Penyaringan Spam Short Message Service Menggunakan Support Vector Machine
Tri Herdiawan Apandi*), Castaka Agus Sugianto**)
Teknik Informatika, Politeknik TEDC Bandung
E-Mail: *[email protected], **[email protected]
Abstrak
Pengguna pesawat selular tidak bisa lepas dari SMS. Tetapi dengan semakin banyak
orang yang menggunakan SMS ini banyak yang menyalah gunakan. Spam SMS
adalah penyalahgunaan yang bisa merugikan pengguna handphone dan provider.
Untuk mencegah spam SMS ini masuk ke dalam handphone banyak cara yang telah
dilalukan. Penyaringan spam SMS adalah salah satunya, dengan menggunakan
Support Vector Machine(SVM). Pesan SMS yang dikumpulkan di lakukan preprosessing, dipecah isi SMS, dilakukan pemilihan fitur, pembuat fitur vector, optimasi parameter, melakukan pelatihan untuk menghasilkan model, dan melakukan prediksi. Optimasi parameter adalah cara untuk mengingkatkan akurasi, dengan menggunakan parameter C= 32 dan γ=0,001953125 untuk data pelatihan dengan akurasi 92,375% dan 10 fold cross validation pada data uji mengingkatkan akurasi sebesar 29% dari yang asalnya 62% pada pemecahan kalimat menjadi kata atau pada
penggunaan Term Frequency. Sedang pada karakter N-grams meningkatkan akurasi
sebesar 43% dari yang asalnya 50% pada data uji dan pada data pelatihan dengan akurasi 93.875% dengan nilai C= 32 dan γ=0,001953125 untuk data latih. Sedangkan untuk hasil akurasi terbaik untuk data latih adalah 96.625% dengan pembobotan term frequency dan untuk data uji akurasi sebesar 95% untuk semua pembobot.
Kata kunci: Spam SMS, SVM, Pembobotan, dan Optimasi Parameter
1.
PENDAHULUAN
Short Message Service (SMS) adalah komunikasi teks layanan komponen telepon,
web atau sistem komunikasi mobile,
menggunakan protokol standar komunikasi yang memungkinkan pertukaran pesan teks
singkat antara fixed line atau perangkat
ponsel. Menurut Asosiasi Telekomunikasi Seluler Indonesia (ATSI) jumlah SMS yang terkirim pada tahun 2011 juga mencapai 260 miliar SMS dan jumlah transaksi data
mencapai 27 ribu terrabyte[1].
Spam SMS adalah penyalahgunaan isi dari SMS yang merugikan peneriman.
Menurut Cloudmark stats, jumlah spam
ponsel bervariasi misalnya di Amerika Utara, kurang dari 1% dari pesan SMS yang spam
di 2011, bagian Asia hingga 30%
mengandung spam SMS[4]. Karena
hambatan masuk yang rendah, maka banyak
spammers yang muncul dan jumlah spam
SMS sangat tinggi. Untuk itu penyaringan SMS sangat dibutuhkan untuk mencegah kerugian yang dihadapi oleh pengguna
handphone itu sendiri, provider, dan
masyarakat umum juga merasa tidak
nyaman.
Pada penelitian terdahulu tentang
penyaringan spam SMS banyak medote yang
telah dilakukan seperti Support Vector
Machine dan Token[8], NaiveBayes[3], dan
sampling algorithm[9]. Kekurangan penggabungan Support Vector Machine dan token adalah pada saat isi dari SMS
menggunakan imbuhan [4]. Naive Bayes
memberikan hasil bahwa waktu
pemrosesannya lebih cepat dan tinggkat akurasi yang wajar[3]. Waktu belajar
NaiveBayes lebih kecil dibandingkan
Decision Trees[12]. Neural Network
memberikan error generalisasi yang lebih
besar daripada SVM[11]. Semua peneliti
sebelumnya menggunakan dataset dalam
bahasa asing. Mengetahui karakteristik
dataset menjadi penting karena menyangkut
penentuan fitur dan preprocessing.
Training pada SVM bertujuan untuk mencari
posisi optimal dari hyperplane di dual space
sedangkan hal ini yang dipakai margin yaitu
jarak antara fungsi pemisah (separating
hyperplane) ke masing-masing kelas.
training set yang paling sempurna. Pada metoda yang lain proses training dilakukan secara berulang sampai didapatkan kedua
kelas secara optimal atau juga local optimal.
