Makalah Pelanggaran Asumsi Multikolinearitas
1. Latar Belakang Masalah
Analisis regresi digunakan untuk membantu mengungkapkan hubungan atau pengaruh satu atau lebih peubah bebas terhadap peubah tak bebas. Dalam analisis regresi terdapat beberapa asumsi, diantaranya adalah galat saling bebas, menyebar normal dengan rataan nol
dan ragamnya
δ
ε2
, serta tidak terdapat multikolinearitas antar peubah bebas.
Masalah multikolinearitas penting diperhatikan dan perlu diatasi karena akan berdampak terhadap pendugaan dan pengujian koefisien regresi. Masalah ini muncul akibat terdapat fungsi linear hampir konstan atau sering disebut dengan tingginya korelasi linear di antara dua atau lebih peubah bebas.
Gejala ini menimbulkan masalah dalam pemodelan regresi. Korelasi yang sangat tinggi akan menghasilkan penaksir bias, tidak stabil dan mungkin jauh dari nilai sasaran (Gonst and Mason, 1977), dan pendugaan parameter model regresi dengan menggunakan metode kuadrat terkecil akan menghasilkan penduga yang tak bias tetapi mungkin penduga tersebut mempunyai ragam yang besar (Walpole dan Myers, 1995). Ragam yang besar ini akan mengakibatkan pengujian hipotesis cenderung menerima Ho, yang berarti koefisien regresi tersebut tidak berbeda nyata dengan nol.
Oleh karena itu, penting bagi setiap analis untuk bisa menanggulangi masalah multikolinearitas tersebut. Makalah ini akan membahas salah satu metode untuk mengatasi
masalah dalam regresi linier ganda, yaitu menggunakan ridge regression.
2. Tujuan
Tujuan analisa dalam makalah ini adalah untuk memperoleh persamaan yang akan digunakan untuk menaksir dan atau mememprediksi.
3. Critical Review
Penyelesaian masalah multikolinearitas ini telah dikembangkan oleh banyak peneliti
melalui berbagai pendekatan, diantaranya dengan menggunakan regresi himpunan terbaik (best
subset regression) dan regresi stepwise (stepwise regression) seperti yang dibahas dalam Draper dan Smith (1992). Namun demikian jika seluruh peubah bebas berkorelasi tinggi pendekatan-pendekatan tersebut sulit dilakukan dan tidak akan memperoleh solusi yang baik.
Pendekatan lain dalam mengatasi multikolinearitas dapat digunakan regresi gulud
(ridge regression), regresi akar laten (latent root regression) dan regresi komponen utama
Regresi komponen utama bermula dari analisis komponen utama pada peubah-peubah bebas yang akan menghasilkan komponen-komponen utama yang saling bebas (orthogonal). Skor komponen utama kemudian diperlakukan sebagai peubah bebas untuk menggantikan peubah bebas asal. Jika semua komponen utama diikutkan dalam regresi, model yang dihasilkan ekuivalen dengan yang diperoleh dari metode kuadrat terkecil sehingga ragam penduga yang besar akibat multikolinearitas tidak tereduksi. Sebaliknya, jika beberapa komponen utama tidak disertakan dalam model regresi maka penduga koefisien regresi pada model asal akan berbias, namun bersamaan dengan itu telah terjadi reduksi besar-besaran pada ragam penduga koefisien regresi (Jollife, 1986).
