NAMED ENTITY RECOGNITION (NER) BAHASA INDONESIA MENGGUNAKAN CONDITIONAL RANDOM FIELD DAN
POS-TAGGING
SKRIPSI
AGUS WILLYAWAN 131402089
PROGRAM STUDI TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2018
NAMED ENTITY RECOGNITION (NER) BAHASA INDONESIA MENGGUNAKAN CONDITIONAL RANDOM FIELD DAN
POS-TAGGING
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Teknologi Informasi
AGUS WILLYAWAN 131402089
PROGRAM STUDI TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2018
PERSETUJUAN
Judul : NAMED ENTITY RECOGNITION (NER) BAHASA
INDONESIA MENGGUNAKAN CONDITIONAL RANDOM FIELD DAN POS-TAGGING
Kategori : SKRIPSI
Nama : AGUS WILLYAWAN
Nomor Induk Mahasiswa : 131402089
Program Studi : S1 TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Romi Fadillah Rahmat, B.Comp.Sc., M.Sc Dani Gunawan S.T, M.T NIP. 19860303 201012 1 004 NIP. 19820915 201212 1 002
Diketahui/disetujui oleh
Program Studi S1 Teknologi Informasi Ketua,
Romi Fadillah Rahmat, B.Comp.Sc., M.Sc NIP. 19860303 201012 1 004
PERNYATAAN
NAMED ENTITY RECOGNITION (NER) BAHASA INDONESIA MENGGUNAKAN CONDITIONAL RANDOM FIELD DAN
POS-TAGGING
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan,
Agus Willyawan 131402089
UCAPAN TERIMAKASIH
Segala puji dan syukur Penulis sampaikan kepada Tuhan Yang Maha Esa yang telah memberikan berkat-Nya yang melimpah sehingga Penulis dapat menyelesaikan skripsi ini dengan baik untuk memperoleh gelar Sarjana Komputer, Program Studi S1 Teknologi Informasi Universitas Sumatera Utara.
Penulis menyadari bahwa penelitian ini tidak akan terwujud tanpa bantuan banyak pihak.
Dengan kerendah hati, Penulis ucapkan terima kasih kepada:
1. Kedua orang tua Penulis, Bapak Agus Hendrik Wiryanto dan Ibu Hui Tjhin yang telah membesarkan Penulis dengan sabar dan penuh kasih sayang, serta doa dari mereka yang selalu menyertai selama ini. Penulis juga berterima kasih kepada seluruh anggota keluarga Penulis yang namanya tidak dapat disebutkan satu persatu.
2. Bapak Prof. Dr. Opim Salim Sitompul, M.Sc. selaku Dekan Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
3. Ketua dan Sekretaris Program Studi S1 Teknologi Informasi, Bapak Romi Fadillah Rahmat, B.Comp.Sc., M.Sc. dan Ibu Sarah Purnamawati, S.T., M.Sc.
4. Bapak Dani Gunawan ST, M.T selaku Dosen Pembimbing 1 dan Bapak Romi Fadillah Rahmat, B.Comp.Sc., M.Sc. selaku Dosen Pembimbing 2 yang bersedia meluangkan waktu, pikiran, saran dan kritiknya untuk Penulis dalam menyelesaikan skripsi ini.
5. Bapak Dedy Arisandi, S.T., M.T., sebagai Dosen Pembanding 1 dan Ibu Ulfi Andayani, S.Kom., M.Kom., sebagai Dosen Pembanding 2 yang telah memberikan masukkan dan kritikan yang membangun dan bermanfaat dalam penulisan skripsi ini.
6. Semua Dosen serta Pegawai di lingkungan Fakultas Ilmu Komputer dan Teknologi Informasi yang telah membantu dan membimbing Penulis selama proses perkuliahan.
ABSTRAK
Pada teks Bahasa Indonesia terdapat banyak informasi seperti nama orang, nama tempat atau nama organisasi. Namun, untuk memperoleh informasi tersebut pada teks yang panjang memerlukan waktu yang lama. Untuk mengatasi permasalahan yang terjadi, maka digunakan Named Entity Recognition untuk memperoleh informasi tersebut dalam waktu yang singkat. Named Entity Recognition dapat memperoleh informasi seperti nama orang, nama tempat, nama organisasi dan sebagainya pada sebuah teks.
Tujuan dari penelitian ini adalah untuk membuat model data Named Entity Recognition Bahasa Indonesia yang mampu untuk melakukan pengenalan informasi pada teks Bahasa Indonesia dimana pada penelitian ini hanya dibatasi informasi nama orang, nama tempat atau nama organisasi berdasarkan teks yang dimasukkan. Metode yang diajukan adalah penggunaan metode Conditional Random Field untuk membuat model dari Named Entity Recognition dan POS-Tagging untuk meningkatkan jumlah data berlabel. Data yang digunakan pada pembuatan model Named Entity Recognition yaitu data tidak berlabel yang diperoleh dari Wikipedia dan data berlabel yang diperoleh dari DBpedia. Dari model yang dihasilkan pada penelitian ini memperoleh nilai precision dan recall di atas 75% dan nilai F1 sebesar 77%.
Kata kunci: Named Entity Recognition, POS-Tagging, Conditional Random Field, Natural Language Processing, Information Extraction, Bahasa Indonesia.
NAMED ENTITY RECOGNITION (NER) BAHASA INDONESIA USING CONDITIONAL RANDOM FIELD AND POS-TAGGING
ABSTRACT
In Indonesian text, there are a lot of information such as person, place or organisation.
However, if the text is so long, the information will need a lot of time to be obtained.
To overcome this problem, Named Entity Recognition is used to obtain information from text in a short time. Named Entity Recognition can obtain information such as person, location, organisation and others from a text. The purpose of this research is to make the model of Named Entity Recognition for Indonesian Language that capable for recognize the information from Indonesian text. This research limit for three type of information such as person, place and organisation according to the text which is input.
The method proposed are the use of Conditional Random Field to generate the Named Entity Recognition model and Part-of-Speech Tagging to increase the number of labelled data. The dataset which is used in this research are the unlabelled data from Wikipedia article and the labelled data from DBpedia. From the model that has been generated from this research, the testing result obtain the number of precision and recall above 75% and the number of the F1 about 77%.
Keywords: Named Entity Recognition, POS-Tagging, Conditional Random Field, Natural Language Processing, Information Extraction, Indonesian Language.
DAFTAR ISI
Halaman PERSETUJUAN iii PERNYATAAN iv
UCAPAN TERIMA KASIH v
ABSTRAK vi
ABSTRACT vii
DAFTAR ISI viii
DAFTAR TABEL x
DAFTAR GAMBAR xi
BAB 1 PENDAHULUAN
1.1 Latar Belakang 1
1.2 Rumusan Masalah 2
1.3 Batasan Masalah 2
1.4 Tujuan Penelitian 3
1.5 Manfaat Penelitian 3
1.6 Metodologi Penelitian 3
1.7 Sistematika Penulisan 4
BAB 2 LANDASAN TEORI
2.1 Named Entity Recognition 6
2.2 Conditional Random Field 6
2.3 Part-of-speech Tagging 7
2.4 Wikipedia 8
2.5 DBpedia 8
2.6 SPARQL 9
2.7 WikiExtractor Tool 9
2.8 Language Detection 10
2.9 Penelitian Terdahulu 10
BAB 3 ANALISIS DAN PERANCANGAN SISTEM
3.1 Dataset 15
3.1.1 Wikipedia 15
3.1.2 DBpedia 16
3.2 Perancangan Sistem 17
3.2.1 Ekstraksi XML 18
3.2.2 Sentence Tokenizing 19
3.2.3 Pengecekan Bahasa 20
3.2.4 POS-Tagging 22
3.2.5 Entity Tagging 23
3.2.6 Pemodelan NER 24
3.3 Tahap Training 26
3.4 Tahap Testing 27
3.5 Evaluasi 27
BAB 4 IMPLEMENTASI DAN PENGUJIAN
4.1 Spesifikasi Perangkat Keras dan Perangkat Lunak 28
4.2 Dataset 29
4.3 Hasil Proses POS-Tagging 31
4.4 Hasil Proses Training 32
4.5 Hasil Proses Testing 33
4.6 Implementasi Sistem Bagian Depan 38 BAB 5 KESIMPULAN DAN SARAN
5.1 Kesimpulan 40
5.2 Saran 41
DAFTAR PUSTAKA
DAFTAR TABEL
Halaman
Tabel 2.1. Penelitian Terdahulu 11
Tabel 3.1. Kategori Kelas Kata 22
Tabel 4.1. Hasil Pengujian Model NER yang telah Dilatih dengan Data
pre-processing untuk Entitas Location 33 Tabel 4.2. Hasil Pengujian Model NER yang telah Dilatih dengan Data
pre-processing untuk Entitas Organisation 34 Tabel 4.3. Hasil Pengujian Model NER yang telah Dilatih dengan Data
pre-processing untuk Entitas Person 34
Tabel 4.4. Hasil Pengujian Model NER yang telah Dilatih dengan Data
pre-processing secara keseluruhan 35
Tabel 4.5. Hasil Pengujian Model NER yang telah Dilatih dengan Data
pos-tagging untuk Entitas Location 35
Tabel 4.6. Hasil Pengujian Model NER yang telah Dilatih dengan Data
pos-tagging untuk Entitas Organisation 36 Tabel 4.7. Hasil Pengujian Model NER yang telah Dilatih dengan Data
pos-tagging untuk Entitas Person 36
Tabel 4.8. Hasil Pengujian Model NER yang telah Dilatih dengan Data
pos-tagging secara keseluruhan 37
Tabel 4.9. Hasil Pengujian Model NER yang telah Diperbaiki untuk Entitas
Organisation 38
DAFTAR GAMBAR
Halaman Gambar 2.1. Tahapan proses Conditional Random Field 7
Gambar 3.1. Contoh data dump Wikipedia 16
Gambar 3.2. Contoh Sintaks SPARQL untuk memperoleh data entitas DBpedia 17
Gambar 3.3. Arsitektur Umum 18
Gambar 3.4. Contoh Artikel Wikipedia 19
Gambar 3.5. Contoh Sentence Tokenize 20
Gambar 3.6. Contoh Pengecekkan Bahasa 21
Gambar 3.7. Contoh POS-Tagging 23
Gambar 3.8. Contoh Properties File pemodelan NER 25
Gambar 4.1. Contoh Hasil Ekstraksi XML 29
Gambar 4.2. Contoh Hasil Memformat Teks 30
Gambar 4.3. Contoh Data Entitas DBpedia Indonesia 31
Gambar 4.4. Contoh Hasil Data POS-Tagging 31
Gambar 4.5. Contoh Hasil Data Entity Tagging 32
Gambar 4.6. Halaman Utama 39
BAB 1 PENDAHULUAN
1.1. Latar Belakang
Pada dokumen teks terdapat banyak informasi yang penting seperti nama orang, nama organisasi atau nama tempat. Untuk memperoleh informasi dalam dokumen teks secara manual, manusia harus membaca seluruh isi dokumen. Apabila dokumen teks tersebut sangat panjang, maka diperlukan waktu yang lama bagi manusia untuk memperoleh informasi yang terdapat pada teks tersebut. Oleh karena itu, dibuatlah Named Entity Recognition yang dapat digunakan untuk memperoleh infomasi penting seperti nama orang, organisasi dan tempat pada sebuah dokumen teks secara otomatis. Dengan adanya Named Entity Recognition, perolehan informasi pada dokumen teks dapat dilakukan dalam waktu yang lebih singkat.
