vii
ABSTRAK
Outlier adalah adalah obyek yang berbeda dibandingkan obyek – obyek lain dalam suatu dataset. Dalam penambangan data, deteksi outlier adalah satu satu bidang penelitian yang terus berkembang. Umumnya metode deteksi outlier tidak memperhatikan secara khusus class label pada dataset dan hanya fokus pada dataset yang seragam. Padahal, dataset yang nyata biasanya mempunyai multiatribut. Pada deteksi outlier dengan algoritma Enhanced Class Outlier Distance Based (ECODB), data yang menyimpang dari kumpulan class-nya dapat ditemukan. Algoritma ECODB dapat diterapkan pada dataset dengan atribut campuran numerik dan kategorikal.
Algoritma ECODB akan menghitung nilai Class Outlier Factor (COF) dari tiap instances berdasarkan masukan nilai k dan top N. K adalah jumlah tetangga terdekat dari suatu instances, sedangkan top N adalah jumlah instances yang dideteksi sebagai outlier yang diurutkan secara kecil ke besar berdasarkan nilai COF. COF adalah nilai probabilitas/derajat sebuah instance dapat menjadi outlier. Outlier adalah data dengan nilai COF terendah.
Pada penelitian ini dilakukan pendeteksian outlier menggunakan algoritma ECODB. Data yang digunakan adalah data debitur BPR XYZ yang mengangsur kredit pada bulan Agustus 2013. Data tersebut berjumlah 97 record dalam format Microsoft Excel (.xls). Pada penelitian ini akan diketahui bagaimana pengaruh nilai k dan top N dalam proses deteksi outlier menggunakan algoritma ECODB. Pengujian dilakukan dengan cara menghitung data debitur BPR XYZ menggunakan algoritma ECODB dengan masukan k dan top N yang berbeda. Kemudian hasil perhitungan tersebut dibandingkan untuk mendapatkan kesimpulan. Selain itu juga dilakukan review hasil deteksi outlier oleh petugas bank.
Dari hasil pengujian efek perubahan nilai k dan top N dapat disimpulkan bahwa penentuan nilai k dan top N pada algoritma ECODB berpengaruh terhadap outlier yang dihasilkan. Nilai k dan top N yang terlalu kecil atau besar menyebabkan hasil deteksi outlier tidak optimal. Berdasarkan hasil pengujian review dan validitas oleh petugas bank dapat disimpulkan bahwa hasil deteksi outlier yang diperoleh layak dinyatakan sebagai outlier.
Kata kunci : penambangan data, deteksi outlier, ecodb, enhanced class outlier distance based
xi
ABSTRACT
Outlier is an object which is different from any objects in one dataset. In data mining, outlier detection is one of growing researches. Generally, outlier detection methods find exception or rare cases in a dataset without considered class label as an important thing and only can be used on dataset that have single datatypes. In fact, real world dataset usually have mixed datatypes. On outlier detection using Enhanced Class Outlier Distance Based (ECODB) algorithm, data which is different from its class can be found. ECODB algorithm can be applied on dataset that have numerical and categorical attributes.
ECODB algorithm count the Class Outlier Factor (COF) from each instances based on k and top N value. K is the nearest neighbors of instances, whereas top N is the number of top class outlier that rank from greatest to the least based on COF value. COF is the probability/degree from an instance to be considered as outlier. Outlier is data which have least COF value.
In this thesis, ECODB algorithm was used to perform outlier detection. The data used in this thesis is credit data of BPR XYZ debtor whom lessened their credit on August 2013. This data consist of 97 records on Microsoft Excel format (.xls). In this thesis, it can be understand how k and top N value influenced on outlier detection using ECODB algorithm.
The testing can be done by counting credit data of BPR XYZ using ECODB algoritm with various input of k and top N. The results was compared to provide the conclusion. Besides, it also validated the results of outlier detection by reviewing the bank officer.
Based on the testing, it can be concluded that the determination of k and top N value influence the results of outlier detection. Very small or very high of k and top N value cause unoptimal outlier detection. Also, based on validation testing by bank officer, the results of the outlier detection using ECODB algorithm are confirmed as outliers.
Keyword : data mining, outlier detection, ecodb, enhanced class outlier distance based
DETEKSI OUTLIER PADA DATA CAMPURAN
NUMERIK DAN KATEGORIKAL MENGGUNAKAN
ALGORITMA ENHANCED CLASS OUTLIER
DISTANCE BASED (ECODB)
(Studi Kasus : Data Kredit BPR XYZ)
TUGAS AKHIR
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Disusun Oleh :
MARIA KRISTILIA WIDOWATI
085314080
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
2014
i
DETEKSI OUTLIER PADA DATA CAMPURAN
NUMERIK DAN KATEGORIKAL MENGGUNAKAN
ALGORITMA ENHANCED CLASS OUTLIER
DISTANCE BASED (ECODB)
(Studi Kasus : Data Kredit BPR XYZ)
TUGAS AKHIR
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Disusun Oleh :
MARIA KRISTILIA WIDOWATI
085314080
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
2014
ii
OUTLIER DETECTION ON MIXED ATTRIBUTES
NUMERICAL AND CATEGORICAL DATA USING
ENHANCED CLASS OUTLIER DISTANCE BASED
(ECODB) ALGORITHM
(Case Study : Credit Data of BPR XYZ)
A Thesis
Presented as Partial Fulfillment of the Requirements To Obtain the Sarjana Komputer Degree In Informatical Engineering Study Program
By :
MARIA KRISTILIA WIDOWATI
085314080
INFORMATICS ENGINEERING STUDY PROGRAM
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
2014
v
HALAMAN PERSEMBAHAN
“Janganlah gelisah hatimu; percayalah kepada Allah,
percayalah juga kepada-Ku.”
(Yohanes 14:1)
“Tidak ada yang mustahil bagi orang yang percaya!”
(Markus 9:32)
“Pendidikan mempunyai akar yang pahit, tetapi buahnya manis.”
(Aristoteles)
“Tidak ada orang yang gagal selama dia menikmati hidup.”
(William Feather)
“Setiap hal yang terjadi, baik ataupun buruk, selalu ada yang
menarik dan dapat dipelajari.”
Tugas akhir ini saya persembahkan untuk :
Allah Tritunggal
Orangtuaku, saudara- saudaraku,
sahabat
–
sahabatku
dan orang
–
orang terkasih.
vii
ABSTRAK
Outlier adalah adalah obyek yang berbeda dibandingkan obyek – obyek lain dalam suatu dataset. Dalam penambangan data, deteksi outlier adalah satu satu bidang penelitian yang terus berkembang. Umumnya metode deteksi outlier tidak memperhatikan secara khusus class label pada dataset dan hanya fokus pada dataset yang seragam. Padahal, dataset yang nyata biasanya mempunyai multiatribut. Pada deteksi outlier dengan algoritma Enhanced Class Outlier Distance Based (ECODB), data yang menyimpang dari kumpulan class-nya dapat ditemukan. Algoritma ECODB dapat diterapkan pada dataset dengan atribut campuran numerik dan kategorikal.
Algoritma ECODB akan menghitung nilai Class Outlier Factor (COF) dari tiap instances berdasarkan masukan nilai k dan top N. K adalah jumlah tetangga terdekat dari suatu instances, sedangkan top N adalah jumlah instances yang dideteksi sebagai outlier yang diurutkan secara kecil ke besar berdasarkan nilai COF. COF adalah nilai probabilitas/derajat sebuah instance dapat menjadi outlier. Outlier adalah data dengan nilai COF terendah.
Pada penelitian ini dilakukan pendeteksian outlier menggunakan algoritma ECODB. Data yang digunakan adalah data debitur BPR XYZ yang mengangsur kredit pada bulan Agustus 2013. Data tersebut berjumlah 97 record dalam format Microsoft Excel (.xls). Pada penelitian ini akan diketahui bagaimana pengaruh nilai k dan top N dalam proses deteksi outlier menggunakan algoritma ECODB. Pengujian dilakukan dengan cara menghitung data debitur BPR XYZ menggunakan algoritma ECODB dengan masukan k dan top N yang berbeda. Kemudian hasil perhitungan tersebut dibandingkan untuk mendapatkan kesimpulan. Selain itu juga dilakukan review hasil deteksi outlier oleh petugas bank.
Dari hasil pengujian efek perubahan nilai k dan top N dapat disimpulkan bahwa penentuan nilai k dan top N pada algoritma ECODB berpengaruh terhadap outlier yang dihasilkan. Nilai k dan top N yang terlalu kecil atau besar menyebabkan hasil deteksi outlier tidak optimal. Berdasarkan hasil pengujian review dan validitas oleh petugas bank dapat disimpulkan bahwa hasil deteksi outlier yang diperoleh layak dinyatakan sebagai outlier.
Kata kunci : penambangan data, deteksi outlier, ecodb, enhanced class outlier distance based
viii
ABSTRACT
Outlier is an object which is different from any objects in one dataset. In data mining, outlier detection is one of growing researches. Generally, outlier detection methods find exception or rare cases in a dataset without considered class label as an important thing and only can be used on dataset that have single datatypes. In fact, real world dataset usually have mixed datatypes. On outlier detection using Enhanced Class Outlier Distance Based (ECODB) algorithm, data which is different from its class can be found. ECODB algorithm can be applied on dataset that have numerical and categorical attributes.
