Analisis Support vector machines pada Deteksi Misuse untuk Intrusion Detection System
Faris Alfa Mauludy1, Adiwijaya2, GiaSeptiana3
1Prodi S1 Teknik Informatika, Telkom Informatics School, Universitas Telkom
1
[email protected] , [email protected], [email protected]
Abstrak
Intrusion Detection System digunakan untuk melindungi sistem, menganalisa serta memprediksi kebiasaan aktivitas komputer. Aktivitas tersebut terbagi menjadi normal dan ancaman. Cyber Threats sudah tidak asing lagi diera globalisasi seperti ini. Kebutuhan akan security system pun semakin besar, oleh karena itu dibuatlah solusi intrusion detection system. Dalam mendeteksi intrusi juga dikenal ada dua pendekatan yaitu anomaly detection dan misuse detection. Pada penelitian kali ini akan dibahas pendekatan dengan misuse detection, dimana pendekatan dengan cara mengenali pola terlebih dahulu, kemudian baru melakukan klasifikasi. Misuse detection hanya mengenali pola yang telah dipelajari. Untuk melakukan klasifikasi digunakan metode Support vector
machines (SVM). Metode ini efektif untuk mengurangi ruang data, karena SVM tidak tergantung pada besarnya
ruang. Hasil dari penelitian adalah analisis performansi berdasarkan parameter yang diberikan. Kata Kunci : Intrusion Detection System, Misuse Detection, Support vector machines
1. Pendahuluan
Intrusion Detection adalah sebuah gangguan atau ancaman yang berpotensi melakukan usaha yang disengaja untuk mengakses informasi, memanipulasi informasi, atau membuat sistem menjadi rusak dan tidak dapat digunakan[2]. Untuk menangani hal tersebut, maka dikenalkan Intrusion Detection System atau bisa disingkat IDS adalah sebuah sistem yang digunakan untuk mengecek dan mengklasifikasikan jaringan komputer melalui dataset yang ada untuk mengetahui bahwa aktivitas yang ada termasuk normal atau instrusi[7].Ada beberapa pendekatan dalam pendeteksian intrusi yaitu misuse detection dan anomaly detection. Misuse detection dikenal juga sebagai signature-based atau knowledge-based systems. Pendekatan tersebut memiliki prinsip yang sama dengan kebanyakan anti-virus software, dimana misuse detection mengenali pola serangan yang telah dikenali sebelumnya, jika ada pola yang terdeksi maka alarm akan langsung berbunyi[1]. Fokus penelitian ini adalah pendeteksian intrusi dengan pendekatan misuse dan menggunakan cara klasifikasi untuk mengetahui intrusi. Misuse perlu mempelajari pola yang sudah ada, jadi mudah untuk mengenali serangan. Keuntungan utamanya adalah misuse detection dapat mengenali langsung ancaman yang diketahui dan tingkat false Alarms yang sangat rendah[1]. Untuk mengani masalah klasifikasi tersebut diperlukan metode yang tepat dalam menangani hal tersebut. yaitu Support vector machines. SVM terkenal dapat menangani 2-class question. SVM juga relatif tidak sensitif pada jumlah data serta kompleksitas dari klasifikasi tidak bergantung pada dimensi dari ruang. Oleh karena itu SVM memiliki potensi untuk mempelajari pola yang besar[9].
2. Landasan Teori dan Perancangan 2.1 Intrusion Detection System
Intrusion Detection System adalah aplikasi software atau hardware yang dapat mendeteksi serangan dalam
sebuah sistem atau jaringan [7]. Sedangkan intrusion detection adalah Proses memonitoring segala aktivitas yang terdapat dalam sistem komputer atau jaringan dan mengenali itu sebagai intrusion, yang didefinisikan sebagai sesuatu yang mengancam ketersediaan, integritas, dan kerahasiaan atau untuk menembus mekanisme keamanan sumber daya jaringan [3].
1. Detection Model : Misuse Detection
Misuse detection dikenal juga sebagai signature-based atau knowledge-based systems. Pendekatan tersebut memiliki prinsip yang sama dengan kebanyakan anti-virus software, dimana misuse detection mengenali pola serangan yang telah dikenali sebelumnya, jika ada pola yang terdeksi maka alarm akan langsung berbunyi [1].
