PREDIKSI POLA PENYEBARAN PENYAKIT DEMAM BERDARAH DENGUE DI KABUPATEN SUKOHARJO
MENGGUNAKAN METODE ORDINARY BLOCK KRIGING Ellisa Ratna Dewi1, Sri Suryani P 2, Yuliant Sibaroni3
1,2,3Prodi Ilmu Komputasi Telkom University, Bandung
1ellFellix@gmail.com, 2wati100175@gmail.com,3yuliant2000@yahoo.com
Abstrak
Sistem prediksi pola penyebaran penyakit Demam Berdarah Dengue di kabupaten Sukoharjo ini dibentuk dengan meggunakan model semivariogram dan metode estimasi Ordinary Block Kriging. Model dan metode ini dipilih sebagai alat untuk memprediksi pola penyebaran penyakit di kabupaten Sukoharjo karena tidak membutuhkan informasi sebelumnya mengenai mean data, sehingga lebih mudah dalam penggunaanya. Validasi silang dipilih sebagai alat ukur validitas model agar model memiliki kriteria kelayakan untuk digunakan pada proses berikutnya.
Model terbaik dihasilkan oleh Gaussian dengan validasi 0.3140, dengan variansi kriging sebesar 0.0251 pada grid 0.05. Dari grid tersebut dapat disimpulkan bahwa penyebaran terbesar berada di kecamatan Kartasura, Gatak, Baki, dan Grogol. Sedangkan error yang dihasilakan dari hasil pengujian sistem dengan membandingkan data asli populasi terjangkit dengan hasil estimasi adalah 0.158845523 atau sekitar 15%. Hasil prediksi ini mengindikasikan bahwa terdapat faktor X yang mempengaruhi penyebaran penyakit Demam Berdarah Dengue di kabupaten Sukoharjo.
Kata kunci : semivariogram, ordinary kriging, validasi silang, grid
Pendahuluan
Demam Berdarah Dengue (DBD) merupakan penyakit yang diakibatkan oleh virus dengue yang disebarkan melalui gigitan nyamuk Aedes Aegypti dan Aedes Albopictus yang sebelumnya telah terinfeksi oleh penderita DBD yang lain. Indonesia merupakan negara yang memiliki angka kematian paling tinggi akibat DBD dibandingkan negara-negara lain di ASEAN[17]. Wilayah Sukoharjo menjadi salah satu wilayah endemis demam berdarah yang dapat dikatakan tinggi di Indonesia[17]. Beberapa kasus demam berdarah tersebut, banyak yang menimbulkan kematian. Penyebab kematian tersebut dipicu oleh beberapa faktor antara lain keterlambatan penanganan medis dan rendahnya kesadaran masyarakat akan pencegahanya. Masyarakat banyak yang tidak menyadari akan keberadaan penyakit, salah satunya disebabkan minimnya informasi yang mereka peroleh.
Beberapa alasan diatas yang mendorong penulis untuk melakukan penelitian berkaitan dengan prediksi pertumbuhan penyakit DBD khususnya di wilayah Sukoharjo. Prediksi dilakukan dengan menggunakan metode Ordinary Block Kriging. Metode kriging merupakan sebuah metode untuk melakukan penaksiran suatu nilai di suatu wilayah. Metode ini yang nantinya digunakan untuk mengestimasi tinggi rendahnya populasi penduduk yang terjangkit DBD di suatu wilayah.
Pendekatan model Semivariogram Eksperimentaldilakukan dengan menggunakan data angka yang menunjukkan jumlah penderita DBD dan koordinat lokasi terjangkit. Kemudian dilakukan pembentukan model Semivariogram Teoritis yang kemudian digunakan untuk mencocokan apakah model semivariogram yang terbentuk melalui data, sesuai dengan model semivariogram teoritis bakunya. Nilai estimasi yang telah didapat dengan Ordinary Block Kriging, kemudian akan dibuat sebuah interpolasi warna, dimana warna tersebut menunjukkan tinggi rendahnya nilai prediksi. Sehingga mudah diketahui pola penyebaran penyakit DBD di kabupaten Sukoharjo. Hal ini dimaksudkan untuk mempermudah petugas kesehatan setempat mengetahui daerah mana di kabupaten Sukoharjo yang memiliki potensi besar untuk terkena penyakit DBD, sehingga himbauan pencegahan kepada masyarakat dapat disampaikan lebih dini dan tingkat kematian
akibat demam berdarah di wilayah Sukoharjo dapat ditekan. Dengan kata lain, pengguna dapat memprediksi daerah yang rawan terjangkit penyakit DBD di wilayah Sukoharjo.
Landasan Teori
1. Demam Berdarah Dengue (DBD)
DBD disebabkan oleh virus Dengue yang ditularkan oleh nyamuk Aedes Aegypti, Aedes Scutellaris dan
Aedes Albopictus. Kepadatan populasi nyamuk-nyamuk tersebut berada diantara bulan September sampai
November dan puncaknya antara bulan Maret sampai Mei, yaitu pada musim pancaroba. Peningkatan populasi nyamuk tersebut mengindikasikan bahwa meningkat pula kemungkinan terkenanya wabah DBD di daerah endemis[6].
