KLASIFIKASI CITRA AKSARA BALI MENGGUNAKAN METODE SUPPORT VECTOR MACHINE
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Informatika
Oleh:
Edrick Hernando 175314002
PROGRAM STUDI INFROMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
2021
ii
IMAGE CLASSIFICATION OF BALINESE SCRIPT USING SUPPORT VECTOR MACHINE METHOD
THESIS
Presented as Partial Fulfillment of The Requirements To Obtain the Sarjana Komputer Degree
In Informatic Study Program
by:
Edrick Hernando 175314002
INFORMATICS STUDY PROGRAM FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
2021
iii
iv
v
HALAMAN PERSEMBAHAN
“Percayalah pada apa yang engkau perjuangkan, jika engkau sendiri tidak mempercayainya, siapa lagi yang akan percaya”
vi
vii
viii ABSTRAK
Aksara bali yang berkembang di pulau bali dapat ditemukan pada daun lontar.
Aksara yang cukup banyak ini perlu dilakukan identifikasi dengan bantuan teknologi untuk tujuan pelestarian aksara.
Proses identifikasi tersebut dapat dilakukan dengan menggunakan metode support vector machine. Metode support vertor machine dilakukan dengan cara memisahkan dua buah kelas yang berbeda menggunakan hyperplane.
Hasil klasifikasi berupa akurasi beserta hasil prediksi label untuk inputan data baru. Akurasi yang didapatkan mencapai 93.6% untuk mengklasifikasikan 18 kelas dengan jumlah data masing-masing kelas 20 buah dengan menggunakan ciri Intensity of Character berukuran 5x5 dan validasi 5-fold validation.
Dapat disimpulkan bahwa SVM dapat mengklasifikasikan citra aksara Bali dengan akurasi yang cukup tinggi.
Kata kunci : Aksara Bali, Intensity of Character, Support Vector Machine, K- Fold cross validation.
ix ABSTRACT
The Balinese script that develops in Bali island can be found on palm leaves.
The number of characters needed to be identified with the help of technology for the purpose of preserving characters.
This identification process can be done using the support vector machine method. The support vertor machine method is done by separating two different classes using a hyperplane.
The classification results are in the form of accuracy and label prediction results for new data input. The accuracy obtained reached 93.6% for classifying 18 classes with the amount of data for each class of 20 using the Intensity of Character feature of 5x5 pixel and 5-fold validation.
It can be concluded that SVM can classify Balinese script images with a fairly high accuracy.
Key words : Balinese Script, Intensity of Character, Support Vector Machine, K-Fold cross validation.
x
KATA PENGANTAR
Puji dan syukur penulis panjatakan kepada Tuhan Yang Maha Esa atas rahmat dan karunia-Nya, sehingga penulis dapat menyelesaikan tugas akhir dengan judul “Klasifikasi Citra Aksara Bali Menggunakan Metode Support Vecotr Machine” dengan baik dan tepat waktu. Tugas akhir ini merupakan salah satu persyaratan yang wajib untuk ditempuh sebagai syarat akademik untuk memperoleh ggelar sarjana komputer program studi Informatika Universitas Sanata Dharma Yogyakarta.
Selama proses penelitian, penulis mendapat banyak dukungan dari berbagai pihak sehingga sudah sepantasnya penulis menyampaikan terima kasih yang kepada:
1. Ibu Dr. Anastasia Rita Widiarti, M.Kom selaku dosen pembimbing tugas akhir yang telah bersedia memberikan arahan, masukan, waktu serta motivasi kepada penulis selama menyelesaikan skripsi.
2. Keluarga tercinta yang selalu memberikan dukungan dan doa sehingga membuat penulis semakin semganat dalam mengerjakan serta menyelesaikan tugas akhir ini.
3. Bapak Sudi Mungkasi, S.Si., M.Math.Sc., Ph.D. selaku dekan Fakultas Sains dan Teknologi.
4. Seluruh dosen Informatika Universitas Sanata Dharma yang telah mendidik dan memberikan ilmu pengetahuan kepada penulis yang digunakan sebagai bekal untuk menyelesaikan tugas akhir ini.
5. Teman-teman yang sudah meluangkan wakut dan tenaganya dalam membantu penulis dalam memberikan solusi ketika mengalami kebuntuan.
6. Teman-teman dari server Chill Out Impact Discord yang senantiasa memberikan saran dalam penulisan naskah dan menemani penulis melepas stress dalam pengerjaan tugas akhir.
7. Saudara Felix Prihantoro yang sudah suka rela meminjamkan laptop-nya untuk membantu penulis mengerjakan program tugas akhir.
xi
xii DAFTAR ISI
HALAMAN PERSETUJUAN ... Error! Bookmark not defined.
HALAMAN PENGESAHAN ... iii
HALAMAN PERSEMBAHAN ... v
PERNYATAAN KEASLIAN KARYA ... Error! Bookmark not defined. LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH .. vi
ABSTRAK ... viii
ABSTRACT ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR ISI GAMBAR ... xvi
BAB 1. PENDAHULUAN ... 1
1.1. LATAR BELAKANG ... 1
1.2. RUMUSAN MASALAH ... 2
1.3. TUJUAN ... 2
1.4. MANFAAT PENELITIAN ... 2
1.5. BATASAN MASALAH ... 3
1.6. SISTEMATIKA PENULISAN ... 3
BAB 2. LANDASAN TEORI ... 4
2.1 AKSARA BALI ... 4
2.2 PENGERTIAN CITRA... 5
2.3 PEMORESESAN CITRA... 6
2.3.1 Binerisasi ... 6
2.3.2 Filtering ... 6
2.3.3 Segmentasi ... 6
2.3.4 Penipisan ... 7
2.4 EKSTRAKSI CIRI ... 7
xiii
2.5 SUPPORT VECTOR MACHINE ... 8
2.5.1. Multi Class SVM ... 16
2.6 K-FOLD CROSS VALIDATION ... 18
BAB 3. METODE PENELITIAN... 19
3.1. PENGUMPULAN DATA ... 19
3.2. KEBUTUHAN PERANGKAT HARDWARE DAN SOFTWARE ... 20
3.3. LABELING DATA MANUAL ... 20
3.4. GAMBARAN UMUM KLASIFIKASI SVMMENGGUNAKAN DATA CITRA AKSARA BALI ... 22
3.5. DESAIN ALAT UJI ... 30
3.6. DESAIN USER INTERFACE... 42
3.7. SKENARIO PENGUJIAN ... 43
BAB 4. HASIL PENELITIAN DAN ANALISIS ... 45
4.1. PENGUMPULAN DATA ... 45
4.2. IMPLEMENTASI PEMBAGIAN DATA TRAINING DAN TESTING ... 46
4.3. IMPLEMENTASI KALSIFIKASI SVM ... 47
4.4. PENGUJIAN DAN EVALUASI ... 50
4.5.1. Pengujian Data Imbalance ... 51
4.5.2. Pengujian Data Balance ... 57
BAB 5. PENUTUP ... 79
5.1. KESIMPULAN ... 79
5.2. SARAN... 79
Daftar Pustaka ... 80
xiv
DAFTAR ISI TABEL Tabel 2.1 Huruf Konsonan (Aksara Wyanjana)
https://id.wikipedia.org/wiki/Aksara_Bali ... 4
Tabel 2.2 Huruf Vokal (Aksara Swara) ... 5
Tabel 2.3 Ilustrasi citra ukuran 9x9 ... 8
Tabel 2.4 Ilustrasi hasil IoC citra 9x9 menjadi 3x3 ... 8
Tabel 2.5 Contoh data sampel ... 12
Tabel 2.6 Plot hyperplane ... 14
Tabel 2.7 Hasil Klasifikasi ... 15
Tabel 2.8 Contoh kombinasi biner 3 kelas dengan metode one against one ... 16
Tabel 2.9 Contoh kombinasi biner 3 kelas dengan metode one against all ... 18
Tabel 3.1 Hasil labeling data ... 20
Tabel 3.2 Atribut dan label ke-5 citra aksara Bali ... 22
Tabel 3.3 Matrix dari ke-5 persamaan ... 23
Tabel 3.4 Representasi citra biner dalam matlab ... 32
Tabel 3.5 Contoh hasil ekstraksi ciri IoC ukuran 3x3 ... 36
Tabel 3.6 3-fold cross validation ... 42
Tabel 4.1 Array yang menyimpan ciri dan label citra ... 46
Tabel 4.2 Contohp embagian data latih dengan 3 fold ... 47
Tabel 4.3 Contoh [embagian data uji dengan 3 fold ... 47
Tabel 4.4 Implementasi fungsi SVM matlab ... 48
Tabel 4.5 Variabel rank ... 49
Tabel 4.6 Hasil voting ... 49
Tabel 4.7 Variabel output ... 50
Tabel 4.8 Confusion Matrix Hasil klasifikasi data set imbalance dengan IoC=4 7 Fold ... 65
Tabel 4.9 Confusion Matrix Hasil Klasifikasi data set balance dengan IoC=5 5 Fold ... 66
Tabel 4.10 Durasi Klasifikasi dengan IoC=3 data imbalance ... 67
Tabel 4.11 Durasi Klasifikasi dengan IoC=4 data imbalance ... 67
Tabel 4.12 Durasi Klasifikasi dengan IoC=5 data imbalance ... 68
xv
Tabel 4.13 Durasi Klasifikasi dengan IoC=3 data balance ... 68
Tabel 4.14 Durasi Klasifikasi dengan IoC=4 data balance ... 69
Tabel 4.15 Durasi Klasifikasi dengan IoC=5 data balance ... 69
Tabel 4.16 Hasil pengujian data tunggal ... 74
Tabel 4.17 Hasil Pengujian Keseluruhan ... 76
xvi
DAFTAR ISI GAMBAR
Gambar 2.1 merupakan ilustrasi SVM saat menentukan Hyperplane terbaik yang
mungkin untuk set data (Nugroho dkk., 2003) ... 9
Gambar 2.2 Pemetaan data ke ruang vektor berdimensi yang lebih tinggi ... 12