2.Jenis Serangan
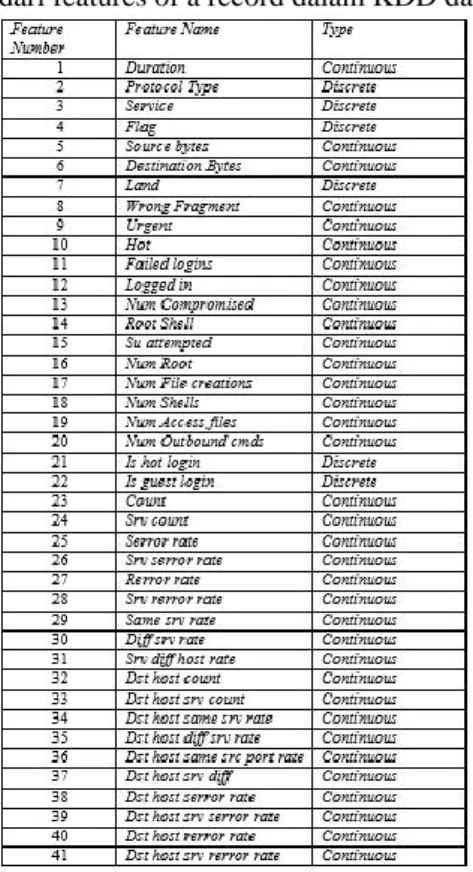
Tabel 2. Jenis intrusi/Serangan Kemudian diberikan juga list dari features of a record dalam KDD dataset:
Tabel 3. Tabel features of record 2.2 Support vector machines
Support vector machines (SVM) merupakan teknik atau metode klasifikasi yang menggunakan ruang
hipotesis beberapa fungsi linier kedalam suatu feature space (ruang ciri) berdimensi tinggi. Proses SVM merupakan teknik klasifikasi biner (2-class) yang pada dasarnya berusaha menemukan fungsi pemisah atau hyperplane untuk memisahkan data set kedalam dua kelas yang berbeda. Pada saat ini metode SVM mengalami perkembangan sehingga dapat digunakan untuk mengklasifikasikan data set kedalam banyak kelas (multiclass)[6][12].
2.3 SVM Nonlinearly Separable Data
SVM pada Nonlinearly Separable Data[5][6][12] Pendekatan yang dapat dilakukan untuk data yang tidak dapat dipisahkan secara linier yaitu dengan mentranformasikan data ke dalam dimensi ruang fitur (feature space) sehingga dapat dipisahkan secara linier pada feature space.
Gambar 1. Pemetaan dari input space (a) ke feature space (b) oleh fungsi φ
Pada Gambar 2.2 (a) terlihat bahwa fungsi ⃑ memetakan data ⃑ ke ruang vektor yang berdimensi lebih
tinggi. Pada ruang vektor yang baru ini, hyperplane yang memisahkan kedua kelas secara linier tersebut dapat
dikonstruksikan. Pada Gambar 2.2 (b) mengilustrasikan sebuah fungsi yang memetakan tiap data pada ruang
input tersebut ke ruang vektor baru yang berdimensi lebih tinggi (dimensi tiga). Notasi matematika dari pemetaan ini adalah sebagai berikut :
Sering kali terdapat kondisi dimana fungsi tidak tersedia atau tidak dapat dihitung, tetapi dot product dari
dua vektor dapat dihitung baik di dalam input space maupun di feature space. Dengan kata lain, sementara
mungkin tdak diketahui, dot product ( ) masih bisa dihitung di feature space. pada SVM,
masalah tersebut dapat diatasi dengan penggunaan fungsi kernel, dimana batasan perlu diekspresikan dalam
bentuk dot product dari vektor data xi. Sebagai konsekuensi, batasan yang menjelaskan permasalah dalam
klasifikasi harus diformulasikan kembali sehingga menjadi bentuk dot product. Dalam feature space ini dot product <.> menjadi
, dimana suatu fungsi kernel akan menggantikan dot product, sehingga representasi rumusnya
menjadi :
( ) ( )
Ada banyak fungsi kernel[14] seperti fungsi linier, RBF, Polynomial dan Sigmoid, Pada penelitian ini fungsi kernel yang digunakan adalah fungsi kernel Polynomial dimana hyperplane yang dibentuk membentuk kurva persamaan polynomial (bersuku banyak). didefinisikan dengan persamaan :
𝑟
Dimana p merupakan degree atau derajat dari fungsi. Sehingga permasalahan optimasi dapat diselesaikan dengan :
⃑ 𝑟 ∑ ∑ ( ) ∑ dengan batasan :
∑
dimana C adalah parameter yang menentukan besarnya penalti akibat error dalam klasifikasi data. Data latih
dengan nilai ⃑ merupakan support vector.