ECODB algorithm count the Class Outlier Factor (COF) from each instances based on k and top N value. K is the nearest neighbors of instances, whereas top N is the number of top class outlier that rank from greatest to the least based on COF value. COF is the probability/degree from an instance to be considered as outlier. Outlier is data which have least COF value.
In this thesis, ECODB algorithm was used to perform outlier detection. The data used in this thesis is credit data of BPR XYZ debtor whom lessened their credit on August 2013. This data consist of 97 records on Microsoft Excel format (.xls). In this thesis, it can be understand how k and top N value influenced on outlier detection using ECODB algorithm.
The testing can be done by counting credit data of BPR XYZ using ECODB algoritm with various input of k and top N. The results was compared to provide the conclusion. Besides, it also validated the results of outlier detection by reviewing the bank officer.
Based on the testing, it can be concluded that the determination of k and top N value influence the results of outlier detection. Very small or very high of k and top N value cause unoptimal outlier detection. Also, based on validation testing by bank officer, the results of the outlier detection using ECODB algorithm are confirmed as outliers.
Keyword : data mining, outlier detection, ecodb, enhanced class outlier distance based
x
KATA PENGANTAR
Puji syukur penulis panjatkan ke hadirat Tuhan Yang Maha Esa atas penyertaan-Nya sehingga penulis dapat menyelesaikan tugas akhir dengan judul “Deteksi Outlier pada Data Campuran Numerik dan Kategorikal Menggunakan Algoritma Enhanced Class Outlier Distance Based (ECODB) (Studi Kasus : Data Kredit BPR XYZ)”. Penulisan tugas akhir ini ditujukan untuk memenuhi salah satu syarat memperoleh gelar Sarjana Komputer Jurusan Teknik Informatika.
Terselesaikannya penulisan tugas akhir ini tidak lepas dari peran serta beberapa pihak, baik secara langsung maupun secara tidak langsung. Oleh karena itu, penulis ingin menyampaikan terima kasih kepada pihak - pihak yang telah ikut membantu dalam penulisan tugas akhir ini, baik dalam memberi bimbingan, petunjuk kerjasama, kritikan, maupun saran,antara lain kepada:
1. Ibu P.H. Prima Rosa, S.Si., M.Sc., selaku Dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta dan dosen pembimbing yang telah memberikan masukan sehingga tugas akhir ini dapat terselesaikan. 2. Ibu Ridowati Gunawan, S.Kom., M.T., selaku Ketua Program Studi Teknik
Informatika Universitas Sanata Dharma Yogyakarta dan dosen penguji. 3. Sri Hartati Wijono, S.Si., M.Kom, selaku dosen penguji.
4. Seluruh staff pengajar dan karyawan Program Studi Teknik Informatika Fakultas Sains dan Teknologi Universitas Sanata Dharma.
5. Direktur Utama BPR XYZ dan Kepala Bagian Humas BPR XYZ yang telah memberikan ijin untuk melakukan penelitian di BPR XYZ.
6. Kedua orang tua tersayang, bapak Yohanes Suradi dan ibu Firmina Sri Rahayuningsih yang selalu mendoakan, memberi petuah dan semangat sehinggatugas akhir ini dapat terselesaikan.
xi
memberikan semangat, perhatian, penghiburan dan doa sehingga penulis dapat menyelesaikan tugas akhir ini.
8. Sahabat – sahabatku, alm. Vina, alm. Yoana, Murni, Rosa, Devi, mbak Putri, Vina, Veni, Monic, Eny, Ria, Ita, Nana, Endah, Etik, Dhesie, Caca, Ulays, Veverly, Justin, Helan, dan Violya.
9. Dan semua pihak yang tidak dapat disebutkan satu per satu yang telah membantu terselesaikannya tugas akhir ini.
Penulis menyadari bahwa tugas akhir ini masih jauh dari sempurna. Oleh karena itu, penulis dengan senang hati menerima sumbangan pikiran, baik saran maupun kritik untuk perbaikan – perbaikan di masa datang. Akhir kata, penulis berharap semoga laporan ini dapat bermanfaat bagi semua pihak.
Yogyakarta, Oktober 2014
xii
DAFTAR ISI
HALAMAN JUDUL……….. i
HALAMAN PERSETUJUAN.……….. iii
HALAMAN PENGESAHAN..……….. iv
HALAMAN PERSEMBAHAN..………... v
PERNYATAAN KEASLIAN KARYA..………... vi
ABSTRAK..………..……….. vii
ABSTRACT..……….………... viii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI.……… ix
KATA PENGANTAR……… x
DAFTAR ISI………... xii
DAFTAR TABEL………..…. xv
DAFTAR GAMBAR……….. DAFTAR LAMPIRAN………... xvi xvii BAB I PENDAHULUAN A. Latar Belakang Masalah………..………. 1
B. Rumusan Masalah………….………...……… 2
C. Tujuan Penelitian...………..…………. 3
D. Batasan Masalah...………..………. 3
E. Manfaat Penelitian……….. 4
F. Metodologi Penelitian………. 4
G. Sistematika Penulisan……….………. 5
BAB II LANDASAN TEORI A. Penambangan Data……….……….….. 7
1. Pengertian dan Fungsi Penambangan Data………...…. 7
2. Pemrosesan Awal Data………..…. 8
B. Outlier……….……….. 12
xiii BAB III METODE PENELITIAN
A. Metodologi Penelitian………..……… 19
B. Instrumen Penelitian………….………...……… 20
C. Teknik Pengumpulan Data...………..… 20
D. Teknik Pengolahan Data...………..…….. 23
E. Tahap – Tahap Penelitian……….…………. 23
F. Contoh Perhitungan Algoritma ECODB……….. 25 BAB IV HASIL DAN PEMBAHASAN
A. Sumber Awal Data……….…….…….…….……... B. Pemrosesan Awal Data……….………..….
1. Seleksi Data……….….
2. Pengisian Missing Value……….. 3. Normalisasi Data……….. C. Penambangan Data Dengan Microsoft Excel……….. 1. Menormalisasi Data………... 2. Mencari Jarak Dari Tiap Data Dengan Menggunakan Fungsi
Jarak Mixed Euclidian Distance………...
3. Menghitung PCL………..
4. Meranking List Top N Outlier Dari Instance Dengan Nilai PCL(T,K) Terkecil……….... 5. Menghitung Nilai Deviation(T)¸ Norm(Deviation(T)), Kdist(T),
Dan Norm(Kdist(T))……….…. 6. Menghitung Nilai COF (Class Outlier Factor)……….... 7. Mengurutkan List Top N Secara Ascending Sesuai Nilai COF.... D. Hasil Deteksi Outlier Berdasarkan Algoritma ECODB Dengan
Microsoft Excel……….
E. Kesimpulan Hasil Percobaan Perhitungan Dengan Masukan K dan Top N Yang Berubah - Ubah………. F. Kesimpulan Hasil Pengujian Review dan Validitas oleh Pengguna..
xiv BAB V PENUTUP
A.Kesimpulan……….………... 73
G. Saran……….………....
DAFTAR PUSTAKA……….………
LAMPIRAN……….……….……….