Berbeda dengan SVM training dilakukan
sekali dan akan mendapatkan nilai yang
optimal, ini memcegah terjadinya overfitting
karena overtrained. Berdasarkan hasil
peneliti sebelumnya, bisa disimpulkan bahwa SVM memiliki kinerja dasar terbaik [8].
Tujuan dari penelitian adalah mengetahui
pengaruh hasil akurasi pencacah karakter N-grams dan pengumpulan dataset Berbahasa Indonesia
2.
TINJAUAN PUSTAKA
2.1.SVM
Dalam teknik ini, kita berusaha untuk menemukan fungsi pemisah(klasifier) yang optimal yang bisa memisahkan dua set data dari dua kelas yang berbeda[12]. SVM dibagi menjadi 2 yaitu lineary separeable dan nonlineary separeable. Pada penelitian ini
menggunakan nonlineary separeable.
Nonlinearly separable. Dimana kasus tidak dapat diselesaikan dengan menggunakan
solusi pemisahan hard-margin, maka formula
SVM harus dimodifikasi agar lebih fleksibel
(untuk kasus tertentu) dengan
menambahakan variabel slack [11, 13].
Selain menggunakan variabel slack, data yang tidak dapat dipisahkan secara linier
dapat diklasifikasikan dengan
mentransformasikan data ke dalam dimensi
ruang fitur (feature space) sehingga dapat
dipisahkan secara linier pada feature space
[11,13]. Data dipetakan dengan
menggunakan fungsi pemetaan (tranformasi)
ke dalam feature space sehingga
terdapat bidang pemisah yang dapat
memisahkan data berdasarkan kelasnya [13].
SVM menggunakan “kernel trick” untuk
mengatasi permasalahan tersebut. Terdapat
dot product . Jika fungsi kernel
adalah maka ,
maka fungsi transformasi tidak perlu
diketahui secara persis [8]
2.2.Estimasi Parameter Terbaik
Akurasi model yang dihasikan dari data pelatihan menggunakan SVM bergantung pada fungsi kernel serta parameter yang digunakan. Oleh karena itu diperlukan
estimasi parameter terbaik untuk
mengoptimasi kinerjanya. Ada beberapa cara
yang dapat dilakukan antara lain cross
validation, dan -estimator yang
merupakan modifikasi dari leave-one-out
yang diusulkan oleh Joachims (1999).
K-folds cross validation dapat digunakan untuk menentukan nilai parameter
dan parameter kernel yang tidak overfit
terhadap data pelatihan [13]. Dengan metode ini, data yang diambil secara acak kemudian
dibagi menjadi buah partisi dengan ukuran
yang sama. Selanjutnya, dilakukan iterasi
sebanyak . Setiap iterasi digunakan sebuah
partisi sebagai data pengujian, sedangkan
partisi sisanya digunakan sebagai data pelatihan. Jadi akan dicoba berbagai nilai parameter dan parameter terbaik ditentukan
melalui k-folds cross validation Nilai
parameter terbaik ditemukan pelatihan
dilakukan dengan menggunakan keseluruhan data. Pencarian nilai parameter ini disebut
juga grid search.[8]
3.
PENELITIAN SEBELUMNYA
Pada peneliti ini terdiri dari 4827 ham
SMS dan 747 spam SMS dengan melakukan
variasi 16 model. Sebelum dilakukan penyaringan terdapat 2 pemrosesan awal yaitu:
a. Tok1 dengan menyaring alamat email,
domain, subdaomain dan tokenisasi.
b. Tok2 dengan membuang tanda baca dan
angka.
Hasil dari penelitian ini menghasilkan akurasi 96,64% dengan menggunkan SVM dan Tok1[11].
Peneliti selanjutnya membahas teknik terbaik
yang dapat dilakukan dengan cara
menyimpang daftar blacklist, whitelist dan
memnyimpan daftar dari spam SMS
contohnya “free”, “hot selling” dan “imprassion”. Sedangkan untuk metode klasifikasi menggunkan Bayesian[7].