Fungsi keputusan menjadi :
∑ ⃑ 𝑏
dimana :
𝑤 ∑ ⃑ 𝑏 ∑ ⃑ [ ]
2.4 Multiclass SVM
Seperti yang telah dijelaskan sebelumnya, SVM sebenarnya digunakan untuk klasifikasi biner (dua kelas), dalam kasus multiclass, SVM yang digunakan adalah dengan mengkombinasikan beberapa SVM biner tersebut.
Metode “One-against-all” salah satunya. Dibangun sejumlah k SVM biner, dengan k adalah jumlah kelas. Untuk setiap model klasifikasi ke-i dilatih dengan menggunakan keseluaruhan data, untuk mencari solusi permasalahan Contohnya, untuk persoalan klasifikasi dengan 4 buah jumlah kelas, digunakan 4 buah SVM biner pada tabel di bawah ini dan penggunaannya pada pengklasifikasian data baru. Untuk lebih jelasnya perhatikan ilustrasi pada Tabel 2.3 dan Gambar 2.3[6][10].
Tabel 1. Contoh kombinasi biner dengan metode “One-against-all”
yi = 1 yi = -1 Hipotesis
Kelas 1 Bukan Kelas
1
𝑤 𝑏
Kelas 2 Bukan Kelas
2
Gambar 2. Contoh klasifikasi dengan metode “One-against-all” 2.5 Pemodelan PerformansiKinerjaKlasifikasi
Agar diketahui kinerja program telah memberikan prediksi dengan baik, intrusion detection system harus bisa membedakan antara intrusi dan normal dalam lingkungan sistem.
Berikut ini adalah tabel matrik evaluasi hasil deteksi sistem :
Tabel 4. matrik hasil evaluasi deteksi sistem
Evaluasi kinerja deteksi intrusi menggunakan parameter utama yaitu:
a. Detection Rate (jumlah intrusi yang berhasil dideteksi oleh sistem dibagi dengan total jumlah
intrusi yang ada pada dataset =
b. True Negative Rate (jumlah data normal yang benar dideteksi oleh sistem dibagi dengan jumlah
data normal pada dataset) =
c. Akurasi ( mengukur berapa data yang dapat diklasifikasikan dengan benar oleh sistem
=
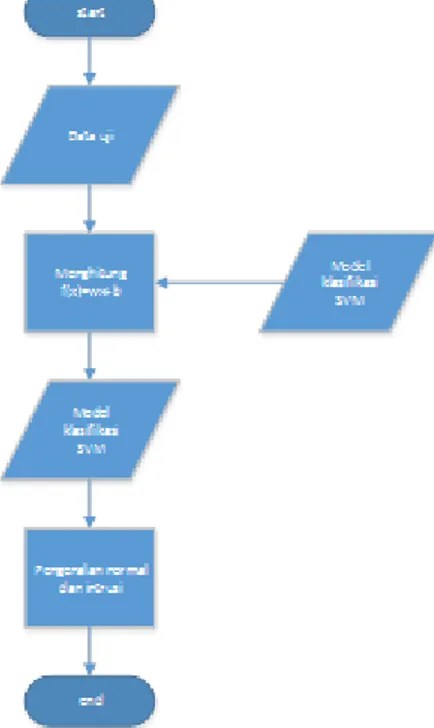
2.6 PerancanganSistem
Sistem yang akan dibangun pada penelitian ini merupakan simulasi yang berfungsi sebagai suatu model dengan menggunakan metode support vector machines(SVM) yang akan diuji keakuratannya. SVM diterapkan sebagai classifier pada misuse detection. Analisa yang dilakukan adalah keakuratan learning machine yang dibuat berdasarkan dataset, jumlah atribut, dan jumlah simbol. SVM yang dibentuk dimaksudkan untuk mendeskripsikan kelas sesuai dengan data training.
