1
BAB 1 PENDAHULUAN
1.1 BAHASA PEMROGRAMAN
Manusia dapat melakukan interaksi secara efektif dengan menggunakan media bahasa. Bahasa memungkinkan penyampaian gagasan dan pemikiran, tanpa itu komunikasi akan sulit terjadi. Dalam lingkungan pemrograman komputer, bahasa pemrograman bertindak sebagai sarana komunikasi antara manusia dan permasalah-annya dengan komputer yang dipakai untuk membantu memperoleh pemecahan. Bahasa pemrograman menjembatani antara pemikiran manusia yang sering tidak terstruktur dengan kepastian yang diperlukan oleh komputer untuk melakukan eksekusi. Suatu solusi untuk suatu masalah akan menjadi lebih mudah bila bahasa pe-mrograman yang dipergunakan lebih dekat dengan permasalahan tersebut. Oleh karena itu, bahasa harus memiliki konstruksi yang merefleksikan terminologi dan elemen yang dipergunakan dalam mendeskripsikan masalah dan independen dari komputer yang di-pergunakan. Bahasa pemrograman seperti ini biasanya bahasa tingkat tinggi. Komputer digital, di sisi lain, menerima dan memahami hanya bahasa tingkat rendah mereka sendiri, terdiri dari deretan nol dan satu, yang sulit dipahami oleh manusia.
Bahasa pemrograman berdasarkan tingkat ketergantungannya dengan mesin bisa meliputi:
1. Bahasa mesin
Merupakan bentuk terendah dari bahasa komputer. Setiap ins-truksi dalam program direpresentasikan dengan kode numerik, yang secara fisik berapa deretan angka 0 dan Sekumpulan instruksi dalam bahasa mesin bisa dibentuk menjadi microcode, yaitu semacam prosedur dalam bahasa mesin.
2. Bahasa assembly
Merupakan bentuk simbolik dari bahasa mesin. Setiap kode ope-rasi memiliki kode simbolik, misalnya ADD untuk penjumlahan (additiori) dan MUL untuk perkalian (multiplication). Sekumpul-an instruksi dalam bahasa assembly bisa dibentuk menjadi makr-oinstruksi. Pada bahasa assembly tersedia alat bantu untuk diag-nostik atau debug yang tidak terdapat pada bahasa mesin. Con-toh produk yang ada untuk pengembangan dan debug bahasa assembly di pasaran saat ini, misalnya Turbo Assembler dari Borland, Macro Assembler dari Microsoft, DEBUG ya&g-tersedia pada DOS, dan Turbo Debugger. Instruksi dalam bahasa Assem-bly biasanya terdiri
2
dari beberapa field, misalnya field operasi diikuti satu atau lebih operan. 3. Bahasa tingkat tinggi (user oriented)
Disebut tingkat tinggi karena lebih dekat dengan manusia. Mem-berikan fasilitas yang lebih banyak, kontrol program yang ter-struktur, kalang (nested), block, dan prosedur. Contohnya: Pascal, BASIC
4. Bahasa yang problem oriented
Memungkinkan penyelesaian untuk suatu masalah atau aplikasi yang spesifik. Contohnya: SQL (Structured Query Language) un-tuk aplikasi database, COGO untuk aplikasi teknik sipil. Bahasa yang problem oriented kadang dimasukkan pula sebagai bahasa tingkat tinggi.
Dalam buku ini akan difokuskan pada pengembangan kompi-lator untuk bahasa tingkat tinggi prosedural seperti Pascal.
Keuntungan bahasa tingkat tinggi dibandingkan bahasa tingkat rendah sebagai berikut: 1. Kemudahan untuk dipelajari, tidak membutuhkan latar belakang pengetahuan mengenai
perangkat keras (hardware) karena sifat-nya yang machine independent. 2. Lebih mendekati permasalahan yang akan diselesaikan
3. Pemrogram tidak perlu mengetahui bagaimana representasi data ke dalam bentuk internal di meinory. Kemampuan untuk konversi data, seperti floating point misalnya sudah tersedia. Pekerjaan tersebut ditangani oleh suatu sistem yang mentranslasi-kan program bahasa tingkat tinggi ke dalam bahasa mesin.
4. Memberikan banyak pilihan struktur kontrol seperti: • kondisional (IF-THEN-ELSE)
• looping (REPEAT-.UNTIL, FOR) • struktur blok (BEGIN..END) • nested statement
Struktur kontrol ini memberikan fasilitas untuk pemrograman terstruktur, sehingga program mudah dibaca, dipahami dan dimodifikasi. Ini akan mengurangi biaya pemrograman karena program lebih sederhana.
5. Program lebih mudah di-debug. Bahasa tingkat tinggi menyediakan konstruksi yang mengurangi kesalahan pemrograman yang biasa muncul pada bahasa tingkat rendah. Sebagai contoh, deklarasi suatu variabel akan menjadi sesuatu yang berguna dalam mendeteksi kesalahan penggunaan variabel, Bahasa-bahasa biasanya mengharuskan penggunaan pointer secara konsisten. Suatu program yang terstruktur
3
lebih mudah di-debug daripada yang tidak terstruktur.
6. Kemampuan struktur data yang lebih baik, sehingga memfasilitasi pengekspresian suatu solusi dari masalah tertentu.
7. Karena ketersediaan feature seperti prosedur, bahasa tingkat tinggi memungkinkan suatu deskripsi modular dan hirarkis dalam pemrograman. Suatu pekerjaan bisa diserahkan pada suatu tim, dan memungkinkan pembagian kerja.
8. Kompatibilitas dan dokumentasi yang lebih baik dalam pengembangan program
9. Tidak bergantung pada mesin (machine independent) sehingga memiliki portabilitas tinggi. Program hanya memerlukan sedikit perubahan untuk bisa dieksekusi pada mesin yang berbeda arsitektur internalnya dan instruksi bahasa mesinnya. Portabilitas
ini akan mengurangi biaya.
Agar dapat dieksekusi, sebuah program dalam bahasa tingkat tinggi tentu saja harus ditranslasikan ke dalam bahasa mesin. Pada bagian berikutnya akan dibahas mengenai translator.
1.2 TRANSLATOR
Sebuah translator melakukan pengubahan source code/source program (program sumber) ke dalam target codelobject code/object program (program objek). Source code ditulis dalam bahasa sumber, sedang object code bisa berupa suatu bahasa pemrograman lain atau bahasa mesin pada suatu komputer. Ada beberapa macam translator:
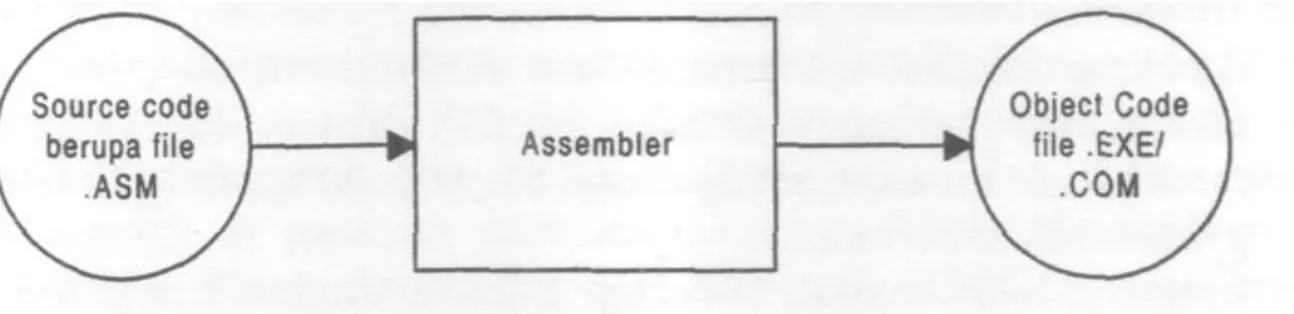
1. Assembler
Source code adalah bahasa assembly, object code adalah bahasa mesin. Contohnya: Turbo Assembler dan Macro Assembler.
