KLASIFIKASI DOKUMEN SKRIPSI TEKNIK INFORMATIKA DENGAN MENGGUNAKAN ALGORITMA K-MEDOID
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh : Taufik NIM : 07 5314 072
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
2012
i
CLASSIFICATION OF INFORMATIC ENGINEERING FINAL PROJECT DOCUMENT USING K-MEDOID ALGORITHM
A THESIS
Presented as Partial Fulfillment of the Requirements To Obtain the Sarjana Komputer Degree
In Informatics Engineering Department
By: Taufik NIM : 07 5314 072
DEPARTMENT OF INFORMATIC ENGINEERING FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
2012
ii
iii
v
HALAMAN PERSEMBAHAN
Tuhan tidak pernah terlambat dan tidak pula terlalu cepat. Dia tidak selalu memberikan apa yang kita minta, tapi yakinlah Dia selalu memberi apa yang terbaik buat kita. Karena dengan kuasa-Nya, semua akan indah
pada waktunya.
Untuk menjadi kupu-kupu yang cantik, sebuah telur membutuhkan usaha dan proses yang panjang, begitu juga dengan sebuah kesuksesan,
dibutuhkan usaha dan proses untuk mencapainya
Skripsi ini saya persembahakan untuk
Keluarga, teman- teman seperjuangan dan sahabat
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini tidak memuat karya/ bagian karya orang lain, kecuali yang telah disebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta , 24 Januari 2012
Penulis
Taufik
vi
PERNYATAAN PERSETUJUAN
PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan dibawah ini, saya mahasiswa Universitas Sanata Dharma: Nama : Taufik
NIM : 075314072
Demi pengembangan ilmu pengetahuan, saya memberikan kepada perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul :
KLASIFIKASI DOKUMEN SKRIPSI TEKNIK INFORMATIKA DENGAN MENGGUNAKAN ALGORITMA K-MEDOID
Beserta perangkat yang diperlukan ( bila perlu ). Dengan demikian saya memberikan kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan , mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikannya di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royalty kepada saya selama tetap mencantumkan nama saya sebagai penulis. Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di Yogyakarta,
Pada tanggal : 24 Januari 2012 Yang menyatakan
Taufik
vii
viii
KLASIFIKASI DOKUMEN SKRIPSI TEKNIK INFORMATIKA DENGAN MENGGUNAKAN ALGORITMA K-MEDOID
Abstraksi
Skripsi merupakan syarat lulusnya seorang mahasiswa yang mengambil jenjang Strata 1. Oleh karena itu, seiring bertambahnya lulusan , maka bertambah pula dokumen skripsi. Dengan jumlah dokumen yang sangat besar, maka akan lebih mudah mencari suatu dokumen apabila dokumen–dokumen tersebut telah diorganisir dan dikelompokkan atau diklasifikasi sesuai dengan kategorinya. Skripsi ini bertujuan untuk membuat suatu aplikasi yang mampu mengklasifikasikan dokumen skripsi menggunakan system temu balik informasi dan dikombinasikan dengan algoritma clustering K-Medoid.
ix
Untuk melakukan klasifikasi pengelompokan dokumen, digunakan algoritma clustering K- Medoid. Medoid merupakan obyek yang mempunyai nilai total jarak minimal terhadap obyek – obyek lain dalam satu cluster dan menjadi median dari cluster tersebut dan terletak paling tengah.
x
CLASSIFICATION OF INFORMATIC ENGINEERING FINAL PROJECT DOCUMENT USING K-MEDOID ALGORITHM
Abstract
Thesis is a requirement of graduation of a student who took Strata 1. Therefore , the concomitant increase in graduates, it also increased thesis document. With a very large number of documents,it will be easier to find a document if these documents have been organized an grouped or classified according to the category. This thesis aims to create an application that’s able to classify a thesis document using information retrieval and combined with clustering algorithm K-Medoid
This document clustering process begins with the parsing, stemming and indexing process. Weighting algorithm that used is TF-IDF algorithm. Put simply, this algorithm is related with frequency of occurance of the word in one document and another documents. The result from index processing can be used to built a Matrix representative of a vector space model. The components of this matrix is documents and terms. CosSim is an algorithm that is used to measure the proximity between documents.
xi
xii
KATA PENGATAR
Puji syukur kepada Tuhan Yang Maha Esa yang telah memberikan karunia kekuatan dan kesempatan sehingga penulis dapat menyelesaikan tugas akhir dengan judul “KLASIFIKASI DOKUMEN SKRIPSI DENGAN MENGGUNAKAN ALGORITMA K- MEDOID”.
Terima kasih yang sebesar-besarnya kepada semua pihak yang telah memberikan dukungan, semangat , serta bantuan sehingga penulis mampu menyelesaikan skripsi ini :
1. Bapak Yosef Agung Cahyanta,S.T.,M.T., selaku Dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta
2. Ibu Ridhowati Gunawan, S.Kom.,M.T. selaku ketua jurusan Program Studi Teknik Informatika Universitas Sanata Dharma Yogyakarta 3. Bapak Puspaningtyas Sanjoyo Adi S.T.,M.T., selaku dosen pembimbing
atas kesabaran , saran dan waktu yang diberikan
4. Ibu Sri Hartati Wijono, S.Si.,M.Kom., dan Bapak J.B.Budi Darmawan, S.T.,M.Sc., selaku dosen penguji atas saran dan kritikannya.
5. Drs. Rubiyanto, M.,M. dan Herry Rochmanto atas dukungan moral kepada penulis
7. Teman –Teman komunitas jimbez ( Leonardus ,S.Kom,Albertus Dio, S.Kom,Robertus Atyantama, Mariano Lucky Z, Amiko B., Markus Herjuno, Andriyudha P.Yohanes Sapto Prabowo) atas dukungan penuh yang diberikan.
8. Teman-teman TI’07 dan semua pihak yang telah berperan serta baik secara langsung maupun tidak langsung sehingga penulis mampu menyelesaikan skripsi ini.
Penulis menyadari bahwa masih banyak kekurangan dalam penyusunan skripsi ini. Saran dan kritik sangat diharapkan untuk perbaikan kedepannya. Semoga dapat bermanfaat
Yogyakarta, 21 Januari 2012
xiv
DAFTAR ISI
HALAMAN JUDUL BAHASA INDONESIA ... i
HALAMAN JUDUL BAHASA INGGRIS ... ii
HALAMAN PERSETUJUAN ... Error! Bookmark not defined. HALAMAN PENGESAHAN ... Error! Bookmark not defined. HALAMAN PERSEMBAHAN ... v
HALAMAN PERNYATAAN KEASLIAN KARYA ... vi
HALAMAN PERSETUJUAN PUBLIKASI ... vii
ABSTRAK ... viii
1.5 Metodologi Penelitian ... 4
1.6 Sistematika Penulisan ... 5
BAB II : TINJAUAN PUSTAKA ... 7
2.1 Temu Kembali Informasi( information retrieval) ... 7
2.1 Indexing dalam information retrieval ... 7
2.1.1 Parsing Dokumen ... 8
2.2.2 Stemming ... 10
2.3 Pembobotan kata ... 15
2.4 Model Ruang Vektor/ Vetor Space Model ... 16
2.6 Evaluasi Pengujian Sistem ... 27
2.6.2 Uji Presisi ... 29
BAB III: ANALISA DAN PERANCANGAN ... 30
3.1 Metode Pengembangan Perangkat Lunak ... 30
3.1.1 AUP(Agile Unified Process) ... 30
Filosofi AUP ... 31
3.2 Gambaran Umum Sistem ... 32
3.2.1 Analisis Kebutuhan ... 38
3.3 Analisa Sistem ... 39
3.3.1 Model Use Case ... 39
3.3.2 Skenario Usecase ... 43
3.3.3 Diagram Aktivitas ... 56
3.3.4 Model Analisis ... 68
3.3.5 Diagram Kelas Keseluruhan ... 89
3.4 Model Desain ... 90
3.4.1 kelas Perancangan ... 90
3.4.2 Atribut dan Method ... 101
3.4.3 Prototype Antar muka ... 128
3.4.3.8 Lihat hasil cluster ... 134
3.4.4 Desain Database ... 134
3.5 Rencana Pengujian dan Evaluasi ... 138
