i
LAPORAN KEMAJUAN
PENELITIAN TERAPAN UNGGULAN PERGURUAN TINGGI
SISTEM PENDETEKSI JALAN RUSAK
MENGGUNAKAN AUGMENTED REALITY MAPS
PADA SMARTPHONE
Tahun Ke 1 Dari Rencana 2 Tahun
KETUA TIM
Nur Wakhidah, S.Kom., M.Cs. NIDN : 0626047901
ANGGOTA TIM
Susanto, S.Kom., M.Kom. NIDN : 0621027601
Astrid Novita Putri, S. Kom., M. Kom. NIDN : 0605119001 Siti Asmiatun, S. Kom., M. Kom. NIDN : 0625029101
UNIVERSITAS SEMARANG
SEPTEMBER 2018
iv
RINGKASAN
Kondisi jalan di Indonesia khususnya di Semarang sering mengalami kerusakan di musim hujan. Jika kondisi tidak segera diperbaiki, itu dapat menimbulkan bahaya kepada pengguna jalan seperti menaikkan penggunaan bahan bakar dan perawatan kendaraan dan bahaya terburuk mengancam lalu lintas keselamatan. Solusi dari masalah ini adalah memberikan informasi terkini tentang kondisi permukaan jalan sehingga lembaga setempat dapat segera melakukan perbaikan jalan. Penelitian ini membahas pengumpulan data kondisi jalan menggunakan sensor akselerometer di smartphone. Sensor akselerometer akan mencatat data berdasarkan gerakan pahat. Untuk merekam data dari sensor accelerometer perlu metode. Penelitian ini mengembangkan sistem yang menggunakan sistem sensor akselerator untuk mengidentifikasi kondisi permukaan jalan menggunakan metode deteksi lubang dan Z-Diff. Kedua kombinasi metode menghasilkan tingkat akurasi 74%, dan itu berarti bahwa sistem memiliki tingkat akurasi yang cukup tinggi dalam mengidentifikasi jalan kerusakan atau yang perlu diperbaiki. Dengan tersedianya lokasi jalan yang rusak, pekerjaan dinas perhubungan Semarang diharapkan dapat segera memperbaiki kondisi jalan.
Kata kunci: Jalan, Permukaan, Otomatis, Smartphone, Accelerometer, Pothole, Z-Diff.
v
PRAKATA
Puji syukur kehadirat Allah SWT atas terlaksananya 70% Tahun Ke-1 dari Rencana Dua Tahun kegiatan Penelitian Terapan Unggulan Perguruan Tinggi yang berjudul ‘Sistem Pendeteksi Jalan Rusak Menggunakan Augmented Reality Maps Pada Smartphone”. Kegiatan Penelitian Terapan Unggulan Perguruan Tinggi ini didanai mulai tahun 2018, dan dengan kerja sama yang baik dari semua pihak, akhirnya kegiatan penelitian ini dapat berlangsung dengan lancar.
Ucapan terimakasih dihaturkan untuk :
1. Direktur Riset dan Pengabdian Masyarakat, Direktorat Jenderal Penguatan Riset dan Pengembangan, Kemenristekdikti;
2. Koordinator Kopertis Wilayah VI Propinsi Jawa Tengah;
3. Bapak Andy Kridasusila,S.E.,M.M, selaku Rektor Universitas Semarang (USM);
4. Bapak Iswoyo, S.Pt, MP, selaku Ketua Lembaga Penelitian dan Pengabdian Kepada Masyarakat (LPPM) USM;
5. Bapak Susanto, S.Kom, M.Kom, selaku Dekan FTIK USM;
6. dan Rekan-rekan sejawat di FTIK yang telah membantu kami sehingga kegiatan penelitian ini dapat berjalan dengan baik.
Besar harapan kami, output dari kegiatan penelitian ini dapat bermanfaat bagi para pengguna daan juga dapat bermanfaat bagi masyarakat pada umumnya.
vi
DAFTAR ISI
HALAMAN PENGESAHAN ... ii
URAIAN UMUM ... iii
RINGKASAN ... iv
PRAKATA ... vi
DAFTAR ISI ... vi
DAFTAR TABEL ... vii
DAFTAR GAMBAR ... viii
BAB 1. PENDAHULUAN ... 1
BAB 2. TINJAUAN PUSTAKA ... 7
BAB 3. TUJUAN DAN MANFAAT PENELITIAN ... 22
BAB 4. METODE PENELITIAN ... 24
BAB 5. HASIL YANG DI CAPAI... 31
BAB 6. RENCANA TAHAP BERIKUTNYA ... 44
BAB 7. KESIMPULAN DAN SARAN ... 45 DAFTAR PUSTAKA
vii
DAFTAR TABEL
Tabel 2.1 Simbol-Simbol Use Case Diagram ... 18
Tabel 2.2 Simbol-Simbol Activity Diagram... 19
Tabel 2.3. Simbol-Simbol Sequence Diagram ... 21
Tabel 3.1. Luaran Penelitian ... 23
Table 5.1. Hasil Identifikasi Permukaan Jalan Wilayah Semarang Timur ... 38
Tabel 5.2 Hasil Pengumpulan Data ... 39
viii
DAFTAR GAMBAR
Gambar 1.1 Urutan Kecelakaan di Dunia Menurut WHO ... 1
Gambar 2.1 Bidang Ilmu Data Mining ... 9
Gambar 2.2. Tahap-Tahap Data Mining ... 10
Gambar 2.3. Pengintegralan sederhana terhadap suatu sinyal ... 14
Gambar 2.4. sensor accelerometer ... 15
Gambar 2.5 sensor accelerometer vector dan sumbu ... 15
Gambar 2.6 Rumus Classifier Naïve Bayesian ... 17
Gambar 4.1 Tahapan Penerapan algoritma ... 25
Gambar 4.2 Kombinasi Alghoritma Pothole Patrol dan Alghoritma Z-Diff ... 27
Gambar 4.3 Arsitektur Sistem ... 29
Gambar 4.4 Tahapan Pengolahan Data ... 29
Gambar 4.5 Model Prototype ... 30
Gambar 5.1. Use Case aplikasi sensor accelerometer pada smartphone android 31 Gambar 5.2 Activity Diagram Menginput Nama Jalan ... 32
Gambar 5.3. Activity Diagram Memilih dan Menginput Data Accelometer ... 33
Gambar 5.4. Activity Diagram Menampilkan Export Excel Data Jalan Rusak .. 33
Gambar 5.5. Activity Diagram Exit ... 34
Gambar 5.6. Menampilkan Sequence Diagram ... 35
Gambar 5.7 Antar muka Halaman Utama ... 36
Gambar 5.8 Proses Rekam Data... 36
Gambar 5.9 Pemodelan Klasifikasi Naive Bayesian Pada Rapid Miner ... 43
II-1
BAB 1
PENDAHULUAN
1.1. Latar Belakang
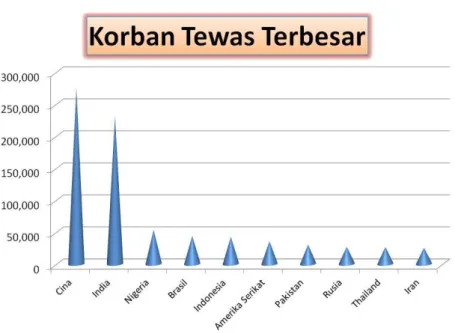
Kecelakaan lalu lintas memang sering menjadi masalah di dunia, maupun di Indonesia khususnya, yang disebabkan pula oleh kelalaian pengendara, tidak disiplin dalam mematuhi lalu lintas, kondisi jalan yang berlubang, adalah salah satu faktor terjadinya kecelakaan. Menurut Badan Kesehatan Dunia (WHO) dalam dua tahun terakhir ini, kecelakaan lalu lintas di Indonesia dinilai menjadi pembunuh terbesar ketiga. Global Status Report on Road Safety 2013 menempatkan Indonesia sebagai negara urutan kelima tertinggi angka kecelakaan lalu lintas di dunia (Sharanjit, K. A, Indra S.N dan Lusiana. 2015).
Gambar 1.1 Urutan Kecelakaan di Dunia Menurut WHO
Kecelakaan lalu lintas umumnya terjadi karena berbagai faktor penyebab seperti : pelanggaran atau tindakan tidak hati-hati para pengguna (pengemudi dan pejalan kaki), kondisi jalan, kondisi kendaraan, cuaca dan pandangan yang terhalang. Pelanggaran lalu lintas yang cukup tinggi serta
II-2
kepemilikan kendaraan pribadi yang semakin hari semakin meningkat, hal ini secara tidak langsung akan memicu terjadinya kecelakaan lalu lintas (Agus SW, 2011). Khusus di kota Semarang, berdasarkan data dari Polwitabes Semarang didapatkan angka kecelakaan lalulintas di Kota Semarang masih cukup tinggi. Sebagai contoh pada tahun 2012 kasus kecelakaan sebanyak 1094 dengan jumlah korban meninggal dunia sebanyak 176 orang, korban luka berat sebanyak 56 orang dan luka ringan sebanyak 901 orang (Lina AW, 2014).
Sebagai langkah awal untuk melakukan upaya mengurangi angka kecelakaan dapat dilakukan dengan mengidentifikasi faktor penyebab kecelakaan dan memperbaiki dari penyebab kecelakaan. Salah satu faktor penyebab kecelakaan adalah karena faktor kondisi jalan. Kondisi jalan rusak dapat menyebabkan kecelakaan bagi pengguna jalan yang kurang berhati-hati dalam mengemudikan kendaraannya dengan kecepatan tinggi maupun rendah. Meskipun faktor perilaku pengendara mempunyai proporsi tinggi sebanyak 90% sebagai faktor penyebab terjadinya kecelakaan lalu lintas (Woro R dan Ita PS, 2007), tetapi dengan adanya perbaikan pada faktor kondisi jalan yang rusak diharapkan dapat mengurangi angka kekecelakaan lalu lintas.
Pada tahun 2011 Artis Mednis dkk telah melakukan penelitian tentang deteksi jalan rusak menggunakan sensor accelerometers yang terdapat pada smartphone. Penelitian tersebut menggunakan algoritma pothole detection (Z-Thresh, Z-Diff, STDEF, G-Zero) menghasilkan akurasi sebesar 90% dengan data real time (A.Madnis dkk, 2011). Sensor akselerometer juga dikemukaan Otniel dkk dalam penelitiannya pada tahun 2016 tentang rancang bangun sistem deteksi bump menggunakan android smartphone dengan sensor akselerometer bahwa sensor akselerometer pada andorid dapat mendeteksi guncangan apabila pengguna android melewati polisi tidur maupun kerusakan jalan. Aplikasi yang dihasilkan dapat mengirimkan data real time dari sensor akselerometer ke server yang kemudian pada server data diolah dan ditampilkan dalam bentuk peta
II-3
digital. Akurasi yang dihasilkan dari aplikasi tersebut rata-rata sebesar 89,48% (O.Y Hutabarat dkk, 2016 ). Sedangkan penelitian dari Nidhi Karla dkk yang berjudul Analzing Driving and Road Events Via SmartPhone menyimpulkan bahwa sensor akselerometer pada smartphone dapat mendeteksi kondisi jalan rusak, bump, dan rough patch dengan menggunakan data set (N.Karla dkk 2014).
