ILMU KOMPUTER
Volume 5 Nomor 2 September 2012
Daftar Isi :
PERANCANGAN DAN IMPLEMENTASI AUTOMATED DOCUMENT INTEGRATION DENGAN MENGGUNAKAN ALGORITMA COMPLETE LINKAGE AGGLOMERATIVE HIERARCHICAL CLUSTERING ... 1 Gede Aditra Pradnyana, Ngurah Agus Sanjaya ER
SISTEM PENDUKUNG KEPUTUSAN DALAM PEMILIHAN TEMPAT KOST DENGAN METODE PEMBOBOTAN ( STUDI KASUS : SLEMAN YOGYAKARTA) ... 11 I Wayan Supriana
SISTEM TUTORIAL MATEMATIKA DISKRET DALAM MENUNJANG PROSES BELAJAR BERBASIS KOMPETENSI ... 17 I Gede Santi Astawa
PENENTUAN KOMPOSISI BAHAN PAKAN IKAN LELE YANG OPTIMAL DENGAN MENGGUNAKAN METODE IWO-SUBTRACTIVE CLUSTERING ... 22 Agus Muliantara
SISTEM PENGAMANAN DATA SIDIK JARI MENGGUNAKAN ALGORITMA AES PADA SISTEM KEPENDUDUKAN BERBASIS RADIO FREQUENCY IDENTIFICATION (RFID) ... 29 I Gede Andika Putra,I Made Widhi Wirawan
PENINGKATAN RELEVANSI HASIL PENCARIAN KATA KUNCI DENGAN PENERAPAN MODEL RUANG VEKTOR PADA SISTEM INFORMASI RUANG BACA DI JURUSAN ILMU KOMPUTER UNIVERSITAS UDAYANA ... 36 Ngurah Agus Sanjaya, Agus Muliantara, I Made Widiartha
A CASE STUDY OF IT IMPLEMENTATION IN PUBLIC UNIVERSITY : IT’S BARRIERS AND CHALLANGES ... 43 I Made Agus Setiawan
JURUSAN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS UDAYANA
SUSUNAN DEWAN REDAKSI JURNAL ILMU KOMPUTER
Jurusan Ilmu Komputer
Fakultas Matematika dan Ilmu Pengetahuan Alam
Universitas Udayana
Ketua
Agus Muliantara, S.Kom, M.Kom
Penyunting
Drs. Wayan Santiyasa, M.Si
Ngurah Agus Sanjaya, S.Kom, M.Kom
Cokorda Rai Adi Paramarta, S.T, M.M
Ida Bagus Gede Dwidasmara, S.Kom.M.Cs
Penyunting Tamu
Imas Sitanggang, S.Si, M.Kom (IPB)
Ir. A.A. Gede Raka Dalem, M.Sc (Hons)
Prof. Pieter Hartel (Twente University)
Pelaksana
I Made Widiartha, S.Si, M.Kom
Dra. Luh Gede Astuti, M.Kom
Gede Santi Astawa, ST, M.Cs
Ida Bagus Mahendra, S.Kom, M.Kom
Alamat Redaksi
Jurusan Ilmu Komputer
Fakultas Matematika dan Ilmu Pengetahuan Alam
Universitas Udayana
Kampus Bukit Jimbaran
–
Badung
Telpon. 0361
–
701805
Email : [email protected]
Website : www.cs.unud.ac.id
ISSN : 1979-5661 -1-
PERANCANGAN DAN IMPLEMENTASI AUTOMATED DOCUMENT INTEGRATION DENGAN MENGGUNAKAN ALGORITMA COMPLETE LINKAGE AGGLOMERATIVE
HIERARCHICAL CLUSTERING
Gede Aditra Pradnyana1, Ngurah Agus Sanjaya ER2 Program Studi Teknik Informatika, Jurusan Ilmu Komputer
Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Udayana
Email : [email protected], [email protected]
ABSTRAK
Salah satu cara yang umum digunakan untuk memperoleh informasi adalah dengan membaca beberapa dokumen yang membahas topik yang sama. Walaupun cara ini merupakan yang paling mudah namun pada pelaksanaannya banyak menghabiskan waktu. Penggunaan suatu sistem
automated document integration yang membantu menemukan kalimat penting dari masing-masing
dokumen akan menghemat waktu serta tenaga yang diperlukan. Keluaran dari sistem yang dikembangkan dalam penelitian ini adalah suatu dokumen yang dibentuk dari integrasi (cluster) kalimat-kalimat dari dokumen asli.
Kesamaan dokumen yang akan diintegrasikan ditentukan oleh cosine similarity. Sistem kemudian menghitung TF-IDF (term frequency-inverse document frequency) masing-masing kalimat pada dokumen. TF-IDF merupakan bobot dari suatu kalimat yang mencerminkan tingkat kepentingan dari kalimat pada suatu dokumen serta terhadap kalimat-kalimat lain pada dokumen yang berbeda. Kalimat-kalimat yang memiliki kesamaan yang tinggi kemudian digabungkan secara agglomerative
hierarchical menggunakan metode complete linkage. Hasil uji coba memperlihatkan 75% responden
menyatakan keluaran sistem adalah benar.
Kata kunci: automated document integration, complete linkage agglomerative hierarchical clustering, cosine similarity
ABSTRACT
A common way of gaining knowledge or information is by reading through documents which discuss the same topic. Despite being the easiest method to implement, it requires a lot of time and effort. Thus, the use of an automated text integration system which serves in finding important sentences from each original document, greatly reduces the time and effort needed. The research output which implements this system is a new document constructed from clustered sentences in the original documents.
The similarities of documents to be clustered is determined by using the cosine similarity. The system further calculates the TF-IDF (Term Frequency-Inverse Document Frequency) of each sentence in the documents. The TF-IDF serves as a weight of the sentence in a document to describe how important it is in comparison with other sentences in different documents. Sentences with high similarities are then clustered in an agglomerative hierarchical way using a complete linkage method. Experimental results show that 75% of respondents confirm that the output is correct.
Keywords: automated document integration, complete linkage agglomerative hierarchical clustering, cosine similarity
1. PENDAHULUAN
Perkembangan teknologi informasi yang semakin pesat dewasa ini membuat para
ISSN : 1979-5661 -2- informasi sehingga informasi yang beredar pun semakin banyak. Salah satu cara untuk memperoleh informasi adalah dengan membaca beberapa dokumen yang pada kenyataannya banyak membahas topik yang sama. Namun hal ini akan sangat menyulitkan pembaca untuk menangkap topik bahasan utama dari dokumen-dokumen tersebut karena harus mengingat isi dokumen yang telah dibaca sebelumnya. Pembaca harus mengintegrasikan dahulu dokumen-dokumen yang dia baca di dalam pikirannya sebelum dapat merangkum maksud dan topik utama dokumen-dokumen tersebut secara keseluruhan. Selain itu, seringkali ada pembaca yang tidak ingin membaca seluruh dokumen tersebut karena faktor waktu yang dibutuhkan terlalu lama atau adanya keterbatasan waktu.
Seiring berkembangnya teknologi informasi, maka saat ini telah diperoleh suatu solusi yang memungkinkan pembaca dapat membuat integrasi dari beberapa dokumen tersebut menjadi suatu kesatuan dokumen dengan mudah. Maksud dari integrasi dokumen disini adalah sebuah proses untuk menghasilkan suatu dokumen baru dari beberapa dokumen dengan menggunakan bantuan komputer, tanpa menghilangkan arti dan bagian-bagian penting dari tiap dokumen tersebut. Tujuan dari integrasi dokumen ini adalah untuk mengambil sumber informasi dengan memperhatikan sebagian besar bagian-bagian berupa kalimat-kalimat yang penting dari setiap dokumen yang berbeda dan menampilkan kepada pembaca dalam bentuk suatu dokumen baru yang sesuai dengan kebutuhan pembaca. Setelah melalui proses ini, diharapkan pembaca dapat terbantu dalam menyerap informasi penting yang ada dalam kumpulan dokumen yang berbeda dengan topik bahasan yang sama, karena pembaca tidak perlu lagi membaca kumpulan dokumen satu per satu. Proses integrasi dokumen ini akan menghasilkan suatu produk teks yang memiliki atau mengandung semua bagian penting dari dokumen-dokumen awal, namun memiliki susunan antar kalimat atau antar paragraf yang berbeda.
Adapun algoritma yang digunakan dalam proses integrasi dokumen ini adalah
agglomerative hierarchical clustering dengan
metode complete linkage. Agglomerative
hierarchical clustering adalah suatu metode
hierarchical clustering yang bersifat
bottom-up yaitu menggabungkan n buah cluster
(beberapa dokumen) menjadi satu cluster
tunggal (sebuah dokumen hasil integrasi).
Agglomerative hieararchical clustering
merupakan metode yang umum digunakan dalam clustering dokumen dan memiliki beberapa kelebihan, antara lain : tidak memperhitungkan initial centroid sehingga tepat digunakan dalam proses pengelompokan dokumen dan kinerja information retrieval
berbasis hierarchical clustering memiliki hasil yang lebih baik jika dibandingkan dengan metode partitional clustering (Hamzah, 2009). Algoritma agglomerative hierarchical
clustering dengan metode complete linkage
memiliki hasil clustering yang lebih baik dibandingkan dengan metode linkage yang lainnya (Soebroto, 2005).