Chaiyapor kemapatapan melakukan penelitian dengan dua bahasa yaitu Bahasa Thailand dan Bahasa Inggris. Penelitian ini mengumpulkan 400 SMS, terdiri dari 120
spam SMS dan 280 ham SMS. Dengan
melakukan 2 metode pemrosesan awal :
a. M1 : melakukan teks normalisai dan
segmentasi bahasa Thailand.
b. M2: melakukan teks normalisasi dan
disegmentasi akan diterjemahkan dan
dilakukan proses semantic.
Hasilnya metode SVM dan M2
menghasilkan akurasi sebesar 95,67 dan
Naïve Bayes dan M2 menghasilkan akurasi 86,31[3].
Dijelaskan bahwa data SMS yang
dipakai adalah 875 yang terdiri dari 450 ham
dan 425 spam SMS dalam Bahasa Inggris.
Melakukan pembobotan biner dengan
menggunakan klasifikasi naïve bayes, akurasi
yang dihasilkan adalah 98.29%[10].
4.
METODOLOGI
Gambar 1. Dekripsi Umum
Data yang dikumpulkan sebanyak 900 data SMS terdiri dari 800 data latih dan 100 data uji. Setelah dilakukan pengumpulan data makan akan dilalukan pemrosesan awal
yaitu akromin, stop word dan token. Setalah
dilakukan proses itu akan dilakukan
pemecarah kata yang dibagi menjadi dua bedasarkan kata dan n-grm. Setelah isi dari sms di pecah-pecah baik kedalan kata atau ke
dalam karakter N-grams, dilakukan
pembobotan fitur setelah terbentuk akan ada model a dan model b.
Fitur dipilih berdasarkan nilai terbesar. Setelah itu dilakukan pembentukan vektor fitur sebagai inputan dari SVM. Sebelum dilakukan pelatihan data dilakukan proses optimasi parameter. Setelah itu akan dilihat model mana yang memiliki akurasi yang paling baik
5.
PENGUJIAN
Pengujian dilakukan dengan 2 model yaitu model a menggunakan pemecah kalimat menjadi kata, sedangkan model b
menggunankan karakter N-grmas. Untuk
pemecah kata menjadi kalimat/uni gram
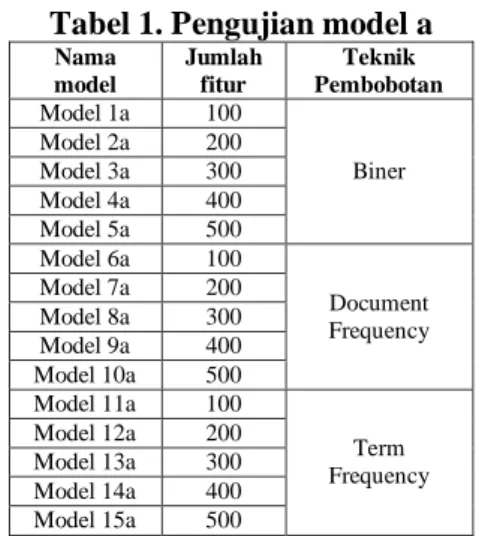
terdapat 15 model yang akan di uji. Pada model a ini menggunakan 500 fitur karena pada data latih sebanyak 100 SMS terdapat 676 fitur, sehingga dengan memilih 500 fitur diharapkan dapat meningkatkan akurasi. Sisa dari fitur yang tidak dipakai karena memiliki bobot yang rendah. Dapat dilihat pada Tabel 1.
Tabel 1. Pengujian model a
Nama model Jumlah fitur Teknik Pembobotan Model 1a 100 Biner Model 2a 200 Model 3a 300 Model 4a 400 Model 5a 500 Model 6a 100 Document Frequency Model 7a 200 Model 8a 300 Model 9a 400 Model 10a 500 Model 11a 100 Term Frequency Model 12a 200 Model 13a 300 Model 14a 400 Model 15a 500
Model 1a adalah pembobotan yang menggunaka 100 fitur yang paling sering muncul, pada model 1a menggunakan
pembobotan biner. Model 7a adalah
pembobotan yang menggunaka 200 fitur yang paling sering muncul pada suatu dokumen, pada model 7a menggunakan
pembobotan document frequency. Sedangkan
Model 15a adalah pembobotan yang
menggunaka 500 fitur yang paling sering muncul pada seluruh dokumen, pada model
15a menggunakan pembobotan term
frequency.
