Penerapan algoritma C4.5 untuk deteksi penyakit kanker serviks
Bebas
105
0
0
Teks penuh
(2) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. IMPLEMENTATION OF C4.5 ALGORITHM FOR CERVICAL CANCER DETECTION. A THESIS. Present as Partial Fullfillment of Requirements to Obtains Sarjana Komputer Degree in Informatics Engineering Study Program. By : Ventya Fernitha 155314088. INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATICS ENGINEERING FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY YOGYAKARTA 2019. ii.
(3) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. iii.
(4) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. iv.
(5) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. HALAMAN MOTTO. “Kita berdiri paling tinggi dan paling kuat ketika kita berlutut dan berserah dihadapan-Nya.”. “I can do all things through Christ who strengthens me” Philipians 4 : 13. v.
(6) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. vi.
(7) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. ABSTRAK. Algoritma C4.5 merupakan metode klasifikasi dan prediksi dalam teknik penambangan data yang digunakan untuk mengidentifikasi pola tersembunyi dalam data untuk memperoleh informasi atau pengetahuan yang berguna dari suatu data yang berjumlah besar. Pada penelitian ini algoritma C4.5 diterapkan untuk mendeteksi penyakit kanker serviks dengan mengklasifikasi hasil biopsi pasien berdasarkan atribut yang mempengaruhi risiko kanker serviks dari dataset sebuah Rumah Sakit di Caracas, Venezuela. Data tersebut berjumlah 858 data dalam kondisi imbalanced data karena terdapat kelas yang mendominasi dari kelas lainnya. Masalah imbalanced data dapat menyebabkan hasil dari klasifikasi tidak akurat. Untuk mengatasi masalah tersebut, peneliti menerapkan teknik undersampling terhadap data mayoritas agar data yang dimiliki menjadi seimbang dan memperoleh hasil yang akurat. Peneliti melakukan pengujian dengan jumlah 165 data. Pada pengujian dengan perbandingan data training dan data testing secara descending sebesar 80:20 menghasilkan tingkat akurasi tertinggi sebesar 75,76%. Berdasarkan hasil perhitungan dapat disimpulkan bahwa algoritma C4.5 dapat diterapkan dan menemukan aturan klasifikasi yang menarik dari pohon keputusan yang terbentuk.. Kata kunci : algoritma C4.5, undersampling, kanker serviks. vii.
(8) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. ABSTRACT. C4.5 algorithm is a method of classification and prediction in data mining techniques that used to identify hidden patterns in data to obtain information or knowledge from a large amount of data. In this research, the C4.5 algorithm was applied to detect cervical cancer by classifying the patient's biopsy results based on attributes that affect the risk of cervical cancer from the dataset of a hospital in Caracas, Venezuela. The used of 858 data is imbalanced data conditions because there are dominating classes from other classes. Imbalanced data problems can cause the inacurate classification. To overcome this problem, researchers applied the undersampling technique to the majority data so the data will be balanced and obtained accurate results. The researcher conducted a test with 165 data. The testing with comparison of training data and descending data testing of 80:20 show the highest accuracy rate was 75.76%. Based on the results of the calculation it can be concluded that the C4.5 algorithm can be applied and find interesting classification rules from the formed decision tree. Keyword: C4.5 algorithm, undersampling, cervical cancer.. viii.
(9) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. ix.
(10) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. KATA PENGANTAR Puji syukur penulis haturkan kepada Tuhan Yang Maha Esa karena berkat, rahmat dan karunia-Nya, penulis dapat menyelesaikan tugas akhir ini yang berjudul. “PENERAPAN. ALGORITMA. C4.5. UNTUK. DETEKSI. PENYAKIT KANKER SERVIKS”. Penulisan skripsi ini tidak lepas dari peran pentingnya berbagai pihak yang telah memberi banyak dukungan, doa dan motivasi kepada penulis dalam proses penyelesaian skripsi hingga selesai. Oleh karena itu, dalam kesempatan ini penulis dengan kerendahan hati mengucapkan terima kasih kepada : 1.. Tuhan Yesus Kristus yang memberikan kekuatan, berkat dan selalu menyertai penulis.. 2.. Kedua orang tua tercinta, Gilbert Alfried Djohan dan Newiwatie Tajah Setia, S.Sos. yang selalu memberikan doa, perhatian, kepercayaan, dukungan moral maupun fasilitas serta kasih sayang.. 3.. Kakak-kakak penulis, Hefriandhi, S.H., Winda Roslina S.Pd., Andre Fernadi, S.AN., Erlina dan Alexandro Andreas Herman Kandou, S.H. yang selalu memberikan doa, dukungan dan motivasi.. 4.. Bapak Drs. Johanes Eka Priyatma, M.Sc., Ph.D. selaku Rektor Universitas Sanata Dharma dan selaku Dosen Pembimbing Skripsi yang telah memberikan waktu luangnya untuk membimbing serta memberikan saran dan dukungan kepada penulis selama menyusun tugas akhir.. 5.. Bapak Sudi Mungkasi, S.Si., M.Math.Sc., Ph.D. selaku Dekan Fakultas Sains dan Teknologi.. 6.. Ibu Dr. Anastasia Rita Widiarti, M.Kom. selaku Ketua Program Studi Teknik Informatika Universitas Sanata Dharma.. 7.. Bapak Eko Hari Parmadi, S.Si., M.Kom. selaku Dosen Pembimbing Akademik yang telah memberikan bimbingan dan saran selama penulis menempuh studi.. x.
(11) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. xi.
(12) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. DAFTAR ISI. HALAMAN JUDUL................................................................................................ i TITTLE PAGE ......................................................................................................... ii HALAMAN PERSETUJUAN ............................... Error! Bookmark not defined. HALAMAN PENGESAHAN ................................ Error! Bookmark not defined. HALAMAN MOTTO ............................................................................................. v PERNYATAAN KEASLIAN KARYA ................ Error! Bookmark not defined. ABSTRAK ............................................................................................................ vii ABSTRACT ......................................................................................................... viii LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPERLUAN KEPENTINGAN AKADEMIS .... Error! Bookmark not defined. KATA PENGANTAR ............................................................................................ x DAFTAR ISI ......................................................................................................... xii DAFTAR TABEL ................................................................................................. xv DAFTAR GAMBAR ........................................................................................... xvi BAB 1PENDAHULUAN ....................................................................................... 1 1.1.. Latar Belakang .................................................................................. 1. 1.2.. Rumusan Masalah ............................................................................. 3. 1.3.. Tujuan Penelitian .............................................................................. 3. 1.4.. Manfaat Penelitian ............................................................................ 3. 1.5.. Batasan Masalah................................................................................ 3. 1.6.. Sistematika Penulisan ....................................................................... 4. BAB IITINJAUAN PUSTAKA .............................................................................. 5 2.1.. Penambangan Data ............................................................................ 5. 2.1.1.. Definisi Penambangan Data .............................................................. 5. 2.1.2.. Fungsi Penambangan Data ................................................................ 5. 2.1.3.. Tahap-Tahap Penambangan Data ..................................................... 6. 2.2.. Algoritma C4.5 .................................................................................. 8. 2.2.1.. C4.5 ................................................................................................... 8. 2.2.2.. Contoh Penerapan C4.5 ................................................................... 12. xii.
(13) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 2.3.. Kanker Serviks ................................................................................ 22. 2.3.1.. Definisi Kanker Serviks .................................................................. 22. 2.3.2.. Penyebab Kanker Serviks ............................................................... 23. 2.3.3.. Faktor Risiko Kanker Serviks ......................................................... 23. 2.3.4.. Diagnosis Kanker Serviks ............................................................... 24. 2.4.. Imbalanced Data.............................................................................. 25. 2.5.. Split Validation ............................................................................... 26. 2.6.. ConfusionMatrix ............................................................................. 27. BAB IIIMETODOLOGI PENELITIAN............................................................... 29 3.1.. Sumber Data .................................................................................... 29. 3.2.. Tahapan Penelitian .......................................................................... 33. 3.2.1.. Knowledge Discovery in Database (KDD) ..................................... 33. 3.2.2.1 Pembersihan Data (Data Cleaning) ............................................ 33 3.2.2.2 Integrasi Data (Data Integration) ................................................ 35 3.2.2.3 Seleksi Data (Data Selection)...................................................... 35 3.2.2.4 Transformasi Data (Data Transformation) ................................. 36 3.2.2.5 Penambangan Data (Data Mining) .............................................. 41 3.2.2.6 Evaluasi Pola (Pattern Evaluation) ............................................. 42 3.2.2.7 Presentasi Pengetahuan (Knowledge Presentation) .................... 42 3.2.2. 3.3.. Analisis dan Kesimpulan................................................................. 42 Perancangan Perangkat Lunak ........................................................ 42. 3.3.1.. Perancangan Umum ........................................................................ 42. 3.3.1.1 Input ............................................................................................. 43 3.3.1.2 Proses........................................................................................... 43 3.3.1.3 Output .......................................................................................... 46 3.3.2.. Model Fungsi .................................................................................. 46. 3.3.2.1 Diagram Use Case ....................................................................... 46 3.3.2.2 Narasi Use Case .......................................................................... 47 3.3.2.3 Diagram Aktivitas ....................................................................... 54 3.3.3.. Model Perancangan ......................................................................... 57. 3.3.3.1 Perancangan Antarmuka .............................................................. 57 3.3.3.2 Diagram Kelas Analisis ............................................................... 61. xiii.
(14) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 3.3.3.3 Entity Relationship Diagram (ERD) ........................................... 62 3.3.3.4 Desain Basis Data Logikal .......................................................... 63 3.4.. Spesifikasi Alat ............................................................................... 63. BAB IVIMPLEMENTASI DAN ANALISIS HASIL .......................................... 64 4.1.. Implementasi Program .................................................................... 64. 4.1.1.. Halaman Masuk .............................................................................. 64. 4.1.2.. Halaman Utama............................................................................... 64. 4.1.3.. Data Pasien ...................................................................................... 65. 4.1.4.. Partisi Data ...................................................................................... 65. 4.1.5.. Proses Algoritma C4.5 .................................................................... 66. 4.1.6.. Kinerja ............................................................................................. 68. 4.1.7.. Uji Data Tunggal ............................................................................. 69. 4.2.. Pengujian Perangkat Lunak (Black Box)......................................... 70. 4.2.1.. Rencana Pengujian Validasi Black Box .......................................... 70. 4.2.2.. Hasil Pengujian Validasi ................................................................. 70. 4.3.. Hasil Perangkat lunak ..................................................................... 70. 4.4.. Kelebihan dan Kekurangan Perangkat lunak .................................. 72. 4.4.1.. Kelebihan Perangkat lunak ............................................................. 72. 4.4.2.. Kekurangan Perangkat lunak .......................................................... 72. BAB VPENUTUP ................................................................................................. 73 5.1.. Kesimpulan ..................................................................................... 73. 5.2.. Saran ................................................................................................ 73. DAFTAR PUSTAKA ........................................................................................... 74 LAMPIRAN .......................................................................................................... 76. xiv.
