Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN
METODE NAÏVE BAYES
SKRIPSI
Diajukan untuk memenuhi bagian dari
syarat memperoleh gelar Sarjana Komputer
Departemen Pendidikan Ilmu Komputer
oleh
Rany Kasman
0905544
DEPARTEMEN PENDIDIKAN ILMU KOMPUTER
FAKULTAS PENDIDIKAN MATEMATIKA DAN ILMU PENGETAHUAN ALAM
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN
METODE NAÏVE BAYES
oleh
Rany Kasman
Sebuah skripsi yang diajukan untuk memenuhi salah satu syarat memperoleh gelar
Sarjana pada Fakultas Pendidikan Matematika dan Ilmu Pengetahuan Alam
©Rany Kasman 2015
Universitas Pendidikan Indonesia
November 2015
Hak cipta dilindungi Undang-Undang
Skripsi ini tidak boleh diperbanyak seluruhnya atau sebagian,
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN
METODE NAÏVE BAYES
oleh
Rany Kasman
0905544
Disetujui dan Disahkan oleh:
Pembimbing I
Yudi Wibisono, M.T. NIP. 197507072003121003
Pembimbing II
Herbert Siregar, M.T. NIP. 19700502200812100
Mengetahui,
Ketua Program Studi Ilmu Komputer
Eddy Prasetyo Nugroho, M.T. NIP. 19750515200801101
Ketua Departemen Pendidikan Ilmu Komputer
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
ABSTRAK
Konsumsi informasi berita yang semakin tinggi telah menjadi kebutuhan
vital bagi masyarakat. Hal ini berdampak pada cepatnya perkembangan lalu lintas
informasi di tengah masyarakat. Salah satu sumber informasi yang berperan
penting dalam penyebaran berita adalah tweet yang dikirimkan melalui media
sosial Twitter. Dengan banyaknya informasi yang beredar melalui tweet tentunya
akan menyulitkan pembaca untuk mengetahui informasi berita spesifik yang
tersebar. Pada penelitian ini penulis terfokus pada pengklasifikasian informasi
berita ke dalam kategori berita dengan sumber data tweet. Teknik yang digunakan
adalah algoritma Naïve Bayes dengan dua tahap klasifikasi. Tahap pertama
digunakan untuk memisahkan antara tweet berita dan tweet bukan berita.
Sedangkan tahap kedua digunakan untuk memisahkan tweet berita tersebut ke
dalam kategori berita yang telah disiapkan. Hasil klasifikasi pada tahap pertama
menghasilkan akurasi sebesar 77,35%, sedangkan hasil klasifikasi pada tahap
kedua menghasilkan akurasi sebesar 61,21%. Tweet yang telah terkelompok di
masing-masing kategori ditampilkan pada dashboard user untuk memudahkan
pengguna dalam mengakses informasi berita. Dari penelitian ini menunjukkan
bahwa algoritma Naïve Bayes layak digunakan untuk pengklasifikasian informasi
berita dengan sumber data tweet berbahasa Indonesia.
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
ABSTRACT
As the increase of news consumption has become a vital necessity of
society. This condition affects on the rapid growth of information traffic in the
community. One of information source that plays an important role in
dissemination of news is tweet that sent via Twitter. With the amount of
information circulating through Twitter will certainly make it difficult for readers
to know the specific information that scattered. In this research author focused on
the classification of news information into several categories with tweets as the
data source. Author used Naïve Bayes algorithm with two-stage classifications.
The first stage is used to separate tweets as news and non-news, while the second
one is used to separate news tweets into categories that have been prepared. The
result of the first stage shows the classification accuracy of 77,35%, while the
second stage shows the classification accuracy of 61,21%. Tweets that have been
classified in each category will displayed on user dashboard and allow user to
access the news information comfortably. This research pointed that Naïve Bayes
algorithm can be used for the classification of news information with tweets in
Bahasa as the data source.
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
DAFTAR ISI
PERNYATAAN ... Error! Bookmark not defined.
KATA PENGANTAR ... Error! Bookmark not defined.
UCAPAN TERIMA KASIH ... Error! Bookmark not defined.
ABSTRAK ... Error! Bookmark not defined.
ABSTRACT ... Error! Bookmark not defined.
DAFTAR ISI ... vii
DAFTAR TABEL ... x
DAFTAR GAMBAR ... xii
DAFTAR LAMPIRAN ... xiv
BAB I PENDAHULUAN ... Error! Bookmark not defined.
1.1 Latar Belakang ... Error! Bookmark not defined.
1.2 Identifikasi Masalah ... Error! Bookmark not defined.
1.3 Batasan Masalah ... Error! Bookmark not defined.
1.4 Tujuan Penelitian ... Error! Bookmark not defined.
1.5 Manfaat Penelitian ... Error! Bookmark not defined.
1.6 Sistematika Penulisan ... Error! Bookmark not defined.
BAB II TINJAUAN PUSTAKA ... Error! Bookmark not defined.
2.1 News Aggregator ... Error! Bookmark not defined.
2.1.1. Google News (news.google.com) .... Error! Bookmark not defined.
2.1.2. Techmeme (www.techmeme.com) .. Error! Bookmark not defined.
2.2 Text Mining ... Error! Bookmark not defined.
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
2.3.2. Naïve Bayes ... Error! Bookmark not defined.
2.3.3. Evaluasi dan Validasi Klasifikasi... Error! Bookmark not defined.
2.3 Imbalanced Dataset ... Error! Bookmark not defined.
2.4 Twitter ... Error! Bookmark not defined.
2.5.1. Twitter API ... Error! Bookmark not defined.
BAB III METODOLOGI PENELITIAN ... Error! Bookmark not defined.
3.1 Desain Penelitian ... Error! Bookmark not defined.
3.2 Metode Penelitian ... Error! Bookmark not defined.
3.2.1. Proses Pengumpulan Data ... Error! Bookmark not defined.
3.2.2. Proses Pengembangan Perangkat LunakError! Bookmark not
defined.