Gambar 2.3 Visualisasi hyperplane data uji ... 14
Gambar 2.4 Skema klasifikasi menggunakan metode SVM one against one ... 17
Gambar 2.5 Skema Klasifikasi dengan metode one against all ... 18
Gambar 3.1 Data Citra Aksara Bali ... 19
Gambar 3.2 Diagram desain alat uji ... 30
Gambar 3.3 Diagram Preprocessing ... 31
Gambar 3.4 Citra aksara Bali yang telah dibinerkan ... 32
Gambar 3.5 Citra sebelum dan setelah cropping ... 33
Gambar 3.6 Citra sebelum dan setelah di resize. ... 33
Gambar 3.7 Citra sebelum dan setelah thinning ... 34
Gambar 3.8 Klasifikasi dengan 3 kelas (Haritama, 2017) ... 37
Gambar 3.9 kelas 1 dan kelas 2 ... 37
Gambar 3.10 kelas 1 dan 3 ... 38
Gambar 3.11 kelas 2 dan kelas 3 ... 38
Gambar 3.12 Hasil voting ... 39
Gambar 3.13 Visualisai pemodelan one against all... 41
Gambar 3.14 Desain User Interface ... 42
Gambar 4.1 Penyimpanan Citra Aksara Bali ... 45
Gambar 4.2 Grafik Akurasi dengan IoC=3 dan 3-Fold data imbalance ... 51
Gambar 4.3Grafik Akurasi dengan IoC=3 dan 5-Fold data imbalance ... 52
Gambar 4.4 Grafik Akurasi dengan IoC=3 dan 7-Fold data imbalance ... 52
Gambar 4.5 Grafik Akurasi dengan IoC=4 dan 3-Fold data imbalance ... 53
Gambar 4.6 Grafik Akurasi dengan IoC=4 dan 5-Fold data imbalance ... 54
Gambar 4.7 Grafik Akurasi dengan IoC=4 dan 7-Fold data imbalance ... 54
Gambar 4.8 Grafik Akurasi dengan IoC=5 dan 3-Fold data imbalance ... 55
Gambar 4.9 Grafik Akurasi dengan IoC=5 dan 5-Fold data imbalance ... 56
xvii
Gambar 4.10 Grafik Akurasi dengan IoC=5 dan 7-Fold data imbalance ... 57
Gambar 4.11 Grafik Akurasi dengan IoC=3 dan 3-Fold data balance ... 57
Gambar 4.12 Grafik Akurasi dengan IoC=3 dan 5-Fold data balance ... 58
Gambar 4.13 Grafik Akurasi dengan IoC=3 dan 7-Fold data balance ... 59
Gambar 4.14 Grafik Akurasi dengan IoC=4 dan 3-Fold data balance ... 60
Gambar 4.15 Grafik Akurasi dengan IoC=4 dan 5-Fold data balance ... 60
Gambar 4.16 Grafik Akurasi dengan IoC=4 dan 7-Fold data balance ... 61
Gambar 4.17 Grafik Akurasi dengan IoC=5 dan 3-Fold data balance ... 62
Gambar 4.18 Grafik Akurasi dengan IoC=5 dan 5-Fold data balance ... 63
Gambar 4.19 Grafik Akurasi dengan IoC=5 dan 7-Fold data balance ... 63
Gambar 4.20 Grafik Akurasi SVM dengan kernel RBF ... 70
Gambar 4.21 Grafik Akurasi SVM dengan kernel polynomial ... 71
Gambar 4.22 Perbandingan akurasi dengan Kernel Linear, RBF, dan Polynomial ... 71
Gambar 4.23 Grafik Akurasi SVM One against All ... 72
Gambar 4.24 Perbandingan akurasi pemodelan One against One dengan One against All ... 72
Gambar 4.25 Hasil uji klasifikasi dengan Data Tunggal ... 73
1
BAB 1. PENDAHULUAN
1.1. Latar Belakang
Aksara adalah suatu simbol visual yang tertera pada kertas maupun media lainnya seperti daun lontar untuk mengungkapkan unsur-unsur yang ekspresif dalam suatu bahasa. Aksara sering digunakan pada zaman kerajaan ataupun peradaban kuno. Salah satu aksara yang ditemukan dalam daun lontar adalah aksara Bali. Seiring waktu aksara sudah jarang digunakan lagi dan mayoritas menggunakan abjad alfabet. Maka informasi dari aksara yang ada akan hilang seiring waktu jika tidak dilestarikan
Hal ini memunculkan sebuah ide di mana aksara yang tersimpan pada daun lontar dapat dibaca dan di identifikasi oleh suatu sistem secara otomatis. Ada beberapa hal yang harus dilakukan untuk membuat sistem tersebut, salah satunya membuat database yang menyimpan aksara yang ada pada lontar. Database tersebut yang akan digunakan untuk proses identifikasi. Proses identifikasi dilakukan dengan melakukan klasifikasi. Akan tetapi untuk melakukannya diperlukan sekumpulan data.
Data set yang digunakan pada penelitian ini merupakan hasil dari sebuah penelitian mengenai segmentasi citra aksara Bali. Data set yang digunakan sudah dilabeli dengan menggunakan hasil label clustering dari penelitian sebelumnya yang nantinya akan digunakan dalam proses klasifikasi. Klasifikasi merupakan salah satu supervised learning. Sehingga data yang sudah ada hanya akan divalidasi satu sama lain.
Salah satu metode klasifikasi yang dapat digunakan adalah Support Vector Machine atau SVM. Support Vector Machine merupakan superivsed learning algorithm yang berusaha menemukan hyperplane yang terbaik antar dua buah class pada input space. Berdasarkan penelitian yang dilakukan oleh Sianturi, metode SVM dapat digunakan dalam klasifikasi tulisan tangan aksara Batak Toba dengan akurasi mencapai 83.7607% (Sianturi, 2019). Lalu berdasarkan penelitian yang dilakukan oleh Yulianti, dkk, dengan metode SVM dapat digunakan untuk mengklasifikasikan Aksara Sasak dengan akurasi mencapai 92.52% (Yulianti dkk.,
2019). Perbedaan yang dilakukan dari kedua penelitian yang disebutkan tadi adalah pertama, data yang digunakan pada penelitian ini berupa aksara Bali. Kedua ekstraksi ciri yang digunakan dalam penelitian ini adalah Intensity of Character (IoC), sedangkan pada penelitian yang dilakukan oleh Sianturi, menggunakan Freeman Chain Code (FCC) dan penelitian yang dilakukan oleh Yulianti, dkk, menggunakan Moment Invariant. Belum ada penelitian yang menangani klasifikasi citra aksara Bali dengan menggunakan metode SVM.
Pada data citra aksara Bali yang akan digunakan dalam penelitian ini, SVM dapat digunakan untuk mengklasifikasikan data tersebut. Hal ini dikarenakan SVM mencari hyperplane yang terbaik antara kelas setiap data pada input space.
Pencarian hyperplane juga dapat dilakukan secara linear maupun non-linear yang memungkinkan data dapat dipisahkan oleh hyperplane secara akurat.
1.2. Rumusan Masalah
Rumusan Masalah pada penelitian ini adalah sebagai berikut :
1. Bagaimana cara membangun sistem menggunakan metode SVM untuk mengklasifikasikan citra aksara Bali?
2. Berapa akurasi yang didapat dari penerapan metode SVM dengan menggunakan K-Fold Cross Validation?
1.3. Tujuan
Tujuan dari penelitian ini adalah sebagai berikut :
1. Membangun sistem yang mengklasifikasikan citra aksara Bali dengan menggunakan metode SVM.
2. Mengetahui akurasi dari penerapan metode SVM dengan menggunakan K- Fold Cross Validation.
1.4. Manfaat Penelitian
Manfaat dari penelitian ini adalah sebagai berikut:
1. Menambah pengetahuan mengenai algoritma dan penggunaan dari Support Vector Machine untuk diterapkan dalam data berbentuk citra aksara.
2. Membantu pihak-pihak yang terkait dalam penelitian citra aksara.
1.5. Batasan Masalah
Batasan-batasan masalah dari penelitian ini adalah:
1. Data citra yang digunakan adalah data citra aksara Bali sebanyak 1001 dalam bentuk data digital.
2. Ekstraksi ciri menggunakan ciri Intencity of Character yang berukuran 3X3, 4X4, dan 5X5.
3. Validasi menggunakan K-Fold Cross Validation dengan nilai k yang digunakan adalah 3, 5, dan 7
1.6. Sistematika Penulisan BAB 1: PENDAHULUAN
Bab ini berisi tentang latar belakang masalah, rumusan masalah, tujuan, manfaat, batasan masalah serta sistematika penulisan dari penelitian yang akan dilakukan
BAB 2: LANDASAN TEORI
Bab ini berisi tentang teori-teori dasar yang berkaitan dengan penelitian yang akan dilakukan, yang meliputi dari objek yang digunakan, metode preprocessing yang digunakan, ekstraksi ciri yang digunakan, dan klasifikasi yang digunakan.
BAB 3: METODOLOGI PENELITIAN
Bab ini berisi tentang langkah-langkah yang dilakukan dalam penelitian yang bertujuan untuk menjawab dan menyelesaikan rumusan masalah yang dimiliki.
BAB 4: HASIL PENELTIAN DAN ANALISIS
Bab ini berisi tentang penjelasan mengenai sistem yang akan dibangun, penerapan algoritma serta rancangan yang telah dibuat, cara penggunaan sistem, serta hasil analisa dari pengujian-pengujian yang dilakukan.
BAB 5: PENUTUP
Bab ini berisi kesimpulan dari hasil penelitian serta saran yang diusulkan untuk dapat mengembangkan penelitian ini.
4
BAB 2.