xv
DAFTAR TABEL
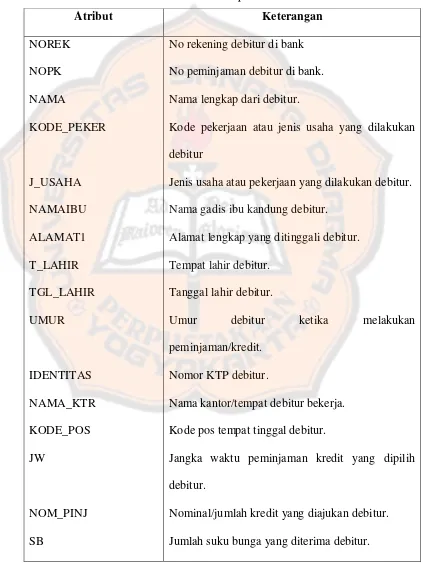
Tabel 3.1. Atribut – atribut pada dataset debitur ……….…..…….………..……... 21
Tabel 3.2. Hasil perhitungan PCL tiap instance ….……….….……….... 27
Tabel 3.3 Hasil perhitungan Deviation dan KDistdari tiap instance..….………... 28
Tabel 3.4. Hasil perhitungan COF dari tiap instance….……….….…….…….... 28
Tabel 4.1. Contoh atribut pada dataset debitur sebelum normalisasi….……….... 37
Tabel 4.2. Contoh atribut pada dataset debitur setelah normalisasi….……….. 38
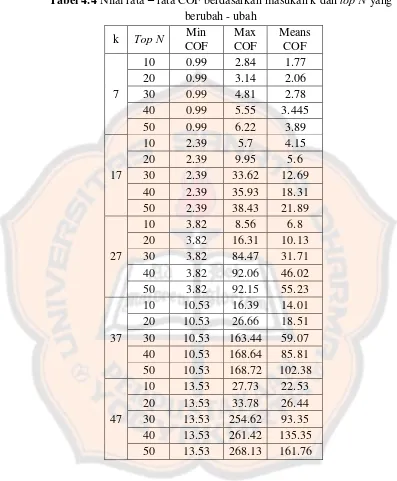
Tabel 4.3. Hasil deteksi outlier dengan masukan k dan top N yang berubah – ubah... 44
Tabel 4.4. Nilai rata – rata COF berdasarkan masukan k dan top N yang berubah – ubah 47 Tabel 4.5 Nilai COF dengan k = 7 dan top N = 10………..………..………..………... 48
Tabel 4.6 Nilai COF dengan k = 7 dan top N = 20………..………..………..……….... 48
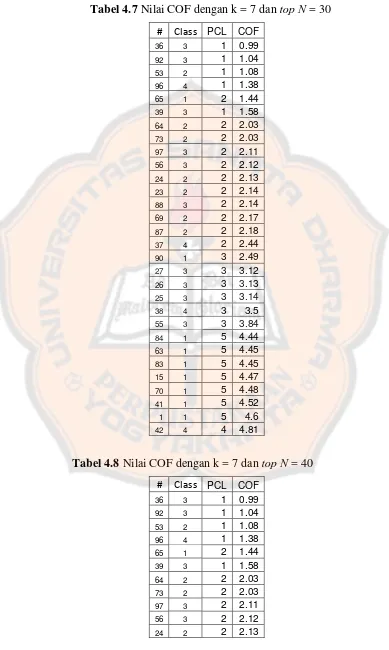
Tabel 4.7 Nilai COF dengan k = 7 dan top N = 30………..………..………..……….... 49
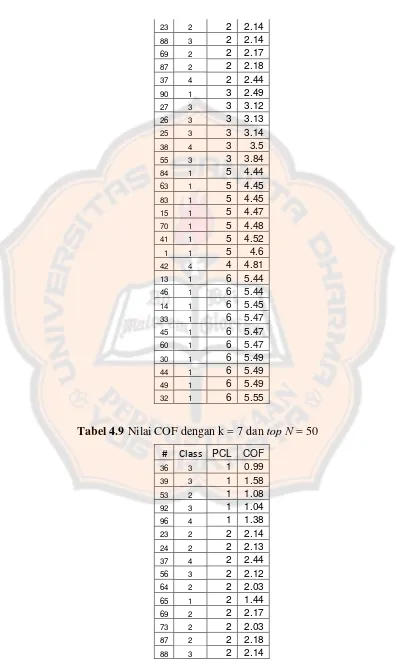
Tabel 4.8 Nilai COF dengan k = 7 dan top N = 40………..………..………..……….... 49
Tabel 4.9 Nilai COF dengan k = 7 dan top N = 50………..………..………..……….... 50
Tabel 4.10 Nilai COF dengan k = 17 dan top N = 10………..………..………..……….. 51
Tabel 4.11 Nilai COF dengan k = 17 dan top N = 20………..………..………..……….. 52
Tabel 4.12 Nilai COF dengan k = 17 dan top N = 30………..………..………..……….. 52
Tabel 4.13 Nilai COF dengan k = 17 dan top N = 40………..………..………..……….. 53
Tabel 4.14 Nilai COF dengan k = 17 dan top N = 50………..………..………..……….. 54
Tabel 4.15 Nilai COF dengan k = 27 dan top N = 10………..………..………..……….. 55
Tabel 4.16 Nilai COF dengan k = 27 dan top N = 20………..………..………..……….. 55
Tabel 4.17 Nilai COF dengan k = 27 dan top N = 30………..………..………..……….. 56
Tabel 4.18 Nilai COF dengan k = 27 dan top N = 40………..………..………..……….. 57
Tabel 4.19 Nilai COF dengan k = 27 dan top N = 50………..………..………..……….. 58
Tabel 4.20 Nilai COF dengan k = 37 dan top N = 10………..………..………..……….. 59
Tabel 4.21 Nilai COF dengan k = 37 dan top N = 20………..………..………..……….. 59
Tabel 4.22 Nilai COF dengan k = 37 dan top N = 30………..………..………..……….. 60
xvi
Tabel 4.24 Nilai COF dengan k = 37 dan top N = 50………..………..………..……….. 61 Tabel 4.25 Nilai COF dengan k = 47 dan top N = 10………..………..………..……….. 62 Tabel 4.26 Nilai COF dengan k = 47 dan top N = 20………..………..………..……….. 63 Tabel 4.27 Nilai COF dengan k = 47 dan top N = 30………..………..………..……….. 63 Tabel 4.28 Nilai COF dengan k = 47 dan top N = 40………..………..………..……….. 64 Tabel 4.29 Nilai COF dengan k = 47 dan top N = 50………..………..………..……….. 65
xvii
DAFTAR GAMBAR
Gambar 2.1 Metode pemrosesan awal data……….………..……... 8
Gambar 2.2 Set data dengan outlier……….…...…... 12
Gambar 3.1 Contoh dataset debitur……….………...…... 25
Gambar 3.2 Data debitur yang telah dinormalisasi……….… 26
Gambar 3.3 Perhitungan jarak setiap instance dari data debitur……… 26
Gambar 3.4 Tujuh tetangga terdekat dari tiap instance………... Gambar 4.1 Atribut pada data debitur setelah tahap seleksi data……….... 27 36 Gambar 4.2 Isi data debitur setelah tahap pengisian missing value………. 37
Gambar 4.3 Contoh formula normalisasi data……….……….... 39
Gambar 4.4 Contoh formula mencari jarak……….……….…… 40
Gambar 4.5 Contoh formula menghitung PCL……….………...… 40
Gambar 4.6 Contoh meranking kecil ke besarberdasarkannilai PCL(T,K) terkecil... 41
Gambar 4.7 Contoh formula menghitung Deviation……… 42
Gambar 4.8 Contoh formula menghitung Norm(Deviation(T))………...…… 42
Gambar 4.9 Contoh formula menghitung Kdist……….. 42
Gambar 4.10 Contoh formula menghitung Norm(KDist(T))………... 43
Gambar 4.11 Contoh formula menghitung COF (Class Outlier Factor)………….… 43
xviii
DAFTAR LAMPIRAN
1. Tabel data debitur sebelum mengalami pemrosesan awal……… 77
2. Hasil seleksi atribut data debitur………... 78
3. Hasil pengisian missing value………... 79
4. Hasil normalisasi data………... 80
1
BAB I
PENDAHULUAN
A. Latar Belakang Masalah
Outlier adalah kumpulan obyek - obyek yang dipandang sangat berbeda dibandingkan keseluruhan data (Han dan M. Kamber, 2006). Dalam penambangan data, deteksi outlier adalah satu satu bidang penelitian yang terus berkembang (Maryono, 2010). Deteksi data outlier sangat bermanfaat untuk mendeteksi adanya perilaku atau kejadian yang tidak normal seperti deteksi penipuan penggunaan kartu kredit, deteksi intrusi jaringan, penggelapan asuransi, diagnosa medis, segmentasi pelanggan, dan sebagainya (Breunig, et. al., 2000).
Ada bermacam – macam teknik yang digunakan untuk mendeteksi outlier pada data. Namun, pada banyak metode deteksi outlier tidak memperhatikan secara khusus class label pada dataset. Akibatnya data yang merupakan outlier dalam suatu class label tidak dapat dideteksi. Selain itu, metode – metode tersebut hanya fokus pada set data yang seragam, yaitu hanya terdiri dari salah satu tipe atribut saja (Maryono, 2010). Padahal, set data yang nyata tidak hanya mempunyai atribut numerik, tetapi juga mempunyai atribut kategorikal (Aggarwal, 2013).
2
terdapat pada data debitur tersebut dapat dilakukan pendeteksian outlier menggunakan algoritma Enhanced Class Outlier Distance Based (ECODB).
Menurut Hewahi dan M. K. Saad (2009), algoritma Enhanced Class Outlier Distance Based (ECODB) dapat digunakan untuk mendeteksi outlier pada data dengan multiatribut. Algoritma ini akan menghitung nilai Class Outlier Factor (COF) dari tiap instances berdasarkan masukan nilai k dan top N. K adalah jumlah tetangga terdekat dari suatu instances, sedangkan top N adalah jumlah instances yang dideteksi sebagai outlier yang diurutkan secara kecil ke besar berdasarkan nilai COF. COF adalah nilai probabilitas/derajat sebuah instance dapat menjadi outlier. Outlier adalah data dengan nilai COF terendah.
Pada penelitian ini dilakukan pendeteksian outlier pada data debitur BPR XYZ menggunakan algoritma ECODB. Hasil penelitian ini diharapkan dapat memberi gambaran apakah algoritma ECODB dapat digunakan untuk mendeteksi outlier pada data debitur dengan atribut campuran numerik dan kategorikal dengan kasus data debitur BPR XYZ dan bagaimana pengaruh nilai k dan top N dalam proses deteksi outlier menggunakan algoritma ECODB. Setelah outlier dideteksi, pihak bank dapat menganalisa data dan outlier untuk menemukan faktor tertentu yang berpengaruh pada keunikan data debitur tersebut.
B. Rumusan Masalah
Berdasarkan latar belakang masalah di atas, maka masalah yang dapat diselesaikan adalah sebagai berikut :
3
1. Apakah algoritma ECODB dapat digunakan untuk mendeteksi outlier pada data debitur dengan atribut campuran numerik dan kategorikal dengan kasus data debitur BPR XYZ?