3.3 Alat dan Bahan Penelitian ... Error! Bookmark not defined.
3.3.1. Alat Penelitian ... Error! Bookmark not defined.
3.3.2. Bahan Penelitian... Error! Bookmark not defined.
BAB IV HASIL PENELITIAN DAN PEMBAHASANError! Bookmark not
defined.
4.1 Pengembangan Perangkat Lunak ... Error! Bookmark not defined.
4.1.1. Analisis Kebutuhan Perangkat LunakError! Bookmark not
defined.
4.1.2. Perancangan ... Error! Bookmark not defined.
4.1.3. Implementasi ... Error! Bookmark not defined.
4.1.4. Pengujian ... Error! Bookmark not defined.
4.2 Pembahasan Eksperimen ... Error! Bookmark not defined.
4.2.1 Pengumpulan Data ... Error! Bookmark not defined.
4.2.2 Pelabelan Data ... Error! Bookmark not defined.
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
4.2.4 Feature Selection ... Error! Bookmark not defined.
4.2.5 Text Classification ... Error! Bookmark not defined.
4.2.6 Evaluasi dan Validasi ... Error! Bookmark not defined.
4.2.7 Analisa Hasil Uji ... Error! Bookmark not defined.
4.3 Eksperimen ... Error! Bookmark not defined.
4.4 Hasil Eksperimen ... Error! Bookmark not defined.
4.4.1. Klasifikasi Tahap Pertama ... Error! Bookmark not defined.
4.4.2. Klasifikasi Tahap Kedua ... Error! Bookmark not defined.
4.5 Hasil Penilaian Kuesioner ... Error! Bookmark not defined.
4.6 Pembahasan Hasil Eksperimen... Error! Bookmark not defined.
4.7 Pembahasan Hasil Penilaian Kuesioner .. Error! Bookmark not defined.
BAB V KESIMPULAN DAN SARAN ... Error! Bookmark not defined.
5.1 Kesimpulan ... Error! Bookmark not defined.
5.2 Saran ... Error! Bookmark not defined.
DAFTAR PUSTAKA ... Error! Bookmark not defined.
LAMPIRAN ... Error! Bookmark not defined.
Lampiran 1. Daftar Stopwords ... Error! Bookmark not defined.
Lampiran 2. Daftar Sinonim ... Error! Bookmark not defined.
Lampiran 3. Daftar Sinonim Spesial ... Error! Bookmark not defined.
Lampiran 4. Contoh Tweet pelabelan Tahap 1 (200 data)Error! Bookmark
not defined.
Lampiran 5. Contoh Tweet pelabelan Tahap 2 (200 data)Error! Bookmark
not defined.
Lampiran 6. Kuesioner ... Error! Bookmark not defined.
[Type text]
DAFTAR TABEL
Tabel 2.1 Contoh Dataset ... Error! Bookmark not defined.
Tabel 2.2 Hasil Perhitungan TF ... Error! Bookmark not defined.
Tabel 2.3 Hasil Perhitungan TF dan IDF ... Error! Bookmark not defined.
Tabel 2.4 Hasil Perhitungan TF-IDF ... Error! Bookmark not defined.
Tabel 4.1 Pelaksanaan Pengujian Black Box... Error! Bookmark not defined.
Tabel 4.2 Daftar User Dengan Bidang Kompetensi Politik dan Hukum ... Error!
Bookmark not defined.
Tabel 4.3 Daftar User dengan Bidang Kompetensi BisnisError! Bookmark not
defined.
Tabel 4.4 Daftar User dengan Bidang Kompetensi EkonomiError! Bookmark
not defined.
Tabel 4.5 Daftar User dengan Bidang Kompetensi AgamaError! Bookmark not
defined.
Tabel 4.6 Daftar User dengan Bidang Kompetensi TeknologiError! Bookmark
not defined.
Tabel 4.7 Daftar User dengan Bidang Kompetensi PendidikanError! Bookmark
not defined.
Tabel 4.8 Daftar User dengan Bidang Kompetensi OlahragaError! Bookmark
not defined.
Tabel 4.9 Daftar User dengan Bidang Kompetensi HiburanError! Bookmark not
defined.
Tabel 4.10 Daftar Wartawan ... Error! Bookmark not defined.
Tabel 4.11 Contoh Tweet yang Terkumpul ... Error! Bookmark not defined.
Tabel 4.12 Identitas Responden ... Error! Bookmark not defined.
Tabel 4.13 Contoh Hasil Pelabelan Tweet pada Tahap PertamaError! Bookmark
not defined.
Tabel 4.14 Contoh Hasil Pelabelan Tweet pada Tahap KeduaError! Bookmark
not defined.
Tabel 4.15 Hasil Preprocessing ... Error! Bookmark not defined.
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
Tabel 4.17 Hasil Perhitungan Klasifikasi ... Error! Bookmark not defined.
Tabel 4.18 Contoh Hasil Postprocessing ... Error! Bookmark not defined.
Tabel 4.19 Hasil Akurasi Klasifikasi Tahap PertamaError! Bookmark not
defined.
Tabel 4.20 Contoh Hasil Klasifikasi Tahap PertamaError! Bookmark not
defined.
Tabel 4.21 Hasil Akurasi Klasifikasi Tahap KeduaError! Bookmark not
defined.
Tabel 4.22 Contoh Hasil Klasifikasi Tahap Kedua Error! Bookmark not defined.
Tabel 4.23 Hasil Klasifikasi Tahap Kedua ... Error! Bookmark not defined.
Tabel 4.24 Precision dan Recall Klasifikasi Tahap KeduaError! Bookmark not
defined.
Tabel 4.25 Hasil Jawaban Kuesioner ... Error! Bookmark not defined.
Tabel 4.26 Hasil Perhitungan Likert Pertanyaan PertamaError! Bookmark not
defined.
