PENDAHULUAN
Latar Belakang
Web merupakan salah satu sarana untuk menyediakan berbagai informasi pada jaringan internet. Adanya hyperlink pada web memungkinkan pengguna menjelajahi web untuk mencari informasi atau halaman yang diperlukan (halaman target). Hal ini menyebabkan pengembang web harus menentukan struktur web yang baik dalam mengorganisasikan web agar pengguna dapat menemukan halaman target dengan mudah pada web tersebut.
Namun demikian, struktur web yang baik menurut pengembang belum cukup memberikan kemudahan kepada pengguna dalam mencari halaman target. Struktur ini mungkin saja tidak sesuai dengan struktur yang diharapkan pengguna sehingga tidak sedikit pengguna menemukan halaman target tidak pada lokasi yang diharapkan (lokasi harapan) tetapi berada di lokasi lainnya (lokasi aktual). Pengguna akan melakukan penelusuran balik ketika tidak menemukan informasi pada lokasi harapan dan meneruskan penelusurannya hingga halaman target ditemukan (Srikant & Yang 2001). Oleh karena itu, diperlukan suatu cara untuk memperbaiki struktur web sehingga struktur web tersebut sesuai dengan harapan pengguna.
Srikant & Yang (2001) memperkenalkan suatu metode untuk memperbaiki struktur web agar sesuai dengan harapan pengguna dengan cara menambahkan link dari lokasi harapan ke halaman targetnya. Dalam memperbaiki struktur web, metode ini menggunakan data perilaku pengguna web selama menjelajahi web yang tercatat dalam data log. Terdapat dua langkah utama pada metode ini. Pertama, menemukan lokasi-lokasi harapan dari suatu halaman target dengan menggunakan Algoritme Find Expected Locations. Kedua, menentukan lokasi-lokasi harapan yang perlu direkomendasikan untuk ditambahkan link ke halaman tergetnya dengan menggunakan algoritme optimasi sebagai upaya untuk memperbaiki struktur web agar sesuai dengan harapan pengguna.
Tujuan
Tujuan penelitian ini adalah mengimplementasikan Algoritme Find Expected Location dan algoritme optimasi
(FirstOnly, OptimizeBenefit, dan
OptimizeTime) untuk menemukan dan
menentukan lokasi-lokasi harapan yang perlu direkomendasikan untuk ditambahkan link ke halaman targetnya. Selain itu, penelitian ini juga bertujuan membandingkan kinerja ketiga algoritme optimasi.
Ruang Lingkup
Ruang lingkup penelitian ini dibatasi pada: 1 Struktur web yang diteliti merupakan struktur dummy, bukan struktur dari suatu web asli.
2 Data yang diteliti adalah path halaman yang dikunjungi pengguna yang dibangkitkan dengan suatu algoritme berdasarkan struktur web yang dibuat.
Manfaat
Penelitian ini diharapkan dalam penerapannya pada suatu web dapat membantu administrator memperbaiki struktur web sebagai upaya meningkatkan pelayanan penyediaan informasi yang diperlukan oleh pengguna.
TINJAUAN PUSTAKA
Web
Web merupakan suatu layanan sajian informasi yang menggunakan konsep
hyperlink, yang memudahkan surfer (sebutan
bagi pemakai komputer yang melakukan penelusuran informasi di internet). Informasi yang disajikan dengan web menggunakan konsep multimedia, seperti teks, gambar, animasi, suara, dan film (Sidik 2006).
