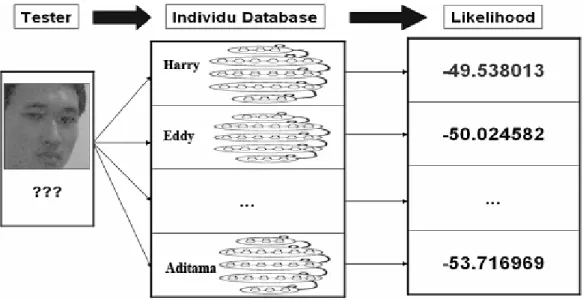
5
Universitas Kristen Petra
2.1. Metode Pengenalan Wajah
Sistem pengenalan wajah (Face Recognition) merupakan suatu proses pembelajaran yang harus dilakukan oleh komputer untuk dapat melakukan pengenalan terhadap wajah manusia, jika terdapat sebuah citra wajah yang ingin diidentifikasi dan terdapat pula kumpulan citra wajah (face database) yang sudah diketahui sebelumnya. Sama seperti halnya pada manusia, untuk dapat mengenali wajah, seseorang minimal pernah bertemu ataupun melihat orang tersebut, dari kondisi tersebut dalam otak manusia akan tersimpan ciri-ciri yang dimiliki oleh wajah orang yang dilihatnya. Hal yang sama juga dilakukan komputer dalam melakukan pengenalan wajah, yakni komputer perlu diberi pengetahuan tentang bagaimana cara melakukan pencocokan (matching) antara satu wajah dengan wajah yang lain, ini adalah sebuah proses yang cukup sulit untuk dipelajari oleh komputer.
Disamping proses learning yang cukup sulit, ada cukup banyak hambatan lain yang dimiliki oleh sistem tersebut, yaitu:
• Database wajah yang cukup besar sehingga memerlukan memory cukup besar, terdapat hubungan timbal balik yang cukup erat antara speed dan accuracy.
• Proses komputasi yang cukup kompleks.
• Setiap wajah manusia memiliki kesamaan struktur yaitu: dahi, mata, hidung, mulut, dagu, sehingga semakin sulit untuk dibedakan.
• Variasi pose dan ekspresi wajah.
• Pengaruh iluminasi cahaya dan latar belakang (background) citra.
• Komputer tidak bisa secara fleksibel mengenali perubahan wajah seseorang secara drastis.
Universitas Kristen Petra
2.1.1. Metode Hidden Markov Model (HMM) Secara Umum
Metode Hidden Markov Model mulai diperkenalkan dan dipelajari pada akhir tahun 1960, metode yang berupa model statistik dari rantai Markov ini semakin banyak dipakai pada tahun-tahun terakhir terutama dalam bidang recognition (speech, face, handwriting), seperti dijelaskan oleh Lawrence R.
Rabiner (1989) dalam laporannya yang berjudul “A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition”.
Proses dalam dunia nyata secara umum menghasilkan observable output yang dapat dikarakterisasikan sebagai signal. Signal bisa bersifat diskrit (karakter dalam alfabet) maupun kontinu (pengukuran temperatur, alunan musik). Signal bisa bersifat stabil (nilai statistiknya tidak berubah terhadap waktu) maupun nonstabil (nilai signal berubah-ubah terhadap waktu). Dengan melakukan pemodelan terhadap signal secara benar, dapat dilakukan simulasi terhadap sumber dan pelatihan sebanyak mungkin melalui proses simulasi tersebut, sehingga model dapat diterapkan dalam sistem prediksi, sistem pengenalan, maupun sistem identifikasi. Secara garis besar model signal dapat dikategorikan menjadi 2 golongan yaitu: model deterministik dan model statistikal. Model deterministik menggunakan nilai-nilai properti dari sebuah signal seperti:
amplitudo, frekuensi, fase dari gelombang sinus. Sedangkan model statistikal menggunakan nilai-nilai statistik dari sebuah signal seperti: proses Gaussian, proses Poisson, proses Markov, dan proses Hidden Markov.
2.1.1.1. Hidden Markov Model
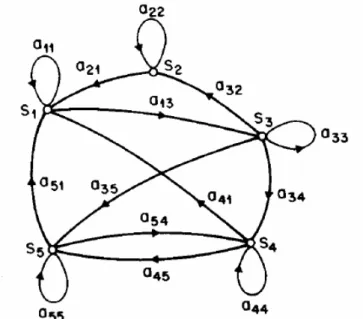
Sistem dengan N state, S1, S2, …, SN, seperti diilustrasikan pada gambar 2.1. (dimana N=5 adalah untuk penyederhanaan).
Universitas Kristen Petra
Gambar 2.1. Markov Chain Dengan 5 State (S1 sampai S5) Dengan Transisi State
Sumber: Rabiner, Lawrence R. “A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition.” Proceedings of IEEE, vol. 77, no.
2: pp. 257-286. February 1989.
Sesuai dengan perjalanan waktu, sistem mengalami perubahan state (diperbolehkan untuk kembali ke state yang sama) berdasarkan himpunan nilai probabilitas dari state tersebut. Notasi yang dipakai untuk perubahan waktu adalah t = 1, 2, …, state aktif pada waktu t adalah qt, dan state transition probabilities aij
dengan persamaan:
[
q S q Si]
P
aij = t = j | t−1 = 1= i,j =N (2.1)
dimana nilai dari state transition memiliki batasan:
≥0
aij (2.2)
1
1
∑
== N
j
aij (2.3)
dimana nilai ini memenuhi standar stochastic/probabilistic.