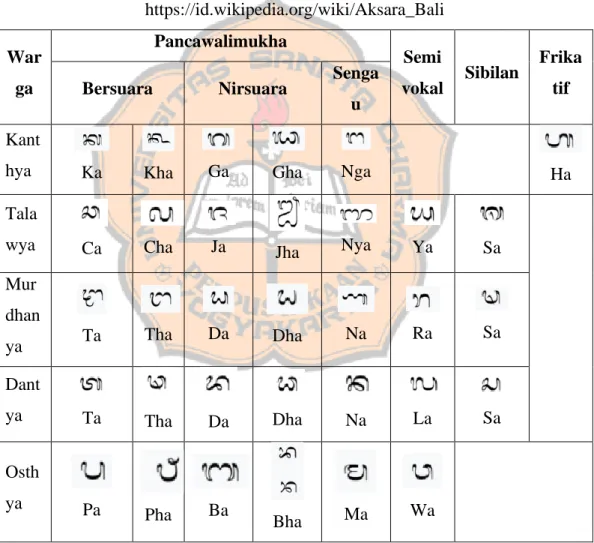
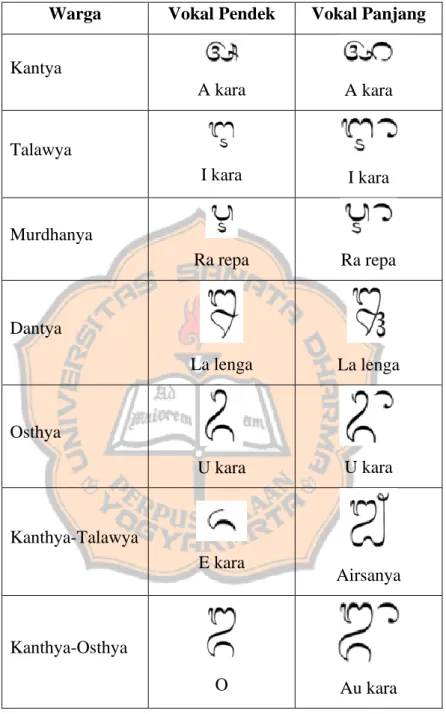
LANDASAN TEORI 2.1 Aksara BaliAksara Bali dikenal juga sebagai hanacaraka merupakan salah satu aksara tradisional Nusantara yang berkembang di pulau Bali, Indonesia. Aksara ini umum digunakan untuk menulis dalam bahasa Bali ataupun Sansekerta. Aksara Bali memiliki 33 huruf konsonan yang dapat dilihat pada Tabel 2.1 dan 14 huruf vokal yang dapat dilihat pada Tabel 2.2.
Tabel 2.1 Huruf Konsonan (Aksara Wyanjana) https://id.wikipedia.org/wiki/Aksara_Bali War
ga
Pancawalimukha
Semi
vokal Sibilan Frika tif Bersuara Nirsuara Senga
u Kant
hya Ka Kha Ga Gha Nga Ha
Tala
wya Ca Cha Ja Jha Nya Ya Sa
Mur dhan
ya Ta Tha Da Dha Na Ra Sa
Dant
ya Ta Tha Da Dha Na La Sa
Osth
ya Pa Pha Ba
Bha Ma Wa
Tabel 2.2 Huruf Vokal (Aksara Swara) https://id.wikipedia.org/wiki/Aksara_Bali
Warga Vokal Pendek Vokal Panjang
Kantya
A kara A kara
Talawya
I kara I kara
Murdhanya
Ra repa Ra repa
Dantya
La lenga La lenga
Osthya
U kara U kara
Kanthya-Talawya
E kara
Airsanya
Kanthya-Osthya
O Au kara
2.2 Pengertian Citra
Citra adalah kombinasi antara titik, garis, bidang, dan warna untuk menciptakan suatu objek-biasanya objek fisik atau manusia. Citra didefinisikan sebagai suatu fungsi kontinu dalam dua dimensi dari intensitas cahaya (Gonzalez
& Woods, 2002). Di mana setiap titik citra dapat dinyatakan dengan rumus
0 < 𝑓(𝑥, 𝑦) < ∞ ( 2.1) Dengan 𝑓(𝑥, 𝑦) menyatakan intensitas cahaya pada lokasi (𝑥, 𝑦).
Citra digital dapat digambarkan sebagai suatu matriks yang terdiri atas baris dan kolom, di mana setiap elemennya merupakan nilai intensitas kecerahan. Titik dari setiap matriks dinamakan dengan piksel. Citra digital merupakan kumpulan dari piksel dengan jumlah piksel tertentu.
2.3 Pemoresesan Citra
Pemrosesan Citra merupakan pengolahan gambar dengan menggunakan komputer sehingga menjadi citra dengan kualitas yang lebih baik (Widiarti &
Himamunanto, 2013). Pengolahan atau pemrosesan citra dilakukan pada setiap piksel (x,y) agar didapatkan hasil yang maksimal.
2.3.1 Binerisasi
Binerisasi merupakan tahap pertama dalam mengolah piksel pada suatu citra. Dalam proses ini dilakukan pemisahan latar obyek dengan obyek melalui penentuan nilai ambang threshold. Binerisasi mengubah citra menjadi citra hitam putih di mana nilai elemen dalam matriks citra menjadi 1 yang berarti warna putih dan 0 yang berarti warna hitam.
2.3.2 Filtering
Filtering atau reduksi derau merupakan proses penghilangan noise yang terdapat pada sebuah citra digital. Tahap ini menjadi salah satu hal penting dalam pemrosesan citra karena mampu menghilangkan piksel-piksel yang tidak diperlukan sehingga mengurangi error dalam proses pengenalan obyek.
2.3.3 Segmentasi
Segmentasi merupakan proses pemisahan citra menjadi obyek-obyek tersendiri yang ada dalam citra tersebut. Segmentasi terbagi menjadi dua tahap, pertama pemisahan obyek dengn obyek lain yang berada pada satu baris yang sama. Kedua mendapatkan huruf secara individu dengan mendapatkan kolom- kolom karakter citra aksara dari baris yang telah dipotong pada tahap pertama.
2.3.4 Penipisan
Penipisan merupaakn metode digunakan untuk mendapatkan rangka objek, dengan cara mereduksi obyek citra yang menjadi suatu informasi yang sifatnya mendasar. Salah satu metodenya yaitu Rosenfeld yang mana metode ini bekerja dengan cara membuang bagian piksel yang merupakan bagian tepi dari obyek citra.
2.4 Ekstraksi Ciri
Ekstraksi ciri merupakan tahap untuk memperoleh ciri dari suatu obyek yang ada pada citra, di mana ciri tersebut menunjukan obyek tersebut berbeda dengan obyek lainnya. Salah satu metode yang cukup dikenal dalam melakukan tahap ini adalah Intensity of Character.
Intensity of character mengekstrak ciri dari citra menggunakan matriks berukuran NxN, di mana setiap unit 1x1 berisikan n pixel hasil penjumlahan pixel yang bernilai 0. Sebagai contoh sederhana, berikut merupakan proses gambaran untuk mendapatkan ciri IoC berukuran 3x3.
Jika terdapat citra biner berukuran sebesar 9x9 piksel seperti yang terlihat pada Tabel 2.3, maka untuk setiap unit IoC 1x1 nya akan mencakup matrix sebesar 3x3.
Tabel 2.3 Ilustrasi citra ukuran 9x9
1 1 1 1 1 1 0 1 1
1 1 1 0 0 0 0 0 1
1 0 0 1 1 0 1 1 0
0 0 0 1 1 0 0 1 0
0 0 1 1 1 0 0 1 0
1 0 1 1 1 1 0 1 1
1 0 1 0 1 0 0 1 1
1 1 0 1 1 0 0 1 1
1 1 1 1 1 1 1 1 1
Untuk setiap unit 1x1, akan menyimpan nilai yang merupakan banyaknya piksel berwarna hitam untuk setiap area 3x3nya. Maka pixel bernilai 0 atau berwarna hitam akan dijumlahkan pada setiap unitnya di mana perbedaan warna menunjukkan perbedaan unitnya. Ciri ini yang akan digunakan dalam proses klasifikasi. Bentuk dari citra biner pada Tabel 2.3 yang dikenai IoC 3x3 dapat dilihat pada Tabel 2.4.
Tabel 2.4 Ilustrasi hasil IoC citra 9x9 menjadi 3x3 2 4 4
6 2 5 2 3 2
2.5 Support Vector Machine
Support Vector Machine (SVM) pertama kali diperkenalkan oleh Vapnik pada tahun 1992 sebagai rangkaian harmonis konsep-konsep unggulan dalam bidang pattern recognition. SVM merupakan metode machine learning yang bertujuan untuk menemukan hyperplane terbaik yang memisahkan dua buah kelas pada input space. SVM adalah sistem pembelajaran yang menggunakan ruang hipotesa berupa fungsi-fungsi linier dalam sebuah ruang fitur berdimensi tinggi (Yulianti dkk., 2019).
Gambar 2.1 merupakan ilustrasi SVM saat menentukan Hyperplane terbaik yang mungkin untuk set data (Nugroho dkk., 2003)
Pada Gambar 2.1, terdapat ilustrasi yang menjelaskan cara SVM mencari Hyperplane. Terdapat dua label pada Gambar 2.1, di mana pada kedua gambar berusaha mencari garis pemisah atau discrimination boundaries. Gambar 2.1 (a) terdapat discrimination boundaries yang banyak, akan tetapi tidak diketahui yang mana yang dapat memisahkan kedua buah kelas secara maksimal.
Pada Gambar 2.1 (b), kedua buah kelas dipisahkan dengan menggunakan SVM, di mana didapatkan discirimination boundaries terbaik yang disebut Hyperplane dalam SVM. Dalam pencarian hyperplane dengan menggunakan SVM, terdapat pula margin yang merupakan jarak antara data dari suatu kelas yang paling dekat dengan hyperplane.
Metode SVM berkaitan dengan penambangan data karena mampu memprediksi label suatu data baru. Fungsi ini didefnisikan sebagai :
𝑓(𝑥) = 𝑤. 𝑥 + 𝑏 ( 2.2) Setiap data latih dinyatakan oleh (𝑥𝑖, 𝑦𝑖), di mana i=1, 2, ..., N, dan 𝑥𝑖= {𝑥𝑖1, 𝑥𝑖2 , … , 𝑥𝑖𝑞 }𝑇 merupakan fitur set untuk data latih ke-i.