(15) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. DAFTAR TABEL. Tabel 2.1 Perbedaan Algoritma C4.5 dan ID3 ........................................................ 8 Tabel 2.2 Data Pasien ............................................................................................ 12 Tabel 2.3 Perhitungan Root/Node 1 ...................................................................... 17 Tabel 2.4 Data Pasien dengan Dx:CIN = False .................................................... 19 Tabel 2.5 Perhitungan Node 1.1 ............................................................................ 19 Tabel 2.6 Data Pasien Dx:CIN = False dan IUD (years) = 6-11 .......................... 21 Tabel 2.7 Perhitungan Node 1.1.2 ......................................................................... 21 Tabel 2.8 Confusion Matrix .................................................................................. 27 Tabel 3.1 Atribut Data Kanker Serviks ................................................................. 29 Tabel 3.2 Detail Kelas Biopsy ............................................................................... 32 Tabel 3.3 Beberapa atribut yang Memiliki Sedikit Nilai Kosong ......................... 33 Tabel 3.4 Narasi Use Case Login ......................................................................... 47 Tabel 3.5 Narasi Use Case Masukkan Data .......................................................... 48 Tabel 3.6 Narasi Use Case Partisi Data ................................................................ 49 Tabel 3.7 Narasi Use Case Proses Algoritma C4.5 .............................................. 50 Tabel 3.8 Narasi Use Case Uji Data Tunggal ....................................................... 52 Tabel 3.9 Narasi Use Case Hapus Semua Data .................................................... 53 Tabel 4.1 Rencana Pengujian Validasi Black Box ................................................ 70 Tabel 4.2 Akurasi Split Validation Ascending ...................................................... 71 Tabel 4.3 Akurasi Split Validation Descending .................................................... 71 Tabel 4.4 Akurasi Split Validation Random ......................................................... 71. xv.
(16) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. DAFTAR GAMBAR. Gambar 2.1 Tahap-tahap penambangan data (Han & Kamber, 2006) .................... 7 Gambar 2.2 Pohon Keputusan Node 1 (Root Node) ............................................. 18 Gambar 2.3 Pohon Keputusan Node 1.1 ............................................................... 20 Gambar 2.4 Pohon Keputusan Node 1.1.2 ............................................................ 22 Gambar 2.5 Ilustrasi Split Validation .................................................................... 27 Gambar 3.1 Diagram Flowchart ........................................................................... 46 Gambar 3.2 Diagram UseCase.............................................................................. 47 Gambar 3.3 Diagram Aktivitas Login ................................................................... 54 Gambar 3.4 Diagram Aktivitas Masukkan Data ................................................... 54 Gambar 3.5 Diagram Aktivitas Partisi Data ......................................................... 55 Gambar 3.6 Diagram Aktivitas Proses Algoritma C4.5 ........................................ 55 Gambar 3.7 Diagram Aktivitas Uji Data Tunggal ................................................ 56 Gambar 3.8 Diagram Aktivitas Hapus Semua Data.............................................. 56 Gambar 3.9 Perancangan Halaman Masuk ........................................................... 57 Gambar 3.10 Perancangan Halaman Utama ......................................................... 57 Gambar 3.11 Perancangan Halaman Data Pasien ................................................. 58 Gambar 3.12 Perancangan Halaman Partisi Data ................................................. 58 Gambar 3.13 Perancangan Halaman Proses Algoritma C4.5 ............................... 59 Gambar 3.14 Perancangan Halaman Pohon Keputusan ........................................ 59 Gambar 3.15 Perancangan Halaman Kinerja ........................................................ 60 Gambar 3.17 Diagram Kelas Analisis ................................................................... 61 Gambar 3.18 Entity Relationship Diagram (ERD) ............................................... 62 Gambar 3.19 Desain Basis Data Logikal .............................................................. 63 Gambar 4.1 Halaman Masuk................................................................................. 64 Gambar 4.2 Halaman Utama ................................................................................. 64 Gambar 4.3 Tampilan Data Pasien........................................................................ 65 Gambar 4.4 Tampilan Partisi Data ........................................................................ 66 Gambar 4.5 Tampilan Proses Algoritma C4.5 ...................................................... 67 Gambar 4.6 Tampilan Pohon Keputusan dan Rule C4.5 ...................................... 67. xvi.
(17) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Gambar 4.7 Tampilan Proses Kinerja ................................................................... 68 Gambar 4.8 Tampilan Hasil Kinerja ..................................................................... 68 Gambar 4.9 Tampilan Input Uji Data Tunggal ..................................................... 69 Gambar 4.10 Hasil Akurasi Confusion Matrix ..................................................... 72. xvii.
(18) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. BAB 1. PENDAHULUAN. 1.1. Latar Belakang Penambangan. data. merupakan. proses. mengidentifikasi. pola. tersembunyi dalam data untuk memperoleh informasi atau pengetahuan yang berguna dari suatu data yang berjumlah besar. Terdapat beberapa teknik penambangan data, salah satunya yaitu Decision Tree dengan algoritma C4.5. Algoritma C4.5 merupakan metode klasifikasi dan prediksi yang sudah banyak digunakan dalam implementasi penentuan keputusan karena memiliki banyak kelebihan. Beberapa kelebihan dari algoritma ini dapat menangani pruning, mengolah data numerik diskret, dapat menangani nilai atribut yang hilang serta menghasilkan aturanaturan yang mudah diinterpretasikan. Kemajuan algoritma C4.5 yang begitu pesat saat ini telah memperoleh banyak manfaat seperti halnya dalam bidang kesehatan. Penambangan data dengan teknik pembelajaran mesin yang canggih dapat dijadikan penelitian dalam bidang medis untuk mengidentifikasi berbagai masalah kesehatan. Pengetahuan yang diperoleh dengan teknik penambangan data dapat membantu dalam mempercepat proses diagnosis beberapa penyakit salah satunya seperti penyakit kanker serviks. Kanker serviks adalah jenis kanker yang muncul pada leher rahim. Kanker jenis ini sering disebut dengan silent killer karena wanita dengan kanker serviks stadium awal dan pre-kanker tidak merasakan gejala sama sekali hingga sel kanker menyebar ke jaringan di sekitarnya membentuk tumor. Gejala-gejala kanker serviks baru akan muncul saat kanker sudah memasuki stadium lanjut(di atas stadium dua). Padahal, jika kanker serviks terdeteksi sejak dini akan lebih mudah untuk disembuhkan. Berdasarkan penelusuran mengenai pengaruh risiko kanker serviks, terdapat beberapa faktor risiko yang diduga berpengaruh. Beberapa faktor. 1.
(19) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. yang diduga berpengaruh terhadap penyebab munculnya kanker serviks yaitu meliputi usia, faktor seksual yang meliputi usia pertama kali melakukan hubungan seks, pasangan seks yang berganti-ganti, paritas, kurang menjaga kebersihan genital, merokok, riwayat penyakit kelamin, trauma kronis pada serviks, serta penggunaan kontrasepsi oral dalam jangka waktu lama(Diananda, 2007). Wen Wu & Hao Zhou (2017) melakukan klasifikasi untuk mendiagnosis penyakit kanker serviks dengan menggunakan tiga metode berbasis Support Vector Machine (SVM).Tiga metode tersebut yaitu SVM-standar, SVM-RFE (Recursive Feature Elimination) dan SVMPCA (Principal Component Analysis). Dataset yang digunakan yaitu dataset faktor risiko kanker serviks dari Rumah Sakit Universitario de Caracas di Caracas, Venezuela. Dataset berisi 32 atribut mengenai faktor risiko yang meliputi informasi demografis, kebiasaan, dan catatan rekam medis. Selanjutnya, dilakukan perbandingan pada hasil ketiga metode yang. digunakan. dalam. mengklasifikasi. dataset. tersebut.. Hasil. menunjukan bahwa SVM-PCA lebih baik dibanding metode yang lain. Berdasarkan uraian tersebut pada penelitian ini penulis mencoba mengaitkan kasus dengan menggunakan teknik penambangan data (data mining) dengan algoritma C4.5 dalam membangun sebuah perangkat lunak untuk mendeteksi penyakit kanker serviks dengan memprediksi hasil biopsi pasien berdasarkan atribut yang mempengaruhi risiko kanker serviks. Biopsi merupakan tes yang dilakukan dengan mengambil sampel dari jaringan serviks untuk memverifikasi apakah pasien menderita kanker serviks atau tidak. Tes biopsi memakan waktu 5-6 hari untuk mengkonfirmasi keberadaan kanker, diagnosis yang tertunda tersebut dapat memakan waktu seumur hidup bagi seorang pasien. Dengan dibangunnya suatu perangkat lunak untuk mendeteksi penyakit kanker serviks menggunakan algortima C4.5, diharapkan dapat mempercepat proses diagnosis biopsi sehingga dapat dilakukan proses pengobatan sedini mungkin.. 2.
(20) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 1.2. Rumusan Masalah Berdasarkan latar belakang di atas, maka masalah yang akan diselesaikan adalah bagaimana menerapkan algoritma C4.5 untuk mendeteksi penyakit kanker serviks dan menghitung akurasi yang diperoleh dengan membandingkan hasil klasifikasi yang dilakukan oleh perangkat lunak dengan hasil klasifikasi pada data kanker serviks yang digunakan. 1.3. Tujuan Penelitian Tujuan dari penelitian ini adalah : 1. Membangun sebuah perangkat lunak untuk mendeteksi penyakit kanker serviks dengan menerapkan algoritma C4.5. 2. Untuk mengetahui seberapa baik algoritma C4.5 diterapkan pada perangkat lunak. 1.4. Manfaat Penelitian Manfaat dari penelitian ini adalah : 1. Membantu mempercepat proses diagnosis biopsi dalam mendeteksi penyakit kanker serviks dengan menerapkan algoritma C4.5. 2. Menambah wawasan bagi pembaca yang ingin mempelajari algoritma C4.5. 1.5. Batasan Masalah a. Perangkat lunak yang dibangun hanya dapat digunakan untuk mendeteksi penyakit kanker serviks berdasarkan beberapa faktor yang diduga berpengaruh terhadap munculnya kanker serviks, bukan memberikan cara penanganan. b. Data yang digunakan adalah data yang diperoleh dari UCI Machine Learning yang dikumpulkan dari Rumah Sakit Universitario de Caracas di Caracas, Venezuela. c. Perangkat lunak yang dibangun untuk mendeteksirisiko penyakit kanker serviks hanya akan berfokus pada target biopsi.. 3.
(21) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 1.6. Sistematika Penulisan BAB I. : Pendahuluan Bab ini berisi tentang latar belakang, rumusan masalah, tujuan. penelitian, batasan masalah dan perangkat lunakatika penulisan. BAB II. : Tinjauan Pustaka Bab ini berisi tentang teori yang berkaitan dengan judul atau. masalah pada tugas akhir yang digunakan sebagai penunjang penelitian dan menjadi dasar atau sumber tertulis dari apa yang akan dilakukan. BAB III. : Metodologi Penelitian. Bab ini berisi tentang data, tahapan penelitian, perancangan perangkat lunak yang akan dibuat dan spesifikasi alat. BAB IV. : Implementasi dan Analisis Hasil. Bab ini berisi tentang implementasi perangkat lunak berdasarkan analisis dan perancangan yang dibuat sebelumnya, uji coba perangkat lunak serta analisis hasil. BAB V. : Penutup. Bab ini berisi tentang kesimpulan dan saran dari penelitian yang telah dilakukan.. 4.
