ADMINISTRASI
__________________________
Tata Kelola Administrasi
BigQ Manager V.2.1
Disajikan oleh : Hardiyanto
Dan Team Penyusun TMBigData dan AIHub, January 2020
Buku ini adalah materi yang disertakan dalam pembelian sebuah lisensi dari piranti lunak BigQ Manager. Hak cipta buku ini dimiliki oleh
TMBigData, dilarang keras untuk menggandakan, mendistribusikan, merubah isi untuk kemudian didistribusikan lagi menggunakan media yang berbeda tanpa seijin pihak TMBigData.
Daftar Isi
Pendahuluan...4
Istilah Istilah...4
Sebelum Memulai Latihan...4
Sistem BigQ...5
Mesin Mesin Peladen (Servers)...5
Pengaturan Keamanan...5
Objek dan Proses di BigQ...6
Memulai BigQ...7
Gambar 1. Tampilan utama BigQ...7
Cluster’s Attributes...8
Gambar 2. Pembuatan Cluster’s Atrributes...8
Name Node...8
Gambar 3. Pembuatan Name Node...9
HDFS Users...9
Gambar 4. Pembuatan User BigQ Web...10
Gambar 5. Pembuatan Password User BigQ Web...11
Gambar 5. Pembuatan HDFS Users...11
Management...12
Gambar 6. Tampilan ACL Management...12
Gambar 7. Contoh Pengisian Form ACL Management...13
Gambar 8. Contoh Pengisian Akhir Form ACL Management...14
Gambar 9. Informasi Yang Ditampilkan Sistem ACL...15
Data Prosesor...15
Gambar 10. Data Processors...16
Log...16
Delegasi...16
Gambar 11. Pembuatan User Delegator...17
Berbagi Dokumentasi...17
Gambar 12. Pembuatan Dokumentasi...17
What’s Next...18
Memahami Objek Dan Proses Big Data...19
Studi Kasus...19
Persiapan...19
Gambar 13. Hasil Pembuatan BigQ Web User...21
Gambar 14. Hasil Pembuatan HDFS User...21
Gambar 15. Hasil Pengaturan ACL Management...22
Gambar 16. Hasil Data Prosesor...22
Gambar 17. Tampilan Dashboard Pengguna...23
Mempersiapkan Sumber Data...24
Gambar 18. Hasil Pembuatan Konfigurasi Sumber data...24
Destinasi File Big Data Parquet...24
Gambar 19. Daftar Destinasi File Big Data Parquet...24
Proses Big Data...25
a. Big Data Storing...25
Gambar 20. Konfigurasi Big Data Storing...25
Gambar 22. Konfirmasi Pengiriman Proses...26
Gambar 23. Pemberitahuan...27
Gambar 24. Hasil Storing Pertama...27
b. Inspection...28
Gambar 25. Parquet Inspection...28
Gambar 26. Dialog Inspection...28
Gambar 27. Daftar Record Inspection...28
Gambar 28. Hasil Inspeksi...29
c. Big Data Append...30
Gambar 29. Memilih Destinasi Big Data File Untuk Proses Append...30
Gambar 30. Pengeditan Destinasi Big Data File...30
Gambar 31. Proses Storing Parsial Ke 1 (satu)...31
Gambar 32. Hasil Proses Parsial Ke 1 (satu)...32
Gambar 33. Proses Storing Parsial Ke 2 (dua)...33
Gambar 34. Hasil Proses Parsial Ke 2 (dua)...34
Gambar 35. Hasil Inspeksi Union...34
d. Mempartisi Destinasi Big Data File...35
Gambar 36. Partisi Destinasi File Big Data...36
Gambar 37. Hasil Proses Partisi...37
Review...39
Komparasi Ukuran...39
Bekerja Dengan Timestamp...39
Drilling Data...40
Drilling Dalam Lingkup Intranet...40
a. Membuat Konektifitas Database...41
Gambar 38. Dialog Konektifitas Database...41
Gambar 39. Dialog Parameter Konektifitas Database...42
b. Bekerja Menyenangkan Dengan IDE...43
Gambar 40. Bekerja menggunakan Dbeaver...43
Gambar 41. Hasil Query 1 (satu)...44
Gambar 42. Hasil Query 2 (dua)...44
Gambar 43. Hasil Query 3 (tiga)...45
Drilling Dalam Lingkup Internet...45
Data Analisis Dengan Microsoft Power BI...46
Installasi...46
Persiapan Big Data file Parquet...46
Koneksi Dengan Power BI...46
Gambar 44. Dialog Koneksi Power BI...47
Gambar 45. Konfigurasi ODBC...47
Gambar 46. Pengisian Username dan Password...48
Gambar 47. Preview Data...49
Gambar 48. Contoh Visualisasi Dengan Power BI...50
Penutup...51
Storing File Tidak Terstruktur...51
Monitoring...51
Kebutuhan Piranti Keras Saat Operasional...51
Pendahuluan
BigQ Manager V.2.1 yang selanjutnya dalam buku ini hanya disebut BigQ, adalah piranti lunak yang dibuat oleh perusahaan TMBigData, piranti lunak ini bersifat tertutup (closed source), dan didistribusikan melalui penjualan salinan dan lisensi.
Buku ini menganggap sistem BigQ telah terpasang dan berjalan dengan baik, semua petunjuk pada buku ini mencakup secara spesifik tata kelola yang berlaku untuk pengguna level administrator di sistem BigQ, selanjutnya pengguna level administrator ini disebut administrator saja. Sebagai administrator anda diharapkan mempunyai bekal :
1. Paham penggunaan aplikasi berbasis web
2. Paham istilah istilah umum teknologi informasi dan komputer
3. Paham tata kelola pengaturan para pengguna sistem (user administration) Sangat bermanfaat jika anda juga memiliki pemahaman yang baik di bidang :
1. Tata kelola jejaring (network) komputer server 2. Tata kelola Database server
3. Tata kelola Linux Server
Memiliki pemahaman di atas akan sangat mempercepat pemahaman penggunaan sistem BigQ ini.
Istilah Istilah
Dalam buku ini, istilah istilah yang berhubungan dengan teknologi komputer tidak diterjemahkan ke dalam bahasa Indonesia, oleh karena itu mohon dipahami arti arti populer kata atau kalimat seperti save, create, edit, user, username, password, server, data processor, email, browser, record dan lain sebagainya.
Sebelum Memulai Latihan
Dalam proses latihan dan pembelajaran mintalah terlebih dahulu kepada pihak kami, TMBigData, sebuah lisensi versi evaluasi untuk dipakai sebagai sarana uji coba sebelum masuk ke phase sebenarnya. Biaya pembelian yang anda bayar untuk sebuah sistem BigQ sudah termasuk :
1. Lisensi BigQ V.2.1 versi standar atau enterprise untuk di install di secara on premise rack to rack atau sistem container, atau diinstall di cloud atau di private cloud
2. Lisensi BigQ V.2.1 versi evaluasi untuk diinstall on-premise di satu server menggunakan sistem container
Untuk menggunakan lisensi versi evaluasi, kewajiban anda hanya menyediakan sarana 1 (satu) piranti keras dengan minimum spesifikasi jenis intel core i7, 16GB ram, 8 core cpu dan ssd sebesar 256GB yang akan dipakai dalam proses latihan ini. Kunjungi lebih jelas di situs https://tmbigdata.sg
Sistem BigQ
Mesin Mesin Peladen (Servers)
Pada kondisi umum dan baku (default), sistem BigQ ini dipasang oleh Team TMBigData baik di tempat anda langsung ataupun remote installation (installasi jarak jauh), jika sistem BigQ ini sudah terpasang dengan baik maka akan terdiri dari :
No Hostname IP Address Kegunaan
1 singlenova-en 10.10.10.63 Sistem BigQ utama 2 hdfs-master 10.10.10.50 HDFS namenode 3 hdfs-node1 10.10.10.51 HDFS datanode 1 4 hdfs-node2 10.10.10.52 HDFS datanode 2 5 hdfs-node3 10.10.10.53 HDFS datanode 3 6 spark-master 10.10.10.70 Data Prosesor master 7 spark-slave1 10.10.10.71 Data Prosesor slave
8 driller 10.10.10.80 Peladen sistem yang mengatur pembacaan, perpindahan data dari satu sistem ke sistem lain ataupun explorasi data
9 datasource 10.10.10.81 Contoh Database server MySQL, PostgreSQL dan Microsoft SQL
10 bdtransport 10.10.10.90 BDTransport adalah opsional, hanya dibutuhkan untuk proses store data tidak terstruktur (unstructured data), bisa terinstall ataupun tidak. Hubungi support center kami untuk lebih dalam tentang fasilitas ini
Alamat alamat IP (Internet Protocol) para peladen tentu saja tidak lah baku seperti diatas, mungkin berbeda sesuai dengan keinginan pihak pembeli atau pengguna.
