PENERAPAN METODE PENGGEROMBOLAN
BERDASARKAN GAUSSIAN MIXTURE MODELS
DENGAN MENGGUNAKAN ALGORITMA EXPECTATION
MAXIMIZATION
ULA SUSILAWATI
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2011
RINGKASAN
ULA SUSILAWATI. Penerapan Metode Penggerombolan Berdasarkan Gaussian Mixture Models dengan Menggunakan Algoritma Expectation Maximization. Dibimbing oleh BUDI SUSETYO dan UTAMI DYAH SYAFITRI.
Model-based clustering bertujuan untuk mengoptimalkan kemiripan antara individu dengan menggunakan pendekatan model probabilistik. Keseluruhan data diasumsikan berasal dari campuran dua atau lebih sebaran peluang dengan proporsi tertentu. Data dapat digerombolkan dengan menggunakan Gaussian Mixture Models (GMM), yaitu mixture dari G sebaran peluang Gaussian. Masing-masing sebaran mewakili suatu gerombol dengan parameter tertentu. Parameter tersebut diduga menggunakan algoritma Expectation Maximization (EM) dengan nilai awal parameter diperoleh dari agglomerative hierarchical clustering. Metode ini menggunakan Bayes Information Criterion (BIC) untuk menentukan jumlah gerombol terbaik dengan berbagai karakteristik geometrik matriks peragam dari sebaran Gaussian. Dalam penelitian ini, GMM diterapkan pada beberapa pola sebaran data. Data dibangkitkan dari sebaran Gaussian dengan beberapa kondisi parameter, antara lain parameter vektor rataan dan matriks peragam ketiga gerombol identik, vektor rataan ketiga gerombol identik dengan matriks peragam yang berbeda, vektor rataan yang berbeda dengan matriks peragam yang identik, dan terakhir adalah parameter vektor rataan dan matriks peragam yang berbeda. Keefektifan GMM pada data tersebut dapat diketahui dengan menghitung rataan tingkat kesalahan klasifikasi. Kondisi lain yang dipertimbangkan dalam membangkitkan data adalah jarak antar pusat gerombol dan keragaman setiap gerombol untuk melihat keefektifan metode jika ketiga gerombol saling berjauhan, saling berdekatan, maupun saling tumpang tindih.
Hasil simulasi menunjukkan bahwa GMM efektif memisahkan gerombol yang memiliki pola
sebaran dengan ragam setiap peubah pada setiap gerombol bernilai kecil dan
dengan jarak antar pusat gerombol yang besar. Rataan tingkat kesalahan klasifikasi berkurang jika jarak antar pusat gerombol semakin besar, hal ini disebabkan oleh semakin sedikitnya amatan yang saling tumpang tindih dengan amatan pada gerombol yang lain. Ragam setiap peubah yang besar juga dapat meningkatkan tingkat kesalahan klasifikasi. Gerombol dengan ragam antar peubah pada setiap gerombol yang lebih besar daripada jarak antar pusat gerombol, memiliki rataan tingkat kesalahan klasifikasi yang sangat besar. Sedangkan untuk kasus dengan atau tanpa adanya korelasi tidak mempengaruhi tingkat kesalahan klasifikasi.
PENERAPAN METODE PENGGEROMBOLAN
BERDASARKAN GAUSSIAN MIXTURE MODELS
DENGAN MENGGUNAKAN ALGORITMA EXPECTATION
MAXIMIZATION
ULA SUSILAWATI
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Statistika pada
Departemen Statistika
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2011
Judul Skripsi : Penerapan Metode Penggerombolan Berdasarkan Gaussian Mixture
Models dengan Menggunakan Algoritma Expectation Maximization
Nama
: Ula Susilawati
NRP
: G14061319
Menyetujui:
Pembimbing I,
Pembimbing II,
Dr. Ir. Budi Susetyo, MS
Utami Dyah Syafitri, S.Si,M.Si
NIP 196211301986031003
NIP 197709172005012001
Mengetahui:
Ketua Departemen Statistika
Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Dr. Ir. Hari Wijayanto, M.Si
NIP 196504211990021001
RIWAYAT HIDUP
Penulis dilahirkan di Garut pada tanggal 17 Nopember 1988. Penulis merupakan putri ketiga dari pasangan Ayung Wahyudin dan Yeti Sumiati.
Penulis menyelesaikan sekolah dasar pada tahun 2000 di SD Negeri Paminggir IV, kemudian melanjutkan studi di SMP Negeri 1 Garut hingga tahun 2003. Selanjutnya, penulis menyelesaikan pendidikan sekolah menengah atas hingga tahun 2006 di SMA Negeri 1 Tarogong Garut. Pada tahun 2006 penulis melanjutkan studi di Institut Pertanian Bogor melalui Undangan Seleksi Masuk IPB (USMI). Setelah satu tahun menjalani perkuliahan Tingkat Persiapan Bersama (TPB), pada tahun 2007 penulis diterima sebagai mahasiswa Departemen Statistika FMIPA IPB, dengan minor Ilmu Konsumen. Selama masa kuliah penulis aktif sebagai anggota himpunan keprofesian Gamma Sigma Beta (GSB). Penulis juga berkesempatan menjadi asisten Metode Statistika dan Perancangan Percobaan I pada tahun 2009. Penulis pernah menjadi tim khusus pada acara Statistika Ria 2008, Pesta Sains 2008 dan Lomba Jajak Pendapat Statistika 2009. Penulis melaksanakan kegiatan praktik lapang di Lembaga Survei Indonesia selama bulan Februari hingga April 2010.
KATA PENGANTAR
Assalamu’alaikum Wr. Wb.
Segala puji dan syukur penulis panjatkan kepada Allah SWT atas segala limpahan rahmat dan karuniaNya sehingga penulis dapat menyelasaikan karya ilmiah dengan judul “Penerapan Metode Penggerombolan Berdasarkan Gaussian Mixture Models dengan Menggunakan Algoritma Expectation Maximization”. Shalawat serta salam semoga selalu tercurah kepada Rasulullah Muhammad SAW, beserta keluarga, sahabat, dan umatnya. Karya ilmiah ini merupakan salah satu syarat untuk memperoleh gelar Sarjana Statistika pada Departemen Statistika, Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor.
Ucapan terima kasih penulis sampaikan kepada semua pihak yang telah membantu penulis dalam penyusunan karya ilmiah ini, yaitu kepada:
1. Bapak Dr. Ir. Budi Susetyo, MS dan Ibu Utami Dyah Syafitri, S.Si, M.Si selaku pembimbing yang telah membimbing, mengarahkan, dan memberikan masukan serta perhatiannya kepada penulis.