Tabel 4.27 Hasil Perhitungan Likert Pertanyaan KeduaError! Bookmark not
defined.
Tabel 4.28 Hasil Perhitungan Likert Pertanyaan KetigaError! Bookmark not
defined.
Tabel 4.29 Hasil Perhitungan Likert Pertanyaan KeempatError! Bookmark not
defined.
Tabel 4.30 Hasil Perhitungan Likert Pertanyaan KelimaError! Bookmark not
defined.
Tabel 4.31 Hasil Perhitungan Likert Pertanyaan KeenamError! Bookmark not
defined.
Tabel 4.32 Hasil Perhitungan Likert Pertanyaan KetujuhError! Bookmark not
[Type text]
DAFTAR GAMBAR
Gambar 2.1 Halaman Depan Google News ... Error! Bookmark not defined.
Gambar 2.2 Sumber Berita Google News ... Error! Bookmark not defined.
Gambar 2.3 Halaman Depan Techmeme ... Error! Bookmark not defined.
Gambar 2.4 Arsitektur Text Mining ... Error! Bookmark not defined.
Gambar 2.5 Timeline Twitter ... Error! Bookmark not defined.
Gambar 3.1 Desain Penelitian ... Error! Bookmark not defined.
Gambar 3.2 Linear Sequential Model ... Error! Bookmark not defined.
Gambar 4.1 Rancangan Aplikasi Tweet AggregatorError! Bookmark not
defined.
Gambar 4.2 Use Case Aplikasi ... Error! Bookmark not defined.
Gambar 4.3 Rancangan Basis Data Aplikasi ... Error! Bookmark not defined.
Gambar 4.4 Rancangan Antar Muka Hasil KlasifikasiError! Bookmark not
defined.
Gambar 4.5 Rancangan Bagian Header ... Error! Bookmark not defined.
Gambar 4.6 Rancangan Bagian Daftar Kategori BeritaError! Bookmark not
defined.
Gambar 4.7 Rancangan Bagian Daftar Tweet BeritaError! Bookmark not
defined.
Gambar 4.8 Rancangan Antar Muka Halaman PreprocessingError! Bookmark
not defined.
Gambar 4.9 Rancangan Antar Muka Halaman Hasil PelabelanError! Bookmark
not defined.
Gambar 4.10 Rancangan Antar Muka Halaman DatasetsError! Bookmark not
defined.
Gambar 4.11 Tampilan Dashboard Tweet AggregatorError! Bookmark not
defined.
Gambar 4.12 Tampilan Cloudword... Error! Bookmark not defined.
Gambar 4.13 Tampilan Menu Preprocessing ... Error! Bookmark not defined.
Gambar 4.14 Tampilan Halaman Labeled Tweets . Error! Bookmark not defined.
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
Gambar 4.16 Tampilan Menu Pelabelan Tweet ... Error! Bookmark not defined.
Gambar 4.17 Diagram Hasil Klasifikasi Kelas ‘Relevan’Error! Bookmark not
defined.
Gambar 4.18 Diagram Hasil Klasifikasi Kelas Tidak RelevanError! Bookmark
not defined.
Gambar 4.19 Diagram Hasil Klasifikasi Kelas ‘Politik dan Hukum’ ... Error! Bookmark not defined.
Gambar 4.20 Diagram Hasil Klasifikasi Kelas ‘Bisnis’Error! Bookmark not
defined.
Gambar 4.21 Diagram Hasil Klasifikasi Kelas ‘Ekonomi’Error! Bookmark not
defined.
Gambar 4.22 Diagram Hasil Klasifikasi Kelas ‘Agama’Error! Bookmark not
defined.
Gambar 4.23 Diagram Hasil Klasifikasi Kelas ‘Teknologi’Error! Bookmark not defined.
Gambar 4.24 Diagram Hasil Klasifikasi Kelas ‘Kenegaraan’Error! Bookmark
not defined.
Gambar 4.25 Diagram Hasil Klasifikasi Kelas ‘Internasional’Error! Bookmark
not defined.
Gambar 4.26 Diagram Hasil Klasifikasi Kelas ‘Pendidikan’Error! Bookmark
not defined.
Gambar 4.27 Diagram Hasil Klasifikasi Kelas ‘Kesehatan’Error! Bookmark not defined.
Gambar 4.28 Diagram Hasil Klasifikasi Kelas ‘Olahraga’Error! Bookmark not
defined.
Gambar 4.29 Diagram Hasil Klasifikasi Kelas ‘Hiburan’Error! Bookmark not
xiv
DAFTAR LAMPIRAN
Lampiran 1. Daftar Stopwords ... Error! Bookmark not defined.
Lampiran 2. Daftar Sinonim ... Error! Bookmark not defined.
Lampiran 3. Daftar Sinonim Spesial ... Error! Bookmark not defined.
Lampiran 4. Contoh Tweet pelabelan Tahap 1 (200 data)Error! Bookmark not
defined.
Lampiran 5. Contoh Tweet pelabelan Tahap 2 (200 data)Error! Bookmark not
defined.
1
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
BAB I
PENDAHULUAN
Dalam bab ini akan dibahas latar belakang dilaksanakannya penelitian,
identifikasi masalah, batasan masalah, tujuan penelitian, manfaat penelitian, dan
sistematika penulisan.
Latar Belakang
Seiring dengan pesatnya perkembangan zaman, kebutuhan informasi di
tengah masyarakat juga mulai berkembang. Masyarakat tidak lagi mengkonsumsi
informasi sebagai kebutuhan semu yang sesaat, namun telah menjadikan
informasi tersebut sebagai kebutuhan kontinyu dan rutin. Berbagai kebutuhan
informasi dimulai dari informasi dunia politik, hukum, ekonomi, bisnis, sampai
hiburan telah menjadi konsumsi vital bagi masyarakat. Semakin tingginya
kebutuhan akan informasi juga akan berdampak pada tingkat peredaran informasi
tersebut di tengah masyarakat.
