19
BAB III
ANALISA DAN PERANCANGAN SISTEM
3.1 Persiapan Data
Dalam pengerjaan tugas akhir ini data yang digunakan adalah kalimat tanya Berbahasa Indonesia, dimana kalimat tanya tersebut diambil dari soal-soal pada buku seperti Psikotes dan Lembar Kerja Siswa (LKS). Selain itu sebagai penunjang literatur pengambilan data yang lain, data kalimat tanya juga diambil dari situs bukusekolahdigital.com. Data yang terkumpul kemudian diklasifikasikan secara manual terlebih dahulu untuk mengetahui setiap target kelas dari masing-masing kalimat tanya. Jumlah data yang digunakan dalam penelitian ± 600 data kalimat tanya. Data Kalimat Tanya disimpan dalam format
Comma Separated Value (CSV). Berikut contoh dari data tugas akhir seperti pada
Tabel 3.1.
Tabel 3.1 Data Kalimat Tanya
Identifikasikan sebab terjadinya kemajemukan oleh beragam suku bangsa yang tersebar di wilayah Indonesia?
Mengapa sifat unsur non logam semakin bertambah pada pergeseran dari kiri ke kanan dalam tabel periodik? Jelaskan!
Apakah situasi dan kondisi kehidupan masyarakat Indonesia dari hari ke hari kian memburuk merupakan salah satu dampak dari globalisasi? Kemukakan pendapatmu!
Temukan perbedaan pelaksanaan Politik Bebas Aktif Indonesia sejak masa awal kemerdekaan hingga masa Reformasi!
Buktikan pernyataan bahwa Sosiologi merupakan ilmu sosial, bersifat heterogen, ilmu murni, dan abstrak!
Kelompokkan tumbuhan-tumbuhan dikotil dan monokotil berdasarkan persamaan dan perbedaan ciri yang dimiliki!
Dalam sistem klasifikasi, data yang telah diperoleh kemudian dilakukan pembagian data yaitu data latih (Data Train) dan data uji (Data Testing). Pembagian data tersebut akan dibagi menjadi 80% sebagai data latih dan 20% sebagai data uji yang didalam data tersebut mengandung 6 level ranah kognitif berdasarkan Taksonomi Bloom. 6 level aspek kognitif dalam Taksonomi Bloom antara lain Mengingat, Memahami, Menerapkan, Menganalisis, Mengevaluasi, dan Membuat. Berikut contoh data kalimat tanya aspek kognitif berdasarkan
20 Taksonomi Bloom pada Tabel 3.2.
Tabel 3.2 Kalimat Tanya Aspek Kognitif berdasarkan Taksonomi Bloom
KALIMAT TANYA TARGET
KELAS
Identifikasikan sebab terjadinya kemajemukan oleh beragam
suku bangsa yang tersebar di wilayah Indonesia? Mengingat Mengapa sifat unsur non logam semakin bertambah pada
pergeseran dari kiri ke kanan dalam tabel periodik? Jelaskan! Memahami Apakah situasi dan kondisi kehidupan masyarakat Indonesia
dari hari ke hari kian memburuk merupakan salah satu dampak dari globalisasi? Kemukakan pendapatmu!
Menerapkan Temukan perbedaan pelaksanaan Politik Bebas Aktif
Indonesia sejak masa awal kemerdekaan hingga masa Reformasi!
Menganalisis Buktikan pernyataan bahwa Sosiologi merupakan ilmu sosial,
bersifat heterogen, ilmu murni, dan abstrak! Mengevaluasi Kelompokkan tumbuhan-tumbuhan dikotil dan monokotil
berdasarkan persamaan dan perbedaan ciri yang dimiliki! Membuat
3.2 Analisis Data
Pada pengerjaan tugas akhir ini, peneliti akan merancang sebuah sistem klasifikasi dari suatu kalimat tanya menggunakan algoritma Support Vector Machine. Dalam sistem klasifikasi ini terdapat 6 target kelas berdasarkan Taksonomi Bloom untuk aspek kognitif. Proses awal dalam melakukan klasifikasi yaitu, proses labelisasi data kalimat tanya ke dalam target kelas pada masing-masing data kalimat tanya.