2. Ibu Dr. Ir. Erfiani, MS selaku penguji luar pada ujian skipsi saya. Terima kasih atas saran dan masukannya.
3. Kedua orang tua, suami, dan Rasha Abqari Pratama atas doa dan dukungan yang tiada terputus untuk penulis.
4. Staf Dosen, Tata Usaha dan Perpustakaan Departemen Statistika FMIPA IPB.
5. Teman-teman mahasiswa Departemen Statistika FMIPA IPB angkatan 43 dan 44 atas diskusi dan motivasi yang diberikan kepada penulis.
Semoga Allah SWT membalas segala kebaikan yang telah diberikan kepada penulis dan semoga karya ilmiah ini dapat bermanfaat bagi pihak yang membutuhkan.
Bogor, Mei 2011
DAFTAR ISI
Halaman
DAFTAR TABEL ... viii
DAFTAR GAMBAR ... viii
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan ... 1
TINJAUAN PUSTAKA ... 1
Gaussian Mixture Models (GMM) ... 1
Algoritma Expectation Maximization (EM) ... 2
Penentuan Jumlah Gerombol ... 3
METODOLOGI ... 3
Data ... 3
Metode ... 5
HASIL DAN PEMBAHASAN ... 6
Ketiga Gerombol Berasal dari Populasi Identik ... 6
Ketiga Gerombol Berasal dari Populasi Berbeda ... 7
SIMPULAN DAN SARAN ... 9
Simpulan ... 9
Saran ... 9
DAFTAR PUSTAKA ... 10
DAFTAR TABEL
Halaman Tabel 1. Interpretasi geometrik dari berbagai parameterisasi sebaran Gaussian
pada Mclust ... 2 Tabel 2. Deskripsi setiap kasus simulasi yang dibangkitkan ... 4 Tabel 3. Rataan tingkat kesalahan klasifikasi setiap kasus simulasi ... 8
DAFTAR GAMBAR
Halaman Gambar 1. Rataan tingkat kesalahan klasifikasi pada kasus simulasi dimana
ketiga gerombol berasal dari populasi identik ... 7 Gambar 2. Rataan tingkat kesalahan klasifikasi pada kasus simulasi dimana
ketiga gerombol berasal dari populasi berbeda ... 9 Gambar 3. Rataan miss classification rate pada setiap kasus simulasi ... 9
1
PENDAHULUAN
Latar BelakangAnalisis gerombol merupakan suatu
metode yang membagi individu ke dalam kelompok yang bermakna dan berguna. Analisis gerombol mengelompokkan objek berdasarkan informasi yang diperoleh pada
data yang menggambarkan objek dan
keterkaitannya. Tujuannya adalah membentuk gerombol dimana objek-objek yang terletak pada gerombol yang sama relatif lebih homogen dibandingkan dengan objek pada gerombol yang lain.
Secara umum terdapat dua metode penggerombolan, yaitu metode hirarki dan metode nonhirarki. Metode hirarki dimulai dengan mengelompokkan dua atau lebih objek yang mempunyai kesamaan paling dekat, kemudian berlanjut pada objek selanjutnya sehingga gerombol terlihat membentuk hirarki yang jelas antar objek, hasil penggerombolannya
dapat digambarkan melalui dendogram.
Metode hirarki digunakan bila banyaknya gerombol yang akan dibentuk tidak diketahui sebelumnya dan banyaknya amatan tidak
terlalu besar. Sedangkan pada metode
nonhirarki, proses penggerombolan dimulai dengan terlebih dahulu menentukan jumlah
gerombol. K-means merupakan metode
nonhirarki yang paling banyak digunakan (Johnson & Wichern 2002).
Metode nonhirarki lainnya adalah metode
penggerombolan dengan menggunakan
mixture model. Mixture model dapat
diterapkan pada data kategorik, kontinyu maupun keduanya, metode ini juga dapat mengidentifikasi pencilan dan pemilihan gerombol berdasarkan kriteria tertentu (McLachlan & Basford 1988). K-means
menggunakan jarak metrik dalam
mendefinisikan setiap gerombol yang
terbentuk, sedangkan metode penggerombolan berdasarkan mixture model menggunakan distribusi statistik dalam mendefinisikan setiap gerombl yang terbentuk.
Model-based clustering ini bertujuan untuk mengoptimalkan kemiripan antara individu dengan menggunakan pendekatan model probabilistik. Pendekatan tersebut dapat memodelkan data yang dimiliki dengan menerapkan pengaturan karakteristik yang
berbeda-beda dan menentukan jumlah
gerombol yang sesuai dengan data seiring proses pemodelan karakteristik dari masing-masing gerombol tersebut.
Metode ini mengasumsikan bahwa
keseluruhan individu adalah campuran dari G
sebaran peluang, mewakili G gerombol, dimana masing-masing sebaran secara khas mempunyai parameter sebaran. Salah satu metode yang digunakan untuk menduga
parameter adalah melalui algoritma
Expectation Maximization (EM). Algoritma EM merupakan algoritma iteratif populer yang dapat digunakan untuk menemukan penduga parameter dengan memaksimumkan fungsi loglikelihood. EM dimulai dengan inisialisasi nilai awal dugaan parameter mixture model, kemudian secara iteratif memperbaharui dugaan parameternya. Inisialisasi nilai awal
diperoleh menggunakan agglomerative
hierarchical clustering, sedangkan banyaknya gerombol ditentukan dengan menggunakan Bayes Information Criterion (BIC). Penerapan metode ini pada data kontinyu dapat menggunakan Gaussian Mixture Models (GMM).
Tujuan
Tujuan penelitian ini adalah menerapkan
metode penggerombolan menggunakan
Gaussian Mixture Models (GMM) terhadap
beberapa pola sebaran data kemudian
membandingkan hasil penggerombolan
dengan klasifikasi yang sebenarnya.
TINJAUAN PUSTAKA
Gaussian Mixture Models (GMM) Model-based clustering mengasumsikan bahwa data dibangkitkan oleh campuran dari
sebaran peluang dengan masing-masing
komponen mewakili gerombol berbeda,
sehingga dapat memodelkan atau
mengelompokkan individu di dalam suatu data set menjadi kelompok-kelompok data yang sebelumnya tidak terdefinisi. Apabila model merupakan mixture dari G komponen Gaussian, maka disebut Gaussian Mixture Models.
Likelihood mixture model dengan G komponen didefinisikan sebagai:
dimana y1, y2, …, yn merupakan pengamatan
yang saling bebas dan merupakan fungsi kepekatan peluang dari parameter pada komponen ke-k dalam mixture, merupakan peluang suatu pengamatan berada pada
komponen ke-k .
