PENGELOMPOKAN PEMINJ AM BUKU
DENGAN METODE
K-MEANS
DI PERPUSTAKAAN PUSAT UPN “VETERAN”
J AWA TIMUR
SKRIPSI
Disusun Oleh :
INTAN FITRI ANDYNI
1032010054
J URUSAN TEKNIK INDUSTRI
FAKULTAS TEKNOLOGI INDUSTRI
UNIVERSITAS PEMBANGUNAN NASIONAL “VETERAN”
J AWA TIMUR
SKRIPSI
PENGELOMPOKAN PEMINJ AM BUKU
DENGAN METODE K-MEANS
DI PERPUSTAKAAN PUSAT UPN ”VETERAN” J AWA TIMUR
Disusun oleh :
INTAN FITRI ANDYNI NPM : 1032010054
Telah diper tahankan dihadapan dan diter ima oleh Tim Penguji Skr ipsi J ur usan Teknik Industr i Fakultas Teknologi Industr i
Univer sitas Pembangunan Nasional “Veter an” J awa Timur Pada Tanggal 30 Desember 2013
Tim Penguji : Pembimbing :
1. 1.
Ir. Budi Santoso, MMT Ir . Handoyo, MT
NIP. 19561205 198703 1 001 NIP. 19570209 198503 1 003
2. 2.
Ir . Ir iani, MMT Dwi Sukma D ST, MT
NIP. 19621126 198803 2 001 NIP. 19810726 200501 1 002
3.
Ir . Handoyo, MT
NIP. 19570209 198503 1 003
Mengetahui
Dekan Fakultas Teknologi I ndustr i
Univer sitas Pembangunan Nasional ”Veter an” J awa Timur Sur abaya
SKRIPSI
PENGELOMPOKAN PEMINJ AM BUKU
DENGAN METODE K-MEANS
DI PERPUSTAKAAN PUSAT UPN ”VETERAN” J AWA TIMUR
Disusun oleh :
INTAN FITRI ANDYNI NPM : 1032010054
Telah diper tahankan dihadapan dan diter ima oleh Tim Penguji Skr ipsi J ur usan Teknik Industr i Fakultas Teknologi Industr i
Univer sitas Pembangunan Nasional “Veter an” J awa Timur Pada Tanggal 30 Desember 2013
Tim Penguji : Pembimbing :
1. 1.
Ir. Budi Santoso, MMT Ir . Handoyo, MT
NIP. 19561205 198703 1 001 NIP. 19570209 198503 1 003
2. 2.
Ir . Ir iani, MMT Dwi Sukma D ST, MT
NIP. 19621126 198803 2 001 NIP. 19810726 200501 1 002
3.
Ir . Handoyo, MT
NIP. 19570209 198503 1 003
Mengetahui
Ketua J ur usan Teknik Industr i Fakultas Teknologi Industr i
Univer sitas Pembangunan Nasional “Veter an” J awa Timur Sur abaya
KATA PENGANTAR
Puji syukur kehadirat Allah SWT atas segala karunia dan anugerah-Nya sehingga
penulis dapat menyelesaikan penyusunan Tugas Akhir ini.
Tugas Akhir ini disusun untuk memenuhi persyaratan kelulusan Program Sarjana
Strata-1 (S-1) di Jurusan Teknik Industri Fakultas Teknologi Industri Universitas
Pembangunan Nasional “Veteran” Jawa Timur dengan judul :
“Pengelompokan Peminjam Buku Dengan Metode K-Means Di Per pustakaan Pusat UPN ”Veter an” J awa Timur .
Penyelesaian penyusunan Tugas Akhir ini tentunya tidak terlepas dari peran serta
berbagai pihak yang telah memberikan bimbingan dan bantuan baik secara langsung
maupun tidak langsung. Oleh karena itu tidak berlebihan bila pada kesempatan kali ini
penulis mengucapkan terima kasih kepada :
1. Kedua orang tua yang telah memberikan banyak dukungan secara moril, materil
serta doa, sehingga penyelesaian laporan ini dapat segera terselesaiakan.
2. Bapak Ir. Sutiyono, MT, selaku Dekan Fakultas Teknologi Industri Universitas
Pembangunan Nasional “Veteran” Jawa Timur.
3. Bapak Dr. Minto Waluyo, MM, selaku Ketua Jurusan Teknik Industri Universitas
Pembangunan Nasional “Veteran” Jawa Timur.
4. Bapak Ir.Handoyo, MT, selaku Dosen Pembimbing Utama Skripsi.
5. Bapak Dwi Sukma.D, ST, MT, selaku Dosen Pembimbing Pendamping Skripsi.
6. Bapak Drs. Ananta Prathama, Msi, selaku kepala UPT Perpustakaan.
7. Staf perpustakaan yang telah membantu untuk memberikan data sirkulasi
8. Bapak Ir. Mokh. Suef, MSc(Eng), yang telah memberi pinjaman buku-bukunya.
Terimakasih untuk om suef yang juga telah membantu ketika penulis mengalami
kendala dalam perkuliahan.
9. Teman-teman angkatan 2010 khususnya asisten laboratorium Optimasi dan
Pemrograman Komputer yang telah memberikan semangat dalam penyelesaian
Tugas Akhir ini. Serta untuk citra dan diska yang bersedia menemani dan selalu
membantu ketika penulis mengalami kendala selama perkuliahan hingga
penyelesaian Tugas Akhir.
10. Pihak-pihak lain yang terkait baik secara langsung maupun tidak langsung dalam
penyelesaian Tugas Akhir ini yang tidak dapat disebutkan satu per satu.
Penulis menyadari sepenuhnya bahwa penyusunan Tugas Akhir ini terdapat
kekurangan, maka dengan segala kerendahan hati penulis mengharapkan saran dan kritik
yang bersifat membangun.
Akhir kata semoga Tugas Akhir ini dapat bermanfaat bagi semua pihak yang
membaca. Terima Kasih.
Surabaya, Desember 2013
DAFTAR ISI
KATA PENGANTAR... i
DAFTAR ISI ... iii
DAFTAR GAMBAR ... v
DAFTAR TABEL ... vi
BAB I. PENDAHULUAN. ... 1
1.1 Latar Belakang... 1
1.2 Perumusan Masalah ... 2
1.3 Batasan Masalah ... 3
1.4 Asumsi ... 3
1.5 Tujuan Peneleitian ... 4
1.6 Manfaat Peneleitian ... 4
1.7 Sistematika Penulisan ... 4
BAB II. TINJ AUAN PUSTAKA ... 6
2.1 Data Mining... 6
2.1.1 Teknik Data Mining ... 7
2.2 Teknik Klastering ... 13
2.2.1 Klasifikasi Metode Klastering... 15
2.2.2 K-Mean s ... 17
2.2.3 Contoh Penerapan Algoritma K-Means Cluster Analysis ... 23
2.3 Penentuan Sampel... 30
2.4 Peneliti Terdahulu ... 32
BAB III. METODOLOGI PENELITIAN ... 34
3.2 Identifikasi dan Definisi Operasional Variabel ... 34
3.3 Metode Pengumpulan Data ... 35
3.4 Metode Pengolahan Data ... 36
3.5 Langkah-langkah Pemecahan Masalah ... 37
BAB IV. HASIL DAN PEMBAHASAN ... 42
4.1 Pengumpulan Data ... 42
4.2 Penentuan Sampel ... 44
4.3 Pengolahan Data ... 46
4.4 Hasil dan Pembahasan ... 61
BAB V. KESIMPULAN DAN SARAN... 64
5.1 Kesimpulan ... 64
5.2 Saran ... 64
DAFTAR PUSTAKA
DAFTAR GAMBAR
Gambar 2.1 Decision Tree ... 10
Gambar 2.2 Contoh Clustering ... 12
Gambar 2.3 Contoh Dendogram ... 16
Gambar 2.4 Ilustrasi Langkah-langkah Dalam Algoritma K-Means ... 20
DAFTAR TABEL
Tabel 2.1 Tabel Observasi………. 23
Tabel 2.2 Hasil Perhitungan……….……. 25
Tabel 2.3 Group Assignment……….………. 25
Tabel 2.4 Distance Pada Iterasi 1.………... 27
Tabel 2.5 Table Group Assignment.………... 27
Tabel 2.6 Distance Pada Iterasi 2.………... 29
Tabel 2.7 Table Group Assignment Iterasi 2..………... 29
Tabel 2.8 Hasil Akhir Cluster……...………... 29
Tabel 2.9 Krejcie dan Morgan.………... 30
Tabel 4.1 Kode Buku Berdasarkan DDC……….….... 43
Tabel 4.2 Kode Mahasiswa Berdasarkan Jurusan……….. 43
Tabel 4.3 Krejcie dan Morgan……….. 44
Tabel 4.4 Jumlah Peminjam Tanggal 3-14 Juni 2013..……..……... 46
Tabel 4.5 Jumlah Peminjam Tanggal 17-28 Juni 2013………...…... 47
Tabel 4.6 Jumlah Peminjam Tanggal 1-12 Juli 2013….…………...… 48
Tabel 4.7 Jumlah Peminjam Tanggal 15-26 Juli 2013..………...…... 49
Tabel 4.8 Jumlah Peminjam Tanggal 29-31 Juli dan 2-6 September 2013………. 50
Tabel 4.9 Jumlah Peminjam Tanggal 19-20 September 2013...……... 51
Tabel 4.11 Jumlah Peminjam Bulan Juni, Juli dan September 2013…... 53
Tabel 4.12 Hasil Klasterisasi………...……….…………... 60
DAFTAR LAMPIRAN
Lampiran A Data Sirkulasi Peminjaman Buku Bulan Juni, Juli dan September
2013
Lampiran B Jarak Terpendek Iterasi 0
Lampiran C Jarak Terpendek Iterasi 1
Lampiran D Jarak Terpendek Iterasi 2
Lampiran E Hasil Iterasi
Abstraksi
Penelitian ini bertujuan ini untuk melakukan pengelompokan aktifitas peminjam buku di perpustakaan pusat UPN “Veteran” Jawa Timur dari berbagai jurusan yang ada.
