Real Time Handwriting Recognition for Mathematic
Expressions using Hidden Markov Model
Yuliana Melita Pranoto a, Endang Setyati a,b, Edwin Pramana a, Yosi Kristian a,b, Renato Budiman a a Department of Information Technology Sekolah Tinggi Teknik Surabaya, Surabaya 60284, Indonesia b Department of Electrical Engineering Institut Teknologi Sepuluh November Surabaya, Surabaya 60111, Indonesia
Abstract—Mathematic is an important subject, even in our
daily live we use mathematic all the time. Calculator as a major tools to help calculate mathematic formulas has become a major requirement in mobile or desktop computer use. Calculator App nowdays can handle basic to complex mathematic formulas. Meanwhile, there are more and more touchscreen-based gadgets nowdays. This simple fact sparks the idea to do a research on online handwriting-based calculator so people can directly write the formula and get the result. This paper is the first phase of research to recognize mathematic expression from user handwriting. Hidden Markov Model (HMM) algorithm is chosen because this is one of the most used algorithm in pattern recognition, such as voice recognition, handwriting recognition, POS tagging and gesture. Every input from handwriting will be processed in several phases, starts from preprocessing and feature extraction. These features will then be transformed into a form of codeword based on codebook which is built by using training data with Vector Quantization. These set of codewords are then compared with HMM models previously built with training data. Experiment was performed covering two things: feature modication experiment and codewords number experiments. Best result is gained for four features combination and 60 units of codewords.
Keywords—Hidden Markov Model; mathematic expression; handwriting; codebook; codeword
I. INTRODUCTION
Mathematic is a very common in our daily life. It is no secret that most people do not like mathematic, eventhough this subject has been introduced since kindergarten. For this reason several practical methods are continuously developed to provide better ways for students to learn mathematic.
On [1] mathematical expression recognition consists of two major steps: symbol recognition and structural analysis. Symbol recognition is the basis of the structural analysis, which consists of two stages: symbol segmentation and symbol recognition. The input data of online handwritten mathematical expression is set of strokes. A mathematic symbol may consist of more than one stroke. The purpose of Symbol segmentation is to transform the strokes into a set of symbols and then will be classified in the symbol recognition stage. The symbol recognition uses neural network and the structural analysis uses explicit syntactic rules to parse the mathematical expressions.
Character recognition is the most common type of symbol recognition [2]. This research uses template matching and structure analysis method to recognize characters. Template
matching is done by taking the total sum of the differences between input image character and template image character, each of those are normalized. During structure analysis, features that describe the geometric and topological structures of a symbol are extracted. Structure analysis gives features with high tolerance to noise and style variations.
A number of researches have been proposed for online handwritten mathematic symbol recognition. Some of these methods are based on nearest neighbor classification in a feature space of approximately 50 dimensions [3], while in [4] proposed a progressive expression partitioning, extended elastic matching and progressive structural analysis to generate the progressive recognition result. Extended elastic matching algorithm will take consideration of slope and curative information during its matching process, while the conventional elastic matching only considers euclidean distance between points without analyzing the slopes and curvatures at those points.
On the other hand, [5] proposed a straightforward approximation of the dynamic time warping algorithm, with focus on recognizing single-stroke symbols. Interestingly, [6] proposed a mathematical symbols recognition using HMM and Segmental K-means. The segmental K-means algorithm is used to get initialize the Gaussian Mixture Models parameters that represent the probability distribution of the HMM. [7] is using support vector machines and neural networks to recognize symbols. When some classification result errors, they use immediate feedback and undo-redo.
This research focuses on real-time handwriting mathematic expression recognition. The HMM model which is used as classification process is a discrete model. Five features are extracted from each input stroke. We use Vector Quantization for compression techniques because HMM discrete data can only be used in single dimension array / scalar.
Vector Quantization consist of two different parts, i.e codebook and codeword. Codebook is set of codewords, while codeword is a code used as a replacement of the 5 features. Codebook will be built using set of available training data and will be compressed into several codewords.
TABLE I. RECOGNIZED SYMBOLS
0 1 2 3 4 5 6 7 8 9
x + / - ( ) ∑ π sin cos
Shortly after a user draws mathematic expression on the screen, the system will do the preprocessing, feature extraction and clasify the expression. Mathematic symbols that currently can be recognized as an input are listing on table I.
