ABSTRAK
Debitur atau nasabah bank memang merupakan aset yang sangat penting dalam lembaga keuangan atau bank. Bukan tanpa alasan pihak bank memperhatikan profil nasabah, karena bagaimanapun juga hal ini merupakan bagian yang sangat penting sebagai dokumentasi bank dan siap jika dibutuhkan sewaktu – waktu. Profil nasabah itu sendiri berisi tentang identitas seseorang yang juga menjelaskan kondisi seseorang. Beberapa hal yang dimaksud diantaranya adalah data tentang pekerjaan, data pribadi, data keluarga dan lain sebagainya. Dengan data nasabah yang lengkap, maka pastinya proses pendataan juga akan semakin mudah. Bahkan pihak bank pun harus lebih meneliti setiap nasabah yang masuk terutama jika mereka menghendaki untuk mengajukan kredit. Banyak kasus yang terjadi di bank adalah adanya non performing loan atau kredit macet. Itulah sebabnya pihak bank harus lebih teliti sebelum mengabulkan permohonan kredit.
Pada tugas akhir ini akan di terapkan algoritma Fuzzy C-Means (FCM) untuk mengelompokkan data nasabah bank. Hasil tugas akhir ini yaitu sebuah perangkat lunak yang dapat digunakan sebagai alat bantu untuk pengelompokkan data nasabah bank menggunakan algoritma FCM. Pengujian terhadap sistem ini adalah pengujian menggunakan hasil banding antara sistem dengan uji manual dan uji validalitas.
Berdasarkan hasil pengujian menggunakan hasil banding dengan 15 data dengan nilai jumlah cluster (c) sebanyak 2, pemangkat atau pembobot (w) sebanyak 2, banyak iterasi (i) sebanyak 10 serta toleransi error (e) sebanyak 0.00001, maka dapat disimpulkan bahwa sistem pengelompokan ini dapat menghasilkan keluaran yang sesuai dengan yang diharapkan pengguna. Serta dapat disimpulkan bahwa algoritma FCM dapat mengelompokkan sekumpulan data bertipe numerik.
ABSTRACT
Debtor or the bank customer is a very important asset in the financial institution or bank. Not without reason the banks pay attention to the customer's profile, but in any case this is a very important part as documentation bank and is ready if needed at any - time. Customer profile itself contains the identity of a person who also describes the condition of a person. Some of those mentioned include data on employment, personal data, family data, and so on. With complete customer data, then of course the data collection process will also be easier. Even the banks must be examined every customer that goes especially if they want to apply for credit.Many cases that occurred in the bank is the existence of non-performing loans or bad credit. That is why the bank should be more careful before granting the loan application.
In this final project will apply the Fuzzy C-Means (FCM) algorithm to segment customer data bank. The results of this thesis is a software that can be used as a tool for grouping data bank customers using FCM algorithm. Testing of the system is to use the results of comparative testing between systems with manual test and the validity test.
Based on test results using the results of the appeal by the 15 data values cluster number (c) by 2, rank or weighting (w) by 2, many iterations (i) 10 as well as the tolerance error (e) of 0.00001, it can beconcluded that the clustering system can produce output that corresponds to the expected users. As well as it can be concluded that the FCM algorithm can segment the data set numeric type.
i
PENERAPAN FUZZY C-MEANS CLUSTERING PADA DATA NASABAH BANK
HALAMAN JUDUL
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh :
Pryscilia Angeline Tanjung NIM : 125314086
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
THE APPLICATION OF FUZZY C-MEANS CLUSTERING ON BANK CUSTOMER DATA
A THESIS
HALAMAN JUDUL (BAHASA INGGRIS)
Presented as Partial Fulfillment of the Requirements
To Obtain the Sarjana Komputer Degree
In Informatics Engineering Study Program
By :
Pryscilia Angeline Tanjung NIM : 125314086
INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
iii
iv
v
HALAMAN PERSEMBAHAN DAN MOTTO
“Janganlah takut, sebab Aku menyertai engkau, janganlah
bimbang, sebab Aku ini Allahmu; Aku meneguhkan, bahkan
akan menolong engkau; Aku akan memegang engkau
dengan tangan kanan-
Ku yang membawa kemenangan. “ –
Yesaya 41 : 10
“Akuilah Dia dalam segala lakumu, maka Ia akan
meluruskan jalanmu” –
Amsal 3:6
“God will make a way when there seems to be no way.”
vi
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa tugas akhir yang saya tulis tidak mengandung atau memuat hasil karya orang lain, kecuali yang telah disebutkan dalam daftar pustaka dan kutipan selayaknya karya ilmiah.
Yogyakarta, 31 Agustus 2016
Penulis
vii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma Yogyakarta :
Nama : Pryscilia Angeline Tanjung
NIM : 125314086
Demi pengembangan ilmu pengetahuan, saya memberikan kepada perpustakaan Universitas Sanata Dharma karya ilmiah yang berjudul:
PENERAPAN FUZZY C-MEANS CLUSTERING PADA DATA NASABAH BANK
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada perpustakaan Universitas Sanata Dharma Yogyakarta hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengelola dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikan di internet atau media lain untuk kepentingan akademis tanpa meminja ijin dari saya maupun memberikan royalti kepada saya selama tetap mencantumkan nama saya sebagai penulis. Demikian pernyataan yang saya buat dengan sebenarnya.
Dibuat di Yogyakarta,
Pada tanggal: 31 Agustus 2016 Yang menyatakan,
viii
KATA PENGANTAR
Puji syukur kepada Tuhan Yesus kristus, karena pada akhirnya penulis dapat menyelesaikan penelitian tugas akhir ini yang berjudul “Penerapan Fuzzy C-Means Clustering Pada Data Nasabah Bank”.
Dalam menyelesaikan seluruh penyusunan tugas akhir ini, penulis tak lepas dari doa, bantuan, dukungan, dan motivasi dari banyak pihak. Oleh karena itu, penulis ingin mengucapkan banyak terima kasih kepada :
1. Tuhan Yesus Kristus yang selalu memberikan berkat, anugerah, kekuatan, hikmat serta kasih-Nya yang berlimpah sehingga penulis dapat menyelesaikan tugas akhir ini.
2. Kedua Orang tua saya, Anatasia Rinie Natan dan Benno Kakerissa atas doa, kasih sayang, perhatian, kepercayaan, dukungan baik moral maupun finansial yang diberikan kepadaku.
3. Papa Anghany Tanjung, untuk segala dukungan dalam bentuk doa dan saran yang selalu diberikan kepadaku.
4. Adikku tersayang, Nadine Tamina Benesia Kakerissa, serta para sepupuku Vania, Clarissa dan Zuriel yang selalu memberi keceriaan dalam penyusunan tugas akhir. 5. Tanteku Ronna Natan dan keluarga besar Natan, yang selalu memberikan
semangat, doa dan motivasi dalam penyusunan tugas akhir ini.
6. Bapak Sudi MungkasiS.Si.,M.Math.Sc.,Ph.D selaku Dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
7. Ibu Dr.Anatasia Rita selaku Ketua Program Studi Teknik Informatika Universitas
Sanata Dharma Yogyakarta.
8. Bapak Eko Hari Parmadi S.Si., M.Kom. selaku Dosen Pembimbing yang telah dengan sabar membimbing dan memberikan motivasi dalam pengerjaan tugas akhir penulis.
9. Romo Dr. C Kuntoro Adi, S.J. M.A., M.Sc. selaku Dosen Pembimbing Akademik. 10. Seluruh Dosen dan Karyawan jurusan Teknik Informatika Universitas Sanata
ix
11. Keluarga PMK Apostolos, Lika, Yere, Nenu, Dovan, Anggit, Kintan, Kiki, Putra, Anna, Rely, Agni, Mbak Yudist, Kak Defidan teman – teman apostolos yang lain terimakasih atas doa, dan dukungan kalian bagi penulis.
12. Untuk sahabat – sahabatku Imas, Dhesty, Nita, Itha, Aldy, Astrid, Liadan Riris
terima kasih untuk persahabatan yang terjalin selama perkuliahan ini.
13. Novi, Tia, Mbak Tri, Jay dan seluruh teman – teman TI angkatan 2012 untuk bantuannya, kebersamaannya selama pengerjaan tugas akhir ini dan menjalani masa perkuliahan.
14. Serta semua pihak yang telah membantu penyusunan tugas akhir ini yang tidak dapat disebutkan satu persatu.
Penulis menyadari bahwa penulisan laporan tugas akhir ini masih memiliki banyak kekurangan. Untuk itu, penulis sangat membutuhkan saran dan kritik untuk perbaikan di masa yang akan datang. Semoga penulisan laporan tugas akhir ini berguna dan bermanfaat bagi semua pihak.
Yogyakarta, 31 Agustus 2016
x ABSTRAK
Debitur atau nasabah bank memang merupakan aset yang sangat penting dalam lembaga keuangan atau bank. Bukan tanpa alasan pihak bank memperhatikan profil nasabah, karena bagaimanapun juga hal ini merupakan bagian yang sangat penting sebagai dokumentasi bank dan siap jika dibutuhkan sewaktu – waktu.Profil nasabah itu sendiri berisi tentang identitas seseorang yang juga menjelaskan kondisi seseorang. Beberapa hal yang dimaksud diantaranya adalah data tentang pekerjaan, data pribadi, data keluarga dan lain sebagainya. Dengan data nasabah yang lengkap, maka pastinya proses pendataan juga akan semakin mudah. Bahkan pihak bank pun harus lebih meneliti setiap nasabah yang masuk terutama jika mereka menghendaki untuk mengajukan kredit. Banyak kasus yang terjadi di bank adalah adanya non performing loan atau kredit macet. Itulah sebabnya pihak bank harus lebih teliti sebelum mengabulkan permohonan kredit.