Berdasarkan sirkulasi peminjaman buku di perpustakaan pusat UPN “Veteran” Jawa Timur, selama 3 bulan yaitu Juni, Juli dan September terdapat 1922 data. Selama ini perpustakaan pusat UPN “Veteran” Jawa Timur belum mengetahui mahasiswa dari jurusan mana saja yang melakukan aktifitas sebagai peminjam buku dan kelompok buku mana saja yang banyak dipinjam. Sehingga tidak dapat direkomendasikan dengan baik kelompok buku yang diprioritaskan untuk diperbanyak.
Dengan adanya masalah tersebut, maka dilakukan penelitian pengelompokan peminjam dan kelompok buku yang banyak dipinjam dengan metode k-means untuk menunjang proses belajar mengajar.
Berdasarkan penelitian ini diperoleh 3 klaster, dengan persebaran data pada klaster 1 (kurang aktif) terdapat 778 mahasiswa, klaster 2 (cukup aktif) terdapat 267 mahasiswa dan klaster 3 (aktif) terdapat 877 mahasiswa.
Serta untuk kelompok buku yang sering dipinjam dari 3 klaster tersebut adalah kelompok buku teknologi terapan dalam bidang manajemen khususnya yaitu akuntansi dan manajemen umum.
Abstract
This research is to perform clustering of activity in the central library book borrowers UPN "Veteran" East Java from a variety of majors. Based on borrowing books at the library circulation center UPN "Veteran" East Java, for 3 months are June, July and September is 1922 data. The center’s library UPN "Veteran" East Java don’t know of any department that perform activities as a borrower of books and book groups which are much borrowed. So it can’t be recommended priority groups to be reproduced.
Given these problems , then conducted research grouping and group borrower are many books borrowed by k-means clustering method to support the teaching and learning process.
This research were obtained 3 clusters. Data in cluster 1 (less active) there are 778 students , cluster 2 (moderately active) there are 267 students and cluster 3 (active) there are 877 students.
For groups that are often borrowed books from the 3 cluster is a applied technology in technology management especially accounting and general management.
BAB I
PENDAHULUAN
1.1 Latar Belakang
Keberadaan perpustakaan tidak dapat dipisahkan dari budaya manusia.
Tinggi rendahnya peradaban suatu bangsa dapat dilihat dari kondisi perpustakaan
yang ia miliki. Pada hakekatnya perpustakaan merupakan hasil budaya berupa
lembaga yang mengumpulkan, menyimpan, mengatur baik berupa karya cetak
maupun karya rekam sebagai sumber informasi dan belajar dari generasi ke
generasi. Di Indonesia ada lima jenis perpustakaan dan kelima jenis perpustakaan
ini yaitu perpustakaan nasional, perpustakaan umum, perpustakaan khusus dan
perpustakaan perguruan tinggi.
Adapun koleksi perpustakaan perguruan tinggi diadakan melalui seleksi
yang mengacu kepada kebutuhan program-program studi yang diselenggarakan
dan diorganisasikan sedemikian rupa sehingga dapat menjamin efektivitas dan
efisiensi layanan kepada kebutuhan civitas academica. Pada setiap civitas
academica pun tidak dapat disamakan setiap kebutuhannya karena memiliki
kebutuhan berbeda pada literaturnya. Literatur yang digunakan mahasiswa setiap
jurusan pun berbeda. Dengan adanya pengelompokan yang terorganisir pada
setiap penggunanya dalam hal ini adalah peminjam dari berbagai jurusan maka
dapat diketahui kelompok literatur apa saja yang paling sering dipinjam oleh
Selama ini perpustakaan pusat UPN “Veteran” Jawa Timur belum
mengetahui aktifitas kelompok peminjam dan kelompok buku mana saja yang
sering dipinjam untuk digunakan berbagai jurusan serta keaktifan mahasiswa
dalam meminjam.
Dengan adanya masalah tersebut, maka dilakukan penelitian
pengelompokan peminjaman buku dengan metode k-means. Dengan harapan
dapat diketahui mahasiswa dari jurusan mana saja yang aktif sebagai peminjam
buku di perpustakaan pusat sehingga dapat memberi rekomendasi pengadaan
literatur yang mendapat prioritas untuk diperbanyak dalam rangka untuk
menunjang proses belajar mengajar.
Teknik data mining dengan menggunakan K-Means cluster analysis dapat
dimanfaatkan untuk melakukan proses penggalian informasi dari data yang masih
tersembunyi dalam jumlah yang besar dan kompleks. Dimana K-means cluster
analysis merupakan salah satu metode cluster analysis non hirarki yang berusaha
untuk mempartisi data yang ada kedalam satu atau lebih cluster atau kelompok
data berdasarkan karakteristiknya, sehingga data yang mempunyai karakteristik
yang sama dikelompokan dalam satu cluster yang sama dan data yang mempunyai
karakteristik yang berbeda dikelompokan ke dalam cluster yang lain.
1.2 Perumusan Masalah
Berdasarkan latar belakang diatas, maka dapat dirumuskan suatu
Bagaimana mengelompokan peminjam berdasarkan kelompok buku
sehingga dapat memberi rekomendasi pengadaan literatur yang akan
diprioritaskan.
1.3 Batasan Masalah
Agar penulisan dapat berjalan dengan baik dan sesuai dengan alurnya maka
perlu diberikan batasan-batasan masalah sebagai berikut:
1. Output yang dihasilkan berupa kelompok-kelompok (clustering) peminjam
berdasarkan jurusan.
2. Data yang diambil adalah data peminjaman buku selama 3 bulan yaitu Juni,
Juli dan September 2013.
3. Jurusan favorit tidak menetukan keaktifan peminjaman.
4. Keaktifan mahasiswa berdasarkan jumlah mahasiswa setiap jurusan
1.4 Asumsi
Sedangkan beberapa asumsi yang digunakan dalam penelitian ini adalah
sebagai berikut:
1. Data tidak berubah selama penelitian.
2. Atribut yang digunakan sesuai dengan kebutuhan penelitian, yaitu jurusan dan
peminjam dari berbagai kelompok buku.
1.5 Tujuan Penelitian
Adapun tujuan penelitian ini adalah melakukan pengelompokan peminjam
berdasarkan kelompok buku sehingga dapat memberi rekomendasi pengadaan
literatur yang akan diprioritaskan.
1.6 Manfaat Penelitian
Manfaat yang dapat diambil dari penelitian ini adalah:
1. Penelitian ini diharapkan dapat membantu memberikan saran mengenai
rekomendasi buku yang sesuai dengan kelompok-kelompok peminjam dan
dapat meningkatkan jumlah peminjaman buku pada perpustakaan pusat UPN
“Veteran” Jawa Timur.
2. Dapat mengetahui adanya kesamaan atau kemiripan peminjaman dari berbagai
jurusan dengan kelompok buku yang dipinjam.
1.7 Sistematika Penulisan
Adapun sistematika penulisan dari tugas akhir ini adalah sebagai berikut:
BAB I PENDAHULUAN
Bab ini berisi latar belakang, perumusan masalah, batasan dan
asumsi yang digunakan, tujuan dan manfaat penelitian, serta
sistematika penulisan.
BAB II TINJ AUAN PUSTAKA
Bab ini berisi dasar-dasar teori yang digunakan dalam penelitian,
antara lain definisi dan metode data mining, analisis klaster,
BAB III METODE PENELITIAN
Bab ini berisi waktu dan lokasi penelitian, variabel-variabel yang
digunakan, pengumpulan data serta langkah-langkah dalam
melakukan penelitian yaitu hal-hal yang dilakukan atau urutan
kerja menyeluruh selama pelaksanaan penelitian.
BAB IV HASIL DAN PEMBAHASAN
Bab ini berisi pengolahan dari data yang telah dikumpulkan serta
analisa dari hasil pengolahan data.
BAB V KESIMPULAN DAN SARAN
Bab ini berisi kesimpulan dan saran dari hasil penelitian sehingga
dapat memberikan suatu rekomendasi sebagai masukan bagi pihak
perpustakaan.
DAFTAR PUSTAKA
BAB II
TINJ AUAN PUSTAKA
2.1 Data Mining
Santosa (2007) menyatakan bahwa data mining sering juga disebut
knowledge discovery in database (KDD), adalah kegiatan yang meliputi
pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau
hubungan dalam set data berukuran besar. Keluaran dari data mining ini bisa
dipakai untuk memperbaiki pengambilan keputusan di masa depan. Sehingga
istilah pattern recognition sekarang jarang digunakan karena ia termasuk bagian
dari data mining.