4
2. Kompilator (Compiler)
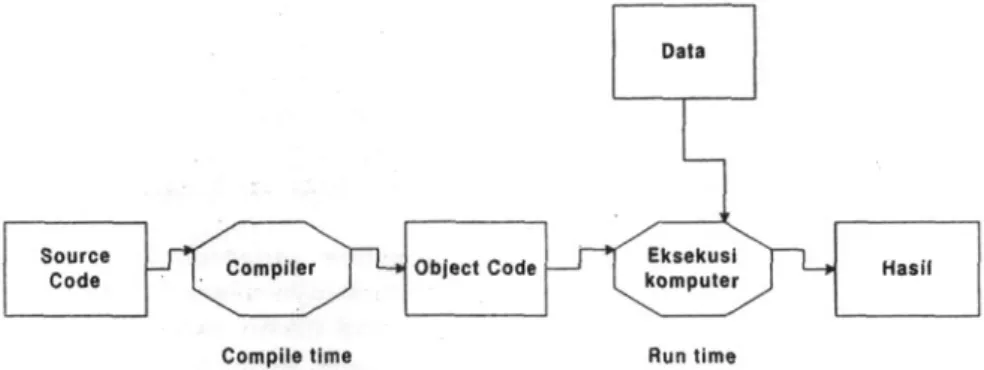
Source code adalah bahasa tingkat tinggi (misal bahasa Pascal), object code adalah bahasa raesin atau bahasa assembly. Source code dan data diproses pada saat yang berbeda. Contohnya: Turbo Pascal. Proses kompilasi dapat dilihat pada gambar 1.2.
Gambar 1.2 Proses Kompilasi
Compile time adalah saat pengubahan source code ke object code. Run time adalah saat eksekusi object code.
1. Interpreter
Interpreter tidak membangkitkan object code, hasil translasi hanya dalam bentuk internal. Contoh interpreter: BASICA/GW-BASIC, LISP, SMALLTALK. Source code dan data diproses pada saat yang sama. Proses interpretasi dapat dilihat pada gambar 1.3.
Run time Gambar 1.3 Proses Interpretasi
Selanjutnya dalam buku ini akan difokuskan pada kompilator dan teknik pengembangannya.
5
1.3 MODEL KOMPILATOR
Pengembangan kompilator untuk sebuah bahasa merupakan pekerjaan yang kompleks. Kompleksitas kompilator bisa dikurangi bila perancang bahasa pemrograman mempertimbangkan bermacam-macam faktor perancangan. Karena kita berhubungan dengan bahasa tingkat tinggi, bagaimanapun suatu model dasar dari kompilator dapat diformulasikan. Sebuah kompilator umumnya memiliki dua tugas pokok:
1. Fungsi Analisis
Fungsi Analisis biasa disebut sebagai Front End. Tugasnya melakukan dekomposisi program sumber menjadi bagian-bagian dasarnya
2. Fungsi Sintesis
Fungsi Sintesis biasa disebut sebagai Back End. Tugasnya melakukan pembangkitan dan optimasi program objek
6
BAB 2
PERANCANGAN BAHASA PEMROGRAMAN
2.1 SUMBER PERANCANGAN BAHASA PEMROGRAMAN
Gagasan untuk perancangan bahasa pemrograman bisa berasal dari bahasa alami (natural language), matematika, dan bahasa pe-mrograman yang sudah ada. Penjelasannya masing-masing sebagai berikut:
1. Konstruksi yang diturunkan dari bahasa alami berguna untuk kejelasan dan kemudahan pembacaan. Sebuah instruksi akan mengerjakan 'mirip' dengan arti instruksi itu. Hal ini memberikan kenyamanan untuk para pemrogram, khususnya yang belum berpengalaman. Di sisi lain bisa pula menimbulkan ambiguitas/ke-dwiarti-an yang tidak diinginkan dalam sebuah bahasa pemrograman. Bagaimanapun, bahasa alami bisa digunakan sebagai panduan untuk perancangan sintaks sebuah bahasa pemrograman.
2. Matematika telah banyak dipakai untuk aturan-aturan yang terdapat pada bahasa pemrograman, misalnya ekspresi aritmatika. Tetapi seorang pemrogram dan ahli matematika menggunakan metode dan memecahkan masalah yang berbeda. Meskipun matematika merupakan suatu sumber yang berguna, perlu kehatihatian saat mengadopsi notasi matematika untuk suatu konsep.
3. Bahasa pemrograman yang sudah ada bisa menjadi sumber yang bagus untuk perancangan bahasa pemrograman. Tetapi perlu ketelitian saat menggunakannya, karena bahasa yang sudah ada itu mungkin mengandung kesalahan yang serius. Beberapa fasilitas yang diinginkan bisa dibatasi untuk meningkatkan kemudahan baca (readability) dan pemeriksaan kesalahan, dengan mengamati bagian mana dari bahasa yang jarang digunakan. Misalnya motivasi untuk tidak menggunakan instruksi GOTO da-tang dari pengamatan bahwa pemrogram yang baik tidak menggunakan GOTO untuk membuat struktur yang lebih mudah di-pahami.
2.2 TUJUAN PERANCANGAN BAHASA PEMROGRAMAN Perancangan sebuah bahasa pemrograman bertujuan untuk:
1. Komunikasi dengan manusia
Jika sebuah program sulit dimengerti oleh manusia, akan terjadi kesulitan juga untuk memeriksa dan melakukan pemeliharaan/modifikasi. Masalah ini tidak bisa dipecahkan
7
dengan sekedar me-nambahkan komentar atau melalui dokumentasi tersendiri. Pemrogram tidak suka menambahkan komentar yang berlebihan, sementara dokumentasi program sering tidak lengkap dan sudah kadalu-warsa. Sebuah program yang mudab dibaca/dimengerti adalah se-buah dokumentasi yang baik. Sintaks sebuah bahasa pemrograman harus merefleksikan semantiknya. Keterbatasan kemampuan pikir manusia menyulitkan untuk memahami suatu struktur yang kompleks, sementara kompilator tidak, Misalkan saja algoritma manipulasi dengan stack. Mungkin suatu statement bermakna ambigu bagi manusia, sementara sudah cukup jelas bagi kompilator, misalnya instruksi aritmatika berikut:
a/b/c bisa berarti
a dibagi dengan b, baru hasilnya dibagi dengan c atau
a dibagi dengan hasil pembagian b dengan c 2. Pencegahan dan deteksi kesalahan
Sebuah bahasa pemrograman yang baik perlu mengidentifikasi error yang mungkin terjadi. Sebingga mempermudah deteksi kesalah-an dan menghilangkannya.
3. Usability
Bahasa pemrograman harus mudah dipelajari dan diingat. Sekali seorang pemrogram familiar dengan bahasa itu, dia tidak harus melihat manual terus-meneras. Usability berkaitan dengan aspek kenyamanan seorang pemrogram menggunakan bahasa.
4. Efektifitas pemrograman
Efektifitas di sini berkaitan dengan pemrograrnan sebagai bagian dari rekayasa perangkat lunak. Hal yang menjadi perhatian besar pada rekayasa perangkat lunak adalah bagaimana mencatat keputusan yang dibuat selama pengembangan program. Program sendiri adalah tempat terbaik untuk mencatat keputusan tersebut. Bahasa pemrograman harus memfasilitasi suatu statement yang jeias dari keinginan pemrogram. Bilamana mungkin, bahasa harus me-mungkinkan pemrogram untuk menyatakan keinginan mereka dan membiarkan kompilator melakukan implementasinya. Suatu bahasa yang jelas dan mudah dibaca akan mencegah pemrogram yang 'eer-das' untuk melakukan 'tricky". Salah satu contoh rancangan pre-sedensi operator yang buruk adalah di dalam bahasa C, yang me-miliki selusin tingkat prioritas.
5. Compilability
Pengembangan sebuah kompilator menipakan pekerjaan yang tidak sederhana. Sebuah bahasa yang terlalu kompleks akan menyulitkan pembuatan kompilator untuk bahasa tersebut.
8
Kornplek-sitas tersebut bisa muncul baik pada tahapan analisis maupun sin-tesis. Kompleksitas biasanya muncul pada bahasa di mana koma dan parenthesis (kururig buka/tutup) digunakan pada banyak aturan yang berbeda. Sebagai contoh, parenthesis bisa dipakai pada:
• Pengelompokan sub-ekspresi
• Membatasi argumen pada pemanggilan prosedur • Membatasi parameter pada definisi prosedur • Menentukan indeks pada array
• Ekspresi logika
Dalam kasus tersebut diperlukan look-ahead parser yang mampu melihat dua atau tiga token ke depan, sehingga memperlambat kompilasi dan menambah ukuran tabel untuk parsing. Feature bahasa yang kompleks tapi jarang dibutuhkan lebih baik tidak dimasukkan. Salah satu contoh skema yang sederhana tetapi powerful adalah metode passing parameter dengan call by value dan call by reference. Sebisa mungkin rancangan bahasa dibuat selengkap mung-kin sebelum masuk ke tahapan implementasi kompilator.