Nyamuk Aedes memiliki kebiasan menggigit berulang, yaitu menggigit orang secara bergantian dalam waktu singkat. Bila nyamuk Aedes menggigit dan menghisap darah orang yang menderita DBD, maka virus tersebut akan masuk ke dalam tubuh nyamuk. Selanjutnya dibutuhkan waktu 8-11 hari, mulai virus masuk ke dalam tubuh nyamuk sampai virus mencapai kelenjar ludah dan siap ditularkan kepada korban lain.
Nyamuk yang telah terinfeksi virus kemudian menghisap darah manusia, sehingga bersama ludah nyamuk tersebut, virus akan masuk ke dalam tubuh manusia. Virus tersebut kemudian berkembang biak dan menyebabkan gangguan pada pembuluh darah kapiler serta pembekuan darah. Setelah masa inkubasi 1-2 hari, maka dalam waktu 3-15 hari penderita akan mengalami salah satu dari 4 gejala sebagai berikut[6] : a. Abortif, dimana penderita tidak merasakan gejala apapun.
b. Dengue klasik, penderita mengalami demam tinggi selama 4-7 hari, nyeri tulang, dan muncul bintik-bintik merah.
c. Dengue Haemorrhagic Fever, gejala yang hampir sama dengan dengue klasik, tetapi penderita sudah
mengalami pendarahan pada hidung, mulut dan lain-lain.
d. Dengue Syok Syndrome, merupakan gejala yang sama dengan Dengue Haemorrhagic Fever, akan tetapi ditambah dengan syok dan sering terjadi kematian.
Nyamuk DBD banyak hidup dan cepat berkembang dalam suatu wilayah dikarenakan beberapa hal sebagai berikut [18]:
a. Adanya perubahan musim dari musim panas ke musim penghujan atau sebaliknya.
b. Bak mandi rumah tangga yang jarang dikuras, akan menyebabkan banyak berkembangnya jentik-jentik nyamuk.
c. Sampah dan barang bekas yang tidak dikubur atau dibakar, sehingga mengakibatkan tertampungnya air di saat musim hujan.
d. Saluran air atau selokan yang tergenang dan tidak mengalir di sekitar lingkungan rumah tangga.
e. Kurangnya kesadaran masyarakat, terutama anak-anak sekolah dan guru-guru terhadap tempat-tempat gelap yang jauh dari jangkauan manusia seperti laci meja, bawah meja dan bangku-bangku yang jarang digunakan.
f. Kurangnya kesadaran dan perhatian masyarakat akan kebersihan lingkungan. 2. Data Spasial
Data spasial merupakan data pengukuran yang memuat informasi lokasi di permukaan bumi, misalnya Z(si), i=1,2,..n dimana Z menyatakan lokasi dengan koordinat si. Terdapat 3 tipe dasar data spasial, yaitu
geostatistik (geostatisticaldata), data area (lattice area), dan pola titik (point pattern)[4]. Data spasial dapat berupa data diskret atau kontinu dan memiliki lokasi yang beraturan (regular) maupun yang tidak beraturan
(irregular). Data yang beraturan (regular) adalah data spasial dimana titik-titik yang menjadi obyek
pengamatan berada pada perpotongan koordinat, sehingga memiliki jarak yang sama. Sedangkan data tak beraturan (irregular) menunjukkan lokasi titik yang berada pada suatu wilayah terletak secara acak atau random, sehingga memiliki jarak yang berbeda.
Terdapat dua tahapan utama dalam menganalisis data spasial, yaitu tahap analisis struktural dan tahap penaksiran parameter[5]. Analisis struktural merupakan tahap pencocokan model Semivariogram Eksperimental pada Semivariogram Teoritis. Sedangkan tahap penaksiran parameter adalah proses prediksi parameter proses spasial berdasarkan informasi semivariogram data spasial.
3. Model Semivariogram Eksperimental
Model semivariogram merupakan sebuah alat yang digunakan untuk menjelaskan korelasi spasial antara data atau penelitian[5]. Jika fungsi matematika atau semivariogram telah fit/sesuai pada semivariogram eksperimental, model ini dapat digunakan untuk menaksir nilai di titik/lokasi yang tidak disampel/diketahui[1]. Penggunaan Semovariogram Eksperimental untuk mengestimasi fungsi kovariansi lebih baik dibandingkan yang lain karena Semivariogram Eksperimental tidak memerlukan informasi sebelumnya mengenai mean dari sebuah populasi. Secara teoritis, semivariogram merupakan bagian dari ekspektasi selisih kuadrat nilai sampel yang dipisahkan dengan vektor h. Persamaan Semivariogram Eksperimental dapat ditulis sebagai berikut[5] :
γ(h) = ∑ [ ]
(1) (2.1)
dimana :
xα : lokasi titik sampel
: nilai data pada lokasi
n(h) : banyaknya pasangan eksperimen [ ] yang berjarak h.