Dalam proses clustering, kesamaan antara satu dokumen dengan dokumen yang lain diukur dengan fungsi kesamaan
(similarity) tertentu. Dalam sistem automated
document integration ini digunakan algoritma
cosine similarity dalam pengukuran kesamaan
antar dokumen. Sebelum proses clustering
dilakukan, suatu dokumen akan melalui proses
parsing, stemming, dan pembobotan kalimat
(TF – IDF) serta pembobotan relasi antar
kalimat. Proses stemming dilakukan dengan menggunakan algoritma porter stemmer for
Bahasa Indonesia.
2. TINJAUAN PUSTAKA
2.1 Complete Linkage Agglomerative Hierarchical Clustering
Salah satu kategori algoritma clustering yang banyak dikenal adalah hierarchical clustering.
Hierarchical clustering merupakan salah satu
algoritma clustering yang fungsinya dapat digunakan untuk pengelompokkan dokumen
(document clustering). Dari teknik
hierarchical clustering, dapat dihasilkan suatu
kumpulan partisi yang berurutan, dimana dalam kumpulan tersebut terdapat :
Cluster-cluster yang mempunyai
poin-poin individu. Cluster-cluster ini berada di level yang paling bawah.
Sebuah cluster yang didalamnya terdapat poin-poin yang dipunyai semua cluster didalamnya. Single
cluster ini berada di level yang paling
ISSN : 1979-5661 -3- Dalam algoritma hierarchical clustering, cluster yang berada di level yang lebih atas
(intermediate level) dari cluster yang lain
dapat diperoleh dengan cara mengkombinasikan dua buah cluster yang berada pada level dibawahnya. Hasil keseluruhan dari algoritma hierarchical
clustering secara grafik dapat digambarkan
sebagai tree, yang disebut dengan dendogram
(Tan, 2006).
Pada algoritma agglomerative
hierarchical clustering ini, proses hierarchical
clustering dimulai dari cluster-cluster yang
memiliki poin-poin individu yang berada di level paling bawah. Pada setiap langkahnya, dilakukan penggabungan sebuah cluster
dengan cluster lainnya, dimana cluster-cluster
yang digabungkan berada saling berdekatan atau mempunyai tingkat kesamaan yang paling tinggi (Tan, 2006).
Salah satu metode yang digunakan dalam Agglomerative Hierarchical Clustering
adalah Complete linkage (furthest neighbor
methods). Complete Linkage adalah suatu
metode yang menggunakan prinsip jarak minimum yang diawali dengan mencari jarak terjauh antar dua buah cluster dan keduanya membentuk cluster baru. Pada awalnya, dilakukan perhitungan jarak terpendek dalam
D = {dik} dan menggabungkan objek-objek yang bersesuaian misalnya, U dan V , untuk mendapatkan cluster (UV). Kemudian jarak-jarak antara (UV) dan cluster W yang lain dihitung dengan cara :
d(UV)W = max{duw , dvw}
2.2 Algoritma Cosine Similarity
Metode Cosine Similarity merupakan metode yang digunakan untuk menghitung
similarity (tingkat kesamaan) antar dua buah
objek. Secara umum penghitungan metode ini didasarkan pada vector space similarity
measure. Metode cosine similarity ini
menghitung similarity antara dua buah objek (misalkan D1 dan D2) yang dinyatakan dalam dua buah vektor dengan menggunakan
keywords (kata kunci) dari sebuah dokumen
sebagai ukuran.
Metode pengukuran kesesuaian ini memiliki beberapa keuntungan, yaitu adanya normalisasi terhadap panjang dokumen. Hal ini memperkecil pengaruh panjang dokumen. Jarak euclidean (panjang) kedua vektor digunakan sebagai faktor normalisasi. Hal ini
diperlukan karena dokumen yang panjang cenderung mendapatkan nilai yang besar dibandingkan dengan dokumen yang lebih pendek.
Perhitungan cosine similarity yang memperhitungkan perhitungan pembobotan kata pada suatu dokumen dapat dinyatakan dengan perumusan :
)
,
(
d
iq
iCosSim
t j ij t j ij t j ij ij i i i id
q
d
q
d
q
d
q
1 2 1 2 1.
)
.
(
Keterangan :qij = bobot istilah j pada dokumen i = tfij * idfj
dij = bobot istilah j pada dokumen i = tfij * idfj
2.3 Proses Parsing dan Stemming
Parsing adalah sebuah proses untuk
membuat sebuah kalimat menjadi lebih bermakna. Hal ini dilakukan dengan cara memecah kalimat tersebut menjadi kata-kata atau frase-frase (Budhi, 2005). Proses parsing
merupakan proses penguraian dokumen yang semula berupa kalimat-kalimat berisi kata-kata dan tanda pemisah antar kata seperti titik (.), koma (,), spasi dan tanda pemisah lain menjadi kata-kata saja.
Stemming merupakan suatu proses
yang terdapat dalam sistem IR (Information
Retrieval) yang mentransformasi kata-kata
yang terdapat dalam suatu dokumen ke kata-kata akarnya (root word) dengan menggunakan aturan-aturan tertentu untuk meningkatkan kualitas informasi yang didapatkan (Agusta, 2009). Proses tersebut akan menghilangkan imbuhan yang terkandung dalam suatu kata yang diproses. Sebagai contoh, kata bersama, kebersamaan, menyamai, setelah melaui proses stemming
akan menjadi kata “sama”. Proses ini akan mendukung tingkat ketelitian dalam perhitungan daftar keyword pada proses berikutnya. Algoritma stemming untuk Bahasa Indonesia yang dikenal antara lain Algoritma Porter Stemmer dan Algoritma Nazief & Adriani. Porter Stemmer for Bahasa Indonesia
dikembangkan oleh Fadillah Z. Tala pada tahun 2003. Implementasi Porter Stemmer for
Bahasa Indonesia berdasarkan English Porter
Stemmer yang dikembangkan oleh W.B.
ISSN : 1979-5661 -4- 2.4 Proses Stopword Removal
Kebanyakan bahasa resmi di berbagai negara memiliki kata fungsi dan kata sambung seperti preposisi dan kata hubung yang hampir selalu muncul pada dokumen-dokumen teks. Kata-kata ini umumnya tidak memiliki arti yang lebih untuk memenuhi kebutuhan seorang searcher dalam mencari informasi. Kata-kata tersebut (misalnya a, an, the, on
pada bahasa Inggris) yang disebut sebagai kata tidak penting misalnya “di”, “oleh”, “pada”, “sebuah”, “karena”, dan kata sambung lainnya. Sebelum proses stopword removal dilakukan, terlebih dulu dibuat daftar stopword(stoplist). Preposisi, kata hubung dan partikel biasanya merupakan kandidat stoplist. Stopword
removal merupakan proses penghilangan kata
tidak penting pada suatu dokumen, melalui pengecekan kata-kata hasil stemmer dokumen tersebut apakah termasuk kata di dalam daftar kata tidak penting (stoplist) atau tidak
2.5 Perhitungan Bobot Kalimat dan Bobot Relasi Antar Kalimat
2.5.1 TF-IDF (Terms Frequency-Inverse Document Frequency )
Metode ini merupakan metode untuk menghitung nilai/bobot suatu kata (term) pada dokumen. Metode ini akan mengabaikan setiap kata-kata yang tergolong tidak penting. Oleh sebab itu, sebelum melalukan metode ini, proses stemming dan stopword removal harus dilakukan terlebih dahulu oleh sistem. Karena melakukan pembobotan suatu kalimat bukan kata, pada metode ini terdapat 5 proses yang berbeda untuk perhitungan nilai suatu kalimat, yaitu (Budhi, 2008):
1. Kecocokan kata-kata pada kalimat dengan daftar kata kunci/keyword. Idenya adalah semakin tinggi nilai suatu kalimat, maka kalimat tersebut semakin penting keberadaannya di dalam suatu dokumen.
2. Menghitung frekuensi kata-kata suatu kalimat terhadap keseluruhan dokumen dan hasilnya akan dibagi dengan jumlah kata pada dokumen tersebut.
3. Bagian ketiga ini sangat sederhana yaitu hanya melihat posisi kalimat di dalam suatu paragraf. Berdasarkan metode deduktif
induktif sesuai kaidah Bahasa Indonesia, ide pokok suatu paragraf terdapat pada kalimat yang berada di awal dan atau akhir dari paragraf tersebut.
4. Bagian keempat ini sangat berhubungan dengan hasil pemetaan dokumen. Pada bagian keempat ini akan dihitung jumlah relasi (yang disimbolkan dengan
edge) suatu kalimat di dalam dokumen. Idenya adalah semakin banyak relasi yang dimiliki suatu kalimat dengan kalimat lainnya di dalam suatu dokumen maka kalimat tersebut kemungkinan mendiskusikan topik utama suatu dokumen.
5. Bobot kelima ini merepresentasikan seberapa penting sebuah kalimat dibandingkan dengan kalimat-kalimat lain yang terdapat pada semua dokumen yang akan diintegrasikan.
Setelah mendapatkan hasil dari kelima bobo diatas, selanjutnya nilai tf akan dihitung dengan persamaan berikut:
tf = bobot1 + bobot2 + bobot3 + bobot4 + bobot5 Faktor lain yang diperhatikan dalam pemberian bobot adalah kejarangmunculan kalimat (sentence scarcity) dalam koleksi. Kalimat yang muncul pada sedikit dokumen harus dipandang sebagai kata yang lebih penting (uncommon sentences) daripada kalimat yang muncul pada banyak dokumen. Pembobotan akan memperhitungkan faktor kebalikan frekuensi dokumen yang mengandung suatu kalimat (inverse document frequency).
