Factorization by Score Matching
Zhiyun Lu, Zhirong Yang⋆, and Erkki Oja
Department of Information and Computer Science⋆⋆
Aalto University, 00076, Finland
{zhiyun.lu,zhirong.yang,erkki.oja}@aalto.fi
Abstract. Nonnegative Matrix Factorization (NMF) based on the fam-ily ofβ-divergences has shown to be advantageous in several signal pro-cessing and data analysis tasks. However, how to automatically select the best divergence among the family for given data remains unknown. Here we propose a new estimation criterion to resolve the problem of selectingβ. Our method inserts the point estimate of factorizing matri-ces fromβ-NMF into a Tweedie distribution that underliesβ-divergence. Next, we adopt a recent estimation method called Score Matching forβ selection in order to overcome the difficulty of calculating the normal-izing constant in Tweedie distribution. Our method is tested on both synthetic and real-world data. Experimental results indicate that our se-lection criterion can accurately estimateβcompared to ground truth or established research findings.
Keywords: nonnegative matrix factorization, divergence, score match-ing, estimation
1
Introduction
Nonnegative Matrix Factorization (NMF) has been recognized as an important tool for signal processing and data analysis. Ever since Lee and Seung’s pioneer-ing work [13, 14], many NMF variants have been proposed (e.g. [5, 12]), together with their diverse applications including text, images, music, bioinformatics, etc. (see e.g. [11, 6]). See [4] for a survey.
Divergence or approximation error measure is an important dimension in the NMF learning objective. Originally the approximation error was measured by squared Euclidean distance or generalized Kullback-Leibler divergence [14]. Later these measures were unified and extended to a broader parametric divergence family calledβ-divergence [12].
Compared to the vast number of NMF cost functions, our knowledge about how to select the best one among them for given data is small. It is known that a
⋆corresponding author
⋆⋆ This work is supported by the Academy of Finland in the project Finnish Center of
largeβ leads to more robust but less efficient estimation. Some more qualitative discussion on the trade-off can be found in [2, 3] and references therein. Currently, automatic selection among a parametric divergence family generally requires extra information, for example, ground truth data [1] or cross-validations with a fixed reference parameter [15], which is infeasible in many applications, especially for unsupervised learning.
In this paper we propose a new method for the automatic selection of β -divergence for NMF which requires no ground truth or reference data. Our method can reuse existing NMF algorithms for estimating the factorizing ma-trices. We then insert the estimated matrices into a Tweedie distribution which underlies the β-divergence family. The partition function or normalizing con-stant in Tweedie distribution is intractable except for three special cases. To overcome this difficulty, we employ a non-maximum-likelihood estimator called Score Matching, which avoids calculating the partition function and has shown to be both consistent and computationally efficient.
Evaluating the estimation performance is not a trivial task. We verify our method by using both synthetic and real-world data. Experimental results show that the estimated β conforms well with the underlying distribution that is used to generate the synthetic data. Empirical study on music signals using our method is consistent to previous research findings in music.
After this introduction, we recapitulate the essence of NMF based on β -divergence in Section 2. Our main theoretical contribution, including the prob-abilistic model, Score Matching background, and the selection criterion, is pre-sented in Section 3. Experimental settings and results are given in Section 4. Finally we conclude the paper and discuss some future work in Section 5.
2
NMF Based on
β
-Divergence
Denote R+ ={x|x ∈ R, x ≥ 0}. Given X ∈ Rm×n+ , Nonnegative Matrix
Fac-torization finds a low-rank approximation matrix X ≈ Xb = W H such that W ∈Rm×k+ andH ∈Rk×n+ , withk <min(m, n).
The approximation error can be measured by various divergences, among which a parametric family called β-divergence has shown promising results in signal processing and data analysis. NMF using β-divergence, here called β -NMF, solves the following optimization problem:
minimize
W≥0,H≥0 Dβ(X||Xb), (1)
where theβ-divergence between two nonnegative matrices is defined by
Dβ(X||Xb) = 1 β(β−1)
X
ij
Xijβ+ (β−1)Xbijβ−βXijXbijβ−1
(2)
Kullback-Leibler (KL) divergence
Whenβ→0,β-divergence is called Itakura-Saito (IS) divergence:
DIS(X||Xb) =
The performance of NMF can be improved by using the most suitableβ-divergence, not restricting to the squared Euclidean distance or Kullback-Leibler divergence, as in the original NMF (e.g. [6]).
Theβ-NMF optimization problem is non-convex and usually there are only local optimizers available. A popular algorithm iterates the following multiplica-tive update rules [12]:
where the division and the power are taken elementwise, and ‘.’ refers to ele-mentwise multiplication. The cost functionDβ(X|W H) monotonically decreases under the above updates forβ ∈[1,2] and thus usually converges to a local min-imum [12]. Empirical convergence of β outside this range is also observed in most cases. Moreover, there are several other more comprehensive algorithms forβ-NMF (see e.g. [7]).