Salah satu strategi untuk memilih komponen utama dalam regresi komponen utama adalah mengabaikan komponen utama yang bersesuaian dengan akar ciri terkecil. Akan tetapi Jollife (1986) menyarankan untuk memperhatikan kontribusi komponen utama tersebut terhadap peubah tak bebas Y. Jollife (1982) dalam Hwang dan Nettleton (2003) menyajikan beberapa contoh di kehidupan nyata dimana komponen utama yang bersesuaian dengan akar ciri kecil mempunyai korelasi yang tinggi dengan Y. Hwang dan Nettleton (2003) membahas sebuah metode untuk memilih himpunan bagian komponen utama yang dapat meminimumkan kuadrat tengah galat (mean square error–MSE= KTG) dari penduga parameter regresi ß. Mereka menunjukkan bahwa suatu koefisien regresi komponen utama yang signifikan dan berbeda dari nol tidaklah cukup untuk menjamin keabsahan penggunaan komponen utama tersebut untuk menduga ß, melainkan suatu koefisien regresi komponen utama haruslah cukup jauh dari nol untuk menjamin bahwa reduksi biasnya cenderung lebih bermanfaat. Dengan menggunakan kriteria ini, Hwang dan Nettleton (2003) menunjukkan bagaimana membangun suatu penduga regresi komponen utama baru yang secara substansial mempunyai kuadrat tengah galat lebih minimum dibandingkan dengan regresi komponen utama yang umum digunakan.
Sedangkan metode yang digunakan dalam penelitian ini adalah metode regresi ridge. Regresi ridge merupakan modifikasi dari metode kuadrat terkecil dengan cara menambah tetapan bias q yang kecil kepada nilai diagonal matriks XtX. Besarnya tetapan bias q
mencerminkan besarnya bias dalam koefisien penduga ridge dan q yang bernilai nol merupakan implementasi dari metode kuadrat terkecil. Hoerl, Kennard, dan Balwin (1975) dalam Gusriani (2004) menyarankan pemilihan nilai q dengan meggunakan rumus HKB (Hoerl, Kennard, dan Balwin) dengan prosedur iterasi.
4. Metodologi Multikolinearitas
1. Menentukan matriks korelasi dari semua peubah bebas
Prosedur ini merupakan pemeriksaan yang paling sederhana dan paling mudah. Nilai korelasi yang tinggi antara peubah satu dengan yang lainnya memperlihatkan adanya hubungan linier pada peubah-peubah tersebut.
2. VIF (Variance Inflation Factor)
Mulitikolinearitas dalam peubah bebas dapat diperiksa dengan melihat nilai Variance
Inflation Factors (VIF). Nilai VIF ini diperoleh dari diagonal utama hasil perhitungan
matriks (XtX)-1. Apabila salah satu dari nilai VIF lebih dari 10, maka dapat diidentifikasikan
bahwa peubah Xj berhubungan erat dengan peubah-peubah X lainnya atau dengan kata lain
dalam peubah bebas terdapat masalah multikolinearitas (Myers,1990). Nilai Variance
Inflation Factors (faktor inflasi ragam) dapat juga dihitung berdasarkan rumus : VIFj = ( 1- R2j) -1
Dengan R2
j adalah koefisien determinan yang diperoleh jika peubah xj diregresikan dengan
p-1 peubah bebas lainnya. VIF memperlihatkan kenaikan ragam dugaan parameter yang dipengaruhi oleh keberadaan multikolinearitas (Sen dan Srivastava 1990, dalam Gusriani 2004).
3. Akar ciri dari XtX
Beberapa peneliti menentukan kondisi XtX dengan menentukan indeks kondisi :
Nilai ≥30 menunjukkan adanya masalah multikolinieritas pada XtX , (dalam Gusriani
2004).
Selain cara-cara diatas ada satu hal yang dapat dijadikan acuan untuk melihat keberadaan multikolinearitas, yaitu dengan melihat koefisien determinasi R2 (Gujarati, 1995). Apabila nilai R 2 tinggi tetapi tidak satupun parameter dugaannya signifikan, maka hal ini menunjukkan adanya kasus multikolinearitas.
Regresi Ridge
Regresi ridge merupakan salah satu metode yang dapat digunakan untuk mengatasi masalah multikolinearitas melalui modifikasi terhadap metode kuadrat terkecil (Neter, Waserman dan Kutner, 1990, dalam Herwindiati 1997). Modifikasi tersebut ditempuh dengan cara menambah tetapan bias q yang relatif kecil pada diagonal matriks XtX, sehingga
Pemilihan besarnya tetapan bias q merupakan masalah yang perlu diperhatikan. Tetapan bias q yang diinginkan adalah tetapan bias yang menghasilkan bias relatif kecil dan menghasilkan koefisien penduga yang relatif stabil. Ada beberapa acuan yang digunakan untuk memilih besarnya q, diantaranya dengan melihat besarnya VIF dan melihat pola kecendrungan ridge trace. Ridge Trace berupa plot dari penduga regresi ridge secara bersama dengan berbagai kemungkinan nilai tetapan bias q (Gibbons dan McDonald, 1984, dalam Herwindiati 1997). Nilai q yang dipilih yaitu q yang memberikan nilai penduga regresi ridge
yang relatif stabil.