Proses stochastic di atas bisa disebut observable markov model dimana output dari proses adalah set dari state dalam suatu waktu, dimana tiap state berupa physical (observable) event. Contoh berikut mengilustrasikan markov chain, yaitu 3-state markov model dari cuaca, diasumsikan 1 kali dalam sehari
Universitas Kristen Petra
(misalnya pada siang hari) dilakukan observasi terhadap cuaca dan dikategorikan sebagai berikut:
State 1 : rain State 2 : cloudy State 3 : sunny
Jika cuaca pada hari t adalah salah satu dari ketiga state di atas, maka bisa dibuat matriks A yang menyatakan state transition probabilities sebagai berikut:
=
=
8 . 0 1 . 0 1 . 0
2 . 0 6 . 0 2 . 0
3 . 0 3 . 0 4 . 0 } {aij A
Jika cuaca pada hari pertama (t = 1) adalah sunny (state 3), maka berapa probabilitas (berdasarkan model yang diberikan) bahwa cuaca pada 7 hari ke depan adalah “sun – sun – sun – rain – rain – sun – cloudy – sun” atau dinyatakan dengan urutan observasi O dimana O = {S3, S3, S3, S1, S1, S3, S2, S3} untuk t = 1, 2, …, 8. Nilai probabilitas dari urutan observasi O dari model tersebut bisa dihitung dengan persamaan:
dimana notasi:
[
i]
i =Pq1 =S
π 1= i = N (2.4)
dipakai untuk menyatakan initial state probabilities.
Jika model berada pada suatu state, maka berapa probabilitas model tetap bertahan pada state tersebut selama d hari ? Atau dengan perkataan lain yaitu
Universitas Kristen Petra
seberapa lama cuaca sunny bertahan ? Probabilitas dapat dievaluasi dengan urutan observasi sebagai berikut:
maka nilai probabilitas adalah:
(2.5) nilai dari pi(d) adalah (discrete) probability density function dari durasi d pada state i. Berdasarkan pi(d) maka dapat dihitung jumlah observasi yang diharapkan (durasi) pada suatu state, yaitu:
(2.6)
maka jumlah hari berturut-turut dengan cuaca sunny, berdasarkan model tersebut, yaitu: 1/(0.2)=5, untuk cloudy adalah 2.5, dan rain 1.67.
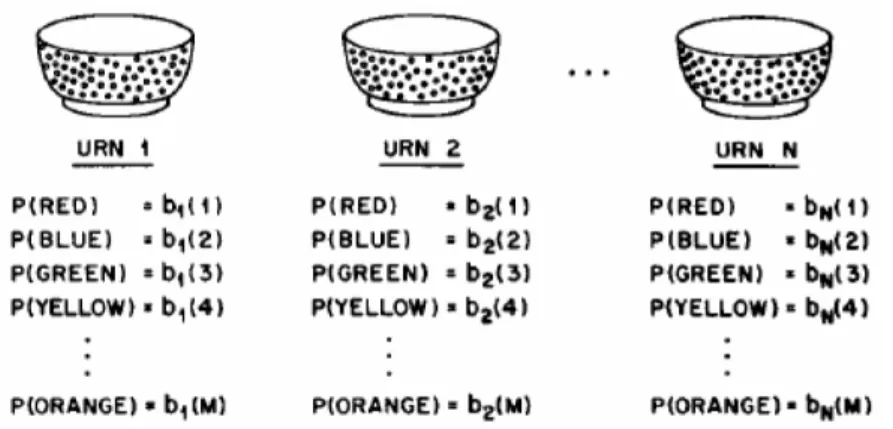
Contoh berikut merupakan contoh HMM (model mangkuk dan kelereng), seperti diilustrasikan pada Gambar 2.2. Diasumsikan terdapat N mangkuk, yang masing-masing berisikan sejumlah besar kelereng berwarna, dan terdapat sebanyak M warna yang unik dari kelereng tersebut. Observasi dilakukan dengan memilih sebuah mangkuk awal dan mengambil kelereng dari mangkuk tersebut secara random dan warna dari kelereng tersebut disimpan sebagai nilai observasi.
Kemudian kelereng tersebut dikembalikan ke mangkuk asal dan kembali dilakukan pemilihan mangkuk dan pengambilan kelereng, proses ini diulangi terus-menerus hingga batas tertentu. Keseluruhan proses ini menghasilkan urutan observasi warna kelereng, yang dapat disamakan sebagai observable output dari sebuah HMM.
Universitas Kristen Petra
Gambar 2.2. Model Mangkuk Dan Kelereng Dengan N-State Mengilustrasikan Discrete Symbol HMM
Sumber: Rabiner, Lawrence R. “A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition.” Proceedings of IEEE, vol. 77, no.
2: pp. 257-286. February 1989.
Model ini menjelaskan struktur HMM dimana mangkuk adalah state dan terdapat probabilitas warna pada tiap state, probabilitas pilihan mangkuk adalah state transition matriks dari HMM.
2.1.1.2. Elemen HMM
Suatu model HMM secara umum memiliki unsur-unsur sebagai berikut:
a. N, yaitu jumlah state dalam model. Secara umum state saling terhubung satu dengan yang lain, dan suatu state bisa mencapai semua state yang lain dan sebaliknya (disebut model ergodic). Namun hal tersebut tidak mutlak, terdapat kondisi lain dimana suatu state hanya bisa berputar ke diri sendiri dan berpindah ke satu state berikutnya, hal ini bergantung pada implementasi dari model. Pada contoh mangkuk dan kelereng, state adalah mangkuk, maka N adalah jumlah mangkuk. Individual state dinyatakan dengan
S=
{
S1,S2,L,SN}
, dan state pada waktu t adalah qt .b. M, yaitu jumlah observation symbol secara unik pada tiap statenya, misalnya:
karakter dalam alfabet, dimana state adalah huruf dalam kata dan pada contoh mangkuk dan kelereng, observation symbol adalah warna kelereng, maka M
Universitas Kristen Petra
adalah jumlah warna kelereng secara unik. Individual observation symbol dinyatakan dengan V= {v1, v2, …, vM}.