𝑦𝑖𝜖{−1, +1} menyatakan label kelas. Hyperplane klasifikasi linier SVM, dinotasikan dengan :
𝑤. 𝑥𝑖 + 𝑏 = 0 ( 2.3)
W dan b adalah parameter model. 𝑤. 𝑥𝑖 merupakan inner-product dalam antara w dan 𝑥𝑖. Data 𝑥𝑖 yang masuk ke dalam kelas -1 adalah data yang memenuhi pertidaksamaan berikut:
𝑤. 𝑥𝑖 + 𝑏 ≤ −1 ( 2.4)
Sementara data 𝑥𝑖 yang masuk ke dalam kelas +1 adalah data yang memenuhi pertidaksamaan berikut :
𝑤. 𝑥𝑖 + 𝑏 ≥ +1 ( 2.5) Keterangan w=bobot, xi=nilai masukan atribute ke-i, b=bias
Margin terbesar dapat ditemukan dengan memaksimalkan nilai jarak antara hyperplane dan titik terdekatnya, yaitu 1
||𝑤||. Hal ini dapat dirumuskan sebagai permasalahan Quadratic Programming (QP), yaitu mencari titik minimal persamaan (2.8), dengan memperhatikan constraint pertidaksamaan (2.7)
min𝑤 → 𝜏(𝑤) =1
2‖𝑤⃗⃗ ‖2 ( 2.6) 𝑦𝑖(𝑥𝑖 ∙ 𝑤 + 𝑏) − 1 ≥ 0 ( 2.7) Permasalahan ini dapat dipecahkan dengan berbagai teknik komputasi, di
antaranya Lagrange Mulitplier
( 2.8) Keterangan a=Lagrange mulitpliers, yang bernilai nol atau positif (𝑎 ≥ 0)
Nilai optimal dari persamaan dapat dihitung dengan meminimalkan L terhadap w dan b, dan memaksimalkan L terhadap ai. Dengan memperhatikan sifat bahwa pada titik optimal gradien L=0, persamaan dapat dimodifikasi sebagai maksimalisasi problem yang hanya mengandung ai sebagaimana persamaan (2.9) dan pertidaksamaan (2.10) berikut
𝐿𝑑 = ∑ 𝑎𝑖 −1
2
𝑙𝑖=1 ∑𝑙𝑖,𝑗=1𝑎𝑖𝑎𝑗𝑦𝑖𝑦𝑗𝑥⃗⃗⃗ 𝑖. 𝑥⃗⃗⃗ ( 2.9) 𝑗
𝑎 ≥ 0(𝑖 = 1,2, … , 𝑙) ∑𝑙𝑖=1𝑎𝑖𝑦𝑖=0 ( 2.10) Dari hasil perhitungan ini diperoleh ai yang kebanyakan bernilai positif. Data yang berkorelasi dengan ai positif yagn disebut sebagai support vector. Fungsi pemisah dapat didefinisikan sebagai berikut.
g(x):=sgn(f(x)) ( 2.11) dengan f(x)=wTx+b ( 2.12)
Pada kenyataanya, masalah di dunia nyata sangat jarang untuk dapat diselesaikan secara linear. Untuk menyelesaikan problem non-linear, SVM dimodifikasi sedemikian rupa dengan cara memasukkan fungsi Kernel. Dalam non linear SVM, pertama data xi dipetakan oleh fungsi 𝜙xi ke ruang vektor yang berdimensi lebih tinggi. Pada ruang vektor yang baru ini, hyperplane yang memisahkan kedua class tersebut dapat dikonstruksikan.
Ilustrasi dari konsep di atas dapat dilihat pada Gambar 2.2. Pada Gambar 2.2. kiri diperlihatkan data dengan space berdimensi dua. Terlihat data kelas merah dan data kelas kuning pada input space dua dimensi tidak dapat dipisahkan secara linear. Selanjutnya pada Gambar 2.2. kanan menunjukkan fungsi dari 𝜙 yang memetakan tiap data pada input space tersebut ke ruang vektor baru yang berdimensi lebih tinggi atau tiga dimensi, sehingga kedua kelas dapat dipisahkan secara lienar oleh hyperplane.
Gambar 2.2 Pemetaan data ke ruang vektor berdimensi yang lebih tinggi
Selanjutnya proses pembelajaran pada SVM bergantung pada dot product dari data yang sudah ditransformasikan ke ruang dimensi yang lebih tinggi dalam menentukan titik-titik support vectornya.
Berikut Ilustrasi cara Kerja Support Vector Machine dengan data seperti pada Tabel 2.5.
Tabel 2.5 Contoh data sampel
x1 x2 yi
4 4 1
6 4 -1
4 6 -1
4 8 1
Terdapat dua atribut yaitu x1 dan x2 yang akan menghasilkan dua bobot yaitu w1 dan w2. Kemudian margin diminimalkan menggunakan rumus pada persamaan 2.4 dengan syarat sebagai berikut.
𝑦𝑖(𝑤.𝑥𝑖+ 𝑏)≥ 1, 𝑖 = 1,2, … , 𝑁 ( 2.13)
𝑦𝑖(𝑤1+ 𝑥𝑖+ 𝑤2+ 𝑥𝑖+ 𝑏) ≥ 1 ( 2.14)
Sehingga diperoleh persamaan berikut.
a. 1(4w1+4w2+b) ≥1→(4w1+4w2+b) ≥1 b. -1(6w1+4w2+b) ≥1→(-6w1-4w2-b) ≥1 c. -1(4w1+6w2+b) ≥1→(-4w1-6w2-b) ≥1 d. 1(4w1+8w2+b) ≥1→(4w1+8w2+b) ≥1
Selanjutnya mencari nilai w dan b dari persamaan (a) dan (b) sebagai berikut.
((4w1+4w2+b) ≥1)+((-6w1-4w2-b) ≥1) -2w1=2
w1=-1
Kemudian mencari nilai w dan b dari persamaan (c) dan (d) sebagai berikut.
((-4w1-6w2-b) ≥1)+((4w1+8w2+b) ≥1) 2w2=2
w2=1
sehingga nilai b yand didapat dari persamaan (a) dan (d) adalah:
((4w1+4w2+b) ≥1)+((4w1+8w2+b) ≥1) 2b=-2
b=-1
Maka Persamaan hyperplane menjadi:
w1x1+w2x2+b=0 -1x1+1x2-1=0 x2-1=x1
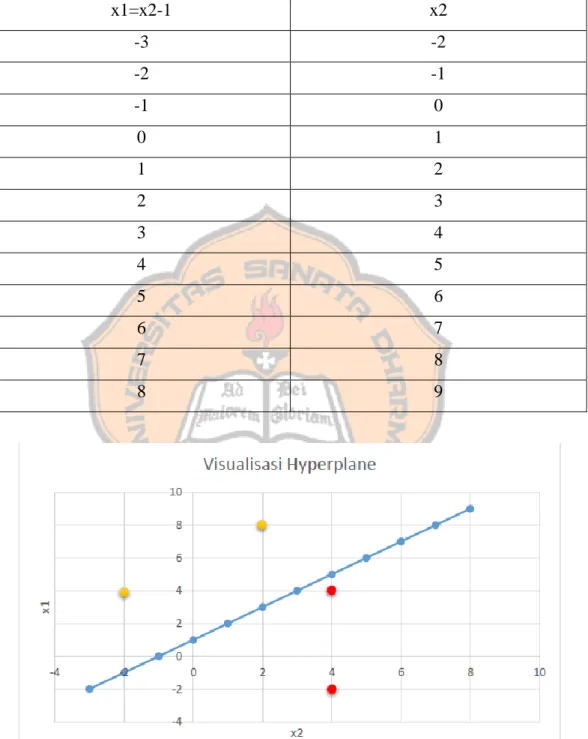
Selanjutnya dibuat plot hyperplane dengan fungsi -x1+x2-1 menggunakan data seperti pada tabel 2.6.
Tabel 2.6 Plot hyperplane
x1=x2-1 x2
-3 -2
-2 -1
-1 0
0 1
1 2
2 3
3 4
4 5
5 6
6 7
7 8
8 9
Gambar 2.3 Visualisasi hyperplane data uji
Setelah ditentukan garis hyperplane seperti pada Gambar 2.3, maka langkah selanjutnya yaitu mengklasifikasikan data uji melalui hyperplane dengan menggunakan fungsi f(x)=-x1+x2-1 dengan g(x):=sgn(f(x)). Gambar 2.3 menunjukkan garis hyperplane yang memisahkan data uji yang terdapat pada Gambar 2.3 dengan label kelas positif disimbolkan dengan warna kuning dan kelas negatif dengan warna merah.
Tabel 2.7 Hasil Klasifikasi
No X1 X2 Hasil Klasifikasi (Kelas=sgn(f(x))
1 4 4 Sgn(-4+4-1)=-1
2 2 8 Sgn(-2+8-1)=1
3 -2 4 Sgn(-(-2)+4-1)=1
4 4 -2 Sgn(-4-2-1)=-1
Pada umumnya terdapat empat fungsi kernel yang dapat digunakan yaitu:
1. Kernel Linier
𝐾(𝑥, 𝑥𝑘) = 𝑥𝑘𝑇x ( 2.15) 2. Kernel Polynomial
𝐾(𝑥, 𝑥𝑘) = (𝑥𝑘𝑇x + 1)𝑑 ( 2.16) 3. Kernel Gaussian (Radial Basis Function, RBF)
𝐾(𝑥, 𝑥𝑘) = exp {−‖𝑥 − 𝑥𝑘‖22/𝜎2} ( 2.17) 4. Kernel Sigmoid
𝐾(𝑥, 𝑥𝑘) = tanh [𝐾𝑋𝑘𝑇𝑋 + 𝜃] ( 2.18)
Fungsi kernel memberi kemudahan karena hanya perlu mengetahui fungsi kernel yang digunakan untuk menentukan support vector. Kemudian SVM akan mengklasifikasi sebuah objek data x yang diformulasikan dengan persamaan :
𝑓(𝑥) = ∑𝑛𝑖=1,𝑥𝑖∈𝑆𝑉𝑎𝑖𝑦𝑖𝐾(𝑥, 𝑥𝑖) + 𝑏 ( 2.19)
2.5.1. Multi Class SVM
SVM pada awalnya hanya dapat mengklasifikasikan data ke dalam dua kelas. Setelah berkembangnya riset dan penelitian, SVM dapat berkembang menjadi multi kelas (multi class) yang artinya teknik ini dapat mengklasifikasikan lebih dari dua kelas. Dalam mengimplementasikan SVM multi kelas dapat menggunakan dua pendekatan, yaitu dengan menggabungkna beberap SVM iner dan yang kedua yaitu menggabungkan semua data dari semua kelas ke dalam sebuah bentuk permasalahan optimasi.
