5 2. 𝑣𝑘𝑗 merupakan centroid term ke-j
terhadap cluster ke-k
3. 𝜇𝑖𝑘 merupakan derajat keanggotaan dokumen ke-i terhadap cluster ke-k 4. 𝑖 adalah indeks dokumen
5. 𝑗 adalah indeks term 6. 𝑘 adalah indeks cluster
7. w adalah derajat fuzzy, w ∈ [1,∞]. Algoritme Fuzzy C-Means secara keseluruhan adalah sebagai berikut:
1. Memasukkan data yang akan dikelompokkan berupa martiks berukuran nxm (n adalah jumlah dokumen, m adalah jumlah kata) dan tentukan parameter yang terlibat, yaitu:
Jumlah cluster (c); Tingkat fuzzy (w);
Maksimum iterasi (MaxIter); Error terkecil yang diharapkan (e); Fungsi objektif awal ( 𝑃0= 0); Iterasi awal ( t = 1);
2. Membangkitkan bilangan acak
𝜇
ik sebagai derajat keanggotaan, dengan i adalah indeks dokumen (i=1,2,…,n) dan k adalah indeks cluster (k = 1,2,…,c) sebagai elemen-elemen matriks partisi awal𝜇
. 3. Menghitung pusat cluster ke-k: 𝑉𝑘𝑗dengan k = 1, 2, 3, …,c dan j=1, 2, 3, …,m. 𝑉𝑘𝑗 = 𝜇𝑖𝑘 𝑤 x 𝑥𝑖𝑗 𝑛 𝑖=1 𝜇𝑖𝑘 𝑤 𝑛 𝑖=1
.
4. Menghitung fungsi objektif pada iterasi ke-t, 𝑃𝑡= 𝑥𝑖𝑗− 𝑣𝑘𝑗 2 𝑚 𝑗 =1 𝜇𝑖𝑘 𝑤 𝑐 𝑘=1 𝑛 𝑖=1 .
5. Meng-update derajat keanggotaan
𝜇
𝑖𝑘 = 𝑋𝑖𝑗−𝑉𝑘𝑗 2 𝑚 𝑗 =1 −1 𝑤 −1 𝑋𝑖𝑗−𝑉𝑘𝑗 2 𝑚 𝑗 =1 −1 𝑤 −1 𝑐 𝑘 =1.
6. Mengecek kondisi berhenti:
Jika ( |𝑃𝑡 – 𝑃𝑡−1 | < e) atau (t > MaxIter) maka berhenti.
Jika tidak : t = t+1, mengulangi kembali iterasi dimulai dari langkah ke-3.
Evaluasi
Evaluasi dilakukan dengan menghitung F-Measure keseluruhan cluster hasil
clustering. Untuk menghitung F-Measure dibutuhkan pengetahuan mengenai pengelompokan dokumen yang telah dianggap benar. Dalam penelitian ini, pengelompokan dokumen yang telah dianggap benar adalah pengelompokan yang dilakukan dengan cara manual (Ramdani 2011).
Lingkungan Implementasi
Lingkungan implementasi yang dalam penelitian ini adalah sebagai berikut:
Perangkat lunak:
Sistem operasi Windows 7
PHP
Sphinx Perangkat keras:
Processor Intel Core 2 Duo 1,50GHz RAM 2 GB
Hardisk dengan kapasitas 120 GB
HASIL DAN PEMBAHASAN
Karakteristik DokumenDokumen yang digunakan dalam penelitian ini adalah dokumen berbahasa Indonesia yaitu dokumen jurnal hortikultura dan dokumen tanaman obat. Jumlah dokumen yang digunakan adalah 324 dokumen untuk jurnal hortikultura dan 93 dokumen tanaman obat. Koleksi dokumen jurnal hortikultura terbagi ke dalam tiga cluster, yaitu Ekofisiologi dan Agronomi, Pemuliaan dan Teknologi Benih, serta Proteksi. Dokumen tanaman obat terbagi ke dalam tujuh cluster, yaitu Kronis, Kulit, Nyeri-Radang-Demam, Pencernaan, Perawatan, Pernapasan, dan Saluran kemih.