Halaman-halaman web perlu diorganisasikan dengan baik agar pengunjung mudah menemukan informasi yang diperlukan. Pengorganisasian halaman tersebut dapat dilakukan dengan menggunakan beberapa struktur berikut (Veer
et al. 2004):
a Struktur Berurut
Dengan cara ini, halaman-halaman web diorganisasikan secara berurutan layaknya halaman-halaman pada sebuah buku seperti dapat dilihat pada Gambar 1. Pada setiap halaman terdapat link menuju halaman sebelum atau sesudah halaman tersebut atau mungkin juga terdapat link menuju halaman pertama dari web tersebut.
b Struktur Bertingkat
Pada struktur bertingkat, halaman-halaman web terbagi atas halaman-halaman menu atau indeks dan halaman-halaman isi. Halaman-halaman tersebut disusun secara bertingkat dan dikelompokkan berdasarkan kategorinya seperti dapat dilihat pada Gambar 2. Jika diperlukan, halaman-halaman menu dapat dibuat 2 (dua) tingkat atau lebih seperti dapat dilihat pada Gambar 3.
Gambar 2 Struktur Bertingkat (Veer et al. 2004)
Gambar 3 Struktur Bertingkat dengan 3 (tiga) Tingkat (Veer et al. 2004)
c Kombinasi Struktur Berurut dan Bertingkat
Struktur ini merupakan gabungan antara struktur berurut dan struktur bertingkat seperti dapat dilihat pada Gambar 4. Selain terdapat halaman menu yang memungkinkan pengguna untuk menuju halaman-halaman isi dari web, dengan cara ini pengguna juga dapat menuju halaman isi dari halaman isi lainnya.
Gambar 4 Kombinasi Struktur Berurut dan Bertingkat (Veer et al. 2004) d Struktur Jaringan
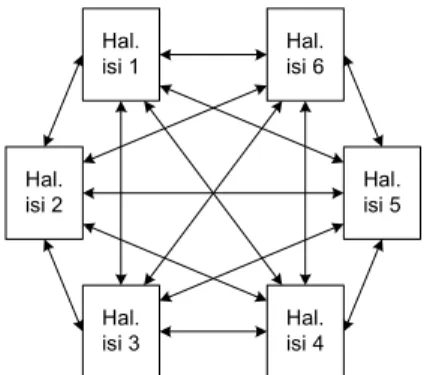
Pada struktur jaringan, setiap halaman terhubung dengan halaman lainnya seperti dapat dilihat pada Gambar 5.
Pengorganisasian dengan cara ini sesuai untuk web yang mempunyai jumlah halaman terbatas dan pengembang web sulit untuk memprediksi urutan penelusuran halaman yang mungkin dilakukan oleh pengguna.
Gambar 5 Struktur Jaringan (Veer et al. 2004)
Data Log
Data log adalah data sekunder yang mencatat setiap request halaman web oleh pengguna selama menjelajahi web. Data log terdiri atas tiga jenis, yaitu data log yang tersimpan di server, client, dan server proxy. Data log yang tersimpan di server merupakan data yang paling banyak digunakan dalam algoritme mining (Ivancsy & Vajk 2006).
Data log pada server mempunyai format yang berbeda-beda sesuai dengan web server yang digunakan. Apache-server memepunyai format data log seperti contoh berikut (Huysman et al. 2004):
195.162.218.155 - - [27/Jun/2002:00:01:54 +0200] “GET / shop/detail.html HTTP/1.1” 200 38890“http://www.msn.com/shopping/food” “Mozilla/4.0 (compatible; MSIE 6.0;Windows NT 5.1;SKY11a)
Komponen pertama pada contoh data log di atas, 195.162.218.155, menunjukkan alamat IP dari pengguna yang melakukan request halaman pada server. Komponen kedua menunjukkan waktu terjadinya request halaman oleh pengguna. Komponen ketiga, “GET /shop/detail.html HTTP/1.1”, merupakan bagian request yang terdiri atas tiga bagian. Bagian pertama, GET, menunjukkan metode request. Bagian kedua, /shop/detail.html, menunjukkan halaman yang di-request. Bagian terakhir, HTTP/1.1, menunjukkan protokol yang digunakan untuk melakukan request halaman web. Komponen keempat, 200, menunjukkan status request. Komponen kelima, 38890, menunjukkan ukuran halaman yang di-request dalam satuan
byte. Komponen berikutnya, alamat http://www.msn.com/shopping/food, adalah
halaman yang melakukan request. Komponen terakhir menunjukkan browser yang digunakan oleh pengguna.