Rencana pengujian di bagi dalam dua bentuk yaitu: ... 138
BAB IV : IMPLEMENTASI DAN PENGUJIAN ... 141
4.1 Implementasi ... 141
4.1.1 Implementasi Antar Muka ... 141
4.1.2 Implementasi Control ... 148
4.1.3 Implementasi Model ... 149
4.1.4 implementasi Entity ... 150
4.2 Pengujian ... 153
4.2.1 Pengujian terintegrasi ... 153
xvi
BAB V : KESIMPULAN ... 174
5.1 Kesimpulan ... 174
5.2 Saran ... 175
DAFTAR PUSTAKA ... 177
LAMPIRAN I ... 180
LAMPIRAN II ... 202
LAMPIRAN III ... 224
xvii
DAFTAR TABEL
Tabel 2.1 kombinasi awalan akhiran yang tidak diijinkan ... 14
Tabel 2.2 cara menentukan tipe awalan untuk kata yang diawalai dengan “te-“ ... 14
Tabel 2.3 jenis awalan berdasarkan tipe awalannya ... 15
Tabel 3.6 Skenario Insert stopword ... 48
Tabel 3.7 Skenario Update Stopword ... 49
Tabel 3.8 Skenario Delete Stopword ... 50
Tabel 3.9 Skenario Insert Kata Dasar ... 51
Tabel 3.10 Skenario Update Kata Dasar ... 52
Tabel 3. 11 Skenario Delete Kata Dasar ... 53
Tabel 3.12 Skenario Melakukan Klustering ... 54
Tabel 3.13 Skenario Memasukkan Dokumen ... 55
Tabel 3.14 Skenario Lihat Cluster ... 56
Tabel 3.15 Aktifitas Login ... 57
Tabel 3.16 Aktifitas Insert User ... 58
Tabel 3. 17 Aktifitas Delete User ... 59
Tabel 3.18 Aktifitas Insert stopword ... 60
Tabel 3.19 Aktifitas Update Stopword ... 61
Tabel 3.20 Aktifitas Delete Stopword ... 62
Tabel 3.21 Aktifitas Insert Kata Dasar ... 63
Tabel 3.22 Aktifitas Update Kata dsara ... 64
Tabel 3..23 Aktifitas Delete Kata dasar ... 65
Tabel 3.24 Aktifitas Memasukkan Dokumen ... 66
Tabel 3.25 Aktifitas Klustering ... 67
Tabel 3.26 Aktifitas Lihat Cluster... 68
Tabel 3.27 Kelas Perancangan ... 92
Tabel 3. 30 Diagram Relasional indek ... 137
Tabel 4 1 Implementasi Control... 149
Tabel 4 2Implementasi Model ... 149
Tabel 4 3 Rencana Pengujian ... 155
Tabel 4 4 Pengujian ... 158
Tabel 4 5 hasil pengujian relevansi ... 163
Tabel 4 7 pengujian keyword cluster 2 ... 165
Tabel 4 8 pengujian keyword cluster 3 ... 165
Tabel 4 9 hasil perhitungan berdasarkan keyword ... 167
xix
Gambar 3. 6 Diagram Kelas Keseluruhan ... 90
Gambar 3. 7 Antarmuka Login ... 129
Gambar 3. 8 Antarmuka MainFrame ... 129
Gambar 3. 9 Antarmuka Manajemen User ... 130
Gambar 3. 10 Antarmuka Manajemen Katadasar ... 131
Gambar 3. 11 Antarmuka Manajemen Stopword ... 132
Gambar 3. 12 Antarmuka Skripsi dialog ... 133
Gambar 3. 13 Antarmuka Klustering ... 133
Gambar 3. 14 Antarmuka Lihat kluster ... 134
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Skripsi adalah istilah yang digunakan di Indonesia untuk mengilustrasikan suatu karya tulis ilmiah berupa paparan tulisan hasil penelitian sarjana S1 yang membahas suatu permasalahan atau fenomena dalam bidang ilmu tertentu dengan menggunakan kaidah-kaidah penulisan skripsi yang merupakan persyaratan untuk mendapatkan status sarjana (S1) di setiap Perguruan Tinggi Negeri (PTN) maupun Perguruan Tinggi Swasta (PTS) yang ada di Indonesia. Oleh karena itu seiring dengan bertambahnya jumlah lulusan, maka hal ini berbanding lurus terhadap jumlah dokumen skripsi yang dihasilkan.
Dengan jumlah dokumen yang sangat besar, maka akan lebih mudah mencari suatu dokumen apabila dokumen–dokumen tersebut telah diorganisir dan dikelompokkan sesuai dengan kategorinya. Sebuah dokumen dapat dikelompokkan kedalam kategori tertentu berdasarkan kata-kata ataupun kalimat yang ada di dalam dokumen tersebut. Pengelompokan dokumen mempunyai manfaat yang sangat besar mengingat jumlah dokumen yang terus bertambah banyak.
digunakan, Oleh karena itu , dibutuhkan suatu metode untuk mengelompokkan dokumen–dokumen tersebut secara otomatis
Ada banyak algoritma clustering untuk mengelompokkan dokumen, salah satunya adalah algoritma K Medoid. K Medoid merupakan generalisasi dari K mean dimana algoritma ini menggunakan medoid sebagai pengganti mean. Teknik dasar dari algoritma K medoid ini adalah untuk menemukan k cluster dalam n object dengan cara first arbitrarily finding a representative object (medoid). Kelebihan algorima K medoid adalah mampu bekerja dengan semua jenis pengukuran (distance measures) seperti Euclidean distance, Manhattan distance atau Minkowski distance. Disamping itu algoritma ini juga mampu mengatasi masalah outliers.
Penggunaan algoritma K medoid sebagai algoritma clustering ini diharapkan mampu menghasilkan suatu aplikasi pengelompokkan dokumen yang bermanfaat bagi teknologi informasi
1.2 Rumusan Masalah
Berdasarkan latar belakang diatas, ada beberapa pokok masalah, diantaranya adalah sebagai berikut:
1. Kebutuhan akan pengklasifikasian dokumen skripsi untuk memudahkan pengorganisasian dokumen skripsi.
2. Proses clustering secara otomatis.
Dari beberapa pokok masalah tersebut, maka dapat ditarik suatu rumusan masalah yaitu bagaimana membangun suatu aplikasi pengelompokkan dokumen skripsi teknik informatika dengan mengimplementasikan algoritma K Medoid sebagai algoritma clustering.
1.3 Tujuan Penelitian
Adapun tujuan penulisan skripsi adalah sebagai berikut:
1. Membangun sistem klasifikasi dokumen skripsi Teknik Informatika
2. Untuk melihat bagaimana performa algoritma clustering K Medoid dalam mengelompokkan sutau object yang berbentuk dokumen teks
1.4 Batasan Masalah
Adapun batasan dari aplikasi klasifikasi dokumen skripsi Teknik Informatika ini adalah sebagai berikut :
1. Dokumen yang dapat diproses adalah dokumen berbasis portable document file( .pdf)
3. Jumlah K cluster merupakan masukan dari user
1.5 Metodologi Penelitian
Metodologi penelitian yang digunakan dalam pembuatan tugas akhir ini adalah sebagai berikut:
1. Metode pengumpulan data : a. Studi literatur
Mencari dan mengumpulkan literatur - litaratur yang berkaitan dengan permasalahan yang dikerjakan, yaitu mengenai klasifikasi dokumen dengan menggunakan algoritma K Medoid
b. Pembagian kuisioner untuk melakukan uji presisi aplikasi
2. Metode pengembangan sistem
Metode pengembangan sistem yang digunakan dalam pengembangan aplikasi ini adalah AUP (Agile Unified Process).
.
1.6 Sistematika Penulisan
Bab I Pendahuluan
Memberikan gambaran secara umum tentang isi skripsi yang meliputi:
latar belakang, rumusan masalah, batasan masalah, tujuan dan manfaat, metode penelitian dan sistematika penulisan.
Bab II Landasan Teori
Berisi konsep dasar sistem temu-kembali informasi (information retrieval system), bagian-bagian dari sistem temu kembali informasi, teknik-teknik temu kembali informasi dan metode klasifikasi K Medoid
Bab III Analisa dan Perancangan
Berisi gambaran umum sistem, usecase diagram, sekenario perancangan, analisa peracangan, perancangan basis data, perancangan tampilan masukan dan keluaran untuk pengguna.
Bab ini menjelaskan tentang implementasi ke dalam bentuk program berdasarkan desain yang telah dibuat dan pengujian applikasi dalam bentuk olah hasil kuisioner.
Bab V Kesimpulan dan Saran
Bab ini berisi semua simpulan yang didapatkan dari penelitian yang telah dilakukan. Simpulan menjawab rumusan masalah yang dituliskan pada bab pendahuluan secara ringkas dan jelas.
