PROSIDING SENTRINOV Vol. 001, Tahun 2015 | ISSN: 2477 – 2097 325 PENELUSURAN CITRA ASET BERBASIS KEMIRIPAN CITRA
MENGGUNAKAN FITUR BENTUK, WARNA DAN TEKSTUR SERTA KLUSTERING K-MEANS
Jumi¹, Achmad Zaenuddin²
¹,2 Jurusan Administrasi Niaga, Politeknik Negeri Semarang Email: [email protected], [email protected]
Abstract
Similarity an image is one of the key fields to retrieving back (image retrieval) an image of the assets. The similarity a query image with the image of database is one of the key fields to search process back (image retrieval) based on image of the assets. The similarity a query image with the image database can be done by performing analysis based on image features are features of shapes, colors and textures. This research has been carried out analysis of image search based similarity on features of shapes, colors and textures by using invariant moment, moment color and texture as well as statistical euclidean distance as distance measuring similarity. The results of test showed that the combination of these three features are features of shape, color and texture as well as grouping data with K-Means Clustering has resulted similarity accuracy rate reached more than 90 %%. That in previous studies analyzing the accuracy of similarity based on shape features have an accuracy level of 70%. It shows that the combination of these three features and a K-Means Clustering has improved the accuracy of image search on the database assets.Keywords: Similarity, Image, retrieval, invariant, moment.
Key Words : Similarity, Image, retrieval, invariant, moment. Abstrak
Kemiripan (similarity) sebuah citra merupakan salah satu key field untuk melakukan proses
pencarian kembali (image retrieval) sebuah citra dalam hal ini citra aset. Kemiripan sebuah
citra query dengan citra database dapat dilakukan dengan melakukan analisa berdasarkan fitur citra yaitu fitur bentuk, warna dan tekstur. Pada penelitian ini telah dilakukan analisa pencarian kemiripan citra berdasarkan fitur bentuk, warna dan tekstur dengan menggunakan metode Invariant moment, color moment dan statistical texture serta euclidean distance
sebagai pengukur jarak kemiripannya. Hasil pengujian menunjukkan bahwa kombinasi dari ketiga fitur yaitu fitur bentuk, warna dan tekstur serta pengelompokan data dengan K-Means Clustering telah menghasilkan tingkat akurasi kemiripan mencapai lebih dari
90%%. Bahwa pada penelitian sebelumnya tingkat akurasi analisa kemiripan berdasarkan fitur bentuk mempunyai tingkat akurasi sebesar 70%. Hal tersebut menunjukkan bahwa kombinasi ketiga fitur dan K-Means Clustering telah meningkatkan akurasi penelusuran
pada database citra aset.
Kata kunci : Similarity, Image, retrieval, invariant, moment.
PENDAHULUAN
Teknologi informasi yang selalu berkembang memungkinkan penelusuran informasi menggunakan fitur citra yang berukuran besar sebagai key field.Hal ini karena
tersedianya software dan hardware yang mendukung pengolahan data citra yang
PROSIDING SENTRINOV Vol. 001, Tahun 2015 | ISSN: 2477 – 2097 326
akurasi penelusuran yang beragam karena dipengaruhi oleh berbagai variabel diantaranya adalah ketelitian dan ketepatan dalam proses perhitungan nilai fitur.
Citra sebuah obyek secara umum mempunyai mempunyai tiga fitur dominan yaitu fitur bentuk, warna dan tekstur. Seperti contohnya pada citra obyek aset memiliki fitur bentuk yang lebih dominan untuk membedakan kemiripan antara citra aset yang satu dengan citra aset yang lainnya.Sedangkan fitur warna dan tekstur citra aset adalah sebagai fitur penunjang untuk pengukuran kemiripan citra (Vadivel, A. dkk., 2004). Pengukuran kemiripan citra dapat dikelompokkan dengan tiga kelompok utama yaitu pertama kemiripan bentuk, kedua kemiripan warna dan yang ketiga kemiripan tekstur (Gonzales, R.C. and Woods, R.E., 2008). Kemiripan digunakan sebagai kunci pengurutan pada penelusuran data berbasis citra. Semakin mendekati nilai nol maka semakin tinggi tingkat kemiripannya (Gonzales, R.C. and Woods, R.E., 2008). Penelusuran dilakukan dengan membandingkan kemiripan fitur antara fitur citra query dengan fitur citra pada database (Castleman, K.R, 1996).
