatan yang mungkin untuk memastikan model data konseptual mendukung transaksi yang diperlukan:
a. Mendeskripsikan transaksi; b. Menggunakan jalur transaksi.
Langkah 1.9 : Me-review model data konseptual dengan user
Tujuan dari langkah ini adalah untuk me-review model data konseptual lokal bersama user guna memastikan bahwa model yang ada sudah merupakan representasi yang „benar‟ dari kebutuhan data enterprise.
Sebelum mengakhiri langkah 1, perlu me-review model data konseptual dengan user. Model data konseptual meliputi ER diagram dan dokumentasi yang mendukung penggambaran model data. Jika terdapat anomaly dalam model data, perlu dilakukan perubahan yang sesuai, yang mungkin membutuhkan perulangan langkah sebelumnya. Proses ini berlangsung terus sampai user siap untuk „sign off‟ model menjadi representasi yang „benar‟ sebagai bagian dari enterprise yang dimodelkan.
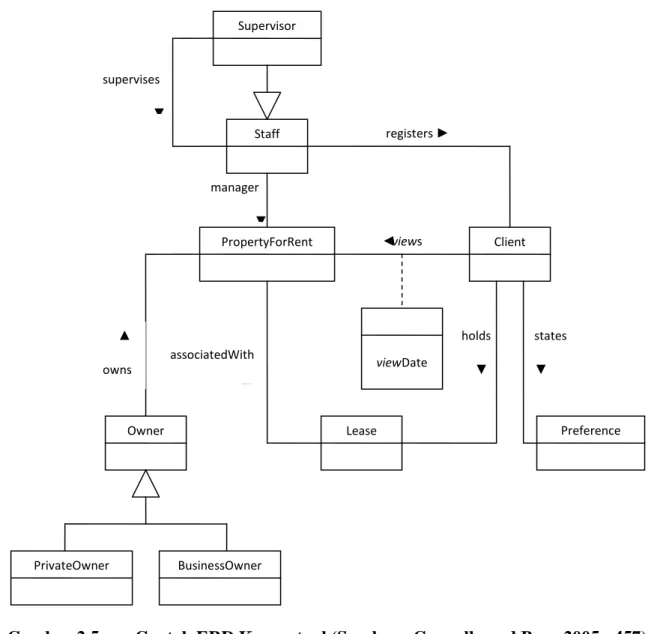
Hasil akhir dari perancangan Basis data konseptual adalah memproses pembuatan suatu model dari informasi yang akan digunakan di dalam suatu organisasi, yang independensinya tidak tergantung pada apapun.
Gambar 2.5 Contoh ERD Konseptual (Sumber : Connolly and Begg 2005,p457)
2.1.7.2 Perancangan Basis data Logikal
Menurut Connolly and Begg (2005, p294), perancangan Basis data fisikal adalah suatu proses pembuatan suatu model dari data yang digunakan di dalam suatu perusahaan berdasarkan model data yang spesifik, tetapi tidak tergantung pada suatu DBMS dan pertimbangan fisikal lainnya.
BusinessOwner manager ▼ holds ▼ associatedWith ▼ states ▼ ◄views registers ► supervises ▼ Staff StaffNo Supervisor PrivateOwner Owner ownerNo Client clientNo PropertyForRent propertyNo Lease leaseNo Preference viewDate Comment ▲ owns
Langkah 2 : Membangun dan Menvalidasi Model Data Logikal
Tujuan dari langkah ini adalah untuk menerjemahkan model data konseptual kedalam model data logikal dan kemudian memvalidasi model tersebut untuk mengecek apakah secara struktur benar dan mendukung transaksi yang dibutuhkan.
Langkah 2.1 : Relasi turunan untuk model data logikal
Tujuan dari langkah ini adalah untuk membuat suatu relasi untuk model data logikal yang merepresentasikan suatu entity, relasinya dan juga atribut yang telah diidentifikasi. Adapun pendeskripsian bagaimana relasi dapat diturunkan dari struktur dibawah ini yang terjadi dalam model data konseptual antara lain:
a. Tipe entity kuat b. Tipe entity lemah
c. tipe relasi binary one-to-many (1.*) d. tipe relasi binary one-to-one (1.1) e. tipe relasi rekursif one-to-one (1.1) f. tipe relasi superclass atau subclass g. tipe relasi binary many-to-many h. Tipe relasi kompleks
i. Atribut multi-valued
Langkah 2.2 : Memvalidasi relasi dengan menggunakan normalisasi
Tujuan dari langkah ini adalah untuk menvalidasi relasi dalam model data logikal dengan menggunakan teknik normalisasi. Tujuan dari normalisasi adalah :
a. Meminimalkan jumlah atribut yang perlu untuk mendukung kebutuhan data dari suatu perusahaan;
b. Atribut dengan relasi logikal yang dekat (digambarkan sebagai functional dependency) yang ditemukan dalam relasi yang sama.
c. Meminimalkan redundancy dengan tiap atribut direpresentasikan hanya sekali dengan pengecualian atribut yang membentuk semua atau sebagian foreign key yang penting untuk berpartisipasi dalam relasi yang terhubung.