Sedangkan menurut Larose (2004) dalam Nango (2012) menyatakan
bahwa data mining adalah suatu proses pencarian korelasi, pola dan tren baru
yang berguna dalam media penyimpanan data berukuran besar menggunakan
teknologi pengenalan pola seperti teknik-teknik statistik dan matematis. Istilah
lain yang sering digunakan antara lain knowledge mining from data, knowledge
extraction, data/ pattern analysis, data archeology, dan data dredging.
Tujuan data mining menurut Baskoro (2010) dalam Nango (2012)
menyatakan bahwa adapun tujuan dari adanya data mining adalah:
a. Explanatory, yaitu untuk menjelaskan beberapa kegiatan observasi atau suatu
kondisi.
b. Confirmatory, yaitu untuk mengkonfirmasikan suatu hipotesis yang telah ada.
2.1.1 Teknik Data mining
Perkembangan bidang data mining yang semakin pesat, menimbulkan
banyak tantangan baru, aplikasi-aplikasi dari metode dan teknik, statistik
serta sistem basis data yang ada tidak dapat secara langsung menyelesaikan
masalah-masalah yang ada dalam data mining.
Oleh karena itu maka perlu dilakukan studi-studi terkait untuk
menemukan metode data mining baru atau suatu teknik terintegrasi untuk
sebuah sistem data mining yang efektif dan efisien. Telah banyak kemajuan
dalam hal riset dan pengembangan dari data mining, juga banyak teknik
data mining dan sistem baru yang akhir-akhir ini dikembangkan.
Dalam melakukan analisis data mining secara umum teknik-teknik
pengolahan data terbagi menjadi 2 pendekatan yaitu Supervised learning dan
Unsupervised learning. Dalam pendekatan unsupervised learning metode analisis
dilakukan dengan dengan tanpa adanya latihan (training) dan tanpa adanya label
dari data. Dalam kategori ini adalah clustering analysis dan association rule
analysis.
Pendekatan lain adalah supervised learning, yaitu metode analisis dengan
menggunakan latihan (training). Dalam pendekatan supervised learning ini untuk
menemukan fungsi keputusan, fungsi pemisah atau fungsi regresi digunakan
beberapa contoh data yang mempunyai output atau label selama proses training,
disini kita ingin menemukan fungsi yang bisa dinyatakan sebagai y= f(x). Data
untuk training terdiri dari vector/matrik input dan output(label). Matrik/Vektor
Dalam unsupervised learning kita tidak mempunyai data output atau Y.
Karena hasil dari data mining ini akan digunakan untuk pengambilan keputusan
maka sifat mudah difahami dan mudah pencariannya menjadi sangat penting,
sebab bagaimanapun apabila hasil tersebut sulit untuk difahami maka
kemungkinan akan sulit juga diinterpretasikan dengan benar, yang pada akhirnya
dihawatirkan akan menghasilkan keputusan yang kurang tepat atau bahkan salah.
(Saepulloh, 2010)
Menurut Han Jiawei (2011) ada beberapa teknik data mining yang
digunakan, diantaranya adalah:
1. Association Rule Mining/ Market Basket Analsysis
Aturan asosiasi (Association rules) atau analisis afinitas (affinity analysis)
berkenaan dengan studi tentang ’apa bersama apa’. Ini bisa berupa studi
transaksi di supermarket, misalnya seseorang yang membeli susu bayi juga
membeli sabun mandi. Di sini berarti susu bayi bersama dengan sabun mandi.
Karena awalnya berasal dari studi tentang database transaksi pelanggan untuk
menentukan kebiasaan suatu produk dibeli bersama produk apa, maka aturan
asosiasi juga sering dinamakan market basket analysis. Market Basket Analysis
adalah Analisis dari kebiasaan membeli customer dengan mencari asosiasi dan
korelasi antara item-item berbeda yang diletakkan customer dalam keranjang
belanjaannya. Dari jumlah besar aturan yang mungkin dikembangkan, perlu
memiliki aturan-aturan yang cukup kuat tingkat ketergantungan antar item
dalam antecedent dan consequent. Untuk mengukur kekuatan aturan asosiasi
adalah rasio antara jumlah transaksi yang memuat antecedent dan consequent
dengan jumlah transaksi. Confidence adalah rasio antara jumlah transaksi yang
meliputi semua item dalam antecedent dan consequent dengan jumlah transaksi
yang meliputi semua item dalam antecedent.
Dimana :
S = Support
Σ(Ta+Tc) =Jumlah transaksi yang mengandung antencendent dan
consequencent
Σ(T) = Jumlah transaksi
Dimana :
C = Confidence
Σ(Ta+Tc) =Jumlah transaksi yang mengandung antencendent dan
consequencent
Σ(Ta) = Jumlah transaksi yang mengandung antencendent
Fungsi ini paling banyak digunakan untuk menganalisa data dalam rangka.
keperluan strategi pemasaran, desain katalog, dan proses pembuatan keputusan
bisnis. Contoh dari aturan asosiatif dari analisa pembelian di suatu pasar
membeli roti bersamaan dengan susu. Dengan pengetahuan tersebut, pemilik
pasar swalayan dapat mengatur penempatan barangnya. Penting tidaknya suatu
aturan asosiatif dapat diketahui dengan dua parameter support yaitu persentase
kombinasi item tersebut dalam database dan Confidence yaitu kuatnya
hubungan antar item dalam aturan asosiatif.
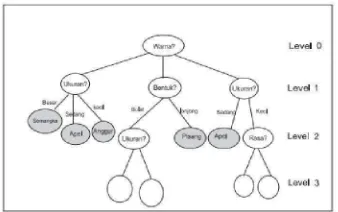
2. Decision tree
Decision tree adalah salah satu metode classification yang paling populer
karena mudah untuk diinterpretasi oleh manusia. pada dasarnya konsep
decision tree yaitu mengubah data menjadi pohon keputusan dan aturan-aturan
keputusan. Dalam decision tree kita tidak menggunakan vektor jarak untuk
mengklasifikasikan obyek. Seringkali kita mempunyai data observasi dengan
atribut-atribut yang bernilai nominal. Misalkan obyek kita adalah sekumpulan
buah-buahan yang bisa dibedakan berdasarkan atribut bentuk, warna, ukuran
dan rasa. Dalam kumpulan buah itu mungkin ada semangka dan pisang yang
bisa dibedakan berdasarkan bentuk, warna, ukuran dan rasa. Bentuk, warna,
ukuran dan rasa adalah besaran nominal, yaitu bersifat kategoris dan tiap nilai
tidak bisa dijumlahkan atau dikurangkan. Disini didasarkan pada
pengelompokan objek berdasarkan atribut dan nilainya.
Dalam gambar diatas akan nampak di situ ada 4 level pertanyaan. Dalam setiap
level ditanyakan nilai atribut melalui sebuah simpul. Jawaban dari pertanyaan
itu dikemukakan lewat cabang-cabang. Langkah ini akan berakhir di suatu
simpul jika di situ sudah jelas kelas atau jenis obyek yang kita cari. Kalau
dalam satu tingkat suatu obyek sudah diketahui termasuk dalam jenis buah apa,
maka kita berhenti di level tersebut. Jika tidak, kita susul dengan pertanyaan di
level berikutnya hingga jelas ciri-cirinya dan kita bisa menentukan jenis
buahnya. Dengan cara ini akan mudah mengelompokkan obyek ke dalam
beberapa kelompok. Dalam decision tree setiap atribut ditanyakan di simpul.
Jawaban dari atribut ini dinyatakan dalam cabang sampai akhirnya ditemukan
kategori/ jenis dari suatu obyek di simpul terakhir.
Konsep entropy digunakan untuk penentuan pada atribut mana sebuah pohon
akan terbagi. Semakin tinggi entropy sebuah sampel, semakin tidak murni
sampel tersebut. Rumus yang digunakan untuk menghitung entropy sampel S
adalah sebagai berikut :
Entropy (S) = -p1 log2 p1 – p2 log2 p2
Dimana p1, p2, ....,pn masing-masing menyatakan proposi kelas 1, kelas 2, ...,
kelas n dalam output.
Aplikasi klasifikasi decision tree telah digunakan dalam banyak area seperti
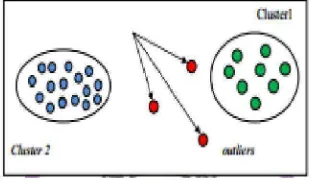
3. Clustering
Clustering adalah proses pengelompokan kumpulan data menjadi beberapa
kelompok sehingga objek di dalam satu kelompok memiliki banyak kesamaan
dan memiliki banyak perbedaan dengan objek di kelompok lain. Clustering
sendiri juga disebut unsupervised learning, karena clustering lebih bersifat
untuk dipelajari dengan diperhatikan. Cluster analysis merupakan proses
partisi satu set objek data ke dalam himpunan bagian. Setiap himpunan bagian
adalah cluster, sehingga objek yang di dalam cluster mirip satu sama dengan
lainnya, dan mempunyai perbedaan dengan objek dari cluster yang lain.
Gambar 2.2 Contoh Clustering (Baskoro dalam Novianti, 2012)
Cluster analysis banyak digunakan dalam berbagai aplikasi seperti business
inteligence, image pattern recognition, web search, biology, dan security. Di
dalam business inteligence, clustering bisa mengatur banyak customer ke
dalam banyak group. Clustering juga dapat digunakan sebagai outlier
detection, di mana outliers bisa menjadi menarik daripada kasus yang biasa.