(22) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. BAB II. TINJAUAN PUSTAKA 2.1. Penambangan Data 2.1.1. Definisi Penambangan Data Penambangan data atau Data Mining merupakan suatu proses untuk menemukan informasi atau pengetahuan yang berguna dari suatu data yang berjumlah besar. Data mining juga disebut sebagai serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data (Pramudiono, 2007). Data mining, sering juga disebut sebagai Knowledge Discovery in Database (KDD). KDD adalah kegiatan yang meliputi pengumpulan, pemakaian data, historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar (Santoso, 2007). Menurut Turban et.al.(2005) data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining. adalah proses yang menggunakan teknik. statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar.. 2.1.2. Fungsi Penambangan Data Menurut Yusuf W. dkk (2006) dikutip oleh (Citra, 2015) data mining dapat menjalankan fungsi-fungsi sebagai berikut : 1.Deskripsi Deskripsi dapat membantu dalam menjelaskan pola dan tren yang terjadi, pola dan trend data sering dideskripsikan. Model data mining harus transparan, sehingga hasilnya dapat mendeskripsikan pola dengan jelas. 2.Estimasi. 5.
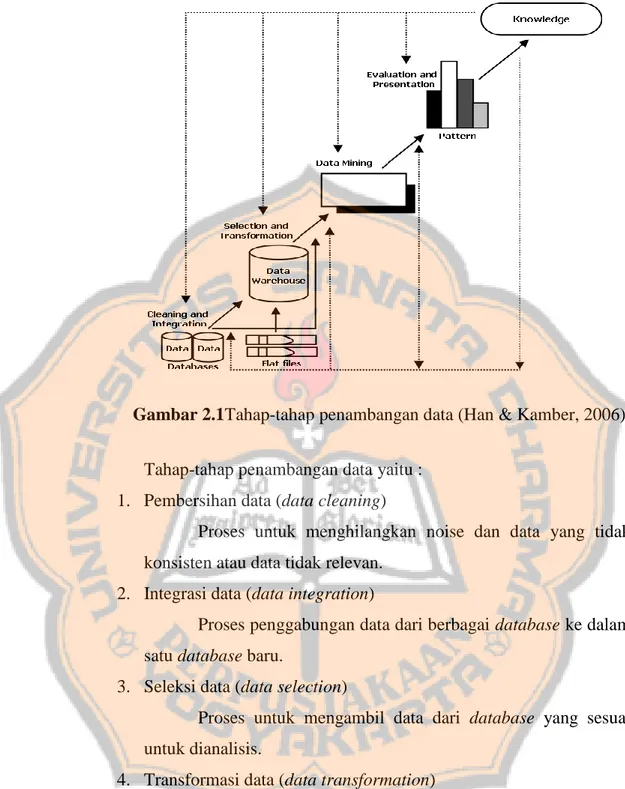
(23) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Estimasi sama dengan deskripsi kecuali variabel targetnya numerik. ketimbang. kategorikal.. Model. yang. dibuat. menggunakan record yang lengkap, yang telah menyediakan nilai variabel target prediktor. 3.Prediksi Prediksi sama dengan klasifikasi dan estimasi yang membedakannya hanya hasil dalam prediksi yang terjadi dimasa yang akan datang. 4.Klasifikasi Variabel target dalam kasifikasi adalah kategorikal. Mode data mining memeriksa set record yang besar, di mana setiap record memiliki informasi variabel target dan set input. 5.Clustering Pengelompokan record, observasi atau kasus ke dalam objek-objek yang mirip disebut dengan clustering. Didalam clustering tidak terdapat variabel target, clusteringmencoba memfregmentasi seluruh set data ke dalam subgroup yang relatif homogen, di mana kemiripan atar record diminimalisasikan. sedangkan. kemiripan. luar cluster. didalam. record. dimaksimalkan. 6.Asosiasi Asosiasi adalah suatu tugas untuk menemukan atributatribut yang terjadi bersamaan yang mencoba menemukan aturan untuk mengkuantifikasi hubungan antara dua atau lebih atribut.. 2.1.3. Tahap-Tahap Penambangan Data Rangkaian proses penambangan data dapat dibagi menjadi beberapa tahap yang diilustrasikan seperti pada Gambar 2.1.. 6.
(24) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Gambar 2.1Tahap-tahap penambangan data (Han & Kamber, 2006) Tahap-tahap penambangan data yaitu : 1. Pembersihan data (data cleaning) Proses untuk menghilangkan noise dan data yang tidak konsisten atau data tidak relevan. 2. Integrasi data (data integration) Proses penggabungan data dari berbagai database ke dalam satu database baru. 3. Seleksi data (data selection) Proses untuk mengambil data dari database yang sesuai untuk dianalisis. 4. Transformasi data (data transformation) Proses mengubah atau menggabung data ke dalam format yang sesuai untuk diproses dalam data mining. 5. Penambangan data (data mining) Proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari suatu data. 6. Evaluasi pola (pattern evaluation). 7.
(25) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Proses mengidentifikasi pola-pola menarik yang ditemukan. Pola-pola menarik maupun model prediksi pada hasil dari tahap data mining dievaluasi untuk menilai apakah hipotesa yang ada tercapai atau tidak. 7. Presentasi pengetahuan (knowledge presentation) Visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna. Dalam tahap terakhir ini, presentasi hasil data mining dalam bentuk pengetahuan yang bisa dipahami semua orang merupakan salah satu tahapan yang diperlukan.. 2.2. Algoritma C4.5 2.2.1. C4.5 Menurut Quinlan J.R, Algoritma Classification version 4.5 atau biasa disebut C4.5 adalah algoritma yang paling terkenal (Pramudiono, 2003). Algoritma C4.5 merupakan algoritma yang digunakan untuk membentuk. pohon. keputusan. (decision. tree).. Pohon. keputusan. merupakan metode klasifikasi dan prediksi yang berguna untuk mengeksplorasi data, menemukan hubungan tersembunyi antara sejumlah calon variabel input dengan sebuah variabel target. Algoritma ini merupakan pengembangan dari algoritma Iterative Dichotomiser (ID3). Perbedaan utama algoritma C4.5 dari ID3 yaitu : Tabel 2.1 Perbedaan Algoritma C4.5 dan ID3 Algoritma C4.5 Algoritma ID3 1. C4.5 dapat menangani atribut 1. ID3 hanya mampu menangani kontinyu dan diskrit 2.C4.5. dapat. menangani. atribut diskrit data 2. ID3 tidak dapat menangani data. training dengan missing value.. training dengan missing value.. 3. Hasil pohon keputusan C4.5 3. Hasil pohon keputusan ID3 tidak. 8.
(26) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. akan terpangkas setelah dibentuk. terpangkas setelah dibentuk. 4. Pemilihan atribut yang dilakukan 4. Pemilihan atribut yang dilakukan dengan menggunakan Gain Ratio.. dengan menggunakan Information Gain.. Secara umum algoritma C4.5 untuk membangun pohon keputusan adalah sebagai berikut : 1) Memilih atribut sebagai akar(root) dengan menghitung nilai entropy, information gain, split information dan gain ratio. Atribut yang memiliki nilai gain ratio tertinggi akan dipilih sebagai simpul akar dari pohon. 2) Membuat cabang untuk masing-masing nilai. 3) Membagi kasus dalam cabang 4) Mengulangi proses perhitungan untuk masing-masing cabang sampai semua kasus pada cabang memiliki kelas yang sama. Untuk mengukur efektifitas suatu atribut dalam melakukan teknik pengklasifikasian sampel data dapat menggunakan information gain. Sebelum mencari nilai gain, dilakukan perhitungan untuk mencari peluang kemunculan suatu record dalam atribut (entropy) dengan menggunakan rumus 2.1 berikut : ( ). ∑ ..........................(2.1). Keterangan : S : Himpunan kasus n. : Jumlah partisi S. pi : Proporsi dari Si terhadap S. 9.
(27) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Untuk melakukan perhitungan information gain digunakan seperti rumus 2.2sebagai berikut:. (. ). ( ). ∑. ( ) .........(2.2). Keterangan : S : Himpunan kasus A : Atribut n. : jumlah partisi atribut A. |Si| : Jumlah kasus pada partisi ke i |S| : Jumlah kasus dalam S Dalam algoritma C4.5, pemilihan atribut dilakukan dengan menggunaan gain ratio. Atribut dengan nilai gain ratio tertinggi dipilih sebagai atribut test untuk simpul. Untukmenghitung gain ratio perlu diketahui suatu term baru yang disebut dengan split information.Split information dihitung dengan menggunakan rumus 2.3 sebagai berikut : (. ). ∑ ....................(2.3). Di mana : S1 sampai Sc adalah c subset yang dihasilkan dari pemecahan S dengan menggunakan atribut A yang mempunyai sebanyak c nilai. Untuk menghitung gain ratio digunakan rumus 2.4 sebagai berikut :. 10.
(28) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. (. (. ). ) (. ) ....................(2.4). Pada saat membangun pohon keputusan, banyaknya cabang mungkin karena adanya noise atau outlierpada data training. Pemangkasan pohon (pruning) dapat dilakukan untuk mengenali dan menghilangkan cabang tersebut agar pohon lebih kecil dan lebih mudah dipahami. Selain itu, pemangkasan pohon juga perlu dilakukan karena dalam teknik klasifikasi yang akan dijalankan nantinya akan mengeluarkan pola atau rule yang dibentuk berdasarkan struktur pohon, jadi jika struktur pohon tidak teratur atau kurang sederhana, maka rule yang dihasilkan pun akan rumit untuk diimplementasikan. Ada dua metode yang dapat digunakan untuk melakukan pemangkasan pohon keputusan, yaitu : 1. Prepruning Prepruningyaitu melakukan pemangkasansubtree lebih awal, yakni dengan memutuskan untuk tidak lebih jauh mempartisi data training. Pada pendekatan prepruning, sebuah pohon dipangkas dengan cara menghentikan pembangunannya jika partisi yang akan dibuat dianggap tidak signifikan. Keuntungan dari prepruningyaitu lebih hemat waktu dalam proses pembentukan pohon keputusan. 2. Postpruning Postpruning yaitu menyederhanakan pohon dengan cara memangkas beberapa cabang subtree setelah pohon selesai dibangun. Langkah-langkah pemangkasan pohon : 1. Hitung Pessimistic error rate parent. 2. Hitung Pessimistic error rate child. 3. Jika Pessimistic error rate child>parent, maka lakukan pemangkasan. 4. Jika Pessimistic error rate child<parent, maka lanjutkan split.. 11.
