PERANCANGAN DAN PEMBUATAN WEB CRAWLER
APLIKASI PANDUAN PEMBELIAN SPESIFIKASI
KOMPUTER RAKITAN ONLINE DENGAN
MEMANFAATKAN GOOGLE GEARS
Pawestri Dwi Utami – Royyana Muslim I – Henning T.C
Jurusan Teknik Informatika, Fakultas Teknologi Informasi, Institut Teknologi Sepuluh Nopember, email: [email protected], [email protected], [email protected]
Abstrak Semakin berkembangnya
teknologi dan cepatnya aliran data serta informasi yang tersebar di internet menuntut masyarakat untuk mengetahui informasi yang up to date. Untuk mendapatkan informasi tersebut, umumnya masyakarat menggunakan search engine atau mesin pencari yang dapat memudahkan dalam pencarian informasi. Beberapa search engine yang tersedia di internet memanfaatkan web crawler untuk mendapatkan informasi yang dibutuhkan oleh user. Web crawler merupakan sebuah aplikasi yang akan berjalan menjelajahi halaman-halaman situs di internet kemudian mengambil informasi yang tersedia di masing-masing halaman tersebut.
Aplikasi yang akan dibuat kali ini adalah aplikasi web crawler yang akan mencari informasi tentang komputer rakitan yang tersedia di beberapa situs di internet. Situs-situs yang akan dikunjungi telah ditentukan sebelumnya. Data-data yang diperoleh dari proses crawling tersebut akan disimpan di database yang kemudian dapat digunakan oleh user untuk melakukan kombinasi spesifikasi komputer sesuai dengan yang diinginkan.
Pemanfaatan Google Gears dalam aplikasi ini digunakaan agar web dapat berjalan secara offline tanpa adanya koneksi dengan jaringan internet. Google Gears memungkinkan aplikasi untuk berjalan di komputer lokal sehingga proses pencarian semakin lebih mudah dan cepat.
Kebutuhan spesifikasi komputer setiap individu berbeda-beda. Dengan adanya aplikasi ini, diharapkan mampu membantu pengguna dalam mencari spesifikasi komputer rakitan sesuai dengan kebutuhannya.
Kata Kunci: Search engine, Crawler, Google Gears.
1. PENDAHULUAN
Perkembangan teknologi yang cukup pesat saat ini memungkinkan untuk mendapatkan aliran data dan informasi dengan mudah dan cepat. Karena data dan informasi tersebut semakin dibutuhkan, maka manusia berusaha untuk mengembangkan teknologi yang mendukung agar pertukaran data semakin cepat dan akurat. Dengan berbagai teknologi yang tersedia, sedikit banyak telah membantu dalam memenuhi kebutuhan akan informasi.
Sebagian besar data dan informasi yang didapat berasal dari internet dimana informasi tersebut terus berkembang dan mengalami perubahan setiap waktu. Hal tersebut menyebabkan banyaknya data dan informasi yang tersebar di internet. Untuk memudahkan user dalam mencari data, pada umumnya digunakan search engine untuk mencari data dan informasi yang dibutuhkan. Dengan
menggunakan search engine, user dapat
menentukan data apa yang akan dicari dan batasannya sehingga hanya data yang sesuai kriteria saja yang akan ditampilkan.
Beberapa search engine telah
memanfaatkan web crawler untuk
memperoleh informasi tersebut. Web crawler merupakan sebuah perangkat lunak yang digunakan untuk menjelajahi halaman-halaman di internet dan akan mengambil informasi-informasi yang tersedia di halaman web tersebut. Web crawler juga dapat digunakan untuk mencari informasi dengan topik tertentu sehingga disebut dengan topical web crawler.