6. Efisiensi
Efisiensi merupakan bahasan yang penting dalam sejarah pengembangan bahasa pemrograman. Dalam hal ini harus diingat pula bahwa mesin akan lebih murah, sementara pemrogram akan semakin mahal. Kita tidak bisa memaksakan efisiensi 10 persen dengan usaha yang dikeluarkan cukup keras, karena hasilnya tidak sebanding dengan 'investasi' yang dilakukan. Perbedaan dalam efi-siensi 10 atau 20 persen bisa ditoleransi. Tetapi tidak untuk per-bedaan dalam kelipatan 2 atau 10 karena alasan-alasan berikut:
• Bagaimanapun cepat dan murahnya perangkat keras, akan lebih murah dan cepat bilamana menjalankan sebuah program yang efisien
• Kecepatan dan harga dari peripheral tidak meningkat secepat CPU
• Tidak seharusnya user dikorbankan dengan memaksa mereka mengeluarkan uang untuk peningkatan perangkat keras
Salah satu hal yang penting adalah menentukan penyebab utama dari inefisiensi. Penyebab terbesar biasanya adalah ketidakcocokan antara perangkat keras dengan bahasa. Mencoba untuk membuat bahasa terlalu 'dekat' dengan perangkat keras juga akan memberikan hasil yang buruk. Optimasi suatu kompilator bukanlah jawaban utama. Suatu optimasi kompilator menimbulkan kesulitan dan memerlukan banyak waktu untuk dibuat. Harus dilakukan secara hati-hati supaya semantik dari bahasa tidak berubah karena proses optimasi. Optimizer umumnya juga berjalan lebih lambat daripada kompilator sederhana. Efisiensi
9
bukanlah hanya permasalahan ke-cepatan-ukuran, karena akses I/O dan paging memori termasuk juga dalam efisiensi. Peningkatan yang signifikan dalam efisiensi bisa didapat dengan membuat bahasa lebih sederhana sehingga mudah untuk menghasilkan kode yang efisien.
7. Machine Independent
Sebuah bahasa dikatakan machine independent jika dan hanya jika sebuah program yang telah sukses dikompilasi dan dieksekusi pada suatu mesin, saat dipindahkan ke mesin lainnya akan berjalan dengan input dan output yang tepat sama. Perlu diperhatikan ma-chine independence tidak diharuskan untuk semua bahasa pemro-gramau. Misalnya bahasa yang ditujukan untuk penulisan sistem operasi bisa memiliki ketergantungan tertentu pada mesin. Beberapa masalah yang berkaitan dengan independensi suatu bahasa misal-nya:
Aritmatika floating point
Kumpulan (set) karakter yang ada Karakter kontrol.
8. Kesederhanaan (simplicity)
Kebanyakan pemrogram menginginkan bahasa yang seder-hana. Tetapi kesederhanaan bisa pula berarti kekurangan di sisi lain. Bahasa BASIC, contohnya, merupakan bahasa yang sederhana, tetapi tidak dirancang secara baik. Simplicity tidak bisa dicapai de-ngan keterbatasan struktur yang akan menghasilkan chaos. Sim-plicity juga tidak bisa dicapai dengan generalitas yang tidak terbatas, karena akan menghasilkan bahasa yang sangat sulit untuk diimplementasikan secara lengkap. Kesederhanaan bisa dicapai melalui:
• Pembatasan-pembatasan tujuan • Perhatian pada keterbacaan • Pendefinisian yang baik • Konsep yang sederhana. 9. Uniformity
Uniformity bisa didefinisikan sebagai mengerjakan hal yang sama dengan cara yang sama. Bila diadopsi sebagai prinsip bahasa pemrograman, ini bisa menolong mengurangi hal-hal yang harus diingat pemrogram, karena akan lebih mudah memahami bagaimana suatu feature akan dilakukan. Seperti aspek-aspek yang lain, uniformity bisa menjadi berguna atau tidak tergantung dari bagaimana penerapannya. Suatu contoh penerapan uniformity yang berguna misalkan pemakaian ekspresi pada ALGOL, dimanapun dibutuhkan suatu nilai aritmatika bisa digunakan ekspresi apa pun. Contoh pe-nerapan uniformity yang tidak berguna
10
misalnya gagasan mengenai ekspresi dan statement pada ALGOL. Suatu bahasan dalam kasus uniformity adalah bagaimana menghilangkan kasus khusus. Kasus-kasus khusus seperti ini memiliki masalah:
Membuat bahasa menjadi lebih kompleks
Menuju pada implementasi yang berbeda, beberapa akan mengimplementasikannya dengan tidak tepat, yang lain. mungkin akan menghilangkannya
Menjadi lebih sulit untuk dihilangkan meskipun terdapat ke-kurangannya. 10. Orthogonality
Gagasan mendasar dari orthogonality adalah setiap fungsi bekerja tanpa perlu mengetahui struktur dari yang lain. Misalkan operasi aritmatika menggabungkan dua nilai, tidak memperdulikan bagaimana nilai tersebut didapatkan. Alternatif untuk orthogonality adalah diagonality.
11. Generalisasi dan spesialisasi
Pemikiran mendasar dari generalisasi adalah: "jika kita dibolehkan melakukan ini, maka lakukanlah hal lain dengan cara se-rupa". Dalam cara serupa dengan orthogonality, merupakan pelengkap bagi simplicity. Jika digunakan berlebihan, bisa menghasilkan pemakaian yang jarang, atau feature yang mengandung kesalahan yang sulit diimplementasikan. Pada beberapa bahasa terdapat fungsi built-in yang menerima berapa pun jumlah argumen, di mana jarang user menggunakannya.
11
BAB 3
KONSEP DAN NOTASI BAHASA
3.1 HIRARKI CHOMSKY
Pada bagian ini akan dibahas beberapa konsep pada Teori Bahasa yang akan kita perlukan nanti. Teknik kompilasi sebenarnya bisa dianggap sebagai kelanjutan dari konsep-konsep yang dipelajari dalam Teori Bahasa, dan dalara implementasinya mengarnbil se-bagian dari konsep-konsep tersebut.
Tata bahasa (grammar) bisa didefinisikan secara formal sebagai kumpulan dari himpunan-himpunan variabel, simbol-simbol terminal, simbol awal, yang dibatasi oleh aturan-aturan produksi. Pada tahun 1959 seorang ahli bernama Noam Chomsky melakukan penggolongan tingkatan bahasa menjadi empat, yang disebut dengan Hirarki Chomsky. Penggolongan tersebut bisa dilihat pada tabel berikut:
Bahasa Mesin otomata Batasan Aturan Produksi
Regular / Tipe 3 Finite State Automata (FSA) meliputi Deterministic Finite Automata (DFA) & Non-deterministic Finite Automata (NFA)
α adalah sebuah simbol variabel
β maksimal memiliki sebuah simbol variabel yang bila ada terletak di posisi paling kanan
Bebas Konteks / Context Freel Tipe 2
Push Down Automata ('PDA) α berupa sebuah simbol variabel
Context Sensitive/ Tipe 1
Linier Bounded Automata |α|≤β Unrestricted
Phase Structure Natural La-nguage Tipe 0
Mesin Turing tidak ada batasan
Bisa kita lihat penggolongan di atas berdasarkan pembatasan yang dilakukan pada aturan produksinya. Aturan produksi merupakan pusat dari tata bahasa, yang menspesifikasikan bagaimana suatu tata bahasa melakukan transformasi suatu string ke bentuk lainnya, dan melalui aturan produksi tersebut didefinisikan suatu bahasa yang berhubungan dengan tata bahasa tersebut. Di sini semua aturan produksi dinyatakan dalam bentuk α→β (bisa dibaca: α menghasilkan β, atau dibaca α menurunkan β, di mana α menyatakan simbol-simbol pada ruas kiri aturan produksi (sebelah kiri tanda →) dan β menyatakan simbol-simbol pada ruas kanan aturan produksi (sebelah kanan tanda →, dan bisa disebut juga sebagai hasil produksi).
12
Simbol-simbol tersebut bisa berupa simbol terminal atau simbol non-terminal/variabei. Simbol variabel/non terminal adalah simbol yang masih bisa diturunkan, sedang simbol terminal sudah tidak bisa diturunkan lagi. Simbol terminal biasanya (dan pada buku ini) dinyatakan dengan (huruf kecil, misal 'a'/b'/c'. Simbol non terminal/variabel biasanya diriyatakan huruf besar, misal 'A'.'B', 'C'.
Dengan menerapkan aturan produksi, suatu tata bahasa bisa menghasilkan sejumlah string. Himpunan semua string tersebut adalah bahasa yang didefinisikan oleh tata bahasa tersebut.