Contoh aplikasi yang digunakan adalah outlier detection berfungsi untuk
2.2 Teknik Klastering
Menurut Santosa (2007), Teknik klaster termasuk teknik yang sudah cukup
dikenal dan banyak dipakai dalam data mining. Sampai sekarang para ilmuwan
dalam bidang data mining masih melakukan berbagai usaha untuk melakukan
perbaikan model klaster karena metoda yang dikembangkan sekarang masih
bersifat heuristik. Usaha-usaha untuk menghitung jumlah klaster yang optimal dan
pengklasteran yang paling baik masih terus dilakukan. Dengan demikian
menggunakan metoda yang sekarang, kita tidak bisa menjamin hasil
pengklasteran kita sudah merupakan hasil yang optimal. Namun, hasil yang
dicapai biasanya sudah cukup bagus dari segi praktis.
Tujuan utama dari metoda klaster adalah pengelompokan sejumlah data/
obyek kedalam klaster (group) sehingga dalam setiap klaster akan berisi data yang
semirip mungkin. Dalam klastering kita berusaha untuk menempatkan obyek yang
mirip (jaraknya dekat) dalam satu klaster dan membuat jarak antar klaster sejauh
mungkin. Ini berarti obyek dalam satu klaster sangat mirip satu sama lain dan
berbeda dengan obyek dalam klaster-klaster yang lain. Dalam teknik ini kita tidak
tahu sebelumnya berapa jumlah klaster dan bagaimana pengelompokanya.
Ada dua pendekatan dalam klastering: partisioning dan hirarki. Dalam
partisioning kita mengelompokkan obyek xi, x2, ..., xm ke dalam k klaster. Ini
bisa dilakukan dengan menentukan pusat klaster awal, lalu dilakukan realokasi
obyek berdasarkan kriteria tertentu sampai dicapai pengelompokkan yang
optimum. Dalam klaster hirarki, kita mulai dengan membuat m klaster dimana
anggotanya adalah m obyek. Pada setiap tahap dalam prosedurnya, satu klaster
digabung dengan satu klaster yang lain. Kita bisa memilih berapa jumlah klaster
yang diinginkan dengan menentukan cut-off pada tingkat tertentu.
Sedangkan menurut Hill (2007) dalam Saepulloh (2012) menyatakan
cluster analysis is usually used as an initial analytic tool, giving data mining
analysts the ability to identify general groupings in the data. Cluster analysis
merupakan salah satu metode data mining yang bersifat tanpa latihan
(unsupervised analisys) yang mempunyai tujuan untuk mengelompokan data
kedalam kelompok-kelompok dimana data-data yang berada dalam kelompok
yang sama akan mempunyai sifat yang relatif homogen.
Jika ada n objek pengamatan dengan p variable maka terlebih dulu
ditentukan ukuran kedekatan sifat antar data, ukuran kedekatan sifat data yang
bisa digunakan adalah jarak euclidius (Euclidean distance) antara dua objek dari
p dimensi pengamatan, jika objek pertama yang akan diamati adalah X =
[x1,x2,x3,….xp] dan Y=[y1,y2,y3,….yp] maka euclidean distance dirumuskan
sebagai berikut :
Secara formal definisi dari cluster analysis adalah sebagai berikut:
Misalkan S adalah himpunan objek yang mempunyai n buah elemen,
S = {o1,o2,o3…on}
Cluster analysis membagi S menjadi k himpunan C1,C2,C3…Ck,
himpunan bagian dari S, Ci ⊆ S . Solusi atau keluaran dari sebuah cluster
Analysis dinyatakan sebagai himpunan dari semua cluster,
1 2 3
{ , , .... k | i , i 1, 2.. } C= C C C C C ⊆ ∀ ∈S k
Jika S adalah himpunan objek yang mempunyai n buah elemen dan terdiri dari r
variable maka ketika S dibagi menjadi k cluster, maka model dari cluster dapat
didefinisikan dengan dua buah matrik yaitu matrik data Dnxk = (dik) dan matrik
variable Frxk = (fjk),
1, data ke i anggota kluster ke k
0,data ke i bukan anggota kluster ke k
ik d =
1, Variable ke j anggota kluster ke k
0, Variable ke j bukan anggota kluster ke k
jk f =
Proses clustering mengasumsikan bahwa data akan menjadi anggota dari satu dan
hanya satu cluster. (Hill, 2007 dalam Saepulloh, 2012)
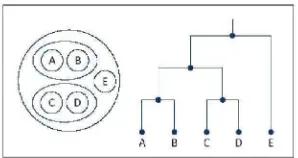
2.2.1 Klasifikasi Metode Klastering
Metode klastering pada dasarnya ada dua jenis, yaitu metode cluster
analysis hirarki (hierarchical clustering method) dan Metode cluster analysis non
hirarki (non hierarchical clustering method). Metode clustering hirarki digunakan
apabila belum ada informasi jumlah cluster yang akan dipilih, metode hirarki akan
menghasilkan cluster-cluster yang bersarang (nested) sehingga masing-masing
cluster dapat memiliki sub-cluster. Prinsip utama metode cluster analysis hirarki
pohon biner) berdasarkan suatu fungsi kriteria tertentu. Pohon tersebut disebut
dendogram.
Gambar 2.3 Contoh Dendogram (Saepulloh,2010)
Semakin tinggi level simpul pohon maka semakin rendah tingkat
similaritas antar objeknya, metode cluster analysis hirarki dapat dilakukan dengan
dua pendekatan yaitu bottom-up (agglomerative) dan top-down (divisive). Pada
pendekatan aggromerative setiap objek pada awalnya berada pada cluster
masing-masing, kemudian setiap cluster yang paling mirip akan dikelompokan
dalam satu cluster, hingga membentuk suatu hirarki cluster. Sedangkan pada
pendekatan divisive, pada awalnya hanya terdapat satu buah cluster tunggal yang
beranggotakan seluruh objek, kemudian dilakukan pemecahan atas cluster
tersebut menjadi beberapa sub-cluster, contoh algoritma metode cluster hirarki
adalah HAC (Hieararchical Aggromerative Clustering) dengan beberapa variasi
perhitungan similaritas antar cluster seperti single-link, complete-link dan group
average.
Sedangkan metode cluster analysis non hirarki biasa juga disebut dengan
partitional clustering bertujuan mengelompokan n objek kedalam k cluster (k < n)
dimana nilai k sudah ditentukan sebelumnya. Salah satu prosedur clustering non
hirarki adalah menggunakan metode K-Means clustering analisis, yaitu metode
jarak tiap objek ke pusat cluster (centroid) adalah minimum, titik pusat cluster
terbentuk dari rata-rata nilai dari setiap variable.
Secara umum proses cluster analysis dimulai dengan perumusan masalah
clustering dengan mendefinisikan variable-variable yang akan digunakan sebagai
dasar proses cluster. Konsep dasar dari cluster analysis adalah konsep pengukuran
jarak (distance) atau kesamaaan (similarity), distance adalah ukuran tentang
jarak pisah antar objek sedangkan similaritas adalah ukuran kedekatan.
Pengukuran jarak (distance type measure) digunakan untuk data-data yang
bersifat metrik, sedangkan pengukuran kesesuaian (matching type measure)
digunakan untuk data-data yang bersifat kualitatif atau non metrik. Proses
clustering yang baik seharusnya menghasilkan cluster-cluster yang berkualitas
tinggi dengan sifat-sifat sebagai berikut:
a. Setiap objek pada cluster memiliki kemiripan (intra cluster similarity) yang
tinggi satu sama lainnya.
b. Kemiripan objek pada cluster yang berbeda (inter cluster similarity) rendah.
( Saepulloh, 2010)
2.2.2 K-Means
Cluster analysis merupakan salah satu metode data mining yang bersifat
tanpa latihan (unsupervised analisys), K-means cluster analysis merupakan salah
satu metode cluster analysis non hirarki yang berusaha untuk mempartisi data
karakteristiknya, sehingga data yang mempunyai karakteristik yang sama
dikelompokan dalam satu cluster yang sama dan data yang mempunyai
karakteristik yang berbeda dikelompokan ke dalam cluster yang lain. Tujuannya
adalah untuk meminimalkan objective function yang di set dalam proses
clustering, yang pada dasarnya berusaha untuk meminimalkan variasi dalam satu
cluster dan memaksimalkan variasi antar cluster.
