7
TINJAUAN PUSTAKA
2.1 Pendekatan Teori Basis Data 2.1.1 Pengertian Basis Data
Menurut Connolly dan Begg (2010:15), basis data adalah sekumpulan data yang terbagi dan terhubung secara logikal dan deskripsi dari data-data yang dirancang untuk memenuhi kebutuhan informasi suatu perusahaan. Data tersebut dapat digunakan secara bersamaan oleh banyak departemen dan pengguna. Data terintegrasi dengan jumlah minimum duplikasi. Database tidak lagi dimiliki oleh satu departemen tetapi merupakan sumber daya perusahaan bersama. Database menyimpan data operasional organisasi dan deskripsi dari data tersebut.
Menurut Martyn Prigmore (2008:10), basis data adalah sesuatu yang tetap, menjelaskan diri sendiri, koleksi yang terstruktur dari hal-hal yang terkait dengan data.
2.1.1.1 Database Management System (DBMS)
Menurut Connolly dan Begg (2010:66), DBMS adalah sistem perangkat lunak yang memungkinkan pengguna untuk mendefinisikan, membuat, dan mengatur akses ke basis data. DBMS adalah software yang berinteraksi dengan program aplikasi pengguna dan database.
DBMS menyediakan fasilitas sebagai berikut:
1. Data Definition Language (DDL)
DDL memungkinkan pengguna untuk menentukan tipe data dan struktur dan kendala pada data yang akan disimpan dalam database.
2. Data Manipulation Language (DML)
DML memungkinkan pengguna untuk memasukkan, mengubah, menghapus, dan mengambil data dari database. Memiliki sebuah repositori pusat untuk semua data dan deskripsi data yang memungkinkan DML untuk memberikan fasilitas yang disebut query language. Query language yang paling umum adalah Structured Query Language (SQL) dan telah menjadi bahasa standar untuk DBMS relasional.
3. DBMS menyediakan akses terkontrol ke database. Sebagai contoh, dapat memberikan:
• Sistem keamanan, yang mencegah pengguna yang tidak sah mengakses database.
• Sistem integritas, yang mempertahankan konsistensi data yang tersimpan.
• Sistem kontrol untuk konkurensi, yang memungkinkan akses bersama database.
• Sistem kontrol untuk pemulihan, yang mengembalikan database ke keadaan yang konsisten sebelumnya setelah kegagalan perangkat keras atau perangkat lunak.
• Katalog yang dapat diakses pengguna, yang berisi deskripsi dari data dalam database.
Menurut Martyn Prigmore (2008:11), DBMS mengelola semua interaksi dengan basis data, meskipun terlibat dalam memanipulasi skema basis data atau instansi database. Pengguna tidak pernah mengakses data secara langsung dimana basis data tersebut disimpan, melainkan menggunakan DBMS untuk memanipulasi data. Faktanya, DBMS itu rumit dan sangat sulit digunakan. Aplikasi database biasanya menambahkan aplikasi perangkat lunak tambahan diantara pengguna dan DBMS.
Menurut Martyn Prigmore (2008:46) DBMS memiliki fungsi utama sebagai berikut:
1. Definisi data (DDL) memungkinkan pengguna untuk mendefinisikan dan merubah skema basis data. Selain itu, DDL juga memungkinkan pengguna untuk menyediakan akses dan pengelolaan untuk kamus data.
2. Manipulasi data (DML) memungkinkan pengguna untuk memanipulasi instansi basis data.
3. Integritas, untuk meyakinkan perubahan instansi pada basis data, memenuhi semua constraint pada basis data.
4. Concurrency, memungkinkan banyak penngguna untuk
mengakses ke basis data.
5. Keamanan, menyediakan identifikasi, pembuktian keaslian dan otorisasi dari tindakan pengguna.
6. Komunikasi, memungkinkan client dan server untuk berkomunikasi.
2.1.1.1.1 Komponen dari Lingkungan DBMS
Menurut (Connolly dan Begg, 2010:68-71), terdapat lima komponen utama dalam lingkungan DBMS yang terdiri dari:
1. Hardware
DBMS dan aplikasi memerlukan hardware untuk dijalankan. Hardware dapat berupa personal computer, mainframe atau jaringan komputer. Hardware yang digunakan bergantung pada kebutuhan organisasi dan DBMS yang digunakan.
2. Software
Komponen software terdiri dari perangkat lunak DBMS itu sendiri dan program aplikasi, bersama-sama dengan sistem operasi, termasuk
perangkat lunak jaringan jika DBMS akan digunakan melalui sebuah jaringan.
3. Data
Data adalah sebuah komponen yang mungkin paling penting dalam lingkungan DBMS. Data bertindak sebagai jembatan antara komponen mesin dan komponen manusia. Data juga menggabungkan sistem katalog.
4. Procedures
Prosedur mengacu pada instruksi dan aturan yang mengatur desain dan penggunaan database. Para pengguna sistem dan staf yang mengelola database memerlukan sebuah dokumentasi prosedur tentang cara menggunakan atau menjalankan sistem. Sebagai contoh, sebuah prosedur mungkin terdiri dari petunjuk tentang cara untuk log in, memulai dan menutup DBMS atau membuat back up data.
5. People
Komponen terakhir adalah orang-orang yang terlibat dengan system dari DBMS itu sendiri. Misalnya DBA (Database Administrator) atau DA (Data Administrator).
2.1.1.1.2 Peran di Lingkungan Database
Terdapat tempat jenis peran utama yang dapat di identifikasi dari orang yang berpartisipasi dalam lingkungan DBMS (Connolly dan Begg, 2010:71-73) :
1. Data and Database Administrators
Data Administrator (DA) bertanggung jawab atas pengelolaan sumber daya data, yang termasuk perencanaan database, pengembangan dan pemeliharaan standar, kebijakan dan prosedur, dan desain database konseptual atau logikal. Data Administrator berkonsultasi dengan manajer senior dan memberi saran untuk
memastikan bahwa arah pengembangan database pada akhirnya akan mendukung tujuan perusahaan.
Database Administrator (DBA) bertanggung jawab untuk realisasi fisik database, termasuk desain fisik database dan implementasi, keamanan dan kontrol integritas, pemeliharaan sistem operasional, dan memastikan kinerja yang memuaskan dari sebuah aplikasi untuk pengguna. Peran DBA lebih berorientasi teknis daripada peran DA, karena membutuhkan pengetahuan yang terperinci dari target DBMS dan lingkungan dari sistem.
2. Database Designers
Dalam proyek desain database yang cukup besar dapat didefinisikan dua jenis desainer, yaitu: logical database designer dan physical database designer. Tugas dari logical database designer berkaitan dengan mengidentifikasi atribut data, hubungan antara data, dan kendala pada data yang akan disimpan dalam database. Physical database designer memutuskan bagaimana desain database logis secara fisik diwujudkan. Misalnya memilih struktur penyimpanan yang spesifik dan metode akses untuk data untuk mencapai kinerja yang baik atau merancang langkah-langkah keamanan yang diperlukan pada data. 3. Application Developers
Setelah database telah diimplementasikan, program aplikasi yang menyediakan fungsionalitas yang diperlukan untuk pengguna akhir harus diterapkan. Ini adalah tanggung jawab dari seorang application developers.
4. End-Users
End-Users dapat disebut sebagai pengguna akhir. Para pengguna akhir adalah client untuk database, yang telah dirancang dan diimplementasikan, dan sedang dipertahankan untuk melayani kebutuhan informasi mereka. Terdapat dua
pengguna akhir yang dapat diklasifikasikan menurut cara mereka menggunakan system yaitu naïve users dan sophisticated users.
2.1.1.2 Database Application and System
Menurut Connolly and Begg (2010:54), aplikasi database hanyalah sebuah program yang berinteraksi dengan database di beberapa titik dalam pelaksanaannya. Sedangkan database system adalah kumpulan program aplikasi yang berinteraksi dengan database bersama dengan DBMS dan database itu sendiri.
2.1.1.3 Structured Query Language
Menurut Connolly dan Begg (2010:184), SQL adalah contoh dari sebuah bahasa yang transform-oriented atau bahasa yang dirancang untuk menggunakan relasi untuk mengubah suatu input menjadi sebuah output yang di perlukan. Sesuai dengan standar ISO, SQL memiliki dua komponen utama yaitu Data Definition Language (DDL) untuk mendefinisikan struktur database atau mengendalikan akses ke data dan Data Manipulation Language (DML).
