PENERAPAN ALGORITMA MIXCBLOF BERBASIS KLASTER UNTUK IDENTIFIKASI OUTLIER PADA DATA HASIL UJIAN NASIONAL,
INDEKS INTEGRITAS, DAN AKREDITASI SMA DI DAERAH ISTIMEWA YOGYAKARTA
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh :
I. Kristanto Riyadi NIM : 135314062
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
PENERAPAN ALGORITMA MIXCBLOF BERBASIS KLASTER UNTUK IDENTIFIKASI OUTLIER PADA DATA HASIL UJIAN NASIONAL,
INDEKS INTEGRITAS, DAN AKREDITASI SMA DI DAERAH ISTIMEWA YOGYAKARTA
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh :
I. Kristanto Riyadi NIM : 135314062
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
iii
IMPLEMENTATION OF MIXCBLOF ALGORITHM BASED CLUSTER
FOR OUTLIER IDENTIFICATION IN NATIONAL DATA SCORES,
INTEGRITY INDEX, AND ACCREDITATION OF SENIOR HIGH SCHOOL IN YOGYAKARTA
FINAL PROJECT
Present as Partial Fullfillment of the Requirements to Obtain the Sarjana Komputer Degree in Informatics Engineering Study Program
By :
I. Kristanto Riyadi NIM : 135314062
INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
vi
HALAMAN PERSEMBAHAN
“Mintalah, maka akan diberikan kepadamu; carilah, maka kamu
akan mendapat; ketoklah, maka pintu
akan dibukakan bagimu”
(Mat 7:7)
Karya ini kupersembahkan kepada :
Orangtuaku, P. Sutarmijan dan M.Sumaryati
Saudara-saudaraku
viii
ABSTRAK
Dalam makalah ini dijabarkan mengenai algoritma MixCBLOF untuk
mendeteksi outlier pada data hasil Ujian Nasional, Indeks Integritas Ujian Nasional, dan Akreditasi SMA di Daerah Istimewa Yogyakarta. Penulis
menggunakan Knowledge Discovery in Database (KDD) yang terdiri dari
pembersihan data, integrasi data, seleksi data, transformasi data, dan
penambangan data. Pada tahap pembersihan data dan integrasi data dilakukan
secara manual. Selanjutnya penulis merancang perangkat lunak sebagai alat untuk
melakukan tahap evaluasi pola dari hasil penambangan data yang diperoleh dari
perangkat lunak. Perangkat lunak diujikan dengan menggunakan dua dataset yang
merupakan data hasil Ujian Nasional, Indeks Integritas Ujian Nasional, dan
Akreditasi SMA tahun ajaran 2014/2015 di Daerah Istimewa Yogyakarta jurusan
IPA dan jurusan IPS. Berdasarkan penelitian yang telah dilakukan, dapat
diketahui bahwa algoritma MixCBLOF dapat digunakan untuk mendeteksi outlier pada data hasil Ujian Nasional, Indeks Integritas Ujian Nasional, dan Akreditasi
SMA. Pendeteksian outlier dipengaruhi oleh nilai b dan nilai Akreditasi SMA.
ix
ABSTRACT
This paper describes the MixCBLOF algorithm to detect outliers on National Examination data, Integrity Index of National Examination, and SMA
Accreditation in Yogyakarta. The writer uses Knowledge Discovery in Database
(KDD) which consists of data cleaning, data integration, data selection, data
transformation, and data mining. At the data cleaning stage and data integration
conducted them manually. Furthermore the writer designed the software as a tool
to perform the pattern evaluation stage of the data mining obtained from the
software. The software is tested using two datasets which are National Exam
result data, Integrity Index of National Examination, and SMA Accreditation in
the academic year of 2014/2015 in Yogyakarta majoring in science and social
studies majors. Based on the research that has been done, it can be seen that
MixCBLOF can be used to detect outliers on National Examination, Integrity Index of National Examination, and SMA Accreditation. Outlier detection is influenced by b value and value of SMA Accreditation.
xi
KATA PENGANTAR
Puji syukur kepada Tuhan Yesus Kristus yang selalu menyertai dan membimbing saya dalam menyelesaikan skripsi yang berjudul “Penerapan Algoritma MixCBLOF Berbasis Klaster untuk Identifikasi Outlier Pada Data Hasil Ujian Nasional, Indeks Integritas, dan Akreditasi SMA di Daerah Istimewa Yogyakarta”.
Skripsi ini tidak dapat saya selesaikan tanpa bantuan dan dukungan dari
pihak lain. Untuk itu, dalam kesempatan ini penulis ingin mengucapkan terima
kasih kepada:
1. Tuhan Yesus Kristus dan Bunda Maria yang selalu memberikan
anugerah, rahmat, kekuatan, dan keberuntungan sehingga penulis
dapat menyelesaikan tugas akhir ini.
2. Bapak Sudi Mungkasi, S.Si, M.Math.Sc., Ph.D. selaku Dekan
Fakultas Sains dan Teknologi.
3. Ibu Dr. Anastasia Rita Widiarti selaku Ketua Program Studi Teknik
Informatika dan juga selaku Dosen Metodologi Penelitian yang telah
memberikan waktu, bimbingan, dan nasihat kepada penulis.
4. Ibu Paulina Heruningsih Prima Rosa, M.Sc. selaku Dosen
Pembimbing Skripsi yang telah memberikan waktu, bimbingan,
nasihat, dan motivasi kepada penulis.
5. Bapak Alb. Agung Hadhiatma, M.T. selaku Dosen Pembimbing
Akademik penulis.
6. Seluruh Dosen, sekretariat, laboran, staff, dan perpustakaan yang telah
membimbing dan membantu selama proses perkuliahan di Universitas
Sanata Dharma.
7. Orangtuaku, Petrus Sutarmijan dan Maria Sumaryati serta
saudara-saudaraku terkasih, terima kasih atas doa, kesabaran, perhatian,
dukungan dan kesempatan yang diberikan sehingga skripsi ini dapat
xiii
DAFTAR ISI
HALAMAN JUDUL ... ii
TITLE PAGE ... iii
HALAMAN PERSETUJUAN ...Error! Bookmark not defined. HALAMAN PENGESAHAN...Error! Bookmark not defined. PERNYATAAN KEASLIAN KARYA ...Error! Bookmark not defined. ABSTRAK ... viii
ABSTRACT ... ix
PERSETUJUAN PUBLIKASI KARYA ILMIAH ...Error! Bookmark not defined. KATA PENGANTAR ... xi
DAFTAR ISI ... xiii
DAFTAR TABEL ... xvii
DAFTAR GAMBAR ... xix
BAB IPENDAHULUAN ... 1
1.1 LATAR BELAKANG ... 1
1.2 RUMUSAN MASALAH ... 4
1.3 TUJUAN ... 4
1.4 BATASAN MASALAH ... 4
1.5 MANFAAT PENELITIAN... 5
1.6 METODOLOGI PENELITIAN ... 5
1.7 SISTEMATIKA PENULISAN ... 6
BAB IILANDASAN TEORI ... 8
2.1 PENAMBANGAN DATA ... 8
2.1.1 Pengertian Penambangan Data ... 8
2.1.2 Asal-usul Penambangan Data ... 8
2.1.3 Tugas-tugas Penambangan Data ... 9
2.1.4 Knowledge Discovery in Databases (KDD) ... 10
2.2 OUTLIER ... 12
2.2.1 Pengertian Outlier ... 12
xiv
2.3 MixCBLOF (Mix Cluster Based Local Outlier Factor) ... 14
2.3.1 CBLOF (Cluster Based Local Outlier Factor) ... 14
2.3.2 NCBLOF (Numerical Cluster Based Local Outlier Factor) ... 16
2.3.3 Algoritma MixCBLOF ... 17
2.4 STRUKTUR DATA ... 18
BAB IIIMETODOLOGI PENELITIAN... 21
3.1 BAHAN RISET/ DATA ... 21
3.2 PERALATAN PENELITIAN ... 27
3.3 TAHAP-TAHAP PENELITIAN ... 27
BAB IVPEMROSESAN AWAL DAN PERANCANGAN PERANGKAT LUNAK PENAMBANGAN DATA ... 31
4.1 PEMROSESAN AWAL ... 31
4.1.1 Pembersihan Data ... 31
4.1.2 Integrasi Data ... 31
4.1.3 Seleksi Data ... 32
4.1.4 Transformasi Data ... 35
4.2 PERANCANGAN PERANGKAT LUNAK PENAMBANGAN DATA ... 35
4.2.1 Perancangan Umum ... 35