Langkah 2.3 : Memvalidasi relasi dengan transaksi user
Tujuan dari langkah ini adalah untuk memastikan bahwa relasi di dalam model data logikal mendukung transaksi yang dibutuhkan, seperti detail dalam spesifikasi kebutuhan user. Pada langkah ini, dilakukan pengecekan bahwa relasi yang dibuat pada langkah sebelumnya juga mendukung transaksi ini, dan karena itu dipastikan juga bahwa tidak ada error dalam relasi yang telah dibuat.
Langkah 2.4 : Mengecek batasan integritas
Tujuan dari langkah ini adalah untuk mengecek batasan integritas yang direpresentasikan dalam model data logikal. Batasan integritas merupakan batasan yang diharapkan dapat menjaga Basis data agar tidak menjadi incomplete (tidak lengkap), inaccurate (tidak akurat), atau inconsistent (tidak konsisten).
Dibawah ini terdapat enam tipe batasan integritas, antara lain : a. Data yang dibutuhkan;
c. Multiplicity; d. Integritas entity; e. Integritas referensial; f. Batasan umum.
Langkah 2.5 : Me-review model data logikal dengan user
Tujuan dari langkah ini adalah untuk me-review model data logikal dengan user untuk memastikan bahwa model tersebut sesuai dengan representasi yang benar dari kebutuhan data perusahaan. Apabila user merasa tidak puas dengan model tersebut maka dilakukan pengulangan kembali langkah-langkah sebelumnya jika diperlukan.
Hubungan antara Model Data Logikal dan Data Flow Diagram
Suatu model data logikal merefleksikan struktur dari penyimpanan data suatu perusahaan. Data Flow Diagram (DFD) menunjukan aliran data suatu perusahaan dan disimpan di dalam datastores. Semua atribut seharusnya berada di dalam suatu tipe entity, jika memang atribut tersebut ditangani di dalam perusahaan dan kemungkinan akan dilihat mengalir disekitar perusahaan sebagai aliran data. Ketika dua teknik tersebut digunakan untuk memodelkan spesifikasi kebutuhan user, kita dapat menggunakan salah satunya untuk mengecek kekonsistenan dan kelengkapan dari yang lainnya. Terdapat aturan yang mengontrol relasi antara dua teknik tersebut, antara lain : a. Setiap datastore harus merepresentasikan semua jumlah tipe entity;
Langkah 2.6 : Menggabungkan model data logikal kedalam model global ( langkah optional )
Tujuan dari langkah ini adalah untuk menggabungkan suatu model data logikal lokal kedalam satu model data logikal global yang merepresentasikan semua sudut pandang user terhadap Basis data.
Pada langkah ini, hanya penting untuk rancangan Basis data dengan multiple user yang dikelola menggunakan pendekatan sudut pandang integrasi. Untuk memfasilitasi gambaran proses penggabungan, digunakan model data logikal lokal dan model data logikal global . Model data logikal lokal merepresentasikan satu atau lebih tetapi tidak semua sudut pandang user terhadap Basis data. Sedangkan model data logikal global merepresentasikan semua sudut pandang user terhadap Basis data. Dalam langkah ini, dilakukan penggabungan dua atau lebih model data logikal lokal kedalam satu model data logikal global. Aktivitas penggabungan tersebut meliputi :
Langkah 2.6.1 : Penggabungan model data logikal lokal kedalam model global
Tujuan dari langkah ini adalah untuk menggabungkan model data logikal lokal kedalam satu model data logikal global.
Beberapa tugas dari pendekatan ini adalah sebagai berikut :
1. Me-review nama dan isi dari suatu entity atau relasi dan candidate key-nya. 2. Me-review nama dan isi dari suatu relasi atau foreign key.
3. Menggabungkan entity atau relasi dari model data lokal.
data lokal.
5. Menggabungkan relasi atau foreign key dari model data lokal.
6. Memasukkan (tanpa penggabungan) relasi atau foreign key yang unik untuk setiap model data lokal.
7. Mengecek entity atau relasi dan relasi atau foreign key yang hilang. 8. Mengecek foreign key.
9. Mengecek batasan integritas.
10. Menggambar ER global atau diagram relasi. 11. Meng-update dokumentasi.
Langkah 2.6.2 : Memvalidasi model data logikal global
Tujuan dari langkah ini adalah untuk menvalidasi relasi yang dibuat dari model data logikal global dengan menggunakan teknik normalisasi dan juga memastikan bahwa relasi yang dibuat mendukung transaksi yang dibutuhkan, jika perlu.
Langkah 2.6.3 : Me-review model data logikal global dengan user Tujuan dari langkah ini adalah untuk me-review model data logikal global dengan user untuk memastikan bahwa model yang dibuat tersebut merupakan representasi yang benar terhadap kebutuhan data perusahaan.
Langkah 2.7 : Mengecek kemungkinan pengembangan di masa depan Tujuan dari langkah ini adalah untuk menentukan bagian mana yang kelihatannya akan berubah ke masa depannya dan juga memperhatikan supaya model data logikal
dapat mengakomodasi perubahan tersebut.