Dari beberapa penelitian diatas, maka penelitian ini menggunakan sensor akselerometer untuk mendeteksi kerusakan jalan. Mengacu pada penelitian sebelumnya belum ada yang menerapkan deteksi kondisi jalan ke dalam gambar visual maka penelitian ini akan menggunakan teknologi augmented reality untuk memvisualkan hasil dari deteksi kerusakan jalan. Beberapa penelitian tentang augmented reality juga pernah dijelaskan seperti dalam penelitiannya Eric Murphy pada tahun 2010 tentang Head Pose Estimation and Augmented Reality Tracking: An Integrated System and Evaluation For Monitoring Diver Awarenes menghasilkan sebuah aplikasi yang dapat mendeteksi kepala pengendara mobil dan memvisualisasikan dengan 3D menggunakan teknologi augmented reality (E.M.Chutorian, 2010). Penelitian Yayuk pada tahun 2014 yang berjudul tentang “Aplikasi Android Untuk Pencarian Lokasi Tempat Ibadah di Wilayah Bekasi” berhasil menerapkan teknologi augmented reality yang dimanfaatkan untuk menampilkan tempat ibadah di kota Bekasi berupa gambar visual alamat dan nomor telepon (Y.D Trianti, 2014).
1.2. Batasan Masalah
Pada pengembangan penelitian ini akan dibatasi oleh beberapa hal sebagai berikut :
a. Data yang digunakan dalam penelitian ini adalah wilayah Semarang Timur yang terdiri dari Kecamatan Genuk, Kecamatan Pedurungan dan Kecamatan Gayamsari.
b. Pengambilan data yang terdiri dari koordinat x, y, dan z diambil dari sensor akselerometer yang terdapat pada smartphone
II-4
c. Deteksi kerusakan jalan menggunakan algoritma Z-Diff, kemudian dikelompokkan menggunakan algoritma K-Means dan diklasifikasikan menggunakan algoritma Naive Bayes ke dalam 2 kategori yaitu area rusak berat dan area rusak ringan.
d. Penerapan sistem berbasis platform android.
1.3. Perumusan Masalah
Dari uraian latar belakang di atas, maka dapat dirumuskan masalah yang dihadapi yaitu bagaimana membangun sebuah sistem pendeteksi kerusakan jalan yang akan digunakan untuk mengelompokkan area dan mengklasifikasikan jenis kerusakan pada area tersebut untuk mengurangi angka kecelakaan khususnya di Kota Semarang.
5
BAB 2
TINJAUAN PUSTAKA
2.1 Penelitian Terkait
Dari beberapa penelitian yang terkait yang ada hubungannya dengan pedeteksi jalan rusak dapat di simpulkan sebagai berikut : Pada penelitian (Madnis Artis dkk, 2011) yang di lakukan oleh Artis Mednis, dkk. di simpulkan bahwa untuk mendeskrpisikan jalan rusak menggunakan accelerometer yang sudah terdapat pada OS Android, dapat di optimalisasikan pada analisis performanya dengan beberapa alghoritma dan nilai presentase tertinggi menggunakan alghoritma Z-Diff dengan nilai 92%. Selanjutnya mengenai paper yang telah dilakukan oleh Hsiu Wen Wang, dkk. Pada penelitian ini (Wang Wen Hsiu dkk, 2015) membahas mengenai metode pendeteksiaan lubang secara real time menggunakan accelometers untuk media sistem transportasi terpadu dengan di normalisasi dengan perhitungan sudut Euler dan di tambahkan alghoritma Z-Thersh dan G-Zero untuk deteksi lubang dengan cepat menggunakan GPS sehingga dapat terakurasi dengan baik untuk keamanan lalu lintas.
Kemudian penelitian (O.Yehezkiel dkk, 2016) yang telah di lakukan oleh Otniel, dkk. mengenai accelometers dengan pendeteksian bump menggunakan android dengan pengiriman lokasi menggunakan GPS, skenario yang di uji berdasarkan lokasi, Z-Thresh, Decision tree, kecepatan dan peletakkan smartphones di tampilkan pada peta digital berdasarkan lokasi menggunakn metode alghoritma Z-Thresh dengan nilai threshold, dan hasil akhir dari akurasi adalah 89,48%.
Penelitian terkait selanjutnya(Eriksson, 2008) oleh jakob Eriksson mengenai sensor mobile untuk pemantauan permukaan jalan menggunakan accelometers kondisi keamanan di jalan, menggunakan Pothole Patrol (P2) arsitektur untuk sensor monitoring dengan pendeteksian berdasarkan lubang dan permukaan jalan, kemudian di buat record setelah itu di clustering
6
berdasarkan wilayah di Boston, kemudian setelah di clustering di perlukan perbaikan karena 90% memiliki anomali jalan.
Penelitian yang terakhir mengenai jalan rusak adalah penelitian (Karla dkk, 2014) yang di lakukan oleh Nidhi Kaira, dkk. Di India juga pada kondisi lalu lintas kondisi jalan kurang baik, begitu pula kondisi jalan yang ada di perlukan sensor accelometers untuk mendeteksi kondisi jalan seperti lubang benturan, jalan yang tidak rata, dengan pengemudi jalan lurus, pengereman normal, pengereman mendadak, jalan belok kanan, dan kiri kemudian di klasifikasikan dengan threshold yang ditentukan oleh peneliti.
Dapat di simpulkan dari penelitian (Madnis Artis dkk, 2011), (Wang Wen Hsiu dkk, 2015), (O.Yehezkiel dkk, 2016), (Eriksson, 2008), (Karla dkk, 2014) di perlukan suatu aplikasi mendeteksi lubang menggunakan accelemoters kemudian di clustering berdasarkan daerah di Semarang Bagian Barat, kemudian di klasifikasikan, untuk mempermudah informasi dapat di akses dengan augmented reality maps dan kami melajutkan dari penelitian referensi di atas dengan pengimplementasi kan di Semarang Bagian Timur, sehingga pengendara yang melewati jalan tersebut dapat memahami kondisi jalan yang ada.
2.2 Pengertian Data Mining
Menurut Fajar Astuti Hermawati (Hermawati dkk, 2013) mendefinisikan data mining merupakan proses iteratif dan interaktif untuk menemukan pola atau model baru yang dapat digeneralisasi untuk masa yang akan datang, bermanfaat dan dapat dimengerti dalam suatu database yang sangat besar (massive databases). Data mining berisi pencarian trend atau pola yang diinginkan dalam database besar untuk membantu pengambilan keputusan di waktu yang akan datang. Pola-pola ini dikenali oleh perangkat tertentu yang dapat memberikan suatu analisa data yang berguna dan berwawasan yang kemudian dapat dipelajari dengan lebih teliti, yang mungkin saja menggunakan perangkat pendukung keputusan lainnya..
7
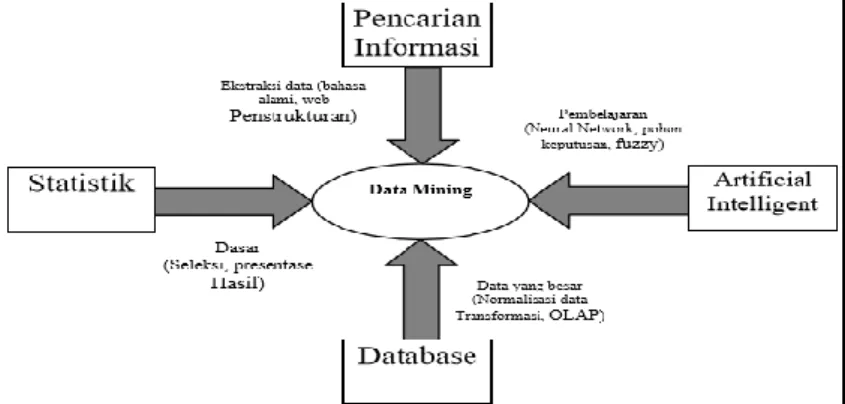
Gambar 2.1 Bidang Ilmu Data Mining
Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam basis data. Data Mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai basis data besar (Kusrini dan Luthfi, 2009).
Data mining adalah suatu proses ekstraksi atau penggalian data yang belum diketahui sebelumnya, namun dapat dipahami dan berguna dari database yang besar serta digunakan untuk membuat suatu keputusan bisnis yang sangat penting (Connolly dan Begg, 2010).
Data mining biasa juga disebut dengan “Knowledge Discovery in Database (KDD)” atau menemukan pola tersembunyi pada data. Data mining adalah proses dari menganalisa data dari prespektif yang berbeda dan menyimpulkannya ke dalam informasi yang berguna (Segall, et al, 2008).
Pada prosesnya data mining akan mengekstrak informasi yang berharga dengan cara menganalisis adanya pola-pola ataupun hubungan keterkaitan tertentu dari data-data yang berukuran besar. Data mining berkaitan dengan bidang ilmu-ilmu lain, seperti Database System, Data Warehousing, Statistic, Machine Learning, Information Retrieval, dan Komputasi Tingkat Tinggi. Selain itu data mining didukung oleh ilmu lain seperti Neural Network, Pengenalan Pola, Spatial Data Analysis, Image Database, Signal Processing.
8
2.3 Tahap-Tahap Data Mining
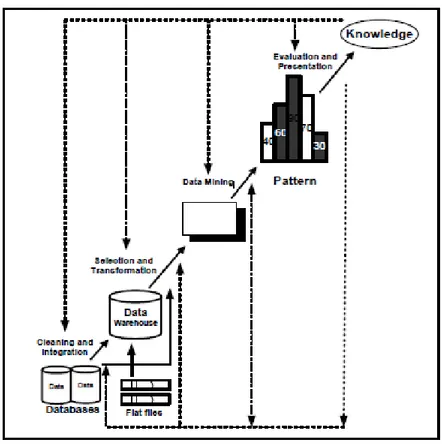
Sebagai suatu rangkaian proses, data mining dapat dibagi menjadi beberapa tahap yang diilustrasikan pada Gambar 2.2. Tahap-tahap tersebut bersifat interaktif, pengguna terlibat langsung atau dengan perantaraan knowledge base.