Proses labelisasi tersebut nantinya akan dibagi menjadi 2 jenis data yaitu data latih (Data Train) dan data uji (Data Testing). Dari data latih tersebut kemudian dilakukan penentuan fitur. Penentuan fitur tersebut bertujuan untuk proses pengklasifikasian kalimat tanya sehingga dalam setiap feature memiliki masing-masing target kelas. Setelah proses penentuan fitur dilakukan, tahap selanjutnya adalah proses pembuatan model klasifikasi menggunakan algoritma Support Vector Machine menggunakan open source WEKA. Data latih (Data
Train) dan data uji (Data Testing) kemudian diinputkan ke dalam sistem untuk
dilakukan proses klasifikasi yang bertujuan mengetahui target kelas dari kalimat tanya.
21
Dari hasil pengujian klasifikasi kalimat tanya menggunakan algoritma Support Vector Machine tersebut akan diperoleh tingkat akurasi (accuracy), presisi (precision) dan recall.
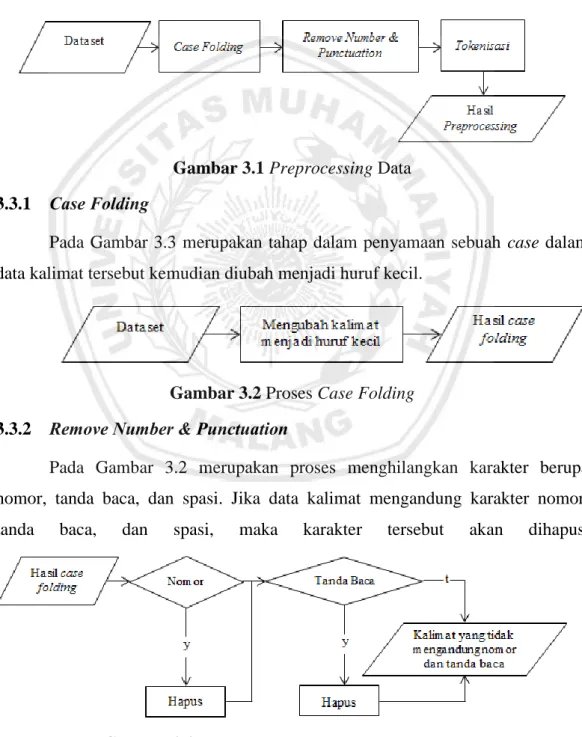
3.3 Preprocessing Data
Pada tahapan preprocessing yang digunakan penelitian yaitu meliputi
remove number & punctuation, case folding, dan tokenisasi. Berikut merupakan
gambaran sistem pada tahap preprocessing pada Gambar 3.1.
Gambar 3.1 Preprocessing Data 3.3.1 Case Folding
Pada Gambar 3.3 merupakan tahap dalam penyamaan sebuah case dalam data kalimat tersebut kemudian diubah menjadi huruf kecil.
Gambar 3.2 Proses Case Folding 3.3.2 Remove Number & Punctuation
Pada Gambar 3.2 merupakan proses menghilangkan karakter berupa nomor, tanda baca, dan spasi. Jika data kalimat mengandung karakter nomor, tanda baca, dan spasi, maka karakter tersebut akan dihapus.
22
3.3.3 Tokenisasi
Pada Gambar 3.3 merupakan tahap pemisahan data string setelah proses penginputan kalimat sehingga kalimat menjadi token atau potongan kata tunggal.
Gambar 3.4 Proses Tokenisasi 3.4 Perancangan Pelatihan Klasifikasi SVM
Pada perancangan model klasifikasi pengerjaan tugas akhir ini menggunakan model algoritma Support Vector Machine. Adapun proses pelatihan dilakukan dengan menginputkan data hasil preprocessing yang kemudian disesuaikan dengan format yang ada pada WEKA sebagai software SVM yang digunakan. Berikut merupakan tahapan dalam melakukan pelatihan klasifikasi SVM pada Gambar 3.5.