Pengaturan Keamanan
Pada kondisi baku (default), sistem BigQ menggunakan keamanan subnet isolated, artinya semua akses menuju peladen sangat dibatasi oleh sistem keamanan iptables Linux, ini bertujuan agar sistem big data anda aman dan terkendali dari semua gangguan luar.
No Nama host IP Address Level Keamanan
1 singlenova-en 10.10.10.63 Dapat diakses terbatas melalui intranet atau publik melalui port 8069 atau 8070 atau 8071 2 hdfs-master 10.10.10.50 Hanya dapat diakses oleh node1,
hdfs-node2, hdfs-node3 dan dapat diakses oleh singlenova-en serta bdtransport pada port 9000 serta dapat diakses oleh driller pada port
31010
3 hdfs-node1 10.10.10.51 hdfs datanode 1 hanya dapat diakses oleh hdfs-master, hdfs-node2 dan hdfs-node3 4 hdfs-node2 10.10.10.52 hdfs datanode 2, hanya dapat diakses oleh
hdfs-master, hdfs-node1 dan hdfs-node3 5 hdfs-node3 10.10.10.53 hdfs datanode 3, hanya dapat diakses oleh
hdfs-master, hdfs-node1 dan hdfs-node2 6 spark-master 10.10.10.70 Data prosesor master, dapat diakses oleh
singlenova-en pada port 8080, 8081 serta 7077. spark-master juga dapat diakses oleh spark-slave1
7 spark-slave1 10.10.10.71 Data prosesor slave hanya dapat diakses oleh spark-master
8 driller 10.10.10.80 Dapat diakses terbatas atau publik pada port 31010, dibuka jika anda menginginkan koneksi langsung ke layanan layanan BI seperti Power BI , Tableu ataupun Database IDE seperti DataGrip, DBeaver dan lain lain dengan proteksi username dan password, lebih lanjut tentang keamanan layanan silahkan lihat di bab Drilling Data
9 datasource 10.10.10.81 datasource dapat diakses oleh singlenova-en dan spark-master pada port 3306 (MySQL) , 5432 (PostgreSQL) atau 1433 (Microsoft SQL).
10 bdtransport 10.10.10.90 Akses terbatas.
Pengaturan akses masuk dan keluar bisa dimodifikasi oleh anda melalui Linux iptables ataupun router yang biasanya dilakukan oleh network administrator di tempat anda, silahkan anda berkonsultasi dengan nya.
Objek dan Proses di BigQ
Dalam BigQ, objek adalah destinasi file big data, jika data tersebut terstruktur maka disimpan dalam format Parquet, jika data tersebut tidak terstruktur maka disimpan dalam format aslinya. Proses dalam BigQ didefinisikan menjadi dua, yaitu :
1. BigQ Proses Utama yang terdiri dari proses ingest, store, append, inspection atau data proses, selanjutnya dalam buku ini disebut BigQ Proses Primer (dalam huruf warna maroon) 2. BigQ User Proses yang terdiri dari proses user impersonasi, create, revoke dan regrant,
Memulai BigQ
Buka browser Chrome atau Safari (Mac) ataupun browser yang sudah mendukung html 5.0, isikan url http://10.10.10.63:8069 (port mungkin saja 8069, 8070 ataupun 8071 sesuai keinginan pengguna pada saat installasi). Dalam kondisi pertama kali, BigQ ini sudah memiliki user level administrator dengan username ‘admin’ dan password ‘admin’ (tanpa kutip) , serta user level pengguna dengan username ‘demouser’ dan password ‘1234567’ (tanpa kutip), masuklah dengan pengguna level administrator terlebih dahulu , tampilan dashboard administrator adalah seperti pada gambar 1 (satu).
Gambar 1. Tampilan utama BigQ
Hanya terdapat 2 (dua) menu atas yaitu ‘Big Data’ dan ‘Settings’ serta terdapat 5 (lima) menu dan beberapa sub menunya di navigasi kiri. Struktur menu ‘Big Data’ navigasi kiri adalah sebagai berikut : + HDFS Management - Clusters Attributes - Name Node - HDFS Users - ACL Management - Admin Logs + Location - Data Sources - Data Processors + Big Data Storage
- Big Data Destination - Big Data Storing - User Log
+ Inspection
- Parquet Inspection + Document
- Help
Cluster’s Attributes
Menu Cluster’s Attributes berfungsi untuk penamaan atau labelling, ini untuk memudahkan anda mengenali hdfs cluster, hdfs adalah Hadoop Distributed File System, selanjutnya hanya disebut hdfs. karena BigQ ini mempunya kapabilitas mengatur beberapa hdfs clusters, setidaknya harus ada 1 (satu) nama atau label untuk memulai menggunakan BigQ ini. Untuk membuat penamaan atau labeling, buka menu Cluster’s Attributes dan klik tombol biru ‘Create’ di top header menu dibawah navigasi atas utama.
Gambar 2. Pembuatan Cluster’s Atrributes
Isikan bidang isian ‘Cluster Name’ dengan nama yang mudah diingat, dan tambahkan bidang isian ‘Description’ dengan deskripsi yang jelas. Simpan dengan mengklik tombol ‘Save’.
Name Node
Menu ‘Name Node’ berfungsi untuk memetakan lokasi hdfs namenode. Klik menu tersebut dan buat sebuah atau beberapa (jika mempunyai lebih dari 1 hdfs namenode) dengan cara menekan tombol ‘Create’, seperti tampak pada gambar 3.
Gambar 3. Pembuatan Name Node
Pada bidang isian ‘Cluster’ pilih nama cluster nya, berikan title yang jelas pada bidang isian ‘Title’. Untuk Bidang isian ‘HDFS URL’ gunakan format URL yang benar dengan format
hdfs://ip.address:port , seperti contoh hdfs://10.10.10.50:9000 .
Setiap 1 (satu) hdfs namenode memiliki 1 (satu) hdfs administrator, hdfs administrator di sini bukan BigQ web administrator, tetapi adalah user yang memiliki hak akses penuh kepada sistem hdfs tersebut. Untuk setiap hdfs namenode pihak TMBigData yang memasang sistem ini akan memberikannya kepada anda. Isikan bidang isian ‘HDFS Admin Username’ dengan nama yang telah anda terima dari pihak kami, selanjutnya jika semua bidang isian sudah benar, simpanlah dengan mengklik tombol ‘Save’, ‘HDFS Admin Username’ adalah informasi yang cukup sensitif, BigQ akan menyandikan (encrypted) secara otomatis isian tersebut.
Bagaimana jika anda memiliki hdfs namenode dari pihak ketiga dan anda ingin
mengintegrasikannya dengan sistem BigQ ? Sepanjang hdfs namenode yang anda miliki tersebut sesuai dengan spesifikasi yang dikehendaki oleh BigQ, maka ini dapat dilakukan.
HDFS Users
Di menu ini, anda akan mengatur para user agar mereka dapat melakukan BigQ Proses Primer tanpa melibatkan anda sebagai administrator. Seorang hdfs user juga adalah seorang BigQ web user, oleh karena itu sebelum membuat seorang hdfs user anda harus membuat terlebih dahulu BigQ web user. Klik menu navigasi paling atas ‘Settings’ , maka menu navigasi sebelah kiri akan berubah dengan struktur menu sebagai berikut :
+ Users & Companies - Users
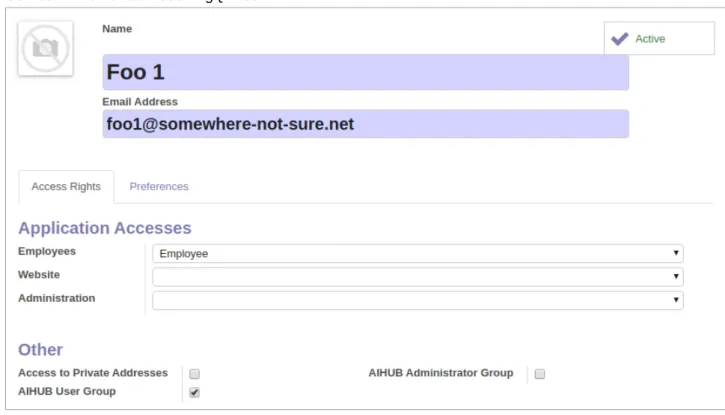
Klik menu ‘Users’ dan tekan tombol biru ‘Create’ Gambar 4. Pembuatan User BigQ Web
Isikan nama pada bidang isian ‘Name’, isikan alamat email pada bidang isian ‘Email Address’ (nantinya email ini akan digunakan untuk masuk ke dalam BigQ web sebagai username), Pilih Employee pada bidang isian ‘Employees’, kosongkan bidang isian ‘Website’ dan ‘Administration’ dan centang pilihan ‘AIHUB User Group’. Anda dapat mengupload photo user dengan mengklik ikon kamera. Selanjutnya, pada bagian tab ‘Preferences’ isikan bidang isian sesuai dengan informasi user. Simpan dengan mengklik tombol biru ‘Save’. Setelah itu rubah kata kuncinya dengan
Gambar 5. Pembuatan Password User BigQ Web
Jika proses pembuatan BiqQ web user ini selesai, kembali ke menu navigasi atas ‘Big Data’ dan klik menu ‘HDFS Users’. Buatlah record baru dengan mengklik tombol biru ‘Create’ seperti gambar 5 di bawah ini :
Gambar 5. Pembuatan HDFS Users
Pilih bidang isian ‘Cluster’ dengan nama yang telah dibuat sebelumnya, pilih bidang isian ‘Name’ dengan user yang baru saja dibuat. Untuk bidang isian ‘HDFS Username’ kita bisa mengisikan nama yang berbeda dari nama user, misal BigQ web user tersebut adalah ‘Foo 1’ maka isikan bidang isian tersebut dengan misalnya ‘foo1hdfs’, pengisian bidang ini tidak boleh menggunakan spasi dan karakter yang dapat diterima adalah hanya a sampai dengan z, serta angka 0 sampai dengan 9, juga tidak boleh diawali dengan angka, untuk ‘HDFS Username’ ini diharapkan menggunakan huruf kecil semua menganut pakem Linux User Formated.