Saat ini, penelitian mengenai Named Entity Recognition untuk Bahasa Indonesia telah banyak dilakukan. Pada tahun 2015, Leonandya et al melakukan sebuah penelitian Named Entity Recognition Bahasa Indonesia dengan menggunakan algoritma Semi- Supervised. Pada penelitian tersebut, data yang digunakan adalah data artikel Wikipedia Indonesia dan data entitas yang diperoleh dari DBpedia Indonesia. Hasil dari penelitian tersebut dapat digunakan untuk melakukan entity tagging pada kalimat atau teks Bahasa Indonesia. Namun, pada penelitian tersebut, terdapat kekurangan pada proses automatic tagging. Automatic tagging merupakan proses untuk melakukan tagging pada setiap kata atau frasa dengan jenis entitasnya. Pada penelitian tersebut, automatic tagging tidak dapat melakukan tag entitas pada kata atau frasa yang seharusnya memiliki entitas.
Masalah tersebut terjadi karena tidak terdaftarnya entitas dari kata atau frasa tersebut pada DBpedia.
Berdasarkan latar belakang di atas, Penulis mencoba meningkatkan kemampuan automatic tagging dengan mengimplementasikan POS-Tagging yang disertai dengan beberapa aturan yang ditambahkan pada proses automatic tagging tersebut. Penulis mengimplementasikan POS-Tagging dengan tujuan untuk memperoleh seluruh kata atau frasa yang memiliki kemungkinan mempunyai jenis entitas dan selanjutnya kata atau frasa tersebut akan dilakukan pengecekkan dengan rule yang telah disediakan dan akan dilakukan tag entitas berdasarkan aturan yang digunakan. Dengan demikian, Penulis mengajukan penelitian dengan judul “Named Entity Recognition (NER) Bahasa Indonesia menggunakan Conditional Random Field dan POS-Tagging”.
1.2.Rumusan Masalah
Berdasarkan penelitian Named Entity Recognition Bahasa Indonesia yang telah dilakukan sebelumnya, terdapat kekurangan pada saat sistem melakukan automatic tagging. Automatic tagging yang dimaksud adalah proses pelabelan entitas pada kata atau frasa. Pada penelitian tersebut, automatic tagging tidak dapat melakukan pelabelan pada banyak kata atau frasa yang seharusnya memiliki entitas. Oleh karena itu, diperlukan suatu metode yang dapat meningkatkan kemampuan automatic tagging dalam melakukan tag entitas.
1.3. Batasan Masalah
Untuk membatasi cakupan permasalahan yang akan dibahas dalam penelitian ini, Penulis membuat batasan masalah, antara lain:
1. Penelitian ini hanya mengklasifikasikan tiga jenis entitas, yaitu person, organisation dan location.
2. Penelitian ini hanya dapat menerima input berupa kalimat atau teks Bahasa Indonesia yang telah sesuai dengan pedoman Penulisan Ejaan Bahasa Indonesia (EBI).
1.4. Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk menghasilkan model Named Entity Recognition Bahasa Indonesia yang dapat digunakan untuk mempermudah proses menentukan jenis entitas pada kata atau frasa yang terdapat pada kalimat atau teks Bahasa Indonesia.
1.5. Manfaat Penelitian
Manfaat yang dapat diperoleh dari penelitian ini sebagai tahapan awal dalam Information Extraction Bahasa Indonesia.
1.6. Metodologi Penelitian
Adapun tahapan-tahapan yang dilakukan pada pelaksanaan penelitian adalah sebagai berikut:
1. Studi Literatur
Studi literatur dilakukan dalam rangka pengumpulan bahan referensi mengenai Named Entity Recognition, POS-Tagging dan Conditional Random Field dari beberapa jurnal, artikel, buku dan beberapa sumber referensi lainnya.
2. Analisis Permasalahan
Pada tahap ini dilakukan analisis terhadap studi literatur yang telah dikumpulkan pada tahap sebelumnya untuk mendapatkan pemahaman mengenai metode yang diterapkan yakni Conditional Random Field dan POS-Tagging serta masalah yang akan diselesaikan yakni Named Entity Recognition Bahasa Indonesia.
3. Perancangan
Pada tahap ini dilakukan perancangan arsitektur, pengumpulan data, pembagian data yang telah didapatkan ke dalam training dataset dan testing dataset serta perancangan antarmuka. Proses perancangan dilakukan berdasarkan hasil analisis studi literatur yang telah diperoleh.
4. Implementasi
Pada tahap ini dilakukan implementasi ke dalam kode sesuai dengan analisis dan perancangan yang telah dilakukan pada tahap sebelumnya.
5. Pengujian
Pada tahap ini dilakukan pengujian terhadap hasil yang didapatkan melalui implementasi metode Conditional Random Field dan POS-Tagging dalam klasifikasi jenis entitas kata atau frasa dalam teks Bahasa Indonesia untuk memastikan hasil klasifikasi sesuai dengan yang diharapkan.
6. Dokumentasi dan Laporan
Pada tahap ini dilakukan dokumentasi dan penyusunan laporan hasil evaluasi dan analisis serta implementasi metode Conditional Random Field dan POS- Tagging dalam klasifikasi jenis entitas kata atau frasa dalam teks Bahasa Indonesia.
1.7. Sistematika Penulisan
Sistematika penulisan dari skripsi ini terdiri atas lima bagian utama sebagai berikut:
Bab 1: Pendahuluan
Bab ini berisi latar belakang dari penelitian ini, rumusan masalah, tujuan penelitian, batasan masalah, manfaat penelitian, metodologi penelitian serta sistematika penulisan.
Bab 2: Landasan Teori
Bab ini berisi teori-teori yang diperlukan untuk memahami permasalahan yang dibahas pada penelitian ini. Teori-teori yang berhubungan dengan Named Entity Recognition, Conditional Random Field dan POS-Tagging akan dibahas pada bab ini.
Bab 3: Analisis dan Perancangan Sistem
Bab ini menjabarkan arsitektur umum, langkah-langkah pre-processing yang dilakukan serta analisis dan penerapan metode Conditional Random Field dan POS-Tagging untuk entity tagging pada kata atau frasa Bahasa Indonesia.
Bab 4: Implementasi dan Pengujian
Bab ini berisi pembahasan tentang implementasi dari perancangan yang telah dijabarkan pada Bab 3. Selain itu, hasil yang didapatkan dari perancangan yang dilakukan akan dijabarkan pada Bab ini.
Bab 5: Kesimpulan dan Saran
Bab ini berisi kesimpulan dari rancangan yang telah dibahas pada Bab 3, serta hasil penelitian yang dijabarkan pada Bab 4. Bagian akhir dari bab ini akan berisi saran-saran untuk pengembangan penelitian selanjutnya.