Pada tugas akhir ini akan di terapkan algoritma Fuzzy C-Means (FCM) untuk mengelompokkan data nasabah bank. Hasil tugas akhir ini yaitu sebuah perangkat lunak yang dapat digunakan sebagai alat bantu untuk pengelompokkan data nasabah bank menggunakan algoritma FCM. Pengujian terhadap sistem ini adalah pengujian menggunakan hasil banding antara sistem dengan uji manual dan uji validalitas.
Berdasarkan hasil pengujian menggunakan hasil banding dengan 15 data dengan nilai jumlah cluster (c) sebanyak 2, pemangkat atau pembobot (w) sebanyak 2, banyak iterasi (i) sebanyak 10 serta toleransi error (e) sebanyak 0.00001, maka dapat disimpulkan bahwa sistem pengelompokan ini dapat menghasilkan keluaran yang sesuai dengan yang diharapkan pengguna. Serta dapat disimpulkan bahwa algoritma FCM dapat mengelompokkan sekumpulan data bertipe numerik.
xi ABSTRACT
Debtor or the bank customer is a very important asset in the financial institution or bank. Not without reason the banks pay attention to the customer's profile, but in any case this is a very important part as documentation bank and is ready if needed at any - time. Customer profile itself contains the identity of a person who also describes the condition of a person. Some of those mentioned include data on employment, personal data, family data, and so on. With complete customer data, then of course the data collection process will also be easier. Even the banks must be examined every customer that goes especially if they want to apply for credit.Many cases that occurred in the bank is the existence of non-performing loans or bad credit. That is why the bank should be more careful before granting the loan application.
In this final project will apply the Fuzzy C-Means (FCM) algorithm to segment customer data bank. The results of this thesis is a software that can be used as a tool for grouping data bank customers using FCM algorithm. Testing of the system is to use the results of comparative testing between systems with manual test and the validity test.
Based on test results using the results of the appeal by the 15 data values cluster number (c) by 2, rank or weighting (w) by 2, many iterations (i) 10 as well as the tolerance error (e) of 0.00001, it can beconcluded that the clustering system can produce output that corresponds to the expected users. As well as it can be concluded that the FCM algorithm can segment the data set numeric type.
xii DAFTAR ISI
HALAMAN JUDUL... i
HALAMAN JUDUL (BAHASA INGGRIS) ... ii
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv
HALAMAN PERSEMBAHAN DAN MOTTO ... v
PERNYATAAN KEASLIAN KARYA ... vi
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... vii
KATA PENGANTAR ... viii
ABSTRAK ... x
ABSTRACT ... xi
DAFTAR ISI ... xii
DAFTAR GAMBAR ... xvi
DAFTAR TABEL... xvii
1.5. Metodologi Penelitian ... 3
1.6. Sistematika Penulisan ... 5
BAB II LANDASAN TEORI... 7
2.1 Penambangan Data ... 7
2.1.1 Pengertian Penambangan Data ... 7
2.1.2 Teknik dalam Penambangan Data ... 8
2.1.3 Tujuan Penambangan Data... 8
2.1.4 Knowledge Discovery in Databases (KDD) ... 9
2.1.5 Konsep Clustering ... 11
2.2 Fuzzy C-Means(FCM)... 12
2.2.1 Algoritma Fuzzy C-Means(FCM) ... 12
xiii
2.5.1 Pengertian Nasabah... 21
2.6 Kredit ... 22
2.6.1 Pengertian Kredit ... 22
2.6.2 Unsur – unsur Kredit ... 22
2.7 Notasi Pemodelan Sistem ... 23
2.7.1 Use Case Diagram ... 23
2.7.1.1 Simbol Use Casedan Aktor ... 23
2.7.1.2 Relasi (Relationship) ... 24
2.7.2 Pemodelan Proses ... 25
BAB III METODOLOGI PENELITIAN ... 27
3.1 Gambaran Umum... 27
3.2 Desain Penelitian ... 27
3.2.1 Studi Pustaka ... 27
3.2.2 Data ... 27
3.2.3 Perancangan Aplikasi... 28
3.3 Kebutuhan Perangkat Lunak dan Keras ... 32
3.3.1 Kebutuhan Perangkat Lunak ... 32
3.3.2 Kebutuhan Perangkat Keras ... 33
BAB IV PERANCANGAN SISTEM ... 34
4.1 Analisis Kebutuhan ... 34
4.1.1 Identifikasi sistem ... 34
4.2 Desain Logikal (Logical Design)... 35
4.2.1 Desain Proses ... 35
4.2.1.1 Use Case Diagram ... 35
4.2.1.2 Input Sistem ... 36
4.2.1.3 Proses Sistem ... 36
xiv
4.2.1.5 Desain Proses Umum Sistem ... 37
4.2.1.6 Diagram Aktivitas (Activity Diagram)... 38
4.2.1.7 Diagram Kelas (Class Diagram) ... 40
4.2.1.8 Diagram Konteks (Context Diagram) ... 40
4.3 Desain Fisikal (Physical Design)... 41
4.3.1 Desain Manajemen Dialog ... 41
4.3.1.1 Halaman Utama... 41
4.3.1.2 Halaman Input Berkas atau Data ... 41
4.3.1.3 Halaman Fuzzy C-Means ... 42
4.3.1.4 Halaman Panduan... 43
BAB V IMPLEMENTASI SISTEM DAN ANALISA HASIL ... 44
5.1 Implementasi Sistem ... 44
5.1.1 Implementasi Tampilan Antarmuka ... 45
5.1.1.1 Halaman Utama... 45
5.1.1.2 Halaman Input Data ... 45
5.1.1.3 Halaman Fuzzy C-Means ... 48
5.1.1.4 Halaman Panduan... 51
5.1.2 Implementasi Kelas... 52
5.1.2.1 Implementasi Kelas HalamanUtama ... 52
5.1.2.2 Implementasi Kelas HalamanInputData ... 53
5.1.2.3 Implementasi Kelas FuzzyCMeans ... 55
5.1.2.4 Implementasi Kelas HalamanFuzzyCMeans ... 58
5.1.2.5 Implementasi Kelas Panduan ... 60
5.2 AnalisisHasil... 60
5.2.1 Pengujian Algortima FCM pada Sistem ... 61
5.2.2 Pengujian Perbandingan Hasil Secara Manual dan Sistem ... 62
5.2.3 Pengujian Perubahan nilai Pemangkat / Pembobot (w) ... 63
5.2.4 Pengujian Kualitas cluster menggunakan Silhouette Index ... 70
5.3 Kelebihan dan Kekurangan Sistem ... 71
5.3.1 Kelebihan Sistem ... 71
5.3.2 Kekurangan Sistem ... 72
BAB VI KESIMPULAN DAN SARAN ... 73
xv
xvi
DAFTAR GAMBAR
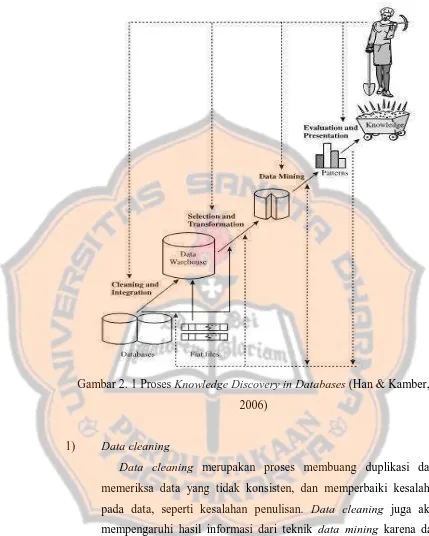
Gambar 2. 1 Proses Knowledge Discovery in Databases (Han & Kamber, 2006) ... 10
Gambar 2. 2 Simbol Use Case... 23
Gambar 2. 3 Simbol Aktor ... 24
Gambar 2. 4 Simbol kesatuan luar / external agent ... 25
Gambar 2. 5 Simbol Arus data ... 26
Gambar 2. 6 Simbol Proses ... 26
Gambar 2. 7 Simbol Data Store ... 26
Gambar 4. 1Use Case Diagram ... 36
Gambar 4. 2 Proses Umum Sistem ... 37
Gambar 4. 3 Activity Diagram Input Data ... 38
Gambar 4. 4 Activity Diagram Proses Clustering ... 38
Gambar 4. 5 Activity Diagram Seleksi Atribut ... 39
Gambar 4. 6 Activity Diagram Simpan hasil clustering ... 39
Gambar 4. 7 Diagram Kelas ... 40
Gambar 4. 8 Diagram Konteks ... 41
Gambar 4. 9 Halaman Utama ... 41
Gambar 4. 10 Halaman Input Data ... 42
Gambar 4. 11 Halaman Fuzzy C-Means ... 42
Gambar 4. 12 Halaman Panduan ... 43
Gambar 5. 1 Halaman Utama ... 45
Gambar 5. 2 Halaman Input Data ... 46
Gambar 5. 3 Halaman Input Data (berkas .xls atau .csv) ... 46