Gambar 3. Sistem yang akan dibangun
1. Tahap Preprosesing
Dataset sebelum preprosesing :
Tabel 5. Dataset sebelum preprosesing
Kemudian dataset pada tiap features of a record diubah menjadi angka, misal pada feature Protocol Type untuk TCP diberi angka 1, untuk UDP diberi angka 2, untuk ICMP diberi angka 3 dan seterusnya. Tujuannya karena pada dasarnya SVM berbasiskan vektor sehingga data perlu di transformasikan ke dalam angka. Maka akan didapatkan data sebagai berikut:
Tabel 6. Dataset setelah preprosesing Duration Protocol Type Service Flag 0 TCP telnet SF 1 UDP Smptp RSTR 26 ICMP ftp_data SF 27 TCP Finger SF 29 UDP private RSTR Duration Protocol Type Service Flag 1 1 1 1 2 2 2 2 3 3 3 1
2. Tahap Normalisasi
Misalditerapkanuntukmencari x‟ pada feature duration barispertamapadaTabel 6. adalah : x‟= x‟ = x‟ = 0, sehinggauntukkeseluruhan data makadidapatkan data sebagaiberikut :
Tabel 7. Dataset setelah normalisasi
Duration Protocol Type Service Flag
0 0 0 0
0,25 0,25 0,25 0,25
0,5 0,5 0,5 0
0,75 0 0,75 0
1 0,25 1 0
3. Tahap Pemodelan dengan Menggunakan Metode SVM
Pada penelitian ini SVM dipisah dengan 2 proses utama yaitu pertama adalah pemodelan SVM dan yang kedua adalah proses klasifikasi SVM itu sendiri. Pada pemodelan SVM ini dilakukan pencarian Support Vector dimana Support Vector tersebut merupakan data-data yang memiliki nilai koefisien langrange atau ∝ lebih besar dari nol, yang nantinya Support Vector ini digunakan hyperplane atau garis pemisah antar kelas.
Sedangkan untuk proses multiclass itu sendiri yang digunakan adalah SVM one against all, dimana akan dibangun 5 kelas. Kelas 1 merepresentasikan kondisi normal sedangkan 4 kelas lainnya merepresentasikan ancaman (DOS,U2R,R2L, dan Probe).
Gambar 4. Tahap pemodelan dengan SVM (Tahap Pelatihan) 4. Tahap Proses Klasifikasi SVM
Pada tahap pengujian SVM dilakukan adalah dengan memetakan data-data uji kedalam ruang berdimensi SVM, kemudian digunakan hyperplane berdasarkan Support Vector yang
dihasilkan pada tahap pemodelan SVM sebelumnya. Pada tahapan ini dilakukan klasifikasi sebanyak 5 kelas yang telah didefiniskan sebelumnya.
Gambar 5. Proses klasifikasi dengan SVM (Tahap Pengujian)
3. Pengujian dan Analisis 3.1. Tujuan Pengujian
Pengujian sistem ini bertujuan untuk mengimplementasikan metode Support vector machines serta menganalisa performansi yang telah dihasilkan oleh sistem berupa hasil klasifikasi yang nantinya digunakan untuk perhitungan performansi sistem berdasarkan pada pengaruh nilai tingkat toleransi terhadap kesalahan sistem (parameter C), nilai degree fungsi kernel polynomial, dan banyaknya data latih.