2
1 jika berada pada gerombol ke-k
0
lainnya
Tabel 1. Interpretasi geometrik dari berbagai parameterisasi sebaran Gaussian pada Mclust (Fraley & Raftery 2010)
Pengidentifikasi Model Sebaran Volume Bentuk Orientasi
E (univariate) Sama
V (univariate) Variabel
EII Spherical Sama Sama NA
VII Spherical Variabel Sama NA
EEI Diagonal Sama Sama Coordinate axes
VEI Diagonal Variabel Sama Coordinate axes
EVI Diagonal Sama Variabel Coordinate axes
VVI Diagonal Variabel Variabel Coordinate axes
EEE Ellipsoidal Sama Sama Sama
EEV Ellipsoidal Sama Sama Variabel
VEV Ellipsoidal Variabel Sama Variabel
VVV Ellipsoidal Variabel Variabel Variabel
kepekatan peluang normal ganda (Gaussian), , dengan parameter vektor rataan dan
matriks peragam didefinisikan sebagai:
Pada GMM, setiap gerombol berbentuk ellipsoidal yang terpusat di . Matriks
peragam menentukan karakteristik
geometrik yaitu bentuk, volume, dan orientasi (Fraley & Raftery 2002).
Banfield dan Raftery (1993)
mengembangkan kerangka metode ini dengan memparameterisasi matriks peragam melalui dekomposisi nilai ciri dalam bentuk
dimana merupakan matriks ortogonal dari
vektor ciri, merupakan matriks diagonal yang elemennya proposional terhadap nilai
ciri dari dan merupakan skalar.
Karakteristik geometrik tersebut dapat dibuat beragam antar gerombol atau dibuat sama.
Interpretasi geometrik dari berbagai
parameterisasi sebaran Gaussian pada
Mclust dapat dilihat pada Tabel 1. Parameter GMM diduga menggunakan algoritma iteratif Expectation Maximization.
Algoritma Expectation Maximization (EM)
Algoritma EM merupakan pendekatan umum Maximum Likelihood (ML) untuk data yang tidak lengkap. Data terdiri dari n pengamatan peubah ganda yang diperoleh
dari , dimana merupakan peubah
yang teramati dan merupakan peubah yang
tidak teramati, yaitu peubah yang
menempatkan objek masuk ke gerombol tertentu. Jika saling bebas dan terdistribusi identik menurut sebaran peluang f dengan
parameter , maka likelihood data lengkap adalah
sedangkan likelihood data yang tidak lengkap adalah:
Penduga ML untuk berdasarkan data
teramati dengan memaksimumkan .
Algoritma EM merupakan metode iteratif, dimana dalam setiap iterasinya terdiri dari dua tahap. Expectation-Step (E-Step), tahap ini menghitung nilai harapan bersyarat dari fungsi loglikelihood data lengkap menggunakan penduga parameternya. Maximization-Step (M-Step), tahap ini menghitung parameter yang memaksimalkan nilai harapan dari fungsi loglikelihood yang diperoleh pada E-Step.
Algoritma EM dalam mixture model menyatakan bahwa data lengkap
, dimana
merupakan bagian dari data yang tidak teramati, dengan
Asumsikan bahwa saling bebas dan
terdistribusi identik berdasarkan sebaran multinomial dari G kategori dengan peluang . Fungsi kepekatan peluang dari pengamatan yang diberikan oleh adalah sehingga loglikelihood data lengkap adalah :
3
E-Step pada algoritma EM untuk GMM adalah:
Sedangkan pada M-Step, penduga parameter
yang memaksimalkan , dihitung
menggunakan yang dihitung pada E-Step (Fraley & Raftery 2002).
Algoritma EM membutuhkan inisialisasi
nilai awal untuk yang dapat
ditentukan menggunakan agglomerative
hierarchical clustering dengan model
. Metode ini dimulai dengan menjadikan setiap individu sebagai gerombol
kemudian digabungkan sehingga
memaksimalkan classification likelihood
(Fraley & Raftery 1998). Ketika dibuat
beragam antar gerombol, nilai loglikelihood
maksimum dapat diperoleh dengan
meminimumkan kriteria:
dimana (Fraley 1996).
Penentuan Jumlah Gerombol
Jumlah gerombol terbaik dapat ditentukan dengan memilih model terbaik. Pendekatan yang umum digunakan sebagai kriteria pemilihan model adalah Bayes Information Criterion (BIC). Nilai untuk BIC dapat diperoleh dengan menggunakan rumus:
dimana adalah likelihood dari data
untuk model , adalah loglikelihood
mixture maksimum untuk model dan adalah jumlah parameter bebas yang diduga
dalam model. Model terbaik dipilih
berdasarkan nilai BIC terbesar.
Metode penggerombolan menggunakan
algoritma EM dengan nilai awal
menggunakan agglomerative hierarchical
clustering untuk GMM dapat diterapkan menggunakan paket Mclust ver 3.4.8 pada R ver 2.12.1.
METODOLOGI
DataData yang digunakan dalam penelitian ini adalah data simulasi yang dibangkitkan dengan menggunakan fungsi mvrnorm pada
program R ver 2.12.1. Setiap kasus simulasi terdiri dari tiga gerombol yang dibangkitkan dari sebaran normal ganda (Gaussian) dengan empat peubah. Gerombol yang dibangkitkan masing-masing sebanyak seratus amatan sehingga peluang suatu amatan masuk ke setiap gerombol bernilai sama (
).
Penelitian ini secara garis besar
membangkitkan gerombol yang berasal dari sebaran Gaussian dengan empat kondisi parameter yaitu, parameter vektor rataan dan matriks peragam ketiga gerombol identik, vektor rataan ketiga gerombol identik dengan matriks peragam yang berbeda, vektor rataan yang berbeda dengan matriks peragam yang identik, dan terakhir adalah parameter vektor rataan dan matriks peragam yang berbeda. Selain itu peneliti juga mempertimbangkan jarak antar pusat gerombol dan keragaman setiap gerombol untuk melihat keefektifan metode jika ketiga gerombol saling berjauhan, saling berdekatan, maupun saling tumpang tindih. Besarnya jarak antar dua pusat gerombol diperoleh dengan menggunakan rumus jarak antar dua vektor, yaitu
. Berdasarkan
pertimbangan diatas, parameter vektor rataan dan matriks peragam ketiga gerombol yang dibangkitkan adalah sebagai berikut:
1. .
Ketiga gerombol berasal dari sebaran yang identik, sehingga memiliki vektor rataan dan matriks peragam yang identik. Vektor rataan ketiga gerombol adalah:
Sedangkan matriks peragam ketiga
gerombol adalah:
a. ragam peubah pada setiap gerombol
bernilai kecil , sehingga
memiliki struktur matriks peragam:
b. ragam peubah pada setiap gerombol
bernilai besar , sehingga
4
Tabel 2. Deskripsi setiap kasus simulasi yang telah dibangkitkan
1, 9, dan 25 K1 K2 K3 K4 K5 K6 K7 K8 K9 1, 9, dan 25 K10 K11 K12 K13 K14 K15 K22 K23 K24 , , dan K16 K17 K18 K19 K20 K21 K25 K26 K27 2. .
Ketiga gerombol memiliki vektor rataan yang identik dengan matriks peragam yang berbeda. Vektor rataan ketiga gerombol adalah:
Sedangkan struktur matriks peragam ketiga gerombol adalah:
3. .