Nilai dari tf akan dikalikan dengan nilai idf seperti pada persamaan dibawah ini (Intan, 2005):
Keterangan :
ISSN : 1979-5661 -5-
tf = jumlah kemunculan kata/term dalam dokumen
N= jumlah semua dokumen yang ada dalam database
n= jumlah dokumen yang mengandung kata/term
idf = inverse document frequency
2.5.3 Perhitungan Bobot Edge
Untuk perhitungan bobot edge akan digunakan persamaan berikut (Sjobergh, 2005) :
Nilai overlap i,j diperoleh dengan
menghitung jumlah kata yang sama antara kalimat ke-i dan kalimat ke-j dengan mengabaikan stopword yang ada di dalam kalimat-kalimat tersebut. Kemudian hasil dari persamaan diatas akan digunakan untuk menentukan nilai relasi dari setiap kalimat berdasarkan hasil pemetaan dari dokumen.
3. DESAIN AUTOMATED DOCUMENT INTEGRATION SYSTEM
Tahap awal yang dilakukan dalam pengembangan sistem adalah penentuan input, proses, dan output dari sistem yang akan dibuat. Input – input yang masuk dan akan diproses dalam sistem dapat dibagi menjadi 2 bagian yaitu :
1. Penentuan input sistem yang berupa kumpulan dokumen yang akan diintegrasikan. Dokumen disini berperan sebagai suatu kumpulan data-data mentah yang akan dijadikan objek pada penelitian ini. Dokumen berupa artikel-artikel mengenai teknologi informasi dalam Bahasa Indonesia dengan format file PDF. 2. Penentuan input yang kedua adalah
input dari user yang berupa nilai toleransi kesamaan antar dokumen yang akan diintegrasikan ( similarity
tolerance value ) ke sistem.
Setelah melakukan teknik kajian pustaka pada tahap sebelumnya, secara garis besar proses-proses yang ada pada sistem dapat dibagi ke dalam dua subsistem yaitu : 1. Subsistem Pre-Integration
Proses – proses yang ada pada subsistem ini adalah :
a. Proses upload dokumen ke dalam sistem.
b. Proses konversi dokumen dengan format file PDF menjadi file txt. c. Proses devide to word atau
parsing yaitu proses yang
memecah kalimat-kalimat dalam file txt menjadi kata-kata.
d. Proses stopword removal atau menghilangkan kata-kata tidak penting.
e. Proses stemming dengan algoritma Porter Stemmer for Bahasa Indonesia.
f. Proses perhitungan kesamaan dokumen dengan algoritma
Cosine Similarity.
2. Subsistem Integration Process
Proses – proses yang ada pada subsistem ini adalah :
a. Proses perhitungan bobot kalimat dengan metode TF-IDF.
b. Proses perhitugan bobot relasi antar kalimat.
c. Proses clustering dengan algoritma Complete Linkage
Agglomerative Hierarchical
Clustering
Pada proses integrasi dengan algoritma agglomerative hierarchical
clustering, awalnya semua kalimat yang
terdapat dalam tabel kalimat dianggap sebagai
atomic cluster – atomic cluster. Langkah
pertama yang dilakukan adalah mencari cluster-cluster dengan jarak terdekat, atau pasangan kalimat yang memiliki bobot relasi antar kalimat yang paling kecil. Pencarian dilakukan dengan menggunakan perintah
query select yang mengurutkan data-data pada
tabel kalimat_relasi secara ascending
berdasarkan bobot relasinya. Langkah selanjutnya adalah melakukan update jarak
cluster yang baru terbentuk dengan
cluster-cluster lainnya dengan metode maximum
distance. Setelah semua kalimat telah
ISSN : 1979-5661 -6- Asumsinya, bila secara natural kalimat – kalimat tersebut bergabung, dapat dianggap kalimat – kalimat tersebut memiliki similarity
yang cukup tinggi dan membahas topik bahasan yang sama. Sementara untuk memproses kalimat – kalimat tersisa yang tidak mau bergabung kedalam cluster – cluster
besar, dipakai aturan sebagai berikut:
Bila hanya 1 kalimat akan digabungkan pada paragraf terakhir.
Bila lebih dari satu kalimat, kalimat – kalimat yang tersisa tersebut akan dipaksakan bergabung menjadi satu paragraf tersendiri.
Sementara, Output-output yang dihasilkan sistem melalui pemrosesan input dari user adalah :
a. Report tingkat kesamaan antar
dokumen yang akan diintegrasikan. b. Dokumen hasil proses integrasi yang
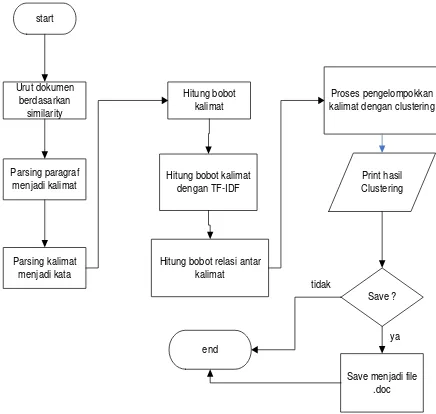
dapat disimpan dalam format file .doc. Berikut ini adalah gambar rancangan alur pada subsistem Integration secara garis besar :
start
Parsing paragraf menjadi kalimat
Parsing kalimat menjadi kata
Hitung bobot kalimat
Hitung bobot kalimat dengan TF-IDF Urut dokumen
berdasarkan similarity
Hitung bobot relasi antar kalimat
Proses pengelompokkan kalimat dengan clustering
Print hasil Clustering
Save ?
Save menjadi file .doc end
ya tidak
Gambar 1. Perancangan Alur pada Subsistem
Integration
4. PENGUJIAN SISTEM
4.1 Pengujian Sistem dengan White Box
Pengujian white box yang digunakan dalam pembuatan automated document integration system ini adalah pengujian basis
path. Pengujian tersebut ditujukan untuk
mencari path-path yang dilalui saat program
dijalankan. Pengujian basis path pada penelitian ini difokuskan pada proses perhitungan bobot relasi antar kalimat dan proses integrasi dengan algoritma complete
linkage agglomerative hierarchical clustering.
Alur logika dari sistem diujicoba dengan menyediakan kasus ujicoba yang melakukan semua kondisi atau perulangan yang ada pada sistem. Dimana setelah melakukan pengujian, setiap path yang ada dalam tiap proses dapat dijalan dengan baik.
4.2 Pengujian Proses Integrasi
Pengujian terhadap proses integrasi dilakukan dengan membandingkan proses integrasi dengan perhitungan manual dan dengan sistem. Dokumen yang dipergunakan adalah dokumen dengan judul Data Mining 1
dan Data Mining 2. Pada akhir pengujian
didapatkan hasil bahwa hasil integrasi secara manual menghasilkan dokumen yang sama dengan dokumen yang diintegrasikan oleh sistem. Berikut ini adalah contoh dokumen yang akan diintegrasikan dengan automated
document integration system.
“Data Mining 1”
Data Mining memang salah satu cabang ilmu komputer yang relatif baru. Dan sampai sekarang orang masih memperdebatkan untuk menempatkan data mining di bidang ilmu mana, karena data mining menyangkut database, kecerdasan buatan (artificial intelligence), statistik, dsb. Ada pihak yang berpendapat bahwa data mining tidak lebih dari machine learning atau analisa statistik yang berjalan di atas database. Namun pihak lain berpendapat bahwa database berperanan penting di data mining karena data mining mengakses data yang ukurannya besar (bisa sampai terabyte) dan disini terlihat peran penting database terutama dalam optimisasi query-nya.
ISSN : 1979-5661 -7- transaksi yang dimasukkan oleh hypermarket semacam Carrefour atau transaksi kartu kredit dari sebuah bank dalam seharinya dan bayangkan betapa besarnya ukuran data mereka jika nanti telah berjalan beberapa tahun. Pertanyaannya sekarang, apakah data tersebut akan dibiarkan menggunung, tidak berguna lalu dibuang, ataukah kita dapat menambangnya untuk mencari emas, berlian yaitu informasi yang berguna untuk organisasi kita. Banyak diantara kita yang kebanjiran data tapi miskin informasi.
“Data Mining 2”
Data Mining (DM) adalah salah satu bidang yang berkembang pesat karena besarnya kebutuhan akan nilai tambah dari database skala besar yang makin banyak terakumulasi sejalan dengan pertumbuhan teknologi informasi. Definisi umum dari DM itu sendiri adalah serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data. Dalam review ini, penulis mencoba merangkum perkembangan terakhir dari teknik-teknik DM beserta implikasinya di dunia bisnis.
Perkembangan data mining(DM) yang pesat tidak dapat lepas dari perkembangan teknologi informasi yang memungkinkan data dalam jumlah besar terakumulasi. Sebagai contoh, toko swalayan merekam setiap penjualan barang dengan memakai alat POS(point of sales). Database data penjualan tsb. bisa mencapai beberapa GB setiap harinya untuk sebuah jaringan toko swalayan berskala nasional. Perkembangan internet juga punya andil cukup besar dalam akumulasi data.
Tetapi pertumbuhan yang pesat dari akumulasi data itu telah menciptakan kondisi yang sering disebut sebagai “rich of data but poor of information” karena data yang terkumpul itu tidak dapat digunakan untuk aplikasi yang berguna. Tidak jarang kumpulan data itu dibiarkan begitu saja seakan-akan “kuburan data” (data tombs).