Gambar 3.5 Proses Perancangan Klasifikasi SVM
Proses ekstraksi fitur perlu dilakukan guna hasil dari proses pengklasifikasian lebih akurat. Berikut merupakan tabel ekstraksi fitur.
23
Tabel 3.3 Daftar Ekstraksi Fitur
No Fitur Deskripsi
1 Kata WH <true, false> Kata Kunci 5W + 1H 2 Kata Kerja <true, false> Kata Kunci Kerja
3 Kata Perbandingan <true, false> Kata Kunci Perbandingan 4 Kata Definisi <true, false> Kata Kunci Definisi 5 Kata Kausalitas <true, false> Kata Kunci Kausalitas 6 Kata Penyebutan <true, false> Kata Kunci Penyebutan 7 Kata Preposisi <true, false> Kata Kunci Preposisi 8 Kata Penjelas <true, false> Kata Kunci Penjelas 9 Kata Pilihan <true, false> Kata Kunci Pilihan 10 Kata Tujuan <true, false> Kata Kunci Tujuan 11 Kata Cara <true, false> Kata Kunci Cara 12 Kata Waktu <true, false> Kata Kunci Waktu 13 Kata Tambahan <true, false> Kata Kunci Tambahan 14 Kata Mengingat <true, false> Kata Kunci Mengingat 15 Kata Memahami <true, false> Kata Kunci Memahami 16 Kata Menerapkan <true, false> Kata Kunci Menerapkan 17 Kata Menganalisis <true, false> Kata Kunci Menganalisis 18 Kata Mengevaluasi <true, false> Kata Kunci Mengevaluasi 19 Kata Membuat <true, false> Kata Kunci Membuat
20 Class <nominal> Untuk mendefinisikan target kelas
Dari proses ekstraksi feature yang telah dilakukan, selanjutnya adalah proses pemodelan berdasarkan data latih yang sudah ada. Pada saat proses pembentukan model dilakukan menggunakan open source WEKA. Dengan WEKA, data latih tersebut kemudian akan diproses untuk menghasilkan model klasifikasi berdasarkan algoritma yang dipakai yaitu algoritma Support Vector
Machine.
Setelah proses pemodelan selesai dibangun, kemudian sistem akan melakukan pengujian untuk memberikan informasi berupa keakuratan presentasi data uji dari model yang telah dibuat. Jika nilai yang diperoleh sama dengan nilai yang ada pada data uji, maka proses klasifikasi yang dilakukan oleh sistem sudah benar atau berhasil.
3.5 Perancangan Pengujian
Perancangan pengujian dalam penelitian ini yaitu meliputi berbagai tahap yang dilakukan sistem nantinya sebagai gambaran dari proses pengujian yang
24
akan dilakukan saat sistem sudah siap digunakan dan hasil dari klasifikasi sesuai target yang diinginkan. Berikut merupakan perancangan pengujian:
3.5.1 Preprocessing
Pada tahap preprocessing data kalimat diinputkan dengan format *.csv kemudian sistem akan melakukan preprocessing pada data tersebut, yang meliputi tahap case folding yaitu mengubah huruf menjadi kecil, remove number & puntuation yaitu penghilangan nomor, tanda baca dan spasi, dan tahap terakhir adalah tokenisasi yaitu proses pemisahan data menjadi token atau potongan kata tunggal. Berikut merupakan contoh dari proses sebelum dan sesudah dilakukan preprocessing terdapat pada Tabel 3.5 dan Tabel 3.6.
Tabel 3.4 Data Kalimat Tanya Sebelum Proses Preprocessing
Tulislah faktor penghambat yang dihadapi untuk melaksanakan berbagai aktivitas ekonomi yang dominan berkembang di daerah tempat tinggalmu?