(29) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Untuk menghitung Pessimistic error rate digunakan rumus 2.5 berikut. √. ..................(2.5) Jika c= 25% (default untuk C4.5) maka z= 0,69 (dari distribusi normal) f = nilai perbandingan error rate. n = total sample.. 2.2.2. Contoh Penerapan C4.5 Berikut merupakan contoh sederhana penerapan algoritma C4.5 untuk menyelesaikan kasus apakah pasien mengidap penyakit kanker serviks atau tidak, berdasarkan IUD (years) yang menyatakan berapa tahun pasien menggunakan alat kontrasepsi IUD, First Sexual Intercourse menyatakan umur pasien saat pertama kali melakukan hubungan seksual, Dx:CINmenyatakan hasil diagnosis Cervical Intraepithelial Neoplasiadan status STDs:HIV menyatakan apakah pasien menderita penyakit menular seksual jenis HIV. Pada tabel 2.2 berikut akan digunakan untuk membentuk pohon keputusan: Tabel 2.2 Data Pasien IUD (years). First Sexual. Dx : CIN. Intercoure. STDs : HIV. BIOPSY. 0-5. 10 - 16. False. True. No. 0-5. 10 - 16. False. False. No. >= 12. 10 - 16. False. True. Yes. 6 - 11. 17 - 23. False. True. Yes. 6 - 11. >= 24. True. True. Yes. 6 - 11. >= 24. True. False. Yes. 12.
(30) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. >= 12. >= 24. True. False. Yes. 0-5. 17 - 23. False. True. No. 0-5. >= 24. True. True. Yes. 6 - 11. 17 - 23. True. True. Yes. 0-5. 17 - 23. True. False. Yes. >= 12. 17 - 23. False. False. Yes. >= 12. 10 - 16. True. True. Yes. 6 - 11. 17 - 23. False. False. No. Pada tabel 2.2, atribut-atributnya adalah IUD (years), First Sexual Intercourse, Dx:CIN dan STDs:HIV. Setiap atribut memiliki nilai masing-masing. Sedangkan kelasnya ada pada kolom Biopsy, yaitu kelas “Yes” atau “No”. Data tersebut memiliki 14 kasus yang terdiri dari 10 “Yes” dan 4 “No”.. Langkah 1, menghitung Entropy Total dari masing-masing nilai Biopsy dengan rumus 2.1 : EntropyTotal(10Yes,4No) =(-10/14*log2(10/14)) + (-4/14*log2(4/14)) =0,346733448 + 0,516387121 = 0,863120569 Langkah 2, menghitung Entropy dari atribut IUD (years) dengan rumus 2.1: EntropyIUD (years)0 - 5(2Yes,3No)=(-2/5*log2(2/5)) + (-3/5*log2(3/5)) =0,528771238 + 0,442179356 = 0,970950594 EntropyIUD (years)6-11(4Yes,1No)=(-4/5*log2(4/5)) + (-1/5*log2(1/5)) =0,257542476 + 0,464385619 = 0,721928095 EntropyIUD (years)>= 12(4Yes,0No)=(-4/4*log2(4/4)) + (0/4*log2(0/4)). 13.
(31) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. =0+ 0 =0 EntropyTotal(IUD (years))=5/14*(0,970950594)+5/14* (0,721928095)+0 =0,346768069 + 0,257831463 + 0 = 0,604599532 Langkah 3, menghitung Information Gain dari atribut IUD (years) dengan rumus 2.2: Gain(Total,IUD (years))=0,863120569 - 0,604599532 = 0,258521037 Langkah 4, menghitung Split Information dari atribut IUD (years) dengan rumus 2.3: SplitInformation(Total,IUD (years)). = (-5/14*log2(5/14)) + (-5/14*log2(5/14)) + (-4/14*log2(4/14)) = 1,577406283. Langkah 5, menghitung Gain Ratio dari atribut IUD (years) dengan rumus 2.4: GainRatio(Total,IUD (years)) =0,258521037/1,577406283 = 0,16388995 Ulangi langkah 2, menghitung Entropy dari atribut First Sexual Intercourse dengan rumus 2.1: EntropyFirstSexualIntercourse10 - 16(2Yes,2No) =(-2/4*log2(2/4))+ (2/4*log2(2/4)) =0,5 + 0,5 =1 EntropyFirstSexualIntercourse17 - 23(4Yes,2No) =(-4/6*log2(4/6)) + (-2/6*log2(2/6)) =0,389975 + 0,528320834. 14.
(32) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. = 0,918295834 EntropyFirstSexualIntercourse>= 24(4Yes,0No)=(-4/4*log2(4/4)) + (0/4*log2(0/4)) =0+ 0 =0 EntropyTotal(FirstSexualIntercourse) = 4/14 * 1 + 6/14 * (0,918295834) + 0 =0,285714286 + 0,393555357 + 0 = 0,679269643 Ulangi langkah 3, menghitung Information Gain dari atribut First Sexual Intercourse dengan rumus 2.2: Gain(Total,FirstSexualIntercourse). =0,863120569 - 0,679269643 = 0,183850926. Langkah 4, menghitung Split Information dari atribut First Sexual Intercourse dengan rumus 2.3: SplitInformation(Total,FirstSexualIntercourse)= (-4/14*log2(4/14)) +(-6/14*log2(6/14)) +(-4/14*log2(4/14)) = 1,556656707 Langkah 5, menghitung Gain Ratio dari atribut First Sexual Intercourse dengan rumus 2.4: GainRatio(Total,FirstSexualIntercourse)=0,183850926/ 1,556656707 = 0,118106275. Ulangi langkah 2, menghitung Entropy dari atribut Dx:CIN dengan rumus 2.1: EntropyDx:CINFalse(3Yes,4Np). =(-3/7*log2(3/7))+(-4/7*log2(4/7)) =0,523882466+ 0,46134567. 15.
(33) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. = 0,985228136 EntropyDx:CINTrue(7Yes,0No). =(-7/7*log2(7/7))+(-0/7*log2(0/7) =0 + 0 =0. EntropyTotal(Dx:CIN). = 7/14*(0,985228136) + 0 =0,492614068 + 0 = 0,492614068. Ulangi langkah 3, menghitung Information Gain dari atribut Dx:CIN dengan rumus 2.2: Gain(Total, Dx:CIN). =0,863120569 - 0,492614068 = 0,370506501. Langkah 4, menghitung Split Information dari atribut Dx:CIN dengan rumus 2.3: SplitInformation(Total,Dx:CIN) = (-7/14*log2(7/14)) + (-7/14*log2(7/14)) =1 Langkah 5, menghitung Gain Ratio dari atribut Dx:CIN dengan rumus 2.4: GainRatio(Total,Dx:CIN). =0,370506501/1 = 0,370506501. Ulangi langkah 2, menghitung Entropy dari atribut STDs:HIV dengan rumus 2.1: EntropySTDs:HIVFalse(2Yes,4No)=(-2/6*log2(2/6))+(-4/6*log2(4/6)) =0,528320834+ 0,389975 = 0,918295834 EntropySTDs:HIVTrue(6Yes,2No) =(-6/8*log2(6/8))+(-2/8*log2(2/8) =0,311278124 + 0,5 = 0,811278124 EntropyTotal(STDs:HIV). = 6/14*(0,918295834) + 8/14 *. 16.
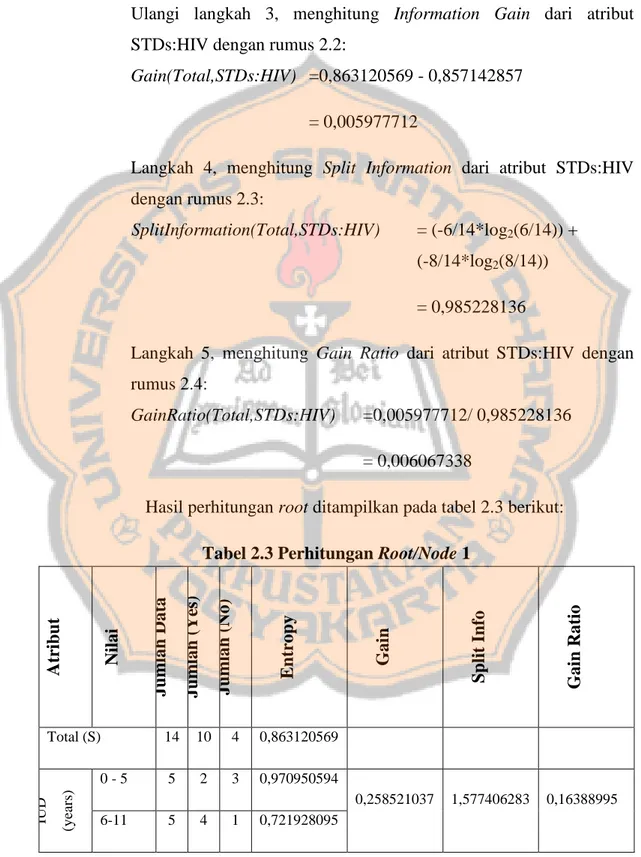
(34) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. (0,811278124) =0,393555357 + 0,4635875 = 0,857142857 Ulangi langkah 3, menghitung Information Gain dari atribut STDs:HIV dengan rumus 2.2: Gain(Total,STDs:HIV) =0,863120569 - 0,857142857 = 0,005977712 Langkah 4, menghitung Split Information dari atribut STDs:HIV dengan rumus 2.3: SplitInformation(Total,STDs:HIV). = (-6/14*log2(6/14)) + (-8/14*log2(8/14)) = 0,985228136. Langkah 5, menghitung Gain Ratio dari atribut STDs:HIV dengan rumus 2.4: GainRatio(Total,STDs:HIV). =0,005977712/ 0,985228136 = 0,006067338. Hasil perhitungan root ditampilkan pada tabel 2.3 berikut:. (years). IUD. Total (S). 14. 10. 4. 0,863120569. 0-5. 5. 2. 3. 0,970950594. 6-11. 5. 4. 1. 0,721928095. 0,258521037. 17. 1,577406283. Gain Ratio. Split Info. Gain. Entropy. Jumlah (No). Jumlah (Yes). Jumlah Data. Nilai. Atribut. Tabel 2.3 Perhitungan Root/Node 1. 0,16388995.
(35) Intercourse. STDs:HIV. Dx:CIN. First Sexual. PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. >= 12. 4. 4. 0. 0. 10 - 16. 4. 2. 2. 1. 17 - 23. 6. 4. 2. 0,918295834. >= 24. 4. 4. 0. 0. False. 7. 3. 4. 0,985228136. True. 7. 7. 0. 0. False. 6. 2. 4. 0,918295834. True. 8. 6. 2. 0,183850926. 1,556656707. 0,118106275. 0,370506501. 1. 0,370506501. 0,005977712. 0,985228136. 0,006067338. 0,811278124. Dari hasil perhitungan pada tabel 2.3 di atas diperoleh nilai Gain Ratio tertinggi adalah atribut Dx:CIN yaitu 0,370506501. Dengan demikian atribut terbentuk sebagai root. Pada atribut Dx:CIN terdapat dua nilai atribut, yaitu “False” dan “True”. Pada status Dx:CIN “True”, memiliki 7 kasus dan semuanya bernilai “Yes”. Hal ini menunjukan bahwa Dx:CIN “True” menjadi daun atau leaf. Jika divisualisasi maka pohon keputusan akan tampak seperti Gambar 2.2.. Yes. Gambar 2.2 Pohon Keputusan Node 1 (Root Node). Berdasarkan Gambar 2.2 di atas, node 1.1 akan dianalisis lebih lanjut. Untuk mempermudahnya, maka Tabel 2.2 difilter dengan. 18.