2. Bagaimana pengaruh nilai k dan top N dalam proses deteksi outlier menggunakan algoritma ECODB?
C. Tujuan Penelitian
Tujuan dari penelitian ini adalah :
1. Menguji apakah algoritma ECODB dapat digunakan untuk menemukan outlier pada data debitur dengan atribut campuran numerik dan kategorikal dengan kasus data debitur BPR XYZ. 2. Mengetahui pengaruh nilai k dan top N dalam proses deteksi
outlier menggunakan algoritma ECODB.
D. Batasan Masalah
Penelitian ini mempunyai beberapa batasan, yaitu :
1. Data yang digunakan adalah data debitur BPR XYZ yang mengangsur kredit pada bulan Agustus 2013. Data tersebut berjumlah 97 record dalam format Microsoft Excel.
2. Algoritma yang digunakan adalah algoritma ECODB (Enhanced Class Outlier Distance Based).
3. Proses deteksi outlier dan analisa menggunakan Microsoft Excel.
4
E. Manfaat Penelitian
Penelitian ini mempunyai manfaat sebagai berikut :
1. Mengetahui apakah algoritma ECODB dapat digunakan untuk menemukan outlier pada data debitur dengan atribut campuran numerik dan kategorikal dengan kasus data debitur BPR XYZ. 2. Mengetahui pengaruh nilai k dan top N dalam proses deteksi
outlier menggunakan algoritma ECODB.
3. Membantu pihak bank untuk menemukan faktor tertentu yang berpengaruh pada keunikan data debitur.
F. Metodologi Penelitian
Metodologi yang digunakan pada penelitian ini adalah menggunakan metode KDD (Knowledge Discovery in Database), yang dikemukakan oleh Han dan Kamber (2006). Langkah dari metodologi tersebut adalah sebagai berikut :
1. Seleksi Data ( Data Selection )
Proses pemilihan atribut-atribut yang relevan untuk dilakukan penambangan data. Atribut yang tidak relevan akan dihilangkan karena akan membiaskan hasil penambangan data.
2. Pembersihan Data (Data Cleaning)
5
konsisten. Dalam penelitian ini dilakukan pengisian missing value.
3. Transformasi Data (Data Transformation)
Proses transformasi pada data yang sudah diseleksi ke dalam bentuk yang sesuai untuk ditambang.
4. Penambangan Data (Data Mining)
Proses mengaplikasikan metode untuk mendapatkan pola pada suatu kumpulan data. Dalam penelitian ini, metode yang digunakan adalah metode analisis outlier dengan menggunakan algoritma ECODB.
5. Evaluasi Pola ( Pattern Evaluation )
Proses penerjemahan pola-pola yang dihasilkan dari penambangan data. Tahap ini merupakan bagian dari proses KDD yang mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesa yang ada sebelumnya.
G. Sistematika Penulisan
Secara umum dalam menyelesaikan penelitian ini, disusun suatu sistematika sebagai berikut :
BAB I : PENDAHULUAN
Berisi latar belakang masalah, rumusan masalah, tujuan penelitian, batasan masalah, manfaat penelitian, metodologi penelitian dan sistematika penulisan.
6
BAB II : LANDASAN TEORI
Berisi teori - teori yang mendukung penelitian, antara lain mengenai penambangan data, outlier dan algoritma Enhanced Class Outlier Distance Based (ECODB).
BAB III : METODE PENELITIAN
Berisi penjelasan mengenai langkah atau metode yang dilakukan untuk menyelesaikan masalah dalam penelitian ini.
BAB IV : HASIL DAN PEMBAHASAN
Berisi penjelasan tentang hasil analisa yang diperoleh dari penelitian. Pada bab ini, akan dijabarkan secara lengkap proses perhitungan menggunakan Microsoft Excel, hasil deteksi outlier yang didapat, hasil analisa algoritma ECODB yang diterapkan ke dalam data debitur dan hasil pengujian review dan validitas outlier oleh petugas bank BPR XYZ.
BAB VII : PENUTUP
Berisi kesimpulan dan saran yang bermanfaat bagi pengembangan penelitian ini lebih lanjut.
7
BAB II
LANDASAN TEORI
A. Penambangan Data
1. Pengertian dan Fungsi Penambangan Data
Menurut Santosa (2007) “penambangan data adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Keluaran dari penambangan data bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan”. Tool penambangan data mampu memprediksi tren dan perilaku sehingga mampu membuat perusahaan semakin proaktif dan memperkaya pengetahuan atau informasi dalam membuat keputusan (Lee S dan Santana, 2010).
Menurut Lee S dan Santana (2010), fungsi penambangan data yang digunakan untuk keperluan implementatif mencakup :
a. Mendeteksi pola kecurangan bertransaksi, klaim kartu kredit, dll.
b. Memodelkan pola dan perilaku pembeli/konsumen. c. Mengoptimasi performansi produk barang atau jasa.
d. Mendeteksi kejadian pada perilaku, seperti menelusuri riwayat aktivitas yang unik atau tidak wajar.
8
e. Memperlengkapi perusahaan dalam menemukan pola dan korelasi data yang menuntun pada pengetahuan dan temuan bernilai lainnya.
2. Pemrosesan Awal Data
Data yang belum diproses disebut data mentah. Data mentah perlu disiapkan terlebih dahulu agar bisa dipakai dalam proses penambangan data. Pada data mentah sering ditemukan noisy, missing value (nilai yang hilang), dan data yang tidak konsisten. Data dengan kualitas rendah akan menghasilkan kualitas penambangan yang buruk (Han dan Kamber, 2006). Maka perlu ditingkatkan kualitasnya dengan melakukan pemrosesan awal data.
Sumber : Han dan Kamber, 2006
Gambar 2.1 Metode pemrosesan awal data Ada beberapa metode pemrosesan awal data, yaitu :
a. Pembersihan data (data cleaning)
9
Data yang akan ditambang mungkin saja mengalami missing value, noisy, atau tidak konsisten. Pembersihan data diperlukan untuk mengisi missing value, menghaluskan data yang noisy, mengidentifikasi dan menghilangkan outlier, dan menangani data yang tidak konsisten (Han dan Kamber, 2006).
Ada beberapa langkah pembersihan data untuk menangani data yang missing value atau noisy.
1. Missing value
a. Membiarkan nilai yang hilang.
b. Mengisi nilai yang hilang secara manual.
c. Menggunakan konstanta \Unknown atau ∞ untuk mengisi nilai yang hilang.
d. Mengisi nilai yang hilang dengan nilai rata – rata atribut.
e. Mengisi nilai yang hilang dengan nilai rata – rata sampel dari kelas yang sama.
f. Mengisi dengan nilai yang paling besar kemungkinan/kesesuaiannya dengan nilai yang hilang (Han dan Kamber, 2006).
2. Noisy
a. Metode binning.
10
1. Smoothing dengan rata – rata (means) dari bin.
Tiap nilai dari bin diganti dengan nilai rata – rata bin.
2. Smoothing dengan nilai tengah (median) dari bin.
Tiap nilai dari bin diganti dengan nilai nilai tengah bin.
3. Smoothing dengan batas bin.
Nilai terendah dan tertinggi diidentifikasi sebagai batas bin. Setiap nilai bin diubah sesuai nilai batas bin yang paling mendekati (Han dan Kamber, 2006).
b. Regresi. c. Clustering.
b. Integrasi data (data integration)
Integrasi data adalah suatu teknik mengkombinasikan data dari beberapa sumber dalam satu tempat penyimpanan, misalnya gudang data (data warehouse). Sumber tersebut bisa berupa multiple database, data cube atau flat file (Han dan Kamber, 2006).
c. Transformasi data (data transformation)
11
Data mentah perlu dilakukan proses transformasi untuk meningkatkan performanya. Dalam tranformasi data, data diubah menjadi bentuk yang bisa ditambang (Han dan Kamber, 2006).
Ada beberapa metode transformasi data, yaitu : 1. Smoothing.
2. Agregasi. 3. Generalisasi. 4. Normalisasi.
5. Konstruksi atribut. (Han dan Kamber, 2006) d. Reduksi data (data reduction)
Data yang kompleks akan membutuhkan waktu yang lama untuk menambang. Teknik reduksi data sangat membantu mereduksi data yang kompleks tanpa mengurangi integritas dari data yang asli dan tidak mengurangi kualitas informasi yang dihasilkan (Han dan Kamber, 2006).
Ada beberapa metode yang digunakan untuk mereduksi data, yaitu :
1. Agregasi data cube. 2. Mereduksi dimensi. 3. Mengkompresi data.
4. Mereduksi semua data (mengganti data yang asli dengan model data).
12
5. Pendiskretan dan konsep hirarki (Han dan Kamber, 2006).
B. Outlier
Menurut Han dan Kamber (2006), data outlier adalah kumpulan obyek - obyek yang dipandang sangat berbeda dibandingkan keseluruhan data. Jadi dapat dikatakan, outlier adalah data yang berbeda/tidak sama atau tidak konsisten dengan keseluruhan set data.