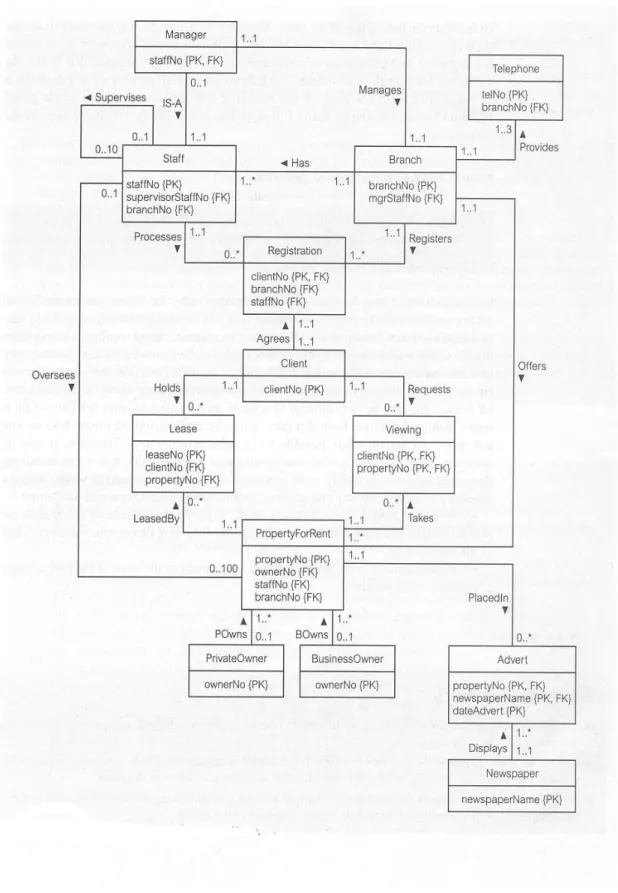
Hasil akhir dari perancangan Basis data logikal adalah merancang suatu model informasi berdasarkan spesifik model yang ada (seperti model relasional), tetapi tidak tergantung terhadap suatu DBMS dan perangkat keras lainnya. Basis data logikal merancang suatu map untuk setiap lokal konseptual data. Jika terdapat lebih dari satu pandangan user, maka model data logikal lokal akan dikombinasikan menjadi suatu model data logikal global yang merepresentasikan semua pandangan user dari suatu perusahaan.
2.1.7.3 Perancangan Basis data Fisikal
Menurut Connolly and begg (2005, p294), perancangan Basis data fisikal adalah suatu proses untuk mendeskripsikan pengimplementasian dari suatu Basis data pada media penyimpanan secondary; dengan mendeskripsikan relasi dasar, organisasi file, dan indeks yang digunakan untuk mencapai keefisienan dalam mengakses data, dan batasan integritas, serta pengukuran keamanan apapun yang berhubungan.
Langkah 3 : Menerjemahkan Model Data Logikal Sesuai DBMS Yang Dituju Tujuan dari langkah ini adalah untuk membuat suatu skema Basis data relasional dari model data logikal yang dapat diimplementasikan ke DBMS yang dituju.
Langkah 3.1 : Merancang relasi dasar
Tujuan dari langkah ini adalah untuk memutuskan bagaimana merepresentasikan relasi dasar yang diidentifikasi dalam model data logikal pada DBMS yang dituju.
Untuk memulai proses perancangan Basis data fisikal, pertama-tama dapat dilakukan dengan menyatukan dan mengasimilasikan informasi mengenai relasi yang dirancang selama perancangan Basis data logikal. Informasi yang diperlukan dapat berasal dari kamus data dan definisi relasi yang didefinisikan menggunakan Database Design Language (DBDL). Untuk setiap relasi yang diidentifikasi pada model data logikal, dapat didefinisikan berisi :
a. Nama relasi;
b. Daftar simple atribut dalam tanda kurung;
d. Batasan integritas referensial untuk setiap foreign key yang diidentifikasi. e. Dari kamus data, dari setiap atributnya dapat diketahui :
f. Domain atribut tersebut yang terdiri dari tipe data, panjang, dan berbagai constraint pada domain tersebut;
g. Suatu optional nilai default untuk atribut; h. Apakah atribut dapat diisi dengan nilai null;
i. Apakah atribut dapat diturunkan dan jika demikian bagaimana perhitungannya.
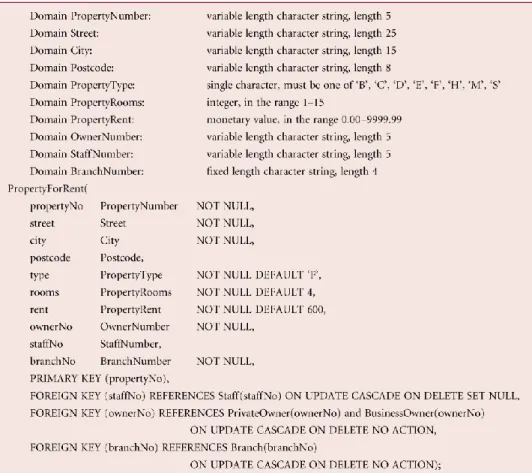
Gambar 2.7 DBDL untuk relasi PropertyForRent (Sumber : Connolly and Begg 2005,p499)
Langkah 3.2 : Merancang representasi derived data (data turunan)
Tujuan dari langkah ini adalah untuk memutuskan bagaimana merepresentasikan suatu data turunan yang terdapat pada model data logikal pada DBMS yang dituju.