2.1.1.3.1 Data Manipulation Language (DML)
Menurut Connolly dan Begg (2010:188), Data Manipulation Language (DML) digunakan untuk mengambil dan memperbarui data. Terdapat empat statement umum yang digunakan dalam DML yaitu:
1. SELECT
Statement SELECT digunakan untuk mengambil data dari sebuah database
2. INSERT
Statement INSERT digunakan untuk memasukan data ke dalam database
3. UPDATE
Statement UPDATE digunakan untuk merubah data dari sebuah database
Statement DELETE digunakan untuk menghapus data dari sebuah database 2.1.1.3.2 Data Definition Language (DDL)
Menurut Connolly dan Begg (2010:235), Data Definition Language (DDL) digunakan untuk mendefinisikan struktur database atau mengendalikan akses ke data. SQL Data Definition Language (DDL) memungkinkan objek database seperti skema, domain, tabel, views, dan indeks dibuat dan dihapus (Connolly dan Begg (2010:236). Terdapat berapa statement umum yang digunakan dalam DDL yaitu:
1. CREATE SCHEMA 2. DROP SCHEMA 3. CREATE DOMAIN 4. ALTER DOMAIN 5. DROP DOMAIN 6. CREATE TABLE 7. ALTER TABLE 8. DROP TABLE 9. CREATE VIEW 10.DROP VIEW 11.CREATE INDEX 12.DROP INDEX 2.1.2 Database Lifecycles
Database merupakan komponen yang sangat penting dari suatu sistem informasi dalam organisasi dengan skala yang cukup besar. Pengembangan sebuah sistem database harus berkaitan dengan siklus hidup dari sistem informasi tersebut. Tahapan pengembangan siklus hidup sistem database tidak harus berurutan, tetapi melibatkan beberapa jumlah pengulangan tahapan sebelumnya melalui sebuah feedback loop.
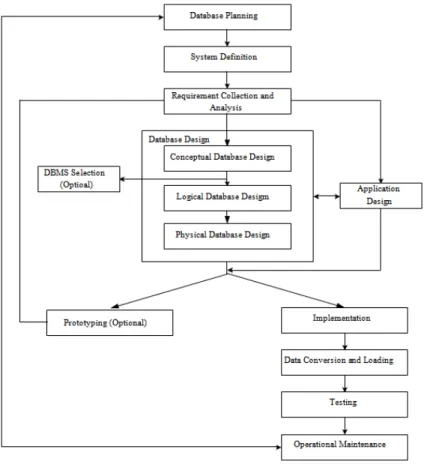
Dalam siklus hidup pengembangan sistem basisdata terdapat beberapa tahapan yang digambarkan sebagai berikut:
Gambar 2.1 Database Lifecycles Sumber: Connolly dan Begg, 2010:314
2.1.2.1 Database Planning
Kegiatan manajemen yang memungkinkan tahapan siklus pengembangan sistem database untuk direalisasikan lebih efektif dan efisien.
Perencanaan database harus terintegrasi dengan keseluruhan strategi sistem informasi dari sebuah organisasi. Ada tiga isu utama yang terlibat dalam merumuskan strategi sistem informasi, yaitu:
1. Identifikasi rencana dan tujuan perusahaan dengan penentuan kebutuhan sistem informasi berikutnya.
2. Evaluasi sistem informasi saat ini untuk menentukan kekuatan dan kelemahan yang ada.
3. Penilaian peluang dari teknologi informasi yang mungkin menghasilkan keuntungan kompetitif.
Perencanaan database juga harus mencakup pengembangan standar yang mengatur bagaimana data akan dikumpulkan, bagaimana format harus ditentukan, apa dokumentasi yang diperlukan dan dibutuhkan, dan bagaimana desain dan implementasi harus dilanjutkan. Metodologi yang digunakan untuk menyelesaikan masalah hal di atas menurut (Connolly dan Begg, 2010:315) adalah:
1. Menentukan mission statement untuk sistem database. Mission
statement mendefinisikan tujuan utama dari database
sistem. Sebuah mission statement membantu untuk memperjelas tujuan dari sistem database dan memberikan jalan yang lebih jelas terhadap penyusunan atau pembuatan sistem database yang diperlukan secara lebih efesien dan efektif.
2. Menentukan mission objectives untuk sistem database. Setiap mission objectives harus mengidentifikasi tugas tertentu yang harus dukung oleh sistem database. Pernyataan misi dan tujuan dapat disertai dengan beberapa informasi tambahan yang menentukan, secara umum, pekerjaan yang harus dilakukan, sumber daya yang dapat digunakan untuk melakukannya, dan uang untuk membayar untuk itu semua.
2.1.2.2 System Definition
Menurut Connolly dan Begg (2010:316), System Definition menjelaskan ruang lingkup dan batas-batas dari aplikasi database dari
sudut pandang pengguna utama. Hal yang diperlukan di sini adalah mengindentifikasi batasan-batasan dalam sistem yang sedang diinvestigasi dan bagaimana batasan tersebut berinteraksi dengan bagian lain dari sistem informasi organisasi. Hal lain yang sangat penting adalah untuk mengidentifikasi batasan untuk pengguna dan area aplikasi di masa yang akan datang.
2.1.2.3 Requirement Collection and Analysis
Menurut Connolly dan Begg (2010:316), requirement collection and analysis adalah proses mengumpulkan dan menganalisis informasi tentang bagian dari organisasi yang didukung oleh sistem database, dan menggunakan informasi ini untuk mengidentifikasi persyaratan untuk sistem baru. Tahap ini melibatkan pengumpulan dan analisis informasi mengenai bagian dari perusahaan yang akan disediakan oleh database. Ada banyak teknik untuk mengumpulkan informasi ini, yang disebut teknik pencarian fakta ( fact-finding technique).
Ada lima teknik pencarian fakta umum digunakan menurut Connolly dan Begg (2010:344):
1. Memeriksa dokumentasi (examining documentation)
Memeriksa dokumentasi dapat berguna untuk mendapatkan beberapa informasi yang berkaitan dengan kebutuhan yang muncul untuk database atau informasi pada bagian lain dari perusahaan yang terkait dengan masalah. Dengan memeriksa dokumen, formulir, laporan, dan file yang terkait dengan sistem saat ini diharapkan seorang database developer bisa mendapatkan beberapa pemahaman tentang sistem yang berlangsung dalam organisasi dengan cepat.
2. Wawancara (Interviewing)
Wawancara adalah teknik yang paling umum digunakan, dan biasanya merupakan teknik yang paling berguna dalam pencarian fakta. Teknik ini dilakukan dengan cara mewawancarai individu yang
berkaitan dengan sistem untuk mengumpulkan informasi secara tatap muka. Terdapat beberapa tujuan dari penggunaan teknik wawancara yaitu untuk mengumpulkan fakta-fakta, memeriksa kebenaran fakta yang ada dan mengklarifikasinya, mengidentifikasikan kebutuhan-kebutuhan, dan mengumpulkan ide-ide atau pendapat.
3. Observasi (Observing the Enterprise in Operation)
Observasi merupakan salah satu teknik pencarian fakta yang paling efektif untuk memahami sistem. Teknik ini dilakukan dengan cara berpartisipasi atau menonton seorang individu melakukan kegiatan untuk mempelajari sistem yang sedang berjalan. Sangat berguna ketika terdapat kompleksitas aspek-aspek tertentu dari sistem yang mencegah penjelasan yang jelas oleh pengguna akhir (end-user).
4. Penelitian (Research)
Sebuah teknik pencarian fakta yang berguna untuk penelitian aplikasi dan masalahnya. Teknik ini bisa dilakukan dengan mencari referensi seperti jurnal, buku, dan melalui internet untuk menemukan bagaimana orang lain memecahkan masalah serupa atau mirip.
5. Kuesioner (Questionnaires)
Kuesioner adalah dokumen dengan tujuan khusus yang memungkinkan fakta dikumpulkan dari banyak orang dengan tetap menjaga kontrol atas tanggapan mereka. Teknik ini sangat berguna dalam berhadapan dengan banyak orang karena dapat mentabulasi fakta-fakta yang sama secara efisien. Ada dua jenis pertanyaan yang bisa diajukan dalam kuesioner, yaitu free-format dan fixed-format. Free-format menawarkan kebebasan responden yang lebih besar dalam memberikan jawaban sementara fixed-format memerlukan tanggapan dari responden. Responden harus memilih dari jawaban yang tersedia.
requirement collection and analysis adalah tahap awal untuk desain database. Jumlah data yang akan dikumpulkan tergantung pada sifat dari masalah dan kebijakan perusahaan. Kegiatan penting lainnya yang terkait dengan tahap ini adalah memutuskan dalam menangani situasi di mana terdapat lebih dari satu tampilan pengguna (user-view) untuk sistem database. Ada beberapa pendekatan utama untuk mengelola persyaratan sistem database dengan beberapa pandangan pengguna (user-view), yaitu:
1. Pendekatan terpusat (Centralized Approach)
Persyaratan untuk setiap tampilan pengguna (user-view) digabung menjadi satu set persyaratan untuk sistem database baru. Sebuah model data yang mewakili semua pandangan pengguna (user-view) dibuat selama tahap desain database.