Identifikasilah hal apa saja yang diperlukan untuk mengatasi berbagai masalah yang muncul dalam kehidupan bermasyarakat!
Deskripsikan akibat yang terjadi jika kemerdekaan dalam menyampaikan pendapat tidak ada peraturan?
Bagaimana persamaan kalor untuk menaikkan suhu benda dan kalor untuk mengubah wujud benda? Coba jelaskan!
Tabel 3.5 Data Kalimat Tanya Sesudah Proses Preprocessing
tulislah faktor penghambat yang dihadapi untuk melaksanakan berbagai aktivitas ekonomi yang dominan berkembang di daerah tempat tinggalmu
identifikasilah hal apa saja yang diperlukan untuk mengatasi berbagai masalah yang muncul dalam kehidupan bermasyarakat
deskripsikan akibat yang terjadi jika kemerdekaan dalam menyampaikan pendapat tidak ada peraturan
bagaimana persamaan kalor untuk menaikkan suhu benda dan kalor untuk mengubah wujud benda coba jelaskan
3.5.2 Ekstraksi Fitur
Selesai tahap preprocessing, kemudian dilakukan tahap ekstraksi fitur yang sebelum diinputkan, data kalimat tersebut sudah dilakukan pelabelan secara manual dan disimpan dalam format *.csv. Proses ekstraksi fitur dilakukan dengan 2 jenis ekstraksi yaitu untuk fitur sintaktik dan fitur bag-of-word. Pada tahap ekstraksi dilakukan bertujuan untuk memberikan nilai biner pada setiap kata yang
25
memiliki nilai fitur masing-masing untuk memudahkan proses penargetan kelas.
a. Fitur Sintaktik
Fitur sintaktik adalah fitur dari sebuah soal yang diekstrak berdasarkan susunan kata pada soal tersebut [22]. Berikut merupakan tabel proses dari ektraksi fitur sintaktik, dimana jika pada kata tersebut mengandung nilai fitur maka kata tersebut akan bernilai 1 dan jika tidak bernilai fitur maka akan bernilai 0. Pada penilaian ekstraksi fitur ini penilaian untuk fitur menggunakan biner.
Tabel 3.6 Proses Ekstraksi Fitur Sintaktik Kalimat Tanya
tulislah faktor penghambat yang dihadapi untuk melaksanakan berbagai aktivitas ekonomi yang dominan berkembang di daerah tempat tinggalmu
Kata
WH Kerja Kata Perbandingan Kata Definisi Kata Kausalitas Kata Penyebutan Kata Preposisi Kata Kata Penjelas Pilihan Kata Kata Tujuan
0 1 0 0 0 0 1 0 0 0
Kata
Cara Waktu Kata Tambahan Kata Mengingat Kata MemahamiKata MenerapkanKata MenganalisisKata MengevaluasiKata MembuatKata Label
0 0 1 1 1 1 0 0 0 Mengingat
Kalimat Tanya
identifikasilah hal apa saja yang diperlukan untuk mengatasi berbagai masalah yang muncul dalam kehidupan bermasyarakat
Kata WH Kata Kerja Kata Perbandingan Kata Definisi Kata Kausalitas Kata Penyebutan Kata
Preposisi Kata Penjelas Kata
Pilihan Kata Tujuan
1 1 0 0 0 0 1 0 0 0 Kata Cara Kata Waktu Kata Tambahan Kata Mengingat Kata Memahami Kata Menerapkan Kata Menganalisis Kata Mengevaluasi Kata Membuat Label 0 0 1 1 1 1 0 0 0 Mengingat Kalimat Tanya
deskripsikan akibat yang terjadi jika kemerdekaan dalam menyampaikan pendapat tidak ada peraturan
Kata
WH Kerja Kata Perbandingan Kata Definisi Kata Kausalitas Kata Penyebutan Kata Preposisi Kata Kata Penjelas Pilihan Kata Kata Tujuan
