TINJAUAN PUSTAKA
2.1. Basis Data Terdistribusi 2.1.1. Sistem Basis Data Terdistribusi
Dalam pengelolaan basis data terdapat dua sistem basis data, yaitu Basis Data Terpusat ( Centralized ) dan Basis Data Terdistribusi ( Distributed ). Perbedaan utama antara sistem basis data terpusat dan terdistribusi adalah jika pada sistem basis data terpusat, data ditempatkan di satu lokasi saja dan semua lokasi lain dapat mengakses data di lokasi tersebut, sedangkan pada system basis data terdistribusi, data di tempatkan di banyak ( lebih dari satu ) lokasi, tetapi menerapkan suatu mekanisme tertentu untuk membuatnya menjadi satu kesatuan basis data, dan hal ini berbeda dengan system basis data terpisah (Isolated) yang mana dalam sistem basis data terpisah, basis data ditempatkan di banyak lokasi, tetapi tidak saling berhubungan sama sekali.
Menurut Özsu MT, Valduriez P. (1999) Basis Data Terdistribusi didefinisikan sebagai berikut :
Suatu Basis Data Terdistribusi ( DDBS ) adalah suatu koleksi beberapa basis data yang secara logika saling berhubungan dan terdistribusi dalam suatu jaringan komputer, sedangkan Sistem Basis Data Manajemen Terdistribusi ( D-DBMS ) adalah Perangkat Lunak yang mengatur Basis Data Terdistribusi (DDB) dan menyediakan suatu mekanisme akses yang membuat distribusi ini dapat diketahui oleh pemakai.
Jadi Sistem Basis Data Terdistribusi ( DDBS )= DDB+ D-DBMS Lokasi-lokasi penempatan basis data dapat terlihat dalam Gambar 1.
Gambar 1. Lingkungan Basis Data Terdistribusi ( Valduriez P. 1999)
2.1.2. Arsitektur Sistem Basis Data Terdistribusi
Dalam arsitektur basis data terdistribusi konsep basis data relasional lebih banyak digunakan, karena dalam operasionalnya dapat disesuaikan dengan sistem basis data terpusat, secara formal relasional basis data terdistribusi mencakup : Global Level, Fragmentation Level dan Allocation Level ( Kuijk 2000 )dan hal ini dapat terlihat dalam Gambar 2 berikut.
Site 2 Site 1 Site 4 Site 4 Site 3 Communication Network
Gambar 2 : Arsitektur Sistem Basis Data Terdistribusi (Kuijk 2000)
- Global Level : suatu skema basis data secara global yang menggambarkan basis data terdistribusi yang seolah-olah tidak seluruhnya terdistribusi. - Fragmentation level : suatu skema fragmentasi yang menggambarkan suatu
pemetaan antara relasi individu dengan fragmentasinya
- Allocation Level : suatu skema alokasi yang menggambarkan pemetaan antara fragmen individu dimana basis data disimpan
Dalam melakukan fragmentasi terdapat kriteria-kriteria yang harus dipenuhi, yaitu : Reconstruction Condition, Completeness Condition dan Disjointness Condition (Kuijk 2000)
Global Schema
Site 1
Fragmentation Schema
Allocation Schema
Site 2 Site n Distributed Database Systems
Site Independent
Site dependent
Jika R adalah tabel relasi, Ai adalah atribut dari R, r adalah record dari R dan Fi kondisi dari operasi seleksi, maka hasil fragmentasi dapat direkonstruksi terlihat dalam Tabel 1.
Tabel 1: Fragmentasi Horizontal, Vertical dan Mixed Fragmentasi (Kuijk 2000).
Type Partitioning Reconstruction
Horizontal r
( )
Ri =σ
Fi( )
r( )
R( )
Un( )
i r Ri R r i 1 = = Vertical r( )
R(
r( )
R)
i A i =π
n r ( Ri ) = ⋈πAi (r (R )) i = 1 Mixed r( )
R(
(r(R)))
i i F A i =π
σ
( )
U1( )
1 1 1 n i r Ri R r i = = ⋈…⋈ … Uk( )
n k i =1rRik2.2 Konsep Aljabar Relasional.