7
BAB II
TINJAUAN PUSTAKA
2.1 Temu Kembali Informasi( information retrieval)
Information Retrieval (IR) adalah suatu bidang ilmu yang mempelajari cara-cara penelusuran atau memanggil (retrieve) kembali atas dokumen-dokumen. Menurut Lancaster (1968) dalam Rijsbergen (1979): “Sebuah information retrieval system (Sistem Temu-kembali Informasi) tidak memberitahu (yakni tidak mengubah pengetahuan) pengguna mengenai masalah yang ditanyakannya. Sistem tersebut hanya memberi-tahukan keberadaan (atau ketidakberadaan) dan keterangan dokumen-dokumen yang berhubungan dengan permintaannya”[8].
2.1 Indexing dalam information retrieval
Dalam information retrieval ( atau disingkat IR), dikenal adanya proses indexing. Indexing merupakan suatu proses untuk melakukan pengindekkan terhadap kumpulan dokumen. Ada beberapa tahap dalam proses pengindekkan, diantaranya adalah sebagai berikut
1. Parsing dokumen adalah pengambilan kata kata dari suatu dokumen
3. Term weight dan inverted index adalah proses pembobotan kata
2.1.1 Parsing Dokumen
Parsing dokumen berkaitan dengan pengenalan dari isi dan struktur dari dokumen teks[6]. Parsing dokumen ini bertujuan untuk mendapatkan term atau kata dari suatu dokumen. Parsing merujuk pada proses pengenalan token yang terdapat dalam rangkaian teks [4]. Beberapa tahapan dalam parsing dokumen adalah tokening dan stopping.
1. Tokening
koordinat
dari citra yang mempunyai nilai keabuan; koordinat yang menunjukkan lokasi;
Dokumen
2. Stopping
Document
koordinat yang menunjukkan lokasi; dari citra yang mempunyai nilai keabuan;
Token
Stemming merupakan suatu proses untuk menemukan kata dasar dari sebuah kata. Dengan menghilangkan semua imbuhan (affixes) baik yang terdiri dari awalan (prefixes), sisipan (infixes), akhiran (suffixes) dan confixes (kombinasi dari awalan dan akhiran) pada kata turunan. Stemming digunakan untuk mengganti bentuk dari suatu kata menjadi kata dasar dari kata tersebut yang sesuai dengan struktur morfologi Bahasa Indonesia yang baik dan benar[2].
Contoh lain ada pada kata dasar dengan huruf pertama “s” misalnya “sapu”. Jika kata tersebut diberi awalan “me”, maka awalan tersebut akan berubah bentuk menjadi “meny”.
Ada dua teknik alternatif yang dapat digunakan untuk proses stemming bahasa Indonesia yaitu dengan menggunakan kamus, atau tanpa menggunakan kamus. Algoritma vega merupakan teknik stemming bahasa Indonesia tanpa mengunakan kamus, sedangkan beberapa algoritma stemming bahasa indonesia dengan menggunakan kamus diantaranya adalah algoritma nazief dan adriani dan algoritma porter . Algortima dengan menggunakan kamus dilakukan dengan membandingkan kata yang telah dihilangkan imbuhannya dengan kata dasar dalam kamus.
Perbedaan kedua algoritma ini terletak pada efisiensi waktu dan presisi yaitu
1. Proses stemming dokumen teks berbahasa Indonesia menggunakan Algoritma Porter membutuhkan waktu yang lebih singkat dibandingkan dengan stemming menggunakan Algoritma Nazief & Adriani.[3]
2. Proses stemming dokumen teks berBahasa Indonesia menggunakan Algoritma Porter memiliki prosentase keakuratan (presisi) lebih kecil dibandingkan dengan stemming menggunakan Algoritma Nazief & Adriani.[3]
1. Cari kata yang akan distem dalam kamus. Jika ditemukan , maka diasumsikan bahwa kata tersebut adalah rootword, maka algoritma berhenti
2. Inflection suffixes (“lah”,”kah”,”ku”,”mu”,”nya”) dibuang. Jika berupa partikel(“lah”,”kah”,”pun”,”tah”), maka langkah ini diulangi lagi untuk menghapus possessive pronouns (“lah”,”kah”,”ku”,”mu”), jika ada.
3. Hapus derivation suffixes (“I”,”an”,”kan”). Jika kata ditemukan di kamus maka algoritma berhenti, jika tidak maka lanjut ke langkah 3a
a. Jika “an” telah dihapus dan huruf terakhir dari kata tersebut adalah “k”, maka “k” ikut dihapus. Jika kata tersebut ditemukan dalam kamus maka algoritma berhenti. Jika tidak ditemukan maka lanjut ke langkah 3b.
b. Akhiran yang dihapus (“I”,”an”,”kan”) dikembalikan , lanjut ke langkah 4.
4. Hapus derivation prefix. Jika pda langkah 3 ada suffix yang dihapus, maka pergi ke langkah 4a. Jika tidak , pegi kelangkah 4b.
b. For i=1 to 3,tentukan tipe awalan kemudian hapus awalan, jika root word belum juga ditemukan lakukan langkah 5, jika sudah maka algoritma berhenti. Catatan : jika awalan kedua dan awalan pertama sama , maka algoritma berhenti.
5. Melakukan recording
6. Jika semua langkah telah selesai tetapi tidak juga berhasil maka kata awal diasumsikan sebagai root word. Proses selesai.
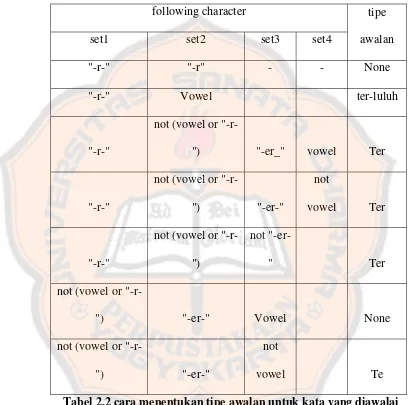
Tipe awalan ditentukan melalui langkah langkah berikut
1. Jika awalannya adalah: “di”,”ke”,”se”, maka tipe awalannya secara berturut turut adalah “di”,”ke”,”se”.
2. Jika awalannya adalah “te”,”me”,”be”,”pe”, maka dibutuhkan sebuah proses tambahan untuk menentukan tipe awalnnya.
3. Jika dua karakter pertama bukan “di”,”ke”,”se”,”te”,”be”,”me” atau “pe” maka berhenti.
4. Jika tipe awalan adalah “none” maka berhenti, jika tipe awalan adalah bukan ‘none” maka awalan dapat dilihat pada table 2.2. Hapus awalan jika ditemukan.
Awalan Akhiran yang tidak di ijinkan
Se i,kan
Tabel 2.1 kombinasi awalan akhiran yang tidak diijinkan
following character tipe
awalan
set1 set2 set3 set4
"-r-" "-r" - - None
"-r-" Vowel ter-luluh
"-r-"
not (vowel or
"-r-") "-er_" vowel Ter
"-r-"
not (vowel or
"-r-") "-er-" not
vowel Ter
"-r-"
not (vowel or "-r-")
not
"-er-" Ter
not (vowel or
"-r-") "-er-" Vowel None
not (vowel or
"-r-") "-er-" not
vowel Te
Tabel 2.2 cara menentukan tipe awalan untuk kata yang diawalai dengan “te-“
Tipe awalan Awalan yang dihapus
di- di- Ke- Ke- Se- Se- Te- Te- Ter- Ter Ter-luluh Ter
Tabel 2.3 jenis awalan berdasarkan tipe awalannya 2.3 Pembobotan kata
Index bobot kata menggambarkan kepentingan relatif dari kata dalam dokumen , dan digunakan dalam menghitung skor untuk ranking[6]. Dalam menetukan bobot suatu istilah tidak hanya berdasarkan frekuensi kemunculan istilah di satu dokumen, tetapi juga memperhatikan frekuensi terbesar pada suatu istilah yang dimiliki oleh dokumen bersangkutan[1].
Teknik yang sering digunakan dalam pemberian bobot adalah teknk TF/IDF(term frequency/inverse document frequency). Term frequency adalah jumlah kemunculan suatu kata dalam sebuah dokumen , sedangkan inverse term frequency adalah inverse dari banyaknya dokumen dimana suatu term tersebut muncul.
