OPTIMASI DECISION TREE PADA ALGORITMA C4.5 MENGGUNAKAN ALGORITMA GENETIKA
TESIS
Oleh
IRFAN SUDAHRI DAMANIK 127038075
PROGRAM MAGISTER S2 TEKNIK INFORMATIKA FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA MEDAN
2016
OPTIMASI DECISION TREE PADA ALGORITMA C4.5 MENGGUNAKAN ALGORITMA GENETIKA
TESIS
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Magister Teknik Informatika
IRFAN SUDAHRI DAMANIK 127038075
PROGRAM MAGISTER S2 TEKNIK INFORMATIKA FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA MEDAN
2016
PERSETUJUAN
Judul : OPTIMASI DECISION TREE PADA
ALGORITMA C4.5 MENGGUNAKAN ALGORITMA GENETIKA
Kategori : Tesis
Nama : Irfan Sudahri Damanik
Nomor Induk Mahasiwa : 127038075
Program Studi : Magister S2 Teknik Informatika
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Rahmat W. Sembiring, M.Sc.IT.,P.hD Prof. Dr. Saib Suwilo, M.Sc
Diketahui/disetujui oleh
Program Studi Magister Teknik Informatika Ketua,
Prof. Dr. Muhammad Zarlis NIP. 195707011986011003
PERNYATAAN
OPTIMASI DECISION TREE PADA ALGORITMA C4.5 MENGGUNAKAN ALGORITMA GENETIKA
T E S I S
Saya mengakui bahwa tesis ini adalah hasil karya saya sendiri kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 01 Agustus 2016
Irfan Sudahri Damanik NIM.127038075
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, saya yang bertanda tangan di bawah ini:
Nama : Irfan Sudahri Damanik
NIM : 127038075
Program Studi : Magister S2 Teknik Informatika Jenis Karya Ilmiah : Tesis
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive Royalty Free Right) atas tesis saya yang berjudul:
OPTIMASI DECISION TREE PADA ALGORITMA C4.5 MENGGUNAKAN ALGORITMA GENETIKA
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non- Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media, memformat, mengelola dalam bentuk database, merawat dan mempublikasikan tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan atau sebagai pemilik hak cipta.
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, 01 Agustus 2016
Irfan Sudahri Damanik NIM.127038075
Telah diuji pada
Tanggal: 01 Agustus 2016
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Saib Suwilo, M.Sc
Anggota : 1. Rahmat W. Sembiring, M.Sc.IT., Ph.D 2. Prof. Dr. Muhammad Zarlis, M.Sc 3. Prof. Dr. Opim Salim Sitompul, M.Sc 4. Prof. Dr. Tulus, M.Si
RIWAYAT HIDUP
DATA PRIBADI
Nama lengkap berikut gelar : Irfan Sudahri Damanik, S.Kom.
Tempat dan Tanggal Lahir : Sarimatodang, 18 Agustus 1986 Alamat Rumah : Jl. Mangga No. 44 Kec. Sidamanik,
Kabupaten Simalungun
Telepon/HP : 082304323995
e-mail : [email protected]
Instansi Tempat Bekerja : AMIK dan STIKOM Tunas Bangsa Alamat Kantor : Jl. Jend. Sudirman Blok A,B No. 1,2,3
Telepon : 0622-22431
DATA PENDIDIKAN
SD : SD NEGERI 091441 Sidamanik Tamat : 1998 SLTP : SMP NEGERI 1 Sidamanik Tamat : 2001 SMA : SMA NEGERI 1 Sidamanik Tamat : 2004 Diploma 3 : AMIK TUNAS BANGSA Tamat : 2007 Strata-1 : STMIK TIME MEDAN Tamat : 2010 Strata-2 : Magister Teknik Informatika USU
KATA PENGANTAR
Pertama-tama kami panjatkan puji syukur kepada Allah SWT atas segala limpahan rahmat dan karunia-Nya sehingga tesis ini dapat diselesaikan. Juga tak lupa kami kirimkan shalawat beserta salam kepada junjungan kami Rasulullah Muhammad SAW yang telah membawa cahaya kebenaran dalam hidup di dunia ini.
Dalam menyelesaikan Tesis ini, peneliti telah mendapat banyak bantuan serta masukan dari berbagai pihak. Oleh karena itu, melalui kesempatan yang berbahagia, peneliti ingin berterima kasih kepada:
1. Bapak Prof. Dr. Runtung Sitepu, SH., M.Hum selaku Rektor Universitas Sumatera Utara atas kesempatan yang telah diberikan kepada peneliti sehingga bisa mengikuti dan menyelesaikan pendidikan Program Magister (S2) Teknik Informatika.
2. Bapak Prof. Dr. Opim Salim Sitompul, M.Sc selaku Dekan Fakultas Ilmu Komputer Dan Teknologi Informasi Universitas Sumatera Utara.
3. Bapak Prof. Dr. Muhammad Zarlis, M.Sc selaku Ketua Program Studi Magister (S2) Teknik Informatika.
4. Bapak M. Andri Budiman, S.T., M.CompSc, M.EM selaku Sekretaris Program Studi Magister (S2) Teknik Informatika.
5. Terima kasih yang terhingga serta penghargaan setinggi-tingginya kepada Bapak Prof. Dr. Saib Suwilo, M.Sc selaku Pembimbing Utama, dan Bapak Rahmat W. Sembiring, M.Sc.IT, P.hD selaku Pembimbing Anggota yang telah membimbing dan menuntun peneliti dengan penuh kesabaran hingga selesainya tesis ini.
6. Terima kasih yang terhingga serta penghargaan setinggi-tingginya kepada Bapak Prof. Dr. Muhammad Zarlis, M.Sc, Bapak Prof. Dr. Opim Salim Sitompul, M.Sc dan Bapak Prof. Dr. Tulus, M.Si selaku pembanding yang telah memberikan masukan dan arahan yang baik demi selesainya tesis ini.
7. Teristimewa untuk ayahanda Alm R. Damanik dan ibunda Almh N. Br Purba beserta Abang Syaiful Bachri Damanik, Aminuddin Damanik, Kakak Ramayati Damanik, Rama Irawani Damanik, Rama Widiyanti Damanik dan seluruh keluarga, kami mengucapkan terima kasih atas segala pengorbanan
kalian baik berupa moril maupun materil hingga selesainya perkuliahan peneliti, budi baik ini tidak bisa dibalas penulis, semoga Allah SWT menerima sebagai amal shaleh.
8. Terima kasih juga kami sampaikan kepada Ketua Yayasan AMIK dan STIKOM Tunas Bangsa Pematangsiantar, Bapak H.M. Ahmad Ridwansyahputra, Ketua STIKOM Tunas Bangsa Bapak Dedy Hartama, S.T., M.Kom yang tidak pernah putus asa dalam memberikan serta Direktur AMIK Tunas Bangsa Bapak Rahmat W. Sembiring, M.Sc.IT, P.hD yang telah memberikan ijin kepada penulis untuk melanjutkan studi, serta teman-teman Dosen, Staff di AMIK dan STIKOM Tunas Bangsa yang banyak mendukung dan memberikan dorongan mulai dari kuliah awal sampai selesainya studi ini, hal yang sama juga saya ucapkan kepada seluruh teman-teman mahasiswa di Program Studi Magister Teknik Informatika FASILKOM-TI USU atas kerja samanya selama ini.
9. Seluruh pegawai dan staf administrasi pada Program Studi Magister (S2) Teknik Informatika pada Fasilkom TI USU Medan yang telah memberikan bantuan dan pelayanan terbaik kepada peneliti selama mengikuti perkuliahan hingga selesai.
10. Teristimewa Buat seseorang yang selalu memberikan motivasi, dukungan dan doa yang tiada pernah putus buat penulis, Citra Dewi Situmorang. Termikasih Untuk semuanya
11. Teman seperjuangan Edrian Hadinata, M.Kom, Edy budi Harjono S, M.Kom, Indra Gunawan, M.Kom, Heru Satria Tambunan, M.Kom, Sumarno, M.Kom, Herry Siagian, M.Kom, Eva Desiana, M.Kom, Eka Irawan, M.Kom dan Semua pihak yang tidak dapat peneliti sebutkan namanya satu persatu
Dengan segala kekurangan dan kerendahan hati semoga kiranya Tuhan Yang Maha Esa membalas segala bantuan dan kebaikan yang telah diberikan kepada penulis.
Medan, Agustus 2016
Irfan Sudahri Damanik NIM.127038075
ABSTRAK
Pentingnya pengefisiensian ruang pencarian rules pada decision tree dengan algoritma C4.5 menjadi fokus oleh banyak peneliti. Oleh sebab itu pengembangan perlu dilakukan agar dapat terbentuk sebuah metode baru yang lebih efisien namun tidak lepas pada akurasi yang dianalisis dari hasil algoritma itu sendiri. Untuk itu dengan menggunakan algoritma genetika (AG) diharapkan dapat mengoptimasi ruang pencarian rules dan menyederhanakan kombinasi rules yang lebih kompleks.
Pengunaan C4.5 dengan Hybrid algoritma genetika dalam pencarian rules yang lebih efektif membutuhkan pemahaman yang lebih dan waktu yang lama. Tetapi pemanfaatan kedua algoritma ini akan sangat efektif jika kasus yang dihadapi sangat kompleks dengan kondisi percabangan yang lebih banyak dengan akurasi yang tinggi.