Dalam contoh ini dapat dijelaskan sebagai berikut ‘Foo 1’ adalah BigQ web user, sementara ‘foo1hdfs’ adalah nama di sistem Linux dan HDFS, ‘Foo 1’ nantinya akan melalukan BigQ Proses Primer melalui BigQ web, dimana ‘Foo 1’ akan bertindak sebagai impersonasi dari ‘foo1dfs’.
Semua file baik data terstruktur maupun yang tidak terstruktur yang disimpan oleh ‘Foo 1’ akan secara otomatis di miliki oleh ‘foo1hdfs’ dalam hdfs.
Jika semuanya sudah terisi dengan benar, simpanlah dengan menekan tombol biru ‘Save’, BigQ akan secara otomatis menyandikan isian di bidang isian ‘HDFS Username’.
Management
Menu ‘Acl Management’ atau Access Control List adalah tempat kita mengatur hak hak akses dan permisi pada suatu objek atau proses dari big data yaitu home folder, data folder, database folder dan skema Parquet file, pada kondisi baku (default), hanya pengguna bersangkutan dan
administrator yang bisa menulis, menghapus, membaca dan proses lainnya pada objek dan proses tersebut. Satu orang hdfs user dapat memiliki ACL lebih satu.
Gambar 6. Tampilan ACL Management
Sedikit berbeda dengan form yang lain, pada tampilan ini juga terdapat beberapa tombol yang terletak di atas form, yaitu tombol ‘Apply’, ‘HDFS Info’, ‘List Files’, ‘Revoke’ dan ‘Regrant’, tombol tombol tersebut hanya dapat digunakan jika semua bidang isian telah tersimpan dan menjadi record baru. Fungsi masing masing tombol tersebut adalah :
NO Tombol Fungsi
1 Apply Ketika di tombol ini ditekan maka sistem BigQ akan membuat home folder, data folder dan database folder di hdfs tujuan, selanjutnya melakukan perubahan ijin yang diperlukan untuk pengguna yang dimaksud. Jika semua folder telah dibuat, maka sistem BigQ akan membuat file big data dalam format Parquet yaitu berkas tempat dimana data terstruktur akan ditempatkan dalam hdfs tujuan. File Big data ini nantinya adalah destinasi dari BigQ Proses Primer, lebih jauh tentang hal
ini bisa dibaca di seksi ‘Studi Kasus’
2 HDFS Info Memberikan informasi singkat hdfs yang sedang dipakai
3 List Files Memberikan informasi singkat susunan folder yang diberikan ke pengguna terkait
4 Revoke Tombol Revoke berwarna merah, menandakan bahwa proses revoke adalah proses yang harus diperhatikan dengan seksama, fungsi revoke ini adalah menarik semua akses seorang user terkait terhadap objek dan proses big data, jika dilakukan, user tersebut tidak lagi dapat melakukan semua proses big data, akses ini hanya dapat dilakukan oleh
administrator saja.
5 Regrant Regrant adalah kebalikan dari revoke, berfungsi memulihkan ijin akses ke semua objek dan proses big data kepada seorang user.
Gambar 7. Contoh Pengisian Form ACL Management
Pilih ‘Name Node’ dan ‘HDFS User’ pada bidang isian masing masing dimana kita telah
membuatnya di awal, bidang isian HDFS URL akan otomatis terisi jika ‘Name Node’ sudah terpilih. Isikan ‘Home Folder’ dengan Foo, ‘Database Folder’ dengan Database, ‘Data Folder’ dengan
Data, biarkan bidang isian ‘Permission’ tetap 448. Abaikan pilihan centang ‘Revoke’ karena secara
default adalah read only. Sebelum mengisikan bidang isian ‘Granted Scheme’ mari kita bahas sedikit masalah ini.
‘Granted scheme’ adalah fasilitas pengaturan destinasi file big data dalam format Parquet, tempat dimana calon data dari sumber data RDBMS (Relational Database Management System) akan disimpan, 1 destinasi file big data ini akan menempati blok berukuran 128MB, artinya jika nanti
tahapan BigQ Proses Primer dilakukan maka menghasilkan output Parquet file, misalnya berukuran 1GB maka akan ditempatkan dalam 8 blok per 128MB dan direplikasi sebanyak 3 kali karena BigQ secara baku/default membuat replikasi sebanyak 3, fungsi administrator di sini menjadi penting karena harus mempersiapkan dan menentukan perencanaan kapasitas dengan baik. Lebih dalam tentang ini dapat dibaca di seksi ‘Studi Kasus’
Penjelasan lebih dalam tentang ‘Granted scheme’ :
Misalnya pengguna ‘Foo 1’ akan bertanggung jawab dalam BigQ Proses Primer di divisi kesehatan, dimana database server divisi kesehatan tersebut memiliki 1 (satu) database dengan 3 table yaitu ‘pasien’, ‘obat’ dan ‘dokter’, maka contoh ‘Granted scheme’ yang harus diisikan adalah
‘pasien,obat,dokter’ pada bidang isian tersebut. Pengisian ini harus dipisahkan dengan koma,
tanpa spasi untuk tiap tiap destinasi. Jika telah selesai, simpan dan lakukan proses ACL dengan menekan tombol ‘Apply’ jika berhasil maka di dalam HDFS target tersebut akan secara otomatis terdapat struktur direktori sebagai berikut /Foo/Data, /Foo/Database . Tampilan akhir pengisian form setelah disimpan
Sedikit ulasan mengenai bidang isian ‘Permission’, dalam contoh kasus ini, administrator memberikan nilai octal 448 yang berarti 0700 dengan fitur :
User Group Other
Read Yes No No
Write Yes No No
Execute Yes No No
Anda bisa merubah nilai isian octal 448 tersebut dengan nilai yang lain (sangat tidak disarankan kecuali anda tahu apa yang anda lakukan), jalan mudah untuk mengetahui nilai octal adalah
menggunakan konversi octal ke decimal dan decimal ke octal pada terminal Linux dengan perintah echo "ibase=8;700" | bc
Jika proses applying ACL ini berhasil maka akan muncul pesan sebagai berikut seperti gambar di bawah ini :
Gambar 9. Informasi Yang Ditampilkan Sistem ACL
Pada kondisi awal ini belum ada satupun file yang dibuat, hanya struktur direktori saja dengan path yang terdapat di hdfs://10.10.10.50:9000/Foo , replikasi 0 (nol), owner (pemilik) foo1hdfs dan informasi lainnya.