Model Pencarian Pengguna
Dalam melakukan pencarian halaman target pada suatu web, pengguna akan mengikuti salah satu model pencarian di bawah ini. Dalam model ini, penggunaan mesin pencarian untuk menemukan halaman web tidak termasuk di dalamnya (Srikant & Yang 2001).
1 Pencarian Satu Halaman Target
Asumsikan pengguna mencari sebuah halaman T. Maka pengguna akan melakukan
langkah-langkah sebagai berikut:
1 Start from the root.
2 While (current location C is not the target pages T) do
a. If any of the links from C seem likely to lead to T, follow the link that appears most likely to lead to T. b. Else, either backtrack and go to the
parent of C with some (unknown) probability, or give up with some probability.
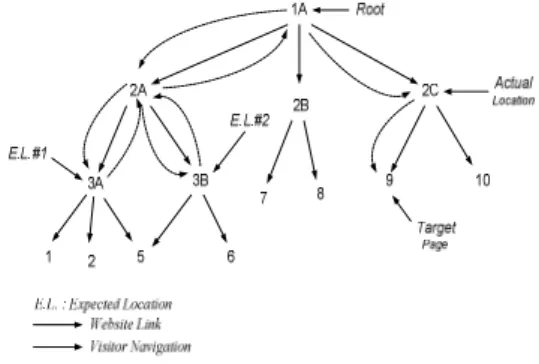
Pengguna akan mengikuti link yang berbeda setelah pengguna melakukan penelusuran balik. Sebagai contoh, pada Gambar 6 dilustrasikan setelah melakukan penelusuran balik dari 3A ke 2A, pengguna akan menuju 3B, tidak kembali ke 3A. 2 Pencarian Beberapa Halaman Target
Asumsikan pengguna mencari beberapa halaman T1, T2, …, Tn. Maka pengguna akan
melakukan langkah-langkah sebagai berikut :
1 For i := 1 to n
a. If i =1, start from the root, else from the current location C.
b. While (current location C is not the target page Ti) do
• If any of the links from C seem
likely to lead to Ti, follow the link that appears most likely to lead to Ti.
• Else, either backtrack and go to
the parent of C with some probability, or give up on Ti and start looking for Ti+1 at step 1a with some probability.
Model pencarian di atas dapat diilustrasikan pada Gambar 6 dan Gambar 7. Gambar 6 mengilustrasikan model pencarian satu halaman target yaitu halaman target 9. Sebelum berhasil menemukannya pada lokasi aktual 2C, pengguna berharap menemukan halaman target 9 pada lokasi harapan 3A atau 3B. Gambar 8 mengilustrasikan model pencarian beberapa halaman target yaitu halaman target 6 dan halaman target 9. Sebelum berhasil menemukannya pada lokasi aktual 3B, pengguna berharap menemukan halaman target 6 pada lokasi harapan 3A. Setelah halaman target 6 ditemukan, pengguna melanjutkan pencarian halaman target 9. Sebelum berhasil menemukannya pada lokasi aktual 2C, pengguna berharap menemukan halaman target 9 pada lokasi harapan 2B.