BAB 2
LANDASAN TEORI
2.1. Named Entity Recognition
Named entities (NEs) merupakan kata benda yang mengacu pada jenis individu tertentu seperti nama organisasi, nama orang, nama lokasi, dan sebagainya. Named entitiy sekarang banyak digunakan pada bidang Natural Language Processing. Named Entity pada awalnya digunakan untuk the Sixth Message Understanding Conference (MUC- 6). Pada saat itu, MUC berfokus pada ekstraksi informasi, seperti memperoleh informasi dari sebuah informasi yang tidak berstruktur seperti artikel berita. Pada saat itu, orang-orang menyadari bahwa sangat penting untuk mengenali jenis informasi seperti nama orang, nama organisasi, nama tempat, waktu, tanggal, nominal uang dan persentase. Proses menandai jenis entitas dinamakan “Named Entity Recognition”.
(Bird, 2009)
Named Entity Recognition (NER) merupakan bagian dari Information Extraction (IE) pada Natural Language Processing (NLP). Named entity recognition merupakan langkah awal pada information extraction dimana Named entity recognition menstrukturkan teks menjadi data. Named entity recognition digunakan untuk mengidentifikasi dan mengklasifikasi kata atau frasa ke dalam jenis entitasnya. Named Entity Recognition dapat diimplementasikan pada machine translation, question answering dan semantic web. (Leonandya, 2015)
2.2. Conditional Random Field
Conditional Random Field adalah metode pemetaan statistik yang diaplikasikan pada pengenalan pola dan machine learning. Pada computer vision, Conditional Random Field sering digunakan untuk pengenalan objek dan segmentasi gambar.
Conditional Random Field telah diaplikasikan dalam bidang-bidang seperti pemrosesan teks, computer vision, dan bioinformatika. Pada bidang Natural Language
Processing, Conditional Random Field diaplikasikan pada Named Entity Recognition, parsing, identifikasi nama protein, segmentasi, klasifikasi telepon pada pengenalan suara dan sebagainya. Selain itu, Conditional Random Field juga diaplikasikan pada segmentasi gambar. (Andrew, 2011)
Conditional Random Field merupakan suatu model probabilistik untuk segmentasi dan pelabelan suatu sekuen data. Conditional Random Field berbentuk model grafik tidak berarah yang mendefinisikan sebuah distribusi log-linear tunggal dari label berurutan terhadap urutan data observasi tertentu. Conditional Random Field merupakan metode pencampuran antara Hidden Markov Model (HMM) dan Maximum Entropy Markov Model (MEMM). (Akbar, 2015)
Secara umum proses Conditional Random Field ditunjukkan pada Gambar 2.1 berikut ini.
Gambar 2.1. Tahapan Proses Conditional Random Field
Pada Gambar 2.1, Ekstraksi fitur merupakan tahapan paling penting dalam membuat model. Fitur yang tepat dapat meningkatkan akurasi sistem yang dibuat. Fungsi fitur adalah sebuah fungsi yang mengkombinasikan sebuah fitur dengan labelnya yang bersesuaian dan antara label yang berdekatan. Penaksiran parameter adalah proses untuk memperoleh nilai optimal parameter fungsi fitur. Nilai optimal parameter fungsi fitur dihitung menggunakan prosedur maksimum likelihood. Prosedur maksimum likelihood merupakan nilai yang menujukkan banyaknya parameter yang terdapat pada data pelatihan. Prosedur maksimum likelihood dapat memaksimalkan kemiripan ciri dari data pelatihan yang telah dimodelkan dengan Conditional Random Field. Proses berikutnya adalah mengimplementasikan model pada data pengujian.
2.3. Part-of-speech Tagging
Part-of-speech (POS) adalah kelas kata yang memiliki sifat tatabahasa yang sama. Kata yang memiliki part-of-speech yang sama memiliki peranan yang sama juga pada struktur tatabahasa sebuah kalimat. Secara umum, Part-of-speech terdiri dari 8 kelas
yaitu kata benda, kata kerja, kata sifat, kata keterangan, kata pengganti, kata perangkai, kata penghubung dan angka. Namun, kadang terdapat sebuah kata yang memiliki lebih dari satu Part-of-speech tergantung fungsi dari kata tersebut pada kalimat tersebut.
Part-of-speech Tagging merupakan proses mengkategorikan kata-kata pada sebuah kalimat atau teks ke jenis kelas masing-masing kata. Sebelumnya, Part-of-speech tagging dilakukan secara manual, sehingga akan menghabiskan lebih banyak waktu, namun kini Part-of-speech Tagging telah dapat dilakukan secara otomatis sehingga lebih memudahkan dan menghemat lebih banyak waktu. (Rashel, 2014)
2.4. Wikipedia
Wikipedia merupakan sebuah ensiklopedia bebas berbasis web yang memuat beragam artikel-artikel yang berisi informasi. Artikel-artikel yang terdapat pada Wikipedia beragam, seperti artikel mengenai suatu tempat, seseorang, sebuah organisasi dan sebagainya. Isi dari artikel pada Wikipedia merupakan hasil kolaborasi dari sejumlah orang yang menulis secara sukarela. Dengan kolaborasi ini membuat isi pada artikel Wikipedia menjadi beragam pada cara penulisan dan cara mendeskripsikan gagasan pada sebuah artikel. Artikel Wikipedia tidak hanya berisi teks, tetapi juga terdapat gambar, tabel, infobox, dan sebagainya. (Andry, 2014)
Pada September 2017, Wikipedia telah mendukung sekitar 299 bahasa dengan estimasi jumlah total dari seluruh artikel sebesar 46.589.758 artikel. Untuk Wikipedia Bahasa Indonesia terdapat lebih kurang 400.000 artikel. Seluruh artikel ini dapat diperoleh secara bebas pada Wikimedia Foundation. Wikimedia Foundation telah mengarsip seluruh artikel Wikipedia untuk masing-masing bahasa,
2.5. DBpedia
DBpedia merupakan sebuah forum yang menyediakan struktur informasi dari artikel Wikipedia. DBpedia Indonesia merupakan sebuah aplikasi berbasis web yang menyediakan bebagai struktur informasi dari Wikipedia Indonesia. DBpedia memiliki
685 jenis entitas yang dapat dilihat pada alamat
http://mappings.dbpedia.org/server/ontology/classes/.
Pada DBpedia, kita tidak hanya dapat melihat jenis entitas, tapi kita juga dapat melihat informasi-informasi lain yang berhubungan dengan suatu artikel Wikipedia.
Akan tetapi, jenis entitas dan informasi tersebut hanya dapat diakses apabila artikel
tersebut telah memiliki struktur informasi pada DBpedia. Sebagai contoh, untuk halaman Wikipedia dengan judul artikel Universitas Sumatera Utara dengan alamat https://id.wikipedia.org/wiki/Universitas_Sumatera_Utara pada Wikipedia, kita juga dapat melihat struktur informasi dari artikel tersebut pada DBpedia dengan nama yang sama dengan judul artikel tersebut yaitu Universitas Sumatera Utara dengan alamat http://id.dbpedia.org/page/Universitas_Sumatera_Utara, pada DBpedia dapat kita lihat jenis entitas dari Universitas Sumatera Utara yaitu Organisation dan kita juga dapat melihat informasi lainnya seperti kota, alamat, moto dan informasi lainnya yang berhubungan dengan Universitas Sumatera Utara. Dengan adanya struktur informasi tersebut dapat memudahkan dalam memperoleh jenis entitas pada kata atau frase yang terdapat pada teks Wikipedia. (Andry, 2014)
2.6. SPARQL
SPARQL merupakan bahasa query RDF dan protokol akses data yang distandarisasi oleh RDF Data Access Working Group (DAWG) of the World Wide Web Consortium untuk semantic web. SPARQL memiliki perbedaan dengan SQL, yakni SPARQL melakukan pemrosesan query dengan mengakses data web yang terhubung melalui URL, sedangkan SQL melakukan pemrosesan query dengan mengakses tabel relasional.
Struktur penulisan query pada SPARQL terdiri dari prefix untuk menyatakan namespace dari prefix, select untuk mendefinisikan field yang diinginkan, from untuk menentukan dataset yang digunakan, dan where untuk menentukan data yang ingin dihasilkan sesuai dengan kondisi yang diinginkan. (DuCharme, 2013) Untuk mengeksekusi query dari SPARQL dapat digunakan SPARQL endpoint. Pada penelitian ini, penulis menggunakan library ARC2 yang merupakan library php yang memiliki fitur untuk mengakses data RDF dengan menggunakan SPARQL.