Gambar 5. 4 Halaman Input Data (hapus atribut)... 47
Gambar 5. 5 Halaman Input Data (hasil hapus atribut) ... 48
Gambar 5. 6 Halaman Fuzzy C-Means ... 49
Gambar 5. 7Halaman Fuzzy C-Means (Clustering)... 50
Gambar 5. 8 Halaman Fuzzy C-Means (Simpan Hasil Clustering) ... 51
Gambar 5. 9 Halaman Panduan ... 52
xvii
DAFTAR TABEL
Tabel 2. 1 Data kunjungan wisata bulan Januari dari tahun 2006 – 2010 ... 14
Tabel 2. 2Komponen Perhitungan ... 14
Tabel 2. 3 Perhitungan Manual (Bangkitkan nilai random) ... 15
Tabel 2. 4 Perhitungan Manual (Hitung Pusat cluster - 1)... 15
Tabel 2. 5 Perhitungan Manual (Hitung Pusat cluster - 2)... 15
Tabel 2. 6 Perhitungan Manual (Hitung Pusat cluster - 3)... 15
Tabel 2. 7 Perhitungan Manual (Pusat Cluster yang baru) ... 16
Tabel 2. 8 Perhitungan Manual (Hitung fungsi objektif (cluster 1)) ... 16
Tabel 2. 9 Perhitungan Manual (Hitung fungsi objektif (cluster 2)) ... 16
Tabel 2. 10 Perhitungan Manual (Hitung fungsi objektif (cluster 3)) ... 17
Tabel 2. 11 Perhitungan Manual (Hitung nilai Total P1, P2, P3) ... 17
Tabel 2. 12 Perhitungan Manual (Memperbaharui Matriks Partisi) ... 17
Tabel 2. 13 Hasil akhir perhitungan fuzzy c-means ... 18
Tabel 3. 1Tabel Atribut Data ... 27
Tabel 3. 2 Tabel Seleksi Atribut ... 29
Tabel 3. 3 Tabel Jumlah Cluster ... 29
Tabel 3. 4 Tabel Matriks Nilai Random... 30
Tabel 3. 5 Tabel Hitung Pusat Cluster ... 79
Tabel 3. 6 Tabel Hitung Fungsi Objektif ... 80
Tabel 3. 7 Tabel Perubahan Matriks ... 83
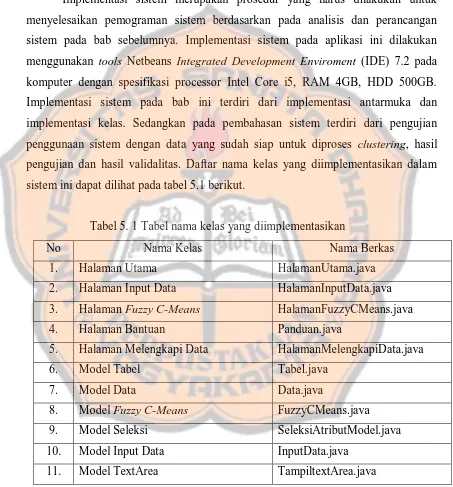
Tabel 5. 1 Tabel nama kelas yang diimplementasikan ... 44
Tabel 5. 2 Hasil perbandingan data uji manual dengan Sistem ... 63
Tabel 5. 3 Uji perubahan nilai pemangkat / pembobot (w) dengan jumlah galat = 0.00001 dan maks iterasi = 10. ... 64
Tabel 5. 4 Uji perubahan nilai pemangkat / pembobot (w) dengan jumlah galat = 0.01 dan maks iterasi = 100. ... 65
xviii
1 BAB I PENDAHULUAN
1.1. Latar Belakang Masalah
Bank memiliki peranan yang sangat penting dalam menggerakkan roda perekonomian nasional. Sebagaimana umumnya negara berkembang, sumber pembiayaan dunia usaha di Indonesia masih di dominasi oleh penyaluran kredit perbankan yang diharapkan dapat mendorong pertumbuhan ekonomi. Kegiatan perkreditan dapat terjadi dalam segala aspek kehidupan manusia. Dengan demikian majunya perekonomian di masyarakat, maka kegiatan perkreditan semakin mendesak kegiatan perekonomian yang dilaksanakan secara tunai.Kegiatan perkreditan ini meliputi semua aspek ekonomi baik di bidang produksi, distribusi, konsumsi, perdagangan, investasi, maupun bidang jasa dalam bentuk uang tunai, barang dan jasa. Dengan demikian, kegiatan perkreditan dapat dilakukan antar individu – individu dengan badan usaha atau antar badan usaha (Wahyudi, 2003).
Individu – individu tersebut disebut dengan debitur atau nasabah bank memang merupakan aset yang sangat penting dalam lembaga keuangan atau bank. Meskipun demikian, ada beberapa hal yang benar-benar harus diperhatikan pada setiap nasabah atau calon nasabah agar tidak ada hal – hal yang tidak diinginkan terjadi di kemudian hari. Bukan tanpa alasan pihak bank memperhatikan profil nasabah, karena bagaimanapun juga hal ini merupakan bagian yang sangat penting sebagai dokumentasi bank dan siap jika dibutuhkan sewaktu – waktu.
biasanya pihak bank akan bisa melakukan identifikasi terhadap kondisi nasabah dengan lebih mudah. Hal inilah yang merupakan salah satu dari tujuan mengetahui profil nasabah sehingga tidak perlu dipertanyakan lagi bahwa profil memang mempunyai peran sangat penting. Dengan data nasabah yang lengkap, maka pastinya proses pendataan juga akan semakin mudah. Bahkan pihak bank pun harus lebih meneliti setiap nasabah yang masuk terutama jika mereka menghendaki untuk mengajukan kredit. Banyak kasus yang terjadi di bank adalah adanya non performing loan atau kredit macet. Itulah sebabnya pihak bank harus lebih teliti sebelum mengabulkan permohonan kredit.
Dari latar belakang tersebut, penulis tertarik untuk menerapkan algoritma Fuzzy C-Means clusteringpada data nasabah bankdengan cara membagi data menjadi kelompok – kelompok yang dapat membantu kegiatan perbankan terlebih dalam melihat profil nasabah ketika nasabah baru ingin melakukan kredit berdasarkan data nasabah bank, serta dapat digunakan sebagai media dan acuan untuk dapat dimanfaatkan secara optimal terutama dalam kegiatan perbankan pada umumnya dengan menggunakan algoritma Fuzzy C-Means clustering.
1.2. Rumusan Masalah
Berdasarkan uraian dari latar belakang masalah, dapat dirumuskan sebuah permasalahan yaitu :
1. Bagaimana menerapkan Fuzzy C-Means clustering untuk melihat profil data nasabah bank?
2. Apakah penerapan algoritma Fuzzy C-Means clustering dapat dipergunakan pada data profil nasabah bank dengan memberikan validalitas yang baik?
1.3. Batasan Masalah
Penyusunan tugas akhir ini dibatasi oleh beberapa hal, sebagai berikut :
1. Metode yang digunakan dalam penelitian ini adalah metode clustering algoritma Fuzzy C-Means clustering.
3. Atribut – atribut clusteringnya berupa jumlah pinjaman, angsuran, dan jangka waktu pinjaman.
4. Atribut dari data berupa jumlah pinjaman, angsuran, agunan, nilai agunan, jangka waktu pinjaman, tunggakan pokok dan tunggakan bunga. 5. Aplikasi dibuat menggunakan pemograman Java berbasisdekstop.
1.4. Tujuan dan Manfaat
1. Tujuan dari penelitian ini adalah membantu, mendesain, mengimplementasikan algoritma Fuzzy C-Means clustering untuk mengelompokkan nasabah bank berdasarkan profil dari nasabah bank yang akan melakukan kredit dengan atribut – atribut yang diperolehdari data nasabah bankBPR dengan menggunakan algoritma Fuzzy C-Means clustering.
2. Manfaat dari penelitian ini adalah memberikan gambaran tentang langkah – langkah implementasi algoritma Fuzzy C-Means clustering dalam menghasilkan pengelompokan profil nasabah bank berdasarkan atribut dari data nasabah bank serta menjadi referensi bagi penelitian yang berkaitan dengan clustering nasabah bank yang lebih lanjut lagi.
1.5. Metodologi Penelitian
Metode yang digunakan untuk merancang sistem dan menyelesaikan permasalahan adalah dengan cara sebagai berikut :
1. Survei Awal
Dilakukan survei awal dengan mengunjungi sebuah Bank Perkreditan Rakyat di DIY untuk mengadakan wawancara untuk memperoleh data mengenai hal – hal yang berhubungan dengan sistem aplikasi yang akan dibuat.