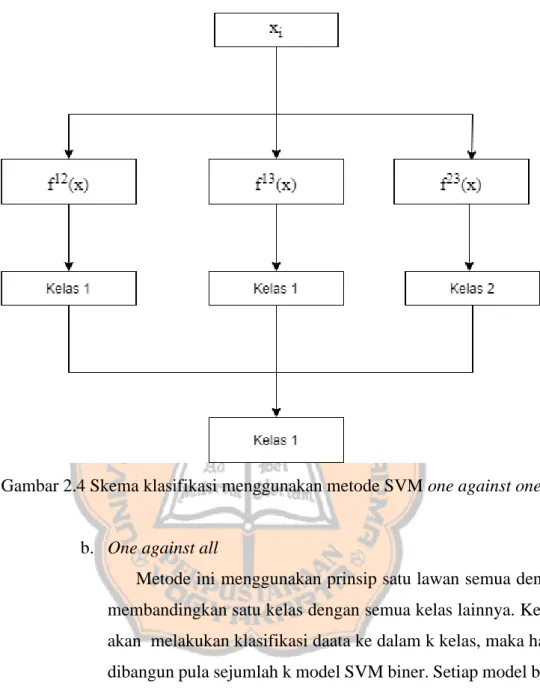
a. One against one
Metode one against one atau satu lawan satu ini akan membandingkna satu kelas dengan kelas lainnya dalam membangun sejumlah model SVM. Ketika akan melakukan klasifikasi data ke dalam k kelas, maka diharuskan untuk membangun sejumlah model dengan rumus sebagai berikut.
𝑘(𝑘−1)
2 (2.20) Keterangan :
K=jumlah kelas
Sehingga jika akan membangun sejumlah SVM biner dengan 3 kelas maka yang harus dibuat yaitu 3(3-1)/2= 3 buah biner SVM. Sehingga setiap kelas harus dibandingkan dengan kelas lainnya seperti pada Tabel 2.8. Voting dilakukan untuk mendapatkan kelas keputusan. Berikut ilustrasi klasifikasi dengan ebuah jumlah kelas.
Tabel 2.8 Contoh kombinasi biner 3 kelas dengan metode one against one
yi=1 yi=-1 Hipotesis
Kelas 1 Kelas 2 𝑓12(𝑥) = (𝑤12)𝑥 + 𝑏12
Kelas 1 Kelas 3 𝑓13(𝑥) = (𝑤13)𝑥 + 𝑏13
Kelas 2 Kelas 3 𝑓23(𝑥) = (𝑤23)𝑥 + 𝑏23
Gambar 2.4 Skema klasifikasi menggunakan metode SVM one against one
b. One against all
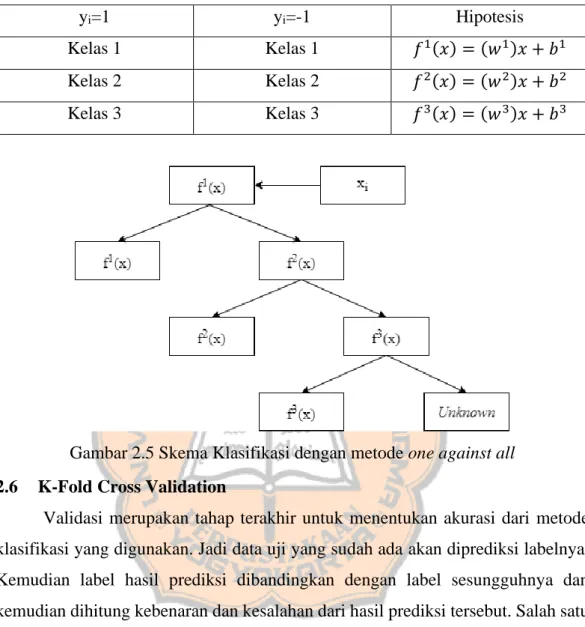
Metode ini menggunakan prinsip satu lawan semua dengan membandingkan satu kelas dengan semua kelas lainnya. Ketika akan melakukan klasifikasi daata ke dalam k kelas, maka harus dibangun pula sejumlah k model SVM biner. Setiap model biner SVM ke-i akan dilatih dengan menggunakan keseluruhan data agar ditemukan apakah merupakan bagian dari kelas ke-i atau bukan ketika diklasifikasikan. Sebagai contoh, ketika akan mengklasifikasikan ke dalam 4 kelas maka perlu dibangun pula 4 buah SVM biner seperti terlihat pada Tabel 2.9.
Tabel 2.9 Contoh kombinasi biner 3 kelas dengan metode one against all
yi=1 yi=-1 Hipotesis
Kelas 1 Kelas 1 𝑓1(𝑥) = (𝑤1)𝑥 + 𝑏1
Kelas 2 Kelas 2 𝑓2(𝑥) = (𝑤2)𝑥 + 𝑏2
Kelas 3 Kelas 3 𝑓3(𝑥) = (𝑤3)𝑥 + 𝑏3
Gambar 2.5 Skema Klasifikasi dengan metode one against all 2.6 K-Fold Cross Validation
Validasi merupakan tahap terakhir untuk menentukan akurasi dari metode klasifikasi yang digunakan. Jadi data uji yang sudah ada akan diprediksi labelnya.
Kemudian label hasil prediksi dibandingkan dengan label sesungguhnya dan kemudian dihitung kebenaran dan kesalahan dari hasil prediksi tersebut. Salah satu metode validasi adalah k-fold cross validation.
K-fold cross validation membagi data menjadi data latih dan data uji dengan cara membagi keseluruhan data menjadi K kelompok di mana K bernilai ganjil dan lebih besar dari dua. Tujuan pembagian ini untuk melakukan pengujian silang keseluruhan data yang digunakan yang digunakan untuk melihat tingkat akurasi sebuah model klasifikasi yang dibangun.
Konsep pembagian data latih dan data uji adalah 1 dari total K kelompok yang akan digunakan. Misalnya jika K bernilai 5 maka data dibagi menjadi 5 kelompok di mana 4 kelompok menjadi data latih dan 1 kelompok menjadi data uji.
19
BAB 3.
METODE PENELITIAN 3.1. Pengumpulan DataPada penelitian ini, data yang digunakan merupakan data dari hasil penelitian dengan “SEGEMENTASI CITRA HURUF DAUN LONTAR” dengan nomor kontrak penelitian No: 019/Penel./LPPM-USD/III/2018, dan penelitian :CLUSTERING CITRA AKSARA BALI HASIL SEGMENTASI CITRA DAUN LONTAR” dengan nomor kontrak No: 019/Penel./LPPM-USD/II/2020. Hasil segmentasi diperoleh 1572 data dan dicluster menjadi 175 kelompok.
Gambar 3.1 Data Citra Aksara Bali
Dalam penelitian ini tidak semua cluster digunakan, hanya 18 cluster saja yang digunakan dengan jumlah data paling sedikit 20 per-cluster. Tujuan pertama adalah untuk memilih cluster yang merupakan Aksara Wyanjana seperti pada Tabel 2.1.
Akan tetapi, dikarenakan tidak semua aksara Wyanjana terkadung dalam data tersebut maka data yang digunakan dipilih dengan aturan jumlah data per-cluster minimal 20 data citra aksara. Dari situ didapatkan 18 kelas dengan total data citra yang digunakan sebanyak 1001
3.2. Kebutuhan Perangkat Hardware dan Software a) Spesifikasi Hardware
1. Prosesor Intel(R) i7-8750H @ 2.20GHz 2. RAM 16 GB
3. SSD 512 GB b) Spesifikasi Software
1. Sistem Operasi Windows 10 2. MATLAB R2019
3.3. Labeling Data Manual
Data yang diolah merupakan data-data citra aksara bali yang telah disegmentasi dan dicluster dari hasil penelitian sebelumnya. Maka data yang ada hanya perlu dilabeli saja. Pemberian label pada data hanya diberikan pada cluster- cluster yang akan digunakan. Sehingga tidak semua cluster akan digunakan dan diberi label.
Tabel 3.1 Hasil labeling data
No Citra Aksara Nama Aksara Cluster Kelas Jumlah
1 Ha C2 1 30
2 Ta C3 2 52
3 Ba C4 3 45
4 Sa C6 4 64
5 Ma C7 5 76
6 Ka C8 6 36
7 Nga C10 7 28
No Citra Aksara Nama Aksara Cluster Kelas Jumlah
8 Koma C12 8 81
9 Ulu C13 9 121
10 Tedong C15 10 49
11 Na C19 11 108
12 Da C20 12 20
13 Wa C23 13 42
14 Taleng C27 14 92
15 Ra C34 15 69
16 Ya C40 16 35
17 Suku C42 17 33
18 Mangkan C53 18 20
Label yang digunakan atau yang akan dimasukkan pada program nanti merupakan label yang bernilai angka pada kolom Kelas. Sedangkan nama aksara dinamai dengan bantuan ahli aksara Bali.