Relasi aljabar adalah bahasa prosedural, dan salah satu cara untuk membangun relasi satu atau lebih relasi berdasarkan konsep aljabar. Dalam basis data relasional relasi aljabar mempelajari bagaimana struktur properti dan kendala-kendala akan menjadi dasar dalam operasi basis data, formulasi query dipetakan pada relasi aljabar dan sejauh mana pendekatan teori set digunakan. Bahasa query memiliki sejumlah operasi yang memanfaatkan satu atau beberapa tabel/relasi basis data sebagai masukkan dan menghasilkan sebuah tabel/relasi basis data yang baru sebagai keluarannya. Operasi dasar dalam Aljabar Relasional antara lain mencakup : Select, Project, Cartesian-Product, Union, Set-Difference (Kuijk 2000).
Konsep optimisasi query dalam Aljabar Relasional yang banyak digunakan adalah operasi-operasi yang berhubungan dengan operasi join. Dalam tesis ini ditampilkan sejumlah contoh dengan menggunakan skema tabel relasi berikut :
peserta (notsp : integer, tgl_lhr : date, tmt_pst : date, gapok : integer) pensiun(nopen : integer, nama : string, tgl_kej : date)
Skema dari tabel-tabel relasi di atas ditunjukkan pada segmen Tabel 2, Tabel 3, Tabel 4 dan Tabel 5.
Tabel 2. : Segmen Tabel peserta S1
notsp tgl_lhr tmt_pst gapok
010013098 12/31/1955 1/1/1975 832000 010018391 12/18/1952 3/1/1973 932000
Tabel 3 : Segmen Tabel peserta S2
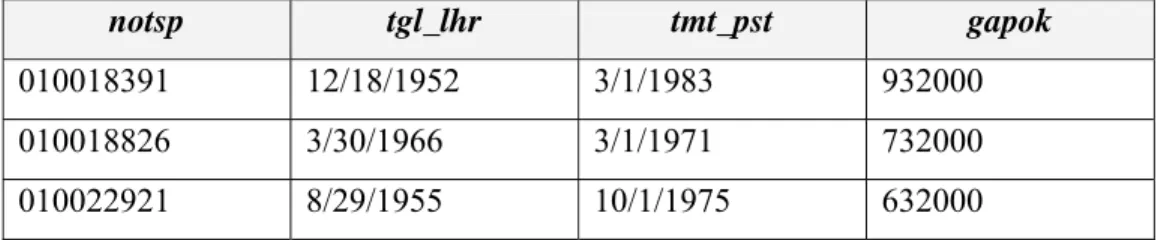
notsp tgl_lhr tmt_pst gapok
010018391 12/18/1952 3/1/1983 932000 010018826 3/30/1966 3/1/1971 732000 010022921 8/29/1955 10/1/1975 632000
Tabel 4 : Segmen Tabel pmk_ke1 R1
notsp Nopen tgl_kej
010013098 0000007700 12/31/1999 010022921 0000008880 12/23/1989 010018391 0000009990 13/21/1990
Tabel 5 : Segmen Tabel pensiun B1
nopen Nama tgl_kej
0000007700 Nangkuh 12/31/1999
0000008880 Abdul Hadi 12/23/1989
0000009990 Siddik 13/21/1990
2.2.1. Selection
Operasi Selection digunakan untuk memilih subset record-record dari tabel sebuah relasi yang memenuhi pilihan. Kondisi harus berupa formula yang proporsional. Tata cara penulisan yang digunakan pada operasi ini adalah :
p adalah <selection condition> berupa predikat pada atribut-atribut di R,
dan R adalah tabel/relasi yang akan diakses oleh operasi selection. Jika merujuk
Tabel 2 pada tabel peserta, perintah mengambil baris data (record) peserta yang tanggal lahirnya ’9/9/1969’, maka operasi ini dapat dituliskan
σ
tgl_lhr = ‘9/9/1969’(peserta)
2.2.2. Projection
Operasi Projection dilakukan untuk memilih atribut-atribut dari tabel/relasi. dan dapat mengambil atribut satu atau lebih. Tata cara penulisan pada operasi ini adalah :
Π<attribute list>(R)
Atribut list adalah daftar atribut yang akan ditampilkan yang ada di R.