c. State Transition Probability A = {aij} dimana:
]
|
[ t j t 1 i
ij P q S q S
a = = − = 1 = i,j = N (2.7)
dalam kasus khusus dimana suatu state dapat mencapai semua state yang lain, dan sebaliknya maka aij lebih dari 1 untuk semua i,j. Untuk tipe HMM yang lain aij sama dengan 1 untuk satu atau lebih i,j.
d. Observation Symbol Probability pada state j, B = {bj,k}, dimana:
bj (k) = P[vk at t | qt = Sj] 1 = j = N 1 = k = M (2.8) e. Initial State Distribution π =
{ }
πi dimana:[
i]
i =Pq1 =S
π 1= i = N (2.9)
Dengan memberikan nilai pada N, M, A, B, dan p , HMM dapat digunakan sebagai generator untuk menghasilkan urutan observasi:
oT
o o o= 1 2...
dimana tiap observasi o adalah salah satu simbol dari V, dan T adalah jumlah t observasi dalam suatu sequence. Berikut adalah langkah-langkahnya:
a. Tentukan initial state q1 =Si berdasarkan dari initial state distribution π . b. Set t =1.
c. Tentukan ot = vk berdasarkan symbol probability distribution pada state Si
yaitu bi (k)
d. Pindah ke state baru qt+1 = Sj berdasarkan state transition probability untuk state Si yaitu a ij .
e. Set t=t+1, kembali ke langkah c jika t<T terpenuhi. Jika tidak, akhiri proses.
Prosedur di atas dapat digunakan baik sebagai generator dari observasi maupun sebagai model yang menunjukkan bagaimana urutan observasi dihasilkan oleh HMM yang sesuai (prosedur inilah yang dipakai untuk melakukan pengenalan wajah).
Universitas Kristen Petra
Dengan notasi sederhana, HMM didefinisikan sebagai triplet )
, ,
( π
λ = A B (2.10)
yang menunjukkan parameter lengkap dari model HMM.
2.1.2. Embedded Hidden Markov Model (HMM)
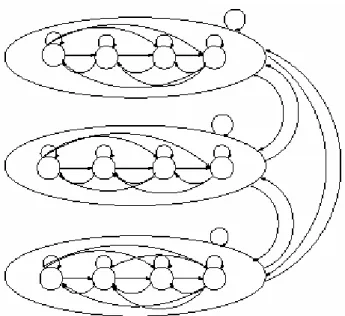
Sebuah embedded HMM (seperti ditunjukkan pada Gambar 2.3) adalah pengembangan dari HMM dimana suatu state pada 1-D HMM adalah juga sebuah HMM, seperti dijelaskan oleh Ara V. Nefian (1998) dalam laporannya yang berjudul “A Hidden Markov Model-Based Approach for Face Detection and Recognition”.
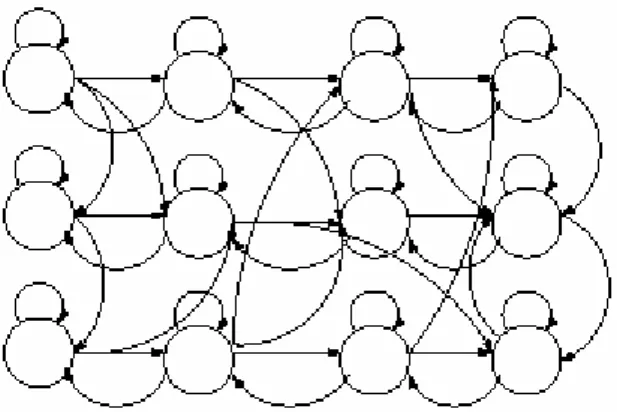
Embedded HMM terdiri dari himpunan super state dimana masing- masing berisi himpunan state pula yang disebut dengan embedded state. Super state memodelkan data citra dua dimensi pada arah vertikal, sedangkan embedded state memodelkan pada arah horizontal. Model Embedded HMM bukan murni 2D HMM (seperti ditunjukkan pada Gambar 2.4) karena transisi antar state pada super state yang berbeda tidak diperbolehkan.
Gambar 2.3. Embedded HMM Dengan 3 Super State
Universitas Kristen Petra
Gambar 2.4. Fully Connected 2 Dimensional HMM
Sebelum dapat menggunakan embedded HMM untuk melakukan pengenalan citra wajah, perlu ditentukan terlebih dahulu jumlah super state pada top-bottom HMM, jumlah embedded state pada masing-masing super state, state transition probabilities, dan observasi yang dihasilkan oleh HMM. Apabila terdapat N0 =5, super state yang digunakan untuk merepresentasikan lima daerah primer dari citra wajah jika dilakukan scan secara vertikal dari atas ke bawah, yaitu: dahi, mata, hidung, mulut, dagu.
Jumlah embedded state ditentukan berdasarkan pada jumlah region yang hendak dicari pada citra wajah jika dilakukan scan secara horizontal dari kiri ke kanan dalam suatu super state. Sebagai contoh pada super state kedua (mata), terdapat dua state untuk sepasang bola mata, dua state untuk masing-masing pelipis (daerah antara mata dan tepi wajah), dan dua state untuk daerah antara mata (sebelah kiri dan kanan hidung), sehingga total berjumlah enam state. Tiap state dimodelkan dengan mixture dari tiga nilai Gaussian density dan matriks kovarians yang digunakan diagonal.
Berikut adalah elemen dari embedded HMM:
a. Himpunan super state sebanyak N , 0 S0 =
{ }
S0,i 1≤ ≤i N0.b. Initial super state probability distribution, π0 ={π0,i} , dimana π0,i adalah nilai probabilitas berada pada super state i pada waktu t =0.
c. Himpunan transisi state antar super state yang berupa matriks dua dimensi,
0 { 0,ij}
A = a , dimana a0,ij adalah nilai probabilitas untuk melakukan transisi dari super state i ke super state j.
