IV. HASIL DAN PEMBAHASAN
A. Persiapan Data Untuk Analisis Jaringan Syaraf
Tahapan pertama sebelum merancang model jaringan syaraf tiruan adalah menyiapkan data. Secara garis besar tahapan-tahapan dalam melakukan persiapan data pada analisis jaringan syaraf adalah sebagai berikut :
1. Analisis data awal a. Analisis kebutuhan
Pada penelitian ini, data diperoleh dari bagian produksi departemen pengawasan mutu (quality control) pada KPBS Pangalengan, Kabupaten Bandung Selatan Provinsi Jawa Barat. Data yang diperoleh adalah data yang memiliki hubungan keterkaitan dengan masalah penelitian yaitu penjualan. Setelah dilakukan wawancara dengan bagian produksi KPBS, diperoleh bahwa faktor-faktor, pada penelitian ini disebut entitas, yang memiliki hubungan keterkaitan dengan masalah penelitian yaitu penjualan adalah data mengenai penjualan masa lalu, kualitas susu, produk susu, distributor susu, jumlah sapi perah dan topografi KPBS Pangalengan. Hamzacebi (2008) menyatakan bahwa banyak faktor yang dapat mempengaruhi proses penjualan diantaranya promosi, new product launching, diversifikasi produk, dan kualitas produk.
b. Pengelompokan Data
Berdasarkan analisis kebutuhan data yang telah dilakukan, data- data (entitas) tersebut dikelompokkan menjadi data yang lebih rinci, pada penelitian ini disebut atribut data. Pengelompokan entitas dan atribut data tersebut adalah sebagai berikut :
1. Distributor (Entitas) Atribut :
a. Lokasi : Sukabumi, Jakarta Barat, Jakarta Timur, Ciamis, Kios Pangalengan, Cirebon, Bandung
b. Jarak : km
c. Lama Perjalanan : Jam
2. Produk (Entitas) Atribut :
a. Jenis : cup, prepack b. Harga : rupiah
c. Rasa : strawberry, coklat
d. Volume : (cup ….. ml, prepack …. ml)
e. Jumlah produk yang terjual dalam satu bulan (cup dan prepack strawberry/coklat)
f. Warna : coklat, merah muda
3. Kualitas (Entitas) Atribut :
a. Kadar protein b. Kadar lemak c. Kadar berat jenis
d. Kadar bahan kering tanpa lemak e. Total plate count
f. Total solid g. Tingkat keasaman
h. Sapi : Jumlah Sapi, Jenis Sapi i. Cuaca : Suhu, Kelembaban
c. Pemilihan Atribut Data
Setelah data dikumpulkan, dilakukan pemilihan atributdata yang akan digunakan untuk pemodelan analisis jaringan syaraf. Pemilihan atribut data pada penelitian ini difokuskan berdasarkan informasi data yang bergerak setiap bulan yang diperoleh dari KPBS Pangalengan. Lou (1993) menyatakan bahwa data yang bersifat stabil (tidak bergerak pada setiap periode waktu tertentu) dan ada data yang hilang dapat berpengaruh secara signifikan terhadap kinerja dan kualitas model
jaringan syaraf. Ada banyak cara pemilihan atribut data diantaranya dengan metode kausalitas (Granger, 1969). Metode kausalitas merupakan suatu metode penentuan atiribut data dengan melihat hubungan sebab akibat antar atribut. Berdasarkan penelitian yang dilakukan oleh Septiani (2005) bahwa kualitas susu mempunyai hubungan sebab akibat terhadap hasil transaksi penjualan. Apabila sebuah produk susu mampu memuaskan dan memenuhi apa yang menjadi keinginan konsumen (kualitas produk susu yang sesuai apa yang diharapkan), maka produk susu tersebut mampu memenangkan persaingan dalam hal jumlah produk yang terjual ke konsumen. Selain itu, Hamzacebi (2000) menyatakan bahwa kualitas susu merupakan salah satu faktor yang dapat mempengaruhi volume penjualan. Dengan demikian, kualitas susu memiliki hubungan sebab akibat dengan volume penjualan. Pada penelitian ini atribut-atirbut data mengenai kualitas susu yang dipilih adalah kadar lemak (X4), kadar bahan kering tanpa lemak (X5), total solid (X6), kadar berat jenis (X7), dan total plate count (X8). Atribut-atribut data tersebut yang merupakan bagian dari kualitas susu memiliki hubungan sebab akibat dengan proses pejualan.
Berikut adalah data hasil pemilihan atribut data yang telah digunakan : a. Jumlah produk cup coklat yang terjual dalam satu bulan (X1)
b. Jumlah produk cup strawberry yang terjual dalam satu bulan (X2) c. Jumlah produk prepack yang terjual dalam satu bulan (X3) d. Kadar lemak (X4)
e. Kadar bahan kering tanpa lemak (X5) f. Total solid (X6)
g. Kadar berat jenis (X7) h. Total plate count (X8)
d. Integrasi Data
Data hasil pemilihan data memungkinkan masih bersifat kacau dan tersebar. Hal ini terutama terjadi saat data masih mengandung teks dan atribut sehingga perlu dilengkapi secara keseluruhan (integrasi).
Integrasi data merupakan suatu tahapan di mana semua hasil pemilihan data diinputkan. Pada penelitian ini, integrasi data dapat dilihat pada Lampiran 2.