Gambar 2.2. Tahap-Tahap Data Mining Sumber: Huda (2010)
Berikut adalah tahap-tahap dalam data mining : 1. Pembersihan data (Data Cleaning)
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten atau data tidak relevan. Pada umumnya data yang diperoleh, baik dari database suatu perusahaan maupun hasil eksperimen, memiliki isian-isian yang tidak sempurna seperti data yang hilang, data yang tidak valid atau juga hanya sekedar salah ketik. Selain itu, ada juga atribut-atribut data yang tidak relevan dengan hipotesa data mining yang dimiliki. Data-data yang tidak relevan itu juga lebih baik dibuang. Pembersihan data juga akan
9
mempengaruhi performasi dari teknik data mining karena data yang ditangani akan berkurang jumlah dan kompleksitasnya.
2. Integrasi data (Data Integration)
Integrasi data merupakan penggabungan data dari berbagai database ke dalam satu database baru. Tidak jarang data yang diperlukan untuk data mining tidak hanya berasal dari satu database tetapi juga berasal dari beberapa database atau file teks. Integrasi data dilakukan pada atribut-aribut yang mengidentifikasikan entitas-entitas yang unik seperti atribut nama, jenis produk, nomor pelanggan dan lainnya. Integrasi data perlu dilakukan secara cermat karena kesalahan pada integrasi data bisa menghasilkan hasil yang menyimpang.
3. Seleksi Data (Data Selection)
Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari database.
4. Transformasi Data (Data Transformation)
Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam data mining. Beberapa metode data mining membutuhkan format data yang khusus sebelum bisa diaplikasikan. Sebagai contoh beberapa metode standar seperti analisis asosiasi dan clustering hanya bisa menerima input data kategorikal. Karenanya data berupa angka numerik yang berlanjut perlu dibagi-bagi menjadi beberapa interval. Proses ini sering disebut transformasi data.
5. Proses Mining
Merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data.
6. Evaluasi Pola (Pattern Evaluation)
Berfungsi untuk mengidentifikasi pola-pola menarik ke dalam knowledge based yang ditemukan. Dalam tahap ini hasil dari teknik data mining berupa pola-pola yang khas maupun model prediksi dievaluasi untuk menilai hipotesa yang ada memang tercapai. Bila ternyata hasil yang diperoleh tidak sesuai
10
hipotesa ada beberapa alternatif yang dapat diambil seperti menjadikannya umpan balik untuk memperbaiki proses data mining, mencoba metode data mining lain yang lebih sesuai, atau menerima hasil ini sebagai suatu hasil yang di luar dugaan yang mungkin bermanfaat.
7. Presentasi Pengetahuan (Knowledge)
Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna. Tahap terakhir dari proses data mining adalah memformulasikan keputusan atau aksi dari hasil analisis yang didapat. Ada kalanya hal ini harus melibatkan orang-orang yang tidak memahami data mining. Oleh sebab itu presentasi hasil data mining dalam bentuk pengetahuan yang bisa dipahami semua orang adalah satu tahapan yang diperlukan dalam proses data mining. Dalam presentasi ini, visualisasi juga bisa membantu mengkomunikasikan hasil data mining.
2.4 Clustering
Clustering atau klasterisasi adalah metode pengelompokan data. Menurut Tan, 2006 clustering adalah sebuah proses untuk mengelompokan data ke dalam beberapa cluster atau kelompok sehingga data dalam satu cluster memiliki tingkat kemiripan yang maksimum dan data antar cluster memiliki kemiripan yang minimum. Tidak diperlukan label kelas untuk setiap data yang diproses dalam clustering karena nantinya label baru bisa diberikan ketika cluster sudah terbentuk. Karena tidak adanya target label kelas untuk setiap data, maka clustering sering disebut juga pembelajaran tidak terbimbing ( unsupervised learning). (Prasetyo, 2014)
Clustering merupakan proses partisi satu set objek data ke dalam himpunan bagian yang disebut dengan cluster. Objek yang di dalam cluster memiliki kemiripan karakteristik antar satu sama lainnya dan berbeda dengan cluster yang lain. Partisi tidak dilakukan secara manual melainkan dengan suatu algoritma clustering. Oleh karena itu, clustering sangat berguna dan bisa menemukan group atau kelompokyang tidak dikenal dalam data. Clustering
11
banyak digunakan dalam berbagai aplikasi seperti misalnya pada business inteligence, pengenalan pola citra, web search, bidang ilmu biologi, dan untuk keamanan (security). Di dalam business inteligence, clustering bisa mengatur banyak customer ke dalam banyaknya kelompok. Contohnya mengelompokan customer ke dalam beberapa cluster dengan kesamaan karakteristik yang kuat. Clustering juga dikenal sebagai data segmentasi karena clustering mempartisi banyak data set ke dalam banyak group berdasarkan kesamaannya. Selain itu clustering juga bisa sebagai outlier detection.
2.5 Klasifikasi
Dalam data mining terdapat beberapa teknik yang memiliki fungsi berbeda-beda yaitu prediksi, estimasi, deskripsi, klasifikasi, pengklasteran dan asosiasi. Klasifikasi merupakan metode yang digunakan untuk menemukan model atau fungsi yang digambarkan dengan perbedaan kelas data atau konsep yang berfungsi untuk memprediksi kelas dari objek yang label kelasnya tidak diketahui. Dalam klasifikasi akan terjadi 2 proses, proses pertama adalah learning (fase training), dimana algoritma klasifikasi diciptakan untuk menganalisa data training kemudian direpresentasikan ke dalam bentuk rule klasifikasi. Proses kedua adalah klasifikasi, dimana data testing akan dipakai untuk memperkirakan akurasi dari rule klasifikasi.
Menurut Gorunescu (2011), terdapat komponen yang mendasari proses klasifikasi sebagai berikut:
1. Class
Variabel dependen berupa data kategorikal yang merepresentasikan suatu label yang melekat pada objek.
2. Predictor
Variabel dependen yang direpresentasikan oleh (data) atribut tertentu. 3. Training dataset
Sekumpulan data yang mengandung nilai dari kedua komponen sebelumnya yang dimanfaatkan untuk pemilihan kelas yang tepat berdasarkan predictor.
12 4. Testing dataset
Sekumpulan data baru yang akan melalui proses klasifikasi menggunakan model yang telah ditentukan. Hasil dari klasifikasi tersebut yang kemudian akan dievaluasi keakuratannya.
2.6 Pengertian Sensor Accelometers
Percepatan merupakan suatu keadaan berubahnya kecepatan terhadap waktu. Bertambahnya suatu kecepatan dalam suatu rentang waktu disebut juga percepatan (acceleration). Jika kecepatan semakin berkurang daripada kecepatan sebelumnya, disebut deceleration. (M.K.P Kumar dkk, 2012)
Bergantung pada arah/orientasi karena merupakan penurunan kecepatan yang merupakan besaran vektor. Berubahnya arah pergerakan suatu benda akan menimbulkan percepatan pula. Untuk memperoleh data jarak dari sensor accelerometer, diperlukan proses integral ganda terhadap keluaran sensor.
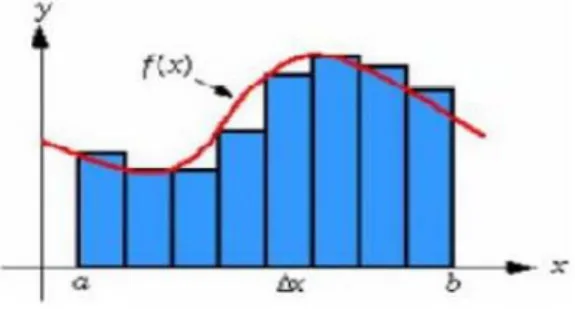
s = (∫( ∫(𝑎𝑎) dt)dt ... (M.K.P Kumar dkk, 2012) Proses penghitungan ini dipengaruhi oleh waktu cuplik data, sehingga jeda waktu cuplik data (dt) harus selalu konstan dan dibuat sekecil mungkin Secara sederhana, integral merupakan luas daerah di bawah suatu sinyal selama rentang waktu tertentu.
Gambar 2.3. Pengintegralan sederhana terhadap suatu sinyal
Accelerometer adalah sebuah perangkat yang mampu mengukur sebuah kekuatan akselerasi. Kekuatan ini mungkin statis (diam) seperti halnya kekuatan konstan dari gravitasi Bumi, atau bisa juga bersifat dinamis karena gerakan atau getaran dari sebuah alat akselerometer.
13
Gambar 2.4 sensor accelerometer
Accelerometer adalah sebuah tranduser yang berfungsi untuk mengukur percepatan, mendeteksi dan mengukur getaran, ataupun untuk mengukur percepatan akibat gravitasi bumi. Accelerometer juga dapat digunakan untuk mengukur getaran yang terjadi pada kendaraan, bangunan, mesin, dan juga bisa digunakan untuk mengukur getaran yang terjadi di dalam bumi, getaran mesin, jarak yang dinamis, dan kecepatan dengan ataupun tanpa pengaruh gravitasi bumi.
Gambar 2.5 sensor accelerometer vector dan sumbu
2.7 K-Means
Algoritma K-Means merupakan algoritma pengelompokan iterative yang melakukan partisi set data ke dalam sejumlah K cluster yang sudah ditetapkan di awal. Algoritma K-means sederhana untuk diimplementasikan dan dijalankan, relatif cepat, mudah beradaptasi, umum penggunaannya dalam praktek. Secara historis, K-means menjadi salah satu algoritma yang paling penting dalam data mining. (Wu dan Kumar, 2009)
Menurut Aryan (2010) K-Means merupakan algoritma yang umum digunakan untuk clustering dokumen. Prinsip utama K-Means adalah menyusun k prototype atau pusat massa (centroid) dari sekumpulan data berdimensi n. Sebelum diterapkan proses algoritma K-means, dokumen
14
akan di preprocessing terlebih dahulu. Kemudian dokumen direpresentasikan sebagai vektor yang memiliki term dengan nilai tertentu. Sedangkan menurut Chen yu (2010), K-Means merupakan algoritma untuk cluster n objek berdasarkan atribut menjadi k partisi, dimana k< n.
Dari teori-teori yang dijabarkan oleh para ahli diatas, bahwa K-means merupakan salah satu metode data clustering non hirarki untuk clustering dokumen yang berusaha mempartisi data yang ada ke dalam bentuk satu atau lebih cluster/kelompok berdasarkan atribut menjadi k partisi, dimana k < n (Aryan, 2017).