2.7. WikiExtractor Tool
WikiExtractor merupakan sebuah tool untuk mengekstrak dan menghasilkan teks yang terdapat pada Wikipedia dump. Tool ini dikembangkan oleh Giuseppe Attardi dengan menggunakan bahasa pemograman python. Tool ini mengekstrak teks yang terdapat pada sebuah artikel Wikipedia dan hasil dari ekstraksi akan memiliki format <doc id=""
revid="" url="" title=""> ... </doc> pada setiap artikelnya. Tanda “…” berisi teks yang terdapat pada artikel tersebut. tool ini juga memberikan pilihan tambahan seperti
menentukan ukuran dari setiap file yang dihasilkan, melakukan kompresi pada file yang dihasilkan, memberi pilihan untuk tetap mempertahankan link yang terdapat pada file dump Wikipedia dan sebagainya. (Attardi, 2015)
2.8. Language Detection
Language Detection adalah sebuah tool yang dapat digunakan untuk mengetahui bahasa yang digunakan pada sebuah kalimat. Tool ini digunakan pada penelitian ini untuk melakukan pemilahan pada teks yang terdapat pada dump Wikipedia, sehingga hanya akan diambil kalimat yang berbahasa Indonesia saja. Tool ini menggunakan bahasa pemograman Java pada pengembangannya. Language detection tool yang dikembangkan oleh Shuyo et al mampu untuk mendeteksi 71 bahasa diantaranya Bahasa Indonesia. Namun, apabila bahasa yang digunakan tidak terdapat pada bahasa yang telah ada, kita dapat melakukan training untuk bahasa tersebut. (Shuyo, 2010)
2.9. Penelitian Terdahulu
Penelitian tentang Named Entity Recognition Bahasa Indonesia telah dilakukan oleh beberapa peneliti sebelumnya. Budi et al. (2005) melakukan penelitian Indonesian Named Entity Recognition (InNER). InNER memanfaatkan pengetahuan hubungan kata, struktur kata dan kategori kata untuk pengenalan jenis entitas pada teks Bahasa Indonesia. Pada penelitian mereka terdiri dari empat tahapan, yakni tokenisasi, penentuan sifat, penentuan aturan kata berdasarkan sifat dan penamaan entitas. Pada penelitian mereka, mereka melakukan pengecekkan kata berdasarkan konteks kata digunakan, tata penulisan kata dan jenis kata tersebut. sedangkan untuk aturan-aturan yang digunakan didasarkan pada sifat dari setiap kata yang telah diperoleh pada tahap sebelumnya. Dengan memanfaatkan pengetahuan tersebut, InNER mampu memperoleh nilai recall sebesar 63,43% dan nilai precision sebesar 71,84%.
Surwaningsih et al. (2014) melakukan penelitian Indonesian Medical Named Entity Recognition (ImNER) memanfaatkan Support Vector Machine (SVM). Dengan menggunakan data berupa 3.000 kalimat yang diambil secara acak, nilai keakuratan yang diperoleh adalah 90%. Penelitian mereka memanfaatkan data jenis kata, sifat kontekstual dari kata, tata penulisan kata dan daftar kata yang umum. Selain itu, mereka juga memanfaatkan daftar kata yang berhubungan dengan medis.
Luthfi et al. (2014) melakukan penelitian Named Entity Recognition Bahasa Indonesia dengan memanfaatkan Wikipedia sebagai data tidak berlabel dan DBpedia sebagai data berlabel. Pada penelitian mereka, data Wikipedia melalui tahap pre- processing. secara umum, pada sebuah artikel Wikipedia apabila pada artikel tersebut terdapat kata yang memiliki link maka link tersebut hanya akan terdapat pada kata yang pertama kali. Oleh karena itu, Luthfi et al, melakukan tag link terhadap kata yang sama dan tidak memiliki link pada artikel tersebut dikarenakan kata yang memiliki link memiliki persentase lebih tinggi untuk mempunyai entitas kata. Selanjutnya, proses entity-tagging dilakukan dengan menggunakan SPARQL untuk setiap kata yang memiliki link. Setelah diperoleh entitas dari kata-kata tersebut, mereka menggunakan Stanford-NER untuk membuat model data NER Indonesia. Dengan model yang dihasilkan, mereka melakukan pengujian pada data yang telah mereka siapkan. Hasil yang diperoleh dari penelitian mereka mampu untuk memperoleh nilai precision yang tinggi sedangkan nilai recall rendah, hal ini dikarenakan terdapatnya kesalahan tag entitas pada saat tahap pelatihan.
Leonandya et al. (2015) melakukan penelitian Named Entity Recognition Bahasa Indonesia dengan menggunakan algoritma Semi-Supervised dengan menggunakan data dari Wikipedia sebagai data tidak berlabel serta data DBpedia sebagai data berlabel. Pada penelitian mereka, data Wikipedia dilakukan pre-processing untuk memperoleh teks dari data tersebut. selanjutnya mereka melakukan tag entitas pada data teks yang telah dihasilkan berdasarkan data dari DBpedia, hasil yang diperoleh dari tahap ini berupa data berlabel dan data tidak berlabel. Selanjutnya digunakan Stanford-NER untuk membuat model data dari data berlabel tersebut. Model data yang dihasilkan ini kemudian akan digunakan sebagai model data untuk pelatihan data tidak berlabel yang telah diperoleh sebelumnya. Hasil data dari pelatihan ini selanjutnya digabung ke data berlabel awal yang telah diperoleh. Tujuan dari tahap pelatihan ini untuk meningkatkan jumlah data berlabel. Selanjutnya, data berlabel yang telah digabung dibuat model kembali dengan Stanford-NER dan digunakan untuk menguji 75 artikel yang telah terlebih dahulu di tag entitasnya. Penelitian ini mampu memperoleh nilai F1 yang baik setiap iterasinya.
Aryoyudanta et al. (2016) memanfaatkan algoritma Co-Training untuk memberdayakan data tidak berlabel untuk memperoleh data berlabel yang baru.
Penelitian ini menggunakan artikel berita sebagai data tidak berlabel, dan DBpedia
sebagai data berlabel. Tahap awal penelitian ini adalah melakukan text-processing pada data tidak berlabel yang kemudian diikuti dengan POS-Tagging. Tujuan digunakan pos- tagging adalah untuk mencari kata-kata yang kemungkinan besar memiliki named entities. Selanjutnya, mereka menggunakan algoritma Co-Training untuk melakukan pelabelan entitas pada data tidak berlabel dengan data dari DBpedia. Untuk melakukan pengujian, mereka menggunakan algoritma Support Vector Machine (SVM) untuk pemodelan data berlabel. Hasil yang diperoleh pada penelitian ini yaitu nilai precision sebesar 73,6%, nilai recall sebesar 80,1% dan F1 sebesar 76,5%.
Taufik et al. (2016) melakukan penelitian Named Entity Recognition untuk pesan microblog Bahasa Indonesia. Penelitian ini menggunakan Conditional Random Field dan beberapa kriteria bahasa dalam Bahasa Indonesia. Penelitian ini dikhususkan untuk jenis teks microblog. Untuk data pelatihan, peneliti memanfaatkan sembilan kriteria, yaitu susunan huruf yang membentuk kata, 3 huruf terakhir pada sebuah kata, panjang kata, tata penulisan kata, kata yang terdapat di dalam kurung, part-of-speech, kata yang berada disekitar, daftar kata berentitas dan daftar kata tidak baku. Dengan kriteria tersebut, peneliti mampu untuk menghasilkan model NER dan memperoleh nilai F1 yang lebih tinggi dibandingkan dengan sistem Named Entity Recognition Bahasa Indonesia formal pada tahap pengujiannya. Rangkuman penelitian terdahulu dapat dilihat pada Tabel 2.1.
Tabel 2.1. Penelitian Terdahulu
No Judul Peneliti (Tahun) Keterangan
1 Named Entity Recognition for the Indonesian
Language: Combining Contextual, Morphological and Part-of-Speech
Budi et al. (2005) • Data : artikel berita
• Metode : Knowledge- based method
• Jenis entitas : Orang, Lokasi dan Organisasi
• Recall : 63,43%
• Precision : 71,84%
2 ImNER Indonesian Medical Named Entity Recognition
Surwaningsih et al.
(2014)
• Data : Artikel medis
• Metode : Support Vector Machine (SVM)
• Jenis entitas : Lokasi, Fasilitas, Diagnosis, Definisi dan Orang
• Tingkat keakuratan : 90%
3 Building an Indonesian Named Entity Recognizer using Wikipedia and DBpedia
Luthfi et al. (2014) • Data : Wikipedia dan DBpedia
• Metode : Simple Tagger dan Heuristic Tagger
• Jenis entitas : Orang, Lokasi dan Organisasi
• Recall rendah, Precision tinggi 4 A Semi-Sepervised Algorithm
for Indonesian Named Entity Recognition
Leonandya et al.
(2015)
• Data : Wikipedia dan DBpedia
• Metode : Semi-
Supervised Algorithm
• Jenis entitas : Orang, Organisasi dan Lokasi
• Keakuratan : tinggi 5 Semi-Supervised Learning
Approach for Indonesian Named Entity Recognition using Co-Training Algorithm
Aryoyudanta et al.
(2016)
• Data : artikel berita dan DBpedia
• Metode : algoritma Co-Training dan POS- Tagging
• Jenis entitas : Orang, Organisasi, Lokasi, Fasilitas, Tanggal dan GPE
• Recall : 80,1 %
• Precision : 73,6%
6 Named Entity Recognition on Indonesian Microblog
Messages
Taufik et al. (2016) • Data : data Twitter
• Metode : Conditional Random Field (CRF)
• Jenis entitas : Orang, Lokasi dan Organisasi
• Recall : 47%
• Precision : 82%
Perbedaan penelitian yang dilakukan dengan penelitian yang dilakukan Leonandya et al adalah penelitian terdahulu melakukan entity-tagging hanya dengan memanfaatkan data entitas yang diperoleh dari DBpedia, sedangkan pada penelitian ini peneliti akan melakukan entity-tagging dengan terlebih dahulu melakukan POS- Tagging pada teks, kemudian dengan memanfaatkan data entitas yang diperoleh dari DBpedia dan beberapa aturan Bahasa Indonesia digunakan saat melakukan entity- tagging. Adapun metode yang diimplementasikan dalam penelitian ini, yakni:
Melakukan beberapa tahap pre-processing yang terdiri dari:
- Ekstraksi data yang Wikipedia dump dengan WikiExtractor tool, - Sentence Tokenizing dengan NLTK Tool,
- Memfilter bahasa yang digunakan dengan Language Detection Tool,
Menggunakan POS-Tagging untuk melabelkan kelas kata masing-masing kata.