2. Proses Pengolahan Data Awal a. Pemeriksaan Data
Tahap pertama dalam data preprocessing adalah melakukan pemeriksaan terhadap data yang telah diintegrasikan. Tujuan dalam melakukan pemeriksaan terhadap data hasil integrasi adalah menemukan masalah pada data. Pemeriksaan data meliputi data kuantitatif dan kualitas. Pemeriksaan data kuantitatif dibentuk dari observasi. Secara umum, pada pemeriksaan data kuantitatif ada dua masalah yang timbul yaitu ukuran/jumlah data yang terlalu besar atau ukuran/jumlah data yang terlalu sedikit. Pemeriksaan terhadap kualitas data biasanya dibentuk dari metode statistik yang meliputi pemeriksaan pada data yang tidak lengkap (data noise dan data missing), data dalam skala numerik yang besar/berbeda, data trend dan data nonstationary (Shewhart, 1931).
Pada penelitian ini hasil pemeriksaan yang telah dilakukan ada beberapa masalah yang ditemukan yaitu data dalam skala numerik yang berbeda dan data terlalu sedikit.
b. Pengolahan Data
Masalah-masalah yang timbul pada pemeriksaan data dapat diperbaiki dengan beberapa solusi. Jumlah data yang besar dapat diselesaikan dengan melakukan data sampling. Data yang diambil adalah data yang relevan terhadap permasalahan penelitian yang dihadapi.
Jumlah data yang sedikit dapat diselesaikan dengan melakukan data re- gathering (pengumpulan kembali). Data yang masih kurang dilakukan
dengan mengumpulkan kembali data yang kurang sampai data yang diinginkan untuk melakukan analisis jaringan syaraf dapat ditemukan.
Nguyen dan Chan (2004) menemukan bahwa jaringan syaraf sedikit mengalami kesulitan ketika data yang tersedia terlalu sedikit atau tidak mencukupi. Data missing (data hilang) dapat dibagi menjadi dua jenis, yaitu atribut hilang dan nilai-nilai pada atribut yang hilang. Hilangnya data pada atribut dapat mempersulit tugas analisis data seperti proses pembelajaran dan jika hal ini terjadi dapat menghambat kinerja analisis data (Famili et al., 1997).
Dalam pelatihan neural network, data dengan skala yang berbeda sering mengakibatkan ketidakstabilan jaringan syaraf (Weigend dan Gershenfeld, 1994). Untuk prediksi syaraf, adanya tren mungkin memiliki efek yang tidak diinginkan pada kinerja prediksi. Demikian pula, peneliti (Tseng et al., 2002; Moody, 1995) telah menunjukkan bahwa data musiman memiliki dampak signifikan terhadap prediksi jaringan syaraf. Demikian pula pada data yang bersifat nonstationary.
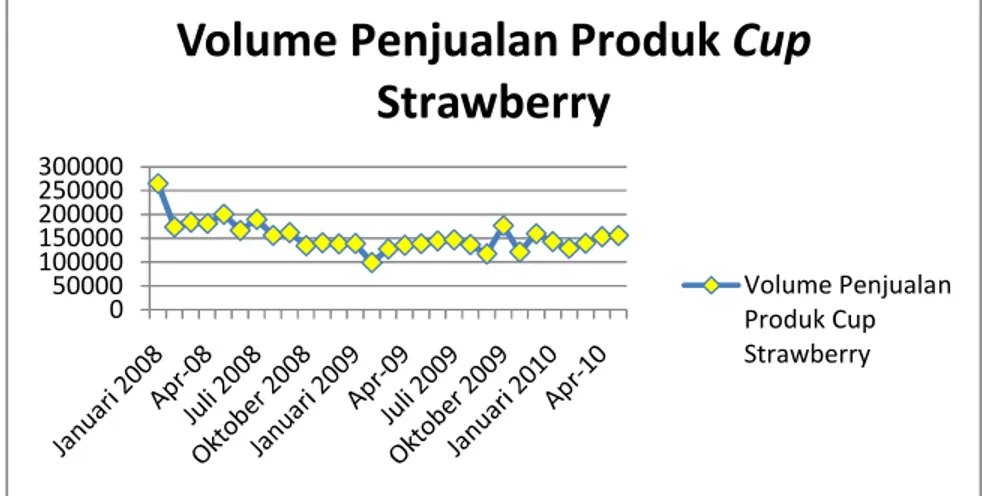
Pada penelitian ini, produk terdiri dari tiga jenis yaitu cup rasa strawberry, cup rasa coklat, dan prepack. Data penjualan produk susu pada jenis cup rasa strawberry, coklat dan prepack bukan merupakan tipe pola data yang bersifat musiman. Hal ini tidak menjadi permasalahan dalam analisis data dalam jaringan syaraf tiruan. Hal ini dapat dilihat pada Gambar 11.
Gambar 11. Pola penjualan produk cup coklat 0
100000 200000 300000 400000
Volume Penjualan Produk Cup Coklat
Volume Penjualan Produk Cup Coklat
Menurut Machfud (1999), pola data musiman terjadi jika suatu deret data dipengaruhi oleh faktor musiman (musim harian, mingguan, bulanan atau tahunan). Pola data musiman mempunyai panjang horizon waktu yan bersifat tetap dan terjadi pada basis periode yang teratur.
Analisa pola data pada volume penjualan susu dilakukan secara tahunan.
Pada Gambar 11 terlihat bahwa tipe pola data volume penjualan produk cup coklat berpola bukan musiman. Hal ini dapat terlihat bahwa periode volume penjualan bulan Juni-Juli 2008 mempunyai pola yang tidak sama pada periode volume penjualan bulan Juni-Juli 2009. Terlihat bahwa pada periode bulan Juni–Juli 2008, volume penjualannya meningkat sedangkan pada periode bulan Juni–Juli 2009 terjadi penurunan volume penjualan yang cukup signifikan.