Universitas Kristen Petra
d. Pada metode ini, tiap super state adalah juga merupakan HMM (disebut embedded HMM), dan struktur dari embedded HMM ini sama dengan 1-D HMM. Namun tidak seperti 1-D HMM, jumlah state, initial state probability, dan state transition matriks, sangat bergantung pada super state dimana embedded HMM tersebut berada. Karena itu masing-masing embedded HMM juga memiliki elemen sebagai berikut:
i. Jumlah embedded state pada super state yang ke k, N1k, dan himpunan embedded state, S1k ={S1,ki,i=1, 2,K,N1k}
ii. Initial state probability distribution pada embedded state, π1k ={π1,ki}, dimana π1,ki adalah nilai probabilitas berada pada state i dari super state k pada waktu t=0.
iii. State Transition Matriks untuk embedded state, A1k ={a1,kij}, dimana a1,kij adalah nilai probabilitas untuk melakukan transisi dari state i ke state j pada super state k.
iv. Probability Distribution Matriks,
0 1,
{ ( )}
k k
j t t
B = b ο , dimana
0 1,
( )
k
j t t
b ο adalah nilai probabilitas dari observasi
0,1
οt t yang dihasilkan pada embedded state j dan super state k. Untuk observation vector
0,1
οt t terdapat dua subscript, yaitu t dan 0 t , dimana 1 t menyatakan waktu dari super state dan 0 t 1 menyatakan waktu dari embedded state, bisa juga dikatakan pada baris t 0 dan kolom t . 1
Untuk discrete embedded HMM diasumsikan
0,1
οt t bisa diperoleh dari himpunan observation symbol dengan jumlah tertentu. Jika P adalah jumlah dari observation symbol yang berbeda dan V adalah himpunan semua observation symbol yang ada (disebut juga buku kode dari model), V =v1,K,vp, pada kasus ini, B adalah observation symbol probability matriks, Bk ={bkj( )}p , dimana:
0 1, 0, 1,
( ) ( | , , )
k k
j t t p k j
b p =P ο =v S S λ (2.11)
Universitas Kristen Petra
Untuk continuous density embedded HMM, observasi diperoleh dari continuous probability density function (seperti pada 1-D HMM), yang berupa finite Gaussian mixtures, dengan bentuk:
0 1, 0 1,
1
( ) ( , , )
k
Mi
k k k k
i t t im t t im im
m
b ο c N ο µ U
=
=
∑
(2.12)untuk 1≤ ≤i N1k, dimana cimk adalah mixture coefficient untuk mixture ke m pada state i super state k, dan
0 1,
( t t, imk, imk )
N ο µ U adalah Gaussian density dengan mean vektor µimk dan kovarian matriks Uimk .
Untuk tied-mixture embedded HMM, yaitu semua komponen Gaussian disimpan, dan dipakai bersama oleh semua state output distribution, dimana state output distribution untuk state i, dinyatakan dengan persamaan berikut:
0 1, 0 1,
1
( ) ( , , )
M
k k k k
i t t im t t m m
m
b ο c N ο µ U
=
=
∑
(2.13)Persamaan diatas berbeda dari persamaan (2.12) dimana parameter komponen Gaussian (mean vector dan kovarian matriks) dan jumlah komponen mixture tidak bergantung pada posisi dari embedded state.
Jika Λ =k {π1k,A B1k, k} adalah himpunan parameter yang membentuk super state ke k, maka embedded HMM bisa dijelaskan melalui triple simbol sebagai berikut:
0 0
( ,A , )
λ= π Λ (2.14)
dimana Λ = Λ Λ{ 1, 2,K,ΛN0}.
Berikut adalah beberapa notasi yang akan sering digunakan dalam penjelasan selanjutnya:
§ οt0,1≤ ≤t0 T0, menyatakan urutan observasi
0,1, 0,2, , 0,1
t t t T
ο ο K ο .
§ ο menyatakan urutan οt0,K,οT0.
§ qt t0 1, ,1≤ ≤t1 T1, menyatakan state dari observasi
0 1,
οt t .
§ Jika
0 1
0 ,
qt t adalah super state dari
0 1,
οt t dan
0 1
1 ,
qt t adalah embedded state dari
0 1,
οt t maka
0 1 0 1 0 1
0 1
, ( , , , )
t t t t t t
q = q q .
Universitas Kristen Petra
§ 0 0 0 1
1 1 1
,1, , ,
t t t T
q =q K q menyatakan urutan embedded state dan
0
0 0 0
0, , T
q =q K q menyatakan urutan super state.
t0
q menyatakan urutan state
0 1, , , 0,1
t t t T
q K q dan
0, , T0
q=q K q .