Contoh aturan produksi: T→α
Bisa dibaca : “T” menghasilkan a” E →T | T+E
bisa dibaca: "E menghasilkan T atau E menghasilkan T+E"
Simbol ' | ' menyatakan 'atau', biasa digunakan untuk mempersingkat penulisan aturan produksi yang mempunyai ruas kiri yang sama. Pada contoh di atas:
E →T | T+E
merupakan pemendekan dari aturan produksi: E →T
E →T+E
Bahasa manusia/ bahasa alami termasuk ke dalam grammar (tata bahasa) Tipe 0/Unrestricted, di mana tidak ada batasan pada aturan produksinya. Misalkan saja:
Abc → De
Pada bahasa Context Sensitive, panjang string pada ruas kiri ≤ panjang ruas kanan ( | α | ≤ |β | ). Contoh aturan produksi yang context sensitive:
Ab→DEF CD →eF.
Perhatikan aturan produksi seperti: S →e
kita ketahui | S | = 1, sedang | έ| = 0, menurut aturan context sensitive aturan produksi itu tidak diperkenankan, tetapi di sini kita buat suatu perkecualian, sehingga S → ε dianggap rnemenuhi context sensitive grammar.
Batasan context sensitive biasanya turut digunakan dalam proses analisis semantik pada tahapan kompilasi.
13
Pada bahasa bebas konteks, batasannya bertambah lagi dengan ruas kiri haruslah tepat satu simbol variabel. Misalnya:
B →CDeFg D →BcDe
Bahasa bebas konteks menjadi dasar dalam pembentukan suatu parser/ proses analisis sintaksis. Bagian sintaks dalam suatu kompilator kebanyakan didefinisikan dalam tata bahasa bebas konteks (context free grammar), yang dideskripsikan secara formai dengan notasi BNF (Backus Naur Form atau Backus Normal Form).
Pada bahasa regular, batasannya bertambah dengan ruas kanan maksimal memiliki sebuah simbol variabel yang terletak di paling kanan. Artinya bisa memiliki simbol terminal saja dalam jumlah tidak dibatasi, tetapi bila terdapat simbol variabel, maka simbol variabel tersebut hanya berjumlah 1 (satu) dan terletak di posisi paling kanan. Misal:
A →e A→efg A→efgH C→D
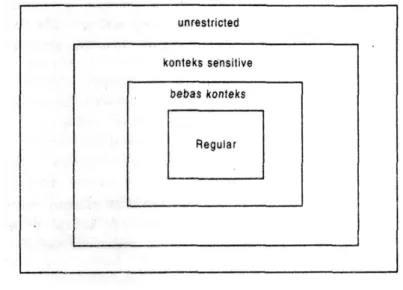
Bisa kita lihat, batasannya makin bertambah dari Tipe 0 ke Tipe 3. Berdasarkan keterkaitannya antar tipe bahasa tersebut, bisa pula dilihat secara sederhana pada gambar 3.1.
14
*Perhatikan:
Aturan produksi seperti ε→Abd
bukan aturan produksi yang legal, karena simbol ε tidak boleh berada pada ruas kiri Aturan produksi yang ruas kirinya hanya memuat simbol terminal saja, seperti
a →bd ab→bd
bukan aturan produksi yang legal (untuk unrestricted grammar sekalipun), karena ruas kiri harus juga memuat simbol yang bisa di-turunkan, sementara contoh di atas ruas kiri hanya terdiri dari sim-bol terminal saja padahal sesuai definisinya simbol terminal sudah tidak bisa diturunkan lagi, berbeda dengan aturan produksi seperti
aA →bd
3.3 NOTASI BNF
Aturan-aturan produksi dapat dinyatakan dalam bentuk BNF (Backus Naur Form/Backus Norm Form). Notasi BNF telah banyak dipakai untuk melakukan definisi formal bahasa pemrograman. Beberapa simbol yang dipakai dalam notasi BNF:
::= identik dengan simbol -> pada aturan produksi | idem dengan simbol serupa pada aturan produksi < > mengapit simbol variabel/non terminal
n pengulangan 0 sampai n kali
contoh:
Terdapat aturan produksi:
E →T | T+E | T-E,T→α Notasi BNF:
E ::= <T> \ <T> + <E> | <T> - <E>, T ::= a
3.4 DIAGRAM SINTAKS
Diagram Sintaks merupakan alat bantu dalam pembentukan parser/ analisis sintaksis. Notasi yang terdapat pada diagram sintaks:
• Empat persegi panjang melambangkan sirnbol variabel/non terminal • Bulatan raelambangkan simbol terminal
15
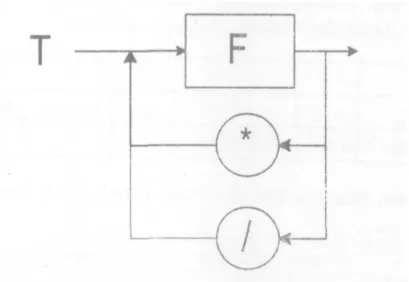
Misal terdapat aturan produksi:
T →F*T | F/ T | F diagram sintaksnya dapat dilihat pada gambar 3.3
Gambar 3.3 Diagram sintaks
Biasanya diagram sintaks digunakan untuk raemperoleh gambaran dari suatu notasi BNF. Misalkan notasi BNF untuk block:
<block> ::= t_BEGIN <statement> t_SEMICOL <statement>
t_END
diagram sintaksnya pada gambar 3.4.
16
BAB 4
ANALISIS LEKSIKAL
4.1 TUGAS SCANNER
Scanner bertugas melakukan analisis leksikal, yaitu mengidentifikasi semua besaran yang membangun suatu bahasa pada suatu program sumber. Scanner adalah bagian dari kompilator yang menerima input berupa stream karakter kemudian memilah program sumber menjadi satuan leksik yang disebut dengan token. Token ini akan menjadi input bagiparser. Tugas Scanner bisa dirangkum sebagai berikut:
1. Melakukan pembacaan kode sumber dengan merunut karakter demi karakter 2. Mengenali besaran leksik
3. Mentransformasi menjadi sebuah token dan menentukan jenis token-nya 4. Mengirimkan token
5. Membuang/mengabaikan blank dan komentar dalam program 6. Menangani kesalahan
7. Menangani tabel simbol
Scanner bekerja berdasarkan mesin Finite State Automata yang ada pada Bahasa Regular. Untuk membantu mengkonstruksi Scanner dapat mempergunakan Diagram Keadaan.
4.2 BESARAN LEKSIK
Besaran pembangun bahasa/leksik meliputi: 1. Identifier
Bisa berupa keywords atau nama. Keywords adalah kata kunci yang sudah didefinisikan oleh suatu bahasa seperti BEGIN, END, IF, ELSE di dalam Pascal. Nama dideklarasikan sendiri oleh pemakai, seperti nama sebuah variabel misalnya. Contoh bila pada suatu program Pascal terdapat deklarasi:
VAR
Nomor: INTEGER; Suhu: REAL;
Maka Nomor dan Suhu akan dikenali sebagai besaran leksik berupa nama variabel yang terdapat pada program tersebut. Sedang-kan VAR, INTEGER, dan REAL merupakan keyword pada program tersebut. Nama bisa berupa nama program, procedure, var, type, constant. Keyword pada Pascal misalnya:
17
2. Nilai konstanta
Adalah suatu konstanta yang terdapat pada program. Bisa berupa konstanta integer, real, boolean, character, string, dan sebagainya. Misalkan saja dalam Pascal pada suatu prograni terdapat statement:
N:= R + 5 * 10 kata:= katal + 'makan' A := 0.333 Selesai := TRUE
Maka 5, 10, 'makan', 0.333, TRUE, termasuk besaran lekdik berupa nilai konstan yang terdapat pada program sumber tersebut.
3. Operator dan delimiter
Operator misalnya operator aritmatika ( +,-,*/, ) operator logika (<, =, >).
Delimiter berguna sebagai pemisah/pembatas, misalnya: ( ) , ;, :, (kurung buka/tutup, koma, titik, titik koma, titik dua), white-space. White-space adalah pemisah yang diabaikan di program, seperti spasi, karakter enter (Carriage Return), ganti baris (Line Feed), akhir file (End OfFile). Contoh beberapa delimiter:
^ , .
: ( |
.. ) ]
[ :
Misalkan terdapat sebuah source program:
PROGRAM Coba; VAR A:INTEGER BEGIN
A:= A+2 END.
Pada contoh di atas, besaran leksik (token)-nya adalah simbol yang bernilai TROGRAM', 'Coba', 'VAR', 'A', 'INTEGER', ':', '+', '2', '.', ';', ':=', 'BEGIN', 'END'.
Misalkan sebuah bahasa memiliki himpunan simbol terminal/token: '<', '>', '=', '<=', '>=', '<>'
18
BAB 5
ANALISIS SINTAKSIS
5.1 POHON SINTAKS
Sebuah pohon (tree) adalah suatu graph terhubung tidak sirkuler, yang memiliki satu simpul (node)/vertex disebut akar (root) dan dari situ memiliki lintasan ke setiap simpul. Gambar 5.1 memberikan contoh sebuah tree yang menguraikan kalimat dalam bahasa Inggris.