Misalkan pada Tabel 2 yaitu dalam tabel peserta akan ditampilkan notsp dan tgl_lhr, untuk semua baris data yang ada pada tabel tersebut, maka perintahnya adalah :
Π
notsp,tgl_lhr(peserta)Dapat pula menampilkan berupa hasil operasi/query. Misalkan akan ditampilkan notsp dan tgl_lhr dngan tmt_pst pada tanggal ’1/1/1975’ saja, maka operasi seleksi dan projeksi harus digunakan secara bersamaan, seperti berikut :
Π
notsp,tgl_lhr(
σ
tmt_pst= ’1/1/1975’(peserta))
2.2.3. Join.
Operasi Join adalah untuk menggabungkan lebih dari satu tabel/relasi. Operasi Join dilambangkan dengan “⋈” dan digunakan untuk mengkombinasikan hubungan record-record dari dua relasi kedalam record tunggal. Pada umumnya operasi PROJECT pada dua relasi R(A1,A2,…An) dan S(B1,B2,…Bm) ditunjukkan oleh :
Hasil dari Join adalah sebuah relasi Q dengan n + m atribut Q(A1,A2,…An, B1,B2,…Bm). Q mempunyai satu record untuk masing-masing kombinasi dari record, satu dari R dan satu dari S. Dalam join, hanya kombinasi-kombinasi dari record-record yang memenuhi kondisi join yang akan tampak pada hasil. Kondisi Join ditentukan oleh atribut-atribut dari relasi R dan S dan evaluasi untuk tiap kombinasi dari record-record
Bentuk dari kondisi Join secara umum adalah :
<condition> AND <condition> AND … AND <condition>
dimana tiap kondisi adalah bentuk dari Aiθ Bj. Ai adalah sebuah atribut dari R dan Bj adalah sebuah atribut dari S. Ai dan Bj mempunyai domain yang sama, dan θ (theta) adalah salah satu dari operator-operator pembanding {<, ≤, ≠, ≥, >,}. Operasi Join dengan sebuah kondisi join yang umum disebut dengan theta join. Contoh : (R ⋈c S) = σc (R x S)
Jadi,
⋈
ditentukan untuk menjadi sebuah cross product diikuti dengan satu selection, Jika diperhatikan c condition dapat merujuk ke atribut baik R maupun S. Referensi ke sebuah atribut dari sebuah relasi, misalnya R , dapat berdasarkan posisi (dari bentuk Ri) atau berdasarkan nama dan bentuk Rname, merujuk pada Tabel 2 dan Tabel 4, maka hasil dariS1
⋈
S1.notsp<R1.notsp R1 ditunjukkan pada Tabel 6, notsp muncul baik dalam S1 maupun R1, maka atribut hasil dari cross product S1 x R1 tidak diberi nama.Tabel 6 : Hasil Join S1 dan R1
notsp tgl_lhr tmt_pst gapok notsp nopen tgl_kej
010018391 12/31/1955 1/1/1975 832000 010022921 0000008880 12/23/1989 010018826 12/18/1952 3/1/1973 932000 010022921 0000008880 12/23/1989
2.2.3.1. Cross Join
Operasi Cross Join yang juga biasa disebut dengan Cross Product atau Cartesian Product dilambangkan dengan “ X “ yang juga merupakan sebuah kumpulan operasi biner. Contoh (R1 X S1) operasinya memungkinkan untuk menggabungkan data dari dua buah tabel atau hasil query yang berakibat semua record di R1 dipasangkan dengan semua record di S1 dan hasil operasi akan memuat semua atribut yang ada di R1 dan di S1 dan operasi ini bersifat komutatif. Operasi Cross Join umumnya tidak berdiri sendiri, tetapi digunakan bersama operasi lainnya, seperti operasi seleksi dan proyeksi dengan berbagai bentuk sesuai kebutuhan, sebagaimana dapat dilihat dalam contoh berikut :