Hoerl dan Kennard (1970) dalam Gusriani (2004) menentukan nilai q dengan menggunakan ridge trace yang merupakan suatu plot data antara dengan beberapa nilai q dalam selang 0-1 hingga tercapai kestabilan pada parameter dugaannya. Akan tetapi pemilihan q dengan ridge trace menjadi prosedur yang subjektif karena memerlukan keputusan peneliti untuk menentukan nilai q yang akan dipilih, (Montgomery dan Peck 1992). Hoerl, Kennard, dan Balwin (1975) dalam Gusriani (2004) menyarankan pemilihan nilai q dengan meggunakan rumus HKB :
dimana
^
β
danσ
^
diperoleh dari metode kuadrat terkecil. Pada penelitian selanjutnya(Montgomery dan Peck 1992), mengajukan prosedur iterasi dengan menggunakan nilai q pada
(2.27) sebagai nilai awal untuk menghitung nilai q dan selanjutnya
^
β
danσ
^
yang digunakandiperoleh dari metode regresi ridge dengan demikian prosedur ini akan berhenti jika
Tahapan penaksiran koefisien ridge regression :
1. Lakukan transformasi tehadap matriks X dan vektor Y, melalui centering and rescaling.
2. Hitung matriks = rxx = matriks korelasi dari variable bebas, serta hitung =
korelasi dari variable bebas terhadap variable tak bebas y.
3. Hitung nilai penaksir parameter β * dengan berbagai kemungkinan tetapan bias
θ , θ ≥
0.
4. Hitung nilai
C
θ dengan berbagai nilaiθ
.5. Tentukan nilai
θ
dengan mempertimbangkan nilaiC
θ.Tentukan koefisien penaksir ridge regression dari nilai
θ
yang bersesuaian.Data
Data yang digunakan untuk contoh pemakaian ini adalah data dari RumahSakit Sardjito Yogyakarta. Data ini menyangkut tentang jam kerja pegawai rumah sakit (Y) yang
diduga bergantung pada rata–rata peningkatan jumlah pasien (X1), tempat tidur harian yang
dipakai perbulan ( X2), dan populasi pasien yang memenuhi syarat pada area rumah sakit,
dalam ribuan (X3).
4. Analisis
4.1 Penaksiran Model Regresi Linier Ganda
Hasil Analisis Regresi dengan menggunakan Metode Kuadrat Terkecil terhadap data pada lampiran 1 tercantum pada tabel nilai penaksir parameter (tabel 5.1).
Pengujian keberartian model regresi ganda yang dilakukan secara parsial atau individu , dengan hipotesis :
Ho : βi = 0 , untuk i=1,2,3 (variabel independen X secara individu tidak
berpengaruh secara signifikan terhadap nilai taksiran Y) H1 : βi ≠ 0 , untuk i=1,2,3 (variabel independen X secara individu
berpengaruh secara signifikan terhadap nilai taksiran Y) α = 5%
Dengan statistik uji t-student, maka kita peroleh nilai Thitung dari masing-masing
variabel X secara individu adalah sebagai berikut :
Tabel 4.1 Penaksir Parameter Metode Kuadrad Terkecil
Dengan kriteria uji :
Tolak Ho jika thitung ≤ -t(n-2;α/2) atau thitung ≥ t(n-2;α/2), terima dalam hal lainnya.