Melakukan entity tagging.
Menggunakan metode Conditional Random Field untuk membuat data model.
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
Bab ini akan membahas tentang implementasi metode yang digunakan untuk menandai jenis entitas pada kata atau frase pada teks Bahasa Indonesia. Bab ini juga membahas mengenai data yang digunakan serta proses-proses yang dilakukan.
3.1. Dataset
Pada penelitian ini akan digunakan dua jenis data yakni, data artikel Wikipedia Indonesia dan DBpedia Indonesia. Data Wikipedia yang diperoleh merupakan data mentah dari artikel-artikel pada Wikipedia, sehingga diperlukan pembersihan pada data tersebut. Data Wikipedia ini akan digunakan sebagai training dataset dan testing dataset. Sedangkan data DBpedia yang diperoleh merupakan daftar kata untuk masing- masing jenis entitas yang digunakan untuk menandai entitas pada data Wikipedia.
Penjelasan lebih rinci akan dibahas pada bagian berikut.
3.1.1. Wikipedia
Penelitian ini menggunakan data artikel dari Wikipedia. Artikel Wikipedia dapat diunduh melalui Wikimedia Foundation yang beralamat di http://dumps.wikimedia.org/.
Data yang diunduh merupakan kumpulan artikel Wikipedia Indonesia. Format yang digunakan adalah XML. Data yang digunakan merupakan data dump per November 2016 yang diunduh pada bulan April 2017. Data ini memiliki sekitar 390.000 artikel Wikipedia Bahasa Indonesia.
Artikel Wikipedia merupakan hasil karya manusia, dengan demikian, masih terdapat beberapa kesalahan pada penulisannya. Selain itu terdapat artikel yang merupakan hasil terjemahan dari artikel bahasa lainnya dan masih terdapat beberapa
penulisan yang menggunakan bahasa asal artikel aslinya. Artikel yang menggunakan bahasa selain Bahasa Indonesia tidak akan digunakan karena pada penelitian ini hanya menggunakan kalimat atau teks Bahasa Indonesia. Untuk menghasilkan data yang dapat digunakan pada penelitian ini, Penulis akan melakukan beberapa proses pada data Wikipedia. Data Wikipedia akan dimanfaatkan untuk proses training dan testing.
Contoh data dump Wikipedia Indonesia dapat dilihat pada gambar 3.1.
Gambar 3.1 Contoh Data Dump Wikipedia
Gambar 3.1 di atas merupakan contoh artikel yang terdapat pada Wikipedia dump dengan format XML. Pada gambar 3.1, terdapat beberapa tag xml seperti tag
<page> yang digunakan sebagai batas dimulainya dan diakhiri sebuah artikel. Di dalam
<page> terdapat beberapa tag yang memberi identitas pada artikel tersebut seperti judul artikel, id dari artikel, format penulisan artikel, serta isi dari artikel tersebut. Pada isi artikel tersebut juga terdapat link yang ditandai dengan tanda “[[…]]” serta gambar.
3.1.2. DBpedia
DBpedia memiliki struktur data untuk artikel Wikipedia. Pada penelitian ini, Penulis menggunakan data entitas yang terdapat pada DBpedia. Entitas yang digunakan pada penelitian ini dibatasi 3 jenis entitas, yakni tempat, organisasi dan orang. Untuk memperoleh data entitas tersebut. Penulis memanfaatkan library ARC2. ARC2 merupakan library php yang menyediakan layanan pemrosesan data SPARQL. Adapun
proses untuk memperoleh daftar kata untuk masing-masing entitas dapat dilihat pada Gambar 3.2
Gambar 3.2 Contoh Sintaks SPARQL Untuk Memperoleh Data Entitas Organisation Pada DBpedia
Pada gambar 3.2 hasil yang diperoleh berupa kata-kata yang memiliki entitas organisation. Entitas organisation digunakan untuk mengambil data organisasi hal ini sesuai dengan ontologi yang terdapat pada baris keempat. Penggalan kode tersebut juga dapat digunakan untuk memperoleh data orang dengan mengganti ontologi yang terdapat pada baris keempat menjadi entitas person
<http://dbpedia.org/ontology/Person> dan untuk memperoleh data lokasi dapat diperoleh dengan cara mengubah ontologi pada baris keempat menjadi entitas location
<http://dbpedia.org/ontology/Location>. Untuk data DBpedia Indonesia terdapat jumlah total 140.993 entitas dimana 19.567 merupakan entitas person, 57.702 entitas location dan 5.773 entitas organisation. Sedangkan DBpedia Bahasa Inggris yang memiliki jumlah total 4.233.000 entitas.
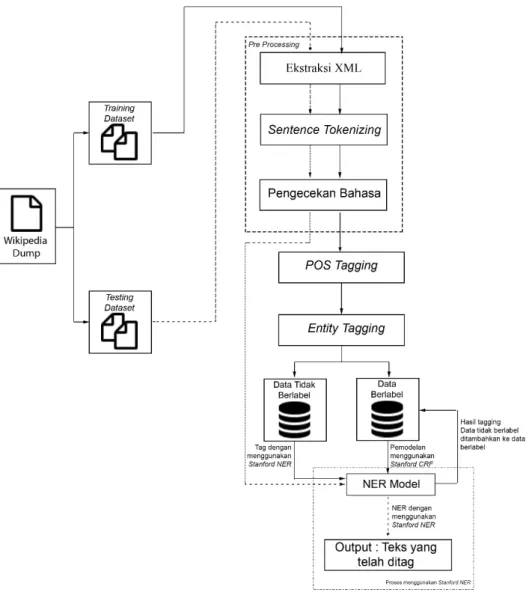
3.2. Perancangan Sistem
Metode yang diajukan Penulis untuk melakukan entity tagging terdiri dari beberapa proses. Seperti yang diilustrasikan pada Gambar 3.3, Proses-proses yang akan dilakukan adalah sebagai berikut: pengumpulan artikel-artikel Wikipedia Indonesia, ekstraksi teks yang terdapat pada artikel-artikel Wikipedia Indonesia, sentence tokenizing menggunakan Natural Language Toolkit, pengecekan bahasa dilakukan pada setiap kalimat yang diperoleh dengan menggunakan language detection tool, proses POS-Tagging untuk setiap kata menggunakan HMM POS-Tagging, proses pelabelan entitas pada masing kata dengan data entitas DBpedia, pemodelan menggunakan Stanford-CRF yang telah mengimplementasikan algoritma Conditional Random Field,
pelatihan model dan pengujian model. Setiap tahapan yang dilakukan akan dijelaskan dengan lebih terperinci pada bagian-bagian selanjutnya.
Gambar 3.3. Arsitektur Umum
3.2.1. Ekstraksi XML
Data dump Wikipedia yang berformat XML masih terdapat konten yang tidak diperlukan seperti infobox, tabel, gambar dan sebagainya. Pada penelitian ini, Penulis hanya menggunakan data teks dari artikel Wikipedia. Untuk memperoleh data teks tersebut, Penulis menggunakan WikiExtractor tool yang dapat diperoleh pada http://medialab.di.unipi.it/wiki/Wikipedia_Extractor. Tool ini dikembangkan oleh Giuseppe et al. Tool ini mampu untuk melakukan filter pada file dump Wikipedia, dan
mengekstrak teks dari artikel-artikel Wikipedia. sebagai contoh, dapat dilihat pada Gambar 3.4.
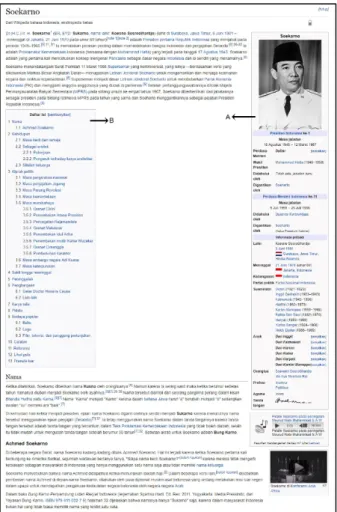
Gambar 3.4. Contoh Artikel Wikipedia
Pada gambar 3.4, dapat dilihat penggalan artikel “Soekarno” yang diambil dari halaman Wikipedia terdapat gambar, infobox yang dapat dilihat pada gambar 3.4 bagian ‘A’, daftar isi yang dapat dilihat pada gambar 3.4 bagian ‘B’ dan rujukan referensi. Pada penelitian ini, artikel pada gambar 3.4 akan diekstraksi dengan menggunakan WikiExtractor tool untuk memperoleh teks yang terdapat dari artikel “Soekarno”
tersebut.
3.2.2. Sentence Tokenizing
Teks yang diperoleh dari hasil ekstraksi tersebut berupa kumpulan paragraf-paragraf.