Sumber : Han dan Kamber, 2006
Gambar 2.2 Set data dengan outlier
Ada beberapa hal yang menyebabkan munculnya outlier, yaitu : 1. Kesalahan pengukuran data.
Sebagai contoh, munculnya data umur seseorang yaitu 999 tahun karena kesalahan pengaturan default program.
2. Data pengukuran berasal dari populasi lain.
13
mencolok antara gaji seorang pimpinan dan gaji karyawan di sebuah perusahaan (Han dan Kamber, 2006).
3. Data pengukuran yang benar tetapi mewakili peristiwa atau keadaan unik yang jarang terjadi.
Misalnya, terdapat ada mahasiswa dengan IPK di atas 3,9 sementara sebagian besar mahasiswa mempunyai IPK di bawah 3,3, maka mahasiswa itu akan dianggap sebagai outlier.
Kebanyakan algoritma penambangan data mencoba untuk mengurangi atau bahkan menghilangkan pengaruh outlier. Padahal outlier sendiri kemungkinan memiliki informasi penting yang tersembunyi (Han dan Kamber, 2006). Deteksi outlier dapat menghasilkan informasi penting yang terdapat pada outlier. Dalam penambangan data, deteksi outlier adalah satu satu bidang penelitian yang terus berkembang (Maryono, 2010). Deteksi data outlier sangat bermanfaat untuk mendeteksi adanya perilaku atau kejadian yang tidak normal seperti deteksi penipuan penggunaan kartu kredit, deteksi intrusi jaringan, penggelapan asuransi, diagnosa medis, segmentasi pelanggan, dan sebagainya (Breunig, et. Al., 2000).
Menurut Han dan Kamber (2006) , pendeteksian outlier dikategorikan menjadi 4 metode yaitu :
a. Statistical Distribution Based Outlier Detection
14
masuk dalam hipotesis kerja, sedangkan data yang ditolak atau tidak sesuai dengan hipotesis kerja maka ditetapkan menjadi hipotesis alternatif (outlier).
b. Distance Based Outlier Detection
Metode ini adalah sebuah metode deteksi outlier dengan menghitung jarak pada obyek tetangga terdekat (nearest neighbor). Di dalam pendekatan ini sebuah obyek dibandingkan dengan obyek – obyek terdekatnya yang didefinisikan sebagai k nearest neighbor. Jika jarak sebuah obyek relatif dekat maka obyek tersebut dikatakan normal, namun jika jarak antar obyek relatif jauh maka obyek tersebut dikatakan tidak normal (outlier).
c. Density Based Local Outlier Detection
Metode density based tidak secara eksplisit mengklasifikasikan sebuah obyek adalah outlier atau bukan, akan tetapi lebih kepada pemberian nilai kepada obyek sebagai derajat kekuatan obyek tersebut dapat dikategorikan sebagai outlier. Ukuran derajat kekuatan ini adalah local outlier factor (LOF). Pendekatan untuk pencarian outlier ini hanya membutuhkan sebuah parameter yaitu MinPts. MinPts adalah jumlah tetangga terdekat yang digunakan untuk mendefinisikan kumpulan lokal suatu obyek. d. Deviation Based Outlier Detection
15
Metode ini mengidentifikasi sebuah outlier dengan memeriksa karakteristik utama dari obyek dalam sebuah kumpulan data. Obyek yang memiliki karakteristik di luar karakteristik utama akan dianggap sebagai outlier (Han dan Kamber, 2006).
C. Algoritma EnhancedClass Outlier Distance Based (ECODB)
Algoritma Enhanced Class Outlier Distance Based (ECODB) adalah algoritma deteksi outlier yang dikembangkan oleh Hewahi dan M. K. Saad (2009). Algoritma ini merupakan penyempurnaan dari algoritma CODB (Class Outlier Distance Based). Pada algoritma ini parameter α dan β dihilangkan sehingga pada penghitungan Deviation(T) dan KDist(T) dilakukan proses normalisasi (Hewahi dan M. K. Saad, 2009). Kedua parameter tersebut dihilangkan untuk menghindari proses trial and error. Langkah – langkah algoritma ECODB adalah sebagai berikut :
1. Untuk dataset yang diberikan, hitung nilai PCL(T,K) untuk semua instance.
PCL(Probability of Class Label) adalah nilai probabilitas/banyaknya kemunculan class label yang sama dengan instance T dibandingkan K tetangga terdekatnya. Misalkan ada 7 tetangga terdekat dari instance T (termasuk dirinya) dari sebuah dataset dengan class label x dan y, dimana 5 dari tetangga terdekat mempunyai class label x dan sisanya mempunyai class label y. Instance T dengan class label y mempunyai nilai PCL 2/7.
16
2. Meranking list top N outlier dari instance dengan nilai PCL(T,K) terkecil. Top N adalah jumlah instances yang dideteksi sebagai outlier yang diurutkan dari kecil ke besar berdasarkan nilai COF.
3. Untuk setiap instance yang berada di list top N, menghitung nilai Deviation(T) dan KDist(T) dan update nilai MaxDev, MinDev, MaxKDist, dan MinKDist.
Misalkan ada subset DCL = {t1, t2, t3, ..., th} dari dataset D= {t1, t2, t3, ..., tn}, dimana h adalah jumlah instance dari DCL dan n adalah jumlah instance di D. Misalkan ada instance T, DCL mengandung seluruh instance yang mempunyai label kelas (class label) yang sama dengan instance T.
Deviation dari T adalah seberapa besar nilai instance T yang menyimpang dari subset DCL. Deviation dihitung dengan menjumlahkan jarak antara instance T dengan setiap instance DCL. Deviation dihitung dengan rumus sebagai berikut :
(2.1) KDist adalah jarak antara instance T pada dataset D dengan K tetangga terdekat, seberapa dekat nilai K instance tetangga terdekat dengan instance T. KDist dihitung dengan rumus sebagai berikut :
17
(2.2)
Kemudian nilai Deviation dan KDist dinormalisasikan dalam range 0 – 1 menggunakan rumus sebagai berikut :
(2.3)
Dimana,
Norm(Deviation(T)) : nilai deviation yang sudah ternormalisasi dari instance T
Norm(KDist(T)) : nilai KDist yang sudah ternormalisasi dari instance T
MaxDev : nilai deviation tertinggi dari top N class outlier MinDev : nilai deviation terendah dari top N class outlier MaxKDist : nilai KDist tertinggi dari top N class outlier
MinKDist : KDist terendah dari top N class outlier
4. Menghitung nilai COF (Class Outlier Factor) dari setiap instance yang berada di list top N. COF adalah derajat dari suatu instance T untuk dikategorikan sebagai outlier.
(2.4) Dimana,
COF(T) : nilai Class Outlier Faktor dari instance T K : jumlah tetangga instance T
18
PCL(T,K) : nilai probabilitas class label dari instance T dengan class label dari K Nearest Neighbors
norm(Devation(T)) : nilai deviation yang sudah ternormalisasi dari instance T
norm(KDist(T)) : nilai KDist yang sudah ternormalisasi dari dari instance T
Class outlier adalah instance – instance yang memenuhi pernyataan berikut :
a. KDist dari K tetangga terdekatnya terkecil. b. Nilai Deviation-nya terbesar.
c. Mempunyai class label yang berbeda dengan K tetangga terdekatnya.
19
BAB III
METODE PENELITIAN
A. Metodologi Penelitian
Penelitian ini dilakukan untuk menemukan outlier pada data debitur dengan data campuran numerik dan kategorikal menggunakan algoritma ECODB. Penelitian ini menggunakan data debitur dari BPR XYZ sebagai bahan studi kasus. Dengan melakukan pendeteksian outlier pada data tersebut, dapat diketahui outlier pada suatu kumpulan data yang mempunyai classs label.
Penelitian dilakukan dengan cara menghitung data debitur BPR XYZ bulan Agustus 2013 berdasarkan teori algoritma ECODB dengan menggunakan Microsoft Excel. Perhitungan akan dilakukan dengan masukan k dan top N yang berbeda. Kemudian hasil perhitungan tersebut akan dibandingkan untuk mendapatkan kesimpulan dan dilakukan review hasil deteksi outlier oleh petugas bank.
Hasil penelitian ini diharapkan dapat memberi gambaran apakah algoritma ECODB dapat digunakan untuk mendeteksi outlier pada data debitur dengan atribut campuran numerik dan kategorikal dengan kasus data debitur BPR XYZ dan bagaimana pengaruh nilai k dan top N dalam proses deteksi outlier menggunakan algoritma ECODB. Setelah outlier dideteksi, pihak bank dapat menganalisa data dan outlier untuk menemukan faktor tertentu yang berpengaruh pada keunikan data debitur tersebut.
20
B. Instrumen Penelitian
Instrumen yang digunakan untuk melakukan penelitian ini adalah sebagai berikut :
1. Microsoft Excel
Microsoft Excel digunakan untuk menghitung dan menganalisa hasil penambangan data menggunakan algoritma ECODB. Data akan mengalami pemrosesan awal dahulu kemudian akan dihitung menggunakan algoritma ECODB. Rumus – rumus perhitungan pada algoritma ECODB akan diterapkan dalam bentuk formula di Microsoft Excel. Perhitungan akan dilakukan dengan masukan k dan top N yang berbeda.