Kata kunci : decision tree, optimasi algoritma c4.5, algoritma genetika.
OPTIMIZATION OF C4.5 DECISION TREE ALGORITHM USING GENETIC ALGORITHM
ABSTRACT
The importance of efficiency in the space of search rules C4.5 decision tree algorithm has been the focus of a lot of researchers. Therefore, the development needs to be conducted to form a new, more efficient method but it can not be separated from the accuracy of the analysis as the results of the algorithm itself. For that purpose, by using a genetic algorithm (GA), it is expected to optimize and simplify the search rules of more complex combinations. The use of C4.5 with Hybrid genetic algorithm in search of a more effective rules requires a better understanding and a long time. But the use of the two algorithms will be mostly effective if the cases faced are very complex, having more branching condition and highly accurate.
Keywords decision tree, optimation c4.5 algorithm, genetic algorithm.
DAFTAR ISI
Halaman
PERSETUJUAN ... ii
PERNYATAAN ... iii
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPERLUAN AKADEMIS ... iv
RIWAYAT HIDUP ... vi
KATA PENGANTAR ... vii
ABSTRAK ... viii
ABSTRACT ... ix
DAFTAR ISI ... x
DAFTAR GAMBAR ... xii
DAFTAR TABEL ... xiv
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 3
1.3 Batasan Masalah ... 4
1.4 Tujuan Penelitian ... 4
1.5 Manfaat Penelitian ... 4
BAB 2 TINJAUAN PUSTAKA ... 5
2.1 Decision Tree ... 5
2.2 Algoritma C4.5 ... 5
2.3 Algoritma Genetika ... 6
2.4 Teknik Encoding ... 10
2.5 Operator Genetik ... 10
2.5.1 Proses Seleksi ... 11
2.5.2 Pindah Silang (Persilangan) ... 12
2.5.3 Proses Mutasi ... 16
2.5 Parameter Genetik ... 18
2.6 Penelitian-Penelitian Terkait ... 18
2.6.1 Penelitian Terdahulu ... 18
2.6.2 Perbedaan Penelitian ... 19
2.6.3 Kontribusi yang diberikan ... 20
BAB 3 METODOLOGI PENELITIAN ... 21
3.1 Pendahuluan ... 21
3.2 Tahapan Penelitian ... 21
3.2.1 Penelitian Awal ... 22
3.2.2 Preprocesing dan Pengumpulan Data ... 22
3.2.3 Perbandingan Metode ... 22
3.2.4 Perbaikan Metode dan Evaluasi ... 23
3.2.5 Diagram Kerja ... 23
3.2.6 Rancangan Penelitian ... 24
3.2.7 Rancangan Modifikasi C4.5 denga Algoritma Genetika ... 25
3.2.8 Dataset Dan Ujicoba ... 25
BAB 4 HASIL DAN PEMBAHASAN ... 27
4.1 Pendahuluan ... 27
4.2 Kinerja Algoritma C4.5 ... 27
4.3 Preprosesing dan Diskritisasi Data ... 28
4.4 Perbandingan Metode ... 29
4.4.1 Training pada algoritma C4.5 ... 30
4.5 Perbaikan Metode ... 38
4.5.1 Modifikasi algoritma C4.5 denga Algoritma Genetika ... 38
4.5.2 Binarisasi Aturan Keputusan (rules) ... 38
4.5.3 Pembetukan Fungsi Fitnes ... 44
4.5.4 Seleksi Kromosom ... 49
4.5.5 Persilangan dan Mutasi aturan Keputusan ... 54
4.6 Pembuatan Algoritma ... 62
4.7 Evaluasi ... 63
BAB 5 KESIMPULAN DAN SARAN ... 64
5.1 Kesimpulan ... 64
5.2 Saran ... 64
BAB 5 DAFTAR PUSTAKA ... 65
DAFTAR GAMBAR
Halaman
Gambar 2.1 Siklus Algoritma Genetika ... 7
Gambar 2.2 Metode Stochastic Universal Sampling ... 12
Gambar 3.1 Metodologi Penelitian ... 23
Gambar 3.2 Rancangan Penelitian ... 24
Gambar 3.3 Rancangan Algoritma Genetika membentuk aturan Keputusan ... 25
Gambar 4.1 Pohon Keputusan Node 1 Light ... 34
Gambar 4.2 Pohon Keputusan Node 1.1 CO2 ... 36
Gambar 4.3 Pohon Keputusan Ocupancy Detection ... 36
Gambar 4.4 Pembuatan Kromosom ... 40
Gambar 4.5 Konversi Aturan pohon Keputusan dalam pembentukan kromosom ... 42
Gambar 4.6 Atribut yang terkena mutasi ... 57
DAFTAR TABEL
Halaman
Tabel 2.1 Teknik Permutasi Encoding ... 10
Tabel 2.2 One Point crossover ... 13
Tabel 2.3 Two Point crossover ... 14
Tabel 2.4 Uniform Persilangan ... 14
Tabel 2.5 Single Arithmetic Persilangan ... 15
Tabel 2.6 Simple Arithmetic Persilangan ... 15
Tabel 2.7 Whole Arithmetic Persilangan ... 16
Tabel 2.8 Contoh Mutasi pada pengkodean Biner ... 17
Tabel 2.9 Contoh Mutasi pada pengkodean Permutasi ... 17
Tabel 2.10 Perbedaan Penelitian ... 19
Tabel 3.1 Dataset UCI Learning Machine Accurate Occupancy detection ... 26
Tabel 4.1 Segmentasi data kontinu ... 29
Tabel 4.2 Sample Dataset Occupancy Detection Matrik 8x15 ... 30
Tabel 4.3 Hasil Perhitungan Entropy keleluruha dataset ... 31
Tabel 4.4 Analisis Perhitungan Entropi Dan Gain Node 1 ... 33
Tabel 4.5 Sampel data filter Node 1.1 ... 34
Tabel 4.6 Hasil perhitungan Entropi data filter Node 1.1 ... 35
Tabel 4.7 Analisis Perhitungan Entropi Dan Gain Node 1.1. ... 35
Tabel 4.8 Konversi Segmen Ke Biner ... 41
Tabel 4.9 Konversi data Testing ... 43
Tabel 4.10 Konstanta Optimasi Algoritma Genetika ... 44
Tabel 4.11 Nilai Benar-Benar ... 46
Tabel 4.12 Nilai Benar Salah ... 47
Tabel 4.13 Nilai Salah Benar ... 47
Tabel 4.14 Nilai Salah Salah ... 47
Tabel 4.15 Nilai Perhitungan Maksimum Fitnes ... 48
Tabel 4.16 Akurasi Rules pada Data Training ... 48
Tabel 4.17 Kromosom dengan Populasi baru ... 52
Tabel 4.18 Rules Hasil Proses Seleksi ... 53
Tabel 4.19 Kromosom ... 54
Tabel 4.20 Perubahan Kromosom Setelah Persilangan ... 56
Tabel 4.21 Nilai Random Mutasi ... 58
Tabel 4.22 Hasil Mutasi ... 59
Tabel 4.23 Hasil Konversi Kromosom ke Rules ... 61
Tabel 4.24 Maksimum fitnes Generasi Pertama ... 61
Tabel 4.25 Hasil Maksimum Fitness Generasi 20 ... 62
Tabel 4.26 Rules Terakhir Hasil Mutasi ... 63
BAB 1 PENDAHULUAN
1.1 Latar Belakang
Pohon keputusan merupakan metode klasifikasi dan prediksi yang sangat kuat dan terkenal. Metode pohon keputusan mengubah fakta yang sangat besar menjadi pohon keputusan yang merepresentasikan aturan. Aturan dapat dengan mudah dipahami dengan bahasa alami. Manfaat utama dari penggunaan pohon keputusan adalah kemampuannya untuk mem-break down proses pengambilan keputusan yang kompleks menjadi lebih sederhana sehingga pengambilan keputusan akan lebih menginterpretasikan solusi permasalahan dengan mengubah bentuk data (tabel) menjadi model pohon keputusan, mengubah model pohon keputusan menjadi aturan.
Pohon keputusan juga berguna untuk mengeksplorasi data, yaitu menemukan hubungan tersembunyi antara sejumlah calon variabel input dengan sebuah variabel target.
Beberapa metode yang dapat di gunakan untuk proses pohon keputusan antara lain dengan metode ID3, C4.5, C5, cart, Sprint, SLIQ Public, ClS, naive bayes, Random Forest, Random Tree, id3+, Oci dan Clouds. Dari sekian algoritma tersebut, yang nantinya akan penulis kembangkan dan gunakan adalah C4.5
Quinlan dalam bukunya yang berjudul C4.5 : “Program for Machine Learning” menyatakan bahwa dalam mengkonstruksi pohon, C4.5 memuat seluruh kasus ke dalam memori sehingga dibatasi oleh ketersediaan memori dan skalabilitas C4.5 dinilai kurang baik. Hal ini akan membuat Performance dari algoritma tersebut kurang maksimal.
Galathiya, et al. (2012) melakukan penelitian dengan melakukan pengembangan pada algoritma pohon keputusan C4.5 dan melakukan perbandingan terhadap algoritma Naive Bayes, Sequential Minimal Optimization
(SMO), dan multilayer perceptron dengan menggunakan sejumlah data sets dan pengujian akurasi berdasarkan kepada Correctly Classified Instances dan Relative Absolute Error. Hasilnya, algoritma pohon keputusan C4.5 yang dikembangkan memiliki tingkat akurasi sekitar 1-3% lebih baik pada 7 data sets dari total 9 data sets.