Data Prosesor
Salah satu tugas administrator yang cukup krusial adalah membagi sumber daya para peladen (servers), terutama data prosesor, dimana data prosesor ini sangat memakan sumber daya ram dan cpu. BigQ menggunakan Apache Spark sebagai pemangku tugas data processors, administrator dapat menentukan berapa ram dan cpu yang boleh digunakan oleh seorang user pada saat melakukan BigQ Proses Primer. Pilih menu ‘Data Processors’ dan buat record baru dengan menekan tombol biru ‘Create’ seperti tampak pada gambar 10 di bawah ini :
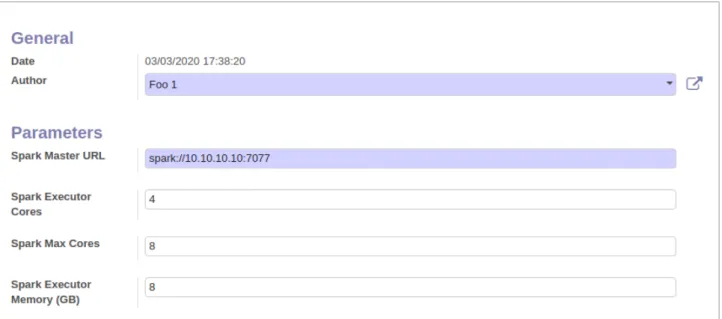
Gambar 10. Data Processors
Pilih bidang isian ‘Author’ untuk pengguna yang dikehendaki, dalam hal ini adalah ‘Foo 1’, isikan ‘Spark Master URL’ dengan format seperti pada gambar 10, tentukan nilai ‘Spark Executor Cores’ yaitu berapa banyak cpu yang bisa digunakan oleh pengguna ‘Foo 1’, tentukan nilai ‘Spark Max Cores’, yaitu jika dalam kondisi tidak dipakai maka pengguna ‘Foo 1’ dapat memaksimalkan sumber daya cpu sampai n (nilai n), isikan ‘Spark Executor Memory’, nilai ini baiknya adalah sebesar maksimum ram yang dimiliki peladen (server) dikurangi beberapa GB untuk sistem, sebagai kisaran umum, jika peladen data prosesor memiliki ram 32 GB maka cukup isikan nilai antara 24 -30 GB. Nilai nilai ini akan digunakan untuk per 1 (satu) tugas untuk BigQ Proses Primer, record ini hanya dapat dipakai oleh pengguna ‘Foo 1’ dan administrator saja, oleh karena itu administrator harus mendefinisikan beberapa record baru untuk beberapa user berdasarkan jumlah dan kompleksitas data yang akan diproses di kemudian hari. Jika pada saat proses terjadi alokasi ram habis, maka tugas akan dihentikan secara otomatis menunggu ketersediaan ram ataupun selesai dengan error. Sebagai administrator anda pun bisa memberhentikan tugas tugas yang dikirim ke data prosesor.
Log
BigQ mendefinisikan log sebagai informasi sensitif, log dibagi per user dan administrator. Jika seorang user melakukan proses terhadap objek big data dan terjadi error pada sistem maka user hanya akan mendapatkan log yang hanya berisi informasi informasi sederhana dengan
menggunakan penomoran tiket khusus, log error dengan laporan yang komplit akan dilaporkan ke administrator dengan nomor tiket yang sama. Pengguna bisa meminta laporan tersebut setelah administrator melakukan proses audit error tersebut
Delegasi
Walaupun administrator dapat melakukan apapun dalam BigQ web ini, ada kalanya administrator mendelegasikan beberapa fungsi penting kepada seseorang lainnya, untuk membuat delegator, administrator diharuskan membuat BigQ user terlebih dahulu dan memasukan nya pada group
‘AIHUB Administrator Group’, anda dapat mengikuti langkah langkah pembuatan BigQ user ini di seksi C.1.3 hdfs user. Pada saat membuat user delegator, pastikan bahwa user yang anda buat adalah baru, jangan menambahkan user yang telah ada kepada group ‘AIHUB Administrator Group’.
Gambar 11. Pembuatan User Delegator
Berbagi Dokumentasi
BigQ dilengkapi sebuah fasilitas untuk berbagi dokumentasi, ini dimaksudkan untuk beragam tujuan seperti :
1. Membuat artikel untuk dibaca bersama.
2. Membagi pengalaman dalam konteks big data. 3. Dan lainnya.
Dokumentasi ini hanya bisa dibuat oleh administrator, untuk membuat sebuah dokumentasi, klik menu ‘Help’ dan klik tombol biru ‘Create’ seperti tampak di gambar 12.
Dokumentasi dalam BigQ adalah sebuah dokumen html, di mana proses pembuatan dokumentasi ini menggunakan html editor yang mudah, anda dapat menambahkan gambar, memberikan tautan dan lainnya. Isikan bidang isian ‘Title’ dengan nama yang jelas dan informatif, berikan nomor pada bidang isian ‘Context id’, dan lakukan pembuatan dokumen.
What’s Next
Sampai di sini, administrator telah menyelesaikan beberapa tahapan penting yaitu : 1. Mengerti distribusi dan lokasi para peladen (servers)
2. Mengerti keamanan baku para peladen (servers)
3. Dapat melakukan pengaturan ‘cluster’s attributes’, ‘hdfs namenode’ dan ‘hdfs users’ 4. Dapat melakukan pengaturan access control list hdfs.
5. Dapat melakukan pengaturan data prosesor. 6. Memahami konsep log BigQ.
7. Membuat delegasi administrasi. 8. Membuat atau berbagi dokumentasi.
Beberapa fasilitas seperti pengaturan sumber data (data sources), tugas BigQ Proses Primer
dilakukan oleh pengguna biasa BigQ.
BigQ menyederhanakan tugas tugas administrator , tetapi penting bagi administrator untuk mengetahui proses proses yang dilakukan oleh user, di bab bab selanjutnya akan dikupas bagaimana seorang user melakukan aktifitas terhadap objek dan proses big data.
Memahami Objek Dan Proses Big Data
Secara umum BigQ adalah organizer objek dan proses big data. Objek dan proses dalam BigQ didefiniskan sebagai berikut, “Objek adalah Parquet file, merupakan destinasi penyimpanan file data terstruktur dalam format kolom”, sementara proses dalam BigQ didefinisikan sebagai berikut :
1. Ingest, ingestion, atau proses awal menarik data dari beragam sumber data terstruktur rdbms seperti MySQL atau PostgreSQL.
2. Pemrosesan data yang ditarik ini menggunakan data prosesor. 3. Store, Storing, proses penyimpanan ke destinasi objek.
4. Append, Hadoop ekosistim mempunyai filsafah “write once read many times”, yang berarti sekali simpan dapat dibaca berkali kali, tetapi ada suatu saat jika proses ingest, store atau proses data harus dilakukan parsial, sequential atau historical, yaitu jika data disimpan harian, mingguan, bulanan atau tahunan pada destinasi big data ataupun ketika perangkat keras ram dan cpu tidak mencukupi untuk memproses dalam satu tarikan.
5. Inspection, ini adalah sebuah fitur dari BigQ yang digunakan untuk menginspeksi sebuah objek data.
No 1 sampai dengan 5 disebut BigQ Proses Primer . Pengaturan destinasi objek dan data prosesor dilakukan oleh administrator (baca di seksi ‘ACL Management’), sementara proses big data dilakukan oleh pengguna biasa, walaupun sebenarnya administrator dapat melakukannya tetapi tidak disarankan. Untuk memahami pengguna melakukan proses big data silahkan baca buku “Operasional BigQ Manager V.2.1”.
Studi Kasus Persiapan
BigQ sistem secara baku menyertakan sebuah server database uji coba yang diberi nama host ‘datasource’ dengan alamat ip 10.10.10.81 (alamat ip bisa berbeda, sesuai keinginan pengguna pada saat pemasangan), terdapat 3 (tiga layanan) peladen database, yaitu MySQL 5.7.29 Server,
PostgreSQL 9.5.19 dan Microsoft SQL Server 15.00.4013.
Ketiga database server tersebut memiliki database bernama ‘Example’ (dengan kapital E) dan memiliki table bernama ‘citizen’ (huruf kecil semua). Akses ke masing masing database untuk pengguna MySQL adalah ‘root’, PostgreSQL ‘masterdb’, Microsoft SQL ‘SA’ dengan password ‘Super4dmin’ untuk semuanya. Keterangan lengkap untuk table ‘citizen’ dapat dilihat di table di bawah ini
No Kolom Tipe data Range
1 id Integer 1 – 608769
2 year Small integer 2009 – 2018 (tidak ada
2 sex Small integer 2 – 3 (2 kode wanita, 3 kode pria)
3 name Varchar
4 area1 Small integer 14 – 26 (dipakai
sebagai kode area 1)
5 area2 Small integer 1 – 80 (dipakai sebagai
kode area 2)
6 area3 Small integer 1 - 40 (dipakai sebagai
kode area 3) Contoh 10 data dari table citizen :
Ukuran total data ini jika didump ke format sql tanpa dikompres adalah sekitar 32.4 MB. Kita akan mencoba BigQ Proses Primer dengan 3 (tiga) tujuan Parquet file big data yaitu destinasi tanpa partisi, destinasi multi partisi dan destinasi incremental/parsial. Tugas administrator adalah :
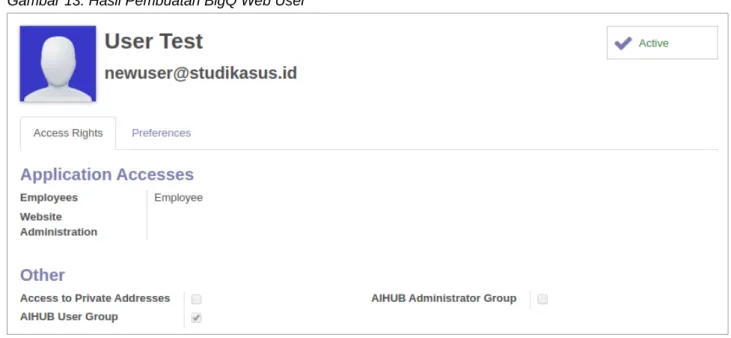
1. Membuat BigQ web user baru dengan nama ‘User Test’, username ‘[email protected]’ dan group ‘AIHUB User Group’. Untuk password silahkan tentukan sendiri, lebih jauh lihat kembali seksi C.3. HDFS Users.