2. Studi Pustaka
3. Pengembangan Aplikasi
Pada tahap ini penulis menggunakan metode Knowledge Discovery in Database (KDD) yang ditulis oleh Jiawei Han, Micheline Kamber
dan Jian Pei. Adapun metode KDD mempunyai tahapan – tahapan sebagai berikut :
a. Data Cleaning
Pada tahap ini merupakan proses dimana data yang tidak dibutuhkan atau pengganggu (noise) dan data yang tidak konsisten akan dihapus.
b. Data integration
Pada tahap ini merupakan proses dimana bermacam – macam data dari berbagai sumber akan digabungkan menjadi satu kesatuan.
c. Data Selection
Pada tahap ini merupakan proses dimana untuk melakukan analisis, data relevan akan diperoleh dari database.
d. Data Transformation
Pada tahap ini merupakan proses dimana data diubah (transformasi) atau digabungkan sehingga menjadi tepat untuk ditambang dengan misalnya melakukan operasi penjumlahan atau penggabungan.
e. Data Mining
Pada tahap ini merupakan proses pokok dimana metode cerdas dilaksanakan untuk menggali pola dari data.
f. Pattern Evaluation
Pada tahap ini merupakan proses identifikasi pola yang sungguh menarik menampilkan basis pengetahuan dalam suatu ukuran ketertarikan dengan menggunakan uji evaluasi Silhouette Index.
g. Knowledge Presentation
menampilkan hasil tambang dari pengetahuan kepada pengguna.
4. Analisis Hasil
Pada tahap ini dilakukan validasi terhadap hasil pengujian sistem aplikasi terhadap hasil perhitungan manual yang dilakukan dengan Microsoft Excel dan pembahasan uji kualitas clusterSilhouette Index
(SI).
1.6. Sistematika Penulisan
Tugas akhir ini disusun dalam suatu laporan yang dibagi secara sistematis menjadi 6 bab, adapun ringkasannya sebagai berikut :
a. Bab I : Pendahuluan
Bab ini memuat latar belakang masalah, rumusan masalah, batasan masalah, tujuan penelitian, metodologi penelitian dan sistematika penulisan.
b. Bab II : Landasan Teori
Bab ini menguraikan berbagai teori yang di dapatkan dari sumber pustaka yang digunakan untuk penyusunan tugas akhir, antara lain yaitu penambangan data, konsep clustering, algoritma fuzzy c-means clustering, bank, kredit, serta Silhouette index.
c. Bab III : Metodologi Penelitian
Bab ini berisi tentang gambaran umum sistem yang akan dibangun, data yang digunakan, desain penelitian, kebutuhan perangkat keras dan perangkat lunak.
d. Bab IV : Perancangan Sistem
Bab ini menjelaskan tentang proses – proses perancangan sistem yang akan dibangun, meliputi analisa sistem, use case diagram, serta perancangan sistem seperti desain umum sistem, diagram ER (Entity Relationship), context diagram, activity diagram, dan rancangan antar
muka.
Bab ini berisi tentang implementasi perancangan antarmuka dan analisa dari hasil pembuatan sistem, yakni membahas tentang hasil pengujian yang dilakukan pada sistem untuk mencari kekurangan sistem.
f. Bab VI : Kesimpulan dan Saran
7 BAB II LANDASAN TEORI
2.1 Penambangan Data
2.1.1 Pengertian Penambangan Data
Penambangan data atau data miningadalah serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data (Pramudiono, 2007). Penambangan data didefinisikan sebagai proses menemukan pola-pola dalam data. Proses ini otomatis atau seringnya semi otomatis. Pola yang ditemukan harus penuh arti dan pola tersebut memberikan keuntungan, biasanya keuntungan secara ekonomi. Data yang dibutuhkan dalam jumlah besar (Witten & Frank, 2005). Secara sederhana, penambangan data adalah penambangan atau penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data yang sangat besar (Davies & Beynon, 2004). Penambangan data sering juga disebut knowledge discovery in database (KDD), adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Keluaran dari penambangan data ini bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan (Santoso, 2007).
Menurut Tan et.al (2006),data mining adalah teknologi yang memadukan metode analisis data tradisional dengan algoritma yang canggih untuk memproses volume data yang besar. Dalam bukunya disebutkan bahwa penambangan data adalah proses menemukan informasi yang berguna dari repositori data yang besar secara otomatis.
2.1.2 Teknik dalam Penambangan Data
Teknik dalam penambangan data terbagi atas dua kategori utama, yaitu prediktif dan deskriptif. Kategori prediktif bertujuan untuk memprediksi nilai dari atribut tertentu berdasarka pada nilai dari atribut-atribut lain. Sedangkan kategori deskriptif bertujuan untuk menurunkan pola-pola(korelasi, trend, cluster, trayektori dan anomali) yang meringkas hubungan yang pokok dalam data. Berikut adalah teknik dalam penambangan data :
1. Asosiasi
Asosiasi adalah pencarian aturan-aturan asosiasi yang menunjukkan kondisi-kondisi nilai atribut yang sering terjadi bersama-sama dalam sekumpulan data. Asosiasi sering digunakan untuk menganalisa market basket dan data transaksi.
2. Klasifikasi
Klasifikasi adalah proses menemukan model (fungsi) yang menjelaskan dan membedakan kelas-kelas atau konsep, dengan tujuan agar model yang diperoleh dapat digunakan untuk memprediksikan kelas atau objek yang memiliki label kelas yang tidak diketahui.
3. Clustering
Berbeda dengan klasifikasi, clustering dapat digunakan untuk menentukan atau menganalisis objek data dimana label kelas tidak diketahui dengan cara mengelompokkan data untuk membentuk kelas baru.
4. Outlier
Outlier merupakan objek data yang tidak mengikuti perilaku umum dari data. Outlier dapat dianggap sebagai noise atau pengecualian. Analisis data outlier dinamakan outlier mining. Teknik ini berguna dalam fraud detection dan rare events analysis.
2.1.3 Tujuan Penambangan Data
Untuk menjelaskan beberapa kondisi penelitian, seperti mengapa penjualan truk pick-up meningkat di Colorado.
2. Confirmatory
Untuk mempertegas hipotesis, seperti halnya dua kali pendapatan keluarga lebih suka dipakai untuk membeli peralatan keluarga dibandingkan dengan satu kali pendapatan keluarga.
3. Exploratory
Untuk menganalisa data yang memiliki hubungan yang baru. Misalnya, pola apa yang cocok untuk kasus penggelapan kartu kredit.
2.1.4 Knowledge Discovery in Databases (KDD)
Penambangan data tidak dapat terpisahkan dari proses knowledge discovery in databases atau biasa disebut dengan KDD. Proses KDD
merupakan sebuah proses mengubah data mentah menjadi suatu informasi yang berguna. KDD sendiri masih memiliki beberapa proses didalamnya, yaitu data cleaning, data integration, data selection, data transformation, data mining, pattern evaluation, dan knowledge presentation (Han &
Gambar 2. 1 Proses Knowledge Discovery in Databases (Han & Kamber, 2006)
1) Data cleaning
Data cleaning merupakan proses membuang duplikasi data,
memeriksa data yang tidak konsisten, dan memperbaiki kesalahan pada data, seperti kesalahan penulisan. Data cleaning juga akan mempengaruhi hasil informasi dari teknik data mining karena data yang ditangani akan berkurang jumlah dan kompleksitasnya.
2) Data integration
Tahapan cleaning dan integration pada KDD mengasumsikan bahwa integrator data harus menghapus noise dari data awal secara paralel dengan mengintegrasikan beberapa data set.
3) Data selection
Pemilihan data yang relevan dan dapat dilakukan analisis dari data operasional. Data hasil pemilihan disimpan dalam database yang terpisah.
4) Data transformation
Proses tranformasi data kedalam bentuk format tertentu sehingga data tersebut sesuai untuk proses data mining. Sebagai contoh beberapa metode standar seperti analisis asosiasi dan clustering hanya bisa menerima input data kategorikal.
5) Data mining
Proses mencari pola atau informasi menarik dengan menggunakan teknik, metode atau algoritma tertentu.
6) Pattern evaluation
Mengidentifikasi pola-pola yang benar-benar menarik dari hasil data mining. Dalam tahap ini hasil dari teknik data mining berupa
pola-pola yang khas maupun model prediksi dievaluasi untuk menilai apakah hipotesa yang ada memang tercapai atau tidak.
7) Knowledge presentation
Menampilkan pola informasi yang dihasilkan dari proses data mining, visualisasi ini membantu mengkomunikasikan hasil data
mining dalam bentuk yang mudah dimengerti.
2.1.5 Konsep Clustering
Pada dasarnya clustering merupakan suatu metode untuk mencari dan mengelompokkan data yang memiliki kemiripan karakteristik (similarity) antara satu data dengan data yang lain. Tujuan utama dari
metode clustering adalah pengelompokan sejumlah data/obyek ke dalam cluster (group) sehingga dalam setiap cluster akan berisi data yang semirip
Clustering melakukan pengelompokan data yangdidasarkan pada
kesamaan antar objek, oleh karena ituklasterisasi digolongkan sebagai metode unsupervisedlearning.
Karakteristik terpenting dari hasil clustering yang baik adalah suatu instance data dalam suatu cluster lebih “mirip” dengan instance yang lain di dalam cluster tersebut daripada dengan instance di luar dari cluster itu. Ukuran kemiripan (similarity measure) tersebut bisa bermacam – macam dan mempengaruhi perhitungan dalam menentukan anggota suatu cluster. Jadi tipe data yang akan di-cluster juga menentukan ukuran apa yang tepat untuk digunakan dalam suatu algoritma.