Hasil dari proses integrasi kedua dokumen diatas adalah sebagai berikut :
Kehadiran data mining dilatar belakangi dengan problema data explosion yang dialami akhir-akhir ini dimana banyak
organisasi telah mengumpulkan data sekian tahun lamanya (data pembelian, data penjualan, data nasabah, data transaksi dsb). Hampir semua data tersebut dimasukkan dengan menggunakan aplikasi komputer yang digunakan untuk menangani transaksi sehari-hari yang kebanyakan adalah OLTP (On Line Transaction Processing). Bayangkan berapa transaksi yang dimasukkan oleh hypermarket semacam Carrefour atau transaksi kartu kredit dari sebuah bank dalam seharinya dan bayangkan betapa besarnya ukuran data mereka jika nanti telah berjalan beberapa tahun.
Pertanyaannya sekarang, apakah data tersebut akan dibiarkan menggunung, tidak berguna lalu dibuang, ataukah kita dapat menambangnya untuk mencari emas, berlian yaitu informasi yang berguna untuk organisasi kita. Banyak diantara kita yang kebanjiran data tapi miskin informasi.
Dan sampai sekarang orang masih memperdebatkan untuk menempatkan data mining di bidang ilmu mana, karena data mining menyangkut database, kecerdasan buatan (artificial intelligence), statistik, dsb. Ada pihak yang berpendapat bahwa data mining tidak lebih dari machine learning atau analisa statistik yang berjalan di atas database. Namun pihak lain berpendapat bahwa database berperanan penting di data mining karena data mining mengakses data yang ukurannya besar (bisa sampai terabyte) dan disini terlihat peran penting database terutama dalam optimisasi query-nya. Data Mining memang salah satu cabang ilmu komputer yang relatif baru.
Tetapi pertumbuhan yang pesat dari akumulasi data itu telah menciptakan kondisi yang sering disebut sebagai “rich of data but poor of information” karena data yang terkumpul itu tidak dapat digunakan untuk aplikasi yang berguna. Tidak jarang kumpulan data itu dibiarkan begitu saja seakan-akan “kuburan data” (data tombs). Perkembangan internet juga punya andil cukup besar dalam akumulasi data.
ISSN : 1979-5661 -8- yang selama ini tidak diketahui secara manual dari suatu kumpulan data. Dalam review ini, penulis mencoba merangkum perkembangan terakhir dari teknik-teknik DM beserta implikasinya di dunia bisnis. Perkembangan data mining(DM) yang pesat tidak dapat lepas dari perkembangan teknologi informasi yang memungkinkan data dalam jumlah besar terakumulasi. Sebagai contoh, toko swalayan merekam setiap penjualan barang dengan memakai alat POS(point of sales). Database data penjualan bisa mencapai beberapa GB setiap harinya untuk sebuah jaringan toko swalayan berskala nasional.
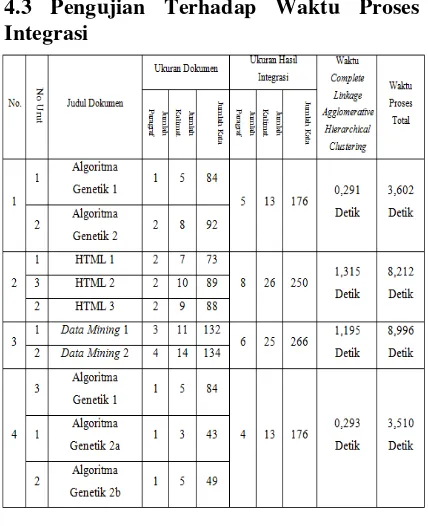
4.3 Pengujian Terhadap Waktu Proses Integrasi
Tabel 1. Hasil Pengujian Waktu
Untuk mendapatkan hasil uji coba yang terbaik mengenai lama proses clustering
dan proses integrasi keseluruhan yang dilakukan sistem maka perlu dilakukan uji coba terhadap berbagai dokumen yang beda. Dari dokumen yang berbeda-beda tersebut yang perlu diperhatikan adalah dari segi jumlah dokumen yang diintegrasi, jumlah paragraf dari setiap dokumen asli, dan jumlah kalimat dari setiap dokumen asli. Pengujian waktu proses ini diujikan dengan keadaan hardware dan software sebagai berikut : Processor Intel Pentium Dual Core
T2390 1,86 Ghz, RAM 1 GB. Hasil pengujian
sistem terhadap waktu dapat dilihat pada tabel 1.
4.4 Evaluasi Relevansi Sistem
Pengujian ini dilakukan dengan cara meminta bantuan 100 orang responden yang merupakan mahasiswa Jurusan Ilmu Komputer Universitas Udayana untuk membaca dokumen – dokumen asal yang berjenis eksposisi dan narasi serta membaca dokumen hasil integrasi, kemudian menjawab 3 pertanyaan berikut:
1) Menurut anda, apakah kata-kata pada dokumen hasil integrasi tersebut telah terorganisir dengan baik (tiap paragraf memberikan arti yang jelas dan dapat dipahami) ? A. Ya B. Tidak
2) Menurut anda, apakah dokumen hasil integrasi tersebut telah memberikan gambaran secara umum dari keseluruhan dokumen yang ada sebelumnya ? A. Ya B. Tidak
3) Menurut anda, apakah dokumen hasil integrasi dapat memberikan informasi - informasi penting yang terdapat pada dokumen sebelumnya secara jelas? A. Ya B. Tidak
Berdasarkan hasil survei relevansi didapatkan kesimpulan bahwa sistem akan bekerja lebih baik pada dokumen yang bertipe eksposisi dibandingkan dengan dokumen yang bertipe narasi. Dimana lebih dari 75 persen mengatakan bahwa hasil integrasi dokumen yang bertipe eksposisi dapat mewakili dokumen asli, memiliki susunan antar paragraf yang jelas, dan tetap mengandung informasi penting dari dokumen awal.
5. KESIMPULAN DAN SARAN 5.1 Kesimpulan
Secara umum sistem automated
document integration dapat dibagi
menjadi dua subsistem yaitu subsistem
pre-integration dan subsistem
integration. Adapun proses yang
termasuk dalam subsistem
pre-integration adalah proses devide to
ISSN : 1979-5661 -9- yang sebelumnya didahului dengan proses pembobotan kalimat dengan metode TF-IDF(term
frequency-inverse document frequency) dan
pembobotan relasi antar kalimat.
Hasil dari pengujian terhadap waktu dari proses integrasi dan proses
hierarchical clustering, menunjukkan
bahwa semakin banyak dokumen paragraf dan kalimat yang yang diproses maka akan membutuhkan
running time yang semakin besar pula.
Berdasarkan hasil survei relevansi sistem kepada 100 orang responden, didapatkan kesimpulan bahwa sistem akan bekerja lebih baik pada dokumen yang bertipe eksposisi dibandingkan dengan dokumen yang bertipe narasi. Dimana lebih dari 75 persen mengatakan bahwa hasil integrasi dokumen yang bertipe eksposisi dapat mewakili dokumen asli, memiliki susunan antar paragraf yang jelas, dan tetap mengandung informasi penting dari dokumen awal.
5.2 Saran
Sistem automated document
integration memiliki kelemahan dalam
menentukan urutan dokumen yang diintegrasi. Dalam sistem automated
document integration ini urutan
dokumen ditentukan berdasarkan tingkat kesamaannya dengan metode
cosine similarity. Padahal cosine
similarity merupakan metode yang
bersifat simetris, sehingga tidak dapat menentukan suatu urutan. Untuk pengembangan selanjutnya disarankan agar menggunakan metode pengukuran kesamaan yang asimetris.
Pada pengembangan selanjutnya, sistem dapat dikembangkan untuk melakukan integrasi dokumen-dokumen dengan bahasa lain, tidak terbatas pada dokumen yang berbahasa Indonesia saja.
Pada pengembangan selanjutnya, sistem dapat dikembangkan dengan menggunakan algoritma lain sehingga dapat mengintegrasi dokumen narasi dengan baik, disamping itu juga dapat diteliti hasilnya dalam mengintegrasi
jenis dokumen selain dokumen berjenis eksposisi dan narasi.
6. DAFTAR PUSTAKA
Agusta, Ledy. 2009. Perbandingan Algoritma Stemming Porter Dengan Algoritma Nazief & Adriani Untuk Stemming
Dokumen Teks Bahasa Indonesia.
Bali : Fakultas Teknologi Informasi Universitas Kristen Satya Wacana. Budhi, Gregorius S, Arlinah I. Rahardjo, dan
Hendrawan Taufik. 2008.
Hierarchical Clustering Untuk
Aplikasi Automated Text Integration.
Surabaya : UK Petra Jurusan Teknik Informatika.
Budhi, Gregorius S, Ibnu Gunawan dan Ferry Yuwono. 2005. Algoritma Porter Stemmer For Bahasa Indonesia Untuk Pre-Processing Text Mining Berbasis Metode Market Basket
Analysis. Surabaya : UK Petra
Jurusan Teknik Informatika.
Hamzah, Amir. 2009. Temu Kembali Informasi Berbasis Kluster Untuk Sistem Temu Kembali Informasi Teks
Bahasa Indonesia. Yogyakarta :
Jurusan Teknik Informatika, Fakultas Teknologi Industri Institut Sains & Teknologi AKPRIND.