2. Membuat hdfs user baru untuk untuk BigQ web user pada nomor 1, BigQ web user nya adalah ‘[email protected]’, hdfs username (impersonasi nya) adalah ‘newuser123’ 3. Membuat ACL untuk user baru tersebut dan memberikan nama home folder nya ‘Userbaru’,
database folder nya ‘Database’, data folder nya ‘Data’ dan ‘Granted Scheme’ nya ‘TestTanpaPartisi,TestDenganPartisi,TestParsial’ (case sensitive).
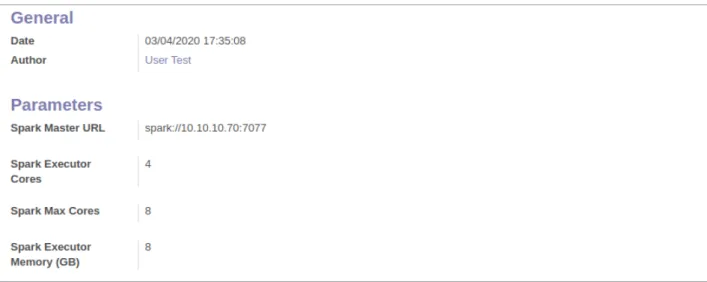
4. Membuat konfigurasi data prosesor untuk user di nomor 1 dengan rincian ‘Author’ adalah ‘User Test’, ‘Spark Master URL’ nya spark://10.10.10.70:7077, ‘Spark Executor Cores’ 4, ‘Spark Max Cores’ 8, ‘Spark Executor Memory’ 8
Jika semua telah dikonfigurasi dengan baik dan benar serta melalui tahapan yang benar maka hasil hasil nomor 1 sampai dengan 4 di atas dapat dilihat di gambar gambar di bawah ini :
id year name sex age area1 area2 area3
1 2011 EHA 2 80.14 14 7 3
2 2011 EHA 2 70.84 14 7 6
3 2012 RIZAL SETIAWAN 3 13.11 14 7 6
4 2013 BELA FITRIANI 2 9.45 14 6 1
5 2012 KASEM 2 65.03 14 9 7
6 2012 UDIN NURDIN GUNAWAN 3 66.13 14 3 6
7 2012 MILDA SHAVIRA 2 13.05 14 5 3
8 2013 SUMARDJI SUHADI 3 66.11 14 2 4
9 2012 PALETEHAN 3 54.03 14 14 2
Gambar 13. Hasil Pembuatan BigQ Web User
Gambar 14. Hasil Pembuatan HDFS User
Pada gambar tersebut di atas bidang isian ‘HDFS username’ yaitu ‘newuser123’ telah dienkripsi secara otomatis oleh BigQ.
Gambar 15. Hasil Pengaturan ACL Management
Pada gambar di atas, ACL dari ‘User Test’ telah melewati proses applying. Gambar 16. Hasil Data Prosesor
Perhatikan dengan seksama bagian bidang pilihan ‘Author’, pilih ‘User Test’ karena data prosesor ini akan dibuat khusus untuk ‘User Test’ bukan pengguna lainnya.
Keluarlah dari BigQ web, dengan logout, dan relogin dengan username ‘[email protected]’ jika berhasil maka anda akan dibawa ke dashboard pengguna baru tersebut.
Gambar 17. Tampilan Dashboard Pengguna
Bahasan penggunaan BigQ untuk pengguna non administrator bisa dibaca di buku “Petunjuk Operasional BigQ Manager V.2.1”. Kami tidak akan menjelaskan secara rinci di buku ini. Di sini anda sudah bertindak sebagai pengguna ‘User Test’, sebagai user biasa anda :
1. Tidak dapat merubah konfigurasi hdfs user.
2. Tidak dapat membuat tetapi dapat merubah konfigurasi data prosesor. 3. Tidak dapat merubah destinasi file big data Parquet.
kewajiban anda adalah :
1. Mempersiapkan sumber data.
2. Melakukan proses BigQ Proses Primer pada destinasi tujuan file big data Parquet yang telah ditentukan oleh administrator.
Mempersiapkan Sumber Data
Klik menu ‘Datasource’ dan buat konfigurasi akses database seperti dijelaskan pada seksi A.1. Persiapan. Hasilnya adalah :
Gambar 18. Hasil Pembuatan Konfigurasi Sumber data
Password ‘Super4dmin’ pada gambar tersebut sudah terenkripsi otomatis oleh BigQ.
Destinasi File Big Data Parquet
Destinasi adalah spesifik per user dan ditentukan oleh administrator, anda hanya bisa melihat destinasi yang dibuat oleh administrator untuk anda, semua bidang isian adalah read only untuk anda kecuali bidang isian centang ‘Allow Append’ yang bisa anda rubah, dalam kondisi baku, semua konfigurasi destinasi adalah false untuk ‘Allow Append’, artinya semua destinasi tersebut tidak bisa dilakukan untuk proses append. Untuk melihat destinasi yang dibuat oleh administrator , anda bisa mengklik menu ‘Big Data Destination’, dan akan terlihat sebagai berikut :
Gambar 19. Daftar Destinasi File Big Data Parquet.
Proses Big Data
Seperti berulang dijelaskan di halaman sebelumnya, BigQ mendefinisikan proses big data sebagai aktifitas ingest, store, memproses data, inspection dan append. Secara umum proses proses tersebut dilakukan di menu ‘Big Data Storing’ dan ‘Inspection’.
a. Big Data Storing
Klik menu ‘Big Data Storing’ dan buat record konfigurasi baru, simpan dan akan tampak seperti gambar di bawah ini :
Gambar 20. Konfigurasi Big Data Storing.
Catatan, untuk database PostgreSQL dan Microsoft SQL tidak membutuhkan tambahan opsi jdbc pada bidang isian ‘Additional JDBC options’, jika anda menggunakan database MySQL,
tambahkan pada bidang isian tersebut
‘useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC’ (tanpa tanda petik), serverTimezone bisa disesuaikan misalnya ‘Asia/Jakarta’.
Pada form ‘Big Data Storing’ terdapat tombol merah ‘Add Job To Scheduler’ seperti tampak pada gambar di bawah ini :
Gambar 21. Job Scheduler
Fungsi tombol tersebut adalah memerintahkan BigQ untuk melakukan proses storing dengan konfigurasi aktif yang tampak pada gambar di atas. Jika semua parameter tersebut sudah benar, silahkan lakukan proses tersebut, proses ini akan dikirim kepada ‘scheduler’ melalui proses di belakang layar (background process) , sistem scheduler akan mengatur secara FIFO first in first out semua proses yang dikirim oleh user, hanya administrator saja yang dapat melihat proses ini. Bagaimana anda tahu bahwa proses yang anda kirim telah selesai ? Lama proses di big data sangat tergantung dari kekuatan dan ketersediaan perangkat keras anda terutama ram dan cpu, banyaknya proses yang dikirim oleh para users, kecepatan network antara sumber data dan sistem BigQ dan faktor lainnya, anda dapat memonitor log di menu ‘User log’, jika proses berhasil atau gagal, sistem log akan memberikan catatannya pada anda dengan penamaan tiket khusus.
Selanjutnya, lanjutkan dengan menekan tombol ‘Add Job To Scheduler’, sistem akan mengkonfirmasi ulang hal ini :
Klik tombol ‘OK’ untuk melanjutkan, dan dialog pemberitahuan akan muncul sebagai berikut seperti tampak pada gambar di bawah ini :
Gambar 23. Pemberitahuan
Klik ikon ‘X’ atau tekan tombol ‘escape’ pada keyboard untuk menutup nya. Untuk melihat hasilnya, klik menu ‘User Log’ dan carilah record terakhir di daftar log, jika ada, klik untuk membuka hasilnya seperti tampak pada gambar di bawah ini :
b. Inspection
Inspection adalah proses inspeksi destinasi file big data Parquet, fungsi ini hanya sederhana yaitu : 1. Mengambil meta data, informasi skema dan lokasi file big data Parquet.