Ketiga gerombol memiliki vektor rataan yang berbeda dengan matriks peragam
yang identik. Kondisi yang diterapkan adalah:
a. Jarak antar pusat gerombol kecil d12=d23=5.830952 dan d13=7.071068.
Vektor rataan ketiga gerombol adalah:
Sedangkan matriks peragam ketiga gerombol yaitu:
i. ragam peubah pada setiap gerombol
bernilai kecil , struktur
matriks peragam seperti pada 1.a ii. ragam peubah pada setiap gerombol
bernilai besar , struktur
matriks peragam seperti pada 1.b b. jarak antar pusat gerombol besar
d12=d23=20.92845 dan d13=25.17936.
Vektor rataan ketiga gerombol adalah:
Sedangkan matriks peragam ketiga gerombol adalah:
5
i. ragam peubah pada setiap gerombol
bernilai kecil , struktur
matriks peragam seperti pada 1.a ii. ragam peubah pada setiap gerombol
bernilai besar , struktur
matriks peragam seperti pada 1.b
4. .
Ketiga gerombol memiliki vektor rataan dan matriks peragam yang berbeda. Kondisi yang diterapkan adalah:
a. jarak antar pusat gerombol kecil d12=d23=5.830952 dan d13=7.071068.
Vektor rataan ketiga gerombol seperti pada 3.a dan struktur matriks peragam ketiga gerombol seperti pada 2. b. jarak antar pusat gerombol besar
d12=d23=20.92845 dan d13=25.17936.
Vektor rataan ketiga gerombol seperti pada 3.b dan struktur matriks peragam ketiga gerombol seperti pada 2. Untuk mengkaji pengaruh adanya korelasi dan besar kecilnya korelasi antar peubah terhadap hasil penggerombolan, maka dicobakan =0, =0.2, dan =0.8 pada setiap kondisi di atas
( ).
Setiap kasus simulasi dilakukan sebanyak sepuluh kali ulangan. Untuk mempermudah
penelitian, maka setiap kondisi yang
diterapkan pada ketiga gerombol hasil bangkitan notasi seperti terlihat pada Tabel 2.
Metode
Tahapan yang dilakukan dalam
membangkitkan individu pada setiap kasus simulasi adalah sebagai berikut:
1. Menentukan banyak gerombol (G=3), banyak peubah (p=4), banyak amatan setiap gerombol (n1=n2=n3=100), dan
sebaran setiap gerombol (Gk~Normal
Ganda).
2. Menentukan parameter sebaran masing-masing gerombol, yaitu vektor rataan
( dan matriks peragam
( ). Matriks peragam tersebut
diperoleh dengan cara sebagai berikut:
a. Menentukan matriks yang
merupakan matriks diagonal
berdimensi 4x4 dengan elemen
diagonalnya adalah standar deviasi masing-masing peubah, k=1,2,3.
b. Menentukan matriks merupakan
matriks berdimensi 4x4 dengan
elemennya adalah korelasi antar peubah, k=1,2,3.
c. Menghitung matriks peragam masing gerombol dengan masing-masing gerombol,
3. Membangkitkan peubah acak sebanyak n1
untuk gerombol 1, .
4. Membangkitkan peubah acak sebanyak n2
untuk gerombol 2,
5. Membangkitkan peubah acak sebanyak n3
untuk gerombol 3, .
6. Menggabungkan ketiga gerombol tersebut menjadi sebuah kasus simulasi.
7. Ulangi tahap 2-6 untuk kondisi
penggerombolan yang telah ditentukan. Sedangkan tahapan yang dilakukan dalam analisis data pada setiap kasus simulasi adalah sebagai berikut:
1. Membuat plot skor komponen utama pada setiap kasus simulasi untuk melihat tebaran data dan banyaknya gerombol yang dapat terbentuk.
2. Menerapkan metode penggerombolan
berdasarkan GMM dengan menggunakan paket Mclust pada program R dengan prosedur penggerombolan sebagai berikut: a. Melakukan agglomerative hierarchical
clustering dengan menggunakan model
,
sehingga diperoleh untuk G=1,2,…,M; M merupakan jumlah gerombol maksimum. Untuk menentukan nilai awal, maka lakukan M-Step saat iterasi m=0.b. M-Step:
tergantung model, seperti yang terdapat dalam Ceuleux & Govaert (2006).
Setelah diperoleh nilai
dan , lakukan E-Step untuk
k=1,2,…,G. c. E-Step:
6
d. Menghitung nilai loglikelihood untuk data lengkap, kemudian ulangi E-Step dan M-Step untuk iterasi ke (m+1) hingga diperoleh nilai loglikelihood yang konvergen.
e. Menghitung nilai BIC.
f. Melakukan tahap a-e untuk banyak geombol berbeda, G=1,2,…,M. g. Membandingkan nilai BIC untuk
setiap solusi gerombol yang terbentuk. Nilai BIC yang dipilih adalah nilai terbesar sehingga dapat diketahui model dan banyaknya gerombol yang sesuai dengan data.
Tahap 2 menghasilkan banyaknya
gerombol, dugaan parameter sebaran
masing-masing gerombol ), , ,
dan nilai BIC.
3. Untuk setiap kasus simulasi:
a. Membuat plot skor komponen utama dengan menggunakan warna berbeda pada setiap amatan jika berasal dari gerombol berbeda.
b. Membandingkan plot skor komponen utama pada tahap 1 dengan tahap 3a. c. Membandingkan banyaknya gerombol
yang terbentuk dengan banyak
gerombol yang sebenarnya.
d. Membandingkan dugaan parameter yang dihasilkan pada tahap 2 dengan parameter yang sebenarnya.
e. Membandingkan hasil klasifikasi tiap
amatan yang dihasilkan metode
tersebut dengan klasifikasi yang sebenarnya, kemudian buat tabel
miss-match setiap ulangan untuk
menghitung rataan miss classifications rate (tingkat kesalahan klasifikasi) setiap gerombol.
4. Membandingkan persentase rataan miss classifications rate untuk setiap kasus simulasi. Metode GMM dikatakan efektif jika mempunyai rataan tingkat kesalahan klasifikasi kurang dari 10%.
HASIL DAN PEMBAHASAN
Data yang dibangkitkan untuk setiap kasus simulasi terdiri dari tiga gerombol. Ketiga gerombol tersebut berasal dari sebaran normal ganda (Gaussian) dengan parameter vektor rataan ( dan matriks peragam ( ) yang dibuat sama maupun berbeda. Terdapat 27 kasus simulasi yang dibedakan atas parameter sebaran, jarak antar pusat gerombol, ragam setiap peubah pada setiap gerombol, dan nilai korelasi.