2. Pendekatan tampilan terintregrasi (view integration)
Persyaratan untuk setiap tampilan pengguna (user-view) dibuat sebagai daftar terpisah. Model data yang mewakili setiap tampilan pengguna (user-view) dibuat dan digabung selama tahapan desain database.
2.1.2.4 Database Design
Menurut Connolly dan Begg (2010:320), database design adalah proses menciptakan desain yang akan mendukung mission statement dan mission objectives perusahaan untuk sistem database yang diperlukan.
2.1.2.4.1 Approaches to Database Design
Terdapat beberapa pendekatan dalam melakukan desain database menurut Connolly dan Begg (2010:321), yaitu:
1. Bottom-Up
Pendekatan bottom-up dimulai pada tingkat dasar atribut (properties of entities and relationships) dengan melalui
proses analisa antar atribut-atribut yang saling berhubungan, mengelompokkan dalam suatu relasi yang mewakili tipe entitas dan relasi antar entitas. Pendekatan bottom-up cocok untuk merancang database yang sederhana dengan jumlah atribut yang relatif kecil
2. Top-Down
Pendekatan ini sangat sesuai dalam merancang database yang bersifat kompleks. Pendekatan ini dimulai dengan pengembangan data model yang berisi beberapa entitas tingkat tinggi dan relasinya. Selanjutnya menerapkan top-down refinements untuk mengidentifikasi entitas dengan tingkat yang lebih rendah, relasi, dan atribut terkait. Pendekatan top-down dapat diilustrasikan dengan menggunakan konsep entity-relationship (ER) model, kemudian mengidentifikasikan entitas, dan relasi antar entitas dalam suatu organisasi.
3. Inside-Out
Pendekatan ini berkaitan dengan pendekatan bottom-up. Tetapi terdapat perbedaan dengan terlebih dahulu mengidentifikasi satu set entitas utama sebelum mengidentifikasi dan mempertimbangkan entitas, hubungan, dan atribut lain yang berkaitan dengan entitas awal yang telah diidentifikasi.
4. Mixed
Menggunakan pendekatan bottom up dan top down untuk beberapa bagian dari data model sebelum menggabungkan semua bagian-bagian tersebut.
2.1.2.4.2 Phases of Database Design
Tahapan-tahapan dalam merancang database adalah:
Menurut Connolly dan Begg (2010:322), conceptual database design adalah suatu proses membangun sebuah model dari data yang digunakan dalam suatu perusahaan dan independen dari semua pertimbangan fisik.
2. Logical Database Design
Menurut Connolly dan Begg (2010:323), logical database design adalah suatu proses membangun sebuah model dari data yang digunakan dalam suatu perusahaan berdasarkan model data tertentu, tetapi independen dari DBMS tertentu dan pertimbangan fisik lainnya.
3. Physical Database Design
Menurut Connolly dan Begg (2010:324), physical database design adalah suatu proses memproduksi sebuah deskripsi implementasi pada penyimpanan sekunder yang menggambarkan relasi dasar, organisasi file, indeks yang digunakan untuk mencapai akses yang efisien terhadap data, kendala integritas terkait dan langkah-langkah keamanan.
2.1.2.5 DBMS Selection
Menurut Connolly dan Begg (2010:325-329) DBMS selection adalah pemilihan suatu DBMS yang tepat untuk mendukung sistem database. Terdapat beberapa langkah dalam memilih DBMS yaitu:
1. Mendefinisikan kerangka referensi studi 2. Mendaftar dua atau tiga produk
3. Mengevaluasi produk
4. Merekomendasikan pilihan dan laporan produk
2.1.2.6 Application Design
Menurut Connolly dan Begg (2010:329), application design adalah rancangan user interface dan program aplikasi yang menggunakan dan
memproses database. Terdapat dua aspek desain aplikasi, yaitu desain transaksi (transaction design) dan desain antarmuka pengguna (user-interface design).
2.1.2.6.1 Transaction Design
Menurut Connolly dan Begg (2010:330-331), transaksi adalah suatu tindakan, atau serangkaian tindakan yang dilakukan oleh pengguna tunggal atau program aplikasi, yang mengakses atau mengubah isi database. Dari perspektif DBMS, sebuah transaksi mentransfer database dari satu kondisi yang konsisten ke kondisi lain. Tujuan dari desain transaksi adalah untuk menetapkan dan mendokumentasikan karakteristik tingkat tinggi dari transaksi yang dibutuhkan pada database, termasuk:
1. Data yang akan digunakan dalam transaksi 2. Karakteristik fungsional dari transaksi 3. Output transaksi
4. Hal yang penting bagi pengguna
5. Tingkat yang diharapkan dari penggunaan
Ada tiga jenis utama transaksi: retrieval transactions, update transactions, dan mixed transactions.
1. Retrieval transactions digunakan untuk mengambil data yang akan ditampilkan dalam pembuatan laporan.
2. Update transactions digunakan untuk menyisipkan record baru, menghapus catatan lama, atau memodifikasi catatan yang ada dalam database.
3. Mixed transactions melibatkan baik retrieval transactions dan update transactions.
2.1.2.6.2 User Interface Design Guidelines
Menurut Connolly dan Begg (2010:331-333), terdapat beberapa pedoman dalam merancang sebuah antarmuka pengguna yang baik, yaitu:
1. Judul yang bermakna
2. Instruksi yang mudah dipahami
3. Pengelompokan secara logis dan posisi fields yang berurutan 4. Layout untuk form atau report menarik
5. Label field yang dikenal
6. Terminologi dan singkatan yang konsisten 7. Penggunaan warna yang konsisten
8. Batasan dan ruang yang terlihat bagi field data-entry 9. Pergerakan kursor mudah
10.Perbaikan kesalahan bagi individu dan keseluruhan field 11.Pesan kesalahan dimunculkan untuk data atau nilai yang salah 12.Penandaan optional field yang jelas
13.Pesan Penjelasan untuk field harus muncul 14.Pemberian tanda jika suatu proses telah selesai
2.1.2.7 Prototyping
Menurut Connolly dan Begg (2010:333), prototyping adalah membangun sebuah model kerja dari sistem database. Sebuah prototipe adalah model kerja yang biasanya tidak memiliki semua fitur yang diperlukan atau menyediakan semua fungsionalitas dari sistem akhir. Tujuan utama dari pengembangan prototipe adalah untuk memungkinkan pengguna dalam menggunakan prototipe untuk mengidentifikasi fitur dari sistem yang bekerja dengan baik atau tidak, dan mungkin menyarankan perbaikan atau fitur baru ke sistem database. Ada dua strategi prototyping yang digunakan saat ini: requirements prototyping dan evolutionary prototyping.
1. Requirements prototyping menggunakan prototipe untuk menentukan persyaratan sistem database yang ditawarkan dan setelah persyaratan tersebut lengkap maka prototipe tersebut akan dibuang.
2. Evolutionary prototyping digunakan untuk tujuan yang sama,tetapi terdapat perbedaan penting yaitu bahwa prototipe tidak dibuang melainkan disimpan dan akan di kembangkan menjadi sistem database yang berkerja.
2.1.2.8 Implementation
Menurut Connolly dan Begg (2010:333-334), implementation adalah realisasi fisik database dan perancangan aplikasi. Implementasi database dicapai dengan menggunakan data definition language (DDL) dari DBMS yang dipilih atau graphical user Interface (GUI), yang menyediakan fungsi yang sama dan menyembunyikan laporan low level DDL.
2.1.2.9 Data Conversion and Loading
Menurut Connolly dan Begg (2010:334), data conversion and loading adalah mentransfer data yang ada ke dalam database baru dan mengkonversi aplikasi yang ada untuk berjalan pada database baru. Tahap ini diperlukan hanya jika sistem database baru menggantikan sistem lama.