Othman & Yau (2007) melakukan penelitian berjudul “Comparison of Different Classification Techniques using WEKA for Breast Cancer”. Metode pengujian yang digunakan berupa percentage split sebesar 75%, artinya 75% data digunakan sebagai data training dan 25% sisanya sebagai data testing. Pengujian akurasi berdasarkan kepada Correctly Classified Instances, Incorrectly Classified Instances,danTime Taken. Hasilnya, algoritma Naive Bayes memiliki tingkat akurasi tertinggi dan waktu pembangunan model tercepat dibandingkan dengan Radial Basis Function, Decision Tree and Pruning, Single Conjunctive Rules Learner, dan Nearest Neighbors Algorithm.
Quinlan dalam bukunya yang berjudul C4.5 : “Program for Machine Learning” menyatakan bahwa dalam mengkonstruksi pohon, C4.5 memuat seluruh kasus ke dalam memori sehingga dibatasi oleh ketersediaan memori dan skalabilitas C4.5 dinilai kurang baik. Untuk mengatasi kekurangan dari algoritma tersebut, penulis mencoba untuk mengurangi penggunaan memori dengan mencari kasus yang memiliki probabilitas tertinggi dalam membentuk pohon keputusan sehingga lebih efisien namun tidak lepas pada akurasi yang dianalisis dari hasil algoritma itu sendiri
John Holland, dalam bukunya yang berjudul “Adaption in Natural and Artificial Systems”, mengemukakan komputasi berbasis evolusi. Tujuannya membuat komputer dapat melakukan apa yang terdapat di alam. Sebagai seorang pakar komputer, Holland memfokuskan diri memanipulasi string dalam bentuk binary bit.
Holland mengemukakan algoritma tersebut sebagai suatu konsep abstrak dari evolusi alam. Tahapan algoritma genetika yang dikemukakan oleh Holland dapat direpresentasikan sebagai suatu tahapan berurutan sebagai suatu bentuk populasi dari kromosom buatan menjadi sebuah populasi baru (Negnevitsky, 2005).
Dalam algoritma genetika ada sejumlah operasi yang mendukung keberhasilan algoritma genetika seperti pembangkitan populasi awal, perhitungan fitness tiap
kromosom, seleksi kromosom, persilangan, dan mutasi kromosom. Proses persilangan merupakan proses pembentukan kromosom anak (offspring). Persilangan bertujuan menambah keanekaragaman string dalam satu populasi dengan penyilangan antar string yang diperoleh dari reproduksi sebelumnya. Terdapat beberapa jenis persilangan di antaranya adalah persilangan 1 titik (single point crossover), 2 titik (two point crossover), dan arithmetic persilangan (Konar, 2005). Metode arithmetic persilangan dapat dibagi menjadi 3 jenis, yaitu single arithmetic persilangan, simple arithmetic persilangan, dan whole arithmetic persilangan (Picek et al., 2013).
Perbedaan metode persilangan ini dalam menghasilkan kromosom terbaik akan mempengaruhi kinerja algoritma genetika. Algoritma genetika akan berhenti jika sejumlah generasi maksimum tercapai atau level fitness yang ditentukan telah terpenuhi
Berdasarkan latar belakang tersebut di atas, penulis mencoba melakukan penelitian untuk melakukan optimasi dari pohon keputusan C4.5 dengan menggunakan Algoritma Genetik (AG). Adapun sumber data sets adalah UC Irvine Machine learning Repository (UCI Machine learning Repository). Dataset yang diambil menggabarkan data kelayakan sebuah ruangan berdasarkan intesitas cahaya, kelembapan, kadar C02 dan Temperatur. Atas dasar inilah, penulis tertarik untuk mengambil judul: OPTIMASI DECISION TREE PADA ALGORITMA C4.5 DENGAN MENGGUNAKAN ALGORITMA GENETIKA.
1.2. Perumusan Masalah
Algoritma Decision tree pada C4.5 memiliki aturan ruang pencarian yang besar sehingga performance sebagai parameter untuk menemukan optimasi dalam penerapan algoritma belum optimal hal ini karena dalam mengkonstruksi pohon, C4.5 memuat seluruh kasus ke dalam memori sehingga dibatasi oleh ketersediaan memori dan skalabilitas C4.5 dinilai kurang baik. Algoritma genetika merupakan sebuah algoritma yang sering digunakan untuk memecahkan sebuah pencarian nilai dalam sebuah optimasi. Aturan ruang pencarian yang terdapat dalam algoritma C4.5 dapat dilakukan menggunakan algoritma genetika untuk menghasilkan ruang pencarian yang lebih sedikit.
1.3. Batasan Masalah
Rumusan masalah di atas, dibatasi dengan beberapa hal sebagai berikut:
1. Data yang akan digunakan adalah data sets yang diperoleh dari UC Irvine Machine learning Repository (UCI Machine Learning Repository), dataset yang diambil menggabarkan data kelayakan sebuah ruangan berdasarkan intesitas cahaya, kelembapan, kadar C02 dan Temperatur.
2. Metode Algoritma genetik dengan menggunakan persilangan dan Mutasi Operation.
3. Hasil pengujian optimasi berupa untuk penilaian nilai maksimum untuk menemukan rules yang optimal pada algoritma native C4.5 dengan membandingkan Algoritma C4.5 dengan modifikasi dengan algoritma genetika.
1.4. Tujuan Penelitian
Adapun tujuan penelitian ini adalah untuk membentuk rules yang optimum pada pohon keputusan algoritma C4.5 menggunakan algoritma genetika dengan menerapkan metode persilangan dan mutasi operation.
1.5. Manfaat Penelitian
Manfaat yang diharapkan dari hasil penelitian ini adalah sebagai berikut:
1. Dapat mengetahui lebih dalam tentang algoritma pohon keputusan pada data mining.
2. Mengetahui rules yang optimum menggunakan algoritma genetika dengan menerapkan operasi persilangan (pindah silang) dan mutasi.
3. Mengetahui lebih mendalam pengaruh metode persilangan dan mutasi dalam mendapatkan hasil yang optimal pada pohom keputusan.
4. Hasil penelitian dapat menjadi rujukan para pembaca dalam memahami performance algoritma klasifikasi, terutama aspek performace.
BAB 2
TINJAUAN PUSTAKA
2.1 Decision Tree
Decision tree merupakan metode klasifikasi yang paling popular digunakan, selain karena pembangunannya relatif cepat, hasil dari model yang dibangun mudah untuk dipahami.
Pada decision tree terdapat 3 jenis node, yaitu :
a. Root Node, merupakan node paling atas, pada node ini tidak ada input dan bisa tidak mempunyai output atau mempunyai output atau mempunyai output lebih dari satu.
b. Internal Node, merupakan node percabangan, pada node ini hanya terdapat satu input dan mempunyai output minimal dua.
c. Leaf node atau terminal node, merupakan node akhir, pada node ini hanya terdapat satu input dan tidak mempunyai output.
2.2. Algoritma C 4.5
Algoritma C 4.5 adalah salah satu metode untuk membuat decision tree berdasarkan training data yang telah disediakan. Algoritma C 4.5 merupakan pengembangan dari ID3. Beberapa pengembangan yang dilakukan pada C 4.5 adalah sebagai antara lain bisa mengatasi missing value, bisa mengatasi continue data, dan pruning. Dengan keunggulan ini maka penulis menggunakan algoritma ini dalam membuat pohon keputusan.
Pohon keputusan merupakan metode klasifikasi dan prediksi yang sangat kuat dan terkenal. Metode pohon keputusan mengubah fakta yang sangat besar menjadi pohon keputusan yang merepresentasikan aturan. Aturan dapat dengan mudah dipahami dengan bahasa alami. Dan mereka juga dapat diekspresikan dalam bentuk bahasa basis data seperti Structured Query Language untuk mencari record pada
kategori tertentu. Pohon keputusan juga berguna untuk mengeksplorasi data, menemukan hubungan tersembunyi antara sejumlah calon variabel input dengan sebuah variabel target.
Karena pohon keputusan memadukan antara eksplorasi data dan pemodelan, pohon keputusan sangat bagus sebagai langkah awal dalam proses pemodelan bahkan ketika dijadikan sebagai model akhir dari beberapa teknik lain. Sebuah pohon keputusan adalah sebuah struktur yang dapat digunakan untuk membagi kumpulan data yang besar menjadi himpunan-himpunan record yang lebih kecil dengan menerapkan serangkaian aturan keputusan. Dengan masing-masing rangkaian pembagian, anggota himpunan hasil menjadi mirip satu dengan yang lain.
Sebuah model pohon keputusan terdiri dari sekumpulan aturan untuk membagi sejumlah populasi yang heterogen menjadi lebih kecil, lebih homogen dengan memperhatikan pada variabel tujuannya. Sebuah pohon keputusan mungkin dibangun dengan seksama secara manual atau dapat tumbuh secara otomatis dengan menerapkan salah satu atau beberapa algoritma pohon keputusan untuk memodelkan himpunan data yang belum terklasifikasi.