2.1.2.1. Algoritma Decoding
Jika terdapat urutan observasi ο , maka tujuan dari algoritma Decoding, adalah untuk mencari himpunan state q yang memaksimalkan nilai P( , | )ο q λ . Untuk mendeskripsikan algoritma yang efisien dalam mencari himpunan state, digunakan variabel:
1
0 0 0 0
1 01
0
0
1 1 1
, ,
( ) max max ( , , , , , )
t t
t t t t
q q
q
i P q q q i
δ ο ο λ
− −
= =
K K K (2.15)
Seperti ditunjukkan pada persamaan di atas,
0( )
t i
δ menyatakan probabilitas terbaik untuk observasi dan urutan state pada single state path yang berakhir pada
t0
ο di super state i. Dari persamaan (2.15), cukup jelas bahwa
( , | ) maxi T0( )
P ο q λ = δ i . Algoritma Decoding dapat diimplementasikan secara efisien dengan menggunakan kalkulasi terhadap variabel
0 1( )
t i
δ + dari nilai sebelumnya
0( )
t j
δ . Dari persamaan (2.15), bisa dihitung:
1
0 0 0 0
1 1 0
0
0 0 0
0
1 1 1 1 0,
, ,
1 0
1 1 1
( ) max[max max ( , , , , , , | )
( , , , )]
t t
t t t t ji
j q q q
t t t
i P q q q j a
P q q i
δ ο ο λ
ο λ
+ + −
+ + +
= =
=
K K K
(2.16)
persamaan di atas dapat ditulis sebagai berikut:
1
0 0 0 0
1 01
0
1 0 0 0
01
0
1 , , 1 1 1 0,
1 0
1 1 1
( ) max[max max [ ( , , , , , , ) ]]
max[ ( , | , )]
t t
t
t j q q q t t t ji
t t t
q
i P q q q j a
P q q i
δ ο ο λ
ο λ
−
+
+ −
+ + +
= =
=
K K K
(2.17)
maka
1
0 0 0 0 0
01
0
1( ) max ( ) 0, max ( 1, 1| 1 , )
t
t t ji t t t
all j q
i j a P q q i
δ δ ο λ
+ = + + + + = (2.18)
Dari persamaan di atas, untuk melakukan penghitungan
0( )
t i
δ , digunakan algoritma Viterbi untuk urutan
t0
ο dan mencari urutan terbaik dari embedded state pada super state i. Kemudian algoritma Viterbi dipakai untuk menghitung urutan
Universitas Kristen Petra
observasi
1, , T0
ο K ο . Gambar 2.5. berikut menunjukkan langkah-langkah dari algoritma decoding untuk embedded HMM:
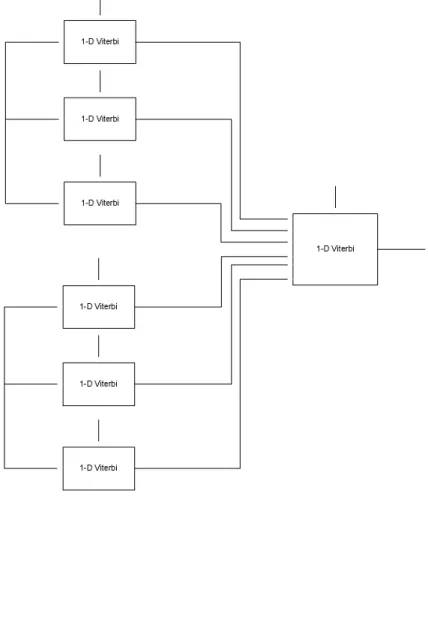
Gambar 2.5. Algoritma Decoding Untuk Embedded HMM
Sumber: Nefian, Ara V. and Hayes, M.H. A Hidden Markov Model-Based Approach for Face Detection and Recognition. Atlanta, GA: Georgia Institute of Technology, August 1999
a. Step 1:
Hitung 1
0 0 0 0 0
1 0
max ( , , )
t
i
t q t t t
P = Pο q q =i λ dengan menggunakan algoritma Viterbi untuk setiap super state dan tiap urutan observasi
t0
ο . b. Step 2:
i. Inisialisasi
1 0,1 0
1
( ) ( ) 0
i Pi
i
δ π
ψ
=
=
Universitas Kristen Petra
array
0( )
t i
ψ digunakan untuk menyimpan nilai yang memaksimalkan
0( )
t i δ . ii. Rekursi
0 0
0
0 0
1 1 0,
[1, ]
1 1 0,
[1, ]
( ) max [ ( ) ] ( ) arg max [ ( ) ]
i
t ji t
j N
t ji
j N
i j a P
i j a
δ δ
ψ δ
∈ −
∈ −
=
=
iii. Terminasi
0 0
0 0
0
*
[1, ] 0 *
[1, ]
max ( )
( ) arg max [ ( )]
j N T
T T
j N
P j
q j
δ
δ
∈
∈
=
=
P pada persamaan di atas menunjukkan * maxall qP( , | )ο q λ dan
0
0 *
(qT ) adalah super state pada T dari path q yang memaksimalkan 0 P( , | )ο q λ . iv. Backtracking
Path terbaik q, yang memaksimalkan P( , | )ο q λ diperoleh dari array
0( )
t i
ψ sebagai berikut:
0 0 0
0 * 0 *
1 1
(qt ) =ψt+ ((qt+ ) )
Untuk mengurangi kompleksitas komputasi pada algoritma di atas dan untuk menghindari masalah underflow yang sering terjadi pada kalkulasi yang melibatkan banyak multiplikasi probabilitas, maka semua algoritma di atas dapat diubah ke dalam bentuk logaritmik. Pada representasi ini, semua nilai probabilitas diganti dengan nilai lognya dan multiplikasi diubah menjadi penambahan.
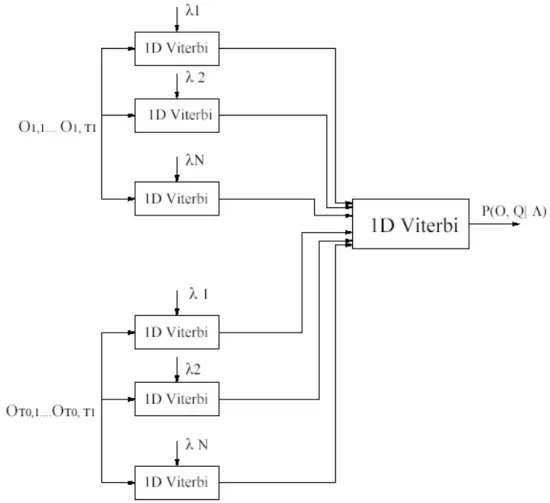
Waktu yang dibutuhkan oleh algoritma decoding, dapat dikurangi secara signifikan jika digunakan arsitektur paralel. Seperti ditunjukkan pada Gambar 2.5, semua nilai Viterbi yang diperoleh pada step pertama dari algoritma, dapat dihitung secara independen antara satu dengan yang lain, karena itu semua nilai ini dapat dihitung dalam waktu yang bersamaan dengan menggunakan implementasi paralel. Maka total delay yang digunakan oleh algoritma decoding dapat dikurangi hingga dua kali lipat dibandingkan algoritma Viterbi standar.