[image:41.595.100.522.181.608.2]2. Grafik
Grafik digunakan untuk melihat persebaran dari hasil perhitungan dengan masukan k dan top N yang berbeda. Dengan memperhatikan grafik, maka dapat diambil kesimpulan tentang pengaruh nilai nilai k dan top N dalam mendeteksi outlier mengunakan algoritma ECODB.
C. Teknik Pengumpulan Data
21
[image:42.595.102.525.186.749.2]Humas BPR XYZ. Data tersebut terdiri dari 33 atribut seperti dalam tabel berikut :
Tabel 3.1 Atribut – atribut pada dataset debitur
Atribut Keterangan
NOREK NOPK NAMA KODE_PEKER J_USAHA NAMAIBU ALAMAT1 T_LAHIR TGL_LAHIR UMUR IDENTITAS NAMA_KTR KODE_POS JW NOM_PINJ SB
No rekening debitur di bank No peminjaman debitur di bank. Nama lengkap dari debitur.
Kode pekerjaan atau jenis usaha yang dilakukan debitur
Jenis usaha atau pekerjaan yang dilakukan debitur. Nama gadis ibu kandung debitur.
Alamat lengkap yang ditinggali debitur. Tempat lahir debitur.
Tanggal lahir debitur.
Umur debitur ketika melakukan
peminjaman/kredit. Nomor KTP debitur.
Nama kantor/tempat debitur bekerja. Kode pos tempat tinggal debitur.
Jangka waktu peminjaman kredit yang dipilih debitur.
22
JAMINAN
NJOP_NT PINJ_KE
TUNG_POK
TUNG_BNG
TUNG_POKOK TUNG_BUNGA POKOK_BLN
BUNGA_BLN
GAJI/PENDAPATAN JML_TANGGUNGAN UANG _DIBAWA STATUS_PINJAMAN
JML_SETORAN/BULAN
Jaminan yang digunakan debitur untuk mengajukan kredit.
Nilai barang yang dijadikan jaminan oleh debitur. Jumlah berapa kali debitur melakukan peminjaman di BPR XYZ.
Jumlah berapa kali debitur menunggak mengangsur kredit.
Jumlah berapa kali debitur menunggak mengangsur bunga.
Jumlah total kredit yang ditunggak oleh debitur. Jumlah total bunga yang ditunggak oleh debitur. Jumlah kredit yang harus diangsur debitur tiap bulan.
Jumlah bunga yang harus diangsur debitur tiap bulan.
Gaji atau pendapatan debitur tiap bulan.
Jumlah anggota keluarga yang ditanggung debitur. Jumlah uang yang dibawa pulang debitur.
Keterangan apakah debitur saat mengajukan kredit telah melakukan peminjaman kredit di bank lain atau tidak.
Jumlah setoran yang harus diangsur debitur di bank lain tiap bulan.
23
KOLBI1 Status peminjaman debitur baik atau bermasalah.
D. Teknik Pengolahan Data
Sampel data debitur akan diproses terlebih dahulu dengan teknik transformasi data (data transformation), pembersihan data (data cleaning), dan reduksi data (data reduction) untuk mengatasi missing value, noisy, data yang tidak konsisten, dan pemilihan atribut yang digunakan. Selanjutnya data akan dihitung berdasarkan teori algoritma ECODB dengan menerapkan rumus perhitungan pada formula Microsoft Excel. Perhitungan akan dilakukan dengan masukan k dan top N yang berbeda.
Kemudian hasil perhitungan tersebut akan dibandingkan dan dilakukan review hasil deteksi outlier oleh petugas bank untuk mengetahui kebenaran data yang dianggap mempunyai derajat tinggi sebagai outlier. Untuk membandingkan hasil deteksi outlier menggunakan algoritma ECODB, data hasil perhitungan akan ditampilkan dalam bentuk grafik. Grafik digunakan untuk melihat persebaran dari hasil perhitungan masukan k dan top N yang berbeda. Dengan memperhatikan grafik, maka dapat diambil kesimpulan tentang pengaruh nilai nilai k dan top N dalam mendeteksi outlier mengunakan algoritma ECODB.
E. Tahap – Tahap Penelitian
Langkah – langkah yang akan dilakukan untuk melakukan penelitian adalah sebagai berikut :
1. Studi kepustakaan
24
Studi kepustakaan melalui berbagai sumber yang mampu dipertanggungjawabkan seperti buku, jurnal, makalah dan paper seminar untuk mendapatkan teori mengenai penambangan data, outlier, dan algoritma ECODB (Enhanced Class Outlier Distance Based).
2. Pengumpulan Data
Pengumpulan data sekunder berupa data debitur BPR XYZ bulan Agustus 2013 sebanyak 97 record.
3. Penerapan algoritma ECODB
Mendeteksi outlier pada data debitur BPR XYZ bulan Agustus 2013 berdasarkan teori algoritma ECODB menggunakan Microsoft Excel. Perhitungan akan dilakukan dengan masukan k dan top N yang berbeda.
5. Analisa hasil perhitungan
Membandingkan hasil perhitungan dengan masukan k dan top N yang berbeda – beda untuk mendapatkan kesimpulan dan melakukan review hasil deteksi outlier oleh petugas bank. Review hasil deteksi outlier perlu dilakukan untuk mengetahui kebenaran data yang dianggap mempunyai derajat tinggi sebagai outlier. 6. Pengambilan kesimpulan
Pengambilan kesimpulan berdasarkan hasil yang diperoleh dari langkah – langkah sebelumnya.
25
F. Contoh Perhitungan Algoritma ECODB
Berikut contoh perhitungan berdasarkan algoritma ECODB secara manual. Misalkan ada dataset debitur berjumlah 13 record dengan atribut KODE_PEKER, UMUR, NOM_PINJ, SB, JW, JAMINAN, NJOP_NT, PINJ_KE, TUNG_POK, TUNG_BNG, TUNG_POKOK, TUNG_BUNGA,
POKOK_BLN, BUNGA_BLN, GAJI/PENDAPATAN,
JML_TANGGUNGAN, UANG _DIBAWA, STATUS_PINJAMAN,
JML_SETORAN/BULAN, dan STATUS sebagai berikut :
Gambar 3.1 Contoh dataset debitur
Pertama, tiap atribut bertipe numerik dinormalisasikan dengan range 0 - 1. Hasil normalisasi dapat dilihat pada gambar 3.2. Atribut bertipe kategorikal adalah KODE_PEKER, JAMINAN, dan STATUS_ PINJAMAN.
26
Gambar 3.2 Data debitur yang telah dinormalisasi
Kemudian dicari jarak dari setiap instance dengan menggunakan fungsi jarak Mixed Euclidian Distance. Pada fungsi ini setiap instance bertipe kategorikal akan diberi nilai 0 jika mempunyai kategori yang sama dan diberi nilai 1 jika mempunyai kategori yang berbeda, sedangkan atribut numerik akan dihitung menggunakan rumus :
(3.5)
Gambar 3.3 Perhitungan jarak setiap instance dari data debitur
[image:47.595.71.553.106.723.2]27
Setelah menghitung jarak dari setiap instance, tahap selanjutnya adalah mencari k tetangga terdekat, dengan asumsi k = 7. K melambangkan jangkauan suatu instance terhadap tetangganya. Maka, dicari 7 tetangga terdekat dari setiap instance.
Gambar 3.4 Tujuh tetangga terdekat dari tiap instance
Selanjutnya mencari nilai PCL dari tiap instance. PCL adalah nilai probabilitas class label dari instance T dengan class label dari k tetangga terdekat. PCL dihitung dengan cara membagi jumlah tetangga terdekat instance T yang mempunyai class label yang sama (termasuk instance T sendiri) dengan nilai k. Misalkan ada 7 tetangga terdekat dari instance T (termasuk dirinya) dari sebuah dataset dengan class label x dan y, dimana 5 dari tetangga terdekat mempunyai class label x dan sisanya mempunyai class label y. Instance T dengan class label y mempunyai nilai PCL 2/7. Class label yang digunakan adalah nilai/isi dari atribut STATUS.
Tabel 3.2 Hasil perhitungan PCL tiap instance PCL PCL/7 Dev v'Dev Kdist v'Kdist COF
1 7 1.00
28
2 7 1.00
3 7 1.00
4 7 1.00
5 7 1.00
6 2 0.29
7 2 0.29
8 3 0.43
9 3 0.43
10 3 0.43 11 5 0.71 12 7 1.00 13 5 0.71
[image:49.595.100.517.111.644.2]Kemudian meranking list top N dari instance dengan nilai PCL terkecil. Misalkan top N = 5, maka dicari 5 instance dengan nilai PCL terkecil. Ranking top N dapat dilihat pada tabel 3.3. Instance yang di-bold adalah instance dengan nilai PCL terkecil. Selanjutnya mencari nilai Deviation(T) dan KDist(T) dari instance pada top N berdasarkan rumus (2.4) dan (3.5).