II. METHODOLOGY RESEARCH
A set of name-labeled strokes are required during the training phase. These strokes are the training data which will be sent through several phases, i.e preprocessing, feature extraction, and Hidden Markov Model (HMM) [8]. We need to reduce noice from the available strokes and enhancing performance for the data which will be classified and this is where preprocessing does its job.
In feature extraction phase, all available strokes features are harvested, which are Pen Up / Pen Down, Normalized Distance, normalized Y Coordinate, Vicinity Slope, and Curvature. All of these features enable us to identify labels for the strokes.
Fig. 1. Methodology Flow Diagram
HMM model which is used as classification process is discrete model [9]. In HMM, previously extracted features are called a set of observation data. These features are in 5 dimensions array, therefore this array need to be delivered to VQ (Vector Quantization) because observation of HMM discrete data can only be used in single dimension array / scalar.
Vector Quantization comprised of two parts, which are codebook and codeword. To get codeword from features array, we can use distance-measure formula (to find codeword which its features are the most similar to that feature-array). After we
get the codewords, the HMM model will be built by using both Baum-Welch Algorithm and Forward-Backward Algorithm, after that it is saved according to its label.
After training process, we go to testing phase. For handwriting recognition, sets of x and y coordinates from input / strokes which came from user drawing will be delivered to preprocessing process and feature extraction. After features from available strokes have been harvested, then the next step is to get codeword from the codebooks which was already built during training process and then compare them with the whole available HMM model. Matched value between HMM model with these codebook will be calculated using forward algorithm. Model with the highest value will be taken as label for the particular stroke. The methodology flow diagram is depicted in Figure 1. In the next sections we will discuss 5 sub processes for our mathematic expression recognition.
A. Hidden Markov Model
Hidden Markov Model (HMM) is a popular modelling system in pattern recognition, hand-writing recognition, POS tagging and gesture. HMM is an improved version of Markov Model or generally known as Markov model with hidden states. In this research, HMM is used in our classification process.
In Markov Model or Markov Chain, every state is clearly visible and only has “state transition” as its parameter. While in HMM, states are not directly visible, but the output (which depends on the state) are visible. Every state has probability distribution for every possible outputs.
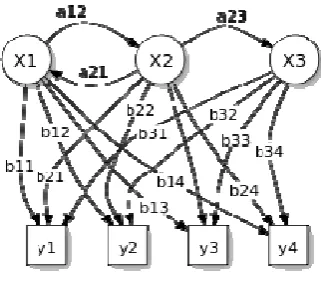
Fig. 2. Hidden Markov Model
In Figure 2, variable y is the possible observation, is the possible transition from state i state j and is the probability in state i. There are three parameters in HMM: a, b, and π. Parameter a represents possible transition from state, parameter b represents distribution of possibilities, and π represents distribution of beginning state. HMM model is usually represented by λ symbol, therefore λ(a, b, π).
Training / HMM Model Re-estimation ( ) is performed to get better HMM model. Re-estimation is using Baum-Welch algorithm and Forward-Backward. Estimation process will be
User input
Build stroke
Strokes
Classification
Classification result
Training data
parsing
Improved Classification
performed continuosly until is achived or reach the maximum number of allowed iteration.
In classification phase, every observed data set will be compared with all available HMM model by using Forward algorithm. HMM Model which has the higest probability will be selected as a model to represent the observed data.
B. Preprocessing
Preprocessing is used to reduce noice and improve quality of the data which will be classified. The method we used in this research is similar to [10] but has fewer steps. There are four type of preprocessing used here: Duplicate Point Filtering, Size Normalization, Smoothing, and Speed Normalization.
1. Duplicate Point Filtering
In this phase, every coordinates which has similar x and y with previous or subsequence stroke will be erased. Duplicate coordinates are considered not providing useful information during handwriting recognition.
2. Size Normalization
To reduce variation from every possible strokes, Size Normalization is used to normalized dot y to have value range from 0 to 1.
3. Smoothing
Smoothing is used to reduce stroke’s noise. Smoothing can be performed by replacing value for each coordinate with a value calculated as average from previous, current and subsequent coordinates.
4. Speed Normalization
Speed Normalization (resampling) is used to eliminate effect from handwriting speed. Resampling is necessary because there are distance differences between coordinates in every stroke.