Plot skor komponen utama dibuat untuk memperlihatkan pola tebaran data yang terbentuk sesuai dengan kondisi ketiga gerombol yang dibangkitkan pada setiap kasus simulasi. Plot tersebut dapat memberikan gambaran untuk setiap gerombol yang saling berjauhan, saling berdekatan, maupun saling tumpang tindih. Setiap amatan diberikan warna berbeda jika berasal dari gerombol yang berbeda, sesuai dengan klasifikasi yang
sebenarnya. Metode penggerombolan
berdasarkan GMM diterapkan pada setiap kasus simulasi. Untuk memberikan gambaran mengenai gerombol yang dihasilkan metode ini, dibuat plot skor komponen utama dengan memberikan warna berbeda jika berasal dari gerombol yang berbeda, sesuai dengan hasil penggerombolan berdasarkan metode tersebut. Metode ini dikatakan efektif jika memiliki rataan tingkat kesalahan klasifikasi kurang dari 10%. Semakin kecil rataan tingkat kesalahan klasifikasi, maka metode ini semakin efektif dalam menggerombolkan kasus simulasi tersebut.
Kedua plot skor utama setiap kasus simulasi yang dibuat pada salah satu ulangan dapat dilihat pada Lampiran. Misalnya plot skor komponen utama untuk K7, ketiga
gerombol memiliki pusat gerombol yang sama dengan matriks peragam yang berbeda. Data saling tumpang tindih dengan membentuk pola seperti tiga lingkaran yang mempunyai pusat yang sama dengan diameter yang berbeda. Berdasarkan hasil metode, terbentuk dua gerombol yang memiliki pusat gerombol yang hampir sama dengan matriks peragam yang berbeda. Terlihat juga bahwa gerombol 2
dan gerombol 3 didefinisikan sebagai
gerombol yang sama.
Ketiga Gerombol Berasal dari Populasi Identik [ ]
Data yang terdiri dari tiga gerombol dengan vektor rataan dan matriks peragam yang identik terdapat pada K1, K2, K3, K4, K5,
dan K6. Tiga kasus pertama memiliki ragam
setiap peubah yang kecil sedangkan tiga kasus selanjutnya memiliki ragam setiap peubah yang besar.
Metode penggerombolan berdasarkan
GMM memisahkan gerombol sehingga
masing-masing gerombol memiliki sebaran
Gaussian dengan parameter berbeda.
Penerapan metode pada kasus simulasi dengan ketiga gerombol yang berasal dari populasi identik telah menghasilkan satu gerombol. Hal ini ditemukan pada K1, K3, K4, dan K6.
7
penerapan metode ini pada nilai korelasi antar peubah sebesar 0.2 (K2 dan K5) telah
menghasilkan dua gerombol. Kedua gerombol yang dihasilkan memiliki vektor rataan berbeda dengan matriks peragam yang sama. Rataan tingkat kesalahan klasifikasi yang diperoleh untuk K2 sebesar 40.9% dan untuk
K5 sebesar 30.7%. Rataan tingkat kesalahan
klasifikasi pada tiga nilai korelasi yang dicobakan untuk kasus-kasus tersebut dapat dilihat pada Gambar 1.
Gambar 1. Rataan tingkat kesalahan
klasifikasi pada kasus simulasi untuk ketiga gerombol yang berasal dari populasi identik
Ketiga Gerombol Berasal dari Populasi Berbeda
Matriks peragam ketiga gerombol berbeda
[ ]
Penerapan metode penggerombolan
berdasarkan GMM pada data yang terdiri dari tiga gerombol dengan vektor rataan yang identik dan matriks peragam yang berbeda yaitu pada K7, K8, dan K9 telah menghasilkan
dua gerombol yang saling tumpang tindih. Kedua gerombol yang dihasilkan memiliki vektor rataan yang hampir sama dengan matriks peragam yang berbeda. Jumlah gerombol yang seharusnya terbentuk adalah sebanyak tiga gerombol dengan vektor rataan identik dan matriks peragam berbeda (ketiga gerombol saling tumpang tindih). Rataan tingkat kesalahan klasifikasi yang diperoleh untuk K7, K8, dan K9 secara berturut-turut
sebesar 38.5%, 39%, dan 38.8%. Metode ini kurang efektif diterapkan pada data yang saling tumpang tindih.
Vektor rataan ketiga gerombol berbeda
[ ]
K10 terdiri dari tiga gerombol yang
memiliki vektor rataan berbeda dengan jarak
antar pusat gerombol yang bernilai kecil, matriks peragam identik dengan ragam setiap peubah pada setiap gerombol bernilai kecil, dan tidak terdapat korelasi antar peubah. Penerapan metode ini pada K10 menghasilkan
tiga gerombol dengan vektor rataan berbeda dan matriks peragam yang identik. Rataan tingkat kesalahan klasifikasi yang diperoleh sebesar 0.33%. Sedangkan pada kondisi yang sama dengan korelasi sebesar 0.2 untuk K11
dan korelasi sebesar 0.8 untuk K12, setelah
metode diterapkan, terbentuk tiga gerombol tanpa adanya kesalahan klasifikasi.
Data yang terdiri dari tiga gerombol yang memiliki vektor rataan berbeda dengan jarak antar pusat gerombol yang bernilai kecil, matriks peragam identik dengan ragam antar peubah pada setiap gerombol bernilai besar yaitu terdapat pada K13, K14, dan K15.
Metode penggerombolan berdasarkan GMM menghasilkan satu gerombol dengan rataan tingkat kesalahan klasifikasi sebesar 66.67% jika diterapkan pada K13. Jumlah gerombol
berbeda pada beberapa ulangan diperoleh pada K14 dan K15. Sebanyak satu gerombol
pada lima ulangan dan dua gerombol pada ulangan lainnya dengan rataan tingkat kesalahan klasifikasi sebesar 66.9% diperoleh pada K14. Sedangkan sebanyak satu gerombol
pada tujuh ulangan dan tiga gerombol pada ulangan lainnya dengan rataan tingkat klasifikasi sebesar 50.87% diperoleh pada K15.
Ragam setiap peubah pada setiap gerombol yang bernilai besar menyebabkan amatan menyebar jauh dari rataannya, sehingga jika
jarak antar pusat gerombolnya kecil
menyebabkan banyak amatan yang tumpang tindih dengan amatan pada gerombol lain. Metode penggerombolan berdasarkan GMM tidak efektif diterapkan untuk kasus simulasi dengan pola tersebut.
K16, K17, dan K18 memiliki vektor rataan
berbeda dengan jarak antar pusat gerombol bernilai besar dan matriks peragam identik dengan ragam setiap peubah pada setiap gerombol yang bernilai kecil. Setiap amatan
cenderung menggerombol di sekitar
rataannya. Penerapan metode pada ketiga kasus tersebut menghasilkan tiga gerombol tanpa adanya kesalahan klasifikasi.
Hasil penggerombolan pada K19, K20, dan
K21 menghasilkan tiga gerombol dengan
rataan tingkat kesalahan klasifikasi masing-masing sebesar 2.53%, 1.2% dan 0%. Kasus-kasus simulasi tersebut memiliki vektor rataan berbeda dengan jarak antar pusat gerombol yang besar, matriks peragam identik dengan ragam setiap peubah yang besar.