Berikut ini adalah rumus pembobotan TF/IDF
w(t,d)= tf t d * idf t = tf (t d) * log (N/dt)
w(t,d )= bobot dari term (kata) dalam document d
tf t d = frekuensi kemunculan tern (kata) dalam dokumen d
idf t = inverse document frequency dari kata t
N = jumlah seluruh dokumen
dt = jumlah dokumen yang mengadung term (kata) t
2.4 Model Ruang Vektor/ Vetor Space Model
Model ini diperkenalkan oleh salton[7] dan telah dipergunakan secara luas. Dalam model ini, dokumen dan query diasumsikan menjadi bagian dari t-dimensional vector space, dimana t adalah jumlah dari index term( kata, stems, frase , dan lain-lain[6].
Dalam model ruang vector, koleksi dokumen direpresentasikan dengan matrik term document. Misalkan terdapat sekumpulan kata T sejumlah n , yaitu T=(T1,T2,…..Tn) dan sekumpulan dokumen D yaitu D=(D1,D2,….Dn), dan wij
T1 T2 ...Tn
D1 W11 W12...W1n
D2 W21 W22...W2n
: : : : : : : : Dm W1m W2m....Wnm
Pada model ini:
1. Vocabulary merupakan kumpulan semua term berbeda yang tersisa dari dokumen setelah preprocessing dan mengandung t term index. Term-term ini membentuk suatu ruang vector
2. Setiap term i di dalam dokumen atau query j, diberikan suatu bobot (weight) bernilai real wij
3. Dokumen dan query diekspresikan sebagai vektor t dimensi dj = (w1, w2, ..., wtj) dan terdapat n dokumen di dalam koleksi, yaitu j = 1, 2, ..., n.
2.5 Algoritma Klasifikasi K-Medoid
Algoritma klasifikasi K-Medoid merupakan variant dari algoritma K-Means. Mean value object cluster dari object cluster sebagai reference point dapat digantikan dengan medoid yang mana object dari medoid ini berada lebih central dalam sebuah object cluster.
Algoritma K-Medoid adalah sebuah classical partitioning technique dari clustering yang mengelompokkan data set dari n objects kedalam k clusters yang disebut apriori[9].
Algoritma K-medoid terdiri dari 3 langkah yaitu:
Langkah 1 : (memilih initial medoids)
1-1. Menggunakan Euclidean distance sebagai pengkuran, komputasikan jarak antara setiap pasang dari semua object
1 … . . ; 1 … … . .
1-2. Hitung Pij untuk mencari dugaan awal pusat cluster
1-3. Hitung di tiap-tiap object dan urutkan secara ascending . Pilih k object yang mempunyai nilai paling minimum sebagai initial group medoids.
1 …
1-4. Tandai tiap tiap object ke medoid terdekat.
1-5. Hitung current optimal value, jumlah jarak dari semua object ke medoid masing masing yang mempunyai jarak terpendek
Langkah 2 : (menemukan medoid baru)
Ganti current medoid di tiap tiap cluster dengan object yang meminimalkan jarak total ke object lain dalam cluster tersebut
Langkah 3 : (New assignment)
3-1. Masukkan tiap object ke medoid baru yang terdekat.
Keunggulan algoritma Medoid dibandingkan dengan algoritma K-Means adalah algoritma K-Medoid lebih kuat dalam menangani nooise dan outliers[10]. Selain itu, jenis pengukuran yang dapat diterapkan dalam algoritma ini pun tidak hanya Ecludian Distance. Namun , baik K-mean maupun K-Medoid memerlukan user untuk menentukan k, yaitu jumlah cluster[10].
Berikut ini merupakan contoh pengklusteran dengan menggunakan algoritma K- medoid
Obyek
ke x y 1 2 6 2 3 4 3 3 8 4 4 7 5 6 2 6 6 4 7 7 3 8 7 4 9 8 5 10 7 6
Langkah 1.1: hitung jaran antar object dengan menggunakan ecludian distance
Obj
ke 1 2 3 4 5 6 7
1 0 2.236068 2.236068 2.236068 5.656854 4.472136 5.830952
2 2.236068 0 4 3.162278 3.605551 3 4.123106
3 2.236068 4 0 1.414214 6.708204 5 6.403124
4 2.236068 3.162278 1.414214 0 5.385165 3.605551 5
5 5.656854 3.605551 6.708204 5.385165 0 2 1.414214
6 4.472136 3 5 3.605551 2 0 1.414214
7 5.830952 4.123106 6.403124 5 1.414214 1.414214 0
8 5.385165 4 5.656854 4.242641 2.236068 1 1
9 6.082763 5.09902 5.830952 4.472136 3.605551 2.236068 2.236068
10 5 4.472136 4.472136 3.162278 4.123106 2.236068 3
Obj
ke 8 9 10
1 5.38516 6.082763 5
2 4 5.09902 4.472136
6 1 2.236068 2.236068
7 1 2.236068 3
8 0 1.414214 2
9 1.41421 0 1.414214
710 2 1.414214 0
Kemudian langkah ke 1.2 yaitu hitung P
Obj ke 1 2 3 4 5 6 7
1 0 0.071072 0.053595 0.068422 0.162859 0.179143 0.191671 2 0.057136 0 0.095874 0.096764 0.103803 0.120173 0.135532 3 0.057136 0.127137 0 0.043274 0.193127 0.200288 0.210479 4 0.057136 0.100511 0.033896 0 0.155037 0.14443 0.164356
5 0.144543 0.1146 0.160785 0.164783 0 0.080115 0.046487
6 0.114271 0.095353 0.119842 0.110328 0.057579 0 0.046487
7 0.148992 0.13105 0.153473 0.152997 0.040715 0.05665 0
8 0.137601 0.127137 0.135586 0.129822 0.064376 0.040058 0.032871 9 0.155426 0.162069 0.139759 0.136845 0.103803 0.089572 0.073502 10 0.127759 0.142144 0.10719 0.096764 0.118703 0.089572 0.098614
Obj ke 8 9 10
2 0.148506 0.15742 0.14967 3 0.210019 0.18002 0.14967 4 0.157514 0.13807 0.105833 5 0.083017 0.11131 0.137989 6 0.037126 0.06903 0.074835 7 0.037126 0.06903 0.100402
8 0 0.04366 0.066935
9 0.052505 0 0.04733
10 0.074253 0.04366 0
Langkah ke 1.3 hitung Sigma P
Pj Pij
1 1.281823 2 1.064878 3 1.371148 4 1.056781 5 1.043633
6 0.724856
7 0.890438
8 0.778046
10 0.898659
Langkah 1.4
Dari tabel diatas didapat 2(k=2) object dengan nilai paling minimal yaitu obyek ke 6 dan 8,lalu masukkan obyek ke pusat (medoid) terdekat sehingga didapat hasil sebagai berikut:
anggota 6(cluster 1) 1,2,3,4,5,6 anggota 8( cluster 2) 7,8,9,10
Langkah 1.5 hitung current optimal value
CURRENT PUSAT 6 (cluster1) 18.07769 CURRENT PUSAT 8 (cluster 2) 4.414214
Langkah 2 Ganti medoid sekarang dengan obyek yang mempunyai total distance paling minimal ke objek lain .
Cluster 1: cluster 2: 1 16.83719
2 16.0039
10 6.414214
Medoid yang baru adalah obyek ke 2 dan 8
Langkah 3.1 masukkan obyek ke medoid baru yang terdekat; anggota 2 (cluster 1) 1,2,3,4
anggota 8 (cluster 2) 5,6,7,8,9,10
Langkah 3.2 hitung current optimal value baru, jika sama dengan current optimal value sebelumnya maka berheti , jika tidak sama maka ulangi ke langkah 2
current opt val cluster 1 9.398346 current opt val cluster 2 7.650282
Karena berbeda , maka kembali ke langkah 2 yaitu menemukan medoid baru. Cluster 1 : cluster 2:
Dari perhitungan diatas maka didapatkan medoid yang baru yaitu 1 dan 8 Langkah 3.1 , hitung current optimal value :
current optimal value cluster 2 7.650282
Karena masih berbeda maka kembali ke langkah 2 yaitu masukkan objek ke medoid terdekat dimana medoid tersebut adalah 1 dan 8. Karena medoid yang didapatkan sama , maka anggota cluster pus sama sehingga current optimal value yang didapatkan sama .Karena current optimal value yang didapatkan sama dengan yang sebelumnya, maka algoritma berhenti disini dengan hasil
Cluste1 cluster2
5 13.37894 6 8.88635 7 9.064495
8 7.650282
9 10.90611 10 12.77339
1 6.708204
2 9.398346 3 7.650282 4 6.812559
2.6 Evaluasi Pengujian Sistem
Untuk melihat bagaimana kualitas cluster yang terbentuk , maka dilakukan pengujian berdasarkan evaluasi kuantitatif(validasi cluster) dan berdasarkan isi( uji presisi). Berikut ini penjelasan tentang evaluasi pengujian yang akan dilakukan
2.6.1 Validasi Cluster
adalah : Hubert Statistic, Indeks Dunn, Indeks Davies-Bouldin, Root-means-square standard deviation.[15]
Indeks yang akan digunakan untuk menguji validitas cluster yang terbentuk nantinya adalah indeks Dunn. Berikut ini merupakan formula dari indeksDunn
min min, , ′
Dengan d(i,j) merupakan jarak antara cluster i dan cluster j, dan d’(k) merupakan jarak maksimal intra cluster dari cluster k.