C. Feature Extraction
Features in a stroke will be extracted to be used later in Vector Quantization phase. Features extracted are:
1. Pen Up / Down
This feature saves information whether or not the writing tool touch the screen at time t. This feature is in binary (only 0 or 1).
2. Normalized Distance to Stroke Edge
This feature is using Pen Up/Down feature to produce its value by calculating the distance of beginning and ending of the stroke.
3. Normalized Y-Coordinate
Normalized Y-Coordinate will take y coordinate which has passed size normalization.
4. Vicinity Slope
Vicinity from a coordinate (x(t), y(t)) is get by calculating angle between two lines which connect (x(t-2), y(t-2)) and
(x(t+2), y(t+2)) and horizontal line at coordinate (x(t-2), y(t-2)).
5. Curvature
Curvature from a coordinate (x(t), y(t)) is acquired by calculating angle between straight line which connects (x(t-2), y(t-2)) with (x(t), y(t)) and straight line which connects (x(t), y(t)) with (x(t+2), y(t+2)).
Vector Quantization (VQ) is used to compress data. VQ works by dividing a large set of available vectors to a group which has the closest distance to the particular vector. K-means or other clustering technique is used for this purpose. These VQ groups are called codeword, while sets of codeword is called codebook. In this research, VQ is used to convert features which are harvested from a stroke to sets of codewords.
D. Training
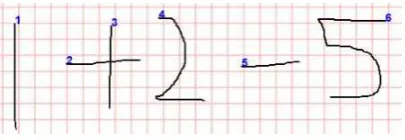
Training is a process where the entire available training data are processed into an information which can be used to recognize input from user. A training data can comprises of many strokes saved into a single file or folder. Figure 3 shows a mathematic expression which is used as a training data. From figure 3 can be seen that the expression contains 6 strokes. Stroke indices are marked with blue-colored number.
Fig. 3. Data training example
TABLE II. DATA TRAINING EXAMPLE
Num Label
Min Max
Length Coordinates Number
x y X Y
1 1 456 104 458 234 130.47 39
2 - 521 147 613 152 92.64 31
3 1 574 106 576 208 102.32 52
4 2 632 94.97 693 198 203.25 109
5 - 739 149 811 155 73.41 29
6 5 834 95.97 917 193 292.19 134
In this research, training data contains many mathematic expressions or symbols which separated into different files but still in the same folder. This expression contains one or more stroke (see figure 3). Every mathematic expression or symbol will be saved in JSON form. Example values of mathematic expression for figure 3 can be seen on table 2.
2 is labeled as “-“ and stroke number 3 is labeled as “1”. Labelling is performed manually. Min and max column is used to save minimal and maximum coordinate from strokes. The number of coordinates on table 2 are the number of coordinates necessary to form a stroke.
Fig. 4. Training System Architecture
By using this training data, training process is performed: Preprocessing, Feature Extraction, and HMM. The System architechture of training process can be seen from figure 4. First, the available training data will be processed in preprocessing to reduce noise and to normalized form for all strokes. After preprocessing, features from each stroke will be extracted and will be used to built a codebook by using data compression technique which is Vector Quantization.
After the codebook is finished, the last process is to form HMM model for each available symbols. HMM models will be used in classification process to classify stroke written by user.
E. Classification
Classification process uses models premade in training process. Classification process itself is a process that transforms user input (in form of strokes) into math expression
that can be recognized by software and then displayed in human readable form.
There are three process needed to get result from handwriting, which are: building stroke process which is useful to enrich information in a stroke, classification process to recognize available strokes, and parsing process to improve classification result.
In building stroke process, input received from the user is rebuilt into a form which conform to the software. Example of this process can be observed on table 2.
In classification process, strokes built from previous phase is reprocessed again into several steps: sorting strokes, building tree, classifying all leaves from the tree, and the last is to combine symbols which comprise from more than one stroke.
1. Sorting strokes
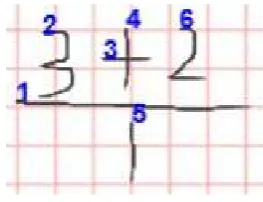
In sorting stroke phase, all strokes will be sorted based on position, from leftmost to rightmost. Stroke sorting is performed because input written by user is not obligated to be in sequence. Please see figure 5.