Gambar 12. Pola penjualan produk cup strawberry
Pada Gambar 12 terlihat bahwa tipe pola data volume penjualan produk cup strawberry berpola bukan musiman. Hal ini dapat terlihat bahwa periode volume penjualan bulan Juni-Juli 2008 mempunyai pola yang tidak sama pada periode volume penjualan bulan Juni-Juli 2009.
Terlihat bahwa pada periode bulan Juni–Juli 2008, volume penjualannya meningkat sedangkan pada periode bulan Juni–Juli 2009 terjadi kestabilan volume penjualan.
500000 100000 150000 200000 250000 300000
Volume Penjualan Produk Cup Strawberry
Volume Penjualan Produk Cup Strawberry
Gambar 13. Pola penjualan produk prepack
Pada Gambar 13 terlihat bahwa tipe pola data volume penjualan produk prepack berpola bukan musiman. Hal ini dapat terlihat bahwa periode volume penjualan bulan Juni-Juli 2008 mempunyai pola yang tidak sama pada periode volume penjualan bulan Juni-Juli 2009. Terlihat bahwa pada periode bulan Juni–Juli 2008, volume penjualannya stabil sedangkan pada periode bulan Juni–Juli 2009 terjadi penurunan volume penjualan yang cukup signifikan.
Pada penelitian ini, setelah dilakukan pemeriksaan terhadap data yang diperoleh pada tahap awal ditemukan beberapa masalah, yaitu data yang terlalu sedikit dan data dalam skala yang berbeda. Data yang terlalu sedikit ini telah diselesaikan dengan mengumpulkan kembali data yang masih kurang. Permasalahan data dalam skala yang berbeda dapat diselesaikan dengan metode normalisasi. Normalisasi data ini bertujuan untuk meningkatkan keakurasian dari hasil output dan memfasilitasi proses learning dari jaringan syaraf dan membantu menghilangkan noise pada data. Ini merupakan operasi kritis sebab jaringan syaraf adalah pencocok pola, sehingga ketika pola data telah ditunjukan maka akan mengubah perilaku jaringan syaraf. Proses normalisasi dilakukan dengan mentransformasikan data sesuai fungsi aktivasi yang digunakan. Pada penelitian ini, fungsi aktivasi yang digunakan adalah fungsi aktivasi sigmoid biner yang memiliki range keluaran [0,1]. Data bisa
0 50000 100000 150000 200000 250000
Volume Penjualan Produk Prepack
Volume Penjualan Produk Prepack
ditransformasikan ke interval [0,1]. Tapi akan lebih baik jika ditrasformasikan ke interval yang lebih kecil, misal pada interval [0.1,0.9]. Hal ini mengingat fungsi sigmoid merupakan fungsi asimtotik yang nilainya tidak pernah mencapai 0 ataupun 1 (Siang, 2009).
Jika a adalah data minimum dan b adalah data maksimum, transformasi linier yang dapat digunakan untuk mentrasformasikan data ke interval [0.1,0.9] adalah
x′=0.8 (x − a) b − a + 0.1 Hasil normalisasi dapat dilihat pada Lampiran 3.
3. Analisis Data Akhir a. Pembagian Data
Setelah data preprocessing, data yang diperoleh dari tahap sebelumnya akan digunakan untuk pelatihan jaringan dan generalisasi.
Penyusunan data dalam tahap ini adalah untuk membagi data ke dalam himpunan bagian untuk proses pembelajaran jaringan syaraf. Biasanya, data set dibagi menjadi data pelatihan dan data pengujian. Yao dan Tan (2000) menyatakan sejauh ini, tidak ada aturan baku untuk menentukan ukuran jumlah baik data set pelatihan atau data uji. Penentuan jumlah data pelatihan dan data uji dapat dilakukan dengan mengggunakan metode K-fold cross validation yang merupakan bagian dari proses validasi.
Proses pelatihan dan pengujian sangat menentukan proses validasi. Pada penelitian ini, proses validasi menggunakan metode K-fold cross validation. Metode K-fold cross validation adalah salah satu metode cross validation yang membagi data menjadi k subdata. Salah satu subbagian data dijadikan sebagai validator dan testing sedangkan K- 1 data digunakan sebagai data pelatihan dan pengujian. Proses diatas dilakukan berulang sebanyak K kali untuk setiap subbagian data. Hasil dari pengujian adalah rata-rata dari K kali pengujian pada data tersebut.
Dalam penelitian ini digunakan K-9 fold cross validation. Pada penelitian ini terdapat 261 data awal. Dengan menggunakan K-9 fold
cross validation, 8 sub kelompok data akan digunakan untuk pelatihan dan pengujian dan 1 sub kelompok data digunakan untuk prediktor.
Delapan sub kelompok data tersebut adalah volume penjualan produk cup coklat (X1), cup strawberry (X2), prepack (X3), kadar lemak (X4), kadar bahan kering tanpa lemak (X5), total solid (X6), kadar berat jenis (X7), dan total plate count (X8). Sedangkan satu sub kelompok data tersebut adalah volume penjualan bulan depan (Y).
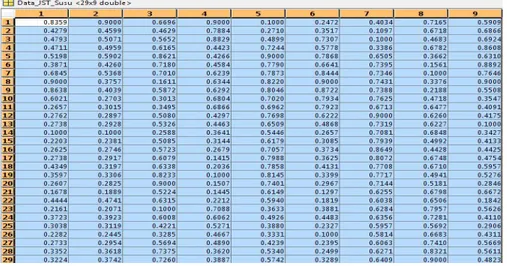
Tabel 2. Data JST untuk peramalan penjualan produk susu
Tabel 3. Data pelatihan JST untuk peramalan penjualan produk susu
X1 X2 X3 X4 X5 X6 X7 X8 Y
Dari 9 sub kelompok data terdapat 29 pola. Kemudian dari 29 pola ini, data dibagi menjadi 2 bagian yaitu 80% (23 pola) digunakan untuk data pelatihan dan 20% (6 pola) digunakan untuk data pengujian.