Bentuk sederhana dari formula tersebut diatas adalah sebagai berikut :
D
Dimana dmin merupakan jarak paling minimal antar 2 object di cluster yang berbeda sedangkan dmax adalah jarak terbesar antar dua objek dalam satu cluster( kadang disebut dengan diameter).
2.6.2 Uji Presisi
Evaluasi pengujian yang kedua bertujuan untuk melihat presisi dari hasil yang didapat sehingga dapat disimpulkan apakah aplikasi ini merupakan sebuah aplikasi yang mampu menangani pengklasifikasian dokumen atau tidak.
Hasil presisi didapat dari kesesuaian dokumen hasil aplikasi dengan hasil kuisioner terhadap responden
BAB IIII
A
ANALISA
A DAN PE
ERANCAN
NGAN
3.1 Metode Penggembangann Perangkat Lunak
3.1.1 AAUP(Agile Unified Prrocess)
Filosofi AUP
AUP mengadopsi filosofi “serial in the large “ dan “iterative in the small”.
1. Serial in the large
Ada 4 tahap dalam serial AUP yaitu
a. Inception. Bertujuan untuk mengidentifikasi lingkup awal proyek, arsitektur potensi untuk sistem.
b. Elaborasi. Bertujuan untuk membuktikan arsitektur sistem. c. Konstruksi. Bertujuan untuk membangun perangkat lunak
secara teratur, bertahap dan memenuhi kebutuhan prioritas tertinggi stakeholder
d. Transisi. Bertujuan untuk memvalidasi dan mengembangkan sistem kedalam lingkungan produksi
2.Iterative in the small
Dalam tiap proses iterasi AUP, terdapat tahapan –tahapan sebagai berikut:
2. Implementation. Model ditranslasikan ke dalam bentuk source code.
3. Testing. Melakukan evaluasi terhadap hasil dari implementasi
4. Deployment. Bertujuan untuk mendapatkan feedback dari end user.
5. Configuration and project management.
6. Environtment management. Environtment management mengkoordinasikan proses infrastruktur seperti standards,tools, dan teknologi pendukung lainnya yang tersedia bagi tim.
3.2 Gambaran Umum Sistem
Clustering K-Medoid Dokumen
dokumen .
Indexing dan pemberian bobot
database
Gambar 3. 2 Alur Sederhana Sistem
Berikut ini gambar alur indexing dan pembobotan kata
dokumen
Parsing dokumen
Gambar 3. 3 Gambar Alur Indexing
Bobot-bobot dari term yang disimpan dalam database tersebut digunakan sebagai variable dalam algoritma K-Medoid.
Secara umum, Algoritma K-Medoid mempunyai tiga langkah penting ( telah dijelaskan di bab II ) diantaranya adalah sebagai berikut:
tokening stopping
stemming
Pembobotan TF/IDF
Simpan bobot
Langkah 1 : (memilih initial medoids)
1-1. Menggunakan Cosine Similarity sebagai pengkuran, komputasikan jarak antara setiap pasang dari semua object. Cosine Similarity memberikan hasil yang lebih baik daripada ecludian distance, namun memerlukan waktu yang
lebih lama [14]
, cos , | || |Q. D |Q||D|1 Qi. Di
1-2. H unit g Pij untuk membuat inisialisai awal pusat cluster.
∑ i=i….n;j=1…n
1-3. Hitung P ij di tiap-tiap object dan urutkan secara ascending . Pilih k object yang mempunyai nilai paling minimum sebagai initial group medoids.
∑ i=1….n;j=1…n
1-4. Tandai tiap tiap object ke medoid terdekat.
1-5. Hitung current optimal value, jumlah jarak dari semua object ke medoid masing masing.
Ganti current medoid di tiap tiap cluster dengan object yang mempunyai jarak total minimal ke object object lain dalam cluster tersebut
Langkah 3 : (New assignment)
3-1. Masukkan tiap object ke medoid baru yang terdekat.
3-2. Hitung optimal value yang baru,jumlah jarak dari semua object ke masing masing medoid, jika optimal value sama dengan medoid optimal value sebelumnya , maka berhenti. Jika tidak , maka ulangi langkah 2.
Dalam pengelompokan dokumen teks ini, ada beberapa aturan yang berbeda dengan algoritma diatas. Beberapa aturan tambahan yang digunakan dalam pembuatan algoritma K medoid untuk pengelompokan dokumen teks adalah sebagai berikut :
1. Untuk mendapatkan medoid baru , P merupakan jumlah total dari cosine similarity untuk kemudian dipilih 3 object yang mempunyai cosine similarity terbesar sebagai inisialisai awal pusat cluster atau awal medoid
2. Current optimal value merupakan jarak total maksimal dari satu objek ke semua object lain dalam satu cluster.
Berikut ini gambaran sederhana proses klasifikasi dokumen dengan algoritma K-Medoid
Inisialisasi awal pusat cluster
Hitung jarak tiap object
Masukkan object ke cluster terdekat
Cari medoid baru
Gambar 3. 4 Alur Sederhana K-Medoid database
Ganti current medoid dengan medoid baru yang terdekat Medoid baru==
medoid sebelumnya
Tidak
Ya
Untuk pemberian nama pada masing – masing cluster yang nantinya akan digunakan sebagai keyword, digunakan tahap – tahap sebagai berkut [14] :
1. Ambil pasangan term dan frequency ( frekuensi bisa berupa tf atau pun df) dari setiap dokumen dalam cluster.
2. Urutkan pasangan <term,freq> berdasarkan frequency 3. Ambil beberapa term teratas sebagai label
Misalnya:
Berikut ini beberapa pasangan term dan freq yang sudah terurut
<system, 700>
<informasi, 654>
<jual, 500>
<langgan,789>
Maka nama dari cluster tersebut adalah system informasi
Beberapa kata tersebut juga bisa digunakan sebagai keyword dari cluster. Kelemahan dari cara ini adalah terkadang pasangan kata yang diambil tidak mencermikan nama dari cluster tersebut
3.2.1 Analisis Kebutuhan
Berikut ini merupakan analisis kebutuhan dari proses pembangunan aplikasi pengklasifikasian dokumen skripsi:
2. Sistem mampu memanajemen atau mengelola stoplist.
3. Sistem mampu memanajemen atau mengelola kamus kata dasar.
4. Sistem mampu memanajemen atau mengelola user.
5. Klasifikasi dokumen dilakukan oleh administrator dan super admin.
3.3 Analisa Sistem
3.3.1 Model Use Case
3.3.1.1 Aktor
Ada dua jenis user yang menjadi aktor dalam aplikasi ini, yaitu super admin, admin . Super admin dan admin mempunyai hak akses yang sama, hanya saja aktor super admin mempunyai hak akses untuk mengelola user sedangkan admin tidak. Berikut ini tabel mengenai aktor beserta hak aksesnya.