Kriteria uji ini bisa juga dilihat dari nilai p. Tolak Ho jika nilai p ≤ α, terima dalam hal lainnya. Dari tabel 4.1 diatas diperoleh model regresi sebagai berikut :
^
Y
= -12.414 – 163.950 X1 + 6.230 X2 + 13.023 X3Dilihat dari Tabel 4.1 dan 4.2 diatas maka dapat disimpulkan koefisien penaksir tidak bisa ditaksir secara tepat, hal ini ditunjukkan oleh nila galat baku yang cukup besar dan nilai p yang lebih besar dari α menunjukkan bahwa tidak ada satu pun variabel independen X secara individu yang berpengaruh secara signifikan terhadap nilai taksiran Y. Begitu juga apabila dilihat dari thitung yang lebih kecil dari ttabel berarti semua variabel regressor X secara individu
tidak berpengaruh secara signifikan terhadap nilai taksiran Y.
Sedangkan apabila kita uji keberartian model secara simultan atau bersama sama untuk semua β , maka hipotesisnya adalah sebagai berikut :
Ho :
β
= 0 , (variabel independen X secara simultan tidak bergantung terhadap nilaitaksiran Y)
H1 :
β
≠ 0 , (variabel independen X secara simultan bergantung terhadap nilai taksiran Y)α = 5%
Dengan menggunakan statistik uji ANAVA atau uji F, maka berdasarkan taksiran parameter melalui Metode Kuadrat Terkecil untuk regresi linier ganda pada data dalam lampiran 1 diperoleh tabel ANAVA sebagai berikut:
Tabel 4.3 ANAVA Metode Kuadrat Terkecil
R2 = 0.978
Dengan kriteria uji:
Tolak H0 jika Fhitung ≥ F(p;n-p-1;α/2) atau bisa juga dilihat dari nilai p, tolak Ho jika nilai p ≤ α.
Dari tabel diatas terlihat bahwa nilai p < α. Ini berarti semua variabel X secara simultan berpengaruh terhadap nilai taksiran Y. Hal ini berbeda jika pengujian dilakukan
dengan hasil uji hipotesis yang signifikan dari koefisien β . Hal ini menunjukkan adanya kolinieritas.
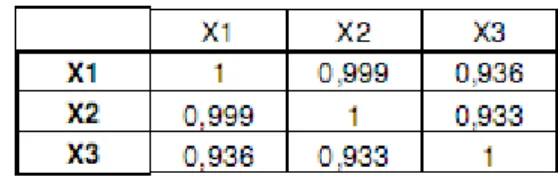
Di bawah ini disajikan tabel hasil perhitungan nilai korelasi antar variabel independen.
Tabel 4.4 Matriks dari Variabel X
Dari tabel 4.4 terlihat korelasi yang sangat tinggi antar variabel independen-nya. Hal ini menunjukkan adanya multikolinieritas.
4.2. Penaksiran Model Ridge Regression
Dalam analisis ridge regression digunakan data yang sudah ditransformasi melalui metode centering and rescaling (lampiran 2).
Dalam memilih tetapan θ untuk dapat menaksir ridge regression digunakan statistik Cp Mallows
(Cθ). Nilai Cθ dengan berbagai nilai kemungkinan tetapan θ disajikan dalam tabel 4.5 berikut :
Tabel 4.6 Nilai Cθ dengan berbagai nilai θ
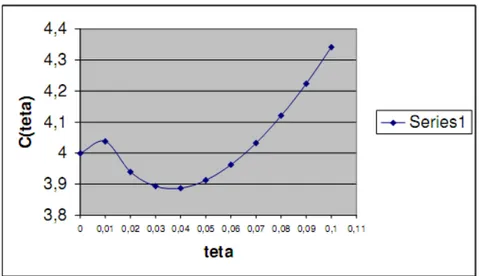
Dari tabel 4.5 dibuat grafik dengan sumbu datar θ dan sumbu tegak Cθ , hasilnya disajikan dalam Grafik 4.1
Nilai θ yang terpilih adalah pada saat Cθ minimum. Dari tabel 4.5 dan grafik 4.1
terlihat bahwa nilai θ yang meminimumkan Cθ adalah θ = 0.04.