2.2 Fuzzy C-Means(FCM)
Fuzzy clustering adalah salah satu teknik untuk menentukan cluster
optimal dalam suatu ruang vektor yang didasarkan pada bentuk normal Euclidian untuk jarak antar vektor. Ada beberapa algoritma clustering data,
salah satu diantaranya adalah Fuzzy C-Means (FCM). Fuzzy C-Means (FCM) adalah suatu teknik pengclusteran data yang mana keberadaan tiap – tiap titik data dalam suatu cluster yang ditentukan oleh derajat keanggotaan. Teknik ini pertama kali diperkenalkan oleh Jim Bezdek pada tahun 1981.
Konsep dasar FCM, pertama kali adalah menentukan pusat cluster, yang akan menandai lokasi rata – rata untuk tiap – tiap cluster. Pada kondisi awal, pusat cluster ini masih belum akurat. Tiap – tiap titik data memiliki derajat keanggotaan untuk tiap – tiap cluster. Dengan cara memperbaiki pusat cluster dan derajat keanggotaan tiap – tiap titik data secara berulang, maka akan dapat dilihat bahwa pusat cluster akan bergerak menuju lokasi yang tepat. Perulangan ini didasarkan pada minimisasi fungsi obyektif yang menggambarkan jarak dari titik data yang diberikan ke pusat cluster yang terbobot oleh derajat keanggotaan titik data tersebut.
2.2.1 Algoritma Fuzzy C-Means(FCM)
Algoritma dari Fuzzy C-Means adalah sebagai berikut (Kusumadewi, 2004) :
Input data yang akan di cluster X, berupa matriks berukuran n x m
Error terkecil yang diharapkan = ξ Fungsi obyektif awal = P0 = 0;
Iterasi awal = t = 1;
c) Bangkitkan Bilangan Random
Bangkitkan bilangan random μik, i = 1,2,...,n; k = 1,2,...,c; sebagai
elemen – elemen matriks partisi awal U. Hitung jumlah setiap kolom (atribut) :
Qj = μik
d) Hitung Pusat Cluster ke-k
Hitung pusat cluster ke-k : Vkj, dengan k = 1,2,...,c; dan j = 1,2,...,m.
Vkj =
μik w ∗Xij
=1
μ=1 ik w
e) Hitung Fungsi Obyektif
Hitung fungsi obyektif pada iterasi ke-t, Pt :
Pt = Xij − Vkj
f) Hitung Perubahan Matriks
� = Xij− Vkj g) Cek Kondisi Berhenti
Jika ( | Pt – Pt-1 | < ξ ) atau (t > MaxIter) maka berhenti; Jika tidak: t = t + 1, ulangi langkah 4.
2.2.2 Contoh Penerapan Algoritma FCM
Berikut contoh penerapan perhitungan FCM pada kasus kunjungan wisata di Yogyakarta, dengan data wisata yang digunakan sebagai sampel perhitungan, yaitu (Yehuda, 2012):
Tabel 2. 1 Data kunjungan wisata bulan Januari dari tahun 2006 – 2010
Januari
i 2006 2007 2008 2009 2010
1. (Kraton Yogyakarta) 45.540 31.723 43.103 47.486 58.235 2. (Taman Sari) 4.104 5.422 5.424 22.292 12.575 3. (Gembira Loka) 43.783 45.357 51.066 88.967 86.857 4. (Purawisata) 8.615 13.246 11.346 9.460 13.215
Berdasarkan data dari tabel 2.1 ditentukan beberapa komponen perhitungan yang ditunjukkan dalam tabel 2.2 sebagai berikut.
Tabel 2. 2Komponen Perhitungan
No Komponen Perhitungan Keterangan
1. Banyaknya cluster yang diinginkan c = 3
2. Pangkat (pembobot) w = 2
3. Maksimum Iterasi T = 1
4. Error terkecil e = 0,01
5. Fungsi Objektif awal P0 = 0
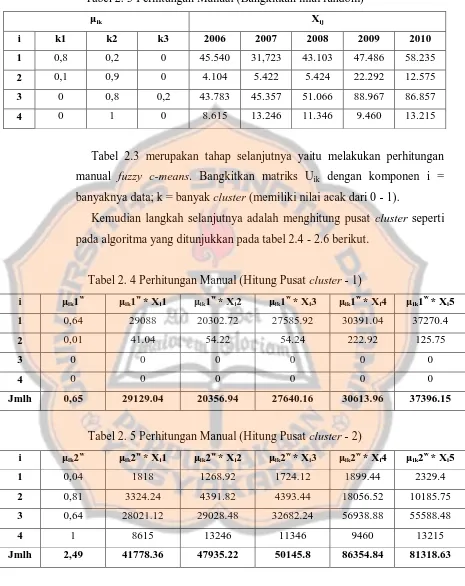
Tabel 2. 3 Perhitungan Manual (Bangkitkan nilai random)
Tabel 2.3 merupakan tahap selanjutnya yaitu melakukan perhitungan manual fuzzy c-means. Bangkitkan matriks Uik dengan komponen i =
banyaknya data; k = banyak cluster (memiliki nilai acak dari 0 - 1).
Kemudian langkah selanjutnya adalah menghitung pusat cluster seperti pada algoritma yang ditunjukkan pada tabel 2.4 - 2.6 berikut.
Tabel 2. 4 Perhitungan Manual (Hitung Pusat cluster - 1)
i μik1
Jmlh 0,65 29129.04 20356.94 27640.16 30613.96 37396.15
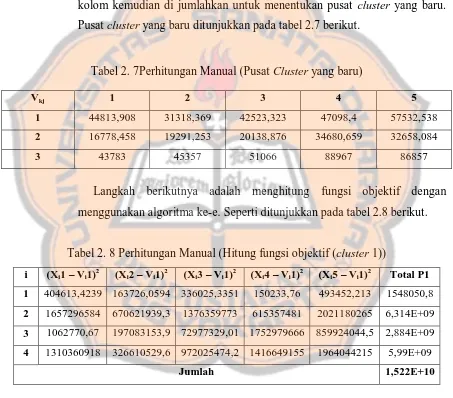
Tabel 2. 5 Perhitungan Manual (Hitung Pusat cluster - 2)
i μik2
Tabel 2. 6 Perhitungan Manual (Hitung Pusat cluster - 3)
3 0,04 1751.32 1814.28 2042.64 3558.68 3474.28
4 0 0 0 0 0 0
Jmlh 0,04 1751.32 1814.28 2042.64 3558.68 3474.28
Pada tabel 2.4 – 2.6 ditunjukkan bagaimana cara mendapatkan pusat cluster dengan menggunakan algortima ke-d. Dimana angka acak
dipangkatkan dua, kemudian hasil dari angka acak yang telah diberi pembobot dua di kalikan dengan data kunjungan wisata. Masing – masing kolom kemudian di jumlahkan untuk menentukan pusat cluster yang baru. Pusat cluster yang baru ditunjukkan pada tabel 2.7 berikut.
Tabel 2. 7Perhitungan Manual (Pusat Cluster yang baru)
Vkj 1 2 3 4 5
1 44813,908 31318,369 42523,323 47098,4 57532,538
2 16778,458 19291,253 20138,876 34680,659 32658,084
3 43783 45357 51066 88967 86857
Langkah berikutnya adalah menghitung fungsi objektif dengan menggunakan algoritma ke-e. Seperti ditunjukkan pada tabel 2.8 berikut.
Tabel 2. 8 Perhitungan Manual (Hitung fungsi objektif (cluster 1))
i (Xi1 – Vi1)2 (Xi2 – Vi1)2 (Xi3 – Vi1)2 (Xi4 – Vi1)2 (Xi5 – Vi1)2 Total P1
1 404613,4239 163726,0594 336025,3351 150233,76 493452,213 1548050,8
2 1657296584 670621939,3 1376359773 615357481 2021180265 6,314E+09
3 1062770,67 197083153,9 72977329,01 1752979666 859924044,5 2,884E+09
4 1310360918 326610529,6 972025474,2 1416649155 1964044215 5,99E+09
Jumlah 1,522E+10
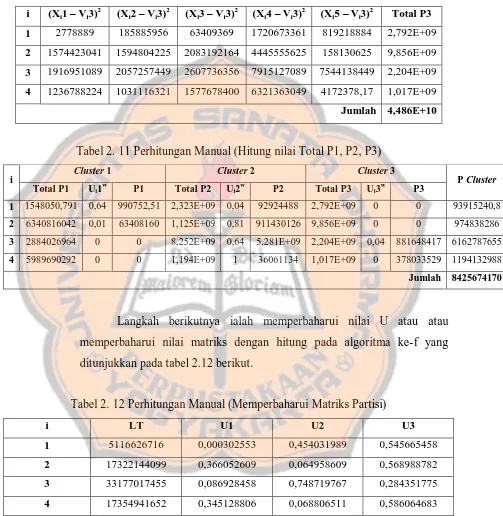
Tabel 2. 9 Perhitungan Manual (Hitung fungsi objektif (cluster 2))
i (Xi1 – Vi2)
1 822057330,3 155548479,9 527351014 163976767,6 654178614,8 2,323E+09
2 160641881,3 191243795,8 216527561 153478862,8 403330276,5 1,125E+09
4 66642042,76 36061134,37 77214659,59 636081622 378033528,5 1,194E+09
Jumlah 1,289E+10
Tabel 2. 10 Perhitungan Manual (Hitung fungsi objektif (cluster 3))
i (Xi1 – Vi3)
1 2778889 185885956 63409369 1720673361 819218884 2,792E+09
2 1574423041 1594804225 2083192164 4445555625 158130625 9,856E+09
3 1916951089 2057257449 2607736356 7915127089 7544138449 2,204E+09
4 1236788224 1031116321 1577678400 6321363049 4172378,17 1,017E+09
Jumlah 4,486E+10
Tabel 2. 11 Perhitungan Manual (Hitung nilai Total P1, P2, P3)
i Cluster 1 Cluster 2 Cluster 3 P Cluster
Langkah berikutnya ialah memperbaharui nilai U atau atau memperbaharui nilai matriks dengan hitung pada algoritma ke-f yang ditunjukkan pada tabel 2.12 berikut.