Aktor Hak akses
Super admin Login
Mengelola user( tambah,edit, hapus) Mengelola kamus (tambah,edit,hapus) Mengelola stoplist(tambah,edit, hapus) Melakukan klustering
Lihat cluster
Admin Login
Mengelola kamus (tambah,edit,hapus) Mengelola stoplist(tambah,edit, hapus) Melakukan klustering
Memasukkan dokumen Lihat cluster
Tabel 3.1 Hak Akses User
3.3.1.2 Diagram Use Case
Gambar 3. 5 Diagram UseCase 3.3.1.3Tabel Use Case
Berikut ini adalah penjelasan dari tiap-tiap use case dalam diagram use case yang akan disajikan dalam tabel use case
No ID Use Case
Nama Use case
Deskripsi use case Aktor
1 KM-01 Login Verifikasi untuk
dan mengakses menu-menu sesuai dengan hak akses dari aktor
3 KM-03 Delete user Menghapus user
admin
stopword baru ke dalam stoplist
-Super admin -Admin 5 KM-05 Edit stopword Mengubah stopword
dalam daftar stoplist
kamus 9 KM-09 Delete kata
dasar
10 KM-10 Melakukan klustering
Clustering -Super admin
-Admin 11 KM-11 Memasukkan
dokumen 12 KM-12 Lihat Cluster Melihat hasil
peng-cluster-an skripsi
-Super Admin -Admin
Tabel 3.2 Use Csse
3.3.2 Skenario Usecase
Skenario Usecase merupakan deskripsi dari interaksi antara aktor atau pengguna terhadap system. Skenario usecase merupakan rincian dari tabel usecase
Use case : Login
Pre kondisi : sistem sudah berjalan (running) Actor : admin, super admin
Deskripsi : use case ini menggambarkan verifikasi admin atau super admin
untuk masuk kedalam sistem
Aksi aktor Reaksi sistem
1. Aktor mengklik menu system ,kemudian menu item login
2. Sistem menampilkan login dialog
3.Aktor mengisikan username dan password
4.Aktor mengklik tombol login
5..sistem melakukan pengecekan
username dan password
6. sistem menampilkan halaman utama sesuai dengan role dari aktor Skenario alternatif
4.aktor mengklik tombol login
6. kembali ke login dialog
Tabel 3.3 Skenario Login
ID Use case :KM-02
Use case : insert user
Pre kondisi :sistem berada di halaman manajemen user
Actor : super admin
Deskripsi : use case ini menggambarkan proses memasukkan admin baru
Aksi aktor Reaksi sistem
1. Aktor memasukkan username dan password baru serta memverifikasi password baru
2. Aktor mengklik tombol insert
3. Sistem akan menampilkan
pengecekan terhadap username yang sudah ada
4. Jika berhasil maka system
menampilkan pesan sukses
5. Sistem akan kembali ke form
2. aktor mengklik tombol insert
3. sistem akan melakukan
pengecekan username yang sudah ada dan mengecek ke absahan password
4. jika username dan password mengandung kekeliruan maka akan muncul dialog username sudah ada atau password yang dimasukkan salah
5 sistem kembali ke insert user dialog
Tabel 3.4 Skenario Insert User
ID Use case : KM-03 Use case : delete user
Pre kondisi :system berada di halaman manajemen user
Actor : super admin
Aksi aktor Reaksi sistem 1. Aktor mengklik username yang
akan di delete
2. Aktor mengklik tombol delete
3. Sistem akan menghapus username
dan password sesuai permintaan aktor
4. Jika berhasil maka sistem
menampilkan pesan sukses
5. Sistem akan kembali ke form
manajemen user
Tabel 3.5 Skenario Delete User
ID Use case :KM-04 Use case : Insert stopword
Pre kondisi :sistem berada di manajemen stopword
Aktor : super admin, admin
Deskripsi : use case ini menggambarkan proses memasukkanstopword baru
Aksi actor Reaksi system
3. Sistem akan melakukan pengecekan terhadap kata yang sudah ada,jika belum ada maka berhasil
4. Jika berhasil maka sistem
menampilkan pesan sukses
5. System akan kembali from
manajemen stop word Skenario alternatif
2. aktor mengklik tombol insert
3. . sistem akan melakukan
pengecekan kata yang sudah ada
4. jika kata sudah ada maka system
akan menampilkan pesan bahwa kata tersebut sudah ada dalam stoplist
5. system kembali ke from manajemen
stopword
Tabel 3.6 Skenario Insert stopword
ID Use case :KM-05
Use case : edit stopword
Actor : super admin, admin
Deskripsi : use case ini menggambarkan proses mengubah stopword yang sudah ada
Aksi aktor Reaksi sistem
1. Aktor memilih kata yang akan di edit
2. Aktor memasukkan kata baru pada field yang tersedia
3. Aktor mengklik tombol edit
4. Sistem akan mengubah kata tersebut
5. Jika berhasil maka system
menampilkan pesan sukses
6. System akan kembali ke form
manajemen stopword Skenario alternatif
2. aktor belum memasukkan kata baru 3. aktor mengklik tombol edit
4. sistem akan menampilkan pesan
bahwa update stopword field kosong
Tabel 3.7 Skenario Update Stopword
Use case : delete stopword
Pre kondisi :sistem berada di manajemen stopword
Actor : super admin, admin
Deskripsi : use case ini menggambarkan proses menghapus stopword yang sudah ada
Aksi aktor Reaksi sistem
1. Aktor memilih kata yang akan di hapus
2. Aktor mengklik tombol delete
3. Sistem akan menghapus kata tersebut
4. Jika berhasil maka system
menampilkan pesan sukses
5. System akan kembali ke form
manajemen stopword
Tabel 3.8 Skenario Delete Stopword
ID Use case :KM-07 Use case : insert kata dasar
Pre kondisi :sistem berada di manajeen kamus
Deskripsi : usecaseinimenggambarkanprosesmemasukkankatadasar baru
Aksi aktor Reaksi sistem
1. Aktor memasukkan kata baru 2. Aktor mengklik tombol insert
3. Sistem akan melakukan pengecekan
terhadap kata yang sudah ada
4. Jika berhasil maka sistem
menampilkan pesan sukses
5. Sistem akan kembali ke form
manajemen kata dasar Skenario alternatif
2. aktor mengklik tombol insert
3. sistem akan melakukan pengecekan
kata yang sudah ada
4. jika kata sudah ada maka sistem
akan menampilkan pesan bahwa kata tersebut sudah ada dalam kamus
5. sistem kembali ke insert kata dasar
dialog
ID Use case :KM-08
Usecase : editkatadasar
Prekondisi: systemberadadihalaman manajemen kamus
Aktor : super admin, admin
Deskripsi : use case ini menggambarkan proses mengubah kata dasar
Aksi aktor Reaksi sistem
1. Aktor memilih kata yang akan di edit
2. Aktor mengisikan kata baru pada field yang tersedia
3. Aktor mengklik tombol edit
4. Sistem akan mengubah kata tersebut
5. Jika berhasil maka sistem
menampilkan pesan sukses
6. Sistem akan kembali ke form
manajemen kamus Skenario alternatif
2. actor belum memasukkan kata baru 3. aktor mengklik tombol update
4. sistem akan menampilkan pesan
bahwa kata baru kosong
ID Use case :KM-09 Usecase : deletekatadasar
Prekondisi: systemberadadihalaman manajemen kamus
Aktor : super admin, admin
Deskripsi : use case ini menggambarkan proses menghapus kata dasar
Aksi aktor Reaksi sistem
1. Aktor memilih kata yang akan di hapus
2. Aktor mengklik tombol delete
3. Sistem akan menghapus kata tersebut
4. Jika berhasil maka sistem
menampilkan pesan sukses
5. Sistem akan kembali ke form
manajemen kamus
Tabel 3. 11 Skenario Delete Kata Dasar
ID Use case :KM-10
Usecase : melakukan klustering
Prekondisi: systemberadadihalaman klustering
Deskripsi : use case ini menggambarkan proses clustering yang dilakukan oleh user
Aksi aktor Reaksi sistem
1. Aktor mengklik tombol proses
2. Sistem akan melakukan proses
clustering
3. Jika berhasil maka sistem
menampilkan pesan sukses
4. Sistem akan kembali ke form
clustering Skenario alternatif
5. aktor mengklik tombol proses
6. Jika jumlah skripsi < 3 sistem akan
menampilkan pesan error
Tabel 3.12 Skenario Melakukan Klustering
ID Use case :KM-11
Usecase : memasukkan dokumen
Prekondisi: systemberadadihalaman manajemen skripsi
Deskripsi : use case ini menggambarkan proses memasukkan dokumen yang dilakukan oleh user
Aksi aktor Reaksi sistem
1. Aktor mengklik tombol browse
2. Sistem akan menampilkan
filechooser 3. Aktor memilih dokumen
4. Sistem akan menampilkan path dan
nama file pada field yang tersedia 5. Aktor mengisikan judul dokumen
6. Actor mengklik tombol insert
7. Sistem akan memasukkan dokumen
8. Jika berhasil sistem akan
menampilkan pesan pembobotan sukses
Skenario alternatif
6. aktor mengklik tombol insert
7. System menampilkan pesan field
tidak lengkapi
Tabel 3.13 Skenario Memasukkan Dokumen
Use case : lihat cluster
Pre kondisi : aktor telah masuk kedalam sistem
Actor : admin, super admin
Deskripsi : use case ini menggambarkan melihat hasil cluster
Aksi actor Reaksi sistem
1. Aktor mengklik tombol lihat cluster
2. Sistem menampilkan halaman lihat
cluster
Tabel 3.14 Skenario Lihat Cluster
3.3.3 Diagram Aktivitas
3.3.3.1 Diagram Aktivitas Login
User Sistem
Menjalankan aplikasi pengelompokan
Mengklik menu system dan menu item login
Mengklik menu system dan menu
Menampilkan Login Dialog
Mengisikan username dan password
Mengklik tombol login
Memverifikasi masukan user
Menampilkan pesan error
Apakah data sesuai?