Akan diambil data dari penggabungan tabel S1 dan R1 untuk tmt_pst=‘1/11975’ dan tgl_kej = ‘12/23/1989’ operasinya dapat dituliskan sebagai berikut :
σ
tmt_pst= ’1/1/1975’ ∧ tg_kej = ’ 2/23/1989’ ∧ S1.notsp =R1.notsp ( S1 X R1)2.2.3.2. Natural Join
Sebuah query yang melibatkan operasi Cartesian Product umumnya menggunakan operasi seleksi untuk memberikan hasil query yang diinginkan. Contoh : cari dari semua peserta yang telah pensiun dan tampilkan nama dan tanggal kejadian, notsp diambil dari gabungan Tabel 4 (pmk_ke1) dan Tabel 5 (pensiun). Mula-mula akan menggunakan operasi Cartesian Product tabel pensiun yang menyimpan data nama dan nopen kemudian dari tabel pmk_ke1 yang menyimpan data notsp, kemudian menyeleksi yang sesuai dengan kriteria yang diminta yaitu no_tsp dari Tabel 4 yaitu tabel pmk_ke1 dan Tabel 5 yaitu tabel pensiun
Πnama,notsp,tgl_kej
(
σ
PMK.nopen=Pensiun.nopen(pmk_ke1 X pensiun))Bentuk di atas dapat disederhanakan dengan operasi natural join yang menggabungkan operasi cartesian product dan operasi seleksi dengan menggunakan simbol
⋈
, operasi natural join membentuk sebuah cartesian product dari kedua argumennya, lalu menetapkan sebuah seleksi untuk baris-baris data yang memiliki kesamaan nilai untuk atribut-atribut yang muncul di keduaargumennya dan akhirnya mengabaikan data-data duplikat dan perintahnya sebagai beikut :
Πnama,notsp,tgl_kej(pmk_ke1 ⋈ pensiun))
Secara formal, jika S1 memiliki himpunan atribut s dan R1 memiliki himpunan atribut r, maka dapat didefinisikan :
S1
⋈
R1 =Πs r(σ
s1.a1=r1.a2 ∧ s1.a1=r1.a2∧...∧ s1.an=r1.an(
S1X R1)
Dimana s =domain atribut dari S1
r = domain atribut dari R1
s r = { a1, a2, a3, …, an }
Jika tidak ada atribut yang sama di kedua ekspresi S1 dan R1 atau s r =0, maka : S1
⋈
R1 = S1 X R12.2.4 Operasi Himpunan
Operasi Himpunan yang digunakan adalah Union, Intersection dan Difference.
2.2.4.1. Union (R S)
Operasi ini untuk menggabungkan data dari dua kelompok baris data (row) yang sejenis (memiliki hasil proyeksi yang sama)
Simbol dari operasi ini adalah : R S
Atribut notsp terdapat pada Tabel 5 (pensiun) dan Tabel 4 (pmk_ke1), sehingga notsp pada kedua tabel tersebut dapat diproyeksikan dengan operasi Union :
Π
tglkej (pensiun)Π
tglkej (pmk_ke1)Pada operasi Union R S terdapat dua syarat yang dipenuhi yaitu :
1) S dan R harus memiliki jumlah atribut yang sama.
2) Domain dari atribut ke i dari S dan atribut ke i dari R haruslah sama, dan harus berlaku untuk semua atribut di S dan R
2.2.4.2. Intersection (R S)
Operasi Intersection digunakan untuk menyatakan atau mendapatkan irisan (kesamaan anggota) dari dua buah kelompok data dari suatu tabel atau hasil query.
