BAB 2
LANDASAN TEORI
Bab ini membahas tentang teori penunjang dan penelitian sebelumnya yang berhubungan dengan analisa datadan algoritma Fuzzy C-Means untuk mangetahui pola perilaku konsumen.
2.1. Pola Perilaku Konsumen
Perilaku konsumen adalah proses dan aktivitas ketika seseorang berhubungan dengan pencarian, pemilihan, pembelian, penggunaan, serta pengevaluasian produk dan jasa demi memenuhi kebutuhan dan keinginan (Duncan, 2005). Perilaku konsumen merupakan hal-hal yang mendasari konsumen untuk membuat keputusan pembelian. Untuk barang berharga jual rendah (low-involvement) proses pengambilan keputusan dilakukan dengan mudah, sedangkan untuk barang berharga jual tinggi (high-involvement) proses pengambilan keputusan dilakukan dengan pertimbangan yang matang (Kincaid, 2003).
memahami sikap konsumen dalam menghadapi sesuatu, seseorang dapat menyebarkan ide dengan lebih cepat dan efektif.
2.2. Penambangan Data (Data Mining)
Data mining merupakan pemilihan atau menggali pengetahuan dari jumlah data yang
banyak (Han dan Kamber, 2001).Data mining disebut penemuan pengetahuan atau menemukan pola yang tersembunyi dalam data. Data mining adalah analisis otomatis dari data yang berjumlah besar atau kompleks dengan tujuan untuk menemukan pola atau kecenderungan yang penting yang biasanya tidak disadari keberadaanya (Pramudiono, 2006).
Data mining merupakan analisis dari peninjauan kumpulan data untuk
menemukan hubungan yang tidak diduga dan meringkas data dengan cara yang berbeda dengan sebelumnya,yang dapat dipahami dan bermanfaat bagi pemilik data (Larose, 2006). Dengan kata lain, data mining adalah proses menganalisis data dalam jumlah besar dan membentuk suatu pola sehingga menjadi informasi yang berguna.
Berdasarkan definisi-definisi yang telah disampaikan, hal penting yang terkait dengan data mining adalah :
1.Data mining merupakan suatu proses otomatis terhadap data yang sudah ada. 2. Data yang akan diproses berupa data yang sangat besar.
3. Tujuan data mining adalah mendapatkan hubungan atau pola yang mungkin memberikan indikasi yang bermanfaat.
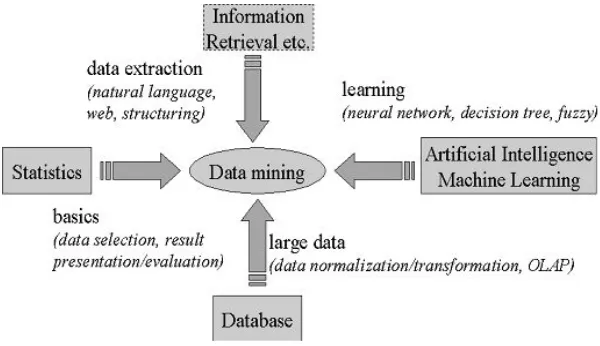
Data mining bukanlah suatu bidang ilmu yang sama sekali baru. Salah satu kesulitan untuk mendefinisikan data mining dikarenakan data mining mewarisi banyak aspek dan teknik dari bidang-bidang ilmu yang sudah mapan terlebih dahulu. Gambar 2.1 menunjukkan bahwa data mining memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligence), machine learning, statictic,
8
Gambar 2.1. Bidang Ilmu Data Mining
2.2.1. Tahapan Data Mining
Istilah data mining dan Knowledge Discovery in Database (KDD) seringkali digunakan secara bergantian untuk menjelaskan proses penggalian informasi yang tersembunyi dalam suatu basis data yang besar. Dalam implementasinya, data mining
merupakan bagian dari proses KDD. Sebagai komponen dalam KDD, data mining
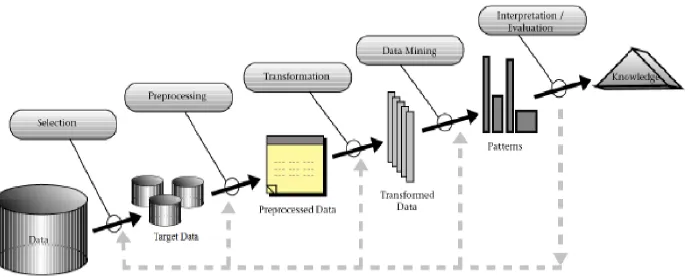
berkaitan dengan ekstraksi dan penghitungan pola-pola dari data yang ditelaah dalam basis data. KDD mencakup keseluruhan proses pencarian pola/informasi dalam basis data yang dimulai dari pemilihan dan persiapan data sampai representasi pola yang ditentukan dalam bentuk yang mudah dimengerti oleh pihak berkepentingan. Proses KDD secara garis besar terdiri atas beberapa tahap (Fayyad, 1996).