Hartini, Entin. 2004. Metode Clustering
Hirarki. Pusat Pengembangan
Teknologi dan Komputasi Batan. Intan, Rolly dan Andrew Defeng. 2005.
HARD: Subject-based Search Engine
menggunakan TF-IDF dan Jaccard’s
Coefficient. Surabaya : UK Petra
Jurusan Teknik Informatika.
Kendall, Kenneth E dan Julie E. Kendall. 2006. Analisis dan Perancangan
Sistem.Edisi kelima. Indeks. Jakarta.
Mandala, Rila dan Hendra Setiawan. 2002. Peningkatan Performansi Sistem Temu-Kembali Informasi dengan Perluasan Query Secara Otomatis. Bandung : Departemen Teknik Informatika Institut Teknologi Bandung.
Pramudiono, Iko. 2003. Pengantar Data
Mining: Menambang Permata
Pengetahuan di Gunung Data.
ISSN : 1979-5661 -10- Pressman, Roger S. 2005. Software
Engineering A practitioner’s
Approach Sixth Edition. New York :
Mc-Graw-Hill.
Sjobergh, Jonas dan Kenji Araki. 2005.
Extraction Based Summarization Using Shortest Path Algorithm.
Sweden : KTH Nada.
Soebroto dan Arief Andy. 2005. Hybrid
Average Complete Clustering
sebagai Algoritma Kompromi antara Kualitas dan Waktu Komputasi
Proses Clustering. Surabaya : Institut
Teknologi Sepuluh November. Steinbach, Michael, George Karypis dan Vipin
Kumar. 2005. A Comparisont of Document Clustering Techniques.
Minnesota : University of Minnesota, Department of Computer Science and Engineering.
ISSN : 1979-5661 -11-
SISTEM PENDUKUNG KEPUTUSAN DALAM PEMILIHAN TEMPAT KOST DENGAN METODE PEMBOBOTAN
( STUDI KASUS : SLEMAN YOGYAKARTA)
ABSTRAK
Penentuan tempat tinggal di daerah yang baru dikenal dipengaruhi oleh banyak factor, diantaranya lokasi, fasilitas, sistem kontrak dan harga. Makalah ini menentukan kriteria-kriteria yang digunakan didalam pemilihan tempat tinggal. kriteria-kriteria tersebut dianalisis menggunakan metode pembobotan. Hasil analisis yang didapat berupa kriteria lokasi untuk menentukan tempat kost yang paling sesuai.
Kata kunci: Pembobotan, kriteria, analisis
ABSTRACT
Determination of residence in the newly recognized influenced by many factors, such as location, facilities, contracts and pricing. This paper determines the criteria used in the selection of a place to stay. criteria were analyzed using the methods of weighting. The results of the analysis are obtained in the form of criteria to determine the location of the most appropriate place of boarding.
Keywords: Weighting, criteria, analysis
1. PENDAHULUAN
Persoalan pengambilan keputusan pada dasarnya adalah bentuk pemilihan dari berbagai altrenatif tindakan yang mungkin dipilih yang prosesnya melalui mekanisme tertentu, dengan harapan akan menghasilkan sebuah keputusan yang terbaik. Penyusunan model keputusan adalah suatu cara untuk mengembangkan hubungan-hubungan yang logis yang mendasari persoalan keputusan ke dalam suatu model matematis, yang mencerminkan hubungan yang terjadi di antara faktor-faktor yang terlibat, sehingga proses keputusan harus diambil melalui proses yang bertahap, sistematik, konsisten dan diusahakan dalam setiap langkah melalui dari awal telah mengikutsertakan dan mempertimbangkan berbagai faktor.
Demikian juga halnya dengan pemilihan kost bagi mahasiswa yang menuntut ilmu di jogjakarta. Terkadang mahasiswa yang tidak mengetahui daerah jogjakarta tentunya akan menemui banyak kesulitan ataupun banyak kendala dalam memilih tempat kost. Penentuan tempat kost mana yang harus dipilih oleh mahasiswa dipengaruhi oleh banyak faktor, diantaranya lokasi, fasilitas, sistem kontrak dan harga. Makalah ini bertujuan untuk mencari kriteria-kriteria yang digunakan didalam memilih kost oleh mahasiswa yang kuliah dijogjakarta. Kriteria-kriteria tersebut dianalisis menggunakan sistem pembobotan. Hasil analisis yang didapat dengan menjumlahkan hasil seluruh kriteria dan membagi dengan banyaknya kriteria .
I Wayan Supriana
Program Pascasarjana Ilmu Komputer Fakultas MIPA Universitas Gadjah Mada Skip Utara, Yogyakarta, 55281
ISSN : 1979-5661 -12- 2. METODE PENELITIAN
Metode pembobotan yang digunakan dalam sistem ini adalah pembobotan secara langsung, artinya pengguna langsung memberikan bobot pada setiap kriteria dalam skala tertentu. Bobot yang telah diinput kemudian dinormalisasi untuk mendistribusikan nilai kepada seleruh kriteria sehingga jika semua bobot kriteria diproses oleh sistem akan menghasilkan satu nilai sebagai pertimbangan keputusan bagi pengguna.
Menurut Simon dalam buku Komputerisasi Pengambilan Keputusan. Proses pengambilan keputusan melalui tahapan:
1.1. Tahap Penelusuran (intelligence)
Dalam perancangan yang dilakukan melahirkan rumusan masalah berupa sistem pendukung keputusan pemilihan tempat kost berdasarkan kriteria dari pemlih.
1.2. Tahap Perancangan (Design)
Setelah perumusan masalah, dilanjutkan dengan penetapan kriteria-kriteria yang dipakai dalam memilih tempat kost.
1.3. Tahap Pemilihan (Choice)
Dengan mengacu pada kriteria-kriteria penilaian yang telah ditetapkan, dibuat model-model penilaian secara matematis.
1.4. Tahap Implementasi (Implementation) Struktur Sistem Pendukung Keputusan diimplementasikan dengan bahasa pemrograman Poxpro. Sedangkan komponen-komponen Sistem Pendukung Keputusan yang digunakan adalah:
1. Subsistem manajemen data, menyediakan data bagi sistem yang berasal dari data internal dan eksternal.
2. Subsistem manajemen model, berfungsi sebagai pengelola berbagai model
3. Subsistem antar muka pengguna, merupakan fasilitas yang mampu mengintegrasikan sistem terpasang dengan pengguna secara interaktif.
Perancangan basis data sistem pendukung keputusan yang akan memberikan pemahaman secara keseluruhan berupa hubungan antar obyek data, aliran informasi dan transformasi dari data input manjadi output yang digambarkan secara grafik berupa entitas relationship diagram flow.
3. PERANCANGAN SISTEM
3.1. Model dan Bobot Penilaian Sistem Pendukung Keputusan
Model (kriteria) sistem pendukung keputusan pemilihan tempat tinggal/kost dibuat dalam 4 jenis kriteria yaitu : model lokasi, model fasilitas, model sistem kontrak rumah dan model harga. Dimana masing-masing model tersebut memiliki beberapa elemen yang akan menentukan hasil akhir sistem pendukung keputusan yang akan digunakan oleh para pengguna dalam menentukan suatu keputusan. Setiap elemen bobot penilaian yang berbeda-beda tergantung dari hasil jenis model.
Batasan penilaian dimulai dari 10 sebagai
range terendah sampai dengan 100 sebagai
range tertinggi, sehingga pada akhirnya
kelayakan pemilihan tempat tinggal/kost diukur dengan nilai sebagai : 80-100 kategori diterima oleh pengguna untuk ditempati, 60-79 kategori dipertimbangkan apakah ditempati atau tidak, 0-59 kategori ditolak artinya tidak layak ditempati.
Bobot penilaiannya sudah ditentukan berdasarkan kriteria yang telah ditetapkan oleh peneliti dengan bersumber pada hasil penelitian, namun hal ini untuk seterusnya bisa diadakan perubahan-perubahan searah dengan tuntutan kebutuhan. Bahwa sistem pada proses penilaiannya mengacu kepada pemenuhan kriteria-kriteria yang telah ditetapkan serta mengacu pada beberapa kasus yang telah terjadi, sehingga benar-benar mempunyai tolak ukur yang baik.
3.2.Perancangan Basis Data
Perancangan basis data digunakan untuk mendukung fasilitas pengolahan data, dimana model yang digunakan dalam perancangan basis data adalah model E-R (
Entity-Relationship), berikut adalah ER dari sistem
pendukung keputusan pemilihan tempat kost di jogjakarta.
ISSN : 1979-5661 -13-
3.3.Perancangan Basis Model
Dalam mendukung proses pengambilan keputusan, digunakan model pembobotan yang dibangun untuk menentukan prioritas tempat tinggal dalam menghasilkan keluran sistem secara keseluruhan melakukan langkah-langkah sebagai berikut:
a. Input nilai kriteria masing-masing model b. Input bobot masing-masing kriteria c. Hitung normalisasi dari bobot
NK =
n
BBT
x
SBK
n i%
)
(
1
Nilai akhir = n
NK
Dimana SBK : Kriteria BBT : Bobot kriteria
NK : Nilai kriteria
Rancangan model untuk mengevaluasi pemilihan tempat tinggal adalah sebagai berikut:
1. Kriteria lokasi
Model lokasi dimaksudkan untuk menentukan kenyamanan tempat tinggal yang akan di ditempati oleh mahasiswa serta berapa besar nilai dari masing-masing point tersebut. Dengan pemberian nilai mulai dari terkecil 10 sampai terbesar 100.