Selain menggunakan persamaan 1, pembentukan model Semivariogram Eksperimental juga dapat dilakukan dengan model yang sudah ada. Parameter-parameter inputan yang harus diperhatikan dalam pembuatan model Semivariogram Eksperimentaladalah[2] :
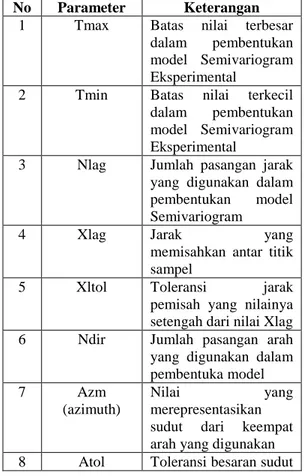
Tabel 1 : Parameter Pembentukan ModelSemivariogram Eksperimental No Parameter Keterangan
1 Tmax Batas nilai terbesar dalam pembentukan model Semivariogram Eksperimental
2 Tmin Batas nilai terkecil dalam pembentukan model Semivariogram Eksperimental
3 Nlag Jumlah pasangan jarak yang digunakan dalam pembentukan model Semivariogram
4 Xlag Jarak yang
memisahkan antar titik sampel
5 Xltol Toleransi jarak
pemisah yang nilainya setengah dari nilai Xlag 6 Ndir Jumlah pasangan arah yang digunakan dalam pembentuka model
7 Azm
(azimuth)
Nilai yang
merepresentasikan sudut dari keempat arah yang digunakan 8 Atol Toleransi besaran sudut
yang nilainya setengah dari nilai Azimuth 9 Bandwidth Jarak terjauh dari titik
sampel yang masuk ke dalam perhitungan model semivariogram 10 Jenis
Variogram
Jenis variogram yang akan dibentuk. Jika modelnya
semivariogram, maka jenis variogramnya adalah 1
2.4 Model Semivariogram Teoritis
Model semivariogram baku (Semivariogram Teoritis Gaussian) sebagai dasar dalam pencocokan model Semivariogram Eksperimental yaitu[7] :
Model Gaussian (2) Keterangan : : Nilai Semivariogram : Nilai Sill
: Nilai jarak Semivariogram Eksperimental α : Nilai Range
Gambar 1 : Model Teoritis Gaussian 2.5 Validasi Silang (Cross Validation)
Pengujian validasi model semivariogram adalah dengan menggunakan metode Validasi Silang (Cross
Validation). Metode validasi silang merupakan salah satu metode uji validitas model semivariogram yang
menggunakan residual atau selisih antara nilai dari data sampel dan nilai taksiran tanpa data sampel. Nilai taksiran tersebut diperoleh dengan perhitungan estimasi menggunakan metode Ordinary Block Kriging. Prosedur Validasi Silang[10,8]
1. Menghitung nilai taksiran z*(s2) dengan metode Ordinary Kriging menggunakan informasi dari nilai
sampel z(s1). Sehingga nilai taksiran di z(s2) yaitu z*(s2) dapat dinyatakan sebagai berikut:
z*(s2)= ω1 .z(s1). (3)
Dimana :
z*(s2) : nilai taksiran untuk data yang berada pada lokasi s2.
ω1 : bobot nilai untuk z(s1).
2. Membandingkan nilai z*(s1) dengan nilai z(s1). Kemudian menghitung nilai residual atau selisihnya
antara nilai taksiran dengan nilai sebenarnya dari data pada lokasi s2. Sehingga dapat dituliskan menjadi
:
r(s1) = z*(s1) - z(s1) (4) (2.7)
3. Menghitung nilai taksiran untuk z*(s3) dengan menggunakan informasi dari nilai data sampel z(s1) dan
z(s2). Kemudian menghitung residual untuk nilai pada lokasi s3 yaitu r(s3). Sehingga, jika menggunakan
dua buah informasi data untuk menghitung nilai taksiran, maka dapat dituliskan sebagai berikut[8] : z*(sn)= ∑ (ωn-1 .z(sn-1))(5)
4. Menghitung keseluruhan nilai taksiran sebanyak data sampel dan membandingkan serta menghitung nilai residual semua nilai taksiran terhadap nilai data sebenarnya.
5. Menghitung variansi nilai taksiran. Nilai variansi dapat dihitung dengan persamaan sebagai berikut[8] : σ2= ∑
(6)
Dimana :
σ2 : nilai variansi Ordinary Kriging minimum : nilai bobot estimasi Ordinary Kriging ke-i.
: nilai semivariogram jarak antara lokasi data ke-0 dengan lokasi data ke-i m : parameter Lagrange
6. Menghitung korelasi validasi silang dengan menggunakan persamaan. Kedekatan prediksi terhadap nilai sebenarnya diukur melalui kuantitas[5] :
*
+ (7)
dimana z*(Sn) merupakan taksiran z(Sn) tanpa adanya data z(Sn). Korelasi diatas dapat diartikan hasil validasi
silang semakin baik, apabila nilai yang dihasilkan adalah mendekati 0. 7. Uji Statistik Q1
Hasil dari validasi silang di atas harus diuji terlebih dahulu menggunakan Statistik Uji Q1, untuk menentukan apakah model yang dihasilkan layak dan dapat diterima. Model diterima atau layak untuk digunakan apabila hasil validasi <
√ , dengan n adalah banyak data yang digunakan dalam validasi silang. Model dikatakan
baik apabila nilai validasi silang yang dihasilkan mendekati 0 (semakin kecil)[10]. Estimasi Ordinary Block Kriging
Kriging merupakan salah satu metode penaksiran data spasial yang memberikan penaksiran linear tak bias terbaik dari suatu nilai titik atau rata-rata blok[14]. Kriging memiliki beberapa jenis metode antara lain Simple Kriging, Ordinary Kriging, dan Universal Kriging.
Ordinary Kriging merupakan metode yang melakukan perkiraan sebuah nilai pada suatu titik dari suatu wilayah dimana mean tidak diketahui[2]. Metode ini dipilih karena dapat melakukan estimasi terhadap nilai yang berupa blok maupun titik.