0 20 40 60 0 0.2 0.8 ra ta an t in g k at k esal ah an k la si fi k asi ( %) korelasi 1.a 1.b
8
Tabel 3. Rataan tingkat kesalahan klasifikasi setiap kasus simulasi
1, 9, dan 25 0 40.9±9.29 0 0 30.7±10.4 0 38.5±0.63 39±1.07 38.8±1.59 1, 9, dan 25 0.33±0.32 0 0 66.67 66.87±0.3 50.87±25.44 13.3±1.03 14.2±1.76 3.50±0.53 1, 9, dan 25 0 0 0 2.53±0.53 1.2±0.39 0 0.53±0.42 0.07±0.14 0
Vektor rataan dan matriks peragam ketiga gerombol berbeda [ ]
Kasus simulasi yang memiliki vektor rataan dan matriks peragam berbeda dengan jarak antar pusat gerombol bernilai kecil yaitu terdapat pada K22, K23, dan K24. K22 mewakili
data dengan kondisi tersebut tanpa adanya korelasi antar peubah, K23 mewakili data
dengan korelasi antar peubah sebesar 0.2, dan K24 mewakili data dengan korelasi antar
peubah sebesar 0.8. Penerapan metode penggerombolan berdasarkan GMM pada ketiga kasus tersebut menghasilkan tiga gerombol dengan rataan tingkat kesalahan klasifikasi sebesar 13.3% untuk K22, sebesar
14.2% untuk K23, dan sebesar 3.5% untuk K24.
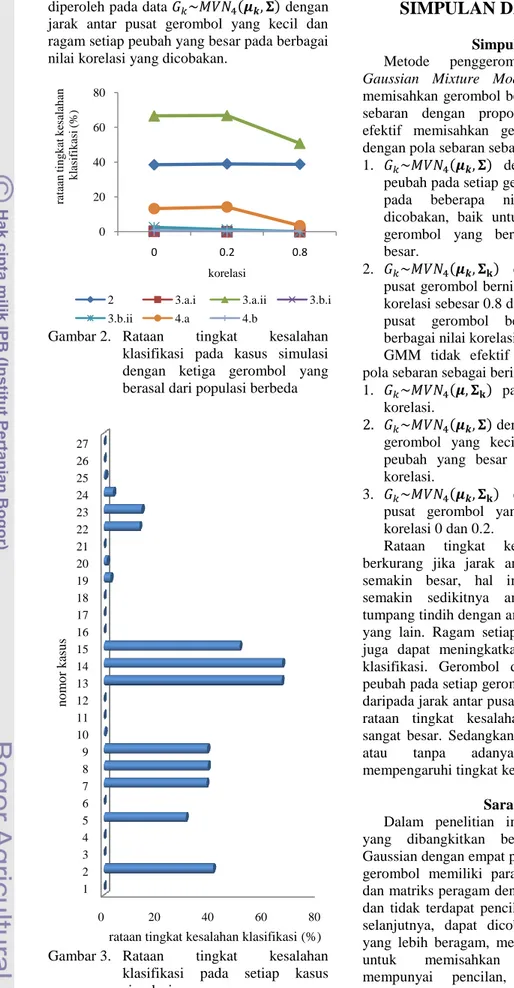
Vektor rataan dengan jarak antar pusat gerombol yang besar dan matriks peragam berbeda untuk setiap gerombol terdapat pada K25, K26, dan K27. Nilai rataan tingkat
kesalahan klasifikasi sebesar 0.53% dan 0.07% masing-masing dihasilkan oleh K25 dan
K26, sedangkan pada K27 tidak terdapat
kesalahan klasifikasi.
Tabel 3 menunjukkan bahwa secara umum, rataan tingkat kesalahan klasifikasi berkurang jika jarak antar pusat gerombol semakin besar, hal ini disebabkan oleh
semakin sedikitnya amatan yang saling tumpang tindih dengan amatan pada gerombol yang lain. Ragam setiap peubah yang besar juga dapat meningkatkan tingkat kesalahan klasifikasi. Gerombol dengan ragam antar peubah pada setiap gerombol yang lebih besar daripada jarak antar pusat gerombol, memiliki rataan tingkat kesalahan klasifikasi yang sangat besar. Sedangkan untuk kasus dengan
atau tanpa adanya korelasi tidak
mempengaruhi tingkat kesalahan klasifikasi.
Hal ini disebabkan oleh metode
penggerombolan berdasarkan GMM
mempertimbangkan parameterisasi ,
dimana untuk data yang memiliki korelasi
antar peubah diberikan model
dan untuk data yang tidak memiliki korelasi antar peubah diberikan
model . Pada kasus dimana terdapat
korelasi antar peubah, nilai korelasi antar peubah sebesar 0.8 memberikan rataan tingkat kesalahan yang lebih kecil daripada kasus dengan nilai korelasi antar peubah sebesar 0.2. Penjabaran diatas untuk kasus simulasi dengan ketiga gerombol yang berasal dari populasi berbeda dapat terlihat pada Gambar 2.
Gambar 3 memperlihatkan bahwa rataan tingkat kesalahan klasifikasi terbesar
9
diperoleh pada data dengan
jarak antar pusat gerombol yang kecil dan ragam setiap peubah yang besar pada berbagai nilai korelasi yang dicobakan.
Gambar 2. Rataan tingkat kesalahan
klasifikasi pada kasus simulasi dengan ketiga gerombol yang berasal dari populasi berbeda
Gambar 3. Rataan tingkat kesalahan
klasifikasi pada setiap kasus simulasi
SIMPULAN DAN SARAN
SimpulanMetode penggerombolan berdasarkan
Gaussian Mixture Models (GMM) dapat memisahkan gerombol berdasarkan parameter sebaran dengan proporsi tertentu. GMM efektif memisahkan gerombol pada kasus dengan pola sebaran sebagai berikut:
1. dengan ragam setiap
peubah pada setiap gerombol bernilai kecil
pada beberapa nilai korelasi yang
dicobakan, baik untuk jarak antar pusat gerombol yang bernilai kecil maupun besar.
2. dengan jarak antar
pusat gerombol bernilai kecil pada tingkat korelasi sebesar 0.8 dan dengan jarak antar pusat gerombol bernilai besar pada berbagai nilai korelasi yang dicobakan. GMM tidak efektif pada kasus dengan pola sebaran sebagai berikut:
1. pada berbagai tingkat
korelasi.
2. dengan jarak antar pusat
gerombol yang kecil dan ragam setiap peubah yang besar pada berbagai nilai korelasi.
3. dengan jarak antar
pusat gerombol yang kecil pada nilai korelasi 0 dan 0.2.