2.1.2.10 Testing
Menurut Connolly dan Begg (2010:334), testing adalah suatu proses menjalankan sistem database dengan maksud menemukan kesalahan. Testing juga harus mencakup kegunaan dari sistem database. Evaluasi harus dilakukan terhadap spesifikasi kegunaan. Kriteria- kriteria yang dapat digunakan untuk melakukan evaluasi adalah:
1. Learnability - Berapa lama waktu yang dibutuhkan pengguna baru untuk mengerti sebuah sistem
2. Performance - Seberapa baik sistem merespon pekerjaan pengguna
3. Robustness - Seberapa toleran sistem dalam menghadapi kesalahan pengguna
4. Recoverability - Seberapa baik sistem pulih dari kesalahan
penggunaannya
5. Adapatability - Seberapa lama sistem beradaptasi dalam suatu model kerja
2.1.2.11 Operational Maintenance
Menurut Connolly dan Begg (2010:335), operational maintenance adalah proses pemantauan dan pemeliharaan sistem database setalah proses instalasi dilakukan. Pada tahap sebelumnya, sistem database telah diimplementasikan dan diuji. Sistem sekarang bergerak ke tahap pemeliharaan (Operational Maintenance), yang melibatkan kegiatan-kegiatan berikut:
1. Memantau kinerja sistem. Jika performa mengalami penurunan maka diperlukan untuk melakukan perbaikan atau pengaturan ulang sistem database
2. Memelihara dan meningkatkan sistem database jika diperlukan.
2.1.3 Entity Relationship
2.1.3.1 Entity Relationship Modelling
Menurut Connolly dan Begg (2010:371), Entity relationship modelling atau ER merupakan pendekatan top-down pada perancangan basis data yang diawali dengan mengidentifikasi data penting yang disebut entitas (entities) dan hubungan (relationship) antar data yang harus di representasikan dalam model. Selain itu, beberapa rincian juga ditambahkan seperti informasi yang akan disimpan mengenai entities dan relationship disebut atribut dan constraint atau kendala pada entitas hubungan dan atribut.
2.1.3.1.1 Entity Types
Menurut Connolly dan Begg (2010:372-374), entity type adalah sekelompok objek dengan properti yang sama, yang diidentifikasi oleh perusahaan yang memiliki keberadaan yang independen atau bebas. Keberadaan objek tersebut dapat bersifat asli (physical) dan abstrak (conceptual).
2.1.3.1.2 Relationship Types
Menurut Connolly dan Begg (2010:374-376), relationship types adalah seperangkat asosiasi antara satu atau lebih tipe entitas yang berpartisipasi. Tiap jenis hubungan diberi nama yang menggambarkan fungsinya.
2.1.3.1.2.1 Degree of Relationship Type
Menurut Connolly dan Begg (2010:376-378), degree of relationship type berkaitan dengan entitas yang terlibat dalam
relationship tertentu yang disebut sebagai peserta (participant) dalam hubungan tersebut. Jumlah peserta dalam relationship disebut tingkat hubungan (Degree of Relationship Type). Oleh karena itu, tingkat hubungan menunjukkan jumlah jenis entitas terlibat dalam sebuah relationship.
2.1.3.1.2.2 Recursive Relationship
Menurut Connolly dan Begg (2010:378-379), recursive relationship adalah hubungan di mana tipe entitas yang sama berpartisipasi lebih dari sekali dalam peran yang berbeda. Relationship dapat diberikan nama peran untuk menunjukkan tujuan bahwa entitas setiap partisipan bermain dalam sebuah relationship. Nama peran dapat menjadi hal yang penting bagi hubungan rekursif (recursive relationship) untuk menentukan fungsi dari masing-masing partisipan. Nama peran biasanya tidak diperlukan jika fungsi entitas partisipan dalam relationship telah jelas.
2.1.3.1.3 Attributes
Menurut Connolly dan Begg (2010:379), attribute adalah sebuah properti dari suatu entitas atau tipe hubungan. Atribut memegang nilai-nilai yang menggambarkan setiap kejadian entitas dan merupakan bagian utama dari data yang disimpan dalam basis data.
Menurut Connolly dan Begg (2010:379), attribute domain adalah himpunan nilai-nilai yang diperbolehkan untuk satu atau lebih atribut. Attribute domain dapat diklasifisikan menjadi 3 bagian yaitu:
• single-valued dan multi-valued attribute • derived attribute
2.1.3.1.3.1 Simple and Composite Attributes
Menurut Connolly dan Begg (2010:379-380), simple attribute merupakan sebuah atribut yang terdiri dari komponen tunggal dengan keberadaan independen. Contohnya position dan salary dari staff. Simple attribute tidak dapat dibagi lagi menjadi komponen yang lebih kecil. Simple attribute bisa disebut juga sebagai atomic attributes.
Menurut Connolly dan Begg (2010:380), composite attributes merupakan sebuah atribut yang terdiri dari beberapa komponen, masing-masing dengan keberadaan independen. Beberapa atribut dapat dibagi lagi untuk menghasilkan komponen yang lebih kecil dengan keberadaan independen sendiri. Contohnya street, city dan postal code.
2.1.3.1.3.2 Single-Valued and Multi-Valued Attributes
Menurut Connolly dan Begg (2010:380), single-valued attribute merupakan sebuah atribut yang memegang nilai tunggal untuk setiap kejadian dari suatu jenis entitas. Contohnya entitas branch yang mempunyai nilai satuan dari branch number (branchno).
Menurut Connolly dan Begg (2010:380), multi-valued attribute merupakan sebuah atribut yang memegang beberapa nilai untuk setiap kejadian dari suatu jenis entitas. Contohnya entitas branch yang mempunyai banyak nilai untuk atribut nomor telepon (telno).
2.1.3.1.3.3 Derived Attributes
Menurut Connolly dan Begg (2010:380-381), derived attributes merupakan sebuah atribut yang mewakili nilai yang diturunkan dari nilai atribut terkait atau sekumpulan atribut dan tidak perlu sejenis dalam entitasnya. Contohnya, nilai untuk durasi atribut dari entitas sewa dihitung dari rentStart dan rentFinish atribut dan juga dari entitas sewa. Hal tersebut mengacu pada atribut durasi sebagai atribut turunan, dan nilai yang berasal dari atribut rentStart dan rentFinish.
2.1.3.1.3.4 Keys
Menurut Connolly dan Begg (2010:381-382), key mempunyai tipe-tipe antara lain:
• Candidate key
Kumpulan minimal dari suatu atribut yang secara unik mengidentifikasi setiap kejadian dari suatu entitas tersebut.
• Primary key
Kandidat key yang dipilih secara unik untuk mengidentifikasi setiap kejadian dari suatu entitas.
• Composite key
Sebuah kandidat key yang terdiri dari dua atau lebih atribut.
2.1.3.1.4 Strong and Weak Entity Type
Menurut Connolly dan Begg (2010:383), strong entity type merupakan sebuah tipe entitas yang keberadaanya tidak bergantung pada entitas lainnya.
Menurut Connolly dan Begg (2010:383), weak entity type merupakan sebuah tipe entitas yang keberadaanya bergantung pada entitas lainnya.
2.1.3.1.5 Structural Constraints
Menurut Connolly dan Begg (2010:385-388), structural constraint dibagi menjadi 3 yaitu:
1. Multiplicity
Jumlah dari kemungkinan kejadian dari suatu entitas yang mungkin berhubungan dengan kejadian tunggal dari jenis entitas terkait melalui hubungan tertentu. Tingkatan umum untuk suatu relationship disebut binary. Hubungan relationship biasanya disebut sebagai one-to-one (1:1), one-to-many (1:*), dan many-to-many (*:*).
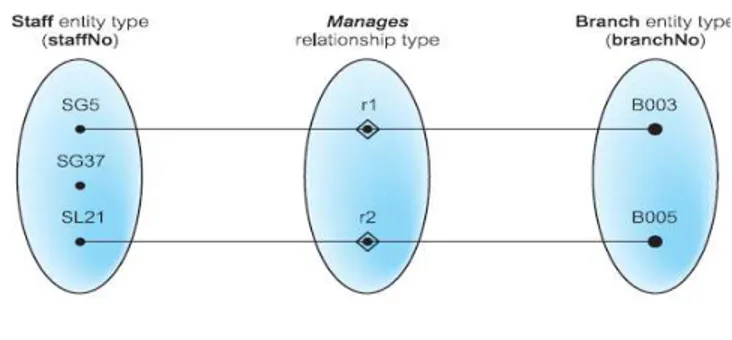
• one-to-one (1:1)
Tiap relationship merupakan hubungan antara sebuah kejadian pada entitas yang satu dengan sebuah kejadian pada entitas lainnya yang ada dalam relationship tersebut.