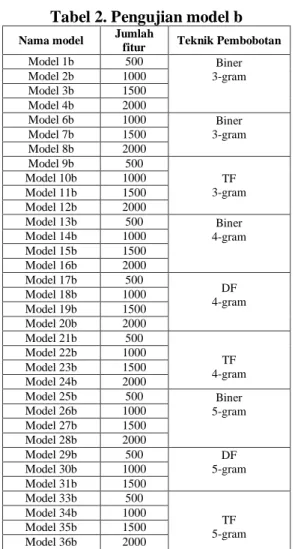
Untuk pemecah kata menjadi
kalimat/uni gram terdapat 36 model yang akan di uji. Pada model b dipilih 2000 fitur teratas karena pada data latih terdapat 3453 fitur. Sisa dari fiturnya tidak dipakai karena hanya memiliki bobot yang rendah.
Tabel 2. Pengujian model b
Nama model Jumlah
fitur Teknik Pembobotan
Model 1b 500 Biner 3-gram Model 2b 1000 Model 3b 1500 Model 4b 2000 Model 6b 1000 Biner 3-gram Model 7b 1500 Model 8b 2000 Model 9b 500 TF 3-gram Model 10b 1000 Model 11b 1500 Model 12b 2000 Model 13b 500 Biner 4-gram Model 14b 1000 Model 15b 1500 Model 16b 2000 Model 17b 500 DF 4-gram Model 18b 1000 Model 19b 1500 Model 20b 2000 Model 21b 500 TF 4-gram Model 22b 1000 Model 23b 1500 Model 24b 2000 Model 25b 500 Biner 5-gram Model 26b 1000 Model 27b 1500 Model 28b 2000 Model 29b 500 DF 5-gram Model 30b 1000 Model 31b 1500 Model 33b 500 TF 5-gram Model 34b 1000 Model 35b 1500 Model 36b 2000
Model 1b adalah pembobotan yang menggunakan 500 fitur yang paling sering muncul, pada model 1b menggunakan
pembobotan biner dan pemecah kata
menggunakan karakter 3-grams. Model 2b adalah pembobotan yang menggunaka 1000 fitur yang paling sering muncul pada suatu
dokumen. Model 18b menggunakan
pembobotan document frequency dan
pemecah kata menggunakan 4-grams. Model 36b adalah pembobotan yang menggunaka 2000 fitur yang paling sering muncul pada
seluruh dokumen, pada model 36b
menggunakan pembobotan term frequency
dan pemecah kata menggunakan karakter 5-grams.
6.
HASIL DAN PEMBAHASAN
6.1.Karakteristik Spam SMS
Data yang dikumpulkan sebanyak 450 spam SMS dengan rincian sebagai berikut:
1. Iklan dengan jumlah 380 SMS, terdiri
dari 49 SMS yang lebih dari 160 karakter
dan 206 SMS yang kurang dari 160 karakter
2. Penipuan dengan Jumlah 70 SMS, terdiri
dari 11 SMS yang lebih dari 160 karakter dan 100 SMS yang kurang dari 160 karakter
3. Panjang SMS yang lebih dari 160
karakter sebanyak 60 SMS
4. Panjang SMS yang kurang dari 160
karakter sebanyak 390 SMS.
Hasil analisis dari data spam SMS memiliki
karakteristik berikut:
1. Bersifat iklan maupun penipuan
2. Banyak kata - kata sambung
3. Banyak kata - kata singkatan
4. Banyak tanda baca
6.2.Pengaruh Karakter N-grams
Hasil pengujian dari model a dapat dilihat pada Gambar 1.
Gambar 2. Hasil Akurasi Model a Gambar 2 menunjukkan diagram hasil klasifikasi SMS dengan menggunakan tiga metode pembobotan. Dari diagram tersebut
terlihat metode pembobotan yang
memberikan hasil akurasi paling bagus
adalah metode pembobotan dengan
menggunakan Term Frequency sebesar 91% pada 300 fitur. Kemudian disusul dengan metode Document Frequency sebesar 90% pada 500 fitur dan sedangkan yang tingkat akurasinya paling rendah adalah Term Frequency pada 100 fitur.