Seluruh dokumen yang digunakan dalam penelitian ini berformat plain-text yang memiliki struktur XML. Struktur tulisan dokumen jurnal hortikultura dapat dilihat pada Gambar 2, sedangkan struktur tulisan dokumen tanaman obat dapat dilihat pada Gambar 3.
Dokumen dikelompokkan ke dalam beberapa tag sebagai berikut:
<DOCID></DOCID>,
menunjukkan ID dari dokumen jurnal hortikultura.
<DOCNO></DOCNO>,
menunjukkan ID dari dokumen tanaman obat.
6
<docId>dok001.txt</docId>
<content>Akhir-akhir ini kentang menjadi tanaman prioritas dan mempunyai nilai ekonomi tinggi. Produksi umbi kentang di
Indonesia masih rendah sehingga ……</content> <DOCNO>001</DOCNO> <nama>Akar Kuning</nama> <namal>Arcangelisia flava (L.) Merr.</namal> <fam>Menispermaceae</fam> <penyakit>Pencernaan</penyakit> <content>Famili:Menispermaceae… </content> <content></content>,
menunjukkan isi atau informasi dari dokumen.
<nama></nama>, menunjukkan nama tanaman obat pada dokumen tanaman obat.
<namal></namal>,
menunjukkan nama latin tanaman obat pada dokumen tanaman obat. <fam></fam>,
menunjukkan nama family dari tamanan obat pada dokumen tanaman obat.
<penyakit></penyakit>, menunjukkan penyakit yang berkaitan dengan tanaman obat pada dokumen tanaman obat.
Dalam penelitian ini, pemrosesan text hanya dilakukan pada text yang berada di antara tag <content> dan </content>, sehingga text yang berada di dalam tag lainnya tidak diproses.
Gambar 2 Struktur dokumen jurnal hortikultura.
Gambar 3 Struktur dokumen tanaman obat. Pembuangan Stopwords dan Term
Pada tahap praproses dilakukan pembuangan term di dalam dokumen yang termasuk ke dalam stopwords dan term yang memiliki bobot (tf.idf) kurang dari threshold. Threshold yang digunakan pada penelitian ini adalah sebesar 1.5 dan 3 untuk dokumen jurnal hortikultura, sedangkan untuk dokumen tanaman obat digunakan threshold sebesar 1.5 dan 0.75. Ukuran threshold yang berbeda antara dokumen jurnal hortikultura dengan dokumen tanaman obat dikarenakan
karakteristik dokumen yang berbeda. Ukuran threshold yang dipilih disesuaikan dengan seluruh koleksi dokumen, sehingga dari setiap dokumen terdapat kata-kata yang memiliki bobot lebih besar dari threshold dan merepresentasikan dokumennya. Karena semakin sering suatu kata muncul pada suatu dokumen (selain kata yang termasuk ke dalam stopwords), maka diduga semakin penting kata itu untuk dokumen tersebut (Manning et al. 2009).
Clustering Dokumen dengan Fuzzy
C-Means
Clustering dokumen jurnal hortikultura dan dokumen tanaman obat dilakukan dengan menggunakan algoritme Fuzzy C-Means (FCM) dengan input sebagai berikut: 1. Term yang telah dihitung bobotnya
menggunakan tf.idf dan bernilai lebih dari threshold
2. Jumlah cluster (c), yaitu tiga cluster untuk dokumen jurnal hortikultura dan tujuh cluster untuk dokumen tanaman obat 3. Pengontrol tingkat fuzzy (w), yaitu dua
dan untuk pembanding sebesar tiga 4. Jumlah maksimum iterasi (maxIter)
sebesar 100 iterasi
5. Nilai error (e) sebesar 1−10.
Untuk meringkas dan memudahkan penulisan nama cluster, maka dilakukan penamaan seperti pada Tabel 2.
Tabel 2 Keterangan penamaan cluster Dokumen Jurnal Hortikultura C1 Ekofisiologi dan Agronomi C2 Pemuliaan dan Teknologi Benih C3 Proteksi
Dokumen Tanaman Obat C1 Kronis C2 Kulit C3 Nyeri-Radang-Demam C4 Pencernaan C5 Perawatan C6 Pernapasan C7 Saluran kemih
7 T = 3 T = 1.5 Series 1 72.42% 78.19% 72.42% 78.19% 0.00% 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% 70.00% 80.00% 90.00% 100.00%
A
ku
ras
i
w = 2 w = 21. Clustering Dokumen Jurnal Hortikultura Perhitungan pertama adalah melakukan clustering terhadap dokumen jurnal hortikultura dengan menggunakan nilai w = 2 dan threshold = 3. Tabel aktual-prediksinya dapat dilihat pada Tabel 3 dan Confusion Matrix dari hasil nilai aktual-prediksinya ditunjukkan pada Tabel 4.