Metode ini meliputi sequential threshold, pararel threshold dan optimizing
threshold, Sequential threshold melakukan pengelompokan dengan terlebih
dahulu memilih satu objek dasar yang akan dijadikan nilai awal cluster, kemudian
semua cluster yang ada dalam jarak terdekat dengan cluster ini akan bergabung,
lalu dipilih cluster kedua dan semua objek yang mempunyai kemiripan dengan
cluster ini akan digabungkan, demikian seterusnya sehingga terbentuk beberapa
cluster dengan keseluruhan objek terdapat didalamnya. (Saepulloh, 2010)
Santosa (2007) menyatakan bahwa, dari beberapa teknik klastering yang
paling sederhana dan umum dikenal adalah klastering k-means. Dalam teknik ini
kita ingin mengelompokkan obyek ke dalam k kelompok atau klaster. Untuk
melakukan klastering ini, nilai k harus ditentukan terlebih dahulu. Biasanya user
atau pemakai sudah mempunyai informasi awal tentang obyek yang sedang
dipelajari, termasuk berapa jumlah klaster yang paling tepat. Secara detail kita
bisa menggunakan ukuran ketidakmiripan untuk mengelompokkan obyek kita.
data titik cukup dekat, maka dua obyek itu mirip. Semakin dekat berarti semakin
tinggi kemiripannya. Semakin tinggi nilai jarak, semakin tinggi
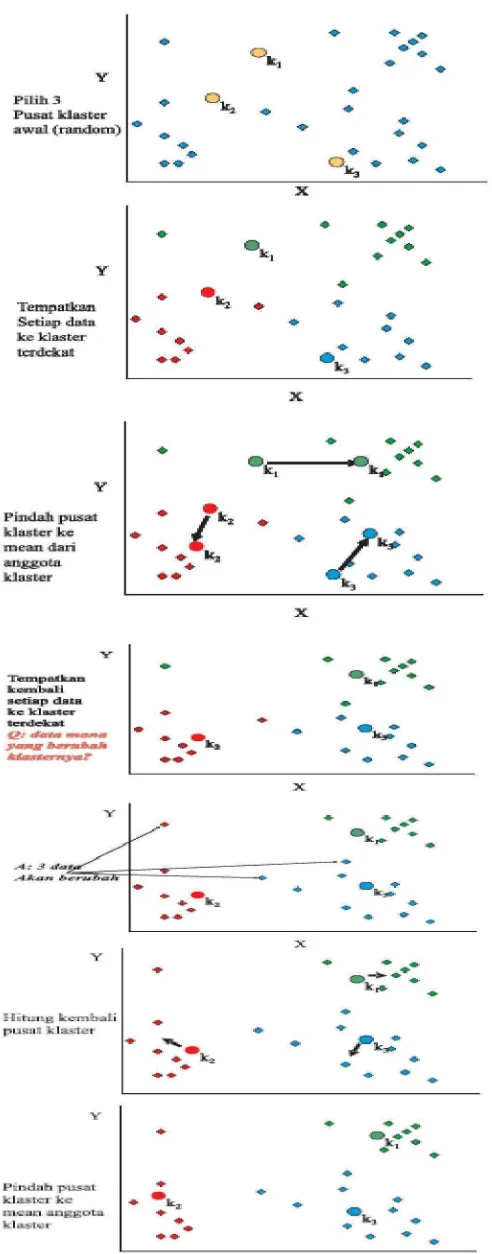
ketidakmiripannya. Algoritma k-means klastering dapat diringkas sebagai berikut:
a. Pilih jumlah klaster k
b. Inisialisasi k pusat klaster Ini bisa dilakukan dengan berbagai cara. Yang paling
sering dilakukan adalah dengan cara random. Pusat-pusat klaster diberi nilai
awal dengan angka-angka random.
c. Tempatkan setiap data/ obyek ke klaster terdekat. Kedekatan dua obyek
ditentukan berdasar jarak kedua obyek tersebut. Demikian juga kedekatan
suatu data ke klaster tertentu ditentukan jarak antara data dengan pusat klaster.
Dalam tahap ini perlu dihitung jarak tiap data ke tiap pusat klaster. Jarak paling
dekat antara satu data dengan satu klaster tertentu akan menentukan suatu data
masuk dalam klaster mana.
d. Hitung kembali pusat klaster dengan keanggotaan klaster yang sekarang Pusat
klaster adalah rata-rata dari semua data/ obyek dalam klaster tertentu. Jika
dikehendaki bisa juga memakai median dari klaster tersebut. Jadi rata-rata
(mean) bukan satu-satunya ukuran yang bisa dipakai.
e. Tugaskan lagi setiap obyek dengan memakai pusat klaster yang baru. Jika
pusat klaster sudah tidak berubah lagi, maka proses pengklasteran selesai.
Adapun rumus untuk pengerjaan Algoritma K-Means adalah sebagai berikut:
A. Me ne nt uka n Ba nya k nya Clu ste r k
Untuk menentukan nilai banyaknya cluster k dilakukan dengan
beberapa pertimbangan sebagai berikut: (Saepulloh, 2010)
1. Pertimbangan teoritis, konseptual, praktis yang mungkin diusulkan untuk
menentukan berapa banyak jumlah cluster.
2. Besarnya relative cluster seharusnya bermanfaat, pemecahan cluster
yang menghasilkan 1 objek anggota cluster dikatakan tidak bermanfaat
sehingga hal ini perlu untuk dihindari.
B. Me ne nt uka n Cent roid
Penentuan centroid awal dilakukan secara random/ acak dari data/
objek yang tersedia sebanyak jumlah kluster k, kemudian untuk menghitung
centroid cluster berikutnya ke i, vi digunakan rumus sebagai berikut:
C. Me ng h it u ng J arak Ant ara Dat a De nga n Ce ntroid
Menurut Santosa (2007), untuk menghitung jarak antara data dengan
centroid dapat dihitung dengan menggunakan rumus:
Dimana P : Dimensi data
| . | : Nilai Absolut
Sedangkan untuk euclidean distance jarak antara data dengan centroid
dihitung dengan menggunakan rumus:
Dimana P : Dimensi data
| . | : Nilai Absolut
D. Penga lo k as ia n U la ng Dat a Keda la m Ma s in g- ma s ing Clust er
Untuk melakukan pengalokasian data kedalam masing-masing cluster
pada saat iterasi dilakukan secara umum dengan dua cara yaitu dengan cara
pengalokasian dengan cara hard k-means, dimana secara tegas setiap objek
dinyatakan sebagai anggota cluster satu dan tidak menjadi anggota cluster
lainnya. Cara lain adalah dengan cara fuzzy k-means dimana masing-masing
objek diberikan nilai kemungkinan untuk bisa bergabung dengan setiap
E. Konv erg ens i
Pengecekan konvergensi dilakukan dengan membandingkan matrik
group assignment pada iterasi sebelumnya dengan matrik group assignment
pada iterasi yang sedang berjalan. Jika hasilnya sama maka algoritma
k-means cluster analysis sudah konvergen, tetapi jika berbeda maka belum
konvergen sehingga perlu dilakukan iterasi berikutnya. (Saepulloh, 2010)
2.2.3 C on t oh P en e r a p a n A lgo r it m a K-M e an s Clu st er A n a ly sis
Untuk mempermudah memahami algoritma k-means cluster analysis maka
berikut ini adalah contoh sederhana pemakaian algoritma k-means cluster,
Misalkan kita mempunyai dua variable X1 dan X2 dengan masing-masing
mempunyai item-item A, B, C dan D sebagai berikut:
Tabel 2.1 Tabel Observasi
Item Observasi
X1 X2
A 1 1
B 2 1
C 4 3
D 5 4
Tujuannya adalah membagi semua item menjadi 2 cluster ( k = 2) , dengan
menggunakan algoritma yang disebutkan diatas maka langkah-langkah yang
a. Tentukan k sebagai jumlah cluster yang akan di bentuk
k = 2
b. Bangkitkan k Centroid (titik pusat cluster) awal secara random
Secara random kita tentukan A dan B sebagai centroid yang pertama, sehingga
diperoleh c1= (1,1) dan c2= (2,1)
c. Hitung jarak setiap data ke masing-masing centroid dari masing-masing cluster
dengan Euclidian distance sebagai berikut :
Sehingga distance yang diperoleh adalah sebagai berikut:
d. Alokasikan masing-masing data ke dalam centroid yang paling terdekat
Proses alokasi dilakukan dengan melihat minimum distance. Dari table
distance diatas maka terlihat bahwa jarak item A terdekat pada cluster C1
sehingga item A dialokasikan kepada cluster C1, sementara item B, Item C,
Item D jarak terdekatnya pada cluster C2, sehingga item B, C, D dialokasikan
pada cluster C2. Dengan menggunakan rumus alokasi dibawah ini,
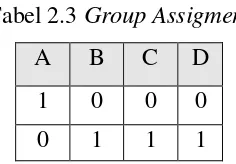
Maka diperoleh table group assigmentnya adalah sebagai berikut:
Tabel 2.3 Group Assigment
A B C D
1 0 0 0
0 1 1 1
e. Lakukan iterasi-1, kemudian tentukan posisi centroid baru dengan cara
menghitung rata-rata dari data-data yang berada pada centroid yang sama.
Maka diperoleh centroid baru untuk kedua cluster tersebut adalah
C1 = (1,1), karena beranggotakan 1 anggota
1
karena nilai centroidnya berbeda maka langkah no 3 diulangi kembali sebagai
Sehingga distance yang diperoleh pada iterasi 1 adalah sebagai berikut:
Tabel 2.4 Distance Pada Iterasi 1
Cluster
Distance
A B C D
C1 0 1 3,61 5
C2 3,14 2,36 0,47 1,89
g. Alokasikan masing-masing data ke dalam centroid yang paling terdekat
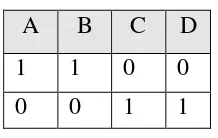
Maka diperoleh table group assigmentnya pada iterasi 1 adalah sebagai
berikut:
Tabel 2.5 Table Group Assigmentnya
A B C D
1 1 0 0
0 0 1 1
Karena hasil table group assignment pada iterasi 1 berbeda dengan table
group assignment sebelumya maka hasilnya belum konvergen sehingga perlu
dilakukan iterasi berikutnya, sebagai berikut:
h. Lakukan iterasi-2, tentukan posisi centroid baru dengan cara menghitung
rata-rata dari data-data yang berada pada centroid yang sama.