Tabel 2. 12 Perhitungan Manual (Memperbaharui Matriks Partisi)
i LT U1 U2 U3
1 5116626716 0,000302553 0,454031989 0,545665458
2 17322144099 0,366052609 0,064958609 0,568988782
3 33177017455 0,086928458 0,748719767 0,284351775
4 17354941652 0,345128806 0,068806511 0,586064683
Tabel 2.12 merupakan data yang nantinya akan menentukan hasil cluster. Jika perhitungan pada algoritma terakhir atau menghitung kondisi
cluster sudah didapat maka akan dilakukan pembulatan satu angka
dibelakang desimal sesuai dengan Error terkecil yang ditentukan pertama kali. Berikut hasil clustering ditunjukkan pada tabel 2.13.
Tabel 2. 13 Hasil akhir perhitungan fuzzy c-means
C1 C2 C3
0,0 0,5 0,5
0,4 0 0,6
0,1 0,7 0,2
0,3 0,1 0,6
2.3 Silhouette Index
Jika DBI digunakan untuk mengukur validasi seluruh cluster dalam set data, maka Silhouette Index (SI) dapat digunakan untuk memvalidasi baik sebuah data, cluster tunggal (satu cluster dari sejumlah cluster), atau bahkan keseluruhan cluster. Metode ini paling banyak digunakan untuk memvalidasi cluster yang menggabungkan nilai kohesi dan separasi. Untuk menghitung nilai
SI dari sebuah data ke-i, ada 2 komponen yaitu ai dan bi. aiadalah rata – rata
jarak ke-i terhadap semua data lainnya dalam satu cluster, sedangkan bi
didapatkan dengan menghitung rata – rata jarak data ke-i terhadap semua data dari clusteryang lain tidak dalam satu cluster dengan data ke-i, kemudian yang terkecil ([Tan et al, 2006], [Petrovic, 2003]).
Berikut formula untuk menghitung ai :
= 1
− 1 ( , �)
�=1
�≠
, = 1,2,…, … … … …(2.5)
( , �) adalah jarak data ke-i dengan data ke-r dalam satu
clusterj, sedangkan adalah jumlah data dalam cluster ke-j.
= min
Untuk mendapatkan Silhouette Index (SI) data ke-i menggunakan persamaan berikut :
�� = −
max{ , }… … … …(2.7)
Nilai ai mengukur seberapa tidak mirip sebuah data dengan cluster
yang diikutinya, nilai yang semakin kecil menandakan semakin tepatnya data tersebut berada dalam cluster tersebut. Nilai bi yang besar menandakan
seberapa jeleknya data terhadapcluster yang lain. Nilai SI yang didapat dalam rentang [-1, +1]. Nilai SI yang mendekati 1 menandakan bahwa data tersebut semakin tepat berada dalam cluster tersebut. Nilai SI negatif (ai> bi)
menandakan bahwa data tersebut tidak tepat berada dalam cluster tersebut (karena lebih dekat ke cluster yang lain).SI bernilai 0 (atau mendekati 0) berarti data tersebut posisinya berada di perbatasan di antara dua cluster.
Untuk nilai SI dari sebuah cluster didapatkan dengan menghitung rata – rata nilai SI semua data yang bergabung dalam cluster tersebut, seperti pada persamaan berikut :
2.4.2 Jenis – jenis Bank a. Bank Sentral
Bank Sentral ialah jenis bank yang bertugas untuk menerbitkan uang kertas dan juga uang logam untuk dijadikan sebagai alat pembayaran yang sah di dalam suatu negara dan juga mempertahankan konversi yang dimaksud terhadap emas maupun perak maupun keduanya.
b. Bank Umum
Bank Umum ialah jenis bank yang bukan saja dapat untuk meminjamkan ataupun menginvestasikan berbagai jenis tabungan yang diperolehnya, namun tetapi juga dapat memberikan pinjaman dari menciptakan sendiri suatu uang giral.
c. Bank Perkreditan Rakyat (BPR)
Bank Perkreditan Rakyat ialah jenis bank yang melaksanakan kegiatan usaha dengan secara konvensional maupun yang didasarkan pada suatu prinsip syariah yang dalam kegiatannya tidak dapat memberikan jasa di dalam lalu lintas pembayaran.
d. Bank Syariah
Bank Syariah ialah jenis bank yang beroperasi dengan berdasarkan prinsip bagi hasil maupun sesuai dengan kaidah ajaran islam mengenai hukum riba.
2.4.3 Fungsi Bank
a. Fungsi Bank Sebagai Agent Of Trust
Fungsi bank sebagai agent of trust ialah suatu lembaga yang berlandaskan pada suatu kepercayaan. Dasar utama pada kegiatan perbankan yaitu kepercayaan, baik itu sebagai penghimpun dana ataupun penyaluran dana. Dalam hal tersebut, masyarakat akan mau menyimpan dana – dananya di bank apabila dilandasi dengan kepercayaan.
b. Fungsi Bank Sebagai Agent Of Development
negara. Kegiatan bank tersebut berupa penghimpun dan juga penyalur dana sangatlah diperlukan bagi lancarnya suatu kegiatan perekonomian di sektor riil. Dalam hal tersebut bank memungkinkan masyarakat itu untuk melakukan kegiatan untuk investasi, distribusi dan juga kegiatan konsumsi barang serta jasa, mengingat bahwa kegiatan investasi, distribusi dan juga konsumsi tidak terlepas dari adanya penggunaan uang.
c. Fungsi Bank Sebagai Agent Of Services
Fungsi bank sebagai agent of services ialah merupakan lembaga yang memberikan suatu pelayanan kepada masyarakat. Dalam hal tersebut bank memberikan jasa pelayanan perbankan kepada masyarakat agar masyarakat tersebut merasa aman dan juga nyaman dalam menyimpan dananya itu. Jasa yang ditawarkan di dalam bank tersebut sangat erat kaitannya dengan suatu kegiatan perekonomian masyarakat secara umum.
2.5 Nasabah
2.5.1 Pengertian Nasabah
Dalam peraturan Bank Indonesia No. 7/7/ PBI 2005 jo No. 10/10 PBI/2008 tentang penyelesaian pengaduan nasabah pasal 1 angka 2 yang dimaksud dengan nasabah atau mitra adalah pihak yang menggunakan jasa bank, termasuk pihak yang tidak memiliki rekening namun memanfaatkan jasa bank untuk melakukan transaksi keuangan. Didalam UU No. 10 Tahun 1998 tentang perbankan dimuat tentang jenis dan pengertian nasabah. Dalam pasal 1 angka 17 disebutkan bahwa pengertian nasabah yaitu pihak yang menggunakan jasa bank.
Menurut Djaslim Saladin dalam bukunya “Dasar-Dasar Manajemen Pemasaran Bank” yang dikutip dari “Kamus Perbankan” menyatakan bahwa “Nasabah atau mitra adalah orang atau badan yang mempunyai rekening simpanan atau pinjaman pada bank”.
rekening koran atau deposito atau tabungan serupa lainnya pada sebuah bank”.
Dari uraian diatas dapat disimpulkan bahwa karakter nasabah atau mitra yaitu orang atau badan yang mempunyai rekening simpanan atau deposito atau tabungan atau pinjaman pada bank dimana orang atau badan tersebut mempunyai sifat, sikap dan tindakan yang jujur dan bertanggung jawab atau kebiasaan untuk melakukan hal-hal yang baik yang membedakan seseorang dari orang lain.
2.6 Kredit
2.6.1 Pengertian Kredit
Istilah kredit berasal dari bahasa Yunani “Credere” yang berarti kepercayaan, oleh karena itu dasar dari kredit adalah kepercayaan. Seseorang atau semua badan yang memberikan kredit (kreditur) percaya bahwa penerima kredit (debitur) di masa mendatang akan sanggup memenuhi segala sesuatu yang telah dijanjikan itu dapat berupa barang, uang atau jasa (Thomas. S, dkk, 1998).
2.6.2 Unsur – unsur Kredit
Kredit yang diberikan oleh suatu lembaga kredit merupakan pemberian kepercayaan. Berdasarkan hal tersebut di atas, maka unsur – unsur kredit adalah (Thomas. S, dkk, 1998) :
a. Kepercayaan
Kepercayaan, yaitu keyakinan dari si pemberi kredit bahwa prestasi yang diberikannya baik dalam bentuk uang, barang, atau jasa akan benar – benar diterimanya kembali dalam jangka waktu tertentu di masa yang akan datang.
b. Waktu
c. Degree of Risk
Degree of Risk, yaitu suatu tingkat risiko yang akan dihadapi
sebagai akibat dari adanya jangka waktu yang memisahkan antara pemberian prestasi dengan kontra prestasi yang akan diterima kemudian hari.
d. Prestasi
Prestasi, yaitu objek kredit yang tidak saja diberikan dalam bentuk uang, tetapi juga dalam bentuk barang atau jasa.