Perkembangan lalu lintas informasi yang semakin cepat di tengah
masyarakat tentunya tidak terlepas dari peranan media informasi. Dengan adanya
media informasi online banyak membantu masyarakat untuk mengetahui
informasi yang beredar dengan mudah. Informasi ini ditampung dan ditampilkan
dalam suatu website berita untuk kemudian diakses oleh pengguna secara online.
Namun dengan karakteristik dari website berita yang hanya menampilkan
kumpulan berita secara tidak terorganisir akan menyulitkan pengguna untuk
mengetahui berita yang diinginkan pada suatu kategori tertentu dan akan sangat
tidak praktis jika pengguna harus membaca semua berita untuk mendapatkan
berita yang diinginkan.
News aggregator dibentuk untuk mengurangi usaha dan waktu dari
pengguna untuk mengetahui berita yang diinginkannya. News aggregator ini
mengumpulkan berita dari berbagai sumber atau website berita ke dalam satu
2
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
Sudah terdapat banyak news aggregator yang dapat diakses saat ini, diantaranya
adalah Google News yang dapat diakses pada tautan https://news.google.com/ dan
TechMeme yang dapat diakses pada tautan https://techmeme.com/. Google News
mengumpukan berita-berita terbaru yang berasal dari berbagai website berita dan
mengelompokkannya ke dalam kategori berita tertentu. Sedangkan TechMeme
lebih terpusat pada topik mengenai teknologi dan mengumpulkan berita teknologi
pada satu website portal TechMeme.
Sumber berita tentunya tidak hanya terfokus pada berita yang telah diliput
oleh wartawan dan ditampilkan pada website berita. Banyak informasi berguna
yang tersebar secara cepat di media sosial. Wicaksono, seorang jurnalis
beritagar.id pada meet up class “Peran Social Media dalam Diseminasi Berita” di
Social Media Week (SMW) di Pacific Place, Jakarta pada Selasa (24 Februari
2015) mengatakan bahwa bahwa 8 dari 10 wartawan Indonesia mendapatkan ide
berita dari media sosial. Berita yang diperoleh wartawan dari media sosial itulah
yang kemudian dipublikasikan pada media informasi. Salah satu media sosial
yang memegang peranan penting dalam penyebaran informasi adalah Twitter.
Twitter merupakan salah satu media sosial yang populer dan banyak
digunakan saat ini. Twitter memungkinkan pengguna untuk terhubung dengan
orang-orang di seluruh dunia dan saling bertukar pesan maupun buah pemikiran.
Twitter memungkinkan penggunanya untuk mengirim dan membaca pesan
dengan panjang sebanyak 140 karakter dan ditampilkan pada halaman profil
pengguna. Pesan ini dinamakan tweet atau kicauan. Tweet dapat berupa pesan
teks, gambar, video, maupun pesan atau media yang berasal dari link eksternal
lainnya.
Twitter dapat diakses menggunakan perangkat komputer atau mobile dengan
memanfaatkan layanan internet. Pengguna dapat mengakses Twitter dengan
membuka langsung website resmi Twitter pada tautan berikut ini
https://twitter.com/ dan langsung memanfaatkan semua fitur umum Twitter yang
tersedia. Selain itu pengguna juga dapat mengakses Twitter melalui aplikasi
third-party twitter client seperti TweetDeck, Hootsuite, Tweetbot, dan lain sebagainya.
3
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
seperti multiple account, penjadwalan pengiriman tweet, pengaturan user
interface, pengaturan navigasi yang lebih mudah, dan lainnya. Twitter juga
memungkinkan pengguna untuk mengirim tweet melalui Short Message Service
(SMS).
Kemudahan yang ditawarkan oleh Twitter menarik banyak pengguna dari
berbagai kalangan dan jumlah penggunanya bertambah setiap harinya. Hal ini
tentunya akan berbanding lurus dengan tingkat penyebaran informasi di
masyarakat. Dengan banyaknya informasi yang beredar melalui Twitter maka
perlu diperhatikan tingkat relevan dari informasi tersebut. Untuk mem-filter
informasi yang beredar ini maka diperlukan sumber-sumber terpercaya yang
berkecimpung langsung di bidang berita tersebut. Seperti contohnya adalah berita
berbau politik dan hukum berasal dari tokoh-tokoh berkompeten yang terjun
langsung di bidang tersebut sehingga informasi yang dihasilkan lebih relevan,
mendalam, dan menarik. Informasi ini cenderung menyebar lebih cepat jika
dibandingkan dengan informasi yang berasal dari website berita lainnya.
Untuk mengumpulkan informasi yang tersebar melalui Twitter maka
dibentuk suatu website portal seperti news aggregator berbasis tweet yang disebut
juga dengan tweet aggregator. Pada tweet aggregator, tweet yang berisi informasi
berguna dari orang-orang yang berkompeten dikumpulkan dan dikelompokkan ke
dalam beberapa kategori seperti kategori politik dan hukum, hiburan, ekonomi,
kesehatan, bisnis, teknologi, olahraga, dan lainnya. Pengelompokkan ini
dilakukan dengan menggunakan teknik klasifikasi teks dengan pembelajaran
mesin.