The quick brown foxjumped over the lazy dog
Pohon sintaks/ pohon penurunan (syntaz tree/derivation treel parse tree) berguna untuk menggambarkan bagaimana memperoleh suatu string (untai) dengan cara menurunkan simbol-simbol variabel menjadi simbol-simbol terminal. Setiap simbol variabel akan diturunkan menjadi terminal, sampai tidak ada yang belum tergantikan.
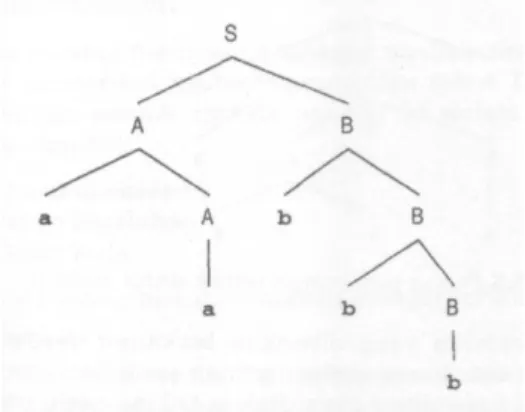
Misal terdapat tata bahasa bebas konteks dengan aturan produksi (simbol awal S, selanjutnya di dalam bab ini digunakan sebagai simbol awal untuk tata bahasa bebas konteks adalah S):
S →AB A →aA | a B →bB | b
Akan kita gambarkan pohon penurunan untuk memperoleh untai: 'aabbb' Pada pohon tersebut simbol awal akan menjadi akar (root). Setiap kali penurunan dipilih aturan produksi yang menuju ke solusi. Simbol-simbol variabel akan menjadi simpul-simpul yang mempunyai anak. Simpul-simpul yang tidak mempunyai anak akan menjadi simbol terminal, Kalau kita baca simbol terminal yang ada pada gambar 5.2 dari kiri ke kanan akan diperoleh untai 'aabbb'.
19
Proses penurunan atau parsing bisa dilakukan dengan cara:
Penurunan terkiri (leftmo&t derivation): simbol variabel terkiri yang diperluas terlebih dulu
Penurunan terkanan (rightmost derivation): simbol variabel terkanan yang diperluas terlebih dulu
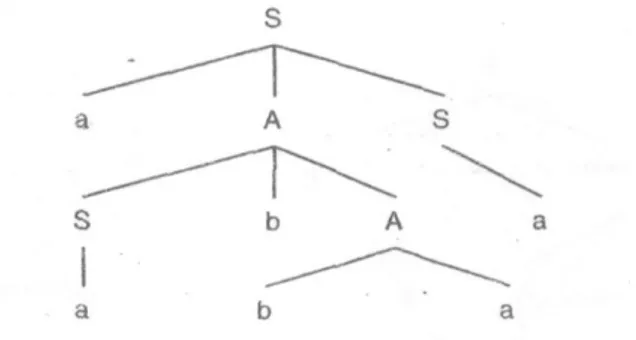
Misal terdapat tata bahasa bebas konteks: S →aAS | a A →SbA | ba
Untuk memperoleh untai 'aabbaa' dari tata bahasa bebas konteks di atas ('=>' bisa dibaca 'menurunkan'):
• Dengan penurunan terkiri: S => aAS => aSbAS => aabAS => aabbaS => aabbaa • Dengan penurunan terkanan: S => aAS => aAa => aSbAa => aSbbaa => aabbaa
Kita lihat pohon penurunannya pada gambar 5.3. Meskipun proses penurunannya berbeda akan tetap memiliki pohon penurunan yang sama.
Gambar 5.3 Pohon penurunan untuk untai 'aabbaa'
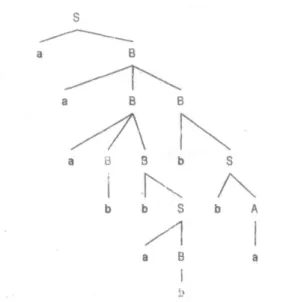
Biasanya persoalan yang diberikan berkaitan dengan pohon penurunan, adalah untuk mencari penurunan yang hasilnya menuju kepada suatu untai yang diteiitukan. Dalam hal ini, perlu untuk melakukan percobaan pemilihan aturan produksi yaag bisa menuju ke soiusi. Misalkan sebuah tata bahasa bebas konteks memiliki aturan produksi:
S → aB | bA A →a \ aS | bAA B → b \ bS | aBB
20
Pohon penurunan untuk memperoleh 'aaabbaobba' bisa dilihat pada gambar 5.4.
Gambar 5.4 Pohon penurunan untuk untai 'aaabbabbba'
5.2 METODE PARSING
Proses Parsing merupakan tahapan analisis sintaksis yang berguna untuk memeriksa urutan kemunculan token. Di dalam mengimplementasikan sebuah metode parsing ke dalam program perlu diperhatikan tiga hal:
• Rentang waktu eksekusi • Penanganan kesalahan • Penanganan kode
Metode Parsing bisa digolongkan sebagai berikut: 1. Top Down
Kalau dilihat dari terminologi pohon penurunan, metode ini rae-lakukan penelusuran dari root/puncak menuju ke leaf/daun (sim-bol awal sampai simbol terminal). Metode top down sendiri meliputi:
a. Backtrack / backup: Brute Force
b. No backtrack: Recursive Descent Parser 2. Bottom Up
Metode ini melakukan penelusuran dari leaf/dauri menuju ke roof/puncak. Pembahasan kita selanjutnya hanyalah metode Top Down Parsing
21
BAB 6
ANALISIS SEMANTIK KODE ANTARA, DAN PEMBANGKITAN KODE
6.1 ANALISIS SEMANTIK
Dalam rangkaian proses kompilasi, analisis semantik masih termasuk dalam bagian front end (bagian yang menangani analisa source prograrri). Proses ini merupakan kelanjutan dari proses kom-pilasi sebelumnya, yaitu proses scanning (analisa leksikal) dan proses parsing (analisa sintaks). Bagian terakhir dari tahapan analisis ada-lah analisis semantik. Pada tahap ini dilakukan pengecekan pada struktur akhir yang telah diperoleh dan diperiksa kesesuaiannya dengan komponen program yang ada.
Pada hakekatnya, semantic analyzer ini memanfaatkan pohon sintaks yang dihasilkan pada proses parsing (analisa sintaks). Secara teori, sebenarya diinginkan agar proses analisa sintaks dan analisa semantik adalah dua hal yang terpisah. Akan tetapi, pada tingkat praktis, hal ini sulit untuk dilakukan. Proses analisa sintaks dan analisa semantik merupakan dua proses yang sangat erat kaitannya, dan sulit sekali untuk benar-benar dipisahkan.
Secara global, fungsi dari semantic analyzer adalah untuk menentukan makna dari serangkaian instruksi yang terdapat dalam program sumber. Fungsi ini adalah sesuatu yang unik dan berbeda dengan bagian lain dari keseluruhan proses kompilasi. Sebagai contoh, andaikata terdapat suatu ekspresi :
A:=(A+B)*(C+D)
maka, penganalisa semantik harus mampu menentukan aksi apa yang akan dilakukan oleh operator-operator tersebut. Dalam sebuah proses kompilasi, andaikata parser menjumpai ekspresi seperti di atas, parser hanya akan mengenali simbol-simbol ':=', '+', dan '*'. Parser tidak tahu makna apa yang tersimpan di balik simbol-simbol tersebut. Untuk mengenali makna dari rangkaian simbol tersebut, kompiler akan memanggil rutin semantik. Rutin ini akan menentu-kan aksi khusus yang dilakukan oleh rangkaian simbol tersebut.
Untuk bisa mengetahui maknanya, rutin ini mungkin akan memeriksa: Apakah variabel yang ada telah didefinisikan sebelumnya
Apakah variabel-variabel tersebut tipenya sama
22
Untuk dapat menjalankan fungsinya tersebut dengan baik, semantic analyzer seringkali menggunakan tabel simbol (akan diterangkan lebih lanjut secara lebih jelas). Pemeriksaan bisa dilakukan pada tabel identifier, tabel display, dan tabel blok, misal pada fteld link.
Pengecekan yang dilakukan oleh analisis semantik adalah : a) Memeriksa keberlakuan nama-nama meliputi pemeriksaan :
- Duplikasi
Pada tahap ini dilakukan pengecekan apakah sebuah nama terjadi pendefinisian lebih dari dua kali. Pengecekan dilaku-kan pada bagian pengelola blok.