2.7 Notasi Pemodelan Sistem 2.7.1 Use Case Diagram
Use case diagram adalah diagram yang menggambarkan interaksi
antara sistem dengan sistem eksternal dan pengguna. Use case diagram akan menggambarkan secara grafikal pengguna sistem dan cara user berinteraksi dengan sistem (Whitten, 2004).
2.7.1.1 Simbol Use Casedan Aktor
Use case digambarkan secara grafik dengan bentuk elips
horizontal dengan nama user case tertera dibawah atau didalam elips.
Gambar 2. 2 Simbol Use Case
Gambar 2. 3 Simbol Aktor 2.7.1.2 Relasi (Relationship)
Relasi digambarkan dengan sebuah garis diantara dua simbol di dalam usecase diagram. Arti relasi dapat berbeda antara satu dengan yang lainnya tergantung pada bagaimana cara garis digambarkan dan tipe simbol apa yang disambungkan.
Ada beberapa jenis relasi yang digunakan untuk menggambarkan use case diagram yaitu :
1. Association
Associationadalah relasi antara aktor dan sebuah use case dimana
terjadi interaksi diantara keduanya. 2. Extends
Extendsyaitu sebuah relasi antara extension use case dan use case
yang di-extend. Exetension use case adalah sebuahuse case yang berisi langkah – langkah yang diekstrak dari sebuah use case yang lebih kompleks agar menjadi use case lebih sederhana dan kemudian diberikan tambahan fungsinya.
3. Uses atau includes
Uses atau includesyaitu sebuah relasi antara abstract use case dan
use case yang mengurangi redundansi antara satu atau lebih use
case dengan cara mengkombinasikan langkah – langkah yang umum ditemukan dalam case-nya.
4. Depend on
Depend onyaitu sebuah relasi use caseyang menentukan bahwa use case yang lain harus dibuat sebelum current use case dan dapat
dimulai dari satu use case dan menunjuk ke use case yang bergantung padanya. Setiap relasi depends on diberi label “<<depends on>>”.
5. Inheritance
Inheritanceyaitu sebuah relasi use case yang tingkah laku pada
umumnya menggambarkan dua aktor yang menginisiasi use case yang mana yang ditugaskan dan dieksplorasi dalam abstrak aktor yang baru untuk mengurangi redundansi. Aktor yang lain dapat menurunkan interaksi dari abstrak aktor. Relasi ini digambarkan dengan garis anak panah yang dimulai pada satu aktor dan menunjuk ke abstrak aktor yang memiliki interaksi turunan dari aktor yang pertama.
2.7.2 Pemodelan Proses
Pemodelan proses (Whitten et.al, 2004) adalah teknik yang digunakan untuk mengorganisasikan dan mendokumentasikan proses dari sistem. Data Flow Diagram (DFD) merupakan sebuah model proses yang digunakan untuk menggambarkan aliran data yang melalui sebuah sistem dan proses yang digunakan untuk menggambarkan aliran data yang melalui sebuah sistem dan proses yang dibentuk oleh sistem. Berikut adalah simbol – simbol yang digunakan dalam DFD :
1. Kesatuan luar (external agent / enternal entity)
Kesatuan luar (external agent / enternal entity) merupakan suatu kesatuan yang berbeda di luar sistem yang sedang dikembangkan yang akan memberikan input atau menerima output dari sistem. Suatu kesatuan luar dapat disimbolkan dengan notasi kotak bujur sangkar.
Entity
2. Arus data (data flow)
Arus data (data flow) yang mengalir diantara proses, penyimpanan data dan kesatuan luar. Arus data adalah data yang menjadi input ke proses atau output dari sebuah proses. Arus data dapat berbentuk formulir atau dokumen yang digunakan oleh proses, laporan tercetak yang dihasilkan oleh sistem, tampilan atau output di layar komputer, surat/memo, blangko isian, transmisi data. Arus data diberi simbol garis dengan anak panah.
Gambar 2. 5 Simbol Arus data
3. Proses
Proses merupakan kegiatan atau kerja yang dilakukan orang, mesin atau komputer dari suatu hasil arus data yang masuk ke dalam proses untuk dihasilkan arus data yang keluar dari proses.Suatu proses dapat ditunjukkan dengan simbol persegi panjang dengan sudut – sudut yang tumpul.
Process
Gambar 2. 6 Simbol Proses
4. Simpanan data (Data store)
Simpanan data (Data store) dapat berupa file / database di sistem komputer, arsip/catatan manual, tabel acuan, agenda buku. Dinamai dengan kata benda.
27 BAB III
METODOLOGI PENELITIAN
3.1 Gambaran Umum
Penelitian ini bertujuan untuk membangun sebuah sistem yang mampu melakukan proses pengelompokan data nasabah bank menggunakan metode clustering pada teori data mining (penambangan data) dengan algoritma Fuzzy
C-Means. Data nasabah bank diperoleh dari sebuah Bank Perkreditan Rakyat di
daerah DIY. Data yang digunakan berisi jumlah pinjaman, tunggakan pokok, tunggakan bunga, angsuran, nilai agunan, agunan dan jangka waktu pinjaman. Hasil yang diharapkan dalam sistem ini adalah dapat mempermudah kinerja perbankan dalam proses mengelompokkan data nasabah bank menggunakan algoritma Fuzzy C-Means clustering.
3.2 Desain Penelitian 3.2.1 Studi Pustaka
Studi pustaka dilakukan dengan membaca buku, jurnal serta sumber lain yang berkaitan dengan data mining clustering khususnya clustering fuzzy c-means.
3.2.2 Data
Data yang Digunakan
Data yang digunakan adalah data nasabak bank BPR. Data nasabah bank yang dimaksud meliputi jumlah pinjaman, tunggakan pokok, tunggakan bunga, angsuran, nilai agunan, agunan dan jangka waktu pinjaman.
Tabel 3. 1Tabel Atribut Data
Nama Atribut Keterangan
Jumlah Pinjaman Besar pinjaman yang di pinjam
Tunggakan Pokok Besar tunggakan pokok kredit tanpa
angsuran yang telah jatuh tempo
Angsuran Biaya yang harus dibayarkan setiap bulan selama peminjaman
Nilai Agunan Besar nilai jaminan yang diserahkan debitur
Agunan Nama nilai jaminan yang diserahkan debitur
Jangka Waktu Pinjaman Jangka waktu jatuh tempo pinjaman
Teknik Pengumpulan Data
Teknik pengumpulan data yang digunakan adalah wawancara dan seleksi data. Wawancara dilakukan dengan melakukan tanya jawab dengan salah satu karyawan bank BPR. Melalui wawancara tersebut penulis dapat memperoleh data nasabah bank. Setelah data nasabah bank telah diperoleh kemudian diolah penulis untuk memperoleh profil data nasabah yang ingin melakukan kredit dengan ketentuan tertentu, seperti berapa besar agunan yang dimiliki dengan pinjaman yang akan dilakukan.
3.2.3 Perancangan Aplikasi
Metodologi yang digunakan dalam penelitian ini adalah metode Knowledge Discovery in Database (KDD). Metode KDD memiliki
beberapa tahapan sebagai berikut :
a. Pembersihan Data (Data Cleaning)
Pada tahap pertama ini dilakukan proses pembersihan data untuk menghilangkan data yang tidak dibutuhkan atau pengganggu (noise) seperti data yang tidak terisi dan data yang tidak konsisten.
b. Integrasi Data (Data Integration)
Pada tahap selanjutnyaadalah proses penggabunganbermacam – macam data dari berbagai sumber menjadi satu kesatuan.Data yang ada sudah terdapat dalam 1 file sehingga tahap ini tidak dilakukan. c. Seleksi Data (Data Selection)
diperlukan dalam penelitian ini. Atribut yang dapat dilanjutkan untuk penelitian adalah :
Tabel 3. 2 Tabel Seleksi Atribut
Nama Atribut Jumlah Pinjaman Tunggakan Pokok Tunggakan Bunga Angsuran
Nilai Agunan
Jangka Waktu Pinjaman
d. Transformasi Data (Data Transformation)
Pada tahap ini merupakan proses dimana data diubah (transformasi) atau digabungkan sehingga menjadi tepat untuk ditambang dengan misalnya melakukan operasi penjumlahan atau penggabungan. Beberapa metode data mining membutuhkan format data yang khusus sebelum bisa diaplikasikan. Pada tahap ini tidak dilakukan tahap transformasi, dikarenakan metode yang digunakan tidak membutuhkan format yang khusus.
e. Data Mining
Pada tahap ini merupakan proses utama saat metode diterapkan untuk mengekstraksi pola data, menemukan knowledgeberharga dan tersembunyi dari data. Pada proses saat ini digunakan aplikasi Microsoft Excel.