3.2. Hasil Pengujian
Skenario 1
` Gambar 6. Diagram Hasil Pengujian Skenario 1
Semakin besar nilai tingkat toleransi terhadap kesalahan sistem (parameter C) maka semakin menurun nilai akurasi yang dihasilkan. Ini menunjukkan bahwa nilai C≥0,5 telah memberikan hyperplane bidang pemisah yang optimal. Gambarannya adalah ketika nilai C lebih besar dari nol maka toleransi sistem terhadap kesalahan klasifikasi akan diperketat. Namun berbeda pada kasus ini, karena dari hasil pengujian terlihat bahwa dengan nilai parameter C yang kecil, ini membuktikan bahwa nilai α yang dihasilkan adalah optimal, walaupun seharusnya ketika sistem diperketat semakin
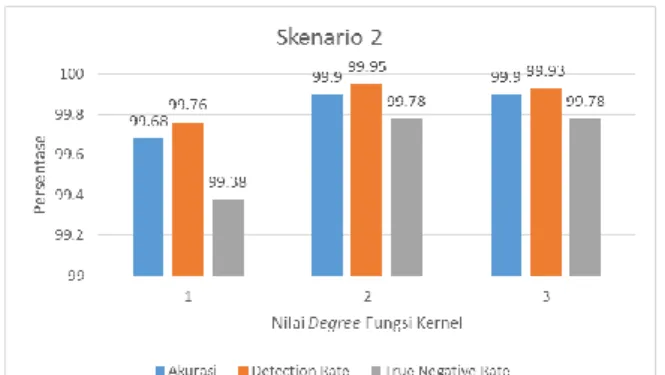
Gambar 7. Diagram Hasil Pengujian Skenario 2
Dalam pemilihan nilai degree fungsi kernel polynomial Support vector machines yang semakin besar atau tinggi maka hasil klasifikasi (akurasi) yang dihasilkan akan lebih baik. Terbukti bahwa nilai degree fungsi kernel yang lebih besar akan membuat semakin fleksibelnya hyperplane bidang pemisah yang akan berujung pada nilai akurasi. Dalam pengujian ini ditunjukkan nilai degree fungsi kernel dengan angka 2 telah memberikan akurasi optimal. Nilai degree fungsi kernel dengan angka 3 juga menunjukkan hasil optimal, namun pengujian dengan angka 3 membutuhkan waktu yang lebih lama, karena bentuk kurva yang dihasilkan berbentuk persamaan bersuku banyak, oleh karena itu dengan angka 2 saja cukup untuk menghasilkan akurasi yang optimal.
3.3. Skenario 3
Gambar 8. Diagram Hasil Pengujian Skenario 3
Pengaruh dari pembagian data latih dapat meningkatkan akurasi serta ketepatan dalam mengklasifikasikan data normal dan 4 jenis serangan (yang terbagi ke dalam 22 kelas). Dalam pengujian di atas bisa dilihat pula bagaimana Training dengan jumlah data 394.021 dimana memiliki penyebaran data yang sangat merata pada setiap kelas dan mendominasi banyaknya data hampir diseluruh data training yang kemudian akan menyebabkan data testing yang dihasilkan hampir mendekati sempurna.
Selain pada nilai tingkat toleransi terhadap kesalahan sistem (parameter C) dan nilai degree fungsi kernel, pengaruh data uji juga terhadap performansi kinerja klasifikasi juga sangat berpengaruh. Apabila penyebaran data tidak tepat, semisal dalam kasus ini data normal yang diberikan dalam training lebih banyak dari data intrusi maka hasil klasifikasi tidak akan bagus. Penting juga bahwa sebelum melakukan
training untuk menganalisa data testing. Menganalisa disini artinya adalah mencari berapa banyak data.
4. Kesimpulan
Berdasarkan implementasi dan pengujian yang telah dilakukan pada Penelitian ini maka diperoleh beberapa kesimpulan sebagai berikut:
1. Metode Support vector machines multiclass one-againts-all dapat diterapkan untuk misuse detection pada Intrusion Detection System dengan performansi tertinggi sebesar 99,93%.