Gambar 6 Website dan Model Pencarian Satu Halaman Target (Srikant & Yang 2001)
Gambar 7 Web dan Model Pencarian Beberapa Halaman Target (Srikant & Yang
2001)
Data Preprocessing
Data log tidak dapat digunakan langsung untuk proses analisis karena banyaknya data pengotor dan format yang tidak sesuai dengan algoritme yang digunakan. Selain itu juga tidak semua komponen dalam data log diperlukan dalam suatu proses analisis. Hal ini menyebabkan diperlukannya tahap data
mentah menjadi data yang siap digunakan untuk proses analisis. Data preprocessing terdiri atas aktivitas-aktivitas berikut ini (Cooley et al. 1999):
1 Data Cleaning
Data log mentah mengandung banyak sekali record yang tidak sesuai dalam proses analisis. Misalnya, record yang mencatat
request gambar yang sebenarnya tidak
dilakukan oleh pengguna secara langsung, melainkan karena pada halaman yang
di-request pengguna terdapat gambar sehingga request gambar secara otomatis dilakukan
oleh browser. Selain itu, record yang mencatat request yang dilakukan oleh robots (crawler) suatu mesin pencarian juga merupakan record yang tidak sesuai dalam proses analisis. Record ini harus dibersihkan sehingga dihasilkan data log yang mencatat
request halaman yang benar-benar dilakukan
oleh pengguna. 2 User Identification
Tahap ini bertujuan untuk menentukan
request halaman yang dilakukan oleh
pengguna yang sama. Ada beberapa metode dalam membedakan pengguna satu dengan yang lainnya. Masing-masing metode mempunyai kelebihan dan kekurangan. Salah satu metode yang dapat digunakan yaitu dengan menggunakan kombinasi alamat IP dan browser yang digunakan pengguna. Dengan metode ini diasumsikan semua
request dalam data log dengan alamat IP dan browser yang sama dilakukan oleh pengguna
yang sama. Kelebihan metode ini yaitu tidak diperlukannya informasi tambahan karena alamat IP dan browser yang digunakan pengguna tercatat dalam data log. Akan tetapi, dengan metode ini tidak selalu diperoleh hasil yang sesuai. Sebagai contoh jika ada beberapa pengguna berbagi alamat IP dan masing-masing menggunakan browser yang sama, maka dengan metode ini request halaman dari masing-masing pengguna dianggap berasal dari satu pengguna yang sama.
3 Session Identification
Pengguna biasanya mengunjungi sebuah web beberapa kali pada waktu yang berbeda (sesi). Setelah data log dikelompokkan berdasarkan pengguna pada langkah sebelumnya, pada tahap ini data log tersebut dikelompokkan lagi berdasarkan sesinya. Metode yang digunakan pada tahap ini adalah berdasarkan selang waktu antara request suatu halaman dengan request halaman beriktunya.
Ketika ada dua urutan request halaman yang dilakukan oleh pengguna yang sama dalam rentang waktu yang cukup lama, maka dua
request tersebut dianggap terjadi pada sesi
yang berbeda. Rentang waktu 25,5 menit cukup digunakan untuk membedakan dua sesi yang berbeda (Catledge & Pitkow 1995). 4 Path Completion
Suatu browser biasanya menerapkan sistem cache untuk menyimpan halaman-halaman yang baru saja dikunjungi dengan tujuan untuk mengurangi waktu yang diperlukan untuk melakukan request halaman. Ketika pengguna menekan tombol back pada
browser, maka halaman yang ditampilkan
adalah halaman yang berasal dari sistem
cache, bukan hasil request dari server. Hal ini
menyebabkan request halaman yang dilakukan pengguna tidak tercatat pada data
log.
Tujuan dari tahap ini yaitu untuk menambahkan request halaman yang tidak tercatat pada data log untuk setiap sesi sehingga dihasilkan path perilaku request pengguna yang lengkap. Struktur web diperlukan untuk melakukan proses ini.
Namun demikian, tahap ini tidak selalu diperlukan dalam data preprocessing. Hal ini tergantung pada proses analisis yang akan dilakukan.
5 Transaction Identification
Tahap terakhir dari data preprocessing adalah transaction identification. Pada tahap ini path yang dihasilkan dari tahap sebelumnya akan dipecah berdasarkan transaksinya. Transaksi merupakan sebuah sub-path yang mempunyai arti tertentu. Sama halnya dengan path completion, tahap ini tidak selalu diperlukan, tergantung pada proses analisis yang akan dilakukan.