- Terdefinisi
Melakukan pengecakan apakah sebuah nama yang dipakai pada tubuh program sudah terdefinisi atau belum. Pengecekan dilakukan pada semua tempat kecuali blok.
b) Memeriksa tipe
Melakukan pemeriksaan terhadap kesesuaian tipe dalam statement-statement yang ada. Misalkan bila terdapat suatu operasi, diperiksa tipe operan. Contohnya bila ekspresi yang mengikuti instruksi IF berarti tipenya boolean, akan diperiksa tipe identifter dan tipe ekspresi. Bila ada operasi antara dua operan maka tipe operan pertama harus bisa dioperasikan dengan operan kedua.
Analisa Semantik sering juga digabungkan pada pembangkitan kode antara yang menghasilkan outpui intermediate code. Inter mediate code ini nantinya akan digunakan pada proses kompilasi berikutnya (pada bagian back end compilation)
6.2 KODE ANTARA
Kode Antara/ Intermediate Cods merupakan hasil dari tahapan analisis, yang dibuat oleh kompilator pada saat mentranslasikan program dari bahasa tingkat tinggi. Kegunaan dari kode antara:
• Untuk memperkecil usaha daiarn membangun kompilator dari sejumlah bahasa ke sejumlah mesin Dengan adanya kode antara yang lebih machine independent maka kode antara yang dihasilkan dapat digunakan lagi pada mesin lainnya
• Proses optimasi masih lebih mudah. Beberapa strategi optimisasi lebih mudah dilakukan pada kode antara daripada pada program sumber atau pada kode assembiy dan kode mesin. • Bisa melihat program internal yang gampang dimengerti. Kode antara ini akan lebih mudah
23
Kerugian dari kode antara, dengan rnelakukan dua kali translasi, maka butuh waktu yang relatif lebih lama. Selanjutnya akan dibahas dua macam kode antara yaitu Notasi Postfix dan N-Tuple.
6.3 NOTASI POSTFIK
Sehari-hari kita biasa menggunakan operasi dalam notasi infix (letak operator di tengah). Pada notasi Postfix operator diletakkan paling akhir maka disebut juga dengan notasi Sufix atau Reverse Polish. Sintaks notasi Postfix:
<operan> <operan> <operator> Misalkan ekspresi:
(a+b)*(c+d)
kalau kita nyatakan dalam Postfix: ab+cd+*
Kita dapat mengubah instruksi kontrol program yang ada ke dalam notasi Postfix. Misal: IF <exp> THEN <stmt 1> ELSE <stmt 2>
diubah ke dalam Postfix
<exp> <label1> BZ <stmt1> <label2> BR <stmt2> ↑ ↑ labell Iabel2 Keterangan:
BZ: branch if zero (zero=salah) (bercabang/meloncat jika kondisi yang dites salah ) BR: branch ( bercabang/meloncat tanpa ada kondisi yang dites )
Arti dari notasi Postfix di atas adalah:
"Jika kondisi ekspresi salah, maka intruksi akan meloncat ke Label1 dan menjalankan statement2. Bila kondisi ekspresi benar, maka statementl akan dijalankan lalu meloncat ke Label2. Label1 dan Label2 sendiri menunjukkan posisi tujuan loncatan, untuk Labell posisinya tepat sebelum statement2, dan Label2 setelah statement2. "
Dalam implementasi ke kode antara, label bisa berupa nomor baris instruksi. Untuk lebih jelasnya bisa dilihat contoh berikut:
IF a>b THEN c:= d ELSE
24
Bila diubah ke dalam Postfix
11 a 12 b. 13 > 14 22 ( menunjuk labell) 15 BZ 16 c 17 d 18 : = 19 20 25 ( menunjuk label2 } 21 BR 22 c 23 e 24 = 25
Notasi Postfix di atas bisa dipahami sebagai berikut: Bila ekspresi (a>b) salah, maka lorcat ke instruksi no 22
Bila ekspreoi (a>b) benar, tidak terjadi loncatan, intruksi berlanjut ke 16 bampai 18, lalu loncat ke no 25
Contoh lain:
WHILE <exp> DO <stat> diubah ke Postfix
<exp> <label1> BZ <stat> <label2> BR
↑ ↑ Iabel2 labell Contoh, instruksi: a:= l WHILE a<5 DO a: = a+l diubah ke Postfix: 10 a 11 1 12 : = 13 a 14 5 15 < 16 26. ( menunjuk label1) 17 BZ 18 a 19 a 20 1
25
21 -*- 22 : = 23 24 13 ( menunjuk Iabel2) 25 BR 6.4 NOTASI N-TUPLEBila pada Postfix setiap baris instruksi hanya terdiri dari satu tupel, pada notasi N-tuple setiap baris bisa terdiri dari beberapa tupel. Format umum dari Notasi N-Tuple adalah:
Operator…………..N-l operan Selanjutnya akan dibahas notasi 3 tupel dan 4 tupel.
6.4.1 Triples Notation Notasi tripel memiliki format
<operator> <operand> <operand> Contoh, instruksi:
A:=D*C+B/E
Bila dibuat kode antara tripel: 1. *,D,C
2. / , B, E 3. +, (1), (2) 4. : = ,A, (3)
Perlu diperhatikan presedensi dari operator, yaitu operator perkalian dan pembagian mendapat prioritas dibanding penjumlahan dan pengurangan
Contoh lain:
IF x > y THEN x : = a-b ELSE
x:= a+b
Kode antara tripel-nya:
1. >, x, y
2. BZ, (1), (6) (Bila kondisi (1) salah loncat ke no (6)) 3. -, a, b
4. : = , x, (3) 5. BR, , (8) 6. +, a, b 7. :.,x,(6)
26
Kekurangan dari notasi tripel adalah sulit pada saat melakukan optimasi, maka dikembangkan Indirect Triples yang memiliki dua list (senarai), yaitu list instruksi dan list eksekusi. List instruksi berisi notasi tripel, sedang list eksekusi mengatur urutan eksekusinya. Misal terdapat urutan instruksi:
A : = B+C*D/E F : = C*D List Instruksi: 1. *, C, D 2. /, (1) , E 3. +, B, (2) 4. : = , A, (3) 5. : = ,F, (1) List Eksekusi 1. 1 2. 2 3. 3 4. 4 5. 1 6. 5 6.4.2 Quadruples Notation Format notasi Quadrupel
<operator> <operan> <operan> <hasil>
Hasil adalah temporary variable yang bisa ditempatkan pada memory atau register. Masalah yang ada bagaimana mengelola temporary variable (hasil) seminimal mungkin. Contoh instruksi:
A:= D*C+B/E
Bila dibuat dalam kode antara:
1. *,D,C,T1 2. /,B,E,T2 3. +,T1,T2,A
27
BAB 7
CARA PENANGANAN KESALAHAN \
7.1 KESALAHAN PROGRAM
Sebuah kompilator akan sering menemui program yang mengandung kesalahan, maka kompilator harus memiliki strategi apa yang harus dilakukan untuk menangani kesalahan-kesalahan tersebut. Kesalahan program bisa merupakan:
1. Kesalahan leksikal
Misalkan kesalahan mengeja keyword, contoh: THEN ditulis sebagai TEN 2. Sintaks
Misalkan operasi aritmatika dengan jumlah parenthesis (kurung) yang tidak pas, contoh: A:= X+(B*(C+D)
3. Semantik
Beberapa macam kesalahan semantik:
a. Tipe data yang salah, contoh dalam program dideklarasikan: VAR Siswa: integer { variabel Siswa bertipe integer }
tetapi selanjutnya ada instruksi yang melakukan operasi dengan tipe yang salah pada variabel Siswa
Siswa:= 'Yanuar' { dilakukan operasi assignment dengan tipe data string } b. Variabel belum didefinisikan, contoh di dalam program ada instruksi:
B:=B+1;
sementara variabel B belum dideklarasikan
7.2 PENANGANAN KESALAHAN
Langkah - langkah penanganan kesalahan: • Mendeteksi kesalahan
• Melaporkan kesalahan
28
Sebuah kompilator yang menemukan kesalahan akan melakukan pelaporan kesalahan, yang biasanya meliputi:
• Kode kesalahan
• Pesan kesalahan dalam bahasa natural • Nama dan atribut identifier
• Tipe-tipe yang terkait bila type checking Misal terdapat pesan kesalahan:
Error 162 Jumlah: unknown identifier bisa diartikan:
kode kesalahan = 162
pesan kesalahan = unknown identifter nama identifier = Jumlah
Adanya pesan kesalahan tersebut akan memudahkan pemrogram dalam mencari dan mengoreksi sumber dari kesalahan
7.3 REAKSI KOMPILATOR PADA KESALAHAN
Terdapat beberapa tingkatan reaksi yang dilakukan oleh kompilator saat menemukan kesalahan
I. Reaksi-reaksi yang tidak dapat diterima (tidak melaporkan error): • Kompilator crash: Berhenti atau hang
• Looping: Kompilator masih berjalan tapi tidak pernah berakhir karena hoping tak berhingga (indefinite/onbounded loop)
• Menghasilkan program objek yang salah: Kompilator melanjutkan proses sampai selesai tapi program objek yang dihasilkan salah. Ini berbahaya bila tidak diketahui oleh pemrogram, karena baru akan muncul saat program dieksekusi.