Gambar 2.2 One-to-one (1:1) Relationship Sumber: Connolly dan Begg (2010:386)
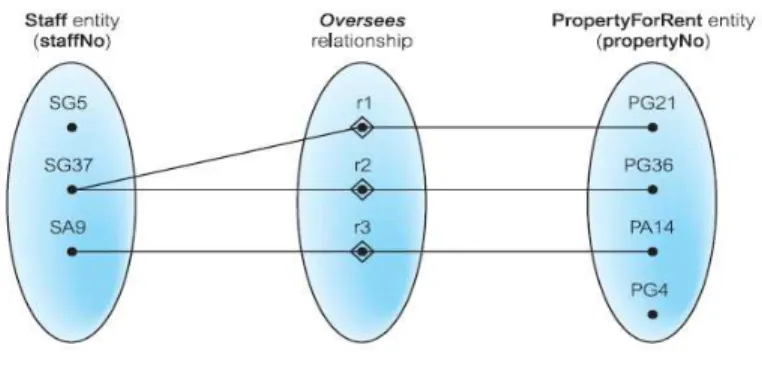
• one-to-many (1:*)
Tiap relationship merupakan hubungan antara kejadian pada entitas satu dengan satu atau lebih entitas lainnya.
Gambar 2.3 One-to-many (1:*) Relationship Sumber: Connolly dan Begg (2010:387)
• many-to-many (*:*)
Tiap relationship merupakan hubungan antara kejadian pada entitas satu atau lebih dengan satu atau lebih entitas lainnya.
Gambar 2.4 Many-to-many (1:*) Relationship Sumber: Connolly dan Begg (2010:388)
1. Multiplicity for Complex Relationships
Menurut Connolly dan Begg (2010:389), multiplicity for complex relationships merupakan jumlah dari kemungkinan kejadian dari suatu entitas dalam suatu hubungan n-ary ketika nilai (n-1) yang lain tetap. Contohnya multiplicity untuk hubungan terner (ternacity) merupakan
potensi kejadian entitas (occurences entity) suatu entitas tertentu dalam hubungan ketika dua nilai lainnya yang mewakili dua entitas lainnya adalah tetap.
2. Participation
Menurut Connolly dan Begg (2010:390-391), participation menentukan apakah semua atau hanya beberapa kejadian entitas berpartisipasi dalam sebuah hubungan. Partisipasi entitas dalam suatu relationship muncul sebagai nilai minimum untuk rentang multiplicity dalam suatu relationship.
3. Cardinality
Menurut Connolly dan Begg (2010:391-392), cardinality menjelaskan jumlah maksimum kemungkinan akan hubungan kejadian untuk entitas yang berpartisipasi dalam relationship tertentu.
2.1.3.1.6 Problems with ER Models
Menurut Connolly dan Begg (2010:392-393), problem with ER model bisa diartikan sebagai perangkap koneksi (connection trap). Connection trap memiliki 2 tipe sebagai berikut:
1. Fan traps
Fan trap terjadi ketika sebuah model merepresentasikan sebuah relationship diantara tipe entitas. Akan tetapi jalan antara entity occurences bersifat ambigu.
2. Chasm traps
Chasm trap terjadi ketika sebuah model menyarankan akan keberadaan suatu relationship antara entity type. Akan tetapi, jalan tidak menunjukan di antara entity occurences.
2.1.3.2 Enhanced Entity–Relationship Modeling
Menurut Connolly dan Begg (2010: 399), sebagai konsep dasar, ER modeling masih memiliki kekurangan dan batasan dalam mewakili atau merepresentasikan persyaratan baru dari sebuah aplikasi yang lebih kompleks. Untuk memperbaiki kekurangan tersebut, dikembangkanlah additional ‘semantic’ modeling concepts. Model ER didukung dengan konsep additional ‘semantic’ modeling disebut Enhanced Entity–Relationship (EER) model.
Terdapat tiga konsep tambahan yang paling penting dan berguna dalam EER model, yaitu specialization atau generalization, aggregation, dan composition.
2.1.3.2.1 Specialization atau Generalization
Menurut Connolly dan Begg (2010:400), konsep spesialisasi atau generalisasi berkaitan erat dengan tipe entitas khusus yang dikenal sebagai superclass dan subclass. Konsep ini juga berkaitan dengan sebuah proses yang disebut attribute inheritance. Terdapat dua jenis batasan utama dalam hubungan superclass atau subclass yang disebut participation and disjoint constraints.
2.1.3.2.1.1 Superclass dan Subclass
Menurut Connolly dan Begg (2010:400), superclass adalah sebuah tipe entitas yang mencakup satu atau lebih sub kelompok yang berbeda dari kejadian tersebut, yang perlu diwakili dalam data model. Sedangkan subclass adalah sebuah pengelompokan yang berbeda dari munculnya suatu tipe entitas, yang perlu untuk diwakili dalam sebuah data model. Setiap anggota subclass juga merupakan anggota dari superclass.
2.1.3.2.1.2 Attribute Inheritance
Menurut Connolly dan Begg (2010:402), sebuah entitas dalam subclass merepresentasikan objek 'real world ' yang sama seperti di dalam superclass dan mempunyai atribut subclass tertentu yang berkaitan dengan superclass. Entitas dalam subclass juga mewarisi semua atribut dari superclass.
2.1.3.2.1.3 Specialization
Menurut Connolly dan Begg (2010:402), specialization adalah proses memaksimalkan perbedaan antara anggota dari suatu entitas dengan mengidentifikasi karakteristik yang membedakan mereka. Specialization menggunakan pendekatan top-down untuk mendefinisikan satu set superclasses dan subclass yang berkaitan dengannya.
2.1.3.2.1.4 Generalization
Menurut Connolly dan Begg (2010:403), generalization adalah proses meminimalkan perbedaan antara entitas dengan mengidentifikasi karakteristik umum mereka. Proses generalisasi adalah dengan menggunakan pendekatan bottom-up, yang menghasilkan identifikasi superclass yang bersifat umum dari tipe entitas yang asli.
2.1.3.2.2 Aggregation
Menurut Connolly dan Begg (2010:411), aggregation mempresentasikan hubungan ‘has-a’ atau ‘is-part-of’ antara tipe-tipe entitas, dimana salah satu adalah sebagai ‘whole’ dan yang lainnya sebagai ‘part’.
2.1.3.2.3 Composition
Menurut Connolly dan Begg (2010:412), compostion adalah sebuah bentuk agregasi yang khusus yang mereperesentasikan hubungan antar entitas, dimana terdapat strong ownership dan dalam waktu yang bersamaan antara ‘whole’ dengan ‘part’.
2.1.4 Normalization
Menurut Connoly dan Begg (2010:415), normalisasi merupakan salah satu teknik desain database, yang dimulai dengan pengecekan hubungan (disebut fungsional dependensi) antar atribut. Atribut menjelaskan beberapa properti dari data atau hubungan antara data yang penting bagi perusahaan.
Normalisasi menggunakan serangkaian tes (digambarkan sebagai bentuk NF) untuk membantu mengidentifikasi pengelompokan optimal untuk atribut untuk mengidentifikasi himpunan relasi yang cocok yang mendukung kebutuhan data dari perusahaan.
2.1.4.1 The Purpose of Normalization
Menurut Connoly dan Begg (2010:416), normalisasi didefinisikan sebagai sebuah teknik untuk membuat suatu hubungan dengan sifat yang diinginkan sesuai dengan kebutuhan data suatu perusahaan.
Menurut Connoly dan Begg (2010:416), tujuan dari normalisasi adalah untuk mengidentifikasi suatu relasi yang cocok yang mendukung data persyaratan suatu perusahaan.
Ciri-ciri suatu relasi yang baik antara lain:
1. Jumlah minimal atribut yang diperlukan untuk mendukung kebutuhan data perusahaan.
2. Atribut dengan hubungan logis dekat (digambarkan sebagai ketergantungan fungsional) yang ditemukan dalam hubungan yang sama.
3. Redundansi minimal dengan setiap atribut diwakili hanya sekali dengan penting kecuali atribut yang membentuk semua atau sebagian dari foreign key yang penting untuk bergabung dengan relasi yang terkait.