Penelitian sebelumnya tentang penelusuran kemiripan citra berdasarkan ekstraksi ciri bentuk, warna dan tekstur telah dilakukan tanpa memperhatikan bobot fitur dan
clustering dengan hasil akurasi kemiripan mencapai lebih dari 85% (Jumi and Harjoko,
2012). Beberapa penelitian sejenis yang berkaitan dengan penelusuran informasi citra berbasis CBIR (Content Based Image Retrieval) menggunakan metode pembobotan
fitur citra diantaranya adalah penelusuran citra menggunakan kombinasi fitur warna dan vektor fitur tekstur tertimbang (Vadivel, A. dkk., 2004). Penelusuran dengan pembobotan fitur tekstur menggunakan DCT (Discrette Cosine Transform)juga telah
dilakukan untuk penelusuran citra berbasis CBIR (Dong, L. And Edmund, Y.L., 2006). Nilai fitur akan menjadi koefisien bobot citra yang akan dipakai sebagai dasar penelusuran.Pengindeksan citra berbasis nilai fitur warna tertimbang coocurence matrix,
menghasilkan nilai akurasi penelusuran yang relatif tinggi (Joshua Z., H., dkk, 2005). Pada penelitian ini dilakukan pembobotan nilai fitur warna dan pengindeksan berdasarkan kesamaan elemen diagonal dan non diagonal.
PROSIDING SENTRINOV Vol. 001, Tahun 2015 | ISSN: 2477 – 2097 327
pengelompokan data berdasarkan formula bobot variabel (Taoying, L., and Yan, C., 2008). Penggunaan k-means juga dilakukan dengan mengkombinasikan bobot entropy.Pada penelitian ini clustering dilakukan dengan memperhitungkan nilai entropinya (Xiang, Y., H., dkk, 2003).
METODE YANG DIUSULKAN
Pada beberapa penelitian yang sudah dilakukan diatas belum ada yang menggunakan penggabungan metode klusteringdan kombinasi fitur berdasarkan fitur bentuk, warna dan tekstur untuk proses penelusuran citra berbasis CBIR. Pada penelitian ini telah dilakukan retrieval imagedengan metode klustering dan kombinasi
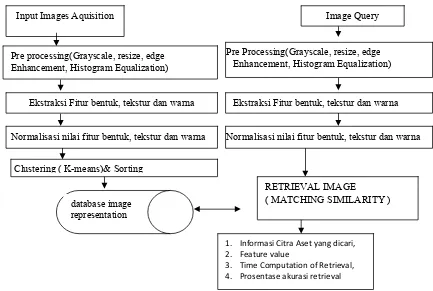
ketiga fitur dengan tahapan penelitian yang ditunjukkan oleh Gambar 1.
Gambar 1. Gambaran Umum Penelusuran Citra
Berdasarkan Gambar 1, maka rincian tahapan penelusuran pada penelitian ini adalah sebagai berikut :
1. Preprocessing
Preprocessing merupakan tahapan perbaikan kualitas citra sebelum ekstraksi fitur dengan tujuan meningkatkan akurasi hasil ekstraksi fitur citra.Terdapat perbedaan
preprocessing pada ekstraksi fitur bentuk dengan ekstraksi fitur warna dan Input Images Aquisition
Ekstraksi Fitur bentuk, tekstur dan warna
Normalisasi nilai fitur bentuk, tekstur dan warna
RETRIEVAL IMAGE
Normalisasi nilai fitur bentuk, tekstur dan warna Image Query
Pre Processing(Grayscale, resize, edge Enhancement, Histogram Equalization)
PROSIDING SENTRINOV Vol. 001, Tahun 2015 | ISSN: 2477 – 2097 328
tekstur.Perbedaan preprocessing tersebut untuk mendapatkan citra yang berkualitas sebelum ekstraksi fitur.