Maka diperoleh centroid baru untuk kedua cluster tersebut adalah
1
i. karena nilai centroid-nya berbeda dengan iterasi 1 maka langkah berikutnya
menghitung kembali distance-nya sebagai berikut:
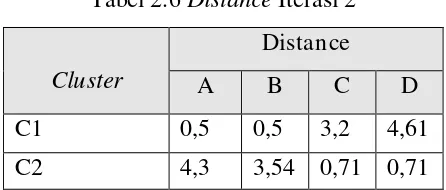
Sehingga distance yang diperoleh pada iterasi 1 adalah sebagai berikut:
Tabel 2.6 Distance Iterasi 2
Cluster
Distance
A B C D
C1 0,5 0,5 3,2 4,61
C2 4,3 3,54 0,71 0,71
j. Alokasikan masing-masing data ke dalam centroid yang paling terdekat
Maka diperoleh table group assigmentnya pada iterasi 2 adalah sebagai
berikut:
Tabel 2.7 Table Group Assigment Iterasi 2
A B C D
1 1 0 0
0 0 1 1
Dari hasil table assignment pada iterasi 2 ternyata hasilnya sama dengan
table group assignment pada iterasi 1 sehingga pada iterasi 2 ini sudah konvergen
sehingga tidak perlu dilakukan iterasi kembali, dan hasil akhir cluster yang
diperoleh adalah pada tabel dibawah ini:
Tabel 2.8 Hasil Akhir Cluster
Item Observasi Cluster
X1 X2
A 1 1 1
B 2 1 1
C 4 3 2
2.3 Penentuan Sampel
Menurut Sugiono (2007), populasi adalah wilayah generalisasi yang terdiri
atas objek/ subjek yang mempunyai kualiatas dan karakteristik tertentu yang
ditetapkan oleh peneliti untuk dipelajari kemudian ditarik kesimpulannya. Sampel
adalah bagian dari populasi yang menjadi objek penelitian. Penentuan besarnya
sampel dalam suatu penelitian merupakan hal yang sangat penting. Fokus utama
dalam menentukan besarnya sampel yaitu bagaimana agar besarnya sampel yang
ditetapkan oleh peneliti dapat mewakili populasi darimana sampel tersebut
diambil. Berdasarkan pada pengkajian yang dilakukan terhadap beberapa metode
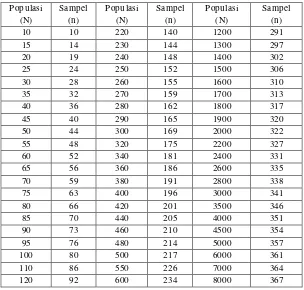
penentuan besarnya sampel digunakan tabel Krejcie dan Morgan untuk
memperhatikan dan memperhitungkan karakteristik populasi ke dalam penentuan
besarnya sampel.
Tabel 2.9 Krejcie dan Morgan
Populasi
Adapun rumus yang digunakan oleh Krejcie dan Morgan adalah:
Dimana:
Berdasarkan pada perhitungan diatas, dapat diketahui beberapa keterangan
mengenai Tabel Krejcie-Morgan sebagai berikut:
1. Tabel Krejcie-Morgan dapat dipakai untuk menentukan ukuran sampel, hanya
jika penelitian bertujuan untuk yang menduga proporsi populasi.
2. Asumsi tingkat keandalan 95%, karena menggunakan nilai = 3,841 yang
artinya memakai a=0,05 pada derajat bebas 1.
3. Asumsi keragaman populasi yang dimasukkan dalam perhitungan adalah
P(1-P), dimana P=0,5.
2.4 Peneliti Terdahulu
Adapun peneliti terdahulu yang dapat digunakan sebagai acuan penelitian
ini adalah sebagai berikut:
1. Prabowo hadi (2011) dengan judul “penggolongan suara berdasarkan usia
dengan menggunakan metode k-means”. Tujuan penelitian ini adalah agar
system dapat mengelompokkan suara dewasa dan anak-anak. Teknologi wicara
adalah salah satu teknologi aplikasi yang telah ditemukan beberapa tahun lalu.
Salah satunya adalah speaker recognition yang merupakan suatu proses yang
sering disebut dengan verifikasi pengucap. Pada saat ada sinyal wicara masuk,
sistem akan melakukan proses pengolahan wicara. Kemudian hasil ekstraksi
sinyal baru tersebut akan dibandingkan dengan hasil ekstraksi sinyal standar
yang terdapat di database menggunakan metode DFT dan K-means sehingga
akan dibandingkan dengan hasil pengklusteran, apakah suara tersebut masuk
dalam range centroid 1 (dewasa) atau centroid 2 (anak anak). Hasil dari
Software ini adalah berupa clustering suara dewasa dan anak anak, yang mana
nantinya system akan membedakan suara dewasa dan anak anak dengan
melihat nilai formant 2 nya.
2. Dwi Novianti Nango (2012) dengan judul “penerapan algoritma k-means untuk
clustering data anggaran pendapatan belanja daerah di kabupaten XYZ”.
Tujuan penelitian ini adalah mengelompokkan data APBD tahun 2006-2011
yang memiliki kemiripan karakteristik berdasarkan kedekatan jarak,
menggunakan teknik clustering dengan algoritma K-Means. Dengan
diharapkan dapat mengelompokkan dan menentukan jumlah cluster yang
paling tepat/ akurat juga memprediksi nilai belanja tidak langsung serta nilai
belanja langsung yang akan datang terhadap data APBD Kabupaten XYZ.
Berdasarkan penelitian yang dilakukan dapat diketahui bahwa pembentukan
cluster dengan 3 nilai centroid adalah cluster yang terbaik, Untuk nilai
pendapatan tahun 2012 sebesar Rp 394.083.451.404,-,diperoleh hasil estimasi
nilai belanja tidak langsung sebesar Rp 199.533.334.595,76,- sampai Rp
203.564.311.052,24. Serta estimasi nilai belanja langsung sebesar Rp
176.135.846.021,76,- sampai Rp 180.166.822.478,24,-.
3. Eliyani, Tulus, Fahmi (2013) dengan judul “pengenalan tingkat kematangan
buah pepaya paya rabo menggunakan pengolahan citra berdasarkan warna
RGB dengan k-means clustering”. Tujuan penelitian ini adalah menemukan
metode yang tepat yang bisa diterapkan pada peralatan yang mampu dan
mempunyai keahlian memilih dan memilah kondisi buah yang akan dijual
berdasarkan jarak kirim untuk lokal, provinsi atau antar negara. Disini timbul
permasalahan bagaimana mengenali buah sehingga sesuai dengan kondisi
nyata. Metode pengolahan citra mempunyai kemampuan untuk menganalisa
kondisi kematangan pepaya dengan menggunakan nilai Red, Green, Blue
(RGB) sebagai acuan. Penentuan klasifikasi dengan metode K-means
clustering yang menggunakan selisih jarak eucludian sebagai acuannya. Untuk
hasil pada kelompok pepaya muda 60% berhasil dikenali sebagai pepaya muda,
kelompok pepaya mengkal 90% berhasil dikenali sebagai masak mengkal
BAB III
METODOLOGI PENELITIAN
Untuk menyelesaikan permasalahan dalam penelitian ini maka digunakan
metode penelitian yang sistematis dan terarah untuk mencapai tujuan penelitian.
Dalam rangkaian penelitian ini terdapat beberapa langkah-langkah penelitian
yaitu:
3.1 Tempat dan Waktu Penelitian
Dalam penelitian ini, pengambilan data dilakukan di Perpustakaan Pusat
UPN “Veteran” Jawa Timur Surabaya. Sedangkan waktu yang digunakan untuk
melakukan pengambilan data pada bulan Juni, Juli dan September 2013.
3.2 Identifikasi dan Definisi Operasional Var iabel
Pada suatu penelitian, variabel dapat diartikan sebagai faktor-faktor yang
berpengaruh pada peristiwa yang diamati dan mempunyai variasi nilai. Jadi
identifikasi variabel adalah mengidentifikasi faktor-faktor yang terlibat dalam
penelitian yang mempunyai variasi nilai dan besaran. Variabel penelitian ini
tergantung dari objek yang diteliti, landasan teori dan metode yang dipakai dalam
permasalahan yang akan diteliti ini. Variabel yang akan digunakan adalah sebagai
a. Variabel Terikat
Variabel terikat adalah variabel yang nilainya tergantung dari variasi
perubahan variabel bebas. Dalam penelitian ini yang termasuk variabel terikat
yaitu prioritas buku yang direkomendasikan untuk ditambah.
b. Variabel Bebas
Variabel bebas adalah variabel yang mempengaruhi variasi perubahan nilai
variable terikat. Dalam penelitian ini yang termasuk variabel bebas antara lain
meliputi:
1. Jurusan
2. Jumlah peminjam kelompok buku karya umum
3. Jumlah peminjam kelompok buku filsafat
4. Jumlah peminjam kelompok buku agama
5. Jumlah peminjam kelompok buku ilmu-ilmu sosial
6. Jumlah peminjam kelompok buku bahasa
7. Jumlah peminjam kelompok buku ilmu-ilmu murni
8. Jumlah peminjam kelompok buku teknologi terapan
9. Jumlah peminjam kelompok buku kesenian
10. Jumlah peminjam kelompok buku kesusasteraan
11. Jumlah peminjam kelompok buku sejarah
3.3 Metode Pengumpulan Data
Dalam suatu penelitian, data merupakan kedudukan yang paling tinggi,
sebagai alat pembuktian hipotesis. Data yang akurat syarat utama bagi terciptanya
tujuan penelitian agar dapat memberikan suatu keputusan yang tepat. Data yang
digunakan dalam penelitian ini adalah data sekunder dan data primer. Data
sekunder merupakan data yang diperoleh peneliti dengan melakukan
pengumpulan data yang ada di perpustakaan (dokumen perpustakaan). Serta study
kepustakaan yang tujuannya untuk memperoleh wawasan serta landasan teori
yang akan digunakan untuk pemecahan masalah mengenai klaster. Adapun data
yang diperoleh dari perpustakaan adalah berupa data sirkulasi peminjaman buku.