Atribut yang nilainya didapatkan dengan mengevaluasi atribut lain dikenal sebagai atribut turunan atau atrribut kalkulasi. Sebagai contoh :
Jumlah staff yang bekerja pada suatu branch (cabang);
Total gaji bulanan untuk semua staff;
Jumlah properti yang di-handle oleh anggota staff.
Gambar 2.8 Relasi PropertyForRent dan Staff dengan atribut turunan noOfProperties (Sumber : Connolly and Begg 2005,p500)
Langkah 3.3 : Merancang kendala umum
Tujuan dari langkah ini adalah untuk merancang kendala umum untuk DBMS yang dituju.
Meng-update suatu relasi yang mungkin dibatasi oleh batasan integritas yang mengatur transaksi „real world‟ yang direpresentasikan oleh peng-update-an tersebut. Perancangan batasan tersebut sekali lagi tergantung pada DBMS yang dipilih. Beberapa sistem menyediakan fasilitas-fasilitas dibandingkan yang lainnya untuk mendefinisikan kendala umum. Seperti langkah sebelumnya, jika sistem tersebut mempunyai aturan sesuai aturan standar SQL, beberapa batasan dapat diterapkan.
CONSTRAINT StaffNotHandlingTooMuch
CHECK (NOT EXISTS (SELECT staffNo FROM PropertyForRent
GROUP BY staffNo
HAVING COUNT(*) > 100))
Langkah 4 : Merancang Organisasi File dan Indeks
Tujuan dari langkah ini adalah untuk menentukan organisasi file yg optimal untuk menyimpan relasi dasar dan indeks yang dibutuhkan untuk mencapai kinerja yang diharapkan. Karena itu, cara dimana relasi dan tuples yang ada akan disimpan pada penyimpanan secondary.
Langkah 4.1 : Menganalisis transaksi
Tujuan dari langkah ini adalah untuk memahami fungsionalitas dari suatu transaksi dimana akan dijalankan pada Basis data untuk menganalisis transaksi yang penting.
Untuk membuat perancangan Basis data fisikal yang efektif perlu untuk mempunyai pengetahuan mengenai transaksi atau query yang akan dijalankan di dalam
Basis data. Hal ini termasuk informasi kualitatif dan kuantitatif. Dalam menganalisis transaksi, dapat diidentifikasikan kriteria kinerja sebagai berikut :
Transaksi yang sering digunakan, dan akan berdampak besar terhadap kinerja keseluruhan;
Transaksi yang kritis untuk operasi bisnis;
Durasi waktu dalam harian atau mingguan yang akan mendapatkan banyak permintaan pada Basis data (disebut peak load).
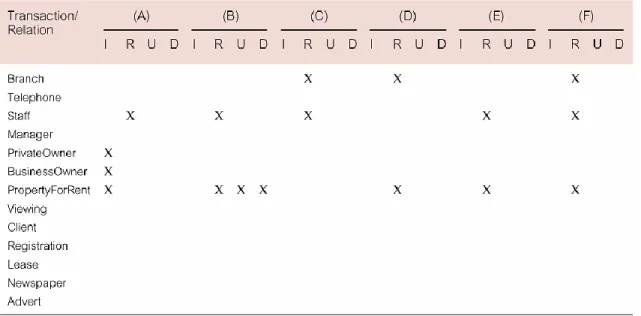
Gambar 2.9 Contoh Analisis Transaksi Pada Relasi (Sumber : Connolly and Begg 2005,p504)
Gambar 2.10 Contoh Penggunaan Transaksi (Sumber : Connolly and Begg 2005,p504)
Gambar 2.11 Contoh Form Analisis Transaksi (Sumber : Connolly and Begg 2005,p507)
Langkah 4.2 : Memilih organisasi file
Tujuan dari langkah ini adalah untuk menentukan organisasi file yang efisien untuk setiap relasi dasar.
Beberapa organisasi file efisien untuk bulk loading data kedalam Basis data tetapi setelah itu tidak efisien. Dengan kata lain, kita ingin menggunakan struktur penyimpanan yang efisien untuk mengeset Basis data dan kemudian mengubahnya untuk penggunaan operasional normal.
Karena itu, tujuan dari langkah ini adalah untuk memilih organisasi file yang optimal untuk tiap relasi, jika DBMS yang dituju memperbolehkannya. Dalam banyak kasus yang ada, suatu relasional DBMS akan memberikan sedikit bahkan tanpa pilihan dalam memilih organisasi file, walaupun beberapa akan mempunyai indeks yang spesifik. Beberapa macam organisasi file yang ada adalah sebagai berikut :
Heap
Hash
Indexed Sequential Office Access Method (ISAM)
B*-three
Clusters.
Jika DBMS yang dituju tidak memperbolehkan adanya pemilihan organisasi file, maka langkah ini dapat dihilangkan.