Variabel tujuan biasanya dikelompokkan dengan pasti dan model pohon keputusan lebih mengarah pada perhitungan probability dari tiap-tiap record terhadap kategori-kategori tersebut atau untuk mengklasifikasi record dengan mengelompokkannya dalam satu kelas. Pohon keputusan juga dapat digunakan untuk mengestimasi nilai dari variabel continue meskipun ada beberapa teknik yang lebih sesuai untuk kasus ini.
2.3 Algoritma Genetika
Algoritma genetika adalah suatu algoritma stokastik yang memodelkan proses evolusi dari spesies biologi melalui seleksi alam (Konar, 2005). Secara umum, populasi ini dibangkitkan secara random dan solusi yang adalah dibangkitkan sesudah tahapan konsekutif dari proses persilangan dan mutasi. Setiap individu dari populasi memiliki nilai yang diasosiasikan ke dalam suatu nilai fitness, di dalam kaitannya untuk menyelesaikan suatu permasalahan (Rabunal, 2006).
Algoritma genetika yang dikemukakan oleh John Holland menggunakan konsep kromosom yang digunakan untuk menyatakan alternatif solusi dari suatu permasalahan. Tiap kromosom terdiri dari deretan bit string yang berupa bit 0 atau 1 yang disebut sebagai gen. Setiap kromosom dapat mengalami pertukaran materi genetis antara kromosom. Sedangkan proses mutasi akan mengganti secara acak nilai gen di beberapa lokasi pada kromosom. Selain itu dikenal pula istilah invertion yang akan membalikkan urutan beberapa gen yang berurutan di dalam kromosom. (Mitchel, 1999).
Adapun proses dari algroritma genetika secara umum dapat dilihat pada Gambar 2.1.
Gambar 2.1. Siklus Algoritma Genetika (Konar, 2005)
Fase awal dari algoritma genetika adalah inisialisasi populasi yang menyatakan alternatif solusi. Elemen dari populasi adalah dideskripsikan dalam bentuk deretan bit string yang berisi bit 0 atau 1 yang disebut sebagai kromosom.
Kemudian langkah selanjutnya adalah menghitung nilai fitness berdasarkan gen yang ada pada kromosom dalam tiap populasi. Berdasarkan nilai fitness dari tiap koromosom, maka tahapan selanjutnya adalah tahapan seleksi yang berfungsi untuk
memilih kromosom yang terpilih sebagai parent yang akan menjalani persilangan.
Proses persilangan yang berjalan dengan beberapa variasi operator persilangan berperan penting dalam membentuk kromosom anak (offspring) yang juga berperan penting untuk menambah keanekaragaman string di dalam suatu populasi.
Kromosom selanjutnya akan masuk ke dalam tahap mutasi yang berfungsi untuk memastikan bahwa keanekaragaman (diversity) dari kromosom dalam suatu populasi tetap terjaga, untuk menghindari terjadinya konvergensi prematur yang berujung pada terjadinya solusi yang local optima.
Goldberg (1989) mengemukakan bahwa algoritma genetik mempunyai karakteristik-karakteristik yang perlu diketahui sehingga dapat dibedakan dari prosedur pencarian atau optimasi yang lain, yaitu:
1. Algoritma genetika dengan pengkodean dari himpunan solusi permasalahan berdasarkan parameter yang telah ditetapkan dan bukan parameter itu sendiri.
2. Algoritma genetika mencari solusi dari sejumlah individu-individu yang merupakan solusi permasalahan, bukan hanya dari satu individu.
3. Algoritma genetika berpatokan pada objektif (fitness), sebagai cara untuk mengevaluasi individu yang mempunyai solusi terbaik, bukan turunan dari suatu fungsi.
4. Algoritma genetik menggunakan aturan-aturan transisi peluang, bukan aturan- aturan deterministik.
Variabel dan parameter yang digunakan pada algoritma genetik adalah: (Kuhn et al., 2013) :
1. Inisialisasi populasi yang digunakan. Pada bagian ini ditentukan jumlah individu (kromosom) dan gen yang dilibatkan pada setiap generasi.
2. Evaluasi nilai fitness dari setiap individu.
3. Seleksi kromosom yang akan dijadikan kromosom parent untuk dilibatkan di dalam proses persilangan berdasarkan nilai fitness.
4. Penentuan nilai PC (Probability Persilangan) yang menentukan peluang terjadinya persilangan pada setiap individu.
5. Mutasi rate yang menentukan sejumlah gen yang dillibatkan dalam proses mutasi.
Secara umum struktur dari suatu algoritma genetika dapat didefenisikan dengan langkah-langkah sebagai berikut: (Negnevitsky, 2005)
1. Membangkitkan populasi awal
Populasi awal dibangkitkan secara acak sehingga didapatkan solusi awal.
Populasi itu sendiri terdiri atas sejumlah kromosom yang merepresentasikan solusi yang diinginkan.
2. Menghitung Fitness dari Tiap Generasi.
Pada tiap generasi, kromosom akan melalui proses evaluasi dengan menggunakan alat ukur yang dinamakan fitness. Nilai fitness suatu kromosom menggambarkan kualitas kromosom dalam populasi tersebut.
Nilai fitness ditentukan oleh nilai fungsi objektif. Fungsi objektif tersebut menunjukkan hasil penjumlahan jarak pada tiap kromosom. Semakin tinggi nilai fitness akan semakin besar kemungkinan kromosom tersebut terpilih ke generasi berikutnya. Jadi nilai fungsi objektif berbanding terbalik dengan nilai fitness, semakin kecil nilai fungsi objektif semakin besar nilai fitness- nya.
3. Evaluasi Solusi.
Proses ini akan mengevaluasi setiap populasi dengan menghitung nilai fitness setiap kromosom dan mengevaluasinya sampai terpenuhi kriteria berhenti.
Bila kriteria berhenti belum terpenuhi maka akan dilanjutkan dengan proses perkawinan. Beberapa kriteria berhenti sering digunakan antara lain: berhenti pada generasi tertentu, berhenti setelah beberapa generasi berturut-turut didapatkan nilai fitness tertinggi tidak berubah, berhenti pada n generasi yang tidak didapatkan nilai fitness yang lebih tinggi.
4. Proses Persilangan
Menentukan nilai PC (Probability Persilangan) dan kemudian menentukan pasangan kromosom yang akan terlibat di dalam proses persilangan berdasarkan nilai PC yang dibangkitkan tersebut dengan menggunakan salah satu metode persilangan.
5. Proses Mutasi
Menentukan nilai mutasi rate, dan kemudian berdasarkan nilai bilangan random yang dibangkitkan akan dapat ditentukan gen-gen yang terlibat di dalam proses mutasi tersebut.
6. Menjadikan Kromosom Anak hasil dari Proses Persilangan dan Mutasi sebagai Populasi Baru.
2.4. Teknik Encoding
Proses encoding adalah salah satu proses yang sulit di dalam algoritma genetika. Hal ini disebabkan karena proses encoding untuk setiap permasalahan berbeda karena tidak semua teknik encoding cocok untuk tiap permasalahan. Proses encoding menghasilkan string yang kemudian disebut kromosom. String terdiri dari sekumpulan bit yang dikenal sebagai gen. Jadi satu kromosom terdiri dari sejumlah gen (Coley,1999).
Ada bermacam-macam teknik encoding yang dapat dilakukan dalam algoritma genetika. Beberapa teknik encoding itu antara lain adalah binary encoding, permutasi encoding, value encoding, dan tree encoding . Pada Permutasi Encoding, kromosom-kromosom adalah kumpulan angka yang mewakili posisi di dalam sebuah rangkaian. Dalam permutatiom encoding, setiap kromosom adalah sebuah string dari nomor-nomor seperti diilustrasikan pada tabel 2.1
Tabel 2.1. Teknik Permutasi Encoding
Kromosom (rules) 1 2 3 4 5 6 7 8 9
Gen (Light, C02,
Kelembapan,Temperature)
0 1 1 0 0 0 0 1 1
2.5. Operator Genetik
Algoritma genetik merupakan proses pencarian yang heuristik dan acak sehingga penekanan pemilihan operator yang digunakan sangat menentukan keberhasilan algoritma genetik dalam menemukan solusi optimum suatu masalah yang diberikan.
Hal yang harus diperhatikan adalah menghindari terjadinya konvergensi prematur, yaitu mencapai solusi optimum yang belum waktunya, dalam arti bahwa solusi yang
diperoleh adalah hasil local optima. Operator pada algoritma genetika terdiri atas sejumlah parameter kontrol yang terdiri-dari: (Taiwo et al., 2013)
1. Ukuran populasi: mendefinisikan berapa banyak kromosom dan berapa banyak gen di dalam satu kromosom yang terlibat selama proses pencarian.
2. Probabilitas persilangan: menspesifikasikan probabilitas persilangan di antara dua kromosom.
3. Probabilitas mutasi: menspesifikasikan probabilitas dari dilakukannya mutasi bit-wise.
4. Kriteria terminasi: menspesifikasikan kondisi berakhirnya pencarian solusi pada algoritma genetika.
2.5.1. Proses Seleksi
Proses seleksi berhubungan erat dengan nilai fitness yang diperoleh oleh setiap individu. (Reeves, 2003). Individu yang dibentuk yang memiliki fungsi objektif yang paling kecil akan memiliki nilai probabilitas yang tinggi untuk kemungkinan terpilih.