Tata penulisannya adalah (R S) yang ekivalen dengan penggunaan operasi dasar
Set-Difference S – ( S – R ). Contoh untuk mendapatkan notsp mana saja yang
sama-sama dipunyai, baik dari Tabel 2 (peserta) maupun Tabel 4 (pmk_ke1), query tersebut dapat dipenuhi dengan operasi
Π
notsp (Peserta)Π
notsp (pmk_ke1)2.2.4.3. Difference (R - S)
Operasi difference merupakan pengurangan data di tabel/hasil proyeksi
pertama R oleh data/hasil proyeksi yang kedua S Simbolnya adalah : R – S
Ketentuannya sama dengan operasi Union yaitu harus mempunyai jumlah atribut yang sama baik di S maupun di R, contoh :
Π
tglkej(pensiun)
–Π
tglkej(pmk_ke1)
2.3. Proses Query
Dalam Database Manajemen System (DBMS) akses data dapat dilakukan dengan berbagai macam cara. Ada banyak plan (rencana) yang dapat diikuti oleh DBMS dalam memproses dan menghasilkan jawaban sebuah query. Semua rencana pada akhirnya akan menghasilkan jawaban (output) yang sama tetapi pasti mempunyai biaya yang berbeda-beda.
Kebanyakan aplikasi secara nyata adalah permintaan-permintaan secara langsung dari user yang memerlukan informasi tentang bentuk maupun isi dari basis data. Apabila permintaan user terbatas pada sekumpulan query-query standar, maka query-query tersebut dapat dioptimisasi secara manual oleh pemrograman. Tetapi bagaimanapun juga, sebuah sistem optimisasi query otomatis menjadi penting apabila query-query khusus dinyatakan dengan
menggunakan bahasa query yang digunakan secara umum seperti Structure Query Language (SQL).
Optimisasi query memberikan suatu pemecahan untuk menangani masalah dengan cara menggabungkan sejumlah besar teknik-teknik dan strategi, yang meliputi transformasi-transformasi logika dari query-query pada sistem file penyimpanan data. Setelah ditransformasikan, sebuah query dipetakan ke dalam sebuah langkah-langkah operasi untuk menghasilkan data-data yang diminta.
QueryLanguage (SQL)
Hasil Query
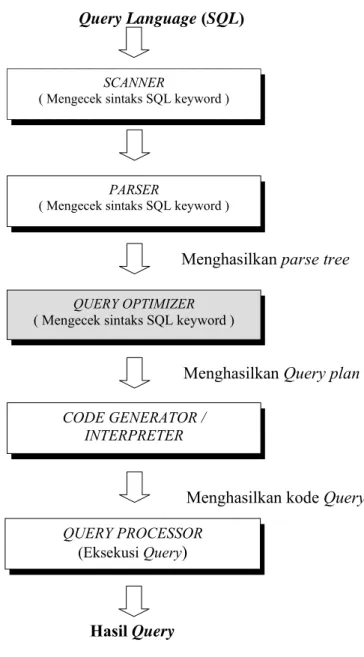
Gambar 3. Tahapan proses sebuah Query (Swamy 2001)
PARSER
( Mengecek sintaks SQL keyword )
CODE GENERATOR / INTERPRETER
QUERYPROCESSOR
(Eksekusi Query)
QUERYOPTIMIZER
( Mengecek sintaks SQL keyword )
SCANNER
( Mengecek sintaks SQL keyword )
Menghasilkan Query plan
Menghasilkan kode Query Menghasilkan parse tree
Sebuah query yang diekspresikan dalam sebuah bahasa query tingkat tinggi seperti SQL mula-mula harus dibaca, diuraikan dan disahkan (scanning, parsing, validating). Query tersebut kemudian dibentuk menjadi sebuah struktur data yang biasa disebut dengan query tree.
Kemudian DBMS merencanakan sebuah strategi eksekusi untuk mendapatkan kembali hasil dari query dari file-file basis data. Tahapan-tahapan proses dari sebuah query didalam sebuah sistem basis data ditunjukkan pada Gambar 3 dan berikut penjelasan dari masing-masing tahapan :
Scanner melakukan identifikasi (pengenalan) perintah-perintah seperti SQL keywords, atribut, dan relation name. Proses ini disebut dengan scanning.
