BAB 2
TINJAUAN PUSTAKA
2.1. Kompresi Data
Kompresi data adalah proses mengkodekan informasi menggunakan bit atau information-bearing unit yang lain yang lebih rendah daripada representasi data yang tidak terkodekan dengan suatu sistem enkoding tertentu. Contoh kompresi sederhana yang biasa kita lakukan misalnya adalah menyingkat kata-kata yang sering digunakan tapi sudah memiliki konvensi umum. Misalnya: kata “yang” dikompres menjadi kata “yg”. [12]
Pengiriman data hasil kompresi dapat dilakukan jika pihak pengirim/yang melakukan kompresi dan pihak penerima memiliki aturan yang sama dalam hal
kompresi data. Pihak pengirim harus menggunakan algoritma kompresi data yang sudah baku dan pihak penerima juga menggunakan teknik dekompresi data yang sama dengan pengirim sehingga data yang diterima dapat dibaca di-decode kembali dengan benar.[12]
Proses kompresi data didasarkan pada kenyataan bahwa pada hampir semua jenis data selalu terdapat pengulangan pada komponen data yang dimilikinya, misalnya didalam suatu teks kalimat akan terdapat pengulangan penggunaan huruf alphabet dari huruf a sampai dengan huruf z.[13] Kompresi data melalui proses
terhadap data teks/biner, gambar (JPEG, PNG, TIFF), audio (MP3, AAC, RMA, WMA), dan video (MPEG, H261, H263).
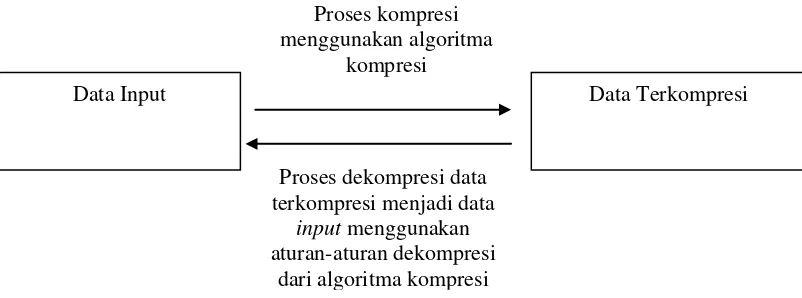
Proses kompresi dan dekompresi data dapat ditunjukan melalui diagram blok seperti pada Gambar 2.1.
Gambar 2.1. Diagram Blok Proses Kompresi dan Dekompresi Data
Kompresi data dibagi menjadi dua kategori yaitu: 1. Kompresi data bersifat loseless
Algoritma kompresi tergolong lossless jika memungkinkan data yang sudah dikompres dapat direkonstruksi kembali persis sesuai dengan data original. Teknik ini menjamin tidak ada kehilangan sedikitpun detil atau kerusakan pada data.[12] Lossless compression disebut juga dengan reversible compression
karena data asli bisa dikembalikan dengan sempurna. Akan tetapi rasio kompresinya sangat rendah, misalnya pada gambar seperti GIF dan PNG.[13] Contoh data yang cocok adalah gambar medis, teks, program, spreadsheet dan lain-lain. Beberapa algoritma yang tergolong dalam jenis ini adalah algoritma Shannon-Fano, algoritma Deflate, algoritma Run Length Coding, algoritma Huffman, algoritma LZW, dan algoritma Arithmetic Coding.[12]
Data Input Data Terkompresi
Proses kompresi menggunakan algoritma
kompresi
Proses dekompresi data terkompresi menjadi data
input menggunakan
2. Kompresi data bersifat lossy
Algoritma kompresi tergolong lossy jika tidak memungkinkan data yang sudah dikompres dapat direkonstuksi kembali persis sesuai dengan data asli. Kehilangan detil-detil yang tidak berarti dapat diterima pada waktu proses kompresi. Hal ini memanfaatkan keterbatasan panca indera manusia. Maka, sebuah perkiraan yang mendekati keadaan original dalam membangun kembali data merupakan hal yang diperlukan untuk mencapai keefektifan kompresi. Contoh data yang cocok adalah gambar, suara dan video. Adapun beberapa algoritma yang tergolong dalam jenis ini adalah algoritma Wavelet Compression, CELP, JPEG, MPEG-1 dan WMA.[12]
2.2. File Teks
File teks (disebut juga dengan flat file) adalah salah satu jenis file komputer yang tersusun dalam suatu urutan baris data teks biasanya diwakili oleh 8 bit kode ASCII (atau EBCDIC)[7].
ASCII (American Standard Code for Information Interchange) dan EBCDIC (Extended Binary Coded Decimal Interchange Code) merupakan cikal bakal dari set karakter lainnya. ASCII merupakan set karakter yang paling umum digunakan hingga sekarang. Set karakter ASCII terdiri dari 128 buah karakter yang masing-masing memiliki lebar 7-bit atau tujuh angka 0 dan 1, dari 0000000 sampai dengan 1111111.