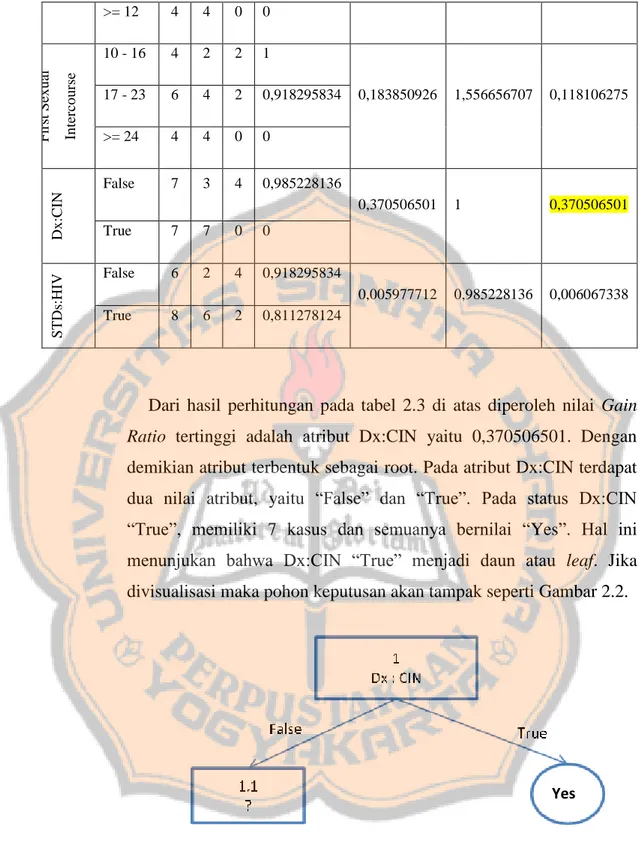
(36) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. mengambil. data. yang. memiliki. Dx:CIN. =. False. sehingga. menghasilkan Tabel 2.4 seperti berikut: Tabel 2.4 Data Pasien dengan Dx:CIN = False IUD. NO. FIRST SEXUAL. (YEARS) INTERCOURSE. DX:CIN. STDS:HIV. BIOPSY. 1. 0-5. 10 - 16. False. True. No. 2. 0-5. 10 - 16. False. False. No. 3. >= 12. 10 - 16. False. True. Yes. 4. 6-11. 17 - 23. False. True. Yes. 5. 0-5. 17 - 23. False. True. No. 6. >= 12. 17 - 23. False. False. Yes. 7. 6-11. 17 - 23. False. False. No. Kemudian data di Tabel 2.3 dianalisis dan dihitung dengan mengulangi. langkah-langkah. perhitungan. seperti. yang. sudah. dilakukan sebelumnya. Hasil perhitungan tersebut ditampilkan pada Tabel 2.5 berikut.. 3. 4. 0,985228136. 0-5. 3. 0. 3. 0. 6-11. 2. 1. 1. 1. >= 12. 2. 2. 0. 0. 10 - 16. 3. 1. 2. 0,918295834. 4. 2. 2. 1. 17 - 23. 19. Gain Ratio. Split Info. Gain. Entropy. Jumlah (No). Jumlah (Yes). 7. e. Intercours. Sexual. First. IUD (years). Total (S). Jumlah Data. Nilai. Atribut. Tabel 2.5 Perhitungan Node 1.1. 0,69951385. 1,556656707. 0,449369374. 0,020244207. 0,985228136. 0,020547736.
(37) STDs:HIV. PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. >= 24. 0. 0. 0. 0. False. 3. 1. 2. 0,918295834 0,020244207. True. 4. 2. 2. 0,985228136. 0,020547736. 1. Dari hasil perhitungan pada tabel 2.5 di atas diperoleh nilai Gain Ratio tertinggi adalah atribut IUD (years) yaitu 0,449369374. Dengan demikian atribut IUD (years) terbentuk menjadi node 1.1. Pada atribut IUD (years) “>= 12” memiliki 2 kasus dan semuanya bernilai “Yes”, sedangkan pada atribut IUD (years) “0 - 5” memiliki 3 kasus dan semuanya bernilai “No”. Dengan demikian kedua nilai tersebut dijadikan daun atau leaf. Jika divisualisasikan maka pohon keputusan akan tampak seperti Gambar 2.3.. Ye s. Ye. No. Gambar 2.3 Pohon Keputusan Node 1.1. Untuk menganalisis node 1.1.2, kembali dilakukan filter untuk data yang memiliki atribut bernilai Dx:CIN = False dan IUD (years) = 6-11 sehingga data yag dihasilkan seperti pada Tabel 2.5.. 20.
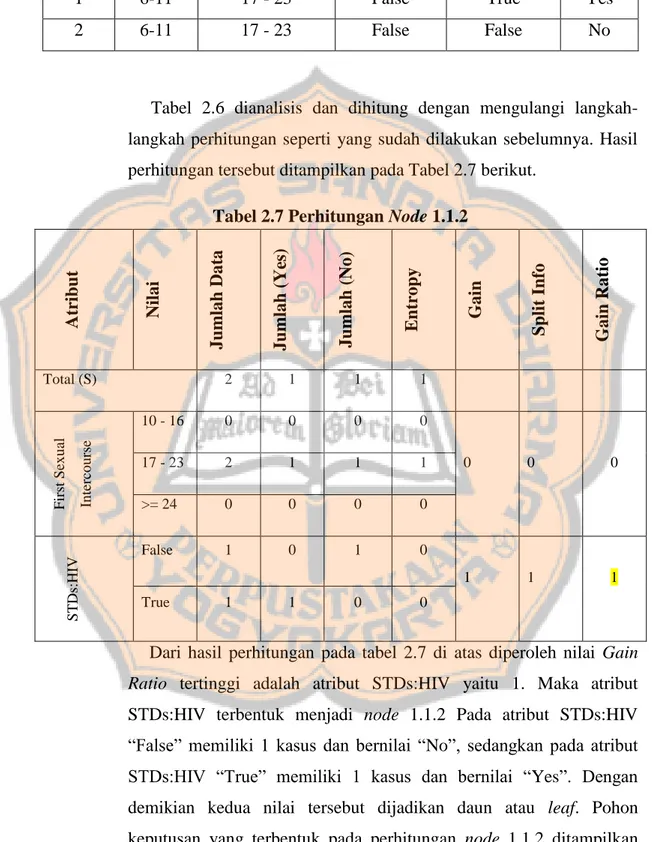
(38) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Tabel 2.6 Data Pasien Dx:CIN = False dan IUD (years) = 6-11 NO. IUD. FIRST SEXUAL. (YEARS) INTERCOURSE. DX:CIN. STDS:HIV. BIOPSY. 1. 6-11. 17 - 23. False. True. Yes. 2. 6-11. 17 - 23. False. False. No. Tabel 2.6 dianalisis dan dihitung dengan mengulangi langkahlangkah perhitungan seperti yang sudah dilakukan sebelumnya. Hasil perhitungan tersebut ditampilkan pada Tabel 2.7 berikut.. Intercourse. STDs:HIV. First Sexual. Total (S). 2. 1. 1. 1. 10 - 16. 0. 0. 0. 0. 17 - 23. 2. 1. 1. 1. >= 24. 0. 0. 0. 0. False. 1. 0. 1. 0. True. 1. 1. 0. Gain Ratio. Split Info. Gain. Entropy. Jumlah (No). Jumlah (Yes). Jumlah Data. Nilai. Atribut. Tabel 2.7 Perhitungan Node 1.1.2. 0. 0. 0. 1. 1. 1. 0. Dari hasil perhitungan pada tabel 2.7 di atas diperoleh nilai Gain Ratio tertinggi adalah atribut STDs:HIV yaitu 1. Maka atribut STDs:HIV terbentuk menjadi node 1.1.2 Pada atribut STDs:HIV “False” memiliki 1 kasus dan bernilai “No”, sedangkan pada atribut STDs:HIV “True” memiliki 1 kasus dan bernilai “Yes”. Dengan demikian kedua nilai tersebut dijadikan daun atau leaf. Pohon keputusan yang terbentuk pada perhitungan node 1.1.2 ditampilkan pada Gambar 2.4 berikut:. 21.
(39) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Y. Y. No. No. Y. Gambar 2.4 Pohon Keputusan Node 1.1.2. Dengan memperhatikan pohon keputusan pada Gambar 2.4 di atas, diketahui bahwa semua kasus telah masuk dalam kelas. Dengan demikian pohon keputusan tersebut merupakan pohon terakhir yang terbentuk. 2.3. Kanker Serviks 2.3.1. Definisi Kanker Serviks Kanker serviks adalah jenis kanker yang muncul pada leher rahim. Pengertian kanker serviks adalah suatu proses keganasan yang terjadi pada leher rahim, sehingga jaringan di sekitarnya tidak dapat melaksanakan fungsi sebagaimana mestinya. Keadaan tersebut biasanya disertai dengan adanya perdarahan dan pengeluaran cairan vagina yang abnormal, penyakit ini dapat terjadi berulang-ulang (Prayetni, 2007).. 22.
(40) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 2.3.2. Penyebab Kanker Serviks Kanker serviks 99,7 % disebabkan oleh Human Papilloma Virus (HPV). HPV adalah virus yang paling sering dijumpai pada penyakit menular seksual dan diduga berperan dalam proses terjadinya kanker. Saat ini terdapat 138 jenis HPV yang sudah teridentifikasi, 40 diantaranya dapat ditularkan melalui hubungan seksual. HPV yang dapat menyebabkan kanker serviks yaitu HPV risiko sedang maupun tinggi. Beberapa penelitian mengemukakan bahwa 90% kanker serviks disebabkan oleh HPV tipe 16 dan 18. Dari kedua tipe ini, HPV tipe 16 telah menyebabkan lebih dari 50% kanker serviks. Seseorang. yang sudah. terinfeksi. HPV. 16. maka. memiliki. kemungkinan terkena kanker serviks sebesar 5% (Rasjidi, 2009).. 2.3.3. Faktor Risiko Kanker Serviks Menurut Diananda (2007), faktor-faktor yang mempengaruhi kanker serviks yaitu : 1.Usia > 35 tahun mempunyai risiko tinggi terhadap kanker serviks. 2.Melakukan hubugan seksual pada usia kurang dari 20 tahun. Hubugan seks idealnya dilakukan setelah seorang wanita benar-benar matang. 3. Wanita dengan aktivitas seksual yang tinggi, dan sering berganti-ganti. pasangan.. Berganti-ganti. pasangan. memungkinkan seseorang tertular penyakit kelamin, seperti HPV. 4. Penggunaan antiseptik dengan menggunakan obat-obatan antiseptik maupun deodoran ketika mencuci vagina dapat mengakibatkan iritasi yang mengakibatkan terjadinya kanker. 5. Wanita yang merokok. Wanita perokok memiliki risiko 2 kali lebih besar terkena kanker serviks dibandingkan dengan wanita yang tidak merokok.. 23.