4.2.1.1 Input Sistem ... 35
4.2.1.2 Proses Sistem ... 36
4.2.1.3 Output Sistem ... 37
4.2.2 Diagram Use Case ... 37
4.2.3 Diagram Aktivitas ... 39
4.2.4 Diagram Kelas Analisis ... 39
4.2.5 Diagram Sekuen ... 39
4.2.6 Perancangan Struktur Data ... 39
4.2.7 Diagram Kelas Disain ... 41
4.2.8 Algoritma per Method ... 41
4.2.9 Perancangan Antarmuka ... 41
4.2.9.1 Perancangan Halaman Awal ... 42
4.2.9.2 Perancangan Halaman Proses ... 43
xv
4.2.9.4 Perancangan Halaman Tentang ... 47
BAB VIMPLEMENTASI PENAMBANGAN DATA DAN EVALUASI HASIL ... 48
5.1 IMPLEMENTASI RANCANGAN PERANGKAT LUNAK ... 48
5.1.1 Implementasi Kelas Model ... 48
5.1.2 Implementasi Kelas View ... 48
5.1.3 Implementasi Kelas Control ... 57
5.2 EVALUASI HASIL ... 58
5.2.1 Pengujian Perangkat Lunak (Black Box) ... 58
5.2.1.1. Rencana Pengujian Black Box ... 58
5.2.1.2. Prosedur Pengujian Black Box dan Kasus Uji ... 58
5.2.1.3. Evaluasi Pengujian Black Box ... 58
5.2.2 Pengujian Perbandingan Hasil Pencarian Outlier Secara Manual dengan Hasil Pencarian Outlier menggunakan Perangkat Lunak ... 59
5.2.2.1. Pencarian Outlier Secara Manual... 59
5.2.2.2. Pencarian Outlier menggunakan Perangkat Lunak ... 59
5.2.2.3. Evaluasi Pengujian Perbandingan Hitung Manual dengan Hasil Perangkat Lunak ... 61
BAB VIANALISIS HASIL DAN PEMBAHASAN ... 62
6.1. DATASET ... 62
6.2. HASIL IDENTIFIKASI OUTLIER ... 62
6.2.1. Hasil Identifikasi Outlier Dataset Jurusan IPA ... 62
6.2.2. Hasil Identifikasi Outlier Dataset Jurusan IPS ... 72
6.3. ANALISIS HASIL IDENTIFIKASI OUTLIER ... 82
6.3.1. Analisis Hasil Identifikasi Outlier Dataset Jurusan IPA ... 82
6.3.2. Analisis Hasil Identifikasi Outlier Dataset Jurusan IPS ... 84
6.4. KELEBIHAN DAN KEKURANGAN PERANGKAT LUNAK ... 85
6.4.1. Kelebihan Perangkat Lunak ... 85
6.4.2. Kekurangan Perangkat Lunak ... 85
BAB VIIPENUTUP ... 86
7.1. KESIMPULAN ... 86
7.2. SARAN ... 88
xvi
LAMPIRAN 1 : NARASI USE CASE ... 91
LAMPIRAN 2 : DIAGRAM AKTIVITAS ... 95
LAMPIRAN 3 : DIAGRAM KELAS ANALISIS... 98
LAMPIRAN 4 : DIAGRAM SEQUENCE ... 99
LAMPIRAN 5 : DIAGRAM KELAS DISAIN ... 102
LAMPIRAN 6 : ALGORITMA PER METHOD ... 103
LAMPIRAN 7 : PROSEDUR PENGUJIAN DAN KASUS UJI ... 110
xvii
DAFTAR TABEL
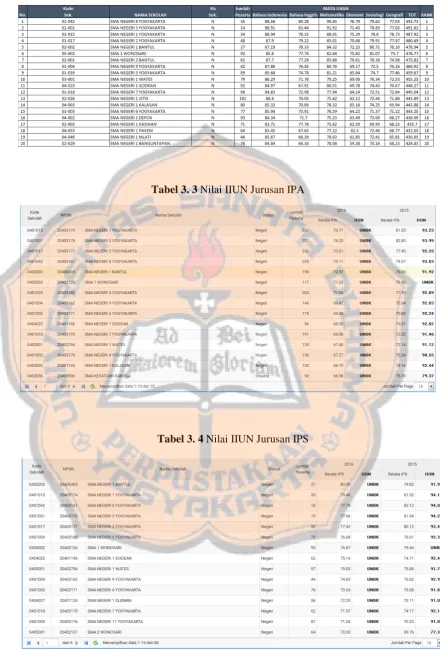
Tabel 3. 1 Nilai UN Jurusan IPA ... 21
Tabel 3. 2 Nilai UN Jurusan IPS ... 22
Tabel 3. 3 Nilai IIUN Jurusan IPA ... 22
Tabel 3. 4 Nilai IIUN Jurusan IPS ... 22
Tabel 3. 5 Nilai Akreditasi SMA ... 23
Tabel 3. 6 Atribut Data Nilai UN Jurusan IPA ... 23
Tabel 3. 7 Atribut Data Nilai UN Jurusan IPS ... 24
Tabel 3. 8 Atribut Data NIlai IIUN Jurusan IPA ... 25
Tabel 3. 9 Atribut Data Nilai IIUN Jurusan IPS ... 26
Tabel 3. 10 Atribut Data Nilai Akreditasi SMA ... 26
Tabel 4. 1 Hasil Integrasi Jurusan IPA ... 32
Tabel 4. 2 Hasil Integrasi Jurusan IPS ... 32
Tabel 4. 3 Hasil Seleksi Atribut Jurusan IPA ... 33
Tabel 4. 4 Hasil Seleksi Atribut Jurusan IPS ... 34
Tabel 5. 1 Implementasi Kelas Model ... 48
Tabel 5. 2 Implementasi Kelas View ... 48
Tabel 5. 3 Spesifikasi detail kelas Hal_Utama.java ... 49
Tabel 5. 4 Spesifikasi detail kelas Hal_Proses.java ... 50
Tabel 5. 5 Spesifikasi detail frame frameDeteksi ... 53
Tabel 5. 6 Spesifikasi detail kelas Hal_Bantuan.java ... 54
Tabel 5. 7 Spesifikasi detail kelas Hal_Tentang.java ... 56
Tabel 5. 8 Implementasi kelas Controller ... 57
Tabel 5. 9 Rencana pengujian Black Box ... 58
xviii
Tabel 6. 2 Hasil pengujian kedua jurusan IPA ... 64
Tabel 6. 3 Hasil pengujian ketiga jurusan IPA ... 65
Tabel 6. 4 Hasil pengujian keempat jurusan IPA ... 65
Tabel 6. 5 Hasil pengujian kelima jurusan IPA ... 66
Tabel 6. 6 Hasil pengujian keenam jurusan IPA ... 67
Tabel 6. 7 Hasil pengujian ketujuh jurusan IPA ... 68
Tabel 6. 8 Hasil pengujian kedelapan jurusan IPA ... 69
Tabel 6. 9 Hasil pengujian kesembilan jurusan IPA ... 70
Tabel 6. 10 Hasil pengujian kesepuluh jurusan IPA ... 71
Tabel 6. 11 Hasil pengujian pertama jurusan IPS ... 72
Tabel 6. 12 Hasil pengujian kedua jurusan IPS ... 73
Tabel 6. 13 Hasil pengujian ketiga jurusan IPS ... 74
Tabel 6. 14 Hasil pengujian keempat jurusan IPS ... 75
Tabel 6. 15 Hasil pengujian kelima jurusan IPS ... 76
Tabel 6. 16 Hasil pengujian keenam jurusan IPS ... 77
Tabel 6. 17 Hasil pengujian ketujuh jurusan IPS ... 78
Tabel 6. 18 Hasil pengujian kedelapan jurusan IPS ... 79
Tabel 6. 19 Hasil pengujian kesembilan jurusan IPS ... 80
Tabel 6. 20 Hasil pengujian kesepuluh jurusan IPS ... 81
Tabel 6. 21 Hasil Identifikasi Outlier jurusan IPA ... 83
xix
DAFTAR GAMBAR
Gambar 2. 1 Asal-usul Penambangan Data ... 9
Gambar 2. 2 Proses KDD ... 11
Gambar 2. 3 Ilustrasi ArrayList ... 19
Gambar 2. 4 Ilustrasi Matriks ... 19
Gambar 4. 1 Diagram Flowchart ... 36
Gambar 4. 2 Diagram Flowchart Deteksi Outlier ... 37
Gambar 4. 3 Diagram Use Case... 38
Gambar 4. 4 Perancangan Arraylist ... 40
Gambar 4. 5 Perancangan Matriks ... 40
Gambar 4. 6 Rancangan Antarmuka Halaman Utama ... 42
Gambar 4. 7 Rancangan Antarmuka Halaman Proses ... 43
Gambar 4. 8 Rancangan Antarmuka Frame Hasil ... 44
Gambar 4. 9 Rancangan Dialog Pilih Penyimpanan ... 45
Gambar 4. 10 Rancangan Halaman Bantuan ... 46
Gambar 4. 11 Rancangan Halaman Tentang ... 47
Gambar 5. 1 Implementasi Antarmuka Hal_Utama ... 50
Gambar 5. 2 Implementasi Antarmuka kelas Hal_Proses ... 52
Gambar 5. 3 Implementasi Antarmuka frameDeteksi ... 54
Gambar 5. 4 Implementasi Antarmuka Hal_Bantuan ... 55
Gambar 5. 5 Implementasi Antarmuka Hal_Tentang ... 57
Gambar 5. 6 Hasil Penambangan Data menggunakan Perangkat Lunak ... 60
BAB I
PENDAHULUAN
1.1Latar Belakang
Dewasa ini, teknologi berkembang dengan begitu pesat. Perkembangan
teknologi mengakibatkan data juga ikut semakin berkembang, sehingga
jumlah data semakin banyak. Data dengan ukuran yang sangat banyak muncul
dari berbagai bidang, mulai dari bidang kesehatan/ forensik, bidang
pendidikan, dan bidang-bidang lainnya. Namun, seringkali data yang
mempunyai ukuran yang sangat besar biasanya jarang atau bahkan tidak
menghasilkan suatu informasi. Semakin bertambah banyaknya data,
kemungkinan besar ada beberapa/banyak data yang tidak terpakai dalam suatu
analisis tertentu. Untuk itu diperlukan sebuah alat untuk menambang data
yang sangat banyak yang tidak memiliki suatu informasi menjadi sebuah
informasi yang berguna. Maka dari itu, data mining atau yang biasa disebut penambangan data mempunyai peran yang sangat tinggi untuk melakukan
proses menambang data yang sangat banyak, sehingga dapat disimpulkan
bahwa penambangan data merupakan proses dari menemukan pengetahuan
atau pola yang menarik dari jumlah data yang besar/banyak (Han & Kamber,
2012).