Metode Ordinary Kriging dapat digunakan untuk memperkirakan nilai sebuah titik, dirumuskan dalam persamaan[3] :
Z*OK ∑ (8)
Z*OK merupakan sebuah data spasial nilai titik X0 dengan bobot yang didekati oleh data spasial nilai titik
lain yaitu .
Sedangkan untuk memperkirakan nilai sebuah blok, maka persamaan Ordinary Kriging untuk blok (Ordinary
Block Kriging) adalah sebagai berikut[3] :
Z*Vo ∑ (9)
Sistem Ordinary Kriging secara umum dituliskan dengan [3] : OK= 2∑ ( )
∑
(10)
dengan ( ) merupakan semivariogram eksperimental nilai titik untuk mendekati semivariogram teoritis nilai titik dan merupakan parameter Lagrange.
Berdasarkan persamaan (10), sistem Ordinary Block Kriging dengan bobot , = 1,..n dapat dituliskan sebagai berikut[3] :
BK= {∑
∑
(11)
Dimana, merupakan semivariogram eksperimental nilai titik untuk mendekati semivariogram teoritis
nilai titik terhadap blok , v menyatakan blok. merupakan mean, tetapi dalam metode Ordinary Kriging,
mean tidak diketahui sehingga dalam perhitungan nilai matriks dapat diabaikan.
Metode Ordinary Block Kriging dapat ditulis dalam bentuk matriks, sebagai berikut [3]:
( ) ( ) ( )(12)
Sedangkan keakuratan sistem prediksi dengan menggunakan metode Ordinary Block Kriging dapat diukur dari variansi krigingnya. Persamaan variansi kriging untuk blok adalah sebagai berikut[3] :
σ2BK = μBK – γ(V0,V0) + ∑ αBKγ(Xα,V0) (13)
Toleransi estimasi dapat dilihat dari nilai variansi krigingny, yaitu jika <0.1[1]. 2.7 Root Mean Square Error (RMSE)
RMSE merupaka suatu indikator kesalahan yang didasarkan pada total kuadratik dari simpangan antara hasil model dengan hasil observasi[19,20].
Persamaan RMSE dapat dituliskan sebagai berikut :
n X X RMSE n i data hasil
1 2 ) ( (14)Xdata : nilai yang didapatkan dari data asli hasil pengamatan
Xhasil : nilai yang didapatkan dari hasil perhitungan
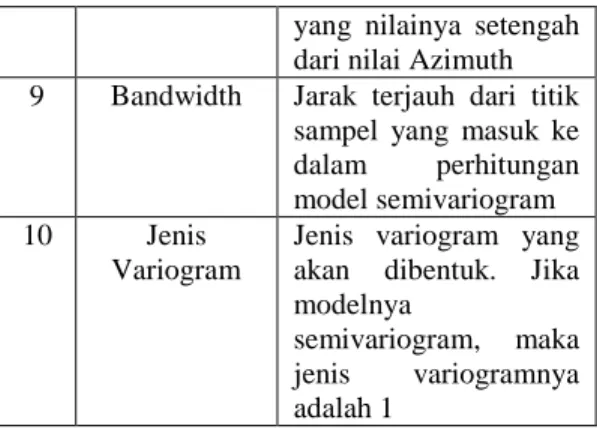
Perancangan Sistem Dan Antarmuka
2. Diagram Alir
1. Input
Data yang digunakan dalam penelitian ini adalah data koordinat (x,y) dan populasi penduduk terjangkit DBD di kabupaten Sukoharjo. Tiap titik koordinat (x,y), populasi penduduk diambil dari setiap kecamatan dengan akumulasi keseluruhan desa dalam waktu lima tahun berturut-turut. Karena data belum stasioner, maka dari itu perlu dilakukan normalisasi data. Hal ini bertujuan untuk meminimalkan error.
2. Proses
Proses dalam pembuatan sistem prediksi pola penyebaran penyakit DBD dalam penelitian ini adalah sebagai berikut :
1. Pembentukan Model Semivariogram Eksperimental.
Data yang telah masuk, akan dibentuk model Semivariogram Eksperimental. Perhitungan model Semivariogam Eksperimental ini melibatkan jarak dan arah. Terdapat empat arah yang dihitung dalam pembentukan model Semivariogram, yaitu arah Utara-Selatan (arah 1 dengan sudut 0º), arah Timur-Barat (arah 2 dengan sudut 45º), arah Barat Daya-Timur Laut (arah 3 dengan sudut 90º), dan arah Tenggara-Barat Laut (arah 4 dengan sudut 135º). Inputan parameter yang ada pada Tabel 2.1 harus benar-benar disesuaikan dengan data untuk mendapatkan model Semivariogram Eksperimental yang baik. Model Semivariogram Eksperimentalyang telah didapat kemudian di plot untuk memudahkan dalam pencocokan model pada proses berikutnya.
2. Pencocokan Model dengan Semivariogram Teoritis
Plot dari model Semivariogram Eksperimental yang telah didapatkan, kemudian didekati dengan model Semivariogram Teoritis. Semua model Semivariogram Teoritis dicocokan dengan plot Semivariogram Eksperimentalhingga didapatkan model terbaik dengan parameter terbaik.