Pada proses pelatihan dan pengujian ini, sub kelompok data yang ke-9 digunakan sebagai prediktor (validator).
Pada Tabel 3, baris merupakan pola dan kolom (sub kelompok) adalah atribut yang digunakan untuk meramalkan. Delapan sub kelompok data tersebut dalam perhitungan analisis korelasi variabel X1, X2, X3, X4, X5, X7, dan X8 merupakan variabel bebas dan variabel Y merupakan variabel tidak bebas. Pola (epoch) pada penelitian ini adalah data atribut pada bulan Januari 2008 – Mei 2010, sedangkan atributnya adalah volume penjualan produk cup coklat, cup strawberry, prepack, kadar lemak, kadar bahan kering tanpa lemak, total solid, kadar berat jenis dan total plate count. Pada Tabel 4 dapat dilihat bahwa jumlah data pelatihan yang digunakan untuk pembelajaran adalah sebanyak 23 pola, yaitu bulan Januari 2008 – Nopember 2009 dan delapan atribut, yaitu volume penjualan produk cup coklat, cup strawberry, prepack, kadar lemak, kadar bahan kering tanpa lemak, total solid, kadar berat jenis dan total plate count. sedangkan atribut 9, yaitu volume penjualan bulan depan, digunakan sebagai data prediksi dalam proses pembelajaran.
Tabel 4. Data pengujian JST untuk peramalan penjualan produk susu
Pada Tabel 4 dapat dilihat bahwa jumlah data yang digunakan untuk pengujian adalah sebanyak 6 pola, yaitu bulan Desember 2009 –
Mei 2010 dan delapan atribut, yaitu volume penjualan produk cup coklat, cup strawberry, prepack, kadar lemak, kadar bahan kering tanpa lemak, total solid, kadar berat jenis dan total plate count. sedangkan atribut 9, yaitu volume penjualan bulan depan, digunakan sebagai data prediksi dalam proses pengujian.
b. Validasi Data
Validasi data digunakan untuk melihat kemampuan kinerja JST dalam mengenali pola data aktual. Dalam melakukan validasi data ini digunakan data dari hasil pelatihan dan pengujian yang telah dilakukan.
Dari masing-masing kelompok hasil pengujian tingkat pengenalan dihitung dan setelah semua hasil pengujian tingkat pengenalan dihitung maka tingkat pengenalan dari cross validation didapat dari nilai rata-rata dari semua kelompok subdata. Nilai rata-rata ini merupakan total tingkat kesalahan (error) yang diperoleh dari tiap sub kelompok data hasil pengujian tingkat pengenalan. Pada penelitian ini, proses validasi menggunakan metode K-fold cross validation. Metode K-fold cross validation adalah salah satu metode cross validation yang membagi data menjadi k subdata. Salah satu sub bagian data dijadikan sebagai validator dan testing sedangkan K-1 data digunakan sebagai data pelatihan dan pengujian.
B. Model Jaringan Syaraf 1. Arsitektur Jaringan
Arsitektur jaringan merupakan gambaran hubungan antar- lapisan yang digunakan dalam proses pembelajaran. Setiap unit sel pada satu lapisan dihubungkan penuh terhadap sel-sel unit pada lapisan di depannya sehingga akan ditemukan bobot dan bias dari hubungan antar- lapisan tersebut (Hermawan, 2006).
Kelemahan JST yang terdiri dari layar tunggal membuat perkembangan JST menjadi terhenti pada sekitar tahun 1970an.
Penemuan backpropagation yang terdiri dari beberapa layar membuka
cakrawala. Terlebih setelah berhasil ditemukannya berbagai aplikasi yang dapat diselesaikan dengan backpropagation.
Pada penelitian ini digunakan arsitektur jaringan backpropagation. Backpropagation melatih jaringan untuk mendapatkan keseimbangan antara kemampuan jaringan untuk mengenali pola yang digunakan selama pelatihan serta kemampuan jaringan untuk memberikan respon yang benar terhadap pola masukan serupa (tapi tidak sama) dengan pola yang dipakai selama pelatihan.
Gambar 14. Arsitektur jaringan peramalan penjualan produk susu
2. Tahap Pelatihan
Tahap pelatihan dilakukan dengan menggunakan perangkat lunak (software) MATLAB yang telah menyediakan fungsi-fungsi pelatihan pada jaringan syaraf tiruan dengan algoritma perambatan galat mundur (backpropagation). Tahap pelatihan ini menggunakan jaringan layar jamak (multi layer network) dengan dua hidden layer dengan
momentum. Perintah yang dipakai untuk membentuk jaringan syaraf newff yang formatnya adalah sebagai berikut :
net=newff(PR,[S1...SN],{TF1...TFN},BTF,BLF,PF) dengan:
- net = jaringan backpropagation yang terdiri dari n layar
- PR = matriks Rx2 yang berisi nilai minimum dan maksimum R buah elemen masukannya
- Si (i = 1, 2,…,n) = jumlah unit pada layar ke-i (i = 1, 2,…,n) - TFi (i = 1, 2,…,n) = fungsi aktivasi yang digunakan pada layar
ke-i (i = 1, 2,…,n). Default-nya = logsig (sigmoid biner).
- BTF = fungsi training backpropagation. Defaultnya trainrp.
- BLF = fungsi pembelajaran backpropagation bobot dan bias.
Default-nya learngdm.