Tabel 3.3 Hasil perhitungan Deviation dan KDistdari tiap instance PCL PCL/7 Dev v'Dev Kdist v'Kdist COF
1 7 1.00 13.55 0.90 11.31 0.77 2 7 1.00 13.32 0.89 11.17 0.73 3 7 1.00 12.90 0.86 10.38 0.47 4 7 1.00 14.19 0.95 11.60 0.87 5 7 1.00 13.66 0.91 10.97 0.66
6 2 0.29 0.50 0.00 10.53 0.52
7 2 0.29 0.50 0.00 9.81 0.28
8 3 0.43 0.77 0.02 8.96 0.01
9 3 0.43 0.76 0.02 8.93 0.00
10 3 0.43 1.48 0.07 8.95 0.01
11 5 0.71 14.70 0.98 11.35 0.78 12 7 1.00 14.32 0.95 11.74 0.91 13 5 0.71 14.98 1.00 12.01 1.00
29
instance pada top N berdasarkan rumus (2.4). Kemudian meranking tiap instance pada list top N berdasarkan nilai COF terkecil.
Tabel 3.4 Hasil perhitungan COF dari tiap instance
PCL PCL/7 Dev v'Dev Kdist v'Kdist COF
7 2.00 0.29 0.50 0.00 9.81 0.28 2.28
6 2.00 0.29 0.50 0.00 10.53 0.52 2.52
10 3.00 0.43 1.48 0.07 8.95 0.01 2.94
9 3.00 0.43 0.76 0.02 8.93 0.00 2.98
8 3.00 0.43 0.77 0.02 8.96 0.01 2.99
11 5.00 0.71 14.70 0.98 11.35 0.78 4.80 13 5.00 0.71 14.98 1.00 12.01 1.00 5.00 3 7.00 1.00 12.90 0.86 10.38 0.47 6.61 5 7.00 1.00 13.66 0.91 10.97 0.66 6.75 2 7.00 1.00 13.32 0.89 11.17 0.73 6.84 1 7.00 1.00 13.55 0.90 11.31 0.77 6.87 4 7.00 1.00 14.19 0.95 11.60 0.87 6.92 12 7.00 1.00 14.32 0.95 11.74 0.91 6.96
Dari tabel di 3.4, ditemukan instance yang menjadi outlier yaitu instance nomor 7, 6, 10, 9, dan 8. Dimana nasabah no. 7 dan 6 meminjam dengan jumlah cukup besar (dibandingkan dengan tetangga terdekatnya) dan menunggak sebanyak 6 kali. Sedangkan nasabah no. 10, 9, dan 8 mempunyai jumlah pinjaman yang terkecil tetapi mempunyai tunggakan sebanyak 4 – 5 kali.
30
BAB IV
HASIL DAN PEMBAHASAN
A. Sumber Data
Sumber data dalam penelitian ini adalah data debitur BPR XYZ bulan Agustus 2013 sebanyak 97 data record. Data tersebut dalam format Microsoft Excel (.xls). Data ini diperoleh setelah mendapat ijin pengambilan dan penggunaan data untuk penelitian dari Kepala Humas BPR XYZ. Data tersebut terdiri dari 32 atribut seperti dalam tabel 3.1.
Data debitur tersebut akan dihitung menggunakan algoritma ECODB untuk mendeteksi outlier yang terdapat pada data tersebut. Setelah outlier dideteksi, pihak bank dapat menganalisa data dan outlier untuk menemukan faktor tertentu yang berpengaruh pada keunikan data debitur tersebut. Sebelum ditambang, data akan akan mengalami pemrosesan awal terlebih dahulu untuk menghasilkan data dengan kualitas yang baik untuk diolah.
B. Pemrosesan Awal Data
1. Seleksi Data
31
NOREK, NOPK, NAMA, KODE_PEKER, J_USAHA, NAMAIBU, ALAMAT1, T_LAHIR, TGL_LAHIR, UMUR, IDENTITAS, NAMA_KTR, KODE_POS, JW, NOM_PINJ, SB, JAMINAN, NJOP_NT,
PINJ_KE, TUNG_POK, TUNG_BNG, TUNG_POKOK,
TUNG_BUNGA, POKOK_BLN, BUNGA_BLN, GAJI/PENDAPATAN, JML_TANGGUNGAN,STATUS_PINJAMAN,JML_SETORAN/BULAN dan KOLBI1.
Atribut NOREK, NOPK, NAMA, NAMAIBU, ALAMAT1, T_LAHIR, IDENTITAS, NAMA_KTR dan KODE_POS tidak digunakan karena dianggap tidak relevan jika digunakan pada proses deteksi outlier. Hal ini berdasarkan keterangan atribut pada tabel 3.1.
Atribut J_USAHA dan TGL_LAHIR juga tidak digunakan. Atribut – atribut tersebut cukup relevan jika digunakan. Tetapi nilai dari atribut tersebut dapat digantikan dengan atribut lainnya dengan nilai yang mirip atau sama maka atribut – atribut tersebut tidak digunakan dalam penelitian. J_USAHA diganti dengan KODE_PEKER dan atribut TGL_LAHIR diganti dengan UMUR sehingga data tersebut tidak kompleks lagi dan juga mempunyai kualitas informasi yang baik untuk ditambang.
Atribut – atribut yang tersisa adalah KODE_PEKER, UMUR NOM_PINJ, SB, JW, JAMINAN, NJOP_NT, PINJ_KE, TUNG_POK,
TUNG_BNG, TUNG_POKOK, TUNG_BUNGA, POKOK_BLN,
32
_DIBAWA, STATUS_PINJAMAN, JML_SETORAN/BULAN, dan KOLBI1. Hasil seleksi atribut dapat dilihat di lampiran 2.
Hasil yang di peroleh dari tahap seleksi atribut telah menghasilkan sejumlah 20 atribut dan 97 instances. Berikut ini beberapa keterangan yang berkaitan dengan atribut – atribut terpilih, yaitu :
a. KODE_PEKER
Atribut ini berisi kode pekerjaan berdasarkan jenis usaha yang dijalankan debitur. Kode pekerjaan tersebut adalah 010 dan 014. Atribut ini bertipe kategorikal.
b. UMUR
Atribut ini berisi umur dari tiap debitur ketika mengajukan kredit. Dalam atribut ini diketahui debitur paling muda berusia 18 tahun dan debitur paling tua berusia 63 tahun. Rata – rata umur debitur ketika mengajukan kredit adalah 44, 5 tahun. Atribut ini bertipe numerik.
c. NOM_PINJ
Atribut ini berisi jumlah pinjaman kredit yang diajukan debitur dan telah disetujui oleh bank/kreditur. Nominal pinjaman ditetapkan dalam rupiah (Rp). Atribut ini bertipe numerik. d. SB
Atribut ini berisi jumlah suku bunga yang diterima debitur. Suku bunga ditetapkan dalam bentuk persen (%).Atribut ini bertipe numerik.
33
e. JW
Atribut ini berisi jangka waktu kredit yang diajukan nasabah. Jangka waktu kredit ditetapkan dalam waktu tertentu selama beberapa bulan. Atribut ini bertipe numerik.
f. JAMINAN
Atribut ini berisi bentuk jaminan yang diberikan debitur sebagai salah satu syarat pengajuan kredit. Bentuk – bentuk jaminan tersebut adalah BPKB, GAJI, SERTIFIKAT, dan TANAH. Atribut ini bertipe kategorikal.
g. NJOP_NT
Atribut ini berisi nilai/harga jaminan yang dipunyai debitur berdasarkan hasil perkiraan bank. Nominal nilai jaminan ditetapkan dalam rupiah (Rp). Atribut ini bertipe numerik. h. PINJ_KE
Atribut ini berisi keterangan sejumlah berapa kali debitur pernah mengajukan kredit di BPR Shinta Bhakti Wedi. Atribut ini umumnya digunakan untuk mengetahui reputasi pengajuan kredit debitur, khususnya selama mengajukan kredit di BPR Shinta Bhakti Wedi. Atribut ini bertipe numerik.
i. TUNG_POK
Atribut ini berisi keterangan berapa kali debitur menunggak mengangsur kredit. Atribut ini bertipe numerik.
j. TUNG_BNG
34
Atribut ini berisi keterangan berapa kali debitur menunggak mengangsur bunga. Atribut ini bertipe numerik.
k. TUNG_POKOK
Atribut ini berisi jumlah total kredit yang ditunggak oleh debitur. Atribut ini bertipe numerik.
l. TUNG_BUNGA
Atribut ini berisi jumlah total bunga yang ditunggak oleh debitur. Atribut ini bertipe numerik.
m. GAJI/PENDAPATAN
Atribut ini berisi jumlah gaji atau pendapatan debitur tiap bulan. Atribut ini bertipe numerik.
n. JML_TANGGUNGAN
Atribut ini berisi jumlah anggota keluarga yang ditanggung oleh debitur. Atribut ini bertipe numerik.
o. UANG_DIBAWA
Atribut ini berisi jumlah nominal uang yang dibawa pulang/diperoleh debitur setiap bulannya. Atribut ini bertipe numerik.
p. STATUS_PINJAMAN
Atribut ini berisi keterangan apakah debitur saat mengajukan kredit telah melakukan peminjaman kredit di bank lain atau tidak. Atribut ini bertipe kategorikal.
q. JML_SETORAN/BULAN
35
Atribut ini berisi besar jumlah setoran yang harus diangsur debitur di bank lain setiap bulannya (jika debitur saat mengajukan kredit telah melakukan peminjaman kredit di bank lain). Atribut ini bertipe numerik.
r. POKOK_BLN
Atribut ini berisi jumlah kredit yang harus diangsur debitur setiap bulan. Atribut ini bertipe numerik.
s. BUNGA_BLN
Atribut ini berisi jumlah bunga yang harus diangsur debitur setiap bulan. Atribut ini bertipe numerik.
t. KOLBI1
Atribut ini adalah atribut yang digunakan untuk menyatakan status kredit debitur. Dimana nilai 1 berarti debitur mengangsur dengan baik (lancar), 2 berarti debitur sedikit tersendat dalam mengangsur (kurang lancar), 3 berarti debitur cukup tersendat dalam mengangsur kredit (diragukan), dan 4 berarti debitur berhenti mengangsur (macet). Atribut ini merupakan class label pada data debitur tersebut.