Menurut Connoly dan Begg (2010:416-417), manfaat menggunakan database yang memiliki relasi yang tepat antara lain:
1. Database akan lebih mudah bagi pengguna untuk mengakses dan memelihara data
2. Database mengambil storage disk minimal pada komputer.
2.1.4.2 Data Redundancy
Menurut Connoly dan Begg (2010:418), tujuan utama dari desain database relasional adalah untuk pengelompokan atribut ke dalam hubungan untuk meminimalkan data yang redundansi. Jika tujuan ini tercapai, potensi manfaat untuk implementasi database meliputi:
1. Update data yang disimpan dalam database yang dicapai dengan jumlah operasi minimal sehingga mengurangi data yang kurang konsisten yang terjadi dalam database
2. Pengurangan dalam ruang penyimpanan file yang diperlukan oleh relasi dasar sehingga dapat meminimalkan biaya.
2.1.4.3 Functional Dependencies and Determinant
Menurut Connoly dan Begg (2010:420-421), functional dependencies menggambarkan hubungan antara atribut dalam suatu relasi. Functional dependencies merupakan atau atribut semantik dalam suatu relasi. Semantik menunjukkan bagaimana atribut berhubungan satu sama lain, dan menentukan functional dependencies antar atribut. Ketika terjadi functional dependencies, ketergantungan tersebut ditentukan sebagai kendala (constraint) antar atribut.
Menurut Connoly dan Begg (2010:421), determinant mengacu pada atribut, atau kelompok atribut, di sisi pasangan relasi dari ketergantungan fungsional (functional dependencies).
2.1.4.4 The Process of Normalization
Menurut Connoly dan Begg (2010:428-436), normalisasi memiliki 6 proses antara lain:
1. UNF (Unnormalized Form)
Sebuah tabel yang berisi satu atau lebih pengulangan kelompok. 2. 1NF
Suatu relasi di mana persimpangan (intersection) tiap baris dan kolom berisi satu dan hanya satu nilai.
Dalam format ini, tabel adalah dalam form UNF dan disebut sebagai tabel UNF. Untuk mengubah tabel UNF ke bentuk 1NF, diperlukan untuk mengidentifikasi dan menghapus kelompok yang berulang dalam tabel. Kelompok yang berulang diantaranya atribut, atau kelompok atribut dalam tabel yang terjadi dengan beberapa nilai untuk single occurence dari atribut nominated key untuk table
tersebut. Pada konteks ini, istilah key mengacu pada atribut yang secara unik mengidentifikasi setiap baris dalam tabel UNF.
3. 2NF
Suatu relasi yang ada di Bentuk 1NF dan tiap atribut non-primary-key sepenuhnya functional dependent pada primary key.
Proses normalisasi dari 1NF ke 2NF melibatkan penghapusan partial dependencies (ketergantungan parsial). Jika terdapat ketergantungan parsial, diperlukan penghapusan atribut sebagian tergantung dari hubungan dengan menempatkan relasi baru bersama dengan determinannya
4. 3NF
Suatu relasi yang ada di 1NF dan 2NF dan di mana tidak ada atribut non-primary-key adalah transitif bergantung pada primary key (PK).
Proses normalisasi 2NF ke 3NF melibatkan penghapusan transitive dependencies. Jika terdapat dependensi transitif, diperlukan penghapusan transitif tergantung atribut dari relasi dengan menempatkan atribut dalam relasi baru bersama dengan determinannya.
2.1.5 Database Design Methodology
2.1.5.1 Conceptual Database Design Methodology
Menurut Connolly dan Begg (2010:322), conceptual database design adalah suatu proses membangun sebuah model dari data yang digunakan dalam suatu perusahaan dan independen dari semua pertimbangan fisik.
2.1.5.1.1 Langkah 1 Membangun Konseptual Data Model Menurut Connolly and Begg (2010:470-471), langkah pertama di dalam perancangan konseptual basis data untuk membuat satu (atau lebih) model data konseptual dari data yang dibutuhkan oleh perusahaan. Model data konseptual terdiri dari:
• Tipe entitas; • Tipe relationship;
• Atribut dan atribut domain; • Primary keys dan alternate keys; • Integrity constraints.
Model data konseptual di dukung oleh dokumentasi, termasuk diagram ER dan sebuah kamus data, dimana dihasilkan melalui pengembangan dari model. Detail dari tipe pendukung dokumentasi yang dapat dihasilkan saat melalui bermacam-macam tahapan. Proses-proses yang termasuk di langkah 1 adalah:
Langkah 1.1 Identifikasi tipe entitas Langkah 1.2 Indentifikasi tipe relasi
Langkah 1.3 Identifikasi dan asosiasi atribut dengan entitas atau tipe relasi
Langkah 1.5 Menentukan kandidat, primary, dan alternate key atribut
Langkah 1.6 Memilih penggunaan dari konsep model yang ditingkatkan (tahap opsional)
Langkah 1.7 Memeriksa model untuk redundansi
Langkah 1.8 Memvalidasi model konseptual dengan transaksi pengguna
Langkah 1.9 Mengulas data model konseptual dengan user. Langkah 1.1 Identify entity
Menurut Connolly and Begg (2010:471), tujuan dari identifikasi entitas adalah mengidentifikasi tipe entitas yang dibutuhkan.
Tahap pertama dalam membangun model data konseptual adalah menentukan objek utama yang dibutuhkan oleh pengguna. Objek-objek ini adalah tipe entitas untuk model data. Satu metode untuk mengidentifikasi entitas adalah dengan memeriksa spesifikasi kebutuhan pengguna.
Sebuah alternatif untuk mengidentifikasi entitas adalah melihat objek-objek yang mempunyai eksistensi di dalam hak nya masing-masing.
Langkah 1.2 Identifikasi tipe relasi
Menurut Connolly and Begg (2010:472-473), tujuan dari identifikasi tipe relasi adalah mengidentifikasi relasi penting yang ada diantara tipe entitas.
Setelah mengidentifikasi entitas, langkah berikutnya adalah untuk mengidentifikasi semua hubungan yang ada pada entitas tersebut. Salah satu metode ketika mengidentifikasi entitas adalah dengan melihat kata benda dalam spesifikasi user requirements. Dapat menggunakan tata bahasa dari persyaratan spesifikasi untuk mengidentifikasi relasi. Biasanya, hubungan ditunjukkan oleh verba atau ekspresi verbal.
Fakta bahwa persyaratan spesifikasi mencatat hubungan ini adalah penting bagi perusahaan, dan harus dimasukkan dalam model.
Untuk membuat model diharuskan berhati-hati untuk melihat hubungan kompleks yang mungkin melibatkan lebih dari dua jenis entitas dan hubungan rekursif yang melibatkan hanya satu jenis entitas.
Penggunaan Entity - Relationship (ER) diagram
Penggunaan entity relationship memvisualisasikan sistem yang kompleks daripada menguraikan deskripsi tekstual spesifikasi persyaratan pengguna yang panjang. entity-relationship (ER) diagram mewakili entitas dan bagaimana mereka berhubungan antara satu dengan yang lainnya dengan lebih mudah. Melalui tahap desain basis data, direkomendasikan bahwa penggunaan ER diagram digunakan untuk membantu membuat sebuah gambaran dari bagian perusahaan yang akan di buat modelnya. Penggunaan object-oriented paling baru yang disebut UML (Unified Modeling Language) tetapi fungsinya yang mirip.
Menentukan multiplicity constraints dari relationship types Menurut Connolly and Begg (2010:473-474), setelah mempunyai model relasi yang telah diidentifikasi, langkah selanjutnya adalah menentukan multiplisitas dari setiap relasi. Jika nilai spesifik untuk multiplisitas diketahui, batas atas atau batas bawah membuktikan kebenaran nilai tersebut.
Multiplisitas constraints digunakan untuk memeriksa dan merawat kualitas data. Constraints ini adalah pernyataan mengenai kejadian entitas yang dapat diterapkan saat database diperbarui untuk menentukan iya atau tidaknya perbaharuan melanggar aturan dari perusahaan. Model yang termasuk dalam multiplisitas constraints lebih eksplisit merepresentasikan semantik dari relasi dan hasil di dalam representasi yang lebih baik dari kebutuhan data perusahaan.
Memeriksa fan dan chasm traps
Menurut Connolly and Begg (2010:474), setelah mempunyai identifikasi relasi yang diperlukan, memeriksa setiap relasi di ER model adalah representasi yang benar dari dunia nyata, dan dengan fan atau chasm traps yang belum terbentuk secara tidak sengaja.
Langkah 1.3 Identify and associate attributes with entity or relationship types
Menurut Connolly and Begg (2010:474), tujuan dari mengidentifikasi dan mengasosiasi atribut dengan entitas atau tipe
relasi adalah untuk mengasosiasi atribut dengan entitas yang layak atau relationship types.
Tahap berikutnya di dalam metodologi adalah untuk mengidentifikasi tipe dari fakta mengenai entitas dan relasi yang dipilih untuk di sajikan ulang di dalam basis data. Pada cara yang sesuai untuk mengidenfitikasi entitas dengan melihat nomina atau frase nomina pada spesifikasi persyaratan pengguna. Atribut-atribut dapat diidentifikasi dimana nomina atau frase nomina adalah sebuah properti, kualitas, tanda pengenal, atau karakteristik dari salah satu relasi atau entitas.