- PF = fungsi perhitungan performance/error. Default-nya MSE.
Gambar 15. Syntax data pelatihan peramalan penjualan produk susu
Pada Gambar 15, perintah newff membuat model jaringan syaraf net dengan input delapan kolom (atribut) yaitu dari kolom 1 (volume penjualan produk cup coklat sampai kolom 8 (total plate count)), jumlah neuron pada hidden layer 1 berjumlah 30, jumlah neuron pada hidden layer 2 berjumlah 20, dan jumlah neuron pada output layer berjumlah 1 , fungsi aktivasi yang digunakan pada hidden layer 1 dan 2 adalah fungsi aktivasi
sigmoid biner (logsig), fungsi aktivasi yang digunakan pada output layer adalah fungsi aktivasi identitas (pureline).
Dalam menentukan perubahan bobot dan bias pada pelatihan digunakan fungsi learngdm, sedangkan untuk menghitung error digunakan fungsi mse.
Beberapa parameter pelatihan yang diset sebelum dilakukan pelatihan adalah sebagai berikut :
- net.trainParam.show yang digunakan untuk menampilkan frekuensi perubahan mse. Pada penelitian ini, nilai yang diset adalah 5.
- net.trainParam.epoch yang digunakan untuk menentukan jumlah epoch maksimum pelatihan. Satu epoch adalah satu siklus yang melibatkan seluruh pola data training (training pattern). Pada penelitian ini, nilai yang diset adalah 1000.
- net.trainParam.goal yang digunakan untuk menampilkan batas nilai mse agar iterasi dihentikan. Iterasi akan berhenti jika mse lebih kecil daripada batas yang ditentukan dalam net.trainParam.goal atau jumlah epoch mencapai batas yang ditentukan dalam net.trainParam.epoch. Pada penelitian ini, nilai yang diset adalah 0,0001.
- net.trainParam.lr yang digunakan untuk menentukan laju pemahaman.
Proses belajar menjadi sangat lambat jika learning rate yang digunakan terlalu kecil akan tetapi bila learning rate yang digunakan terlalu besar maka proses belajar jaringan akan berisolasi atau menyebar (Suyanto, 2007). Pada penelitian ini, nilai yang diset adalah 0,3.
- net.trainParam.mc yang digunakan untuk menentukan momentum. Pada penelitian ini, nilai yang diset adalah 0,9.
Pada pelatihan ini, digunakan fungsi pelatihan jaringan trainrp.
Penggunaan trainrp karena pada jaringan backpropagation ini menggunakan fungsi aktivasi sigmoid biner. Fungsi sigmoid akan menerima masukan dari range tak berhingga menjadi keluaran pada range [0,1].
Semakin jauh titik dari x = 0 semakin kecil gradiennya. Pada titik yang cukup jauh ini dari x = 0, gradiennya mendekati 0 (Siang, 2009). Hal ini menimbulkan masalah pada waktu menggunakan metode penurunan
tercepat (yang iterasinya didasarkan atas gradien) yang digunakan pada penelitian ini. Gradien yang kecil ini dapat menyebabkan bobot yang kecil, walaupun nilai yang diperoleh masih jauh dari titik optimal. Permasalahan ini dapat diselesaikan dengan cara membagi arah dan perubahan bobot menjadi 2 bagian yang berbeda. Pada saat digunakan metode penurunan tercepat, yang diambil hanya arahnya saja, sedangkan perubahan bobot dilakukan dengan cara lain.
Setelah memasukkan semua parameter pada pelatihan, dilakukan running pada software MATLAB. Gambar berikut adalah hasil pelatihan.
Gambar 16. Hasil pelatihan jaringan syaraf
Pada Gambar 16, diperoleh hasil pelatihan dengan rincian sebagai berikut :
1. Proses pelatihan berhenti pada iterasi ke 122 dari 1000 iterasi yang diinginkan.
2. Waktu untuk mencapai iterasi ke 122 adalah 1 detik.
3. Error yang dihasilkan tercapai dari parameter yang diinginkan, yaitu 0.000101.
4. Gradien yang dihasilkan adalah 0.0039.
Data di atas menunjukkan bahwa parameter yang diinginkan pada proses pelatihan tercapai dan berlangsung cepat. Proses pelatihan yang cepat ini dengan MSE 0.000101 dicapai pada epoch 122 dipengaruhi oleh beberapa faktor. Hal ini disebabkan karena proses pelatihan jaringan dengan algoritma backpropagation standar biasanya lambat. Beberapa hal yang bisa membuat proses belajar jaringan lebih cepat adalah penambahan parameter learning rate dan momentum. Kinerja algoritma selama pelatihan sangat dipengaruhi oleh besarnya laju pemahaman yang dipakai. Proses pelatihan jaringan menjadi sangat lambat jika learning rate yang digunakan terlalu kecil maupun terlalu besar (Suyanto, 2007).
Dalam algoritma backpropagation dengan menggunakan momentum, perubahan bobot didasarkan atas gradien yang terjadi untuk pola yang dimasukkan saat itu. Momentum akan membuat jaringan melakukan penyesuaian bobot yang lebih besar selama koreksinya memiliki arah yang sama dengan pola ada. Sedangkan learning rate yang kecil digunakan untuk mencegah respon yang terlalu besar terhadap error dari satu pola proses belajar.
Tingkat kesalahan galat (error) yang diperoleh pada proses pelatihan ini dicapai dengan waktu 1 detik.