Tabel 3 Nilai aktual-prediksi jurnal hortikultura dengan w = 2 dan threshold = 3
Prediksi C1 C2 C3 aktual C1 81 17 10 C2 5 65 32 C3 29 41 44
Tabel 4 Confusion matrix jurnal hortikultura dengan w = 2 dan threshold = 3
TRUE FALSE TRUE TP 190 FP 134 FALSE FN 134 TN 514 Berdasarkan Tabel 4, total pengujian koleksi dokumen jurnal hortikultura terhadap tiga cluster dengan nilai w = 2 dan threshold = 3 terdapat 190 dokumen yang dikelompokkan secara benar, dan total dokumen yang salah dikelompokkan sebanyak 134 dokumen. Nilai recall untuk hasil ini adalah 58.64% dan nilai precision adalah 58.64%. Oleh karena itu perhitungan di atas menghasilkan F-Measure sebesar 58.64% dan akurasi sebesar 72.42%.
Perhitungan kedua adalah melakukan clustering terhadap dokumen jurnal hortikultura dengan menggunakan nilai w = 2 dan threshold = 1.5. Tabel aktual-prediksinya dapat dilihat pada Tabel 5 dan Confusion Matrix dari hasil nilai aktual-prediksinya ditunjukkan pada Tabel 6.
Berdasarkan Tabel 6 dapat dilihat bahwa total pengujian koleksi dokumen jurnal hortikultura terhadap tiga cluster dengan nilai w = 2 dan threshold = 1.5 terdapat 218 dokumen yang dikelompokkan secara benar, dan total dokumen yang salah dikelompokkan sebanyak 106 dokumen. Nilai recall untuk hasil ini adalah 67.28% dan nilai precision adalah 67.28%. Oleh karena itu perhitungan
di atas menghasilkan F-Measure sebesar 67.28% dan akurasi sebesar 78.19%.
Tabel 5 Nilai aktual-prediksi jurnal hortikultura dengan w = 2 dan threshold = 1.5
Prediksi C1 C2 C3 aktual C1 72 19 17 C2 8 78 16 C3 28 18 68
Tabel 6 Confusion matrix jurnal hortikultura dengan w = 2 dan threshold = 1.5
TRUE FALSE TRUE TP 218 FP 106 FALSE FN 106 TN 542
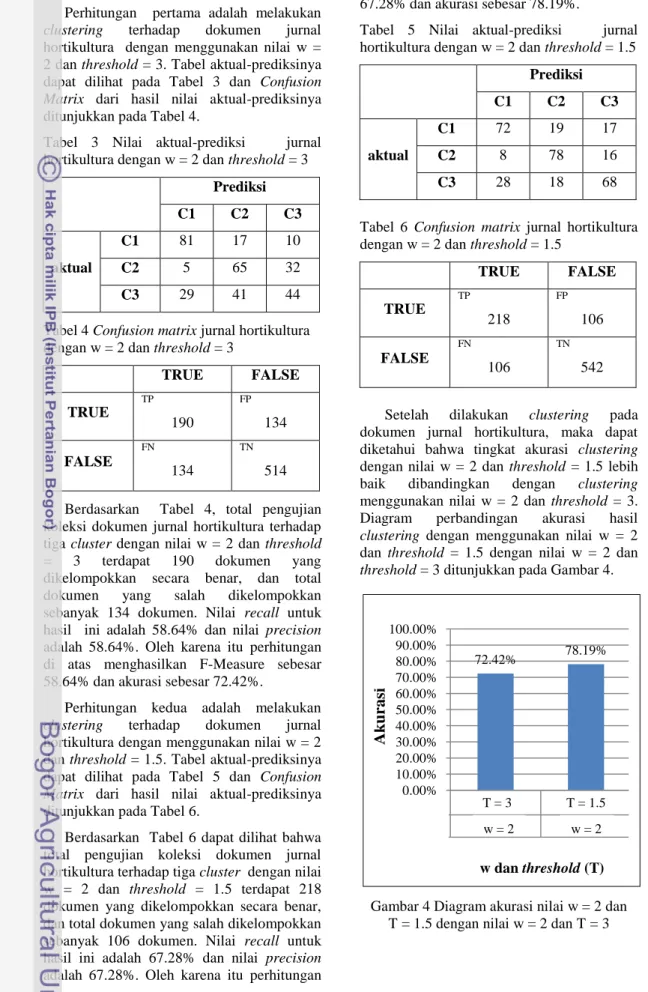
Setelah dilakukan clustering pada dokumen jurnal hortikultura, maka dapat diketahui bahwa tingkat akurasi clustering dengan nilai w = 2 dan threshold = 1.5 lebih baik dibandingkan dengan clustering menggunakan nilai w = 2 dan threshold = 3. Diagram perbandingan akurasi hasil clustering dengan menggunakan nilai w = 2 dan threshold = 1.5 dengan nilai w = 2 dan threshold = 3 ditunjukkan pada Gambar 4.