Algoritme Find Expected Location
Algoritme Find Expected Location merupakan algoritme yang digunakan untuk mencari lokasi-lokasi harapan dari suatu halaman target berdasarkan perilaku pencarian pengguna. Halaman yang menjadi titik penelususran balik pengguna dianggap sebagai lokasi harapan. Algoritme Find
Expected Locations dituliskan sebagai berikut
(Srikant & Yang 2001):
1 Build hash table of links in the website. 2 Partition web log by visitor:
Sort the web log file by visitor ID as the
primary key and time as the secondary key, or
Partition the web log file by hashing on
visitor ID and sort each partition separately, or
Scan web log and extract sequence of
pages for each visitor ID, passing them onto step 3.
3 For each visitor, partition web log such that each subsequence terminates in a target page.
4 For each visitor and target page, find any expected locations for that target page : Let {P1, P2, … ,Pn} be the set of visited pages, where Pn is a target page.
Let B :=
φ
denote the list of backtrack pages.For i:=2 to n-2 begin
If ((Pi-1 = Pi+1) or (no link from Pi to Pi+1))
add Pi to B. //Pi is backtrack point.
End
If (B not empty)
Add (Pn, B, Pn-1) to (current URL, backtrack list, Actual Location) table;
Pada algoritme dapat dilihat bahwa langkah 2 (dua) dan 3 (tiga) sudah termasuk dalam data preprocessing. Pada data
preprocessing, langkah 2 (dua) merupakan
tahap user identification sedangkan langkah 3 (tiga) merupakan tahap transaction identification.
Tabel hash adalah tabel yang menjelaskan
link antara satu halaman dengan halaman
lainnya. Tabel ini dibuat karena adanya cache dalam web browser. Ketika pengguna melakukan penelusuran balik, request halaman tujuan penelusuran balik tidak tercatat dalam data log karena halaman tersebut telah dikunjungi sebelumnya. Oleh karena itu ketika ada dua request halaman yang berurutan pada data log yang tidak mempunyai link diantara keduanya, halaman pertama dianggap sebagai lokasi harapan.
Algoritme ini mempunyai kelemahan yaitu hanya pengunjung yang berhasil menemukan halaman target yang dapat menghasilkan
lokasi harapan untuk halaman target tersebut. Pengunjung yang menyerah sebelum menemukan halaman target tidak dapat ditelusuri (Srikant & Yang 2001).
Algoritme Optimasi
Algoritme optimasi digunakan untuk menentukan lokasi-lokasi harapan yang perlu ditambahkan link ke halaman targetnya. Misal Algoritme Find Expected Location
menghasilkan tabel dengan kolom-kolom T,
E1, E2, ..., En, dan A. T berisi halaman target, E1 sampai En adalah n lokasi harapan pertama
untuk suatu halaman target, dan A adalah lokasi aktual dari halaman target tersebut. Kemudian data dikelompokkan berdasarkan nilai T, sehingga diperoleh contoh hasil seperti pada Tabel 1.
Tabel 1 Contoh hasil Find Expected Location
T E1 E2 E3 E4 A Record1 T1 P1 P2 AL Record2 T1 P1 AL Record3 T1 P2 P3 P4 P1 AL Record4 T1 P3 P2 AL Record5 T1 P4 P2 AL
Setelah dikelompokkan, lokasi harapan
yang direkomendasikan untuk ditambahkan
link ke halaman target yang bersangkutan
dapat dicari dengan salah satu algoritme optimasi di bawah. Ketiga algoritme ini dapat menghasilkan halaman rekomendasi yang berbeda-beda (Srikant & Yang 2001). 1 FirstOnly
Algoritme ini merekomendasikan lokasi-lokasi harapan yang sering dikunjungi pertama kali (lokasi-lokasi harapan pada E1)
yang memenuhi nilai threshold S, tanpa memperhatikan lokasi-lokasi harapan berikutnya (E2,E3,...,En). Threshold S
merupakan jumlah minimum suatu lokasi harapan yang terdapat pada E1 untuk suatu
halaman target sehingga lokasi harapan tersebut perlu direkomendasikan untuk ditambahkan link ke halaman targetnya. Berikut ini algoritme FirstOnly:
Count the support for all the pages in E1 Sort the pages by their support
Present all pages whose support is greater than or equal to S to administrator.