Dalam proses seleksi parent, ada banyak metode yang dapat diterapkan. Dua metode umum yang sering digunakan yaitu (Chipperfield. et.al, 2005):
1. Seleksi Roda Roulette (Roulette Wheel Selection)
Roulette wheel selection adalah metode seleksi yang paling sederhana. Pada metode ini semua kromosom (individu) di dalam suatu populasi adalah ditempatkan pada roulette wheel sesuai dengan nilai fitness mereka. Besarnya ukuran tiap segmen di dalam roulette adalah sebanding dengan nilai fitness dari tiap individu. Semakin besar nilai fitness maka semakin besar pula ukuran segmen di dalam roulette wheel, kemudian roulette wheel diputar.
Individu yang sesuai dengan segmen pada roulette wheel ketika berhenti yang akan dipilih. (Kumar, 2012).
2. Stochastic Universal Sampling
Karakteristik metode ini adalah memiliki nilai bias nol dan penyebaran yang minimum. Individu-individu dipetakan dalam suatu segmen garis secara berurutan sedemikian hingga tiap-tiap segmen individu memiliki ukuran
yang sama dengan ukuran fitness-nya. Kemudian diberikan sejumlah pointer sebanyak individu yang ingin diseleksi pada garis tersebut (Pencheva et.al, 2009). Misal N adalah jumlah individu yang akan diseleksi, maka jarak antar pointer adalah 1/N dan posisi pointer pertama diberikan secara acak pada range [1 , 1/N]. Metode stochastic universal sampling dapat dilihat pada Gambar 2.2.
Gambar 2.2 Metode Stochastic Universal Sampling (Pencheva, 2009)
2.5.2. Pindah Silang (Persilangan)
Operator persilangan memainkan peran penting di dalam menghasilkan generasi baru.
Operator persilangan adalah operator genetika yang mengombinasikan dua kromosom parents untuk menghasilkan kromosom offspring. Tujuan utama dari adanya persilangan adalah menghasilkan kromosom baru yang lebih baik daripada kedua parent karena mengambil karakteristik terbaik dari tiap parent. Proses persilangan yang terjadi selama proses evolusi sesuai dengan nilai persilangan probability yang didefinisikan oleh pengguna (Abuiziah, 2013).
Kromosom yang terpilih untuk mengalami persilangan ditentukan melalui nilai probability persilangan (Pc). Suatu kromosom terpilih untuk mengalami persilangan jika nilai random kromosom (Rc) < Pc. Besarnya nilai Pc adalah diantara 0.4 sampai dengan 0.9 (Coley, 1999). Persilangan bertujuan menambah keanekaragaman string dalam satu populasi dengan penyilangan antara gen-gen dari induk (Robandi, 2006).
Beberapa jenis persilangan sebagai berikut:
1) Persilangan Pengkodean Biner
Ada beberapa metode persilangan dengan pengkodean biner, yaitu sebagai berikut:
a. One Point crossover
Pada one point crossover, sebuah bilangan acak mendefinisikan segmen yang membagi kromosom ke dalam dua bagian. Kromosom offspring dihasilkan melalui kombinasi kromosom yang dihasilkan pada segmen point berdasarkan bilangan acak tersebut. Bagian pertama adalah sebelum segmen point mengambil kromosom parent yang pertama dan bagian kedua setelah bilangan random adalah mengambil kromosom parent yang kedua. (Andrade, 2008). Illustasi dari proses one point crossover dapat dilihat pada Tabel 2.2.
Tabel 2.2. One Point crossover
Kromosom Parent 1 11001011
Kromosom Parent 2 11011111
Offspring 11001111
b. Two Point crossover
Two point crossover hampir sama dengan one point crossover. Perbedaannya adalah bahwa pada two point persilangan, cut point yang digunakan adalah sebanyak 2, dan dibangkitkan secara acak (Mendes, 2013). Illustrasi dari proes two point crossover dapat dilihat pada Tabel 2.3.
Tabel 2.3. Two Point crossover
Kromosom Parent 1 11001011
Kromosom Parent 2 11011111
Offspring 11011111
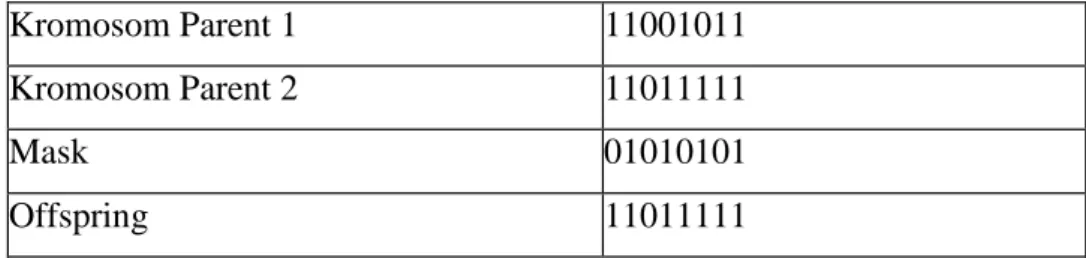
2) Uniform Persilangan
Pada uniform persilangan, sebuah vektor bit acak yang berukuran sama dengan kromosom yang digunakan. Di dalam proses untuk menghasilkan kromosom
offspring, akan dipilih bit-bit dalam mask vektor bit acak. Jika yang terpilih adalah bit 0, berarti kromosom offspring diperoleh dari parent 1 dan jika yang terpilih adalah bit 1 berarti kromosom offspring diperoleh dari parent 2 (Andrade, 2008).
Illustrasi dari proses uniform persilangan dapat dilihat pada Tabel 2.4.
Tabel 2.4. Uniform Persilangan
Kromosom Parent 1 11001011
Kromosom Parent 2 11011111
Mask 01010101
Offspring 11011111
3) Arithmetic Persilangan
Kromosom offspring diperoleh dengan melakukan operasi aritmatika terhadap parent (induk). Terdapat 3 jenis arithmetic persilangan, yaitu sebagai berikut. (Picek et al.,2013).
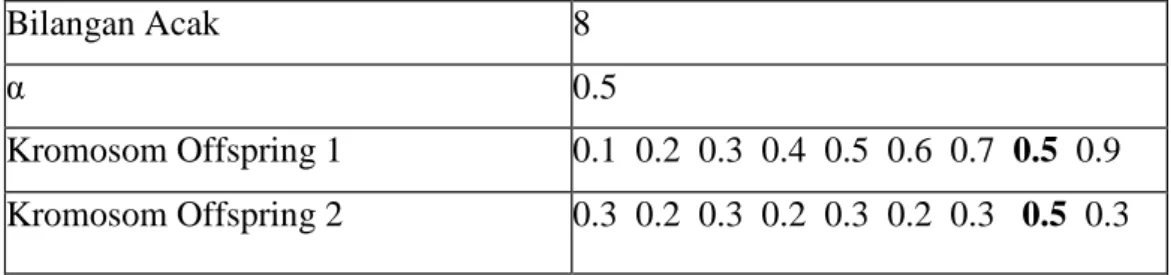
1. Single Arithmetic Persilangan
Pada single arithmetic persilangan, pindah silang terjadi pada salah satu gen yang posisinya ditentukan dengan cara membangkitkan suatu bilangan acak. Pada posisi gen yang ditentukan, nilai gen akan ditentukan melalui operasi aritmatika terhadap nilai gen dari parent menurut persamaan 2.2 (Eiben, 2014). Adapun operasi aritmatika pada single arithmetic persilangan dapat dilihat pada Persamaan 2.1 dan Tabel 2.5.
Child
=
x1,...,xk,yk(1)xk,...,xn ...(Persamaan 2.1)Ket:
α = Variabel pengali yang nilainya berkisar dari 0-1
Tabel 2.5. Single Arithmetic Persilangan
Kromosom Parent 1 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Kromosom Parent 2 0.3 0.2 0.3 0.2 0.3 0.2 0.3 0.2 0.3
Bilangan Acak 8
α 0.5
Kromosom Offspring 1 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.5 0.9 Kromosom Offspring 2 0.3 0.2 0.3 0.2 0.3 0.2 0.3 0.5 0.3
2. Simple Arithmetic Persilangan
Pada simple arithmetic persilangan, tentukan bilangan random sebagai titik potong antara 0 sampai sepanjang kromosom pada masing-masing parent. Untuk gen pada kromosom offspring untuk batas sebelum titik potong disalin dari gen pada kromosom parent. Untuk gen setelah titik potong, gen yang ada dibentuk dari operasi aritmatika pada gen dari kromosom parent dengan persamaan seperti pada persamaan 2.3 (Picek, 2013). Illustrasi dari proses simple arithmetic persilangan dapat dilihat pada Tabel 2.9.