Untuk memudahkan pada proses pengecekan bahasa, dilakukan sentence tokenizing pada artikel Wikipedia. Setiap kalimat pada setiap paragraf akan dipisah sehingga hanya
terdapat satu kalimat pada setiap baris. Proses ini dilakukan dengan menggunakan Natural Language Tookit. Contoh sentence tokenizing dapat dilihat pada gambar 3.5.
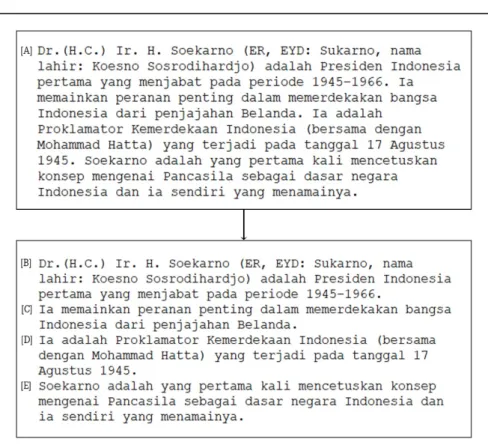
Gambar 3.5. Contoh Sentence Tokenizing
Pada gambar 3.5 [A] merupakan contoh paragraf yang belum melalui proses sentence tokenizing. Paragraf ini memiliki tiga buah kalimat, hasil dari sentence tokenizing dapat dilihat pada gambar 3.5 [B] sampai dengan 3.5 [E] yang merupakan hasil pemisahan dari keempat kalimat yang terdapat pada gambar 3.5 [A].
3.2.3. Pengecekan bahasa
Penelitian ini lebih mengutamakan kata-kata dalam Bahasa Indonesia, sedangkan pada artikel Wikipedia Indonesia masih terdapat kata-kata dalam bahasa asing. Untuk meminimalkan kata-kata dalam bahasa asing, Penulis melakukan pengecekan bahasa pada setiap kalimat yang diperoleh pada tahap sebelumnya. Untuk melakukan pengecekan bahasa, dilakukan dengan menggunakan language detector tool yang dikembangkan oleh Shuyo et al. Tool ini mampu untuk mengenali 71 jenis bahasa.
Adapun cara kerja dari tool ini adalah tool ini menerima input berupa kalimat,
selanjutnya tool ini akan mendeteksi penggunaan bahasa pada kalimat tersebut dan menampilkan bahasa yang digunakan beserta persentase dari pemakaian bahasa tersebut pada kalimat tersebut. Dikarenakan pada penelitian ini hanya akan digunakan kalimat Bahasa Indonesia, sehingga Penulis melakukan penambahan pada tahap ini, dari hasil yang diperoleh dari language detector tool, Penulis akan memeriksa bahasa yang dihasilkan dari tool tersebut, apabila bahasa yang digunakan bukan Bahasa Indonesia, kalimat tersebut tidak akan digunakan pada tahapan selanjutnya. Contoh pengecekkan bahasa dapat dilihat pada Gambar 3.6.
Gambar 3.6. Contoh Pengecekkan Bahasa
Gambar 3.6 merupakan contoh pengecekkan bahasa yang dilakukan dengan language detector tool, pada Gambar 3.6 kalimat-kalimat tersebut tidak dihapus dikarenakan pada kalimat tersebut tidak terdapatnya kata atau frasa yang berasal dari
bahasa asing. Oleh karena itu, kelima kalimat tersebut akan digunakan pada penelitian ini.
3.2.4. POS-Tagging
Untuk memperoleh data training yang lebih baik, Penulis menggunakan POS-Tagging untuk meningkatkan kualitas dari data training. POS-Tagging digunakan untuk mengetahui kelas kata masing-masing kata dimana kelas kata ini kemudian akan digunakan untuk menentukan kata-kata yang memiliki entitas person, location atau organisation. Untuk POS-Tagging, Penulis menggunakan “HMM based POS-Tagging”
yang dikembangkan oleh Wicaksono et al. POS-Tagging ini dapat mengkatergorikan kata ke dalam 35 jenis kelas kata yang dapat dilihat pada Tabel 3.1.
Tabel 3.1. Kategori Kelas Kata
No POS Nama No POS Nama
1 OP Open Parenthesis 19 MD Modal
2 CP Close Parenthesis 20 CC Coor-Conjunction
3 GM Slash 21 SC Subor-Conjunction
4 ; Semicolon 22 DT Determiner
5 : Colon 23 UH Interjection
6 " Quotation 24 CDO Ordinal Numerals 7 . Sentence Terminator 25 CDC Collective Numerals
8 , Comma 26 CDP Primary Numerals
9 - Dash 27 CDI Irregular Numerals
10 … Ellipsis 28 PRP Personal Pronouns 11 JJ Adjective 29 WP WH-Pronouns 12 RB Adverb 30 PRN Number Pronouns 13 NN Common Noun 31 PRL Locative Pronouns 14 NNP Proper Noun 32 NEG Negation
15 NNG Genitive Noun 33 SYM Symbols 16 VBI Intransitive Verb 34 RP Particles 17 VBT Transitive Verb 35 FW Foreign Words 18 IN Preposition
Gambar 3.7. Contoh POS-Tagging
Gambar 3.7. merupakan contoh POS-Tagging, pada gambar 3.7 bagian [A]
merupakan kalimat yang akan dilakukan POS-Tagging dan gambar 3.7 bagian [B]
merupakan kalimat yang telah melalui proses POS-Tagging. Pada gambar 3.7 bagian [B], jenis kelas kata dengan katanya dipisah oleh tanda garis miring ( / ). Pada hasil POS-Tagging tersebut dapat dilihat beberapa jenis kelas kata pada kalimat tersebut seperti common noun (NN), proper noun (NNP), verb (VBI), Ordinal Numerals (CDO) dan sebagainya. Singkatan dari hasil POS-Tagging yang terdapat pada gambar 3.7 bagian B dapat dilihat pada tabel 3.1.
3.2.5. Entity Tagging
Pada tahap ini, teks yang telah melewati tahapan sebelumnya akan di tag dengan entitas masing-masing kata yang terdapat pada DBpedia. Adapun entitas yang akan di tag adalah “person” untuk nama orang, “location” untuk nama tempat atau lokasi,
“organisation” untuk nama organisasi dan “O” untuk kata yang tidak memiliki entitas.
Terdapat dua proses pada tahap ini. Pertama, entity tagging pada teks hasil pre- processing dan kedua, entity tagging pada teks hasil POS-Tagging. Cara kerja kedua proses ini hampir sama yaitu, sistem akan melakukan pengecekkan pada setiap kalimat teks dengan data entitas yang diperoleh dari DBpedia, apabila terdapat kata pada kalimat yang memiliki entitas pada data DBpedia, sistem akan melakukan tag kata tersebut dengan entitasnya. Namun pada proses kedua, Penulis menambahkan beberapa rule untuk data yang belum memiliki entitas sehingga dapat menambah jumlah data yang memiliki entitas. Rule yang digunakan adalah kata-kata yang umumnya
menunjukkan nama tempat, nama orang dan nama organisasi. Kata-kata yang menunjukkan nama tempat seperti “Pelabuhan”, “Laut”, “Terminal” dan sebagainya.
Kata-kata yang menunjukkan nama orang seperti “Bapak”, “Ibu”, “Profesor” dan sebagainya. Kata-kata yang menunjukkan nama organisasi seperti “Bank”,
“Universitas”, “Sekolah”, “Partai” dan sebagainya. Contoh penggunaan rule yang dapat dilihat pada kalimat berikut yang telah dilakukan pos-tagging “Amir/NNP sedang/RB berbicara/VBI dengan/IN Bapak/NN Budi/NNP Santoso/NNP ./.” Pada kalimat tersebut dapat dilihat terdapat dua nama orang yaitu Amir dan Bapak Budi Santoso dan satu nama organisasi yaitu Partai Golongan Karya. Apabila nama orang dan nama organisasi tesebut tidak memiliki data entitas pada DBpedia maka pada penelitian ini data tersebut akan diproses berdasarkan rule yang telah disediakan. Secara umum, kata yang memiliki entitas Location, Person atau Organisation memiliki kelas kata NNP (Proper Noun). Dengan demikian, Penulis melakukan pengecekkan dengan memanfaatkan daftar kata yang telah disediakan dan jenis kelas katanya. Pertama, dilakukan pengecekkan kata pada kalimat yang terdapat pada daftar kata yang telah disediakan, pada kalimat tersebut terdapat dua kata yang memenuhi yaitu “Bapak”. Selanjutnya, Penulis melakukan pengecekkan pada kata setelah kata tersebut, apabila jenis kelas kata setelah kata tersebut adalah NNP (Proper Noun) maka kata tersebut akan di tag dengan jenis entitasnya. Seperti kata “Bapak”, setelah kata “Bapak” terdapat kata Budi dan Santoso yang memiliki kelas kata NNP. Oleh karena itu, pada penelitian ini Bapak Budi Santoso pada kalimat tersebut akan di tag dengan entitas Person.