Aplikasi yang dibangun menggunakan web crawler untuk melakukan pencarian ke halaman-halaman web yang terdapat di internet untuk mencari data-data mengenai komputer rakitan. Tidak semua website akan dikunjungi oleh web crawler ini, hanya web-web yang telah ditentukan sebelumnya yang
akan menjadi tujuan crawling. Setelah data yang diinginkan telah ditemukan, maka data tersebut akan disimpan di database dan akan digunakan untuk proses selanjutnya.
Selain itu, aplikasi ini juga memanfaatkan Google Gears agar web berjalan secara offline sehingga web tetap dapat diakses walaupun tanpa koneksi internet. Dengan menggunakan Google Gears, aplikasi akan berjalan lebih cepat sehingga proses pencarian informasi semakin cepat pula karena proses crawling akan dijalankan di background process.
2. Web Crawler
Web Crawler merupakan program yang pengumpul informasi yang hasilnya akan disimpan pada sebuah database. Sebuah web crawler akan berjalan menelusuri halaman web dan mengumpulkan dokumen-dokumen atau data-data di dalamnya. Selanjutnya web crawler akan membangun sebuah daftar indeks untuk memudahkan proses pencarian.
Gambar 2.1 Arsitektur Web Crawler
Gambar 2.1 merupakan arsitektur dari
sistem crawler. Crawler diawali dengan
adanya daftar URL yang akan dikunjungi, disebut dengan seeds. Setelah crawler mengunjugi URL tersebut, kemudian mengidentifikasi semua hyperlink dari halaman itu dan menambahkan kembali ke
dalam seeds. Hal ini dinamakan crawl
frontier. Setelah web crawler mengunjungi halaman-halaman web yang ditentukan di
dalam seeds, maka web crawler membawa
data-data yang dicari oleh user kemudian
menyimpanya ke sebuah storage. Web
crawler dapat dibuat untuk mencari informasi yang berhubungan dengan topik tertentu saja. Web crawler yang hanya mengumpulkan topik tertentu saja disebut dengan topical web crawler.
Proses crawling merupakan proses
dimana web crawler mengumpulkan data-data dari halaman web. Web crawler dimulai
dengan sekumpulan URL, kemudian men-download setiap halamannya, mendapatkan link dari setiap page yang dikunjungi kemudian mengulangi kembali proses crawling pada setiap link halaman tersebut. 3. Google Gears
Google Gears adalah sebuah open source untuk browser yang memungkinkan seorang developer dapat membuat web yang mampu berjalan secara offline. Yang dimaksud dengan berjalan secara offline adalah sebuah web tetap dapat diakses di komputer lokal tanpa terhubung dengan koneksi internet. Tidak semua aplikasi dapat dijalankan secara offline, hanya website yang telah didesain secara khusus untuk google gears yang dapat menggunakan seluruh fitur dan kemampuan gears ini secara maksimal. Google gears merupakan software open source yang berada dibawah lisensi New BSD, dimana dengan lisensi ini memungkinkan seorang user untuk meng-install gears ke software milik pribadi tanpa ada batasan apapun. Ada 2 cara yang dapat dilakukan dalam menggunakan aplikasi gears, yang pertama adalah dengan menambahkan API atau software yang tersedia pada aplikasi yang akan didistribusikan kepada end user. Cara yang kedua adalah dengan menulis sebuah web yang memerlukan instalasi gears pada komputer user.
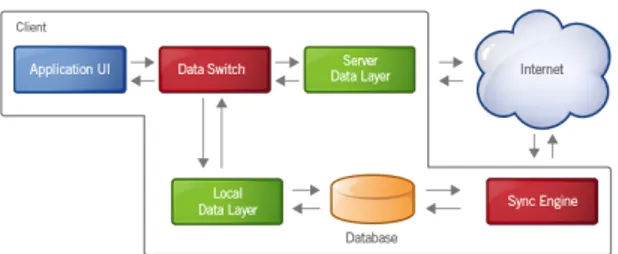
Gambar 3.1 Arsitektur Google Gears
Dari gambar 3.1 terlihat bahwa adanya sinkronisasi dari client jika terhubung dengan internet. Ketika proses sinkronisasi ini berjalan, maka akan diperoleh data-data yang kemudian disimpan ke database lokal dan akhirnya dapat ditampilkan melalui user interface.