Langkah 1.4 Determine attribute domains
Menurut Connolly and Begg (2010 :478 ), tujuan dari menentukan domain atribut adalah untuk menentukan domain untuk atribut pada model data konseptual.
Sebuah domain adalah kumpulan dari nilai dari satu atau lebih atribut yang menarik nilanya masing-masing. Untuk contohnya dapat didefinisikan:
• Atribut domain dari nomer staff yang valid sebagai variable dengan lima karakter, dengan dua karakter pertama yang berbentuk huruf dan karakter selanjutnya sebagai angka dengan jangkauan 1-999 seperti SA001;
• Nilai yang memungkinkan untuk atribut jenis kelamin dari entitas staf adalah ‘M’ atau ‘F’. Domain dari atribut ini adalah single character string yang memuat nilai ‘M’ atau ‘F’.
Data model yang telah sepenuhnya dikembangkan akan menetapkan domains dari setiap atribut yang terdapat didalamnya, yaitu:
• Kumpulan nilai yang dibolehkan untuk atribut; • Ukuran dan format dari atribut.
Langkah 1.5 Determine candidate, primary, and alternate key attributes
Menurut Connolly and Begg (2010: 479), tujuan dari menentukan atribut candidate, primary, dan alternate key adalah untuk mengidentifikasi candidate key untuk setiap tipe entitas dan jika ada lebih dari satu candidate key, untuk memilih satu untuk menjadi primary key dan yang lain sebagai alternate key.
Tahap ini mengidentifikasi candidate key untuk sebuah entitas dan setelah memilihnya salah satu akan menjadi primary key. Sebuah candidate key adalah sebuah kumpulan dari atribut dari sebuah entitas unik yang menjelaskan setiap kejadian dari entitas. Dapat juga mengidentifikasi lebih dari satu candidate key, pada kasus tertentu, diharuskan memilih satu untuk menjadi primary key, dan candidate key yang lainnya disebut alternate key.
Saat memilih sebuah primary key diantara candidate keys, gunakan panduan ini untuk membuat pilihan:
• Candidate key dengan set atribut minimal;
• Candidate key yang nilainya paling jarang berubah;
• Candidate key dengan karakter paling sedikit (untuk atribut tekstual);
• Candidate key dengan nilai paling kecil (untuk atribut numerik);
• Candidate key yang paling mudah digunakan dari sudut
Langkah 1.6 Consider use of enhanced modeling concepts (optional step)
Menurut Connolly and Begg (2010:480), tujuan dari memilih penggunaan dari meningkatkan konsep model seperti specialization/generalization, aggregation, dan composition.
Pada tahap ini, terdapat tindakan yang bersifat optional untuk melanjutkan pengembangan dari ER model menggunakan advanced modelling concept yang menggunakan specialization atau generalization, aggregation, dan composition. Jika memilih pendekatan specialization, dapat terlihat perbedaan diantara entitas dengan cara mendefinisikan satu atau lebih dari subclasses dari superclass. Jika memilih pendekatan generalisasi, untuk mengidentifikasi fitur umum antara entitas untuk mendefinisikan sebuah superclass yang digeneralisasi. Agregation digunakan untuk menggambarkan ‘mempunyai’ atau ‘bagian dari’ relasi diantara tipe entitas dimana salah satu merepresentasikan ‘semua’ dan yang satu sebagai ‘bagian’.
Langkah 1.7 Check model for redudancy
Menurut Connolly and Begg (2010:482), tujuan dari tahap ini adalah untuk memeriksa pengulangan atau redundansi yang ada pada model.
Pada tahap ini, dilakukan pemeriksaan terhadap conceptual data model dengan tujuan spesifik untuk mengidentifikasi dimana terdapat sebuah pengulangan yang terjadi dan menghilangkan pengulangan yang ada. Ada tiga aktifitas yang dilakukan pada tahap ini:
1. Memeriksa ulang one-to-one (1:1) relationship; 2. Menghilangkan redundant relationship;
3. Mempertimbangkan time dimension.
Langkah 1.8 Validate conceptual model against user transactions
Menurut Connolly and Begg (2010:483), tujuan dari memvalidasi conceptual model terhadap user transactions adalah memastikan conceptual data model dan mendukung transaksi yang dibutuhkan.
Ada dua pendekatan yang memungkinkan dalam memastikan bahwa conceptual data model mendukung transaksi yang dibutuhkan:
1. Describing the transactions
Pendekatan ini dilakukan dengan cara memeriksa semua informasi seperti entities, relationships, dan atribut-atributnya yang dibutuhkan dari setiap transaksi yang disediakan oleh model dengan cara mendokumentasikan deskripsi dari setiap transactions requirements.
2. Using transaction pathways.
Pendekatan kedua untuk memvalidasi data model dengan
required transactions melibatkan diagram yang
merepresentasikan langkah yang diambil dari setiap transaksi secara langsung pada ER diagram.
Langkah 1.9 Review conceptual data model with user
Menurut Connolly and Begg (2010:485), tujuan meninjau ulang conceptual data model dengan penguna adalah untuk memastikan model yang dibuat sesuai dengan representasi dari data requirements di perusahaan. Sebelum menyelesaikan tahap pertama pada conceptual data model sebaiknya memeriksa data model terlebih dahulu dengan user, termasuk ER diagram dan dokumen pendukung yang mendeskripsikan data model. Jika ada kejanggalan terdapat pada data model, diharuskan untuk membuat perubahan, dimana membutuhkan pengulangan pada tahap-tahap sebelumnya. Tahap diulang sampai pengguna telah siap menerima model sebagai representasi yang benar dari bagian perusahaan yang dibuat modelnya.
2.1.5.2 Logical Database Design Methodology for the Relational Model Menurut Connolly dan Begg (2010:323), logical database design adalah suatu proses membangun sebuah model dari data yang digunakan dalam suatu perusahaan berdasarkan model data tertentu, tetapi independen dari DBMS tertentu dan pertimbangan fisik lainnya.
2.1.5.2.1 Langkah 2 Build and Validate Logical Data Model Menurut Connolly and Begg (2010:490), tujuan dari membangun dan memvalidasi logical data model adalah untuk menerjemahkan conceptual data model menjadi logical data model dan untuk memvalidasi model ini, dan memeriksanya apakah strukturnya benar dan dapat membantu transaksi yang dibutuhkan.
Dalam langkah ini, tujuan utamanya adalah menerjemahkan conceptual data model yang sudah dibuat di Langkah 1 medefinisikan logical data model dari persyaratan perusahaan. Tujuan ini dicapai melalui aktifitas berikut ini:
Langkah 2.1 Derive relations for logical data model Langkah 2.2 Validate relations using normalization Langkah 2.3 Validate relations against user transaction Langkah 2.4 Check integrity constraints
Langkah 2.5 Review logical data model with user
Langkah 2.6 Merge logical data models into global model (optional step)
Langkah 2.7 Check for future growth
Langkah 2.1 Derive relations for logical data model
Menurut Connolly and Begg (2010:492), langkah ini bertujuan membuat relations untuk logical data model untuk menggambarkan entities, relationship, dan attributes yang sudah diidentifikasi.
Dideskripsikan bagaimana relations diperoleh dengan struktur berikut, yang mungkin terdapat di conceptual data model:
1. Strong entity types; 2. Weak entity types;
3. One-to-many (1:*) binary relationship types; 4. One-to-one (1:1) binary relationship types; 5. One-to-one (1:1) recursive relationship types; 6. Superclass/subclass relationship types;
7. Many-to-many (*:*) binary relationship types; 8. Complex relationship types;
9. Multi-valued attributes.
Langkah 2.2 Validate relations using normailzation
Menurut Connolly and Begg (2010:501), langkah ini bertujuan untuk memvalidasi relations pada logical data model menggunakan normalisasi. Pada langkah ini terjadi validasi dari kelompok atribut di setiap relasi menggunakan aturan normalisasi.
Proses dari normalisasi mengambil sebuah relasi melewati beberapa langkah untuk memeriksa apakah sesuai komposisi atribut di dalam relasinya dengan menggunakan aturan First Normal Form (1NF), Second Normal Form (2NF), dan Third Normal Form (3NF)
Langkah 2.3 Validate relations against user transactions
Menurut Connolly and Begg (2010:502), langkah ini bertujuan memastikan relasi di dalam logical data model mendukung transaksi yang dibutuhkan, sesuai dengan user requirements specification.
Langkah 2.4 Check integrity constraints
Menurut Connolly and Begg (2010:502), langkah ini bertujuan untuk memeriksa integritas dari constraints yang digambarkan pada logical data model.