Penambangan data memiliki beberapa langkah untuk menemukan sebuah
pengetahuan dari sebuah data, yang biasa disebut dengan Knowledge Discovery in Databases (KDD). Langkah-langkah tersebut yaitu data cleaning, data integration, data selection, data transformation, data mining, pattern evaluation, dan knowledge presentation. Langkah 1 sampai dengan langkah 4 merupakan proses untuk mengolah data agar data siap untuk
Penambangan data memiliki banyak teknik atau metode, salah satu teknik
dalam penambangan data yang dikenal adalah mencari data yang tidak sesuai
dengan harapan, yang biasa disebut outlier detection (Han & Kamber, 2012). Outlier merupakan sebuah pengamatan yang menyimpang begitu banyak dari pengamatan lainnya untuk membangkitkan kecurigaan bahwa hal tersebut
dihasilkan oleh berbagai mekanisme (Hawkins, 1980).
Pendeteksian outlier mempunyai 5 pendekatan, yaitu statistical approach, proximity-based approach, clustering-based approach, classification-based approach, dan high-dimensional data (Han & Kamber, 2012). Pada setiap pendekatan mempunyai beberapa algoritma yang bisa diterapkan untuk
mengidentifikasi atau pendeteksian outlier. Salah satu contoh yaitu algoritma MixCBLOF (Mix Cluster Based Local Outlier Factor) yang merupakan salah satu algoritma dengan pendekatan clustering-based. Algoritma MixCBLOF ini merupakan pengembangan dari algoritma CBLOF (Cluster Based Local Outlier Factor) yang hanya dapat menangani outlier dengan set data yang seragam yaitu set data numerik (Maryono & Djunaidy, 2010). Namun,
Maryono & Djunaidy pada tahun 2010 mengembangkan algoritma CBLOF
menjadi algoritma MixCBLOF yang dapat menangani outlier dengan set data campuran atau bisa dikatakan dapat menggunakan set data numerik dan set
data kategorikal.
Teknik pendeteksian outlier dengan menggunakan algoritma MixCBLOF ini kemungkinan dapat diterapkan pada bidang pendidikan di Sekolah
Menengah Atas (SMA). Pendidikan pada jenjang SMA memiliki data Ujian
Nasional (UN) berupa nama sekolah, nilai UN, nilai Indeks Integritas Ujian
Nasional (IIUN), dan Akreditasi sekolah. Nilai Ujian Nasional (UN)
merupakan nilai yang dihasilkan dari Ujian Nasional yang diselenggarakan
secara nasional pada sekolah-sekolah (sekolah menengah pertama, dan
sekolah menengah atas), atribut nilai UN merupakan atribut numerik. Nilai
Indeks Integritas Ujian Nasional (IIUN) merupakan penilaian kejujuran dalam
pelaksanaan Ujian Nasional, atribut nilai IIUN merupakan atribut numerik.
3
sekolah-sekolah yang memenuhi syarat kebakuan dan kriteria tertentu, atribut
nilai akreditasi sekolah merupakan atribut kategorikal.
Maria Renia Octaviani (2015) sudah pernah melakukan penelitian
mengenai outlier yang digunakan sebagai topik skripsi yaitu pendeteksian outlier pada nilai Ujian Nasional Sekolah Menengah Atas di Provinsi Daerah Istimewa Yogyakarta pada tahun ajaran 2011-2014 dengan menggunakan
algoritma INFLO (Influenced Outliernes). Penelitian ini merupakan pengembangan penelitian di atas, karena pendeteksian outlier pada penelitian ini dilakukan pada nilai Ujian Nasional, nilai Indeks Integritas Ujian Nasional,
dan nilai Akreditasi seluruh SMA yang ada di DIY pada tahun 2015 dengan
menggunakan algoritma MixCBLOF. Pemilihan data UN SMA tahun 2015
karena pada tahun tersebut IIUN baru digunakan.
Penelitian ini diharapkan dapat menghasilkan informasi atau suatu
pengetahuan mengenai kejadian langka yang ada pada kasus outlier di SMA. Data UN SMA sangat menarik untuk diidentifikasi outlier karena bisa saja pada data UN tersebut memiliki karakter yang unik/ berbeda dengan yang
lainnya. Misalnya seperti nilai UN yang tinggi namun memiliki nilai IIUN/
akreditasi yang rendah begitu pula sebaliknya. Hasil yang didapatkan dari
penelitian ini yaitu menampilkan suatu SMA dengan data UN yang unik
dengan SMA yang lainnya. Hasil dari penelitian ini dapat dianalisa lebih
lanjut oleh pihak yang berwenang untuk kepentingan pendampingan dan
4
1.2Rumusan Masalah
Rumusan masalah pada penelitian ini adalah sebagai berikut:
1. Apakah algoritma MixCBLOF dapat mendeteksi outlier data pada nilai ujian nasional, nilai indeks integritas, dan nilai akreditasi Sekolah
Menengah Atas (SMA) yang ada di Provinsi Daerah Istimewa Yogyakarta
(DIY)?
2. Bagaimana karakteristik data-data atau sekolah yang diidentifikasi sebagai
outlier?
1.3Tujuan
Tujuan dari penelitian ini adalah sebagai berikut:
1. Menganalisa algoritma MixCBLOF dalam mendeteksi outlier data pada nilai ujian nasional, nilai indeks integritas, dan nilai akreditasi Sekolah
Menegah Atas (SMA) Provinsi Daerah Istimewa Yogyakarta (DIY).
2. Menganalisa karakteristik data-data atau sekolah yang diidentifikasi
sebagai outlier.
1.4Batasan Masalah
Batasan masalah pada penelitian ini sebagai berikut:
1. Algoritma yang digunakan yaitu algoritma MixCBLOF (Mix Cluster
Based Local Outlier Factor).
2. Data yang digunakan yaitu nilai Ujian Nasional, nilai Indeks Integritas,
dan nilai Akreditasi selutuh Sekolah Menengah Atas (SMA) di Provinsi
Daerah Istimewa Yogyakarta (DIY) pada tahun ajaran 2014/2015 yang
5
1.5Manfaat Penelitian
Manfaat dari penelitian ini adalah sebagai berikut :
1. Memberikan pengetahuan baru mengenai cara mendeteksi outlier dengan menggunakan algoritma Mix Cluster Based Local Outlier Factor (MixCBLOF).
2. Memberikan informasi mengenai data yang unik dalam nilai hasil Ujian
Nasional, Indeks Integritas Ujian Nasional, dan Akreditasi Sekolah
Menengah Atas (SMA).
1.6Metodologi Penelitian
Metodologi Penelitian yang digunakan dalam menyelesaikan tugas akhir ini
adalah sebagai berikut :
1. Studi Pustaka
Metodologi pertama yang digunakan adalah studi pustaka. Tahap
ini merupakan proses pengumpulan informasi berupa metode atau
algoritma yang digunakan untuk mendeteksi outlier dari berbagai referensi seperti buku, paper/ jurnal, skripsi, atau artikel-artikel lainnya yang ada di
internet. Selanjutnya yaitu mempelajari dan menganalisa dari informasi
yang didapat sehingga menentukan untuk memilih algoritma MixCBLOF
(Mix Cluster Based Local Outlier Factor) untuk melakukan penelitian deteksi outlier pada data Ujian Nasional Sekolah Menengah Atas (SMA).
2. Teknik Knowledge Discovery in Databases (KDD).
Metodologi kedua adalah teknik penambangan data yang dituliskan
oleh Han et.al. (2012). Teknik KDD memiliki beberapa langkah, yaitu :
a. Data Cleaning
Langkah ini merupakan langkah untuk menghilangkan noise/ pengganggu dan data yang tidak konsisten.
b. Data Integration
Langkah ini merupakan suatu proses dimana beberapa sumber data
6
c. Data Selection
Langkah ini merupakan proses untuk melakukan analisis, dimana data
yang relevan diambil dari database. d. Data Transformation
Langkah ini merupakan proses dimana data diubah (transformasi)
menjadi data yang tepat untuk ditambang sehingga dapat dilakukan
proses operasi seperti penjumlahan atau penggabungan.
e. Data Mining
Langkah ini merupakan proses penting di mana metode cerdas yang
diterapkan untuk mengekstrak pola data.
f. Pattern Evaluation
Langkah ini merupakan proses untuk mengidentifikasi pola-pola
menarik yang menampilkan basis pengetahuan dalam suatu ukuran
ketertarikan.
g. Knowledge Presentation
Langkah ini merupakan proses dimana teknik untuk menampilkan
suatu gambaran dan representasi pengetahuan hasil tambang kepada
pengguna.
1.7Sistematika Penulisan
Sistematika penulisan proposal tugas akhir sebagai berikut:
a. Bab I : Pendahuluan
Bab pertama ini berisi mengenai latar belakang, rumusan masalah, tujuan,
batasan masalah, metodologi penelitian dan sistematika penulisan proposal
tugas akhir.
b. Bab II : Landasan Teori
Bab kedua ini berisi mengenai penjelasan teori penambangan data yang
7
c. Bab III : Metode Penelitian
Bab ketiga ini berisi mengenai rencana langkah-langkah yang dilakukan
dalam penelitian, termasuk bagaimana cara mendapatkan data, cara
mengolah data, cara membuat alat uji, cara analisis data, cara pengujian.
d. Bab IV : Pemrosesan Awal dan Perancangan Perangkat Lunak
Penambangan Data
Bab keempat ini berisi mengenai pemrosesan awal dalam proses
Knowledge Discovery in Database (KDD). Selain itu, bab ini juga berisi mengenai perancangan perngkat lunak yang akan digunakan dalam tahap
penambangan data. Perancangan perangkat lunak tersebut terditi dari
perancangan umum, diagram use case, diagram aktivitas, diagram kelas, algoritma per method dan perancangan antarmuka.
e. Bab V : Implementasi Penambangan Data dan Evaluasi Hasil
Bab kelima ini berisi mengenai implementasi rancangan perangkat lunak
penambangan data dan evaluasi hasil yang terdiri dari pengujian perangkat
lunak (black box), pengujian perbandingan hitung manual dengan hasil sistem.
f. Bab VI : Analisis Hasil dan Pembahasan
Bab keenam ini berisi mengenai percobaan-percobaan yang dilakukan
dengan variasi nilai-nilai yang dibutuhkan. Selain itu, bab ini juga berisi
mengenai analisis dari percobaan yang sudah dilakukan.
g. Bab VII : Penutup
Bab terakhir ini menjelaskan mengenai kesimpulan yang diperoleh dari
pembuatan sistem serta saran untuk pengembangan sistem dan penelitian
8
BAB II
LANDASAN TEORI
2.1Penambangan Data
2.1.1 Pengertian Penambangan Data
Menurut Tan et.al. (2006), penambangan data adalah proses
menemukan suatu informasi yang berguna dari data yang besar.