Respon-respon di atas merapakan tingkatan terendah, dan bisa muncul pada kompilator yang dirancang tanpa memper-timbangkan kemungkinan kompilator memproses source code yang mengandung kesalahan.
II. Reaksi yang benar tapi kurang dapat diterima dan kurang bermanfaat
Kompilator menemukan kesalahan pertama, melaporkannya, lalu berhenti (halt). Ini bisa muncul bila pembuat kompilator menganggap jarang terjadi kemunculan error dalam program. Sehingga kemampuan kompilator untuk mendeteksi dan melaporkan kesalahan hanya satu untuk setiap kali kompilasi. Pemrogram akan membuang waktu untuk
29
melakukan pengulangan kompilasi setiap kali terdapat sebuah error. III. Reaksi-reaksi yang dapat diterima
• Reaksi yang sudah dapat dilakukan, yaitu kompilator melaporkan error, dan selanjutnya melakukan:
=> Recovery / pemulihan, lalu melanjutkan menemukan error lain bila masih ada => Repair / perbaikan kesalahan, lalu melanjutkan proses translasi dan menghasilkan program objek yang valid
Kebanyakan kompilator dewasa ini sudah memiliki kemampuan recovery dan repair ini.
• Reaksi yang belum dapat dilakukan, yaitu kompilator mengkoreksi kesalahan, lalu menghasilkan program objek sesuai dengan yang diinginkan pemrogram. Di sini komputernya sudah memiliki kecerdasan untuk 'mengetahui' maksud pemrogram. Tingkatan respon ini belum dapat diimplementasikan pada kompilator yang ada dewasa ini
7.4 ERROR RECOVERY
Pemulihan kesalahan bertujuan mengembalikan parser ke kondisi stabil (supaya bisa melanjutkan proses parsing ke posisi selanjutnya). Strategi untuk melakukan error recovery sebagai berikut:
1. Mekanisme Ad Hoc
Recovery yang dilakukan tergantung dari pembuat kompilator sendiri / spesifik, dan tidak terikat pada suatu aturan tertentu. Cara ini bisa disebut juga sebagai special purpose error recovery.
2. Syntax directed recovery
Melakukan recovery berdasarkan sintaks. Misalkan pada potongan program:
begin A:=A+1
B:=B+1;
C:=C+1 end;
kompilator akan mengenali sebagai (dalam notasi BNF):
begin <statement>?<statement>;<statement> end; ? akan diperlakukan sebagai';' 3. Secondary Error Recovery
30
• Panic mode
Maju terus dan mengabaikan teks sampai bertemu delimiter (misal ';') Contoh pada potongan program:
IF A = l Kondisi:= true;
Pada teks di atas kesalahan karena tidak ada instruksi THEN, kompilator akan maju terus/skip sampai bertemu titik koma
• Unit deletion
Menghapus keseluruhan suatu unit sintaktik (misal: <block>, <exp>, <statement> dan sebagainya). Efeknya mirip dengan panic mode tetapi unit deletion memelihara kebenaran sintaksis dari source program dan mempermudah untuk melakukan error repairing lebih lanjut.
4. Context Sensitive recovery
Berkaitan dengan semantik, misal bila terdapat variabel yang belum dideklarasikan (undefined variabel) maka diasumsikan tipenya berdasar kemunculannya. Misal pada potongan program terdapat instruksi:
sementara di awal program yariabel B belum dideklarasikan, maka berdasar kemunculannya diasumsikan variabel B bertipe string.
7.5 ERROR REPAIR
Perbaikan kesalahan bertujuan memodifikasi source program dari kesalahan dan membuatnya valid, sehingga memungkinkan kompilator untuk melakukan translasi program yang mana akan dialirkan ke tahapan selanjutnya pada proses kompilasi. Mekanisme error repair meliputi:
1. Mekanisme Ad Hoc
Tergantung dari pembuat kompilator sendiri / spesifik 2. Syntax directed repair
Menyisipkan simbol terminal yang dianggap hilang atau membuang terminal penyebab kesalahan. Contoh pada potongan program berikut kurang simbol DO:
WHILE A<1 I:=H-1;
31
Contoh lain: Procedure Increment; begin X:=X+1; end; end;Terdapat kelebihan simbol end, yang menyebabkan kesalahan, maka kompilator akan membuangnya.
3. Context Sensitive repair
Perbaikan dilakukan pada kesalahan:
• Tipe identifier. Diatasi dengan membangkitkan identifier dummy, misalnya pada potongan program:
VAR A:string; begin
A:=0; end;
Kompilator akan memperbaiki kesalahan dengan membangkitkan identifter baru, misal B yang bertipe integer.
• Tipe konstanta
32
BAB 8
TEKNIK OPTIMASI
8.1 DEPENDENSI OPTIMASI
Tahapan optimasi kode bertujuan untuk menghasilkan kode program yang berukuran lebih kecil dan lebih cepat eksekusinya. Berdasarkan ketergantungannya pada mesin, optimasi dibagi menjadi:
1. Machine Dependent Optimizer
Kode dioptimasi sehingga lebih efisien pada mesin tertentu.. Optimasi ini memerlukan informasi mengenai feature yang ada pada mesin tujuan dan mengambil keuntungan darinya untuk meng-hasilkan kode yang lebih pendek atau dieksekusi lebih cepat.
2. Machine Independent Optimizer
Strategi optimasi yang bisa diaplikasikan tanpa tergantung pada mesin tujuan tempat kode yang dihasilkan akan dieksekusi nanti-nya. Bab ini selanjutnya akan membahas optimasi Machine In-dependent yang meliputi optimasi lokal dan optimasi global.
8.2 OPTIMASILOKAL
Optimasi lokal adalah optimasi yang dilakukan hanya pada suatu blok dari source code, cara-caranya:
1. Folding
Mengganti konstanta atau ekspresi yang bisa dievaluasi pada saat compile time dengan nilai komputasinya. Misalkan instruksi:
A := 2+3+B
bisa diganti menjadi
A:=5+B
di situ 5 menggantikan ekspresi 2+3 2. Redundant-Subexpression Eliminalion
Sebuah ekspresi yang sudah pernah dikomputasi, digunakan lagi hasilnya, ketimbang melakukan komputasi ularig. Misalkan ter-dapat urutan instruksi:
A := B + C
X := Y + B + C
33
komputasinya yang sudah ada pada ins'-truksi sebelumnya. Perhatikan, hal ini bisa dilakukan dengan catatan belum ada perubahan pada variabel yang berkaitan.
3. Optimisasi dalam sebuah iterasi
• Loop Unrolling: Menggantikan suatu loop dengan menulis statemerit dalam laop beberapa kali. Hal ini didasari pemikir-an, sebuah iterasi pada implementasi level rendah akan me-meriukan operasi:
=> Inisialisasi/pemberian nilai awal pada variabel loop. Dilakukan sekali pada saat permulaan eksekusi loop
=> Pengetesan, apakah variabel loop telab. mencapai kondisi terminasi
=> Adjustment yaitu penambahan atau pengurangan nilai pada variabel loop deagan jumlah tertentu
=> Operasi yang terjadi pada tubuh perulangan (loop body)
Dalam setiap perulangan akan terjadi pengetesan dan adjustment yang menambah waktu eksekusi. Contoh pada instruksi:
FOR I:= l to 2 DO A (I):=0;
Terdapat instruksi untuk inisialisasi I menjadi 1. Serta operasi penambahan nilai/increment 1 dan pengecekan nilai variabel I pada setiap perulangan. Sehingga untuk perulangan saja memerlukau lima instruksi, ditambah dengan ins-truksi assignment pada tubuh perulangan menjadi tujuh instruksi.
Dapat dioptimasikan menjadi:
A[l]:=0; A[2]:=0,-
Yang hanya memerlukan dua instruksi assignment saja. Untuk menentukan optimasi ini perlu dilihat perbandingan kasusnya dengan tanpa melakukan optimasi. • Freguency Reduction: Pemindahan statement ke tempat yang lebih jarang dieksekusi.