Tabel 1. Kriteria lokasi
No Kriteria Lokasi Nilai Bobot 1 Dekat kampus 100
80 % 2 Dekat jalan raya 80
3 Dekat tempat peribadahan
60
4 Dekat teman sedaerah
40
5 Dekat rumah makan 20 6 Dekat tempat
hiburan
10
Nilai lokasi adalah:
333 , 41 6 ) 8 , 0 10 ( ) 8 , 0 20 ( ) 8 , 0 40 ( ) 8 , 0 60 ( ) 8 , 0 80 ( ) 8 , 0 100 (
x x x x x x
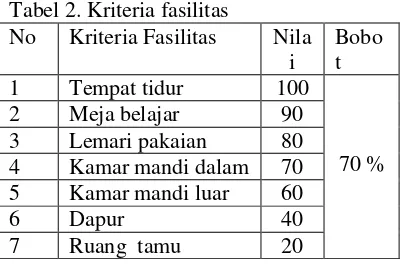
2. Kriteria fasilitas
Model fasilitas dimaksudkan untuk menentukan fasilitas yang didapatkan di tempat kost dan berapa besar nilai dari masing-masing point tersebut. Dengan pemberian nilai mulai dari terkecil 20 sampai terbesar 100.
Tabel 2. Kriteria fasilitas
No Kriteria Fasilitas Nila i
Bobo t 1 Tempat tidur 100
70 % 2 Meja belajar 90
3 Lemari pakaian 80 4 Kamar mandi dalam 70 5 Kamar mandi luar 60
6 Dapur 40
7 Ruang tamu 20
Nilai fasilitas adalah:
46 7 ) 7 , 0 20 ( ) 7 , 0 40 ( ) 7 , 0 60 ( ) 7 , 0 70 ( ) 7 , 0 80 ( ) 7 , 0 90 ( ) 7 , 0 100 (
x x x x x x x
3. Kriteria sistem kontrak
Model sistem kontrak dimaksudkan untuk menentukan sistem pembayaran tempat tinggal. Dengan pemberian nilai mulai dari terkecil 40 sampai terbesar 100. Tabel 3. Kriteria sistem kontrak
N o
Sub Kriteria Sistem kontrak
Nila i
Bobo t 1 Tahunan 100
50% 2 Enam bulan 80
3 Tiga bulan 60
4 Bulanan 40
Nilai sistem kontrak adalah:
35 4 ) 5 , 0 40 ( ) 5 , 0 60 ( ) 5 , 0 80 ( ) 5 , 0 100 (
x x x x4. Kriteria harga
Model harga dimaksudkan untuk menentukan harga dari tempat tinggal. Model ini terdiri dari 4 kriteria yaitu tahunan, enam bulanan, tiga bulanan, dan bulanan. Persentase nilai dari model harga ditentukan berdasarkan hal-hal sebagai berikut.
Tabel 4. Kriteria harga tahunan No Kriteria Harga
tahunan
Nilai Bobot
1 0 - 2.000.000 100
40% 2 2.001.000 -
2.500.000
80
3 2.501.000 - 3.000.000
60
ISSN : 1979-5661 -14- 32 3 ) 4 , 0 60 ( ) 4 , 0 80 ( ) 4 , 0 100 (
x x xTabel 5. Kriteria harga enam bulanan No Kriteria Harga
enam bulan
Nilai Bobo t 1 0 - 1.050.000 80
30 % 2 1.051.000 -
1.300.000
60
3 1.301.000 - 1.550.000
40
Nilai model enam bulanan adalah: 18 3 ) 3 , 0 40 ( ) 3 , 0 60 ( ) 3 , 0 80 (
x x xTabel 6. Kriteria harga tiga bulanan No Kriteria Harga tiga
bulan
Nila i
Bobo t 1 0 - 550.000 70
20% 2 551.000 - 675.000 50
3 676.000 - 6 800.000
30
Nilai kriteria tiga bulanan adalah: 10 3 ) 2 , 0 30 ( ) 2 , 0 50 ( ) 2 , 0 70 (
x x x Tabel 7. Kriteria harga bulanan No KriteriaHarga Bulanan
Nilai Bobot
1 0 - 200.000 60
10% 2 201.000 -
250.000
40
3 251.000 - 300.000
20
Nilai kriteria harga nulanan adalah: 4 3 ) 1 , 0 20 ( ) 1 , 0 40 ( ) 1 , 0 60 (
x x xTotal nilai kriteria harga = 16
4 4 10 18 32
Proses perhitungan keseluruhan model berdasarkan rumus dari pembobotan yang di jelaskan di depan adalah sebagai berikut : Nilai akhir adalah:
30 , 30 4 16 35 46 33 , 41
Berdasarkan nilai akhir yang didapat yaitu 30,30 dimana rentang nilai tersebut <=59 yang artinya tempat kost tersebut tidak dipilih.
3.4.Perancangan Basis Dialog
Rancangan dialog dari sistem pendukung keputusan bertujuan untuk memudahkan terjadinya interaksi antara pengguna dengan sistem, dimana rancangan dialognya menggunakan gaya menu dengan strukturnya seperti gambar berikut ini:
Menu Utama Menu Model Input Model Menu Kriteria Edit Model Hapus Model Input Model Edit Model Hapus Model Laporan Hasil Seleksi Menu Tambahan Informasi Keluar Aplikasi
Gambar 2. Struktur Dialog
3.5.Perancangan Dialog Output Pemilihan Tempat Kost di Yogyakarta
Rancangan dialog output yang dihasilkan oleh sistem berupa laporan penilaian per model, seperti ditunjukkan gambar berikut:
ISSN : 1979-5661 -15- 4. IMPLEMENTASI MODEL
4.1.Menu Utama
Menu utama ditampilkan agar seseorang mengetahui seluruh menu dan sub menu yang ada di dalam sistem aplikasi dimana pengguna dapat memilih menu-menu yang ditampilkan oleh aplikasi.
Gambar 4. Menu Utama
4.2.Menu Input Model
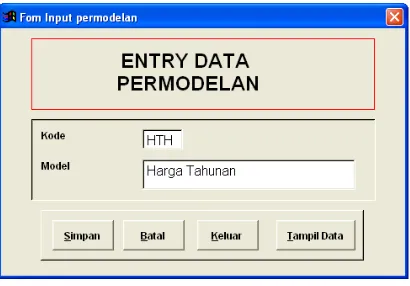
Menu input model digunakan untuk memasukkan model atau kriteria-kriteria dari sistem pemilihan kost. Di dalam menu ini ada beberapa fitur yaitu simpan, batal, keluar dan tampil data. tampil data berisi kriteria-kriteria yang sudah terdapat di dalam sistem.
Gambar 5. Menu Input Model
4.3.Menu Edit Model
Menu edit model digunakan untuk memperbaiki model atau kriteria yang telah diinputkan apabila terjadi perubahan pada model yang ada.
Gambar 6. Menu Edit Model
4.4.Menu Hapus Model
Menu hapus model digunakan untuk menghapus model yang telah diinputkan, apabila model yang dimaksudkan tidak sesuai dengan kelayakan penilaian pemilihan tempat kost.
Gambar 7. Menu Hapus Model
4.5.Menu Input Kriteria
Menu input kriteria digunakan untuk menginput nilai masing-masing kriteria beserta bobot dari model yang digunakan.
Gambar 8. Menu Input Kriteria
4.6.Menu Edit Kriteria
ISSN : 1979-5661 -16- datanya ada kesalahan baik terhadap nilai, bobot dan nama sub kriteria.
Gambar 9. Menu Input Kriteria
4.7.Menu Hapus Kriteria
Menu hapus kriteria digunakan untuk menghapus kriteria yang didalam pemilihan tempat kost tidak sesuai dengan kriteria pemilihan
Gambar 10. Menu Hapus Kriteria
4.8.Menu Lapotan Sistem
Menu laporan didasarkan atas kebutuhan informasi yang telah diidentifikasi pada tahap penentuan syarat-syarat informasi. Laporan yang dihasilkan oleh sistem yaitu laporan penentuan pemilihan tempat kost bagi mahasiswa yang nantinya menentukan apakah seorang mahasiswa memilih tempat kost, mempertimbangkan atau menolak kost tersebut.
5. KESIMPULAN
Konsep rancangan sistem pendukung keputusan penentuan tempat tinggal atau kost diharapkan menjadi acuan bagi pengembangan sistem nantinya atau computer base system.
Dari beragamnya tempat kost yang ada didaerah Yogyakarta diharapkan dapat membantu mahasiswa dalam menentukan tempat kost yang layak sesuai dengan keinginan dari mahasiswa tersebut.