Gambar 4 Diagram akurasi nilai w = 2 dan T = 1.5 dengan nilai w = 2 dan T = 3
8 Selain menggunakan nilai threshold yang
berbeda, untuk mengetahui pengaruh parameter w terhadap hasil clustering dengan menggunakan algoritme FCM, maka dilakukan perhitungan clustering dengan menggunakan nilai w = 3 dengan nilai threshold = 1.5. Tabel aktual-prediksinya dapat dilihat pada Tabel 7 dan Confusion Matrix dari hasil nilai aktual-prediksinya seperti pada Tabel 8.
Tabel 7 Nilai aktual-prediksi jurnal hortikultura dengan w = 3 dan threshold = 1.5
Prediksi C1 C2 C3 aktual C1 65 22 21 C2 12 71 19 C3 33 20 61
Tabel 8 Confusion matrix jurnal hortikultura dengan w = 3 dan threshold = 1.5
TRUE FALSE TRUE TP 197 FP 127 FALSE FN 127 TN 521
Berdasarkan Tabel 8 dapat dilihat bahwa total pengujian koleksi dokumen jurnal hortikultura terhadap tiga cluster dengan nilai w = 3 dan threshold = 1.5 terdapat 197 dokumen yang dikelompokkan secara benar, dan total dokumen yang salah dikelompokkan sebanyak 127 dokumen. Nilai recall untuk hasil ini adalah 60.80% dan nilai precision adalah 60.80%. Oleh karena itu perhitungan di atas menghasilkan F-Measure sebesar 60.80% dan akurasi sebesar 73.87%.
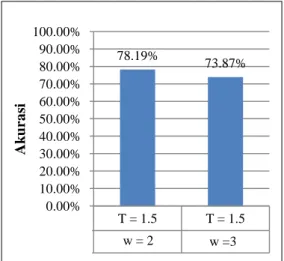
Untuk melihat pengaruh nilai w terhadap hasil clustering dokumen jurnal hortikultura menggunakan algoritme FCM, dapat dibandingkan hasil yang diperoleh antara penggunaan nilai w = 2 dan threshold = 1.5 dengan w = 3 dan threshold = 1.5. Dari hasil yang ditunjukkan sebelumnya oleh Tabel 6 dan Tabel 8, dapat dilihat bahwa selisih hasil dokumen yang secara benar dikelompokkan dengan menggunakan algoritme FCM adalah 21 dokumen, dengan w = 2 yang berhasil melakukan clustering terhadap 21 dokumen tersebut dengan benar. Perbandingan akurasi
antara penggunaan nilai w = 2 dan w = 3 dapat dilihat pada Gambar 5.
Gambar 5 Diagram akurasi nilai w = 2 dan T = 1.5 dengan nilai w = 3 dan T = 1.5 Selisih jumlah dokumen hasil clustering dengan penggunaan nilai parameter w yang berbeda tidak terlalu signifikan yang dapat disebabkan oleh jumlah dokumen yang digunakan tidak terlalu besar. Menurut James Bezdek tahun 1984, tidak ada petunjuk secara teoritikal ataupun secara komputasional mengenai penggunaan parameter w sebagai parameter pengontrol tingkat fuzzy yang optimal. Berdasarkan percobaan yang dilakukan, penggunaan nilai w yang semakin besar akan menyebabkan distribusi data menjadi kurang baik, sehingga menyebabkan akurasi hasil clustering menurun. Oleh karena itu, untuk clustering dokumen tanaman obat hanya akan digunakan nilai w = 2.