Menampilkan halaman utama (sesuai role)
3.3.3.2 Diagram Aktivitas insert user 3.3.3.2 Diagram Aktivitas insert user
User
User sistem sistem
Tabel 3.16 Aktifitas Insert User Tabel 3.16 Aktifitas Insert User
Tampil pesan sukses
Tampil pesan error Apakah
data sesuai
Menampilkan manajemen user
Mengisikan username dan password dan confirm password
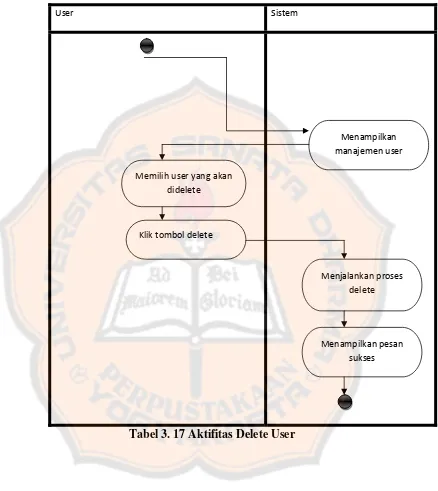
3.3.3.3 Diagram Aktivitas Delete user
User Sistem
Menampilkan manajemen user
Menampilkan pesan sukses Menjalankan proses
delete Klik tombol delete
Memilih user yang akan didelete
Tabel 3. 17 Aktifitas Delete User
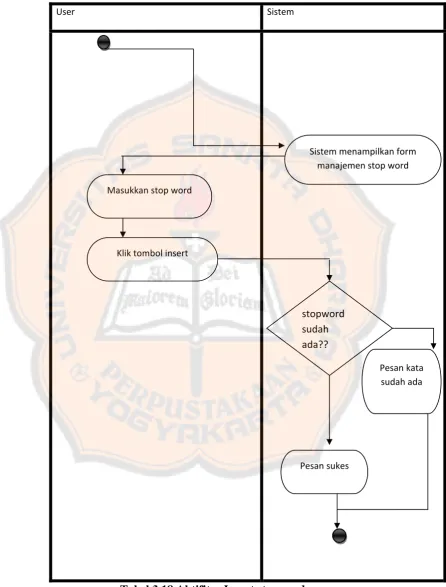
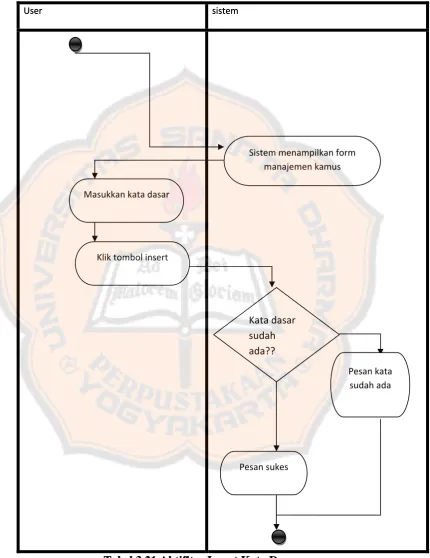
3.3.3.4 Diagram Aktivitas Insert stop word
User Sistem
Sistem menampilkan form manajemen stop word
stopword sudah ada??
Pesan kata sudah ada
Pesan sukes
Klik tombol insert Masukkan stop word
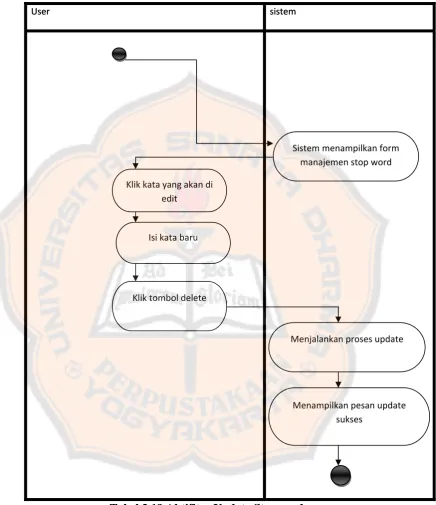
3.3.3.5 Diagram Aktivitas Update Stopword 3.3.3.5 Diagram Aktivitas Update Stopword
User
User sistem sistem
Tabel 3.19 Aktifitas Update Stopword Tabel 3.19 Aktifitas Update Stopword
Klik kata yang akan di edit
Sistem menampilkan form manajemen stop word
Isi kata baru
Menjalankan proses update
Menampilkan pesan update sukses
Klik tombol delete
3.3.3.6 Diagram Aktivitas Delete Stopword 3.3.3.6 Diagram Aktivitas Delete Stopword
User
User sistemsistem
Tabel 3.20 Aktifitas Delete Stopword Tabel 3.20 Aktifitas Delete Stopword
Menjalankan proses delete Klik tombol delete
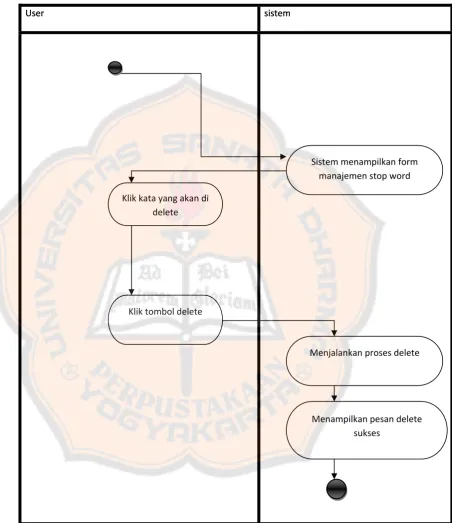
Klik kata yang akan di delete
Sistem menampilkan form manajemen stop word
Menampilkan pesan delete sukses
3.3.3.7 Diagram Aktivasi insert kata dasar 3.3.3.7 Diagram Aktivasi insert kata dasar
User
User sistemsistem
Tabel 3.21 Aktifitas Insert Kata Dasar Tabel 3.21 Aktifitas Insert Kata Dasar Klik tombol insert
Masukkan kata dasar
Pesan kata sudah ada
Sistem menampilkan form manajemen kamus
Kata dasar sudah ada??