6. DAFTAR PUSTAKA
[1]Alter, S.L., 1980, Decision Support System:
Current Practice and Continuing
Challenge, Reading, MA:
Addision-Wesley
[2]Kosasih, S., 2002, Sistem Pendukung
Keputusan, Proyek Peningkatan Penelitian
Tinggi Direktorat Jendral Pendidikan Tinggi Departemen Pendidikan Nasional [3]Little, J. D.C., 1970, Model and Managers:
The Concept of a Calculus, Management
Science, vol.16, no.8
[4]Turban, 2005, Decision Support System
and Intelligent System (Terjemahan: Sitem
ISSN : 1979-5661 -17-
SISTEM TUTORIAL MATEMATIKA DISKRET DALAM MENUNJANG PROSES BELAJAR BERBASIS KOMPETENSI
I Gede Santi Astawa
Jurusan Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Udayana
Email : [email protected]
ABSTRAK
Matematika Diskret merupakan salah satu mata kuliah yang cukup ditakuti oleh mahasiswa. Rasa takut dan malu inilah yang seringkali menjadi hambatan dalam proses belajar mengajar di kelas, karena mahasiswa cenderung untuk diam. Hal ini sangat bertentangan dalam system pembelajaran berbasis KBK, dimana peran aktif mahasiswa menjadi point utama penilaian.
Sebuah aplikasi komputer yang mampu memberikan tutorial matematika diskret kepada mahasiswa menjadi sangat dibutuhkan, karena dengan menggunakan aplikasi ini mahasiswa dapat belajar dan menguji kemampuan dalam mata kuliah matematika diskret secara mandiri.
Dari hasil pengujian, kelompok mahasiswa yang menggunakan system tutorial berbasis computer cenderung memiliki nilai (tingkat pemahaman) yang lebih baik dibandingkan dengan kelompok mahasiswa yang hanya diberikan pembelajaran di kelas.
Kata kunci— Matematika Diskret, KBK, aplikasi komputer.
1. PENDAHULUAN
Kecemasan siswa merupakan salah satu faktor penting yang mempengaruhi hasil belajar siswa[1]. Beberapa hal berpengaruh pada kecemasan dalam diri siswa, seperti tegang saat mengerjakan soal atau saat kelas dimulai, pesimis akan kemampuannya, khawatir jika hasil pekerjaannya buruk, dan juga ketakutan akan ditertawakan oleh teman yang lainnya [2,3]. Kecemasan juga muncul dari faktor di luar diri siswa, seperti: cerita buruk mengenai suatu mata pelajaran,sikap guru, dan juga tingkat persaingan di kelas yang siswa rasakan[1].
Metode belajar mandiri berbantuan komputer dalam proses pembelajaran dikembangkan untuk mengatasi permasalahan kecemasan siswa dalam belajar di kelas. Kombinasi metode kecerdasan buatan, pengetahuan kognitif, dan teknologi modern pada proses pembelajaran akan menghasilkan sebuah sistem pembelajaran yang efektif yang selanjutnya dikenal dengan istilah
Intelligent Computer-Aided Instruction
(ICAI)[4]. Pada beberapa penelitian ICAI
dihubungkan dengan sistem yang meggunakan konten pembelajaran dan strategi pengajaran
sebagai basis data pengetahuan, kemudian menggunakan penalaran berdasarkan pemahaman siswa untuk secara dinamis melakukan adaptasi pada proses pembelajaran, sistem ini dikenal dengan sistem tutorial adaptif [5,6].
Selain berfungsi sebagai alat bantu dalam belajar, bahan pembelajaran berbasis Komputer juga memiliki karakteristik tersendiri. Menurut Slamet Suyanto. Ciri-ciri bahan pembelajaran berbasis komputer adalah sebagai berikut :
1. Sistemik, Bahan pembelajaran berbasis
komputer disusun secara sistemik dan terstruktur. Selain itu pengembangan pembelajaran berbasis komputer juga mempertimbangkan penyusunan peta konsep keilmuwan. Beberapa pilihan yang dapat digunakan dalam menyusun peta konsep, mulai dari konsep mudah ke sulit sampai dengan umum ke khusus, hal ini tergantung dari kebutuhan yang diinginkan.
2. Jelas dan Menarik, Pemaparan konsep yang
ISSN : 1979-5661 -18- jelas dan detail juga termasuk syarat mutlak dalam pengembangan pembelajaran berbasis komputer.
3 Mudah digunakan, Sebagian besar produk
pembelajaran berbasis komputer sangat mudah digunakan, meskipun bagi orang awam sekalipun. Dengan petunjuk penggunaan yang jelas dan memiliki pola logika yang konkrit menjadikan produk PBK mudah dipahami.
4 Mudah diperbaiki, Produk pembelajaran
berbasis komputer juga mudah diperbaiki. Penambahan, pengurangan, dan revisi terhadap isi produk sangat mudah dilakukan. Berbeda halnya dengan bahan cetak, setelah mengalami proses pencetakkan bahan ajar cetak sulit untuk direvisi secara langsung, melainkan harus melakukan pencetakan ulang. Dengan semakin pesatnya perkembangan teknologi, fitur-fitur yang terdapat dalam fasilitas program juga semakin berkembang. Sehingga semakin memudahkan dalam pengeditan produk PBK.
5. Mudah disebarluaskan, Bahan ajar berbasis
komputer sangat mudah untuk disebarluaskan, salah satunya adalah penyebaran menggunakan media internet. 2. METODE PENELITIAN
Langkah-langkah dalam penelitian ini adalah 1. Studi Pustaka, dengan membaca beberapa
jurnal atau hasil penelitian terkait, sahingga aplikasi yang dibuat memiliki arah dan tujuan yang pasti.
2. Analisa kebutuhan system, dilakukan dengan membaca materi-materi pada buku matematika diskret, membuat diagram keterkaitan materi, dan mencari sifat-sifat dari materi.
3. Perancangan system, disesuaikan dengan kesimpulan pada tahap analisa kebutuhan system
4. Aplikasi, system diaplikasikan pada bahasa pemrograman Delphi, dengan database paradox.
5. Pengujian, pengujian dilakukan dengan membagi mahasiswa menjadi dua kelompok pada satu sub bahasan matematika diskret, dimana satu kelompok ditugaskan untuk mencoba system tutorial yang sudah dibuat, dan kelompok lain hanya diberikan pembelajaran dikelas saja. Selanjutnya diadakan sebuah test kecil untuk melihat
tingkat pemahaman siswa pada sub bahasan tersebut.
3. DESAIN SISTEM TUTORIAL
Proses belajar dalam penelitian ini dibagi menjadi empat tahap, yaitu:
1. Tahap membaca, pada tahap ini diberikan materi bacaan, dan siswa diminta menjawab pertanyaan bacaan.
2. Tahap pemahaman materi, pada tahap ini materi bacaan dihilangkan dan siswa diminta menjawab pertanyaan yang berhubungan dengan materi.
3. Tahap contoh soal, pada tahap ini diberikan tiga tipe soal contoh yang lebih bersifat hitungan. Pada tahap ini, apabila jawaban siswa salah, maka sistem akan menanyakan data-data tentang apa yang diketahui atau ditanyakan pada soal tersebut, dan menyiapkan soal dengan tipe yang sama. Tahap ini bertujuan untuk melatih kemampuan siswa dalam menganalisa soal. 4. Tahap latihan soal, pada tahap ini diberikan
beberapa soal yang lebih bersifat hitungan. Tahap ini bertujuan untuk mengetahui tingkat pencapaian siswa pada materi pelajaran yang sedang dipelajari.
Adaptasi pertama dilakukan pada tahap membaca, dengan menggunakan nilai dan waktu untuk menjawab sebagai faktor kelulusan,
apabila siswa dalam tahap ini tidak dapat mencapai batas bawah kelulusan maka sistem akan memberikan materi dan pertanyaan dengan level yang lebih mudah terlebih dahulu sebelum nantinya kembali ke level semula. Terdapat tiga level materi atau soal pada tahap ini yaitu:
Materi dengan lebih banyak contoh-contoh atau pertanyaan-pertanyaan bacaan yang jawabannya merupakan pengulangan dari materi atau contoh yang sudah ada (level rendah).
Materi dengan beberapa contoh-contoh atau pertanyaan-pertanyaan bacaan yang sedikit berbeda dengan materi atau contoh yang diberikan (level sedang).
Materi dengan beberapa contoh atau pertanyaan-pertanyaan bacaan yang jawabannya memerlukan pemahaman maksud dari materi atau contoh yang diberikan (level tinggi).
ISSN : 1979-5661 -19- penyelesaian kasus materi pencacahan pada matakuliah matematika diskret. Langkah pertama akan disusun rencangan data flow diagram
(DFD) dari sistem yang akan dibuat sebagai berikut:
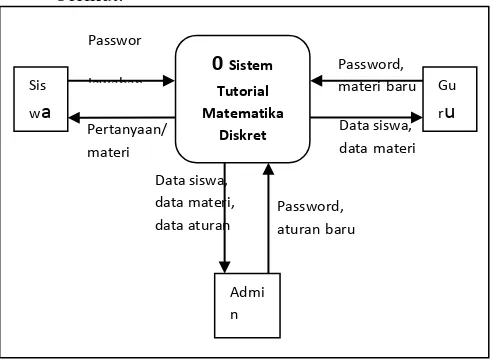
Gambar 1. DFD level 0 sistem tutorial matematika diskret
Dan juga dirancang basis data yang akan digunakan dalam system tutorial, basis data ini pada dasarnya digunakan untuk menyimpan berbagai file yang menyangkut materi belajar, soal-jawaban, hint-hint, dan juga menyimpan file pribadi pengguna system seperti gambar 2.
Rancangan sistem di atas, diimplementasikan pada bahasa pemrograman Delphi 6.0. Bahasa pemrograman Delphi dipilih karena sudah mendukung sistem basis data dengan baik, dan dapat berjalan dengan baik dalam lingkungan sistem operasi Windows XP dan Windows 7 yang dewasa ini banyak digunakan di lingkungan sekolah.