Teknik data mining dikerahkan untuk menjelajahi pada database yang
berukuran besar untuk menemukan pola yang mungkin tetap tidak
diketahui. Penambangan data juga menyediakan kemampuan untuk
memprediksi hasil dari pengamatan masa depan, seperti memprediksi
seorang pelanggan akan menghabiskan uang lebih dari $100 atau tidak
di sebuah department store.
Namun, tidak semua tugas menemukan informasi dapat dicari
menggunakan penambangan data. Meskipun tugas-tugas memiliki sifat
yang penting dan mungkin melibatkan penggunaan algoritma yang
canggih dan struktur data, tetapi tetap mengandalkan teknik ilmu
komputer tradisional dan fitur yang jelas dari data untuk membuat
struktur indeks secara efisien dalam mengatur dan mengambil
informasi. Meskipun demikian, teknik data mining telah digunakan
untuk meningkatkan sistem pencarian informasi.
2.1.2 Asal-usul Penambangan Data
Menurut Tan et.al. (2006), penambangan data mengacu pada
ide-ide seperti pengambilan sampel, estimasi, dan pengujian hipotesis dari
statistik dan algoritma pencarian, teknik pemodelan, dan teori-teori
Artificial Intelligence (AI), pengenalan pola, dan machine learning. Penambangan data juga mempunyai peran pada bidnag lain, termasuk
9
Relasi data mining dengan bidang/ area lainnya dapat digambarkan
sebagai berikut :
Gambar 2. 1 Asal-usul Penambangan Data (Sumber : Han et.al, 2012)
2.1.3 Tugas-tugas Penambangan Data
Menurut Tan et.al. (2006), penambangan data memiliki beberapa
tugas yang menerapkan dua kategori besar yaitu metode prediktif dan
metode deskriptif. Metode prediktif mempunyai tugas untuk
memprediksi nilai atribut tertentu berdasarkan pada nilai-nilai atribut
lainnya. Metode deskriptif mempunyai tugas untuk mendapatkan pola
dari korelasi, klaster, lintasan, dan anomali yang didapatkan dari data
target.
Tugas penambangan data mempunyai empat tugas, yaitu :
a. Analisis Prediktif
Salah satu tugas penambangan data ini mengacu pada tugas yang
membangun model pada variabel target sebagai fungsi dari variabel
penjelas. Analisis prediktif dibagi menjadi dua tipe yaitu klasifikasi
dan regresi. Klasifikasi merupakan tipe prediktif yang digunakan
untuk variabel sasaran diskrit. Regresi merupakan tipe prediktif
yang digunakan untuk variabel target yang bersifat terus-menerus
(kontinyu). Contoh klasifikasi yaitu memprediksi apakah pengguna
10
termasuk klasifikasi karena variabel target bernilai biner, ya atau
tidak. Contoh regresi yaitu prediksi harga masa depan suatu saham.
Hal tersebut termasuk contoh regresi karena harga merupakan
atribut bernilai kontinyu. Namun, pencapaian kedua tipe prediktif
tersebut adalah untuk mempelajari model yang meminimalkan
kesalahan anatara prediksi dengan nilai kebernarannya dari variabel
target.
b. Analisis Asosiasi
Pada tugas penambangan data ini digunakan untuk menemukan
hubungan yang terkait dari suatu transaksi yang terjadi pada item
berdasarkan item lainnya.
c. Analisis Klaster
Pada tugas penambangan data ini digunakan untuk menemukan
suatu kelompok obyek yang terkait erat satu sama lain sehingga
termasuk ke dalam klaster yang sama.
d. Deteksi Anomali
Deteksi anomali merupakan tugas penambangan data yang
digunakan untuk mengidentifikasi pengamatan yang
karakteristiknya sangat berbeda dari sisa data. Pengamatan tersebut
dikenal sebagai anomali atau outlier. Tujuan algoritma deteksi anomali/ outlier adalah untuk menemukan anomali yang nyata dan menghindari obyek yang normal tetapi diidentifikasi sebagai
anomali. Oleh karena itu, deteksi anomali yang baik harus memiliki
tingkat deteksi yang tinggi dan tingkat kesalahan yang rendah.
Aplikasi deteksi anomali seperti deteksi penipuan, gangguan
jaringan, gangguan ekosistem, dll.
2.1.4 Knowledge Discovery in Databases (KDD)
11
informasi/ pengetahuan yang berguna. KDD memiliki beberapa
langkah yaitu data cleaning, data integration, data selection, data transformation, data mining, pattern evaluation, dan knowledge presentation.
Gambar 2. 2 Proses KDD
12
1. Data Cleaning
Langkah ini merupakan langkah untuk menghilangkan noise/ pengganggu dan data yang tidak konsisten.
2. Data Integration
Langkah ini merupakan suatu proses dimana beberapa sumber
data digabungkan menjadi satu kesatuan.
3. Data Selection
Langkah ini merupakan proses untuk melakukan analisis,
dimana data yang relevan diambil dari database. 4. Data Transformation
Langkah ini merupakan proses dimana data diubah
(transformasi) menjadi data yang tepat untuk ditambang
sehingga dapat dilakukan proses operasi seperti penjumlahan
atau penggabungan.
5. Data Mining
Langkah ini merupakan proses penting di mana metode cerdas
yang diterapkan untuk mengekstrak pola data.
6. Pattern Evaluation
Langkah ini merupakan proses untuk mengidentifikasi
pola-pola menarik yang menampilkan basis pengetahuan dalam
suatu ukuran ketertarikan.
7. Knowledge Presentation
Langkah ini merupakan proses dimana teknik untuk
menampilkan suatu gambaran dan representasi pengetahuan
hasil tambang kepada pengguna.
2.2Outlier
2.2.1 Pengertian Outlier
13
yang berbeda. Menurut Hawkins (1980), outlier merupakan pengamatan yang berbeda dari pengamatan lainnya sehingga
menimbulkan kecurigaan bahwa hal itu dihasilkan oleh berbagai
mekanisme.
2.2.2 Pendekatan Deteksi Outlier
Menurut Han et.al. (2012), pendeteksian outlier terdapat beberapa pendekatan, antara lain statistical methods, proximity-based approach, clustering-based approach, classficication-based approach, dan high-dimensional data.
Pendekatan statistical methods atau biasa dikenal sebagai metode berbasis model membuat asumsi mengenai normalitas data.
Pendekatan ini dianggap bahwa obyek data normal dihasilkan oleh
model statistik, sedangkan data yang tidak mengikuti model dianggap
sebagai outlier. Efektivitas statistical methods sangat bergantung pada asumsi apakah model statistik yang dibuat selalu berlaku untuk data
yang diberikan.
Pendekatan proximity-based mengasumsikan bahwa sebuah obyek dikatakan sebagai outlier jika memiliki perbedaan yang signifikan dengan tetangga terdekatnya pada set data yang sama. Efektivitas
metode berbasis proximity sangat bergantung pada jarak atau ukuran yang digunakan. Metode berbasis proximity ini sering mengalami kesulitan dalam mendeteksi outlier jika sebuah obyek yang dikatakan sebagai outlier memiliki kedekatan satu sama lain. Pendekatan proximity-based ini memiliki dua jenis utama deteksi outlier, yaitu distance-based, dan density-based.
Pendekatan clustering-based mengasumsikan bahwa obyek yang bersifat normal tergabung dalam kelompok besar (large cluster),
14
Pendekatan classification-based mengasumsikan bahwa pendeteksian outlier menggunakan pendekatan ini dapat digunakan jika set data training dan label kelas tersedia. Ide umum dari metode
deteksi outlier berbasis classification adalah menentukan model klasifikasi yang dapat membedakan data normal dan outlier. Metode outlier basis classification ini sering menggunakan satu kelas sebagai label untuk menggambarkan data berupa normal atau outlier.
Pendekatan high-dimensional data, memiliki beberapa contoh algoritma yaitu Angle-Based Outlier Degree/ ABOD (Kriegel et.al. 2008), Grid-Based Subspace Outlier Detection (Aggarwal & Yu, 2000), dan Subspace Outlier Degree/ SOD (Kriegel et.al., 2009).
2.3MixCBLOF (Mix Cluster Based Local Outlier Factor)
Deteksi outlier memiliki ketertarikan tersendiri daripada deteksi pada umumnya, karena pendeteksian outlier ini memiliki informasi yang mendasari sebuah perilaku tidak biasanya atau berbeda daripada yang
lainnya. Pada penelitian ini mendeteksi outlier menggunakan algoritma Mix Cluster Based Local Outlier Factor (MixCBLOF) yang dikemukakan oleh Maryono & Djunaidy pada tahun 2010. Algoritma ini tergolong pada
pendekatan clustering-based karena algoritma ini perlu menggunakan proses cluster untuk penentuan outlier.