Universitas Kristen Petra
2.1.2.2. Algoritma Evaluasi
Terdapat dua algoritma untuk menghitung nilai probabilitas P( | )ο λ dari urutan observasi ο dengan model λ, yang biasa disebut algoritma forward dan backward.
2.1.2.2.1. Algoritma Forward untuk Embedded HMM
Notasi yang digunakan untuk variabel forward pada urutan observasi
t0
ο yaitu:
0 1 0 0 1 0 1 0
1 0
, ( , ) ( ,0, , , , , )
t t i j P t t t qt t j qt i
α = ο Kο = = λ (2.19)
serupa dengan persamaan (2.19) variabel backward untuk urutan observasi
t0
ο , yaitu:
0 1 0 1 0 1 0 1 0
1 0
, ( , ) ( , 1, , , | , , , )
t t i j P t t t T qt t j qt i
β = ο + K ο = = λ (2.20)
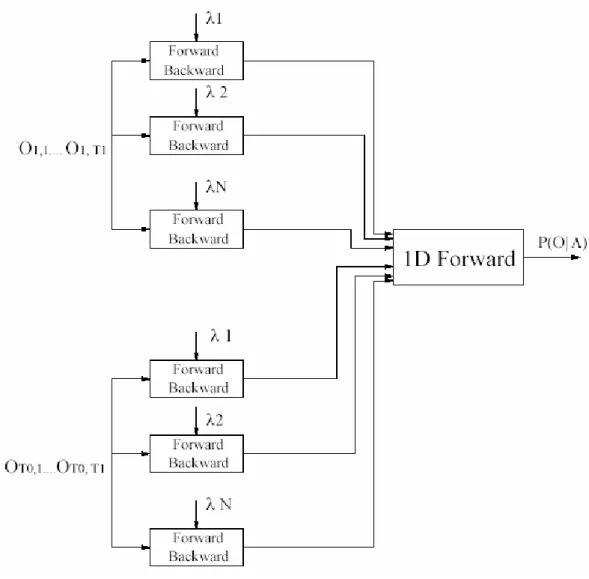
Variable Forward dan Backward dihitung secara iterative menggunakan algoritma forward dan backward untuk 1-D HMM. Gambar 2.6. berikut menunjukkan langkah-langkah dari algoritma forward untuk embedded HMM:
Universitas Kristen Petra
Gambar 2.6. Algoritma Forward Untuk Embedded HMM
Sumber: Nefian, Ara V. and Hayes, M.H. A Hidden Markov Model-Based Approach for Face Detection and Recognition. Atlanta, GA: Georgia Institute of Technology, August 1999
Nilai probabilitas dari urutan observasi
t0
ο , untuk 1-D HMM pada super state i, dihitung dari
0 1, ( , )
t t i j
α dan
0 1, ( , )
t t i j
β sebagai berikut:
0 0 0 1 0 1
1
0
, ,
( t | t , ) t t ( , ) t t ( , )
t
Pο q =i λ =
∑
α i j β i j (2.21)algoritma yang efisien untuk komputasi dari P( | )ο λ diperoleh jika variabel forward untuk urutan observasi
0, 1, , T0
ο ο K ο didefinisikan sebagai berikut:
0 0 0
0
1 1
( ) ( , , , , , )
t i P t qt i
α = ο ο K ο = λ (2.22)
Universitas Kristen Petra
Variabel forward
0( )
t i
α mendeskripsikan probabilitas dari sebagian urutan observasi
0, 1, , T0
ο ο K ο dan super state i dengan model λ. Oleh karena itu ( | )
P ο λ dapat dihitung sebagai:
( | ) t0( )
all i
Pο λ =
∑
α i (2.23)Variabel forward
0( )
t i
α dihitung secara iterative dari nilai sebelumnya dan probabilitas dari
t0
ο , pada super state i,
0 0
( t t0 , ) P ο q =i λ :
0 0 0 0
0
1( ) [ ( ) 0, ] ( | , )
t t ij t t
i
i i a P q i
α + =
∑
α ο = λ (2.24)Berikut adalah langkah-langkah dari algoritma forward untuk embedded HMM:
a. Step 1:
Hitung
0 0 1 0
0
( , , )
i
t t t t
P =P ο q =i λ untuk semua t dan super state i menggunakan 0 1-D HMM forward backward algorithm dengan menggunakan persamaan (2.28).
b. Step 2:
i. Inisialisasi
0( )i 0,iP0i
α =π ii. Rekursi
0 1( ) 0( ) 0, 0
t
i
t t ij
i
i i a P
α + α
=
∑
iii. Terminasi0 0
1 1
( , , , T | ) T ( )
i
P ο ο K ο λ =
∑
α i2.1.2.2.2. Algoritma Backward untuk Embedded HMM
Dengan cara serupa dengan variabel forward pada persamaan (2.22), dapat didefinisikan variabel backward untuk urutan observasi
t0
ο :
0( ) ( 0 1, , 0 i0 , )
t i P t T qt i
β = ο + K ο = λ (2.25)
Universitas Kristen Petra
Variabel backward
0( )
t i
β mendefinisikan probabilitas dari sebagian urutan observasi
0, , 0
t T
ο K ο dimana
0 1
οt − berada pada super state i. Variabel dapat dihitung secara iterative dari nilai ‘future’ nya
0 1( )
t i
β + dan
0 0
( t t0 , ) P ο q =i λ .