TF dan jumlah fitur sedikit memberikan nilai akurasi yang rendah disebabkan karena data yang digunakan pada penelitian ini adalah SMS. Kata tertentu akan memiliki nilai TF besar jika kata tersebut muncul berkali-kali di suatu dokumen/sms tetapi tidak sering muncul di dokumen/sms yang lain. Umumnya suatu kata dalam sms hanya muncul sekali. Padahal dalam metode TF besarnya frekuensi/kemunculan kata pada
suatu dokumen/sms akan sangat
0 20 40 60 80 100 biasa 10 fold
berpengaruh, dan apabila kemunculan kata tersebut di dokumen lain bernilai kecil. Pada penelitian ini fitur-fitur hasil ekstraksi dengan menggunakan metode TF adalah kata-kata yang jarang muncul dan jarang digunakan di dataset yang lain. Oleh karena itu ketika diujikan pada data baru atau data pengujian, fitur-fitur tersebut tidak dapat mengklasifikasikan kelas dengan baik.
TF dengan 300 fitur memberikan hasil
paling baik, TF pada penelitian ini
menggunakan kata atau term dengan jumlah
kemunculannya paling tinggi dari
keseluruhan dokumen pelatihan untuk setiap kelasnya. Mengingat data yang digunakan adalah SMS dengan keterbatasan jumlah karakternya, sehingga ada kemungkinan kata-kata yang sama akan sering diulang atau sering digunakan untuk sms lain yang bertopik sama.
Dari gambar 2 juga terlihat bahwa jumlah fitur yang digunakan dari 500 fitur, 400 fitur,300 fitur, 200 fitur, dan 100 fitur. Jumlah fitur mempengarusi akurasi dari gambar diatas dapat disimpulkan jumlah fitur 500 menghasilkan akurasi yang stabil. Sedangkan pada jumlah fitur yang sedikit mengahasilkan akurasi yang rendah.
Pada grafik diatas menunjukan model 13a mengalami kenaikan 29% dibandingkan
dengan tidak menggunak 10 fold cross
validation. Sedangkan 11a mengalami
penururan setelah dilakukan 10 fold cross
validation sebesar 13%.
Hasil pengujian dari model b dapat dilihat pada Gambar 3.
Gambar 3. Hasil Pengujian Model b Pada Gambar 3 diatas ada 4 akurasi terbaik masing masing adalah biner dengan 1500 fitur, df dengan 1000 fitur, tf dengan 1500 dan tf dengan 1500 fitur.
Pencacah SMS menggunakan karakter 3-grams, 4 grams, dan karakter 5-grams
menunjukan bahwa dengan menggunakan 3 grams menghasilkan akurasi yang stabil. Pada 3 grams membagi kata menjadi 3 huruf,
karena membagi menjadi 3 huruf
menjadikan kata yang dibagi menjadi unik. Berbeda dengan yang laiannya. Sedangkan untuk jumlah fitur yang memiliki akurasi yang paling baik ada 1500 fitur baik dengan pembobot biner, DF dan TF. Karena 1500 fitur yang dipilih mewakili kata-kata yang muncul pada SMS.
7.