Gambar 2. ERD basis data sistem
0 Sistem Tutorial
Matematika Diskret
Sis
wa
Gu
ru
Admi n Passwor
jawaban
Pertanyaan/ materi
Password, materibaru
Data siswa, datamateri
Data siswa, data materi, data aturan
Password, aturanbaru
syarat
materi
Langkah jawab soal Test pendalaman
n m
1 n
1
n
1
n 1
1
Kode nama
Kode nama Kode
soal
jawa
Kode soal
Kode soa jawa rum
Langka
Langka Langka
Langka
Contoh Soal rumus
Variable Variable
memiliki
memiliki
memiliki
memiliki
Soal ujian memiliki
n 1
Kode soa
ISSN : 1979-5661 -20- 4. HASIL DAN PEMBAHASAN
Pengujian system yang akan dilakukan bertujuan untuk mengetahui efektifitas penggunaan system tutorial ini bagi mahasiswa dalam belajar metode pencacahan dalam kuliah matematika diskret. Untuk itu pengujian akan melibatkan 60 orang mahasiswa, dimana 30 mahasiswa dipilih secara acak untuk mencoba sistem yang sudah dibuat. Akan diambil dua nilai test, yaitu test pendahuluan (sebelum mencoba sistem) dan test akhir (setelah selesai mencoba system), analisis statistika akan digunakan untuk menarik kesimpulan dari dua kelompok data yang diperoleh. Sampai saat ini peneliti sudah memberikan test pendahuluan kepada 60 orang mahasiswa yang diambil secara acak dari 97 orang mahasiswa jurusan Ilmu Komputer UNUD angkatan 2012 yang sedang mengambil matakuliah matematika diskret. Gambar 3 dibawah adalah sebaran hasil pretest dan pemilihan subyek penelitian yang dilakukan oleh peneliti, pemilihan diambil secara acak dari golongan mahasiswa dengan hasil pretest rendah, sedang dan tinggi, sehingga diharapkan kondisi awal kedua kelompok mahasiswa yang akan dikenai perlakuan pada saat penelitian adalah sama.
Gambar. 3. Hasil Pretest seluruh mahasiswa
Dari gambar 3 terlihat bahwa nilai pretest tertinggi adalah 63, nilai pretest terendah adalah 15,sedangkan rata-rata perolehan 60 mahasiswa adalah 30,0667. Langkah selanjutnya peneliti membagi subyek penelitian menjadi dua bagian dengan sebaran nilai pretest masing-masing kelompok adalah
Gambar . 4. Perbandingan hasil pretest dua kelompok subyek penelitian
Kelompok pertama adalah kelompok yang diberikan perlakuan belajar di kelas, dengan lebih banyak melakukan pembahasan soal (rata-rata pretest 31,6333), sedangkan kelompok kedua (rata-rata pretest 30,5) merupakan kelompok yang selanjutnya diberikan kesempatan memakai system tutorial yang sudah dirancang.
Dari hasil pretest yang dilakukan, didapatkan hasil perbandingan nilai posttest dan pretest dari masing-masing mahasiswa pada kedua kelompok adaah sebagai berikut:
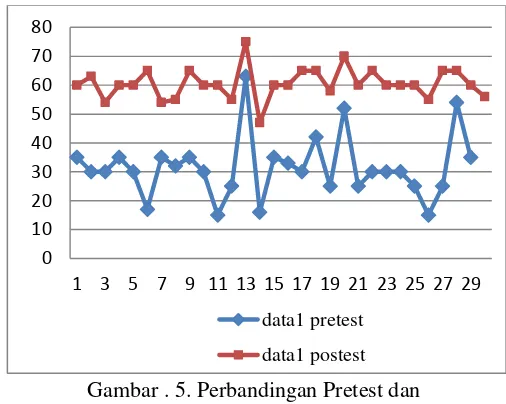
Gambar . 5. Perbandingan Pretest dan Postest kelompok I
0 10 20 30 40 50 60 70
1 5 9 13 17 21 25 29 33 37 41 45 49 53 57
Hasil Pretest 60 Mahasiswa
0 10 20 30 40 50 60 70
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 data1
data2
0 10 20 30 40 50 60 70 80
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29
data1 pretest
ISSN : 1979-5661 -21- Gambar. 6. Perbandingan Pretest dan
Postest kelompok II
Dari gambar 5. dan gambar.6, terlihat kelompok yang mendapat kesempatan mencoba system yang sudah dirancang memiliki kenaikan nilai(selisih nilai posttest-pretest) yang lebih baik dibandingkan kelompok yang hanya belajar di kampus (kelompok I), dengan system pembelajaran yang diberikan pada kelompok I adalah system belajar yang lebih menitik beratkan pada pembahasan contoh kasus. Dalam bentuk table, hasil perbandingan ini dapat dilihat sebagai berikut:
Kelompok I Kelompok II Pretest Postest Pretest Postest Median 30 60 30 65
Modus 30 60 30 60 Rata-rata 31,63 60,57 30,5 66,367 Tertinggi 63 75 60 80 Terendah 15 47 15 54 Sebaran 10,73 5,37 10,957 7,02
Dari table di atas, dapat disimpulkan bahwa penggunaan system tutorial pada mata kuliah matematika diskret khususnya pada materi pencacahan, menghasilkan peningkatan kemampuan mahasiswa yang lebih baik, dengan rata-rata perolehan nilai adalah 66,3667.
5. KESIMPULAN
Berdasarkan proses perancangan, implementasi, dan pengujian prototype system tutorial materi matematika diskret yang telah dilaksanakan, dapat disimpulkan bahwa:
1. Dari hasil analisa kebutuhan system, ditemukan fakta bahwa salah satu kesulitan mahasiswa dalam mempelajari materi pencacahan adalah tidak adanya
panutan bagi mereka dalam belajar dan berlatih diluar jam pelajaran kampus. Sehingga keberadaan sebuah system berbasis computer yang mampu menuntun mereka dalam belajar sangat dibutuhkan.
2. Efektifitas penggunaan system tutorial matematika diskret khususnya materi pencacahan pada 30 orang mahasiswa, adalah sangat baik apabila dibandingkan dengan kelompok mahasiswa yang tidak menggunakan system tersebut.
Pada beberapa tahapan penelitian, juga ditemukan kendala-kendala seperti kesulitan peneliti dalam menentukan hubungan kesalahan yang dibuat mahasiswa dengan tingkat pemahaman mereka. Sehingga disarankan untuk penelitian selanjutnya perlu untuk dibahas beberapa metode pendekatan mengenai hal ini, sehingga system tutorial yang dihasilkan dapat lebih baik.
6. DAFTAR PUSTAKA
[1] Abdurrahman, M., 1999, Pendidikan Bagi
Anak Berkesulitan Belajar. Jakarta :
Rineka Cipta.
[2] Elliot, S.N., Kratochwill, T.R., Litllefield, J., Travers, J.F., 1996,
EducationalPsychology. Second edition,
Madition : Brown dan Benchmark Company.
[3] Indiyani. N.E., Listiara, A., 2006, Efektivitas Metode Pembelajaran Gotong Royong(Cooperative Learning) untuk Menurunkan Kecemasan Siswa dalam Menghadapi Pelajaran Matematika, Jurnal Psikologi Universitas Diponegoro Vol.3, No. 1, Hal 12-20.
[4] Molnar A., 1997, Computers in education: A brief history. THE Journal, 24, http://www.thejournal.com/articles/13739,
diakses tanggal 14 January 2010.
[5] Zarlis, M., 2000, Sistem Tutorial Cerdas dalam Pengajaran Kaidah Berangka bagi Penyelesaian Model Matematik Kamiran dalam Fisik , Disertasi, Universiti Sains Malaysia.
[6] Korhan, G., 2006, Intelligent Tutoring Systems for Education, Tesis, Graduate School of Natural and Applied Sciences, Dokuz Eyl ¨ul University.
[7] Minarti, Yutmini S., dan Suwalni. 2004.
Pengaruh Media Transvisi dan Atribusi
0 20 40 60 80 100
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29
data2 pretest
ISSN : 1979-5661 -22-
Siswa terhadap Prestasi Belajar
Matematika. Jurnal Teknodika 2 (3) : 64 –
88.
[8] Roger S. Pressman, 2009, Software Engineering: A Practitioner's Approach
7th edition, McGraw-Hill
[9] Suja, I., 2005, Pemrograman SQL dan Database Server MySQL, Andi Yogyakarta
[10] Sutomo, dkk. 2004. Penggunaan Alat Peraga dalam Pembelajaran Matematika
dan Motivasi Belajar Siswa. Jurnal
Teknodika 2 (3) : 89 – 112.
[11] Wulan, E.R., dkk. 2004. Keefektifan
Penggunaan Media Model dalam
Pembelajaran Matematika. Jurnal
ISSN : 1979-5661 -23-
PENENTUAN KOMPOSISI BAHAN PAKAN IKAN LELE YANG OPTIMAL DENGAN MENGGUNAKAN METODE IWO-SUBTRACTIVE CLUSTERING
Agus Muliantara
Jurusan Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Udayana
email : [email protected]
ABSTRAK
Pakan selain sebagai salah satu faktor yang dapat meningkatkan produktifitas ikan, juga merupakan satu komponen terbesar dalam biaya produksi. Dapat mencapai 60% dari keseluruhan biaya produksi Saat ini harga pakan buatan sudah sekitar Rp 10.00