(41) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 6. Riwayat penyakit kelamin dan infeksi virus seperti herpes dan kutil genetalia 7. Paritas (jumah kelahiran). Wanita yang memiliki banyak anak dengan jarak persalinan yang terlalu pendek memiliki risiko yang semakin tinggi karena berdampak pada seringnya terjadi perlukaan di organ reproduksinya yang memudahkan munculnya HPV. 8. Penggunaan kontrasepsi oral dalam jangka waktu lama.. 2.3.4. Diagnosis Kanker Serviks Wanita dengan kanker serviks stadium awal dan pre-kanker tidak menimbulkan gejala sama sekali hingga sel kanker menyebar ke jaringan di sekitarnya membentuk tumor. Gejala-gejala kanker serviks baru akan muncul saat kanker sudah memasuki stadium lanjut(di atas stadium dua). Dalam diagnosis penyakit kanker, dokter akan melakukan beragam tes sebagai berikut : 1. Tes Pap Smear Tes pap smear bertujuan untuk mengetahui apakah terdapat pertumbuhan sel yang abnormal pada rahim. Tes ini harus mulai dilakukan pada wanita usia 18 tahun atau ketika telah melakukan aktivitas seksual sebelum itu. Setiap wanita yang telah aktif secara seksual dianjurkan menjalani pap smear secara teratur yaitu 1 kali setiap tahun. 2. Tes HPV Tes HPV adalah tes yang dilakukan untuk mengidentifikasi jenis HPV mana yang paling mungkin menyebabkan kanker serviks. Tes HPV memiliki tujuan yang sama dengan tes pap smear yaitu mendeteksi kanker serviks secara dini. Tes HPV dapat dilakukan bersamaan dengan tes pap smear. 3. Tes Kolposkopi. 24.
(42) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Tes kolposkopi digunakan dokter untuk mengonfirmasi keberadaan sel abnormal di serviks. Tes ini juga dapat digunakan untuk memandu biopsi. Tes kolposkopi menggunakan alat khusus yang bernama kolposkop. Kolposkop tidak dimasukkan ke dalam tubuh dan alat ini dapat memperlihatkan tampilan selsel serviks dan vagina yang diperbesar. 4. Biopsi Biopsi merupakan tes yang dilakukan dengan mengambil sejumlah kecil jaringan sebagai sampel untuk diperiksa menggunakan mikroskop. Biopsi sering dilakukan untuk memastikan suatu diagnosis. Selain untuk diagnosis, biopsi juga dapat dilakukan untuk mengangkat jaringan abnormal dari serviks serta memberikan pengobatan untuk sel pra-kanker. Walaupun tes-tes lain dapat menunjukkan kemungkinan adanya kanker di serviks, tetapi hanya biopsi lah satu-satunya cara pasti dalam mendeteksi kanker.. 2.4. Imbalanced Data Sebuah data dapat dikatakan menjadi tidak seimbang (imbalanced) jika terdapat satu kelas yang direpresentasikan dalam jumlah instance yang kecil bila dibandingkan dengan jumlah instancekelas yang lainnya. Kondisi tersebut dapat menimbulkan masalah pada klasifikasi data yang kasusnya jarang terjadi akan tetapi sangat penting, contohnya pada pengklasifikasian data kecurangan transaksi telepon, pengenalan citra satelit untuk pendeteksian tumpahan minyak, deteksi kkegagalan mesin suatu pabrik, deteksi penyakit yang langka tetapi berbahaya (Barandela et al. 2002). Kondisi imbalanced data dapat terlihat secara nyata pada himpunan data yang memiliki dua kelas. Kelas yang jumlah instance terkecil (minority class) disebut kelas positif dan kelas yang jumlah instance. 25.
(43) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. terbesar (majority class) disebut kelas negatif. Rasio jumlah instance antara kedua kelas yaitu 1:100, 1:1000 dan 1:10000 atau lebih. Ada dua pendekatan yang dapat dilakukan untuk mengatasi kondisi imbalanced. data.. Pendekatan. pertama. yaitu. pada. level. data,. menggunakan teknik pengambilan contoh (sampling technique) dan pendekatan kedua yaitu pada level algoritma. Pendekatan sampling technique terdiri dari dua cara yaitu Oversampling kelas terkecil dan Undersamplingkelas terbesar. 1. Oversampling Teknik pengambilan contoh meningkatkan jumlah kelas terkecil dengan cara mereplikasi data secara acak sehingga jumlahnya sama dengan kelas terbesar. 2. Undersampling Teknik pengambilan contoh mengurangi jumlah data kelas terbesar secara acak sehingga jumlahnya sama dengan kelas terkecil. 2.5. SplitValidation Split Validation merupakan teknik validasi yang membagi data menjadi dua bagian, sebagian sebagai data training dan sebagian lainnya sebagai data testing. Dengan menggunakan split validation akan dilakukan proses training berdasarkan splitratio yang telah ditentukan sebelumnya, kemudian sisa dari split ratio data training akan dianggap sebagai data testing. Data training merupakan data yang akan dipakai dalam melakukan pembelajaran sedangkan data testing merupakan data yang belum pernah dipakai sebagai pembelajaran dan akan digunakan sebagai. data. pengujian. kebenaran. hasil. pembelajaran.. splitvalidation dipaparkan pada Gambar 2.4 berikut :. 26. Ilustrasi.
(44) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Gambar 2.5 Ilustrasi Split Validation. 2.6. ConfusionMatrix Confusion Matrix merupakan suatu metode yang dapat digunakan untuk menghitung akurasi suatu metode klasifikasi pada konsep data mining. Pada dasarnya confusion matrix mengandung informasi yang membandingkan hasil klasifikasi yang dilakukan oleh perangkat lunak dengan hasil klasifikasi yang seharusnya. Tabel 2.8 menyajikan bentuk confusion matrix sebagai berikut : Tabel 2.8 Confusion Matrix PREDIKSI Positif. Negatif. Positif. TP. FN. Negatif. FP. TN. AKTUAL. Keterangan : a. TP (True Positive), yaitu jumlah data yang kelas aktualnya adalah kelas positif dengan kelas prediksinya adalah kelas positif.. 27.
(45) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. b. FN (False Negative), yaitu jumlah data yang kelas aktualnya adalah kelas positif dengan kelas prediksinya adalah kelas negatif. c. FP (False Positive), yaitu jumlah data yang kelas aktualnya adalah kelas negatif dengan kelas prediksinya adalah kelas positif. d. TN (True Negative), yaitu jumlah data yang kelas aktualnya adalah kelas negatif dengan kelas prediksinya adalah kelas negatif. Berdasarkan Tabel 2.8di atas, untuk menghitung akurasi yaitu dengan menggunakan rumus 2.6 berikut :. .............................(2.6). 28.
(46) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. BAB III. METODOLOGI PENELITIAN 3.1. Sumber Data Data yang digunakan oleh penulis dalam penelitian ini adalah data yang diperoleh dari situsUCI Machine Learning yang dapat diakses melalui alamat https://archive.ics.uci.edu/ml/index.php. Data pasien dikumpulkan dari Rumah Sakit Universitario de Caracas di Caracas, Venezuela. Data tersebut berfokus pada prediksi/indikator risiko kanker serviks. Jumlah data sebanyak 858 data pasien, dengan 32 atribut yang terdiri dari informasi demografis, kebiasaan, dan catatan rekam medis serta. 4. label. kelas. yaitu. Hinselmann,. Schiller,. Citology. dan. Biopsy.Namun pada penelitian ini penulis hanya akan berfokus pada target biopsy. Beberapa pasien tidak menjawab beberapa pertanyaan karena masalah privasi (missing value).Atribut data kanker serviks dipaparkan pada tabel 3.1 berikut. Tabel 3.1 Atribut Data Kanker Serviks No. Attribut. 1. Age. 2. 3. Number of sexual. Tipe Data. Keterangan Umur pasien. Integer. Jumlah pasangan seksual. Integer. Umur. Integer. partners First sexual intercourse (age). pasien. melakukan. saat hubungan. seksual pertama. 4. Num of pregnancies. Jumlah kehamilan pasien. Integer. 5. Smokes. Apakah pasien merokok. Boolean. Berapa tahun pasien. Integer. 6. Smokes (years). merokok. 29.
(47) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Berapa bungkus rokok yang 7. 8. 9. Smokes (packs/year). Hormonal contraceptives. Hormonal contraceptives (years). dihabiskan pasien per tahun Apakah pasien. IUD. Boolean. menggunakan kontrasepsi hormonal Berapa tahun pasien. Integer. menggunakan kontrasepsi hormonal Apakah pasien. 10. Integer. Boolean. menggunakan alat kontrasepsi intrauterine device Berapa tahun pasien. 11. IUD (years). Integer. menggunakan kontrasepsi intrauterine device. 12. STDs. 13. STDs (number). Apakah pasien menderita penyakit menular seksual Jumlah penyakit menular. STDs:condylomatosis. Integer. yang diderita pasien Apakah pasien menderita. 14. Boolean. Boolean. penyakit menular seksual jenis condylomatosis Apakah pasien menderita. 15. STDs:cervical. penyakit menular seksual. condylomatosis. jeniscervical. Boolean. condylomatosis Apakah pasien menderita 16. STDs:vaginal condylomatosis. penyakit menular seksual jenis vaginal condylomatosis. 30. Boolean.
(48) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Apakah pasien menderita 17. STDs:vulvo-perineal condylomatosis. Boolean. penyakit menular seksual jenis vulvo-perineal condylomatosis Apakah pasien menderita. 18. STDs:syphilis. Boolean. penyakit menular seksual jenissyphilis Apakah pasien menderita. 19. STDs:pelvic. penyakit menular seksual. inflammatory disease. jenispelvic inflammatory. Boolean. disease Apakah pasien menderita 20. STDs:genital herpes. Boolean. penyakit menular seksual jenisgenital herpes Apakah pasien menderita. 21. STDs:molluscum contagiosum. Boolean. penyakit menular seksual jenismolluscum contagiosum Apakah pasien menderita. 22. STDs:AIDS. Boolean. penyakit menular seksual jenisAIDS Apakah pasien menderita. 23. STDs:HIV. Boolean. penyakit menular seksual jenisHIV Apakah pasien menderita. 24. STDs:Hepatitis B. Boolean. penyakit menular seksual jenisHepatitis B. 25. STDs:HPV. Apakah pasien menderita. 31. Boolean.
(49) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. penyakit menular seksual jenisHPV. 26. 27. 28. 29. 30. STDs: Number of diagnosis. Jumlah diagnosis penyakit. Integer. menular seksual. STDs: Time since first diagnosis. Tahun diagnosis penyakit. Integer. menular seksual pertama kali. STDs: Time since last diagnosis. Tahun diagnosis penyakit. Integer. menular seksual terakhir kali. Dx:Cancer. Hasil diagnosis kanker. Boolean. Hasil diagnosis Cervical. Boolean. Intraepithelial. Dx:CIN. Neoplasia (CIN) Hasil diagnosis Human 31. Dx:HPV. 32. Dx. Boolean. Papilloma Virus (HPV) Hasil diagnosis. Boolean. Contoh data mentah yang digunakan pada penelitian ini dapat dilihat pada lampiran 1. Data yang diperoleh pada penelitian ini merupakan data tidak seimbang (imbalanced data) karena terdapat kelas yang mendominasi dari kelas lainnya. Kelas dari biopsy yang menyatakan pasien tidak menderita kanker serviks merupakan kelas mayoritas, sedangkan kelas dari biopsyyang menyatakan pasien menderita kanker serviks merupakan kelas minoritas. Detail mengenai kelas biopsy pada dataset dipaparkan pada tabel 3.2 berikut. Tabel 3.2 Detail Kelas Biopsy Jumlah Biopsy. 32.