3. Validasi Model dengan Metode Validasi Silang
Beberapa model yang telah dicocokan ke plot eksperimental, kemudian dihitung nilai validasinya. Dengan prosedur dan persamaan yang telah dijelaskan dalam sub bab 2.5, maka akan didapatkan beberapa nilai validasi dari beberapa model dan parameter pada pencocokan model sebelumnya. Nilai-nilai validasi ini selanjutnya akan diuji kelayakanya.
4. Uji Statistik Q1
Nilai-nilai validasi silang yang telah didapatkan pada proses sebelumnya kemudia diuji kelayakanya menggunakan statistik uji Q1. Model diterima jika nilai validasinya <
√ . Jika model diterima, maka akan
berlanjut ke proses selanjutnya. Sedangkan jika model ditolak, maka proses akan dikembalikan pada tahap pencocokan model teoritis, untu menemukan model dan parameter-parameter yang lain.
5. Pembentukan Blok Berdasarkan Karakteristik Wilayah
Jika model diterima, maka langkah selanjutnya adalah pembentukan blok. Blok yang dibentuk merupakan kumpulan dari kecamatan-kecamatan yang memiliki karakteristik sama. Kesamaan karakteristik didasarkan pada beberapa faktor yang mempengaruhi perkembangan nyamuk. Pengelompokan blok ini akan dibandingkan dengan hasil prediksi, apakah hasil prediksi sama dengan keadaan nyata wilayah atau terdapat perbedaan. Jika terdapat perbedaan, itu berarti terdapat kemungkinan adanya faktor lain yang mempengaruhi perkembangan dan penyebaran nyamuk. Blok-blok yang telah dibentuk kemudian dihitung jaraknya, baik dengan titik sampel, maupun denga blok lain. Jarak ini yang digunakan sebagai variabel hitung estimasi dalam proses selanjutnya. Hasil pembetukan blok akan ditampilkan pada lampiran.
6. Estimasi Keseluruhan Wilayah
Estimasi dilakukan untuk keseluruhan wilayah kabupaten Sukoharjo dengan menggunakan grid. Ukuran grid yang semakin kecil, menunjukkan semakin dalam pula estimasi yang dilakukan, karena hampir tidak ada celah dari satu titik ke titik lainya. Sehingga semakin kecil grid, akan menghasilkan variansi yang semakin kecil. Estimasi dihitung dengan menggunakan persamaan pada sub bab 2.6.
7. Interpolasi Keseluruhan Wilayah dan Pemotongan Peta
Interpolasi merupakan sebuah pewarnaan wilayah berdasarkan banyaknya populasi yang terkandung pada wilayah tersebut. Warna akan berubah secara bertahap apabila memasuki wilayah dengan tingkat populasi yang semakin tinggi maupun semakin rendah. Pemotongan peta dilakukan untuk memperjelas
daerah mana saja yang memiliki populasi tinggi dan wilayah yang memiliki populasi rendah. Sehingga kecenderungan penyebaran penyakit DBD dapat diprediksi dengan lebih mudah.
3. Output
Output yang dihasilkan pada penelitian ini adalah peta wilayah Kabupaten Sukoharjo dengan interpolasi warna. Sehingga akan terlihat pola penyebaran penyakit DBD cenderung ke wilayah mana. Diagram Use Case
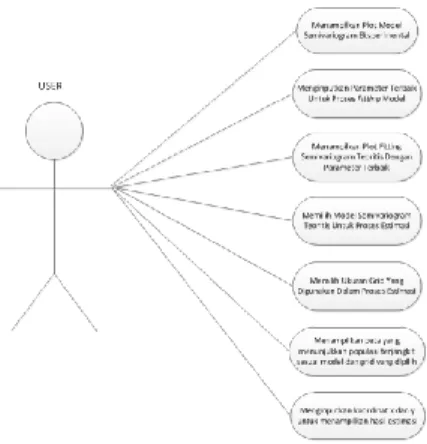
Gambar 3 : Diagram Use Case
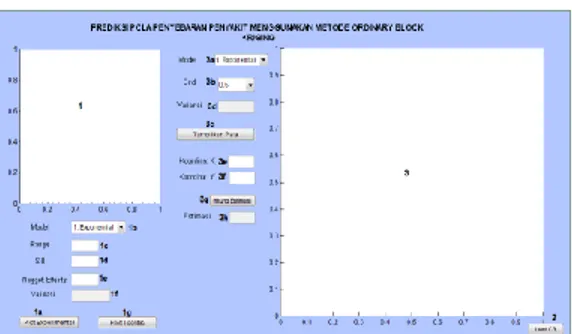
Pengguna (user) sistem prediksi pola penyebaran penyakit DBD ini dapat menjalankan beberapa fungsi yang ada di dalam Graphic User Interface, yaitu :
1. Menampilkan plot model Semivariogram Eksperimental
Dalam menjalankan sistem, yang pertama dilakukan oleh user adalah menampilkan plot model Semivariogram Eksperimental. Hal ini harus dilakukan karena akan berkaitan dengan model Semivariogram Teoritis yang akan digunakan.
2. Menginputkan parameter terbaik untuk proses fitting model
Input parameter diperlukan untuk mendapatkan model Semivariogram Teoritis yang terbaik. Hal ini dilakukan agar mendapatkan validasi yang layak, sehingga model dapat digunakan untuk mencari pola prediksi penyebaran penyakit DBD. Parameter didapatkan dengan melihat nilai range, sill, dan nugget
effect yang ada pada plot model Semivariogram Eksperimental.