3.2.6. Pemodelan Named Entity Recognition
Setelah melakukan tag entitas, selanjutnya Penulis melakukan pemodelan Named Entity Recognition. Model Named Entity Recognition yang dihasilkan bertujuan sebagai kamus data untuk melakukan entity tagging pada kalimat atau teks Bahasa Indonesia.
Sebelum melakukan pemodelan Named Entity Recognition, Penulis terlebih dahulu melakukan tokenisasi pada setiap kata dan entitasnya. Tokenisasi ini akan membagi kata dan entitasnya menjadi 2 kolom, kolom pertama adalah kata dan kolom kedua adalah entitasnya. Selanjutnya, Penulis melakukan pemodelan pada file hasil tokenisasi tersebut dengan menggunakan Stanford-CRF yang telah mengimplementasi metode Conditional Random Field. Pada saat melakukan pemodelan, Penulis hanya
menggunakan konfigurasi awal dari file properties Stanford-CRF yang dapat dilihat pada Gambar 3.8.
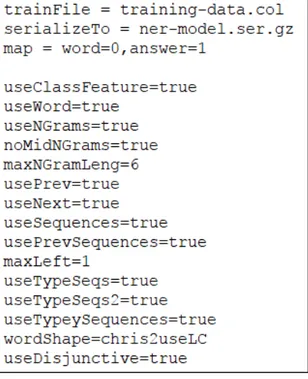
Gambar 3.8. Contoh Properties File Pemodelan NER
Pada Gambar 3.8, terdapat beberapa parameter yang digunakan pada file konfigurasi tersebut. Parameter-parameter tersebut terdiri dari parameter trainFile yang berfungsi untuk menentukan file yang akan dilatih. Parameter serializeTo yang berfungsi untuk menentukan model hasil pelatihan. Parameter map berfungsi untuk menentukan format dari file yang digunakan untuk training dalam hal ini kata terdapat pada kolom pertama dan jenis entitas terdapat pada kolom kedua. Parameter useClassFeature untuk menetukan kriteria dari golongan. Parameter useWord untuk memberikan kriteria dari kata pada file training. Parameter useNGrams untuk menghitung penggunaan sebuah kata. Parameter noMidNGrams untuk tidak menyertakan n-gram yang tidak mengandung kata yang berada di awal dan akhir kalimat. Parameter MaxNGramLeng menentukan panjang maksimal N-Gram.
Parameter usePrev untuk memperoleh kriteria dari kata sebelumnya seperti jenis entitas.
Parameter useNext untuk memperoleh kriteria dari kata setelahnya seperti jenis entitas.
Parameter useSequence untuk menggunakan kombinasi dari kata.
3.3. Tahap Training
Pada bagian ini, akan dijelaskan tahap-tahap yang dilakukan untuk melakukan training Named Entity Recognition Bahasa Indonesia. Pertama, Penulis mempersiapkan data yang akan digunakan yaitu data dump Wikipedia dan data entitas DBpedia. Untuk data dump Wikipedia, Penulis melakukan pre-processing yang terdiri dari ekstraksi teks yang terdapat pada data dump tersebut, menformat susunan kalimat pada teks hasil ekstraksi, dan melakukan seleksi kalimat dengan bahasa yang terdapat pada kalimat tersebut.
Teks yang telah melalui proses pre-processing selanjutnya akan dilakukan POS- Tagging pada masing-masing kata yang terdapat di teks tersebut. Kelas kata ini akan membantu pada tahap melakukan tag entitas awal pada data training.
Tahap entity tagging terbagi menjadi 2 jenis yaitu training dengan teks yang hanya melalui proses pre-processing dan training dengan teks yang telah melalui proses POS-Tagging. Perbedaan kedua jenis training ini terletak pada saat melakukan tag entitas awal pada masing-masing teks. Kedua jenis training ini sama-sama menggunakan data entitas dari DBpedia untuk melakukan tag entitas awal, namun pada training dengan teks yang telah melalui proses POS-Tagging, Penulis menambahkan rule ketika melakukan tag entitas awal yang bertujuan untuk meningkatkan jumlah entitas pada teks.
Setelah melalui tahap tag entitas awal, kedua teks yang telah berlabel tersebut kemudian akan dibuat model Named Entity Recognition dengan menggunakan Stanford-CRF. Setelah model dihasilkan, Penulis melakukan training menggunakan Stanford-NER dan model Named Entity Recognition yang telah dihasilkan, training dilakukan dengan melakukan entity-tagging pada teks yang ketika tahap tag entitas awal belum memiliki entitas. Proses ini bertujuan untuk memperoleh data berlabel yang lebih banyak. Hasil dari pelatihan ini akan digabungkan dengan teks berlabel yang diperoleh pada tahap tag entitas awal. Gabungan dari teks tersebut akan dibangun kembali model Named Entity Recognition dengan Stanford-CRF. Setelah melalui seluruh tahapan ini, tahap training telah selesai dilakukan dan data model hasil training dapat diuji pada tahap testing.
3.4. Tahap Testing
Untuk menguji kemampuan model hasil training, Penulis melakukan pengujian pada data tersebut. Pengujian dilakukan dengan mengambil 1.000 kalimat secara acak yang diperoleh dari artikel Wikipedia yang tidak digunakan ketika tahap training dan dilakukan tag entitas pada kalimat-kalimat tersebut secara manual. Hasil tag entitas secara manual tersebut selanjutnya dilakukan tokenisasi pada setiap kata dan entitasnya.
Selanjutnya, dengan menggunakan Stanford-NER, file testing tersebut diuji dengan model-model yang telah diperoleh pada tahap training.
3.5. Evaluasi
Untuk mengukur keakuratan dari sistem, Penulis menggunakan 6 jenis parameter, yaitu TP (True Positive), FP (False Positive), FN (False Negative), precision, recall dan F1.
TP adalah jumlah entitas yang berhasil di tag dengan benar oleh model. FP adalah jumlah entitas yang berhasl di tag oleh model tetapi bernilai salah. FN adalah jumlah entitas yang tidak berhasil di tag oleh model. Precision merupakan perbandingan antara jumlah entitas yang berhasil di tag dengan benar oleh model dengan jumlah entitas yang berhasil di tag. Persamaaan dari nilai precision dapat dilihat pada persamaan 3.1. Recall merupakan perbandingan antara jumlah entitas yang berhasil di tag dengan benar dengan jumlah entitas yang memiliki entitas tersebut. Persamaan dari nilai recall dapat dilihat pada persamaan 3.2. F1 merupakan nilai untuk mengukur keakuratan data model yang dihasilkan. Persamaan F1 dapat dilihat pada persamaan 3.3.
𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝 = 𝑇𝑇𝑇𝑇+𝐹𝐹𝑇𝑇𝑇𝑇𝑇𝑇 (3.1) 𝑝𝑝𝑝𝑝𝑝𝑝𝑟𝑟𝑟𝑟𝑟𝑟 = 𝑇𝑇𝑇𝑇+𝐹𝐹𝐹𝐹𝑇𝑇𝑇𝑇 (3.2) 𝐹𝐹1 = 𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝 × 𝑝𝑝𝑝𝑝𝑝𝑝𝑟𝑟𝑟𝑟𝑟𝑟
2 × (𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝+𝑝𝑝𝑝𝑝𝑝𝑝𝑟𝑟𝑟𝑟𝑟𝑟) (3.3)
Dimana: TP = jumlah entitas yang berhasil di tag dengan benar FP = jumlah entitas yang berhasil di tag tetapi bernilai salah FN = jumlah entitas yang tidak berhasil di tag
BAB 4
IMPLEMENTASI DAN PENGUJIAN
Bab ini akan membahas hasil yang diperoleh dan implementasi metode Conditional Random Field untuk menandai jenis entitas pada kata atau frase dalam teks Bahasa Indonesia berdasarkan konten sesuai dengan analisis dan perancangan yang telah dibahas pada Bab 3.
4.1. Spesifikasi Perangkat Keras dan Perangkat Lunak
Spesifikasi perangkat keras yang digunakan dalam penelitian ini adalah sebagai berikut:
1. Prosesor Intel® Core™ i5-7200 CPU @ 2.50 GHz.
2. Kapasitas harddisk 1 TB.
3. Memori RAM yang digunakan 4 GB DDR4.
Spesifikasi perangkat lunak yang digunakan untuk membangun aplikasi ini adalah sebagai berikut:
1. Sistem operasi yang digunakan adalah Windows 10 Home Single Language 64- bit (10.0, Build 15063)
2. Aplikasi pengolah presentasi yang digunakan adalah Microsoft Office PowerPoint 2016.
3. Aplikasi PDF Reader yang digunakan adalah Acrobat Reader DC versi 17.009.20058
4. Eclipse Neon
5. Library yang digunakan adalah NLTK, ARC2 dan Stanford-CRF-NER
4.2. Dataset
Pada bagian ini, akan dijelaskan mengenai data yang digunakan dan tahapan pre- processing yang dilakukan pada data-data tersebut. Pada penelitian ini digunakan dua jenis data, yaitu data artikel-artikel Wikipedia Indonesia dan data entitas DBpedia Indonesia. Data artikel Wikipedia dapat diunduh secara bebas pada Wikimedia Foundation. Data yang diunduh berformat XML dan memiliki ukuran sekitar 1,8 GB.