(50) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. No. 803. Yes. 55 Total : 858. 3.2. Tahapan Penelitian Pendekatan sistematis yang akan digunakan dalam merealisasikan tujuan dan rumusan masalah di atas adalah dengan menggunakan langkah-langkah sebagai berikut :. 3.2.1. Knowledge Discovery in Database (KDD) 3.2.2.1. Pembersihan Data (Data Cleaning) Proses pembersihan data untuk menghilangkan noise atau. data yang tidak konsisten. Pada data pasien yang digunakan, terdapat dua atribut yang memiliki banyak nilai kosong dikarenakan masalah privasi pasien. Kedua atribut tersebut yaitu atribut STDs: Time since first diagnosis dan STDs: Time since last diagnosis. Dengan begitu pada proses ini kedua atribut akan dihilangkan. Beberapa atribut yang memiliki sedikit nilai kosong akan diganti dengan nilai rata-rata atau dengan nilai modus tergantung jenis datanya.Pada data integer digunakan cara mengganti nilai kosong dengan nilai rata-rata, sedangkan untuk data boolean maka digunakan cara mengganti nilai kosong dengan nilai modus. Detail mengenai atribut yang memiliki sedikit nilai kosong akan dipaparkan pada tabel 3.3 berikut. Tabel 3.3 Beberapa atribut yang Memiliki Sedikit Nilai Kosong Tipe Data Mengganti Nilai No Attribut Kosong 1. Number of sexual partners. Integer. Mean= 2. 2. First sexual intercourse. Integer. Mean= 17. 33.
(51) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. (age) 3. Num of pregnancies. Integer. Mean = 2. 4. Smokes. Boolean. Modus = 0 (false). 5. Hormonal contraceptives. Boolean. Modus = 1 (true). Hormonal contraceptives. Integer. Mean = 2. 6. (years). 7. IUD. Boolean. Modus = 0 (false). 8. STDs. Boolean. Modus = 0 (false). 9. STDs:condylomatosis. Boolean. Modus = 0 (false). STDs:cervical. Boolean. Modus = 0 (false). Boolean. Modus = 0 (false). Boolean. Modus = 0 (false). 10. condylomatosis STDs:vaginal. 11. condylomatosis STDs:vulvo-perineal. 12. condylomatosis. 13. STDs:syphilis. Boolean. Modus = 0 (false). STDs:pelvic inflammatory. Boolean. Modus = 0 (false). 14. disease. 15. STDs:genital herpes. Boolean. Modus = 0 (false). STDs:molluscum. Boolean. Modus = 0 (false). 16. contagiosum. 17. STDs:AIDS. Boolean. Modus = 0 (false). 18. STDs:HIV. Boolean. Modus = 0 (false). 34.
(52) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 19. STDs:Hepatitis B. Boolean. Modus = 0 (false). 20. STDs:HPV. Boolean. Modus = 0 (false). 21. Dx:Cancer. Boolean. Modus = 0 (false). 22. Dx:CIN. Boolean. Modus = 0 (false). 23. Dx:HPV. Boolean. Modus = 0 (false). 24. Dx. Boolean. Modus = 0 (false). 3.2.2.2. Integrasi Data (Data Integration) Proses penggabungan data dari berbagai database ke dalam. database baru. Integrasi data dapat dilakukan jika data yang diperoleh berasal dari sumber yang berbeda. Pada penelitian ini peneliti memperoleh data langsung dari satu sumber sehingga tidak diperlukan proses integrasi data. 3.2.2.3. Seleksi Data (Data Selection) Proses seleksi data dilakukan untuk atribut data yang tidak. diperlukan akan dibuang atau ditinggalkan. Pada penelitian ini peneliti hanya akan berfokus pada target biopsi sehingga tiga target lainnya yaitu Hinselmann, Schiller dan Citology akan dibuang. Pada atribut STDs: cervical condylomatosis dan STDs: AIDS semua data bernilai sama yaitu false sehingga kedua atribut tersebut akan dibuang karena tidak memiliki nilai pembandingnya. Selanjutnya, terdapat 4 atribut yang dapat dihapus yaitu atribut Smokes, Hormonal Contraceptives, IUD dan STDs. Atribut Smokes dihapus karena terdapat atribut lain yang telah menjelaskan atribut Smokes yaitu Smokes (years) dan Smokes (packs/year). Ketika pasien tidak merokok maka atribut Smokes (years) dan Smokes (packs/year) akan diisi dengan nilai 0, maka dari kedua atribut tersebut pun dapat menjelaskan apakah seseorang tersebut merokok. 35.
(53) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. atau tidak. Hal ini juga berlaku untuk ketiga atribut Hormonal Contraceptives, IUD dan STDs karena atribut-atribut tersebut kurang memberikan informasi yang banyak maka lebih baik dihapus dari dataset. 3.2.2.4. Transformasi Data (Data Transformation) Proses transformasi data atau mengubah data ke dalam. bentuk yang sesuai dilakukan agar data dapat diolah dengan perhitungan algoritma C4.5. Pada tahap ini transformasi dilakukan dengan cara mengubah data ke dalam bentuk kategori. Berikut transformasi yang dilakukan pada masing-masing atribut : 1. Transformasi pada kolom STDs: condylomatosis 0 : False 1 : True 2. Transformasi pada kolom STDs: vaginal condylomatosis 0 : False 1 : True 3. Transformasi. pada. kolom. STDs:. vulvo-perineal. condylomatosis 0 : False 1 : True 4. Transformasi pada kolom STDs: syphilis 0 : False 1 : True 5. Transformasi pada kolom STDs: pelvic inflammatory disease 0 : False 1 : True 6. Transformasi pada kolom STDs: genital herpes 0 : False 1 : True 7. Transformasi pada kolom STDs: molluscum contagiosum 0 : False 1 : True. 36.
(54) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 8. Transformasi pada kolom STDs: HIV 0 : False 1 : True 9. Transformasi pada kolom STDs: Hepatitis B 0 : False 1 : True 10. Transformasi pada kolom STDs: HPV 0 : False 1 : True 11. Transformasi pada kolom Dx: Cancer 0 : False 1 : True 12. Transformasi pada kolom Dx: Cin 0 : False 1 : True 13. Transformasi pada kolom Dx: HPv 0 : False 1 : True 14. Transformasi pada kolom Dx 0 : False 1 : True 15. Transformasi STDs (number) 0 : Zero 1 : One 2 : Two 3 : Three 4 : Four 16. Transformasi STDs : Number of Diagnosis 0 : Zero 1 : One 2 : Two 3 : Three. 37.
(55) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 17. Transformasi pada kolom Age, Number of Sexual Partners, First Sexual Intercourse, Num of Pregnancies, Smokes (years), Smokes (packs/year), Hormonal Contraceptives (years) dan IUD (years). Proses transformasi pada beberapa atribut ini menggunakan teknik discretization untuk mengubah data numerik atau kontinyu ke dalam interval. Teknik discretization yang digunakan yaitu dengan menerapkan metode binning yang membagi partisi ke dalam beberapa bin dengan lebar yang sama (jarak). Berikut langkah-langkahnya : a. Menentukan berapa banyak kelas interval. Pada masing-masing. atribut. tersebut,. peneliti. akan. membagi menjadi 3 kelas interval (k=3). b. Mencari nilai minimal dan maksimal dari masingmasing atribut. . . . . . . Age Nilai minimal. : 13. Nilai maksimal. : 84. Number of Sexual Partners Nilai minimal. :1. Nilai maksimal. : 28. First Sexual Intercourse Nilai minimal. : 10. Nilai maksimal. : 32. Num of Pregnancies Nilai minimal. :0. Nilai maksimal. : 11. Smokes (years) Nilai minimal. :0. Nilai maksimal. : 37. Smokes (packs/year) Nilai minimal. 38. :0.
(56) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Nilai maksimal . . : 37. Hormonal Contraceptives (years) Nilai minimal. :0. Nilai maksimal. : 30. IUD (years) Nilai minimal. :0. Nilai maksimal. : 19. c. Menentukan panjang kelas interval dengan rumus 3.1 berikut :. (. ) .............(3.1). Panjang kelas interval pada tiap atribut adalah : . Age (. . ). Number of Sexual Partners (. . ). First Sexual Intercourse (. . . . ). Num of Pregnancies (. ). (. ). Smokes (years). Smokes (packs/year) (. . ). Hormonal Contraceptives (years) (. 39. ).
(57) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. . IUD (years) (. ). Dari perhitungan di atas maka dihasilkan kategori sebagai berikut : . Age 13 – 36 37 – 60 >= 61. . Number of Sexual Partners 1–9 10 – 18 >= 19. . First Sexual Intercourse 10 – 16 17 – 23 >= 24. . Num of Pregnancies 0–3 4–7 >= 8. . Smokes (years) 0 – 11 12 – 23 >= 24. . Smokes (packs/year) 0 – 11 12 – 23 >= 24. . Hormonal Contraceptives (years) 0–9 10 – 19. 40.
(58) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. >= 20 . IUD (years) 0–5 6 – 11 >= 12. Contoh hasil transformasi data dapat dilihat pada lampiran 2. 3.2.2.5. Penambangan Data (Data Mining) Pada tahap ini diterapkan proses penambangan data dengan. algoritma C4.5. Namun seperti yang telah dijelaskan sebelumnya, data pasien yang akan digunakan berjumlah 858 dalam kondisi imbalanced data. Oleh karena itu, untuk mengatasi masalah tersebut digunakan suatu metode sampling yaitu undersampling. Undersampling merupakan metode untuk mengambil beberapa data mayoritas sehingga jumlah data mayoritas sama besar jumlahnya dengan jumlah data minoritas. Pada proses ini data kelas mayoritas dan minoritas akan diambil dengan perbandingan 1 : 2. Itu artinya kelas biopsy yang bernilai “Yes” akan diambil semua yaitu sejumlah 55 data, sedangkan untuk data kelas biopsy yang bernilai “No” akan diambil sebanyak 110 data sehingga total data yang akan digunakan yaitu 165 data. Data ini selanjutnya dibagi menjadi data training dan data testing. Data training akan digunakan. dalam. proses. pembentukan. pohon. keputuan. menggunakan algoritma C4.5. Proses pembentukan pohon ditentukan dari perhitungan nilai Entropy, Gain, Split Information, dan Gain Ratio untuk setiap atribut. Dari perhitungan tersebut, atribut yang memiliki nilai GainRatio tertinggi akan menjadi simpul akar dari pohon. Proses pembentukan pohon dilakukan secara rekursif hingga seluruh data memiliki kelas. Dalam proses pembentukan pohon keputusan akan dilakukan prepruning yaitu dengan menghitung pessimistic error rate seperti pada rumus 2.5. Setelah perhitungan selesai akan ditampilkan hasil pohon yang terbentuk.. 41.