Algoritma ini merupakan perpaduan dari dua algoritma yaitu Cluster Based Local Outlier Factor (CBLOF) dengan Numerical Cluster Based Local Outlier Factor (NCBLOF). Algoritma ini mengusulkan deteksi outlier menggunakan data campuran berupa data kategorikal dan data numerik. Data
kategorikal diolah menggunakan algoritma CBLOF, sedangkan untuk data
numerik diolah menggunakan algoritma NCBLOF.
2.3.1 CBLOF (Cluster Based Local Outlier Factor)
Menurut He et.al (2003), untuk mengidentifikasi signifikansi data dari
15
derajat yang disebut dengan CBLOF (Cluster Based Local Outlier Factor) yang diukur dengan ukuran klaster di mana ia berada dan jaraknya terhadap klaster terdekat.
Definisi 1 : Misalkan A1, A2, ..., Am adalah himpunan atribut dengan
domain D1, D2, ..., Dm. Set data D terdiri dari record/ obyeknya,
sedangkan transaksi t : t ϵ D. Hasil klasterisasi pada D dinotasikan sebagai C= {C1, C2, ..., Ck} dimana Ci ∩ Cj = Ø dan C1∪ C2∪... ∪ Ck
= D, dengan k adalah jumlah klaster.
Definisi 2 : Misalkan C= {C1, C2, ..., Ck} adalah himpunan klaster
pada set data dengan urutan ukuran klaster adalah |C1| ≥ |C2| ≥ ... ≥ |Ck|.
Ditetapkan tiga parameter numerik α, β, dan b. Didefinisikan b sebagai batas antara klaster besar dan kecil jika memenuhi salah satu formula
berikut:
| | | | | | | |
| | | |
Didefinisikan himpunan klaster besar (large cluster) sebagai LC = {Ci,
i ≤ b} dan klaster kecil (small cluster) didefinisikan dengan SC = {Ci, i
> b}.
Definisi 2 memberikan ukuran kuantitatif untuk membedakan klaster
besar dan klaster kecil. Rumus (2.1) menunjukkan bahwa sebagian
besar data bukan outlier. Oleh karena itu klaster besar mempunyai porsi yang jauh sangat besar. Contohnya jika α diberikan 90% maka artinya klaster besar memuat kurang lebih 90% dari total obyek data
pada set data. Rumus (2.2) menunjukkan fakta bahwa klaster besar dan
klaster kecil harus memiliki perbedaan yang signifikan. Jika diberikan ... (2.2)
16
β sebesar 5, maka artinya setiap klaster besar minimal 5 kali lebih besar dari klaster kecil.
Definisi 3 : Misalkan C= {C1, C2, ..., Ck} adalah himpunan klaster
dengan ukuran |C1| ≥ |C2| ≥ ...≥ |Ck|. Didefinisikan LC dan SC
sebagimana pada Definisi 2. Untuk sebarang record t, didefinisikan
sebagaimana persamaan (2.3).
{| | ( ) | | ( )
2.3.2 NCBLOF (Numerical Cluster Based Local Outlier Factor)
Menurut Maryono dan Djunaidy (2010), ada beberapa cara untuk
mengukur jarak sebuah obyek ke sebuah klaster. Caranya adalah
mengukur jarak sebuah obyek terhadap centroid terdekat atau dapat
juga dengan mengukur jarak relatif obyek dengan centroid terdekat.
Jarak relatif (relative distance) adalah rasio jarak obyek terhadap centroid dibagi dengan jarak rata-rata semua titik terhadap centroid
klaster di mana ia berada. Komponen pada CBLOF mengenai
kemiripan terhadap klaster terdekat juga untuk mendefinisikan
NCBLOF sebagai berikut:
{
| | ( )
| |
Rumus NCBLOF pada persamaan (2.4), didefinisikan dengan
menyesuaikan interpretasi derajat outlier pada CBLOF pada persamaan (2.3).
... (2.3)
17
2.3.3 Algoritma MixCBLOF
Langkah untuk mencari outlier menggunakan algoritma MixCBLOF adalah sebagai berikut :
1. Bagi set data campuran menjadi dua bagian, set data numerik, D1,
dan set data kategorikal, D2.
2. Klasterisasi pada subset data numerik D1 sehingga diperoleh
sejumlah klaster C11, C12, ..., C1p dengan ukuran berturut-turut
|C11| ≥ |C12| ≥ ... ≥ |C1p|
Tentukan klaster besar (LC) dan klaster kecil (SC) menggunakan
Definisi 2 pada halaman 15.
3. Terapkan deteksi outlier berbasis klaster menggunakan atribut numerik terhadap obyek-obyek dalam klaster pada langkah 2
menggunakan teknik deteksi outlier berbasis klaster seperti persamaan (2.4).
{
| | ( )
| |
4. Terapkan deteksi outlier berbasis klaster menggunakan atribut kategorikal terhadap obyek-obyek dalam klaster pada langkah 2
menggunakan CBLOF sebagaimana persamaan (2.3).
{| | ( ) | | ( )
5. Susun derajat outlier pada langkah 3 dan 4 dalam matrik keputusan A=[anm].
[ ]
18
Kemudian, matriks keputusan tersebut dinormalisasi menjadi
sebagai berikut :
[ ]
Didefinisikan n sebagai jumlah data dan m sebagai jumlah atribut. 6. Lakukan pembobotan secara default (bobot sama) atau dengan
metode Entropy.
a. Hitung nilai Entropy ej dan derajat divergensi fj.
b. Hitung bobot tiap kolom/ atribut
7. Gabungkan bobot outlier tiap obyek t1, t2, .., tn pada langkah 6
dengan fungsi agregat untuk mendapatkan derajat outlier akhir OF dari sebuah obyek ti OF(ti ) = . (x1i, x2i, x3i, x4i).
2.4 Struktur Data 2.4.1 ArrayList
Dalam pengembangan sebuah sistem atau aplikasi diperlukan adanya
perancangan sebuah struktur data, perancangan struktur data ini memiliki
fungsi sebagai gambaran sebuah data diolah dan disimpan di dalam program/
sistem. Pada penelitian ini menggunakan konsep Arraylist sebagai tempat penyimpanan data yang dinamis, karena sistem deteksi outlier ini tidak
... (2.5)
... (2.6)
... (2.6)
19
membutuhkan suatu tempat penyimpanan yang terlalu banyak dan tidak
menghabiskan waktu yang terlalu lama pula saat dijalankan.
Arraylist merupakan sebuah kelas yang dapat melakukan penyimpanan data berupa list objek berbentuk array dengan ukurannya dapat berubah
secara dinamis sesuai dengan jumlah data yang dimasukkan. Ilustrasi konsep
Arraylist dapat dilihat pada gambar 2.3.
2.4.2 Matriks
Matriks merupakan struktur data yang digunakan sebagai tempat
penyimpanan pada memori internal dengan memakai dua buah indeks array
yang sering biasa disebut dengan baris dan kolom. Konsep umum untuk array
yang dapat berlaku untuk matriks yaitu kumpulan elemen memiliki tipe yang
sama, dapat berupa tipe dasar integer, string, char, boolean, dll. Ilustrasi
konsep matriks dapat dilihat pada gambar 2.4 berikut.
Gambar 2. 3 Ilustrasi ArrayList
20
Dari ilustrasi di atas adalah konsep matriks dengan ukuran 4x3, artinya memiliki 4 baris dan 3 kolom. Dalam konsep array dapat dituliskan seperti matrix = new int[4][3] dengan keterangan sebagai berikut :
21
BAB III
METODOLOGI PENELITIAN
3.1Bahan Riset/ Data
Data yang digunakan untuk melakukan penelitian berupa file berekstensi
.pdf dan .xls yang diperoleh dari 3 sumber. Sumber yang pertama dari website
milik Kementerian Pendidikan dan Kebudayaan
http://litbang.kemdikbud.go.id/index.php/un. Sumber yang kedua dari website
milik Kementerian Pendidikan dan Kebudayaan
http://puspendik.kemdikbud.go.id/hasil-un/. Sumber yang ketiga dari webiste
Badan Akreditasi Nasional Sekolah/ Madrasah
http://bansm.or.id/sekolah/sudah_akreditasi/4.
Data yang didapatkan dari 3 sumber tersebut merupakan data nilai Ujian
Nasional (UN) per mata pelajaran dan rerata nilai UN, nilai Indeks Integritas
Ujian Nasional (IIUN) SMA, dan nilai Akreditasi sekolah pada tahun 2015
dengan jumlah data 160 SMA di DIY. Pada penelitian ini hanya untuk SMA
jurusan Ilmu Pengetahuan Alam (IPA) dan Ilmu Pengetahuan Sosial (IPS).