2. Mengambil informasi total data
Untuk melakukan inspeksi, klik menu ‘Parquet Inspection’, dan buat sebuah record baru, isikan bidang isian dan simpan record tersebut sampai tampak seperti gambar di bawah ini :
Gambar 25. Parquet Inspection
Jika semua sesuai dengan gambar di atas, tekan tombol ‘Inspect’ yang terdapat di atas form tersebut, dan akan muncul dialog seperti di bawah ini :
Gambar 26. Dialog Inspection
Tutup dialog tersebut di atas dengan menekan ikon ‘X’ atau tombol ‘escape’ di keyboard. Seperti halnya proses storing sebelumnya, proses ini dikirim ke scheduler, dan akan diproses di belakang layar, anda dapat memonitor nya dengan mengklik kembali menu ‘Parquet Inspection’ sehingga tampil list seperti di bawah ini :
Gambar 27. Daftar Record Inspection
c. Big Data Append
Proses append ditujukan untuk menyimpan data secara incremental dan kebutuhan berkala, baik per hari, minggu, bulan atau tahun, untuk melakukan proses append, terlebih dahulu kita harus
membuat destinasi file big data agar diperbolehan untuk proses append. Klik menu ‘Big Data Destination’ dan pilih record ‘hdfs://10.10.10.50:9000/Userbaru/Database/TestParsial’ Gambar 29. Memilih Destinasi Big Data File Untuk Proses Append
Klik tombol ‘Edit’ dan centang pilihan ‘Allow Append’ seperti gambar di bawah ini.
Gambar 30. Pengeditan Destinasi Big Data File
Simpan record tersebut dengan menekan tombol ‘Save’ dan lanjutkan dengan mengklik menu ‘Big Data Storing’, buat record baru seperti tampak di gambar di bawah ini :
Gambar 31. Proses Storing Parsial Ke 1 (satu)
Kita akan membagi 2 (dua) proses append ini, dimulai dari id 1 sampai dengan id 299999, pada proses storing pertama ini, pastikan bidang isian ‘Mode’ adalah ‘New Parquet File’ seperti tampak di gambar tersebut, simpan dan kirim ke job scheduler.
Hasil proses ini jika selesai bisa dilihat di log seperti gambar di bawah ini : Gambar 32. Hasil Proses Parsial Ke 1 (satu)
Selanjutnya, kita akan melakukan proses ke 2 (dua), yaitu penambahan terhadap destinasi yang sama di ‘hdfs://10.10.10.50:9000/Userbaru/Database/TestParsial’ dengan record berikutnya, yaitu id 300000 sampai dengan id 608769.
Gambar 33. Proses Storing Parsial Ke 2 (dua)
Sesuaikan semua bidang isian dengan bidang isian proses pertama kecuali : 1. ‘Description’, isikan agar informatif menunjukan proses kedua
2. ‘Query’, isikan query dengan “SELECT * FROM citizen WHERE id > 299999 AND < 608770”
3. ‘Mode’, pilih ‘Append’
4. Pilihan di ‘Database’, ‘Parquet File’ dan semua seksi di ‘Parquet Parameter’ kecuali ‘Mode’ haruslah identik dengan record pertama. Jika sudah benar, simpan dan kirim ke job
Gambar 34. Hasil Proses Parsial Ke 2 (dua)
Proses ini menghasilkan 1 (satu) file tambahan, jika dua buah file tersebut disatukan, ukuran total hampir sama pula dengan proses storing tanpa proses append yaitu 13,9 Mb (sementara tanpa proses parsial sebesar 14,7 Mb), Ke dua file tersebut secara union terdapat dalam 1 (satu) Parquet yang sama tetapi secara fisik direferensi kepada dua file (karena proses storing 2 kali). Hasil menggunakan teknik append atau parsial ini bisa dilihat di gambar di bawah ini :
Proses ini menghasilkan jumlah data yang sama dengan proses langsung yaitu sebanyak 608769 data. BigQ memiliki fitur yang lebih dalam urusan proses append ini yaitu :
1. Proses append dari server yang sama tetapi database server yang berbeda misalnya database server MySQL terhadap PostgreSQL di host 1
2. Proses append dari server yang berbeda tetapi database server yang sama, misalnya host1 ke host2 antara MySQL dengan MySQL lainnya.
3. Atau diantara pilihan nomor 1 dan 2 (in between)
Sepanjang skema datanya sama atau dibuat sama dengan bantuan user query.
Terdapat perbedaan mendasar ketika kita memproses langsung dan proses append atau parsial dari sisi storage, setiap proses langsung hanya menghasilkan satu file sementara proses append sejumlah ‘n’ kali append, dengan masing masing direplikasi 3, di sini dibutuhkan perencanaan kapasitas yang matang dalam penyediaan storage atau jumlah hdfs datanode yang dibutuhkan.
d. Mempartisi Destinasi Big Data File
BigQ mendukung partisi destinasi file big data Parquet, proses ini adalah mempartisi data
berbasiskan satu atau lebih kolom. Kegunaan membuat partisi ini adalah untuk mempercepat proses query dalam file big data tersebut sepanjang partisi tidak over configure. Over configure di sini berarti kita harus mempartisi berdasarkan kolom yang selalu menjadi acuan query. Gunakan partisi ini seefektif mungkin, ilustrasi menggunakan database contoh studi kasus adalah sebagai berikut, seperti diketahui dan dijelaskan sebelumnya, table ‘citizen’ mempunyai kolom ‘id’ type data integer, ‘year’ type data small integer , ‘name’ type data varchar, ‘sex’ type data small integer, ‘area1’ type data small integer, ‘area2’ type data small integer dan ‘area3’ type data small integer. Total data adalah 608769 record, dengan range id dari 1 - 608769, range ‘year’ dari 2009 – 2018 (tanpa tahun 2010), range ‘sex’ dari 2 – 3 dimana 2 adalah wanita dan 3 adalah pria, ‘area1’ adalah kode lokasi utama dengan range dari 14 – 26, ‘area2’ adalah kode lokasi kedua dengan range 1 – 80, ‘area3’ adalah kode lokasi terakhir, dengan range antara 1 – 40. Jika kita membuat partisi menggunakan ‘year’ sebagai kolom acuan maka akan terdapat 9 partisi atau 9 file destinasi big data secara fisik dalam satu union, jika kita membuat multi partisi dengan acuan ‘year’ dan ‘area1’ maka jumlah partisi adalah 9x13 = 117 partisi atau 117 file destinasi big data dengan replikasi per file tersebut adalah 3. Jika setiap file tersebut berukuran 10Mb maka :
1. Aktual data adalah 117 * 10 Mb = 1,170 Mb
2. Overhead 117 * 4 Mb = 468 Mb (4 Mb adalah default opening file Spark)
3. Jika terdapat 2 nodes data prosesor dengan masing masing cpu 4 core maka tiap core akan menghandle (1,170 + 468) / (2*4) = 1,638/8 = 204,75 Mb data
4. Min (128MB, Max(4MB, 204,75 MB)) = 128MB
5. Maka spark akan melakukan 1,638/128 = 12,8 (13) tugas dalam membuka 1 union file big data tersebut.
Jika partisi yang digunakan hanya berdasarkan ‘year’ , maka jumlah partisi adalah 9, misalkan setiap file berukuran 130 Mb, maka :
1. Aktual data 9 * 130 = 1,170 Mb 2. Overhead 9 * 4 = 36 Mb
3. Jika terdapat 2 nodes data prosesor dengan masing masing cpu 4 core maka tiap core akan menghandle (1,170 + 36) / (2*4) = 1,206/8 = 150.75 Mb data
4. Min (128 Mb, Max(4 Mb, 150,75 MB)) = 128 Mb
5. Maka spark akan melakukan 1206/128 = 9.42 (10) tugas dalam membuka 1 union file big data tersebut.
Maksud perhitungan ini adalah, semakin kecil file dalam jumlah lebih banyak akan membuat data prosesor semakin banyak tugas. Teknik partisi harus selalu dipakai tetapi harus dalam takaran kecil, hindari pembuatan partisi yang menghasilkan banyak file kecil yang hanya akan membuat tidak efisien dalam proses paralel. Partisi sangat diperlukan ketika kita bekerja dengan data historis. Untuk mencoba teknik ini mari kita mulai dengan melakukan proses storing, klik menu ‘Big Data Storing’, dan buat record baru, simpan dan jika semua benar akan terlihat seperti gambar di bawah ini :
Mohon perhatikan destinasi file big data nya, yaitu ditujukan ke ‘hdfs://10.10.10.50:9000/Userbaru/ Database/TestDenganPartisi’, bidang pilihan ‘Mode’ adalah ‘New Parquet File’, centang juga ‘Create Partition’, isikan ‘year’ pada ‘Partition by columns’, selebihnya lihat gambar 36. Jika proses berjalan dengan baik maka hasilnya adalah sebagai berikut :
Gambar 37. Hasil Proses Partisi
Dihasilkan 9 file fisik dalam satu union file Parquet big data, masing masing 1. 1,5 Kb (year=2009), 4 record 2. 1,5 Mb (year=2011), 72,873 record 3. 1,5 Mb (year=2012), 72,081 record 4. 1,3 Mb (year=2013), 61,469 record 5. 1,8 Mb (year=2014), 81,589 record 6. 1,9 Mb (year=2015), 82,835 record 7. 2,2 Mb (year=2016), 93,753 record 8. 2,3 Mb (year=2017), 94,071 record 9. 1,2 Mb (year=2018), 50,094 record
Total union file Parquet tersebut adalah sekitar 13,7 Mb dengan total record sama dengan yang lain yaitu 608,769 record.