2.8 Naive Bayesian
Naïve Bayes merupakan pengklasifikasian dengan metode probabilitas dan statistik yang dikemukakan oleh ilmuwan Inggris Thomas Bayes. Menurut Olson dan Delen (2008, p102) menjelaskan Naïve bayes untuk setiap kelas keputusan, menghitung probabilitas dengan syarat bahwa kelas keputusan adalah benar, mengingat vektor informasi obyek. Algoritma ini mengasumsikan bahwa atribut obyek adalah independen. Probabilitas yang terlibat dalam memproduksi perkiraan akhir dihitung sebagai jumlah frekuensi dari "master" tabel keputusan (Jayaram dkk, 2017)
Sedangkan menurut Han dan Kamber (2011, p351) Proses dari The Naïve Bayesian classifier, atau Simple Bayesian Classifier, sebagai berikut: (Andriani, 2012)
1. Variable D menjadi pelatihan set tuple dan label yang terkait dengan kelas. Seperti biasa, setiap tuple diwakili oleh vektor atribut n dimensi, X = (x1, x2, ..., xn), ini menggambarkan pengukuran n dibuat pada tuple dari atribut n, masing-masing, A1, A2, ..., An.
2. Misalkan ada kelas m, C1, C2, ..., Cm. Diberi sebuah tuple, X, classifier akan memprediksi X yang masuk kelompok memiliki probabilitas posterior tertinggi, kondisi-disebutkan pada X. Artinya, classifier naive bayesian memprediksi bahwa X tuple milik kelas Ci jika dan hanya jika :
15
Gambar 2.6 Rumus Classifier Naïve Bayesian Sumber: Han dan Kamber (2011, p351) Keterangan :
P(Ci|X) = Probabilitas hipotesis Ci jika diberikan fakta atau record X (Posterior probability)
P(X|Ci) = mencari nilai parameter yang memberi kemungkinan yang paling besar (likelihood)
P(Ci) = Prior probability dari X (Prior probability) P(X) = Jumlah probability tuple yg muncul
2.9 Unified Modelling Language (UML)
Unifield Modelling Language (UML) merupakan sebuah bahasa yang berdasarkan grafik atau gambar untuk memvisualisasikan, menspesifikasikan, membangun dan pendokumentasian dari sebuah sistem pengembangan perangkat lunak berbasis objek (Kurnianto, 2012).
Unifield Modelling Language (UML) menyediakan beberapa macam diagram untuk memodelkan aplikasi perangkat lunak berorientasi objek, yaitu : 1. Use Case Diagram
Menurut Sukamto dan Shalahuddin (2013), use case merupakan pemodelan untuk kelakuan (behavior) sistem informasi yang akan dibuat. Use case mendeskripsikan sebuah interaksi antara satu atau lebih aktor dengan sistem informasi yang akan dibuat.
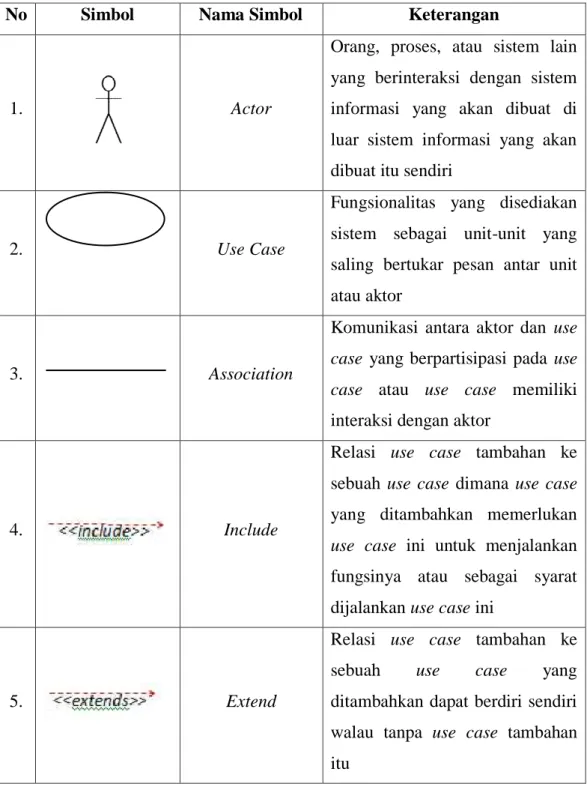
Secara kasar, use case digunakan untuk mengetahui fungsi yang ada di dalam sebuah sistem informasi dan orang yang berhak menggunakan fungsi-fungsi itu. Adapun simbol-simbol yang digunakan dalam use case seperti ditunjukkan pada Tabel 2.1.
16
Tabel 2.1 Simbol-Simbol Use Case Diagram Sumber: Sukamto dan Shalahuddin (2013:156-158)
No Simbol Nama Simbol Keterangan
1. Actor
Orang, proses, atau sistem lain yang berinteraksi dengan sistem informasi yang akan dibuat di luar sistem informasi yang akan dibuat itu sendiri
2. Use Case
Fungsionalitas yang disediakan sistem sebagai unit-unit yang saling bertukar pesan antar unit atau aktor
3. Association
Komunikasi antara aktor dan use case yang berpartisipasi pada use case atau use case memiliki interaksi dengan aktor
4. Include
Relasi use case tambahan ke sebuah use case dimana use case yang ditambahkan memerlukan use case ini untuk menjalankan fungsinya atau sebagai syarat dijalankan use case ini
5. Extend
Relasi use case tambahan ke sebuah use case yang ditambahkan dapat berdiri sendiri walau tanpa use case tambahan itu
17
6. Generalization
Hubungan generalisasi dan spesialisasi (umum-khusus) antara dua buah use case dimana fungsi yang satu adalah fungsi yang lebih umum dari lainnya
2. Activity Diagram
Sukamto dan Shalahuddin (2013), activity diagram menggambarkan workflow (aliran kerja) atau aktivitas dari sebuah sistem atau proses bisnis atau menu yang ada pada perangkat lunak. Diagram aktivitas menggambarkan aktivitas sistem bukan kegiatan aktor, jadi aktivitas yang dapat dilakukan oleh sistem.
Adapun simbol-simbol yang digunakan dalam activity diagram seperti ditunjukkan pada Tabel 2.2.
Tabel 2.2 Simbol-Simbol Activity Diagram Sumber: Sukamto dan Shalahuddin (2013:162-163)
No Simbol Nama Simbol Keterangan
1. Status Awal
Status awal aktivitas sistem, sebuah diagram aktivitas memiliki sebuah status awal
2. Aktivitas
Aktivitas yang dilakukan sistem, biasanya diawali dengan kata kerja
3. Desicion
Asosiasi percabangan dimana jika ada pilihan aktivitas lebih dari satu
18
4. Join
Asosiasi penggabungan dimana lebih dari satu aktivitas digabungkan menjadi satu
5. Status Akhir
Status akhir yang dilakukan sebuah sistem, sebuah diagram aktivitas memiliki sebuah status akhir
6. Swimlane
Memisahkan organisasi bisnis yang bertanggung jawab terhadap aktivitas yang terjadi
3. Sequence Diagram
Sukamto dan Shalahuddin (2013), diagram sekuen menggambarkan objek pada use case dengan mendeskripsikan waktu hidup objek dan message yang dikirimkan dan diterima antar objek. Sequence diagram menunjukkan urutan kejadian dalam suatu waktu. Komponen sequence diagram terdiri atas obyek yang dituliskan dengan kotak segiempat bernama message diwakili oleh garis dengan tanda panah dan waktu yang ditunjukkan dengan progres vertikal. Simbol-simbol yang digunakan dalam sequence diagram seperti ditunjukkan pada Tabel 2.3.
19
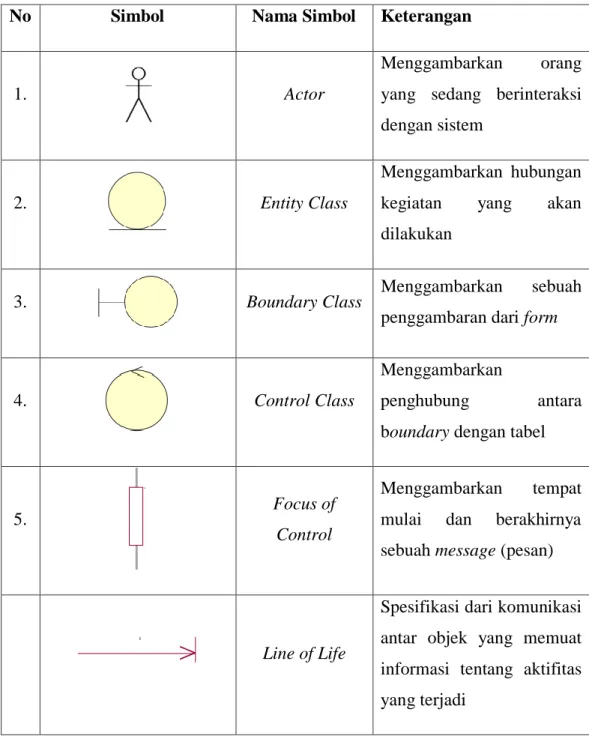
Tabel 2.3. Simbol-Simbol Sequence Diagram Sumber: Sukamto dan Shalahuddin (2013:165)
No Simbol Nama Simbol Keterangan
1. Actor
Menggambarkan orang yang sedang berinteraksi dengan sistem
2. Entity Class
Menggambarkan hubungan kegiatan yang akan dilakukan
3. Boundary Class Menggambarkan sebuah
penggambaran dari form
4. Control Class
Menggambarkan
penghubung antara boundary dengan tabel
5. Focus of
Control
Menggambarkan tempat mulai dan berakhirnya sebuah message (pesan)
Line of Life
Spesifikasi dari komunikasi antar objek yang memuat informasi tentang aktifitas yang terjadi
20
BAB 3
TUJUAN DAN MANFAAT PENELITIAN
5.1. Tujuan Penelitian
Adapun rincian tujuan dari dua tahun rencana penelitian ini, adalah:
3.1.1. Tahun Pertama
a. Mengembangkan pemodelan perangkat lunak untuk mendeteksi kerusakan jalan menggunakan accelerometer pada smartphone berbasis android.
b. Adanya perangkat lunak pendeteksi kerusakan jalan yang digunakan untuk mengumpulkan data kerusakan jalan guna melakukan clustering berdasarkan kelurahan di wilayah Semarang Timur
c. Melakukan klasifikasi kerusakan jalan pada tiap kecamatan ke dalam kategori rusak berat dan rusak ringan.