EBCDIC merupakan set karakter yang merupakan ciptaan dari IBM. Salah satu penyebab IBM menggunakan set karakter di luar ASCII sebagai standar pada komputer ciptaan IBM adalah karena EBCDIC lebih mudah dikodekan pada punch
card yang pada tahun 1960-an masih banyak digunakan. Penggunaan EBCDIC pada
mainframe IBM masih ada hingga saat ini, walaupun punch card sudah tidak digunakan lagi. Seperti halnya ASCII, EBCDIC juga terdiri dari 128 karakter yang masing-masing berukuran 7-bit. Hampir semua karakter pada ASCII juga terdapat pada set karakter EBCDIC.[16]
Akhir dari sebuah file teks sering ditandai dengan penempatan satu atau lebih karakter – karakter khusus yang dikenal dengan tanda end-of-file setelah baris terakhir di suatu file teks. File teks biasanya mempunyai jenis MIME (Multipurpose Internet
Mail Extension) "text/plain", biasanya sebagai informasi tambahan yang menandakan suatu pengkodean. pada sistem operasi Windows, suatu file dikenal sebagai suatu file teks jika memiliki extention misalnya txt, rtf, doc, docx dan lain - lain.[4] Contoh file teks sederhana dapat dilihat pada Gambar 2.2.
2.3. Fibonacci Encoding
Kode Fibonacci adalah variable length code, dimana bilangan bulat yang lebih kecil mendapatkan kode pendek. Kode berakhir dengan dua buah bit satu, dan nilai yang didapatkan adalah jumlah dari nilai-nilai Fibonacci yang sesuai untuk bit yang ditetapkan (kecuali bit terakhir, yang merupakan akhir dari kode).[3] Langkah-langkah pembentukan sebuah kode Fibonacci adalah sebagai berikut:
1. Tentukan sebuah bilangan bulat positif n yang lebih besar atau sama dengan 2. 2. Temukan bilangan Fibonacci f terbesar yang lebih kecil atau sama dengan n,
kurangkan nilai n dengan f dan catat sisa pengurangan nilai n dengan f.
3. Jika bilangan yang dikurangkan adalah bilangan yang terdapat dalam deret Fibonacci F(i), tambahkan angka “1” pada i-2 dalam kode Fibonacci yang akan dibentuk.
4. Ulangi langkah 2, tukar nilai n dengan sisa pengurangan nilai n dengan f sampai sisa pengurangan nilai n dengan f adalah 0.
5. Tambahkan angka “1” pada posisi paling kanan kode Fibonacci yang akan dibentuk.
Untuk melakukan decode sebuah kode Fibonacci, hilangkan angka “1” paling kanan, kemudian substitusi dan jumlahkan kode Fibonacci yang tersisa dengan menggunakan deret Fibonacci. Contoh proses encoding dan decoding sebuah bilangan menjadi kode Fibonacci dapat dilihat sebagai berikut:
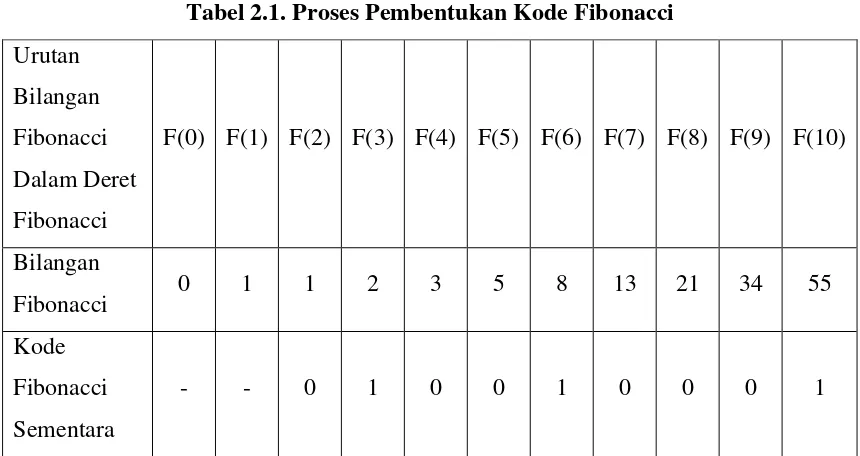
Nilai n = 65. Deret Fibonacci yang paling mendekati nilai n adalah: 0 1 1 2 3 5 8 13 21 34 55
Sehingga pembentukan kode Fibonacci akan terlihat seperti Tabel 2.1.
Tabel 2.1. Proses Pembentukan Kode Fibonacci Urutan
Proses akhir pembentukan kode Fibonacci adalah menambahkan angka “1” pada posisi paling kanan dari kode Fibonacci sementara sehingga kode Fibonacci untuk angka 65 adalah “0100100011”. Sedangkan untuk proses decoding, hilangkan angka “1” paling kanan dalam kode Fibonacci, kemudian substitusi angka 1 dengan
bilangan Fibonacci sesuai urutan dari kiri ke kanan dan jumlahkan seluruh hasil substitusi tersebut. Sehingga proses decode untuk kode Fibonacci “0100100011” adalah sebagai berikut:
Proses decode setelah angka “1” paling kanan dihilangkan: 0 x F(2) + 1 x F (3) + 0 x F(4) + 0 x F(5) + 1 x F(6) + 0 x F(7) + 0 x F(8) + 0 x F(9) + 1 x F(10) = 0 + 2 + 0 + 0 + 8 + 0 + 0 + 0 + 55 = 65. Terbukti bahwa angka 65 diubah menjadi kode Fibonacci menjadi “0100100011”, dan kode Fibonacci “0100100011” setelah
di-decode tetap menjadi angka 65.