Misalkan diberikan nilai threshold S=2, maka dengan algoritme FirstOnly,
1, halaman yang direkomendasikan untuk ditambahkan link ke halaman target T1 adalah
P1.
2 OptimizeBenefit
Algoritme ini merupakan algoritme greedy yang bertujuan untuk memaksimalkan keuntungan bagi web karena tidak kehilangan pengunjung ketika tidak menemukan halaman target pada lokasi harapan yang ke k jika ditambahkan link pada lokasi harapan tersebut. Nilai bk merupakan nilai bobot dari Ek yang menunjukkan berapa bagian
kelompok pengunjung yang akan menyerah jika tidak menemukan halaman target pada lokasi harapan yang ke k. Nilai bk dapat
dihitung dengan rumus berikut:
Ti pada harapan lokasi jenis total k E pada harapan lokasi jenis total bk =
Threshold Sb menunjukkan total bobot
minimum dari lokasi harapan untuk suatu halaman target sehingga lokasi harapan tersebut perlu direkomendasikan untuk ditambahkan link ke halaman targetnya. Berikut ini algoritme OptimizeBenefit:
repeat
foreach record begin for j := 1 to m
Increment support of value(Ej) by bj.
end
Sort pages by support.
P := Page with highest support (break ties at random).
if support(P) Sb begin
Add (P, support(P)) to list of recommended pages. foreach record begin
for k := 1 to n begin if value(Ek) = P Set Ek , Ek+1,…, En to null; end end end until (support(P) < Sb);
Berdasarkan Tabel 1 diperoleh nilai b1 =
1, b2 = 0.5, b3 = b4 = 0.25, sehingga diperoleh support(P2) = 1
×
1+3×
0.5 = 2.5, support(P1) = 2.25, support(P3) = 1.5, dan support(P4) =1.25. Misal diberikan nilai Sb = 2. P2
mempunyai nilai support yang memenuhi Sb
dan paling besar sehingga P2 ditambahkan
pada halaman yang direkomendasikan. Kemudian P2 beserta lokasi-lokasi harapan
setelah P2 untuk setiap record dihapuskan
sehingga diperoleh Tabel 2.
Tabel 2 Lokasi-lokasi harapan setelah melalui perhitungan dengan algoritme
OptimizeBenefit T E1 E2 E3 E4 A Record1 T1 P1 AL Record2 T1 P1 AL Record3 T1 AL Record4 T1 P3 AL Record5 T1 P4 AL
Kemudian dilakukan kembali perhitungan nilai support sehingga diperoleh support(P1) = 2, support(P3) = 1, dan support(P4) = 1. P1
ditambahkan pada halaman yang direkomendasikan. Sampai disini iterasi dihentikan karena nilai support sudah tidak ada yang memenuhi Sb. Dengan menggunakan
algoritme ini halaman yang direkomendasikan yaitu P2 dan P1.
3 OptimizeTime
Algoritme ini bertujuan untuk meminimalisasi banyaknya penelusuran balik yang harus dilakukan pengunjung ketika tidak menemukan halaman target pada lokasi harapan. Seperti halnya algoritme
OptimizeBenefit, algoritme ini juga merupakan algoritme greedy. Banyaknya penelusuran balik yang dapat diminimalisasi dengan menambahkan link pada suatu lokasi harapan manunjukan bobot dari lokasi harapan tersebut. Threshold St merupakan
nilai minimum total jumlah penelusuran balik yang harus dilakukan pengunjung jika tidak dilakukan penambahan link pada suatu lokasi harapan sehingga lokasi harapan tersebut perlu direkomendasikan untuk ditambahkan
link ke halaman targetnya. Berikut ini
algoritme OptimizeTime:
repeat
foreach record begin
Let m be the number of expected locations in this record.