3. Menampilkan plot fitting Semivariogram Teoritis dengan parameter terbaik
Pada aplikasi sistem, user dapat menampilkan plot model Semivariogram Teoritis yang mendekati plot Semivariogram Eksperimental. Hal ini dilakukan agar user mengetahui apakah model teoritis yang dipilih telah mendekati (hampir berhimpit) dengan plot Semivariogram Eksperimentalnya. Apabila plot teoritis masih jauh dari plot eksperimentalnya, user perlu menginputkan ulang parameter-parameter yang dibutuhkan dalam proses fitting.
4. Memilih model Semivariogram Teoritis untuk proses estimasi
Sebelum proses estimasi dilakukan, maka user harus memilih model teoritis mana yang akan digunakan dalam proses estimasi. Model yang dipilih, adalah model yang masuk ke dalam kategori layak uji statistik Q1. Proses pemilihan model ini dilakukan untuk mengetahui model yang paling sesuai digunakan dalam proses prediksi, karena pada proses ini variansi kriging estimasi akan ditampilkan. Dari hasil variansi inilah akan diketahui model yang paling baik yang digunakan pada proses estimasi.
5. Memilih ukuran grid yang digunakan dalam proses estimasi. Grid juga berpengaruh pada variansi kriging yang dihasilkan. Semakin kecil grid, akan menghasilkan variansi kriging yang lebih kecil. Apabila variansi kriging semakin kecil, maka pola penyebaran DBD juga akan semakin terlihat jelas. Grid yang harus dipilih adalah grid 0.5, grid 0.1, dan grid 0.01.
Selanjutnya, fungsi yang dapat dijalankan oleh user adalah fungsi menampilkan peta hasil estimasi. Peta yang ditampilkan adalah peta kabupaten Sukoharjo yang berwarna sesuai dengan banyaknya populasi penduduk yang terjangkt DBD. Peta yang muncul sesuai dengan model dan grid yang dimasukkan oleh
user sebelumnya.
7. Memasukkan koordinat x dan y untuk menampilkan hasil estimasi
Fungsi aplikasi prediksi pola penyebaran penyakit DBD ini juga dapat digunakan untuk menghitung nilai estimasi di koordinat x dan y tertentu. Dalam hal ini user harus memasukkan nilai koordinat x dan y yang ingin ditampilkan hasil estimasinya. Fungsi ini berguna pada proses pengujian sistem, dimana hasil estimasi populasi terjangkit dan data asli populasi terjangkit akan dibandingkan dan dihitung selisih serta rata-rata error nya.
3. Perancangan Antarmuka
Gambar 4 : Graphic User Interface Sistem Hasil Dan Analisis Sistem
Pengumpulan Dan Pengolahan Data i. Pengumpulan Data
Data yang berupa populasi penduduk dan peta wilayah kabupaten Sukoharjo didapatkan dari Badan Pemerintahan Daerah (Bapeda) kabupaten Sukoharjo. Data yang berupa karakteristik wilayah kabupaten Sukoharjo didapatkan dari Badan Pusat Statistik (BPS) kabupaten Sukoharjo. Data yang digunakan dalam pembentukan sistem prediksi ini adalah data tiap kecamatan di kabupaten Sukoharjo dengan akumulasi populasi terjangkit untuk keseluruhan desa dan dalam waktu lima tahun berturut-turut. Sedangkan data karakteristik yang digunakan adalah data dua tahun terakhir, yaitu pada tahun 2011 dan 2012.
ii. Pengolahan Data
Data asli populasi yang didapatkan dari hasil akumulasi bersifat non-stasioner. Oleh karena itu perlu adanya normalisasi data, agar data bersifat stasioner dan mengurangi resiko error. Normalisasi data dilakukan dengan menjadikan logaritma untuk semua data asli. Fungsi logaritma dipilih sebagai cara untuk menormalkan data karena fungsi logaritma menghasilkan nilai yang paling stasioner diatara fungsi Ln dan
Tangen. Sedangkan koordinat data didapatkan dari hitung manual peta wilayah kabupaten Sukoharjo dengan
skala 1:50.000.