Distribusi dokumen hasil clustering pada umumnya akan berubah dengan penetapan jumlah cluster yang berbeda-beda. Untuk melihat distribusi dokumen jurnal hortikultura terhadap jumlah cluster yang ditentukan, maka selain dilakukan clustering menjadi tiga cluster, dilakukan pula clustering menjadi empat cluster dan lima cluster (Tabel 9 dan 10).
Berdasarkan Tabel 9 dan 10, dapat diketahui bahwa koleksi dokumen jurnal hortikultura yang terbagi ke dalam tiga cluster ternyata dapat dikelompokkan ke dalam empat cluster dan lima cluster. Hal tersebut menandakan bahwa dari tiga cluster hasil pengelompokan oleh manusia, ternyata dapat dikelompokkan kembali menjadi sejumlah
T = 1.5 T = 1.5 Series 1 78.19% 73.87% 78.19% 73.87% 0.00% 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% 70.00% 80.00% 90.00% 100.00% A k ur a si w = 2 w =3 w dan threshold (T)
9 cluster lain oleh sistem. Pengelompokan
yang dilakukan oleh sistem mampu menghasilkan cluster dokumen baru yang lebih spesifik, yang sebelumnya berdasarkan pengelompokan oleh manusia dianggap termasuk ke dalam cluster yang lebih umum. Tabel 9 Hasil clustering terhadap empat cluster Prediksi C1 C2 C3 C4 aktual C1 69 13 9 5 C2 21 89 14 3 C3 13 11 74 3 Tabel 10 Hasil clustering terhadap lima cluster Prediksi C1 C2 C3 C4 C5 aktual C1 72 23 11 1 1 C2 12 83 6 0 1 C3 11 20 71 1 1
2. Clustering Dokumen Tanaman Obat Clustering dokumen tanaman obat yang berjumlah 93 dilakukan dengan menggunakan nilai w = 2 dengan nilai threshold sebesar 1.5 dan 0.75. Perhitungan pertama untuk clustering dokumen tanaman obat adalah dengan menggunakan nilai w = 2 dan threshold = 1.5. Tabel aktual-prediksinya dapat dilihat pada Tabel 11 dan Confusion Matrix dari hasil nilai aktual-prediksinya dapat dilihat pada Tabel 12.
Tabel 11 Nilai aktual-prediksi dokumen tanaman obat dengan w = 2 dan threshold = 1.5 Prediksi C1 C2 C3 C4 C5 C6 C7 C1 5 1 1 2 0 0 0 C2 0 7 2 0 0 0 1 C3 0 6 9 0 0 2 3 C4 2 4 0 13 0 1 0 C5 0 2 3 3 10 4 2 C6 0 2 0 0 0 2 0 C7 1 2 0 0 0 0 3
Tabel 12 Confusion matrix dokumen tanaman obat dengan w = 2 dan threshold = 1.5 TRUE FALSE TRUE TP 49 FP 44 FALSE FN 44 TN 514 Berdasarkan Tabel 12 total pengujian koleksi dokumen tanaman obat terhadap tujuh cluster dengan nilai w = 2 dan threshold = 1.5 terdapat 49 dokumen yang dikelompokkan secara benar, dan total dokumen yang salah dikelompokkan adalah 44 dokumen. Nilai recall untuk hasil ini adalah 52.69% dan nilai precision adalah 52.69%. Oleh karena itu perhitungan di atas menghasilkan F-Measure sebesar 52.69% dan akurasi sebesar 86.48%.
Perhitungan kedua untuk clustering dokumen tanaman obat adalah dengan menggunakan nilai w = 2 dan threshold = 0.75. Tabel aktual-prediksinya dapat dilihat pada Tabel 13 dan Confusion Matrix dari hasil nilai aktual-prediksinya ditunjukkan pada Tabel 14.