0 1 0 0 1 0 1 0 0 0 Kata Cara Kata Waktu Kata Tambahan Kata Mengingat Kata Memahami Kata Menerapkan Kata Menganalisis Kata Mengevaluasi Kata Membuat Label 0 0 1 0 1 1 0 0 1 Memahami Kalimat Tanya
bagaimana persamaan kalor untuk menaikkan suhu benda dan kalor untuk mengubah wujud benda coba jelaskan
Kata
26
1 1 1 0 0 0 1 0 0 0
Kata
Cara Waktu Kata Tambahan Kata Mengingat Kata MemahamiKata MenerapkanKata MenganalisisKata MengevaluasiKata MembuatKata Label
0 0 1 0 1 1 0 0 0 Memahami
b. Fitur Bag-of-Words (BoW)
Semua dokumen dapat dipresentasikan secara sederhana menggunakan
Bag-of-words (BoW). BoW adalah sebuah model yang merepresentasikan objek secara global
misalnya kalimat teks atau dokumen sebagai bag (multiset) kata tanpa memperdulikan tata bahasa bahkan urutan kata untuk menjaga keanekaragamannya [23]. Dengan kata lain, BoW merupakan kumpulan kata-kata unik dalam teks dokumen untuk membentuk urutan yang berbeda kemudian dihitung frekuensi kemunculannya. Pada proses ekstraksi fitur Bag-of-Words untuk setiap kata dihitung jumlah kata yang muncul pada berdasarkan panjang kalimat. Berikut merupakan contoh proses ekstraksi untuk fitur sintaktik.
Tabel 3.7 Proses Ekstraksi Fitur Bag-of-Words
tulislah faktor penghambat yang dihadapi untuk melaksanakan berbagai aktivitas ekonomi yang dominan berkembang di daerah tempat tinggalmu
Hasil Ekstraksi
tulislah faktor penghambat yang dihadapi untuk melaksanakan berbagai
1 1 1 2 1 1 1 1
aktivitas ekonomi dominan berkembang di daerah tempat tinggalmu
1 1 1 1 1 1 1 1
identifikasilah hal apa saja yang diperlukan untuk mengatasi berbagai masalah yang muncul dalam kehidupan bermasyarakat
Hasil Ekstraksi
identifikasilah hal apa saja yang diperlukan untuk
1 1 1 1 2 1 1
mengatasi berbagai masalah muncul dalam kehidupan bermasyarakat
1 1 1 1 1 1 1
deskripsikan akibat yang terjadi jika kemerdekaan dalam menyampaikan pendapat tidak ada peraturan
Hasil Ekstraksi
deskripsi
kan akibat yang terjadi jika kemerdekaan
1 1 1 2 1 1
dalam menyampaikan pendapat tidak ada peraturan
1 1 1 1 1 1
bagaimana persamaan kalor untuk menaikkan suhu benda dan kalor untuk mengubah wujud benda coba jelaskan
27
Hasil Ekstraksi
bagaimana persamaan kalor untuk menaikkan suhu benda
1 1 2 2 1 1 1
dan mengubah wujud benda coba jelaskan
1 1 1 1 1 1
3.5.3 Pemodelan Klasifikasi SVM
Setelah didapatkan fitur yang terdapat pada Tabel 3.6 maka fitur ini nantinya akan digunakan sebagai masukan dalam klasifikasi menggunakan algoritma SVM dengan metode one-against-all (OAA). Sebagai contoh dalam dataset terdapat 2 kelas seperti diatas, yang terdiri dari kelas
1 = Mengingat, dan 2 = Memahami
Langkah awal adalah melakukan pembuatan model klasifikasi biner, pada penelitian ini menggunakan SVM OAA. Langkah selanjutnya setiap model klasifikasi ke-i di latih dengan menggunakan keseluruhan data, kemudian di lakukan pencarian untuk mendapatkan fungsi optimasi klasifikasi. Tabel 3.8 merupakan contoh 2 SVM biner dengan metode one-against-all beserta fungsi hasil pelatihan.