Gambar 17. Grafik peramalan penjualan produk susu
Berdasarkan grafik yang disajikan pada Gambar 17, grafik yang menunjukkan performansi yang terbaik yaitu jaringan dengan arsitektur 8-2-1 dengan learning rate 0,3 dan momentum 0,9. Hasil pelatihan mengalami konvergensi tercepat hanya melalui 122 iterasi dan membutuhkan waktu hanya satu detik. Karena pada grafik tersebut tidak terlihat adanya penurunan yang terlalu lambat dan terlalu cepat (Suyanto, 2007). Hanya pada awal pelatihan dan di pertengahan pelatihan terlihat adanya penurunan yang terlalu cepat. Hal ini disebabkan karena pada fungsi pelatihan digunakan syntax trainrp.
3. Tahap Pengujian dan Validasi
Tahap pengujian dilakukan menggunakan data baru yang belum pernah dilatihkan. Berikut adalah syntax yang digunakan untuk melakukan pengujian dan validasi hasil pengujian.
Gambar 18. Syntax untuk pengujian dan validasi
Pada Gambar 18, terlihat bahwa data yang dimasukkan adalah sebanyak 6 data uji. Hal ini dapat terlihat dengan syntax : X = [1:6].
Syntax B = Data_JST_Susu digunakan untuk memanggil data uji yang merupakan bagian dari Data_JST_Susu. Sedangkan untuk data pengujian digunakan syntax : Y = sim(net, B(24:29, 1:8)’). Hasil dari pengujian ini dapat dilihat pada Tabel 5.
Tabel 5. Hasil pengujian
Setelah proses pengujian dilakukan, hasil pengujian dilakukan proses validasi terhadap data aktual. Proses validasi ini dilakukan untuk
melihat kemampuan kinerja jaringan syaraf tiruan yang dibuat dalam mengenali pola data aktual.
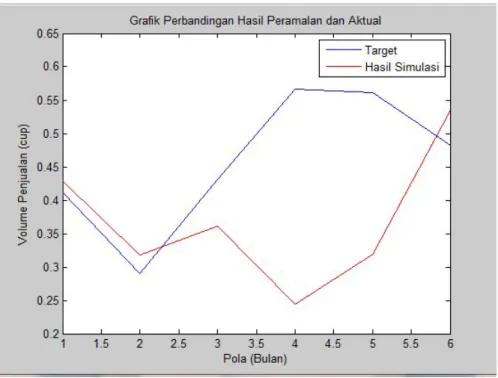
Gambar 19. Grafik hasil validasi
Pada Gambar 19 terlihat bahwa 4 data (67%) sesuai dengan target (data aktual) dan 2 data (33%) tidak sesuai dengan target. Empat data tersebut adalah bulan Desember 2009, Januari 2010, Februari 2010 dan Mei 2010. Hasil ini menunjukkan tingkat kesalahan (error) proses pengujian yang dilakukan dihasilkan nilai yang kecil.
Tabel 6. Perhitungan error Pola
24
Pola 25
Pola 26
Pola 27
Pola 28
Pola
29 Rata-rata ((A-B)2)/6 Aktual (A) 0.4110 0.2916 0.4311 0.5669 0.5611 0.4823
Hasil Uji (B) 0.4286 0.3177 0.3617 0.2436 0.3192 0.5342
MSE (A-B)2 0.0003 0.0007 0.0048 0.1045 0.0585 0.0027 0.0286 Perhitungan error yang digunakan adalah MSE. Pada Tabel 6 disajikan proses perhitungan error berdasarkan hasil peramalan jaringan
syaraf tiruan yang dibandingkan dengan data aktual. Hasil perhitungan error hasil validasi diperoleh MSE = 0.0286. Hal ini menunjukkan kinerja jaringan syaraf tiruan yang dibuat dapat digunakan untuk meramalkan penjualan produk susu.
C. Pelatihan dan Pengujian Dengan Data Yang Lebih Besar
Pada tahap ini digunakan data pelatihan yang lebih besar.
Sedangkan 29 data (pola) sebelumnya digunakan sebagai data untuk pengujian. Data tambahan ini berjumlah 200 (pola) data yang mana data ini akan digunakan untuk pelatihan. Dua ratus data ini diperoleh dari bilangan random dan iterpolasi nilai maksimum dan minimum setiap atribut.
Dikarenakan bilangan pada atribut volume penjualan produk cup coklat, volume penjualan produk cup strawberry, volume penjualan produk prepack merupakan bilangan integer maka dapat dilakukan randomisasi secara langsung. Randomisasi ini dilakukan menggunakan bantuan microsoft excel 2007 dengan memasukkan perintah : randbetween (nilai minimum, nilai maksimum).
Akan tetapi pada bilangan atribut kadar lemak, kadar bahan kering tanpa lemak, total solid, kadar berat jenis dan total plate count bukan merupakan bilangan integer maka harus dilakukan interpolasi untuk mengubah bilangan bukan integer menjadi integer. Proses interpolasi pada dua ratus data ini dilakukan menggunakan bantuan microsoft office excel 2007. Karena dibutuhkan 200 data (pola) bilangan acak maka dilakukan randomisasi bilangan acak dari 200 data (pola). Hal ini dapat dilakukan dengan memasukkan perintah pada microsoft office excel 2007 yaitu randbetween (0,200). Setelah diperoleh bilangan acak dari 0 sampai 200, langkah selanjutnya adalah mencari nilai maksimum dan minimum dari tiap atribut bilangan bukan integer tersebut. Kemudian dicari selisih antara nilai maksimum dan minimum dari tiap atribut bilangan bukan integer tersebut.
Setelah dilakukan interpolasi terhadap dua ratus data tersebut maka langkah selanjutnya adalah melakukan randomisasi. Caranya dihitung dengan persamaan, x = ((bilangan hasil random/200) x selisih)+nilai minimum).