1.1 Preprocessing Fitur Bentuk
a. Resizing
Ukuran citra akan mempengaruhi lamanya waktu ekstraksi fitur, semakin kecil ukurannya, maka semakin cepat komputasi ekstraksi fiturnya. Pada tahapan ini dilakukan resize citra menjadi 300 x 300 pixel.
b. Grayscale
Khusus pada penghitungan fitur bentuk unsur warna tidak diperhitungkan, sehingga dilakukan perubahan citra menjadi grayscale agar proses komputasinya menjadi
lebih cepat.
c. Edge Enhancement dan Histogram Equalization (HE)
Tahapan edge enhancementakan menghasilkan citra baru dengan tepi obyek
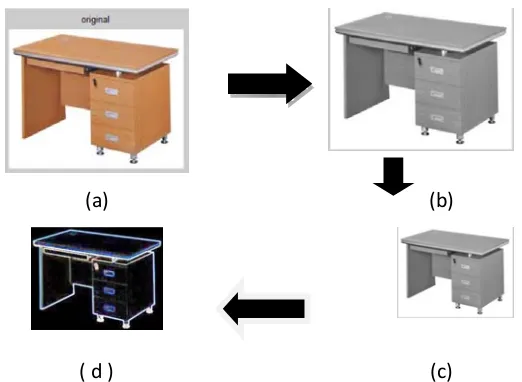
yang lebih jelas atau tajam, sehingga bentuk citra akan lebih jelas. Tahapan ini menggunakan metode konvolusi dengan operator Sobel (Gonzales, R.C. and Woods, R.E., 2008). Hasil penajaman tepi dapat dilihat pada Gambar 2.
(a) (b)
( d ) (c)
Gambar 2. Tahapan Preprocessing Fitur Bentuk, (a) Citra Original, (b) Citra Grayscale, (c) Resize, (d) Citra Hasil Edge Enhancement
1.2 Preprocessing Fitur Warna dan Fitur Tekstur
PROSIDING SENTRINOV Vol. 001, Tahun 2015 | ISSN: 2477 – 2097 329
Semakin besar ukuran citra, maka waktu ekstraksinya juga semakin lama, sehingga diperlukan tahapan resize untuk mempercepat proses komputasinya. Pada
tahapan ini dilakukan resize citra menjadi 300 x 300 pixel. b. Grayscale
Preprocessing grayscale dilakukan untuk ektraksi fitur tekstur agar tekstur lebih
terlihat, sedangkan pada ekstraksi fitur warna tidak dilakukan grayscalekarena nilai
warna yang akandiperhitungkan.
c. Histogram Equalization
Pada tahapan ini dilakukan perataan histogram agar kualitas gambar menjadi
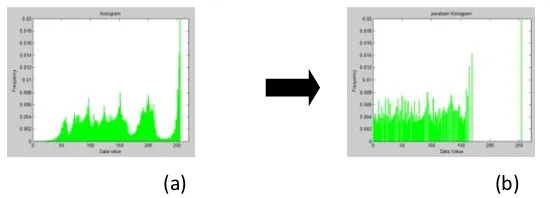
lebih kontras untuk mendapatkan nilai fitur warna dan tekstur yang berkualitas.Hasil perataan histogram dapat dilihat pada Gambar 3 dan Gambar 4.
(a) (b)
Gambar 3.Perbandingan citra sebelum dan sesudah proses histogram, (a) Citra Asli, (b) Citra Hasil Histogram Equalization (HE)
(a) (b)
Gambar 4. Perbandingan histogram,(a) Histogram Citra Asli, (b) Histogram citra Hasil HE
2. Ekstraksi Fitur Bentuk, Warna dan Tekstur
Ekstraksi dilakukan pada ketiga fitur dengan tahapansebagai berikut:
2.1 Ekstraksi Fitur Bentuk.
Ekstraksi fitur bentuk dilakukan dengan menggunakan metode invariant moment.
PROSIDING SENTRINOV Vol. 001, Tahun 2015 | ISSN: 2477 – 2097 330 Invariant Momentakan menghasilkan tujuh nilai invariant moment yang konstan
terhadap RST (Castleman, K.R, 1996). Adapun region digambarkan dengan tujuh
invariant momentyang dapat dicari dari momen sentral: μ00, μ10, μ01, μ20, μ11, μ02,
μ30, μ12, μ21, μ03 , dan dengan mendefisinikan normalized central momentsyaitu ηpq
= μpq / μγ00, dimana γ = 0.5 ( p + q) + 1 untuk p + q = 2, 3, dan seterusnya,yang akhirnya didapat tujuh invariant moments. , ketujuh invariant moments tersebut
ditunjukkan pada persamaan (1) sampai dengan persamaan (7)
M1 η20 η02 (1)
Nilai dari ketujuh invariantmoments ini tidak berubah terhadap rotasi, translasi dan
skala(Xiang, Y., H., dkk, 2003).