Tabel 3.8 Contoh 2 SVM biner
Yi = 1 Yj = -1 Fungsi Hasil Pelatihan
Kelas 1 Bukan Kelas 1 ( ) ( )
Kelas 2 Bukan Kelas 2 ( ) ( )
Langkah selanjutnya adalah hasil ekstraksi fitur Tabel 3.6 di masukkan ke dalam fungsi hasil pelatihan untuk setiap model klasifikasi biner yang sudah dibuat. Jika hasil dari klasifikasi data baru tersebut menyatakan bahwa data tersebut bukan kelas i maka data baru tersebut di masukkan ke dalam fungsi hasil pelatihan berikutnya, sampai hasil dari klasifikasi menyatakan bahwa data baru tersebut adalah kelas i.
28
3.6 Perhitungan SVM
Perhitungan SVM dengan OAA
X1 X2 Yi 6 7 1 7 7 1 4 4 1 2 3 1 5 5 1
29
3.7 Skenario Pengujian
Skenario pengujian dalam penelitian ini yaitu pengujian terhadap hasil dari klasifikasi kalimat tanya berdasarkan target kelas berupa pembagian data yang berjumlah 600 kalimat dengan 6 kelas yaitu sebagai berikut:
1. Data akan dibagi menjadi 2 kelompok, kelompok pertama sebagai data latih dan kelompok kedua sebagai data uji.
2. Terdapat porsi pembagian data latih dan data uji, porsi pembagian data sebagai berikut:
1. 80 % : 20% dimana 480 data digunakan sebagai data latih dan 120 data digunakan sebagai data uji.
2. Untuk setiap klasifikasi SVM di hitung nilai akurasinya dengan persamaan sebagai berikut:
Akurasi = TP + TN TP + TN + FP + FN Presisi = TP TP + FP Recall = TP TP + FN
3. Setelah mendapatkan parameter dalam klasifikasi SVM yang memiliki akurasi terbesar maka parameter tersebut digunakan dalam pengujian menggunakan teknik Cross Validation.
3.8 Pengujian Klasifikasi
Pengujian sistem klasifikasi dilakukan menggunakan confusion matrix yang bertujuan untuk mengetahui tingkat keberhasilan suatu sistem dalam melakukan proses pengklasifikasian. Berikut merupakan contoh dari perancangan pengujian sistem terdapat pada Tabel 3.9.
30
Tabel 3.9 Perancangan Pengujian Klasifikasi
Data Uji Hasil Ket.
Aktual Prediksi
bersama dengan anggota kelompok identifikasilah satu jenis kelainan atau penyakit yang menyerang sistem transportasi
Mengingat Mengingat T
jelaskan perbedaan antara pelaksanaan usaha swasta dengan munculnya kapitalisme dan imperialisme modern di indonesia
Memahami Memahami T
berilah contoh peristiwa peleburan pembekuan penguapan dan pengembunan apakah dalam peristiwa itu memerlukan atau melepaskan kalor
Memahami Memahami T
buatlah poster yang berkaitan dengan salah satu penyakit yang disebabkan oleh virus
Membuat Membuat T
sebutkan provinsi di indonesia yang memiliki tingkat kepadatan penduduk yang tinggi
Mengingat Membuat F
Dari Tabel 3.9 maka diperoleh sebuah confusion matrix yang menggambarkan hasil mengenai sistem klasifikasi seperti pada Tabel 3.10.
Tabel 3.10 Perancangan Confusion Matrix
Aktual Prediksi
Mengingat Memahami Membuat
Mengingat TMeng = 1 FMema = 0 FMem = 0
Memahami FMeng = 0 TMema = 2 FMem = 0
Membuat FMeng = 0 FMema = 0 TMem = 1
Berikut merupakan perhitungan nilai akurasi, presisi, dan recall untuk masing-masing kelas : 1. Akurasi Akurasi =
(
)
Akurasi = 1 + 2 + 1 1 + 2 + 1 + 0 + 0 + 031 Akurasi =