Query Parser mengecek validitas query dan kemudian menterjemahkannya dalam bentuk internal yaitu ekspresi relasi aljabar atau parse tree proses ini disebut dengan parsing.
Query Optimizer memeriksa semua ekspresi-ekspresi aljabar yang sama untuk query yang diberikan dan memilih salah satu dari ekspresi tersebut yang terbaik yang memiliki perkiraan paling murah. Dengan kata lain, tugas dari query optimizer adalah menghasilkan sebuah rencana eksekusi dan proses ini disebut optimisasi query.
Code Generator atau Interpreter mentransformasikan rencana akses yang dihasilkan oleh optimizer ke dalam kode-kode. Setelah itu, kode-kode tersebut dikirimkan ke dalam query processor untuk dijalankan.
Query Processor melakukan eksekusi query untuk mendapatkan hasil query yang diinginkan.
Bagian yang diarsir pada Gambar 3 adalah optimizer yang sudah disediakan oleh DBMS. Tahapan proses query pada Gambar 3 tersebut adalah untuk memberikan gambaran yang jelas tentang bagaimana pada umumnya sebuah query diproses di dalam sebuah Data Base Manajemen Sistem .
2.4. Optimisasi Query
Optimisasi Query adalah suatu proses untuk menganalisis query untuk menentukan sumber-sumber apa saja yang digunakan oleh query tersebut dan apakah penggunaan dari sumber tersebut dapat dikurangi tanpa merubah keluaran. Atau dengan kata lain bahwa optimisasi query adalah sebuah prosedur untuk meningkatkan strategi evaluasi dari suatu query untuk membuat evaluasi tersebut menjadi lebih efektif (Richard 2000).
2.5. Prinsip Optimisasi Query
Prinsip Optimisasi Query terdapat dalam pemilihan strategi query, dan terletak pada penentuan strategi operasi Join. Bahasa query salah satu yang biasa digunakan, misalnya SQL, tetapi untuk beberapa kasus khusus, suatu query dapat mempunyai hubungan dengan pemetaan aljabar. Bentuk yang lebih sederhana sangat diperlukan dari pada bentuk-bentuk aljabar tersebut, dan diasumsikan bahwa operasi gabungan adalah salah satu operasi relasi aljabar ( Ken 2000).
Menurut Richard Vlach (2000), optimisasi query dalam basis data terdistribusi, ada dua aspek yang sangat penting, yaitu :
1. Tranmisi data dan kontrol data ke tempat tujuan sangat dipengaruhi oleh bentuk komunikasi, dan dapat memperlambat keseluruhan proses.
2. Pengolahan data secara paralel transmisi data dapat mempercepat respone
Optimisasi Query adalah proses untuk menunjukkan bahwa baik total biaya maupun total waktu suatu query diminimalkan. Total biaya diukur oleh penggunaan sumber daya sistem seperti CPU atau bentuk komunikasi data. Respone time optimizers yaitu untuk meminimalkan respone time dalam sebuah query bersama-sama secara paralel.
Menurut Özsu MT, Valduriez P. (1999 ) formulasi untuk meminimalkan biaya (cost function) adalah :
Total Cost = I/O cost + CPU cost + communication cost ... (2.1)
Dimana I/O cost = unit disk I/O cost + no. of disk I/Os CPU cost = unit instruction cost + no. of instruction Communicatin cost = message initiation + transmition
Formula (2.1) masing-masing bagiannya dapat mempunyai bobot yang berbeda tergantung dari terdistribusinya data, antara lain :
- Apabila proses query menggunakan Wide Area Networks (WAN), maka biaya
komunikasi sangat dipengaruhi low bandwidth, low speed dan high protocol overhead. Sedangkan algoritma-algoritma yang ada pada umumnya mengabaikan komponen biaya.
- Apabila menggunakan Local Area Networks (LAN), biaya komunikasi dan pengiriman data tidak mempengaruhi, tetapi total biaya dari fungsi-fungsi yang digunakan harus dipertimbangkan.