Untuk menilai mana yang lebih efektif, mari kita bandingankan kecepatan dengan query yang sama pada ketiga destinasi file big data tersebut dengan limit 10,000 record.
SELECT * FROM dfs.`Userbaru/Database/TestTanpaPartisi.parquet`
Planning Queued Execution Total
0.081 sec 0.007 sec 0.363 sec 0.451 sec
SELECT * FROM dfs.`Userbaru/Database/TestParsial.parquet
Planning Queued Execution Total
0.195 sec 0.006 sec 0.243 sec 0.444 sec
SELECT * FROM dfs.`Userbaru/Database/TestDenganPartisi.parquet`
Planning Queued Execution Total
0.063 sec 0.003 sec 0.292 sec 0.358 sec
Perbandingan dengan menggunakan kolom ‘year’ sebagai acuan :
SELECT * FROM dfs.`Userbaru/Database/TestTanpaPartisi.parquet` WHERE year=2017
Planning Queued Execution Total
0.068 sec 0.003 sec 0.398 sec 0.469 sec
SELECT * FROM dfs.`Userbaru/Database/TestParsial.parquet WHERE year=2017
Planning Queued Execution Total
0.074 sec 0.003 sec 0.234 sec 0.311 sec
SELECT * FROM dfs.`Userbaru/Database/TestDenganPartisi.parquet/year=2017`
Planning Queued Execution Total
Review
Sampai tahapan ini administrator diharapkan sudah mengetahui bagaimana seorang pengguna melakukan proses big data yaitu :
1. Melakukan proses store langsung seluruh record dari sebuah sumber data rdbms.
2. Melakukan proses store bertahap, parsial, incremental dan historical seluruh record dari sebuah sumber data rdbms. (proses append)
3. Melakukan proses store langsung seluruh record menggunakan teknik partisi dari sebuah sumber data rdbms.
4. Melakukan inspeksi terhadap sebuah destinasi big data Parquet file.
BigQ mendukung kombinasi kombinasi proses store diatas, misalnya melakukan proses bertahap (parsial, incremental) tetapi digabungkan dengan menggunakan teknik partisi. Silahkan anda mencobanya sendiri kepada destinasi file big data Parquet baru.
Komparasi Ukuran
Database contoh yang bernama ‘Example’ dan table ‘citizen’ yang kita gunakan sebelumnya dalam studi kasus ini di ambil dari sumber data PostgreSQL di host ‘datasource’, jika kita melakukan export ke format csv (comma separated values) ukuran yang dihasilkan adalah sekitar 24,6 MB, sementara jika diexport ke dalam format sql dump adalah sekitar 32,4 MB, dengan menggunakan format file big data Parquet beragam metode store, hanya dihasilkan rata rata 15 MB (tanpa
menggunakan kompresi), jika anda ingin mengekplorasi Parquet file lebih lanjut silahkan kunjungi situs Apache Parquet di https://parquet.apache.org .
Bekerja Dengan Timestamp
Sampai tahapan ini semua proses terhadap destinasi file big data dengan menggunakan sumber data dari beragam peladen database tidak menggunakan kolom dengan tipe data timestamp. Karena BigQ menyimpan file big data dalam format Parquet, secara alami tipe data timestamp ini akan otomatis disimpan dalam tipe data int96. Tipe data ini sangat jarang digunakan dalam beberapa peladen database, tipe data ini susah dibaca juga oleh database ide, juga tidak mendukung layanan seperti Power BI, penulis menyarankan untuk menyimpan tipe data timestamp dengan varchar (string) agar memudahkan proses lintas data, gunakan user query pada saat proses penyimpanan ke destinasi file big data, sebagai contoh user query pada PostgreSQL adalah sebagai berikut :
SELECT id, to_char(create_date, 'YYYY-MM-DD HH24:MI:SS') as create_date FROM some-table ORDERBY id ASC
Drilling Data
BigQ mendefinisikan data yang terdapat dalam sistem big data sebagai valuable assets atau aset yang sangat berharga, dan hanya dapat diakses secara terbatas oleh administrator saja dalam ruang lingkup network yang terbatas pula, tetapi ada kalanya kita ingin mengintegrasikan data data tersebut dengan layanan layanan luar seperti Microsoft Power BI, Tableu dan lainnya untuk proses visualisasi data dan analisis, oleh karena itu dalam ekosistim BigQ, telah disediakan data pipeline (saluran virtual data koneksi) yang disebut driller server yang secara default tidak dapat diakses dari manapun. Jika anda ingin melakukan proses drilling (pengeboran data), ada beberapa tahapan yang harus anda tempuh yaitu :
Drilling Dalam Lingkup Intranet
Bukalah saluran port 31010 pada server driller, pada kondisi baku ada di alamat IP 10.10.10.80, ijinkan satu atau lebih komputer desktop/laptop untuk dapat mengakses alamat dan port driller server tersebut (silahkan tanyakan pada network administrator anda). Proses drilling adalah proses yang menuntut pemahaman teknis seperti :
1. Mengerti pengaturan interkonektifitas dengan jdbc (Java Database Connectivity) 2. Mengerti bahasa SQL (Structured Query Language)
Untuk melakukan drilling, pengguna bebas menggunakan piranti lunak database ide (Integrated Development Environment) yang sangat beragam sepanjang dapat terkoneksi melalui jdbc , penulis menyarankan untuk menggunakan Dbeaver (gratis dapat diunduh di https://dbeaver.io) atau
DataGrip (berbayar, https://www.jetbrains.com/datagrip/), kedua piranti lunak tersebut dapat berjalan di semua major sistem operasi baik Linux, Windows ataupun MacOS, dan memiliki tampilan yang baik serta mudah dalam penggunaan.
Di sini penulis hanya akan memberikan ulasan cara drilling dengan menggunakan Dbeaver database ide.
a. Membuat Konektifitas Database
Jalankan aplikasi Dbeaver, buka menu ‘Database’ → ‘New Database Connection’ Gambar 38. Dialog Konektifitas Database
Pilih ‘Hadoop/BigData’, dan sorot ‘Apache Drill’ dan lanjutkan dengan mengklik tombol ‘Next’. Jika ini adalah pertama kalinya anda membuat koneksi ke driller server, maka Dbeaver akan secara otomatis mengunduh jdbc driver untuk Apache Drill terlebih dahulu.
isikan bidang isian ‘Host’ dengan alamat driller server yaitu 10.10.10.80, ‘Port’ dengan 31010, isikan ‘Username’ dan ‘Password’ . Username dan password akan diberikan oleh pihak
TMBigData, anda dapat merubahnya jika dibutuhkan. Setelah semuanya isian komplit, tekan tombol ‘Test Connection.’ jika koneksi berhasil, simpanlah dengan mengklik tombol ‘Finish’. Anda sudah bisa melakukan drilling dengan menyenangkan.
b. Bekerja Menyenangkan Dengan IDE
Beberapa kelebihan bekerja dengan database ide adalah visualisasi, navigasi dan operasi drilling data yang mudah serta dapat menyimpan aktifitas historical process query sehingga tidak
diperlukan mengulang penulisan kode kode sql. Gambar 40. Bekerja menggunakan Dbeaver
Gambar di atas adalah tampilan awal antar muka Dbeaver, klik ganda (double click) koneksi yang telah kita buat sebelumnya, lanjutkan dengan menekan menu ‘SQL Editor’ → ‘SQL Editor’ , maka akan ditampilkan sebuah tab editor baru tempat kita bekerja dalam proses drilling.