Tipe dari integritas sebuah constraint adalah:
• Required data;
• Attribute domain constraints; • Multiplicity;
• Entity integrity; • Referential integrity;
• General constraints;
Langkah 2.5 Review logical data model with user
Menurut Connolly and Begg (2010:506), langkah ini bertujuan untuk memeriksa ulang logical data model dengan users untuk memastikan model adalah represesentasi sebenarnya dari persyaratan yang dibutuhkan perusahaan. Jika users tidak
puas dengan modelnya maka pengulangan langkah-langkah sebelumnya mungkin dibutuhkan.
Relasi antara Logical Data Model dan Data Flow Diagrams Sebuah logical data model tercermin pada struktur dari penyimpanan data untuk perusahaan. Data flow Diagram (DFD) menunjukan data perusahaan yang bergerak dan disimpan di dalam data stores. Semua atribut seharusnya terlihat jika salah satu entitas diambil, dan mungkin dapat terlihat sedang mengalir disekitar data flow perusahaan. Jika kedua teknik ini digunakan maka dapat melihat konsistensi dan kelengkapan dengan cara: • Setiap data store harus menggambarkan semua entity types; • Atribut pada data flows harus dimiliki oleh entity types.
Langkah 2.6 Merge logical data models into global model (optional step)
Menurut Connolly and Begg (2010:506-517), langkah ini bertujuan untuk menggabungkan data logical lokal menjadi satu global logical data model yang menggambarkan semua pengguna dari database.
Dalam aktifitas ini terdapat langkah yang akan dilalui:
Langkah 2.6.1 Merge logical data models into global model
Langkah ini bertujuan untuk menggabungkan local logical data models menjadi satu global logical data model.
Langkah 2.6.2 Validate global logical data model Langkah ini bertujuan untuk memvalidasi relasi yang dibuat dari global logical data model menggunakan teknik dari normalisasi dan memastikan mendukung transaksi yang dibutuhkan.
Langkah 2.6.3 Review global logical data model with users
Langkah ini bertujuan untuk melihat kembali global logical data model dengan users untuk memastikan bahwa data model adalah representasi yang benar dari data requriements perusahaan.
Langkah 2.7 Check for future growth
Menurut Connolly and Begg (2010:517), langkah ini bertujuan untuk menentukan apakah ada perubahan yang berarti seperti perkiraan masa depan dan untuk menilai apakah logical data model dapat mengakomodasi perubahan ini.
2.1.5.3 Physical Database Design
Menurut Connolly dan Begg (2010:523), physical database design merupakan proses menghasilkan deskripsi implementasi basis data pada penyimpanan sekunder; menggambarkan hubungan dasar, berkas organisasi, dan indeks yang digunakan untuk mencapai akses yang efisien terhadap data, dan setiap kendala integritas terkait dan langkah-langkah keamanan.
Physical Database Design Methodology for Relational Databases
Menurut Connolly dan Begg (2010:524), terdapat langkah-langkah dalam physical database design antara lain:
2.1.5.3.1 Langkah 3 Menerjemahkan Logical Data Model untuk Target DBMS
Menurut Connolly dan Begg (2010:524), Untuk menghasilkan skema database relasional dari logical data model yang dapat diimplementasikan dalam target DBMS. Proses ini memerlukan pengetahuan yang mendalam tentang fungsi yang diinginkan DBMS. Hal-hal yang perlu diketahui oleh seorang desainer dalam tahap ini antara lain:
1. Cara membuat hubungan dasar (based relation)
2. Apakah sistem mendukung definisi primary key, foreign key, dan alternate key;
3. Apakah sistem mendukung definisi data yang dibutuhkan (apakah sistem memungkinkan atribut didefinisikan sebagai NOTNULL);
4. Apakah sistem mendukung definisi domain
5. Apakah sistem mendukung kendala integritas relasional 6. Apakah sistem mendukung definisi batasan integritas
Pada langkah 3 terdapat 3 aktivitas yang diperlukan antara lain:
Langkah 3.1 Perancangan relasi dasar
Menurut Connolly dan Begg (2010:525), Untuk memutuskan bagaimana untuk mewakili relasi dasar yang diidentifikasi dalam logical data model dalam DBMS.
Untuk memulai proses desain physical, pertama-tama dilakukan penyusunan dan pengasimilasian informasi tentang hubungan yang dihasilkan selama desain database logical. Informasi yang diperlukan dapat diperoleh dari kamus data dan definisi hubungan dijelaskan dengan menggunakan Database Design Language (DBDL). Untuk setiap relasi yang diidentifikasi dalam model data logis, memiliki definisi yang terdiri dari:
1. Nama relasi
2. Daftar atribut sederhana dalam tanda kurung
3. Primary key, alternate key(AK), dan foreign key(FK)
4. Referensial integritas kendala (constraint) untuk setiap foreign key yang diidentifikasi.
Berdasarkan kamus data, terdapat beberapa atribut yang harus dimilki antara lain:
1. Domain, yang terdiri dari tipe data, panjang, dan setiap kendala pada domain
2. Nilai standar opsional untuk atribut 3. Apakah atribut dapat berupa nulls
4. Apakah atribut berasal dan, jika demikian, bagaimana harus dihitung
Langkah 3.2 Perancangan representasi data turunan
Menurut Connolly dan Begg (2010:526), Untuk menentukan bagaimana cara untuk mewakili data turunan dalam logical data model di DBMS. Atribut yang nilainya dapat ditemukan dengan memeriksa nilai dari atribut lain dikenal sebagai data turunan atau kalkulasi atribut.
Berdasarkan perancangan basis data secara physical, atribut diturunkan dan disimpan dalam database atau dikalkulasi setiap waktu yang dibutuhkan adalah tradeoff. Hal-hal yang harus dikalkulasi oleh seorang desainer antara lain:
1. Biaya tambahan untuk menyimpan data yang berasal dan tetap konsisten dengan data operasional
2. Dari mana asalnya
3. Biaya untuk menghitung setiap kali diperlukan
Langkah 3.3 Design general constraints
Menurut Connolly dan Begg (2010:528), Untuk merancang constraint secara umum untuk DBMS. Perubahan hubungan (relationship) dapat dibatasi oleh integritas constraint yang mengatur transaksi 'real world' yang diwakili oleh update.
Langkah 4: Merancang file organisasi dan index
Menurut Connolly dan Begg (2010:529), Untuk menentukan organisasi file yang optimal untuk menyimpan relasi dasar dan indeks yang diperlukan untuk mencapai kinerja yang dapat diterima, yaitu: cara di mana hubungan dan tuple akan diselenggarakan pada penyimpanan sekunder.
Desain database fisik harus dipandu oleh data yang alami dan digunakan. Secara umum, database desainer harus memahami beban kerja yang didukung basis data. Selama pengumpulan persyaratan dan tahap analisis, ada persyaratan yang ditetapkan transaksi tertentu mengenai seberapa cepat harus menjalankan atau berapa banyak transaksi harus diproses per detik.
Langkah 4.1 Analisa Transaksi
Menurut Connolly dan Begg (2010:529), Untuk memahami fungsi dari transaksi yang berjalan pada database dan untuk menganalisis transaksi yang penting. Untuk melakukan physical database design secara efektif, maka diperlukan pengetahuan tentang transaksi atau pertanyaan yang akan berjalan pada basis data. Hal ini mencakup baik informasi kualitatif dan informasi kuantitatif. Dalam menganalisa transaksi, diperlukan untuk mengidentifikasi kinerja kriteria, seperti: 1. Transaksi yang sering dijalankan dan memiliki dampak yang signifikan pada kinerja .
2. Transaksi yang penting untuk operasi bisnis.
3. Ketika ada permintaan yang tinggi dibuat pada database dalam sehari / seminggu (disebut juga peak load).
Langkah 4.2 Pemilihan Organisasi File
Menurut Connolly dan Begg (2010:534), Untuk menentukan sebuah organisasi file yang efisien untuk setiap relasi dasar (based relation).
Langkah 4.3 Pemilihan Index
Menurut Connolly dan Begg (2010:535), Untuk menentukan apabila menambahkan indeks akan meningkatkan kinerja sistem. Salah satu pendekatan untuk memilih organisasi file yang sesuai untuk relasi adalah untuk menjaga tuple unordered dan membuat banyak indeks sekunder yang diperlukan. Pendekatan lain adalah untuk mengurutkan tuple dalam relasi dengan menentukan indeks utama atau pengelompokan. Dalam hal ini, pemilihan atribut untuk pemesanan atau pengelompokan