2. Dengan nilai tingkat toleransi terhadap kesalahan sistem (parameter C) sebesar 0,5 dan nilai degree fungsi kernel polynomial bernilai 2 serta pemilihan data latih yang tepat yaitu 394.021 maka didapatkan performansi terbaik dengan akurasi (99,93%), Detection Rate (jumlah intrusi yang berhasil dideteksi oleh sistem dibagi dengan total jumlah intrusi yang ada pada dataset) (99,95%) dan True Negative Rate
(jumlah data normal yang benar dideteksi oleh sistem dibagi dengan jumlah data normal pada dataset) (99,86%).
3. Dalam memilih nilai tingkat toleransi terhadap kesalahan sistem (parameter C), degree fungsi kernel polynomial serta data latih yang tepat akan sangat berpengaruh pada performansi sistem dalam mendapatkan hasil yang optimal.
Dari hasil penelitian ini, beberapa saran yang dapat dilakukan untuk pengembangan berikutnya dapat
dilakukan dengan pemilihan atribut dengan membuang atribut yang kurang penting agar dalam proses training dan testing tidak membutuhkan waktu yang lama serta diharapkan kedepannya dalam proses training dapat dikembangkan sistem dengan penentuan nilai tingkat toleransi terhadap kesalahan sistem (parameter C) dan degree fungsi kernel secara otomatis.
Daftar Pustaka :
[1] Akbar, Shaik. Rao, K. Nageswara. Chandulal, J.A. 2010. “Intrusion Detection System Methodologies Based on Data Analysis”. International Journal of Computer Applications Volume 5.
[2] Anderson. J. P. “Computer Security Threat Monitoring and Surveillance.” Technical Report, James P Anderson Co., Fort Washington, Pennsylvania, 1980.
[3] Baiju, Shah. 2001. “How to Choose Intrusion Detection Solution”SANS Institute Resources. [4] Chandola, Varun, danArindamBanjeree. 2009. “Anomaly Detection”. University of Minnesota.
[5] Fletcher, Tristan. 2009. Support vector machines Explained. Tersedia di http://www.cs.ucl.ac.uk/staff/T.Fletcher diunduhpadatanggal 15 Oktober 2011.
[6] Gunn, Steve R. 1998. Support vector machines for Classification and Regression. Tersedia di http://www.svms.org/tutorials/ diunduhpadatanggal 17 juni 2011.
[7] Han, Jiawai, MichelineKamber. 2001. Data mining : Concepts and Techniques. Simon FrasterUniversity : Morgan Kaufman.
[8] Hsu, Chih-Wei, Chih-Jen Lin. A Comparison of Methods for Multi-class Support vector machines. IEEE Transactions on Neural Networks, 13(2):415-425.2002.
[9] Li, Weijun. Liu, Zhenyu. 2011. “A method of SVM with Normalization in Intrusion Detection”. Intelligent Information Technology Application Research Association. Elseiver Ltd.
[10] Liu, Yi danZheng, Yuan F. One-Against-All Multi-Class SVM Classification Using Reliability Measure. Tersedia di http://www.stat.umn.edu/~xshen/paper/ diunduhpadatanggal 2 Desember 2011.
[11] Platt, John. Fast Training of Support vector machines using Sequential Minimal Optimization, in Advances in Kernel Methods – Support Vector Learning, B. Scholkopf, C. Burges, A. Smola, eds., MIT Press (1998). [12] Sembiring, Krisantus. 2007. PenerapanTeknik Support Vector Machine
untukPendeteksianIntrusipadaJaringan. Bandung :TeknikElektrodanInformatika, ITB.
[13] Wu, Tzeyoung Max. 2009. “Intrusion Detection Systems”. Information Assurance Tools Report, Sixth Edition.
[14] O.A. Marlita, Adiwijaya, A.P. Kurniati, Anomaly Detection pada Intrusion Detection System (IDS) Menggunakan Metode Bayesian Network, Jurnal Penelitian dan Pengembangan Telekomunikasi 17:1 (2012), pp. 53-61
[15] Adiwijaya, “Aplikasi Matriks dan Ruang Vektor”. Graha Ilmu, 2014
[16] N., Nastaiinullah, Adiwijaya, A. P. Kurniati, Anomaly Detection on Intrusion Detection System Using Clique Partitioning, 2nd International Conference on Information and Communication Technology (ICoICT) 2014