22
Gambar 3.3 Nilai IIUN IPA DIY
Gambar 3.5 Nilai Akreditasi Sekolah di DIY
Tabel 3. 3 Nilai IIUN Jurusan IPA
23
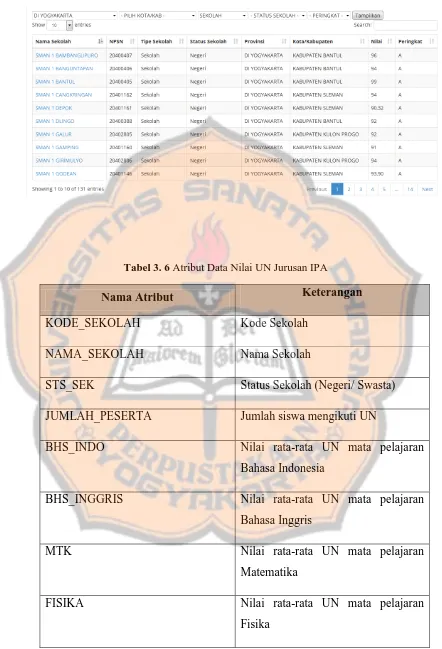
Tabel 3. 6 Atribut Data Nilai UN Jurusan IPA
Nama Atribut Keterangan
KODE_SEKOLAH Kode Sekolah
NAMA_SEKOLAH Nama Sekolah
STS_SEK Status Sekolah (Negeri/ Swasta)
JUMLAH_PESERTA Jumlah siswa mengikuti UN
BHS_INDO Nilai rata-rata UN mata pelajaran
Bahasa Indonesia
BHS_INGGRIS Nilai rata-rata UN mata pelajaran
Bahasa Inggris
MTK Nilai rata-rata UN mata pelajaran
Matematika
FISIKA Nilai rata-rata UN mata pelajaran
24
KIMIA Nilai rata-rata UN mata pelajaran
Kimia
BIOLOGI Nilai rata-rata UN mata pelajaran
Biologi
TOTAL Jumlah nilai rata-rata UN
RANK Nilai ranking sekolah
Tabel 3. 7 Atribut Data Nilai UN Jurusan IPS
Nama Atribut Keterangan
KODE_SEKOLAH Kode Sekolah
NAMA_SEKOLAH Nama Sekolah
STS_SEK Status Sekolah (Negeri/ Swasta)
JUMLAH_PESERTA Jumlah siswa mengikuti UN
BHS_INDO
Nilai rata-rata UN mata pelajaran
Bahasa Indonesia
BHS_INGGRIS
Nilai rata-rata UN mata pelajaran
Bahasa Inggris
MTK
Nilai rata-rata UN mata pelajaran
Matematika
EKONOMI
Nilai rata-rata UN mata pelajaran
Ekonomi
25
Sosiologi
GEO
Nilai rata-rata UN mata pelajaran
Geografi
TOTAL Jumlah nilai rata-rata UN
RANK Nilai ranking sekolah
Tabel 3. 8 Atribut Data NIlai IIUN Jurusan IPA
Nama Atribut Keterangan
KODE_SEKOLAH Kode Sekolah
NPSN Nomor Pokok Sekolah Nasional
NAMA_SEKOLAH Nama Sekolah
STS_SEK Status sekolah (Negeri/ Swasta)
JUMLAH_PESERTA Jumlah siswa mengikuti UN
RERATA_IPA Nilai rata-rata UN jurusan IPA
26
Tabel 3. 9 Atribut Data Nilai IIUN Jurusan IPS
Nama Atribut Keterangan
KODE_SEKOLAH Kode Sekolah
NPSN Nomor Pokok Sekolah Nasional
NAMA_SEKOLAH Nama Sekolah
STS_SEK Status sekolah (Negeri/ Swasta)
JUMLAH_PESERTA Jumlah siswa mengikuti UN
RERATA_IPS Nilai rata-rata UN jurusan IPS
IIUN_IPS Nilai IIUN jurusan IPS
Tabel 3. 10 Atribut Data Nilai Akreditasi SMA
Nama Atribut Keterangan
NAMA_SEKOLAH Nama Sekolah
NPSN Nomor Pokok Sekolah Nasional
TIPE_SEKOLAH Tipe Sekolah (Sekolah/ Madrasah)
STS_SEK Status Sekolah (Negeri/ Swasta)
PROVINSI Provinsi Sekolah
KABUPATEN Kabupaten Sekolah
NILAI Nilai Akreditasi dalam bentuk nominal/
27
PERINGKAT Nilai Akreditasi dalam bentuk huruf
3.2Peralatan Penelitian
Penelitian dilakukan menggunakan spesifikasi perangkat sebagai berikut :
1. Spesifikasi software
a. Netbeans versi 8.0
b. OS Windows 7 64 bit
2. Spesifikasi hardware (Notebook/ Laptop)
a. Processor AMD A6-4400M APU 2,7 GHz
b. Ram 4 GB
c. VGA AMD Radeon HD 7520G
d. Layar 14 inch
e. Harddisk 500 GB
3.3Tahap-tahap Penelitian 1. Studi Kasus
Nilai Ujian Nasional merupakan nilai yang dihasilkan dari Ujian Nasional
untuk mengukur standar pendidikan yang ada di Indonesia. Nilai Indeks
Integritas Ujian Nasional merupakan penilaian kejujuran dalam
pelaksanaan Ujian Nasional. Nilai Akreditasi merupakan pengakuan oleh
badan berwenang terhadap sekolah-sekolah yang memiliki syarat
kebakuan dan kriteria tertentu. Demi menyelenggarakan pendampingan
dan pengembangan suatu sekolah berdasarkan kriteria nilai Ujian
Nasional, nilai Indeks Integritas, dan nilai Akreditasi, diperlukan suatu
informasi mengenai sekolah-sekolah yang memiliki karakteristik berbeda
dibandingkan dengan sekolah lainnya. Untuk mendapatkan informasi
28
Penelitian ini diharapkan dapat menemukan/ menghasilkan informasi
mengenai sekolah yang memiliki karakter berbeda dengan yang lainnya,
sehingga dapat menyelenggarakan pendampingan dan pengembangan
terhadap sekolah tersebut.
2. Penelitian Pustaka
Pada tahap ini, dilakukan penelitian pustaka digunakan untuk memperoleh
informasi dan menggali teori mengenai teknik penambangan data. Dalam
penelitian ini penulis mempelajari referensi-referensi yang berkaitan
dengan teknik penambangan data deteksi outlier khususnya algoritma MixCBLOF dan referensi lainnya yang berguna bagi sistem yang akan
dibangun.
3. Knowledge Discovery in Database (KDD)
Pada tahap penelitian ini dilakukan jika tahap-tahap sebelumnya sudah
dilakukan. Oleh karena itu, tahap ini sangat diperlukan karena penelitian
ini berada pada bidang penambangan data sehingga harus menggunakan
teknik KDD (Knowledge Discovery in Database). Proses KDD terdiri dari data cleaning, data integration, data transformation, data mining, pattern evaluation, dan knowledge presentation. Pada tahap awal dilakukan data cleaning dan data integration pada data SMA se-DIY sehingga data tersebut siap untuk ditambang. Proses awal ini dilakukan secara manual
menggunakan alat bantu Microsoft Excel. Kemudian untuk proses
selanjutnya yaitu data selection, data transformation, dan data mining dilakukan di dalam perangkat lunak yang dibuat. Kemudian proses pattern evaluation dan knowledge presentation dilakukan setelah perangkat lunak selesai dibangun karena kedua proses ini membutuhkan hasil dari alat uji
29
4. Pengembangan Perangkat Lunak
a. Metode Pengembangan Sistem
Metode yang digunakan penulis untuk melakukan pengembangan
sistem menggunakan metode waterfall. Metode waterfall merupakan salah satu metode yang populer karena tidak asing untuk didengar oleh
oleh kalangan pengembang sistem. Menurut Kristanto (2004), metode
waterfall ini diperkenalkan oleh Winston Royce pada tahun 1970. Inti dari metode ini yaitu model klasik yang sederhana dengan aliran
sistem yang linier. Langkah-langkah metode waterfall sebagai berikut : 1. Requirement dan Spesification
Pada tahapan ini merupakan analisa kebutuhan sistem yang
diperlukan dalam pengembangan sistem dengan cara
mengumpulkan data. Selanjutnya, jika analisa kebutuhan sistem
sudah terpenuhi, kemudian merencanakan jadwal pengembangan
software. 2. Design
Tahap desain sistem membagi kebutuhan-kebutuhan menjasi
sistem perangkat lunak atau perangkat keras. Proses tersebut
menghasilkan sebuah arsitektur sistem keseluruhan. Desain
perangkat lunak termasuk menghasilkan fungsi sistem perangkat
lunak dalam bentuk yang mungkin ditransformasi ke dalam satu
atau lebih program yang dapat dijalankan. Tahapan ini merupakan
tahap untuk menentukan alur software sampai pada tahap algoritma
yang detil.
3. Implementation
Tahap ini desain perangkat lunak disadari sebagai sebuah program
lengkap atau unit program. Desain perangkat lunak yang sudah
dibuat kemudian diubah ke dalam bentuk kode-kode program.
Diakhir tahap ini, tiap modul ditesting tanpa diintegrasikan.
30
Unit program diintegrasikan dan diuji menjadi sistem yang lengkap
untuk meyakinkan bahwa persyaratan perangkat lunak telah
dipenuhi.
5. Operation mode & retirement
Tahap ini adalah tahap yang terpanjang. Sistem dipasang dan
digunakan. Pemeliharaan termasuk pembetulan kesalahan yang
tidak ditemukan pada langkah sebelumnya. Perbaikan
implemenetasi unit sistem dan peningkatan jasa sistem sebagai
kebutuhan baru ditemukan.
b. Pengujian
Pengujian dilakukan dengan alat uji yang sudah dibuat pada tahap
sebelumnya. Metode untuk pengujian sistem ini adalah metode
pengujian black box. Pengujian black box berisi pengujian dengan pengisian data secara benar. Hasil yang diperoleh dari alat uji
kemudian dibandingkan dengan hasil penghitungan manual untuk
memperoleh validasi dari alat pengujian tersebut.
5. Analisis dan Pembuatan Laporan
Analisis yang dilakukan adalah analisis hasil dari perangkat lunak yang
dibuat berdasarkan penerapan algoritma MixCBLOF. Analisis yang
dimaksud adalah melakukan analisis dari pola yang terbentuk, artinya mendapatkan nilai masukan k (jumlah kluster), nilai α dan β untuk mendapatkan hasil outlier yang optimal dan sesuai dengan data dari dinas pendidikan provinsi Yogyakarta. Hasil dari semua pengujian tersebut
31
BAB IV
PEMROSESAN AWAL DAN PERANCANGAN PERANGKAT LUNAK PENAMBANGAN DATA
4.1PEMROSESAN AWAL 4.1.1 Pembersihan Data
Pada proses pembersihan data ini adalah membersihkan data
berupa noise (gangguan) seperti nilai yang kosong pada tabel data. Data yang ada noise pada beberapa sekolah berupa nilai IIUN yang tidak teridentifikasi atau sudah melakukan UNBK (Ujian Nasional Basis
Komputer), sekolah dengan tipe madrasah aliyah, dan beberapa sekolah
yang tidak terakreditasi. Maka dari itu, 54 sekolah dari jurusan IPA dan
78 sekolah dari jurusan IPS dihapus dari tabel data.