Child=
xn xk
yk xk
x (1 )
yn ..., 1, ) 1 1 ( ,
...,
1, ...(Persamaan 2.2)
Tabel 2.6. Simple Arithmetic Persilangan
Kromosom Parent 1 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Kromosom Parent 2 0.3 0.2 0.3 0.2 0.3 0.2 0.3 0.2 0.3
Bilangan Acak 6
α 0.5
Kromosom Offspring 1 0.1 0.2 0.3 0.4 0.5 0.6 0.5 0.5 0.6 Kromosom Offspring 2 0.3 0.2 0.3 0.2 0.3 0.2 0.5 0.5 0.6
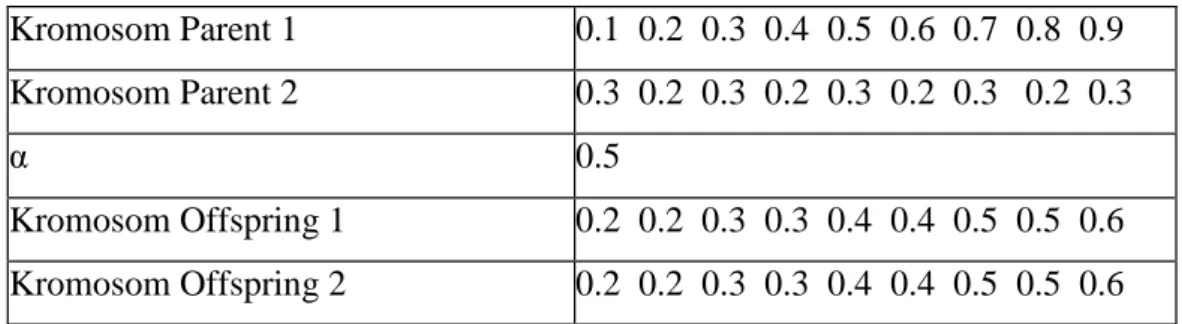
3. Whole Arithmetic Persilangan
Pada whole arithmetic persilangan, gen pada kromosom offspring diperoleh dari hasil operasi aritmatika gen pada kromosom parent, di mana proses aritmatika yang dilakukan sesuai dengan persamaan 2.3 (Eiben, 2014). Illustrasi dari proses whole arithmetic persilangan dapat dilihat pada Tabel 2.7.
Child= a.x(1)y ...(2.3) α = Variabel pengali yang nilainya berkisar dari 0-1
Tabel 2.7. Whole Arithmetic Persilangan
Kromosom Parent 1 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Kromosom Parent 2 0.3 0.2 0.3 0.2 0.3 0.2 0.3 0.2 0.3
α 0.5
Kromosom Offspring 1 0.2 0.2 0.3 0.3 0.4 0.4 0.5 0.5 0.6 Kromosom Offspring 2 0.2 0.2 0.3 0.3 0.4 0.4 0.5 0.5 0.6
2.5.3. Mutasi
Mutasi adalah proses untuk mengubah gen di dalam sebuah kromosom. Mutasi dilakukan setelah proses persilangan dilakukan. Mutasi mengubah offspring baru dengan mengubah 1 menjadi 0 atau 0 menjadi 1. Mutasi dapat terjadi pada setiap posisi di dalam string dengan beberapa probabilitas yang umumnya sangat kecil.
Mutasi adalah dimaksudkan untuk mencegah hasil pencarian mengarah pada keadaan local optima di dalam sebuah area pencarian (Shaikh, 2012).
Operator mutasi merupakan operasi yang menyangkut satu kromosom tertentu.
Beberapa cara operasi mutasi diterapkan dalam algoritma genetik menurut jenis pengkodean terhadap phenotype, antara lain:
1. Mutasi dalam Pengkodean Biner
Mutasi pada pengkodean biner merupakan operasi yang sangat sederhana.
Proses yang dilakukan adalah menginversi nilai pada posisi tertentu yang terpilih secara acak (atau menggunakan skema tertentu) pada kromosom, yang disebut inverse.
Tabel 2.8. Contoh Mutasi pada Pengkodean Biner
Kromosom sebelum mutasi 10010111
Kromosom setelah mutasi 10010011
2. Mutasi dalam Pengkodean Permutasi
Proses mutasi yang dilakukan dalam pengkodean biner dengan mengubah langsung - pada kromosom tidak dapat dilakukan pada pengkodean permutasi karena konsistensi urutan permutasi haru diperhatikan. Salah satu cara yang dapat dilakukan adalah dengan memilih dua posisi (locus) dari kromosom dan kemudian nilainya saling dipertukarkan.
Tabel 2.9. Contoh Mutasi pada Pengkodean Permutasi
Kromosom sebelum mutasi 10010111
Kromosom setelah mutasi 10010011
3. Mutasi dalam Pengkodean Nilai
Mutasi pada pengkodean nilai hampir sama dengan yang dilakukan pada pengkodean biner, tetapi yang dilakukan bukan menginversi nilai . Penerapannya bergantung pada jenis nilai yang digunakan. Sebagai contoh untuk nilai riil, proses mutasi dapat dilakukan seperti yang dilakukan pada pengkodean permutasi, dengan saling mempertukarkan nilai dua gen pada kromosom.
4. Mutasi dalam Pengkodean Pohon
Mutasi dalam pengkodean pohon dapat dilakukan antara lain dengan cara mengubah operator (+, -, *, /) atau nilai yang terkandung pada suatu verteks pohon yang dipilih. Atau, dapat juga dilakukan dengan memilih dua verteks dari pohon dan saling mempertukarkan operator atau nilainya.
2.6. Parameter Genetik
Pengoperasian algoritma genetik dibutuhkan 4 parameter (Juniawati, 2003)yaitu:
1. Probabilitas Persilangan (Persilangan Probability)
Menunjukkan kemungkinan persilangan terjadi antara 2 kromosom. Jika tidak terjadi persilangan maka keturunannya akan sama persis dengan kromosom orangtua, tetapi tidak berarti generasi yang baru akan sama persis dengan generasi yang lama. Jika probabilitas persilangan 100% maka semua keturunannya dihasilkan dari persilangan. Persilangan dilakukan dengan harapan bahwa kromosom yang baru akan lebih baik.
2. Probabilitas Mutasi (Mutasi Probability)
Menunjukkan kemungkinan mutasi terjadi pada gen-gen yang menyusun sebuah kromosom. Jika tidak terjadi mutasi maka keturunan yang dihasilkan setelah persilangan tidak berubah. Jika terjadi mutasi bagian kromosom akan berubah. Jika probabilitas 100%, semua kromosom dimutasi. Jika probabilitasnya 0%, tidak ada yang mengalami mutasi.
3. Jumlah Individu
Menunjukkan jumlah kromosom yang terdapat dalam populasi (dalam satu generasi). Jika hanya sedikit kromosom dalam populasi maka algoritma genetika akan mempunyai sedikit variasi kemungkinan untuk melakukan persilangan antara orang tua karena hanya sebagian kecil dari search space yang dipakai. Sebaliknya jika terlalu banyak maka algoritma genetika akan berjalan lambat.
4. Jumlah Populasi
Menetukan jumlah populasi atau banyaknya generasi yang dihasilkan, digunakan sebagai batas akhir proses seleksi, persilangan, dan mutasi.
2.7. Penelitian-Penelitian Terkait 2.7.1. Penelitian Terdahulu
Agrawal et al.,(2013) meningkatkan kinerja algoritma yang ada dalam hal penghematan waktu dengan menggunakan aturan L'dan serta meningkatkan efisiensi dari pohon keputusan, tetapi juga lebih baik dalam hal Informasi yang dihasilkan.
Laksmi, (2013) dalam penelitian nya melakukan pembahasan dengan membandingkan kinerja ID3, C4.5 dan CART algoritma. Sebuah studi yang dilakukan dengan data kualitatif siswa untuk mengetahui pengaruh data kualitatif dalam keputusan kinerja menggunakan decision tree dari data siswa. Hasil eksperimen menunjukkan bahwa algoritma CART yang memiliki akurasi yang terbaik dalam klasifikasi saat dibandingkan dengan ID3 dan C4.5. Eksperimen ini signifikansi juga menyimpulkan bahwa kinerja siswa dalam ujian dan kegiatan lain yang berpengaruh oleh faktor kualitatif. Di masa depan, yang paling mempengaruhi faktor kualitatif kinerja siswa dapat diidentifikasi menggunakan algoritma genetika.
2.7.2. Perbedaan Penelitian
Perbedaan penelitian yang pernah dilakukan dengan penelitian yang dilakukan oleh peneliti dapat dilihat pada Tabel 2.10.
Tabel 2.10. Perbedaan Penelitian
No Nama Peneliti Persamaan Perbedaan 1 Lakshmi. M.,
A.Martin, R.Mumtaj Begum, V.Prasanna Venkatesan (2013)
Dalam pembahasan meliputi Performance Algoritma C4.5 dalam mengoalah data kualitatif
Melakukan riset perbandingan algoritma c4.5 dengan kinerja ID3, C4.5 dan CART algoritma. Pembahasan Performance dan akurasi hasil analisis beberapa algoritma menggunanakan data kualitatif siswa.
2 Gaurav L.
Agrawal, Hitesh Gupta (2013)
Sama-sama melakukan membahasan untuk menemukan optimasi dalam algoritma C4.5 serta menggabungkan dengan algoritma yang lain
Melakukan pengembangan algoritma decision tree serta meningkatkan kinerja algoritma C4.5 serta dalam hal penghematan waktu dengan menggunakan aturan L'dan.
3 Wei Dai , Wei Ji (2014)
Melakukan pembahasan mengenai algoritma decision tree dengan dalam Algoritma C4.5.
Dalam pembahasan peneliti mengusulkan implementasi MapReduce dalam algoritma C4.5. dengan landasan bahwa dengan perkembangan komputasi awan yang semakin besar dan data besar, algoritma sekuensial pohon keputusan tidak bisa masuk lagi. Pembahasan dilakukan lebih kepada data yang berukuran sangat besar mengingat performance algoritma yang ada tidak akan optimal.