0( ) 0, ( 0 1 0,0 1 , ) 0 1( )
t ij t t t
j
i a P q j j
β =
∑
ο + + = λ β + (2.26)Berikut adalah langkah-langkah dari algoritma backward untuk embedded HMM:
a. Step 1:
Hitung
0 0 1 0
0
( , , )
i
t t t t
P =P ο q =i λ untuk semua t dan super state i, dengan 0 menggunakan 1-D HMM forward-backward algorithm pada persamaan (2.28).
b. Step 2:
i. Inisialisasi
0( ) 1
T i
β =
ii. Rekursi
0( ) 0, 0i 0 1( )
t ij t t
j
i a P j
β =
∑
β +Serupa dengan algoritma decoding, waktu yang dibutuhkan untuk melakukan komputasi dari algoritma evaluasi dapat berkurang secara signifikan jika digunakan arsitektur paralel.
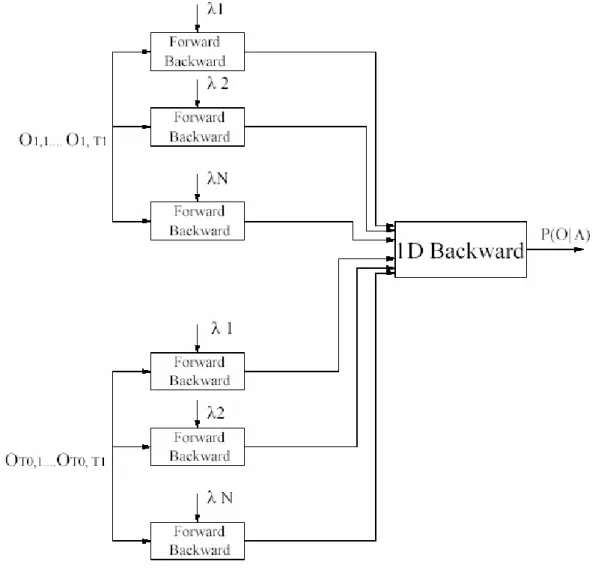
Gambar 2.7. berikut menunjukkan langkah-langkah dari algoritma backward untuk embedded HMM:
Universitas Kristen Petra
Gambar 2.7. Algoritma Backward Untuk Embedded HMM
Sumber: Nefian, Ara V. and Hayes, M.H. A Hidden Markov Model-Based Approach for Face Detection and Recognition. Atlanta, GA: Georgia Institute of Technology, August 1999
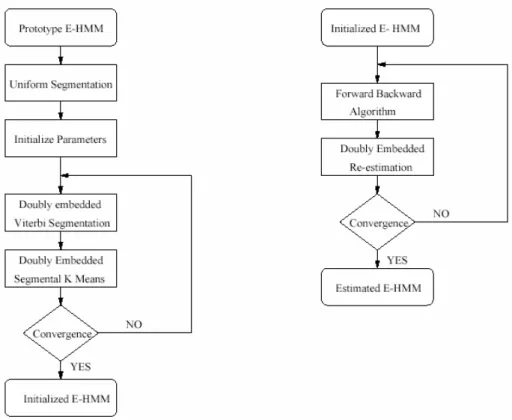
2.1.2.3. Algoritma Estimasi
Estimasi dari parameter pada embedded HMM digunakan untuk secara iterative atau berulang melakukan penyesuaian parameter dari model dengan kriteria optimasi tertentu. Algoritma yang digunakan serupa dengan algoritma Baum-Welch diambil dari 1-D HMM. Terdapat dua jenis embedded HMM yaitu discrete dan continuous mixture, yang digunakan dalam tugas akhir kali ini adalah continuous mixture embedded HMM.
Universitas Kristen Petra
Persamaan (2.12) yang mendefinisikan matriks probabilitas B dari continuous mixture embedded HMM, dapat ditulis seperti berikut:
0 1, 0 1,
( ) ( )
i i i
j t t c bjm jm t t
β ο =
∑
ο (2.27)dimana
0 1,
( )
i jm t t
b ο adalah Gaussian density function dari mixture ke m pada state j super state i. Berikut adalah beberapa notasi yang akan digunakan dalam persamaan-persamaan selanjutnya:
§ kt t0 1, menunjukkan mixture component dari embedded state.
§ kt0 =(kt0,0,kt0,1,K,kt T0,1)
§ k=( , ,k k0 1 K,kT0) elemen dari
t0
k menunjukkan urutan mixture pada embedded state
0
1
qt , sedangkan elemen dari k adalah semua urutan mixture
t0
k . Dengan continuous mixture embedded HMM, urutan state lebih jelas daripada model discrete, dan meliputi baik urutan state maupun array of mixtures k yang berkorespondensi dengan state tersebut.