4.1.2 Integrasi Data
Proses integrasi data merupakan proses untuk melakukan
penggabungan data dari berbagai sumber data yang didapatkan. Data
yang didapatkan berupa 3 file untuk setiap jurusan (IPA/IPS) berupa
data nilai Ujian Nasional, nilai Indeks Integritas Ujian Nasional, dan
nilai Akreditasi SMA tahun 2014/2015. Pada tahap ini dilakukan
penggabungan dari 3 file tersebut menjadi 1 file berupa tabel data untuk
setiap jurusan, sehingga didapatkan 2 file yang terdiri dari 1 file jurusan
32
4.1.3 Seleksi Data
Proses seleksi data merupakan seleksi atribut yang akan digunakan
dalam proses penambangan data. Proses ini dilakukan dengan memilih
atribut yang relevan untuk digunakan dalam penelitian, dan menghapus
atribut yang tidak relevan. Atribut yang dihapus dari data nilai Ujian
Nasional SMA jurusan IPA tahun 2014/2015 adalah atribut STS_SEK,
JUMLAH_PESERTA, dan RANK, sehingga atribut yang digunakan
Tabel 4. 1 Hasil Integrasi Jurusan IPA
33
yaitu KODE_SEKOLAH, NAMA_SEKOLAH, BHS_INDO,
BHS_INGGRIS, MTK, FISIKA, KIMIA, BIOLOGI, dan TOTAL.
Atribut yang dihapus dari data nilai Indeks Integritas Ujian Nasional
SMA jurusan IPA tahun 2014/2015 adalah NPSN, STS_SEK, dan
JUMLAH_PESERTA, sehingga atribut yang digunakan
KODE_SEKOLAH, NAMA_SEKOLAH, RERATA_IPA, dan
IIUN_IPA. Pada atribut yang dihapus dari data nilai Ujian Nasional
SMA jurusan IPS tahun 2014/2015 sama dengan atribut yang dihapus
dari data nilai Ujian Nasional SMA jurusan IPA tahun 2014/2015,
sehingga atribut yang digunakan yaitu KODE_SEKOLAH,
NAMA_SEKOLAH, BHS_INDO, BHS_INGGRIS, MTK, EKONOMI,
SOSIO, GEO, dan TOTAL. Pada atribut yang dihapus dari data nilai
Indeks Integritas Ujian Nasional SMA jurusan IPS tahun 2014/2015
sama dengan atribut yang dihapus dari data nilai Indeks Integritas Ujian
Nasional SMA jurusan IPA tahun 2014/2015, sehingga atribut yang
digunakan yaitu KODE_SEKOLAH, NAMA_SEKOLAH,
RERATA_IPS, dan IIUN_IPS. Atribut yang dihapus dari data nilai
Akreditasi SMA tahun 2014/2015 adalah NPSN, TIPE_SEKOLAH,
STS_SEK, PROVINSI, KABUPATEN, dan NILAI sehingga atribut
yang digunakan yaitu NAMA_SEKOLAH dan PERINGKAT. Atribut
yang digunakan kemudian digabungkan menjadi 1 file, sehingga atribut
yang digunakan untuk SMA jurusan IPA dan IPS dapat dilihat pada
tabel 4.3 dan tabel 4.4.
Tabel 4. 3 Hasil Seleksi Atribut Jurusan IPA
Nama Atribut Keterangan
KODE_SEKOLAH Kode Sekolah
NAMA_SEKOLAH Nama Sekolah
34
Bahasa Indonesia
BHS_INGGRIS Nilai rata-rata UN mata pelajaran
Bahasa Inggris
MTK Nilai rata-rata UN mata pelajaran
Matematika
FISIKA Nilai rata-rata UN mata pelajaran Fisika
KIMIA Nilai rata-rata UN mata pelajaran
Kimia
BIOLOGI Nilai rata-rata UN mata pelajaran
Biologi
TOTAL Jumlah nilai UN jurusan IPA
RERATA_IPA Nilai rata-rata UN jurusan IPA
IIUN_IPA Nilai IIUN jurusan IPA
AKREDITASI Nilai Akreditasi SMA dalam bentuk
huruf
Tabel 4. 4 Hasil Seleksi Atribut Jurusan IPS
Nama Atribut Keterangan
KODE_SEKOLAH Kode Sekolah
NAMA_SEKOLAH Nama Sekolah
BHS_INDO Nilai rata-rata UN mata pelajaran
Bahasa Indonesia
BHS_INGGRIS Nilai rata-rata UN mata pelajaran
Bahasa Inggris
MTK Nilai rata-rata UN mata pelajaran
Matematika
EKONOMI Nilai rata-rata UN mata pelajaran
Ekonomi
SOSIOLOGI Nilai rata-rata UN mata pelajaran
35
GEOGRAFI Nilai rata-rata UN mata pelajaran
Geografi
TOTAL Jumlah nilai UN jurusan IPS
RERATA_IPS Nilai rata-rata UN jurusan IPS
IIUN_IPS Nilai IIUN jurusan IPS
AKREDITASI Nilai Akreditasi SMA dalam bentuk
huruf
4.1.4 Transformasi Data
Pada transformasi data ini terdapat tahapan pengubahan pada data
akreditasi dari karakter menjadi numerik tetapi tidak menghilangkan
sifat aslinya sebagai atribut nominal. Atribut akreditasi memiliki data
berjenis karakter yaitu A, B, dan C yang diubah menjadi data numerik
A=1, B=2, C=3. Proses pengubahan dapat dilakukan secara bebas,
namun pada penelitian ini menggunakan ketentuan A=1, B=2, dan C=3.
4.2PERANCANGAN PERANGKAT LUNAK PENAMBANGAN DATA 4.2.1 Perancangan Umum
4.2.1.1 Input Sistem
36
4.2.1.2 Proses Sistem
Proses sistem yang akan dibangun terdiri dari beberapa tahapan
untuk dapat menemukan aturan yang berfungsi untuk menemukan data
yang dianggap sebagai outlier dari suatu sekolah. Proses tersebut yaitu : 1. Menentukan nilai b, alfa, dan beta yang berfungsi dalam
menentukan klaster besar (LC) dan klaster kecil (SC)
2. Proses clustering untuk menemukan anggota dan jumlah anggota dari setiap cluster
3. Proses deteksi outlier untuk menemukan data yang unik dengan derajat outlier per objek.
Proses umum yang terjadi pada sistem dapat digambarkan dalam
diagram flowchart yang digambarkan pada Gambar 4.1.
37
Proses dari Deteksi Outlier dapat digambarkan dalam bentuk diagram
flowchart yang digambarkan pada Gambar 4.2 berikut.
4.2.1.3 Output Sistem
Sistem akan memberikan keluaran atau output berupa nama sekolah yang diidentifikasi sebagai outlier beserta nilai derajat outlier per objek yang sesuai dengan nilai b, alfa, dan beta. Selain itu sistem juga akan menampilkan daftar-daftar sekolah yang teridentifikasi sebagai
outlier sebanyak nilai threshold yang dimasukkan oleh pengguna.
4.2.2 Diagram Use Case
Diagram use case merupakan sebuah gambaran sistem yang dilihat dari sudut pandang pengguna (user). Sebuah sistem yang akan terbentuk selalu memiliki interaksi antara pengguna dengan sistem yang
38
digambarkan melalui diagram use case. Diagram use case dapat dilihat pada Gambar 4.2 berikut.
Pilih file input
Deteksi menggunakan Algoritma MixCBLOF
Simpan data hasil User
39
Pengguna dalam sistem yang akan dibangun ini hanya terdapat satu pengguna diinisialisasikan dengan “User”. Pengguna dalam sistem ini memiliki 3 interaksi terhadap sistem yaitu memilih file data .xls, deteksi menggunakan algoritma mixcblof, dan menyimpan hasil data. Ketiga
interaksi/ aktifitas yang dilakukan pengguna merupakan interaksi saling
berkaitan sehingga perlu dilakukan secara berurutan. Diagram use case
memiliki narasi dari setiap use case. Narasi tersebut terlampir pada
lampiran 1.
4.2.3 Diagram Aktivitas
Diagram aktivitas merupakan aktivitas dari use case memilih file data .xls, deteksi menggunakan algoritma mixcblof, dan menyimpan hasil
deteksi outlier. Diagram aktivitas memiliki tiga diagram. Diagram aktivitas tersebut terlampir pada lampiran 2.
4.2.4 Diagram Kelas Analisis
Diagram kelas analisis terlampir pada lampiran 3.
4.2.5 Diagram Sekuen
Pada diagram sekuen ini memiliki tiga diagram sequence yaitu memilih file data bertipe .xls, deteksi menggunakan algoritma MixCBLOF, dan menyimpan hasil deteksi outlier. Diagram sequence terlampir pada lampiran 4.
4.2.6 Perancangan Struktur Data
Pada penelitian ini menggunakan struktur data berupa ArrayList (lihat Gambar 2.3) dan Matriks (lihat Gambar 2.4). Pada ArrayList, jumlah sekolah sebagai element data. Setiap data sekolah akan berada
dalam index yang sama. Sebagai contoh, akan digambarkan pada
40
Pada Matriks, terdapat baris dan kolom, baris disesuaikan dengan
jumlah data sekolah, dan kolom disesuaikan dengan jumlah atributnya.
Pada matriks ini digunakan untuk menampung nilai derajat outlier. Sebagai contoh, akan digambarkan pada Gambar 4.4 berikut.