3.1.LocalServer
Modul ini digunakan untuk membuat aplikasi web agar dapat dijalankan dan di-cache secara offline, sehingga dapat diakses tanpa terhubung dengan jaringan internet.
Sebuah aplikasi dapat me-manage cache dengan menggunakan 2 class, yaitu:
•ResourceStore, untuk meng-capture ad-hoc URL dengan menggunakan JavaScript. Dengan class ini, memungkinkan aplikasi untuk mendapatkan data file user yang dibutuhkan untuk dikirimkan bersamaan dengan URL, seperti file PDF atau file image.
•ManagedResourceStore, class yang digunakan untuk mengambil sekumpulan URL yang dideklarasikan di manifest file. Manifest file adalah sebuah file yang berisi data file yang dapat diakses ketika aplikasi berjalan offline. Data file tersebut bisa berupa link URL, image, PDF dan lainnya.
3.2.Database
Modul ini digunakan untuk menyimpan data-data aplikasi web pada komputer user. Setelah dilakukan sikronisasi dari internet ke komputer lokal, maka data hasil sinkronisasi akan disimpan ke database lokal komputer. Database yang dibuat oleh aplikasi google gears akan disimpan di direktori komputer user dimana lokasi penyimpanannya tergantung pada browser dan platform yang digunakan.
3.3.WorkerPool
Modul ini digunakan untuk membuat web dapat beroperasi di background proses, seperti adanya sinkronisasi data antara server dengan
komputer user. Penggunaan WorkerPool
memungkinkan user untuk menjalankan
banyak file JavaScript secara bersamaan di background process tanpa menurunkan kinerja user interface. WorkerPool dapat diasumsikan sebagai sekumpulan proses. Jika ada perubahan variabel di salah satu proses, maka tidak akan mengubah variabel di proses yang lain. Dan jika sebuah worker di-create, maka tidak akan secara otomatis mewarisi
kode script dari parent-nya. Sekumpulan
proses dari WorkerPool saling berhubungan satu dengan lainnya dengan cara mengirimkan objek yang berisi pesan menggunakan fungsi sendMessage().
3.4.HttpRequest API
HttpRequest API mengimplementasikan kumpulan XMLHttpRequest sehingga dapat
digunakan antara worker dan halaman HTML. HttpRequest API menyediakan fitur agar dapat mengakses objek dokumen dan kemampuan untuk mengirimkan request secara sikron.
4. Algoritma Greedy
Algoritma greedy merupakan sebuah
algoritma untuk menentukan solusi optimum dari sebuah persoalan. Solusi optimum adalah sebuah solusi yang bernilai maksimum atau minimum dari sekumpulan alternatif solusi yang memungkinkan untuk dipilih. Algoritma greedy menggunakan metode langkah per langkah dimana pada setiap langkah akan membentuk solusi. Setiap langkah solusi memiliki banyak pilihan. Oleh karena itu, harus dibuat keputusan yang terbaik dalam menentukan pilihan di setiap langkahnya. Keputusan yang telah diambil pada suatu langkah tidak dapat diubah lagi pada langkah selanjutnya.
Algoritma greedy memiliki 5 elemen
penting, antara lain:
1. Himpunan kandidat, berisi
elemen-elemen pembentuk solusi.
2. Himpunan solusi, berisi
kandidat-kandidat yang terpilih sebagai solusi persoalan.
3. Fungsi seleksi (selection function), memilih kandidat yang paling memungkinkan mencapai solusi optimal. Kandidat yang sudah dipilih pada suatu langkah tidak pernah dipertimbangkan lagi pada langkah selanjutnya.