Dua ratus data (pola) ini yang akan digunakan sebagai data untuk pelatihan lebih lanjut.
Proses pelatihan dan pengujian sangat menentukan proses validasi.
Pada penelitian lanjutan ini, proses validasi menggunakan metode K-fold cross validation. Metode K-fold cross validation adalah salah satu metode cross validation yang membagi data menjadi k subdata. Salah satu subbagian data dijadikan sebagai validator dan testing sedangkan K-1 data digunakan sebagai data pelatihan. Proses diatas dilakukan berulang sebanyak K kali untuk setiap subbagian data. Hasil dari pengujian adalah rata-rata dari K kali pengujian pada data tersebut.
Dalam penelitian ini digunakan K-9 fold cross validation. Pada penelitian tahap awal ini terdapat 2061 data awal. Dengan menggunakan K- 9 fold cross validation, 8 sub kelompok data akan digunakan untuk pelatihan dan pengujian dan 1 sub kelompok data digunakan untuk prediktor (validator).
1. Tahap pelatihan
Dari 9 sub kelompok data terdapat 229 pola. Kemudian dari 29 pola ini, data dibagi menjadi 2 bagian yaitu 87% (200 pola) digunakan untuk data pelatihan dan 13% (29 pola) digunakan untuk data pengujian.
Pada proses pelatihan dan pengujian ini, sub kelompok data yang ke-9 digunakan sebagai prediktor (validator).
Pada penelitian lanjutan ini, dua ratus data yang diperoleh secara acak digunakan sebagai data pelatihan. Pada proses pelatihan, terdapat beberapa parameter yang sangat penting, yaitu jumlah neuron pada input layer, hidden layer, output layer, learning rate, momentum, epoch (jumlah iterasi), dan batasan error. Parameter tersebut sangat sensitif dan sulit ditentukan pada awal pelatihan. Sampai saat ini, belum ada formula khusus (standar) yang bisa menemukan jumlah neuron yang optimal pada hidden layer (Suyanto, 2007). Pada penelitian ini, dicoba jumlah input layer 8 node (atribut), hidden layer (2 node), dan output 1 node.
Pada proses pelatihan ini, dalam menentukan arsitektur jaringan optimal dilakukan proses trial dan error terhadap parameter learning rate
dan momentum. Hal ini disebabkan parameter learning rate sangat mempengaruhi proses pelatihan. Proses pelatihan menjadi sangat lambat jika learning rate yang digunakan terlalu kecil akan tetapi bila learning rate yang digunakan terlalu besar maka proses belajar jaringan akan berisolasi atau menyebar (Suyanto, 2007).
Pada penelitian ini, learning rate yang digunakan dimulai dari yang kecil, yaitu 0.005, 0.1, 0.2, 0.3 dan 0.9. Learning rate yang terlalu besar akan mengakibatkan MSE menurun tajam pada awal iterasi, tetapi akan mengakibatkan MSE menjadi berisolasi atau naik turun tidak terkendali. Gambar 20 di bawah ini menunjukkan jaringan dengan learning rate yang besar.
Gambar 20. Perubahan MSE untuk learning rate 0.9
Sebaliknya, learning rate yang terlalu kecil akan mengakibatkan MSE menurun sangat pelan (Suyanto, 2007). Gambar 21 di bawah ini menunjukkan jaringan dengan learning rate yang kecil.
Gambar 21. Perubahan MSE untuk learning rate 0.0001
Permasalahan di atas dapat diminisasi oleh suatu parameter yang dinamakan momentum. Dalam algoritma backpropagation dengan menggunakan momentum, perubahan bobot didasarkan atas gradien yang terjadi untuk pola yang dimasukkan itu. Momentum akan membuat jaringan melakukan penyesuaian bobot yang lebih besar selama koreksinya memiliki arah yang sama dengan pola yang ada. Sedangkan learning rate yang kecil digunakan untuk mencegah respon yang besar terhadap error dari satu pola proses pelatihan. Nilai leaning rate dan momentum yang baik ditentukan dengan cara trial dan error terhadap beberapa nilai learning rate dan momentum. Parameter learning rate dan momentum bernilai antara 0 dan 1.
Pada penelitian ini dilakukan trial dan error terhadap parameter nilai momentum dan learning rate. Nilai learning rate yang diujicobakan pada penelitian ini adalah 0.005, 0.3, 0.2, 0.1 sedangkan nilai momentum yaitu 0.1, 0.6 dan 0.9. Untuk melihat pengaruh parameter terhadap MSE yang dihasilkan, maka penelitian ini dilakukan dengan cara melakukan proses pembelajaran melalui parameter learning rate dan momentum yang berbeda-beda dan dapat dilihat pada Tabel 7di bawah ini.
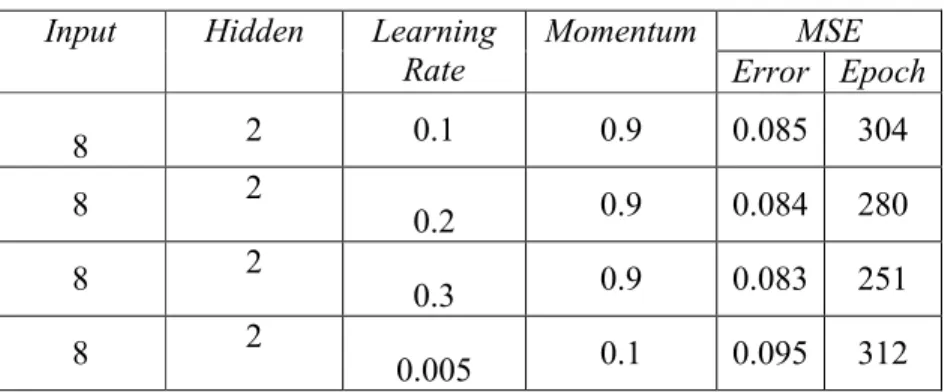
Tabel 7. Penentuan parameter arsitektur jaringan Input Hidden Learning
Rate Momentum MSE
Error Epoch
8 2 0.1 0.9 0.085 304
8 2
0.2 0.9 0.084 280
8 2
0.3 0.9 0.083 251
8 2
0.005 0.1 0.095 312
Dari Tabel 7 dapat diketahui bahwa arsitektur jaringan yang memiliki konfigurasi terbaik adalah nilai learning rate 0.3 dan momentum 0.9. Hal ini menunjukkan bahwa semakin besar nilai learning rate dan momentum maka kemampuan jaringan untuk mencapai nilai error semakin kecil. Grafik hasil pelatihan dengan learning rate 0.3 dan momentum 0.9 dapat dilihat pada Gambar 22.