3.4. Gambaran Umum Klasifikasi SVM Menggunakan Data Citra Aksara Bali
Pada bagian ini menjelaskan bagaimana penerapan klasifikasi SVM pada umunya dengan menggunakan data dari penelitian ini. Diberikan 5 buah citra aksara Bali yang terdiri dari 2 kelas. Citra tersebut dikenai ekstraksi ciri IoC berukuran 2x2 pixel. Sehingga jumlah atribut yang didapatkan sebanyak 4 buah pixel. Berikut atribut dari ciri IoC yang dikenai pada ke-5 citra tersebut.
Tabel 3.2 Atribut dan label ke-5 citra aksara Bali x1 x2 x3 x4 yi
17 16 22 17 1
14 22 23 26 1
15 26 29 27 1
15 14 19 22 -1
15 11 19 17 -1
Lalu nilai atribut yang didapatkan pada Tabel 3.2 dimasukkan kedalam rumus 2.13, sehingga didapatkan persamaan sebagai berikut.
a. 1(17w1+16w2+22 w3+17 w4+b) ≥1→(17w1+16w2+22 w3+17 w4+b) ≥1 b. 1(14w1+22w2+23 w3+26 w4+b) ≥1→(14w1+22w2+23 w3+26 w4+b) ≥1 c. 1(15w1+26w2+29 w3+27 w4+b) ≥1→(15w1+26w2+29 w3+27 w4+b) ≥1 d. -1(15w1+14w2+19 w3+22 w4+b) ≥1→(-15w1-14w2-19 w3-22 w4-b) ≥1 e. -1(15w1+14w2+19 w3+22 w4+b) ≥1→(-15w1-14w2-19 w3-22 w4-b) ≥1 Selanjutnya mencari nilai w dan b dengan menggunakan persamaan yang telah didapatkan dengan menggunakan metode eliminasi. Metode elimnasi yang digunakan adalah Gauss-Jordan dikarenakan jumlah variabel yang melebihi 3.
Pertama ke-5 persamaan dibuat dalam bentuk matrix yang adapat dilihat pada Tabel 3.3.
Tabel 3.3 Matrix dari ke-5 persamaan
17 16 22 17 1 1
14 22 23 26 1 1
15 26 29 27 1 1
-15 -14 -19 -22 -1 1
-15 -11 -19 -17 -1 1
Langkah 1, seluruh nilai pada baris 1 dibagi 17
1 0.941 1.294 1 0.059 0.059
14 22 23 26 1 1
15 26 29 27 1 1
-15 -14 -19 -22 -1 1
-15 -11 -19 -17 -1 1
Langkah 2, nilai pada baris kedua dikurang nilai baris pertama yang dikali 14 1 0.941 1.294 1 0.059 0.059
0 8.824 4.882 12 0.176 0.176
15 26 29 27 1 1
-15 -14 -19 -22 -1 1
-15 -11 -19 -17 -1 1
Langkah 3, nilai pada baris ketiga dikurang baris pertama yang dikali 15 1 0.941 1.294 1 0.059 0.059 0 8.824 4.882 12 0.176 0.176 0 11.882 9.588 12 0.118 0.118
-15 -14 -19 -22 -1 1
-15 -11 -19 -17 -1 1
Langkah 4, nilai pada baris keempat dikurang baris pertama yang dikali -15 1 0.941 1.294 1 0.059 0.059
0 8.824 4.882 12 0.176 0.176 0 11.882 9.588 12 0.118 0.118 0 0.118 0412 -7 -0.118 1.882
-15 -11 -19 -17 -1 1
Langkah 5, nilai pada baris kelima dikurang baris pertama yang dikali -15 1 0.941 1.294 1 0.059 0.059
0 8.824 4.882 12 0.176 0.176 0 11.882 9.588 12 0.118 0.118 0 0.118 0412 -7 -0.118 1.882 0 3.118 0412 -2 -0.118 1.882
Langkah 6, nilai pada baris ketiga dan kedua ditukar
1 0.941 1.294 1 0.059 0.059 0 11.882 9.588 12 0.118 0.118 0 8.824 4.882 12 0.176 0.176 0 0.118 0412 -7 -0.118 1.882 0 3.118 0412 -2 -0.118 1.882
Langkah 7, nilai pada baris kedua dibagi 11.882
1 0.941 1.294 1 0.059 0.059 0 1 0.807 1.01 0.01 0.01 0 8.824 4.882 12 0.176 0.176 0 0.118 0412 -7 -0.118 1.882 0 3.118 0412 -2 -0.118 1.882
Langkah 8, nilai pada baris ketiga dikurang baris kedua yang dikali 8.824 1 0.941 1.294 1 0.059 0.059
0 1 0.807 1.01 0.01 0.01 0 0 -2.238 3.089 0.089 0.089 0 0.118 0412 -7 -0.118 1.882 0 3.118 0412 -2 -0.118 1.882
Langkah 9, nilai pada baris keempat dikurang baris kedua yang dikali 0.118 1 0.941 1.294 1 0.059 0.059
0 1 0.807 1.01 0.01 0.01 0 0 -2.238 3.089 0.089 0.089 0 0 0.317 -7.119 -0.119 1.881 0 3.118 0412 -2 -0.118 1.882
Langkah 10, nilai pada baris kelima dikurang baris kedua yang dikali 3.118 1 0.941 1.294 1 0.059 0.059
0 1 0.807 1.01 0.01 0.01 0 0 -2.238 3.089 0.089 0.089 0 0 0.317 -7.119 -0.119 1.881 0 0 -2.104 -5.149 -0.149 1.851
Langkah 11, nilai pada baris ketiga dibagi -2.238
1 0.941 1.294 1 0.059 0.059 0 1 0.807 1.01 0.01 0.01 0 0 1 -1.381 -0.04 -0.04 0 0 0.317 -7.119 -0.119 1.881 0 0 -2.104 -5.149 -0.149 1.851
Langkah 12, nilai pada baris keempat dikurang baris ketiga yang dikali 0.317 1 0.941 1.294 1 0.059 0.059
0 1 0.807 1.01 0.01 0.01 0 0 1 -1.381 -0.04 -0.04 0 0 0 -6.681 -0.106 1.894 0 0 -2.104 -5.149 -0.149 1.851
Langkah 13, nilai pada baris kelima dikurang baris ketiga yang dikali -2.104 1 0.941 1.294 1 0.059 0.059
0 1 0.807 1.01 0.01 0.01 0 0 1 -1.381 -0.04 -0.04 0 0 0 -6.681 -0.106 1.894 0 0 0 -8.053 -0.232 1.768
Langkah 14 nilai pada baris kelima dan keempat ditukar
1 0.941 1.294 1 0.059 0.059 0 1 0.807 1.01 0.01 0.01 0 0 1 -1.381 -0.04 -0.04 0 0 0 -8.053 -0.232 1.768 0 0 0 -6.681 -0.106 1.894
Langkah 15, nilai pada baris keempat dibagi -8.053
1 0.941 1.294 1 0.059 0.059 0 1 0.807 1.01 0.01 0.01 0 0 1 -1.381 -0.04 -0.04
0 0 0 1 0.029 -0.22
0 0 0 -6.681 -0.106 1.894
Langkah 16, nilai pada baris kelima dikurang baris keempat yang dikali -6.681 1 0.941 1.294 1 0.059 0.059
0 1 0.807 1.01 0.01 0.01 0 0 1 -1.381 -0.04 -0.04
0 0 0 1 0.029 -0.22
0 0 0 0 0.087 0.427
Langkah 17, nilai pada baris kelima dibagi 0.087
1 0.941 1.294 1 0.059 0.059 0 1 0.807 1.01 0.01 0.01 0 0 1 -1.381 -0.04 -0.04
0 0 0 1 0.029 -0.22
0 0 0 0 1 4.937
Langkah 18, nilai pada baris pertama dikurang baris kelima yang dikali 0.059
1 0.941 1.294 1 0 -0.232
0 1 0.807 1.01 0.01 0.01 0 0 1 -1.381 -0.04 -0.04
0 0 0 1 0.029 -0.22
0 0 0 0 1 4.937
Langkah 19, nilai pada baris kedua dikurang baris kelima yang dikali 0.01
1 0.941 1.294 1 0 -0.232
0 1 0.807 1.01 0 -0.039
0 0 1 -1.381 -0.04 -0.04
0 0 0 1 0.029 -0.22
0 0 0 0 1 4.937
Langkah 20 nilai pada baris ketiga dikurang baris kelima yang dikali -0.04
1 0.941 1.294 1 0 -0.232
0 1 0.807 1.01 0 -0.039
0 0 1 -1.381 0 0.157
0 0 0 1 0.029 -0.22
0 0 0 0 1 4.937
Langkah 21, nilai pada baris keempat dikurang baris kelima yang dikali 0.029
1 0.941 1.294 1 0 -0.232
0 1 0.807 1.01 0 -0.039
0 0 1 -1.381 0 0.157
0 0 0 1 0 -0.362
0 0 0 0 1 4.937
Langkah 22, nilai pada baris pertama dikurang baris keempat yang dikali 1
1 0.941 1.294 0 0 0.13
0 1 0.807 1.01 0 -0.039
0 0 1 -1.381 0 0.157
0 0 0 1 0 -0.362
0 0 0 0 1 4.937
Langkah 23, nilai pada baris kedua dikurang baris keempat yang dikali 1.01
1 0.941 1.294 0 0 0.13
0 1 0.807 0 0 0.327
0 0 1 -1.381 0 0.157
0 0 0 1 0 -0.362
0 0 0 0 1 4.937
Langkah 24, nilai pada baris ketiga dikurang baris keempat yang dikali 1-.381
1 0.941 1.294 0 0 0.13
0 1 0.807 0 0 0.327
0 0 1 0 0 -0.343
0 0 0 1 0 -0.362
0 0 0 0 1 4.937
Langkah 25, nilai pada baris pertama dikurang baris ketiga yang dikali 1.294
1 0.941 0 0 0 0.574
0 1 0.807 0 0 0.327
0 0 1 0 0 -0.343
0 0 0 1 0 -0.362
0 0 0 0 1 4.937
Langkah 26, nilai pada baris kedua dikurang baris ketiga yang dikali 0.807
1 0.941 0 0 0 0.574
0 1 0 0 0 0.603
0 0 1 0 0 -0.343
0 0 0 1 0 -0.362
0 0 0 0 1 4.937
Langkah 27, nilai pada baris pertama dikurang baris kedua yang dikali 0.941
1 0 0 0 0 0.006
0 1 0 0 0 0.603
0 0 1 0 0 -0.343
0 0 0 1 0 -0.362
0 0 0 0 1 4.937
Maka didapatkan nilai w1=0.006, w2=0.603, w3=-0.343, w4=-0.362, dan b=4.937.