1. Data Selection
2. Pre-processing/Cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning
pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang tidak konsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (typo), juga dilakukan proses
enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformation
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data mining
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode dan algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretation/Evalution
10
Gambar 2.2. Tahapan Data Mining
(Sumber : Fayyad, 1996)
2.2.2. Pengelompokan Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapatdilakukan, yaitu (Larose, 2005):
1. Deskripsi
Terkadang penelitian analisis secara sederhana ingin mencoba mencari cara untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat menemukan keterangan atau fakta bahwa siapa yang tidak cukup profesional akan sedikit didukung dalam pemilihan presiden. Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecenderungan.
2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih ke arah numerik daripada ke arah kategori. Model dibangun menggunakan record
menghasilkan model estimasi. Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainnya.
3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa datang. Contoh prediksi dalam bisnis dan penelitian adalah :
1. Prediksi harga beras dalam tiga bulan yang akan datang.
2. Prediksi presentase kenaikan kecelekaan lalu lintas tahun depan jika batas bawah kecepatan dinaikkan.
4. Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori.Sebagai contoh, penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu pendapatan tinggi, pendapatan sedang, dan pendapatan rendah.
5. Pengklusteran
Pengklusteran merupakan pengelompokan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan.Cluster adalah kumpulan record yang memiliki kemiripan satu dengan yang lainnya dan memiliki ketidakmiripan dengan record-record dalam cluster
lain.
12
Contoh pengklusteran dalam bisnis dan penelitian adalah:
1. Melakukan pengklusteran terhadap ekspresi dari gen, untuk mendapatkan kemiripan perilaku dari gen dalam jumlah besar.
2. Mendapatkan kelompok-kelompok konsumen untuk target pemasaran dari suatu produk bagi perusahaan yang tidak memiliki dana pemasaran yang besar.
3. Untuk tujuan audit akuntansi, yaitu melakukan pemisahan terhadap perilakufinansial dalam baik dan mencurigakan.
6. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu.Dalam dunia bisnis lebih umum disebut analisis keranjang belanja. Contoh asosiasi dalam bisnis dan penelitian adalah :
1. Menemukan barang dalam supermarket yang dibeli secara bersamaan dan barang yang tidak pernah dibeli secara bersamaan.
2. Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler yang diharapkan untuk memberikan respons positif terhadap penawaran upgrade
layanan yang diberikan.
2.3. Clustering
Clustering (pengelompokan data) mempertimbangkan sebuah pendekatan penting
terlihat memiliki beberapa sifat yang melekat yang mengalami pengelompokan-pengelompokan natural (Hammouda & Karray, 2003).
Namun demikian, penemuan pengelompokan-pengelompokan ini atau upaya untuk mengkategorikan data adalah bukan sebuah tugas yang sederhana bagi manusia kecuali data memiliki dimensionalitas rendah (dua atau tiga dimensi paling banyak).Inilah sebabnya mengapa beberapa metode dalam soft computing telah dikemukakan untuk menyelesaikan jenis masalah ini.Metode ini disebut “Metode-Metode Pengelompokan Data” (Hammouda & Karray, 2003).
Algoritma-algoritma clustering digunakan secara ekstensif tidak hanya untuk mengorganisasikan dan mengkategorikan data, akan tetapi juga sangat bermanfaat untuk kompresi data dan konstruksi model. Melalui pencarian kesamaan dalam data, seseorang dapat merepresentasikan data yang sama dengan lebih sedikit simbol. Dan juga, jika kita dapat menemukan kelompok-kelompok data, kita dapat membangun sebuah model masalah berdasarkan pengelompokan-pengelompokan ini (Dubes & Jain, 1988).
Clustering menunjuk pada pengelompokan record, observasi-observasi, atau kasus-kasus ke dalam kelas-kelas objek yang sama. Cluster adalah sekumpulan record
yang sama dengan satu sama lain dan tidak sama dengan record dalam cluster lain.
Clustering berbeda dari klasifikasi dimana tidak ada variabel target untuk clustering. Tugas clustering mencoba untuk tidak mengklasifikasikan, mengestimasi, atau memprediksi nilai variabel target (Larose, 2005). Bahkan, algoritma clustering
berusaha mensegmentasikan seluruh kumpulan data ke dalam subkelompok-subkelompok atau cluster-cluster homogen secara relatif. Dimana kesamaan record
dalam cluster dimaksimalkan dan kesamaan dengan record diluar cluster ini diminimalkan.