Pesan sukes
3.3.3.8 Diagram Aktivasi Update kata dasar
User sistem
Sistem menampilkan form manajemen kamus
Klik tombol update
Menampilkan pesan update sukses
Menjalankan proses update Isi kata baru
Klik kata yang akan di edit
Tabel 3.22 Aktifitas Update Kata dsara
3.3.3.9 Diagram Aktivasi delete kata dasar 3.3.3.9 Diagram Aktivasi delete kata dasar
User
User sistemsistem
Tabel 3..23 Aktifitas Delete Kata dasar Tabel 3..23 Aktifitas Delete Kata dasar
Menjalankan proses delete Klik tombol update
Menampilkan pesan delete sukses
Klik kata yang akan di delete
Sistem menampilkan form manajemen kamus
3.3.3.10 Diagram Aktivitas memasukkan Dokumen 3.3.3.10 Diagram Aktivitas memasukkan Dokumen
User
User sistemsistem
Tabel 3.24 Aktifitas Memasukkan Dokumen Tabel 3.24 Aktifitas Memasukkan Dokumen
Menampilkan JFile Chooser
Menjalankan proses insert skripsi
Menampilkan pesan sukses Memililih file
Tekan tombol insert Tekan tombol browse
3.3.3.11 Diagram Aktivitas clustering 3.3.3.11 Diagram Aktivitas clustering
User
User sistemsistem
Tabel 3.25 Aktifitas Klustering Tabel 3.25 Aktifitas Klustering
Menjalankan proses klustering Sistem menampilkan form
klastering
Menampilkan pesan proses clustering sukses
3.3.3.12 Diagram Aktivitas lihat Cluster
User sistem
Tabel 3.26 Aktifitas Lihat Cluster
3.3.4 Model Analisis
3.3.4.1 Login
ID UseCase : KM-01
Sistem menampilkan form lihat cluster
Klik tombol lihat cluster
LoginController
User LoginDialog
No Nama Kelas Tipe Deskripsi
1 MainFrame Boundary /Interface Kelas ini berfungsi untuk menampilkan halaman home 2 LoginDialog Boundary/Interface Kelas ini berfungsi untuk
menampilkan halaman Login 3 Logincontroller Controller Kelas ini berfungsi sebagai
verivikator dari username dan password
4 User Entity /Model Kelas ini berfungsi untuk
menyimpan data data user seperti username dan password
Username, password Login(Username,Password,Frame);
isUserExist();
User.getUser();
1. Actor mengklik menu login
2. System menampilkan login dialog
Main Frame LoginDialog LoginControlerr User
3. Actor memasukkan username
dan password
4. Actor menekan tombol login
5. System menampilkan halaman
3.3.4.2 Insert User
ID UseCase : KM-02
Manage User Insert User Controller User
No Nama kelas Tipe Deskripsi
1 ManageUser Boundary/interface Berfungsi untuk
emnampilkan halaman manajemen user
2 InsertUserController Controller Berfungsi mengecek apakah masukan
password dan confirm password sama, selain itu menerima kembalian yang bernilai Boolean untuk menetukan apakan insert user berhasil atau tidak u tuk kemudian di cek role nya
menyimpan data data user
ManageUser InsertUserContr
oller
User
Username, password,confirm password
Insertuser(Username, password,confirm password)c
Pass.match(,conword)
Show message
1. Actor memasukkan username
dan password dan confirm password
2. Actor menekan tombol insert
Insertuser(username,password)==true
3. System menampilkan pesan
3.3.4.3 Delete User
ID UseCase : KM-03
User DeleteUserController
No Nama kelas Tipe Deskripsi
1 ManageUser Boundary/interface Berfungsi untuk emnampilkan halaman manajemen user 2 DeleteUserController Controller Berfungsi menghapus user
sesuai dengan username
3 User Entity/model Berfungsi untuk menyimpan
data data user
deleteUser(Username)
deleteUser(Username)
Show message
1. Actor memilih username
Di table username
2. Actor menekan tombol delete
Manage User
DeleteUserCon troller
User
3. System menampilkan pesan
3.3.4.4 insert stopword ID UseCase : KM-04
Stoplist InsertStoplistrController
No Nama kelas Tipe Deskripsi
1 ManageStoplist Boundary/interface Berfungsi untuk
menampilkan halaman manajemen stop word
2 InsertStoplistController Controller Berfungsi
menambah stopword
3 Stoplist Entity/model Berfungsi untuk
menyimpan data stoplist
Insertstopword(stopword)
Insertstopword(stopwor
Show message
1. Actor mengisikan
stopword
2. Actor menekan tombol insert
ManageSto plist
InsertStoplistCon troller
Stoplist
3.3.4.5 update stopword ID UseCase : KM-05
Stoplist UpdateStoplistrController
ManageStopWord
No Nama kelas Tipe Deskripsi
1 ManageStoplist Boundary/interface Berfungsi untuk menampilkan halaman manajemen stop word 2 UpdateStoplistCo
ntroller
Controller Berfungsi untuk
mengedit stopword
3 Stoplist Entity/model Berfungsi untuk
stopwordupdate
UpdateStopword(id,newkata)
UpdateStopword(id,newkata)
Show message
1. Actor mengisikan mengklik
Table stopword dan mengisikan Stopword yang baru pada field Update stopword
2. Actor menekan tombol update
ManageSto plist
UpdatStoplistCo ntrolleer
Stoplist
3. System menampilkan pesan
3.3.4.6 Delete Stopword ID UseCase : KM-06
Stoplist DeleteStoplistrController
ManageStopWord
No Nama kelas Tipe Deskripsi
manajemen kata dasar 2 DeleteStoplistController Controller Berfungsi untuk menghapus
stopword
3 Stoplist Entity/model Berfungsi untuk menyimpan
data stoplist
stopword
Deletestoplis(stopword)
Deletestoword(stopword)
Show message
1. Actor mengklik table stopword
Untuk memilih kata
2. Actor menekan tombol delete
ManageSto plist
DeleteStoplistCo ntrolleer
Stoplist
3. System menampilkan pesan
3.3.4.7 Insert Kata dasar ID UseCase : KM-07
InsertKataDasarController Kamus
No Nama kelas Tipe Deskripsi
1 ManageKataDasar Boundary/interface Berfungsi untuk
menampilkan halaman manajemen kata dasar 2 InsertKataDasarController Controller Berfungsi menambah kata
dasar
3 Kamus Entity/model Berfungsi untuk menyimpan
data kamus yaitu kata dasar
4 Word Model Berfungsi untuk melakukan
stemming ( merupakan kelas yang dibuat oleh
Puspaningtyas Sanjoyo Adi, S.T.,M.T. )
1. Actor mengisikan
kata dasar
3.3.4.8 Update Kata dasar ID UseCase : KM-08
UpdatetKataDasarController
Word Kamus ManageKataDasar
No Nama kelas Tipe Deskripsi
1 ManageKataDasar Boundary/interface Berfungsi untuk menampilkan halaman manajemen kata dasar 2 UpdateKataDasarCon
troller
Controller Berfungsi mengupdate kata dasar
3 Kamus Entity/model Berfungsi untuk menyimpan
data kamus yaitu kata dasar
4 Word Model Berfungsi untuk melakukan
Katalama,katabaru
1. Actor mengklik table kata dasar
Dan mengisikan kata dasar baru Pada field yang tersedia
2. Actor menekan tombol update
3. System menampilkan pesan
3.3.4.9 Delete Kata Dasar ID UseCase : KM-09
menampilkan halaman manajemen kata dasar
2 DeleteKataDasarController Controller Berfungsi untuk
menghapus kata dasar
3 Kamus Entity/model Berfungsi untuk
menyimpan data kamus yaitu kata dasar
4 Word Model Berfungsi untuk
melakukan stemming ( merupakan kelas yang dibuat oleh Puspaningtyas
1. Actor mengklik table kata dasar
2. Actor menekan tombol delete
3.3.4.10 Klusteringustering
1 ClusteringDialog Boundary/interface Berfungsi untuk menampilkan halaman clustering
2 MatrikClusterControll er
Controller Berfungsi sebagai controller
3 Term Entity/model Berfungsi untuk menyimpan
4 Skripsi Entity/model Berfungsi untuk menyimpan data skripsi
5 Cluster Entity Berfungsi untuk menyimpan
hasil cluster
6 Master_keyword Entity Berfungsi untuk menyimpan
label cluster
Show message
Clustering();
jumlahTerm()
Return resultset jumlahTerm()
Idlabel,judul,label Idskripsi,judul,idlabel
Clusteringdialog Matrik kluster
Skrispi Term cluster Master_ke
yword
indek
1. Actor tombol proses
2. System melakukan proses klustering
3.3.4.11 masukkan dokumen 3.3.4.11 masukkan dokumen ID UseCase : KM-11
SkripsiDialog Indek
Main Frame
1 MainFrame Boundary/interface Berfungsi untuk
menanmpilkan halaman home
2 SkripsiDialog Boundary/interface Berfungsi untuk
3 BobotController Controller Berfungsi menghitung bobot kata dan memasukkan dat dokumen ke database
4 Term Entity/model Berfungsi untuk menyimpan
data term
5 Indek Entity/model Berfungsi untuk menghitung
term frekuensi
6 Word Model Berfungsi untuk melakukan
stemming ( merupakan kelas yang dibuat oleh
Puspaningtyas Sanjoyo Adi, S.T.,M.T. )
7 Tokenizer Model Berfungsi untuk melakukan
pemotongan kalimat dan menyaring stoplword ( merupakan kelas yang dibuat oleh Puspaningtyas Sanjoyo Adi, S.T.,M.T. )
8 Skripsi Entity/model Berfungsi untuk menyimpan
Pathfile,judul, namafile
bobotController(pathfile,judul,namafile)
indek skripsi Term word
skripsidi alog
BobotCon troller
tokeni zer
1. Actor memilih file dan mengisikan Judul skripsi
2. Actor mengklik tombol insert 3. System melakukan pembobotan
3.3.4.12 Lihat Cluster ID UseCase : KM-12
LihatClusterController
CLusert
Master_keyword LihatCluster
No Nama kelas Tipe Deskripsi
1 LihatCluster Boundary/interface Berfungsi untuk
menampilkan halaman manajemen kata dasar
2 LihatClusterController Controller Berfungsi untuk
menghapus kata dasar
3 Cluster Entity Berfungsi untuk
menyimpan data hasil Cluster
4 Master_keyword Entity Berfungsi untuk
menyimpan keyword dari masing masing
87