Penelitian tentang klasifikasi teks dengan menggunakan sumber data tweet
sebelumnya pernah dilakukan oleh Sriram pada tahun 2010. Data yang digunakan
pada penelitian ini adalah tweet berbahasa Inggris dan mengklasifikasikannya ke
dalam kategori topik pembicaraan yang umum dibahas pada Twitter seperti news,
opinions, deals, events, dan private messages. Pengklasifikasian ini dilakukan
berdasarkan informasi profil user dan fitur spesifik yang diekstrak dari tweet
seperti pemendekkan kata, kata slang, frasa berbasis waktu, kata opini, tekanan
4
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
dalam tweet. Sriram dkk menggunakan metode Naïve Bayes, Decision Tree, dan
Sequential Minimal Optimization (SMO). Hasil pengklasifikasian kemudian
dievaluasi dengan menggunakan teknik 5-fold cross validation dan menghasilkan
akurasi tertinggi pada metode Naïve Bayes. (Sriram, 2010)
Penelitian lainnya dilakukan oleh Go dkk pada tahun 2009 dengan
menerapkan klasifikasi teks pada analisis sentimen dengan menggunakan sumber
data tweet. Dataset tweet yang telah dikumpulkan mengandung emotikon sebagai
noisy label. Klasifikasi dilakukan dengan menggunakan metode Naïve Bayes,
Maximum Entrophy, dan Support Vector Machine (SVM) menghasilkan akurasi di
atas 80% saat dilatih menggunakan data emotikon. Data tweet sebelumnya di
praproses dengan menghilangkan username, link, dan perulangan huruf. Namun
dari banyaknya penelitian yang telah ditemukan, penelitian klasifikasi yang
terfokus pada informasi berita berbahasa Indonesia yang tersebar pada Twitter
cukup jarang ditemukan. Jika ada, penelitian yang ditemukan adalah klasifikasi
dengan menggunakan data tweet berbahasa Inggris. Oleh karena itu dilakukan
pembangunan Tweet Aggregator dengan menerapkan klasifikasi informasi berita
berbahasa Indonesia yang tersebar melalui Twitter. (Go, Bhayani, & Huang,
2009)
Tweet aggregator ini dibangun dengan menggunakan salah satu metode
pengklasifikasian teks yang memiliki karakteristik sederhana, mudah
diaplikasikan, dan memiliki akurasi tinggi, yaitu algoritma Naïve Bayes untuk
mengelompokkan tweet berdasarkan kategori yang ada.
Identifikasi Masalah
Identifikasi masalah yang akan dibahas dalam “Pembangunan Tweet
Aggregator dengan Menggunakan Metode Naïve Bayes” adalah:
1. Bagaimana pengklasifikasian tweets berdasarkan kategori tertentu dengan
menggunakan metode Naïve Bayes?
2. Bagaimana tingkat kepuasan pengguna terhadap aplikasi pengelompokan
tweet berita?
5
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
Adapun batasan masalah dalam penelitian ini, diantaranya :
a. Metode yang digunakan adalah algoritma Naïve Bayes untuk
pengklasifikasian teks berdasarkan kategori berita tertentu.
b. Data yang digunakan yaitu data tweets yang berasal dari akun tokoh yang
memiliki kompetensi pada bidang berita. Daftar tokoh berkompeten
didapatkan dari Ensiklopedi Tokoh Indonesia Online pada tautan
http://www.tokohindonesia.com/ dan daftar wartawan terkenal Indonesia.
c. Tweets yang digunakan yaitu tweets berbahasa Indonesia.
d. Pelabelan tweet berita dilakukan atas pemahaman penulis sebagai supervisor
dalam pengklasifikasian tweet.
Tujuan Penelitian
Tujuan diadakannya penelitian ini adalah:
1. Untuk dapat mengklasifikasikan tweets berdasarkan kategori tertentu dengan
menggunakan metode Naïve Bayes.
2. Untuk dapat membuktikan sejauh mana tingkat kepuasan pengguna terhadap
aplikasi pengelompokkan tweet berita.
Manfaat Penelitian
Dengan adanya penelitian ini, diharapkan dapat memudahkan pengguna
untuk mendapatkan berita terbaru dari berbagai macam kategori berita secara
cepat langsung dari orang-orang yang berkompeten di dalamnya.
Sistematika Penulisan
Sistematika penulisan dalam proposal ini sebagai berikut :
BAB I PENDAHULUAN
Bab ini berisi pembahasan masalah secara umum, terdiri dari latar
belakang, rumusan masalah, batasan masalah, tujuan penelitian, dan
sistematika penulisan.
BAB II TINJAUAN PUSTAKA
Bab ini berisi dasar teori yang digunakan dalam penelitian ini. Adapun
6
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
pembangunan tweet aggregator dengan menggunakan metode Naïve
Bayes.
BAB III METODOLOGI PENELITIAN
Bab ini berisi penjelasan langkah-langkah yang akan dilakukan dalam
penelitian.
BAB IV HASIL PENELITIAN
Bab ini berisi uraian tentang hasil penelitian dan pembahasan terhadap
hasil penelitian yang dilakukan
BAB V KESIMPULAN DAN SARAN
28
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
BAB III
METODOLOGI PENELITIAN
Untuk menunjang kegiatan penelitian, dalam bab ini akan dijelaskan desain
penelitian, metode penelitian yang digunakan, serta alat dan bahan penelitian.
3.1Desain Penelitian
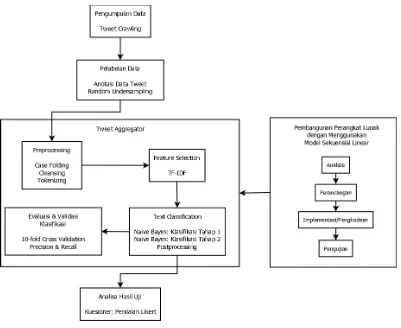
Desain penelitian merupakan tahapan yang akan dilakukan penulis untuk
memberikan gambaran serta kemudahan dalam melakukan penelitian. Tahapan
penelitian yang digunakan dijabarkan pada Gambar 3.1.
29
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
Berikut penjelasan dari desain penelitian:
1. Pengumpulan data
Data yang digunakan dalam penelitian ini diambil dari situs jejaring sosial
Twitter yang dinamakan tweet. Tweet yang saat ini penulis dapatkan sekitar
61.620 tweet dengan cara melakukan crawling dengan memanfaatkan Twitter
API. Data diambil dari bulan Februari 2015 sampai Agustus 2015.