Clustering sering dilaksanakan sebagai langkah pendahuluan dalam proses
14
Aktivitas clustering pola khusus meliputi langkah-langkah berikut (Dubes & Jain, 1988) :
1. Representasi pola (secara opsional termasuk ekstraksi dan/atau seleksi sifat. 2. Defenisi ukuran kedekatan pola yang tepat untuk domain data.
3. Clustering pengelompokan. 4. Penarikan data (jika dibutuhkan). 5. Pengkajian output (jika dibutuhkan).
Representasi pola merujuk pada jumlah kelas, jumlah pola-pola yang ada, dan jumlah, tipe dan skala fitur yang tersedia untuk algoritma clustering. Beberapa informasi ini dapat tidak bisa dikontrol oleh praktisioner. Seleksi sifat (fitur) adalah proses pengidentifikasian subset fitur original yang paling efektif untuk digunakan dalam
clustering. Ekstraksi fitur adalah penggunaan satu atau lebih transformasi dari sifat-sifat input untuk menghasilkan sifat-sifat-sifat-sifat baru yang lebih baik.
Pertimbangkan data himpunan X (dataset) yang terdiri dari point-point data (atau secara sinonim, objek-objek, hal-hal, kasus-kasus, pola, tuple, transaksi) xi = (xi1, …,xid) A dalam ruang atribut A, dimana i = 1, N, dan setiap komponen adalah sebuah atribut A kategori numerik atau nominal. Sasaran akhir dari clustering adalah untuk menentukan point-point pada sebuah sistem terbatas dari subset k, cluster. Biasanya subset tidak berpotongan (asumsi ini terkadang dilanggar), dan kesatuan mereka sama dengan dataset penuh dengan pengecualian yang memungkinkan outlier. Ci adalah sekelompok point data dalam dataset X, dimana X = Ci ..Ck .. Coutliers, Cj1 .. Cj2 =0.
1. Partitioning Methdos
Metode yang membangun berbagai partisi dan kemudian mengevaluasi partisi tersebut dengan beberapa kriteria.Algoritma yang dipakai pada metode ini adalah Means,
K-Medoid, PROCLUS, CLARA, CLARANS dan PAM.
2. Hierarchical Methods
Metode yang membuat suatu penguraian secara hierarchical dari himpunan data dengan menggunakan beberapa kriteria. Metode ini terdiri atas dua jenis, yaitu
Agglomerative yang menggunakan strategi bottom-up dan Disisive yang
menggunakan strategi top-down. Metode ini meliputi algoritma BIRCH, AGNES, DIANA, CURE dan CHAMELEON.
3. Density-Based Methods
Metode ini berdasarkan konektivitas dan fungsi densitas.Metode ini meliputi algoritma DBSCAN, OPTICS dan DENCLU.
4. Grid-Based Methods
Metode ini berdasarkan suatu struktur granularitas multi-level.Metode clustering ini meliputi algoritma STING, WaveCluster dan CLIQUE.
5. Model-Based Methods
Suatu model dihipotesakan untuk masing-masing cluster dan ide untuk mencari best fit dari model tersebut untuk masing-masing yang lain. Metode clustering ini meliputi pendekatan statistik, yaitu algoritma COBWEB dan jaringan syaraf tiruan SOM.
2.4. Fuzzy C-Means
16
Ada beberapa algoritma clustering data, salah satu diantaranya adalah Fuzzy C-Means (FCM). Fuzzy C-Means (FCM) adalah suatu teknik pengclusteran data yang mana keberadaan tiap-tiap titik data dalam suatu cluster ditentukan oleh derajat keanggotaan. Teknik ini pertama kali diperkenalkan oleh Jim Bezdek pada tahun 1981.
Konsep dari Fuzzy C-Means pertama kali adalah menentukan pusat cluster, yang akan menandai lokasi rata-rata untuk tiap-tiap cluster. Pada kondisi awal, pusat cluster ini masih belum akurat. Tiap-tiap titik data memiliki derajat keanggotaan untuk tiap-tiap cluster. Dengan cara memperbaiki pusat cluster dan derajat keanggotaan tiap-tiap titik data secara berulang, maka akan dapat dilihat bahwa pusatcluster akan bergerak menuju lokasi yang tepat. Perulangan ini didasarkan pada minimisasi fungsi objektif yang menggambarkan jarak dari titik data yang diberikan kepusat cluster yang terbobot oleh derajat keanggotaan titik data tersebut.
Output dari Fuzzy C-Means merupakan deretan pusat cluster dan beberapa derajat keanggotaan untuk tiap-tiap titik data. Informasi ini dapat digunakan untuk membangun suatu fuzzy inference system.