3.1.2. Tahun Kedua
a. Mengembangkan pemodelan ke dalam aplikasi augmented reality berbasis Maps.
b. Memudahkan pengguna jalan dengan berinteraksi langsung dengan obyek-obyek tiga dimensi yang dibuat berupa text dan informasi mengenai kondisi jalan, sehingga dapat membantu mengurangi angka kecelakaan khususnya di kota Semarang.
c. Memudahkan pengguna untuk mengetahui titik-titik jalan yang rusak di wilayah Semarang Timur, sehingga pengguna jalan dapat memilih jalan alternatif lain atau dapat mengantisipasi laju kendaraan ketika melewati jalan rusak tersebut.
21
5.2. Luaran Penelitian
Adapun luaran dari penelitian ini tampak pada table 3.1 berikut. Tabel 3.1. Luaran Penelitian
No Jenis Luaran Indikator
Kategori Sub Kategori Wajib Tambahan TS+1 TS+2 1 Artikel ilmiah dimuat di jurnal Internasiona l bereputasi
Submitted Accept Submite
d
Nasional Accepted Accepted
2 Artikel ilmiah dimuat diprosidin g Internasiona l Terindeks Terdaftar Terdaftar Nasional Sudah dilaksanakan Sudah dilaksana kan 3 Hak Kekayaan Intelektual (HKI) Paten Paten sederhana
Hak Cipta Produk Granted Produk
4 Teknologi Tepat Guna Produk Draft Produk
5 Bahan Ajar Sudah terbit Draft Editing
22
BAB 4
METODE PENELITIAN
5.1. Jenis Data
Jenis data yang digunakan dalam penelitian ini yaitu : 1) Data Kualitatif
Jenis data yang didapatkan dari data kelurahan setempat yaitu nama jalan-jalan rawan rusak yang ada di Semarang Timur dan gambar yang di ambil langsung dari hasil foto gambar lubang untuk di upload ke google maps.
2) Data Kuantitatif
Jenis data kuantitatif adalah data yang didapatkan pada accelometers berupa angka x, y, z, time, koordinat, dan speed dari hasil pengambilan data secara langsung yang kemudian akan di filter menggunakan kombinasi algoritma pothole patrol dan z-diff untuk mendapatkan data lokasi jalan berlubang.
5.2. Sumber Data
Sumber data yang digunakan dalam penelitian ini yaitu:
1) Data Primer. Data primer adalah data yang secara langsung dari data jalan di diambil langsung menggunakan accelometers.
2) Data Sekunder. Data sekunder adalah data yang diperoleh secara tidak langsung. Data ini diperoleh dari berbagai literatur dan buku-buku yang ada hubungannya dengan pokok bahasan penelitian.
5.3. Teknik Pengumpulan Data
1) Observasi. Pengumpulan data melalui pengamatan dan mengadakan penelitian secara langsung pada obyek/sistem yang akan dibangun. 2) Studi Pustaka. Metode ini sebagai penunjang dalam proses pengumpulan
data dengan menggunakan literatur-literatur yang ada hubungannya dengan pokok bahasan dalam laporan penelitian.
23
5.4. Metode Sistem yang Diusulkan
4.4.1. Tahapan Penerapan Algoritma Pada Aplikasi Accelerometer
Dalam penelitian tahun pertama, akan mengembangkan aplikasi accelerometer dengan menerapkan kombinasi algoritma untuk pengumpulan data lokasi jalan berlubang menggunakan sensor accelerometer pada smartphone andorid. Algoritma yang digunakan yaitu algoritma pothole patrol dan algoritma Z-Diff.
4.4.2. Alghoritma Pothole Patrol
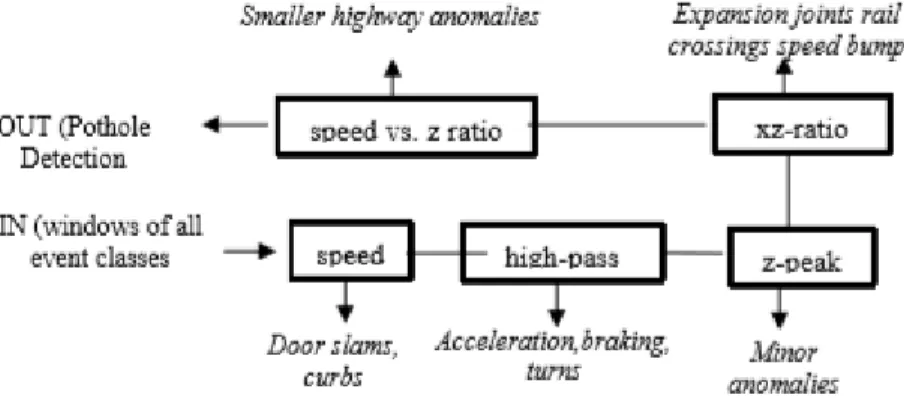
Berikut ini adalah tahapan penerapan algoritma pothole patrol yang dihasilkan dari sensor accelometer dan data percepatan yang dapat mendeteksi anomali permukaan jalan seperti lubang, trotoar, sistem kereta api. Kemudian perilaku pengendara dengan kecepatan dan variabel yang di butuhkan dalam data tergambarkan pada gambar 4.1 di bawah ini :
Gambar 4.1 Tahapan Penerapan algoritma
Uraian berikut tentang tahapan gambar 4.1 di atas adalah :
a. Kecepatan: ini adalah tahap yang mencatat percepatan data sesuai dengan kecepatan, jika kecepatannya nol atau kendaraan berjalan lambat maka data tidak dicatat.
b. High Pass: high pass akan menghilangkan nilai percepatan data dari nilai frekuensi rendah di setiap sumbu-x dan sumbu-z yang masuk. Frekuensi rendah dipengaruhi oleh membungkuk, melanggar, memutar, dan sedikit gerakan pada alat.
24
c. Z-Peak: menentukan tingkat ambang (tz) dalam sumbu-z dan menghilangkan semua data yang melebihi dari tingkat ambang (tz). d. XZ-Ratio: membandingkan sumbu-x dan sumbu-z yang dapat
menghasilkan nilai tx. Data akan dihapus jika 𝑥/𝑧 ≤ tx.
e. Kecepatan Vs z Rasio: membandingkan kecepatan dan sumbu-z dengan rumus z ≤ ts x speed.
4.4.3. Alghoritma Z-Diff
Alghoritma Z-Diff merupakan algoritma yang mempertimbangkan perbedaan nilai pada sumbu Z-Axis yang dihasilkan dari accelerometer. Karena nilai sumbu Z-Axis banyak mengalami penurunan atau kenaikan yang disebabkan dari nilai kecepatan antara waktu t i,j-1 dan waktu t i,j.
Algoritma ini memerlukan nilai ambang batas untuk mendeteksi lubang. Nilai ambang batas diperoleh dari nilai maksimum sumbu Z-Axis untuk percobaan. Rumus yang digunakan untuk menentukan nilai ambang batas sebagai berikut :
Kemudian setelah mendapatkan nilai ambang batas, algoritma ini akan membandingkan dengan 2 nilai yaitu jika hasil dari selisih nilai sumbu Z-Axis dan selisih nilai antara waktu t i,j-1 dan waktu t i,j lebih besar dari nilai
ambang batas maka nilainya 1 yang artinya lubang terdeteksi. Rumus yang digunakan sebagai berikut :
Where a= 1, 1≤i≤ n, i € N, j ≥ , j€N
(madnis dkk, 2011) (madnis dkk, 2011)
25
Penggabungan Alghoritma Pothole Patrol dan Z-Diff sebagai berikut terletak pada gambar 4.2 :
Gambar 4.2 Kombinasi Alghoritma Pothole Patrol dan Alghoritma Z-Diff Uraian berikut tentang tahapan gambar 4.2 di atas:
a. Kecepatan: ini adalah tahap yang mencatat percepatan data sesuai dengan kecepatan, jika kecepatannya nol atau kendaraan berjalan lambat maka data tersebut dihapus.
b. High Pass: high pass akan menghilangkan nilai percepatan data dari nilai frekuensi rendah di setiap sumbu-x dan sumbu-z yang masuk. Frekuensi rendah dipengaruhi oleh membungkuk, melanggar, memutar, dan sedikit gerakan pada alat.
c. Z-Peak: menentukan nilai ambang (tz) di sumbu Z dengan menggunakan algoritma Z-Diff. Kemudian hilangkan semua data yang melebihi dari nilai ambang (tz).
d. XZ-Ratio: membandingkan sumbu-x dan sumbu-z yang dapat menghasilkan nilai tx. Data akan dihapus jika 𝑥 𝑧 ≤ tx.
e. Kecepatan Vs z Rasio: membandingkan kecepatan dan sumbu-z dengan rumus z ≤ ts x speed.
26
4.4.4. Tahapan Keseluruhan Sistem
Arsitektur sistem yang akan kami bangun terdiri dari komponen klasifikasi kondisi jalan sebagai berikut : Jalan Dalam Kondisi Baik, Jalan Dalam Kondisi Rusak Sedang, Jalan Dalam kondisi Rusak, Jalan Dalam Kondisi Rusak Parah dan database di simpan dalam database aplikasi, kemudian anda dapat mencari berdasarkan jalan. Arsitektir pembangunan aplikasi ini terdapat pada aplikasi yang terhubung ke database system, menampilkan antarmuka pengunjung melalui aplikasi mobile phone. Aplikasi ini berfungsi sebagai antarmuka antara masyarakat dengan system aplikasi augmented reality, Pada bagian ini berisi informasi data menampilkan antarmuka pengguna dengan sistem. Fungsi utama database adalah menyimpan data dari aplikasi augmented reality maps, memberikan informasi mengenai kondisi jalan.
Gambar 4.3 Arsitektur Sistem
Gambar 4.3 menunjukkan sistem yang akan dijalankan pada platform android. Sistem deteksi jalan rusak memanfaatkan sensor accelerometer yang mengumpulkan data dari jalan yang terdeteksi rusak. Data yang terkumpul akan diolah dengan menggunakan beberapa algoritma. Tahapan pengolahan data sebagai berikut :
27
Gambar 4.4 Tahapan Pengolahan Data
4.4.5. Metode Pengembangan Sistem
Metode pengembangan sistem menggunakan adalah Metode yang dipakai adalah Prototyping, karena metode ini memiliki perkembangan siklus yang cepat dan pengujian terhadap model kerja (prototipe) dari aplikasi baru melalui proses
Gambar 4.5 Model Prototype
interaksi dan berulang-ulang yang biasa digunakan ahli sistem informasi dan ahli bisnis. Prototyping disebut juga desain aplikasi cepat (Rapid Application Design/RAD) karena menyederhanakan dan mempercepat desain sistem. (Andriani, 2012)
28
5.5. Lokasi Penelitian
Lokasi penelitian dilakukan beberapa kecamatan di wilayah Semarang Timur.