Tweet yang diambil merupakan tweet pribadi dari beberapa user yang
berkompeten di masing-masing bidang kategori berita. Kategori berita ini,
antara lain: politik dan hukum, bisnis, ekonomi, agama, teknologi,
kenegaraan, internasional, pendidikan, kesehatan, olahraga, dan hiburan.
2. Pelabelan
Beberapa data yang telah dikumpulkan dibagi menjadi data training dan data
testing. Data ini dikelompokkan secara manual menurut kelas masing-masing
oleh seorang supervisor (orang yang mendefinisikan kelas dan label pada
training document). Data ini nantinya digunakan untuk membentuk fungsi
klasifikasi.
Data yang telah dilabeli secara manual ini di-sampling dengan menggunakan
teknik random undersampling untuk mendapatkan jumlah data yang
seimbang di setiap kelasnya.
3. Preprocessing
Proses yang dilakukan adalah preprocessing dasar yang meliputi: (Feinerer &
Hornik, 2008)
1)Case Folding, merupakan proses penyeragaman bentuk semua kata
menjadi lowercase.
2)Cleansing, merupakan proses pembersihan data teks dari hal-hal yang
tidak diperlukan
3)Tokenizing, merupakan proses pemecahan string berdasarkan tiap kata
yang menyusunnya.
4)Stopword Removal, merupakan penghapusan stopwords (kata-kata yang
30
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
5)Penyamaan Sinonim, merupakan penyamaan kata-kata dengan
sinonimnya.
Proses ini kemudian dimodifikasi oleh peneliti untuk disesuaikan dengan
sumber data tweet yaitu pada proses cleansing ditambahkan proses sebagai
berikut:
a. Menghapus username yang muncul pada setiap tweet (direpresentasikan
sebagai @username) dihapus.
b. Menghapus tanda “RT” yang muncul di setiap tweet dihapus (RT
merupakan tanda bahwa sebuah tweet merupakan hasil retweet).
c. Menghapus format hashtag yang muncul pada setiap tweet
(direpresentasikan sebagai #hashtag) dihapus.
d. Menghapus penghilangan tanda baca.
e. Menghapus kemunculan angka atau Clean Number.
4. Feature Selection
Pada tahap ini dilakukan proses seleksi fitur dari kumpulan term yang didapat
dari preprocessing. Feature selection dilakukan dengan memberi bobot pada
masing-masing term menggunakan metode Term Frequency * Inverse
Document Frequency (TF*IDF). Fitur yang dipilih merupakan term dengan
bobot yang lebih besar.
5. Text Classification
Pada tahap ini dilakukan proses pengelompokkan tweet berdasarkan
kelas-kelas yang telah ditentukan dengan menggunakan algoritma Naïve Bayes.
Proses pengelompokkan dilakukan sebanyak 2 tahap. Tahap pertama untuk
mengelompokkan tweet berita dan bukan berita, kemudian tahap kedua
dilakukan untuk mengelompokkan tweet ke dalam kelas yang telah
ditentukan, yaitu: politik dan hukum, bisnis, ekonomi, agama, teknologi,
kenegaraan, internasional, pendidikan, kesehatan, olahraga, dan hiburan.
Tweet hasil pengklasifikasian dibersihkan dari username, tanda retweet (RT),
dan format hash tag untuk menghasilkan tweet yang lebih merepresentasikan
31
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
6. Evaluasi dan Validasi Klasifikasi
Pada tahap ini dilakukan pengujian kualitas dari hasil dari classification
dengan menggunakan metode k-fold cross validation. Penulis menggunakan
10-fold cross validation dengan membagi data yang telah dianotasikan
menjadi 10 subset dan melakukan proses training dan testing secara
berulang-ulang pada data yang telah dibagi tersebut. Untuk mengukur tingkat ketepatan
dan keberhasilan hasil klasifikasi dilakukan perhitungan precision dan recall
untuk masing-masing kelas.
7. Analisa Hasil Uji
Pada tahap ini dilakukan pengujian aplikasi untuk mengetahui tingkat
kepuasan pengguna terhadap aplikasi yang dibangun. Pengujian ini dilakukan
dengan menyebarkan kuesioner dan dinilai dengan menggunakan perhitungan
skala Likert.
3.2 Metode Penelitian
Untuk lebih jelasnya, metode penelitian yang dilakukan dijelaskan dalam
sub-bab berikut:
3.2.1. Proses Pengumpulan Data
Data yang digunakan dalam penelitian ini merupakan data yang diambil dari
Twitter dengan mengunakan Twitter API. Tweet diambil pada rentang bulan
Februari 2015 sampai bulan Agustus 2015. Tweet ini diambil dari 100 user yang
kompeten di masing-masing kategori klasifikasi. Kategori-kategori tersebut,
antara lain: politik dan hukum, bisnis, ekonomi, agama, teknologi, kenegaraan,
internasional, pendidikan, kesehatan, olahraga, dan hiburan. Sedangkan user yang
berkompeten didapatkan dari Ensiklopedi Tokoh Indonesia Online pada tautan
http://www.tokohindonesia.com/ dan daftar wartawan terkenal Indonesia.