Lalu dari nilai ini kita masukkan kedalam persamaan untuk mencari hyperplane- nya sehingga didapatkan persamaan hyperplane sebagai berikut:
w1x1+w2x2+w3x3+w4x4+b=0
0.006x1+0.603x2-0.343x3-0.362x4+4.937=0
Persamaan hyperplane tersebut yang akan digunakan untuk menentukan hyperplane dari kedua buah kelas dari citra aksara bali tersebut.
3.5. Desain Alat Uji
Pada bagian ini menampilkan diagram desain alat uji yang akan dibuat pada penelitian ini. Desain yang digunakan diperlihatkan pada gambar berikut.
Gambar 3.2 Diagram desain alat uji
Dari diagram diatas ditampilkan proses yang akan dilakukan secara keseluruhan.
Pertama citra aksara Bali akan dimasukkan kedalam proses prepocessing terlebih dahulu. Hasil yang didapatkan dari proses tersebut berupa citra kerangka aksara Bali, dan hasilnya akan diekstraksi cirinya dengan menggunakan IoC. Ekstraksi ciri tersebut memberikan hasil berupa matrix berukuran NxN yang kemudian digunakan untuk diklasifikasikan dengan metode SVM. Hasil klasifikasi berupa label prediksi yang kemudian akan divalidasi dengan cross validation. Hasil
validasi berupa label yang diperediksi dengan benar akan dihitung yang memberikan berupa akurasi. Berikut dijelaskan secara rinci proses yang ada dalam Gambar 3.2:
1) Preprocessing
Data yang berupa Citra aksara Bali akan diproses terlebih dahulu sebelum langsung digunakan untuk menjadi data training atau data testing. Prose preprocessing yang akan dilakukan berupa gambar berikut.
Gambar 3.3 Diagram Preprocessing
Preprocessing yang dilakukan mencakup sebagai berikut : a. Binerisasi Citra
Pada tahap ini citra masukkan diubah warna citranya dari RGB menjadi biner. Warna biner ini hanya terdiri dari dua yaitu 1 dan 0 di mana 1 menunjukkan warna putih dan 0 menunjukkan warna hitam pada komputer. Proses binerisasi dilakukan dengan menggunakan fungsi bawaan MATLAB yaitu im2bw(). Berikut adalah hasil binerisasi citra.
Gambar 3.4 Citra aksara Bali yang telah dibinerkan
Tabel 3.4 Representasi citra biner dalam matlab
b. Cropping
Pada tahap ini Citra yang telah diubah ke biner akan dicrop.
Tujuannya untuk mengurangi latar yang terdapat pada citra sehingga bisa didapatkan karakter aksara secara utuh tanpa ada- nya ruang lebih. Metode cropping yang digunakan adalah proyeksi profile. Berikut adalah hasil cropping citra.
Gambar 3.5 Citra sebelum dan setelah cropping c. Resize image
Pada tahap ini Citra yang sudah di cropping kita ubah sizenya. Tujuan pengubahan size citra ini agar dapat dikenai ekstraksi ciri IoC di mana metode ini harus membagi cita menjadi beberapa segmen dengan ukuran sama terlebih dahulu.
Resizing dilakukan dengan menggunakan fungsi bawaan matlab imresize(). Berikut adalah hasil resize citra di mana citra pada bagian kiri berukuran 45x48 pixel dan citra pada bagian kanan berukuran 30x30 pixel.
Gambar 3.6 Citra sebelum dan setelah di resize.
d. Thinning
Pada tahap ini Citra yang size-nya sudah kita ubah ke ukuran NxN kita lakukan thinning atau penipisan. Tujuan penipisan ini untuk mendapatkan kerangka dari aksara yang dimasukkan.
Metode bekerja dengan cara membuang pixel yang merupakan bagian tepi dari aksara tersebut. Metode thinning yang digunakan menggunakan algoritma Rosenfeld.
Gambar 3.7 Citra sebelum dan setelah thinning
2) Ekstraksi Ciri
Ekstraksi ciri adalah tahap untuk mendapatkan komponen yang berupa ciri yang terdapat pada citra aksara yang akan digunakan dalam proses klasifikasi data. Pada proses ini, ciri citra yang digunakan adalah Intensity of Character (IoC). Algoritma IoC adalah sebagai berikut.
1. Buka berkas masukan, misal = KarBali 2. Set tinggi = size(KarBali,1)
3. Set lebar = size(KarBali,2) 4. Bagi KarBali menjadi 9 bagian
5. Cari jumlahan piksel yang bernilai 0 di setiap bagian karakter hasil langkah 2
6. Simpan ciri tersebut menjadi ciri dari karakter yang bersangkutan ke dalam file ciriKar.mat
Dalam penelitian ini, ciri yang digunakan adalah Intensity of Character (IoC). Ukuran IoC yang digunakan adalah 3x3, 4x4, dan 5x5. Ciri tersebut diperoleh dengan menghitung nilai setiap pixel hitam yang ada dalam matriks citra hasil preprocessing sehingga setiap baris dan kolom matriks adalah hasil penjumlahan dari pixel hitam tersebut.
Hasil ekstraksi ciri IoC adalah data array yang berisi ciri dari citra aksara sesuai dengan ukuran IoC-nya. Lalu dalam array tersebut dimasukkan juga label dari citra tersebut. Label citra berada pada kolom terakhir dari array. Panjang kolom array bergantung pada ukuran IoC yang digunakan. Ukuran IoC 3x3 menghasilkan panjang kolom sebesar 9 kolom yang berisikan ciri citra dan ditambah 1 kolom yang merupakan label dari citra teresebut menghasilkan 10 kolom. Jika ukuran IoC 4x4, maka panjang kolom sebesar 16 kolom yang berisikan ciri citra ditambah 1 kolom yang merupakan label dari citra menjadi 17 kolom. Jika ukuran IoC 5x5, maka panjang kolom sebesar 25 kolom yang berisikan ciri citra ditambah 1 kolom yang merupakan label dari citra menjadi 26 kolom. Untuk banyak baris dalam array bergantung pada banyak-nya data citra yang akan digunakan.
Tabel 3.5 Contoh hasil ekstraksi ciri IoC ukuran 3x3 Data Ciri IoC 3x3 dan Label Citra
1 2 3 4 5 6 7 8 9 10
10 23 6 9 10 10 18 20 15 1 5 22 21 15 9 10 14 24 9
1 14 19 7 17 21 18 20 20 20
2 8 18 5 13 20 11 17 20 16
2
3) Klasifikasi
Klasifikasi yang digunakan adalah Support Vector Machine dengan menggunakan tools dari Matlab sehingga ciri IoC dari citra yang digunakan hanya tinggal dimasukkan kedalam tools secara terurut. Ciri dari citra dimasukkan kedalam persamaan rumus 2.2 di mana ciri di dari tiap atribut direpresentasikan sebagai x.
SVM yang menggunakan tools Matlab ini menggunakan fungsi biner yang akan ditambahkan fungsi multiclass. Pemodelan SVM multiclass yang digunakan adalah multisvm one against one dan one against all.
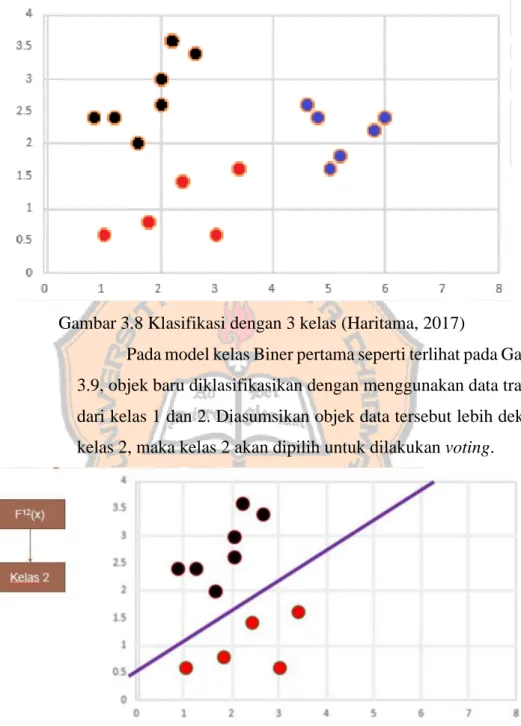
Pada pemodelan SVM one against one, diberikan ilustrasi yang dapat dilihat di Gambar 3.8 di mana terdapat 3 kelas di mana warna hitam merupakan kelas 1, merah merupakan kelas 2, dan biru merupakan kelas 3. Dengan menggunakan konsep multiclass dan metode one against one maka akan dibangun 3 kelas biner. Tiga kelas biner ini diperoleh dengan menggunakan rumus pada persamaan k(k-1)/2 di mana k merupakan jumlah kelas. Sehingga model biner SVM yang dibangun sebanyak 3(3-1)/2=3. Model
biner SVM ini terdiri dari kleas 1 lawan 2, 1 lawan 3, dan 2 lawan 3.
Gambar 3.8 Klasifikasi dengan 3 kelas (Haritama, 2017)
Pada model kelas Biner pertama seperti terlihat pada Gambar 3.9, objek baru diklasifikasikan dengan menggunakan data training dari kelas 1 dan 2. Diasumsikan objek data tersebut lebih dekat ke kelas 2, maka kelas 2 akan dipilih untuk dilakukan voting.