29
BAB 5
HASIL YANG DI CAPAI
Hasil yang diperoleh sampai dengan laporan kemajuan penelitian unggulan perguruan tinggi ini dibuat, meliputi di bawah ini:
5.1. Pembuatan Aplikasi Accelerometer
Penelitian ini membahas tentang pembuatan aplikasi sensor accelerometers sebagai pencatat lokasi jalan berlubang yang ada di Semarang Timur. Metode penelitian ini akan menggunakan metode kombinasi dari penelitian sebelumnya yaitu Algoritma pothole Patrol dan Algoritma Z-Diff. Diharapkan dari penggabungan kedua metode tersebut dapat menghasilkan tingkat akurasi yang lebih baik. Sehingga dapat dimanfaatkan untuk mendapatkan data dan informasi jalan berlubang yang ada di daerah Semarang Timur.
5.1.1. Perancangan Aplikasi a. Use Case Diagram
user
Menu Exit Menginput Nama
Jalan
Memilih dan Menginput Data Accelometer
Menampilkan Eksport Excel Data Jalan Rusak
Gambar 5.1. Use Case aplikasi sensor accelerometer pada smartphone android
30
Pada gambar 5.1 adalah tampilan use case dengan adanya sistem aplikasi mendeteksi jalan rusak menggunakan sensor accelometer, maka usecase sebagai berikut : user sebagai aktor dapat menginput nama jalan, memilih dan menginput data accelometer, menampilkan eksport data excel data jalan rusak, dan menu exit.
b. Activity Diagram
1. Activity Diagram Menginput Nama Jalan
Pada gambar 5.2 di bawah ini menampilkan activity diagram nama jalan, di dalam rancangan activity diagram ini adalah menampilkan tampilan awal aplikasi (menu home), menampilkan halaman utama aplikasi accelometer, menginput nama jalan rusak, dan yang terakhir menampilkan nama jalan rusak.
Menampilkan tampilan awal aplikasi Menampilkan halaman utama aplikasi accelometer
Menginput nama jalan rusak
Menampilkan nama jalan rusak
31
2. Activity Diagram Memilih dan Menginput Data Accelometer
Menampilkan Inputan Data Accelometer Merekam Data, X, Y,Z Pada Jalan Rusak
Menghitung data menggunakan Metode ZDif dan Pothole Detection
Menyimpan Data
Gambar 5.3. Activity Diagram Memilih dan Menginput Data Accelometer
Pada gambar 5.3 menujukkan tampilan menampilkan data inputan accelometer, dengan merekam di jalan dari sensor accelometer menghasilkan nilai x,y,z pada setiap jalan rusak, dan data tersebut dihitung menggunakan metode Zdif dan Pothole Detection.
3. Activity Diagram Menampilkan Export Excel Data Jalan Rusak
Menampilkan data dari inputan Accelometer Menyimpan Data Pada Excel
Menampikan data excel
Gambar 5.4. Activity Diagram Menampilkan Export Excel Data Jalan Rusak
32
Pada gambar 5.4 diatas menjelaskan mengenai tampilan data dari inputan accelometer, kemudian menyimpan data pada excel, yang terakhir menampilkan data dari excel tersebut.
4. Activity Diagram Exit
Memilih Menu Keluar Menampilkan Konfirmasi Keluar
Memilih Tidak
Menampilkan Menu Utama
Memilih Keluar
Keluar Aplikasi
Gambar 5.5. Activity Diagram Exit
Pada gambar 5.5 adalah activity diagram menu exit, pada tampilan ini dijelaskan memilih menu keluar, kemudian menampilkan konfirmasi menu keluar jika memilih iya maka akan menampilkan menu utama aplikasi accelemoter mendeteksi jalan rusak, jika memiih keluar maka akan keluar dari aplikasi.
33
C. Sequence Diagram
Aktor
Aplikasi
Mulai Membuka Aplikasi
Menu Utama
Menampilkan Menu Utama
Input Nama Jalan Aplikasi Accelometer
mengisi nama jalan rusak
mendeteksi x,y,y,z
Z-Dif & Pothole
Menghitung nilai Zdif dan Pothole
Gambar 5.6. Menampilkan Sequence Diagram
Pada tampilan 5.6 menampilkan sequence diagram aplikasi Sensor Accelerometer Pada smartphone android sebagai pencatat lokasi jalan berlubang di Semarang Timur pada sequence diagram ini menjelaskan mengenai tampilan aplikasi.
Pada penelitian ini data yang digunakan diambil dari jalan yang ada di semarang timur. Pengumpulan dataset melalui Ponsel Android yang diletakkan pada saku pengendara. Dataset terdiri dari nilai sumbu x,y,z dari accelerometer, koordinat lokasi berupa latitude dan longitude, dan terakhir ada speed untuk mengetahui kecepatan
kendaraan. Nilai-nilai tersebut digunakan untuk mengidentifikasi
permukaan jalan dan memfilter permukaan jalan yang tidak termasuk
berlubang. Dan diharapkan hasil dari penerapan penelitian ini dapat
dimanfaatkan oleh pihak Dinas setempat guna untuk mengumpulan informasi jalan yang rusak sehingga dengan adanya informasi jalan yang rusak secara up to date dinas setempat dapat segera melakukan perbaikan jalan. Untuk hasil implementasi aplikasi sensor
34
accelerometer dengan menggunakan kombinasi algoritma pothole detection dan z-diff dapat dilihat pada gambar dibawah ini :
Gambar 5.7 Antar Muka Halaman Utama
Gambar 5.8 Proses Rekam Data
35
Pada gambar 5.7 menunjukkan halaman utama dari aplikasi android. Tampilan ini berfungsi untuk menentukan nama jalan yang akan diidentifikasi permukaan jalannya. Kemudian setelah mengisi nama jalan pengguna harus klik tombol mulai untuk memulai merekam data identifikasi permukaan jalan. Pada gambar 5.8 merupakan halaman yang digunakan untuk membaca nilai sumbu x, y, z dari hasil rekaman accelerometer. Di halaman tersebut terdapat lattitude dan longitude untuk merekam lokasi permukaan jalan dan speed untuk merekam kecepatan kendaraan. Hasil rekaman data akan diexport ke dalam file yang bertipe xls.
Penerapan algoritma pothole detection dan Z-Diff terdapat pada proses filter data pada saat merekam menggunakan aplikasi diatas. Data yang diexport kedalam file .xls adalah data yang telah difilter menggunakan algoritma pothole detection dan Z-Diff. Tahapan filter data hasil rekaman aplikasi diatas adalah sebagai berikut :
a. Kecepatan: Tahap ini mencatat data berdasarkan kecepatan, batas kecepatan yang tercatat harus ≥ 10km / jam.
b. High Pass: high pass akan menghilangkan nilai percepatan data dari nilai frekuensi rendah di setiap sumbu-x dan sumbu-z yang masuk. Frekuensi rendah dipengaruhi oleh membungkuk, melanggar, memutar, dan sedikit gerakan pada alat. Batas minimum yang ditentukan dalam sumbu x adalah x ≥ 0 dan sumbu z adalah z ≥ 10.
c. Z-Peak: menentukan nilai ambang (tz) di sumbu Z dengan menggunakan algoritma Z-Diff. Lalu hilangkan semua data yang kurang dari nilai ambang (tz). Nilai ambang () diperoleh dari sumbu Z minimum dari Z-Axis maksimum dalam setiap percobaan, kemudian dihitung dengan rumus z-z-1 / t-t-1. Dan kemudian menyaring data jika z-z-1 / t-t-1≥ sehingga data akan direkam.
d. XZ-Ratio: membandingkan sumbu-x dan sumbu-z yang dapat menghasilkan nilai tx. Data akan dihapus jika 𝑥 𝑧 ≤ tx .. Percobaan penelitian ini menggunakan tx = 0,257
36
e. Kecepatan Vs z Rasio: membandingkan kecepatan dan sumbu-z dengan rumus z ≤ ts x speed. Nilai ts yang digunakan dalam percobaan ini adalah 0,008.
Kedua metode tersebut diterapkan pada system yang memanfaatkan sensor accelerometer dengan tujuan untuk menyaring data sensor accelerometer. Data tersebut digunakan untuk mengidentifikasi permukaan jalan yang perlu diperbaiki sehingga dapat meningkatkan kinerja dinas perhubungan kota semarang untuk memperbaiki jalan dengan cepat. Pengumpulan dataset melalui system yang memanfaatkan sensor accelerometer pada ponsel android. Hasil pengumpulan data digunakan untuk mengidentifikasi permukaan jalan yang perlu diperbaiki di wilayah semarang timur sebagai berikut :
Table 5.1. Hasil Identifikasi Permukaan Jalan Wilayah Semarang Timur
Wilayah Nama Jalan Jumlah Titik
Muktiharjo Lor Jl. Sendang Indah Raya 26 Jl. Muktiharjo Raya 0
Palebon Jl. Palebon Raya 3
Bangetayu Wetan Jl. Al Barokah 4
Tlogosari Kulon 26
Tlogosari Wetan 32
Gayamsari Jl. Slamet Riyadi 1
Pedurungan Jl. Bridjen Sudiarto 2
System mengidentifikasi permukaan jalan dengan metode pothole detection dan Z-Diff. Pengumpulan data dilakukan pada setiap kecamatan di Semarang timur Dari tabel 1 diatas terdapat 94 titik lokasi jalan rusak yang terdeteksi oleh system. Data tersebut diambil dari beberapa jalan yang tingkat kerusakan jalannya tinggi di kecamatan Gayamsari, Pedurungan, dan Genuk wilayah Semarang Timur. Dibawah ini adalah hasil pengumpulan data menggunakan aplikasi accelerometer.