Tabel 13 Nilai aktual-prediksi dokumen tanaman obat dengan w = 2 dan threshold = 0.75 Prediksi C1 C2 C3 C4 C5 C6 C7 C1 4 1 0 2 1 1 0 C2 0 6 1 1 0 2 0 C3 1 0 14 0 0 1 4 C4 5 2 0 12 0 1 0 C5 1 0 7 2 13 1 0 C6 0 0 1 0 0 3 0 C7 0 0 2 0 0 0 4
Tabel 14 Confusion matrix dokumen tanaman obat dengan w = 2 dan threshold = 0.75
TRUE FALSE TRUE TP 54 FP 39 FALSE FN 39 TN 519 Berdasarkan Tabel 14 dapat dilihat bahwa total pengujian koleksi dokumen tanaman obat terhadap tujuh cluster dengan nilai w = 2 dan threshold = 0.75 terdapat 54 dokumen
10 C:\Sphinx\bin>indexer --config c:\sphinx\sphinx.conf --all \Sphinx\bin\searchd --install --config C:\Sphinx\sphinx.conf --servicename SphinxJurnal yang dikelompokkan secara benar, dan total
dokumen yang salah dikelompokkan adalah 39 dokumen. Nilai recall untuk hasil ini adalah 58.06% dan nilai precision adalah 58.06%. Oleh karena itu perhitungan di atas menghasilkan F-Measure sebesar 58.06% dan akurasi sebesar 88.01%.
Setelah clustering dokumen tanaman obat dilakukan, maka dapat dilihat bahwa tingkat akurasi clustering dengan nilai w = 2 dan threshold = 0.75 lebih baik dibandingkan dengan clustering menggunakan nilai w = 2 dan threshold = 1.5. Diagram perbandingan akurasi hasil clustering dokumen tanaman obat dengan menggunakan nilai w = 2 dan threshold = 1.5 dengan nilai w = 2 dan threshold = 0.75 dapat dilihat pada Gambar 6.
Gambar 6 Diagram akurasi nilai w = 2 dan T = 1.5 dengan nilai w = 2 dan T = 0.75
Berdasarkan seluruh hasil perhitungan yang telah dilakukan terhadap dokumen jurnal hortikultura dan dokumen tanaman obat, dapat dilihat bahwa penggunaan threshold sebesar 1.5 untuk dokumen jurnal hortikultura dan threshold sebesar 0.75 untuk dokumen tanaman obat memberikan hasil akurasi yang lebih baik. Berdasarkan hal tersebut dapat diketahui bahwa penggunaan threshold yang sesuai dapat menghasilkan akurasi yang lebih baik. Karena dengan penggunaan threshold yang terlalu besar, menyebabkan range bobot term yang masuk dalam proses clustering menjadi lebih kecil dan menyebabkan tidak ikutnya term penciri yang bernilai lebih kecil dari threshold dalam proses clustering. Oleh karena itu, hasil clustering yang diimplementasikan pada search engine adalah clustering dengan
menggunakan w = 2 dengan threshold = 1.5 untuk dokumen jurnal hortikultura dan w = 2 dengan threshold 0.75 untuk dokumen tanaman obat.
Temu Kembali Informasi
Setelah hasil clustering didapat, maka dokumen-dokumen yang ada dalam koleksi sudah terkumpul dalam cluster masing-masing berdasarkan algoritme FCM. Proses akhir dari penelitian ini adalah proses temu kembali informasi yang dibangun dengan menggunakan Sphinx search. Sebelum tahap temu kembali informasi dengan menggunakan Sphinx search dapat dilakukan, harus melakukan indexing terlebih dahulu terhadap seluruh dokumen dengan perintah seperti pada Gambar 7.
Gambar 7 Perintah indexing dokumen oleh Sphinx search
Indexing dilakukan pada satu file XML yang berisi seluruh koleksi dokumen yang ada yang di dalamnya terdapat beberapa tag yang dikenali oleh Sphinx search. Indexing yang dilakukan oleh Sphinx search bertujuan agar dokumen tersebut dapat dikenali dan dapat ditemu-kembalikan oleh Sphinx search.
Langkah selanjutnya adalah membuat service untuk Sphinx search. Nama service yang digunakan dalam penelitian ini yaitu SphinxJurnal untuk koleksi dokumen jurnal hortikultura dan SphinxTanob untuk koleksi dokumen tanaman obat. Pembuatan service untuk tanaman obat dilakukan dengan cara yang sama dengan mengganti servicename saja. Perintah untuk membuat service ditunjukkan oleh Gambar 8.