(59) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 3.2.2.6. Evaluasi Pola (Pattern Evaluation) Pattern evaluation adalah proses mengidentifikasi pola-. pola sehingga mempresentasikan pengetahuan yang benar-benar menarik yang merupakan hasil dari penambangan data.Tahap ini dilakukan setelah melakukan proses penambangan data sehingga dapat ditarik keputusan atau ditentukan rule berdasarkan pohon keputusan yang diperoleh. 3.2.2.7. Presentasi Pengetahuan (Knowledge Presentation) Pada tahap ini dilakukan proses penyajian pengetahuan dari. hasil penambangan data. Hasil klasifikasi data pasien yang menderita penyakit kanker serviks akan ditampilkan ke dalam bentuk yang mudah dipahami oleh pengguna.. 3.2.2. Analisis dan Kesimpulan Pada tahap ini, hasil implementasi perangkat lunak yang telah dibangun akan dianalisa untuk memastikan apakah sesuai dengan rancangan yang dilakukan sebelumnya. Tahap pengujian berikutnya. adalahuji. validasi. perangkat. lunak. dengan. menggunakan metode pengujian black box. pengujian black box ini berisi pengujian dengan pengisian data secara benar dan tidak benar. Selanjutnya dilakukan pengujian untuk mencari nilai akurasi terbaik dengan membagi data menjadi data training dan testing menggunakan. split. validation.. Hasil. dari semua. tersebut. selanjutnya disusun dalam naskah tugas akhir. 3.3. Perancangan Perangkat Lunak 3.3.1. Perancangan Umum Perangkat lunak yang akan dibangun adalah perangkat lunak yang dapat melakukan deteksi penyakit kanker serviks menggunakan algoritma C4.5 sehingga menghasilkan rule atau kondisi yang digunakan untuk penentuan keputusan pada proses deteksi.. 42.
(60) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 3.3.1.1. Input Input dari perangkat lunak yang dibangun yaitu file dengan. ekstensi .xls yang berupa data pasien dalam bentuk tabel berisi beberapa atribut yang meliputi informasi demografis, kebiasaan dan catatan rekam medis yang kemudian disimpan ke dalam database. 3.3.1.2. Proses Proses perangkat lunak yang akan dibangun terdiri dari. beberapa tahapan untuk mengklasifikasikan data, menghitung akurasi dan uji data tunggal. Secara garis besar tahapan proses perangkat lunak tersebut, yaitu: 1.. Memasukkan data pasien ke dalam database, data yang dimasukkan harus bertipe .xls. Tahapan-tahapan yang akan dilakukan perangkat lunak pada proses memasukkan data pasien yaitu : 1) Membaca file excel yang diupload. 2) Membaca jumlah baris dari data pasien. 3) Membaca kolom dari data pasien yang berisi atribut-atribut menggunakan perulangan for berdasarkan jumlah baris data pasien. 4) Menyisipkan data ke dalam tabel data pasien di database. 5) Menampilkan status data berhasil diinput.. 2.. Melakukan transformasi data Tahapan-tahapan yang akan dilakukan perangkat lunak pada proses melakukan transformasi data yaitu : 1) Membaca data pada tabel data pasien di database. 2) Masing-masing. atribut. akan. dilakukan. transformasi dengan menerapkan percabangan if-else untuk mengetahui kategori mana yang sesuai dengan kondisi data.. 43.
(61) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 3) Update nilai masing-masing atribut pada tabel data pasien di database berdasarkan hasil kategori yang diperoleh. 3.. Membagi data training dan data testing berdasarkan nilai split ratio.. 4.. Melakukan proses algoritma C4.5. Tahapan-tahapan yang akan dilakukan perangkat lunak pada proses algoritma C4.5 yaitu : 1) Menghitung nilai entropy total dan entropy masing-masing atribut 2) Menghitung nilai information gain, split info, dan gain ratio masing-masing atribut. Atribut yang memiliki nilai gain ratio tertinggi akan menjadi simpul akar dari pohon. 3) Membuat cabang untuk masing-masing nilai 4) Membagi kasus dalam cabang 5) Mengulangi. proses. untuk. masing-masing. cabang sampai semua kasus pada cabang memiliki kelas yang sama. Dalam proses pembentukan pohon keputusan dilakukan pemangkasan pohon menggunakan metode prepruning. dengan. menghitung. nilai. pessimistic error rateseperti yang dijelaskan pada bab 2. 5.. Menampilkan tabel perhitungan, pohon keputusan dan rule.. 6.. Melakukan proses kinerja untuk memperoleh akurasi dari algoritma C4.5 Tahapan-tahapan yang akan dilakukan perangkat lunak pada proses kinerja algoritma C4.5 yaitu : 1) Membaca data yang akan digunakan untuk uji akurasi yaitu data testing.. 44.
(62) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 2) Membandingkan nilai masing-masing atribut untuk memperoleh klasifikasi yang dilakukan perangkat. lunak. berdasarkan. rule. yang. terbentuk dari hasil proses algoritma C4.5 yang telah dilakukan sebelumnya. 3) Hasil klasifikasi yang dilakukan perangkat lunak. akan. klasifikasi dengan. dibandingkan. data. pasien. menggunakan. dengan. yang. hasil. seharusnya. confusion. matrix. sehingga diperoleh akurasi dari algoritma C4.5. 7.. Melakukan proses uji data tunggal di mana user akan memasukkan data tunggal dan perangkat lunak akan menampilkan hasil biopsi. Tahapan-tahapan yang akan dilakukan perangkat lunak pada proses uji data tunggal yaitu : 1) Membaca. data. yang. dimasukkan. oleh. pengguna 2) Membandingkan nilai masing-masing atribut untuk memperoleh klasifikasi yang dilakukan perangkat. lunak. berdasarkan. rule. yang. terbentuk dari hasil proses algoritma C4.5 yang telah dilakukan sebelumnya. 3) Menampilkan hasil biopsi yang diperoleh dari proses uji data tunggal. Proses sistem digambarkan dalam diagram flowchart seperti pada Gambar 3.1.. 45.
(63) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Gambar 3.1Diagram Flowchart 3.3.1.3. Output Perangkat lunak yang dibangun akan memberikan output. berupa hasil perhitungan algoritma, pohon keputusan, rule, dan perhitungan akurasi. Selanjutnya untuk uji data tunggal perangkat lunak akan meminta masukan dari user dan akan menampilkan hasil biopsi dalam mendeteksi penyakit kanker serviks.. 3.3.2. Model Fungsi 3.3.2.1. Diagram Use Case. Diagram use case dipaparkan pada Gambar 3.2 berikut.. 46.
(64) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Gambar 3.2 Diagram UseCase. 3.3.2.2. Narasi Use Case Diagram use case menggambarkan mengenai hubungan. antara aktor (pengguna) dengan sistem. Narasi use case akan memperjelas setiap use case sebagai berikut. a. Login Tabel 3.4 Narasi Use Case Login Login NamaUse Case. Login. ID Use Case. 1. Aktor. Pengguna Use case ini mendeskripsikan pengguna masuk ke dalam. Deskripsi. sistem. Kondisi Awal. Pengguna masuk ke sistem dan berada pada halaman login. 47.
(65) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Kondisi Akhir. Pengguna berhasil masuk ke sistem Reaksi Sistem. Aksi Aktor 1. Pengguna memasukkan Typical Course. username dan password 2. Menampilkan halaman utama. b. Masukkan Data Tabel 3.5 Narasi Use CaseMasukkan Data Masukkan Data NamaUse Case. Masukkan Data. ID Use Case. 2. Aktor. Pengguna Use case ini merupakan proses memilih dan memasukkan. Deskripsi. file berekstensi .xls yang akan digunakan dalam proses klasifikasi. Kondisi Awal. Pengguna telah masuk pada halaman utama sistem Menampilkan data dalam bentuk tabel pada halaman data. Kondisi Akhir. pasien Aksi Aktor. Reaksi Sistem. 1. Menekan menu data pasien 2. Menampilkan halaman. Typical Course. data pasien 3. Menekan tombol browse 4. Menampilkan kotak. 48.
(66) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. dialog untuk memilih file yang berada pada direktori komputer 5. Memilih file berekstensi .xls yang akan digunakan dan menekan tombol submit. 6. Memasukkan data ke database dan melakukan transformasi data 7. Menampilkan data dalam bentuk tabel pada halaman data pasien. c. Partisi Data Tabel 3.6 Narasi Use CasePartisi Data Partisi Data NamaUse Case. Partisi Data. ID Use Case. 3. Aktor. Pengguna Use case ini merupakan proses membagi data menjadi data. Deskripsi. training dan data testing berdasarkan nilai split ratio yang dimasukkan pengguna. Pengguna telah memilih file berekstensi .xls dan data telah. Kondisi Awal. ditampilkan pada halaman data pasien. Kondisi Akhir. Menampilkan status jumlah data training dan data testing. Typical Course. Aksi Aktor. 49. Reaksi Sistem.
(67) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 1. Menekan menu partisi data 2. Menampilkan halaman partisi data 3. Memasukkan nilai split ratio dan memilih teknik pengambilan data 4. Menekan tombol proses 5. Membagi data training dan data testing berdasarkan nilai splitratio dan teknik pengambilan data yang dimasukkan pengguna 6. Menampilkan pesan data training berhasil diupdate 7. Menampilkan status jumlah data training dan data testing. d. Proses Algoritma C4.5 Tabel 3.7 Narasi Use CaseProses Algoritma C4.5 Proses Algoritma C4.5 NamaUse Case. Proses Algoritma C4.5. ID Use Case. 4. Aktor. Pengguna. 50.
Gambar


+7


Dokumen terkait
Dokumen kualifikasi perusahaan asli yang diupload atau dokumen yang dilegalisir oleh pihak yang berwenang dan menyerahkan 1 (satu) rangkap rekaman (foto copy).
4. Papan dununge ukara pokok paragraph ing ndhuwur ana ukara nomer …. Miturut papane ukara pokok, paragraph ing ndhuwur diarani …. Ing ngisor iki tembung kang nduweni teges enom
Analisis implementasi Jaminan Kesehatan Nasional (JKN) melalui makna pengalaman partisipan dilihat dari merasa puasnya dengan perawatan di RS meliputi aspek pelayanan, SDM,
Meningkatnya kualitas sanitasi air limbah pemukiman perkotaan Prosentase penduduk yang terlayani sistem air limbah yang memadai 1.. Terwujudnya kualitas sanitasi
Misalnya terkait dengan permasalahan etika dan komunikasi seorang Basuki Tjahaja Purnama, sangatlah tepat bagi tim Mata Najwa untuk menghadirkan Muhammad Sanusi
Oleh karena itu, bagi pertanian yang bersifat land base agricultural, ketersediaan lahan merupakan syarat mutlak atau keharusan untuk mewujudkan peran sektor pertanian
Melihat keberhasilan kegiatan ini dalam meningkatkan pengetahuan remaja tentang tumbuh kembang pada usianya, maka kegiatan ini perlu dilakukan secara berkelanjutan agar
STAD dikembangkan oleh Robert Slavin dan teman-temannya di Universitas John Hopkin, dan merupakan pendekatan pembelajaran kooperatif yang paling sederhana. Guru yang