Langkah 4.3 : Memilih indeks
Tujuan dari langkah ini adalah untuk menentukan apakah dengan adanya penambahan indeks akan meningkatkan kinerja dari suatu sistem.
Salah satu pendekatan untuk memilih organisasi file yang sesuai untuk relasi yaitu menjaga agar tuples tidak berurutan dan membuat indeks secondary sebanyak mungkin. Pendekatan lainnya yaitu untuk mengurutkan tuples dalam relasi dengan menspesifikasi primary atau clustering indeks. Dalam kasus ini, biasanya pemilihan suatu atribut untuk pengurutan atau clustering pada tuples adalah sebagai berikut :
Suatu atribut yang digunakan paling sering untuk operasi join (penggabungan), yang akan membuat operasi penggabungan itu lebih efisien, atau
Suatu atribut yang digunakan paling sering untuk mengakses suatu tuples didalam relasi yang ada.
Apabila pengurutan atribut yang dipilih adalah kunci dari relasi, indeks tersebut akan menjadi primary index. Sedangkan jika pengurutan atribut yang dipilih bukan merupakan kunci dari relasi, indeks tersebut akan menjadi clustering index. Setiap relasi hanya dapat mempunyai primary index atau clustering index.
Langkah 4.4 : Mengestimasi kapasitas disk yang dibutuhkan
Tujuan dari langkah ini adalah untuk mengestimasi jumlah kapasitas disk yang akan dibutuhkan oleh Basis data dalam mendukung implementasi Basis data pada penyimpanan secondary.
Seperti pada langkah sebelumnya, mengestimasi penggunaan disk sangat bergantung pada DBMS yang dituju dan hardware yang digunakan untuk mendukung Basis data. Secara umum, estimasi tersebut dilakukan berdasarkan ukuran tiap tuple dan jumlah tuples dalam relasi.
Langkah 5 : Merancang tampilan untuk user
Tujuan dari langkah ini adalah untuk merancang tampilan user yang diidentifikasi selama tahap pengumpulan dan analisis kebutuhan pada Siklus Hidup Pengembangan Sistem Basis data.
Langkah 6 : Merancang mekanisme keamanan
Tujuan dari langkah ini adalah untuk merancang mekanisme keamanan untuk Basis data seperti yang telah dispesifikasikan user selama tahap analisis dan pengumpulan kebutuhan pada Siklus Hidup Pengembangan Sistem Basis data.
Selama tahap tahap analisis dan pengumpulan kebutuhan pada Siklus Hidup Pengembangan Sistem Basis data, kebutuhan keamanan yang spesifik harus didokumentasikan dalam spesifikasi kebutuhan sistem. Sasaran dari tahap ini adalah untuk memutuskan bagaimana kebutuhan keamanan ini akan direalisasikan. Beberapa sistem menawarkan fasilitas keamanan yang berbeda dari sistem yang lainnya. Sekali lagi, perancang Basis data harus hati-hati terhadap fasilitas yang ditawarkan oleh DBMS yang dituju. Relasional DBMS biasanya menyediakan dua macam keamanan Basis data antara lain :
Keamanan sistem;
Keamanan data.
Keamanan sistem menutupi pengaksesan dan penggunaan Basis data pada tingkat sistem, seperti user name dan password. Sedangkan, keamanan data menutupi pengaksesan dan penggunaan objek Basis data (seperti relasi dan views) dan tindakan dimana user dapat memperoleh objek tersebut.
Definisi dari keamanan Basis data adalah suatu mekanisme yang memproteksi Basis data dari suatu kejadian baik yang disengaja maupun tidak. Suatu Basis data merupakan sumber dari perusahaan yang essential yang perlu dilindungi denagan menggunakan suatu kontrol yang memadai.
Beberapa issue keamanan yang perlu diperhatikan : 1. Pencurian data (Theft and Fraud)
2. Kehilangan kerahasiaan data (Loss of Confidentially) 3. Kehilangan hak pribadi (Loss of Privacy)
4. Kehilangan integritas (Loss of integrity)
5. Kehilangan ketersediaan data (Loss of availability)
Hasil akhir perancangan fisikal Basis data adalah suatu proses yang mendeskripsikan suatu implementasi dari suatu Basis data pada media penyimpanan. Hal ini mendeskripsikan suatu relational dan struktur penyimpanan dan metodologi pengaksesan data oleh user yang efisien, selama batasan integritas dan pengukuran keamanan.
2.1.8 Entity-Relationship Modeling ( ER Modeling )
Model Entity-Relationship merupakan salah satu model yang dapat memastikan pemahaman yang tepat terhadap data dan bagaimana penggunaannya di dalam suatu organisasi (Connolly, 2005, p342). Model ini dimulai dengan identifikasi entiti dan relationship antar data yang harus direpresentasikan di dalam model, dan kemudian ditambahkan atribut dan setiap constraint pada entiti, relationship, dan atributnya.Beberapa konsep dasar dalam model E-R yaitu:
2.1.8.1 Tipe entity
Tipe Entiti adalah sekumpulan objek yang memiliki properti yang sama, yang diidentifikasikan ke dalam organisasi karena keberadaannya yang bebas (independent existance) (Connolly, 2005, p343). Sedangkan entity occurance adalah sebuah objek dari suatu tipe entiti yang dapat diidentifikasikan secara unik (Connolly, 2005, p345).