Gambar 8 Perintah pembuatan service Sphinx search
Sphinx search menerima input query dari pengguna dan mengembalikan dokumen-dokumen yang sesuai dengan query. Dokumen yang sesuai dengan query yang ditemu-kembalikan oleh Sphinx search dapat berupa dokumen-dokumen yang berasal dari
T = 1.5 T = 0.75 Series 1 86.48% 88.01% 86.48% 88.01% 0.00% 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% 70.00% 80.00% 90.00% 100.00% Ak ura si w dan threshold (T) w = 2 w =2
11 seluruh cluster yang ada, atau dapat berasal
dari cluster tertentu saja. Apabila pengguna sudah mengetahui kelas dari informasi yang dibutuhkannya terlebih dahulu, maka proses pencarian akan lebih efisien, karena fokus pencarian informasi hanya dilakukan pada satu cluster saja.
Pengujian Kinerja Sistem
Proses pengujian kinerja sistem dilakukan dengan melakukan pemeringkatan dokumen dengan memperhitungkan ukuran kesamaan antara query dengan dokumen dan query dengan pusat cluster. Ukuran kesamaan antara query q dengan dokumen d pada c adalah:
Sim(q,d|c) = aSim(q,d)+(1-a)Sim(q,c) , dengan
1. Sim(q,d) adalah ukuran kesamaan antara query q dengan dokumen d
2. Sim(q,c) adalah dot product antara query q dengan pusat cluster c.
3. a adalah bobot (0 < a < 1). Pada penelitian ini dipilih a = 0.5.
Pengujian pada Dokumen Jurnal HortikulturaProses pengujian kinerja sistem pada keseluruhan koleksi dokumen tanaman obat menggunakan 15 kueri uji (Lampiran 1). Pencarian dengan kueri uji bertujuan untuk mendapatkan nilai recall dan precision dari sistem temu kembali dokumen jurnal hortikultura. Setelah nilai recall dan precision didapat, kemudian dihitung interpolasi maksimumnya untuk mendapatkan nilai average precision (AVP) yang menggambarkan kinerja sistem secara keseluruhan.
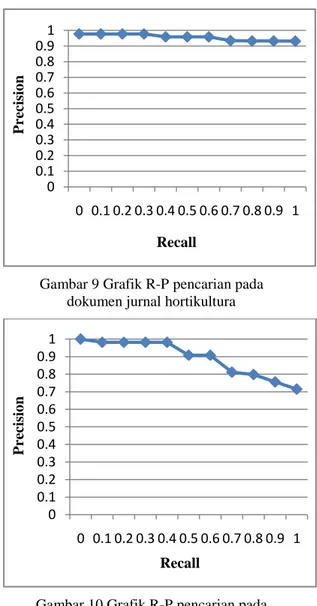
Berdasarkan hasil pengujian terhadap seluruh cluster pada dokumen jurnal hortikultura didapat nilai average precision sebesar 0.9562 (Lampiran 2). Hal tersebut menunjukkan bahwa kinerja sistem temu kembali terhadap hasil clustering dokumen jurnal hortikultura sudah baik. Gambar 9 menunjukkan kinerja sistem pada pencarian dokumen jurnal hortikultura.
Pengujian pada Dokumen Tanaman Obat Proses pengujian kinerja sistem pada dokumen tanaman obat menggunakan 7 kueri uji (Lampiran 3). Pengujian ini dilakukan untuk mendapat nilai recall dan precision dari sistem temu kembali dokumen tanaman obat. Setelah nilai recall dan precision didapat,kemudian dihitung interpolasi maksimumnya untuk mendapatkan nilai average precision (AVP) yang menggambarkan kinerja sistem secara keseluruhan.
Berdasarkan hasil pengujian terhadap seluruh cluster pada dokumen tanaman obat didapat nilai average precision sebesar 0.8931 (Lampiran 4). Hal tersebut menunjukkan bahwa kinerja sistem temu kembali terhadap hasil clustering dokumen tanaman obat sudah baik. Gambar 10 menunjukkan kinerja sistem pada pencarian dokumen tanaman obat.