2.6. Metoda Optimisasi Query
Biaya query sangat dipengaruhi oleh dua hal, yaitu proses secara lokal dan transmisi data antar lokasi, karena berkaitan dengan fungsi biaya. Proses perhitungan diperlukan untuk menghasilkan biaya query yang akurat secara parsial. Karakteristik relasi secara lokal harus diketahui dalam optimisasi waktu. Beberapa diantaranya adalah kardinalitas dari relasi secara lokal, banyaknya byte dalam nilai atribut, dan nilai selectivity factor yang terdapat dalam relasi diperlukan.
Optimisasi proses pengolahan data secara global dengan cara menggunakan metoda secara lokal, dalam pelaksanaannya adalah mengoperasikan atas kedua proses, yaitu memproses data lokal dan memproses data secara lokal yang datang dari lokasi lain.
Besar biaya untuk optimisasi lokal pada umumnya didasarkan pada banyaknya akses dari memori sekunder, ukuran buffers dan ukuran operand. Data yang akan dioperasikan secara lokal dan tambahan struktur data lokal seperti indek, hash tabel akan dapat mempercepat proses secara lokal.
Operasi join adalah operasi yang sangat mahal. Dan diketahui bahwa metoda operasi join secara lokal adalah : nested-loops, sort-merge dan hash join. Walaupun ada metoda optimisasi query global yang mempertimbangkan proses lokal, ongkos proses secara lokal pada umumnya dapat diabaikan jika dibandingkan dengan ongkos transmisi data. Selama transmisi data dioptimisasi, jelas asumsinya bahwa nilai waktu selama transmisi bergantung pada jumlah data yang dialirkan.
Perhitungkan respone time yang minimal, optimisasi global memanfaatkannya secara paralel dan mencoba untuk memperkecil transmisi pada alur yang ”paling buruk”. Operasi secara lokal yang membatasi relasi lokal harus dieksekusi secepat mungkin. Kemudian, utamakan pada optimisasi pada berbagai operasi join. Metoda optimisasi secara dinamis dapat memilah perencanaan ekseskusi query pada tahapan eksekusi. Pada awalnya rencana eksekusi didasarkan pada penilaian hasil secara parsial. Perubahan selama tahap eksekusi didasarkan pada ukuran secara parsial dan perubahan mengarahkan pada sisa query yang akan diproses. (Richard 2000)
2.6.1. Optimisasi Query Basis Formula
Optimisasi basis formula (Rule Based) biasa juga disebut heuristic optimization adalah optimisasi query dengan menggunakan aturan-aturan heuristic dan dijalankan pada rencana query secara logika yang terdiri dari urutan operasi-operasi relasional yang biasanya digambarkan sebagai query tree
2.6.2. Optimisasi Query Basis Biaya
Dalam optimisasi basis biaya dapat digunakan solution space dan cost function yaitu dengan total time atau total cost. Hal ini dapat mereduksi setiap biaya ( dalam setiap termin waktu ) semua komponen satu persatu kemudian melakukan proses optimisasi untuk setiap utilitas dari setiap sumber-sumber daya sehingga meningkatkan kinerja sistem.
Faktor-faktor yang terdapat dalam total cost yang ditunjukkan oleh persamaan (2.1) menghasilkan total cost factor dan tergantung dari arsitektur jaringan yang digunakan. Untuk penggunaan Wide Area Network dipengaruhi
oleh inisiasi pesan dan transmisi cost sangat tinggi, dan biaya pemrosesan secara lokal lambat (kecuali untuk mainframe dan mini komputer). Demikian juga rasio dari komunikasi ke I/O costs adalah = 20 : 1, tetapi untuk penggunaan Local Area Network komunikasi dan proses secara lokal biayanya lebih sedikit dengan rasio
dari komunikasi ke I/O costs = 1 : 1,6 ( Valduriez P. 1999).