Algoritma Fuzzy C-Means
Langkah-langkah yang dilakukan di Algoritma Fuzzy C-Means Clustering meliputi (Kusuma, 2004) :
1. Input data yang akan di cluster X, berupa matriks berukuran n x m (n = jumlah sampel data ; m = atribut setiap data)
Xij data sampel ke-i ( i = 1, 2, .... , n), atribut ke-j ( 1, 2,... , m)
2. Menentukan jumlah dari • Cluster (c)
• Pangkat (w) -> w > 1, nilai w yang paling optimal dan sering dipakai adalah w = 2. (Klawonn, 1997).
• Maksimum Iterasi (MaxIter) • Kriteria penghentian ( )
• Fungsi Objective Awal (P0 = 0)
3. Membangkitkan bilangan Random iki= 1,2,…n., k=1,2,…c sebagai elemenmatriks partisi awal U. Menghitung jumlah setiap kolom ( atribut ) dengan j = 1, 2, .. n dengan persamaan :
Qi = (2.1)
µik =
4. Menghitung pusat cluster ke-k : Vkj ,dengan k = 1,2,...,c; danj =1,2,...,m.
dengan persamaan :
(2.2)
dengan :
= pusat cluster ke-k untuk atribut ke-j
= derajat keanggotaan untuk data sampel ke-i pada cluster ke-k = data ke-i, atribut ke-j
5. Menghitung fungsi obyektif pada iterasi ke- t, dengan persamaan :
= (2.3)
dengan:
= pusat cluster ke-k untuk atribut ke-j
= derajat keanggotaan untuk data sampel ke-i pada cluster ke-k
18
= fungsi objektif pada iterasi ke-t
6. Menghitung perubahan matriks partisi dengan persamaan :
(2.4)
dengan: i = 1,2,...,n; dan k = 1,2,...,c.
Dimana :
= pusat cluster ke-k untuk atribut ke-j
= derajat keanggotaan untuk data sampel ke-i pada cluster ke-k = data ke-i, atribut ke-j
7. Memeriksa kondisi berhenti dengan aturan persamaan
8. Jika: ( |Pt – Pt-1| < ) atau (t >MaxIter) maka berhenti. Jika tidak maka t = t+1, Ulangi langkah ke-4.
2.5. Penelitian Terdahulu
Penelitian yang berhubungan dengan pengolahan data penjualan dan algoritma Fuzzy C-Means seperti pada tabel 2.1 adalah
1. Penerapan data mining pada penjualan menggunakan metode Agglomerative Hierarchical Clustering(Sutrisno, 2013) yang menghasilkan pola penjualan produk mana yang diminati oleh konsumen, kekurangan dalam penelitian ini adalah proses clustering lebih lambat dibandingkan k-means dan metode yang digunakan tidak menentukan jumlah klaster dari awal.
dalam segi metode yang digunakan, metode yang digunakan adalah metode deskripsi yang menggunakan jumlah transaksi penjualan sebagai variabel untuk menghasilkan nilai rata-rata, median dan modus untuk setiap produk.
3. Penerapan data mining pada penjualan produk minuman di PT. Pepsi Coca Cola Indobeverages menggunakan metode Clustering (Irdiansyah, 2013).Pada penelitian ini, metode yang digunakan adalah Agglomerative Hierarchical Clustering. Hasil dari penelitian adalah kelompok karakteristik umum dari grup-grup konsumen yang berbeda. Penelitian dilakukan dengan menggunakan parameter wilayah, jumlah penjualan dan rata-rata penjualan.
4. Penentuan jurusan sekolah menengah atas (Bahar, 2011). Pada penelitian ini algoritma FCM memiliki tingkat akurasi rata-rata 78.39%. Proses klastering dalam penelitian ini dilakukan dengan menentukan jumlahklaster yang terbentuk di awal proses sesuai dengan jumlah kelompok(Jurusan) yang diinginkan. sehingga, tidak dapat dipastikan berapasesungguhnya jumlah klaster ideal yang terbentuk dari data nilai siswa yangada, sehingga akurasi hasil pengelompokkan tidak dapat terukur.
5. Pemilihan peminatan tugas akhir mahasiswa (Sumanto, 2011).Kesimpulan dari penelitian iniadalah pemilihan peminatan tugas akhir mahasiswa sangat menentukan hasil tugas akhir mahasiswa. Tingkat akurasi penerapan FCM untuk pemilihan peminatan tugasakhir pada data yang digunakan pada eksperimen ini mencapai 80%.
Tabel 2.1 Penelitian Terdahulu
20
1 2013 Agglomerative
Hierarchical
Clustering
kekurangan dalam penelitian ini adalah proses clustering lebih lambat dibandingkan k-means dan metode yang digunakan tidak menentukan jumlah klaster dari awal.
2 2013 Metode Deskripsi Kekurangannya karena penelitian hanya menghasilkan nilai rata-rata, median dan modus untuk setiap produk.
3 2013 Agglomerative
Hierarchical
Clustering