Increment support of value(Ej) by m+1-j.
end
Sort pages by support.
P := Page with highest support (break ties at random).
if support(P) St begin
Add (P, support(P)) to list of recommended pages. foreach record begin
for k := 1 to n begin if value(Ek) = P Set Ek , Ek+1,…, En to null; end end end until (support(P) < St);
Misalkan diberikan St = 4. Berdasarkan
Tabel 1, untuk iterasi pertama diperoleh
support(P2) = 1 + 4 + 1 + 1 = 7, support(P1) =
4, support(P3) = 5, dan support(P4) = 4. Maka P2 ditambahkan pada halaman yang
direkomendasikan. Kemudian P2 beserta
lokasi-lokasi harapan setelah P2 untuk setiap record dihapuskan sehingga diperoleh Tabel
3.
Tabel 3 Lokasi-lokasi harapan setelah melalui perhitungan dengan algoritme
OptimizeTime T E1 E2 E3 E4 A Record1 T1 P1 AL Record2 T1 P1 AL Record3 T1 AL Record4 T1 P3 AL Record5 T1 P4 AL
Kemudian dilakukan kembali perhitungan nilai support sehingga diperoleh support(P1) = 2, support(P3) = 1, dan support(P4) = 1.
Pada tahap ini iterasi dihentikan karena tidak ada nilai support yang memenuhi St. Dengan
menggunakan algoritme ini halaman yang direkomendasikan yaitu P2.
Algoritme OptimizeTime identik dengan algoritme OptimizeBenfit. Perbedaan keduanya terdapat pada cara penghitungan nilai bobot dan nilai support.
METODE PENELITIAN
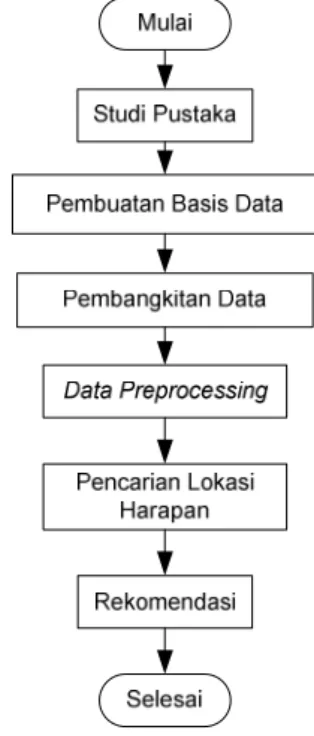
Tahap-tahap yang dilakukan dalam penelitian ini digambarkan pada Gambar 6. Penelitian diawali dengan studi pustaka, kemudian dilanjutkan dengan pembuatan basis data, pambangkitan data, datapreprocessing, pencarian lokasi harapan, dan
diakhiri dengan menentukan lokasi harapan yang perlu direkomendasikan untuk ditambahkan link ke halaman targetnya pada tahap rekomendasi.
Gambar 8 Metode Penelitian
Studi Pustaka
Studi pustaka diawali dengan mempelajari
paper Srikant & Yang (2001) yang
merupakan acuan utama dalam penelitian ini.
Paper ini menjelaskan tentang suatu metode
untuk memperbaiki struktur web agar sesuai dengan harapan pengguna. Algoritme Find
Expected Locations dan algoritme optimasi
yang digunakan dalam penelitian bersumber dari paper ini. Studi pustaka kemudian dilanjutkan dengan mempelajari tulisan-tulisan yang terkait dengan acuan utama.
Pembuatan Basis Data
Berdasarkan studi pustaka yang dilakukan, pada tahap ini dibuat tabel-tabel yang diperlukan dalam penelitian. Penggunaan tabel-tabel basis data dipilih untuk memudahkan dalam melakukan langkah-langkah selanjutnya pada penelitian ini. Basis data dibuat menggunakan Database Management System (DBMS) mysql.