Gambar 3.9 kelas 1 dan kelas 2
Pada model kelas biner yang kedua seperti yang terlihat pada Gambar 3.10 objek baru diklasifikasikan dengan menggunakan data training dari kelas 1 dan 3. Diasumsikan objek data tersebut lebih dekat ke kelas 3, maka kelas 3 akan dipilih untuk dilakukan voting.
Gambar 3.10 kelas 1 dan 3
Pada model kelas biner yang kedua seperti yang terlihat pada Gambar 3..11 objek baru diklasifikasikan dengna menggunakan data training dari kelas 2 dan 3. Diasumsikan objek data tersebut lebih dekat ke kelas 2, maka kelas 2 akan dipilih untuk dlakukan voting.
Gambar 3.11 kelas 2 dan kelas 3
Setelah itu dilakukan voting untuk menentukan kelas klasifikasi. Hasil voting dari ketiga model kelas biner dihitung, kelas mana yang memiliki voting terbanyak. Kelas 2 memiliki voting terbanyak, maka hasil klasifikasi dari data objek baru akan dikategorikan sebagai kelas 2 seperti yang terlihat pada Gambar 3.12.
Gambar 3.12 Hasil voting
Algoritma SVM dengan pemodelan one against one dapat dilihat sebagai berikut:
1. Cari seluruh kelas yang unik dari seluruh label simpan di variabel u.
2. Hitung jumlah kelas yang ada lalu simpan ke variabel numclass
3. Set ix = 1
4. Perulangan selama i=1 sampai numclass-1
5. Cari indeks dari seluruh label_training yang sama dengan u(i) simpan di variabel data1.
6. Set awal1 nilai pada indeks pertama data1 7. Set akhir1 nilai pada indeks terakhir data1 8. Perulangan selama j=i+1 sampai numclass
9. Cari indeks dari seluruh label_training yang sama dengan u(j) simpan di variabel data2
10. Set awal2 nilai pada indeks pertama data2 11. Set akhri2 nilai pada indeks terakhir data2
12. Gabungkan seluruh datatraining pada baris ke awal1 sampai akhir 1 dan datatraining pada baris ke awal2 sampai akhir 2 simpan ke variabel datamasuk
13. Gabungkan labeltraining pada baris ke awal1 sampai akhir 1 dan datatraining pada baris ke awal2 sampai akhir
2 simpan ke variabel label
14. Bangun model svm dengan menggunakan datamasuk dan label sebagai parameter
15. Simpan nilai i kedalam variabel hasil pada indeks ke ix,1 16. Simpan nilai j kedalam variabel hasil pada indeks ke ix,2 17. Prediksi hasil dari datatesting jika diklasifikasi menggunakan model svm tersebut kemudian simpan ke variabel hasil pada index ke ix,3
18. Perulangan dari i=1:numclass 19. Jika i=1, maka
20. Set nilai terbesar = jumlah dari seluruh hasil yang pada indeks ke 3 nya sama dengan nilai u(i)
21. Set nilai output =i 22. Jika tidak, maka
23. Jika nilai terbesar bernilai lebih ecil dari jumlah dari seluruh hasil yang pada indeks ke 3 nya sama dengan nilai u(i) maka
24. Set nilai terbesar = jumlah dari seluruh hasil yang pada indeks ke 3 nya sama dengan nilai u(i)
25. Set output = i
26. Set rank pada indeks ke i,1=i
27. Set rank pada indeks ke 2,1=jumlah dari seluruh hasil yang pada indeks ke 3 nya sama dengan nilai u(i)
28. Return nilai output dan rank
Lalu pada SVM dengan pemodelan one against all dengan menggunakan ilustrasi Gambar 3.8, di mana data terbagi menjadi 3 kelas. Pemodelan SVM one against all membandingkan setiap model klasifikasi ke-i terhadap seluruh data yang ada selain yang memiliki kelas yang sama. Dapat dilihat pada Gambar 3.13, data tersebut terbagi menjadi 3 buah kelas, di mana saat akan melakukan
klasifikasi terhadap kelas 1, seluruh kelas lain selain kelas 1 akan digabungkan sehingga terbentuk kelas biner yang dapat ditemukan hyperplane nya. Hal yang sama juga dapat dilakukan terhadap penentuan hyperplane untuk kelas lainnya. Iltustrasi dari metode one against all dapat dilihat pada Gambar 3.13.
Gambar 3.13 Visualisai pemodelan one against all
Algoritma SVM dengan pemodelan one against all dapat dilihat sebagai berikut.
1. Cari seluruh kelas yang unik dari seluruh label simpan di variabel u.
2. Hitung jumlah kelas yang ada lalu simpan ke variabel numclass
3. Perulangan salam k=1 sampai numclass
4. Ubah seluruh label training menjadi nilai 0 selain label training bernilai k dan disimpan ke variabel G1vAll 5. Bangun model svm dengan menggunakan datamasuk dan
label sebagai parameter
6. Jika prediksi hasil sama dengan k maka perulangan berakhir dan kembalikan nilai k
7. Jika tidak, maka kembali ke nomor 4
8. Kembalikan nilai k
4) Validasi
Merupakan tahap di mana data yang telah diprediksi labelnya divalidasi untuk mendapatkan akurasi dari hasil pelatihan data yang diberikan. Validasi yang digunakan adalah k-fold cross validation.
Pengujian akurasi dari penerapan SVM menggunakan metode k-fold cross validation, yang mana data akan dibagi sesuai dengan nilai k yang ditentukan sebelumnya yaitu 3, 5 dan 7.. Contoh pembagian dari cross validation bisa dilihat pada tabel 3.6.
Tabel 3.6 3-fold cross validation
Percobaan Data Training Data Testing
1 2,3 1
2 1,3 2
3 1,2 3
3.6. Desain User Interface
Gambar 3.14 Desain User Interface
Pada desain GUI yang dibuat, citra yang akan diklasifikasikan adalah 1 buah citra saja atau uji data tunggal. Pertama pengguna harus menekan tombol Cari Citra Inputan terlebih dahulu. Tombol ini berfungsi untuk mencari citra yang ingin
diklasifikasikan. Setelah citra dipilih maka akan ditampilkan pada viewer yang ada pada panel Tampilan Citra. Lalu pengguna menekan tombol Klasifikasi, maka citra yang dipilih akan dikenai preprocessing dan ekstraksi ciri. Setelah itu ciri yang didapatkan akan diklasifikasi dengan menggunakan model yang sudah didapatkan dari hasil pengujian yang telah dilakukan. Setelah proses klasifikasi selesai, maka pada panel Hasil Klasifikasi akan ditampilkan nama aksara yang merupakan hasil prediksi dari klasifikasi tersebut.
3.7. Skenario Pengujian
Pada penelitian ini, hasil ekstraksi ciri yang digunakan menggunakan IoC dengan ukuran 3x3, 4x4, 5x5. Pada setiap ukuran IoC yang digunakan, terdapat 3 ukuran citra yang akan diambil cirinya. Pengujian akurasi dari penerapan SVM menggunakan metode k-fold cross validation, yang mana data akan dibagi sesuai dengan nilai k yang ditentukan sebelumnya yaitu 3, 5 dan 7.
Pengujian dilakukan dengan menggunakan 2 data set. Data set pertama bersifat imbalance, di mana jumlah data pada setiap kelas berbeda-beda. Data set kedua bersifat balance, di mana jumlah data pada setipa kelas sama. Pemodelan SVM yang digunakan adalah one against one. Setelah pengujian dilakukan akan dicari data training dan data testing yang memberikan akurasi tertinggi. Data training, data testing,nilai IoC, ukuran citra, dan nilai cross validatoin yang memberi akurasi tertinggi akan digunakan kembali untuk melakukan pengujian dengan menggunakan kernel dan juga menggunakan pemodelan SVM one against all. Setelah semua pengujian dilakukan kita mengambil data set dan model yang memberikan akurasi tertinggi untuk digunakan kedalam GUI dan uji data tunggal.
Secara ringkas maka variabel yang dimainkan dalam pengujian sebagai berikut:
1. Jumlah data yang digunakan dalam pengujian.
2. Ukuran citra yang digunakan dalam proses preprocessing.
3. Ukuran dari IoC yang digunakan untuk ekstraksi ciri.
4. Jumlah Fold Validation yang digunakan.
Setelah semua tahap tersebut dilakukan maka akan diambil dataset yang memberikan akurasi tertinggi untuk digunakan dalam pengujian berikutnya.
Pengujiannya adalah sebagai berikut:
1. Pengujian dengan menggunakan Kernel RBF.
2. Pengujian dengan menggunakan Kernel Polynomial.
3. Pengujian dengan pemodelan SVM One Against All.
45
BAB 4. HASIL PENELITIAN DAN ANALISIS
Bab ini membahas mengenai tahap-tahap dari pengenalan aksara bali beserta hasil pengujian pengenalan aksara bali menggunakan Support Vector Machine.
4.1. Pengumpulan Data
Pada penelitian ini Jumlah data yang didapatkan sebanyak 1572 citra aksara Bali yang terbagi menjadi 175 cluster. Jumlah citra pada setiap cluster bervariasi sehingga pembagian data yang ada bersifat tidak seimbang (imbalance). Data citra disimpan dalam folder di mana jumlah folder yang ada sesuai jumlah cluster dari data tersebut.
Gambar 4.1 Penyimpanan Citra Aksara Bali
Setiap folder berisikan citra aksara bali yang sudah tersegmentasi dan ter- cluster dari hasil penelitian sebelumnya. Akan tetapi data di-cluster ulang secara manual dikarenakan hasil clustering kurang akurat. Maka data di-cluster ulang berdasarkan kemiripan aksara dan disimpan pada satu folder untuk 1 cluster.
4.2. Implementasi Pembagian Data Training dan Testing
Pada tahap ini kita mulai membagi data training (data latih) dan data testing (data uji). Setelah semua data citra aksara melalui tahap preprocessing dan ekstraksi ciri, kita bagi hasilnya kedalam data latih dan data uji. Hasil ekstraksi ciri disimpan dalam bentuk array pada matlab terdiri dari ciri citra dan label citra.
Tabel 4.1 Array yang menyimpan ciri dan label citra