positif n adalah representasi Fibonacci dari n dengan sebuah penambahan 1 diujung kanannya. Sehingga kode Fibonacci dari 5 adalah 0001|1 dan untuk 33 adalah 1010101|1. Sangat jelas bahwa kode-kode tersebut berakhir dengan sepasang angka “11” dalam kodenya.[10]
Karena kode yang dihasilkan tidak memiliki dua buah bit 1 yang berurutan, maka kepadatan akan terlihat jelas dibandingkan yang lain, apabila sebagian nilai yang dicari adalah nilai-nilai kecil. Namun disisi lain, ini juga membuat kode Fibonacci ini tahan terhadap kesalahan decode.[3]
2.4. Algoritma Shannon-Fano
Algoritma Shannon-Fano ditemukan oleh Claude Shannon dan Robert Fano pada tahun 1949. Merupakan algoritma pertama untuk merancang sebuah set dari
variable-length code terbaik.[11] Pada saat itu metode ini merupakan metode yang paling baik tetapi hampir tidak pernah digunakan dan dikembangkan lagi setelah kemunculan algoritma Huffman.[18]
Kode Shannon-Fano adalah sebuah teknik pengkodean yang dikembangkan pada awal tahun 1950-an yang bertujuan untuk memperkecil jumlah bit yang digunakan dalam sebuah pesan ketika probabilitas dari simbol dalam pesan telah sebelumnya diketahui.[6] Dalam pendekatan algoritma Shannon-Fano, sebuah pohon biner dirancang secara “top-down”.[7]
2.5 Algoritma Deflate
Deflate adalah algoritma kompresi dengan teknik lossless compression. Hal ini
menjawab kebutuhan dalam memperkecil ukuran suatu data untuk penyimpanan atau pengiriman tanpa merusak isinya. Spesifikasi yang diuraikan pada dokumen RFC 1951 “DEFLATE Compressed Data Format Spesification Version 1.3” menjelaskan bahwa algoritma deflate mengkombinasikan algoritma LZ77 dan Huffman, mengambil konsep sliding-window dan prefix-tree.[8] Setelah dilakukan pengujian didapati bahwa algoritma Deflate ini efektif digunakan pada data teks dan data gambar
bitmap.[14]
Deflate adalah sebuah metode kompresi yang populer yang aslinya digunakan untuk software Zip dan Gzip yang sudah terkenal dan telah diadopsi ke dalam berbagai aplikasi penting, seperti:
1. Protokol HTTP ([RFC1945 96] dan [RFC2616 99])
2. Protokol kontrol kompresi PPP compression control protocol ([RFC1962 96] dan [RFC1979 96])
3. Format file citra PNG (Portable Network Graphics) dan MNG (Multiple-Image Network Graphics)
4. PDF (Portable Document File) Adobe”[9]
Dalam proses kompresinya, algoritma Deflate ini terlebih dahulu melakukan proses pengelompokan karakter dengan menggunakan algoritma LZ77. Kemudian
hasil dari pengelompokan, karakter tersebut dikompresi lagi dengan menggunakan algoritma Huffman (Huffman Tree).[11] Algoritma Deflate ini bersifat loseless compression. Hal ini karena algoritma Deflate ini menggabungkan dua algoritma kompresi yang bersifat loseless.[2]
dengan nilai tetap kedalam kamus untuk mencapai kompresi. Jumlah yang dikompresi tergantung dari seberapa panjang frasa yang ada dalam kamus, seberapa besar window
dalam teks yang terlihat, dan entropi dari teks asal sesuai dengan model LZ77. Struktur data utama dalam LZ77 adalah sebuah window teks, dipisahkan ke dalam dua bagian.Bagian pertama berisikan sebuah blok dari teks yang baru dikodekan. Bagian yang kedua biasanya yang lebih kecil adalah look-ahead buffer. Look-ahead buffer
berisi karakter-karakter yang dibaca dari stream input namun belum dikodekan. Ukuran normal dari window teks adalah beberapa ribu karakter. Look-ahead buffer
umumnya lebih kecil, mungkin sepuluh sampai seratus karakter saja. Algoritma ini mencoba untuk mencocokan isi dari look-ahead buffer menjadi sebuah String di dalam kamus.[6]
Algoritma dekompresi untuk LZ77 bahkan lebih sederhana, karena tidak perlu melakukan perbandingan. Algoritma ini membaca sebuah token, output dari frasa yang bersangkutan, output dari karakter itu, kemudian geser dan ulangi. Algoritma ini tetap menjaga window-nya, tapi tidak bekerja dengan pembandingan String.[6]
Kode Huffman, dinamai atas penemunya yaitu D. A. Huffman, menghasilkan jumlah minimum dari kemungkinan kerangkapan dari sebuat set variable-length code