2.7.3. Kontribusi yang Diberikan
Melalui penelitian ini diharapkan dapat diperoleh hasil bahwa penggunaan algoritma genetika mampu mengoptimasi ruang pencarian rules dan menyederhanakan kombinasi rules yang lebih kompleks.
BAB 3
METODOLOGI PENELITIAN
3.1 Pendahuluan
Saat ini cukup banyak peneliti yang telah memperkenalkan beragam metode untuk mengembangkan maupun mengefisiensikan sebuah algoritma. Sebagian peneliti juga meneliti tentang klasifikasi yang paling tepat yang akan di gunakan untuk proses estimasi data.
Begitu juga didalam hal ini, Semua proses yang dilakukan iyalah untuk membangun proses segmentasi klasifikasi yang lebih efisien dari sebelumnya. Proses segmentasi algoritma C4.5 melakukan prediksi terhadap data yang akan menjadi keputusan. Proses klasifikasi dalam algoritma ini menghasilkan cabang-cabang sementara daunnya adalah kelas-kelas atau segmen-segmennya. Sementara proses pemilihan rules yang terjadi memiliki search space yang besar. Metodologi penelitian ini menyertakan algoritma genetika yang menjadi penentu dalam pengoptimalan pencarian dan mengurangi ruang pencarian untuk itu disertakan rincian rencana serta dasar-dasar metode yang digunakan. Untuk menggambarkan proses yang dilakukan dan batasan-batasan dalam metode penelitian disertakan tahapan-tahapan penelitian dan diagram kerja.
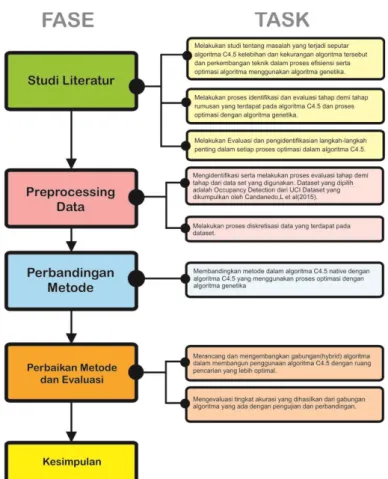
3.2 Tahapan Penelitian
Dalam tahapan kerja dan penelitian ini dilakukan beberapa tahapan sebagai berikut : 1. Penelitian awal
2. Preprocessing dan pengumpulan data 3. Perbandingan metode
4. Perbaikan metode dan evaluasi 5. Kesimpulan
3.2.1 Penelitian Awal
Pada tahapan ini dilakukan pengumpulan bahan dari berbagai sumber pustaka, buku, prosiding, jurnal cetak maupun online, artikel dan sumber-sumber lain yang relevan, yaitu:
1. Melakukan studi tentang masalah yang terjadi seputar algoritma C4.5 kelebihan dan kekurangan algoritma tersebut dan perkembangan teknik dalam proses efisiensi serta optimasi algoritma menggunakan algoritma genetika.
2. Melakukan proses identifikasi dan evaluasi tahap demi tahap rumusan yang terdapat pada algoritma C4.5 dan proses optimasi dengan algoritma genetika.
3. Melakukan Evaluasi dan pengidentifikasian langkah-langkah penting dalam setiap proses optimasi dalam algoritma C4.5.
3.2.2 Preprocessing dan Pengumpulan Data
Tahapan dalam preprosesing data dilakukan beberapa proses, yaitu:
1. Mengidentifikasi serta melakukan proses evaluasi tahap demi tahap dari data set yang digunakan. Dataset yang dipilih adalah Occupancy Detection dari UCI Dataset yang dikumpulkan oleh Candanedo,L et al(2015). Dataset ini berisi tentang deteksi kelayakan sebuah ruangan kantor berdasarkan intensitas cahaya, temperature ruangan, kelembapan dan kadar CO2.
2. Melakukan preprosessing data, yaitu melakukan proses diskretisasi data yang terdapat pada dataset.
3.2.3 Perbandingan Metode
Proses ini dilakukan untuk membandingkan metode dalam algoritma C4.5 native dengan algoritma C4.5 yang menggunakan proses optimasi dengan algoritma genetika. Hal ini dilakukan untuk mendapatkan kinerja algoritma yang terbaik dengan metodologi yang dibentuk.
3.2.4 Perbaikan Metode dan Evaluasi
Untuk tahapan perbaikan metode dan evaluasi, proses yang dilakukan meliputi beberapa hal, yaitu :
1. Merancang dan mengembangkan gabungan(hybrid) algoritma dalam membangun penggunaan algoritma C4.5 dengan ruang pencarian yang lebih optimal.
2. Mengevaluasi tingkat akurasi yang dihasilkan dari gabungan algoritma yang ada dengan pengujian dan perbandingan.
3.2.5 Diagram Kerja
Berdasarkan tahapan penelitian yang telah dijelaskan sebelumnya, pembuatan diagram kerja dibuat untuk memudahkan pemahaman-pemahaman setiap langkah kerja yang harus dilakukan.
Gambar 3.1 Metodologi Penelitian
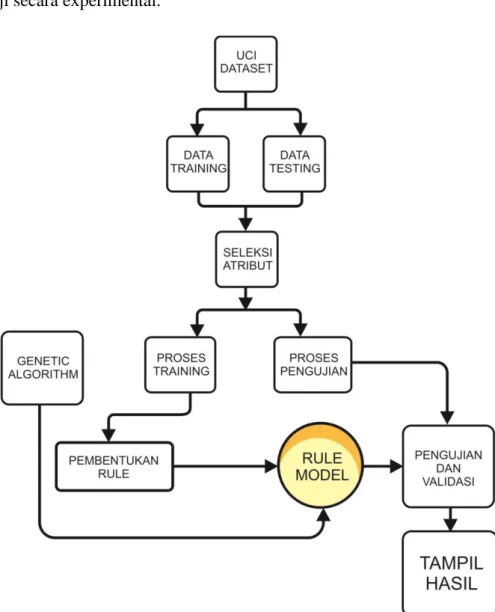
3.2.6 Rancangan penelitian
Model yang terdapat pada rancangan ini diharapkan dapat menghasilkan model pada skala penelitian. Pengambilan nilai perbandingan ruang pencarian rules antara native algoritma C4.5 dengan algoritma C4.5 yang telah dioptimasi oleh algoritma genetika sebagai tolak ukur pada penelitian yang diharapkan mampu mengembangkan metode yang diuji secara experimental.
Gambar 3.2 Rancangan Penelitian
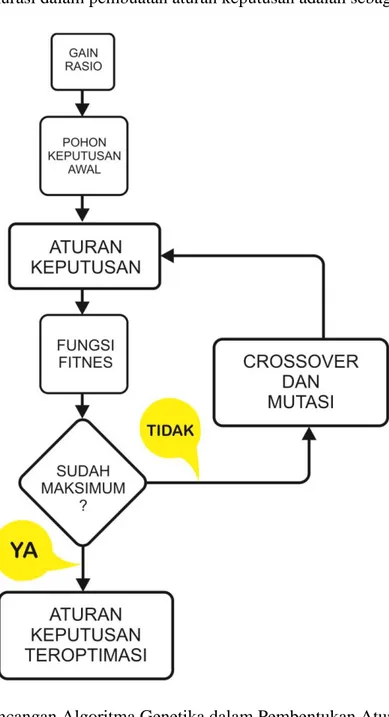
3.2.7 Rancangan Modifikasi C4.5 dengan Algoritma Genetika
Untuk rancangan modifikasi C4.5 dengan algoritma genetika diharapkan dapat meningkatkan akurasi dalam pembuatan aturan keputusan adalah sebagai berikut:
Gambar 3.3 Rancangan Algoritma Genetika dalam Pembentukan Aturan Keputusan
3.2.8 Dataset dan Uji coba
Sebagai pengujian dan proses training digunakan dataset yang diperoleh dari UCI Learning Machine Repository yang telah di donasikan oleh Candanedo,L et al(2015) tentang Accurate occupancy detection. Dataset ini berisi tentang deteksi kelayakan sebuah ruangan kantor berdasarkan intensitas cahaya, temperature ruangan,
kelembapan dan kadar CO2. Jumlah dataset terdiri dari 8 atribut, satu buah atribut tidak disertakan dalam tabel 3.1, yaitu number of data. Baris pada dataset berjumlah 8143 baris. Artinya matrik pada dataset berukuran 8 x 8143.
Tabel 3.1 Dataset UCI Learning Machine Accurate occupancy detection.
No Label Content
1 date time year-month-day
hour:minute:second
2 Temperature in Celsius
3 Relative Humidity %
4 Light Lux
5 CO2 in ppm
6
Humidity Ratio, Derived quantity from temperature and relative humidity
kgwater-vapor/kg-air
7 Occupancy {1=yes,0=no}
BAB 4
HASIL DAN PEMBAHASAN
4.1 Pendahuluan
Dalam bab ini penulis akan memaparkan hasil dan pembahasan dari pengoptimasian pembuatan decision rules pada algoritma C4.5 dengan menggunakan algoritma genetika. Selain itu perbandingan antara ruang pencarian native C4.5 dengan C4.5 yang telah di optimasi dengan algoritma genetika akan di paparkan secara bertahap berikut juga hasil pengujian antara dua buah algoritma tersebut.