1. Menentukan Jumlah Cluster
Tahap ini menentukan jumlah cluster(c), pangkat untuk matriks partisi (w), maksimum iterasi (MaxIter), error terkecil yang diharapkan (ξ), fungsi obyektif awal (P0=0),
dan iterasi awal (t = 1).
Tabel 3. 3 Tabel Jumlah Cluster
Jumlah cluster c = 2 Pangkat untuk matriks partisi w = 2
Maksimum Iterasi MaxIter = 10 Error terkecil yang diharapakan Ξ = 1e-05
Fungsi objektif awal P0 = 0
Iterasi Awal t = 1
2. Bangkitkan Nilai Random
Tahap ini bangkitkan bilangan random μik, i=1,2,...,n;
k=1,2,...,c sebagai elemen matriks partisi awal U.
Tabel 3. 4 Tabel Matriks Nilai Random
Step 2
3. Hitung Pusat Cluster ke-k
Hitung pusat cluster ke-k : Vkj, dengan k = 1,2,...,c; dan j =
μik= derajat keanggotaan untuk data sampel ke-i pada clsuter
4. Hitung Fungsi Objektif
Hitung fungsi objektif pada iterasi ke-t menggunakan persamaan berikut :
μik = derajat keanggotaan untuk data sampel ke-i pada cluster
ke-k
W = pangkat / pembobot. Xij = data ke-i, atribut ke-j
Pt = fungsi objektif pada iterasi ke-t
Tabel yang berisi hitung fungsi objektif ini terlampir pada lampiran 2.
5. Hitung Perubahan Matriks
Hitung perubahan matriks partisi menggunakan persamaan berikut :
μik = derajat keanggotaan untuk data sampel ke-i pada cluster
ke-k.
W = pangkat / pembobot. Xij = data ke-i, atribut ke-j
Tabel yang berisi hitung perubahan matriks ini terlampir pada lampiran 3.
6. Cek Kondisi Berhenti Jika :
(|Pt– Pt-1|< ξ)
Atau
(t > MaxIter)
Maka berhenti. Jika tidak: t = t+1, ulangi langkah ke-4.
f. Evaluasi Pola (Pattern Evaluation)
Pada tahap ini akan dilakukan evaluasi pola dari hasil penamabangan data. Sistem aplikasi clusteringini menggunakan algoritma Fuzzy C-Meansyang akan menghasilkan data nasabah bank yang telah di kelompokkan. Selanjutnya akan dilihat dan dievaluasi kembali apakah hasil clustering sudah sesuai dengan hasil yang sebenarnya sehingga dapat melakukan evaluasi hasil clustering menggunakan uji kualitascluster dengan Silhouette Index (SI).
g. Presentasi Pengetahuan (Knowledge Presentation)
Pada tahap ini mempresentasikan atau menampilkan hasil dari pola yang sudah di dapatkan. Hasil akan di tampilkan dalam sistem aplikasi clustering berbentuk dekstop dengan bahasa Java yang dirancang dengan desain antarmuka yang mudah di pahami oleh pengguna.
3.3 Kebutuhan Perangkat Lunak dan Keras 3.3.1 Kebutuhan Perangkat Lunak
3.3.2 Kebutuhan Perangkat Keras
34 BAB IV
PERANCANGAN SISTEM
4.1 Analisis Kebutuhan 4.1.1 Identifikasi sistem
Kegiatan perkreditan ini meliputi semua aspek ekonomi baik di bidang produksi, distribusi, konsumsi, perdagangan, investasi, maupun bidang jasa dalam bentuk uang tunai, barang dan jasa. Dengan demikian, kegiatan perkreditan dapat dilakukan antar individu – individu dengan badan usaha atau antar badan usaha (Wahyudi, 2003).Individu – individu tersebut disebut dengan debitur atau nasabah bank memang merupakan aset yang sangat penting dalam lembaga keuangan atau bank. Meskipun demikian, ada beberapa hal yang benar-benar harus diperhatikan pada setiap nasabah atau calon nasabah agar tidak ada hal – hal yang tidak diinginkan terjadi di kemudian hari. Bukan tanpa alasan pihak bank memperhatikan profil nasabah, karena bagaimanapun juga hal ini merupakan bagian yang sangat penting sebagai dokumentasi bank dan siap jika dibutuhkan sewaktu – waktu.
kredit macet. Itulah sebabnya pihak bank harus lebih teliti sebelum mengabulkan permohonan kredit.
Sistem ini merupakan implementasi algoritma Fuzzy C-Means clustering untuk melakukan proses pengelompokan atau disebut clustering. Data yang digunakan dalam sistem ini merupakan data yang sudah siap untuk di cluster. Data yang digunakan adalah data nasabah bank BPR di DIY. Data
tersebut meliputi jumlah pinjaman, tunggakan pokok, tunggakan bunga, angsuran, nilai agunan, agunan dan jangka waktu pinjaman. Sistem ini bertujuan untuk membantu dan mempermudah bank dalam proses pengelompokkan nasabah bank yang ingin melakukan kredit berdasarkan data nasabah bank dengan menggunakan algoritma Fuzzy C-Means clustering.
4.2 Desain Logikal (Logical Design) 4.2.1 Desain Proses
4.2.1.1 Use Case Diagram
Operator
Input data .xls atau .csv
System
Seleksi atribut
<< depends on >> << exten
ds >>
<< extends >> Simpan hasil clustering Proses clustering
Input c, w, i, e
Lihat Panduan
Gambar 4. 1Use Case Diagram
4.2.1.2 Input Sistem
Sistem clustering menggunakanFuzzy C-Means clustering hanya dapat menerima masukan dari pengguna berupa file dengan eksrensi .xls atau .csv yang berisi data nasabah bank.
4.2.1.3 Proses Sistem
Sistem ini akan mengimplementasikan algoritma Fuzzy C-Means clustering untuk mengelompokan data nasabah bank BPR
4.2.1.4 Output Sistem
Keluaran yang diperoleh dari sistem yang dibangun adalah data – data nasabah bank yang sudah dikelompokan dan prediksi nasabah yang mungkin dapat melakukan kredit dengan syarat dan ketentuan tertentu.
4.2.1.5 Desain Proses Umum Sistem
Pada gambar 4.2 diperlihatkan proses dari aplikasi mulai dari membuka berkas atau data dengan tipe .xls atau .csv kemudian aplikasi akan menyeleksi atribut yang tidak digunakan dalam berkas atau data. Jika ya maka akan dilanjutkan dengan menginputkan nilai c, w, MaxIter dan e. Kemudian akan di lakukan proses clustering dengan algoritma fuzzy c-means. Kemudian aplikasi akan menampilkan hasil clustering.
Setelah itu akan disimpan ke dalam direktori komputer dengan tipe berkas atau berupa .xls.
Seleksi atribut
Tidak
Mulai File data bertipe .xls atau .csv
Proses seleksi atribut
Ya
Memasukkan nilai c, w, MaxIter, e
Proses clustering fuzzy c-means
Menampilkan hasil
clustering
Proses menyimpan hasil
clustering ke direktori komputer
File hasil deteksi bertipe .xls
selesai
4.2.1.6 Diagram Aktivitas (Activity Diagram)
Diagram aktivitas digunakan untuk menunjukan aktivitas yang dikerjakan oleh pengguna dan sistem dalam setiap use case yang disebutkan dalam gambar 4.1.Berikut adalah diagram aktivitas dari setiap use case:
Menekan tombol “Pilih File”
Memilih file data bertipe .xls atau .csv
USER SYSTEM
Menampilkan kotak dialog pemilihan file
Menampilkan file data yang terpilih ke tabel data halaman preprocessing
Gambar 4. 3 Activity Diagram Input Data
Memasukan nilai “c”, “w”, “MaxIter”, dan “e”
Menampilkan hasil clustering
Menekan tombol Proses
Menekan tombol Submit Menampilkan hasil clustering dan menampilkan tanaman yang cocok ditanama pada cuaca tersebut.
USER SYSTEM
Memilih atribut yang ingin dihapus
Menghapus atribut yang terpilih dari tabel data Menekan tombol Hapus
Menekan tombol Submit Menampilkan halaman Fuzzy C-Means
USER SYSTEM
Gambar 4. 5Activity Diagram Seleksi Atribut
Menekan tombol Simpan
Menekan tombol OK Menyimpan hasil clustering ke dalam file dan direktori yang telah dipilih
USER SYSTEM
Menampilkan kotak dialog untuk pemilihan direktori di komputer untuk penyimpanan
Memilih direktori yang akan digunakan untuk tempat penyimpanan
Mengisikan nama file untuk disimpan
Memilih tipe file untuk disimpan
4.2.1.7 Diagram Kelas (Class Diagram)
Diagram kelas menjelaskan relasi – relasi yang terjadi antar kelas. Kelas Input Data ber-relasi dengan kelas Menu Awal dan kelas Fuzzy C-Means, relasi yang terjadi adalah relasi asosiasi yang berarti
kelas Menu Awal memanggil fungsi dari kelas Input Data untuk menampilkan data yang diinput, kemudian kelas Fuzzy C-Means dipanggil oleh kelas Input Data untuk menjalankan proses clustering.
Gambar 4. 7 Diagram Kelas
4.2.1.8 Diagram Konteks (Context Diagram)
Operator
C, w, MaxIter, e, Data nasabah bank Pengelompokan data nasabah bank,
Hasil prediksi
0
Impelementasi FCM pada Data