Dalam menghitung Respone time dapat mengerjakan hal-hal yang
mungkin secara paralel sehingga dapat meningkatkan total time karena meningkatnya total aktifitas, dan berdasarkan rumus (2.1)
Respone time = CPU time + I/O time + communication time ... (2.2)
Dimana CPU time = unit instruction time * no. of sequential instruction I/O time = Unit I/O time * no.of sequential I/Os
Communication time = unit msg initiation time + no.of sequential msg + unit transmition time * no.of sequential bytes
2.6.3. Fungsi Biaya dari Statistik Basis data
Untuk melihat cost factor yang utama dalam statistik basis data menurut (Valduriez P. 1999), ukuran relasi dari basis data memiliki nilai selectivity factor untuk setiap relasi dalam setiap operasi, yaitu :
1. Operasi joins card(R
⋈
S) SF (R,S) = --- ... (2.3) card(R)*card(S) 2. Operasi Selection size(R) = card(R)*length ... (2.4) card(σ F (R)) = SF σ (F) *card(R) ... (2.5) dimana 1 S F σ (A = value) = --- ... (2.6) card(∏A (R))max(A) – value S F σ (A > value) = --- ... (2.7) max(A) – min(A) value – max(A) S F σ (A < value) = --- ... (2.8) max(A) – min(A)
SF σ (p(A i ) ∧ p(A j )) = SF σ (p(A i )) *SF σ (p(A j ) ... (2.9)
SF σ(p(A i )∨ (p(A j )) = SF σ(p(A i )) + SF σ(p(A j )) – (SF σ(p(A i ))
*SF σ(p(A j ))) ... (2.10)
SF σ (A∈ value) = SF σ (A= value) * card(value) ... (2.11) 3. Projection
card(Π A (R))=card(R) ... (2.12) 4. Cartesian Product
card(R × S) = card(R) .card(S) ... (2.13) 5. Union
Batas atas: card(R ∗S) = card(R) + card(S) ... (2.14) Batas Bawah: card(R ∗S) = max{card(R), card(S)} ... (2.15) 6. Set Difference
Batas atas: card(R–S) = card(R) ... (2.16) Batas bawah: 0 ... (2.17) 7. Join
Dalam kasus khusus: A adalah primary key dari R dan B adalah foreign key dari S;
card(R
⋈
A=B S) = card(S) ... (2.18)Lebih umum:
2.6.4. Optimizer DBMS MySQL
MySQL melakukan optimisasi melalui fasilitas query optimizer. Query
optimizer secara rutin memeriksa dan melakukan transformasi semua ekspresi-ekspresi aljabar yang sama dan memilih salah satu dari ekspresi-ekspresi yang terbaik dan memiliki perkiraan paling murah dengan menggunakan fungsi optimize() dari optimizer MySQL dan secara rutin diaplikasikan pada semua tipe query ([email protected]. 1998-2007 MySQL AB ).
MySQL Optimizer melakukan proses optimisasi menggunakan 5 langkah, yaitu :
1. Menentukan tipe join.
Sistem menetapkan tabel yang akan dibaca dalam join, kemudian menetapkan primary index secara berurutan dalam equality relation dengan nilai indek tidak null, menetapkan jangkauan dari indek dan membaca seluruh tabel menurut indek secara berurutan.
2. Menentukan metode akses dan join
Metode akses dan join dilakukan dengan Query Execution Plan (QEP) dan mencari rencana yang terbaik dengan menggunakan prosedur find_best() dari MySQL Optimizer.
3. Menentukan rentang indek dari tipe join
Tipe join dalam tabel diberi rentang indek agar optimizer dengan mudah mengambil data dari tabel yang berada dalan rentang indek.
4. Menentukan indek dari tipe join
Tipe join dalam tabel diberi indek, agar optimizer dengan mudah mengambil data berdasarkan indek.
5. Menentukan indek dari tipe merge join
Indek merge join digunakan bilamana kondisi atribut join dalam tabel dapat dibentuk kedalam beberapa kondisi indek yang terdiri dari cond_1 OR cond_2 ... OR cond_N. Jika cond_1 OR cond_j , dan dapat digabung menjadi satu rentang yang sama, maka diberikan satu rentang indek, hal ini dilakukan untuk menghindari dan mengeliminasi duplikasi data.