4. Fungsi kelayakan (feasible function), memeriksa apakah suatu kandidat yang telah dipilih dapat memberikan solusi yang layak, yakni kandidat tersebut bersama-sama dengan himpunan solusi yang sudah terbentuk tidak melanggar batasan (constraints) yang ada. Kandidat yang layak dimasukkan ke dalam himpunan solusi, sedangkan kandidat yang tidak layak dibuang dan tidak pernah dipertimbangkan lagi.
5. Fungsi obyektif (objective function), yaitu fungsi yang memaksimumkan atau meminimumkan nilai solusi (misalnya panjang lintasan, keuntungan, dan lain-lain).
5. DESAIN DAN IMPLEMENTASI
Tugas akhir ini dibuat untuk mengaplikasikan konsep web crawler yang memudahkan seorang user melakukan pencarian spesifikasi komputer rakitan yang tersedia online di internet. Web crawler merupakan aplikasi search engine yang digunakan untuk mencari data-data yang dibutuhkan oleh user dengan cara menjelajahi halaman-halaman web yang tersedia di internet.
5.1. Arsitektur Aplikasi
Gambaran umum proses yang terjadi dalam aplikasi ini adalah:
Gambar 5.1 Gambaran proses di dalam sistem aplikasi web crawler
Berdasarkan gambar 3.1, dapat dilihat bahwa di dalam sistem aplikasi Web Crawler, seorang user akan berinteraksi dengan sistem melalui user interface. Dalam user interface tersebut, user akan diminta untuk melakukan kombinasi terhadap komputer rakitan sesuai dengan kebutuhannya kemudian sistem akan melakukan pencarian ke dalam database lokal komputer. Data yang tersedia di dalam database adalah data hasil sikronisasi dari proses crawling yang berjalan saat sistem sedang terhubung dengan internet pada waktu-waktu yang ditentukan sebelumnya. Ketika aplikasi sedang menjalankan proses crawling, maka aplikasi akan melakukan sikronisasi data. Proses sinkronisasi akan menjalankan perintah crawling yang akan menjelajahi halaman-halaman website yang telah ditentukan dan hasilnya akan disimpan ke database komputer lokal. Proses ini akan mengecek ada tidaknya perubahan data yang tersedia di internet. Jika terdapat perubahan harga, maka sistem akan melakukan update terhadap barang yang mengalami perubahan tersebut. Ketika sudah tidak terhubung lagi dengan jaringan (offline), maka user akan mengakses database hasil sinkronisasi.
Pencarian kombinasi komputer rakitan dilakukan dengan memilih kombinasi dari processor, memory dan graphic card dimana
jumlah dari ketiga komponen tersebut tidak melebihi budget yang diinputkan oleh user. Selain itu, pencarian juga didasarkan pada kebutuhan masing-masing user. Kombinasi komputer rakitan yang dapat dipilih oleh user antara lain:
• Kebutuhan untuk perkantoran, dimana komputer memiliki nilai yang hampir sama di semua komponen baik motherboard, processor, memory dan graphic card.
• Kebutuhan untuk multimedia atau
gaming, dimana kombinasi dilakukan dengan mencari nilai graphic card yang tertinggi.
• Kebutuhan untuk server, dimana
kombinasi yang didapat adalah kombinasi komputer rakitan dengan nilai processor yang paling tinggi. • Kebutuhan standar, dimana kombinasi
komputer rakitan tidak memiliki prioritas tertinggi pada salah satu komponen.
Setiap kategori kombinasi komputer rakitan diatas memiliki prioritas yang lebih pada salah satu komponen.
6. UJI COBA
Uji coba ini dilakukan untuk mengetahui performa perangkat lunak jika terjadi perubahan data serta berbagai macam kombinasi yang dilakukan oleh user. Hasil uji coba ditampilkan melalui sebuah alert yang menunjukkan bahwa proses crawling telah selesai beserta dengan waktu yang digunakan selama proses crawling berjalan. Selain itu, uji coba performa juga dilakukan di waktu-waktu yang berbeda dengan tujuan untuk mengetahui pengaruh traffic jalur koneksi internet. Skenario dilakukan untuk mengetahui seberapa lama waktu yang dilakukan ketika crawling halaman-halaman web dari awal hingga memasukkan ke database, waktu ketika meng-update 10 barang, 20 barang dan 50 barang.