3
Selecting
β
divergence for NMF
Different divergences usually correspond to different types of noise in data and there is no universally best divergence. Despite significant progress in optimiza-tion algorithms and in applicaoptimiza-tions using certain β-divergences, there is little research on how to choose the bestβ-divergence for given data. The objective in Eq. (2) cannot be used for selectingβ as it favorsβ→ ∞ifXij >1 andXbij >1 orβ → −∞if 0≤Xij <1 and 0≤Xbij <1. In the following, we propose a new criterion for determining the value ofβ.
3.1 Tweedie distribution
corresponding Tweedie distribution given the β, if the distribution exists. This inspires us to develop a statistical method to selectβ.
Consider the Tweedie distribution with unitary dispersion
p(X;β) = 1
It is important to notice thatW∗ andH∗ can be seen as functions overX and β. Therefore, p(X;β) in Eq. (7) is a distribution ofX parameterized byβ. We can then use certain estimation methods to select the bestβ.
Maximum-Likelihood (ML) estimator seems a natural choice. However, we face the difficulty in calculating the partition function becauseZ(β) is intractable except forβ = 0,1,2. Moreover, no partition function exists for 1< β <2. For β = 1, the partition function is only available for non-negative integers. To avoid these problems, we turn to a non-maximum-likelihood estimator called Score Matching (SM) introduced by Hyv¨arinen [9], which requires only the non-normalized part of the distributions.
3.2 Score Matching for nonnegative data
Consider a non-normalized statistical model of d-dimensional nonnegative vec-tors ξ: p(ξ, θ) = 1
Z(θ)q(ξ, θ), where Z(θ) = R
q(ξ, θ)dξ is difficult to compute. In score matching, the score of a density is the gradient of log-likelihood with respect to the data variable. For real vectorial data, SM minimizes the expected squared Euclidean distance between the scores of true distribution and the model [9]. For nonnegative vectorial data, SM uses data-scaled scores to avoid the dis-continuity of data around zero [10]. Under certain mild conditions, the resulting score matching objective does not rely on the scores of true distribution by us-ing integration by parts. In addition, the expectation can be approximated by sample average:
3.3 Selecting β by Score Matching
We now come back to the Tweedie distribution in Eq. (7). Here we have one nonnegative observation matrix of size m×n, and β is the parameter to be estimated. DenoteXb=W∗H∗. Inserting
we obtain the score matching objective (with some additive constants):
L(β) =X selected by using score matching is
β∗= arg min
β L(β) (13)
which is easily computed by standard minimization.
4
Experiments
Next we empirically evaluate the performance of the proposed selection method. The estimated β using the criterion in Eq. (13) is compared with the ground truth or established results in a particular domain. Because theβ-NMF objective in Eq. (1) is non-convex, only local optimizers are available. We repeat the optimization algorithms multiple times from different starting points to get rid of poor local optima.
4.1 Synthetic data
There are three special cases of the Tweedie distribution which have closed form. We have considered three popularly usedβ values: (1) NMF with squared Eu-clidean distance (β= 2) corresponding to the approximation ofX with additive Gaussian noise; (2) KL-divergence (β = 1) corresponding to approximation of X with Poisson noise; and (3) IS-divergence (β = 0) corresponding to approx-imation of X in multiplicative Gamma noise [6]. We generated synthetic data matricesX according to the above distributions. In evaluation, the estimatedβ should be close to the one used in the ground truth distribution.
In detail, we first randomly generated matricesW0andH0from the uniform
distribution over (0,20). The input matrixXwas then constructed by imposing a certain type of noise (either additive standard normal, Poisson, or multiplicative Gamma with unitary scale and shape) on the productW0H0. Next, we searched
Table 1.Estimation results for synthetic data
matrix size k Euclidean(β= 2) KL(β= 1) IS(β= 0)
30×20 5 2.06±0.04 1.08±0.03 −0.06±0.06
50×30 8 2.02±0.02 1.07±0.02 0.15±0.00
60×25 10 1.99±0.04 1.10±0.00 0.18±0.02
100×20 5 1.99±0.06 1.05±0.00 0.12±0.02
repeated the process ten times and recorded the mean and standard deviation for the selectedβ’s. We have also tried different low rankskand input matrices of different sizes.
The results are shown in Table 4.1. We can see that our method can estimate β quite accurately. For various matrix sizes and low ranks, the selectedβ’s are very close to the ground truth values with small deviations.
4.2 Real-world data: music signal
It is more difficult to evaluate the β selection method for real-world datasets where there is no ground truth. Here we perform the evaluation by compar-ing the estimated results to an established research findcompar-ing for music signals. Many researchers have found that a particular case of β-divergence, Itakura-Saito divergence (β→0) is especially suitable for music signals (see e.g. [6] and references therein). It is interesting to see whether our estimation method can reveal the same finding for music data.