Keberadaan objek-objeknya secara fisik / nyata (physical existance) seperti entiti pegawai, rumah, dan pelanggan, atau secara konseptual / abstrak (conceptual existance) seperti entiti penjualan, pembelian, dan peminjaman.
Setiap tipe entiti dilambangkan dengan sebuah persegi panjang yang diberi nama dari entiti tersebut. Nama tipe entiti biasanya adalah kata benda tunggal. Huruf pertama dari setiap kata pada nama tipe entiti ditulis dengan huruf besar.
Gambar 2.12 Representasi diagram dari tipe entiti Pegawai dan Cabang (Sumber : Connolly and Begg 2005,p345)
Tipe Entiti dapat dilasifikasikan menjadi:
Tipe Entiti Kuat, yaitu tipe entiti yang keberadaannya tidak tergantung pada tipe entiti lainnya (Connolly, 2005, p354)
Tipe Entiti Lemah, yaitu tipe entiti yang keberadaannya bergantung pada tipe entiti lainnya (Connolly, 2005, p355)
Nama Entiti
Gambar 2.13 Representasi diagram tipe entiti kuat dan tipe entity lemah (Sumber : Connolly and Begg 2005,p355)
2.1.8.2 Tipe Relationship
Tipe relationship adalah sekumpulan hubungan antar tipe entiti yang memiliki arti (Connolly, 2005, p346). Sekumpulan relationship occurrence adalah sebuah hubungan yang dapat diidentifikasikan secara unik, yang meliputi sebuah kejadian (occurrence) dari setiap tipe entiti di dalam relationship (Connolly, 2005, p346)
Tipe relationship digambarkan dengan sebuah garis yang menghubungkan entiti-entiti yang saling berhubungan. Garis tersebut diberi nama sesuai dengan nama hubungannya dan diberi tanda panah satu arah disamping nama hubungannya.
Biasanya sebuah relationship dinamakan dengan menggunakan kata kerja, seperti Mengatur, atau dengan sebuah frame singkat yang meliputi sebuah kata kerja, seperti DisewaOleh, sedangkan tanda panah ditempatkan di bawah nama relationship yang mengindikasikan arah bagi pembaca untuk mengartikan nama dari suatu relationship. Huruf pertama dari setiap kata pada suatu relationship ditulis dengan huruf besar.
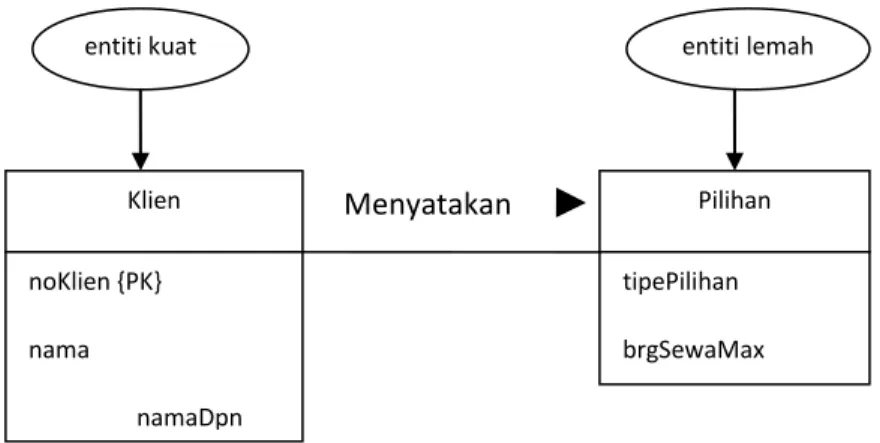
entiti kuat Klien noKlien {PK} nama namaDpn namaBlkng telp entiti lemah Pilihan tipePilihan brgSewaMax Menyatakan
Gambar 2.14 Representasi diagram dari tipe relationship (Sumber : Connolly and Begg 2005,p347)
2.1.8.2.1 Derajat dari Tipe Relationship
Derajat dari tipe relationship adalah jumlah tipe entiti yang ikut di dalam sebuah relationship (Connolly, 2005, p347)
Complex relationship types adalah sebuah relationship antara tiga atau lebih tipe entiti (Connolly, 2005, p348). Sebuah relationship yang memiliki derajat dua dinamakan binary (Connolly, 2005, p348). Gambar 2.4 juga merepresentasikan diagram relationship derajat dua. Sedangkan sebuah relationship derajat tiga dinamakan ternary, dan jika sebuah relationship memiliki derajat empat dinamakan quarternary (Connolly, 2005, p348).
Lambang belah ketupat merepresentasikan relationship yang memiliki derajat lebih dari dua. Nama dari relationship tersebut ditampilkan di dalam belah ketupat. Panah yang biasanya terdapat di bawah nama relationship dihilangkan.
Pegawai Memiliki Cabang Cabang memiliki pegawai
Gambar 2.15 Representasi diagram derajat tiga dari suatu tipe relationship (Sumber : Connolly and Begg 2005,p348)
2.1.8.2.2 Recursive Relationship
Recursive relationship adalah sebuah tipe relationship dimana tipe entiti yang sama ikut serta lebih dari sekali pada peran yang berbeda (Connolly, 2005, p349).