Auxiliary function Q untuk continuous mixture embedded HMM yaitu:
( , ) 1 ( , , ) log ( , , )
( ) q k
Q P q k P q k
λ λ P ο λ ο λ
ο λ
=
∑∑
(2.28)tujuan dari persamaan estimasi yaitu untuk memaksimalkan auxiliary function Q dengan model λ. Probabilitas dari observasi ο , single state path q, dan urutan mixture k yang berkorespondensi dengan q, yaitu:
0 0 0
0 0 0
0 01 0
0
0, 0, ,
( , , ) ( , , | )
t t t t t
q q q
t
Pο q k λ π a Pο q k λ
=
∏
− (2.29)dimana
0 0
( , t , t )
Pο q k λ dapat dijabarkan sebagai:
0 0 0 0
,1 , ,
0 0 0 1 0 1
1 1 1 1 1
0 0 0 0,1 0 1, 1 0 1, 0 1, 0 1, 0 1 0 1, 0 1,
1
1, 1, , , ,
( , , | ) t t t t ( ) t t
t t t t t t t t t t t t t
q q q q
t t t q q q q k t t q k
t
Pο q k λ π a b ο c
=
∏
− (2.30)dengan men-substitusi persamaan (2.29) dan persamaan (2.30), serta menghitung logaritma, menghasilkan:
Universitas Kristen Petra
0 0,1
0 0 0 1
1 ,1
0 0 0 0
0 0
0 0
0 0 1,
1 1 1
, 1 , , 0 1
0 1 0 1 0 1
0 1 0 1
0 0 1, 1
, ,
0 1 0 1
0 1
0, 0, , 1,
1, ,
,
log ( , , ) log log log
log log ( )
log
t
t t t t
t t t
t t t t t t
t t
t t t t
q
q q q q
t t
q q
q q q t t
t t t t
q
q k
t t
P q k a
a b
c
ο λ π π
ο
−
−
= + + +
+ +
∑ ∑
∑∑ ∑∑
∑∑
(2.31)
dengan menggunakan persamaan (2.29), (2.30), (2.31) pada (2.28), auxiliary function ( , )Q λ λ dapat dijabarkan dalam bentuk penjumlahan berikut:
0 0 0
0 01 0
0 0
0 1, 1
0 1, 0
0 0
1 1
, 1 , 0 1 0 1
0 1
0 0 1, 10 1, 0 1, 0 1
1
0, 0, ,
1,
1, ,
,
( , ) 1 [ ( , , ) log ( , , ) log
( | )
( , , ) log
( , , ) log
( , , ) log ( )
t t t
t t t t
t
t t t t
t t
t t t t
q q q
q k q k t
q q
q k t
q
q q
q k t t
q q k t t t
Q P q k P q k a
P
P q k
P q k a
P q k b
λ λ ο λ π ο λ
ο λ
ο λ π
ο λ
ο λ ο
−
−
= +
+
+
+
∑∑ ∑∑ ∑
∑∑ ∑
∑∑ ∑∑
0
0 0 1
, ,
0 1 0 1
0 1
( , , ) log t ]
t t t t
q k t
q
q k
q k t t
Pο q k λ c
+
∑∑ ∑∑
∑∑ ∑∑
(2.32) dan dapat ditulis dalam bentuk yang lebih simpel:
0 0 0 1 0 1 0 1
0 0 1 1
1 1 1 1 1 1 1 1
( , )
N N N N N N N N
a a b c
i i i j i j i j
Q λ λ Qπ Q Qπ Q Q Q
= = = = = = = =
= +
∑
+∑
+∑∑
+∑∑ ∑∑
+ (2.33) dimana,0
0
0 0
0, 0
1
( , , )
( , ) log
( )
N i
i
P k q i
Qπ P
λ π ο π
= ο λ
=
∑
= (2.34)0 0
0 0
0
0
0 0
1
0, 0,
1 1
( , , , | )
( , ) log( )
( | )
N T
t t
a ij ij
j t
P k q i q j
Q a a
P
ο λ
λ ο λ
−
= =
= =
=
∑∑
(2.35)0 1
0 0
1 0
0
0 1
,0 ,0
1, 0, 0,
1 1
( , , , | )
( , ) log( )
( | )
T N
t t
i q
j i t
j t
P k q i q j
Qπ P
ο λ
λ π π
= = ο λ
= =
=
∑∑
(2.36)0
1 1
0 0 1 0 1
1
0 1
0 1 1
, 1 ,
1, 1,
1 1 1
( , , , , | )
( , ) log( )
( | )
T
N T
t t t t t
i i
a jl jl
l t t
P k q i q j q l
Q a a
P
ο λ
λ ο λ
−
= = =
= = =
=
∑∑∑
(2.37)0 1
0 1 0 1 0 1
0 1
0 1
0 1
, , ,
,
1 1
( , , , , | )
( , ) log( ( ))
( | )
N T
t t t t t t
i i
b jm jm t t
t t
P k q i q j k m
Q b b
P
ο λ
λ ο
= = ο λ
= = =
=
∑∑
(2.38)Universitas Kristen Petra
0 1
0 0 1 0 1
0 1
0 1
, ,
1 1
( , , , , | )
( , ) log( )
( | )
N T
t t t t t
i i
c jm jm
t t
P k q i q j k m
Q c c
P
ο λ
λ = = ο λ
= = =
=
∑∑
(2.39)Karena penjabaran dari auxiliary function, global maksimum dari Q diperoleh dari memaksimalkan individual auxiliary function. Maximization dari individual auxiliary function
0, a0, 1
Qπ Q Qπ dan
1
i
Qa yang dibatasi oleh aturan stochastic, yaitu:
0
0, 1
1
N i i
π
=
∑
= (2.40)0
0, 1
1
N ij j
a
=
∑
= (2.41)1
1, 1
1
N i
j i
π
=
∑
= (2.42)1
1, 1
1
N i
jl j
a
=
∑
= (2.43)1
( ) 1
P i j p
b p
=
∑
= (2.44)diperoleh dengan menggunakan cara yang sama seperti telah dijelaskan pada section sebelumnya. Re-estimated parameter yang diperoleh dari multiple independent observation sequence dan dinyatakan dalam kasus probabilitas posteriori diperoleh dari persamaan berikut:
0 0
0 0
1 1
1 1
0,
0 0
1 1
1 1 1 1
( , | , ) ( | , )
( , | , ) ( | , )
R R
r r
r k r
i R N R N
r r
r i k r i
P q i k P q i
P q k P q
ο λ ο λ
π
ο λ ο λ
= =
= = = =
= =
=
∑∑
=∑
∑∑∑ ∑∑
(2.45)0
0 0
0 0
0 0
0
0 0
0 0
0 0
0 0
1
1 1
0,
0 1
1 1
0 0
1
1 1
0 1
1 1
( , , , )
( , | , )
( , | , )
( | , )
R T
r
t t
r t k
ij R T
r t
r t k
R T
r
t t
r t
R T
r t
r t
P q i q j k
a
P q i k
P q i q j
P q i
ο λ
ο λ
ο λ
ο λ
= = −
= = −
= = −
= = −
= =
= =
=
= =
=
∑∑∑
∑∑∑
∑∑
∑∑
(2.46)