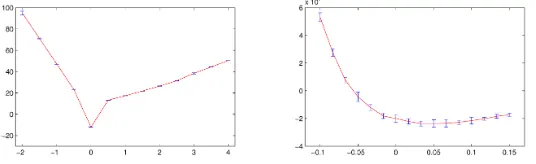
We have tested our method on piano and jazz signals. We extracted the power spectrogram matrix from the music piece by the same procedure as F´evotte et al. [6]. In this way the matrices used as input inβ-NMF are of sizes 513×676 for piano and 129×9312 for jazz. We also followed their choice of the compression rank:k= 5,6 for piano and k= 10 for jazz. The search interval [−2,4] was the same as in the synthetic case. We first performed coarse search using step size 0.5 and then fine search in [−0.1,0.15] with smaller steps. For eachβ, we repeated the NMF algorithms ten times with different starting points and recorded the mean and standard deviation of score matching objectives.
The results for piano and jazz are shown in Figures 1 and 2, respectively. In coarse search, β = 0 is the only value that causes negative score matching objective, which is also the minimum. The fine search results confirm that the minimum or the elbow point is very close to zero for both piano and jazz. These results are well consistent with the previous finding that Itakura-Saito divergence is good for music signals (e.g. [6]).
5
Conclusions and Future Work
Fig. 1.Score matching objectives forβ-NMF on the piano signal: (top) coarse search where objectives are shown in log-scale, (bottom) fine search.
Fig. 2. Score matching objectives forβ-NMF on the jazz signal: (left) coarse search where objectives are shown in log-scale, (right) fine search.
distribution. We have adopted Score Matching, a non-maximum-likelihood es-timation method, to avoid the theoretical and computational difficulty in the partition function of the Tweedie distribution. Experimental results on both synthetic data and music signals showed that our method can estimate the β value accurately compared to ground truth or the known research findings.
The behavior of the selection method needs more thorough investigation. Although our method builds on the Tweedie distribution, the proposed objective is well defined for all β’s, even for those where Tweedie distribution does not exist for nonnegative real matrices. It is also surprising that the score matching works in the selection with only one observation. Here the sample averaging required by score matching might be done in an implicit or alternative way.
connec-tion to other automatic model selecconnec-tion methods such as Minimum Descripconnec-tion Length [8] and Bayesian Ying-Yang Harmony learning [17] needs further study. Several issues still need to be resolved in the future. The selection of the rank k was specified in advance in our method, which would affect the result of the β-selection. It would be interesting to see whether score matching also works for the low rank selection. In addition, β-divergence is a scale dependent measure, upon which scale tuning of the data matrix might be required.
References
1. Choi, H., Choi, S., Katake, A., Choe, Y.: Learning alpha-integration with partially-labeled data. In: Proc. of the IEEE International Conference on Acoustics, Speech, and Signal Processing. pp. 14–19 (2010)
2. Cichocki, A., Amari, S.I.: Families of alpha- beta- and gamma- divergences: Flexible and robust measures of similarities. Entropy 12, 1532–1568 (2010)
3. Cichocki, A., Cruces, S., Amari, S.I.: Generalized alpha-beta divergences and their application to robust nonnegative matrix factorization. Entropy 13, 134–170 (2011) 4. Cichocki, A., Zdunek, R., Phan, A.H., Amari, S.: Nonnegative Matrix and Tensor Factorizations: Applications to Exploratory Multi-way Data Analysis. John Wiley (2009)
5. Dhillon, I.S., Sra, S.: Generalized nonnegative matrix approximations with breg-man divergences. In: Advances in Neural Information Processing Systems. vol. 18, pp. 283–290 (2006)
6. F´evotte, C., Bertin, N., Durrieu, J.L.: Nonnegative matrix factorization with the Itakura-Saito divergence: With application to music analysis. Neural Computation 21(3), 793–830 (2009)
7. F´evotte, C., Idier, J.: Algorithms for nonnegative matrix factorization with the β-divergence. Neural Computation 23(9), 2421–2456 (2011)
8. Grunwald, P.D., Myung, I.J., Pitt, M.A.: Advances in Minimum Description Length: Theory and Applications. MIT Press (2005)
9. Hyvarinen, A.: Estimation of non-normalized statistical models by score matching. Journal of Machine Learning Research 6(1), 695 (2006)
10. Hyvarinen, A.: Some extensions of score matching. Computational statistics & data analysis 51(5), 2499–2512 (2007)
11. Kim, H., Park, H.: Sparse negative matrix factorizations via alternating non-negativity-constrained least squares for microarray data analysis. Bioinformatics 23(12), 1495 (2007)
12. Kompass, R.: A generalized divergence measure for nonnegative matrix factoriza-tion. Neural Computation 19(3), 780–791 (2006)
13. Lee, D.D., Seung, H.S.: Learning the parts of objects by non-negative matrix fac-torization. Nature 401, 788–791 (1999)
14. Lee, D.D., Seung, H.S.: Algorithms for non-negative matrix factorization. Advances in Neural Information Processing Systems 13, 556–562 (2001)
15. Mollah, M., Sultana, N., Minami, M.: Robust extraction of local structures by the minimum of beta-divergence method. Neural Networks 23, 226–238 (2010) 16. Tweedie, M.: An index which distinguishes between some important exponential
families. In: Statistics: Applications and new directions: Proc. Indian statistical institute golden Jubilee International conference. pp. 579–604 (1984)