2.2 Ekstraksi Fitur Warna
Preprocessing dengan histogram equalization pada Gambar 3 menghasilkan citra
yang lebih kontras. Citra tersebut merupakan citra input pada ekstraksi fitur warna. Metode ekstraksi yang digunakan adalah color moment.Metode ini mampu
membedakan citra berdasarkan fitur warnanya (Susilo, A., 2006).
Color Moment merupakan metode yang cukup baik dalam pengenalan ciri
warna.Metode ini menggunakan tiga momen utama dari distribusi warna citra, yaitu
mean, standard deviation, dan skewness (Acharya, T. and Ray, A., K., 2005). Setiap
komponen warna yaitu HSV (Hue, Saturation dan Value) memiliki 3 moment. 2.3 Ekstraksi Fitur Tekstur
Tekstur merupakan keteraturan pola-pola tertentu yang terbentuk dari susunan piksel-piksel pada suatu citra.Nilai tekstur dapat digunakan sebagai salah satu variabel
PROSIDING SENTRINOV Vol. 001, Tahun 2015 | ISSN: 2477 – 2097 331 Statistical Texture merupakan salah satu metode untukmendeskripsikan tekstur
menggunakan pendekatan secara statistikdarihistogram intensitas suatu citra atau region. Statistikal dapat memberikan pengukuran citra seperti kehalusan (smoothness),
kekasaran (coarseness) dan keteraturan (regularity) yang merupakan variabel fitur
tekstur. Nilai fitur tekstur pada penelitian ini diukur menggunakan lima fitur yaitu : smoothness, standard deviasi, skewness, uniformity dan entropy.
2.4 Normalisasi Fitur
Normalisasi penting dilakukan untuk mengelompokkan range atau interval dari nilai-nilai fitur yang berbeda dalam skala yang sama dengan range lebih kecil. Normalisasi dilakukan untuk memberikan bobot yang sama terhadap nilai-nilai fitur yang berbeda dari hasil ekstraksi.Normalisasi pada penelitian ini menggunakan persamaan (8).
(8)
dengan adalah nilai fitur ke-i yang sudah ternormalisasi, adalah nilai fitur ke-i sebelum dke-inormalke-isaske-i, min D merupakan nilai minimum dari masing-masing fitur
dan max D adalah nilai maksimal masing-masing fitur.
2.5 K-Means Clustering
Penggunaan clustering pada penelitian ini betujuan untuk mempercepat proses
retrieval. K-Means merupakan teknik clustering dengan menggunakan centroid (titik
pusat cluster) untuk merepresentasikan sebuah cluster (Adi, 2007). Selain itu K-Means
mampu mengelompokkan data berukuran besar dengan cepat (Arai, K. And Barakbah, A., R., 2007).
Algoritma K-Means digunakan untuk menentukan posisi cluster pada setiap citra dengan cara menghitung terlebih dahulu jarak citra dengan semua centroid menggunakan metode euclidean distance. Pemetaan cluster dilakukan dengan memilih
jarak terdekat dari semua centroid yang ada. Penghitungan jarak menggunakan
PROSIDING SENTRINOV Vol. 001, Tahun 2015 | ISSN: 2477 – 2097 332
(9)
Dimana D H,I adalah jarak citra H dengan centroidI, adalah Nilai fitur ke-n dari
citraH, adalah nilai fitur ke-n dari centroidI dan n adalah banyaknya dimensi
2.5 Pengukuran Kemiripan
Pengukuran kemiripan citra query dengan citra database menggunakan konsep
euclidean distance dan dilakukan hanya pada satu kluster saja. Pengukuran kemiripan
menggunakan persamaan (10) dengan menggunakan sebelas dimensi atau fitur yaitu tiga fitur bentuk meliputi nilai moment invariant ke 3, 5 dan 7, kemudian 3 fitur warna
dengan menggunakan nilai Hue dan 5 fitur tekstur yaitu smoothness, standard deviasi, skewness, uniformity dan entropy.
(10)
Dimana dan adalah fitur dari citra query dan citra database pada dimensi ke-n. Hasil penghitungan kemiripan diurutkan sehingga nilai kemiripan yang mendekati nol mempunyai tingkat kemiripan yang paling tinggi.