4.2 Kinerja Algoritma C4.5
Proses didalam algoritma C4.5 yang pertama adalah menentukan atribut yang menjadi objek akhir dalam keputusan. Ini disebabkan oleh output yang dihasilkan nantinya pada C4.5 adalah decision tree dan proses yang dilakukan oleh algoritma ini menggunakan probabilitas dari total kasus yang menjadi objek akhir tersebut.
Perhitungan selanjutnya adalah algoritma C4.5 menggunakan pembobotan yang diperoleh dari perhitungan entropi yaitu logaritma 2 terhadap nilai probabilitas dari total kasus dengan jumlah entiti setiap atributnya.
Langkah selanjutnya adalah melakukan analisis setiap atribut, menghitung banyaknya kejadian nilai, perhitungan entropi dan gain. Proses perhitungan gain digunakan untuk menentukan node dari pohon keputusan. Nilai gain terbesar akan menjadi node dan segmentasi atau kelas-kelasnya akan menjadi akar(root) sedangkan yang memiliki nilai entiti 0 akan menjadi daunnya.
Proses selanjutnya adalah proses memfilter data sesuai root yang terdapat pada node yang dipilih. Kemudian lakukan secara recursive perhitungan entropi, hitung gain dan filter kembali data sesuai segmentasi dari node yang terpilih.
Beberapa algoritma masih mengutamakan algoritma C4.5 dalam menghasilkan klasifikasi di beberapa jurnal proses C4.5 masih lebih sensitif dibandingkan klasifikasi bayes dan masih lebih mudah di pahami prosesnya dibandingkan dengan Neural Network dan lebih baik untuk data bertipe string. Namun demikian algoritma C4.5 termasuk algoritma yang menghasilkan pohon keputusan atau decision tree sebagai proses akhirnya dan setiap algoritma tersebut memiliki kekurangan dalam ruang pencarian rules base dan perlu dioptimalkan lagi.
Untuk data yang numerik namun kontinu proses dalam algoritma C4.5 mengharuskan peneliti melakukan proses diskritisasi data sehingga data tersebut lebih mudah dioperasionalkan.
4.3 Preprosesing dan Diskritisasi Data
Dataset yang terdapat pada penelitian seperti yang telah disebutkan sebelumnya merupakan data Occupancy Detection dari UCI Dataset yang dikumpulkan oleh Candanedo. Data yang akan diproses merupakan data kontinu dan untuk memudahkan pengoperasionalan algoritma C4.5 maka akan dilakukan preprosesing data. Proses preprosesing pada dataset ini adalah seleksi atribut dan diskritisasi data.
Atribut yang terdapat pada dataset adalah date yang merupakan tanggal dan waktu kapan pengambilan data dilakukan namun data tanggal tidak disertakan dalam penelitian, temperatur ruangan diukur dan dicatat dalam satuan derajat Celsius, relative humidity atau kelembaban relatif ruangan dicatat dalam hitungan persen(%), Light atau cahaya diukur dalam satuan Lux, kadar CO2 didalam ruangan juga diukur dalam ppm, humidity ratio atau perbandingan kelembaban di ukur dalam kgwater- vapor/kg-air dan terakhir adalah occupancy atau kelayakan huni yang ditandai dengan angka biner {1=yes,0=no}.
Proses diskritisasi dan segmentasi data atribut temperatur berkisar antara 19 hingga 23.18 dan memiliki selisih sebesar 4.18 Celcius, oleh karena itu selisih dibagi dua sehingga memiliki batas temp>21.09; temp<=21.09. Begitu juga dengan Relative Humidity dilakukan proses yang sama. Untuk Light data dibagi 4 quartil menjadi Light<200; 200<=Light<618.53; 618.53<=Light<927.8; Light>=927.8, sedangkan CO2 dibagi 5. Seperti tertera pada tabel 4.1 dibawah ini.
Tabel 4.1 Segmentasi data kontinu
No Label Content Seleksi Segmentasi
1 date time year-month-day
hour:minute:second No - 2 Temperature
in Celsius Yes temp>21.09;
temp<=21.09 3 Relative Humidity
% Yes hum>27.93125;
hum<=27.93125
4 Light Lux Yes
Light<200;
200<=Light<618.53;
618.53<=Light<927.8;
Light>=927.8
5 CO2 in ppm Yes
CO2<405.7;
405.7<=CO2<811.4;
811.4<=CO2<1217.1;
1217.1<=CO2<1622.8;
CO2>=1622.8
6
Humidity Ratio, Derived quantity from temperature and relative humidity
kgwater-vapor/kg-air No -
7 Occupancy {1=yes,0=no} Yes Keputusan akhir
Tidak semua atribut diproses didalam algoritma C4.5, seperti date, number of data dan Humidity Ratio dikarenakan pada penelitian ini proses keputusan tidak melibatkan unsur waktu dan urutan baris pada dataset sementara Humidity Ratio adalah hasil perbandingan temperature dan relative humidity.
4.4 Perbandingan Metode
Perbandingan akan dilakukan untuk melihat kinerja dan optimalitas antara algoritma C4.5 native terhadap versi modifikasi C4.5 yang telah dioptimasi dengan algoritma genetika. Untuk itu setiap proses dalam algoritma C4.5 akan diuraikan dengan melakukan training menggunakan dataset yang tersedia dan pengujian mengunakan output yang dihasilkan.
4.4.1 Training pada Algoritma C4.5
Proses training dilakukan dengan menggunakan dataset yang telah tersedia. Parameter yang digunakan untuk proses training menggunakan native algoritma C4.5 ataupun algoritma C4.5 yang dioptimasi oleh algoritma genetika menggunakan dataset dan atribut yang sama.
Dataset Occupancy Detection dari UCI Learning Machine memiliki matrik sebanyak 8 x 8143 baris dan kolom. Sample dataset ditunjukkan pada tabel 4.2 dibawah ini.
Tabel 4.2 Sampel dataset Occupancy Detection berukuran matrik 8 x 15
Number
of Data Date Temper
ature Humidity Light CO2 Humidity Ratio
Occupan cy 1
04/02/2015
17:51 23.18 27.272 426 721.25 0.004793 1 2
04/02/2015
17:51 23.15 27.2675 429.5 714 0.004783 1 3
04/02/2015
17:53 23.15 27.245 426 713.5 0.004779 1 4
04/02/2015
17:54 23.15 27.2 426 708.25 0.004772 1 5
04/02/2015
17:55 23.1 27.2 426 704.5 0.004757 1
6
04/02/2015
17:55 23.1 27.2 419 701 0.004757 1
7
04/02/2015
17:57 23.1 27.2 419
701.66
67 0.004757 1
8
04/02/2015
17:57 23.1 27.2 419 699 0.004757 1
9
04/02/2015
17:58 23.1 27.2 419
689.33
33 0.004757 1
10
04/02/2015
18:00 23.075 27.175 419 688 0.004745 1 11
04/02/2015
18:01 23.075 27.15 419 690.25 0.004741 1 12
04/02/2015
18:02 23.1 27.1 419 691 0.004739 1
13
04/02/2015
18:03 23.1 27.166667 419 683.5 0.004751 1 14
04/02/2015
18:04 23.05 27.15 419 687.5 0.004734 1 15
04/02/2015
18:04 23 27.125 419 686 0.004715 1
Proses selanjutnya adalah menentukan atribut yang menjadi keputusan akhir, dalam penelitian ini atribut occupancy yang berisikan 1=yes atau no=0 yang menjadi keputusan akhir dalam proses training. Setelah atribut keputusan dipilih proses selanjutnya dalam algoritma C4.5 adalah proses preprosesing data seperti yang telah dibahas sebelumnya. Kemudian data tersebut dianalisis, pada data yang tertera memiliki 8143 total kasus yang terdiri dari 1729 kasus berisikan 1 atau “yes” dan sisanya 6414 kasus yang berisikan 0 atau “no” pada atribut Occupancy.
Perhitungan selanjutnya adalah mencari nilai entropy dari keseluruhan dataset yang dipilih, proses perhitungan entropy menggunakan probabilitas antara jumlah total kasus yang berisikan 1 dengan total kasus keseluruhan. Selanjutnya dikali dengan Log(probabilitas,total jenis kasus atribut Occupancy). Perhitungan seperti tertera dibawah ini.
( ) ( (
) (
)) ( (
) ( )) ( )
Berikut ini adalah tabel hasil perhitungan entropy menggunakan dataset Occupancy Detection.
Tabel 4.3 Hasil perhitungan entropy keseluruhan dataset Total
Kasus
Total
"1"
Total
"0" Entropy(S)
8143 1729 6414 0.74591
Setelah mendapatkan entropy dari keseluruhan kasus selanjutnya, lakukan analisis untuk setiap atribut. Hitung jumlah kasus yang merupakan himpunan bagian dari atribut temperature yang lebih kecil dari 21,09 Celcius atau temp<21,09, dan hitung jumlah kasus not occupied dan jumlah kasus yang occupied. Selanjutnya sebaliknya hitung juga temperature yang lebih besar sama dengan 21,09 atau temp l21,09. Kemudian hitunglah entropy setiap segmennya. Perhitungan jumlah kasus pada setiap segmen untuk atribut temperature akan digunakan untuk menghitung probabilitas dan selanjutnya akan di gunakan juga untuk menghitung entropi setiap segmen. Perhitungannya adalah sebagai berikut.