Gambar 22. Grafik hasil pelatihan dengan learning rate 0.3 dan momentum 0.9
Pada Gambar 22 di atas terlihat bahwa tidak adanya penurunan yang terlalu lambat dan terlalu cepat. Pada awal iterasi saja yang terjadi
penurunan cepat akan tetapi hal itu tidak berlangsung lama. Setelah itu penurunan berlangsung tidak terlalu cepat maupun tidak terlalu lambat.
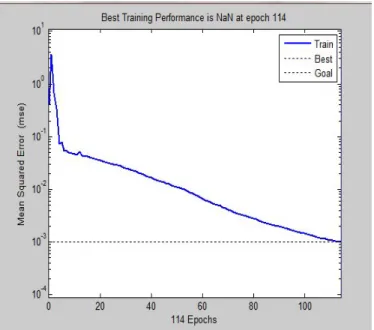
Pelatihan dengan menggunakan learning rate 0.3 dan momentum 0.9 untuk mencapai tingkat kesalahan (error) sama dengan 0.001 dapat dicapai pada iterasi ke-251.
Gambar 23. Hasil Pelatihan dengan learning rate 0.3 dan momentum 0.9 Pada Gambar 23 di atas terlihat bahwa pelatihan dengan learning rate 0.3 dan momentum 0.9 tercapai error 0.001 pada iterasi ke- 251. Dari Tabel 7 juga dapat diketahui bahwa dengan semakin besar nilai learning rate dan momentum maka kemampuan jaringan untuk mencapai nilai error semakin cepat.
2. Tahap Pengujian
Pada tahap pengujian ini, data yang digunakan untuk pengujian adalah data aktual yang diperoleh dari KPBS Pangalengan. Data ini yang akan digunakan untuk menguji hasil pelatihan sebelumnya. Setelah
dilakukan pengujian diperoleh hasil pengujian yang disajikan pada Tabel 8 di bawah ini
Tabel 8. Hasil Pengujian Menggunakan Data yang Lebih Besar
3. Tahap Validasi
Setelah proses pengujian dilakukan, hasil pengujian dilakukan proses validasi terhadap data aktual. Proses validasi ini dilakukan untuk melihat kemampuan kinerja jaringan syaraf tiruan yang dibuat dalam mengenali pola data aktual. Pada tahap validasi ini digunakan metode validasi silang. Validasi silang merupakan suatu metode statistik yang digunakan menganalisa dan mengukur keakuratan hasil percobaan pada data yang independent. Metode validasi silang yang digunakan adalah K- fold cross validation. K-fold cross validation adalah salah satu metode cross validation yang membagi data menjadi k subdata. Perhitungan yang digunakan adalah perhitungan error menggunakan metode means square error (MSE). Pada tahap sebelum dilakukan pelatihan dan pengujian, terdapat 2061 data awal. Dari 2061 data awal dibagi menjadi beberapa sub kelompok data. Dari 2061 data awal dibagi menjadi 9 sub kelompok data dan 229 pola. Dari 9 sub kelompok data tersebut, 8 sub kelompok data digunakan sebagai data pelatihan dan pengujian sedangkan 1 sub kelompok data digunakan sebagai validator.
Gambar 24. Grafik hasil simulasi menggunakan data yang lebih besar Pada Gambar 24 terlihat bahwa 15 data (52%) sesuai dengan target (data aktual). Artinya sesuai dengan data aktual dan 14 data (48%) tidak sesuai dengan target. Dari hasil validasi diperoleh nilai MSE sama dengan 0.083752. Hasil ini menunjukkan tingkat kesalahan (error) proses pengujian yang dilakukan dihasilkan nilai error yang kecil. Akan tetapi jika hasil simulasi menggunakan data pelatihan 200 pola dibandingkan dengan hasil simulasi menggunakan 23 pola, MSE yang dihasilkan lebih besar. Hal ini disebabkan karena data yang digunakan untuk pelatihan merupakan data dari bilangan acak nilai maksimum dan minimum dari 29 pola tiap sub kelompok data.
D. Peramalan Menggunakan Regresi linier
Perhitungan peramalan menggunakan metode regresi linier pada setiap atribut data yaitu variabel bebas (X1, X2, X3, X4, X5, X6, X7, X8) terhadap variabel tidak bebas (Y) diperoleh nilai error yang sangat besar yaitu 1.0365190091460. Hasil error ini sangat jauh berbeda jika dibandingkan dengan error menggunakan peramalan JSPB yaitu sebesar 0.0286. Dengan demikian dalam menyelesaikan permasalahan peramalan yang sulit dimodelkan sehingga dapat diperoleh error yang kecil lebih baik menggunakan JSPB dibandingkan menggunakan metode regresi linier.