Data primer merupakan data yang diperoleh peneliti dengan melakukan
wawancara dengan pihak perpustakaan dan mahasiswa sebagai acuan pembuatan
tolok ukur penelitian.
3.4 Metode Pengolahan Data
Setelah pengumpulan data diperoleh, maka selanjutnya adalah melakukan
pengolahan data dengan menggunakan metode K-Means. Adapun
langkah-langkahnya sebagai berikut:
1. Pilih jumlah klaster k.
2. Inisialisasi k pusat klaster dilakukan adalah dengan cara random. Pusat-pusat
klaster diberi nilai awal dengan angka-angka random.
3. Tempatkan setiap data/ obyek ke klaster terdekat. Kedekatan dua obyek
ditentukan berdasar jarak kedua obyek tersebut. Jarak paling dekat antara satu
data dengan satu klaster tertentu akan menentukan suatu data masuk dalam
4. Hitung kembali pusat klaster dengan keanggotaan klaster yang sekarang. Jika
dikehendaki bisa juga memakai median dari klaster tersebut. Jadi rata-rata
(mean) bukan satu-satunya ukuran yang dapat digunakan.
5. Tugaskan lagi setiap obyek dengan memakai pusat klaster yang baru. Jika
pusat klaster sudah tidak berubah lagi, maka proses pengklasteran selesai.
3.5 Langkah-langkah Pemecahan Masalah
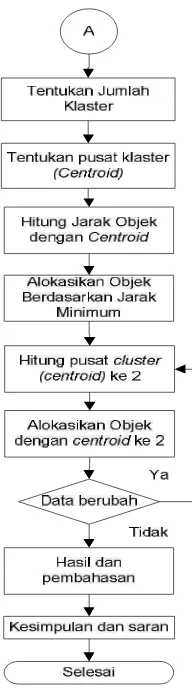
Pada gambar 3.1 akan diuraikan secara singkat mengenai langkah yang akan
Gambar 3.1 Langkah-langkah Pemecahan Masalah
Keterangan Langkah-langkah pemecahan masalah:
1. Mulai
Merupakan langkah awal dari suatu penelitian yang akan dilakukan.
2. Study lapangan
Untuk mengetahui informasi yang dibutuhkan, dilakukan pengumpulan data
dari lapangan (Perpustakaan UPN “Veteran” Jatim).
3. Study literatur
Study literatur diperoleh dari buku, skripsi maupun jurnal yang berkaitan
4. Perumusan masalah
Melakukan perumusan masalah yang akan diteliti kemudian melakukan suatu
pendekatan untuk memecahkan masalah.
5. Tujuan Penelitian
Menetapkan tujuan yang ingin dicapai, sehingga dapat menentukan arah
sasarannya.
6. Identifikasi variabel
Setelah menentukan tujuan penelitian, kemudian ditentukan variabel-variabel
yang akan diidentifikasi menjadi obyek penelitian.
7. Pengumpulan data
Data yang diperlukan dalam penelitian ini adalah Jurusan, Jumlah peminjam
kelompok buku karya umum, Jumlah peminjam kelompok buku filsafat,
Jumlah peminjam kelompok buku agama, Jumlah peminjam kelompok buku
ilmu-ilmu sosial, Jumlah peminjam kelompok buku bahasa, Jumlah peminjam
kelompok buku ilmu-ilmu murni, Jumlah peminjam kelompok buku
teknologi terapan, Jumlah peminjam kelompok buku kesenian, Jumlah
peminjam kelompok buku kesusasteraan dan Jumlah peminjam kelompok
buku sejarah.
8. Penentuan jumlah sampel
Setelah data terkumpul dilakukan penentuan jumlah sampel yang dibutuhkan.
9. Uji kecukupan data
Dari penentuan jumlah sampel, dilakukan uji kecukupan data berdasarkan
10. Data cukup
Jika jumlah sampel mencukupi maka dilanjutkan menentukan jumlah klaster.
Jika sampel belum tercukupi maka perlu dilakukan pengambilan data
kembali.
11. Tentukan jumlah klaster
Pilih jumlah klaster k
12. Tentukan pusat klaster (centroid)
Pusat-pusat klaster diberi nilai awal dengan angka-angka random.
13. Hitung jarak objek dengan centroid
Tempatkan setiap data/ obyek ke klaster terdekat. Kedekatan dua obyek
ditentukan berdasar jarak kedua obyek tersebut. Jarak paling dekat antara satu
data dengan satu klaster tertentu akan menentukan suatu data masuk dalam
klaster mana.
14. Alokasikan objek berdasarkan jarak minimum
Hitung kembali pusat klaster dengan keanggotaan klaster yang akan dihitung.
15. Hitung pusat klaster (centroid) ke 2
Hitung kembali pusat klaster dengan keanggotaan klaster yang sekarang
dengan menggunakan rata-rata atau jika dikehendaki bisa juga memakai
median dari klaster tersebut.
16. Alokasikan objek dengan centroid ke 2
17. Data berubah
Setelah dilakukan pengalokasian objek, jika pusat klaster masih berubah
maka kembali menghitung jarak objek dengan centroid. Tapi jika data
dinyatakan tidak berubah maka dilanjutkan dengan klasterisasi. Data
dikatakan tidak berubah jika dari hasil iterasi pertama hingga iterasi kedua
tidak ada lagi perubahan pada jarak minimum objek dengan centroid.
18. Hasil dan pembahasan
Untuk mengetahui keterangan dari hasil klaster yang didapat, maka dilakukan
pembahasan atau analisa hasil.
19. Kesimpulan dan saran
Dari hasil pengklasteran data, maka dapat diberi kesimpulan dari
permasalahan yang ada dan saran atas kesimpulan yang didapat.
BAB IV
HASIL DAN PEMBAHASAN
Pada bab IV ini akan dilakukan pengumpulan data sekaligus dilakukan
pengolahan data yang sesuai dengan permasalahan yang akan dipecahkan. Data
yang digunakan dalam penelitian ini adalah sirkulasi peminjaman buku di
perpustakaan pusat UPN “Veteran” Jawa Timur bulan Juni, Juli dan September
2013.
4.1 Pengumpulan Data
Data yang digunakan dalam penelitian ini yaitu jurusan dan jumlah
peminjam setiap kelompok buku. Data tersebut didapatkan dari sirkulasi
peminjaman buku di perpustakaan pusat UPN “Veteran” Jawa Timur selama 3
bulan yaitu Juni, Juli dan September 2013. Jumlah peminjam dari jurusan ilmu
ekonomi dan pembangunan adalah 51 mahasiswa, jurusan manajemen 235
mahasiswa, jurusan akuntansi 642 mahasiswa, jurusan agribisnis 94 mahasiswa,
jurusan agroteknologi 40 mahasiswa, jurusan teknik kimia 82 mahasiswa, jurusan
teknik industri 76 mahasiswa, jurusan teknik pangan 51 mahasiswa, jurusan
teknik informatika 58 mahasiswa, jurusan sistem informasi 32 mahasiswa, jurusan
administrasi negara 87 mahasiswa, jurusan administrasi bisnis 51 mahasiswa,
jurusan ilmu komunikasi 186 mahasiswa, jurusan hubungan internasional 27
mahasiswa, jurusan teknik arsitektur 33 mahasiswa, jurusan teknik lingkungan 58
mahasiswa, jurusan teknik sipil 51 mahasiswa, jurusan desain komunikasi visual 9
Adapun kode data yang digunakan dalam pengumpulan data adalah sebagai
berikut:
Tabel 4.1 Kode Buku Berdasarkan DDC
(Dewey Decimal Clasification)
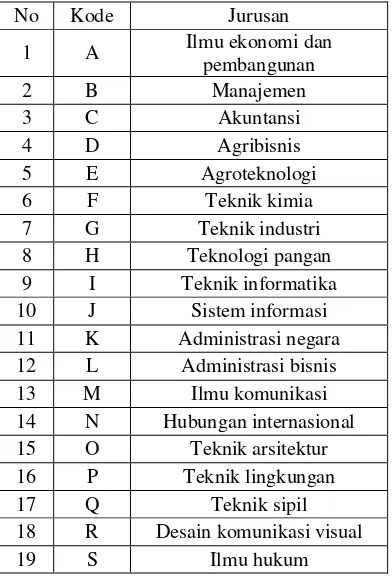
Tabel 4.2 Kode Mahasiswa Berdasarkan Jurusan
No Kode Jurusan
11 K Administrasi negara
12 L Administrasi bisnis
13 M Ilmu komunikasi
14 N Hubungan internasional
15 O Teknik arsitektur
16 P Teknik lingkungan
17 Q Teknik sipil
18 R Desain komunikasi visual
4.2 Penentuan Sampel
Dari hasil pengumpulan data sirkulasi peminjaman buku di perpustakaan
pusat diketahui populasi anggota perpustakaan selama 1 tahun (Januari-November
2013) sebanyak 1.760 mahasiswa sedangkan sirkulasi selama 3 bulan yaitu Juni,
Juli dan September sebanyak 1.922, maka perlu ditentukan sampel untuk
dilakukan pengolahan data. Penentuan besarnya sampel digunakan tabel Krejcie
dan Morgan untuk memperhatikan dan memperhitungkan karakteristik populasi
ke dalam penentuan besarnya sampel.