Fig. 5. Stroke sorting result example
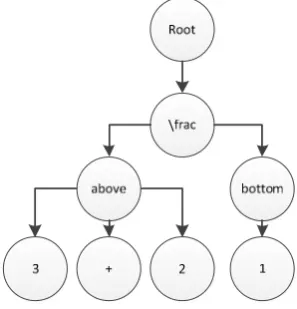
2. Building tree
In building tree phase, all available strokes is transformed into a form of a tree. This step is one of the experiment to simplify creating expression in LaTeX form. This tree form is used in parsing process. Please see figure 6.
Fig. 6. Result of Tree Building Phase
3. Tree Classification
In tree classification phase, all leaves from root will be compared with HMM model which is already built during training process. In this phase, there are two distinct ways to recognize symbols from strokes.
Stroke & Feature 1
Root
Stroke & Feature 2
Stroke & Feature 3
Stroke & Feature 4
Stroke & Feature 5
The first one is by direct examining of strokes to symbols which has definite value. These symbols are period (.), one (1), minus (-), backslash (\), slash (/), parentheses ( ( ), ( ) ).
A stroke is considered as period symbol if its bounding box size is 20x20, is considered as one if it has vicinity slope between 0.24 and 0.26, is considered minus symbol if it has vicinity slope less than or equal to 0.075 or between 0.4 and 0.6, is considered backslash symbol if it has vicinity slope between 0.167 and 0.237, is considered slash symbol if it has vicinity slope between 0.261 and 0.333, is considered as open parentheses if vicinity slope is keep decreasing, and is considered as close parentheses if vicinity slope is keep increasing. Vicinity slope threshold for every checking is 4, it is because vicinity slope feature is taken from 3rd coordinate until the last coordinate minus 2, so the other coordinate values will be filled with 0.
Fig. 7. Result of tree classification
The last step is to find the highest join-probability value for each HMM models for every examined stroke. Calculating join-probability value from a stroke is by transforming extracted features from strokes into codewords. Next, from these codewords, with Forward algorithm, join-probability from strokes can be calculated. Example of the tree after classification phase can be seen on figure 7.
4. Symbol Merge
In symbol merge phase, classified tree will be rechecked again to form symbols which can comprise of more than one stroke. In this research, those recognized symbols are 5, 4, 7, , %, +, x, i, !, and =.
There are seven conditions in which several symbols can be merge into one symbol:
• Small difference in symbols width,
• Crossed symbol,
• Overlapped symbols,
• On top of other symbol (higher),
• Below other symbol (lower),
• On left top of the symbol,
• On right bottom of the symbol.
Figure 8 shows result after symbol merger. Symbol 1 and – is merged because they are fit with the “crossed condition”. After all symbols which can be merged are processed, then the tree is delivered to next phase: parsing process.
Parsing process is the last phase of classification process. This process comprises of two steps: leaves check from symbol and tree fixing phase.
Fig. 8. Symbol Merge Result
Leaves checking phase from a symbol is to group leaves from other symbols (figure 9). For example, user input produces tree as figure 8. Symbol 3, +, 1, dan 2 will be registered as leaves of the symbol -. This is because number 3+2 and 1 are positioned above and bottom of the symbol -. Therefore, symbol – at tree will be considered division symbol. Figure 5 depics user input.
Fig. 9. Leaves check result
The common mistakes in handwritten recognition is the misgrouping strokes into characters. There are two possible situations: strokes that should be recognized as a single character are grouped as parts of separate characters, or strokes that should be recognized as part of separate characters are grouped into a common character [3].
Tree fixing phase is used to fix grammar and check for parentheses. This phase is performed because there are several symbols which are considered similar one to another and therefore merge together to become one model. For example, 5 and s, 0 and o, 9 and g, symbol + and t. Furthermore, 1 is often recognize as symbol ( or ). In this phase, error rate from classification process can be reduced and perform to all element in the tree.
III. EXPERIMENTAL RESULT
All data testing are 49 mathematic expression and includes all symbol in Table 1. Training data used for feature modification and number of codeword are 20 for each symbol, plus 91 mathematic expression. Average speed necessary to
Root
3 - 1 1
- 2
Root
3 + 1
perform classification is 293.88 ms. Average speed is calculated from time required to performed mathematic expression classification divided by the number of mathematic expression.