Ketikan USE dfs di sql editor dan tekan ctrl+enter di keyboard , perintah ini akan menyuruh agar Dbeaver merubah fokus kerja ke dfs. Selanjutnya beri pasangan /* */ agar Dbeaver tidak
mengeksekusi lagi baris ‘Use dfs’, tambahkan di baris baru perintah berikutnya yaitu SHOW FILES IN `Userbaru/Database` , perintah sql saat ini menjadi :
/*USE dfs*/
SHOW FILES IN `Userbaru/Database`
Tekan ctrl+enter di keyboard agar perintah diatas dieksekusi dan akan menghasilkan seperti gambar di bawah ini :
Gambar 41. Hasil Query 1 (satu)
Terlihat file big data Parquet yang dihasilkan pada studi kasus sebelumnya, kita akan mencoba melakukan query lanjutan pada file ‘TestDenganPartisi.parquet’
Perintah query nya adalah seperti di bawah ini dan dilanjutkan dengan menekan ctrl+enter di keyboard
/*USE dfs*/
/*SHOW FILES IN `Userbaru/Database`*/
SELECT * FROM `Userbaru/Database/TestDenganPartisi.parquet`
Hasil nya adalah sebagai berikut : Gambar 42. Hasil Query 2 (dua)
Selanjutnya kita akan mencoba menyaring data (filtering) dengan menggunakan gabungan operator query seperti tampak di bawah ini dan lakukan eksekusi dengan menekan ctrl+enter di keyboard
/*SHOW FILES IN `Userbaru/Database`*/
/*SELECT * FROM `Userbaru/Database/TestDenganPartisi.parquet`*/
SELECT * FROM `Userbaru/Database/TestDenganPartisi.parquet/year=2016` WHERE sex = 2 AND age > 30 AND age < 50 LIMIT 10
Gambar 43. Hasil Query 3 (tiga)
Semua contoh contoh di atas memperlihatkan beberapa keuntungan bekerja dengan database ide, yang dalam hal ini menggunakan Dbeaver. Hasil yang sama jika menggunakan database ide lainnya, keputusan dan kenyamanan piranti lunak database ide sepenuhnya adalah pilihan anda.
Drilling Dalam Lingkup Internet
BigQ dapat diinstall di layanan cloud seperti Google Cloud atau AWS, juga dapat diinstall di private cloud, tidak ada perbedaan mendasar dalam proses drill di lingkup intranet dan internet,
perbedaannya jika menggunakan protocol internet berarti beberapa peladen harus terbuka ke publik dengan pengamanan pembatasan akses, yaitu host singlenova-en dan driller.
Data Analisis Dengan Microsoft Power BI
Installasi
Untuk terkoneksi dengan Microsoft Power BI (selanjutnya disebut Power BI saja), pastikan driller server yang beralamat IP di 10.10.10.80, dengan port 31010 dapat diakses oleh komputer
desktop/laptop yang menjalankan sistem operasi Microsoft Windows (selanjutnya hanya disebut Windows). Untuk membuka akses driller server silahkan baca kembali seksi ‘Drilling Data’ atau konsultasikan dengan network administrator di tempat anda. Power BI tersedia dalam aplikasi desktop terbatas untuk sistem operasi Windows saja, tetapi terdapat versi web aplikasi yang dapat digunakan pada semua sistem operasi. Unduh lah terlebih dahulu aplikasi desktop Power BI
tersebut di alamat https://powerbi.microsoft.com/en-us/desktop/ . Jalankan installasi sampai dengan selesai.
Unduh juga driver ODBC (open database connectivity) untuk Apache Drill di alamat ‘http://package.mapr.com/tools/MapR-ODBC/MapR_Drill/MapRDrill_odbc_v1.3.22.1055/’
pilihlah file yang sesuai dengan desktop/laptop yang menjalankan Power BI, anda dapat mengunduh file installasi untuk 32 bit atau 64 bit. Jalankan installasi odbc driver yang telah anda unduh tersebut sampai selesai.
Persiapan Big Data file Parquet
Anda bisa menggunakan destinasi file big data Parquet yang sudah dibuat di studi kasus sebelumnya atau membuat baru, penulis menyarankan untuk membuat baru dengan hdfs user yang baru pula agar anda terbiasa menjaga keamanan data. Di sini penulis menggunakan sumber data yang sama pada peladen PostgreSQL dengan database ‘Example’ dan table ‘citizen’. Destinasi file big data tersebut di simpan pada hdfs://10.10.10.50:9000/PowerBI/Database/Citizen.parquet dengan hanya mengambil kolom id, sex,age dan area1 semua record sebanyak 608,769 dengan partisi berdasarkan ‘year’, amatlah bijak untuk membatasi data yang diperlukan saja untuk analisis, disamping
memudahkan dalam proses analisis juga mengurangi overhead para peladen.
Koneksi Dengan Power BI
Jalankan Power BI, dan klik ikon ‘Get Data’, sebuah tampilan dialog akan terbuka seperti gambar di bawah ini :
Gambar 44. Dialog Koneksi Power BI
Pada kolom pencarian kiri atas, ketikan ‘odbc’ sehingga akan muncul di list kanan pilihan ‘ODBC’, klik pilihan tersebut, maka akan tampil dialog berikutnya seperti gambar di bawah ini :
Pada bidang pilihan ‘Data source name’, pilih ‘MapR Drill’, klik panah kecil ‘Advanced options’, pada bidang isian ‘Connection string (non-credential properties) (optional)’ isikan :
driver={MapR Drill ODBC Driver};connectiontype=Direct;host=10.10.10.80;port=31010;authenticationtype=Plain
sementara di bidang isian ‘SQL statement (optional)’ isikan :
SELECT id as Person, sex as `Sex`, age as `Age`, area1 as `Residential Code Area` FROM dfs.`PowerBI/Database/Citizen.parquet`
Dan klik tombol kuning ‘OK’, anda akan dibawa ke dialog berikutnya untuk mengisi username dan password seperti gambar di bawah ini :
Gambar 46. Pengisian Username dan Password
Isikan bidang isian ‘User name’ dan ‘Password’ (lihat seksi ‘Drilling Data’), klik tombol kuning ‘Connect’ dan tunggu proses pengambilan data selesai. Jika proses pengambilan data ini selesai, anda akan muncul dialog baru yaitu preview data seperti gambar di bawah ini :
Gambar 47. Preview Data
Lanjutkan dengan mengklik tombol kuning ‘Load’, setelah proses selesai simpanlah workspace di Power BI tersebut dengan mengklik menu ‘File’ → ‘Save’ atau ikon bergambar floopy disk. Anda sudah siap untuk melakukan visualisasi dan analisis data. Buku ini tidak membahas bagaimana anda bekerja dengan Power BI, tetapi kami berbagi file yang bisa dijadikan referensi contoh, silahkan unduh di ‘https://tmbigdata.sg/download/TMPowerBI.pbix’ , file contoh tersebut adalah contoh sederhana visualisasi data yang proses konektifitasnya telah kita lakukan bertahap di bab ini. Contoh visualisasi dapat dilihat di gambar di bawah ini :
Penutup
Storing File Tidak Terstruktur
File tidak terstruktur, misalnya gambar, video, kompresan (compressed file) dan arsip digital dalam format lain tidak memerlukan BigQ Proses Primer, yang berarti tidak membutuhkan keberadaan data prosesor, dalam konteks volume big data, file tidak struktur ini bisa berukuran lebih dari 100 GB sampai lebih dari 1TB per satu file. Dalam melakukan proses penyimpanan file tidak terstruktur ini, BigQ web tidak memberikan antar muka tersebut dengan alasan utama bahwa aplikasi berbasis web berjalan di atas perambah dan mempunyai beragam keterbatasan dan masalah dalam
pengupload ukuran file sebesar di atas, tapi BigQ mensolusikan nya melalui sistem ‘BDTransport’ yaitu peladen upload file besar di host bdtransport, bdtransport ini opsional dan secara baku tidak dipasang di sisi pengguna/pembeli, hanya digunakan jika membutuhkannya sebagai sistem complementary, hubungi layanan dukungan kami untuk mengaktifkan bdtransport.
Monitoring
Seorang administrator dapat memonitoring beberapa kondisi atau proses seperti : 1. Monitoring data prosesor di host spark-master port 8080 dan 8081 2. Monitoring HDFS namenode di host hdfs-master port 50070 3. Monitoring Driller di host driller di port 8047
Sistem monitoring ini secara baku sudah terinstall dan berjalan, tetapi akses kepada port port di atas dalam kondisi steril, jika administrator membutuhkan akses ke sistem monitoring tersebut, silahkan dibuka secara terbatas, semua sistem monitor dalam konteks big data adalah sensitif.
Kebutuhan Piranti Keras Saat Operasional
Seperti diketahui bahwa BigQ dapat dipasang dengan berbagai cara yaitu rack to rack dan container based (on premise), atau cloud/private cloud. Pilihan ini bisa dipilih untuk anda, semua kebutuhan ini bisa disesuaikan dengan skala anda, disamping itu, kebutuhan piranti keras ini sangat mudah untuk diperbesar (scalable) karena sistim BigQ ini didisain secara alami mengikuti ekosistim Hadoop, hubungi pihak TMBigData untuk informasi lebih lanjut.
Pelatihan Di Tempat Anda
Jika anda membutuhkan latihan lebih komprehensif dengan metode tatap muka, kami menyediakan pelatihan dengan trainer yang sudah disertifikasi oleh TMBigData, kunjungi situs web kami di https://tmbigdata.sg untuk informasi lebih lengkap.