Tabel 6.1 Tabel perbandingan waktu crawling dan update
Kecepatan sistem dalam melakukan proses crawling dan update berbeda-beda. Hal tersebut bergantung pada banyak data dan traffic yang ada pada saat itu. Tabel 6.1 memberikan perbandingan ketika crawling dan update dijalankan pada saat traffic sepi dan traffic padat.
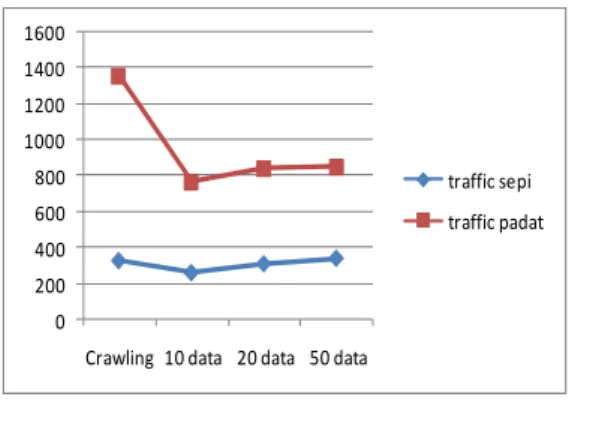
Pada gambar 5.22 dapat dilihat grafik perbandingan waktu ketika traffic sedang sepi dan sedang padat. Dari gambar diatas menunjukkan bahwa kecepatan crawling dan update data bergantung pada traffic koneksi internet. Semakin sepi koneksi jaringan internet semakin cepat pula proses crawling dan update berjalan.
Gambar 6.1 Grafik perbandingan traffic sepi dan traffic padat
7. SIMPULAN
Dari hasil pengamatan selama perancangan, implementasi, dan proses uji coba perangkat lunak yang dilakukan, dapat diambil simpulan sebagai berikut :
1. Penggunaan crawling dalam aplikasi web crawler ini merupakan solusi yang efisien dalam panduan pencarian spesifikasi komputer rakitan online. Hal tersebut dikarenakan proses insert serta update barang tidak dilakukan secara manual, namun dilakukan otomatis oleh crawling.
2. Berjalannya proses crawling di
background process tidak menganggu
kinerja user ketika mengakses
aplikasi web. Selain itu, dengan lamanya proses crawling juga membuat user interface dapat berjalan dengan lancar.
3. Performa crawling dipengaruhi oleh traffic koneksi internet. Jika traffic sedang padat, maka proses crawling berjalan semakin lama pula.
4. Pengimplementasian algoritma greedy dalam mencari solusi yang optimum memberikan hasil yang cukup maksimal dalam melakukan kombinasi komputer rakitan.
8. DAFTAR PUSTAKA
1. [ACH99] Achour, Mehdi, dan Betz, Friedhelm, “PHP Manual”, PH Documentation Group, 1999.
2. [KHA07] Khanna, Rajiv A., dan Kasliwal, Sourabh, “Designing a Web Crawler”, 2007.
3. [WIK01] Wikipedia, The Free
Encyclopedia, Web
Crawler
<URL:http://en.wikipedia.o rg/wiki/Web_Crawler>
4 [WIK02] Wikipedia, The Free
Encyclopedia, Google
Gears
<URL:http://en.wikipedia.o rg/wiki/Google_Gears>
5 [LEV03] Levitin, Anany V., “Introduction to the Design and Analysis of Algorithms”, Addison-Wesley, 2003. 0 200 400 600 800 1000 1200 1400 1600
Crawling 10 data 20 data 50 data
traffic sepi traffic padat