Contoh: FOR I:=l TO 10 DO BEGIN X:=5; A:=A+I; END;
Kita lihat tidak terjadi perubahan/manipulasi pada variabel X di dalam iterasi, karena itu kita bisa mengeluarkan instruksi tersebut ke luar iterasi, menjadi:
34
X:=5; FOR I:=l TO 10 DO BEGIN A:=A+I END; 4. Strength ReductionPenggantian suatu operasi dengan jenis operasi lain yang lebih cepat dieksekusi. Misalkan pada beberapa komputer operasi per-kalian memerlukan waktu lebih banyak untuk dieksekusi dari-pada operasi penjumlahan, maka penghematan waktu bisa di-lakukan dengan mengganti operasi perkalian tertentu dengan penjumlahan. Contoh lain, instruksi:
A:=A+1;
dapatdigantikan dengan:
INC(A);
8.3. OPTIMASI GLOBAL
Di sini hanya akan diceritakan sekilas mengenai Optimasi global. Optimasi global biasanya dilakukan dengan Analisis Flow, yaitu suatu graph berarah yang menunjukkan jalur yang mungkin selama eksekusi program
Kegunaannya:
a. Bagi pemrogram menginformasikan:
• Unreachable /dead code: Kode yang tidak akan pernah di eksekusi. Misalnya terdapat urutan instruksi:
X:=5;
IF X=0 THEN A:=A+1
Instruksi A:=A+1 tidak akan pernah dieksekusi
• Unused parameter pada prosedur: Parameter yang tidak pernah digunakan di dalam prosedur. Contohnya:
procedure Jumlah(a,b, c:integer) ; var x: integer
begin x:=a+b end;
kita lihat parameter c tidak pernah digunakan di dalam prosedur, sehingga seharusnya tidak perlu diikutsertakan.
35
• Unused variabel : Variabel yang tidak pernah dipakai dalam program. Contohnya:
Program Pendek; var a,b:integer; begin
a:=5; end,-
Variabel b tidak pernah dipergunakan dalam program, sehingga bisa dihilangkan. • Variabel yang dipakai tanpa nilai awal. Contohnya:
Program Awal; var a,b: integer; begin
a:=5; a:=a+b; end;
Kita lihat variabel b digunakan tanpa memiliki nilai awal/ belum di-assign. b. Bagi kompilator:
• Meningkatkan efisiensi eksekusi program
36
BAB 9
TABEL INFORMASI
9.1 KEGUNAAN TABEL INFORMASI
Tabel informasi atau tabel simbol dibuat guna mempermudah pembuatan dan implementasi dari semantic analyzer. Tabel simbol ini mempunyai dua fungsi penting dalam proses translasi, yaitu :
1. Untuk membantu pemeriksaan kebenaran semantik dari program sumber
2. Untuk membantu dan mempermudah dalam pembuatan intermediate code dan proses pembangkitan kode.
Hal tersebut dilakukan dengan menambah dan mengambil atribut variabel yang dipergunakan pada program dari tabel. Atribut tersebut, seperti nama, tipe, ukuran variabel bisa ditemukan secara eksplisit pada dekiarasi, atau secara implisit berdasarkan konteks kemunculan nama variabel pada prograrn.
9.2 IMPLEMENTASI TABEL INFORMASI Beberapa jenis tabel informasi:
1. Tabel Identifier: Berfungsi menampung semua identifier yang terdapat dalam program 2. Tabel Array: Berfungsi menampung informasi tambahan untuk sebuah array
3. Tabel Blok: Mencatat variabel-variabel yang ada pada blok yang sama 4. Tabel Real: Menyimpan elemen tabel bernilai real
5. Tabel String Menyimpan informasi string 6. Tabel Display: Mencatat blok yang aktif
9.2.1 Tabel Identifter
Tabel Identifier memiliki field: • No urut identifier dalam tabel • Nama identifter
• Jenis/obyektif dari identifier: Prosedur, fungsi, tipe, variabel, konstanta
• Tipe dari identifier yang bersangkutan: Integer, char, boolean, arry, record, file, no-type • Level: Kedalaman identifier tertentu (depth of block), hal ini menyangkut letak identifier
37
dalam program. Konsepnya sama dengan pembentukan tree, misal: main program = level 0. Field ini digunakan pada run time untuk mengetahui current activation record, dan variabel yang bisa diakses.
Untuk identifter yang butuh tempat penyimpanan dicatat pula: • Alamat relatif/address dari identifier untuk implementasi
• Informasi referensi (acuan) identifier tertentu ke alamat tabel identifter lain yang digunakan untuk mencatat informasi-informasi yang diperlukan yang menerangkannya.
• Link: Menghubungkan identifier ke identifter lainnya, atau yang dideklarasikan pada level yang sama
• Normal: Diperlukan pada pemanggilan parameter, untuk membedakan parameter by value dan reference (berupa suatu variabel boolean)
Contoh kasus, terdapat sebuah listing program sebagai berikut:
Program A; var B:integer;
Procedure X (Z: char); var C:integer
Begin
Tabel Identifter akan mencatat semua identifter:
0 A 1 B 2 X 3 Z 4 C
Contoh implementasi tabel identifier:
Tabld: array [O..tabmax] of record name : string; link : integer; obj : objek; tipe : types; ref : integer; normal : boolean,- level : 0..maxlevel; address : integer; end;
38
dimanaobjek = (konstant, variable, prosedur, fungsi)
types = (notipe,int,reals,booleans,chars,arrays,records)
9.2.2 Tabel Array
Tabel array digunakan untuk menyimpan informasi suatu identifier yang bertipe array. Tabel array memiliki field:
• No urut suatu array dalam tabel
• Tipe dari indeks array yang bersangkutan • Tipe elemen array
• Referensi dari elemen array • Indeks batas bawah array • Indeks batas atas array • Jumlah elemen array
• Ukuran total array (total size = (atas - bawah + l) x elemen size) • Elemen size (ukuran tiap elemen)
Tabel Array diacu dengan field referensi pada Tabel Identifier. Contoh implementasi tabel array:
TabArray: array [l..tabmax] of record
indextype,elementype: types;
elemenref, low, high, elemensize, tabsize:integer end;
9.2.3 Tabel Blok
Tabel blok digunakan untuk menyimpan informasi blok-blok yang ada pada tabel utama. Dengan berdasarkan pada tabel ini, dapat diketahui batas-batas suatu blok pada tabel utama (tabel identifter). Tabel blok memiliki fteld:
• No urut blok • Batas awal blok • Batas akhir blok
• Ukuran parameter/ parameter size • Ukuran variabel/ variabel size • Last variable
39
Contoh implementasi tabel blok:
TabBlok: array [1..tabmax) of record
lastvar, lastpar, parsize, varsize: integer; end;
Dari contoh listing program berikut:
Program A; var B:integer;
Procedure X(Z:char); var C:integer Begin
Akan diperoleh, untuk blok Program A: last variable = 2
variable size = 2 (dianggap integer butuh dua byte) last parameter = 0 (tanpa parameter)
parameter size = 0 Untuk blok Procedure X: last variable = 4
variable size = 2 last parameter = 3
parameter size = 1 (dianggap char butuh satu byte)
9.2.4 Tabel Real
Tabel real ini digunakan untuk menyimpan nilai dari suatu identifier yang bertipe real. Elemen-elemen dari tabel ini adalah sebagai berikut:
• No urut elemen
• Nilai real suatu variabel real yang mengacu ke indeks tabel ini Contoh implementasi tabel real:
TabReal: array [l..tabmax] of real
Pemikirannya di sini setiap tipe yang dimiliki oleh suatu bahasa akan memiliki tabelnya sendiri,
9.2.5 Tabel String
Tabel ini digunakan untuk menyimpan informasi string yang terdapat pada program sumber. Elemen-elemen yang terdapat dalam tabel ini adalah:
40
• No urut elemen
• Karakter-karakter yang merupakan konstanta Contoh implementasi tabel string:
TabString: array [l..tabmax] of string
9.2.6 Tabel Display
Tabel ini menyimpan informasi mengenai blok-blok yang lagi aktif. Elemen-elemen yang terdapat dalam tabel ini adalah:
• No urut tabel • Blok yang aktif
Pengisian tabel display dilakukan dengan konsep stack
Urutan pengaksesan : Tabel Display - Tabel Blok - Tabel Simbol Contoh implementasi tabel display:
TabDisplay: array [1….tabmax] of integer
9.3 INTERAKSI ANTAR TABEL
Pertama kali tabel display akan menunjuk blok mana yang sedang aktif. Dari blok yang aktif ini, akan diketahui identifier-iden-tifier yang termasuk dalam blok tersebut. Untuk pertama kalinya, yang akan diacu adalah identifter yang paling akhir, kemudian iden-iifier sebelumnya, dan seterusnya, Informasi suatu identifier ini mungkin belum lengkap. Untuk itu dari tabel identifier ini mungkin akan dicari kelengkapan informasi suatu identifier ke tabel yang sesuai (tabel real, tabel string, atau tabel array).