36
Gambar 4.1 Atribut pada data debitur setelah tahap seleksi data
2. Pengisian Missing Value
Di dalam dataset debitur yang telah mengalami seleksi atribut terdapat missing value pada kolom GAJI/PENDAPATAN, JML_TANGGUNGAN, UANG _DIBAWA, STATUS_PINJAMAN, JML_SETORAN/BULAN, baris 1, 18, 37, 38, 42, 50, dan 96. Untuk mengatasi hal ini, kolom yang kosong akan diisi dengan means untuk data dengan atribut numerik dan diisi dengan mode untuk data dengan atribut kategorikal (Hewahi dan M. K. Saad, 2007). Hasil pengisian missing value dapat dilihat di lampiran 3.
37
3. Normalisasi Data
Setelah mengisi missing value secara manual dengan teknik means dan mode, dilakukan proses normalisasi atribut. Proses ini dilakukan karena adanya perbedaan range nilai dari tiap – tiap atribut sehingga perlu dilakukan normalisasi agar data memiliki nilai yang tepat dan sama untuk ditambang. Atribut – atribut tersebut akan dinormalisasi agar mempunyai range nilai 0 - 1. Hasil normalisasi dapat dilihat di lampiran 4. Proses normalisasi menggunakan metode min-max normalization sebagai berikut :
(4.6) Dimana,
v’ : nilai yang sudah ternormalisasi v : nilai lama yang belum ternormalisasi min : nilai minimum dari suatu instance max : nilai maksimum dari suatu instance
NewMax : nilai minimum baru dari suatu instance NewMin : nilai maksimum baru dari suatu instance
Berikut contoh proses normalisasi data :
Tabel 4.1 Contoh atribut pada dataset debitur sebelum normalisasi
UMUR NOM_PINJ SB JW NJOP_NT POKOK_BLN BUNGA_BLN
39 30,000,000 11.4 50 3,344,778 600,000 285,000
50 15,000,000 7.2 60 3,229,280 250,000 90,000
52 27,000,000 9.6 40 4,110,556 675,000 216,000
49 21,000,000 9.6 60 3,827,169 350,000 168,000
38
49 30,000,000 9.6 60 3,803,224 500,000 240,000
47 30,000,000 9.6 60 3,984,900 500,000 240,000
51 21,000,000 9.6 50 3,819,900 420,000 168,000
Tabel 4.2 Contoh atribut pada dataset debitur setelah normalisasi
v'umur v'nom_pinj v'sb v'jw v'njop_nt v'pokok_bln v'bunga_bln
0.00 1.00 1.00 0.50 0.13 0.77 1.00
0.85 0.00 0.00 1.00 0.00 -0.31 0.00
1.00 0.80 0.57 0.00 1.00 1.00 0.65
0.77 0.40 0.57 1.00 0.68 0.00 0.40
0.77 1.00 0.57 1.00 0.65 0.46 0.77
0.62 1.00 0.57 1.00 0.86 0.46 0.77
0.92 0.40 0.57 0.50 0.67 0.22 0.40
C. Penambangan Data Dengan Microsoft Excel
Data yang telah mengalami pemrosesan akan ditambang berdasarkan algoritma ECODB. Penambangan data menggunakan Microsoft Excel. Rumus algoritma ECODB akan diterapkan dalam bentuk formula Microsoft Excel.
1. Menormalisasi Data
Sebelum ditambang, data yang telah mengalami pemrosesan awal akan dinormalisasi terlebih dahulu. Proses normalisasi ini dilakukan dengan tujuan membuat data memiliki nilai yang tepat dan sama untuk ditambang. Atribut – atribut tersebut akan dinormalisasi agar mempunyai range nilai 0 – 1. Proses normalisasi menggunakan metode min-max normalization seperti pada rumus (4.6). Formula normalisasi dalam Microsoft Excel adalah sebagai berikut :
=(cell1-min(cell))/(max(cell)-min(cell))*(1-0)+0
39
Gambar 4.3 Contoh formula normalisasi data
2. Mencari Jarak Dari Tiap Data Dengan Menggunakan Fungsi Jarak
Mixed Euclidian Distance
Setelah menormalisasi data, dicari jarak dari tiap data dengan menggunakan fungsi jarak mixed euclidian distance. Pada fungsi ini setiap instance bertipe kategorikal akan diberi nilai 0 jika mempunyai kategori yang sama dan diberi nilai 1 jika mempunyai kategori yang berbeda, sedangkan atribut numerik akan dihitung berdasarkan rumus (5). Formula mencari jarak dalam Microsoft Excel adalah sebagai berikut :
=SQRT((IF(cell1=cell2,0,1))^2+(cell3-cell4)^2+(cell5-
cell6)^2+(cell7-cell8)^2+(cell9-cell10)^2+(IF(cell11=cell12,0,1))^2+(cell13-cell14)^2+ (cell15-cell16)^2+(cell17-cell18)^2+(cell19-cell20)^2+ (cell21-cell22)^2+(cell23-cell24)^2+(cell25-cell26)^2+ (cell27-cell28)^2+(cell29-cell30)^2+(cell31-cell32)^2+
40
Gambar 4.4 Contoh formula mencari jarak
3. Menghitung PCL
PCL(Probability of Class Label) adalah nilai probabilitas/banyaknya kemunculan class label yang sama dengan instance T dibandingkan k tetangga terdekatnya. PCL dihitung dengan cara membagi jumlah tetangga terdekat instance T yang mempunyai class label yang sama (termasuk instance T sendiri) dengan nilai k. Formula menghitung PCL dalam Microsoft Excel adalah sebagai berikut :
[image:61.595.97.527.122.588.2]=cell1/k
Gambar 4.5 Contoh formula menghitung PCL
4. Meranking List Top N Outlier Dari Instance Dengan Nilai PCL(T,K)
Terkecil
41
diranking 10 instance dengan nilai PCL(T,K) terkecil. Untuk meranking instance, digunakan fitur Sort & Filter dalam Microsoft Excel.
Gambar 4.6 Contoh meranking kecil ke besarberdasarkannilai PCL(T,K) terkecil
5. Menghitung Nilai Deviation(T)¸ Norm(Deviation(T)), Kdist(T), Dan
Norm(Kdist(T))
42
ternormalisasi. Formula menghitung Deviation(T)¸ Norm(Deviation(T)), Kdist(T), dan Norm(Kdist(T)) dalam Microsoft Excel adalah sebagai berikut :
a. Mencari Deviation
=cell1+cell2+cell3+...+celln
Gambar 4.7 Contoh formula menghitung Deviation b. Mencari Norm(Deviation(T))
=(cell1-min(cell))/(max(cell)-min(cell))
Gambar 4.8 Contoh formula menghitung Norm(Deviation(T)) c. Mencari Kdist
= cell1+cell2+cell3+...+celln
Gambar 4.9 Contoh formula menghitung Kdist d. Mencari Norm(KDist(T))
=(cell1-min(cell))/(max(cell)-min(cell))
43
Gambar 4.10 Contoh formula menghitung Norm(KDist(T))
6. Menghitung Nilai COF (Class Outlier Factor)
Tahap selanjutnya adalah menghitung COF (Class Outlier Factor) dari setiap instance yang berada di list top N. COF adalah derajat dari suatu instance T untuk dikategorikan sebagai outlier. COF dihitung berdasarkan rumus (2.4). Formula menghitung COF dalam Microsoft Excel adalah sebagai berikut :
=k*cell1-cell2+cell3
Gambar 4.11 Contoh formula menghitung COF (Class Outlier Factor)
7. Mengurutkan List Top N Secara Kecil Ke Besar Sesuai Nilai COF
Tahap terakhir adalah mengurutkan list top N secara kecil ke besar sesuai nilai COF. Misalkan masukan top N = 10, maka akan diranking 10 instance dengan nilai COF terkecil. Untuk meranking instance, digunakan fitur Sort & Filter dalam Microsoft Excel.
44
Gambar 4.12 Contoh meranking kecil ke besarberdasarkannilai COF terkecil
D. Hasil Deteksi Outlier Berdasarkan Algoritma ECODB Dengan Microsoft
Excel
Hasil deteksi outlier berdasarkan algoritma ECODB menggunakan Microsoft Excel dengan masukan k dan top N yang berubah – ubah dapat ditampilkan dalam bentuk tabel – tabel di bawah. Dimana k adalah jumlah tetangga terdekat dari suatu instances, sedangkan