Tabel 5.2 Hasil Pengumpulan Data
Jam Detik x y z latitude longitude speed
37 19:13:43 43 0:00:01 5,60661 0 18,0194 -6,98294 110,475 13,464 19:13:50 50 0:00:07 2,46962 2,14282 11,1486 -6,98306 110,475 15,336 19:14:03 63 0:00:13 12,0075 2,61388 11,4497 -6,98282 110,476 21,564 10:17:10 10 0:00:00 2,07039 0 10,6554 -6,98696 110,458 20,808 10:17:11 11 0:00:01 2,66893 0 10,4447 -6,98688 110,458 22,68 10:17:14 14 0:00:03 2,22243 0 10,4609 -6,9867 110,458 25,344 10:17:27 27 0:00:13 0 0 10,6464 -6,98593 110,458 25,704 10:17:28 28 0:00:01 2,98499 0 11,971 -6,98593 110,458 25,704 10:17:33 33 0:00:05 3,06039 0 11,2408 -6,98562 110,458 16,596 10:17:35 35 0:00:02 2,18411 0 10,6255 -6,98562 110,458 16,596 10:17:41 41 0:00:06 3,34052 0 11,2767 -6,98531 110,459 23,616 10:17:47 47 0:00:06 2,72102 0 10,1065 -6,98487 110,459 21,528 10:17:52 52 0:00:05 0 0 10,7164 -6,98469 110,459 25,812 10:17:55 55 0:00:03 2,78326 0 11,4515 -6,9845 110,459 24,3 10:17:57 57 0:00:02 2,55461 0 11,0612 -6,98435 110,459 21,78 10:18:01 61 0:00:04 3,15137 0 15,6024 -6,98416 110,459 28,008 10:18:19 79 0:00:18 5,79337 0 25,1667 -6,98346 110,459 17,208 10:18:21 81 0:00:02 2,61687 0 17,8272 -6,98336 110,459 15,192 10:18:22 82 0:00:01 0 0 10,9744 -6,98336 110,459 15,192 10:18:44 22 0:00:22 2,65756 0 10,8032 -6,98174 110,46 26,136 10:18:49 5 0:00:05 5,30138 3,62183 12,7491 -6,98146 110,46 16,164 10:18:53 4 0:00:04 2,85989 0 11,634 -6,98114 110,46 22,536 10:18:55 2 0:00:02 0 0 13,6613 -6,98114 110,46 22,536 10:18:56 1 0:00:01 3,60568 0 13,8606 -6,98114 110,46 22,536 10:18:57 1 0:00:01 0 0 12,1542 -6,98105 110,46 20,52 10:18:58 1 0:00:01 2,50974 0 14,7608 -6,98105 110,46 20,52 10:19:19 21 0:00:21 0 0 12,4768 -6,98014 110,46 15,372 10:19:22 3 0:00:03 3,2178 0 12,0883 -6,97997 110,46 23,328 10:19:23 1 0:00:01 3,36804 0 10,0742 -6,97975 110,46 28,476 18:13:41 0 0:00:00 0 3,81696 12,3487 -7,01101 110,473 23,832 18:14:29 48 0,000555556 5,02245 0 10,4782 -7,01247 110,477 40,968 18:37:58 0 0 0 0 15,4761 -7,00766 110,466 18,36 18:38:58 60 0:01:00 2,86647 0 15,5791 -7,0056 110,466 21,276 18:40:12 74 0:01:14 0 0 11,6717 -7,00407 110,468 12,348 19:04:09 0 0:00:00 12,7527 4,5927 17,7602 -6,9679 110,458 24,228 18:28:47 0 0:00:00 2,22781 0 12,8455 -6,99981 110,445 18,648 10:23:02 0 0:00:00 0 0 11,4365 -6,98636 110,46 20,772 10:23:04 2 0:00:02 0 0 13,0867 -6,98618 110,46 26,064
Pada Tabel 5.2 mengenai hasil dari aplikasi accelometer, menghasilkan nilai zdif dan pothole jalan yang di hasilkan berlubang atau tidak berlubang. Di ambil dari nilai tetha, menghitung rentang waktu jarak b dikurangi a, kemudian rentang sumbu z b dikurangi a, jika nilai lebih dari rata rata tetha pertempat maka jalan berlubang.
38
5.2. Mengklasifikasikan Data Menggunakan Algoritma Naive Bayes a. Penentuan Kriteria
a. Sumbu X : Kecil, Besar b. Sumbu Z : Kecil, Besar c. Speed : Cepat, Lambat
b. Analisa Perhitungan Metode Naive Bayesian
Berikut ini adalah tabel traning data jalan rusak menggunakan sensor accelerometer adalah di bawah ini:
Tabel 5.3 Tabel Traning Jalan Rusak
Jam x Nilai X/Z Ratio
X Y z Ket Z Speed
Ket
Speed latitude longitude Kategori 19.13.42 10,8565 0,5554248 Besar 0 19,5463 Besar 13,464 Cepat -6,98294 110,475 Rusak
Berat 19.13.43 5,60661 0,311143 Besar 0 18,0194 Besar 13,464 Cepat -6,98294 110,475 Rusak Berat 19.13.50 2,46962 0,2215184 Kecil 2,142 11,1486 Kecil 15,336 Cepat -6,98306 110,475 Rusak Ringan 19.14.03 12,0075 1,0487174 Besar 2,613 11,4497 Kecil 21,564 Lambat -6,98282 110,476 Rusak Berat 10.17.10 2,07039 0,1943043 Kecil 0 10,6554 Kecil 20,808 Lambat -6,98696 110,458 Rusak Ringan 10.17.11 2,66893 0,2555296 Kecil 0 10,4447 Kecil 22,68 Lambat -6,98688 110,458 Rusak Ringan 10.17.14 2,22243 0,2124511 Kecil 0 10,4609 Kecil 25,344 Lambat -6,9867 110,458 Rusak Ringan 10.17.27 0 0 Kecil 0 10,6464 Kecil 25,704 Lambat -6,98593 110,458 Rusak Ringan 10.17.28 2,98499 0,2493518 Kecil 0 11,971 Kecil 25,704 Lambat -6,98593 110,458 Rusak Ringan 10.17.33 3,06039 0,2722573 Besar 0 11,2408 Kecil 16,596 Cepat -6,98562 110,458 Rusak Berat 10.17.35 2,18411 0,2055536 Kecil 0 10,6255 Kecil 16,596 Cepat -6,98562 110,458 Rusak Ringan 10.17.41 3,34052 0,2962321 Besar 0 11,2767 Kecil 23,616 Lambat -6,98531 110,459 Rusak Berat 10.17.47 2,72102 0,2692347 Besar 0 10,1065 Kecil 21,528 Lambat -6,98487 110,459 Rusak Berat 10.17.52 0 0 Kecil 0 10,7164 Kecil 25,812 Lambat -6,98469 110,459 Rusak Ringan 10.17.55 2,78326 0,2430476 Kecil 0 11,4515 Kecil 24,3 Lambat -6,9845 110,459 Rusak Ringan 10.17.57 2,55461 0,2309523 Kecil 0 11,0612 Kecil 21,78 Lambat -6,98435 110,459 Rusak Ringan 10.18.01 3,15137 0,2019798 Kecil 0 15,6024 Besar 28,008 Lambat -6,98416 110,459 Rusak Berat 10.18.19 5,79337 0,2301998 Kecil 0 25,1667 Besar 17,208 Cepat -6,98346 110,459 Rusak Berat
39
10.18.21 2,61687 0,1467909 Kecil 0 17,8272 Besar 15,192 Cepat -6,98336 110,459 Rusak Berat 10.18.22 0 0 Kecil 0 10,9744 Kecil 15,192 Cepat -6,98336 110,459 Rusak Ringan 10.18.44 2,65756 0,2459975 Kecil 0 10,8032 Kecil 26,136 Lambat -6,98174 110,46 Rusak Ringan 10.18.49 5,30138 0,4158239 Besar 3,62183 12,7491 Kecil 16,164 Cepat -6,98146 110,46 Rusak Ringan 10.18.53 2,85989 0,2458217 Kecil 0 11,634 Kecil 22,536 Lambat -6,98114 110,46 Rusak Ringan 10.18.55 0 0 Kecil 0 13,6613 Kecil 22,536 Lambat -6,98114 110,46 Rusak Ringan 10.18.56 3,60568 0,2601388 Besar 0 13,8606 Kecil 22,536 Lambat -6,98114 110,46 Rusak Berat 10.18.57 0 0 Kecil 0 12,1542 Kecil 20,52 Lambat -6,98105 110,46 Rusak Ringan 10.18.58 2,50974 0,1700274 Kecil 0 14,7608 Kecil 20,52 Lambat -6,98105 110,46 Rusak Ringan 10.19.19 0 0 Kecil 0 12,4768 Kecil 15,372 Cepat -6,98014 110,46 Rusak Ringan 10.19.22 3,2178 0,2661913 Besar 0 12,0883 Kecil 23,328 Lambat -6,97997 110,46 Rusak Berat
10.19.25 3,35 0,2233333 Kecil 0 15 Kecil 25 Lambat -6,97997 110,46 ?
Kemudian Bagaimana Cara Menghitung No 30, Kategori Hasil Apakah Yang Akan di Dapatkan Dalam Hasil Kategori?
Perhitungan Naive Bayesian :
1. Tahap 1 Menghitung jumlah class/label (Kategori)
P(Rusak Berat) = 11/29 P(Rusak Ringan) = 18/29
2. Tahap 2 :
Menghitung Jumlah Untuk Masalah Sama dengan Class Yang Sama (Berdasarkan : Speed)
P(Lambat\Rusak Ringan) = 13/19 P(Lambat\Rusak Berat) = 6/19
Menghitung Jumlah Untuk Masalah Sama dengan Class Yang Sama (Berdasarkan : Ratio X)
P(Kecil\Rusak Ringan) = 16 /16 P(Kecil\Rusak Berat) = 0 / 16
40
Menghitung Jumlah Untuk Masalah Sama dengan Class Yang Sama (Berdasarkan : Ratio Z)
P(Kecil\Rusak Ringan) = 18/24 P(Kecil\Rusak Berat) = 6/24
3. Tahap 3 Mengkalikan Semua Variabel Rusak Ringan dan Rusak Berat
Klasifikasi Bayes Untuk Kategori : Rusak Berat
= P(Rusak Berat). P(Lambat\ Rusak Berat). P(Kecil\ Rusak Berat). P(Kecil\Rusak Berat) = 11/29 *6/19* 0/16* 6/24
= 0,379 *0,315 * 0*0,25 = 0
Klasifikasi Bayes Untuk Kategori : Rusak Ringan
= P(Rusak Ringan). P(Lambat\Rusak Ringan). P(Kecil\Rusak Ringan). P(Kecil\Rusak Ringan) = 18/29 * 13/19 * 16/16 * 18/24
= 0,62* 0,68* 1*0,75 = 0,3162
Dari hasil perhitungan di atas, maka klasifikasi Bayes untuk jalan rusak dari record 30 yang di peroleh adalah “Rusak Ringan” dengan nilai 0,3162 dibandingkan dengan kategori yang rusak berat.
41
c. Implementasi Klasifikasi Naive Bayesian Pada Rapid Miner
Berikut ini adalah pengolahan data dengan menggunakan naive bayesian pada Rapid Miner :
Gambar 5.9 Pemodelan Klasifikasi Naive Bayesian Pada Rapid Miner
Dengan menggunakan pemodelan klasifikasi naive bayesian seperti gambar di atas dengan mengklasifikasi sumbu x dan speed, Semakin besar nilainya, semakin besar kerusakannya .Kemudian Berikut ini adalah hasil implementasi sumbu Z di Curva Berdasarkan Rusak Ringan, Rusak Berat jalan rusak tersebut menggunakan RapidMiner ditunjukan pada gambar di bawah ini.