Sehingga persamaan regresinya menjadi :
Setelah dikembalikan ke variabel-variabel asal diperoleh persamaan regresinya :
Jika kita uji secara simultan untuk semua β, maka hipotesisnya adalah sebagai berikut :
Ho :
β
= 0 , (variabel independen X secara simultan tidak bergantung terhadap nilaitaksiran Y)
H1 :
β
≠ 0 , (variabel independen X secara simultan bergantung terhadap nilai taksiran Y)α = 5%
Dengan menggunakan statistik uji ANAVA atau uji F, maka kita dapatkan tabel untuk metode ridge regression yang disajikan dalam tabel 4.6 berikut :
Tabel 4.6 ANAVA Ridge Regression
Dengan kriteria uji :
Tolak H0 jika Fhitung ≥ F(p;n-p-1;α/2) atau bisa juga dilihat dari nilai p, tolak Ho jika nilai p ≤ α.
Dari table distribusi F diperoleh FTabel = F(3;13;0,025) = 3,41. Ternyata Fhitung ≥ F(p;n-p-1;α/2) sehingga
Pegujian keberartian model ridge regression yang dilakukan secara parsial atau individu dapat dilakukan melalui pengujian hipotesis sebagai berikut :
Ho : βi* = 0 , untuk i=1,2,3 (variabel independen X secara individu tidak
berpengaruh secara signifikan terhadap nilai taksiran Y) H1 : βi* ≠ 0 , untuk i=1,2,3 (variabel independen X secara individu
berpengaruh secara signifikan terhadap nilai taksiran Y) α = 5%
Dengan statistik uji t-student, maka kita peroleh nilai Thitung dari masing-masing variabel X
secara individu adalah sebagai berikut :
Tabel 5.7 THitung
Dengan kriteria uji :
Tolak Ho jika thitung ≤ -t(n-2;α/2) atau thitung ≥ t(n-2;α/2), terima dalam hal lainnya. Kriteria uji ini bisa
juga dilihat dari nilai p. Tolak Ho jika nilai p ≤ α, terima dalam hal lainnya.
Dari table distribusi t-student diperoleh tTabel = t(13;0,0025) = 2,16 dari table 5.7 terlihat bahwa
semua nilai thitung ≥ tTabel sehingga tolak Ho . Hal ini menunjukkan bahwa setiap variable X
secara individu berpengaruh secara signifikan terhadap nilai taksiran Y.
6 Kesimpulan
Berdasarkan penjelasan yang telah diuraikan sebelumnya, kita bisa menyimpulkan hal-hal sebagai berikut :
1. Nilai R2 yang besar tidak diikuti oleh hasil uji hipotesis yang signifkan
dari semua koefsien penaksir bi serta eigen valuenya yang kecil. Hal ini
menunjukan multikolinieritas dalam data.
2. Jika antar variable regressor terjadi multikolinieritas, maka pemanfaatan aljabar matriks dapat digunakan melalui transformasi
centering and rescaling.
LAMPIRAN 1 . Data Mengenai Tenaga Kerja di Rumah Sakit Sardjito Yogyakarta
Y X1 X2 X3
566.52 15.57 472.92 18
696.82 44.02 1339.75 9.5 1033.1
5 20.42 620.25 12.8 1603.6
2 18.74 568.33 36.7 1611.3
7 49.2 1497.6 35.7 1613.2
7 44.92 1365.83 24 1854.1
7 55.48 1687 43.3 2160.5
5 59.28 1639.92 46.7 2305.5
8 94.39 2872.33 78.7 3503.9
3
128.0 2
3655.0
8 180.5 3571.8
9 96 2912 60.9
3741.4 131.42 3921 103.7 4026.5
2 127.21 3865.67 126.8 10343.
81 252.9 7684.1 157.7 11732.
17 409.2 12446.33 169.4 15414.
94 463.7
14098.
4 331.4 18854.
45
510.2
-0.055
62
-0.026
17
-0.028
51
-0.006
06
-0.042 8
-0.032
7
-0.031
33
0.047 433 0.241
224 0.162421 0.163222 0.118991 0.303
644 0.405065 0.405864 0.146086 0.469
22 0.489672 0.490039 0.521245 0.623