Rataan tingkat kesalahan klasifikasi berkurang jika jarak antar pusat gerombol semakin besar, hal ini disebabkan oleh semakin sedikitnya amatan yang saling tumpang tindih dengan amatan pada gerombol yang lain. Ragam setiap peubah yang besar juga dapat meningkatkan tingkat kesalahan klasifikasi. Gerombol dengan ragam antar peubah pada setiap gerombol yang lebih besar daripada jarak antar pusat gerombol, memiliki rataan tingkat kesalahan klasifikasi yang sangat besar. Sedangkan untuk kasus dengan
atau tanpa adanya korelasi tidak
mempengaruhi tingkat kesalahan klasifikasi.
Saran
Dalam penelitian ini, ketiga gerombol yang dibangkitkan berasal dari sebaran Gaussian dengan empat peubah, dimana setiap gerombol memiliki parameter vektor rataan dan matriks peragam dengan kondisi berbeda, dan tidak terdapat pencilan. Untuk penelitian selanjutnya, dapat dicobakan nilai korelasi yang lebih beragam, menggunakan sebaran t
untuk memisahkan gerombol yang
mempunyai pencilan, atau menerapkan
0 20 40 60 80 0 0.2 0.8 ra ta an t in g k at k esal ah an k la si fi k asi ( %) korelasi
2 3.a.i 3.a.ii 3.b.i
3.b.ii 4.a 4.b 0 20 40 60 80 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
rataan tingkat kesalahan klasifikasi (%)
n o m o r k asu s
10
metode Bayes untuk menduga parameter dalam mixture models.
DAFTAR PUSTAKA
Banfield JD, Raftery AE. 1993. Model-based Gaussian and non-Gaussian Clustering. Biometrics 49:803-821
Celeux G, Govaert G. 2006. Gaussian Parsimonious Clustering Methods. INRIA. Perancis.
Fraley C.1996. Algorithms for Model-Based Gaussian Hierarchical Clustering. Technical Report 311.
Fraley C, Raftery AE. 1998. How many
clusters? Which clustering method?
Answers via model-based cluster analysis. The Computer J 41(8).
Fraley C, Raftery AE. 2002. Model based clustering, discriminant analysis, and density estimation. J Amer Stat Assoc 97. Fraley C, Raftery AE. 2010. MCLUST
version 3 for R: normal mixture modeling and model-based clustering. Technical Report 504.
Johnson R.A. dan Wichern D.W. 2002. Applied Multivariate Statistical Analysis. New Jersey: Prentice Hall.
McLachlan GJ, Basford KE. 1988. Mixture Models: Inference and Application to Clustering. New York: Marcel Dekker.
12
Lampiran Plot skor komponen utama setiap kasus simulasi pada ulangan ke 8 dan rataan tingkat kesalahan klasifikasi (TKK) yang dihasilkan metode penggerombolan berdasarkan GMM
Kasus simulasi
Plot skor KU 1 & KU 2 (kondisi populasi)
Plot skor KU 1 & KU 2 (hasil penggeromboaln) Rataan TKK K1 identik identik, kecil, 0%
Total keragaman dua KU 50% 50%
K2
identik
identik, kecil, 40.9%
Total keragaman dua KU 60% 60%
K3
identik
identik, kecil,
0
Total keragaman dua KU 90% 90%
K4
identik
identik, besar,
0%
Total keragaman dua KU 50% 50%
-3 -2 -1 0 1 2 -3 -2 -1 0 1 2 comp1 co m p 2 -3 -2 -1 0 1 2 -3 -2 -1 0 1 2 comp1 co m p 2 -3 -2 -1 0 1 2 3 -3 -2 -1 0 1 2 comp1 co m p 2 -3 -2 -1 0 1 2 3 -3 -2 -1 0 1 2 comp1 co m p 2 -4 -2 0 2 4 -1 .0 -0 .5 0 .0 0 .5 1 .0 comp1 co m p 2 -4 -2 0 2 4 -1 .0 -0 .5 0 .0 0 .5 1 .0 comp1 co m p 2 -10 -5 0 5 10 15 -1 0 -5 0 5 10 15 comp1 co m p 2 -10 -5 0 5 10 15 -1 0 -5 0 5 10 15 comp1 co m p 2
13
Lampiran Plot skor komponen utama setiap kasus simulasi pada ulangan ke 8 dan rataan tingkat kesalahan klasifikasi (TKK) yang dihasilkan metode penggerombolan berdasarkan GMM (lanjutan)
Kasus simulasi
Plot skor KU 1 & KU 2 (kondisi populasi)
Plot skor KU 1 & KU 2 (hasil penggeromboaln) Rataan TKK K5 identik identik, besar, 0%
Total keragaman dua KU 60% 60%
K6
identik
identik, besar, 0%
Total keragaman dua KU 90% 90%
K7
identik berbeda,
38.5%
Total keragaman dua KU 50% 50%
K8
identik berbeda,
39%
Total keragaman dua KU 60% 60%
-10 0 10 20 -1 0 -5 0 5 10 comp1 co m p 2 -10 0 10 20 -1 0 -5 0 5 10 comp1 co m p 2 -20 -10 0 10 20 -6 -4 -2 0 2 4 6 comp1 co m p 2 -20 -10 0 10 20 -6 -4 -2 0 2 4 6 comp1 co m p 2 -10 -5 0 5 10 -1 5 -1 0 -5 0 5 10 pc1 p c2 -10 -5 0 5 10 -1 5 -1 0 -5 0 5 10 comp1 co m p 2 -15 -10 -5 0 5 10 15 -1 0 -5 0 5 10 pc1 p c2 -15 -10 -5 0 5 10 15 -1 0 -5 0 5 10 comp1 co m p 2
14
Lampiran Plot skor komponen utama setiap kasus simulasi pada ulangan ke 8 dan rataan tingkat kesalahan klasifikasi (TKK) yang dihasilkan metode penggerombolan berdasarkan GMM (lanjutan)
Kasus simulasi
Plot skor KU 1 & KU 2 (kondisi populasi)
Plot skor KU 1 & KU 2 (hasil penggeromboaln) Rataan TKK K9 identik berbeda, 38.8%
Total keragaman dua KU 90% 90%
K10
berbeda, dij kecil
identik, kecil,
0.33%
Total keragaman dua KU 88% 88%
K11
berbeda, dij kecil