Relationship dapat diberikan nama peran untuk menentukan fungsi dari setiap entiti yang terlibat dalam relationship tersebut.
Gambar 2.16 Representasi diagram recursive relationship beserta nama peran (Sumber : Connolly and Begg 2005,p349)
Nama peran Nama peran Pegawai Orang yang diawasi Pengawas Mengawasi Pegawai Mendaftarkan Klien Cabang
2.1.8.3 Tipe Atribut Adapun tipe-tipe atribut sebagai berikut:
a. Single valued attribute adalah atribut yang hanya memiliki sebuah nilai untuk setiap occurrence dari sebuah entiti (Connolly, 2005, p351)
b. Multi valued attribute adalah atribut yang memiliki banyak nilai untuk setiap occurrence dari sebuah entiti (Connolly, 2005, p352)
c. Derived attribute adalah atribut yang nilai-nilainya diperoleh dari pengolahan atau diturunkan dari atribut lain yang berhubungan (Connolly, 2005, p352)
2.1.8.4 Keys
Candidate key adalah himpunan atribut yang minimal yang secara unik mengidentifikasikan setiap occurrence dari sebuah tipe entiti (Connolly, 2005, 352).
Composite key adalah sebuah candidate key yang terdiri atas dua atau lebih atribut (Connolly, 2005, p353).
Primary key adalah candidate key yang terpilih untuk mengidentifikasikan secara unik setiap occurrence dari sebuah tipe entiti (Connolly, 2005, p353). Pada sebuah tipe entiti biasanya terdapat lebih dari satu candidate key yang salah satunya harus dipilih untuk menjadi primary key. Pemilihan primary key didasarkan pada panjang atribut, jumlah minimal atribut yang diperlukan dan keunikannya.
Alternate key adalah setiap candidate key yang tidak terpilih menjadi primary key, atau biasa disebut dengan secondary key (Connolly, 2005, p79).
Foreign key adalah sebuah primary key pada sebuah entiti yang digunakan pada entiti lainnya untuk mengidentifikasikan sebuah relationship (Connolly, 2005, p79).
Gambar 2.17 Representasi diagram entiti Pegawai dan Cabang beserta atribut dan primary key-nya (Sumber : Connolly and Begg 2005,p354)
2.1.8.5 Strong and Weak Entity Types
Strong Entity Types, yaitu entity yang keberadaannya tidak bergantung pada entity lain, sedangkan Weak Entity Types, adalah entity yang keberadaannya bergantung pada entity lain. Strong Entity Types sering disebut dengan parent, owner dominant, sedangkan Weak Entity Types disebut dengan child, dependent,subordinate.
2.1.8.6 Batasan Struktural (Struktural Constraints)
Batasan-batasan yang menggambarkan pembatasan pada relasi seperti yang ada pada dunia nyata harus diterapkan pada tipe entiti yang ikut serta pada sebuah relasi. Menurut Connolly (2005, p356) jenis utama dari batasan pada suatu relasi dinamakan multiplicity. Mengatur ► Pegawai noPeg {PK} nama jabatan gaji totalPeg Cabang noCab {PK} alamat jalan kota kodepos telp {1-3} multi-valued attribute derived attribute primary key ◄ Memiliki composite attribute ruang untuk menulis atribut
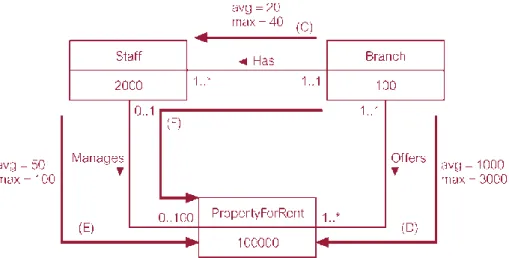
Menurut Connolly (2005, p356) multiplicity adalah jumlah occurrence yang mungkin terjadi pada sebuah tipe entiti yang berhubungan ke sebuah occurrence dari tipe entiti lain pada suatu relasi.
Derajat yang biasanya digunakan pada suatu relasi adalah relasi binary, yang terdiri atas:
2.1.8.6.1 Relasi one-to-one (1:1)
Setiap relasi menggambarkan hubungan antara sebuah entiti occurrence pada entiti yang satu dengan sebuah entiti occurrence pada entiti yang lainnya yang ikut serta dalam relasi tersebut.
Gambar 2.18 Semantic net menunjukkan dua occurrence dari relasi Pegawai Mengatur Cabang (Sumber : Connolly and Begg 2005,p357)
B003 B005 r1 r2 SG5 SG37 SG21 Mengatur tipe relationship
Cabang tipe entiti (noCab) Pegawai tipe entiti
Gambar 2.19 Multiplicity dari relasi one-to-one (1:1) (Sumber : Connolly and Begg 2005,p358)
2.1.8.6.2 Relasi one-to-many (1:*)
Setiap relasi menggambarkan hubungan antara sebuah entiti occurrence pada entiti yang satu dengan satu atau lebih entiti occurrence pada entiti yang lainnya yang ikut serta dalam relasi tersebut.