Ilustrasi pada Gambar 4.4 di atas merupakan contoh ilustrasi
matriks dengan ukuran 4x3, artinya memiliki 4 baris sebagai jumlah
sekolah dan 3 kolom sebagai atributnya yaitu derajat dari atribut Ujian
Nasional, Indeks Integritas Ujian Nasional, dan Akreditasi. Ilustrasi
tersebut menggambarkan penyimpanan derajat outlier per atribut.
Gambar 4. 4 Perancangan Arraylist
41
4.2.7 Diagram Kelas Disain
Diagram kelas disain terlampir pada lampiran 5.
4.2.8 Algoritma per Method
Rincian algoritma per method terlampir pada lampiran 6.
4.2.9 Perancangan Antarmuka
42
4.2.9.1 Perancangan Halaman Awal
Halaman awal merupakan halaman pertama yang akan
dilihat oleh user saat sistem dijalankan. Halaman awal dapat dilihat pada gambar 4.5 berikut ini.
Pada halaman awal ini terdapat beberapa tombol yaitu “BERANDA”, “BANTUAN”, “TENTANG”, dan “Masuk Sistem”. Tombol “BERANDA” merupakan tombol untuk menuju ke halaman awal. Tombol “BANTUAN” merupakan tombol untuk menuju ke halaman bantuan yang berisi mengenai panduan menggunakan sistem. Tombol “TENTANG” merupakan tombol untuk menuju ke halaman tentang yang berisi mengenai informasi pembuat sistem. Tombol
43
“Masuk Sistem” merupakan tombol untuk menuju ke halaman proses sebagai awal untuk memulai proses deteksi outlier.
.
4.2.9.2 Perancangan Halaman Proses
Perancangan antarmuka halaman proses dapat dilihat pada
gambar 4.6 berikut.
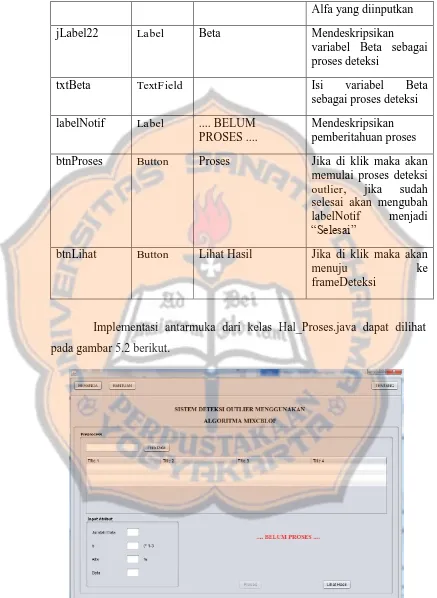
Halaman ini merupakan halaman untuk memproses data.
Pada halaman ini terdapat tiga tombol menu yaitu tombol “BERANDA”, “BANTUAN”, dan “TENTANG”. Tombol “BERANDA” merupakan tombol untuk menuju ke halaman awal. Tombol “BANTUAN” merupakan tombol untuk menuju ke halaman bantuan yang berisi mengenai panduan menggunakan sistem. Tombol “TENTANG” merupakan tombol untuk menuju ke halaman tentang yang berisi mengenai informasi pembuat sistem.
44
Preprocessing data dimulai dengan import data dari file berupa Microsoft Excel dengan ekstensi .xls. Tombol “Pilih Data” merupakan tombol yang digunakan untuk import file data diambil dari direktori komputer user. Setelah memilih file data, maka data tersebut akan tertampil di tabel yang sudah disediakan.
Tahap selanjutnya yaitu mengisikan nilai dari variabel b, Alfa, dan Beta untuk melancarkan preprocessing data, karena jika tidak diisi maka akan muncul pemberitahuan error. Setelah mengisikan ketiga variabel tersebut kemudian menekan tombol “Proses”. Tombol “Proses” merupakan tombol untuk melakukan preprocessing data. Jika proses sudah selesai maka kalimat “Belum Proses” akan diubah menjadi kalimat “Selesai” untuk memberitahukan kepada user bahwa preprocessing sudah selesai.
Tahap preprocessing terakhir yaitu melihat hasil deteksi outlier yang sudah selesai dalam hal pemrosesan data. Tombol “Lihat Hasil” merupakan tombol untuk menuju ke frame hasil deteksi yang berisikan hasil penghitungan berupa derajat outlier semua sekolah.
Perancangan antarmuka frame hasil dapat dilihat pada
gambar 4.7 berikut.
45
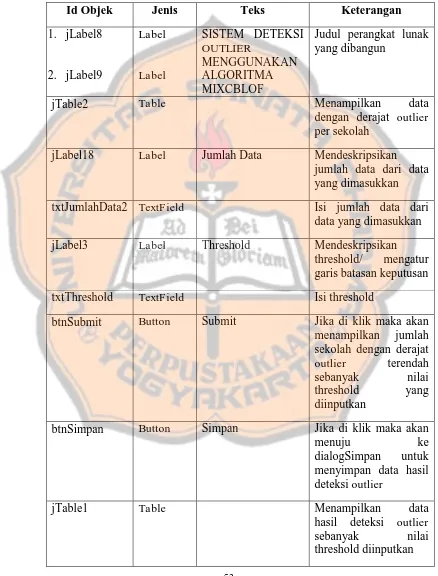
Frame ini merupakan frame untuk menampilkan hasil dari
preprocessing data. Frame ini merupakan salah satu bagian dari Hal-proses. Pada frame ini dibagi menjadi dua bagian yaitu menampilkan
hasil derajat outlier semua sekolah, dan menampilkan hasil outlier sesuai dengan nilai Threshold yang diisi. Jika preprocessing selesai maka tabel atas (tabel pertama) akan terisi dengan data sekolah dan
hasil derajat outlier per sekolah. Setelah itu user mengisikan variabel Threshold untuk menampilkan beberapa sekolah saja yang mempunyai
nilai derajat outlier terkecil, sehingga jumlah sekolah yang terdeteksi sebagai outlier akan ditentukan oleh user. Tombol “Submit” merupakan tombol untuk menampilkan sekolah berdasar variabel Threshold yang diisi oleh user. Tombol “Simpan” merupakan tombol untuk melakukan penyimpanan hasil deteksi outlier. User akan dihadapkan pada dua pilihan (lihat gambar 4.8) yaitu menyimpan hasil semua deteksi outlier atau hanya menyimpan hasil deteksi outlier yang sudah dithreshold.
Jika user memilih tombol “Semua” maka akan menyimpan hasil deteksi outlier semua sekolah (tabel pertama), jika user memilih tombol “Threshold” maka akan menyimpan hasil deteksi outlier beberapa sekolah (tabel kedua).
46
4.2.9.3 Perancangan Halaman Bantuan
Perancangan antarmuka halaman bantuan dapat dilihat pada
gambar 4.9.
Halaman ini merupakan halaman antarmuka bantuan.
Halaman ini berisi mengenai panduan penggunaan sistem. Pada halaman ini terdapat tiga tombol yaitu tombol “BERANDA”, tombol “BANTUAN”, dan tombol “TENTANG”. Tombol “BERANDA” merupakan tombol untuk menuju ke halaman awal. Tombol “BANTUAN” merupakan tombol untuk menuju ke halaman bantuan yang berisi mengenai panduan menggunakan sistem. Tombol “TENTANG” merupakan tombol untuk menuju ke halaman tentang yang berisi mengenai informasi pembuat sistem.
47
4.2.9.4 Perancangan Halaman Tentang
Perancangan antarmuka halaman tentang dapat dilihat pada
gambar 4.10.
Halaman ini merupakan halaman antarmuka tentang.
Halaman ini berisi mengenai informasi pembuat. Pada halaman ini terdapat tiga tombol yaitu tombol “BERANDA”, tombol “BANTUAN”, dan tombol “TENTANG”. Tombol “BERANDA” merupakan tombol untuk menuju ke halaman awal. Tombol “BANTUAN” merupakan tombol untuk menuju ke halaman bantuan yang berisi mengenai panduan menggunakan sistem. Tombol “TENTANG” merupakan tombol untuk menuju ke halaman tentang yang berisi mengenai informasi pembuat sistem.
48
BAB V
IMPLEMENTASI PENAMBANGAN DATA DAN EVALUASI HASIL
5.1Implementasi Rancangan Perangkat Lunak
Perangkat Lunak deteksi outlier ini memiliki 8 buah kelas yang terdiri dari tigas kelas model, satu kelas controller, dan empat kelas view.
5.1.1 Implementasi Kelas Model
Implementasi kelas model dapat dilihat pada tabel 5.1 berikut.
Tabel 5. 1 Implementasi Kelas Model
No. Nama Kelas Nama File Fisik Nama File Excecutable 1. DataSekolah DataSekolah.java DataSekolah.class
2. HasilCluster HasilCluster.java HasilCluster.class
3. OutlierFinal OutlierFinal.java OutlierFinal.class
5.1.2 Implementasi Kelas View
Implementasi kelas view dapat dilihat pada tabel 5.2 berikut.
Tabel 5. 2 Implementasi Kelas View
No. Use Case Antarmuka Nama Kelas
Boundary 1. Memilih file data
.xls
Hal_Proses.class
2. Deteksi menggunakan Algoritma MixCBLOF
Hal_Proses.class
3. Menyimpan data hasil
49
Selanjutnya akan dijelaskan mengenai spesifikasi detail dari setiap
antarmuka yang ada pada perangkat lunak deteksi outlier ini. Spesifikasi detail dari kelas Hal_Utama dapat dilihat pada tabel 5.3 berikut.
Tabel 5. 3 Spesifikasi detail kelas Hal_Utama.java
Id Objek Jenis Teks Keterangan
btnBeranda Button BERANDA Jika di klik maka akan menuju ke halaman Hal_Utama.java
btnBantuan Button BANTUAN