KESIMPULAN
Berikut ini adalah kesimpulan yang
diperoleh selama penelitian dan
pembangunan prototipe penyaringan spam SMS:
1. N-gram menghasilkan akurasi yang
terbaik pada data uji sebesar 95% untuk semua pembobotan dengan jumlah fitur 1000 dan 1500, Sedangkan untuk data
uji dengan nilai C= 512 dan
γ=0.00048828125 dengan akurasi
96,625 dengan pembobotan trem
freqeuncy dan jumlah fiturnya 2000. Kesalahan peneliti setelah dilakukan kajian terhadap data uji 100% (50 SMS spam) data yang dipakai adalah SMS Spam yang berisi tetang penipuan, sedangkan pada data latih 5% dari 400 SMS spam yang mengandung SMS penipuan. Sehingga nilai akurasi dari penelitian ini lebih rendah dari peneliti sebelumnya itu disebabkan oleh fitur pada data latih tidak banyak digunakan pada data uji,
2. 10 fold cross validation digunakan untuk memprediksi keakuratan data latih. Dataset yang telah dibuat dibagi menjadi subset k. Dalam tesis ini nilai dari k adalah 10, maka akan dilakukan 10 iterasi proses latih dan uji, dengan 9/10 subset sebagai data latih dan 1/10
subset sebagai data uji secara
bergantian. Sehingga untuk setiap subset berkesempatan menjadi data uji. Dengan
menggunakan cross validation pada data
uji dapat meningkatkan akurasi 29% dari yang asalnya 62% pada pemecahan
kalimat menjadi kata atau pada
penggunaan Term Frequency.Variabel C
dan γ sangat berpengaruh pada penelitian ini sebab variable c berguna
agar tidak overfiting pada data pelatihan
0% 20% 40% 60% 80% 100% M o d el 1 b M o d el 3 b M o d el 5 b M o d el 7 b M o d el 9 b M o d el 1 1 b M o d el 1 3 b M o d el 1 5 b M o d el 1 7 b M o d el 1 9 b M o d el 2 1 b M o d el 2 3 b M o d el 2 5 b M o d el 2 7 b M o d el 2 9 b M o d el 3 1 b M o d el 3 3 b M o d el 3 5 b
sedangkan variable γ berfungsi untuk
transformasi ke feature space. Grid
search bengfungsi untuk menentukan variable C dan γ terbaik, semakin tinggi C membuat garis pemisah menjadi
hardmargin sedangkan terlalu kecilnya variable C akan banyak data yang salah klasifikasi. Pengaruh variable γ jika
terlalu besar akan mengakibatkan
support vector antara kedua kelas semakin jauh dan jika terlalu kecil mengakibatkan data salah klasifikasi karena akan banyak data yang tidak sesuai dengan kelasnya, bukankah pada SVM hanya mencari bidang pemisah
saja tetapi mencari margin yang optimal
antara support vector. Sedang pada
karakter N-grams diperoleh kenaikan
akurasi 43% dari yang asalnya 50% pada data uji.
3. Sesuai dengan karakteristik pada data
yang telah dikumpulkan ada beberapa pemrosesan awal yang dibutuhkan
a. Akromin adalah mengganti singkatan
dengan kata asalnya
b. Stopwords adalah menbuang kata – kata sambung yang sering mungcul dan tidak bermakna apa-apa
c. Tokenisasi adalah mengbuang
karakter yang tidak perlu.
4. Pada pemecah kalimat menjadi kata
banyaknya fitur menpengaruhi tingkat akurasinya dan pada karakter N-gram tidak mempengaruhi akurasi.
5. Kontibusi dari penelitian ini adalah
penerapan karakter N-grams pada
pencacah kata dan pengumpulan data set SMS spam Berbahasa Indonesia
8.
DAFTAR PUSTAKA
[1] Asosiasi Telekomunikasi Seluler
Indonesia (ATSI) URL:
http://www.teknojurnal.com/2012/01/18 /jumlah-pelangganselulerdiindonesia- hampir-mendekati-jumlah-penduduk-indonesia/ . diakses pada 13 september 2013.
[2] Beahaki M. Faisal “Bayes Spam Classifier pada Pengembangan Aplikasi Mobile SMS”, ITB, 2011
[3] Chaiyaporn Khemapatapan.
Thai-English Spam SMS Filtering. 2010. [4] Cloudmark’s Definitive Guide to SMS
Spam juni 2011
[5] Fletcher. Tristan, “Support Vector
Machines Explained”, Inggris, 2009.
[6] Hastie. Cross-validation and bootstrap.
February 2009.
[7] Hong-yan Zhang. Application of
Bayesian Method to Spam SMS Filtering 2009
[8] Hsu, Chih-Wei, ”A Practical Guide to
Support Vector Classification”, Taiwan, National Taiwan University, 2008. [9] José María Gómez Hidalgo. Content
Based SMS Spam Filtering
[10] M. Taufiq Nuruzzama “Independent and Personal SMS Spam Filtering” Dept. of Informatics Engineering, State Islamic University Sunan Kalijaga ,2011 ,IEEE International Conference on Computer and Information Technology
[11] Tiago A. Almeida ,Contributions to the Study of SMS Spam Filtering: New Collection and Results , September 2011
[12] XIA Hu, FU Yan . Sampling of Mass
SMSPenyaringan Algoritm Based on Frequent Time Domain Area. 2010
[13] Joachims. Thorsten, “Making
Large-Scale SVM Learning Practical”,
Universitait Dortmund, Jerman, 1999