Gambar 2.20 Semantic net menunjukkan tiga occurrence dari relasi Pegawai Melihat RumahSewa (Sumber : Connolly and Begg 2005,p358) SG5 SG37 SG9 PG21 PG36 PA14 PG4 r1 r2 r3 Melihat tipe relationship
RumahSewa tipe entiti (noRumah) Pegawai tipe entiti
(noPeg) 1..1 Mengatur ► 0..1 Pegawai noPeg Cabang noCab setiap cabang diatur
oleh seorang pegawai
Setiap pegawai dapat mengatur nol atau satu
cabang
Gambar 2.21 Multiplicity dari relasi one-to-many (1:*) (Sumber : Connolly and Begg 2005, p359)
2.1.8.6.3 Relasi many-to-many (*:*)
Setiap relasi menggambarkan hubungan antara satu atau lebih entiti occurrence pada entiti yang satu dengan satu atau lebih entiti occurrence pada entiti yang lainnya yang ikut serta dalam relasi tersebut.
PG21
PG36
PA14
PG4
Glasgow Daily
The News West
Aberdeen Express r1 r2 r3 r4 Mengiklankan tipe relationship RumahSewa tipe entiti (noRumah) Koran tipe entiti
(namaKoran) RumahSewa noRumah 0..1 Melihat ► 0..* Pegawai noPeg
setiap rumah sewa dilihat nol atau satu
pegawai
Setiap pegawai dapat melihat nol atau lebih
rumah sewa
Gambar 2.22 Semantic net menunjukkan empat occurrence dari relasi Koran Mengiklankan RumahSewa (Sumber : Connolly and Begg 2005, p360)
Gambar 2.23 Multiplicity dari relasi many-to-many (*:*) (Sumber : Connolly and Begg 2005, p360)
2.1.8.7 Cardinality dan Participation Constraints
Multiplicity sebenarnya terdiri atas dua constraint yang berbeda, yaitu: a. Cardinality
Menurut Connolly (2005, p363) Cardinality adalah nilai maksimum dari relasi occurrence yang mungkin terjadi untuk sebuah entiti yang ikut serta pada suatu relasi. b. Participation Mengiklankan ► 0..* RumahSewa noRumah 1..* Koran namaKoran
setiap rumah sewa diiklankan pada nol atau
lebih koran
Setiap koran mengiklankan satu atau lebih rumah
sewa
Menurut Connolly (2005, p363) Participation menentukan apakah semua atau hanya beberapa entiti occurrence yang ikut serta dalam sebuah relasi. Participation constraint dibagi menjadi:
Mandatory Participation
Menurut Connolly (2005, p363) mandatory participation melibatkan semua entiti occurrence pada relasi tertentu.
Optional Participation
Menurut Connolly (2005, p363) optional participation melibatkan beberapa entiti occurrence pada relasi tertentu.
Representasi diagram terhadap multiplicity sebagai cardinality dan participation constraints dapat dilihat pada gambar 2.24.
Gambar 2.24 Multiplicity sebagai cardinality dan participation constraints pada relasi one-to-one (1:1) Pegawai Mengatur Cabang (Sumber : Connolly and Begg 2005, p363)
2.1.9 Normalisasi
2.1.9.1 Definisi Normalisasi
Menurut Connolly and Begg (2005, p388), “Normalization is a technique for producing a set of relations with desirable properties, given the data requirements of an enterprise”, artinya normalisasi merupakan suatu teknik untuk menghasilkan sekumpulan hubungan dengan properti yang diinginkan, yang memberikan kebutuhan
1..1 Mengatur ► 0..1 Pegawai noPeg Cabang noCab sebuah cabang diatur
oleh seorang pegawai
seorang pegawai mengatur satu
cabang
‘semua cabang diatur pegawai’ (mandatory participation) pada
Cabang
‘tidak semua pegawai mengatur cabang’ (optional participation)
pada Pegawai
Cardinality
data terhadap sebuah perusahaan.
Adapun, tujuan dari normalisasi adalah sebagai berikut :
a. Meminimalkan jumlah atribut yang perlu untuk mendukung kebutuhan data dari suatu perusahaan;
b. Atribut dengan relasi logikal yang dekat (digambarkan sebagai functional dependency) yang ditemukan dalam relasi yang sama;
c. Meminimalkan redundancy dengan tiap atribut direpresentasikan hanya sekali dengan pengecualian atribut yang membentuk semua atau sebagian foreign key yang penting untuk berpartisipasi dalam relasi yang terhubung.
2.1.9.2 Tahap-tahap Normalisasi
Menurut Connoly dan Begg (2005, p388), Normalisasi adalah sebuah teknik untuk menghasilkan sekumpulan relasi dengan property yang diinginkan, yang akanmemberikan kebutuhan data bagi perusahaan. Relasi adalah sebuah table dengan kolom dan baris.
Tahap – tahap normalisasi antara lain :
1. First Normal Form (1NF)
Sebelum memasuki tahap 1NF, status sebelum 1NF disebut dengan Unormalized Form (UNF), yaitu sebuah table yang mengandung satu atau lebih kelompok yang berulang.