2.6 Akurasi Retrieval
Pengukuran akurasi retrieval pada citra sebelum dan sesudah pembobotan maupun clustering dilakukan dengan menggunakan persamaan (11).
(11)
AR (Actual Relevant) : jumlah data yang dianggap relevan oleh user.
AS (Actual Search) : jumlah data yang di retrieve oleh sistem.
HASIL DAN PEMBAHASAN
PROSIDING SENTRINOV Vol. 001, Tahun 2015 | ISSN: 2477 – 2097 333
Contoh hasil pengujian retrieval dilakukan dengan variasi jumlah kluster variasi 9 ditunjukkan pada Gambar 5.
Gambar 5.Retrieval Menggunakan Bobot Bentuk, Warna dan Tekstur
Pada Gambar 5. ditampilkan hasil retrieval dengan rangking kemiripan 1 sampai 10 dari
database citra aset dengan pengujian menggunakan variasi jumlah kluster sebanyak 9. Tahap berikutnya adalahpenghitungan akurasi retrieval pada database citra aset.
Dan selanjutnya dilakukan analisis akurasi retrieval pada database citra aset sebelum dan sesudah clustering dengan jumlah kluster yang bervariasi mulai dari 3 sampai dengan 15 kluster. .
Sebelum Clustering
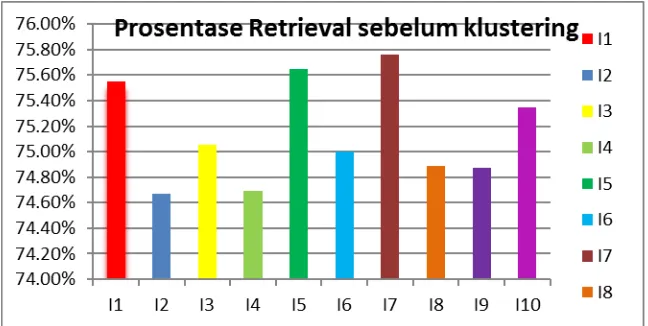
Analisis akurasi retrieval pada tahapan ini menggunakan database citra aset sebelum klustering dengan variasi pembobotan pada fitur bentuk, warna dan tekstur. Nilai akurasi hasil retrieval dengan bobot fitur sama dan bobot fitur bervariasi dapat
dilihat pada Tabel 1.
Tabel 1.
Prosentase Akurasi Retrieval pada Citra Uji
Nama
Citrs I1 I2 I3 I4 I5 I6 I7 I8 I9 I10
Akurasi
Retrieval 75,55% 74,67% 75,05% 74,69% 75,65% 75% 75,76% 74,89% 74,87% 75,35%
Tabel 1 menunjukkan bahwa akurasi retrieval menggunakan kombinasi ketiga nilai fitur dan tanpa klustering pada data uji.
PROSIDING SENTRINOV Vol. 001, Tahun 2015 | ISSN: 2477 – 2097 334 Gambar 6. Grafik AkurasiRetrieval dengan Bobot Fitur Sama dan
BervariasiSebelum Clusteringpada Database Citra Aset
Dari gambar 6., ditunjukkan bahwa Akurasi retrieval pada citra I7 memiliki prosentase yang paling tinggi yaitu 75.76%, sedangkan rata-rata akurasi retrieval sebeum klustering adalah 75%.
Sesudah Clustering
Pengelompokan berdasarkan kemiripan akan lebih mempersempit ruang penelusuran informasi data citra sehingga akan mempersingkat waktu retrieval dan
meningkatkan akurasi retrieval. Tingkat akurasi retrievaldengan variasi bobot dan
jumlah cluster dapat dilihat pada Tabel 2.