Gambar 9 Grafik R-P pencarian pada dokumen jurnal hortikultura
Gambar 10 Grafik R-P pencarian pada dokumen tanaman obat
Pengujian pada dokumen jurnal hortikultura mendapatkan hasil yang lebih baik dari pengujian dokumen tanaman obat. Hal ini karena dokumen jurnal hortikultura lebih memiliki penciri yang berbeda dari dokumen lainnya dibandingkan dengan dokumen tanaman obat, sehingga sistem
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Recall P re cisi o n 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Recall P re cisi o n
12 dapat menemukembalikan dokumen relevan
yang lebih banyak.
KESIMPULAN DAN SARAN
KesimpulanBerdasarkan hasil yang diperoleh, dapat disimpulkan bahwa clustering dengan menggunakan algoritme Fuzzy C-Means dapat diterapkan pada dokumen berbahasa Indonesia dengan topik pertanian. Ditinjau dari segi hasil, kinerja sistem clustering terhadap dokumen jurnal hortikultura lebih baik pada saat menggunakan nilai w = 2 sebagai parameter tingkat fuzzy dan threshold = 1.5 sebagai batas minimun bobot term yang diikutsertakan pada proses clustering. Kinerja sistem clustering terhadap dokumen tanaman obat lebih baik pada saat menggunakan nilai w = 2 sebagai parameter tingkat fuzzy dan threshold = 1.5. Penggunaan threshold pada tahap praproses dapat mengurangi dimensi dokumen dan mempengaruhi hasil clustering. Clustering dokumen jurnal hortikultura yang dikelompokkan menjadi tiga cluster oleh manusia ternyata dapat dikelompokkan menjadi empat cluster dan lima cluster oleh sistem. Sistem mampu mendistribusikan dokumen dan menghasilkan cluster dokumen baru yang lebih spesifik yang sebelumnya berdasarkan pengelompokan oleh manusia dianggap termasuk ke dalam cluster yang lebih umum.
Saran
Salah satu faktor yang menentukan tingkat keakurasian hasil clustering adalah penentuan fitur atau penciri dokumen. Oleh karena itu perlu dicobakan metode lain untuk menentukan fitur dokumen.
DAFTAR PUSTAKA
Ali A. 2011. Sphinx Search Beginner's Guide. Birmingham, England: Packt Publishing. ISBN 978-1-84951-254-1.
Antonius T. 2008. Penggalian Pola Churn Menggunakan Data Mining pada Institusi Perbankan Nasional. [thesis].Jakarta: Program Studi Magister Teknologi Informasi, Universitas Indonesia.
Baeza-Yates R, Ribeiro-Neto B. 1999. Modern Information Retrieval. England: Addison Wesley.
Bezdek C James, Ehrlich R, Full W. 1984. FCM: The Fuzzy C-Means Clustering Algorithm. Computers & Geosciences Vol. 10, No. 2-3, pp. 191-203. Pegamon Press Ltd. USA.
Hadi Y H. 2005. Pembagian Kelas Kuliah Mahasiswa Menggunakan Algoritma Pengklasteran Fuzzy. [skripsi]. Semarang: Jurusan Teknik Elektro, Universitas Diponegoro.
Karypis G, Han E. 2000. Concept Indexing: A Fast Dimensionally Reduction Algorithm with Applications to Document Retrieval & Categorization. Computer Science and Engineering. University of Minnesota. Minneapolis.
Kondadadi R, Kozma R. 2002. A Modified Fuzzy ART for Soft Document Clustering. Memphis: Division of Computer Science, University of Memphis.
Manning C D, Raghavan P, Schutze H. 2009. An Introduction to Information Retrieval. Cambridge: Cambridge University Press.
Ramdani H. 2011. Clustering Konsep Dokumen Berbahasa Indonesia menggunakan Bisecting K-Means. [skripsi]. Bogor: Departemen Ilmu Komputer, Institut Pertanian Bogor. Ridha A. 2002. Pengindeksan Otomatis
dengan Istilah Tunggal untuk Dokumen Berbahasa Indonesia.[skripsi]. Bogor: Departemen Ilmu Komputer, Institut Pertanian Bogor.
Win T T, Mon L. 2010. Document Clustering by Fuzzy C-Mean Algorithm. IEEE : 978-1-4244-5848-6/10.