Tabel 4.3 Krejcie dan Morgan
Populasi
Berdasarkan pada tabel 4.3 dapat diketahui jumlah populasi adalah 1.760 ≈
1.800. artinya disini harus ada jumlah sampel minimal 317 sedangakan jumlah
sirkulasi peminjam sebagai sampling dalam 3 bulan yaitu Juni, Juli dan September
sebanyak 1922. Jadi 1922 > 317, sehingga sampling data yang diolah sudah
4.3 Pengolahan Data
Adapun pengolahan data yang dilakukan sebagai berikut:
Tabel 4.4 Jumlah Peminjam Tanggal 3-14 Juni 2013
No Kode
(Sumber: Perpustakaan UPN “Veteran” Jatim)
Dari hasi tabel diatas diketahui pada tanggal 3-14 Juni 2013 jurusan yang
melakukan peminjaman paling banyak adalah kode jurusan C yaitu akuntansi
dengan jumlah variasi peminjaman kelompok buku sebanyak 4 yaitu karya umum,
ilmu-ilmu sosial, bahasa, ilmu-ilmu murni dan teknologi terapan sedangkan
jurusan yang melakukan peminjaman paling sedikit adalah kode jurusan O dan P
yaitu teknik arsitektur dan teknik lingkungan dengan jumlah variasi peminjaman
Tabel 4.5 Jumlah Peminjam Tanggal 17-28 Juni 2013
(Sumber: Perpustakaan UPN “Veteran” Jatim)
Dari hasi tabel diatas dapat diketahui pada tanggal 17-28 Juni 2013 jurusan
yang melakukan peminjaman paling banyak adalah kode jurusan C yaitu
akuntansi dengan jumlah variasi peminjaman kelompok buku sebanyak 4 yaitu
karya umum, ilmu-ilmu sosial, ilmu-ilmu murni dan teknologi terapan sedangkan
jurusan yang tidak melakukan peminjaman adalah kode jurusan G yaitu teknik
Tabel 4.6 Jumlah Peminjam Tanggal 1-12 Juli 2013
(Sumber: Perpustakaan UPN “Veteran” Jatim)
Dari hasi tabel diatas dapat diketahui pada tanggal 1-12 Juli 2013 jurusan
yang melakukan peminjaman paling banyak adalah kode jurusan C yaitu
akuntansi dengan jumlah variasi peminjaman kelompok buku sebanyak 4 yaitu
karya umum, ilmu-ilmu sosial, bahasa, ilmu-ilmu murni dan teknologi terapan
sedangkan jurusan yang tidak melakukan peminjaman adalah kode jurusan N
Tabel 4.7 Jumlah Peminjam Tanggal 15-26 Juli 2013
(Sumber: Perpustakaan UPN “Veteran” Jatim)
Dari hasi tabel diatas dapat diketahui pada tanggal 15-26 Juli 2013 jurusan
yang melakukan peminjaman paling banyak adalah kode jurusan M yaitu ilmu
komunikasi dengan jumlah variasi peminjaman kelompok buku sebanyak 4 yaitu
karya umum, filsafat, ilmu-ilmu sosial dan teknologi terapan sedangkan jurusan
yang tidak melakukan peminjaman ada 6 kode jurusan yaitu A, D, E, K, L dan N.
Jurusan yang terdapat dalam kode tersebut adalah Ilmu ekonomi dan
pembangunan, agribisnis, agroteknologi, administrasi negara, administrasi bisnis
Tabel 4.8 Jumlah Peminjam Tanggal 29-31 Juli dan 2-6 September 2013
(Sumber: Perpustakaan UPN “Veteran” Jatim)
Dari hasi tabel diatas dapat diketahui pada tanggal 29-31 Juli dan 2-6
September 2013 jurusan yang melakukan peminjaman paling banyak adalah kode
jurusan C yaitu akuntansi dengan jumlah variasi peminjaman kelompok buku
sebanyak 6 yaitu karya umum, filsafat, ilmu-ilmu sosial, bahasa, ilmu-ilmu murni
dan teknologi terapan sedangkan jurusan yang melakukan peminjaman paling
sedikit adalah kode jurusan R yaitu desain komunikasi visual dengan jumlah
Tabel 4.9 Jumlah Peminjam Tanggal 9-20 September 2013
(Sumber: Perpustakaan UPN “Veteran” Jatim)
Dari hasi tabel diatas dapat diketahui pada tanggal 9-20 September 2013
jurusan yang melakukan peminjaman paling banyak adalah kode jurusan C yaitu
akuntansi dengan jumlah variasi peminjaman kelompok buku sebanyak 6 yaitu
karya umum, agama, ilmu-ilmu sosial, bahasa, ilmu-ilmu murni dan teknologi
terapan sedangkan jurusan melakukan peminjaman paling sedikit adalah kode
jurusan R yaitu desain komunikasi visual dengan jumlah variasi peminjaman
Tabel 4.10 Jumlah Peminjam Tanggal 23-30 September 2013
(Sumber: Perpustakaan UPN “Veteran” Jatim)
Dari hasi tabel diatas dapat diketahui pada tanggal 23-30 September 2013
jurusan yang melakukan peminjaman paling banyak adalah kode jurusan C yaitu
akuntansi dengan jumlah variasi peminjaman kelompok buku sebanyak 6 yaitu
filsafat, agama, ilmu-ilmu sosial, bahasa,ilmu-ilmu murni dan teknologi terapan
sedangkan jurusan yang tidak melakukan melakukan peminjaman adalah kode
Setelah data-data yang dikumpulkan terpenuhi maka selanjutnya digunakan
metode k-means untuk mengetahui pengelompokan peminjam berdasarkan
kelompok buku. Adapun langkah-langkahnya sebagai berikut:
Tabel 4.11 Jumlah Peminjam Bulan Juni, Juli dan September 2013
No Kode Kelompok buku Jumlah
(Sumber: Perpustakaan UPN “Veteran” Jatim)
Dari hasi tabel diatas dapat diketahui pada bulan Juni, Juli dan September
2013 jurusan yang melakukan peminjaman paling banyak adalah kode jurusan B
Adapun pengolahan data menggunakan metode k-means dengan software
pendukung yaitu matlab
A.Iterasi 0
1. Penentuan Jumlah Klaster
Tujuannya adalah membagi semua item dengan 3 klaster (k=3), yaitu aktif,
cukup aktif dan kurang aktif.
2. Penentuan Pusat Klaster (Centroid)
Pusat-pusat klaster diberi nilai awal dengan angka-angka random. Secara
random ditentukan centroid sebagai berikut:
C1 = (7, 0, 0, 31, 0, 2, 11, 0, 0, 0)
C2 = (3, 0, 0, 0, 3, 57, 19, 0, 0, 0)
C3 = (35, 12, 0, 101, 0, 2, 33, 3, 0, 0)
3. Hitung Jarak Objek Dengan Centroid
Tempatkan setiap data/ obyek ke klaster terdekat. Kedekatan dua obyek
ditentukan berdasar jarak kedua obyek tersebut. Jarak paling dekat antara
satu data dengan satu klaster tertentu akan menentukan suatu data masuk
dalam klaster mana. Hitung jarak terdekat tiap obyek ke semua pusat cluster
C1 hingga C3. Berikut contoh perhitungannya:
• Jarak terdekat A ke C1
(7−7) + (0− 0) + (0−0) + (31−31) + (0−0)
• Jarak terdekat A ke C2
Kedekatan suatu obyek ke cluster tertentu ditentukan oleh jarak antara
obyek dengan dengan pusat cluster. Dari hasil perhitungan dapat diketahui
hasil perhitungan jarak A dan pusat cluster 1 sebesar 0, jarak A dan pusat
cluster 2 sebesar 63,84. Jadi, jarak paling dekat antara A dengan tiga pusat
cluster tersebut akan menentukan A masuk kedalam cluster tertentu. (Hasil
perhitungan jarak antara obyek dan centroid lainnya dapat dilihat di
lampiran B).
B.Iterasi 1
1. Penentuan Pusat Klaster Baru (Centroid)
Pada iterasi ini tentukan posisi centroid baru dengan cara menghitung
rata-rata dari data-data yang berada pada centroid yang sama. Dengan adanya
tiga klaster yang terbentuk dari iterasi sebelumnya, maka nilai pusat cluster
baru dihitung dengan rumus sebagai berikut:
1
Maka diperoleh centroid baru untuk ketiga cluster tersebut adalah
C1(0) = 7 + 2 + 0 + 46 + 24 + 4 + 4 + 5 + 0 + 3 + 4 + 2 + 3 = 8