TABLE III. RESULT OF FEATURES MODIFICATION
Features combination Accuracy
1, 2, 3, 4, 5 70.03%
1, 2, 3, 4 62.09%
1, 2, 3, 5 71.48%
1, 2, 4, 5 58.85%
1, 3, 4, 5 71.84%
2, 3, 4, 5 69.68%
In feature modification experiment phase, testing is performed by using combination of 5 features and 4 features. The result of this testing can be seen at table 3. Value 1 represents Pen Up / Down, value 2 represents Normalized Distance to Stroke Edge, value 3 represents Normalized Y-Coordinate, value 4 represents Vicinity Slope, and value 5 represents Curvature. From table 3, it is shown highest accuracy that can be achived is 71.84% with combination of features 1, 3, 4, and 5 (Pen Up / Down, Normalized Y-Coordinate, Vicinity Slope, Curvature). The accuracy is calculated using (1).
(1)
In codeword number experiment phase, testing was performed by changing the number of codewords used. This experiment was conducted by changing the codewords to 30, 40, 50, 60, and 70. Testing result can be seen on table 4.
From the result shown in table 4, highest accuracy is 72.92% achived by using 60 codewords. From this result, conclusion can be made that the number of codewords cannot be too many or too few, because if it is, the accuracy rate is reduced.
TABLE IV. RESULT OF CODEWORD NUMBER EXPERIMENT
Codeword Accuracy
30 69.31%
40 71.12%
50 71.84%
60 72.92%
70 72.56%
On the other hand, [6] use 90% samples as the training set and the other 10% as the testing set, for each class of symbol.
There are 20281 samples in the training set and 2202 samples in the testing set. Using segmental K-means the system obtains 74.7% for multi-stroke symbols.
IV. CONCLUSION AND FUTURE WORK
This research proposes a real-time handwriting mathematic expression recognition based on Hidden Markov Model. The proposed system is evaluated the performance of recognition on feature extraction techniques. The result shows that average recognition rates of using four features (Pen Up / Down, Normalized Y-Coordinate, Vicinity Slope, Curvature) are the highest at 71.84%, followed by using four features (Pen Up / Down, Normalized Distance to Stroke Edge, Normalized Y-Coordinate, Curvature) at 71.48%, and using five features at 70.03% .
Currently we are developing the next phase of this research which is online handwriting-based calculator that can be used in touchscreen device.
V. ACKNOWLEDGEMENT
This research is funded by Direktorat Penelitian dan Pengabdian kepada Masyarakat, Ministry of Research, Technology and Higher Education through Hibah Bersaing program of 2015.
REFERENCES
[1] K.-F. Chan and D.-Y. Yeung, “Mathematical expression recognition: a survey,” International Journal on Document Analysis and Recognition, vol. 3, no. 1, pp. 3–15, Aug. 2000.
[2] S. Mori, C. Y. Suen, and K. Yamamoto. Historical review of OCR research and development. Proceedings of the IEEE, 80(7):1029{1058, July 1992.
[3] S. Smithies, K. Novins, and J. Arvo, “A handwriting-based equation editor,” Proc. Graphics Interface, pp. 84–91, June 1999.
[4] B. Vuong, Y. He, and S. Hui, “Towards a web-based progressive handwriting recognition environment for mathematical problem solving,” Expert Systems with Applications, vol. 37, no. 1, pp. 886–893, 2010.
[5] S. Maclean and G. Labahn, “Elastic matching in linear time and constant space,” in Proc. Ninth IAPR Int’l. Workshop on Document Analysis Systems. ACM, 2010, pp. 551–554.
[6] L.Hu and R.Zanibbi, HMM-Based Recognition of Online Handwritten Mathematical Symbols Using Segmental K-means Initialization and a Modified Pen-up/down Feature, In Proc. International Conference on Document Analysis and Recognition,pp.15,2005
[7] Ernesto Tapia dan Ra´ul Rojas. Recognition of On-line Handwritten Mathematical Expressions Using a Minimum Spanning Tree Construction and Symbol Dominance. Springer-Verlag Berlin Heidelberg 2004.
[8] Chanintorn Amornsawaddirak, Cholwich Nattee, Nirattaya Khamsemanan, Mathematical Handwritten Formula Recognition, in: Proceedings of the International Conference of Information and Communication Technology for Embedded Systems, IC-ICTES 2014. [9] Han Shu, On-Line Handwriting Recognition Using Hidden Markov
Models. Electrical Engineering and Computer Science Massachusetts Institute of Technology 1997.