Gambar 5.10 Hasil Klasifikasi
5.3. Mengkelompokkan Data Menggunakan Algoritma K-Means
Data yang dihasilkan dari aplikasi accelerometer sebanyak 2014 titik jalan rusak. Dari data tersebut akan dilakukan pengelompokkan per kecamatan. Tujuan dari pengelompokkan tersebut untuk mengetahui kecamatan ,ana yang paling
42
rawan rusak. Pengelompokkan kecamatan menggunakan algoritma K-mans. Percobaan dilakukan dengan menggunakan parameter-parameter berikut :
Jumlah cluster : 6
Jumlah data :2014 (Untuk sample menggunakan 50 data) Jumlah atribut : 4
Inisialisasi atribut kecamatan dan kelurahan
No Kecamatan Lattitude Longitude Kec Kel
1 Semarang Timur -6,96965 110,434 6,0 6,0 2 Semarang Timur -6,96966 110,435 6,0 6,0 3 Semarang Timur -6,96966 110,435 6,0 6,0 4 Semarang Timur -6,96966 110,435 6,0 6,0 5 Semarang Timur -6,96966 110,435 6,0 6,0 6 Semarang Timur -6,96963 110,435 6,0 6,0 7 Semarang Timur -6,96963 110,435 6,0 6,0 8 Semarang Timur -6,96963 110,435 6,0 6,0 9 Semarang Timur -6,96966 110,435 6,0 6,0 10 Semarang Timur -6,96966 110,435 6,0 6,0 11 Semarang Timur -6,96966 110,435 6,0 6,0 12 Semarang Timur -6,96966 110,435 6,0 6,0 13 Semarang Timur -6,98481 110,431 6,0 6,0 14 Semarang Timur -6,98481 110,431 6,0 6,0 15 Semarang Timur -6,98481 110,431 6,0 6,0 16 Semarang Timur -6,98457 110,432 6,0 6,0 17 Semarang Timur -6,98457 110,432 6,0 6,0 18 Semarang Timur -6,98399 110,432 6,0 6,0 19 Semarang Timur -6,98317 110,431 6,0 6,0 20 Semarang Timur -6,98249 110,432 6,0 6,0 21 Semarang Timur -6,98249 110,432 6,0 6,0 22 Semarang Timur -6,98175 110,431 6,0 6,0 23 Semarang Timur -6,98175 110,431 6,0 6,0 24 Semarang Timur -6,98071 110,431 6,0 6,0 25 Semarang Timur -6,98071 110,431 6,0 6,0 26 Semarang Timur -6,98071 110,431 6,0 6,0 27 Semarang Timur -6,98013 110,431 6,0 6,0 28 Semarang Timur -6,98013 110,431 6,0 6,0 29 Semarang Timur -6,98013 110,431 6,0 6,0 30 Semarang Timur -6,98013 110,431 6,0 6,0 31 Semarang Timur -6,98013 110,431 6,0 6,0
43 32 Semarang Timur -6,9795 110,431 6,0 6,0 33 Pedurungan -6,97451 110,445 3,0 3,0 34 Pedurungan -6,97451 110,445 3,0 3,0 35 Pedurungan -6,97451 110,445 3,0 3,0 36 Pedurungan -6,97482 110,445 3,0 3,0 37 Pedurungan -6,97482 110,445 3,0 3,0 38 Pedurungan -6,97482 110,445 3,0 3,0 39 Pedurungan -6,97482 110,445 3,0 3,0 40 Pedurungan -6,97482 110,445 3,0 3,0 41 Pedurungan -6,97482 110,445 3,0 3,0 42 Pedurungan -6,97482 110,445 3,0 3,0 43 Pedurungan -6,97482 110,445 3,0 3,0 44 Pedurungan -6,97482 110,445 3,0 3,0 45 Pedurungan -6,97501 110,445 3,0 3,0 46 Pedurungan -6,97501 110,445 3,0 3,0 47 Pedurungan -6,97501 110,445 3,0 3,0 48 Pedurungan -6,97501 110,445 3,0 3,0 49 Pedurungan -6,97501 110,445 3,0 3,0 50 Pedurungan -6,97501 110,445 3,0 3,0 Iterasi ke-1
1. Penentuan pusat awal cluster
Untuk penentuan awal di asumsikan:
Diambil data ke- 26 sebagai pusat Cluster Ke-1: (-6.96963, 110.445, 6.0, 6.0) Diambil data ke- 41 sebagai pusat Cluster Ke-2: (-6.97482, 110.445, 3.0, 3.0)
2. Perhitungan jarak pusat cluster
Untuk mengukur jarak antara data dengan pusat cluster digunakan Euclidian distance, kemudian akan didapatkan matrik jarak yaitu C1 dan C2 sebagai berikut :
44
No Kecamatan Lattitude Longitude Kel Kec C1 C2
Jarak Terpendek 1 Semarang Timur -6,96965 110,434 6,0 6,0 0,000021 12,005291 0,000021 2 Semarang Timur -6,96966 110,435 6,0 6,0 0,000030 12,00526 0,000030 3 Semarang Timur -6,96966 110,435 6,0 6,0 0,000030 12,00526 0,000030 4 Semarang Timur -6,96966 110,435 6,0 6,0 0,000030 12,00526 0,000030 5 Semarang Timur -6,96966 110,435 6,0 6,0 0,000030 12,00526 0,000030 6 Semarang Timur -6,96963 110,435 6,0 6,0 0,000000 12,00529 0,000000 7 Semarang Timur -6,96963 110,435 6,0 6,0 0,000000 12,00529 0,000000 8 Semarang Timur -6,96963 110,435 6,0 6,0 0,000000 12,00529 0,000000 9 Semarang Timur -6,96966 110,435 6,0 6,0 0,000030 12,00526 0,000030 10 Semarang Timur -6,96966 110,435 6,0 6,0 0,000030 12,00526 0,000030 11 Semarang Timur -6,96966 110,435 6,0 6,0 0,000030 12,00526 0,000030 12 Semarang Timur -6,96966 110,435 6,0 6,0 0,000030 12,00526 0,000030 13 Semarang Timur -6,98481 110,431 6,0 6,0 0,015196 12,010186 0,015196 14 Pedurungan -6,98481 110,431 3,0 3,0 12,015196 0,010186 0,010186 15 Pedurungan -6,98481 110,431 3,0 3,0 12,015196 0,010186 0,010186 16 Pedurungan -6,98457 110,432 3,0 3,0 12,014949 0,009919 0,009919 17 Pedurungan -6,98457 110,432 3,0 3,0 12,014949 0,009919 0,009919 18 Pedurungan -6,98399 110,432 3,0 3,0 12,014369 0,009339 0,009339 19 Pedurungan -6,98317 110,431 3,0 3,0 12,013556 0,008546 0,008546 20 Pedurungan -6,98249 110,432 3,0 3,0 12,012869 0,007839 0,007839 21 Pedurungan -6,98249 110,432 3,0 3,0 12,012869 0,007839 0,007839 22 Pedurungan -6,98175 110,431 3,0 3,0 12,012136 0,007126 0,007126 23 Pedurungan -6,98175 110,431 3,0 3,0 12,012136 0,007126 0,007126 24 Pedurungan -6,98071 110,431 3,0 3,0 12,011096 0,006086 0,006086 25 Pedurungan -6,98071 110,431 3,0 3,0 12,011096 0,006086 0,006086 26 Pedurungan -6,98071 110,431 3,0 3,0 12,011096 0,006086 0,006086 27 Pedurungan -6,98013 110,431 3,0 3,0 12,010516 0,005506 0,005506 28 Pedurungan -6,98013 110,431 3,0 3,0 12,010516 0,005506 0,005506 29 Pedurungan -6,98013 110,431 3,0 3,0 12,010516 0,005506 0,005506 30 Pedurungan -6,98013 110,431 3,0 3,0 12,010516 0,005506 0,005506 31 Pedurungan -6,98013 110,431 3,0 3,0 12,010516 0,005506 0,005506 32 Pedurungan -6,9795 110,431 3,0 3,0 12,009886 0,004876 0,004876 33 Pedurungan -6,97451 110,445 3,0 3,0 12,004980 0,00031 0,000310 34 Pedurungan -6,97451 110,445 3,0 3,0 12,004980 0,00031 0,000310 35 Pedurungan -6,97451 110,445 3,0 3,0 12,004980 0,00031 0,000310 36 Pedurungan -6,97482 110,445 3,0 3,0 12,005290 0 0,000000 37 Pedurungan -6,97482 110,445 3,0 3,0 12,005290 0 0,000000
45 38 Pedurungan -6,97482 110,445 3,0 3,0 12,005290 0 0,000000 39 Pedurungan -6,97482 110,445 3,0 3,0 12,005290 0 0,000000 40 Pedurungan -6,97482 110,445 3,0 3,0 12,005290 0 0,000000 41 Pedurungan -6,97482 110,445 3,0 3,0 12,005290 0 0,000000 42 Pedurungan -6,97482 110,445 3,0 3,0 12,005290 0 0,000000 43 Pedurungan -6,97482 110,445 3,0 3,0 12,005290 0 0,000000 44 Pedurungan -6,97482 110,445 3,0 3,0 12,005290 0 0,000000 45 Pedurungan -6,97501 110,445 3,0 3,0 12,005480 0,00019 0,000190 46 Pedurungan -6,97501 110,445 3,0 3,0 12,005480 0,00019 0,000190 47 Pedurungan -6,97501 110,445 3,0 3,0 12,005480 0,00019 0,000190 48 Pedurungan -6,97501 110,445 3,0 3,0 12,005480 0,00019 0,000190 49 Pedurungan -6,97501 110,445 3,0 3,0 12,005480 0,00019 0,000190 50 Pedurungan -6,97501 110,445 3,0 3,0 12,005480 0,00019 0,000190 3. Pengelompokkan data
Jarak hasil perhitungan akan dilakukan perbandingan dan dipilih jarak terdekat antara data dengan pusat cluster, jarak ini menunjukkan bahwa data tersebut berada dalam satu kelompok dengan pusat cluster terdekat.
Berikut ini akan ditampilkan data matriks pengelompokkan group, nilai 1 berarti data tersebut berada dalam group.
Tabel G1 No C1 C2 1 1 0 2 1 0 3 1 0 4 1 0 5 1 0 6 1 0 7 1 0 8 1 0 9 1 0 10 1 0 11 1 0 12 1 0 13 1 0 14 0 1