3.2.2. Proses Pengembangan Perangkat Lunak
Metode pengembangan perangkat lunak yang penulis gunakan pada
32
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
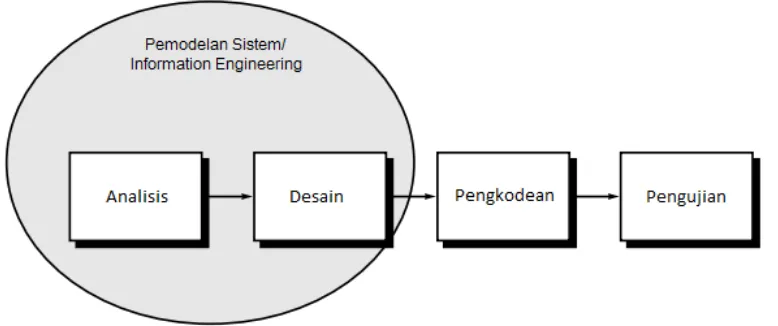
life cycle atau waterfall model. Linear sequential model merupakan proses
pengembangan perangkat lunak yang sistematis dengan pendekatan-pendekatan
sekuensial. Metode ini merupakan pengembangan dari conventional engineering
cycle dan terdiri dari beberapa aktivitas, sebagai berikut: (Pressman, 2001)
1) Pemodelan Sistem / Information Engineering
Tahap penyusunan requirements untuk keseluruhan elemen sistem dan
mengalokasikan subset untuk setiap requirements tersebut. Pemodelan ini
melibatkan proses analisis dan perancangan.
2) Analisis Kebutuhan Perangkat Lunak
Karena proses pengumpulan requirements terfokus pada software, maka
software engineer (“analyst”) harus mengerti domain informasi dari software
tersebut, seperti: fungsi, sifat, performa, dan interface-nya.
Pada tahap ini dilakukan pengumpulan akun user yang memiliki kompetensi
di bidang berita, kemudian tweet dari akun tersebut ditarik menggunakan
Twitter API. Data tweet ini akan menjadi masukkan dari sistem. Kemudian
ditentukan modul-modul pembangun sistem, serta hasil output dari sistem.
3) Perancangan
Proses design menerjemahkan requirement menjadi representasi dari
software. Proses ini terdiri dari beberapa tahap yang terfokus pada atribut dari
program, yaitu:
a. Data structure
b. Software architecture
c. Interface representations
d. Procedural (algorithmic) detail
Design ini didokumentasikan dan menjadi bagian dari software configuration.
Pada proses design penulis merancang dengan menggunakan Unified
Modelling Language (UML).
Pada tahap ini dibuat desain dari sistem yang akan dikembangkan dalam
bentuk Entity Relationship Diagram (ERD), UML, serta rancangan antar
33
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
4) Pengkodean
Merupakan proses penerjemahan design menjadi bentuk yang dapat dibaca
oleh komputer (kode program).
Pada tahap ini dilakukan pengkodean dari semua modul yang sudah
didefinisikan sebelumnya menggunakan bahasa pemograman Java.
5) Pengujian
Setelah proses pengkodean, dilakukan proses testing. Proses testing terfokus
pada logical internal dari software dan functional external, yaitu dengan
mengetes semua fungsi untuk menemukan error dan memastikan input yang
telah ditetapkan akan menghasilkan output yang sesuai.
Pada tahap ini dilakukan pengujian pada setiap modul untuk memastikan
sistem berjalan dengan baik.
Gambaran dari tahapan Linear sequential model dapat dilihat pada Gambar
3.2.
Gambar 1.2 Linear Sequential Model
sumber: Software Engineering: A Practitioner’s Approach Fifth Edition,
2001, hlm.: 29)
3.3 Alat dan Bahan Penelitian
Alat yang digunakan dalam penelitian ini adalah seperangkat komputer yang
dilengkapi dengan perangkat keras dan perangkat lunak pendukung. Sedangkan
34
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
3.3.1. Alat Penelitian
Perangkat keras komputer yang digunakan dalam penelitian ini memiliki
spesifikasi sebagai berikut:
1. Processor Intel® Core™ i5
2. Memori 4 GB RAM
3. Hardisk berkapasitas 720 GB
4. Monitor 14” dengan resolusi 1366x768 pixel
5. Mouse dan keyboard
Adapun perangkat lunak yang digunakan adalah:
1. Microsoft Windows 8.1 Pro
2. Eclipe 4.3
3. Java EE
4. Java Runtime Environment (JRE 8)
5. Apache Tomcat 8.0
6. Xampp 1.8.3
7. Navicat Premium
8. Sublime Text 2
9. Google Chrome
3.3.2. Bahan Penelitian
Adapun bahan penelitian yang digunakan merupakan data yang diambil dari
Twitter. Data yang diambil merupakan tweet pribadi dari beberapa user yang
berkompeten masing-masing kategori berita yang telah ditentukan sebelumnya.
Serta bahan lain berupa kumpulan stopwords yang diambil dari hasil penelitian
yang dilakukan oleh Fadillah Z Talla dengan judul “A Study of Stemming Effects
on Information Retrieval in Bahasa Indonesia” dan kumpulan kata sinonim yang
diambil dari library Tweet Mining berbahasa Indonesia yang dibuat oleh Yudi
Wibisono yang dapat diperoleh pada tautan:
94
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
BAB V
KESIMPULAN DAN SARAN
Pada bab ini akan menjelaskan kesimpulan dan saran dari penelitian.
5.1Kesimpulan
Kesimpulan dari penelitian Pembangunan Tweet Aggregator dengan
menggunakan metode Naïve Bayes adalah sumber data tweet dapat digunakan
untuk mengetahui penyebaran informasi berita di tengah masyarakat. Algoritma
Naïve Bayes layak digunakan untuk mengklasifikasikan tweet berita ke dalam
kategori-kategori yang sesuai. Namun tweet ini tidak langsung masuk ke tahap
klasifikasi. Diperlukan preprocessing tweet terlebih dahulu sebelum tweet tersebut
ditampilkan pada dashboard berita.
Untuk mengelompokkan data tweet ke dalam kategori berita tidak dilakukan
secara langsung. Proses klasifikasi ini dilakukan dengan melalui dua tahap, yaitu
tahap pertama untuk mengklasifikasikan tweet mana yang merupakan informasi
berita dan tweet mana yang tidak merupakan informasi berita, dan tahap kedua
untuk mengklasifikasikan tweet berita tersebut ke dalam kategori berita yang telah
disediakan. Tahapan ini membantu meningkatkan performa pengklasifikasian
tweet ke kategori berita dengan menghilangkan tweet yang tidak relevan yang
banyak tersebar di Twitter. Hasil dari klasifikasi dapat dihitung tingkat akurasinya
dengan menggunakan teknik 10-fold cross validation. Untuk mengetahui tingkat
ketepatan klasifikasi data pada setiap kelas dengan jawaban yang diberikan oleh
hasil dapat diukur dengan perhitungan precision dan tingkat keberhasilan hasil
klasifikasi dapat dihitung dengan menggunakan perhitungan recall.