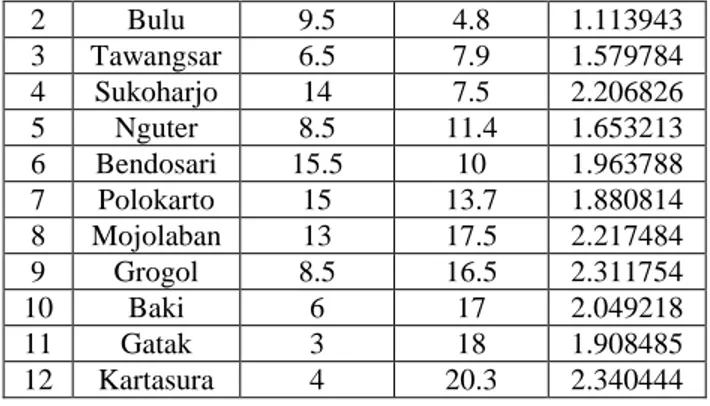
Tabel 3 : Data Hasil Normalisasi
No Kecamatan Koordinat X Koordinat Y Populasi Terjangkit 1 Weru 4.5 3.3 1.60206
4. Model Semivariogram Eksperimental
Model Semivariogram Eksperimental diperoleh dengan menginputkan data dan parameter-parameter pada Tabel 2.1 sesuai dengan data. Hasil inputan parameter tersebut adalah :
Tabel 2 : Parameter Model Semivariogram Eksperimental
Berdasarkan Tabel 2 didapatkan nilai rata-rata Semivariogram Eksperimental beserta jaraknya (lag) yaitu : Tabel 4 : Nilai Semivariogram Rata-rata 4 Arah
Seperti yang telah ditampilkan pada Tabel 4.8, nilai semivariogram yang muncul hanya 4 titik, dari keseluruhan 11 Lag. Hal itu dikarenakan adanya toleransi arah dan sudut yang mempengaruhi nilai smivariogram yang terbentuk. Untuk mempermudah dalam pencocokan/fitting model, maka hasil rata-rata
2 Bulu 9.5 4.8 1.113943 3 Tawangsar 6.5 7.9 1.579784 4 Sukoharjo 14 7.5 2.206826 5 Nguter 8.5 11.4 1.653213 6 Bendosari 15.5 10 1.963788 7 Polokarto 15 13.7 1.880814 8 Mojolaban 13 17.5 2.217484 9 Grogol 8.5 16.5 2.311754 10 Baki 6 17 2.049218 11 Gatak 3 18 1.908485 12 Kartasura 4 20.3 2.340444 No Parameter Inputan Berdasarkan Data 1 Tmax 1x1012 2 Tmin 1x10-12 3 Nlag 11 4 Xlag 6 5 Xltol 3 6 Ndir 4 7 Azm (azimuth) [0 45 90 135] 8 Atol [22.5 22.5 22.5 22.5] 9 Bandwidth [25 25 25 25] 10 Jenis Variogram 1 No Lag Semivariogram 1 4.137406 0.047343 2 4.386129 0.071582 3 9.325585 0.167424 4 9.959722 0.168686
Gambar 5 : Plot Model Semivariogram Eksperimental 5. Model Semivariogram Teoritis
Model Semivariogram Eksperimental yang telah terbentuk kemudian didekati dengan model Semivariogram Teoritis bakunya. Model Semivariogram Teoritis yang mendekati model Semivariogram Eksperimental adalah model Gaussian. Hasil fiiting model Semivariogram Teoritis adalah :
Gambar 6 : Hasil Fitting Model Semivariogram Teoritis Gaussian 6. Validasi Silang Dan Statistik Uji Q1
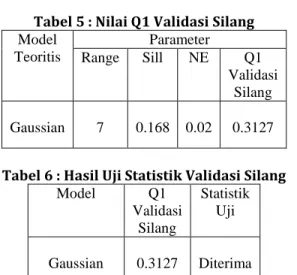
Tabel 5 : Nilai Q1 Validasi Silang Model Teoritis Parameter Range Sill NE Q1 Validasi Silang Gaussian 7 0.168 0.02 0.3127
Tabel 6 : Hasil Uji Statistik Validasi Silang
Model Q1 Validasi Silang Statistik Uji Gaussian 0.3127 Diterima
Dari tabel 5 dan 6 dapat disimpulkan bahwa model Gaussian dengan range 7, sill 0.168, dan nugget effect 0.02. Nilai Q1 Validasi Silang yang dihasilkan adalah 0.3127, dimana nilai tersebut < 0.603023.
7. Estimasi Ordinary Block Kriging
Estimasi Ordinary Block Kriging dilakukan untuk keseluruhan wilayah dengan menggunakan grid. Grid merupakan sebuah persegi virtual dengan ukuran sama disetiap sisinya. Pusat dari tiap grid itu merupakan titik yang dipakai dalam perhitungan estimasi. Keakuratan sistem prediksi diukur dengan menggunakan variansi Ordinary Kriging. Dalam penetitian ini, digunakan 3 ukuran grid untuk model terbaik yaitu model Gaussian.
Tabel 7 : Variansi Kriging Model Gaussian
Variansi terkecil dihasilkan oleh model Gaussian dengan grid 0.05.
Hasil interpolasi peta model terbaik dengan 3 grid adalah sebagai berikut :
Gambar 7 : Pola Prediksi Dengan Model Gaussian Grid 0.5
Gambar 8 : Pola Prediksi Dengan Model Gaussian Grid 0.1 Model Teoritis Q1 Validasi Silang Variansi OK Grid 0.5 Grid 0.1 Grid 0.05 Gaussian 0.3127 0.026 3 0.02 52 0.025 1
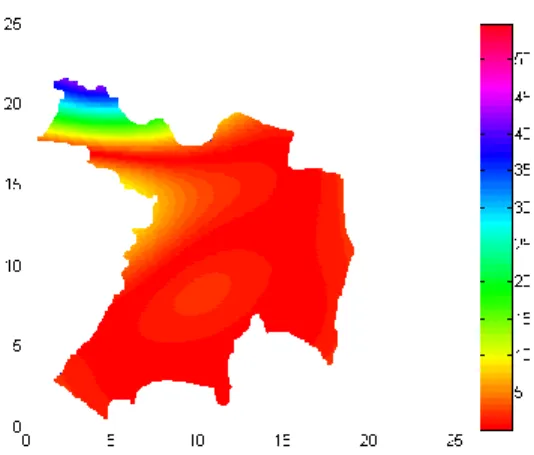
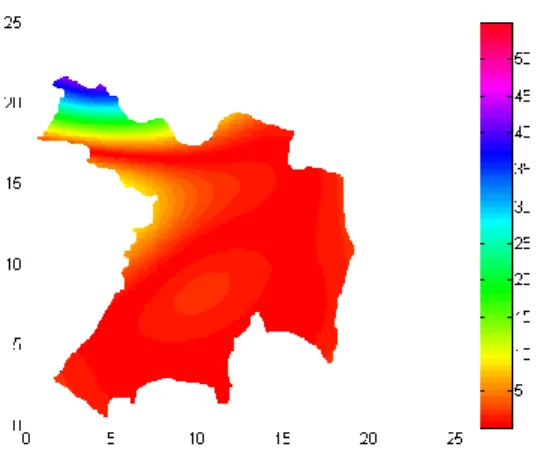
Gambar 9 : Pola Prediksi Dengan Model Gaussian Grid 0.05
Kesimpulan Dan Saran Kesimpulan
Dari hasil dan analisis yang dijelaskan di bab 4 dapat ditarik kesimpulan :
1. Model Semivariogram yang sesuai dan layak digunakan untuk menentukan prediksi pola penyebaran penyakit DBD di kabupaten Sukoharjo adalah model Gaussian dengan range 7, sill 0.168 dan nugget effects 0.02.