identik, kecil,
0%
Total keragaman dua KU 88% 88%
K12
berbeda, dij kecil
identik, kecil,
0%
Total keragaman dua KU 79% 79%
-20 -10 0 10 20 -6 -4 -2 0 2 4 pc1 p c2 -20 -10 0 10 20 -6 -4 -2 0 2 4 comp1 co m p 2 -6 -4 -2 0 2 4 6 -4 -2 0 2 4 pc1 p c2 -6 -4 -2 0 2 4 6 -4 -2 0 2 4 comp1 co m p 2 -6 -4 -2 0 2 4 6 -4 -2 0 2 4 pc1 p c2 -6 -4 -2 0 2 4 6 -4 -2 0 2 4 comp1 co m p 2 -4 -2 0 2 4 -4 -3 -2 -1 0 1 2 3 pc1 p c2 -4 -2 0 2 4 -4 -3 -2 -1 0 1 2 3 comp1 co m p 2
15
Lampiran Plot skor komponen utama setiap kasus simulasi pada ulangan ke 8 dan rataan tingkat kesalahan klasifikasi (TKK) yang dihasilkan metode penggerombolan berdasarkan GMM (lanjutan)
Kasus simulasi
Plot skor KU 1 & KU 2 (kondisi populasi)
Plot skor KU 1 & KU 2 (hasil penggeromboaln) Rataan TKK K13 berbeda, dij kecil identik, besar, 66.67%
Total keragaman dua KU 64% 64%
K14
berbeda, dij kecil
identik, besar,
66.9%
Total keragaman dua KU 60% 60%
K15
berbeda, dij kecil
identik, besar,
50.87%
Total keragaman dua KU 87% 87%
K16
berbeda, dij besar
identik, kecil,
0%
Total keragaman dua KU 99% 99%
-15 -10 -5 0 5 10 15 -1 5 -1 0 -5 0 5 10 pc1 p c2 -15 -10 -5 0 5 10 15 -1 5 -1 0 -5 0 5 10 comp1 co m p 2 -15 -10 -5 0 5 10 15 -1 5 -1 0 -5 0 5 10 pc1 p c2 -15 -10 -5 0 5 10 15 -1 5 -1 0 -5 0 5 10 comp1 co m p 2 -20 -10 0 10 20 30 -1 0 -5 0 5 10 pc1 p c2 -20 -10 0 10 20 30 -1 0 -5 0 5 10 comp1 co m p 2 -15 -10 -5 0 5 10 15 -1 0 -5 0 5 pc1 p c2 -15 -10 -5 0 5 10 15 -1 0 -5 0 5 comp1 co m p 2
16
Lampiran Plot skor komponen utama setiap kasus simulasi pada ulangan ke 8 dan rataan tingkat kesalahan klasifikasi (TKK) yang dihasilkan metode penggerombolan berdasarkan GMM (lanjutan)
Kasus simulasi
Plot skor KU 1 & KU 2 (kondisi populasi)
Plot skor KU 1 & KU 2 (hasil penggeromboaln) Rataan TKK K17 berbeda, dij besar identik, kecil, 0%
Total keragaman dua KU 98.62% 98.62%
K18
berbeda, dij besar
identik, kecil,
0%
Total keragaman dua KU 97.92% 97.92%
K19
berbeda, dij besar
identik, besar,
2.53%
Total keragaman dua KU 81.44% 81.44%
K20
berbeda, dij besar
identik, besar, 1.2%
Total keragaman dua KU 77.73% 77.73%
-15 -10 -5 0 5 10 15 -1 0 -5 0 5 pc1 p c2 -15 -10 -5 0 5 10 15 -1 0 -5 0 5 comp1 co m p 2 -10 -5 0 5 10 -1 0 -5 0 5 pc1 p c2 -10 -5 0 5 10 -1 0 -5 0 5 comp1 co m p 2 -20 -10 0 10 20 -2 0 -1 0 0 10 20 pc1 p c2 -20 -10 0 10 20 -2 0 -1 0 0 10 20 comp1 co m p 2 -20 -10 0 10 20 -2 0 -1 0 0 10 pc1 p c2 -20 -10 0 10 20 -2 0 -1 0 0 10 comp1 co m p 2
17
Lampiran Plot skor komponen utama setiap kasus simulasi pada ulangan ke 8 dan rataan tingkat kesalahan klasifikasi (TKK) yang dihasilkan metode penggerombolan berdasarkan GMM (lanjutan)
Kasus simulasi
Plot skor KU 1 & KU 2 (kondisi populasi)
Plot skor KU 1 & KU 2 (hasil penggeromboaln) Rataan TKK K21 berbeda, dij besar identik, besar, 0%
Total keragaman dua KU 73% 73%
K22
berbeda, dij kecil
berbeda,
13.3%
Total keragaman dua KU 61.05% 61.05%
K23
berbeda, dij kecil
berbeda,
14.2%
Total keragaman dua KU 60.79% 60.79%
-15 -10 -5 0 5 10 15 -3 0 -2 0 -1 0 0 10 20 30 pc1 p c2 -15 -10 -5 0 5 10 15 -3 0 -2 0 -1 0 0 10 20 30 comp1 co m p 2 -15 -10 -5 0 5 10 -1 0 -5 0 5 10 pc1 p c2 -15 -10 -5 0 5 10 -1 0 -5 0 5 10 comp1 co m p 2 -15 -10 -5 0 5 10 -1 5 -1 0 -5 0 5 pc1 p c2 -15 -10 -5 0 5 10 -1 5 -1 0 -5 0 5 comp1 co m p 2
18
Lampiran Plot skor komponen utama setiap kasus simulasi pada ulangan ke 8 dan rataan tingkat kesalahan klasifikasi (TKK) yang dihasilkan metode penggerombolan berdasarkan GMM (lanjutan)
Kasus simulasi
Plot skor KU 1 & KU 2 (kondisi populasi)
Plot skor KU 1 & KU 2 (hasil penggeromboaln) Rataan TKK K24 berbeda, dij kecil berbeda, .8 3.5%
Total keragaman dua KU 94.15% 94.15%
K25
berbeda, dij besar
berbeda,
0.53%
Total keragaman dua KU 89.2% 89.2%
K26
berbeda, dij besar
berbeda,
0.07%
Total keragaman dua KU 87.05% 87.05%
-20 -10 0 10 20 -4 -2 0 2 4 6 8 10 pc1 p c2 -20 -10 0 10 20 -4 -2 0 2 4 6 8 10 comp1 co m p 2 -10 0 10 20 -2 0 -1 0 0 10 pc1 p c2 -10 0 10 20 -2 0 -1 0 0 10 comp1 co m p 2 -30 -20 -10 0 10 -2 0 -1 0 0 10 pc1 p c2 -30 -20 -10 0 10 -2 0 -1 0 0 10 comp1 co m p 2
19
Lampiran Plot skor komponen utama setiap kasus simulasi pada ulangan ke 8 dan rataan tingkat kesalahan klasifikasi (TKK) yang dihasilkan metode penggerombolan berdasarkan GMM (lanjutan)
Kasus simulasi
Plot skor KU 1 & KU 2 (kondisi populasi)
Plot skor KU 1 & KU 2 (hasil penggeromboaln) Rataan TKK K27 berbeda, dij besar berbeda, .8 0%
Total keragaman dua KU 80.57% 80.57%
-15 -10 -5 0 5 10 -1 5 -1 0 -5 0 5 10 pc1 p c2 -15 -10 -5 0 5 10 -1 5 -1 0 -5 0 5 10 comp1 co m p 2