Pengujian kepada responden menunjukkan bahwa secara umum aplikasi ini
dapat diterima dengan baik. Mayoritas responden memberikan penilaian bahwa
aplikasi ini dapat mengklasifikasikan informasi berita dengan baik sehingga
95
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
dibandingkan dengan mencari informasi sendiri ataupun dengan membaca tweet
secara langsung di Twitter. Kekurangan dari aplikasi ini berdasarkan penilaian
dari responden adalah tampilannya yang kurang menarik dan perlu diperbaiki.
5.2 Saran
Saran-saran yang diberikan pada penelitian ini untuk pengembangan
selanjutnya adalah sabagai berikut:
1. Perlu dilakukan text preprocessing yang lebih baik agar data yang digunakan
lebih berkualitas dan meminimalkan noise sekecil mungkin. Cara-cara yang
dapat dilakukan seperti membuat kamus kata baku, memperbaiki daftar
sinonim, memperbaiki daftar stopwords, dan mengatasi kesalahan penulisan
yang sering terjadi pada data tweet.
2. Perlu dilakukan penanganan lebih lanjut pada klasifikasi tahap pertama sehingga dapat meminimalisir kesalahan klasifikasi pada kelas ‘Relevan’. 3. Perlu dilakukan proses pelabelan tweet yang lebih baik. Pelabelan dilakukan
pada rentang waktu yang lama dan menggunakan data yang lebih banyak
untuk meningkatkan kualitas model klasifikasi.
4. Perlu dilakukan penambahan user yang memiliki kompetensi di setiap
kategori berita sehingga akan menambah ragam berita di masing-masing
kategori serta menambah kualitas dan relevansi berita.
5. Menggunakan bahasa pemrograman yang lebih baik untuk pemrosesan data.
96
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
DAFTAR PUSTAKA
Andhika, F. R., & Widyantoro, D. H. (2012). Klasifikasi Topik Terhadap Teks
Pendek pada Jejaring Sosial Twitter.
Banu, T. (2015, Februari 24). News: Social Media Week. Retrieved Agustus 19,
2015, from Social Media Week Jakarta:
http://socialmediaweek.org/jakarta/2015/02/24/peran-social-media-dalam-penyebaran-berita/
Batuwita, R., & Palade, V. (2010). Efficient Resampling Methods for Training
Support Vector Machine with Imbalanced Datasets.
Chawla, N. V. (2005). Data Mining for Imbalanced Datasets: An Overview. In O.
Maimon, & L. Rokach, Data Mining and Knowledge Discovery
Handbook: A Complete Guide for Practitioners and Researchers (pp.
853-854). Springer.
Feinerer, I., & Hornik, K. (2008). Text Mining Infrastructure. Journal of Statistic
Software, Volume 25.
Feldman, R., & Sanger, J. (2007). The Text Mining Handbook. Cambridge:
Cambridge University Press.
Fernandez, A., Garcia, S., Luengo, J., Bernado-Mansilla, E., & Herrera, F. (2010).
Genetics-based Machine Learning for Rule Induction: State of the Art,
Taxonomy, and Comparative Study. IEEE Transactions on Evolutionary
Computation 14, 913-941.
Go, A., Bhayani, R., & Huang, L. (2009). Twitter Sentiment Classification Using
Distant Supervision. 5.
Google News. (2013). About: Google News. Retrieved Januari 2015, from Google
97
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
He, H., & Garcia, E. A. (2009). Learning from Imbalanced Data. IEEE
Transactions on Knowledge and Data Engineering, 1063-1284.
Isbell, K. (2010). The Rise of the News Aggregator: Legal Implications and Best
Practices. Berkman Center Research Publication No. 2010-10, 2-5.
Manning, C. D., Raghavan, P., & Schutze, H. (2009). An Introduction to
Information Retrieval. Cambridge: Cambridge University Press.
Nazir, M. (2003). Metode Penelitian. Jakarta: Ghalia Indonesia.
Pressman, R. S. (2001). Software Engineering: A Practitioner's Approach, Fifth
Edition. Boston: McGraw-Hill.
Sriram, B. (2010). Short Text Classification in Twitter to Improve Information
Filtering. 47-64.
Talla, F. Z. (2002). A Study of Stemming Effects on Information Retrieval in
Bahasa Indonesia.
Techmeme. (2014). About: Techmeme. Retrieved Januari 2015, from Techmeme:
https://www.techmeme.com/about
Tokoh Indonesia. (2015). Ensiklopedi Tokoh Indonesia. Retrieved 2015, from
Tokoh Indonesia: http://www.tokohindonesia.com/
Twitter. (2014). About: Twitter. Retrieved 2015, from Twitter:
https://about.twitter.com/
Twitter. (2015). Twitter Developers: Documentation. Retrieved 2015, from
Twitter: https://dev.twitter.com/overview/documentation
V. Lopez, A., Fernandez, S., Garcia, V., Palade, & Herrera, F. (2013). An Insight
into Classification with Imbalanced Data: Empirical Results and Current
Trends on Using Data Intrinsic Characteristics. Information Sciences 250,
98
Rany Kasman, 2015
PEMBANGUNAN TWEET AGGREGATOR DENGAN MENGGUNAKAN METODE NAÏVE BAYES
Universitas Pendidikan Indonesia | \.upi.edu perpustakaan.upi.edu
Weng, C. G., & Poon, J. (2006). A New Evaluation Measure for Imbalanced