2. Berdasarkan hasil interpolasi dengan model terbaik yaitu Gaussian, tingkat penyebaran penyakit DBD yang paling tinggi berada di sekitar wilayah kecamatan Kartasura, Gatak, Grogol, dan Baki. Kecamatan Sukoharjo da Mojolaban mengalami penurunan tingkat penyebaran DBD. Hal ini terbukti dengan berubahanya warna menjadi orange muda. Sedangkan di wilayah kecamatan Bulu dan Nguter mengalami peningkatan penyebaran DBD.
3. Hasil pengujian sistem dengan mencari nilai RMSE antara data asli populasi terjangkit dan nilai populasi terjangkit hasil estimasi adalah 15%. Sedangkan secara teoritis, keakuratan sistem dilihat dari nilai variansi krigingnya yaitu 0.0251. Ini berarti kesalahan yang diperoleh dari pengamatan lapangan lebih besar dipandingkan kesalahan yang didapatkan dari hasil perhitungan matematis. Hal ini menunjukkan di kasus nyata, masih terdapat faktor lain yang mempengaruhi perkembangbiakan nyamuk, selain faktor-faktor pembentuk blok yang telah dijelaskan dalam bab sebelumnya.
Saran
Beberapa saran yang ingin disampaikan penulis mengenai penelitian ini adalah :
1. Sistem lebih baik apabila bisa melakukan pembentukan model Semivariogram Eksperimental secara dinamis. Sehingga parameter inputan dapat menyesuaikan data secara otomatis, tanpa penginputan ulang. Diperlukan adanya penambahan faktor penyebaran nyamuk selain yang disebutkan diatas (curah hujan, kepadatan penduduk, jumlah keluarga miskin, dan tingkat pengasapan) dalam proses pembentukan blok. Dengan semakin banyaknya karakteristik yng digunakan dalam pembentukan blok, diharapkan akan menghasilkan prediksi yang lebih baik dan faktor X yang belum diketahui menjadi penyebab berkembangnya penyakit di daerah-daerah aman bisa ditemukan.
Daftar Pustaka
1. Adiwijaya, 2014, Aplikasi Matriks dan Ruang Vektor, Graha Ilmu
3. Deutsch, C. V and Journel, A. G., 1992, Geostatistical Software Library and Users’s Guide (GSLIB), Oxfors University Press, New York.
4. Wackernagel, H., 1998, Multivariate Geostatistics, Springer-Verlag Berlin Heiderlberg, New York. 5. Cressie, N.A.C. 1991. Statistics for Spatial Data, revised ed., John Wiley & Sons, new York.
6. Suci Astutik.2004.Metode Kriging Untuk Menaksir Kadar Nikel.Jurusan Matematika FMIPA-Universitas Brawijaya Malang.
7. Yuliant,S dan Sri Suryani.2007.Pemodelan Penyebaran Penyakit Demam Berdarah Dengan Model
Sirk.Jurnal Saintifika.Sekolah Tinggi Teknik Telekomunikasi.
8. McBratney, A.B., and R. Webster. Choosing Functions for Semi-variograms of Soil Properties and Fitting
Them to Sampling Estimates. Journal of Soil Science 37: 617-639. 1986.
9. Burrough,P.A,Principles of Geographical Information System for Land Resources Assessment.New York:Oxford University Press.1986. Oliver,M.A.Kriging:A Method of Interpolation for Geographical
Information Systems. International Journal of Geographical Information Systems.
10. Rheni,P dan Irwan,S.2011.Analisis Spasial Demam Berdarah di Sukoharjo Jawa Tengah dengan
Menggunakan Indeks Moran.Jurnal.Fakultas Matematika dan Ilmu Pengetahuan Alam.UNS.
11. PutuJaya,A.W.2008.Penaksiran Kandungan Bauksit di Mempawah Kalimantan.Fakultas Matematika dan Ilmu Pengetahuan Alam UI.
12. Faktor Yang Mempengaruhi Pembiakan Nyamuk.2012.Web:jevuska.blogspot 13. Root Mean Square Error (RMSE).doc.