Tabel 2
Prosentase Akurasi Retrieval dengan Variasi Bobot Fitur dan Variasi Jumlah Kluster Jumlah
Kluster 3 4 5 6 7 8 9 10 11 12
Prosentase
retrieval 75,59% 75% 76,45% 76,15% 77,75% 77,50% 77,45% 79,65% 79,15% 77,25%
Dari Tabel 2 menunjukkan bahwa variasi jumlah kluster 10 menghasilkan akurasi retrieval paling tinggi yaitu lebih dari 79,65%, Sedangkan rata-rata akurasi retrieval
dengan variasi jumlah kluster adalah 77,19%. Grafik akurasi retrieval pada database
citra aset menggunakan variasi jumlah cluster mulai dari 3 sampai dengan 12 dapat
PROSIDING SENTRINOV Vol. 001, Tahun 2015 | ISSN: 2477 – 2097 335 Gambar 7. Grafik Akurasi Retrieval dengan Variasi Bobot Fitur
dan Variasi Jumlah Kluster
Pada Gambar 7. menunjukkan bahwa akurasi retrieval cenderung naik hingga variasi
jumlah cluster 10 dan cenderung menurun setelah jumlah kluster lebih besar dari 10.
Waktu Komputasi
Waktu komputasi yang digunakan untuk me-retrieve sebuah citra pada database
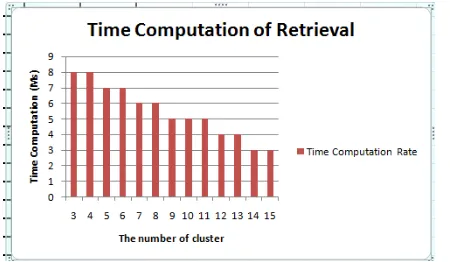
citra aset dipengaruhi oleh besarnya ukuran database citra dan teknik pengelolaan databasenya.Waktu komputasi rata-rata untuk penelusuran pada database citra sebelum klustering adalah dengan variasi jumlah kluster dapat dilihat pada grafik Gambar 8.
Gambar 8. Waktu komputasi rata-rata Retrieval
Pada Gambar 8. Menunjukkan bahwa semakin banyak jumlah kluster maka waktu komputasi semakin cepat.
SIMPULAN
Pada dasarnya tingkat akurasi pada proses penelusuran (retrieval) citra aset
PROSIDING SENTRINOV Vol. 001, Tahun 2015 | ISSN: 2477 – 2097 336
Pada penelitian ini membuktikan bahwa variasi jumlah cluster akan berpengaruh
terhadap peningkatan akurasi dan kecepatan retrieval pada database citra aset. Tingkat
akurasi retrieval paling tinggi adalah pada viarisi jumlah kluster 10.Hasil Penelitian
menunjukkan bahwa waktu komputasi rata-rata yang dibutuhkan untuk retrieval adalah
5 mili-second.
DAFTAR PUSTAKA
A Vadivel , Majumdar, A.K. and Shamik S., 2004,Characteristics Of Weighted Feature Vector In Content-Based Image Retrieval Applications, IEEE.
Gonzales, R. C., Woods, R. E., 2008, Digital Image Processing, ThirdEdition, Pearson
Prentice Hall, New Jersey.
Castleman, K. R., 1996, Digital Image Processing, Prentice Hall Inc., New Jersey.
Jumi and Harjoko, A., 2012, Image Similarity Analysis Based on Shape, Color and Texture Feature of Asset Image, International Conference on Computer Science
Electronics and Instrumentation, Yogyakarta, Indonesia
Dong L. And Edmund Y. L., 2006,Image Indexing Using Weighted Color cooccurrence Matrix and Feature Selection, IEEE.
Joshua Z. H., Michael K. N., Hongqiang R., and Zichen L., 2005, Automated Variable Weighting in k-Means Type Clustering,IEEE, Transactionon Pattern Analysisand
Machine Intelligence,Vol. 27, No. 5.
Taoying, L. And Yan, C., 2008,A Weight Entropy K-Means Algorithm for Clustering Dataset with Mixed Numeric and Categorical Data,Fifth International Conference
on Fuzzy Systems and Knowledge Discovery, 978-0-695-3305, IEEE
Xiang Y. H, Yu-Jin B., and Dong H., 2003,Image Retrieval Based on WeigthedTexture Features using DCT Coefficients of JPEG Images, International Conference
Information and Computer Security (ICICS), Singapore.
Acharya T. and Ray, A. K, 2005, “Image Processing Principle and Applications”, John
Willey & Sons, USA
Susilo, A., 2006, Web Image Retrieval untuk Identifikasi bunga dengan Pengelompokan Content Warna, Proceeding IES, Surabaya
Adi, 2007, Comparison of Agglomerative Heirarchical Clustering Methods for Text Data, International Journal of Information Technology and Decision Making,
ISSN: 0219-6220