Data ini merupakan dump dari seluruh artikel Wikipedia Bahasa Indonesia sampai dengan November 2016. Jumlah artikel yang terdapat pada data ini sekitar 190.000 artikel. Selanjutnya, data artikel Wikipedia ini akan melalui proses pre-processing yang terdiri dari ekstraksi xml, memformat teks dan pengecekkan bahasa. Hasil dari ekstraksi xml dengan WikiExtractor Tool berupa 22 file yang berisi teks dari artikel- artikel Wikipedia dan masing-masing file berukuran sekitar 19MB. Contoh hasil teks artikel Wikipedia dapat dilihat pada Gambar 4.1. Dapat dilihat bahwa untuk setiap artikel yang terdapat pada Wikipedia akan dibatasi dengan sintaks <doc> </doc>.
Gambar 4.1 Contoh Hasil Ekstraksi XML
Kemudian teks tersebut akan melalui proses sentence tokenizing, hasil dari sentence tokenizing menggunakan Natural Language Toolkit dapat dilihat pada gambar 4.2. Pada gambar 4.1 teks tersebut terdiri dari satu baris judul dan dua paragraf. Paragraf pertama dari teks tersebut terdiri dari tiga buah kalimat dan paragraf kedua mempunyai sebuah kalimat. Dengan menggunakan NLTK tool, kalimat pada kedua paragraf tersebut akan dipisah seperti yang dapat dilihat pada gambar 4.2. Pada gambar 4.2, terdiri dari lima baris yang setiap baris hanya memiliki sebuah kalimat, baris pertama adalah judul dari artikel tersebut, baris kedua sampai dengan baris keempat merupakan hasil
pemisahan kalimat dari paragraf pertama pada teks yang terdapat di gambar 4.1 dan baris kelima merupakan kalimat yang terdapat pada paragraf kedua dari teks pada gambar 4.1.
Gambar 4.2. Contoh Hasil Memformat Teks
Selanjutnya setiap kalimat tersebut akan dilakukan pengecekkan bahasa, hasil dari pengecekkan bahasa menggunakan language detector adalah file-file yang telah diseleksi kalimat-kalimatnya. Setelah melalui tahap pre-processing, data artikel Wikipedia ini akan dibagi menjadi dua jenis yaitu training dataset dan testing dataset.
Untuk testing dataset, Penulis menggunakan satu file dari hasil pre-processing dan training dataset menggunakan seluruh file selain file yang digunakan pada tahap testing.
Data entitas DBpedia, Penulis menggunakan ARC2 untuk memperoleh daftar objek untuk masing-masing entitas. ARC2 memiliki fitur untuk mengolah data RDF menggunakan SPARQL yang dibutuhkan untuk memperoleh objek data entitas, hasil dari tahap ini berupa file yang berisi nama objek disertai dengan jenis entitasnya.
Contoh data entitas DBpedia dapat dilihat pada gambar 4.3. Data DBpedia yang terdapat pada gambar 4.3 hanya merupakan sebagian data. Pada gambar 4.3, kata dan jenis entitas dibatasi dengan tanda “/”, dimana kata terdapat disebelah kiri tanda “/” dan jenis entitas berada disebelah kanan tanda “/”.
Gambar 4.3 Contoh Data Entitas Yang Diperoleh Dari DBpedia Indonesia
4.3. Hasil proses POS-Tagging
Pada bagian ini dijabarkan hasil yang didapatkan pada proses POS-Tagging, teks yang telah melalui tahap pre-processing akan diproses dengan POS-Tagging untuk ditandai kelas kata untuk masing-masing kata. Hasil dari POS-Tagging berupa file-file yang berisi kalimat-kalimat yang telah ditandai dengan kelas kata masing-masing kata pada teks tersebut. Contoh dari kalimat yang telah dilakukan POS-Tagging dapat dilihat pada Gambar 4.4. Dapat dilihat kata dan kelas kata yang dibatasi dengan tanda “/”. Kelas kata yang ditandai pada kata tersebut hanya berupa singkatan untuk mengetahui definisi kelas kata dapat dilihat pada Bab.3.
Gambar 4.4. Contoh Hasil Data POS-Tagging
4.4. Hasil proses Training
Setelah diperoleh data dan dilakukan beberapa tahapan pada data tersebut, Penulis akan melakukan training dengan memanfaatkan data tersebut. Training dimulai dengan melakukan entity tagging. Pada entity tagging terdapat dua jenis proses. Pertama, entity tagging dengan data hasil pre-processing dan DBpedia. Kedua, entity tagging dengan data hasil POS-Tagging dan DBpedia disertai beberapa rule. Kedua proses ini menghasilkan hasil yang memiliki format yang sama, yaitu teks yang berisi kata yang telah di tag dengan entitasnya yang dapat dilihat contoh tag pada Gambar 4.5.
Gambar 4.5. Contoh Hasil Entity Tagging
Selanjutnya, hasil entity tagging dibuat menjadi model menggunakan Stanford- CRF yang telah mengimplementasi algoritma Conditional Random Field. Dikarenakan keterbatasan sumber daya, proses pembuatan model tidak dapat berjalan dengan baik.
Oleh karena itu, Penulis membagi proses pembuatan model menjadi 5 jenis, yakni data yang berisi paling sedikit 50 entitas untuk masing jenis entitas, 500 entitas, 1.000 entitas, 2.000 entitas dan 5.000 entitas. Setelah dibagi, Penulis kembali mebuat model dari lima jenis data tersebut. Adapun hasil yang diperoleh dari proses ini adalah sepuluh file model yang dapat digunakan untuk melakukan tag pada teks Bahasa Indonesia.
Setelah diperoleh model Named Entity Recognition, Penulis melakukan tag entitas pada data yang belum berhasil dilabelkan pada tahap entity tagging dengan model yang diperoleh. Hal ini dilakukan untuk meningkatkan jumlah data yang berentitas. Hasil dari proses ini selanjutnya akan digabungkan dengan data model awal.
Gabungan dari data tersebut akan dibuat kembali model data yang baru, Hasil dari
model data yang baru ini selanjutnya akan diuji pada testing dataset untuk dinilai keakuratan model ini.
Adapun hasil yang diperoleh pada akhir pelatihan adalah sepuluh model Named Entity Recognition yang dapat digunakan untuk melakukan tag entitas pada kalimat atau teks Bahasa Indonesia dan digunakan untuk melakukan pengujian.
4.5. Hasil Proses Testing
Pada bagian ini akan dijabarkan hasil dari pengujian data model yang diperoleh pada saat pelatihan. Pengujian ini dilakukan dengan memanfaatkan model-model data yang diperoleh untuk melakukan tag entitas pada testing dataset. Pengujian dilakukan untuk kedua jenis proses dengan model yang diperoleh dari data hasil pre-processing dan model yang diperoleh dari data hasil POS-Tagging disertai beberapa rule. Hasil pengujian untuk setiap entitas pada setiap model data yang diperoleh dari tahap pre–
processing dapat dilihat pada Tabel 4.1, 4.2, 4.3 dan 4.4. Hasil pengujian untuk setiap entitas pada setiap model data yang diperoleh dari tahap POS-Tagging dengan beberapa rule dapat dilihat pada Tabel 4.5, 4.6, 4.7, 4.8.
Tabel 4.1. Hasil Pengujian Model NER Yang Telah Dilatih dengan Data Pre- processing Untuk Entitas Location
Parameter
Jenis Model 50
entitas
500 entitas
1000 entitas
2000 entitas
5000 entitas True Positive
(TP)
86 179 211 219 234
False Positive (FP)
23 40 39 46 49
False Negative (FN)
1280 1187 1155 1147 1132
Precision 78.90% 81.74% 84.40% 82.64% 82.69%
Recall 6.30% 13.10% 15.45% 16.03% 17.13%
F1 11.66% 22.59% 26.11% 26.85% 28.38%
Tabel 4.2. Hasil Pengujian Model NER Yang Telah Dilatih Dengan Data Pre- processing Untuk Entitas Organisation
Parameter
Jenis Model 50
entitas
500 entitas
1000 entitas
2000 entitas
5000 entitas True Positive
(TP)
0 62 83 92 113
False Positive (FP)
4 13 30 28 28
False Negative (FN)
173 110 90 81 60
Precision 0.00% 82.67% 73.45% 76.67% 80.14%
Recall 0.00% 36.05% 47.98% 53.18% 65.32%
F1 0.00% 50.20% 58.04% 62.80% 71.97%
Tabel 4.3. Hasil Pengujian Model NER yang Telah Dilatih Dengan Data Pre- processing Untuk Entitas Person
Parameter
Jenis Model 50
entitas
500 entitas
1000 entitas
2000 entitas
5000 entitas True Positive
(TP)
6 77 116 128 131
False Positive (FP)
19 52 74 81 73
False Negative (FN)
488 417 378 366 363
Precision 24.00% 59.69% 61.05% 61.24% 64.22%
Recall 1.21% 15.59% 23.48% 25.91% 26.52%
F1 2.31% 24.72% 33.92% 36.42% 37.54%
Tabel 4.1, 4.2 dan 4.3 merupakan tabel hasil pengujian model NER yang diperoleh dari teks hasil proses pre-processing yang di tag dengan data entitas dari DBpedia. Tabel 4.1, 4.2 dan 4.3 menunjukkan hasil pengujian untuk setiap jenis entitas.